
Enhancing Fruit Fly Detection in Complex Backgrounds Using Transformer Architecture with Step Attention Mechanism

Abstract
:1. Introduction
- High-precision Transformer model design: A new Transformer model architecture was designed specifically for the characteristics of fruit flies, adjusting the model’s layers, heads, and dimensions to better suit the properties of fruit fly images.
- Step attention mechanism: To further enhance the model’s ability to capture subtle features of fruit flies, a step attention mechanism was proposed, allowing for the model to progressively focus on key features during image sequence processing, thereby improving recognition precision and efficiency.
- Cross-Loss Function: To address the issue of class imbalance in fruit fly identification, a new cross-loss function was designed, effectively enhancing the model’s ability to recognize minority classes, thus improving overall model performance.
- Adaptive Stable Optimizer: To solve potential gradient vanishing or exploding problems during model training, an adaptive stable optimizer was proposed, dynamically adjusting the learning rate and regularization terms to ensure training stability and efficiency.
2. Related Work
2.1. Convolutional Neural Network-Based Object Detection Models
2.1.1. One-Stage Networks
- The input layer divides the input image into a grid of cells (typically , , or higher-resolution grids), each cell responsible for predicting objects whose center points fall within that cell.
- The backbone network serves to extract features from the image. In different versions of YOLO, the backbone network varies. For example, YOLOv1 [27] employed a custom network structure, while starting from YOLOv3 [28], the backbone network adopted Darknet-53 [29], a deep convolutional network with 53 convolutional layers, enhancing feature transfer through residual connections, enabling effective learning even in deep networks.
- The neck network, situated between the backbone network and the prediction layer, further processes the feature maps to make them more suitable for object detection tasks. YOLOv3 and its subsequent versions introduced the Feature Pyramid Network (FPN) [30] as the neck network, aiming to improve the model’s detection capability for small objects by merging feature maps of different scales.
2.1.2. Two-Stage Networks
- The backbone network is responsible for extracting features from the input image. In Faster R-CNN, various convolutional networks can be used as the backbone network, such as VGG-16 [36], ResNet-50 [37], or ResNet-101. These networks extract high-level semantic features from the image through multiple convolutional operations, providing necessary information for subsequent object detection tasks.
- The RPN is the core of Faster R-CNN, generating candidate object regions from the feature maps extracted by the backbone network. The RPN slides a small network over the feature map, predicting multiple scales and aspect ratios of anchor boxes at each position, indicating whether they contain objects and the adjustments to the anchor boxes’ positions. This step generates a set of high-quality candidate regions for further classification and regression.
- The RoI (Region of Interest) Pooling layer converts candidate regions of varying sizes into fixed-size feature maps for uniform classification and bounding box regression. This step ensures a fixed-dimensional feature representation regardless of the original sizes of the candidate regions.
- Finally, for each fixed-size feature map output by the RoI Pooling layer, the network performs two tasks: determining the category of the region (including the background class) and making precise adjustments to the bounding box to more accurately cover the object.
