
Incorporating Multi-Temporal Remote Sensing and a Pixel-Based Deep Learning Classification Algorithm to Map Multiple-Crop Cultivated Areas



Abstract
:1. Introduction
2. Materials and Methods
2.1. Study Area
2.2. Data
2.2.1. MODIS Images and Preprocessing
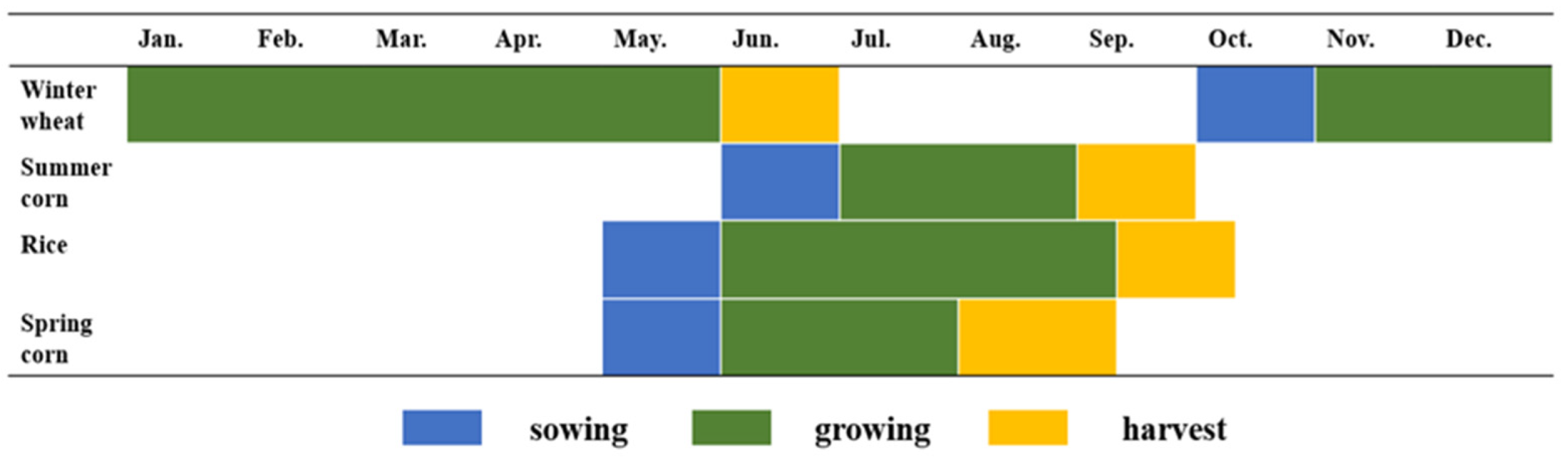
2.2.2. Reference Samples
2.2.3. Cropland Mask
2.3. Methodology
2.3.1. Pixel-Based One-Dimensional Convolutional Neural Network (PB-Conv1D)
2.3.2. Pixel-Based Bi-Long Short-Term Memory (PB-BiLSTM)
2.3.3. Pixel-Based Transformer (PB-Transformer)
2.3.4. Snapshot Ensemble Cyclic Learning Rate
2.3.5. Stochastic Weighted Averaging (SWA)
2.3.6. Ensemble Classifier
2.3.7. Accuracy Assessment
3. Results
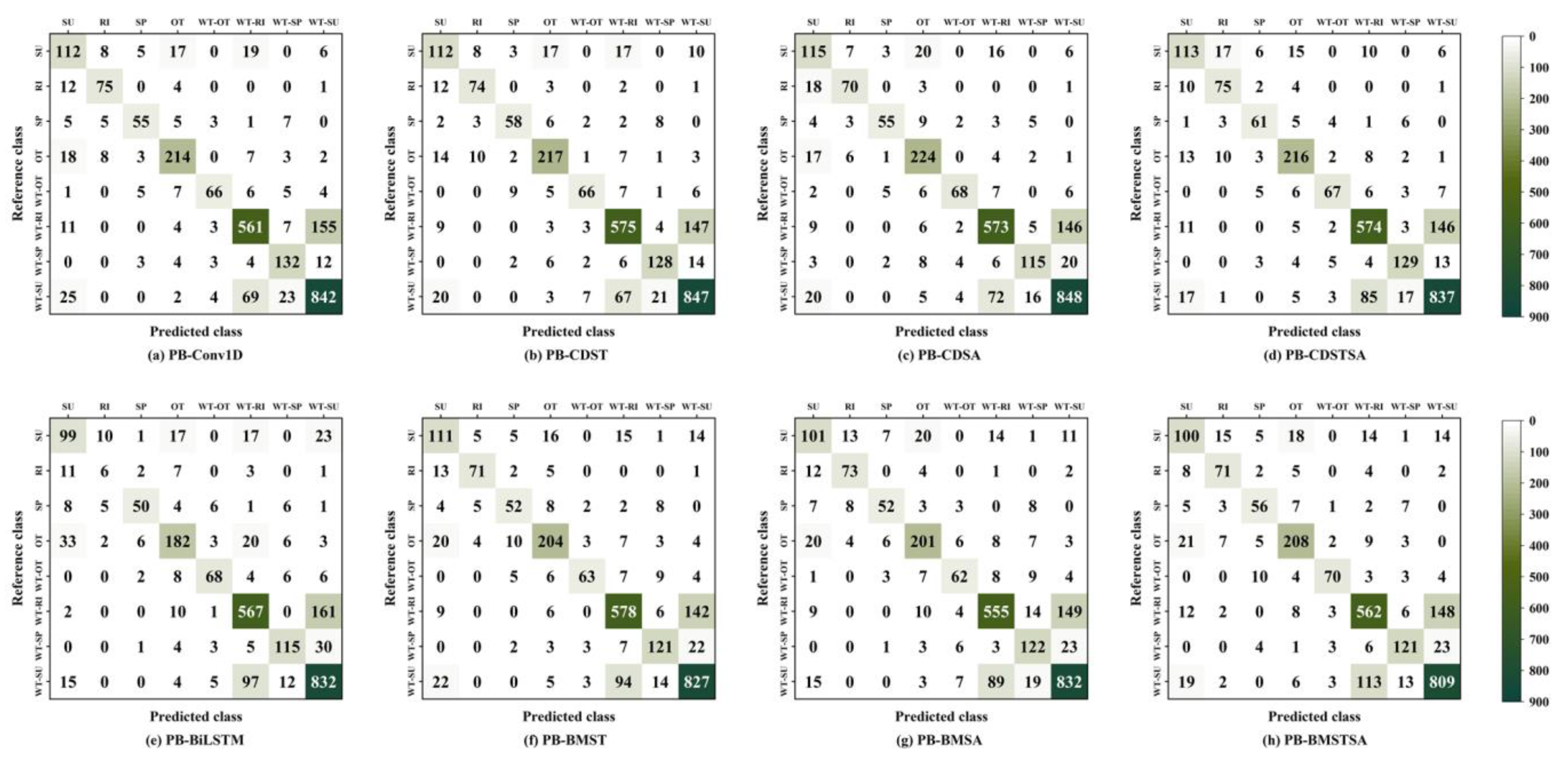
3.1. Evaluate a Single Classification Model
3.2. Evaluation of the Ensemble Classifier
3.3. Multiple-Crop Classification Map
3.4. Accuracy Assessment with Statistical Data
4. Discussion
4.1. Advantage of the Ensemble Model
4.2. Uncertainty and Potential Refinements
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Confusion Matrix


Appendix B. Performance Matrix of Various Model

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Unit/% | SU | RI | SP | OT | WT- OT | WT- RI | WT- SP | WT- SU | OA. | Kappa | Weighted F1 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PB-Conv1D | P.A. | 67.07 | 81.52 | 67.9 | 83.92 | 70.21 | 75.71 | 83.54 | 87.25 | 80.57 | 74.11 | 80.55 |
| UA. | 60.87 | 78.13 | 77.46 | 83.27 | 83.54 | 84.11 | 74.58 | 82.39 | ||||
| F1 | 63.82 | 79.79 | 72.37 | 83.59 | 76.30 | 79.69 | 78.81 | 84.75 | ||||
| PB-CDST | P.A. | 67.07 | 80.43 | 71.6 | 85.1 | 70.21 | 77.6 | 81.01 | 87.78 | 81.36 | 75.09 | 81.29 |
| UA. | 66.27 | 77.89 | 78.38 | 83.46 | 81.48 | 84.19 | 78.53 | 82.39 | ||||
| F1 | 64.79 | 78.65 | 74.83 | 83.58 | 78.16 | 80.59 | 76.41 | 85.1 | ||||
| PB-CDSA | P.A. | 68.86 | 76.09 | 67.90 | 87.84 | 72.34 | 77.33 | 72.78 | 87.88 | 81.00 | 74.60 | 80.96 |
| UA. | 61.17 | 81.4 | 83.33 | 79.72 | 85.00 | 84.14 | 80.42 | 82.49 | ||||
| F1 | 66.67 | 79.14 | 74.84 | 84.27 | 75.43 | 80.76 | 79.75 | 85.00 | ||||
| PB-CDSTSA | P.A. | 67.66 | 81.52 | 75.31 | 84.71 | 71.28 | 77.46 | 81.65 | 86.74 | 81.16 | 74.90 | 81.11 |
| UA. | 68.48 | 70.75 | 76.25 | 83.08 | 80.73 | 83.43 | 80.63 | 82.79 | ||||
| F1 | 68.07 | 75.76 | 75.78 | 83.88 | 75.71 | 80.34 | 81.13 | 84.72 | ||||
| PB-BiLSTM | P.A. | 59.28 | 79.31 | 61.73 | 71.37 | 72.34 | 76.52 | 72.78 | 86.22 | 77.59 | 69.73 | 77.47 |
| UA. | 58.93 | 80.00 | 80.65 | 77.12 | 79.07 | 79.41 | 79.31 | 78.71 | ||||
| F1 | 59.10 | 76.84 | 69.93 | 74.13 | 75.56 | 77.94 | 75.91 | 82.29 | ||||
| PB-BMST | PA. | 66.47 | 77.17 | 64.20 | 80.00 | 67.02 | 78.00 | 76.58 | 85.70 | 79.40 | 72.44 | 79.37 |
| UA. | 62.01 | 83.53 | 68.42 | 80.63 | 85.14 | 81.41 | 74.69 | 81.56 | ||||
| F1 | 64.16 | 80.23 | 66.24 | 80.32 | 75.00 | 79.67 | 75.63 | 83.58 | ||||
| PB-BMSA | PA. | 60.48 | 79.35 | 64.20 | 78.82 | 65.96 | 74.90 | 77.22 | 86.22 | 78.26 | 70.99 | 78.26 |
| UA. | 61.21 | 74.49 | 75.36 | 80.08 | 70.45 | 81.86 | 67.78 | 81.25 | ||||
