
An Automatic Measurement Method for Absolute Depth of Objects in Two Monocular Images Based on SIFT Feature

Abstract
:1. Introduction
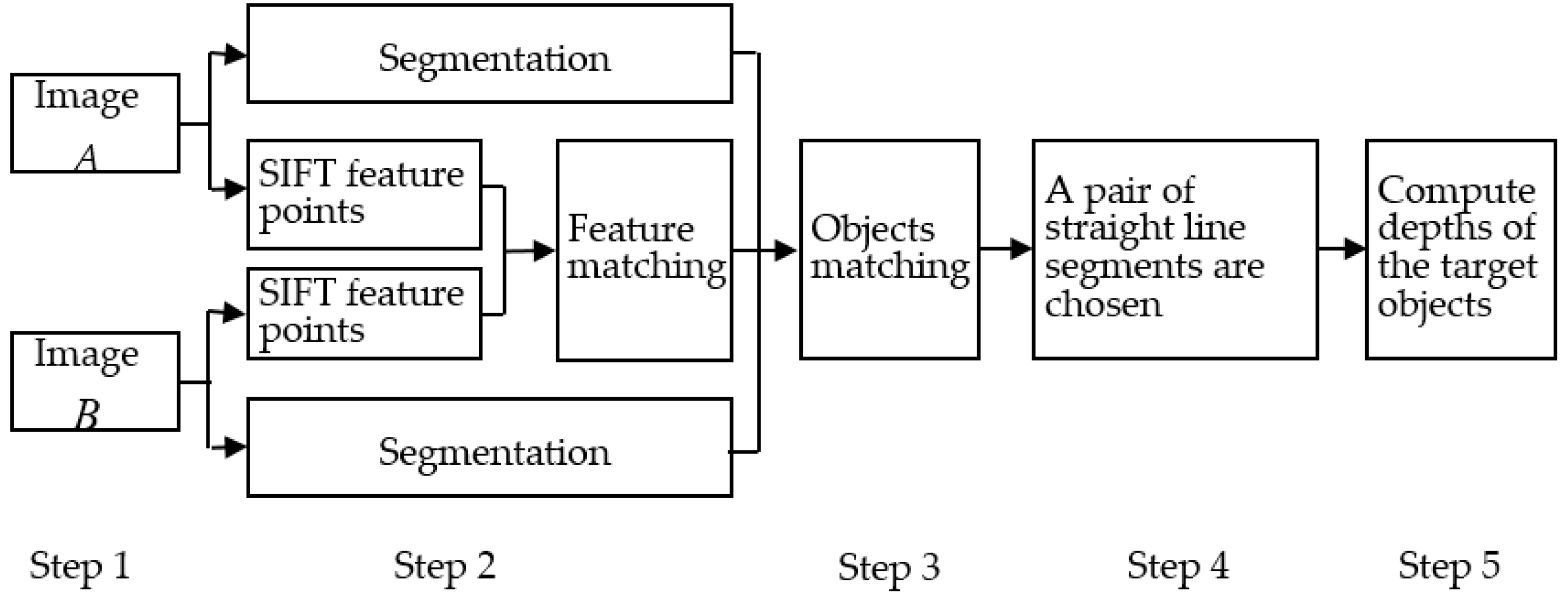
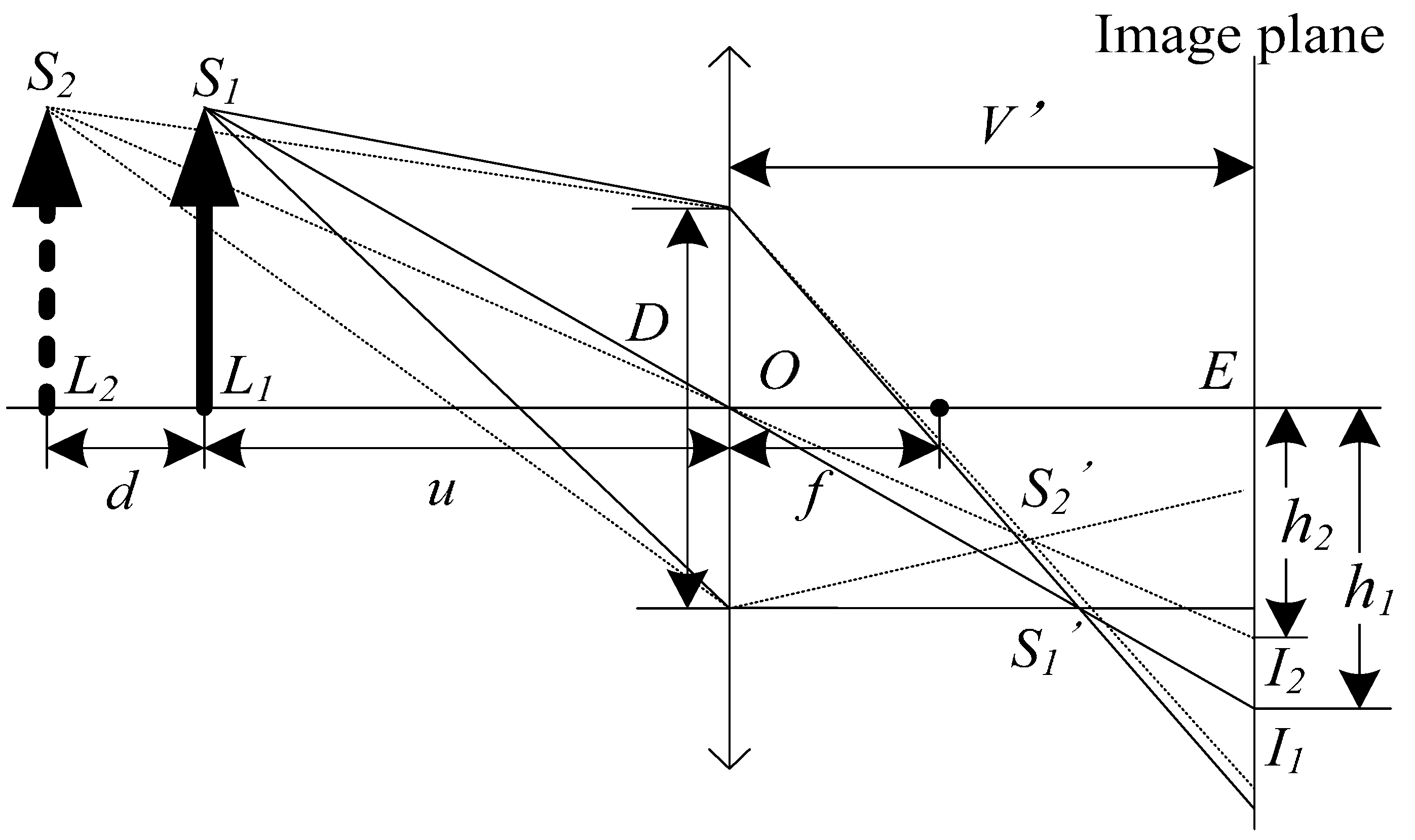
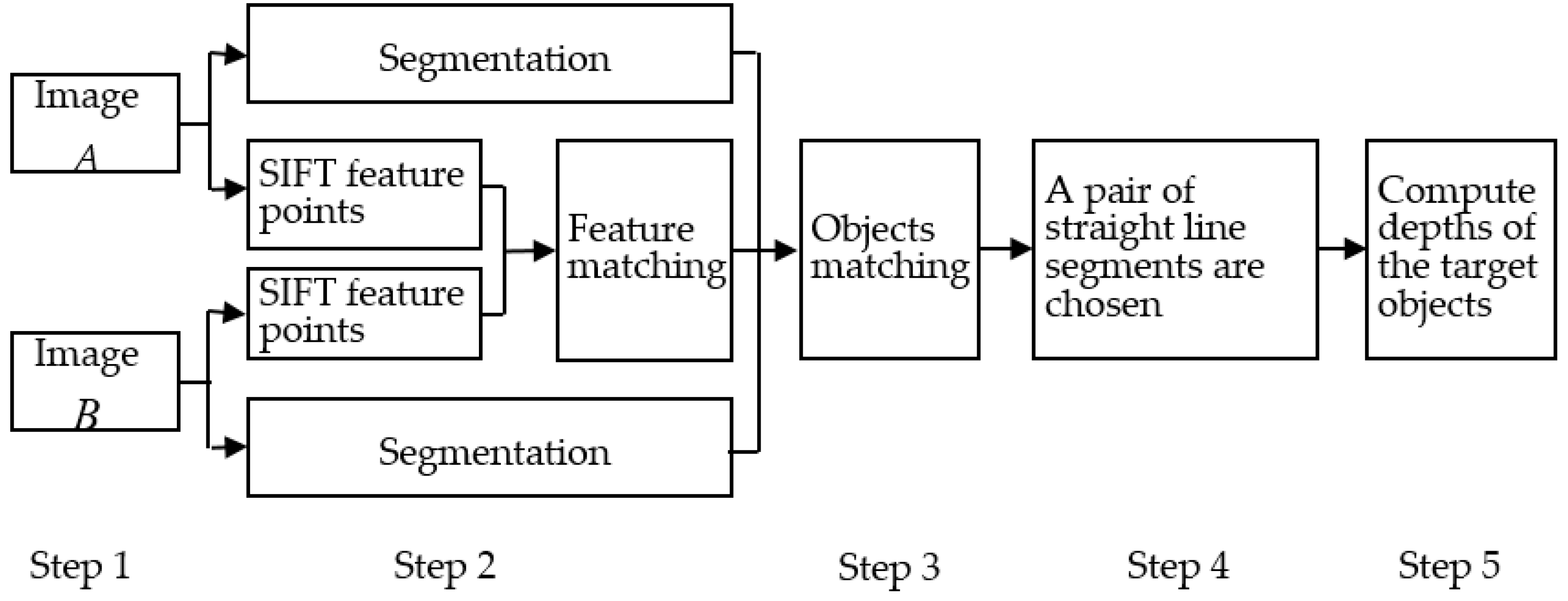
2. The Basic Principles and Algorithm Steps
- Step 1:
- Holding the camera constant, we take the image A and B when the object distance is u and u + d, respectively.
- Step 2:
- Images of objects (namely sub-regions) are obtained by segmenting the image A and B, respectively. Meanwhile, we detect the SIFT feature points in the image A and B, then, match the points.
- Step 3:
- Using the results of segmentation and matching of feature points, we can match the images of objects.
- Step 4:
- A pair of straight line segments are chosen from the image A and B. During the process, the theory of the convex hull is used to decrease the computational complexity, and the knowledge of the similarity triangle is used to avoid the wrong straight line straight being chosen. The lengths of the pair of straight line segments will be used to compute the depth of the object.