2.2. Transformer-Based Object Detection Models
3. Materials and Method
3.1. Dataset Collection
3.2. Dataset Annotation
3.2.1. Bounding Box Annotation
3.2.2. Category Annotation
3.3. Dataset Preprocessing
3.3.1. Image Resizing
3.3.2. Image Normalization
3.3.3. Denoising and Contrast Enhancement
3.4. Image Augmentation
3.5. Proposed Method
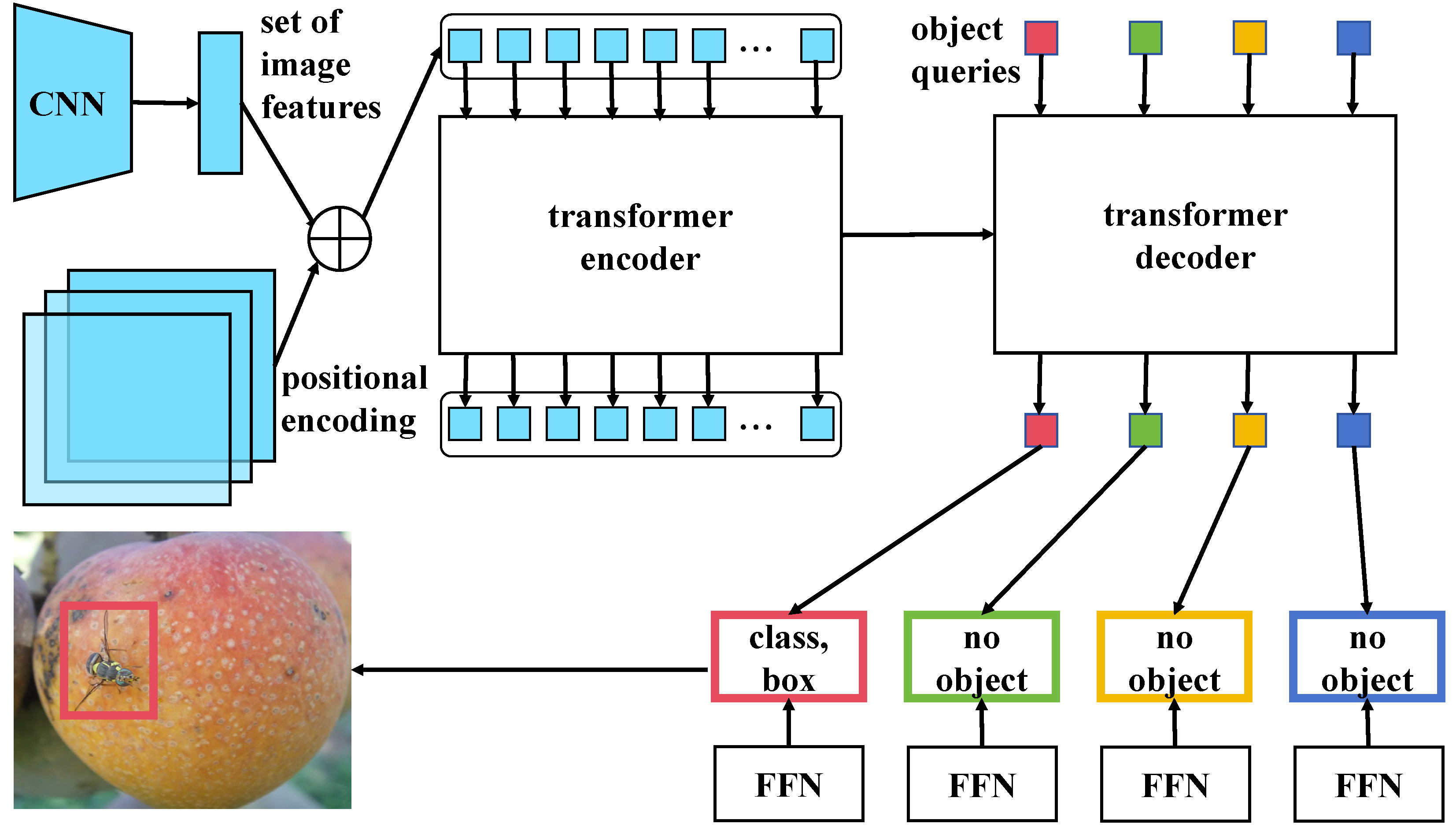
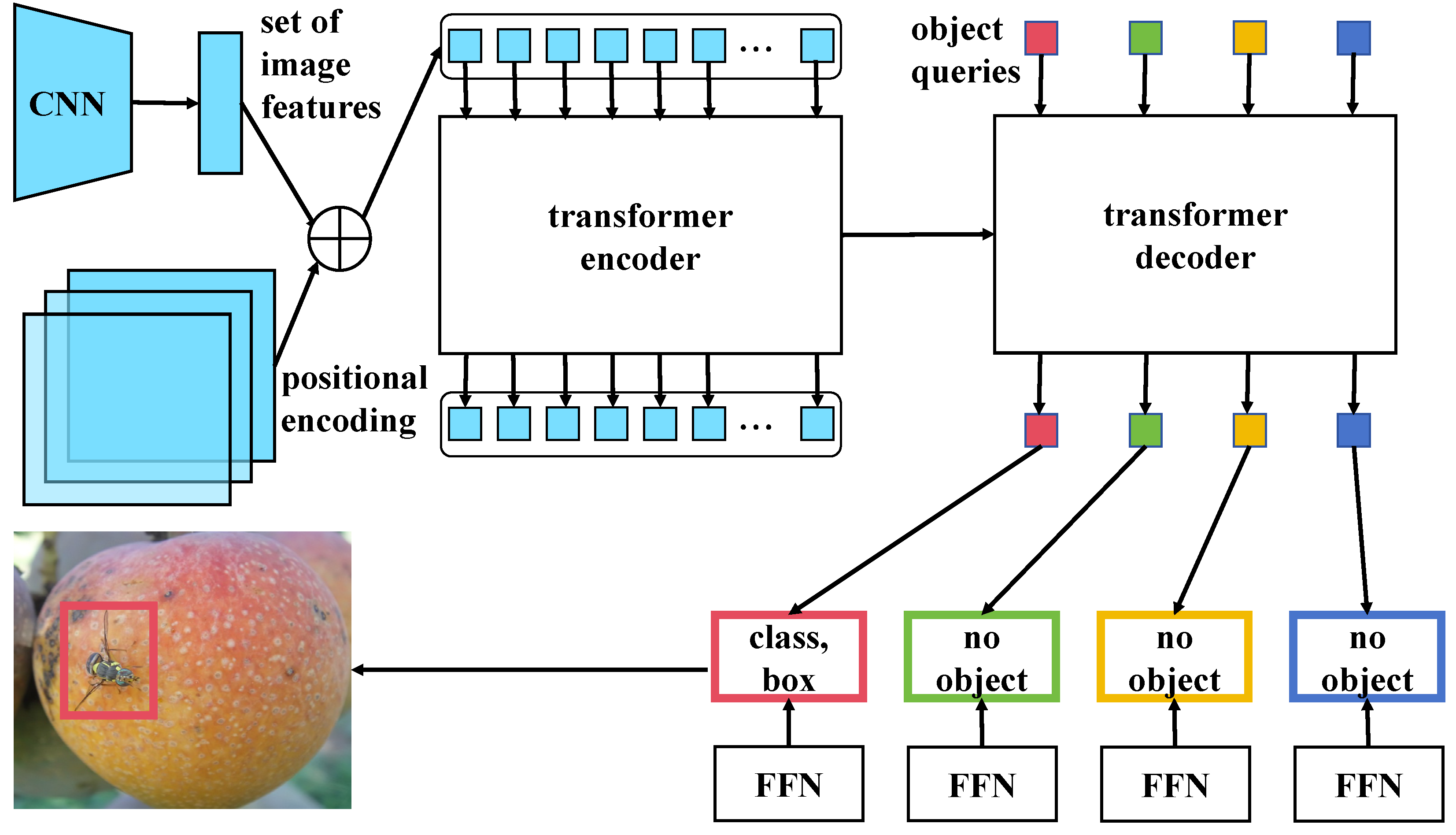
3.5.1. Overview
- High-precision Transformer Structure: The adopted modified Transformer structure is specifically designed for image target detection tasks. Compared to the traditional Transformer, optimizations for image features in the encoder and decoder significantly enhance the model’s capability to process image data and extract target features. Utilizing the self-attention mechanism, this structure effectively captures global dependencies within images, markedly improving the accuracy of fruit fly recognition. This improvement directly responds to the need outlined in the introduction for enhanced handling and recognition accuracy of complex image data.
- Step Attention Mechanism: The introduced step attention mechanism incrementally refines the focus of attention, allowing for the model to concentrate on the details of the target after initially locating it. This mechanism not only boosts the model’s ability to capture image details, but also enhances accuracy and robustness in recognition, effectively addressing the challenge of identifying small targets against complex backgrounds.
- Cross-Loss Function: To balance the issue of class imbalance in target detection tasks and improve the accuracy of boundary box positioning, the cross-loss function is designed. Combining classification and location losses, this function effectively enhances the model’s capabilities in managing class imbalance and improving positioning accuracy.
