A Novel Self-Intersection Penalty Term for Statistical Body Shape Models and Its Applications in 3D Pose Estimation


1
College of Control Science and Engineering, Zhejiang University, Hangzhou 310007, China
2
2012 Lab, Huawei Technologies, Hangzhou 310028, China
*
Author to whom correspondence should be addressed.
Appl. Sci. 2019, 9(3), 400; https://doi.org/10.3390/app9030400
Submission received: 29 December 2018
/
Revised: 17 January 2019
/
Accepted: 21 January 2019
/
Published: 24 January 2019
(This article belongs to the Special Issue Intelligent Imaging and Analysis)
Abstract
:Statistical body shape models are widely used in 3D pose estimation due to their low-dimensional parameters representation. However, it is difficult to avoid self-intersection between body parts accurately. Motivated by this fact, we proposed a novel self-intersection penalty term for statistical body shape models applied in 3D pose estimation. To avoid the trouble of computing self-intersection for complex surfaces like the body meshes, the gradient of our proposed self-intersection penalty term is manually derived from the perspective of geometry. First, the self-intersection penalty term is defined as the volume of the self-intersection region. To calculate the partial derivatives with respect to the coordinates of the vertices, we employed detection rays to divide vertices of statistical body shape models into different groups depending on whether the vertex is in the region of self-intersection. Second, the partial derivatives could be easily derived by the normal vectors of neighboring triangles of the vertices. Finally, this penalty term could be applied in gradient-based optimization algorithms to remove the self-intersection of triangular meshes without using any approximation. Qualitative and quantitative evaluations were conducted to demonstrate the effectiveness and generality of our proposed method compared with previous approaches. The experimental results show that our proposed penalty term can avoid self-intersection to exclude unreasonable predictions and improves the accuracy of 3D pose estimation indirectly. Further more, the proposed method could be employed universally in triangular mesh based 3D reconstruction.
1. Introduction
Estimating a 3D human pose from a single 2D image, and more generally, reconstructing the 3D model from 2D images is one of the fundamental and challenging problems in 3D computer vision due to the inherent ambiguity in inferring 3D from 2D. Choosing the appropriate 3D representation is vital for 3D reconstruction. There are many types of 3D representations for 3D modeling. Voxels, point clouds and polygon meshes are commonly used 3D formats for 3D representation. Voxels can be fed directly to convolutional neural networks (CNNs), therefore a lot of works applied voxels for classification [1,2] and 3D reconstruction [3,4,5]. However voxels are poor in memory efficiency. To avoid this drawback of voxel representation, Fan et al. [6] proposed a method to generate point clouds from 2D images. But since there are no connections between points in the point cloud representation, the generated point cloud is often not close to a surface. Polygon mesh is promising due to its high memory efficiency when compared to voxels and point clouds [7]. Polygon mesh is also convenient to visualize since it is compatible with most existing rendering engines.
There are many works using polygon meshes, especially triangular meshes, to represent 3D pose estimation results. Anguelov et al. [8] proposed the first statistical body shape model called SCAPE, represented as a triangular mesh. Loper et al. [9] proposed another statistical body shape model with higher accuracy called SMPL which is also represented as a triangular mesh. Guan et al. [10,11] employed SCAPE to estimate 3D poses based on manually marked 2D joints. Bogo et al. [12] employed the SMPL human model and minimized the error between the projected human model joints and 2D joints detected by DeepCut [13] to estimate the 3D pose of the human body automatically, this method is iterative optimization-based which results in high accuracy but is time consuming. Pavlakos et al. [14] used a variant of Hourglass [15] to predict 2D joints and 2D masks simultaneously, then the 2D joints and 2D masks were used to regress pose parameters and shape parameters of SMPL separately in a direct prediction way. This approach is much faster than method proposed in [12], however self-intersection occurs on images with pattern of poses that never appeared in the training set.
Other work utilized triangle meshes to represent 3D reconstruction results of objects. Kar et al. [16] trained a mesh deformable model to reconstruct 3D shapes limited to the popular categories. Kato et al. [7] deformed a predefined mesh to approximate the 3D object by minimizing the silhouette error. Wang et al. [17] proposed an end-to-end deep learning architecture which represents a triangular mesh in a graph-based convolutional neural network to estimate the 3D shape of objects from a single image.
However, one of the main disadvantages of representing 3D shapes as triangular meshes is that self-intersection is difficult to prevent. Some examples of 3D pose estimation results with self-intersection are shown in Figure 1. It is impossible for objects in the real world to have surfaces with self-intersection. Therefore previous work paid great attention to avoiding the self-intersection of triangular meshes. Since it is difficult to derive a differentiable expression of the intersection volume directly, approximation is often taken to simplify the derivation. Although approximation provides great convenience to deriving a differentiable penalty term, self-intersection can not be removed strictly since approximation can not describe the original surface accurately.
