1. Introduction
With the continuous advancement of artificial intelligence technology, especially breakthrough developments in speech evaluation technology [
1,
2], large-scale scoring of spoken English exams has become a reality. This transformative technology not only improves the timeliness of evaluations but also enhances objectivity, significantly increasing the reference value of evaluation results. However, existing English spoken language evaluation software or platforms primarily focus on speech-based scoring, considering acoustic features such as pronunciation, frequency, and prosody while neglecting the evaluation of spoken emotions. In fact, emotions play an indispensable role in spoken expression, especially in actual communication, where the emotional expression of language is crucial. For Chinese students, there is a general deficiency in emotional expression, which is particularly evident in the process of learning English. Zhang [
3] believes that Chinese people often reflect on themselves when making mistakes. They are very low-key and rarely mention their achievements. Once they succeed, they often say it is not because of their own efforts but the help of their teachers or parents. Unlike this, people in Western countries advocate for individual efforts, especially those countries that have achieved brilliant military achievements. They often openly express their confidence and honor. Westerners have independent views on themselves and possess relative independence. Taking conversations between Asians and Westerners as an example, cultural differences may lead to significant variations in the expression and interpretation of the same emotions. In Western culture, individuals tend to express their emotions and feelings directly, while in Asian culture, people may be more reserved and indirect. Such differences can lead to misunderstandings and communication barriers. Therefore, incorporating emotional evaluation into the system is of great significance. It helps Chinese students to improve their ability to express emotions in the English language and enhances the evaluation system.
Currently, the discrete emotional model is primarily adopted to describe vocal emotions as independent labels without interrelation, among which the American psychologist Paul Ekman’s classification of six basic emotions—anger, disgust, fear, happiness, sadness, and surprise—is widely used in the current field of emotion-related research [
4]. Speech emotion recognition technology is the process of extracting feature parameters related to emotional representation from speech signals and establishing a mapping model between these feature parameters and emotional categories. Its core goal is to achieve the emotional classification of different speech samples. Despite the significant progress achieved in the field of emotion classification [
5,
6,
7,
8], existing research primarily focuses on classification with limited attention to the quantitative evaluation of emotions, especially in the application of spoken English learning assessments.
To objectively and automatically assess the emotional expression in students’ spoken English, this study meticulously constructs a specialized dataset for the evaluation of emotions in spoken English. This is achieved by leveraging existing public emotion datasets (such as IEMOCAP [
9]), self-generated emotional speech materials utilizing the large language model (LLM) strategy, and students’ emotional speech audio captured by ourselves. Based on the attention-based transformer model, emotional features are successfully decoupled from other speech characteristics like speech rate and intonation in English spoken audio. Deep formalized representations related to emotional features are thus extracted from speech, and a supervised learning method is employed to achieve the automated evaluation (scoring) of emotional expression in the English spoken language. In this study, for the first time in the context of voice communication scenarios, the automated evaluation of emotional expression in spoken English is realized. This enables this study to be specifically applicable in the context of Chinese students’ English oral practice. This advancement aids Chinese students in enhancing their ability to express emotions in spoken English. The main contributions of this paper are as follows:
Combining an LLM with the deep representation of features in the emotional space, this study successfully builds a deep learning framework for the evaluation of emotions in spoken English based on the transformer attention mechanism. This is a first in the academic community, achieving the automated evaluation of emotions in spoken English.
This study integrates emotional speech data generated by an LLM with existing public emotion datasets. Using frequency domain transformations and methods based on the transformer, combined with the membership function method in fuzzy mathematics, it effectively achieves the decoupling of emotional features from other sound features in spoken English and establishes the corresponding deep learning representation of emotional features.
Compared to current multimodal emotion recognition and evaluation methods, this research focuses on training and evaluating vocal emotional expression in spoken English. This not only provides rich emotional expression practice materials for learning spoken English but also automatically provides learners with feedback and evaluation on emotional expression during the learning process, opening a new path for Chinese students to enhance their spoken English abilities.
Section 2 will introduce relevant work related to this paper,
Section 3 will introduce the dataset, models, and methods used in this paper,
Section 4 will describe the experimental methods and results of this paper, and finally
Section 5 will summarize and discuss this paper.
2. Related Work
2.1. Emotion Analysis Research on Spoken Language
Current research primarily focuses on building and evaluating datasets with emotional labels for spoken English emotion analysis models, and significant achievements have been made in emotion classification. In this context, scholars continue to explore more innovative and effective methods. Representative research cases include the following: Paranjape et al. used Longformer, BERT, and BigBird models for emotion classification and combined these with a threshold voting mechanism to derive the final results [
10]; Chiorrini et al. utilized a BERT-based emotion classifier network for the sentiment classification of tweet data [
11]; additionally, Chaudhari et al. employed a vision transformer for facial emotion recognition [
12]. However, these works only use a single data source for emotion recognition and lack multimodal data sources. This leads to less accurate recognition results.
