Tensor Robust Principal Component Analysis via Non-Convex Low Rank Approximation


1
School of Automation, Guangdong University of Technology, Guangzhou 510006, China
2
Department of Mathematics, Southern Illinois University, Carbondale, IL 62901, USA
3
Department of Computer Science, Southern Illinois University, Carbondale, IL 62901, USA
4
School of Mathematical Sciences, South China Normal University, Guangzhou 510631, China
*
Authors to whom correspondence should be addressed.
Appl. Sci. 2019, 9(7), 1411; https://doi.org/10.3390/app9071411
Submission received: 25 January 2019
/
Revised: 25 March 2019
/
Accepted: 29 March 2019
/
Published: 3 April 2019
(This article belongs to the Special Issue Machine Learning and Compressed Sensing in Image Reconstruction)
Abstract
:Tensor Robust Principal Component Analysis (TRPCA) plays a critical role in handling high multi-dimensional data sets, aiming to recover the low-rank and sparse components both accurately and efficiently. In this paper, different from current approach, we developed a new t-Gamma tensor quasi-norm as a non-convex regularization to approximate the low-rank component. Compared to various convex regularization, this new configuration not only can better capture the tensor rank but also provides a simplified approach. An optimization process is conducted via tensor singular decomposition and an efficient augmented Lagrange multiplier algorithm is established. Extensive experimental results demonstrate that our new approach outperforms current state-of-the-art algorithms in terms of accuracy and efficiency.
1. Introduction
An array of numbers arranged on a regular grid with a variable number of axes is described as a tensor. As the dimensionality reaches beyond 3D, conventional data representations such as vector-based and matrix-based become insufficient, and highly dimensional data sets are usually formulated as tensors [1,2,3].
Robust Principal Component Analysis (RPCA) [4,5,6,7,8], aiming to recover the low-rank and sparse matrices both accurately and efficiently, has been widely studied in data compressed sensing and computer vision. It is of great use when we try to solve the problem of subspace learning or Principal Component Analysis (PCA) in the presence of outliers [9]. Especially RPCA is a very useful tool in foreground detection, which is the first step in video surveillance system to detect moving objects [10,11]. Tensor Robust Principal Component Analysis (TRPCA) extends the RPCA from matrix to the tensor case, that is, to recover a low-rank tensor and a sparse (noise entries) tensor.
Tensor rank [12] essentially characterizes the intrinsic "dimension” or “degree of freedom” for highly dimensional data sets. In order to make the rank characteristic be more transparent, one can make use of tensor Singular Value Decomposition (t-SVD) developed recently by Kilmer and Martin [13], rendering the tensor rank approximation approachable. The key for their framework is the well-defined t-product that leads to the 3rd-order tensor space to be an inner product space so that approximation becomes more effective such as in image processing [14,15]. t-SVD allows to define tensor tubal-rank, which appears to be much more approachable such as in the study of image analysis than previous rank definitions [16,17,18]. The characteristic of a low tensor tubal-rank implies that a 3rd-order tensor can be significantly compressed (Theorem 4.3 of [13]), which is particularly important in applications.
Mathematically, TRPCA based on t-SVD [19,20] aims to recover the low tubal rank component and sparse component from noisy observations of size by convex optimization
is a Lagrange multiplier, is sparse if the tensor norm is small. It is well-known that the t-SVD-based tensor nuclear norm (TNN, III.B of [21]) has been proven to be the tightest convex relaxation to -norm of the tensor multi-rank (Theorem 2.4.1 in [15] or Theorem 3.1 in [19]). However, TNN treats the singular values in t-SVD equally to pursue the convexity of the objective function, while the singular values associated with a practical image may emphasize its different properties and should be handled differently, in particular, when some singular values are very large. Due to the gap between the tensor rank function and its lower convex envelop, the adoption of tensor nuclear norm may lead to the approximation of the corresponding tensor tubal-rank being inaccurate. Therefore, a new development of tensor tubal-rank approximation becomes necessary to reflect these fundamental characteristics.
To make the the necessity of a new tensor tubal-rank approximation instead of TNN more transparent, we consider the the matrix RPCA [4] first. Now the goal becomes to recover a low-rank matrix L from highly corrupted observations by minimizing . Here is the summation of the singular values of L. It is easy to see that
Hence, when is very large, for example, and the rest are relatively small, we may have rank. Then the minimization of will attempt to minimize that leads to over-penalizes , and consequently it generates undesirable solution L with small . Recall that our goal is to find a low-rank L, whose largest singular value is not necessarily to be small. In addition, it is worth mentioning that in practice the matrix RPCA problem is very sensitive to small perturbations and this problem can be addressed by relaxing the equality constraints. The authors in [22,23] propose an alternative optimization approach that appears to be suitable to deal with robustness issues in the “Sparse Plus Low-rank” decomposition problem. It has long been noticed that the nuclear norm is not always satisfactory [24], since it over-penalizes large singular values, and consequently may only find a much biased solution. Since the the nuclear norm is the tightest convex relaxation of the rank function [25], a further improvement under the convex setting in general is limited, if it is still possible, in particular when their gap is not very small. In order to alleviate the above problem, the Gamma quasi-norm for matrices is introduced in [26] in RPCA, which results in a tighter approximation of the rank function. For and the singular values of L, denoted by , the Gamma quasi-norm of L is defined as
It is not difficult to see
when and So it overcomes the imbalanced penalization by different singular values in convex nuclear norm. In addition, when goes to 0, the limit of the Gamma quasi-norm is exactly the matrix rank. The Gamma quasi-norm has nice algebraic properties, i.e., unitarily invariant and positive definiteness. Thanks to the unitarily invariance [27], the Gamma quasi-norm minimization problem for :
can be solved very effectively (Theorem 1 of [26]). Moreover, experimental results in [26] show that Gamma quasi-norma-based RPCA outperforms several other convex/non-convex norma-based RPCA in both accuracy and efficiency.