- Adaptive Stable Optimizer: The application of the adaptive stable optimizer dynamically adjusts the learning rate based on the model’s performance during training and introduces a stabilizing factor to reduce fluctuations, accelerating convergence and enhancing performance. This optimizer overcomes the instability issues common with traditional optimizers in training deep networks, ensuring stable and efficient training processes.
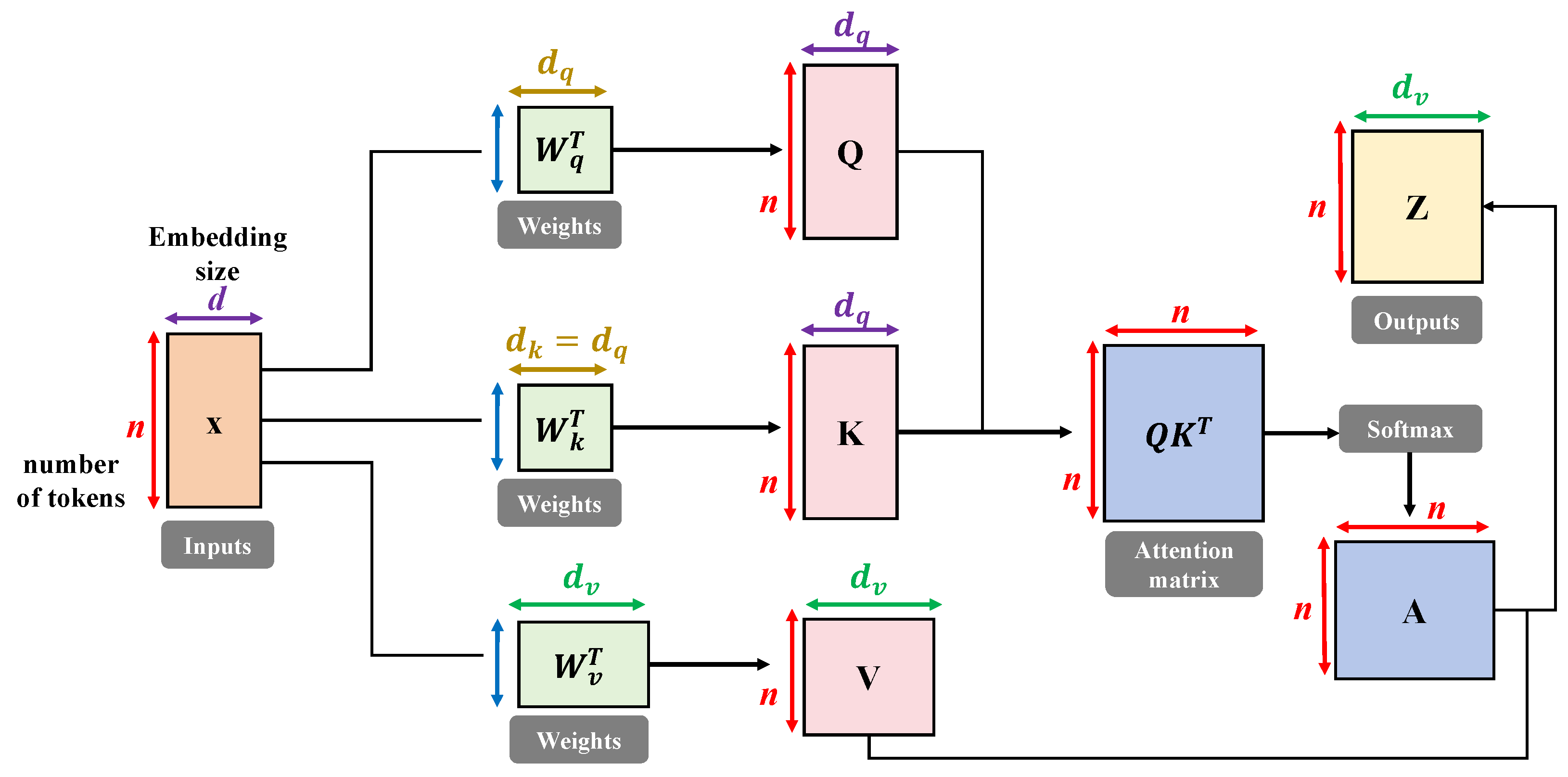
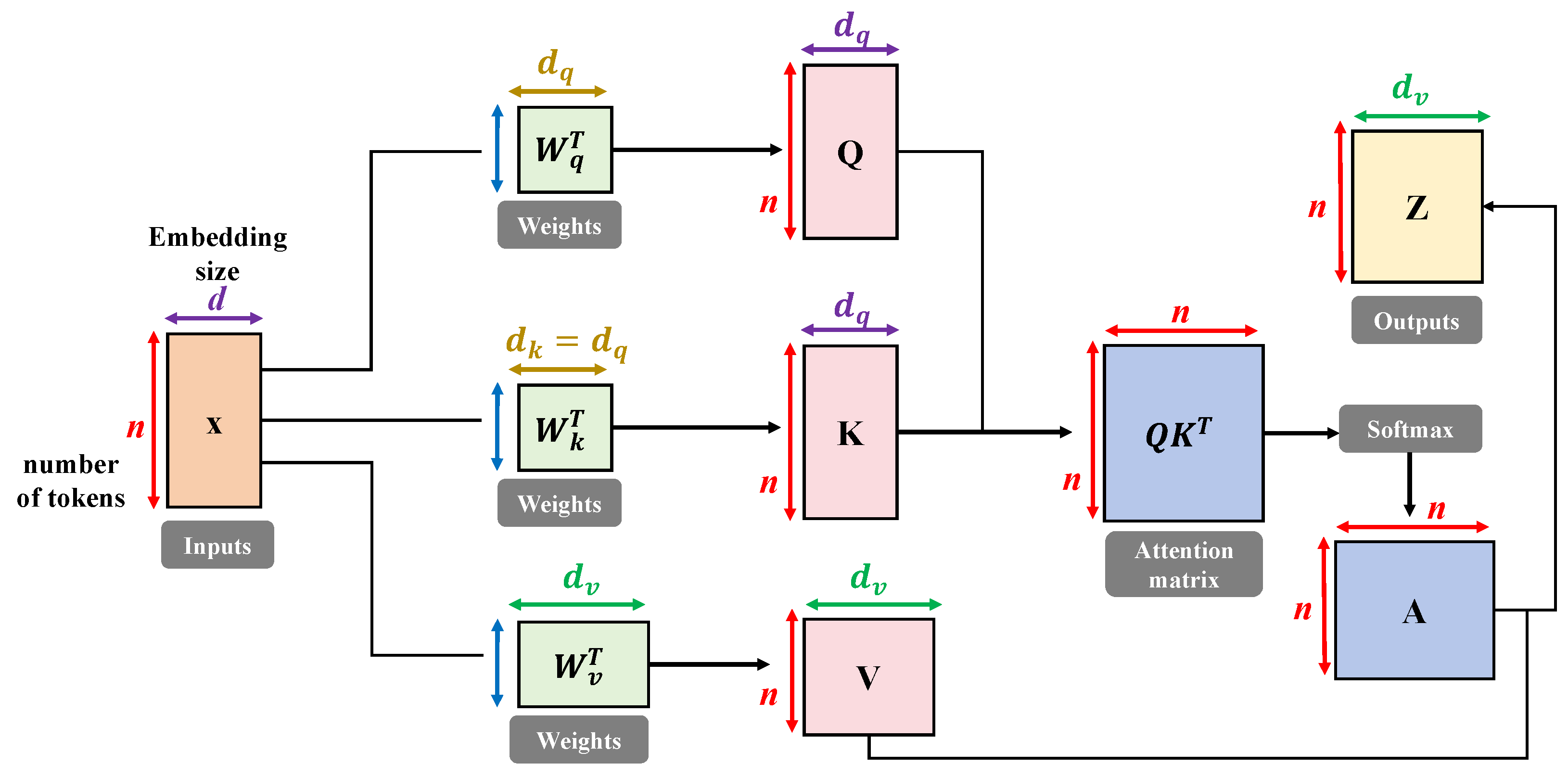
3.5.2. High-Accuracy Transformer for Object Detection Task
3.5.3. Step Attention Mechanism
- Gradual learning strategy: By refining the focus range of attention in steps, the model can learn more local detail information on top of capturing global information, thereby improving recognition precision.