To overcome the weakness of previous methods of preventing self-intersection, this paper proposed a novel self-intersection penalty term (SPT) which is able to avoid self-intersection strictly. Unlike previous approaches, our proposed self-intersection penalty term is defined as the volume of intersection regions which is expensive to compute however, we managed to work around this problem. Notably, no approximation was taken in this paper to derive a differentiable expression. Besides, it is not worthwhile to derive a differentiable expression of intersection volume since calculating the exact volume is not our intention. Moreover, the partial derivatives can be easily derived even without the expression of intersection volume. Inspired by [18], we developed an algorithm to detect vertices of self-intersection regions quickly by only going through triangles in the mesh once. This process is similar to rasterization in computer graphic with linear time complexity. A linked list is applied to store depth values and orientations of triangles intersected with the same detection ray. Then vertices in self-intersection region can be easily detected by going through the linked list. The partial derivatives of the self-intersection term with respect to the coordinate of each vertex are easy to derive from the perspective of geometry. The partial derivatives with respect to vertices not in the region of self-intersection is obviously zero, while the partial derivatives with respect to vertices in the region of self-intersection could be obtained from the normal vectors of neighbouring triangles. The value of the penalty term is assigned as the ratio of number of vertices in self-intersection to number of vertices not in self-intersection. In this way the value of penalty term is easy to compute and indicates the degree of self-intersection in some degree. The experimental results show that the proposed penalty term avoids self-intersection strictly and works effectively. The main contributions of this paper are summarized as follows:
- We proposed a novel self-intersection penalty term which does not require deriving a differentiable expression and generally applies to triangular mesh-based representations.
- We performed 3D pose estimation from 2D joints and compared our method with other state-of-the-art approaches qualitatively and quantitatively to demonstrate the practical value and the superiority of our method.
- To the best of our knowledge, this is the first time the conception of self-intersection in relation to disconnected meshes in the field of 3D reconstruction has been generalized.
The content of this paper consists of five sections. In Section 2 an overview of related work is provided. In Section 3, the details of the proposed self-intersection penalty term are presented. In Section 4, the results of experiments and analysis of the proposed self-intersection penalty term are given. The conclusions are presented in Section 5.
2. Related Work
The work presented in this section is closely related to our work and involves avoiding self-intersection with triangular mesh.
In computer graphics, it is common to use proxy geometries to prevent self-intersection [19,20]. In computer vision, recent works followed this approach to prevent self-intersection of 3D reconstruction results represented as triangular meshes. Sminchisescu et al. [21] defined an implicit surface as a approximation of body shape to avoid self-intersection. Pons et al. [22] applied a set of spheres to approximate the interior volume of body mesh, and used the radius of each sphere to define a penalty term of self-intersection. These approaches are not accurate since the shape of human body can not be described exactly by spheres. To improve the accuracy of this approach, Bogo et al. [12] trained a regressor to generate capsules with minimum error to the body surface, then the authors further defined the penalty term as a 3D isotropic Gaussian derived from the capsule radius. It is worth mentioning that these approaches mentioned above do not strictly avoid self-intersection as approximations were applied to derive a differentiable penalty term. In [17] the authors employed a Laplacian term to prevent the vertices from moving too freely, this penalty term avoids self-intersection to some degree. However this method still does not strictly avoid self-intersection since the Laplacian term acts just like a surface smoothness term preventing the 3D mesh from deforming too much.
Our work differs from previous works by identifying that a differentiable self-intersection penalty term is not necessary and the gradients can be calculated manually. We demonstrated appealing results in 3D pose estimation based on a statistical body shape model.
3. Self-intersection Penalty Term
In this section, the details of our proposed self-intersection penalty term are discussed. We employed the SMPL human body shape model [9] to evaluate our method. Essential notations are provided here. SMPL model defines a function , where are the pose parameters, are the shape parameters and are fixed parameters of the model. The output of this function is a triangular mesh with N = 6890 vertices (i = 1, …, N). The shape parameters represents the coefficients of linear combination of a low number of principal body shapes learned from a dataset containing body scans [23].
3.1. Definition and Description
Our method generally applies to meshes satisfying the conditions described below:
- The mesh is a two-dimensional manifold.
- The mesh describes an orientable surface.
- The mesh is a closed surface.
Since the two-dimensional manifolds do not have to be connected, we can say a mesh with several disconnected parts also satisfies the conditions above. We demonstrated that our proposed method also works with a disconnected mesh in Section 4.
To remove the self-intersection, the triangle mesh should be iteratively deformed by moving each vertex in a specific direction. The moving directions of vertices are obtained by computing the partial derivatives of the self-intersection penalty term which is defined as the volume of the self-intersection region in this paper. This penalty term is denoted as , where V is the coordinates of all the vertices. An ideal self-intersection penalty term should satisfy the following conditions:
- When there is no self-intersection, both the penalty term and the gradient of the penalty term should be zero.
- When there is self-intersection, the value of penalty term indicates the degree of intersection.
- When there is self-intersection, the gradient of penalty term offers meaningful direction for optimization.
Leaving the strategy of computing the value of penalty term aside, the method of computing gradient is discussed first.