In this paper, inspired by the success of the non-convex rank approximation [26], we proposed tensor Gamma quasi-norm via t-SVD to seek a closer approximation and to alleviate the above-mentioned limitations resulted from the tensor nuclear norm, which has not been used for TRPCA yet in literature.
The main contributions of this paper are illustrated as follows:
- We develop new non-convex tensor rank approximation functions that can be used as desirable regularization for the optimization process, which appears to be more effective than current existing approaches in literature.
- An efficient algorithm based on the alternating direction method of multipliers (ADMM) is developed to solve the equivalent optimization problem in the Fourier domain, which is also suitable for general TRPCA problem. In addition, we provided the convergent analysis of the augmented Lagrange multiplier based optimization algorithm.
- Extensive evaluation of the proposed approach on several benchmark data sets has been conducted, and detailed comparison with most recent approaches are provided. Experimental results demonstrate that our proposed approach yields superior performance for image recovery and video background modeling.
The rest of the paper is organized as follows. In Section 2, we roughly describe some related works. Then Section 3 provides factorization strategies for 3rd-order tensors and its relationship to the corresponding tensor approximation problem. And then we present the main results on t-Gamma quasi-norm of 3rd-order tensors. Section 4 introduces our non-convex TRPCA framework and the convergent analysis of the augmented Lagrange multiplier based optimization algorithm. Experimental analysis and results are shown in Section 5 to verify the proposed algorithm. Finally, the paper ends with concluding remarks in Section 6.
2. Related Works
Recently, many authors observed the limitations of t-SVD-based TRPCA [15,19]. It was pointed out in [28] that the classical TRPCA methods based on t-SVD fails to utilize the low rank structure in the third mode. To further exploit the low-rank structures in multiway data, they defined a new TNN that extends TNN with core matrix and proposed a creative algorithm to deal with TRPCA problems. In addition, the authors of [29] presented that there are some weak points in the existing low-rank approximation approaches, for example, people need to predefine the rank values or fail to consider local information of data (e.g., spatial or spectral smooth structure). So they proposed a novel TNN-based low-rank approximation with total variation regularization, which uses the TNN to encode the global low-rank prior of tensor data and the total variation regularization to preserve the spatial-spectral continuity in a unified framework.
It has been noticed by others that TNN is not always satisfactory. For instance, to seek a closer approximation of tensor rank, Kong et al. in [30] introduced t-Schatten-p tensor quasi-norm to replace the TNN. The t-Schatten-p norm is convex when , but non-convex when . In addition, they proved multi-Schatten-p norm surrogate theorem to convert the non-convex t-Schatten-p tensor quasi-norm for into a weighted sum of convex functions. Then based on the multi-Schatten-p norm surrogate, they proposed a novel convex tensor RPCA model.
Besides above, a recent paper [31] developed randomized algorithms for tensor low-rank approximation and decomposition, together with tensor multiplication. Their proposed tubal focused algorithms employ a small number of lateral and/or horizontal slices of the underlying 3rd order tensor, that come with relative error guarantees for the quality of the obtained solutions.
Besides the above-mentioned methods based on t-SVD, there are many other TRPCA methods mainly applied CP (CANDECOMP/PARAFAC) or Tucker decompositions methods in their optimization models. We need to mention that recently Driggs et al. [32] studied TRPCA using a non-convex formulation of the CP based tensor atomic-norm and identified a class of local minima of this non-convex program that are globally optimal.
Presently, background subtraction become more and more important for visual surveillance systems and several subspace learning algorithms based on matrix and tensor tools have been used to perform the background modeling of the scenes. Recently, Sobral et al. [33] developed an incremental tensor subspace learning that uses only a small part of the entire data and updates the low-rank model incrementally when new data arrives and in [34] the authors proposed an online stochastic framework for tensor decomposition of multispectral video sequences. In particular, it is worth mentioning that Bouwmans et al. [35] gave a systematic and complete review of the "low-rank plus sparse matrix decomposition" framework of separating moving objects from the background.
However, all those above mentioned t-SVD-based TRPCA algorithms solve the TRPCA optimization problem under convex regularization. In addition, most analyses of ADMM algorithms are in the convex setting [36]. In our work, we explore the TRPCA method based on the non-convex t-Gamma quasi-norm of 3rd-order tensors. Due to the non-convex nature of our TRPCA model, the convergent analysis of algorithm is difficult to justify. In addition, the analysis of non-convex augmented Lagrangians is not easy, but this compels us to make efforts of clarity and pedagogy. Also it should be noted that there are few works on t-SVD-based TRPCA achieve background modeling. Thus experiments are provided in our paper on two computer vision applications, which are image recovery and video background modeling.
3. Notations and Definitions
Throughout this paper, all boldface Euler script letters () denote tensors, uppercase characters (X) denote matrices, and lowercase letters (a) denote scalars. The field of real numbers is denoted as . We denote as the index set associated with a given tensor. For 3rd-order tensors , we use , , to denote the i-th horizontal, lateral, and frontal slice, respectively. For simplicity, we denote the frontal slice as . The inner product between and of size is defined as . The Frobenius norm of a tensor is defined as . The norm of a tensor is defined as . In this paper, the adopted basic definitions and notations follow the references [13,21,37] for the purpose of an easier comparison.
Definition 1
(Transpose p. 10 of [13]). For , the transpose tensor is an tensor obtained by transposing each frontal slice of and then reversing the order of the transposed frontal slices 2 through .