- Step 5:
- The depth of the object can be computed by the length of the pair of straight line segments.
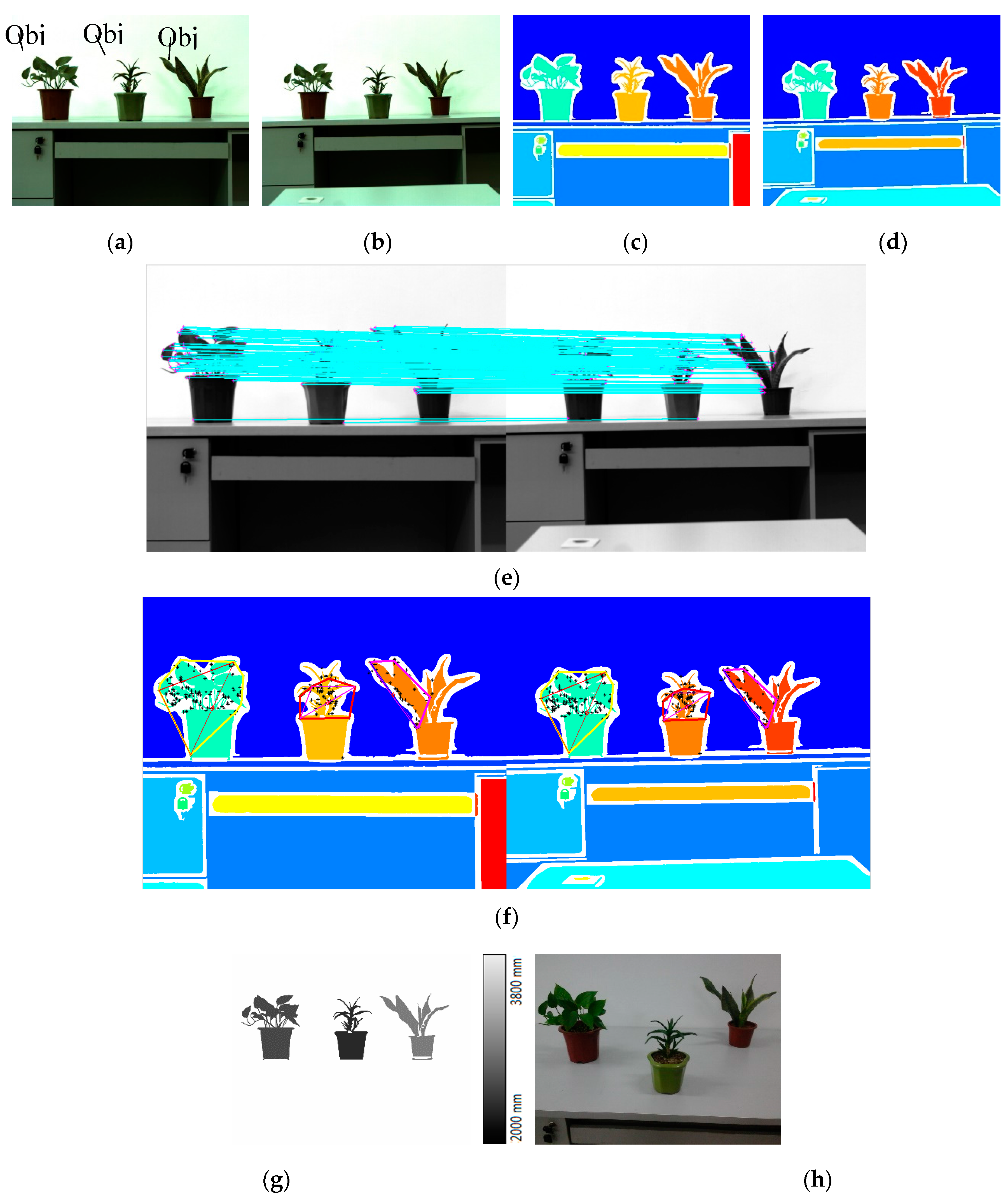
3. Matching the Images of Objects
4. Selecting the Straight Line Segments
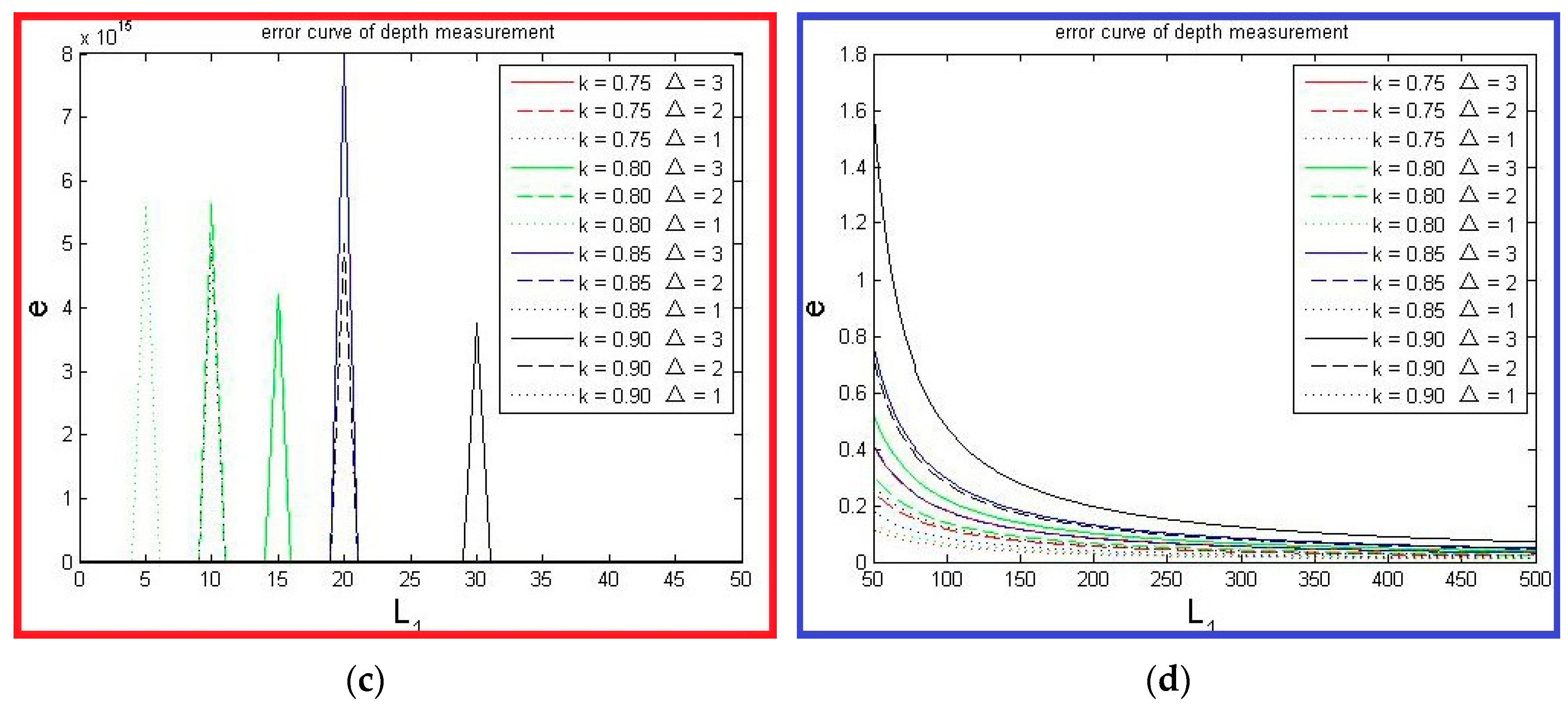
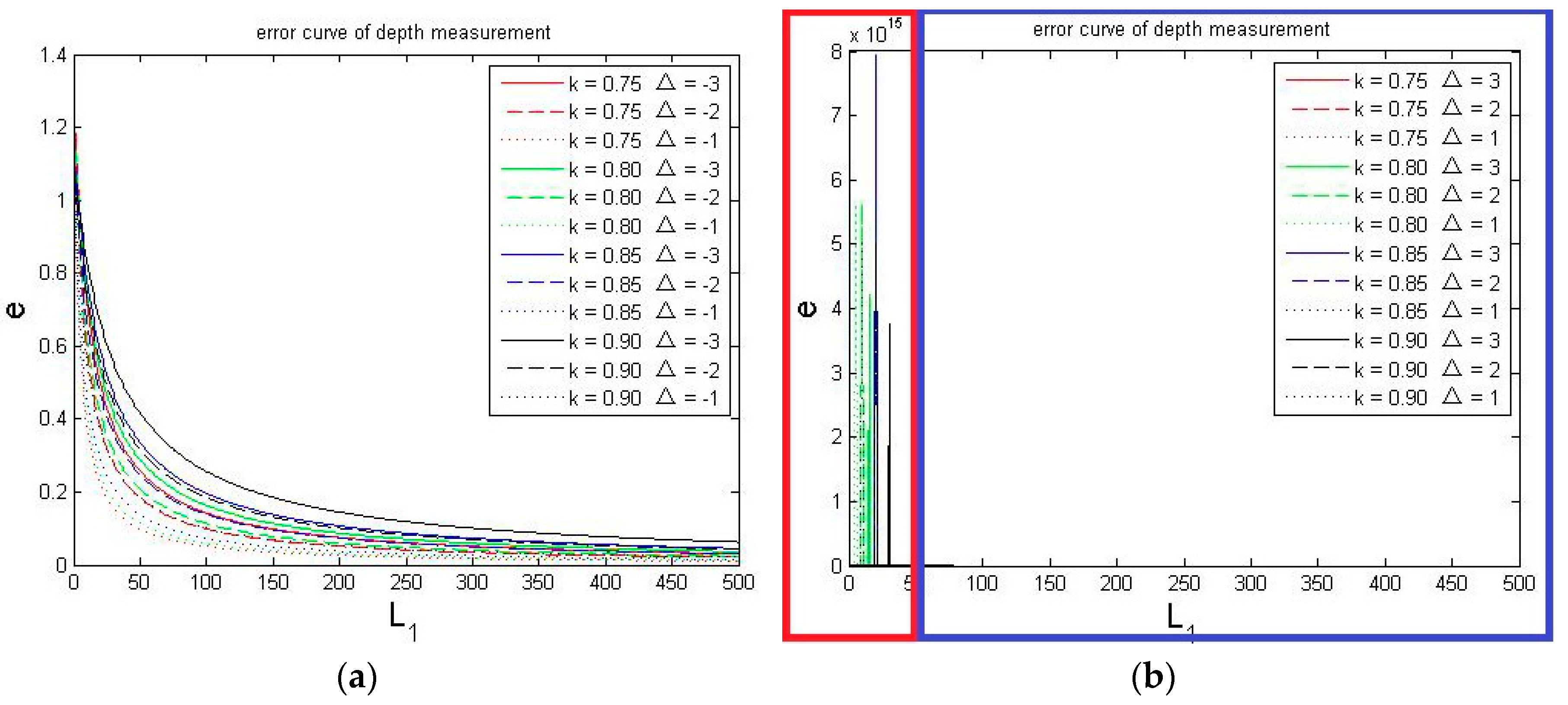
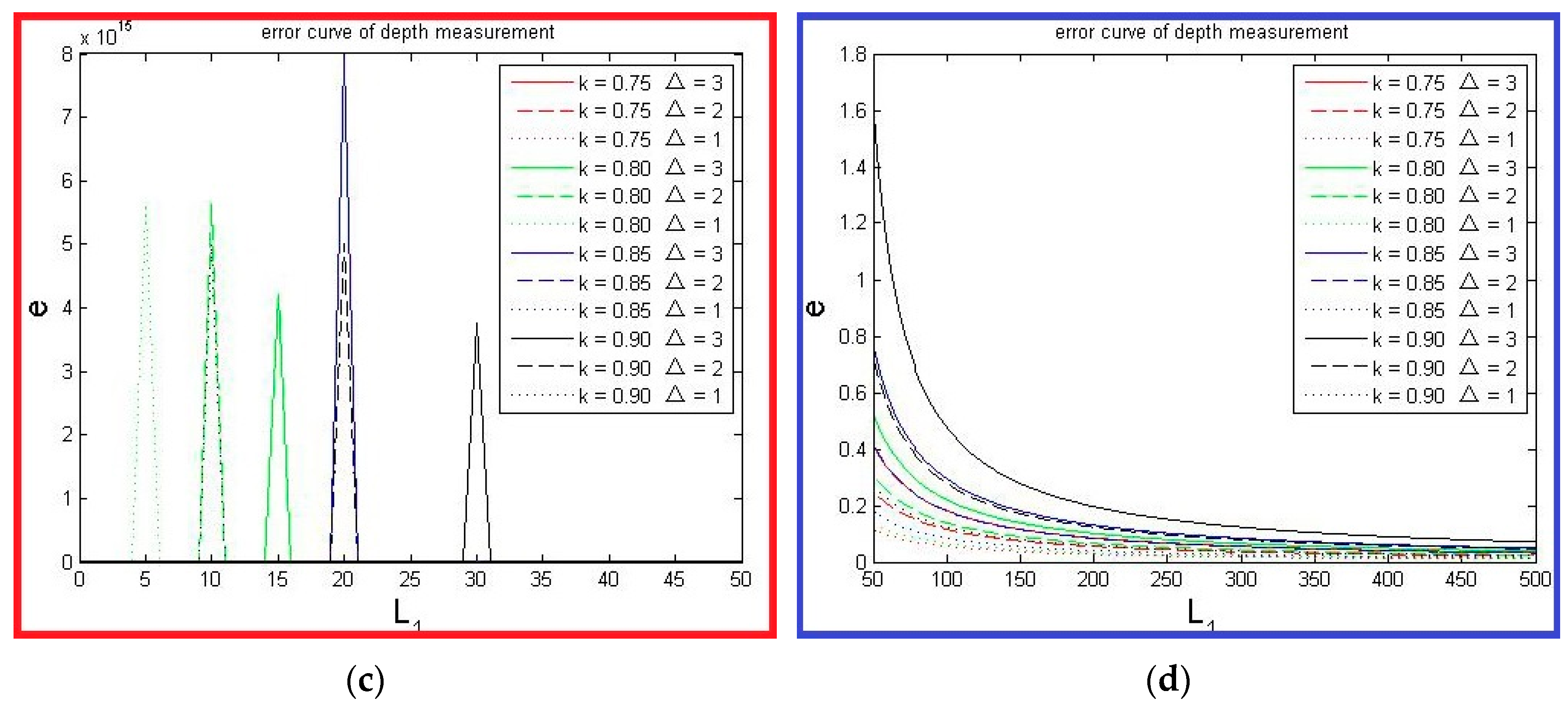
4.1. Theoretical Error Analysis
4.2. Decrease Time Complexity
4.3. Algorithm for Selecting a Pair of Straight Line Segments
| Algorithm 1. The algorithm for selecting a pair of straight line segments. |
|
|
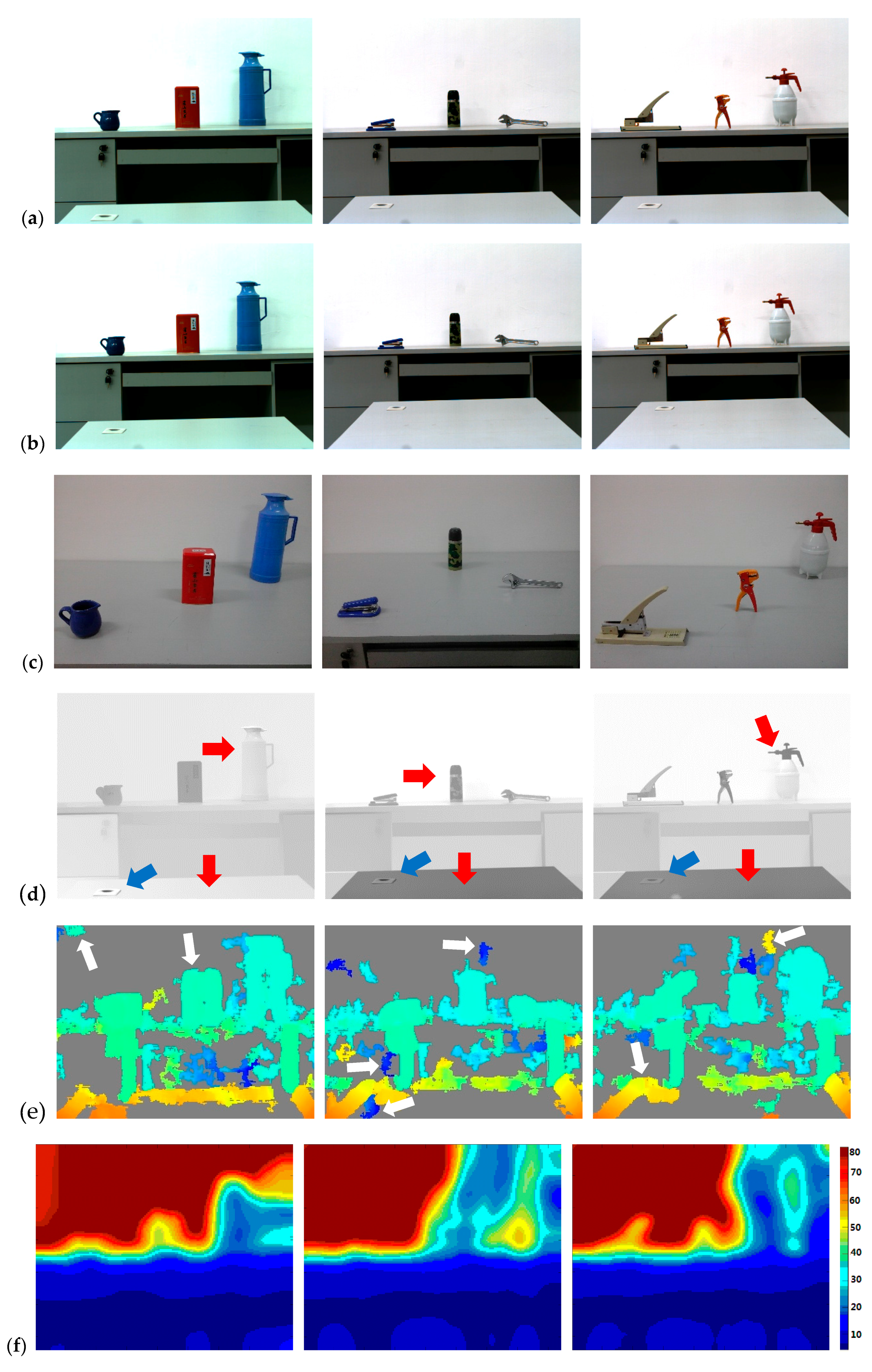
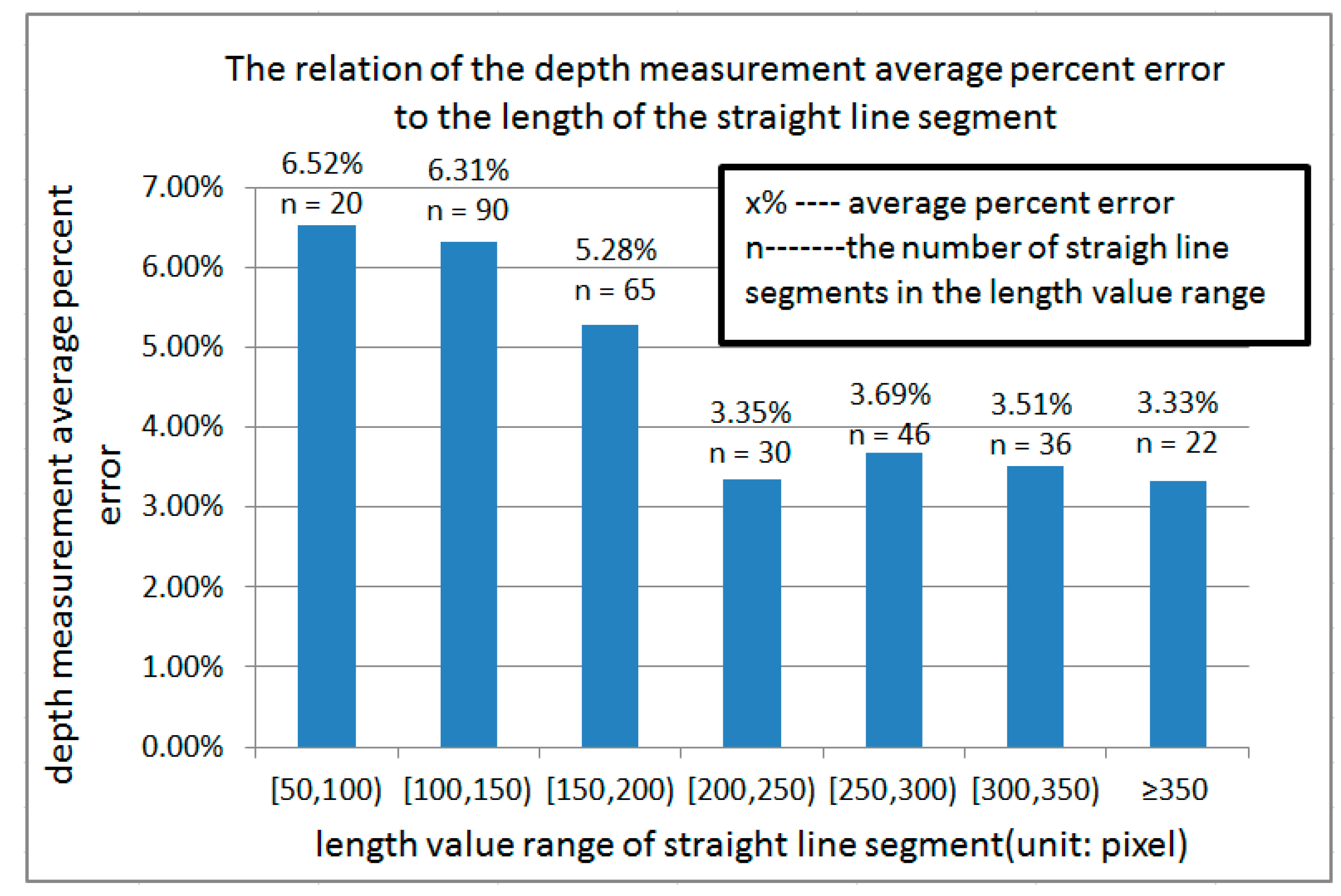
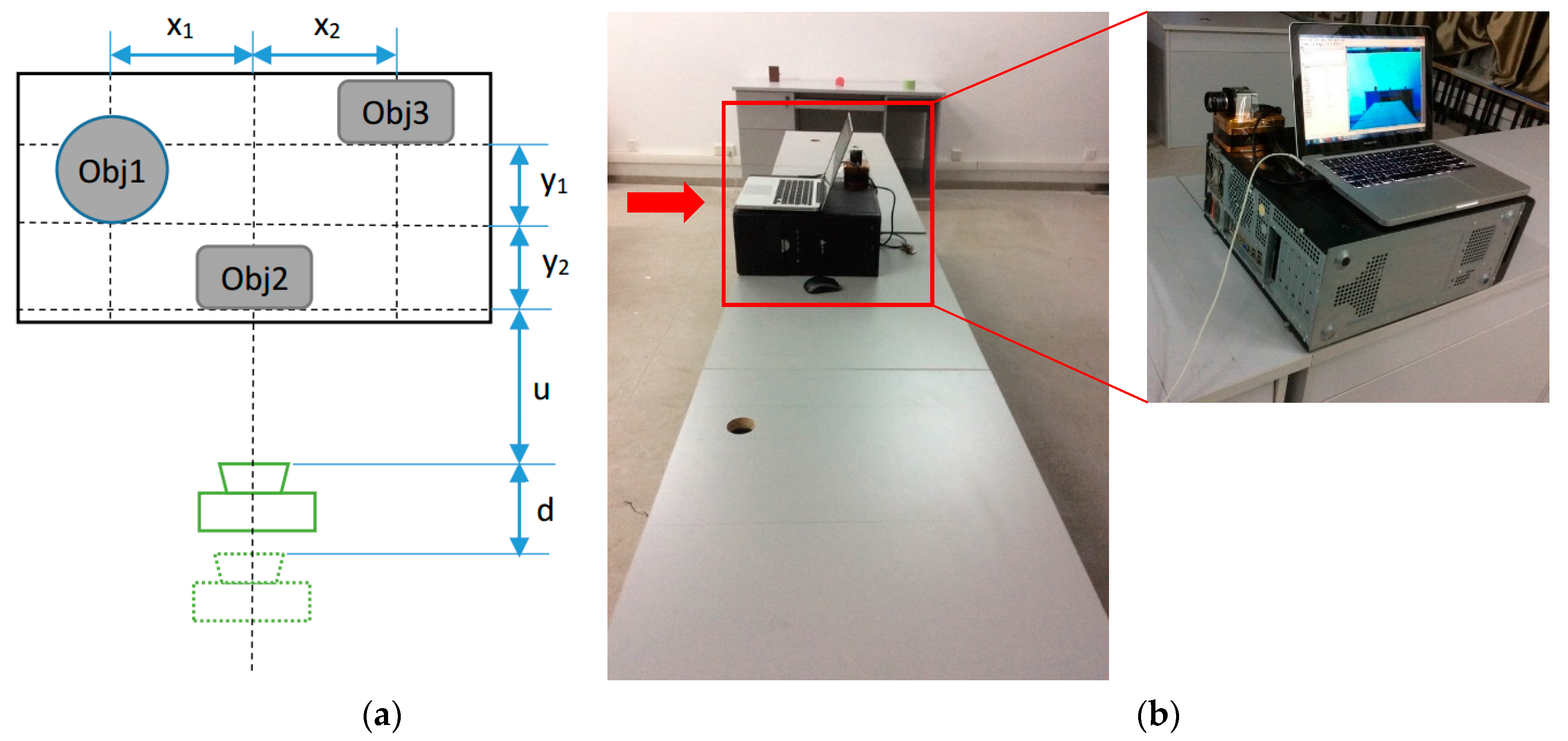
5. Experiments
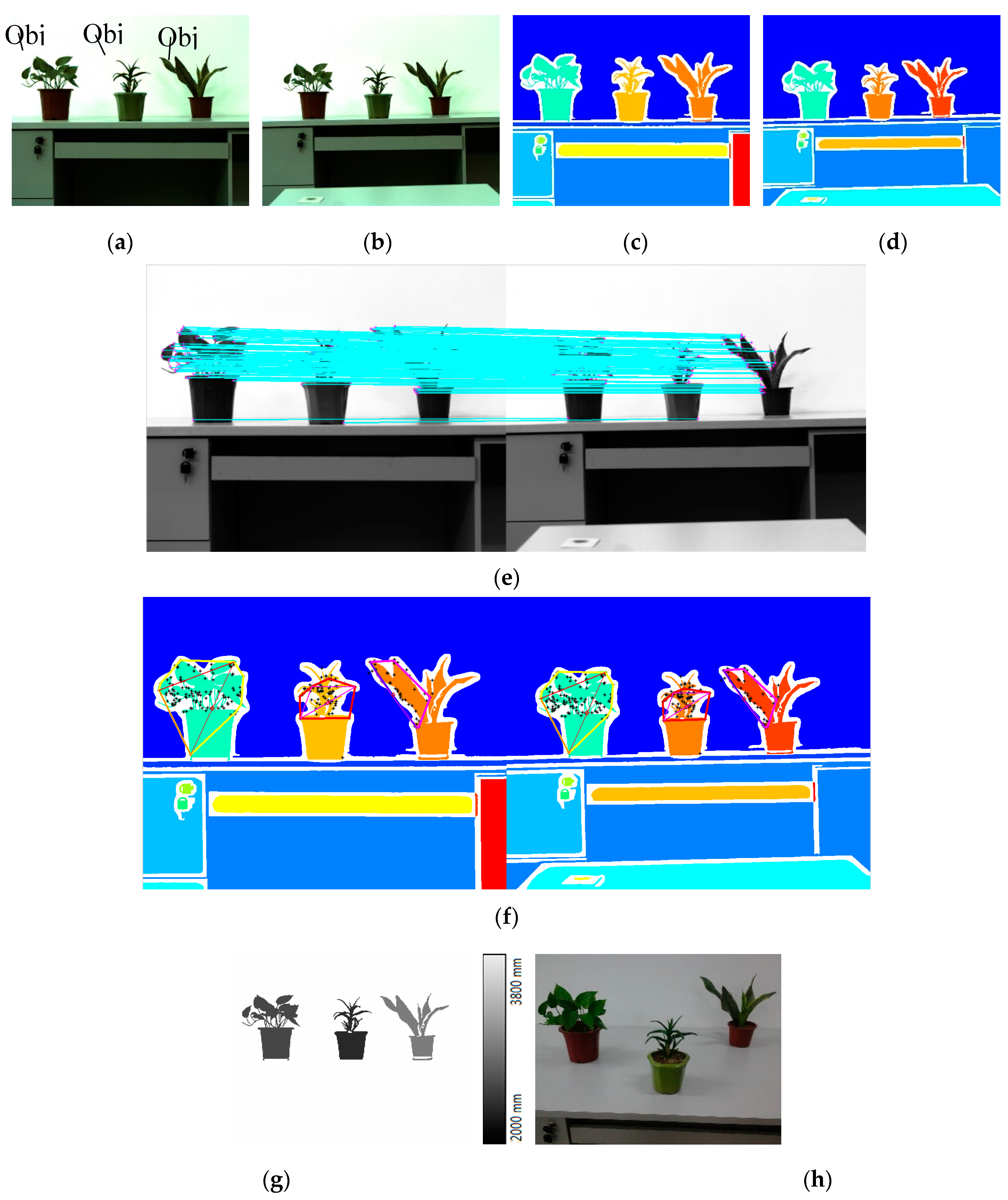
5.1. Images Acquirement
5.2. Experiment Procedure
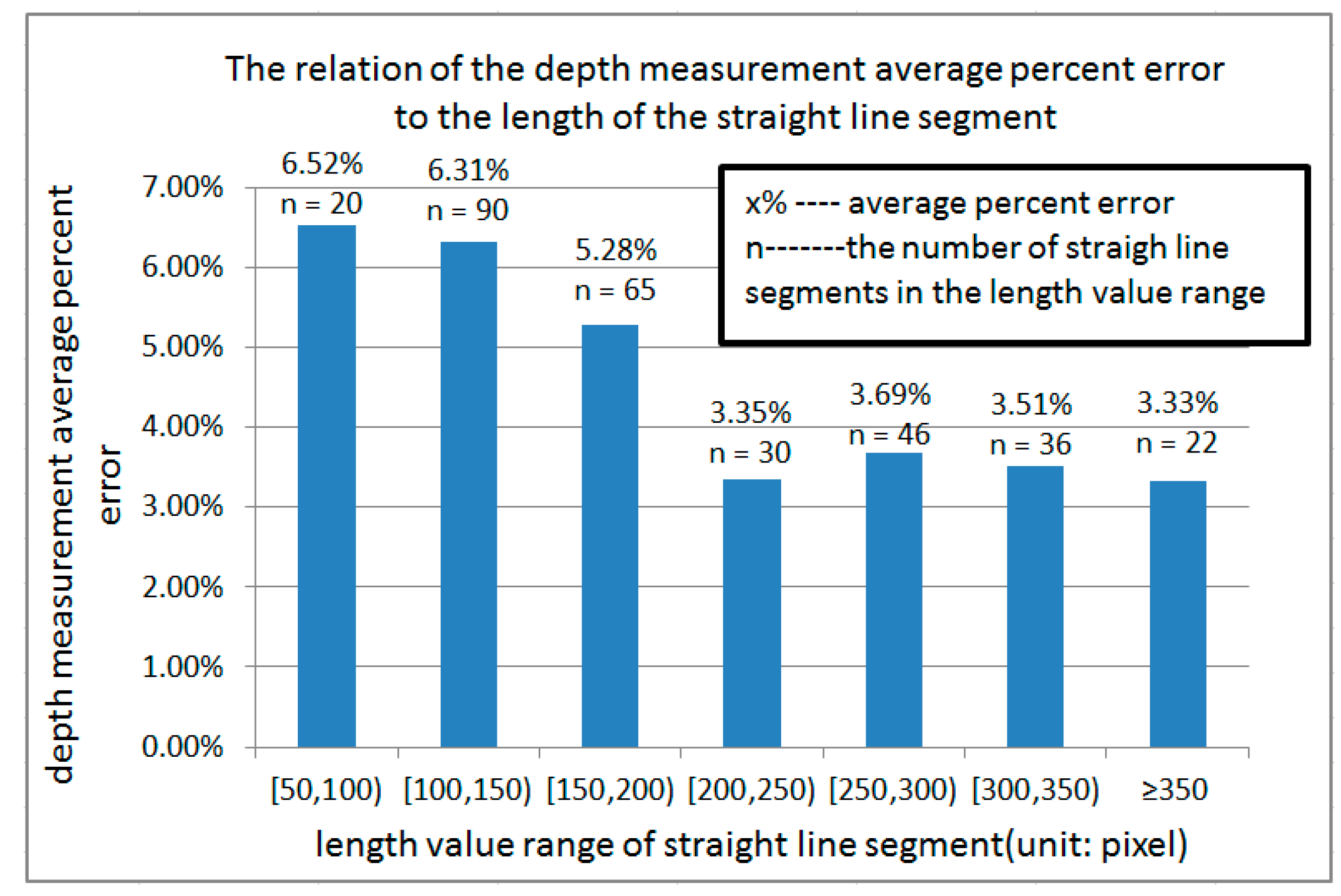
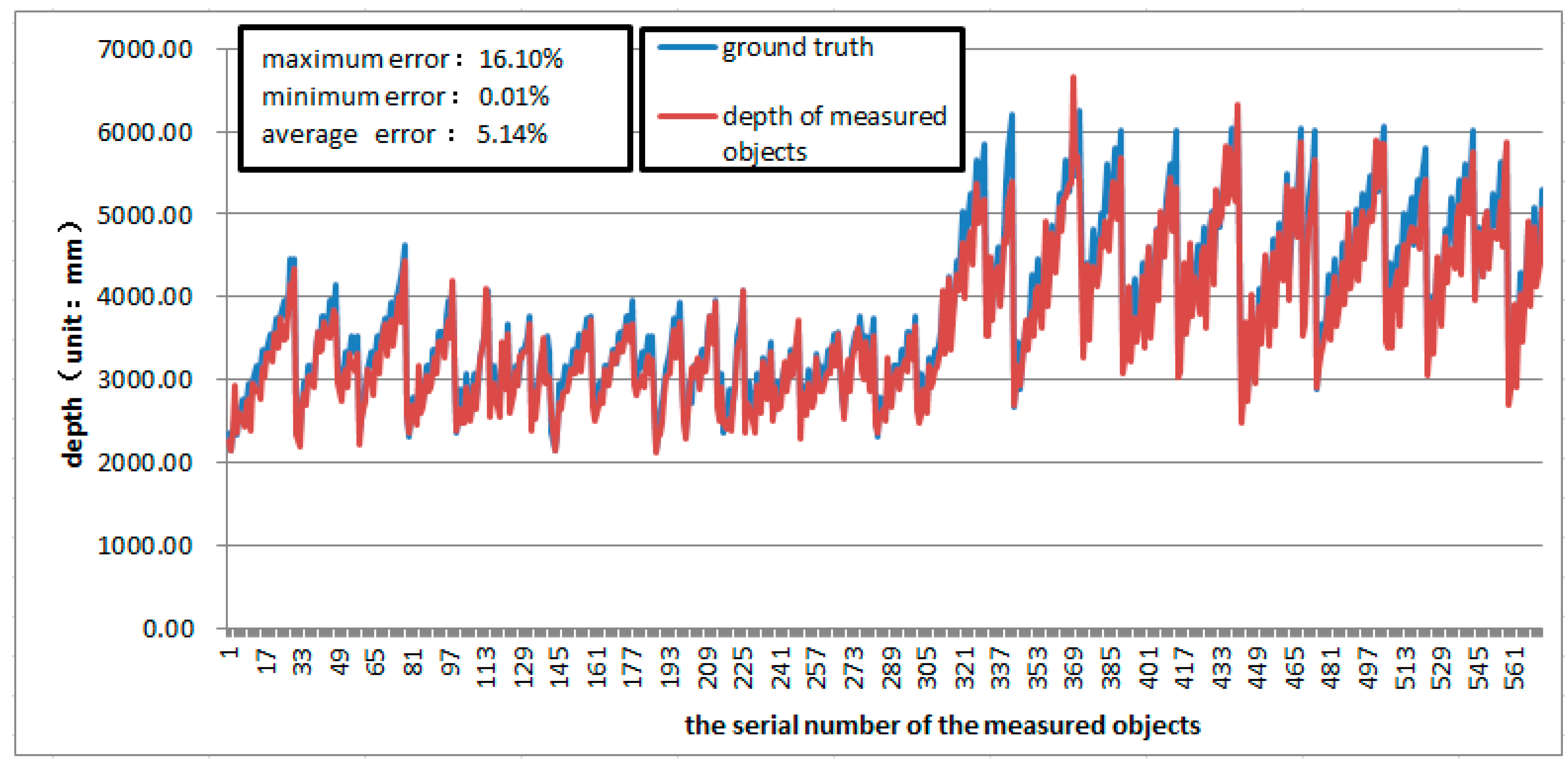
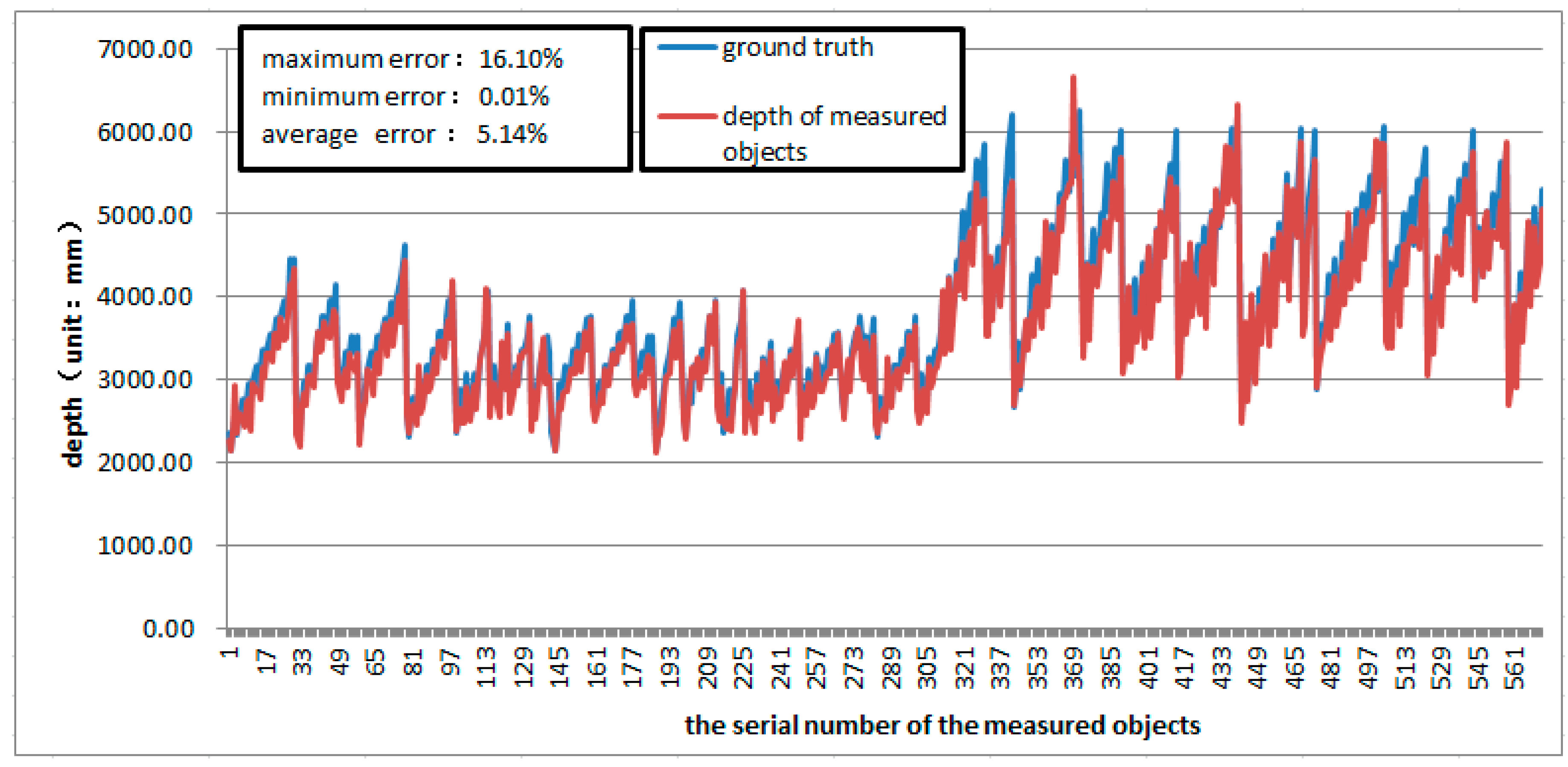
5.3. Our Approach Compared with Others’
6. Discussion
7. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Santos, D.G.; Fernandes, B.J. HAGR-D: A Novel Approach for Gesture Recognition with Depth Maps. Sensors 2015, 15, 28646–28664. [Google Scholar] [CrossRef] [PubMed]
- Huang, H.C.; Hsieh, C.T. An Indoor Obstacle Detection System Using Depth Information and Region Growth. Sensors 2015, 15, 27116–27141. [Google Scholar] [CrossRef] [PubMed]
- Hosni, A.; Rhemann, C. Fast Cost-Volume Filtering for Visual Correspondence and Beyond. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 504–511. [Google Scholar] [CrossRef] [PubMed]
- Jiang, H.; Xiao, J.X. A Linear Approach to Matching Cuboids in RGBD Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013; pp. 2171–2178. [Google Scholar] [CrossRef]
- De-Maeztu, L.; Mattoccia, S. Linear stereo matching. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011; pp. 1708–1715. [Google Scholar] [CrossRef]
- Tao, M.W.; Hadap, S. Depth from Combining Defocus and Correspondence Using Light-Field Cameras. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Sydney, NSW, Australia, 1–8 December 2013; pp. 673–680. [Google Scholar] [CrossRef]
- Chen, C.; Lin, H.T. Light Field Stereo Matching Using Bilateral Statistics of Surface Cameras. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 1518–1525. [Google Scholar] [CrossRef]
- Tao, M.W.; Wang, T.C. Depth Estimation for Glossy Surfaces with Light-Field Cameras. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; pp. 533–547. [Google Scholar] [CrossRef]
- Tao, M.W.; Su, J.C. Depth Estimation and Specular Removal for Glossy Surfaces Using Point and Line Consistency with Light-Field Cameras. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 1155–1169. [Google Scholar] [CrossRef] [PubMed]
- Wang, T.C.; Efros, A.A. Depth Estimation with Occlusion Modeling Using Light-Field Cameras. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 2170–2181. [Google Scholar] [CrossRef] [PubMed]
- Nayar, S.K.; Nakagawa, Y. Shape from Focus. IEEE Trans. Pattern Anal. Mach. Intell. 1994, 16, 824–831. [Google Scholar] [CrossRef]
- Subbarao, M.; Tyan, J.K. Selecting the optimal focus measure for autofocusing and depth-from-focus. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 864–870. [Google Scholar] [CrossRef]