| F1 | 60.84 | 76.84 | 69.33 | 79.45 | 68.13 | 78.22 | 72.19 | 83.66 | ||||
| PB-BMSTSA | PA. | 59.88 | 77.17 | 69.14 | 81.57 | 74.47 | 75.84 | 76.58 | 83.83 | 78.22 | 70.93 | 78.19 |
| UA. | 60.60 | 71.00 | 68.29 | 80.93 | 85.37 | 78.82 | 78.57 | 80.90 | ||||
| F1 | 60.24 | 73.96 | 68.71 | 81.25 | 79.55 | 77.30 | 77.56 | 82.34 | ||||
| PB-Transformer | PA. | 61.68 | 75.00 | 61.73 | 77.65 | 57.45 | 72.87 | 68.35 | 88.19 | 77.28 | 69.61 | 77.24 |
| UA. | 60.59 | 76.67 | 66.67 | 81.48 | 70.13 | 85.04 | 55.96 | 79.53 | ||||
| F1 | 61.13 | 75.82 | 64.10 | 79.52 | 63.16 | 78.49 | 61.54 | 83.64 | ||||
| PB-TRST | PA. | 65.27 | 79.35 | 58.02 | 84.31 | 60.64 | 74.09 | 62.66 | 86.94 | 77.87 | 70.41 | 77.72 |
| UA. | 64.88 | 75.26 | 63.51 | 79.93 | 67.86 | 83.06 | 63.87 | 80.29 | ||||
| F1 | 65.07 | 77.25 | 60.65 | 82.06 | 64.04 | 78.32 | 63.26 | 83.48 | ||||
| PB-TRSA | PA. | 47.9 | 75.00 | 48.15 | 72.94 | 22.34 | 69.91 | 36.71 | 87.98 | 71.29 | 60.79 | 70.09 |
| UA. | 56.34 | 65.71 | 76.47 | 65.72 | 80.77 | 75.73 | 51.32 | 73.89 | ||||
| F1 | 51.78 | 70.05 | 59.09 | 67.14 | 35.00 | 72.70 | 42.80 | 80.32 | ||||
| PB-TRSTSA | PA. | 62.28 | 77.17 | 62.96 | 83.92 | 58.51 | 74.76 | 67.09 | 86.42 | 77.91 | 70.47 | 77.79 |
| UA. | 63.03 | 78.89 | 68.92 | 79.55 | 65.48 | 82.93 | 65.03 | 80.19 | ||||
| F1 | 62.65 | 78.02 | 65.81 | 81.68 | 61.80 | 78.64 | 66.04 | 83.19 | ||||
| PB-CV | PA. | 71.26 | 80.43 | 72.84 | 85.10 | 70.21 | 78.14 | 83.54 | 88.08 | 82.10 | 76.07 | 82.05 |
| UA. | 67.61 | 83.15 | 79.73 | 83.14 | 83.54 | 85.02 | 80.49 | 82.60 | ||||
| F1 | 69.39 | 81.77 | 76.13 | 84.11 | 76.30 | 81.43 | 81.99 | 85.26 | ||||
| PB-BV | P.A. | 67.66 | 80.43 | 69.14 | 85.49 | 80.85 | 79.08 | 81.65 | 87.88 | 82.26 | 76.34 | 82.21 |
| UA. | 66.47 | 77.89 | 76.71 | 85.16 | 86.36 | 84.32 | 80.63 | 83.46 | ||||
| F1 | 67.06 | 79.14 | 72.73 | 85.32 | 83.52 | 81.62 | 81.14 | 85.61 | ||||
| PB-TV | PA. | 62.87 | 77.17 | 64.20 | 84.31 | 62.77 | 73.95 | 63.29 | 88.81 | 78.61 | 71.35 | 78.45 |
| UA. | 65.22 | 78.02 | 68.42 | 79.34 | 71.08 | 85.36 | 62.89 | 80.09 | ||||
| F1 | 64.02 | 77.60 | 66.24 | 81.75 | 66.67 | 79.25 | 63.09 | 84.23 | ||||
| PB-CB | P.A. | 70.66 | 83.70 | 69.14 | 85.49 | 77.66 | 79.89 | 84.18 | 83.49 | 83.43 | 77.87 | 83.34 |
| UA. | 67.05 | 79.38 | 76.71 | 84.82 | 89.02 | 86.55 | 82.61 | 84.36 | ||||
| F1 | 68.80 | 81.48 | 72.73 | 85.16 | 82.95 | 83.09 | 83.39 | 86.82 | ||||
| PB-CBT | P.A. | 70.06 | 82.61 | 71.60 | 86.27 | 77.66 | 79.22 | 82.91 | 90.05 | 83.47 | 77.92 | 83.34 |
| UA. | 67.63 | 79.17 | 76.32 | 84.94 | 86.90 | 87.22 | 82.39 | 84.12 | ||||
| F1 | 68.82 | 80.85 | 73.89 | 85.60 | 82.02 | 83.03 | 82.65 | 86.99 |
References
- Gao, Z.; Guo, D.; Ryu, D.; Western, A.W. Training sample selection for robust multi-year within-season crop classification using machine learning. Comput. Electron. Agric. 2023, 210, 107927. [Google Scholar] [CrossRef]
- Zhang, H.K.; Roy, D.P. Using the 500m MODIS land cover product to derive a consistent continental scale 30m Landsat land cover classification. Remote Sens. Environ. 2017, 197, 15–34. [Google Scholar] [CrossRef]