It is noteworthy that recently, an increasing number of scholars have started to use multimodal information as input for models to enhance the accuracy of emotion recognition: for instance, Pan et al. conducted a review of multimodal emotion recognition methods [
13]; Syed Zaidi et al. used a multimodal dual attention transformer for speech emotion recognition [
14]; Luna-Jiménez et al. proposed an automatic emotion recognizer model composed of speech and facial emotion recognizers [
15], demonstrating the potential of multimodal approaches in emotion recognition and providing new perspectives and directions for future research improvements; Siriwardhana et al. [
5] as well as Tripathi et al. [
6] employed text, audio, and visual inputs combined with self-supervised learning for emotion recognition; Wang et al. [
7] along with Voloshina et al. [
8] each proposed multimodal enhancement fusion methods based on the transformer to improve the accuracy of emotion recognition; and Vu et al. combined multimodal technology with scaled data to recognize emotions from internal human signals [
16].
As stated above, existing research focuses on classification and pays limited attention to the quantitative evaluation of emotions. Therefore, this paper aims to construct an English spoken language emotion evaluation framework based on the transformer attention mechanism by integrating an LLM with deep representations of effective space features. This framework is not only capable of classifying emotions but also possesses a quantitative evaluation function, making it particularly suitable for assessing students’ emotional expression abilities in spoken English.
2.2. Research on Decoupling of Vocal Emotional Features
In previous studies in this field, scholars typically used acoustic features and signal processing techniques to construct the emotional features of spoken pronunciation: for instance, Patel et al. [
17] explained the acoustic changes caused by emotions based on tension, perturbation, and occurrence frequency; and Kanluan et al. [
18] used prosody and spectral features to represent the audio characteristics of emotional speech and conducted a regression analysis with the help of support vector machines. Recently, with the advancement of deep learning technology, some studies have focused on using deep neural networks to more accurately capture and express emotional information in spoken pronunciation. For example, Islam et al. [
19] used three different transformation features, integrated them in a 3D form for input, and utilized deep learning models to recognize emotions in speech. Research in this area is valuable for enhancing the emotional perception capabilities of automatic speech recognition systems and the development of human-computer interaction fields. However, the studies described above limited their work to the use of datasets containing recordings of actual people (instead of combining these with materials created by an LLM). This led to a smaller volume of data and weaker models.
This study takes a step further from this basis by combining artificial intelligence generated content (AIGC) generative deep learning techniques, particularly the transformer model and the membership function method of fuzzy mathematics, to effectively decouple emotional features from other sound features in spoken English. The innovation of this method lies in its ability to more precisely capture and express emotional information in spoken pronunciation, thereby providing a more accurate and robust data foundation for speech emotion recognition.
2.3. Research on the Application of AI in Educational Evaluation
In past studies, scholars have consistently emphasized the importance of emotions in the educational process, arguing that paying attention to students’ emotional states is crucial for effective learning, and some progress has been made [
20]. Orji et al. [
21] and Melweth et al. [
22] have shown, from different perspectives, a moderate positive correlation between the frequency of artificial intelligence usage and teaching capabilities. Despite certain advancements in modern educational technology in integrating AI, most applications are still focused on the transmission of knowledge and the assessment of English pronunciation accuracy, with less attention being paid to students’ emotional expression in spoken English. This has led to a widespread view that AI in student education needs to focus more on emotional aspects, offering a warmer and more humanized educational concept: Liefooghe et al. [
23] believe that models in artificial intelligence should be more humanized in their optimization, promoting the development of personalized adaptation in artificial intelligence; Shao et al. [
24] proposed that the application of AI technology in education should adhere to a people-oriented concept, further promoting the integration of personalization into education; Martínez-Miranda et al. [
25] elucidated the importance of emotions in human intelligence and that computers aimed at mimicking human behavior should not only think and reason but also be able to exhibit human emotions. These works have a profound impact on improving the user experience of educational systems, enhancing learning effects, and promoting personalized teaching. However, many existing AI applications or systems in education have not yet fully integrated emotional intelligence. For example, Liu [
26] preliminarily applied emotion recognition technology in psychological education, which was still insufficient for the comprehensive perception and evaluation of students’ emotional expression states.
This study, by incorporating emotion recognition technology into spoken English learning, not only provides learners with a wealth of materials for practicing emotional expression but also automatically offers timely feedback and evaluation on learners’ emotional expressions. The innovation of this method lies in its focus not only on knowledge transfer but also on the emotional experience of students, promoting a personalized and humanized educational experience, which is conducive to enhancing students’ learning outcomes and the overall educational experience.
3. Method and Model
This study develops a method that integrates an LLM with emotional representation for analyzing and scoring the emotional content in students’ spoken English audio samples. Firstly, using the text and emotional labels from the IEMOCAP dataset, emotionally rich corresponding speech data is synthesized through the LLM. Subsequently, the synthesized speech data is combined with the audio from the IEMOCAP dataset and student spoken language samples to form a comprehensive dataset. Next, an emotion feature encoding network based on the transformer architecture is introduced to deeply extract emotional features from the audio. Finally, an English spoken language emotion evaluation network is designed, which enables the regression analysis and precise (accurate) scoring of students’ emotional expression in spoken English. The overall framework is illustrated in
Figure 1 and specifically includes the following three components:
Step 1. LLM for emotion voice synthesis: the LLM, Typecast [
27], is utilized in this paper to synthesize emotional voice by integrating textual content with emotional labels. This synthesized audio, combined with the IEMOCAP dataset audio and collected students’ spoken language samples, is used to construct a comprehensive dataset for evaluating emotions in students’ spoken language.
