

Ensemble Empirical Mode Decomposition Granger Causality Test Dynamic Graph Attention Transformer Network: Integrating Transformer and Graph Neural Network Models for Multi-Sensor Cross-Temporal Granularity Water Demand Forecasting
Abstract
:1. Introduction
- Existing models that analyze spatiotemporal data often treat spatial and temporal relationships as separate entities. This separation can lead to significant information loss, subsequently diminishing the accuracy of the model’s predictions.
- Furthermore, when dealing with natural scenes, the spatial relationships between sensors might not always be apparent or accessible, complicating the model’s learning process. Consequently, there is a pressing need for innovative graph-building techniques that can facilitate adequate information flow among sensor nodes without relying on predefined spatial relationships.
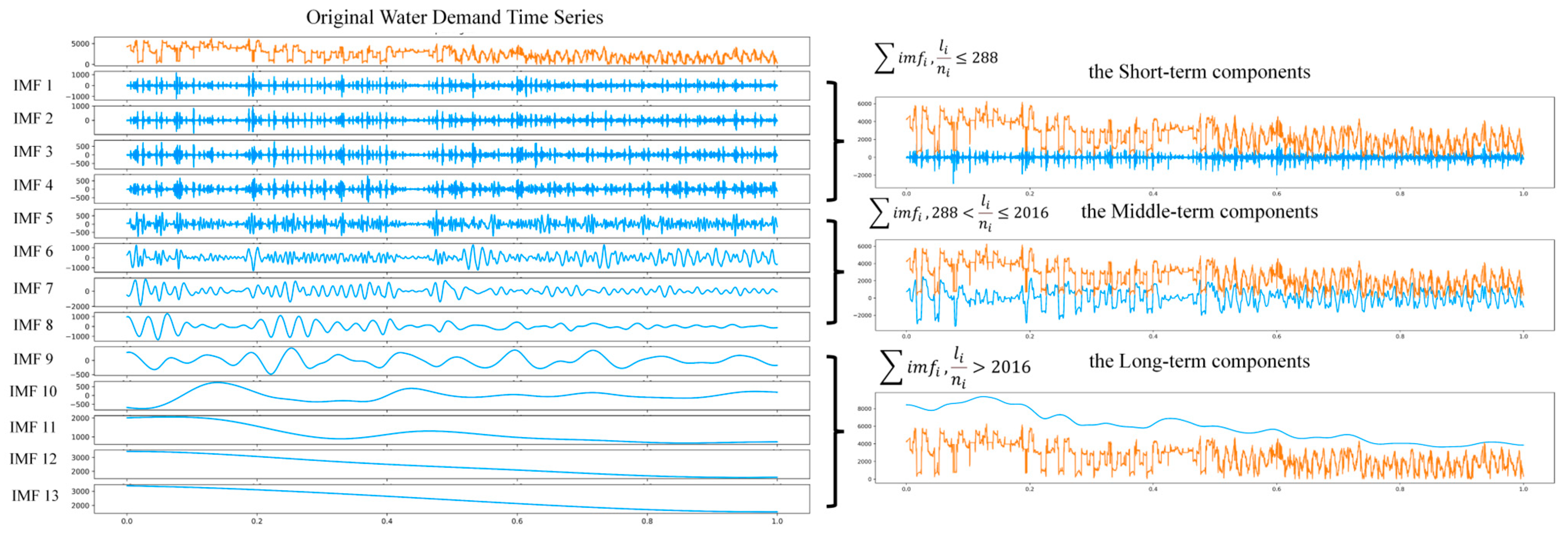
- Additionally, assigning a distinct time series model to each series decomposed using the Empirical Mode Decomposition (EMD) method has proven inefficient. A more streamlined approach is required to fully capitalize on the insights from the decomposed series fully, enhancing the overall model efficiency.
- Enhanced Temporal Information Fusion and Causal Relationship Exploration in Sensor Networks. We utilize EEMD–Granger causality testing to integrate additional temporal information within a fixed time dimension, circumventing the need for model stacking inherent in traditional approaches and facilitating a deeper investigation into the causal interplay among sensor networks.