- Sonobe, R.; Yamaya, Y.; Tani, H.; Wang, X.; Kobayashi, N.; Mochizuki, K. Assessing the suitability of data from Sentinel-1A and 2A for crop classification. GIScience Remote Sens. 2017, 54, 918–938. [Google Scholar] [CrossRef]
- Jia, K.; Li, Q.; Tian, Y.; Wu, B.; Zhang, F.; Meng, J. Crop classification using multi-configuration SAR data in the North China plain. Int. J. Remote Sens. 2012, 33, 170–183. [Google Scholar] [CrossRef]
- Xun, L.; Zhang, J.; Cao, D.; Yang, S.; Yao, F. A novel cotton mapping index combining Sentinel-1 SAR and Sentinel-2 multispectral imagery. ISPRS J. Photogramm. Remote Sens. 2021, 181, 148–166. [Google Scholar] [CrossRef]
- Skakun, S.; Franch, B.; Vermote, E.; Roger, J.C.; Becker-Reshef, I.; Justice, C.; Kussul, N. Early season large-area winter crop mapping using MODIS NDVI data, growing degree days information and a Gaussian mixture model. Remote Sens. Environ. 2017, 195, 244–258. [Google Scholar] [CrossRef]
- Wang, X.; Zhang, S.; Feng, L.; Zhang, J.; Deng, F. Mapping maize cultivated area combining MODIS EVI time series and the spatial variations of phenology over huanghuaihai plain. Appl. Sci. 2020, 10, 2667. [Google Scholar] [CrossRef]
- Wu, Z.; Zhang, J.; Deng, F.; Zhang, S.; Zhang, D.; Xun, L.; Javed, T.; Liu, G.; Liu, D.; Ji, M. Fusion of gf and modis data for regional-scale grassland community classification with evi2 time-series and phenological features. Remote Sens. 2021, 13, 835. [Google Scholar] [CrossRef]
- Bradley, B.A.; Jacob, R.W.; Hermance, J.F.; Mustard, J.F. A curve fitting procedure to derive inter-annual phenologies from time series of noisy satellite NDVI data. Remote Sens. Environ. 2007, 106, 137–145. [Google Scholar] [CrossRef]
- Rhif, M.; Ben Abbes, A.; Martinez, B.; Farah, I.R. A deep learning approach for forecasting non-stationary big remote sensing time series. Arab. J. Geosci. 2020, 13, 1174. [Google Scholar] [CrossRef]
- Sakamoto, T.; Van Nguyen, N.; Ohno, H.; Ishitsuka, N.; Yokozawa, M. Spatio-temporal distribution of rice phenology and cropping systems in the Mekong Delta with special reference to the seasonal water flow of the Mekong and Bassac rivers. Remote Sens. Environ. 2006, 100, 1–16. [Google Scholar] [CrossRef]
- Li, R.; Xu, M.; Chen, Z.; Gao, B.; Cai, J.; Shen, F.; He, X.; Zhuang, Y.; Chen, D. Phenology-based classification of crop species and rotation types using fused MODIS and Landsat data: The comparison of a random-forest-based model and a decision-rule-based model. Soil Tillage Res. 2021, 206, 104838. [Google Scholar] [CrossRef]
- Belgiu, M.; Bijker, W.; Csillik, O.; Stein, A. Phenology-based sample generation for supervised crop type classification. Int. J. Appl. Earth Obs. Geoinf. 2021, 95, 102264. [Google Scholar] [CrossRef]
- Zhong, L.; Hawkins, T.; Biging, G.; Gong, P. A phenology-based approach to map crop types in the San Joaquin Valley, California. Int. J. Remote Sens. 2011, 32, 7777–7804. [Google Scholar] [CrossRef]
- He, T.; Xie, C.; Liu, Q.; Guan, S.; Liu, G. Evaluation and Comparison of Random Forest and A-LSTM Networks for Large-scale Winter Wheat Identification. Remote Sens. 2019, 11, 1665. [Google Scholar] [CrossRef]