Step 2. Emotion feature encoding network: The paper introduces an emotion feature encoding network based on the transformer model, aimed at deeply extracting the emotional spatial features from the audio. This network is capable of eliminating the influence of factors such as timbre, pitch, and content in the audio, ensuring that the emotional features are independent of other audio information. This independence enhances the accuracy of the evaluation.
Step 3. Emotion evaluation network: The paper designs an English spoken language emotion evaluation network, aimed at achieving the accurate scoring of emotional expression in students’ spoken English. For any input of student spoken audio (accompanied by emotion labels), the process begins by utilizing the corresponding text and emotion labels to generate TTS synthesized speech through the LLM. Subsequently, the actual student spoken audio and the TTS synthesized speech are separately input into the emotion feature encoding network, resulting in the corresponding emotion feature encodings. These two types of encodings, along with the emotion mean feature vectors of the IEMOCAP audio dataset corresponding to the emotion labels, are collectively fed into the emotion evaluation network. This process can be treated as a regression problem, where the emotion evaluation network is coarse-tuned through similarity calculations of emotional features extracted from the three types of audios and fine-tuned based on teachers’ scoring. This method allows for the precise scoring of emotional expression in students’ spoken language audio. For a detailed description of the training process, please refer to
Section 3.3.
3.1. Dataset
In this study, audio data from the IEMOCAP dataset, synthetic audio, and students’ spoken English audio are used as the primary data sources. These audio recordings undergo noise addition, speed variation, pitch alteration, and other preprocessing steps to create a comprehensive dataset consisting of 54,464 audio samples. Specifically, this dataset comprises three main components.
3.1.1. IEMOCAP Dataset Audio
IEMOCAP (interactive emotional dyadic motion capture) is a specialized multimodal emotion dataset designed to provide rich resources for research on human emotion expression and recognition. This study focuses on the dialogue portion of the dataset, which includes natural conversations recorded with ten professional actors. These dialogues take place in various contexts and aim to simulate emotional communication in real-life situations. The data includes scripted dialogues as well as spontaneous, emotionally rich interactions, covering a wide range of emotions such as anger, sadness, excitement, surprise, and more. The content of these dialogues holds significant research value and is essential for gaining a deeper understanding of human emotion expression and recognition.
In the data preprocessing phase of this research, 3106 speech samples were selected from the dataset. These samples not only include the speech content but also record the duration of the speech and emotional evaluations. The emotional evaluation part was completed by 3–4 expert evaluators who categorized the emotion of each speech sample into six types: frustration, sadness, anger, neutral, happiness, and excited.
3.1.2. TTS Speech Synthesized Audio
Based on the 3106 dialogues from the IEMOCAP dataset along with their emotional annotations, 2892 speech samples were synthesized using the TTS model, Typecast, ensuring that each synthesized speech corresponds to the highest-scoring emotional category from the original speech’s emotional annotations during the synthesis process.
3.1.3. Student-Recorded Spoken Audio and Teacher Emotional Evaluation Scores
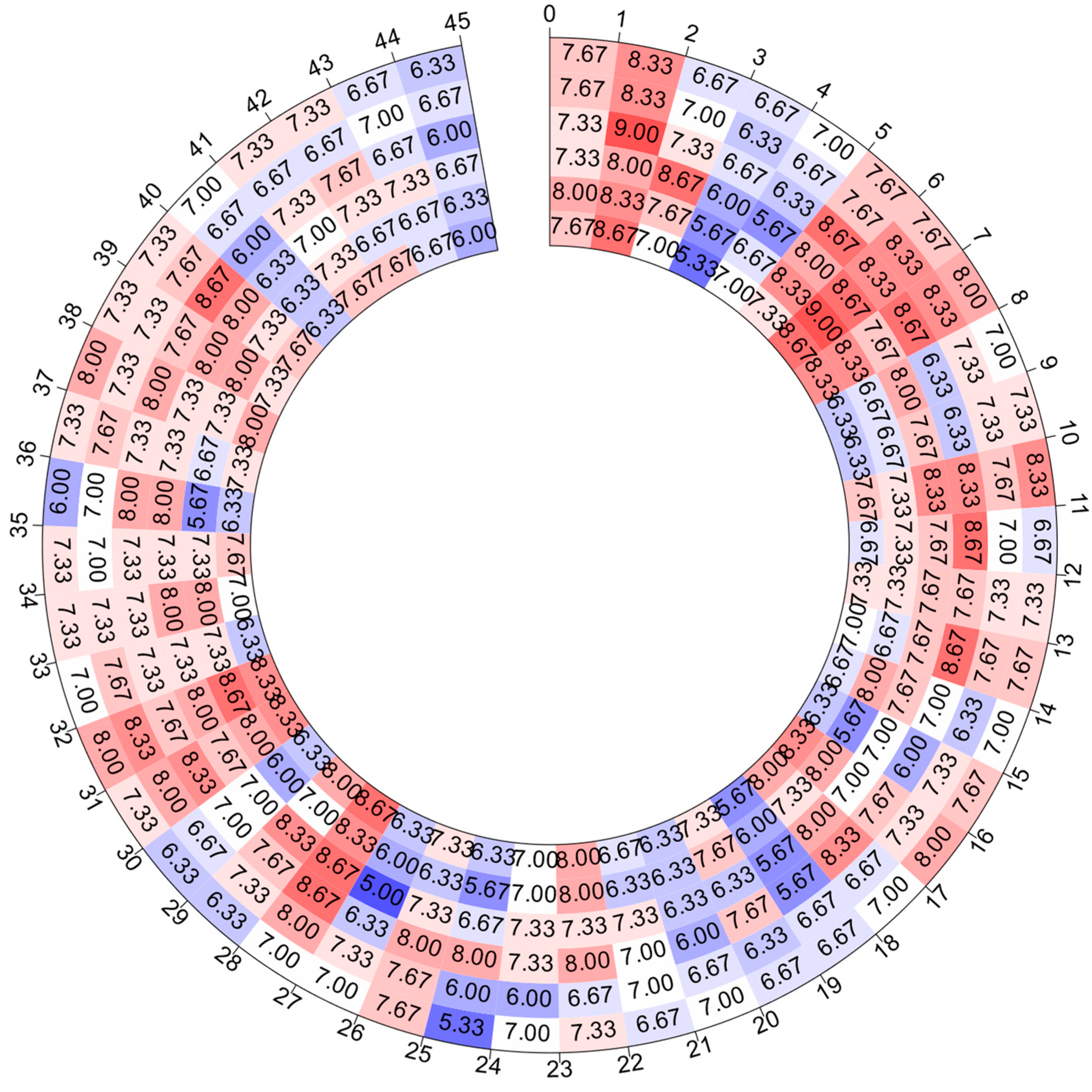
To implement the proposed oral speech emotion evaluation method in actual teaching scenarios for this research, a total of 45 students recorded 810 oral speech audio samples based on 18 representative dialogues from the IEMOCAP dataset. These audio recordings cover the six emotions contained in the 810 dialogues from the IEMOCAP dataset. During the recording process, students referred to the emotional annotations in the IEMOCAP dataset to express the corresponding emotions as accurately as they could. Additionally, we formed a team consisting of English teachers who were responsible for assessing the emotional richness of the recordings. These teacher ratings served as crucial reference standards for the emotional evaluation model used in model training, evaluation, and optimization.
