
Identifying Critical Drivers of Mango, Tomato, and Maize Postharvest Losses (PHL) in Low-Income Countries and Predicting Their Impact

Abstract
:1. Introduction
2. Materials and Methods
2.1. Data Summary
2.2. Random Forest
2.3. Random Forest
2.4. Tuning the Random Forest Model
2.5. Variable Importance
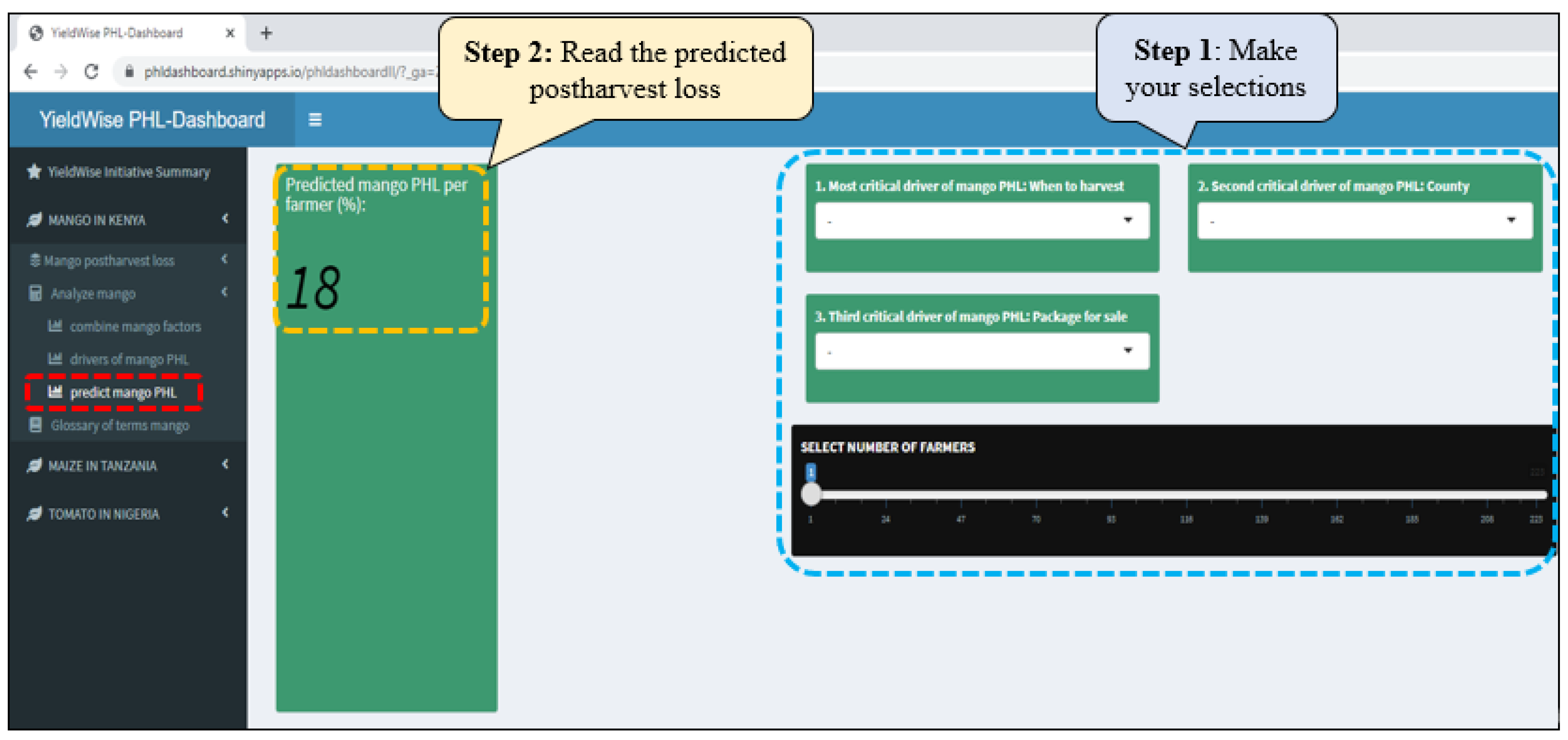
2.6. Predictions
3. Results
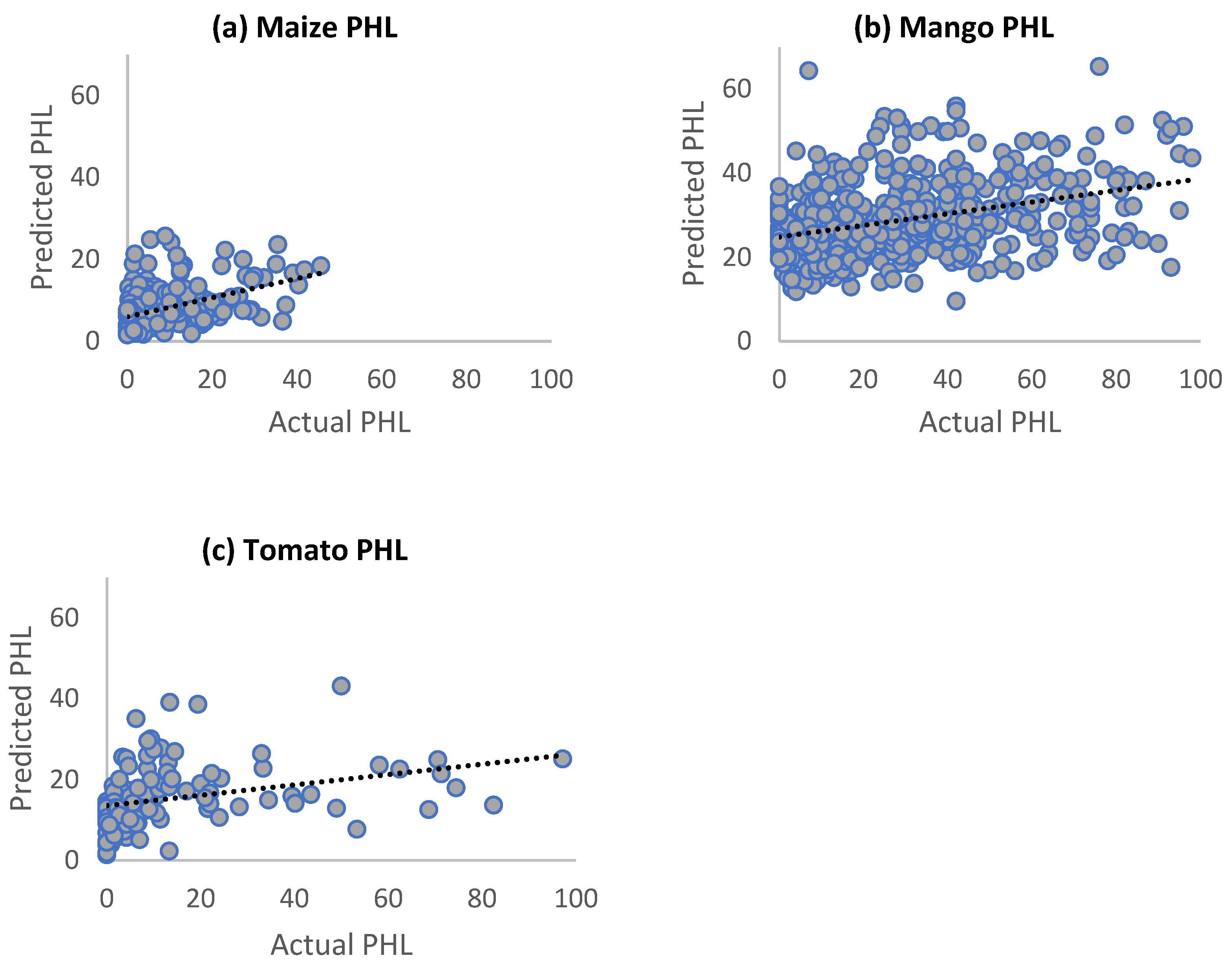
3.1. Random Forest Models
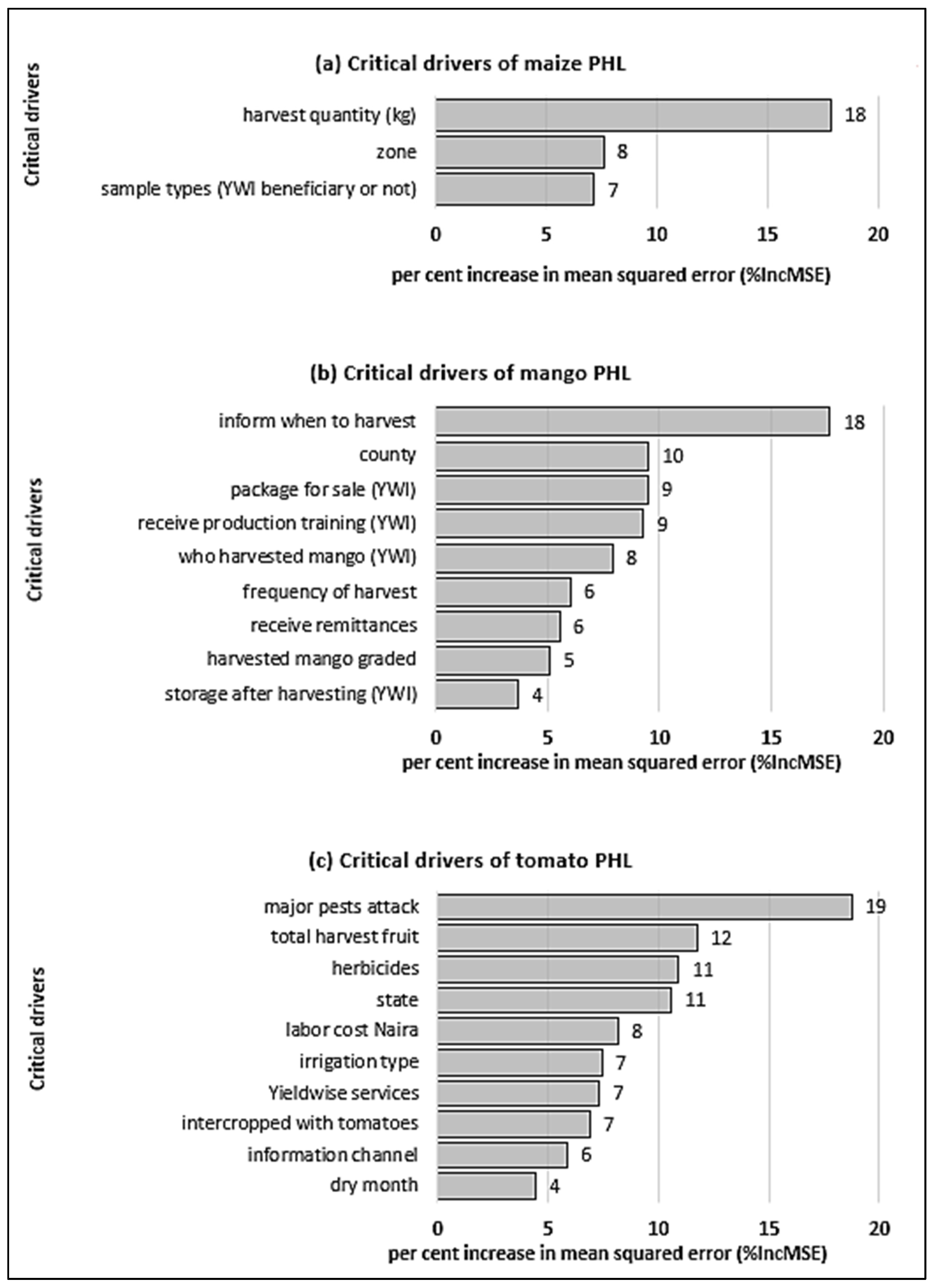
3.2. Critical Drivers of PHL
3.3. Assessing the Critical Drivers of PHL
4. Conclusions
- Three critical drivers of PHL were identified in the maize value chain, nine in the mango value chain, and ten in the tomato value chain. Hence, perishable crops such as tomato and mango have more critical drivers to consider when attempting to reduce PHL than nonperishable crops such as maize.