- Zhang, J.; Feng, L.; Yao, F. Improved maize cultivated area estimation over a large scale combining MODIS-EVI time series data and crop phenological information. ISPRS J. Photogramm. Remote Sens. 2014, 94, 102–113. [Google Scholar] [CrossRef]
- Wang, X.; Zhang, J.; Xun, L.; Wang, J.; Wu, Z.; Henchiri, M.; Zhang, S.; Zhang, S.; Bai, Y.; Yang, S.; et al. Evaluating the Effectiveness of Machine Learning and Deep Learning Models Combined Time-Series Satellite Data for Multiple Crop Types Classification over a Large-Scale Region. Remote Sens. 2022, 14, 2341. [Google Scholar] [CrossRef]
- Antonijević, O.; Jelić, S.; Bajat, B.; Kilibarda, M. Transfer learning approach based on satellite image time series for the crop classification problem. J. Big Data 2023, 10, 54. [Google Scholar] [CrossRef]
- Rußwurm, M.; Courty, N.; Emonet, R.; Lefèvre, S.; Tuia, D.; Tavenard, R. End-to-end learned early classification of time series for in-season crop type mapping. ISPRS J. Photogramm. Remote Sens. 2023, 196, 445–456. [Google Scholar] [CrossRef]
- Zhong, L.; Hu, L.; Zhou, H. Deep learning based multi-temporal crop classification. Remote Sens. Environ. 2019, 221, 430–443. [Google Scholar] [CrossRef]
- Luo, Y.; Zhang, Z.; Li, Z.; Chen, Y.; Zhang, L.; Cao, J.; Tao, F. Identifying the spatiotemporal changes of annual harvesting areas for three staple crops in China by integrating multi-data sources. Environ. Res. Lett. 2020, 15, 074003. [Google Scholar] [CrossRef]
- Xun, L.; Zhang, J.; Cao, D.; Wang, J.; Zhang, S.; Yao, F. Mapping cotton cultivated area combining remote sensing with a fused representation-based classification algorithm. Comput. Electron. Agric. 2021, 181, 105940. [Google Scholar] [CrossRef]
- Chen, S.W.; Tao, C.S. Multi-temporal PolSAR crops classification using polarimetric-feature-driven deep convolutional neural network. In Proceedings of the 2017 International Workshop on Remote Sensing with Intelligent Processing (RSIP), Shanghai, China, 18–21 May 2017; pp. 1–4. [Google Scholar]
- Gadiraju, K.K.; Ramachandra, B.; Chen, Z.; Vatsavai, R.R. Multimodal Deep Learning Based Crop Classification Using Multispectral and Multitemporal Satellite Imagery. In Proceedings of the KDD ‘20: The 26th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Virtual Event, 23–27 August 2020; pp. 3234–3242. [Google Scholar]
- Karim, F.; Majumdar, S.; Darabi, H.; Harford, S. Multivariate LSTM-FCNs for time series classification. Neural Netw. 2019, 116, 237–245. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Bengio, Y. Convolutional Networks for Images, Speech, and Time-Series. In The Handbook of Brain Theory and Neural Networks; MIT Press: Cambridge, MA, USA, 1995. [Google Scholar]
- Yuan, Y.; Lin, L.; Zhou, Z.G.; Jiang, H.; Liu, Q. Bridging optical and SAR satellite image time series via contrastive feature extraction for crop classification. ISPRS J. Photogramm. Remote Sens. 2023, 195, 222–232. [Google Scholar] [CrossRef]