The first step of computing the partial derivatives is separating the vertices into two sets: (1) vertices in the self-intersection region and (2) vertices not in the self-intersection region. We implemented this separation by emitting a beam of detection rays, the density of rays is manually set according to the number of triangles in the mesh. An appropriate setting of density of rays guarantees the accuracy of classification and low memory consumption. There are two typical ways of intersection shown in Figure 2. According to the type of self-intersection, the set of vertices in self-intersection could be further separated into two sets. Overall, the vertices are divided into three sets: (a) vertices in the self-intersection region due to interpenetration of the outer surface, denoted as ; (b) vertices in the self-intersection region due to interpenetration of the inner surface, denoted as and (c) vertices not in the self-intersection region, denoted as ; Based on the classification result, the partial derivative of the penalty term with respect to coordinate of a vertex can be obtained according to the normal vector and which set the vertex is belonging to.
It is worth pointing out that self-intersection described in Figure 2b rarely occurs for statistical body shape model. To maintain the generality of our method, both of these two type of self-intersection are considered in the following discussion.
3.2. Detection and Classification of Vertices
To compute the partial derivatives of our proposed self-intersection penalty term, it is necessary to divide the vertices into three sets: , and . A camera screen with pixels arranged in a square with H rows and W columns is set in front of the 3D mesh such that the orthogonal projection of the 3D mesh falls totally inside the screen. It is worth noting that the camera mentioned here is used only to emit detection rays, not for rendering and visualization. Detection rays are emitted from the center of each pixel to detect self-intersection, as is shown in Figure 3. The detail of the detection and classification is presented in Algorithm 1. To make our algorithm more intuitive, a schematic representation is given in Figure 4.
| Algorithm 1: Illustration of self-intersection detection and classification of vertices |
 |
3.3. Gradients Calculation
The self-intersection penalty term is defined as:
where V denotes the set of coordinates of all vertices, is the volume of the self-intersection region. For the sake of further discussion, a vertex is randomly chosen from the triangular mesh with N vertices. Coordinates of all vertices are frozen, except for . The coordinate of is denoted as .
Under the preceding assumptions, the penalty term can be regarded as a function of , and .
To compute , and , is displaced from to . Then the change in due to the displacement could be represented as:
Further computation is hard to continue without imposing constraints on . First, for the simplest case, is assumed to belong to , that is to say . Since tiny displacement of brings no effect to the volume of self-intersection, it is obvious that:
The gradient of could be represented as:
For the second case , more assumptions need to be made for a detailed discussion. We assume that there are n neighboring triangles sharing as a common vertex. One of the neighboring triangles is denoted as , the area of is represented as and the unit normal vector of is denoted as . An intuitive representation of this situation is shown in Figure 5.
The change in the volume of self-intersection due to tiny displacement of vertex can be represented as:
where , and are unit vectors in the same directions as the positive directions of x, y and z axes.
The gradient can be obtained as:
The equation above can be simplified as:
For the last case , the derivation process of partial derivative is similar to the process described in the second case, and the results are same in magnitude but opposite in sign. The gradient in this case can be obtained as:
In summary, the gradient of self-intersection penalty term with respect to the coordinate of vertex can be represented as:
Employing the equation above for a gradient-based optimization algorithm to remove self-intersection works well in most cases. But when there are great differences between the areas of triangles, the process of optimization tends to be unstable. To solve this problem, a modified version of the gradient formula is presented:
For the value of , it is difficult and unnecessary to calculate the exact volume of the intersection region by coordinates of vertices. Instead, is assigned with the ratio of the number of vertices in self-intersection to the number of vertices not in self-intersection. This ratio is easy to calculate and significant for indicating the degree of self-intersection. The expression of is presented as:
where denotes the number of elements in a set.
So far, the forward and backward processes of our proposed self-intersection penalty term have been defined.
4. Experimental Results and Discussion
In this section, experiments were conducted to evaluated the effectiveness of our proposed self-intersection penalty term (SPT). We employed a statistical body shape model SMPL [9] to show the effectiveness of our method.
4.1. Self-Intersection Removal on a Single SMPL Model
To evaluate the validity of our method, we set the pose parameters to generate triangular meshes with self-intersection deliberately. Then we performed gradient descent algorithm to optimize the pose parameters to remove the self-intersection, the shape parameters were the ground truth values from dataset and were fixed during iterations. The learning rate of gradient descent was set to . The number of detection rays was set to .
The process of iteration is visualized in Figure 6. We can see that the gradient calculated via proposed method works effectively in a gradient descent algorithm to minimize the value of SPT, that is to say, minimize the number of vertices in self-intersection region.
In order to show the necessity of gradient normalization which is presented in Equation (11), an experiment with same conditions as the experiment described above, but without gradient normalization, was conducted. The visualized result is shown in Figure 7. Since there are great differences between the areas of triangles in the body meshes, gradients of vertices differ greatly in magnitudes. This often leads to unstable iterations and unpredictable results and we demonstrated that this problem can be solved by gradient normalization.
4.2. Intersection and Self-Intersection Removal on Multiple SMPL Models
To demonstrate that our method applies to general closed surfaces, an experiment on mesh with two disconnected surfaces was carried out. In the experiment, two SMPL mesh models were generated and were regarded as one mesh, gradient descent was employed to remove the intersection between the two SMPL models and the self-intersection of themselves. We visualized the result in Figure 8.