- The most critical drivers of PHL were the quantity of maize harvested by a smallholder farmer in the maize value chain, the method used to know when to begin mango harvest in the mango value chain, and the type of pest that attacked the tomato plant in the tomato value chain. It was then noted that the most critical drivers are all related to pre-harvest and harvest activities in the field. Hence, PHL reduction efforts should begin in the field before harvest and continue during harvest.
- The critical drivers of PHL fall into two categories: passive critical drivers that are difficult to manipulate, such as the geographic area within which a smallholder farmer lives, and active critical drivers that are easier to manage, such as the services provided by the YieldWise Initiative. Moreover, the geographic location of a smallholder farmer and the smallholder farmers’ affiliation with the YieldWise Initiative were both ubiquitous drivers across all three value chains.
- PHL is impacted by changes in the levels of a critical driver as well as changes in the number of smallholder farmers at each level, although the former has a much higher impact. Hence, the optimum PHL mitigation practices or technologies should be identified first before attempting to increase their adoption among smallholder farmers.
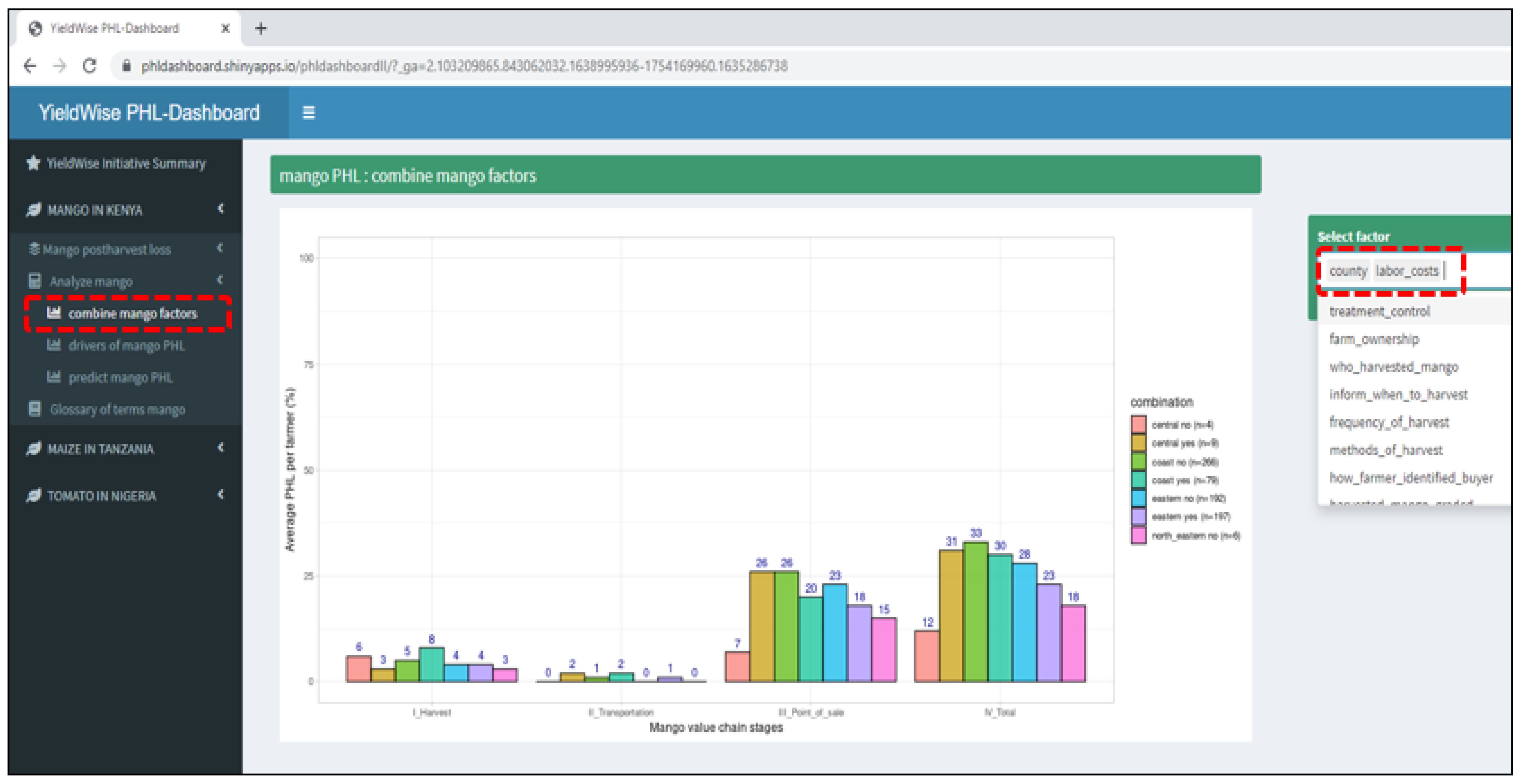
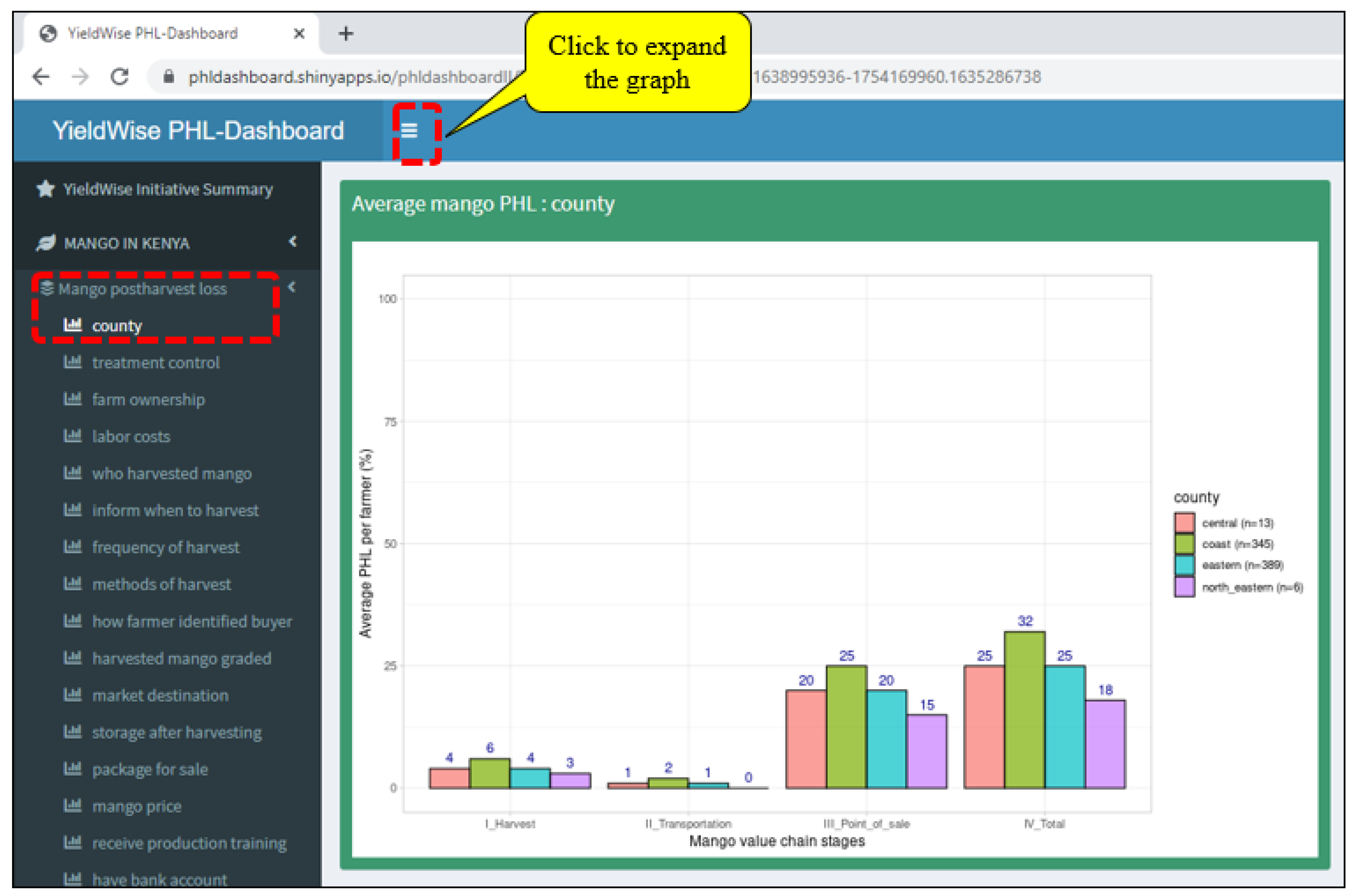
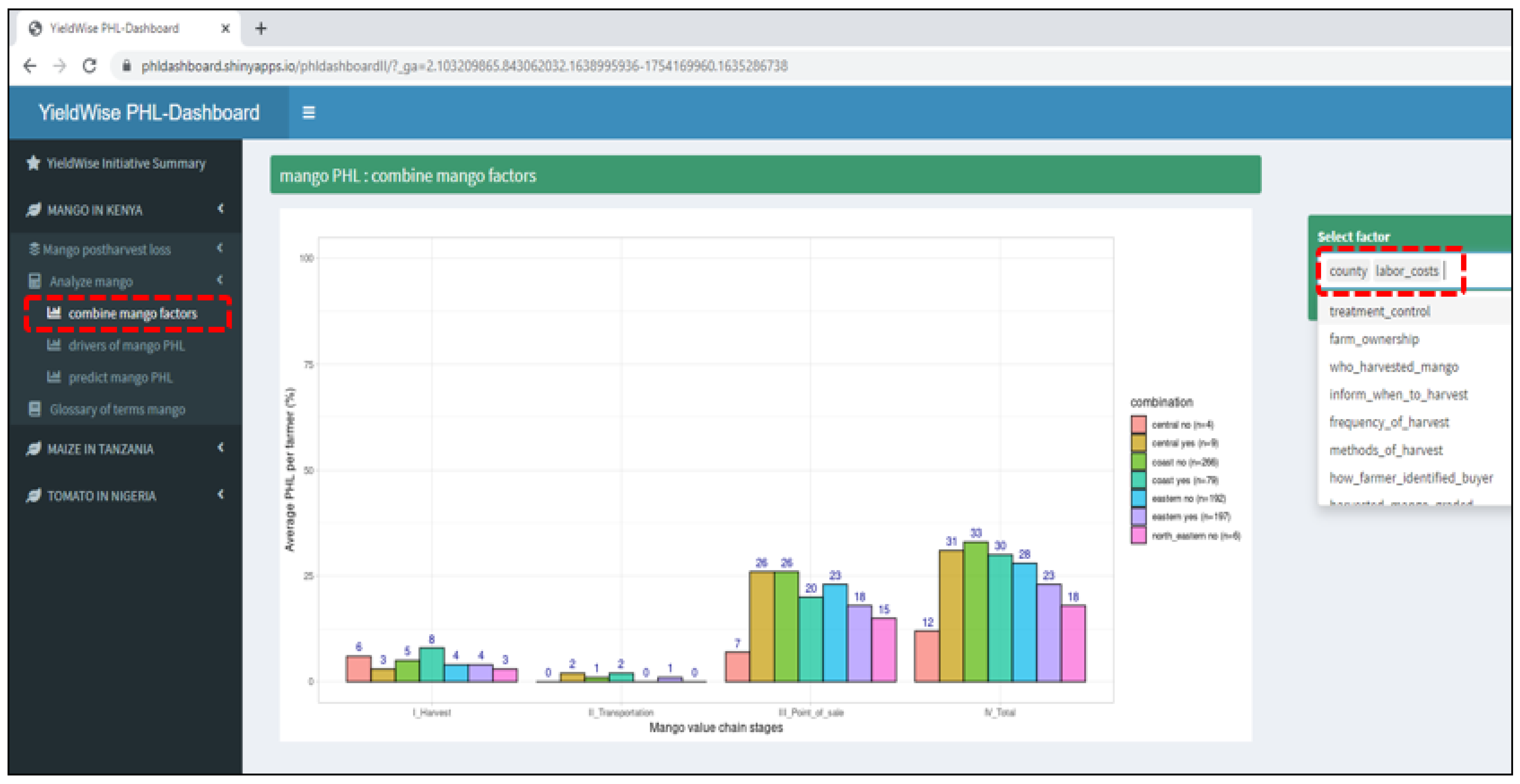
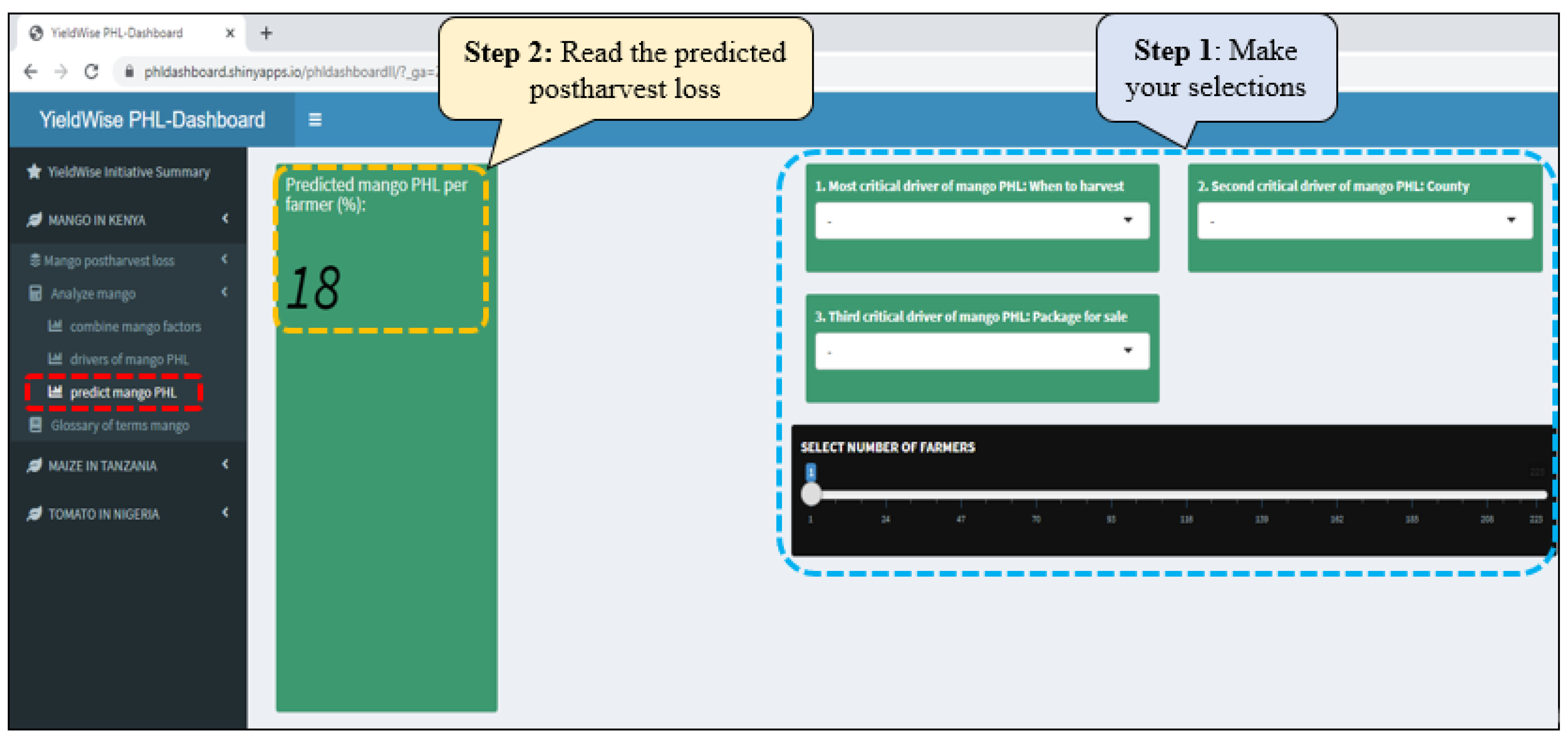
- An online dashboard was created to (a) visually display maize, mango, and tomato PHLs in bar graphs for the numerous variables found in the YieldWise Initiative dataset, (b) rank the critical drivers of maize, mango, and