- Huang, B.; Zhao, B.; Song, Y. Urban land-use mapping using a deep convolutional neural network with high spatial resolution multispectral remote sensing imagery. Remote Sens. Environ. 2018, 214, 73–86. [Google Scholar] [CrossRef]
- Kumar, S.; Shukla, S.; Sharma, K.K.; Kumar Singh, K.; Akbari, A.S. Classification of Land Cover and Land Use Using Deep Learning. Lect. Notes Electr. Eng. 2021, 796, 321–327. [Google Scholar]
- Marcos, D.; Volpi, M.; Kellenberger, B.; Tuia, D. Land cover mapping at very high resolution with rotation equivariant CNNs: Towards small yet accurate models. ISPRS J. Photogramm. Remote Sens. 2018, 145, 96–107. [Google Scholar] [CrossRef]
- Yuan, Q.; Shen, H.; Li, T.; Li, Z.; Li, S.; Jiang, Y. Remote Sensing of Environment Deep learning in environmental remote sensing: Achievements and challenges. Remote Sens. Environ. 2020, 241, 111716. [Google Scholar] [CrossRef]
- Rußwurm, M.; Korner, M. Multi-temporal land cover classification with sequential recurrent encoders. ISPRS Int. J. Geo-Inf. 2018, 7, 129. [Google Scholar] [CrossRef]
- Xu, J.; Zhu, Y.; Zhong, R.; Lin, Z.; Xu, J.; Jiang, H.; Huang, J.; Li, H.; Lin, T. DeepCropMapping: A multi-temporal deep learning approach with improved spatial generalizability for dynamic corn and soybean mapping. Remote Sens. Environ. 2020, 247, 111946. [Google Scholar] [CrossRef]
- Mou, L.; Bruzzone, L.; Zhu, X.X. Learning spectral-spatialoral features via a recurrent convolutional neural network for change detection in multispectral imagery. IEEE Trans. Geosci. Remote Sens. 2019, 57, 924–935. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5999–6009. [Google Scholar]
- Rußwurm, M.; Körner, M. Self-attention for raw optical Satellite Time Series Classification. ISPRS J. Photogramm. Remote Sens. 2020, 169, 421–435. [Google Scholar] [CrossRef]
- Huang, G.; Li, Y.; Pleiss, G.; Liu, Z.; Hopcroft, J.E.; Weinberger, K.Q. Snapshot ensembles: Train 1, get M for free. arXiv 2017, arXiv:1704.00109. [Google Scholar]
- Izmailov, P.; Podoprikhin, D.; Garipov, T.; Vetrov, D.; Wilson, A.G. Averaging weights leads to wider optima and better generalization. arXiv 2018, arXiv:1803.05407. [Google Scholar]
- Luo, K.; Lu, L.; Xie, Y.; Chen, F.; Yin, F.; Li, Q. Crop type mapping in the central part of the North China Plain using Sentinel-2 time series and machine learning. Comput. Electron. Agric. 2023, 205, 107577. [Google Scholar] [CrossRef]
- Li, H.; Tian, Y.; Zhang, C.; Zhang, S.; Atkinson, P.M. Temporal Sequence Object-based CNN (TS-OCNN) for crop classification from fine resolution remote sensing image time-series. Crop J. 2022, 10, 1507–1516. [Google Scholar] [CrossRef]
- Sakamoto, T.; Gitelson, A.A.; Arkebauer, T.J. Near real-time prediction of U.S. corn yields based on time-series MODIS data. Remote Sens. Environ. 2014, 147, 219–231. [Google Scholar] [CrossRef]
- Zhang, X.; Liu, L.; Chen, X.; Gao, Y.; Xie, S.; Mi, J. GLC_FCS30: Global land-cover product with fine classification system at 30m using time-series Landsat imagery. Earth Syst. Sci. Data 2021, 13, 2753–2776. [Google Scholar] [CrossRef]