Similar to matrices whose elements can be grouped by rows or by columns, higher dimensional tensors can be viewed forming by slices along the third mode. For with frontal slices . Then the block circulant is created from the frontal slices in a form of
where for . It is important to notice that the block circulant matrix bcirc keeps the order of frontal slices of in an appropriate way, and thus it better maintains ’s structure in terms of the frontal direction, compared with the direct tensor unfolding along the third mode.
Definition 2
(t-product p. 11 of [13]). Let , we define the matvec and fold operators as is an matrix and .
Let , and . Then the t-product of 3rd-order tensors is defined as
which is a tensor of size .
Definition 3
(Identity, orthogonal and diagonal tensor p.10 of [13]). The identity tensor is a tensor whose first frontal slice is the identity matrix and all other frontal slices are zero. A tensor is orthogonal if where * is the t-product. A tensor is called f-diagonal if each of its frontal slices is diagonal matrix.
It is well known that circulant matrices can be diagonalized by the FFT (21.11 of [38]), similarly, block-circulant matrices can also block-diagonalized as
where , denotes the fast Fourier transform matrix, denotes its conjugate, and the notation ⊗ denotes the standard Kronecker product. In addition, if and only if for (p.4 of [19]).
Since are unitary matrices, we have
Then we have .
Definition 4
(Tensor multi-rank p. 10 of [37]). For tensor with frontal slices , the multi-rank of is a -vector consisting of the ranks of all the .
Please note that the matrix SVD [39] can be performed on each frontal slice of , The matrix has the following Singular Value Decomposition (SVD) (here stands for the set of orthogonal -by- matrices) and is an diagonal matrix with diagonal entries in descending order.
Definition 5
(t-SVD, Theorem 4.1 in [13]). The tensor Singular Value Decomposition (t-SVD) of is given by where and are orthogonal tensors of size and respectively. Σ is an f-diagonal tensor of size , and * denotes the t-product.
Definition 6
(Tensor tubal rank III.B of [21]). The tensor tubal rank is defined as the number of nonzero singular tubes of f-diagonal tensor Σ, which is the maximum of the number of nonzero for .
Definition 7
(Tensor nuclear norm III.B of [21]). The nuclear norm for a given 3rd-order tensor is defined to be
which is equal to
Here is the -th frontal slice of obtained by applying FFT on along the third mode.
In this paper, to overcome the disadvantages of the tensor nuclear norm, we propose smooth but more effective, though being non-convex, t-SVD-based non-convex rank approximation to the data sets represented by 3rd-order tensor. This will make the larger singular values be shrunk less in order to preserve their characteristics. Moreover, under our framework, we establish explicit solutions to the corresponding non-convex tensor norm minimization problems that is not available in current literature.
Definition 8
(Gamma quasi-norm for matrix [26]). Let and the singular values of X, denoted by . We could introduce the Gamma norm of X, which is defined as
Definition 9
(t-Gamma tensor quasi-norm). The Gamma tensor quasi-norm for a given 3rd-order tensor is defined to be
which is equal to
Here is the -th frontal slice of obtained by applying FFT on along the third mode.
Remark 1.
It is not hard to see the t-Gamma tensor quasi-norm is unitarily invariant, that is where and are orthogonal tensors of size and respectively. In addition,
Lemma 1
Now let us consider the tensor t-Gamma quasi-norm minimization problem:
Theorem 1
(t-Gamma tensor rank minimization). Let us consider a 3rd-order tensor , which has t-SVD as in Definition 5. If minimizes
then
where is a f-diagonal tensor. For , let then is the limit point of Fixed Point Iteration
Remark 2.
Theorem 1 provides the connection of the optimal solution between the original domain and the Fourier domain. More importantly, it shows that the minimization problem under our framework is tractable. After the original tensor is transformed to in the Fourier domain, an equivalent minimization problem could be solved by using Lemma 1 for each slice in the Fourier domain. Then the optimal solution in the original domain can be obtained by the inverse Fourier transform , whose detailed approach can be found from the proof in Theorem 1.
(Proof of Theorem 1)
Let , then it can be reformulated as matrix objective function in Fourier domain:
Without loss of generality, for each diagonal block of , , let us consider
From Lemma 1, , and
Following the DC programming algorithm used in Theorem 1 of [26] (similar method has been used in Section III of [41]), we can solve it efficiently using a local minimization method.
Let , it can be approximated using first order Taylor expansion (with Big “O” truncation error) as
Now we consider
and it admits a closed-form solution
where . Here is the solution obtained in the -th iteration. Let
it can be easily seen that , when . The Fixed Point Iteration converge to the local minimum after several iterations (Chapter 1 of [42]), and the proof is thus completed. ☐
4. Tensor Robust Principal Component Analysis with Non-Convex Regularization
A TRPCA model using non-convex regularization can be formulated as
Its augmented Lagrangian function is where is the Lagrangian multiplier, is the penalty parameter for the violation of the linear constraints, and is a constant.
Then, the problem can be updated as:
where the tensor non-negative soft-thresholding operator [43] is defined as
with
Algorithm 1 shows the pseudocode for the proposed non-convex tensor robust component analysis method.
| Algorithm 1 Solve the non-convex TRPCA model (5) by ADMM. |
| Input: The observed tensor , the set of index of observed entries , parameter , stopping criterion . Initialize: , , , , .
|
Theorem 2
(Convergent Analysis). Suppose that is generated from the proposed Algorithm 1, then is bounded. In addition, the accumulation point of is a KKT stationary point, which satisfy the KKT conditions
(Proof of Theorem 2)
satisfies the first-order necessary local optimality condition,
For case, since is nonsmooth at , we redefine subgradient if . Then , hence is bounded. Thus is bounded.