tomato PHL reduction, and (c) explore the relationship between several critical drivers in each value chain, the PHL of each crop, and a desired number of smallholder farmers.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
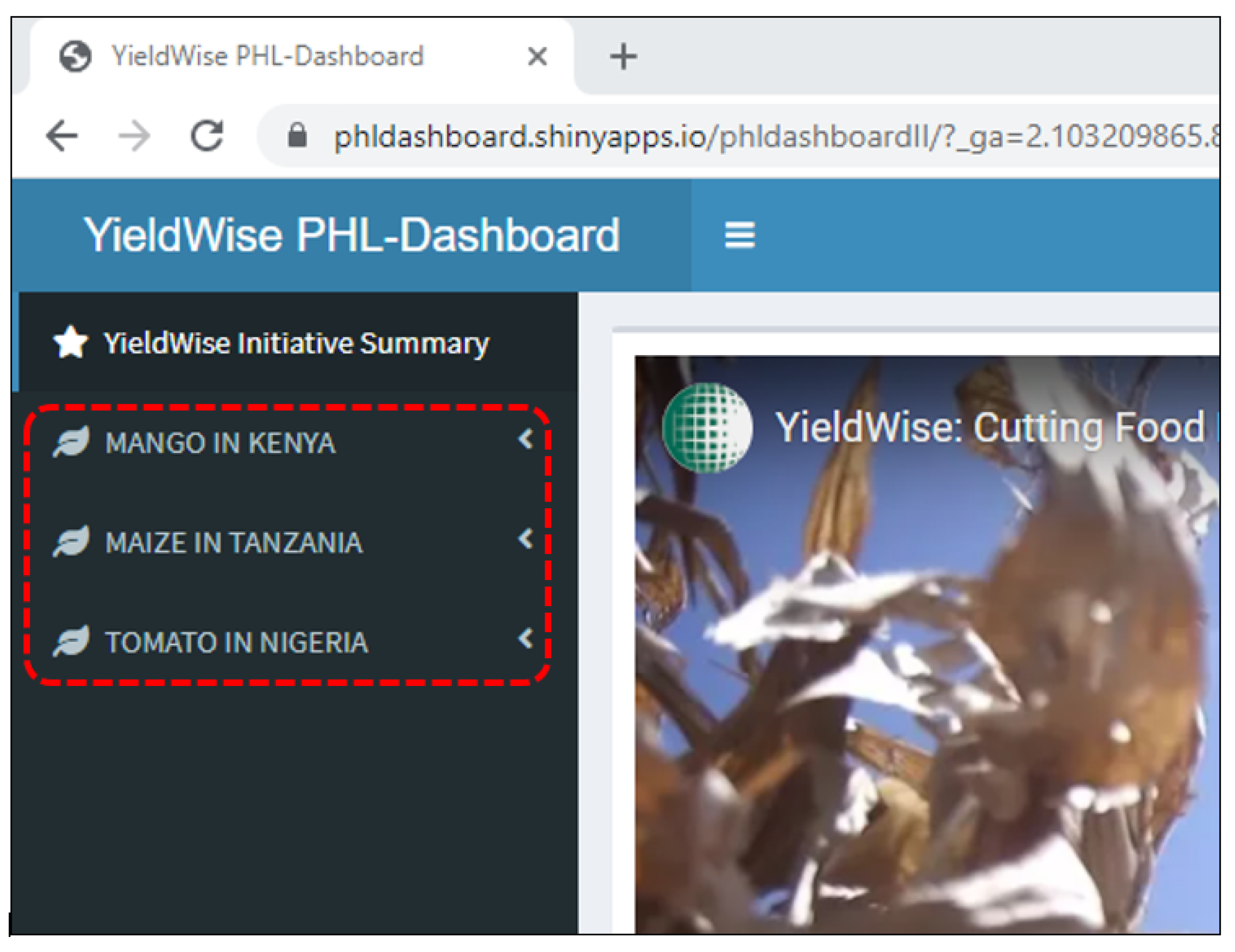
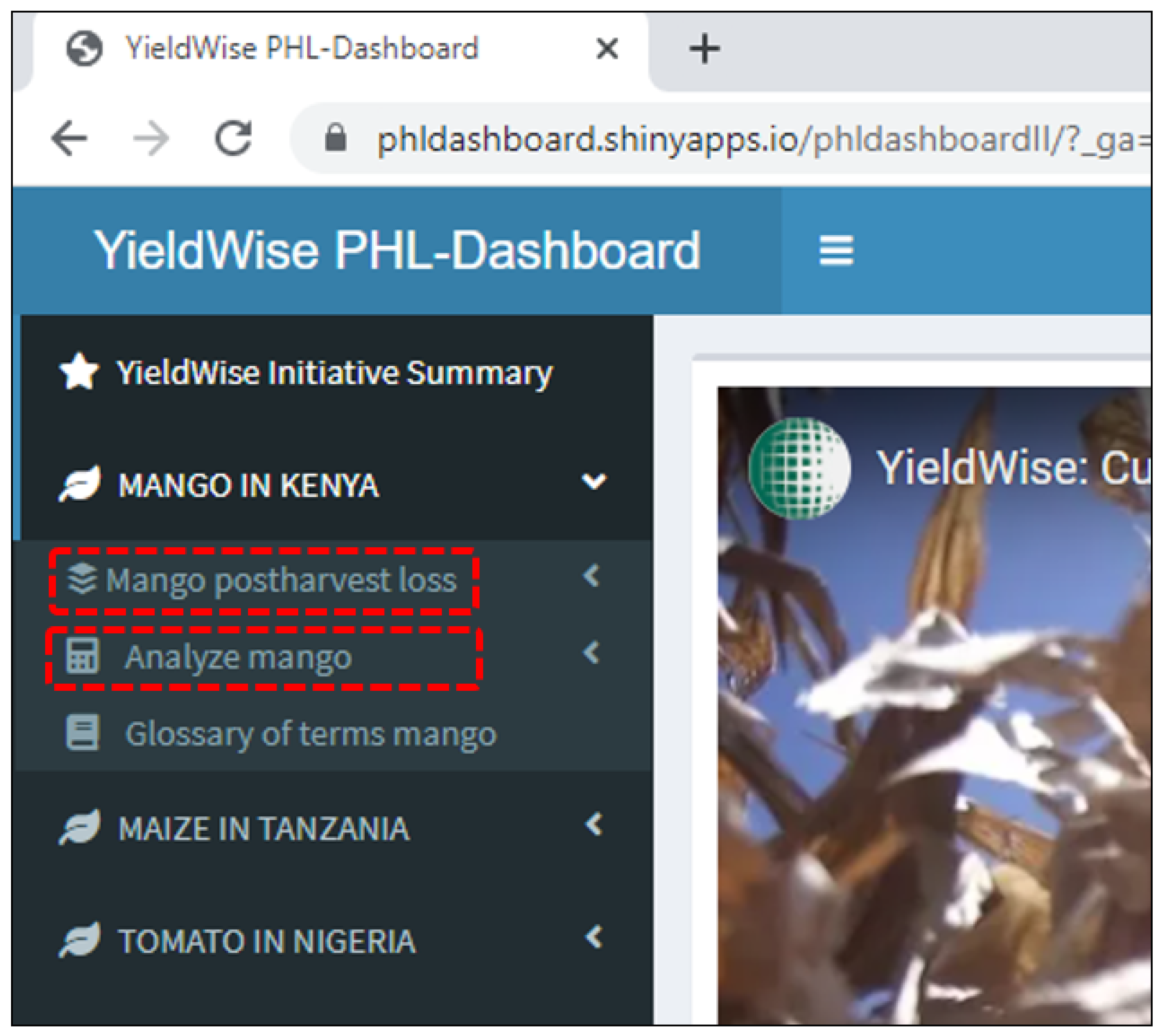
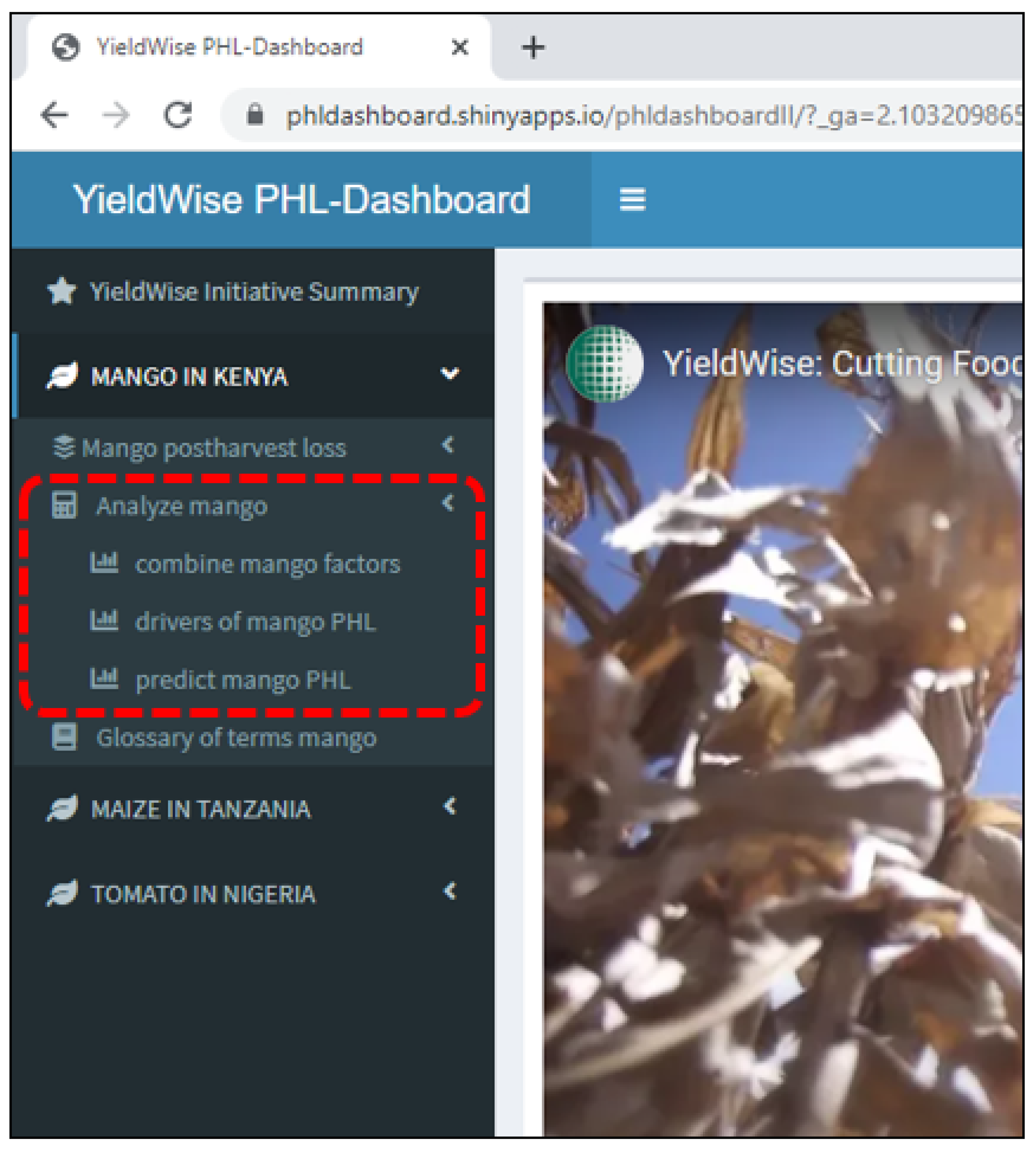
Appendix A. YieldWise Initiative PHL Data Dashboard
- Provides a visual display of the maize, mango, and tomato postharvest losses (PHLs) in the form of bar graphs as a function of the numerous variables found in the Rockefeller YieldWise Initiative datasets.
- Ranks the critical drivers of the maize, mango, and tomato PHLs in order of importance.
- Predicts the maize, mango, and tomato PHLs as a function of their three most critical drivers as well as the number of smallholder farmers of interest.