- Optimized Spatial-Temporal Encoding and Synchronized Modeling. By incorporating causal spatiotemporal embeddings into the Transformer architecture, we have refined positional encoding, enabling the EG-DGATN model to synchronize the treatment of spatiotemporal relationships among water demand sensors. This enhancement outperforms traditional models segregating spatial and temporal data, yielding a more comprehensive and precise predictive framework.
- Innovative Dynamic Graph-Optimized Multi-Head Attention Mechanism. We propose a novel dynamic graph multi-head attention mechanism, which regulates the flow of information in the water supply sensor network and achieves efficient information aggregation. Unlike traditional attention mechanisms, it dynamically adjusts attention weights based on real-time data and changes in the sensor network, better capturing and utilizing the temporal-spatial dependencies within water demand data.
2. Methods
2.1. Objective Description
2.2. Data Preprocessing
2.2.1. EEMD and ADFuller Stationarity Test
2.2.2. Granger Causality Tests and DTW
2.3. EG-DGATN Model Framework
2.3.1. Causal Spatiotemporal Embedding
2.3.2. Dynamic Graph ST-Attention Layer
2.3.3. Input and Output Layers
2.4. Model Evaluation Indicators
3. Experiments
3.1. Dataset Description
3.2. ADF, Granger Test, and Adjacency Matrix Construction
3.3. Baseline Models
- ARIMA: A statistical-based time series forecasting method.
- STGCN [24]: Spatiotemporal graph convolutional network, which utilizes convolutional structures to extract spatiotemporal correlations from time series.
- ASTGCN [25]: An attention-based spatiotemporal graph convolutional network with attention mechanisms for traffic flow prediction, which is used to analyze the spatiotemporal features of the time series.
- DCRNN [26]: Diffusion convolutional recurrent neural network employs diffusion convolution to capture spatial correlations and combines Seq2Seq architecture to capture temporal correlations.
- GNNLSTM [27]: Combines a graph neural network with the LSTM model to learn latent time series patterns on spatiotemporal graphs and address the dependency issues of time series.
- GraphWave [28]: Learns an adaptive adjacency matrix from data through end-to-end supervised training, retaining hidden spatial correlations through this adaptive adjacency matrix.
- R-DGATN: Replaces the Granger causality test graph-building process with a randomly generated adjacency matrix.
- S-DGATN: Replaces the Granger causality test graph-building process using the adjacency matrix of spatial adjacencies.
3.4. Comparative Experiments
3.5. Visualization Experiments
4. Results
4.1. Conclusions
4.2. Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Menapace, A.; Zanfei, A.; Felicetti, M.; Avesani, D.; Righetti, M.; Gargano, R. Burst Detection in Water Distribution Systems: The Issue of Dataset Collection. Appl. Sci. 2020, 10, 8219. [Google Scholar] [CrossRef]
- Zanfei, A.; Menapace, A.; Righetti, M. An Artificial Intelligence Approach for Managing Water Demand in Water Supply Systems. IOP Conf. Ser. Earth Environ. Sci. 2023, 1136, 012004. [Google Scholar] [CrossRef]