Figure 8 shows that our proposed self-intersection penalty term can remove both the intersection between different body meshes and the self-intersection of each body mesh. This property of our method is of great significance for multi-person 3D pose estimation.
4.3. 3D Pose Estimation from 2D Joints
We tested our proposed self-intersection penalty term (SPT) on UP-3D [24] whose sample images were labeled with ground truth 2D joints. To estimate 3D pose from 2D joints, we defined an objective function as:
where K are camera parameters and is the ground truth of 2D joints. represents the error between projected joints of the SMPL model and the ground truth 2D joints.
The shape parameters are fixed during optimization. Since the objective function defined in Equation (13) is differentiable, gradient descent can be directly applied to optimize the pose parameters by minimizing the objective function. To demonstrate that SPT can improve the accuracy of 3D pose estimation by excluding unreasonable predictions, we also performed the optimization of objective function without SPT which can be represented as:
Figure 9 visually compares the results of two different objective functions on a few images from UP-3D dataset. It is obvious that minimizing the error between projected joints and the ground truth 2D joints directly without self-intersection penalty term tends to result in body meshes with self-intersection. The fitting results with SPT are more natural and more reasonable compared with the results without SPT. This experiment demonstrated that it is effective to add our proposed SPT into the objective function to avoid self-intersection of body meshes in optimization-based 3D pose estimation.
4.4. Comparison with State-of-the-Art
To compare our proposed method with other state-of-the-art methods, we conducted an experiment on UP-3D dataset. Since our iterative optimization-based method often fails because of local minima, we used a reduced test set of 139 images selected by Tan et al. [25] to limit the range for the global rotation of body shape model.
We implemented two state-of-the-art methods for qualitative and quantitative comparisons. In the baseline method, the objective function is defined as the reprojection error of 2D joints only. These methods are described in more detail below:
- Reprojection error of 2D joints (RE) onlyThis method only minimizes the error between ground truth 2D joints and projected 2D joints to estimate the 3D pose.
- RE + Laplacian regularization (LR)Laplacian regularization is proposed by Wang et al. [17] to prevent the vertices from moving too freely and potentially avoids mesh self-intersection in triangular mesh based 3D reconstruction. We employed this method in 3D pose estimation and the objective function is defined as the sum of reprojection error of 2D joints and the Laplacian regularization term.
- RE + Sphere approximation (SA)Pons-Moll et al. [22] built a set of spheres as a coarse approximation to the body shape model and derived a differentiable penalty term via calculating the intersection between spheres. To implement this method, We designed a set of spheres to approximate the surface of human body, as is shown in Figure 10. The objective function is defined as the sum of reprojection error of 2D joints and the intersection between spheres.
- RE + SPTThis is our proposed method whose objective function is defined as the sum of the reprojection error of 2D joints and the self-intersection penalty term proposed in this paper.
4.4.1. Qualitative Comparison
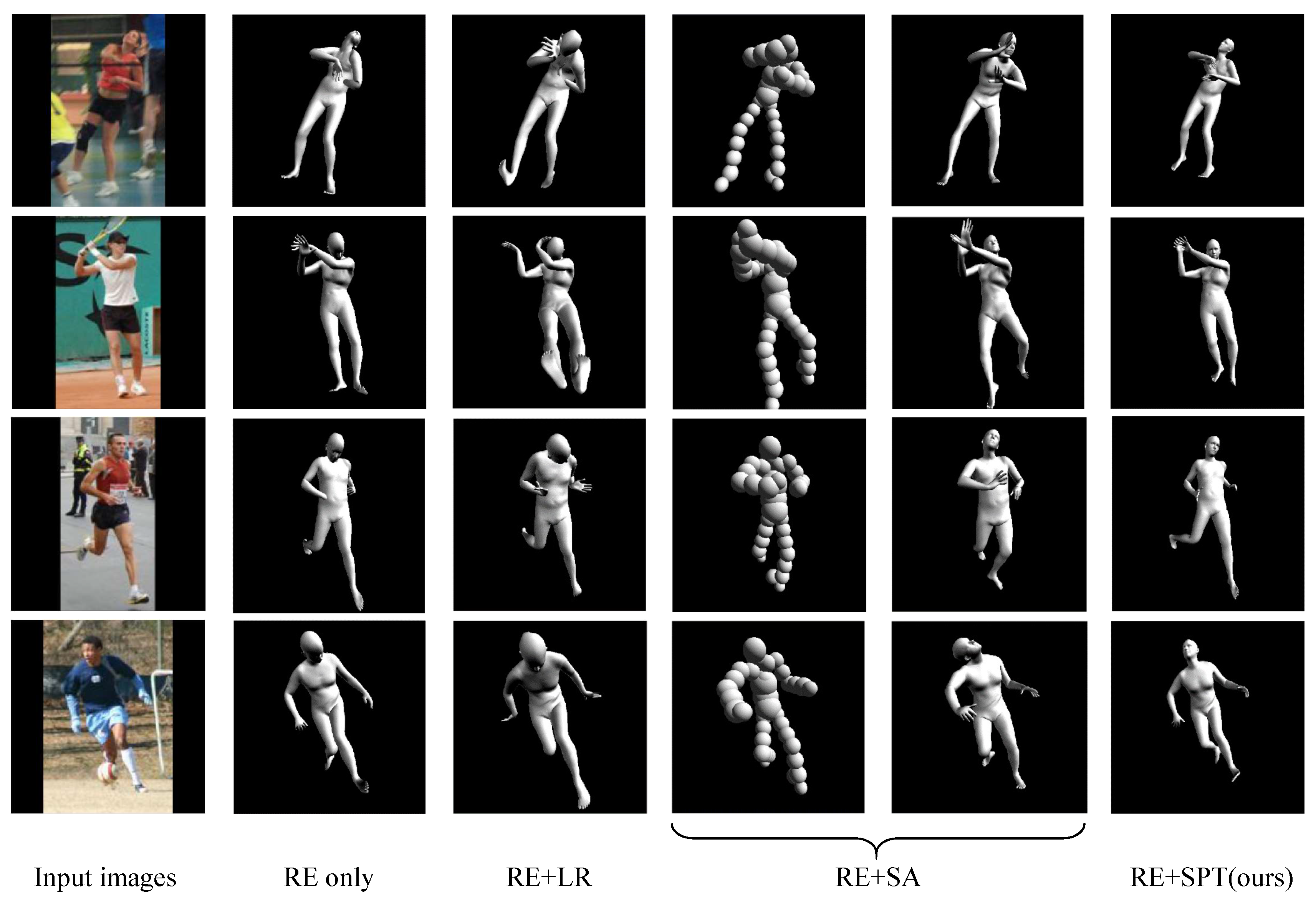
We implemented two state-of-the-art methods and one baseline method for qualitative comparison. Figure 11 presents a part of results from the reduced test set of UP-3D by our proposed method and other methods. These results demonstrate that our proposed method can remove the self-intersection of the statistical body shape model effectively and produces more reasonable results.