With some algebra, we have the following equality
Then,
By induction, we could obtain
Since is bounded, it is not hard to see is upper bounded. Meanwhile,
Since each term on the right-hand side is bounded, is bounded. By the last term on the right-hand, is bounded. Therefore, and are both bounded.
From Bolzano-Weierstrass theorem [39], there must be at least one accumulation point of the sequence . We denote one of the points . Without loss of generality, we assume converge to .
Since
we have
Then is obtained.
Since is optimally obtained by minimizing according to its definition, we have
From Theorem 3 of [26], we know
and is bounded.
Therefore,
is bounded.
From the fact that is equivalent to Tucker product (for its definition see Chapter 3 of [44])
(see the proof of Proposition 3 of [30] and Remark 2.3. of [45]) and using the chain rule [39], we can deduce that
is bounded.
In addition, it is not hard to see
Please note that in Algorithm 1, then ,
Similarly, since is the minimum of the subproblem , we have
Thus Therefore satisfies the the Karush-Kuhn-Tuker (KKT) conditions of the Lagrange function (Chapter 9 of [46]). We thus complete the proof. ☐
5. Experiments
In this section, we conduct several applications to demonstrate the performance of our algorithm. All experiments are implemented in Matlab 2017b on Ubuntu 16.04 LTS with 12 cores, 2.40 GHz CPU and 64 GB RAM.
5.1. Image Recovery
In this part, we focus on noisy color image recovery. A color image with size and 3 channel, i.e., red, green and blue, can be regarded as a third order tensor and each frontal slice of is the corresponding channel of the color image. Please note that each channel of the color image is usually not a low rank matrix, but it is observed that the top singular values dominate the main information [19,47]. Thus we can reconstruct the noisy image in low rank structure.
We perform the experiments on Berkeley Segmentation Dataset [48], which contains 200 color image for training. For each image, we randomly set of pixels to the random values in [0, 255], that is, we corrupt the image on 3 channels simultaneously which is more challenging than make corruptions on only one channel. We compare our t-Gamma algorithms with RPCA [4], Gamma [26], SNN [49] and TRPCA [20], in which RPCA minimizes a weighted combination of the nuclear norm and of the norm in matrix form, Gamma replaces the nuclear norm by matrix Gamma quasi-norm, SNN uses the sum of the nuclear norm for all mode-i matricization of the given tensor, and TRPCA extends the RPCA from the matrix to tensor case. For RPCA and Gamma, we conduct the algorithms on each channel, i.e., regarding each channel of the image as a matrix, and then combine the channel recovery result into a color image. The parameter in RPCA and Gamma is set to as suggested in [4]. However, when the parameter in Gamma is set to as stated in [26], it cannot perform well. We empirically set the in Gamma and t-Gamma. For SNN, we set as suggested in [20]. The parameters in TRPCA and t-Gamma is set to . By using the Peak Signal to Noise Ratio (PSNR) to evaluate the recovery results and PSNR is defined as
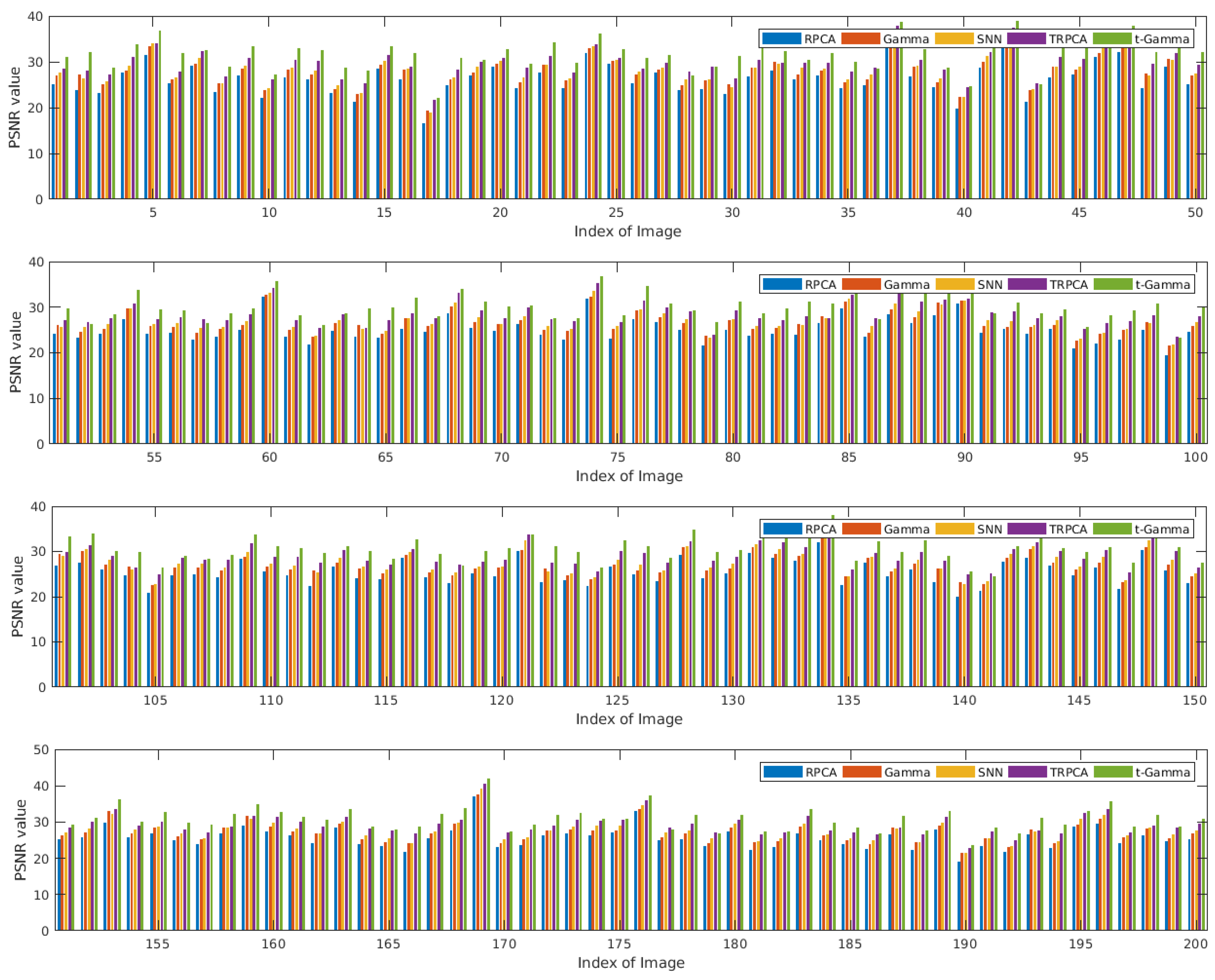
In Figure 1, we give the comparison of PSNR value on 200 images and each subfigure contains 50 results. The sample recovery performance are shown in Figure 2. From Figure 1, we can observe that the proposed t-Gamma algorithm perform better on almost every image and can achieve around 2 dB improvement in many cases. Table 1 shows the average recovery performance obtained by these five algorithms on Berkeley Segmentation Dataset. In Figure 2 we can visually conclude that our algorithm yields a better result than the compare algorithms which can illustrate the merit of the our approach.