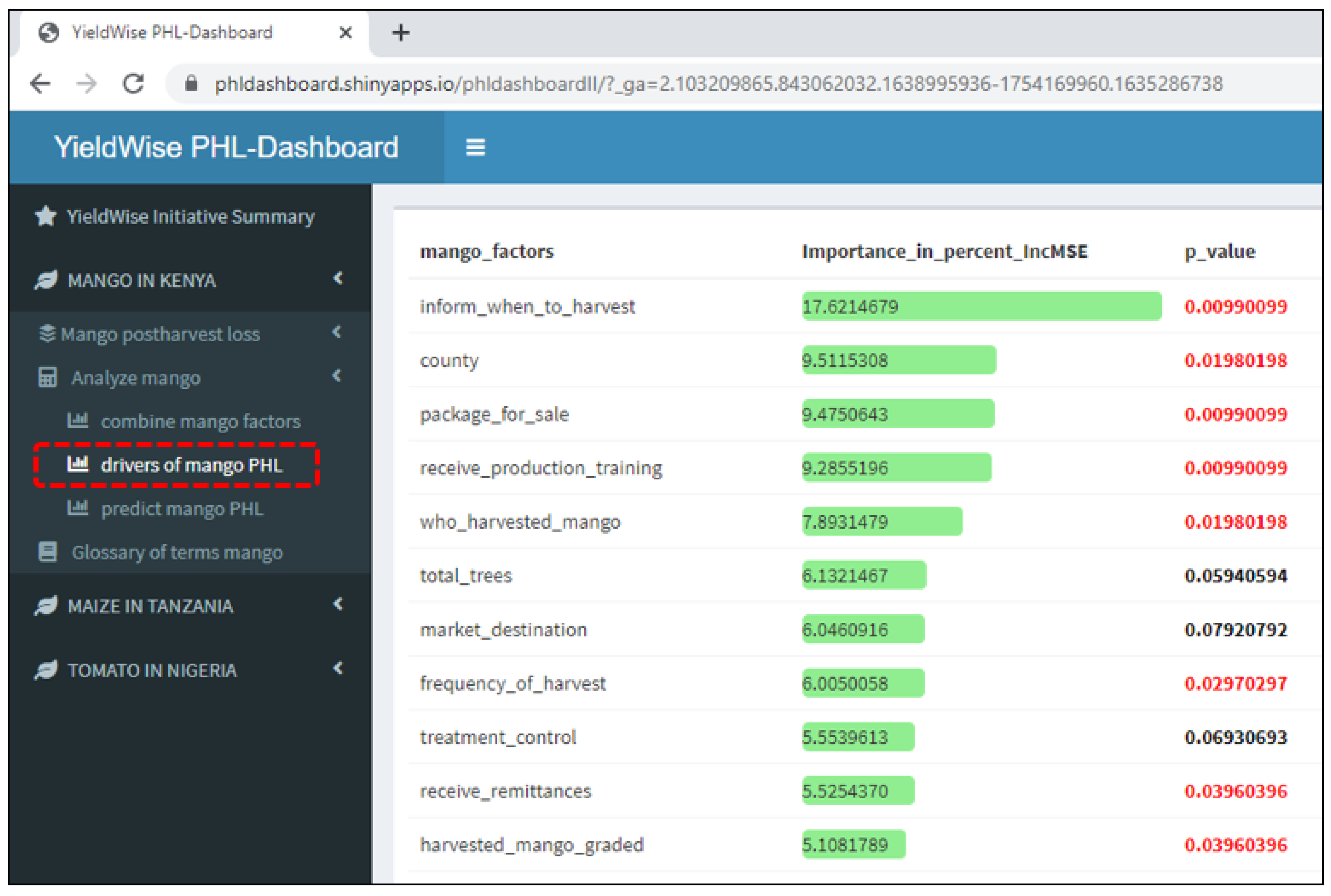
Appendix B. Variable Importance

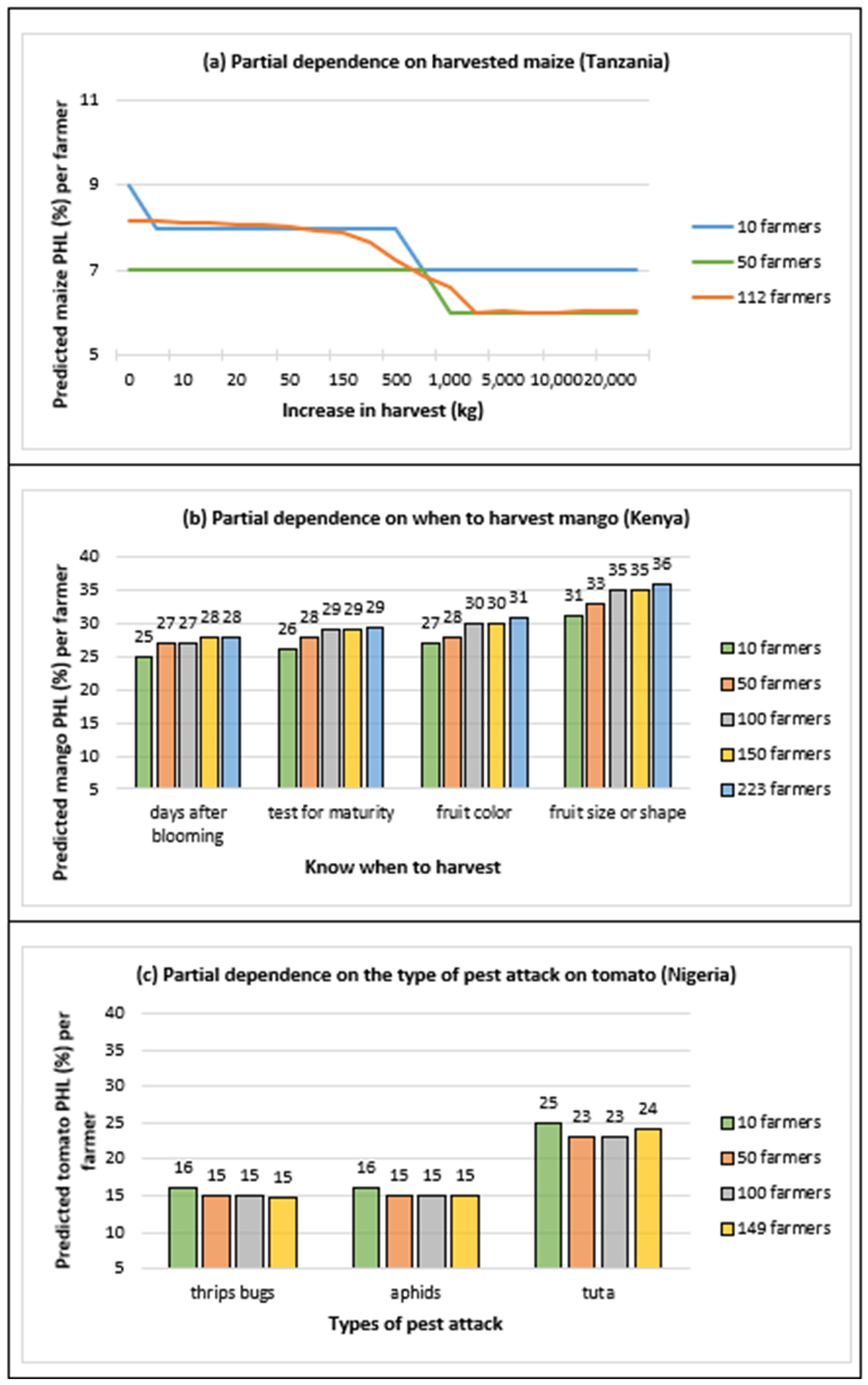
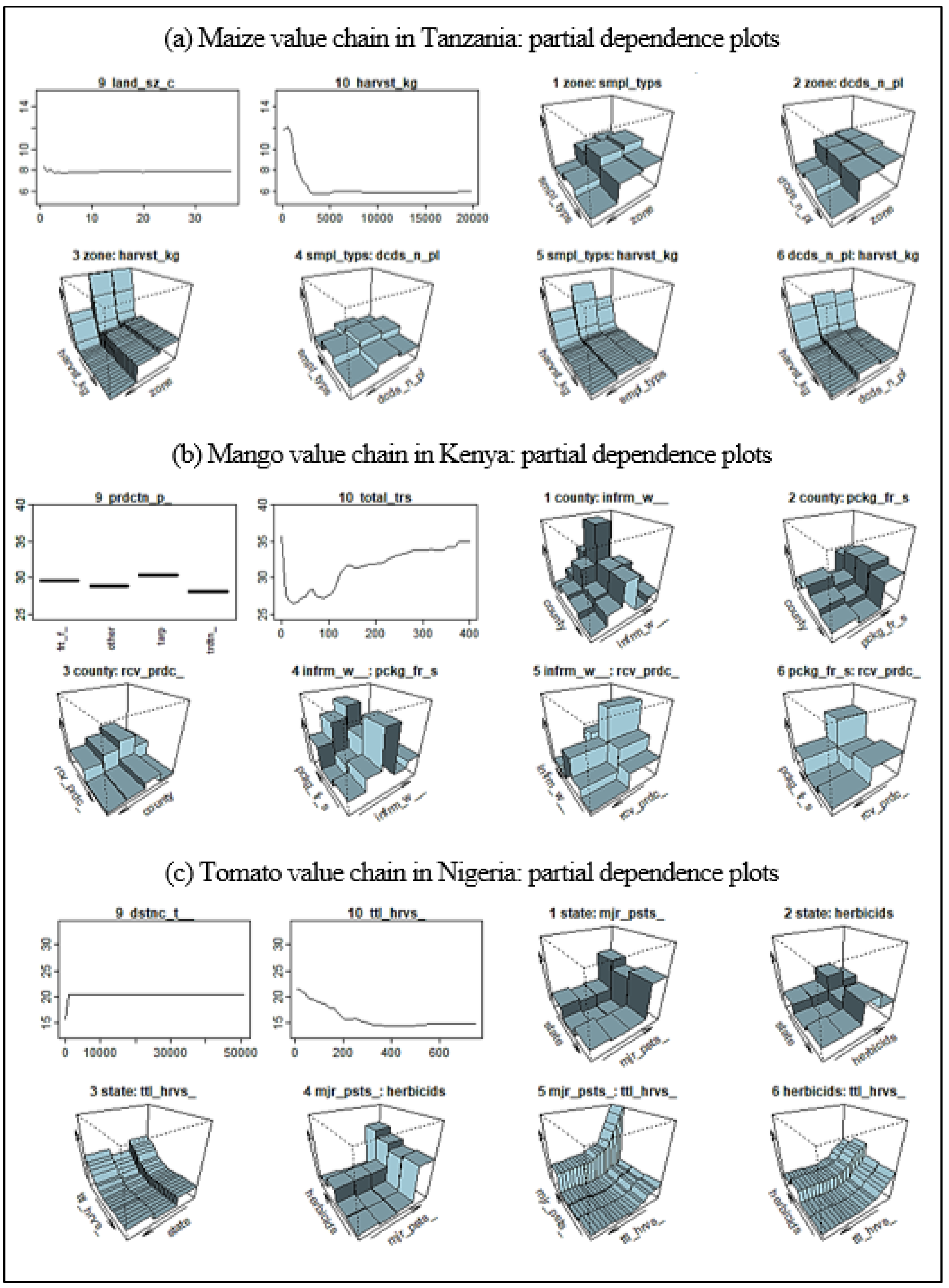
Appendix C. Partial Dependence Plots

References
- FAO. FAOSTAT. 2021. Available online: https://www.fao.org/faostat/en/#data/QCL (accessed on 24 November 2021).