- Picon, A.; Seitz, M.; Alvarez-Gila, A.; Mohnke, P.; Ortiz-Barredo, A.; Echazarra, J. Crop conditional Convolutional Neural Networks for massive multi-crop plant disease classification over cell phone acquired images taken on real field conditions. Comput. Electron. Agric. 2019, 167, 105093. [Google Scholar] [CrossRef]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. Phys. Lett. B 2014, 299, 345–350. [Google Scholar]
- Bermúdez, J.D.; Achanccaray, P.; Sanches, I.D.; Cue, L.; Happ, P.; Feitosa, R.Q. Evaluation of Recurrent Neural Networks for Crop Recognition from Multitemporal Remote Sensing Images. In Proceedings of the Anais do XXVII Congresso Brasileiro de Cartografia, Rio deJaneiro, Brazil, 6–9 November 2017; pp. 800–804. [Google Scholar]
- Xu, J.; Yang, J.; Xiong, X.; Li, H.; Huang, J.; Ting, K.C.; Ying, Y.; Lin, T. Towards interpreting multi-temporal deep learning models in crop mapping. Remote Sens. Environ. 2021, 264, 112599. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Su, H.; Zhang, T.; Lin, M.; Lu, W.; Yan, X.H. Predicting subsurface thermohaline structure from remote sensing data based on long short-term memory neural networks. Remote Sens. Environ. 2021, 260, 112465. [Google Scholar] [CrossRef]
- Cao, C.; Dragićević, S.; Li, S. Short-term forecasting of land use change using recurrent neural network models. Sustainability 2019, 11, 5376. [Google Scholar] [CrossRef]
- Sainte Fare Garnot, V.; Landrieu, L.; Giordano, S.; Chehata, N. Satellite image time series classification with pixel-set encoders and temporal self-attention. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 12322–12331. [Google Scholar]
- Kawaguchi, K. Deep learning without poor local minima. Adv. Neural Inf. Process. Syst. 2016, 29, 586–594. [Google Scholar]
- Chellasamy, M.; Ferré, T.P.A.; Greve, M.H. Evaluating an ensemble classification approach for crop diversity verification in Danish greening subsidy control. Int. J. Appl. Earth Obs. Geoinf. 2016, 49, 10–23. [Google Scholar] [CrossRef]
- Kent, M.; Parkinson, T.; Kim, J.; Schiavon, S. A data-driven analysis of occupant workspace dissatisfaction. Build. Environ. 2021, 205, 108270. [Google Scholar] [CrossRef]
- Powers, D.M.W. Evaluation: From precision, recall and F-measure to ROC, informedness, markedness and correlation. arXiv 2020, arXiv:2010.16061. [Google Scholar]
- Ashourloo, D.; Shahrabi, H.S.; Azadbakht, M.; Aghighi, H.; Matkan, A.A.; Radiom, S. A Novel Automatic Method for Alfalfa Mapping Using Time Series of Landsat-8 OLI Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 4478–4487. [Google Scholar] [CrossRef]
- Xun, L.; Wang, P.; Li, L.; Wang, L.; Kong, Q. Identifying crop planting areas using Fourier-transformed feature of time series MODIS leaf area index and sparse-representation-based classification in the North China Plain. Int. J. Remote Sens. 2019, 40, 2034–2052. [Google Scholar] [CrossRef]
- Chen, H.; Qiu, Y.; Yin, D.; Chen, J.; Chen, X.; Liu, S.; Liu, L. Stacked spectral feature space patch: An advanced spectral representation for precise crop classification based on convolutional neural network. Crop J. 2022, 10, 1460–1469. [Google Scholar] [CrossRef]