- Oliveira, P.J.; Steffen, J.L.; Cheung, P. Parameter Estimation of Seasonal ARIMA Models for Water Demand Forecasting Using the Harmony Search Algorithm. Procedia Eng. 2017, 186, 177–185. [Google Scholar] [CrossRef]
- Guo, B.T. Research on Irrigation Water Forecasting in Irrigation Districts Based on VAR and VEC Models; Chinese Hydraulic Engineering Society: Yichang, China, 2019. [Google Scholar]
- Li, Y.; Wei, K.K.; Chen, K.; He, J.Q.; Zhao, Y.; Yang, G.; Yao, N.; Niu, B.; Wang, B.; Wang, L.; et al. Forecasting monthly water deficit based on multi-variable linear regression and random forest models. Water 2023, 15, 1075. [Google Scholar] [CrossRef]
- Candelieri, A.; Giordani, I.; Archetti, F.; Barkalov, K.; Meyerov, I.; Polovinkin, A.; Sysoyev, A.; Zolotykh, N. Tuning hyperparameters of a SVM-based water demand forecasting system through parallel global optimization. Comput. Oper. Res. 2019, 106, 202–209. [Google Scholar] [CrossRef]
- Mu, L.; Zheng, F.F.; Tao, R.L.; Zhang, Q.Z.; Kapelan, Z. Hourly and daily urban water demand predictions using a long short-term memory based model. J. Water Resour. Plan. Manag. 2020, 146, 05020017. [Google Scholar] [CrossRef]
- Zanfei, A.; Menapace, A.; Granata, F.; Gargano, R.; Frisinghelli, M.; Righetti, M. An Ensemble Neural Network Model to Forecast Drinking Water Consumption. J. Water Resour. Plan. Manag. 2022, 148, 04022014. [Google Scholar] [CrossRef]
- Hu, P.; Tong, J.; Wang, J.C.; Yang, Y.; Turci, L.D. A hybrid model based on CNN and Bi-LSTM for urban water demand prediction. In Proceedings of the 2019 IEEE Congress on Evolutionary Computation, Wellington, New Zealand, 10–13 June 2019. [Google Scholar]
- Lin, Y.; Tao, T.; Xin, K.; Pu, Z.; Chen, L. Graph Deep Learning: Application on Water Distribution Network ShortTerm Water Demand Forecasting. Environ. Eng. 2023, 41, 149–153. [Google Scholar]
- Wen, Q.; Zhou, T.; Zhang, C.; Chen, W.; Ma, Z.; Yan, J.; Sun, L. Transformers in time series: A survey. arXiv 2022, arXiv:2202.07125. [Google Scholar]
- Nie, Y.; Nguyen, N.H.; Sinthong, P.; Kalagnanam, J. A Time Series Is Worth 64 Words: Long-Term Forecasting with Transformers. arXiv 2023, arXiv:2211.14730. [Google Scholar]
- Xu, M.; Dai, W.; Liu, C.; Gao, X.; Lin, W.; Qi, G.; Xiong, H. Spatial-Temporal Transformer Networks for Traffic Flow Forecasting. arXiv 2021, arXiv:2001.02908. [Google Scholar]
- Fang, Z.; Long, Q.; Song, G.; Xie, K. Spatial-Temporal Graph ODE Networks for Traffic Flow Forecasting. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Singapore, 14–18 August 2021; pp. 364–373. [Google Scholar]
- Jin, G.; Liang, Y.; Fang, Y.; Huang, J.; Zhang, J.; Zheng, Y. Spatio-temporal graph neural networks for predictive learning in urban computing: A survey. arXiv 2023, arXiv:2303.14483. [Google Scholar] [CrossRef]
- Tian, H.; Zheng, X.; Zeng, D.D. Analyzing the dynamic sectoral influence in Chinese and American stock markets. Phys. A Stat. Mech. Its Appl. 2019, 536, 120922. [Google Scholar] [CrossRef]
- Zhu, Y.; Gao, Y.; Wang, Z.; Cao, G.; Wang, R.; Lu, S.; Li, W.; Nie, W.; Zhang, Z. A Tailings Dam Long-Term Deformation Prediction Method Based on Empirical Mode Decomposition and LSTM Model Combined with Attention Mechanism. Water 2022, 14, 1229. [Google Scholar] [CrossRef]