- Flanagan, K.; Robertson, K.; Hanson, C. Reducing Food Loss Setting a Global Action Agenda; World Resources Institute: Washington, DC, USA, 2019. [Google Scholar]
- Owuor, T.O. Guide to Export of Fresh and Processed Mango from Kenya: A Manual for Exporters: August 2015. Available online: https://www.scribd.com/document/432862956/Mango-Export-Guide-Final (accessed on 7 April 2023).
- The Rockefeller Foundation. Saving Tomatoes for the Sauce. 2021. Available online: https://www.rockefellerfoundation.org/wp-content/uploads/2021/04/YieldWise-Tomato-Overview-V4.pdf (accessed on 7 April 2023).
- Wilson, R.T.; Lewis, J. The Maize Value Chain in Tanzania. A report from the Southern Highlands Food Systems Programme 2015. Available online: https://www.fao.org/fileadmin/user_upload/ivc/PDF/SFVC/Tanzania_maize.pdf (accessed on 7 April 2023).
- Mboya, R.; Tongoona, P.; Derera, J.; Mudhara, M.; Langyintuo, A. The dietary importance of maize in Katumba ward, Rungwe district, Tanzania, and its contribution to household food security. Afr. J. Agric. Res. 2011, 6, 2617–2626. [Google Scholar]
- Muoki, P.N.; Makokha, A.O.; Onyango, C.A.; Ojijo, N.K.O. Potential contribution of mangoes to reduction of vitamin A deficiency in Kenya. Ecol. Food Nutr. 2009, 48, 482–498. [Google Scholar] [CrossRef] [PubMed]
- Willcox, J.K.; Catignani, G.L.; Lazarus, S. Tomatoes and cardiovascular health. Crit. Rev. Food Sci. Nutr. 2003, 43, 1–18. [Google Scholar] [CrossRef] [PubMed]
- Grant, W.; Kadondi, E.; Mbaka, M.; Ochieng, S. Opportunities for Financing the Mango Value Chain: A Case Study of Lower Eastern Kenya; FSD Kenya: Nairobi, Kenya, 2015; p. 52. [Google Scholar]
- Wangithi, C.M.; Muriithi, B.W.; Belmin, R. Adoption and dis-adoption of sustainable agriculture: A case of farmers’ innovations and integrated fruit fly management in kenya. Agriculture 2021, 11, 338. [Google Scholar] [CrossRef]
- Suri, T.; Udry, C. Agricultural Technology in Africa. J. Econ. Perspect. 2022, 36, 33–56. [Google Scholar] [CrossRef]
- APHLIS. APHLIS+. 2021. Available online: https://www.aphlis.net/en (accessed on 4 May 2021).
- Engineering for Change. Landscape analysis of Post-Harvest Technologies for Mango Production in East Africa. 2020. Available online: https://www.engineeringforchange.org/wp-content/uploads/2020/10/landscape_analysis_mango_postharvest_tech.pdf (accessed on 7 April 2023).
- Ugonna, C.; Jolaoso, M.; Onwualu, A. Tomato Value Chain in Nigeria: Issues, Challenges and Strategies. J. Sci. Res. Rep. 2015, 7, 501–515. [Google Scholar] [CrossRef]
- Sheahan, M.; Barrett, C.B. Food loss and waste in Sub-Saharan Africa: A critical review. Food Policy 2017, 70, 1–12. [Google Scholar] [CrossRef]
- Xie, H.; Perez, N.; Anderson, W.; Ringler, C.; You, L. Can Sub-Saharan Africa feed itself? The role of irrigation development in the region’s drylands for food security. Water Int. 2018, 43, 796–814. [Google Scholar] [CrossRef]
- Flanagan, K.; Lipinski, B.; Goodwin, L. SDG Target 12.3 on Food Loss and Waste: 2019 Progress Report. 2019, pp. 1–16. Available online: https://champions123.org/sites/default/files/2020-09/champions-12-3-2019-progress-report.pdf (accessed on 7 April 2023).
- The Rockefeller Foundation. YieldWise—The Rockefeller Foundation. 2022. Available online: https://www.rockefellerfoundation.org/initiative/yieldwise/ (accessed on 8 January 2022).
- Chikez, H.; Maier, D.; Sonka, S. Mango postharvest technologies: An observational study of the yieldwise initiative in Kenya. Agriculture 2021, 11, 623. [Google Scholar] [CrossRef]
- Best, K.B.; Gilligan, J.M.; Baroud, H.; Carrico, A.R.; Donato, K.M.; Ackerly, B.A.; Mallick, B. Random forest analysis of two household surveys can identify important predictors of migration in Bangladesh. J. Comput. Soc. Sci. 2020, 4, 77–100. [Google Scholar] [CrossRef]
- Finlay, S. Predictive Analytics, Data Mining and Big Data; Springer: Berlin/Heidelberg, Germany, 2014. [Google Scholar] [CrossRef]
- Shmueli, G. To explain or to predict? Stat. Sci. 2010, 25, 289–310. [Google Scholar] [CrossRef]
- Kern, C.; Klausch, T.; Kreuter, F. Tree-based machine learning methods for survey research. Surv. Res. Methods 2019, 13, 73–93. [Google Scholar] [PubMed]
- Kuhn, M.; Johnson, K. Applied Predictive Modeling; Springer Science Business Media: New York, NY, USA, 2013. [Google Scholar] [CrossRef]
- Hengsdijk, H.; de Boer, W.J. Post-harvest management and post-harvest losses of cereals in Ethiopia. Food Secur. 2017, 9, 945–958. [Google Scholar] [CrossRef]
- Criminisi, A.; Shotton, J. Decision Forests for Computer Vision and Medical Image Analysis; Springer Science Business Media: New York, NY, USA, 2013. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning; 8th Printing 2017; Springer: New York, NY, USA, 2013; Volume 102. [Google Scholar] [CrossRef]
- Gholamy, A.; Kreinovich, V.; Kosheleva, O. Why 70/30 or 80/20 Relation Between Training and Testing Sets: A Pedagogical Explanation. Comput. Sci. 2018, 1–6. [Google Scholar]
- Kuhn, M. Building predictive models in R using the caret package. J. Stat. Softw. 2008, 28, 1–26. [Google Scholar] [CrossRef]
- Williams, G. Data Mining with Rattle and R: The Art of Excavating Data for Knowledge Discovery; Springer: New York, NY, USA, 2011. [Google Scholar] [CrossRef]
- Perner, P. Machine Learning and Data Mining in Pattern Recognition. In Proceedings of the 7th International Conference, MLDM 2011, New York, NY, USA, 30 August–3 September 2011; Volume 2961. [Google Scholar]
- Couronné, R.; Probst, P.; Boulesteix, A.-L. Random forest versus logistic regression: A large-scale benchmark experiment. BMC Bioinform. 2018, 19, 27. [Google Scholar] [CrossRef]
- Grömping, U. Variable importance assessment in regression: Linear regression versus random forest. Am. Stat. 2009, 63, 308–319. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Greenwell, B.M. pdp: An R package for constructing partial dependence plots. R J. 2017, 9, 421–436. [Google Scholar] [CrossRef]
- Milborrow, S. Plotting Regression Surfaces with Plotmo Stephen Milborrow. 2019. Available online: http://www.milbo.org/doc/plotmo-notes.pdf (accessed on 7 April 2023).
- Itaoka, K. Regression and Interpretation of Low R-squared. In Proceedings of the Social Research Network 3rd Meeting, Noosa, Australia, 12–13 April 2012. [Google Scholar]
- Hurburgh, C.R., Jr.; Bern, C.J.; Wilcke, W.F.; Anderson, M.E. Shrinkage and Corn Quality Changes in on-Farm Handling Operations. Trans. ASAE 1983, 26, 1854–1857. [Google Scholar] [CrossRef]
- Kiaya, V. Post-Harvest Losses and Strategies to Reduce Them. 2014. Available online: https://www.actioncontrelafaim.org/wp-content/uploads/2018/01/technical_paper_phl__.pdf (accessed on 7 April 2023).