- Wang, Z.; Chen, J.; Xing, F.; Han, Y.; Chen, F.; Zhang, L.; Li, Y.; Li, C. Response of cotton phenology to climate change on the North China Plain from 1981 to 2012. Sci. Rep. 2017, 7, 6628. [Google Scholar] [CrossRef] [PubMed]
- Song, X.P.; Potapov, P.V.; Krylov, A.; King, L.A.; Di Bella, C.M.; Hudson, A.; Khan, A.; Adusei, B.; Stehman, S.V.; Hansen, M.C. National-scale soybean mapping and area estimation in the United States using medium resolution satellite imagery and field survey. Remote Sens. Environ. 2017, 190, 383–395. [Google Scholar] [CrossRef]
- Zhu, Z.; Gallant, A.L.; Woodcock, C.E.; Pengra, B.; Olofsson, P.; Loveland, T.R.; Jin, S.; Dahal, D.; Yang, L.; Auch, R.F. Optimizing selection of training and auxiliary data for operational land cover classification for the LCMAP initiative. ISPRS J. Photogramm. Remote Sens. 2016, 122, 206–221. [Google Scholar] [CrossRef]
- Yang, L.; Jin, S.; Danielson, P.; Homer, C.; Gass, L.; Bender, S.M.; Case, A.; Costello, C.; Dewitz, J.; Fry, J.; et al. A new generation of the United States National Land Cover Database: Requirements, research priorities, design, and implementation strategies. ISPRS J. Photogramm. Remote Sens. 2018, 146, 108–123. [Google Scholar] [CrossRef]
- Massey, R.; Sankey, T.T.; Congalton, R.G.; Yadav, K.; Thenkabail, P.S.; Ozdogan, M.; Sánchez Meador, A.J. MODIS phenology-derived, multi-year distribution of conterminous U.S. crop types. Remote Sens. Environ. 2017, 198, 490–503. [Google Scholar] [CrossRef]
- Jin, S.; Yang, L.; Danielson, P.; Homer, C.; Fry, J.; Xian, G. A comprehensive change detection method for updating the National Land Cover Database to circa 2011. Remote Sens. Environ. 2013, 132, 159–175. [Google Scholar] [CrossRef]
- Jin, S.; Yang, L.; Zhu, Z.; Homer, C. A land cover change detection and classification protocol for updating Alaska NLCD 2001 to 2011. Remote Sens. Environ. 2017, 195, 44–55. [Google Scholar] [CrossRef]














| Category Code | Abbreviations | Training Set | Validation Set | Test Set | Total |
|---|---|---|---|---|---|
| Summer corn | SU | 499 | 166 | 167 | 832 |
| Rice | RI | 274 | 91 | 92 | 457 |
| Spring corn | SP | 241 | 80 | 81 | 402 |
| Other | OT | 764 | 255 | 255 | 1274 |
| Winter wheat-Other | WT-OT | 281 | 94 | 94 | 469 |
| Winter wheat-Rice | WT-RI | 2221 | 741 | 741 | 3703 |
| Winter wheat-Spring corn | WT-SP | 473 | 158 | 158 | 789 |
| Winter wheat-Summer corn | WT-SU | 2894 | 965 | 965 | 4824 |
| Total | 7647 | 2550 | 2553 | 12,750 |
| Model Hyperparameters | Hyperparameters Value |
|---|---|
| Convolutional filters | 3, 5, 7 |
| Convolutional channel | 32, 64, 128, 256 |
| Convolutional layer | 1, 2, 3, 4, 5, 6, 7, 8, 9 |
| dropout | 0, 10%, 20%, 30%, 40%, 50%, 60% |
| Model Hyperparameters | Hyperparameters Value |
|---|---|
| BiLSTM layer | 1, 2, 3, 4, 5, 6, 7, 8, 9 |
| Dropout | 0, 10%, 20%, 30%, 40%, 50% 60%. |
| Model | Iteration | Epochs | Cycles |
|---|---|---|---|
| PB-Conv1D | 600 | 40 | 15 |
| PB-BiLSTM | 800 | 80 | 10 |
| PB-Transformer | 800 | 80 | 10 |
| Predict | |||
|---|---|---|---|