As is can seen from Figure 11, the results obtained by the baseline method without any self-intersection penalty tends to intersects with itself. The Laplacian regularization can not strictly avoid self-intersection and often leads to unnatural results. We can see that it is not suitable to employ Laplacian regularization in statistical body shape model because of the fact that this laplacian term brings negative effect to 3D pose estimation. The method of sphere approximation is very competitive in removing the self-intersection of body mesh, however method requires designing a appropriate set of spheres and we found that it is an excessive trivial procedure to set the radius and the coordinate of each sphere appropriately. In addition, since the body mesh can not be approximated accurately by spheres, this method may lead to fail results by simply removing the intersection between spheres.
Compared with other approach, our proposed method can obtain more visually appealing results from two points. One is that when there is no self-intersection, our proposed SPT will have no effect on the body mesh, this means no side effects on 3D pose estimation. The other is that our proposed approach can avoid the self-intersection of body mesh strictly without taking any approximation.
4.4.2. Quantitative Comparison
To the best of our knowledge, there is no commonly used evaluation metric for methods preventing self-intersection of triangular mesh. In order to compare our method with other state-of-the-art approaches quantitatively, we adopt the per vertex errors as 3D pose estimation metric and we used the percentage of vertices in region of self-intersection computed by our proposed algorithm to evaluate the performance of our method and other state-of-the-art approaches. It should be noted that it is inappropriate to evaluate these methods only by per vertex error or percentage of vertices in self-intersection because an ideal approach of avoiding self-intersection should achieve both minimum per vertex error and minimum percentage of vertices in self-intersection region. Therefore these two evaluation metrics, per vertex error and percentage of vertices in self-intersection, were adopted to conduct a quantitative comparison.
The quantitative results of the baseline method, the other state-of-the-art approaches and our proposed method is shown in Table 1. The Laplacian regularization method achieved a lower percentage of vertices in self-intersection but a higher per vertex error compared to the baseline method, which demonstrates that the Laplacian regularization does work in avoiding self-intersection but the side effect leads to loss of precision in 3D pose estimation. The approach of approximating body shape by a set of spheres outperforms the baseline method both in per vertex error and percentage of vertices in self-intersection. It is undeniable that this method may perform better with more carefully designed spheres, but it will be extremely tedious to implement this method. Our proposed approach outperforms the baseline method and two state-of-the-art methods and avoids the tedious procedure required for the sphere approximation.
4.5. Analysis of Time Efficiency
In order to evaluate the time efficiency of our method, we carried out experiments with a different number of detection rays and SMPL models. All experiments in this section were done on a laptop with Intel(R) Core(TM) i5-3230M processer. The most time-consuming part of our technique is self-intersection detection as is described in Algorithm 1. The highlight of our method is that the time complexity is linear to the number of triangles. The number of detection rays has almost no effect on the elapsed time as is shown in Table 2. As can be seen in the Table 2, the number of detection rays was increased from to but the elapsed time remained approximately constant.