- Weston, L.A.; Barth, M.M. Preharvest factors affecting postharvest quality of vegetables. HortScience 1997, 32, 812–816. [Google Scholar] [CrossRef]
- Mahuku, G.; Nzioki, H.S.; Mutegi, C.; Kanampiu, F.; Narrod, C.; Makumbi, D. Pre-harvest management is a critical practice for minimizing aflatoxin contamination of maize. Food Control. 2019, 96, 219–226. [Google Scholar] [CrossRef]
- Sonka, S.; Lee, H.; Shah, S. The YieldWise Approach to Post-Harvest Loss Reduction: Creating Market-Driven Supply Chains to Support Sustained Technology Adoption. Agriculture 2023, 13, 910. [Google Scholar] [CrossRef]
- Delgado, L.; Schuster, M.; Torero, M. The Reality of Food Losses: A New Measurement Methodology; no. IFPRI Discussion Paper 01686; International Food Policy Research Institute: Washington, DC, USA, 2017; p. 40. [Google Scholar]
- Mathieu, L.; Jacques, J. Quality and maturation of mango fruits of cv. Cogshall in relation to harvest date and carbon supply. Aust. J. Agric. Res. 2006, 57, 419–426. [Google Scholar]
- Dick, E.; N’DaAdopo, A.; Camara, B.; Moudioh, E. Influence of maturity stage of mango at harvest on its ripening quality. Fruits 2009, 64, 13–18. [Google Scholar] [CrossRef]
- Stathers, T.; Holcroft, D.; Kitinoja, L.; Mvumi, B.M.; English, A.; Omotilewa, O.; Kocher, M.; Ault, J.; Torero, M. A scoping review of interventions for crop postharvest loss reduction in sub-Saharan Africa and South Asia. Nat. Sustain. 2020, 3, 821–835. [Google Scholar] [CrossRef]
- Borisade, O.A.; Kolawole, A.O.; Adebo, G.M.; Uwaidem, Y.I. The tomato leafminer (Tuta absoluta) (Lepidoptera: Gelechiidae) attack in Nigeria: Effect of climate change on over-sighted pest or agro-bioterrorism? J. Agric. Ext. Rural Dev. 2017, 9, 163–171. [Google Scholar] [CrossRef]
- Bala, I.; Mukhtar, M.M.; Saka, H.K.; Abdullahi, N.; Ibrahim, S.S. Determination of insecticide susceptibility of field populations of tomato leaf miner (Tuta absoluta) in northern Nigeria. Agriculture 2019, 9, 7. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variables | Levels (Subset) | Number of Farmers or Observations (n) | 21. Average Land Size (ac) per Farmer | 22. Average Maize Harvest (kg) per Farmer per Season | Average Maize PHL (%) per Farmer per Season |
|---|---|---|---|---|---|
| 1. gender | female | 161 | 4 | 2836 | 7 |
| male | 220 | 4 | 4626 | 7 | |
| 2. zone | central | 73 | 8 | 2410 | 13 |
| coastal | 24 | 2 | 2445 | 14 | |
| southern highlands | 284 | 3 | 4365 | 6 | |
| 3. sample types | beneficiary | 146 | 3 | 4627 | 6 |
| control | 139 | 6 | 3210 | 11 | |
| other | 96 | 3 | 3673 | 5 | |
| 4. YieldWise training | female adults | 57 | 2 | 3519 | 6 |
| female youth | 1 | 2 | 6000 | 7 | |
| male adults | 84 | 3 | 5449 | 6 | |
| male youth | 2 | 3 | 2878 | 2 | |
| other | 237 | 5 | 3393 | 8 | |
| 5. decides on planting | female adults | 78 | 3 | 2759 | 9 |
| male adults | 148 | 4 | 4163 | 9 | |
| other | 155 | 4 | 4148 | 5 | |
| 6. decides on harvest | female adults | 77 | 3 | 2865 | 8 |
| male adults | 104 | 5 | 4002 | 10 | |
| male youth | 1 | 3 | 4940 | 3 | |
| other | 199 | 4 | 4184 | 6 | |
| 7. decides on proceeds | female adults | 71 | 3 | 2776 | 9 |
| male adults | 103 | 4 | 4007 | 9 | |
| male youth | 1 | 3 | 4940 | 3 | |
| other | 206 | 4 | 4172 | 6 | |
| 8. tarp supplier | agra aggregator | 76 | 3 | 4399 | 9 |
| agro equipment stores | 147 | 5 | 4572 | 7 | |
| donated | 12 | 5 | 3507 | 10 | |
| other | 146 | 3 | 2916 | 6 | |
| 9. threshing modes | manual | 82 | 3 | 3388 | 9 |
| mechanical | 134 | 6 | 4472 | 7 | |
| other | 165 | 3 | 3619 | 7 | |
| 10. point of sale | farm | 11 | 5 | 3156 | 12 |
| homestead | 28 | 5 | 3199 | 8 | |
| other | 333 | 4 | 3924 | 7 | |
| village market | 8 | 4 | 5013 | 7 | |
| warehouse | 1 | 1 | 3204 | 1 | |
| 11. transport mode | other | 374 | 4 | 3866 | 8 |
| sacks on animal cart | 4 | 6 | 3769 | 2 | |
| sacks on bicycle | 1 | 5 | 7371 | 3 | |
| sacks on wheelbarrow | 2 | 2 | 2950 | 5 | |
| 12. direct client | aggregators | 5 | 2 | 2266 | 11 |
| direct consumers | 4 | 4 | 5884 | 4 | |
| other | 372 | 4 | 3869 | 7 | |
| 13. level of dryness | dry | 25 | 5 | 3923 | 9 |
| humid | 19 | 3 | 4478 | 10 | |
| other | 104 | 4 | 3864 | 5 | |
| very dry | 231 | 4 | 3829 | 8 | |
| very humid | 2 | 3 | 2430 | 15 | |
| 14. sun drying practices | field before harvesting | 149 | 4 | 3572 | 9 |
| other | 108 | 4 | 3818 | 5 | |
| shallow layer stand | 1 | 1 | 1336 | 4 | |
| spread threshed maize | 120 | 4 | 4328 | 7 | |
| ventilated crib for cob | 3 | 4 | 2991 | 11 | |
| 15. mc measurement method | farmer experience | 110 | 5 | 3191 | 10 |
| other | 255 | 4 | 4000 | 7 | |
| salt test | 6 | 3 | 5644 | 4 | |
| smell-based | 1 | 1 | 2440 | 2 | |
| use of machines | 7 | 5 | 9078 | 3 | |
| weight-based | 2 | 4 | 1765 | 5 | |
| 16. storage method | home storage | 32 | 4 | 4240 | 7 |
| improved granaries | 3 | 3 | 5060 | 4 | |
| on ground in house | 28 | 3 | 5135 | 5 | |
| other | 108 | 5 | 3576 | 6 | |
| pics hermetic bags | 13 | 4 | 6115 | 7 | |
| plastic bag | 161 | 4 | 3676 | 9 | |
| plastic silos | 1 | 5 | 3470 | 3 | |
| traditional granaries | 35 | 4 | 3393 | 9 | |
| 17. received training | no | 177 | 4 | 3514 | 9 |
| yes | 204 | 4 | 4178 | 6 | |
| 18. education level | complete college | 2 | 4 | 5400 | 2 |
| complete primary | 293 | 4 | 4001 | 7 | |
| complete secondary | 31 | 5 | 4126 | 5 | |
| complete university | 1 | 2 | 1620 | 1 | |
| dip certificate | 1 | 5 | 3798 | 18 | |
| no formal education | 19 | 3 | 2600 | 12 | |
| other | 7 | 6 | 2585 | 10 | |
| postgraduate | 1 | 3 | 5220 | 0 | |
| some primary | 16 | 3 | 1882 | 10 | |
| some secondary | 10 | 4 | 5501 | 4 | |
| 19. employment status | formal sector | 21 | 3 | 3606 | 5 |
| housewife | 35 | 2 | 3014 | 6 | |
| informal sector | 31 | 6 | 3496 | 11 | |
| not working | 21 | 4 | 2904 | 6 | |
| other | 21 | 4 | 3980 | 8 | |
| retired | 7 | 4 | 5301 | 4 | |
| self employed | 232 | 4 | 4115 | 7 | |
| temporarily employed | 13 | 3 | 3717 | 9 | |
| 20. transport mode I | cattle cart | 56 | 4 | 4102 | 9 |
| covered trucks | 16 | 4 | 4349 | 4 | |
| open trucks | 51 | 4 | 6849 | 5 | |
| other | 197 | 4 | 2989 | 8 | |
| sacks on head | 16 | 6 | 3542 | 7 | |
| sacks on wheelbarrow | 10 | 2 | 2656 | 10 | |
| tractor | 28 | 4 | 4842 | 7 | |
| wheelbarrows no sacks | 7 | 3 | 2586 | 7 |
| Variables | Levels (Subset) | Number of Farmers or Observations (n) | 20. Average Number of Mango Trees per Farmer | 21. Average Mango Price (KES) per Fruit | Average Mango PHL (%) per Farmer per Season |
|---|---|---|---|---|---|
| 1. county | central | 13 | 59 | 5 | 25 |
| coast | 345 | 19 | 5 | 32 | |
| eastern | 389 | 71 | 7 | 25 | |
| northeastern | 6 | 9 | 7 | 18 | |
| 2. treatment control | non beneficiary | 282 | 42 | 6 | 31 |
| YieldWise beneficiary | 471 | 49 | 6 | 27 | |
| 3. farm ownership | no | 135 | 33 | 6 | 28 |
| yes | 618 | 49 | 6 | 28 | |
| 4. labor costs | no | 468 | 33 | 6 | 30 |
| yes | 285 | 69 | 7 | 25 | |
| 5. who harvested mango | buyer | 411 | 58 | 6 | 27 |
| farmer | 181 | 24 | 6 | 33 | |
| other | 161 | 43 | 7 | 27 | |
| 6. inform when to harvest | days after blooming | 5 | 51 | 8 | 14 |
| fruit color | 165 | 70 | 7 | 30 | |
| fruit size or shape | 49 | 22 | 6 | 43 | |
| other | 521 | 41 | 6 | 27 | |
| test for maturity | 13 | 44 | 6 | 29 | |
| 7. frequency of harvest | daily | 53 | 100 | 7 | 31 |
| fortnightly | 231 | 36 | 6 | 29 | |
| monthly | 52 | 44 | 6 | 34 | |
| other | 109 | 51 | 5 | 28 | |
| weekly | 308 | 44 | 7 | 26 | |
| 8. methods of harvest | harvesting tools | 49 | 57 | 9 | 25 |
| other | 160 | 35 | 5 | 25 | |
| traditional practices | 544 | 49 | 6 | 30 | |
| 9. how farmer identified buyer | brokers | 407 | 48 | 6 | 29 |