Figure 2 displays the distribution of scores, including the average spoken scores for each emotion category for each student. The scores on the heat map indicate the degree of high or low scores on oral emotional expression, with the more reddish colors corresponding to higher scores, and the more purplish colors corresponding to lower scores. The different colors and shades of colors can better show the students’ oral emotional expression scores and their distribution.
From
Figure 2, it can be observed that for the majority of students, their ability to express various emotions is consistent. For the same students, their evaluation scores for six types of emotions are distributed around the same value. Only a few students show excellent performance in expressing a specific emotion, as evidenced by significantly higher evaluation scores for one particular type of emotion compared to others.
3.2. Emotional Voice Synthesis Using LLM
3.2.1. English Spoken Language Emotion Synthesis Method and Fine-Tuning of LLM
To ensure sufficient augmentation of the dataset and to provide an accurate reference standard for the subsequent student emotion evaluation network, this study employed an LLM based on the transformer architecture with a masked self-attention mechanism. This model successfully generated 2892 emotionally rich speech data entries, further enhancing the diversity of the dataset. The self-attention mechanism played a central role in this process, enabling the model to more accurately capture and process emotional information.
The overall structure, as shown in
Figure 3, illustrates that the model consists of a series of encoders and decoders. The encoders are responsible for transforming the input text into feature representations, while the decoders utilize these feature representations to generate the corresponding speech output. This design allows the model to flexibly adjust its focus on different parts of the text, thereby better capturing and expressing emotional information.
The LLM based on the Transformer architecture not only demonstrated its capability in handling emotional text but also highlighted its crucial role in emotional voice synthesis technology. The audio generated is not only suitable for assessing students’ spoken language skills but can also serve as standardized audio materials, providing learning guidance for students.
3.2.2. Emotion Label Determination Based on Membership Functions
To enhance the capability of the feature encoding network in extracting emotional features from audio, 2892 text samples were carefully selected with emotional labels based on the IEMOCAP dataset. The LLM, Typecast, was used to generate emotionally expressive spoken audio for these texts. In the IEMOCAP dataset, each speech sample has 3–4 different emotional labels annotated by experts. To determine the primary emotional label for the selected texts, we employed a membership function calculation method based on the normal distribution. This function accurately assesses the membership of each sentence in the IEMOCAP dataset based on six different emotions. Specifically, we utilize the following membership function formula:
where
and
represent the average occurrence and standard deviation of the corresponding emotional evaluation in each sample in the IEMOCAP dataset, respectively, and
x denotes the occurrence count of the corresponding emotional evaluation in each sample. Subsequently, by analyzing the performance of the six emotions, the primary emotional label for each sentence was determined. The method of calculating the primary emotional label for samples accurately captures the information entropy of different emotions within the samples. Information entropy represents the uncertainty of emotional labels in the dataset, and information gain measures the reduction in entropy before and after splitting the dataset using emotional features. The parameters
and
for the membership function are chosen based on the feature with the highest information gain.