In the next experiment, we fixed the number of detection rays and changed the number of SMPL models to test the performance of our method with growing number of triangles. A single SMPL model has about 13,000 triangles. As is shown in Table 3, the elapsed time grows about 30 ms for each additional SMPL model added to the mesh. Result of this experiment demonstrated that the time complexity of our proposed algorithm is linear to the number of triangles.
Our proposed method is obviously more computational compared with traditional methods, but it is worthwhile to apply this method because of the accuracy and generality of our approach. Moreover, the time efficiency of our method is totally acceptable according to the experimental results.
5. Conclusions
In this paper, we proposed a novel self-intersection penalty term for statistical body shape models to remove the self-intersection of the mesh by gradient-based optimization. Unlike most traditional approaches, our method does not require a hard-to-obtain differentiable penalty term, but instead gradients are manually calculated. In the course of analysis, we have demonstrated that it is not necessary to derive differentiable expressions of a penalty term and gradients can be manually calculated from the perspective of geometry. Since no approximation is used in our method, self-intersection can be strictly removed. The highlight of our work is that our method applies to general meshes with different shapes and topology without the need to design a set of appropriate proxy geometries. Despite the fact that our proposed self-intersection penalty term is more time consuming than traditional approaches, the elapsed time of one iteration is totally acceptable according to the experimental results. The applications of our method are not limited to the statistical body shape models presented in this paper. Our proposed self-intersection penalty term can be incorporated into other 3D reconstruction problems based on a triangular mesh, such as the mesh-based 3D reconstruction described in [7,16,17].
Our proposed approach has its limitations. When there are some triangles happened to be parallel to the detection rays, these triangles will not intersect with any detection rays no matter how dense the detection rays are. That is to say, vertices of triangles parallel to the detection rays may be mistakenly classified, and further the gradients with respect to these vertices will be incorrect. We assume that each triangle and its vertices are located in the same region, this assumption does not apply to the situation where the mesh is sparse and in this situation undesirable consequences may be caused. Another limitation is that it is difficult to manually set the number of detection rays appropriately, such that all vertices in self-intersection can be detected and classified correctly with minimum memory consumption.
Future research directions of this work may include modifying the way detection rays are emitted to avoid incorrect results when there are triangles parallel to the detection rays. It may also include developing a strategy to set the number of detection rays appropriately and automatically. We are also interested in reducing the time complexity of our proposed method to make this approach more suitable for gradient-based optimization.
Author Contributions
Conceptualization, Z.W. and H.L.; Methodology, Z.W., H.L. and W.J.; Writing—original draft preparation, Z.W.; Writing—review and editing, Z.W., H.L. and W.J.; Visualization, Z.W. and H.L.; Supervision, W.J.; Funding acquisition, W.J., H.L. and L.C.
Funding
This research was funded by [the National Natural Science Foundation of China] grant number [61633019], [the Public Projects of Zhejiang Province, China] grant number [LGF18F030002] and [Huawei innovation research program] grant number [HO2018085209].
Conflicts of Interest
The authors declare no conflict of interest.
References
- Maturana, D.; Scherer, S. Voxnet: A 3D convolutional neural network for real-time object recognition. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 922–928. [Google Scholar]
- Qi, C.R.; Su, H.; Nießner, M.; Dai, A.; Yan, M.; Guibas, L.J. Volumetric and multi-view cnns for object classification on 3D data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas Valley, NV, USA, 26 June–1 July 2016; pp. 5648–5656. [Google Scholar]
- Choy, C.B.; Xu, D.; Gwak, J.; Chen, K.; Savarese, S. 3D-R2N2: A unified approach for single and multi-view 3d object reconstruction. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Berlin, Germany, 2016; pp. 628–644. [Google Scholar]
- Tatarchenko, M.; Dosovitskiy, A.; Brox, T. Octree generating networks: Efficient convolutional architectures for high-resolution 3D outputs. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; Volume 2, p. 8. [Google Scholar]
- Tulsiani, S.; Zhou, T.; Efros, A.A.; Malik, J. Multi-view supervision for single-view reconstruction via differentiable ray consistency. In Proceedings of the 2017 Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; Volume 1, p. 3. [Google Scholar]
- Fan, H.; Su, H.; Guibas, L.J. A Point Set Generation Network for 3D Object Reconstruction from a Single Image. In Proceedings of the 2017 Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; Voume 2, p. 6. [Google Scholar]
- Kato, H.; Ushiku, Y.; Harada, T. Neural 3D mesh renderer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3907–3916. [Google Scholar]