5.2. Video Background Modeling
5.2.1. Qualitative Experiments
In this part, we consider the background modeling problem, an essential task in video surveillance, which aims to separate the foreground objects from the background. The frames of background in video surveillance are highly correlated and thus it is reasonable to consider it as a low rank tensor. While the objects in the foreground usually only occupy a small part of the image in some frames and hence can regard it as the sparse part.
To solve this problem, we test our algorithm on four example color videos, Hall, MovedObject, Escalator and Lobby http://perception.i2r.a-star.edu.sg/bk_model/bk_index.html, and compare it with RPCA [4], Gamma [26], SNN [49] and TRPCA [20]. We extract frames from these four videos. Suppose the size of frames in the given video is , we stack each frame in each color channel as a column vector of size , where , and then all column vectors into a matrix of size for RPCA and Gamma, and into a tensor of size for SNN, TRPCA and t-Gamma. The parameter is set to for RPCA and Gamma, and for SNN, TRPCA and t-Gamma. The parameter in Gamma and t-Gamma is set to and respectively. As suggested in [20], in SNN is set to .
The background separated results are depicted in Figure 3, Figure 4, Figure 5 and Figure 6. In Figure 3 and Figure 4, we can see that our method could reconstruct the background with fewer ghosting effects and more completely. From Figure 5 and Figure 6, it could be observed that though all the method separate the background from the foreground effectively, the proposed algorithm are more robust to the dynamic foreground and illumination variation, e.g., only Gamma and t-Gamma can remove the steps of moving escalator in Figure 5, while the method Gamma cannot adapt to change of illumination in Figure 6.
5.2.2. Quantitative Experiments
Since the datasets in Section 5.2.1 do not include the ground truth background for each frame of the video, we perform the algorithms on the ChangeDetection.net(CDNet) dataset2014 [50] which consists of visual surveillance and smart environments. However, only part of frames are accompanied with ground truth background and thus we only take out some of frames of the video for testing. That is, we select the frames from 900 to 1000 of the dataset highway, pedestrians and PETS2006 in the baseline category. Hence the size of the video will be , where is the resolution of each frame, and 101 is the number of frames. We compare our algorithm with RPCA [4], Gamma [26], SNN [49] and TRPCA [20]. The parameters setting is conducted from Section 5.2.1.
To evaluate the performance of the experiment results, we use the three metrics for the quantitative measure, that is, Recall, Precision and F-Measure. They are defined as:
where TP, FP and FN are true positives numbers, false positives numbers and false negatives numbers respectively. We primarily use F-Measure for overall evaluation since it combines the metrics Recall and Precision and also makes a balance between Recall and Precision which can be viewed as a good indicators for comparison.
From Table 2, we can see that the proposed algorithm achieves better segmentation performance among the compare methods with respect to the F-Measure. Some of the frames of the segmentation results are shown in Figure 7, it can be observed that among the three dataset in CDNet our method can usually get the clearer and more accurate background segmentation. These quantitative comparison illustrates the superior of t-Gamma tensor quasi-norm as the surrogate of the rank of tensor.
6. Concluding Remarks
In this paper, we conduct the TRPCA with a new t-Gamma tensor quasi-norm used as the regularization for tensor rank function. The t-Gamma tensor quasi-norm is developed via t-SVD in the Fourier domain, which simplifies the required optimization process. Compared with the convex tensor nuclear norm, our regularization approach appears to be more effective in approximating the tensor tubal rank. We incorporate the alternating direction method of multipliers with the t-Gamma tensor quasi-norm to efficiently solve the non-convex TRPCA problem, yielding an approachable framework for non-convex optimization. Numerical experimental results indicate that our approach outperforms the existing methods in distinguishable ways.
Author Contributions
Conceptualization, M.Y.; Data curation, Q.L.; Formal analysis, M.Y.; Funding acquisition, S.C.; Investigation, M.Y. and M.X.; Methodology, Q.L., M.Y. and M.X.; Project administration, S.C., W.L. and M.X.; Resources, M.X.; Software, Q.L.; Supervision, S.C., W.L. and M.X.; Validation, S.C.; Visualization, Q.L.; Writing—original draft, M.Y.; Writing—review & editing, M.X.