| Positive | Negative | ||
| Actual | Positive | True positive (TP) | False negative (FN) |
| Negative | False positive (FP) | True negative (TN) | |
| Classifier | Dropout/% | Learning Rate |
|---|---|---|
| PB-Conv1D | 40 | 0.0001 |
| PB-Conv1D combine Snapshot (PB-CDST) | 40 | 0.0005 |
| PB-Conv1D combine SWA (PB-CDSA) | 40 | 0.0005 |
| PB-Conv1D combine Snapshot and SWA (PB-CDSTSA) | 10 | 0.0005 |
| Classifier | Dropout/% | Learning Rate |
|---|---|---|
| PB-BiLSTM combine Snapshot (PB-BMST) | 10 | 0.0005 |
| PB-Transformer combine Snapshot and SWA (PB-TRSTSA) | 60 | 0.0005 |
| Model Name | Description | k-Value |
|---|---|---|
| PB-CV | The top K best-performing PB-Conv1D, PB-CDST, PB-CDSA, and PB-CDSTSA models were voting | 5 |
| PB-BV | The top K best-performing PB-BiLSTM, PB-BMST, PB-BMSA, and PB-BMSTSA models were voting | 7 |
| PB-TV | The top K best-performing PB-Transformer, PB-TRST, PB-TRSA, and PB-TRSTSA models were voting | 3 |
| PB-CB | The PB-CV and PB-BV were voting | 12 |
| PB-CBT | The PB-CV, PB-BV, and PB-TV were voting | 15 |
| Reference Classes | Classified | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| SU | RI | SP | OT | WT-OT | WT-RI | WT-SP | WT-SU | Total | |
| SU | 6 | 1 | 2 | −2 | 0 | −4 | 1 | −4 | 12 |
| RI | −2 | 3 | 0 | −1 | 0 | 0 | 0 | 0 | 6 |
| SP | 2 | 0 | −2 | 3 | 0 | −1 | −2 | 0 | −4 |
| OT | 3 | −3 | 0 | 1 | −1 | 0 | 2 | −2 | 2 |
| WT-OT | 0 | 0 | −2 | 0 | 7 | −3 | 0 | −2 | 14 |
| WT-RI | −2 | 1 | 0 | 0 | −2 | 17 | −1 | −13 | 34 |
| WT-SP | 0 | 0 | 1 | −4 | 1 | −3 | 5 | 0 | 10 |
| WT-SU | 0 | 0 | 0 | 0 | −4 | −5 | −7 | 16 | 32 |
| Total | 5 | 4 | −3 | 5 | 13 | 33 | 12 | 37 | 106 |
| Reference Classes | Classified | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| SU | RI | SP | OT | WT-OT | WT-RI | WT-SP | WT-SU | Total | |
| SU | 5 | 0 | 1 | −2 | 0 | −1 | 0 | −3 | 10 |
| RI | −1 | 3 | −2 | 0 | 0 | 0 | 0 | 0 | 6 |
| SP | 2 | 0 | 0 | 2 | −2 | 0 | −2 | 0 | 0 |
| OT | 1 | 0 | 0 | 0 | −2 | 1 | 0 | 0 | 0 |
| WT-OT | 0 | 0 | 2 | 0 | −3 | 1 | −1 | 1 | −6 |
| WT-RI | −2 | 0 | 0 | 0 | −1 | 6 | −2 | −1 | 12 |
| WT-SP | 0 | 0 | −1 | 1 | 1 | 0 | 4 | −5 | 8 |
| WT-SU | 1 | −1 | 0 | 0 | 1 | −18 | 2 | 15 | 30 |
| Total | 4 | 4 | 0 | −1 | 0 | 23 | 7 | 23 | 60 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Zhang, J.; Wang, X.; Wu, Z.; Prodhan, F.A. Incorporating Multi-Temporal Remote Sensing and a Pixel-Based Deep Learning Classification Algorithm to Map Multiple-Crop Cultivated Areas. Appl. Sci. 2024, 14, 3545. https://doi.org/10.3390/app14093545
Wang X, Zhang J, Wang X, Wu Z, Prodhan FA. Incorporating Multi-Temporal Remote Sensing and a Pixel-Based Deep Learning Classification Algorithm to Map Multiple-Crop Cultivated Areas. Applied Sciences. 2024; 14(9):3545. https://doi.org/10.3390/app14093545
Chicago/Turabian StyleWang, Xue, Jiahua Zhang, Xiaopeng Wang, Zhenjiang Wu, and Foyez Ahmed Prodhan. 2024. "Incorporating Multi-Temporal Remote Sensing and a Pixel-Based Deep Learning Classification Algorithm to Map Multiple-Crop Cultivated Areas" Applied Sciences 14, no. 9: 3545. https://doi.org/10.3390/app14093545