3.3. Deep Representation of Emotional Features in Spoken English
To unify the feature representation of different audios in the emotional space, an emotion feature encoding network was introduced here based on the transformer architecture. Firstly, a short-time Fourier transform (STFT) was applied to both the audio from the IEMOCAP dataset and the synthesized audio to convert the time-domain representation into a frequency-domain representation. Specifically, the STFT transformation formula is as follows:
where
represents the short-time Fourier transform at time
and frequency
,
denotes the input discrete signal, and
represents the length of the discrete window function signal. The application of a short-time Fourier transform in emotional encoding networks involves transforming the time-domain space into a frequency-domain space, providing a balance between time and frequency. This process significantly mitigates the influence of factors such as emphasis and accent, enabling the network to extract emotional features primarily from the audio and accurately capture the emotion-related characteristics of the audio in a precise and effective manner.
The training process of the emotion feature encoding network is shown as Step 2 in
Figure 1. Firstly, after the spoken audio data input (comprising mainly synthesized audio and audio from the IEMOCAP dataset) underwent a STFT, the corresponding frequency-domain features were obtained. Subsequently, these features were passed through the emotion feature encoding network, which consists of multiple layers of perceptions (MLP) and a transformer, to extract and encode the emotional features of the audio. Next, the features were further processed using an emotion recognition network composed of an MLP network for emotion classification. Using emotional labels, the parameters of the emotion feature encoding network and emotion recognition network were optimized with cross-entropy loss. In this process, because the network can identify corresponding emotional classifications through the intermediate features passed through the encoding network and inputted into the emotion recognition network, these intermediate features are regarded as the output of the emotional feature encoding network. These intermediate features represent a more abstract and meaningful representation of the emotional information in the audio.
To enhance the robustness of the emotion feature encoding network, this study conducted rigorous adjustments to the classifications within the dataset [
28]. The original six emotional labels, including frustration, sadness, anger, neutral, happiness, and excited, were streamlined to four categories, namely sadness, anger, neutral, and happiness. The frustration category was discarded due to its relatively low count, and the happiness and excitement categories were merged into a single happiness category, as suggested by Sahu [
29].
During the training process, to further enhance the model’s robustness, the research team applied various forms of data augmentation to the audio data. This included operations such as pitch shifting, accelerated audio playback, and the addition of Gaussian noise. The design and adjustments in these training processes aimed to make the emotion feature extraction network more robust, providing a more reliable foundation for the deep extraction of emotional information from audios.
Through the aforementioned methods, the effective extraction of emotional features was achieved in English spoken language audio, leading to the establishment of corresponding deep learning representations of emotional features.
3.4. Assessment of Emotional Expression in English Spoken Language
To assess the emotional expression in students’ spoken language audio, an emotion evaluation network was designed in this paper to analyze and evaluate emotional features from three types of audios in the previously constructed dataset, ultimately yielding emotional scores for students’ spoken language audio. The network structure is shown as Step 3 in
Figure 1. Firstly, the audio from the IEMOCAP dataset, students’ spoken language audio, and synthesized audio were individually subjected to short-time Fourier transforms (STFT) to convert them from the time-domain space to the frequency-domain space. Subsequently, these frequency-domain representations were fed into the emotion feature encoding network to extract emotional features from the three types of audios. These emotional features were then processed through a MLP to obtain the final emotion evaluation scores, and the network was trained using mean squared error (MSE) loss.
During the training process, a two-stage approach consisting of coarse-tuning and fine-tuning was employed. Firstly, the coarse-tuning stage was conducted, followed by the fine-tuning stage. The specific procedures for each stage are outlined below.
Coarse-tuning Stage: Firstly, we calculated the cosine similarity between the emotional features of the audio from the IEMOCAP dataset and the emotional features of the other two types of audios. Then, using the cosine similarity between the audio from the IEMOCAP dataset and the synthesized audio as a reference, this reference was compared to the cosine similarity between the audio from the IEMOCAP dataset and the students’ spoken language audio. By calculating the ratio of the difference between the two to the reference similarity and applying Equation (3), a preliminary emotional evaluation score for students’ spoken language was obtained. The specific formula for calculating the evaluation score is as follows:
where
is the cosine similarity of emotional features between audio from the IEMOCAP dataset and synthesized audio,
is the cosine similarity of emotional features between students’ spoken language audio and audio from the IEMOCAP dataset, and
is the median of teachers’ ratings for students’ spoken language. During the coarse-tuning process, only the emotion evaluation network was trained without altering the model parameters of the emotion feature encoding network;
Fine-tuning Stage: In this stage, based on the teachers’ ratings for students’ emotional expression in spoken language, the emotion evaluation network was fine-tuned with the objective of minimizing the mean squared error between the predicted results and teachers’ ratings. During the fine-tuning process, the parameters of the entire network, including both the emotion feature encoding network and the emotion evaluation network, were trained comprehensively.