Funding
This research was funded by the National Science Foundation Division of Mathematical Sciences of the United States (Grant No. 140928), the National Natural Science Foundation of China (Grant Nos. 11671158, U181164, 61201392), the Natural Science Foundation of Guangdong Province, China (Grant No. 2015A030313497) and the Science and Technology Planning Project of Guangdong Province, China (Grant Nos. 2017B090909004, 2017B010124003, 2017B090909001).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Landsberg, J. Tensors: Geometry and Applications; Graduate Studies in Mathematics; American Mathematical Society: Providence, RI, USA, 2012. [Google Scholar]
- Bro, R. Multi-Way Analysis in the Food Industry: Models, Algorithms, and Applications. Ph.D. Thesis, University of Amsterdam (NL), Amsterdam, The Netherlands, 1998. [Google Scholar]
- Yang, M.; Li, W.; Xiao, M. On identifiability of higher order block term tensor decompositions of rank Lr⊗ rank-1. Linear Multilinear Algebra 2018, 1–23. [Google Scholar] [CrossRef]
- Candès, E.J.; Li, X.; Ma, Y.; Wright, J. Robust principal component analysis? J. ACM 2011, 58, 11. [Google Scholar] [CrossRef]
- Wright, J.; Ganesh, A.; Rao, S.; Peng, Y.; Ma, Y. Robust principal component analysis: Exact recovery of corrupted low-rank matrices via convex optimization. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, USA, 7–10 December 2009; pp. 2080–2088. [Google Scholar]
- Kang, Z.; Pan, H.; Hoi, S.C.H.; Xu, Z. Robust Graph Learning From Noisy Data. IEEE Trans. Cybern. 2019, 1–11. [Google Scholar] [CrossRef]
- Peng, C.; Kang, Z.; Cai, S.; Cheng, Q. Integrate and Conquer: Double-Sided Two-Dimensional k-Means Via Integrating of Projection and Manifold Construction. ACM Trans. Intell. Syst. Technol. 2018, 9, 57. [Google Scholar] [CrossRef]
- Sun, P.; Qin, J. Speech enhancement via two-stage dual tree complex wavelet packet transform with a speech presence probability estimator. J. Acoust. Soc. Am. 2017, 141, 808–817. [Google Scholar] [CrossRef] [PubMed]
- Vaswani, N.; Bouwmans, T.; Javed, S.; Narayanamurthy, P. Robust subspace learning: Robust PCA, robust subspace tracking, and robust subspace recovery. IEEE Signal Process. Mag. 2018, 35, 32–55. [Google Scholar] [CrossRef]
- Bouwmans, T.; Zahzah, E.H. Robust PCA via principal component pursuit: A review for a comparative evaluation in video surveillance. Comput. Vis. Image Underst. 2014, 122, 22–34. [Google Scholar] [CrossRef]
- Bouwmans, T.; Javed, S.; Zhang, H.; Lin, Z.; Otazo, R. On the applications of robust PCA in image and video processing. Proc. IEEE 2018, 106, 1427–1457. [Google Scholar] [CrossRef]
- Cichocki, A.; Lee, N.; Oseledets, I.; Phan, A.H.; Zhao, Q.; Mandic, D.P. Tensor networks for dimensionality reduction and large-scale optimization: Part 1 low-rank tensor decompositions. Found. Trends® Mach. Learn. 2016, 9, 249–429. [Google Scholar] [CrossRef]
- Kilmer, M.E.; Martin, C.D. Factorization strategies for third-order tensors. Linear Algebra Appl. 2011, 435, 641–658. [Google Scholar] [CrossRef]
- Hao, N.; Kilmer, M.E.; Braman, K.; Hoover, R.C. Facial recognition using tensor-tensor decompositions. SIAM J. Imaging Sci. 2013, 6, 437–463. [Google Scholar] [CrossRef]
- Zhang, Z.; Ely, G.; Aeron, S.; Hao, N.; Kilmer, M. Novel methods for multilinear data completion and de-noising based on tensor-SVD. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 3842–3849. [Google Scholar]
- Signoretto, M.; De Lathauwer, L.; Suykens, J.A. Nuclear norms for tensors and their use for convex multilinear estimation. Linear Algebra Appl. 2010, 43. Available online: ftp://ftp.esat.kuleuven.be/sista/signoretto/Signoretto_nucTensors2.pdf (accessed on 3 April 2019).