- Anguelov, D.; Srinivasan, P.; Koller, D.; Thrun, S.; Rodgers, J.; Davis, J. SCAPE: Shape completion and animation of people. ACM Trans. Graph. 2005, 24, 408–416. [Google Scholar] [CrossRef]
- Loper, M.; Mahmood, N.; Romero, J.; Pons-Moll, G.; Black, M.J. SMPL: A skinned multi-person linear model. ACM Trans. Graph. 2015, 34, 248. [Google Scholar] [CrossRef]
- Guan, P.; Weiss, A.; Balan, A.O.; Black, M.J. Estimating human shape and pose from a single image. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 27 September–4 October 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 1381–1388. [Google Scholar]
- Guan, P. Virtual human bodies with clothing and hair: From images to animation. Ph.D. Thesis, Brown University, Providence, RI, USA, 2012. [Google Scholar]
- Bogo, F.; Kanazawa, A.; Lassner, C.; Gehler, P.; Romero, J.; Black, M.J. Keep it SMPL: Automatic estimation of 3D human pose and shape from a single image. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Berlin, Germany, 2016; pp. 561–578. [Google Scholar]
- Pishchulin, L.; Insafutdinov, E.; Tang, S.; Andres, B.; Andriluka, M.; Gehler, P.V.; Schiele, B. DeepCut: Joint subset partition and labeling for multi person pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas Valley, NV, USA, 26 June–1 July 2016; pp. 4929–4937. [Google Scholar]
- Pavlakos, G.; Zhu, L.; Zhou, X.; Daniilidis, K. Learning to Estimate 3D Human Pose and Shape from a Single Color Image. arXiv, 2018; arXiv:1805.04092. [Google Scholar]
- Newell, A.; Yang, K.; Deng, J. Stacked hourglass networks for human pose estimation. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Berlin, Germany, 2016; pp. 483–499. [Google Scholar]
- Kar, A.; Tulsiani, S.; Carreira, J.; Malik, J. Category-Specific Object Reconstruction From a Single Image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Wang, N.; Zhang, Y.; Li, Z.; Fu, Y.; Liu, W.; Jiang, Y.G. Pixel2Mesh: Generating 3D Mesh Models from Single RGB Images. arXiv, 2018; arXiv:1804.01654. [Google Scholar]
- Crow, F.C. Shadow algorithms for computer graphics. In Proceedings of the 4th Annual Conference on Computer Graphics and Interactive Techniques, SIGGRAPH’77, San Jose, CA, USA, 20–22 July 1977; ACM: New York, NY, USA, 1977; Volume 11, pp. 242–248. [Google Scholar]
- Ericson, C. Real-Time Collision Detection (The Morgan Kaufmann Series in Interactive 3-D Technology); CRC Press: Boca Raton, FL, USA, 2004. [Google Scholar]
- Thiery, J.M.; Guy, É.; Boubekeur, T. Sphere-meshes: Shape approximation using spherical quadric error metrics. ACM Trans. Graph. 2013, 32, 178. [Google Scholar] [CrossRef]
- Sminchisescu, C.; Triggs, B. Covariance scaled sampling for monocular 3D body tracking. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Kauai, HI, USA, 8–14 December 2001; IEEE: Piscataway, NJ, USA, 2001; p. 447. [Google Scholar]
- Pons-Moll, G.; Taylor, J.; Shotton, J.; Hertzmann, A.; Fitzgibbon, A. Metric regression forests for correspondence estimation. Int. J. Comput. Vis. 2015, 113, 163–175. [Google Scholar] [CrossRef]
- Robinette, K.M.; Blackwell, S.; Daanen, H.; Boehmer, M.; Fleming, S. Civilian American and European Surface Anthropometry Resource (CAESAR), Final Report. Volume 1. Summary; Technical Report; Sytronics Inc.: Dayton, OH, USA, 2002. [Google Scholar]
- Lassner, C.; Romero, J.; Kiefel, M.; Bogo, F.; Black, M.J.; Gehler, P.V. Unite the people: Closing the loop between 3D and 2D human representations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; Volume 2, p. 3. [Google Scholar]
- Tan, J.; Budvytis, I.; Cipolla, R. Indirect deep structured learning for 3D human body shape and pose prediction. In Proceedings of the BMVC, London, UK, 4–7 September 2017; Volume 3, p. 6. [Google Scholar]
Figure 1.
Examples of model-based 3D pose estimation results with self-intersection between body parts.
Figure 1.
Examples of model-based 3D pose estimation results with self-intersection between body parts.

Figure 2.
Two typical way of self-intersection: (a) Self-intersection due to interpenetration of the outer surface. (b) Self-intersection due to interpenetration of the inner surface.
Figure 2.
Two typical way of self-intersection: (a) Self-intersection due to interpenetration of the outer surface. (b) Self-intersection due to interpenetration of the inner surface.

Figure 3.
Schematic representation of our approaches to detect self-intersection (the image of triangular mesh is rendered by Blender).
Figure 3.
Schematic representation of our approaches to detect self-intersection (the image of triangular mesh is rendered by Blender).

Figure 4.
An intuitive representation of our algorithm to detect self-intersection. The detection rays are emitted from the camera, the dashed area represents the self-intersection region. The vertices in red circle were detected to be in self-intersection according to the counter and orientation.
Figure 4.
An intuitive representation of our algorithm to detect self-intersection. The detection rays are emitted from the camera, the dashed area represents the self-intersection region. The vertices in red circle were detected to be in self-intersection according to the counter and orientation.

Figure 5.
A tiny displacement on the vertex . The change in the volume of self-intersection is equal to the sum of volume of several neighboring tetrahedrons.