The loss function for the network in the paper is divided into coarse-tuning loss function,
Lcoarse, and fine-tuning loss function
Lfine, both of which use mean squared error (MSE) loss. Specifically, the loss function formula is as follows:
where, during coarse training,
equals 1 and
equals 0, and during fine training,
equals 0.1 and
equals 1. When the model underwent fine-tuning, lambda values were set to 0.1 and 1 in order to bias the model more towards teacher ratings while also considering the objective factors from the coarse-tuning stage. Through this design, the combination of reference similarity and cosine similarity of students’ audio allowed the network to effectively learn and adjust in both training stages, resulting in more accurate emotional evaluation results.
4. Experiments and Analysis
4.1. Evaluation Metrics
Two main metrics, F1 score and unweighted accuracy (UA), are used in this paper to assess the performance of the emotion feature encoding network. Below is an introduction to these two metrics.
F1 score: The F1 score is a measure that takes into account both precision and recall, providing a balanced assessment of the model’s performance. It is the harmonic mean of precision and recall, making it robust for datasets with imbalanced classes. Specifically, a higher F1 score indicates that the model maintains precision while achieving a higher recall, which means it handles the imbalance between positive and negative cases better. The equation for F1 is as follows.
Unweighted accuracy (UA): Unweighted accuracy refers to the average accuracy of the model across all categories, without considering the number of samples in each category. This allows unweighted accuracy to fairly assess datasets with imbalanced classes, unaffected by sample distribution. By using unweighted accuracy, we can gain a more comprehensive understanding of the overall performance of the model across different categories. Its equation is as follows.
where T represents the correctly predicted sample count, and F represents the falsely predicted sample count.
For the emotion evaluation network, mean squared error (MSE) is chosen as the primary evaluation metric. MSE measures the average of the squares of differences between the model’s predicted outputs and the teachers’ scores. In the context of emotion evaluation, MSE provides a measure of the model’s regression performance on emotion values.
The selection of these evaluation metrics aims to provide a comprehensive understanding of the model’s accuracy, recall, and adaptability to imbalanced data, offering a thorough assessment of model performance.
4.2. Performance Evaluation of Emotion Encoding Network
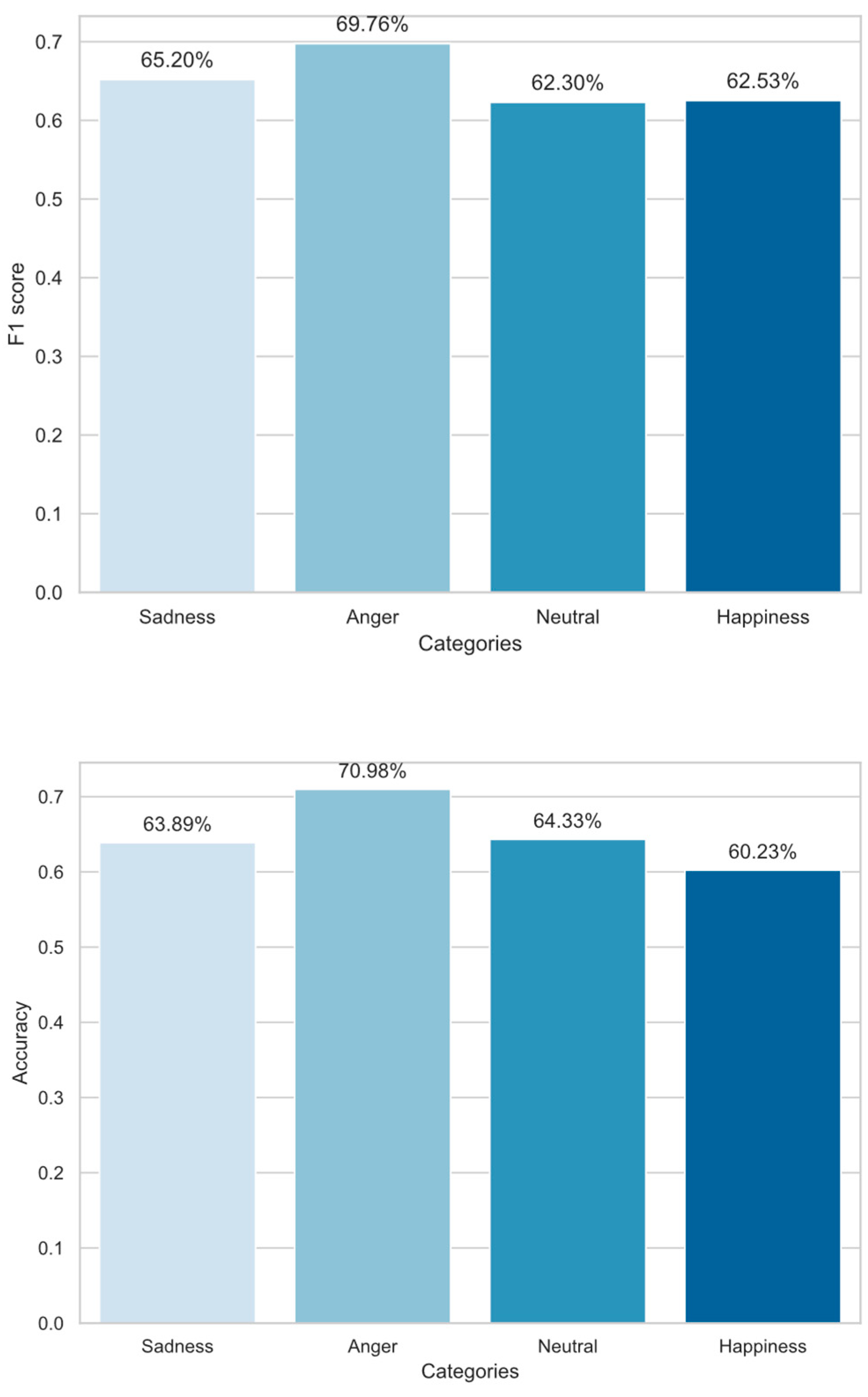
As shown in Step 2 in
Figure 1, the transformer-based emotion encoding network is utilized for emotion recognition experiments on audio from the IEMOCAP dataset and synthesized audio. The experiments covered both raw audio and audio that underwent specific augmentation processing, aiming to comprehensively assess the model’s performance. Considering the specific application context of this research, which is students’ English spoken language emotion evaluation, only spoken audio and their corresponding text were used as input data, and no image information was introduced. Furthermore, following the established method mentioned in the previous section, the 6-class problem of the dataset was adjusted to a 4-class problem to simplify the classification task. The experimental dataset includes 35,248 speech recordings. Detailed experimental results are as shown in
Figure 4.