- Hou, C.; Wei, Y.; Zhang, H.; Zhu, X.; Tan, D.; Zhou, Y.; Hu, Y. Stress Prediction Model of Super-High Arch Dams Based on EMD-PSO-GPR Model. Water 2023, 15, 4087. [Google Scholar] [CrossRef]
- Granger, C.W.J. Investigating causal relations by econometric models and cross-spectral methods. Econometrica 1969, 37, 424–438. [Google Scholar] [CrossRef]
- Grover, A.; Leskovec, J. Node2vec: Scalable Feature Learning for Networks. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD’16, San Francisco, CA, USA, 13–17 August 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 855–864. [Google Scholar]
- Jia, Z.; Li, H.; Yan, J.; Sun, J.; Han, C.; Qu, J. Dynamic Graph Convolution-Based Spatio-Temporal Feature Network for Urban Water Demand Forecasting. Appl. Sci. 2023, 13, 10014. [Google Scholar] [CrossRef]
- Jang, E.; Gu, S.; Poole, B. Categorical reparameterization with gumbel-softmax. arXiv 2016, arXiv:1611.01144. [Google Scholar]
- Feng, A.; Leandros, T. Adaptive Graph Spatial-Temporal Transformer Network for Traffic Flow Forecasting. arXiv 2022, arXiv:2207.05064. [Google Scholar]
- Yu, B.; Yin, H.T.; Zhu, Z.X. Spatio-temporal graph convolutional networks: A deep learning framework for traffic forecasting. In Proceedings of the 27th International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018. [Google Scholar]
- Guo, S.N.; Lin, Y.F.; Feng, N.; Song, C.; Wan, H.Y. Attention based spatio-temporal graph convolutional networks for traffic flow forecasting. In Proceedings of the 33rd AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019. [Google Scholar]
- Li, Y.G.; Yu, R.; Shahabi, C.; Liu, Y. Diffusion convolutional recurrent neural network: Data-driven traffic forecasting. arXiv 2018, arXiv:1707.01926v3. [Google Scholar]
- Huan, J.; Liao, W.; Zheng, Y.; Xu, X.; Zhang, H.; Shi, B. A Deep Learning Model with Spatio-Temporal Graph Convolutional Networks for River Water Quality Prediction. Water Supply 2023, 23, 2940–2957. [Google Scholar] [CrossRef]
- Wu, Z.; Pan, S.; Long, G.; Jiang, J.; Zhang, C. Graph WaveNet for Deep Spatial-Temporal Graph Modeling. arXiv 2019, arXiv:1906.00121. [Google Scholar]
- Shan, S.; Ni, H.; Chen, G.; Lin, X.; Li, J. A Machine Learning Framework for Enhancing ShortTerm Water Demand Forecasting Using Attention-BiLSTM Networks Integrated with XGBoost Residual Correction. Water 2023, 15, 3605. [Google Scholar] [CrossRef]
- Avesani, D.; Righetti, M.; Righetti, D.; Bertola, P. The Extension of EPANET Source Code to Simulate Unsteady Flow in Water Distribution Networks with Variable Head Tanks. J. Hydroinformatics 2012, 14, 960–973. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sensor ID | Short-Term Component | Middle-Term Component | Long-Term Component |
|---|---|---|---|
| #0 | −21.734020 ** | −20.205318 ** | −1.163319 |
| #1 | −21.315542 ** | −19.536680 ** | −4.237318 * |
| #2 | −21.614426 ** | −21.591233 ** | −2.414543 |
| #3 | −21.860299 ** | −24.189444 ** | −3.008508 * |
| #4 | −28.556480 ** | −18.525658 ** | −17.241111 ** |
| Short-Term Component | |||||
|---|---|---|---|---|---|