Figure 5.
A tiny displacement on the vertex . The change in the volume of self-intersection is equal to the sum of volume of several neighboring tetrahedrons.

Figure 6.
Images rendered from the iterative process. First column: Images rendered from initial meshes with self-intersection. Second through fourth columns: Images rendered from optimized meshes every 10 iterations. The self-intersection penalty term (SPT) values in the bottom of each column denote the average SPT of three SMPL models.
Figure 6.
Images rendered from the iterative process. First column: Images rendered from initial meshes with self-intersection. Second through fourth columns: Images rendered from optimized meshes every 10 iterations. The self-intersection penalty term (SPT) values in the bottom of each column denote the average SPT of three SMPL models.

Figure 7.
Images rendered from the iterative process without gradient normalization. First column: images rendered from initial meshes with self-intersection. Second through fourth columns: images rendered from optimized meshes every 10 steps.
Figure 7.
Images rendered from the iterative process without gradient normalization. First column: images rendered from initial meshes with self-intersection. Second through fourth columns: images rendered from optimized meshes every 10 steps.

Figure 8.
Images rendered from the iterative process with two SMPL models. First column: Images rendered from initial meshes with self-intersection. Second through fourth columns: Images rendered from optimized meshes every 10 steps.
Figure 8.
Images rendered from the iterative process with two SMPL models. First column: Images rendered from initial meshes with self-intersection. Second through fourth columns: Images rendered from optimized meshes every 10 steps.

Figure 9.
Visualized results of 3D pose estimation. Images in row (a) are the input images, images in row (b) are fitting results without SPT, images in row (c) are fitting results with SPT.
Figure 9.
Visualized results of 3D pose estimation. Images in row (a) are the input images, images in row (b) are fitting results without SPT, images in row (c) are fitting results with SPT.

Figure 10.
Spheres designed to approximate the human body are kept in the same pose with the body shape model.
Figure 10.
Spheres designed to approximate the human body are kept in the same pose with the body shape model.

Figure 11.
3D pose estimation results by four different methods. First column: Input images. Second column: Results obtained by minimizing reprojection (RE) error of 2D joints only. Third column: Results obtained by minimizing the sum of reprojection error and Laplacian regularization (LR). Fourth column through fifth column: Results obtained by minimizing the sun of reprojection error and the intersection between spheres. Sphere Approximation (SA). Sixth column: Results obtained by our proposed approach.
Figure 11.
3D pose estimation results by four different methods. First column: Input images. Second column: Results obtained by minimizing reprojection (RE) error of 2D joints only. Third column: Results obtained by minimizing the sum of reprojection error and Laplacian regularization (LR). Fourth column through fifth column: Results obtained by minimizing the sun of reprojection error and the intersection between spheres. Sphere Approximation (SA). Sixth column: Results obtained by our proposed approach.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Results of baseline method, other state-of-the-art methods and our proposed approach on reduced test set of UP-3D [24].
Table 1.
Results of baseline method, other state-of-the-art methods and our proposed approach on reduced test set of UP-3D [24].
| Methods | Per Vertex Error (mm) | Percentage of Vertices in Self-Intersection |
|---|---|---|
| RE only | 257.54 | 15.22% |
| RE+LR [17] | 452.72 | 7.64% |
| RE+SA [22] | 186.98 | 0.87% |
| RE+SPT (ours) | 140.31 | 0.23% |
Table 2.
Time consumed by an iteration with different number of detection rays. The number of SMPL models is 1.
Table 2.
Time consumed by an iteration with different number of detection rays. The number of SMPL models is 1.
| Number of Detection Rays | Elapsed Time (ms) |
|---|---|
| 53.84 | |
| 54.96 | |
| 56.76 | |
| 58.32 | |
| 59.28 |
Table 3.
Time consumed by an iteration with different number of SMPL models. The number of detection rays is .
Table 3.
Time consumed by an iteration with different number of SMPL models. The number of detection rays is .
| Number of SMPL Models | Elapsed Time (ms) |
|---|---|
| 1 | 56.76 |
| 2 | 89.80 |
| 3 | 119.25 |
| 4 | 149.58 |
| 5 | 186.76 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Wu, Z.; Jiang, W.; Luo, H.; Cheng, L. A Novel Self-Intersection Penalty Term for Statistical Body Shape Models and Its Applications in 3D Pose Estimation. Appl. Sci. 2019, 9, 400. https://doi.org/10.3390/app9030400
AMA Style
Wu Z, Jiang W, Luo H, Cheng L. A Novel Self-Intersection Penalty Term for Statistical Body Shape Models and Its Applications in 3D Pose Estimation. Applied Sciences. 2019; 9(3):400. https://doi.org/10.3390/app9030400
Chicago/Turabian StyleWu, Zaiqiang, Wei Jiang, Hao Luo, and Lin Cheng. 2019. "A Novel Self-Intersection Penalty Term for Statistical Body Shape Models and Its Applications in 3D Pose Estimation" Applied Sciences 9, no. 3: 400. https://doi.org/10.3390/app9030400
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.