In this research, the emotion recognition method proposed achieved an unweighted accuracy (UA) of 66.6%, surpassing the DialogueCRN algorithm for multimodal emotion recognition, which includes video, audio, and text, with an accuracy of 66.2% [
30]. The F1 score also reached 64.1%, ensuring that the algorithm has robustness to accommodate various differences in student speech tones, with a focus on accuracy in spoken language emotion expression. The research method utilized only audio and text as inputs, relying solely on speech emotion features for feature extraction, achieving accuracy comparable to multimodal emotion recognition that includes video. This demonstrates the clear research significance of spoken language emotion recognition in the context of speech environments. The research objective in this paper was to extract emotion features for subsequent score calculation. The experimental results prove that the emotion encoding network excels in extracting audio emotion features and exhibits good robustness under data augmentation conditions.
4.3. Effectiveness of Emotion Feature Similarity Evaluation
The emotion feature encoding network constructed in this paper aimed to accurately extract and encode emotional features from speech. By comparing cosine similarities between emotion feature vectors, corresponding evaluation scores were derived, providing strong support for the quantitative analysis of emotional features. The data distribution is depicted in
Figure 5, with the central horizontal line representing the average data distribution.
Figure 5 illustrates that the distribution of emotion scores calculated using cosine similarity is relatively broad, while the distribution of teacher ratings is comparatively narrow. This further confirms that the former can provide a more objective assessment of students’ spoken emotional features, whereas the latter may be influenced by encouragement or other factors, reducing the occurrence of very low or perfect scores, which is more in line with practical application requirements. Therefore, during the training stages of the emotion evaluation network, a two-stage approach involving coarse-tuning and fine-tuning was employed, harnessing the advantages of both scores to compensate for their respective limitations.
4.4. Performance Evaluation of the Emotion Evaluation Network
As shown in Step 3 (Training the emotion evaluation network) in
Figure 1, a quantitative analysis of emotions was conducted in student spoken audio, and corresponding scores were generated. This process is divided into two main stages: coarse tuning and fine-tuning. In the coarse-tuning stage, the emotion feature encoding network played a crucial role in extracting emotional features from input audio. By comparing the cosine similarity between the IEMOCAP dataset audio, synthesized audio, and student spoken audio, emotion evaluation scores for students spoken audio were generated, which were subsequently used to train the emotion evaluation model. In the fine-tuning stage, the model was further trained using teachers’ ratings. Mean squared error (MSE) was used as the primary evaluation metric for this part. Detailed experimental results are available in
Figure 6.
In the coarse-tuning stage (represented by the blue dotted line), the model’s mean squared error (MSE) is 2.808. However, in the fine-tuning stage (represented by the orange dotted line), this value decreases to 0.847. As shown in the above graph, during the coarse-tuning stage, the model is in its early training phase, and the loss function decreases rapidly but lacks precision. In contrast, during the fine-tuning stage, the model starts from a lower initial point in terms of loss. Although there may be some fluctuations in loss at the beginning, it demonstrates a stable trend over time.
The experimental results clearly demonstrate that the emotion evaluation network exhibits accuracy in evaluating emotions in student spoken language. The higher mean squared error (MSE) during the coarse-tuning stage may reflect the model’s initial understanding of spoken language emotions during the early learning phase. However, with professional guidance from teachers, the MSE significantly decreases during the fine-tuning stage. This strongly indicates that after careful adjustments, the model’s evaluation results become increasingly consistent with the assessments made by professional teachers.