| farmer-based organization | 12 | 169 | 12 | 12 | |
| other | 81 | 48 | 4 | 33 | |
| own effort | 253 | 38 | 7 | 26 | |
| 10. harvested mango graded | no | 346 | 49 | 5 | 30 |
| yes | 407 | 44 | 7 | 27 | |
| 11. market destination | export | 106 | 88 | 8 | 19 |
| local market | 362 | 45 | 6 | 29 | |
| other | 239 | 34 | 5 | 31 | |
| processing | 41 | 24 | 6 | 34 | |
| supermarket | 5 | 63 | 14 | 25 | |
| 12. storage after harvesting | cold store | 18 | 75 | 6 | 25 |
| other | 49 | 55 | 6 | 29 | |
| traditional practices | 686 | 45 | 6 | 28 | |
| 13. package for sale | other | 314 | 46 | 6 | 31 |
| plastic crates | 320 | 50 | 7 | 24 | |
| traditional practices | 119 | 39 | 6 | 34 | |
| 14. receive production training | no | 534 | 41 | 6 | 31 |
| yes | 219 | 60 | 7 | 21 | |
| 15. have bank account | no | 374 | 35 | 6 | 31 |
| yes | 379 | 58 | 7 | 26 | |
| 16. have mobile money account | no | 95 | 29 | 5 | 32 |
| yes | 658 | 49 | 6 | 28 | |
| 17. receive remittances | no | 467 | 47 | 6 | 28 |
| yes | 286 | 46 | 7 | 29 | |
| 18. taken loan for farm | no | 695 | 44 | 6 | 29 |
| yes | 58 | 71 | 8 | 25 | |
| 19. production PHL practices | fruit fly traps | 125 | 76 | 6 | 25 |
| other | 203 | 53 | 8 | 27 | |
| tarp | 115 | 17 | 5 | 33 | |
| traditional practices | 310 | 41 | 6 | 29 |
| Variables | Levels (Subset) | Number of Farmers or Observations (n) | 21. Average Income (NGN) per Farmer | 22. Average Labor Cost (NGN) per Season | 23. Average Frequency of Pesticide Applications per Season | 24. Average Distance (km) to Market | 25. Average Harvest (kg) per Farmer per Season | Average Tomato PHL (%) per Farmer per Season |
|---|---|---|---|---|---|---|---|---|
| 1. treatment or control | control | 166 | 235,630 | 46,796 | 7 | 18 | 214 | 20 |
| intervention | 337 | 271,738 | 46,151 | 6 | 19 | 253 | 15 | |
| 2. state | jigawa | 134 | 309,038 | 43,330 | 6 | 21 | 185 | 22 |
| kano | 248 | 195,535 | 34,452 | 5 | 20 | 266 | 13 | |
| katsina | 121 | 337,077 | 74,137 | 9 | 12 | 247 | 19 | |
| 3. gender | female | 5 | 316,200 | 11,000 | 6 | 4 | 280 | 14 |
| male | 498 | 259,255 | 46,719 | 6 | 18 | 239 | 17 | |
| 4. dry month | january | 43 | 244,118 | 42,531 | 7 | 20 | 260 | 17 |
| february | 6 | 641,667 | 110,000 | 6 | 4 | 188 | 5 | |
| august | 6 | 185,000 | 57,583 | 6 | 7 | 66 | 14 | |
| september | 52 | 398,327 | 70,133 | 8 | 19 | 219 | 26 | |
| october | 229 | 215,823 | 37,574 | 7 | 21 | 256 | 18 | |
| november | 106 | 289,778 | 63,218 | 5 | 15 | 214 | 15 | |
| december | 61 | 235,737 | 25,149 | 5 | 15 | 249 | 7 | |
| 5. tomato varieties | chibli | 20 | 235,880 | 36,019 | 5 | 13 | 126 | 4 |
| other | 236 | 275,188 | 59,668 | 7 | 17 | 233 | 15 | |
| roma | 65 | 296,261 | 25,218 | 5 | 21 | 229 | 17 | |
| uc82b | 182 | 229,512 | 37,801 | 6 | 19 | 265 | 20 | |
| 6. intercropped with tomatoes | no | 343 | 265,509 | 50,783 | 7 | 20 | 250 | 16 |
| yes | 160 | 247,628 | 36,890 | 6 | 15 | 217 | 19 | |
| 7. main fertilizers | npk | 63 | 158,847 | 29,177 | 5 | 11 | 196 | 24 |
| other | 402 | 284,891 | 52,018 | 7 | 18 | 239 | 15 | |
| ssp | 21 | 144,647 | 9266 | 5 | 39 | 404 | 15 | |
| urea | 17 | 183,476 | 22,176 | 5 | 31 | 208 | 17 | |
| 8. major pests attacks | aphids | 50 | 278,472 | 35,752 | 5 | 7 | 154 | 10 |
| other | 287 | 279,685 | 54,281 | 7 | 16 | 236 | 14 | |
| thrips bugs | 18 | 203,922 | 21,406 | 5 | 9 | 228 | 6 | |
| tuta | 148 | 221,799 | 37,630 | 6 | 27 | 278 | 26 | |
| 9. pesticides usage | combine | 329 | 254,836 | 53,248 | 7 | 18 | 252 | 17 |
| other | 12 | 152,592 | 62,167 | 1 | 4 | 222 | 10 | |
| single | 162 | 277,887 | 31,212 | 6 | 21 | 217 | 16 | |
| 10. diseases attack | leaf blight | 41 | 177,815 | 29,810 | 4 | 11 | 238 | 10 |
| leaf virus | 92 | 180,828 | 26,667 | 6 | 32 | 326 | 18 | |
| nematodes | 43 | 382,616 | 62,744 | 6 | 14 | 216 | 18 | |
| other | 327 | 276,181 | 51,827 | 7 | 16 | 219 | 17 | |
| 11. herbicides | glyphosate | 77 | 193,075 | 33,197 | 6 | 32 | 240 | 15 |
| manual | 337 | 300,756 | 54,205 | 6 | 14 | 233 | 15 | |
| other | 67 | 166,036 | 26,795 | 6 | 19 | 291 | 20 | |
| primextra | 22 | 152,004 | 31,927 | 12 | 29 | 189 | 27 | |
| 12. irrigation type | drip | 104 | 226,746 | 36,039 | 6 | 26 | 250 | 17 |
| flood | 265 | 284,821 | 46,744 | 7 | 15 | 236 | 18 | |
| other | 109 | 266,513 | 61,075 | 5 | 20 | 258 | 12 | |
| sprinkler | 25 | 103,240 | 21,140 | 8 | 8 | 158 | 18 | |
| 13. harvesting containers | other | 9 | 307,444 | 49,889 | 4 | 18 | 223 | 13 |
| plastic crates | 1 | 8500 | 23,000 | 6 | 1 | 170 | 2 | |
| raffia baskets | 474 | 244,296 | 45,798 | 6 | 19 | 246 | 17 | |
| sacks | 19 | 637,816 | 60,031 | 5 | 10 | 98 | 11 | |
| 14. harvest destination | agg center | 9 | 243,889 | 52,333 | 7 | 8 | 99 | 34 |
| buyer picks up | 164 | 264,128 | 54,764 | 7 | 29 | 296 | 17 | |
| market | 197 | 216,168 | 30,184 | 6 | 11 | 202 | 17 | |
| other | 133 | 320,247 | 59,567 | 7 | 16 | 235 | 14 | |
| 15. transportation method | 1-ton truck | 198 | 273,308 | 39,966 | 6 | 16 | 254 | 15 |
| 2-ton truck | 48 | 267,115 | 51,281 | 9 | 17 | 245 | 25 | |
| 30-ton truck | 2 | 850,000 | 25,000 | 10 | 237 | 400 | 23 | |
| 5-ton truck | 1 | 115,000 | 40,000 | 14 | 10 | 234 | 4 | |
| motorcycle | 134 | 225,802 | 35,320 | 5 | 10 | 168 | 17 | |
| other | 81 | 276,929 | 78,418 | 7 | 38 | 345 | 14 | |
| tricycle | 39 | 237,174 | 45,420 | 6 | 10 | 182 | 19 | |
| 16. YieldWise services | credit | 23 | 143,978 | 22,039 | 4 | 52 | 324 | 15 |
| inputs | 19 | 238,474 | 55,237 | 6 | 33 | 239 | 25 | |
| market access | 73 | 151,985 | 37,607 | 5 | 10 | 234 | 15 | |
| none | 177 | 326,968 | 63,824 | 7 | 18 | 208 | 17 | |
| other | 186 | 254,787 | 33,542 | 6 | 17 | 259 | 15 | |
| training | 25 | 259,562 | 59,340 | 6 | 11 | 267 | 24 | |
| 17. information channel | friend | 15 | 234,557 | 26,273 | 7 | 25 | 240 | 27 |
| market | 5 | 239,200 | 45,000 | 11 | 6 | 280 | 30 | |
| neighbor | 3 | 96,667 | 20,167 | 6 | 1 | 197 | 14 | |
| other | 331 | 287,468 | 54,454 | 7 | 19 | 249 | 17 | |
| phone | 3 | 186,000 | 33,333 | 4 | 35 | 227 | 27 | |
| posters | 1 | 50,000 | 5000 | 3 | 2 | 50 | 33 | |
| radio | 145 | 206,384 | 31,118 | 5 | 17 | 220 | 13 | |
| 18. farmer group member | no | 180 | 283,348 | 47,792 | 5 | 14 | 208 | 16 |
| yes | 323 | 246,710 | 45,567 | 7 | 21 | 258 | 17 | |
| 19. inputs on credit | no | 473 | 262,040 | 46,149 | 6 | 18 | 239 | 16 |
| yes | 30 | 224,833 | 49,753 | 8 | 16 | 248 | 24 | |
| 20. contract with Dangote | do not know | 18 | 136,544 | 39,617 | 4 | 10 | 214 | 17 |
| no | 451 | 267,166 | 40,408 | 6 | 19 | 236 | 17 | |
| yes | 34 | 227,653 | 128,929 | 9 | 15 | 301 | 7 |
| Random Forest Predictive Model Value Chain | p-Value | % Var Explained (R-Squared) | Mean Squared Residual |
|---|---|---|---|
| Maize | 0.001 * | 20 | 67 |
| Mango | 0.001 * | 13 | 447 |
| Tomato | 0.001 * | 21 | 327 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chikez, H.; Maier, D.; Olafsson, S.; Sonka, S. Identifying Critical Drivers of Mango, Tomato, and Maize Postharvest Losses (PHL) in Low-Income Countries and Predicting Their Impact. Agriculture 2023, 13, 1912. https://doi.org/10.3390/agriculture13101912
Chikez H, Maier D, Olafsson S, Sonka S. Identifying Critical Drivers of Mango, Tomato, and Maize Postharvest Losses (PHL) in Low-Income Countries and Predicting Their Impact. Agriculture. 2023; 13(10):1912. https://doi.org/10.3390/agriculture13101912
Chicago/Turabian StyleChikez, Hory, Dirk Maier, Sigurdur Olafsson, and Steve Sonka. 2023. "Identifying Critical Drivers of Mango, Tomato, and Maize Postharvest Losses (PHL) in Low-Income Countries and Predicting Their Impact" Agriculture 13, no. 10: 1912. https://doi.org/10.3390/agriculture13101912