- Cichocki, A. Era of big data processing: A new approach via tensor networks and tensor decompositions. arXiv, 2014; arXiv:1403.2048. [Google Scholar]
- Grasedyck, L.; Kressner, D.; Tobler, C. A literature survey of low-rank tensor approximation techniques. GAMM-Mitteilungen 2013, 36, 53–78. [Google Scholar] [CrossRef]
- Lu, C.; Feng, J.; Chen, Y.; Liu, W.; Lin, Z.; Yan, S. Tensor Robust Principal Component Analysis: Exact Recovery of Corrupted Low-Rank Tensors via Convex Optimization. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 5249–5257. [Google Scholar]
- Lu, C.; Feng, J.; Chen, Y.; Liu, W.; Lin, Z.; Yan, S. Tensor Robust Principal Component Analysis with A New Tensor Nuclear Norm. arXiv, 2018; arXiv:1804.03728. [Google Scholar] [CrossRef] [PubMed]
- Semerci, O.; Hao, N.; Kilmer, M.E.; Miller, E.L. Tensor-based formulation and nuclear norm regularization for multienergy computed tomography. IEEE Trans. Image Process. 2014, 23, 1678–1693. [Google Scholar] [CrossRef]
- Ciccone, V.; Ferrante, A.; Zorzi, M. Robust identification of “sparse plus low-rank” graphical models: An optimization approach. In Proceedings of the 2018 IEEE Conference on Decision and Control (CDC), Miami Beach, FL, USA, 17–19 December 2018; pp. 2241–2246. [Google Scholar]
- Ciccone, V.; Ferrante, A.; Zorzi, M. Factor Models with Real Data: A Robust Estimation of the Number of Factors. IEEE Trans. Autom. Control 2018. [Google Scholar] [CrossRef]
- Fazel, S.M. Matrix Rank Minimization with Applications. Ph.D. Thesis, Stanford University, Stanford, CA, USA, 2003. [Google Scholar]
- Recht, B.; Fazel, M.; Parrilo, P.A. Guaranteed minimum-rank solutions of linear matrix equations via nuclear norm minimization. SIAM Rev. 2010, 52, 471–501. [Google Scholar] [CrossRef]
- Kang, Z.; Peng, C.; Cheng, Q. Robust PCA Via Nonconvex Rank Approximation. In Proceedings of the 2015 IEEE International Conference on Data Mining (ICDM), Atlantic City, NJ, USA, 14–17 November 2015; pp. 211–220. [Google Scholar]
- Lewis, A.S.; Sendov, H.S. Nonsmooth analysis of singular values. Part I: Theory. Set-Valued Anal. 2005, 13, 213–241. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, L.; Zhu, C. Improved Robust Tensor Principal Component Analysis via Low-Rank Core Matrix. IEEE J. Sel. Top. Signal Process. 2018, 12, 1378–1389. [Google Scholar] [CrossRef]
- Chen, Y.; Wang, S.; Zhou, Y. Tensor Nuclear Norm-Based Low-Rank Approximation With Total Variation Regularization. IEEE J. Sel. Top. Signal Process. 2018, 12, 1364–1377. [Google Scholar] [CrossRef]
- Kong, H.; Xie, X.; Lin, Z. t-Schatten-p Norm for Low-Rank Tensor Recovery. IEEE J. Sel. Top. Signal Process. 2018, 12, 1405–1419. [Google Scholar] [CrossRef]
- Tarzanagh, D.A.; Michailidis, G. Fast Monte Carlo Algorithms for Tensor Operations. arXiv, 2017; arXiv:1704.04362. [Google Scholar]
- Driggs, D.; Becker, S.; Boyd-Graber, J. Tensor Robust Principal Component Analysis: Better recovery with atomic norm regularization. arXiv, 2019; arXiv:1901.10991. [Google Scholar]
- Sobral, A.; Baker, C.G.; Bouwmans, T.; Zahzah, E.H. Incremental and multi-feature tensor subspace learning applied for background modeling and subtraction. In Proceedings of the International Conference Image Analysis and Recognition, Vilamoura, Portugal, 22–24 October 2014; pp. 94–103. [Google Scholar]
- Sobral, A.; Javed, S.; Ki Jung, S.; Bouwmans, T.; Zahzah, E.H. Online stochastic tensor decomposition for background subtraction in multispectral video sequences. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Santiago, Chile, 7–13 December 2015; pp. 106–113. [Google Scholar]
- Bouwmans, T.; Sobral, A.; Javed, S.; Jung, S.K.; Zahzah, E.H. Decomposition into low-rank plus additive matrices for background/foreground separation: A review for a comparative evaluation with a large-scale dataset. Comput. Sci. Rev. 2017, 23, 1–71. [Google Scholar] [CrossRef]
- Boyd, S.; Parikh, N.; Chu, E.; Peleato, B.; Eckstein, J. Distributed optimization and statistical learning via the alternating direction method of multipliers. Found. Trends® Mach. Learn. 2011, 3, 1–122. [Google Scholar] [CrossRef]
- Kilmer, M.E.; Braman, K.; Hao, N.; Hoover, R.C. Third-order tensors as operators on matrices: A theoretical and computational framework with applications in imaging. SIAM J. Matrix Anal. Appl. 2013, 34, 148–172. [Google Scholar] [CrossRef]
- Tyrtyshnikov, E.E. A Brief Introduction to Numerical Analysis; Springer Science & Business Media: New York, NY, USA, 2012. [Google Scholar]
- Marc Peter Deisenroth, A.A.F.; Ong, C.S. Mathematics for Machine Learning; Cambridge University Press: Cambridge, UK, 2019. [Google Scholar]
- Moreau, J.J. Proximité et dualité dans un espace hilbertien. Bull. Soc. Math. France 1965, 93, 273–299. [Google Scholar] [CrossRef]
- Dong, W.; Shi, G.; Li, X.; Ma, Y.; Huang, F. Compressive Sensing via Nonlocal Low-Rank Regularization. IEEE Trans. Image Process. 2014, 23, 3618–3632. [Google Scholar] [CrossRef] [PubMed]
- Zhang, G.; Lin, Y. Lectures in Functional Analysis; Peking University Press: Beijing, China, 1987. [Google Scholar]
- Donoho, D.L. De-noising by soft-thresholding. IEEE Trans. Inf. Theory 1995, 41, 613–627. [Google Scholar] [CrossRef]
- Lu, H.; Plataniotis, K.; Venetsanopoulos, A. Multilinear Subspace Learning: Dimensionality Reduction of Multidimensional Data; Chapman & Hall/CRC Machine Learning & Pattern Recognition Series; CRC Press: Boca Raton, FL, USA, 2013. [Google Scholar]
- Zhang, Z.; Aeron, S. Exact Tensor Completion Using t-SVD. IEEE Trans. Signal Process. 2017, 65, 1511–1526. [Google Scholar] [CrossRef]
- Luenberger, D.G. Optimization by Vector Space Methods; John Wiley & Sons: New York, NY, USA, 1997. [Google Scholar]
- Liu, J.; Musialski, P.; Wonka, P.; Ye, J. Tensor Completion for Estimating Missing Values in Visual Data. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 208–220. [Google Scholar] [CrossRef] [PubMed]
- Martin, D.; Fowlkes, C.; Tal, D.; Malik, J. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In Proceedings of the Eighth IEEE International Conference on Computer Vision ( ICCV 2001), Vancouver, BC, Canada, 7–14 July 2001; Volume 2, pp. 416–423. [Google Scholar]
- Huang, B.; Mu, C.; Goldfarb, D.; Wright, J. Provable models for robust low-rank tensor completion. Pac. J. Optim. 2015, 11, 339–364. [Google Scholar]
- Goyette, N.; Jodoin, P.-M.; Porikli, F.; Konrad, J.; Ishwar, P. Changedetection.net: A new change detection benchmark dataset, 2012. In Proceedings of the IEEE Workshop on Change Detection (CDW-2012) at CVPR-2012, Providence, RI, USA, 16–21 June 2012. [Google Scholar]
Figure 1.