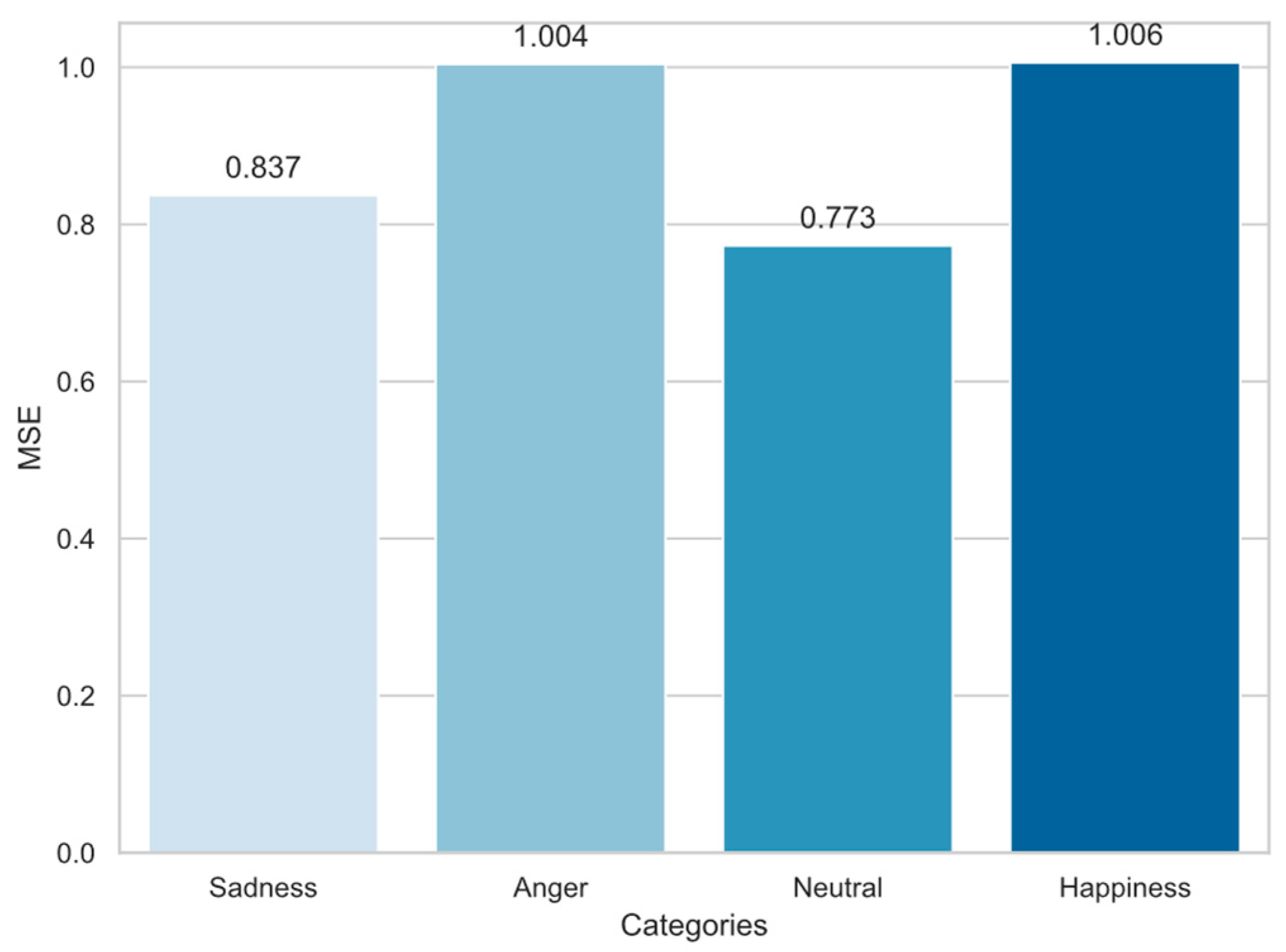
During the inference stage, the evaluation metrics for the four emotion sentiment models obtained by the proposed method are presented in
Figure 7. The mean square error (MSE) for each emotion category is as follows: sadness is 0.837, anger is 1.004, neutral is 0.773, and happiness is 1.006. Through validation, it has been confirmed that the emotion evaluation network is effective and reliable in assessing emotions in student spoken language. As the model continues to learn and adapt, it gradually approaches the assessment level of professional teachers, providing a dependable auxiliary tool for spoken language instruction.
4.5. Experimental Conclusion
After comprehensive experimental validation, the emotion evaluation method proposed in this paper has demonstrated satisfactory results in evaluating the emotion performance in students’ spoken English, thanks to the good performance of the LLM in emotional speech generation, transformer-based emotion encoding networks in emotion feature representation, and emotion evaluation networks in emotion score regression, respectively.
This method is not only versatile but also practical, which provides advanced and effective means for English spoken language learning and emotion evaluation and is expected to provide strong tool support in the field of spoken language education, offering high practical value.
5. Conclusions and Prospects
In the context of artificial intelligence and speech assessment technology, this research has made pioneering strides by incorporating emotion evaluation into the English spoken language evaluation system. By combining an LLM and emotion feature learning, this study has successfully achieved in-depth representation and automatic evaluation of emotional features in English spoken language. This method not only fills the gap in the emotional dimension of existing spoken English language evaluation software but also addresses the specific shortcomings of Chinese students in emotional expression, providing an effective path for improvement.
With further advancements in artificial intelligence technology, we anticipate optimizing and expanding upon this research method. Future research will continue to refine and enhance the English spoken language emotion analysis model, increasing its capability to recognize more complex and nuanced emotional expressions.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