- Pentland, A.P. A New Sense for Depth of Field. IEEE Trans. Pattern Anal. Mach. Intell. 1987, 9, 523–531. [Google Scholar] [CrossRef] [PubMed]
- Subbarao, M.; Gurumoorthy, N. Depth recovery from blurred edges. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Ann Arbor, MI, USA, 5–9 June 1988; pp. 498–503. [Google Scholar] [CrossRef]
- Rajagopalan, A.N.; Chaudhuri, S. Depth estimation and image restoration using defocused stereo pairs. IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 1521–1525. [Google Scholar] [CrossRef] [PubMed]
- Favaro, P.; Soatto, S. Shape from defocus via diffusion. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 518–531. [Google Scholar] [CrossRef] [PubMed]
- Zhuo, S.J.; Sim, T. Defocus map estimation from a single image. Pattern Recogn. 2011, 44, 1852–1858. [Google Scholar] [CrossRef]
- Zhou, C.; Nayar, S. What are good apertures for defocus deblurring? In Proceedings of the IEEE International Conference on Computational Photography (ICCP), San Francisco, CA, USA, 16–17 April 2009; pp. 1–8. [Google Scholar] [CrossRef]
- Kouskouridas, R.; Gasteratos, A. Evaluation of two-part algorithms for objects’ depth estimation. IET Comput. Vis. 2012, 6, 70–78. [Google Scholar] [CrossRef]
- Fang, S.; Jin, R.; Cao, Y. Fast depth estimation from single image using structured forest. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 4022–4026. [Google Scholar] [CrossRef]
- Li, C.M.; Kao, C.Y. Implicit active contours driven by local binary fitting energy. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Minneapolis, MN, USA, 17–22 June 2007; pp. 339–345. [Google Scholar]
- Li, C.M.; Kao, C.Y. Minimization of region-scalable fitting energy for image segmentation. IEEE Trans. Image Process. 2008, 17, 1940–1949. [Google Scholar] [CrossRef] [PubMed]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Lowe, D.G. Object recognition from local scale-invariant features. In Proceedings of the Seventh IEEE International Conference on Computer Vision (ICCV), Kerkyra, Greece, 20–27 September 1999; pp. 1150–1157. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | The Method of the Longest Line | The Method of the Shortest Line | The Method of the Middle Line | The Method of the Random Line |