Comparison of the PSNR values with RPCA [4], Gamma [26], SNN [49], TRPCA [20] and t-Gamma.

Figure 2.
Recovery results on 5 sample images. The first two columns are original and corrupted images reps. The third to seventh columns are recovery images obtained by RPCA, Gamma, SNN, TRPCA and t-Gamma resp. (a) Original; (b) Corrupted; (c) RPCA [4]; (d) Gamma [26]; (e) SNN [49]; (f) TRPCA [20]; (g) t-Gamma.
Figure 2.
Recovery results on 5 sample images. The first two columns are original and corrupted images reps. The third to seventh columns are recovery images obtained by RPCA, Gamma, SNN, TRPCA and t-Gamma resp. (a) Original; (b) Corrupted; (c) RPCA [4]; (d) Gamma [26]; (e) SNN [49]; (f) TRPCA [20]; (g) t-Gamma.

Figure 3.
Background modeling: two example frames from Hall sequences are shown. (a) Original; (b) RPCA [4]; (c) Gamma [26]; (d) SNN [49]; (e) TRPCA [20]; (f) t-Gamma.

Figure 4.
Background modeling: two example frames from MovedObject sequences are shown. (a) Original; (b) RPCA [4]; (c) Gamma [26]; (d) SNN [49]; (e) TRPCA [20]; (f) t-Gamma.

Figure 5.
Background modeling: two example frames from Escalator sequences are shown. (a) Original; (b) RPCA [4]; (c) Gamma [26]; (d) SNN [49]; (e) TRPCA [20]; (f) t-Gamma.

Figure 6.
Background modeling: two example frames from Lobby sequences are shown. (a) Original; (b) RPCA [4]; (c) Gamma [26]; (d) SNN [49]; (e) TRPCA [20]; (f) t-Gamma.

Figure 7.
Visual results for CDNet dataset. Row 1 and row 2 are samples of highway; row 3 and row 4 are samples of pedestrians; row 5 and row 6 are samples of PETS2006. (a) Original; (b) Ground True; (c) RPCA [4]; (d) Gamma [26]; (e) SNN [49]; (f) TRPCA [20]; (g) t-Gamma


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Average PSNR obtained by five Algorithms on 200 images.
| Algorithm | RPCA | Gamma | SNN | TRPCA | t-Gamma |
|---|---|---|---|---|---|
| Average PSNR | 25.5843 | 27.0762 | 27.6329 | 29.1157 | 30.7896 |
Table 2.
Quantitative Evaluation for algorithm on CDNet Datasets
| Dataset | RPCA | Gamma | SNN | TNN | t-Gamma | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Recall | Precision | F-Measure | Recall | Precision | F-Measure | Recall | Precision | F-Measure | Recall | Precision | F-Measure | Recall | Precision | F-Measure | |
| highway | 0.8642 | 0.9109 | 0.8869 | 0.8837 | 0.9067 | 0.895 | 0.6982 | 0.9041 | 0.7879 | 0.8235 | 0.902 | 0.861 | 0.8835 | 0.909 | 0.8961 |
| pedestrians | 0.9983 | 0.9419 | 0.9692 | 0.9982 | 0.9275 | 0.9616 | 0.9955 | 0.9285 | 0.9608 | 0.9983 | 0.9258 | 0.9607 | 0.9982 | 0.9309 | 0.9634 |
| PETS2006 | 0.8151 | 0.7131 | 0.7607 | 0.8326 | 0.7678 | 0.7989 | 0.288 | 0.6974 | 0.4077 | 0.8033 | 0.6853 | 0.7396 | 0.8301 | 0.7805 | 0.8045 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Cai, S.; Luo, Q.; Yang, M.; Li, W.; Xiao, M. Tensor Robust Principal Component Analysis via Non-Convex Low Rank Approximation. Appl. Sci. 2019, 9, 1411. https://doi.org/10.3390/app9071411
AMA Style
Cai S, Luo Q, Yang M, Li W, Xiao M. Tensor Robust Principal Component Analysis via Non-Convex Low Rank Approximation. Applied Sciences. 2019; 9(7):1411. https://doi.org/10.3390/app9071411
Chicago/Turabian StyleCai, Shuting, Qilun Luo, Ming Yang, Wen Li, and Mingqing Xiao. 2019. "Tensor Robust Principal Component Analysis via Non-Convex Low Rank Approximation" Applied Sciences 9, no. 7: 1411. https://doi.org/10.3390/app9071411
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.