| Sensor ID | #0 | #1 | #2 | #3 | #4 |
| #0 | N/A | 0.0063 | 0.0000 | 0.0005 | 0.7162 |
| #1 | 0.0001 | N/A | 0.5182 | 0.0306 | 0.7539 |
| #2 | 0.0000 | 0.2087 | N/A | 0.0000 | 0.6710 |
| #3 | 0.0000 | 0.0009 | 0.0000 | N/A | 0.8560 |
| #4 | 0.2399 | 0.1041 | 0.7045 | 0.7180 | N/A |
| Middle-Term component | |||||
| Sensor ID | #0 | #1 | #2 | #3 | #4 |
| #0 | N/A | 0.0000 | 0.1025 | 0.0000 | 0.0000 |
| #1 | 0.0000 | N/A | 0.0000 | 0.0003 | 0.0014 |
| #2 | 0.0000 | 0.0000 | N/A | 0.0006 | 0.0055 |
| #3 | 0.0000 | 0.0000 | 0.0023 | N/A | 0.0037 |
| #4 | 0.0000 | 0.2030 | 0.0003 | 0.0000 | N/A |
| Long-Term component | |||||
| Sensor ID | #0 | #1 | #2 | #3 | #4 |
| #0 | N/A | N/A | N/A | N/A | N/A |
| #1 | N/A | N/A | N/A | N/A | N/A |
| #2 | N/A | N/A | N/A | 0.0000 | 0.1523 |
| #3 | N/A | 0.0033 | N/A | N/A | 0.0064 |
| #4 | N/A | 0.0021 | N/A | 0.0002 | N/A |
| Model | 15 min | 45 min | 90 min | Parameters | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MAE | RMSE | MAPE | R2 | MAE | RMSE | MAPE | R2 | MAE | RMSE | MAPE | R2 | ||
| ARIMA | 274.63 | 489 | 24.01% | 0.78 | 458.36 | 769.68 | 36.78% | 0.74 | 685.98 | 1284.34 | 48.69% | 0.72 | - |
| STGCN | 204.45 | 350.68 | 8.42% | 0.85 | 295.36 | 423.65 | 17.65% | 0.84 | 320.87 | 440.84 | 19.89% | 0.84 | 1.19M |
| ASTGCN | 149.69 | 330.36 | 6.12% | 0.94 | 250.34 | 396.51 | 14.80% | 0.92 | 300.88 | 423.56 | 18.86% | 0.90 | 1.35M |
| DCRNN | 150.73 | 327.21 | 8.95% | 0.92 | 260.85 | 401.35 | 16.24% | 0.85 | 340.88 | 450.08 | 21.63% | 0.85 | 1.46M |
| GNNLSTM | 120.89 | 298.93 | 8.26% | 0.93 | 263.45 | 398.24 | 15.98% | 0.88 | 311.25 | 424.54 | 18.01% | 0.92 | 2.03M |
| GraphWave | 123.04 | 270.85 | 7.23% | 0.93 | 258.36 | 411.98 | 15.01% | 0.91 | 329.84 | 448.01 | 18.68% | 0.89 | 1.16M |
| EG-DGATN | 92.29 | 190.48 | 4.01% | 0.97 | 218.63 | 298.64 | 10.47% | 0.96 | 222.45 | 302.27 | 11.69% | 0.94 | 1.22M |
| R-DGATN | 129.68 | 311.26 | 8.64% | 0.93 | 288.45 | 409.65 | 16.98% | 0.88 | 330.98 | 432.59 | 18.92% | 0.86 | 1.22M |
| S-DGATN | 126.68 | 309.47 | 8.89% | 0.93 | 283.95 | 403.84 | 16.03% | 0.88 | 329.63 | 433.44 | 19.01% | 0.86 | 1.22M |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, W.; Kang, Y. Ensemble Empirical Mode Decomposition Granger Causality Test Dynamic Graph Attention Transformer Network: Integrating Transformer and Graph Neural Network Models for Multi-Sensor Cross-Temporal Granularity Water Demand Forecasting. Appl. Sci. 2024, 14, 3428. https://doi.org/10.3390/app14083428
Wu W, Kang Y. Ensemble Empirical Mode Decomposition Granger Causality Test Dynamic Graph Attention Transformer Network: Integrating Transformer and Graph Neural Network Models for Multi-Sensor Cross-Temporal Granularity Water Demand Forecasting. Applied Sciences. 2024; 14(8):3428. https://doi.org/10.3390/app14083428
Chicago/Turabian StyleWu, Wenhong, and Yunkai Kang. 2024. "Ensemble Empirical Mode Decomposition Granger Causality Test Dynamic Graph Attention Transformer Network: Integrating Transformer and Graph Neural Network Models for Multi-Sensor Cross-Temporal Granularity Water Demand Forecasting" Applied Sciences 14, no. 8: 3428. https://doi.org/10.3390/app14083428