|---|---|---|---|---|
| Length of the shortest line | 50.19 | 0.15 | 21.29 | 2.31 |
| Length of the longest line | 481.61 | 22.81 | 362.41 | 377.35 |
| Average length | 205.71 | 3.01 | 91.25 | 95.59 |
| Average error of measurement | 4.89% | 535.66% | 20.57% | 173.82% |
| Object | GT 1 | Method 1 | Method 2 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Angmax | i-th 2 | L1 | L2 | MD 3 | EP 4 | Lmax1 | Lmax2 | MD 3 | EP 4 | ||
| obj1 | 3565.38 | 0.35 | 1 | 269.00 | 229.34 | 3470.07 | 2.67% | 269.00 | 229.34 | 3470.07 | 2.67% |
| obj2 | 3389.00 | 2.62 | 3 | 141.41 | 121.31 | 3620.50 | 6.83% | 190.09 | 154.59 | 2612.66 | 22.91% |
| obj3 | 3758.01 | 0.55 | 1 | 302.35 | 257.87 | 3477.98 | 7.45% | 302.35 | 257.87 | 3477.98 | 7.45% |
| Item Compared | Our Method | Kouskouridas et al.’s Method |
|---|---|---|
| Device required | camera | camera and laser depth measurement device |
| Number of images required | 2 | ≥5 images for every measured object |
| Is a sample database required? | NO | YES |
| Can the depth of object which is not registered in the database be measured? | YES | NO |
| Average error percentage | 5.14% | 9.89% |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, L.; Yang, J.; Kong, B.; Wang, C. An Automatic Measurement Method for Absolute Depth of Objects in Two Monocular Images Based on SIFT Feature. Appl. Sci. 2017, 7, 517. https://doi.org/10.3390/app7060517
He L, Yang J, Kong B, Wang C. An Automatic Measurement Method for Absolute Depth of Objects in Two Monocular Images Based on SIFT Feature. Applied Sciences. 2017; 7(6):517. https://doi.org/10.3390/app7060517
Chicago/Turabian StyleHe, Lixin, Jing Yang, Bin Kong, and Can Wang. 2017. "An Automatic Measurement Method for Absolute Depth of Objects in Two Monocular Images Based on SIFT Feature" Applied Sciences 7, no. 6: 517. https://doi.org/10.3390/app7060517
APA StyleHe, L., Yang, J., Kong, B., & Wang, C. (2017). An Automatic Measurement Method for Absolute Depth of Objects in Two Monocular Images Based on SIFT Feature. Applied Sciences, 7(6), 517. https://doi.org/10.3390/app7060517