- Dynamic adjustment of attention: Unlike the static multi-head attention mechanism, the step attention mechanism allows for the dynamic adjustment of attention distribution, more flexibly adapting to the challenges of complex backgrounds and diverse targets in object detection tasks.
3.5.4. Cross-Loss Function
3.5.5. Adaptive Stable Optimizer
- Balance between stability and efficiency: By intelligently combining the stability of SGD with the adaptiveness of Adam, ASO maintains the stability of the optimization process while accelerating convergence, particularly suitable for training deep networks and complex datasets.
- Dynamic learning rate adjustment: The learning rate adjustment of ASO not only takes gradient information into account, but also considers the progress of training, offering more appropriate learning rates at different stages of model training, thus optimizing the training process.
- Improvement in initial instability: Compared to Adam, ASO reduces reliance on the first moment estimate during the initial phase of training, mitigating early training instability and facilitating a quicker transition to effective learning phases.
- Flexible hyperparameter adjustment: ASO provides more adjustment space and strategies, making model training more aligned with the requirements of real-world problems, and reducing the difficulty and complexity of hyperparameter tuning.
3.6. Experimental Setup
3.6.1. Hyperparameter Configuration
- Learning Rate: The learning strategy employed in this manuscript is cosine annealing, a method that gradually decreases the learning rate according to the cosine function, thereby adjusting the learning rate during neural network training. This approach facilitates smoother convergence of the model throughout the training process, particularly in avoiding oscillations caused by excessively high learning rates as it nears the optimal solution. The fundamental mathematical expression for cosine annealing is provided as follows:where represents the learning rate at the current iteration, denotes the maximum learning rate, typically set as the initial learning rate, and signifies the minimum learning rate, which can be a value close to 0. is the current iteration number, and is the total number of iterations in a cycle, after which the learning rate resets to . This equation simulates a cycle of the cosine curve, starting the learning rate at , gradually decreasing it as increases, reaching , and then rising back to , completing a cycle. In this manner, the learning rate exhibits periodic rises and falls, aiding the model in escaping local minima while finely tuning parameters in the later stages of training for optimal training outcomes.
- Batch Size: Regarding the selection of batch size in this manuscript, using two NVIDIA GeForce RTX 3090 graphics cards as an example, the batch size was calculated based on the graphics card’s memory capacity, the model’s parameter volume, and the computational resources required per sample. The RTX 3090 features 24 GB of GDDR6X memory. The steps and considerations for calculating the batch size are as follows: Initially, the total parameter count of the model is 110 M, including weights and biases, typical of a model based on the Transformer architecture. Each parameter is usually stored as a 32-bit floating-point number (float32), requiring 4 bytes of storage space. Subsequently, the memory required to process a single sample is calculated. This includes the storage needs for input data, intermediate activation values, gradients, etc. Considering the 24 GB of memory on the RTX 3090, it is imperative to ensure that the total memory demand for the model’s parameters, a batch of samples, and the gradients and intermediate values generated during training does not exceed this capacity. With the premise of not exceeding the memory capacity, the maximum batch size is calculated based on the memory required by the model to process a single sample. The batch size should be a value that, while adhering to memory constraints, effectively utilizes the GPU’s computational resources to expedite the training process. Assuming the model requires approximately 1 GB of memory per sample (including memory needs for both forward and backward propagation), theoretically, the RTX 3090 can handle a maximum batch size of 24 GB/1 GB × 2 = 48. However, in practical applications, additional memory consumption for model parameters, optimizer states, etc., must be considered, thus the actual chosen batch size is 32.
- Optimizer: Of the multitude of optimizers, the Adam optimizer was selected. It combines the advantages of Adagrad and RMSprop optimizers by adaptively adjusting the learning rate for each parameter, making it suitable for training deep learning models with large-scale data and parameters.
- Loss Function Weights: In the cross-entropy loss function, different weights were assigned to the classification loss and localization loss. After repeated experimental adjustments, the weight for the classification loss was determined to be 1, and the weight for the localization loss was set to 2. This configuration aims to balance the model’s performance between recognition accuracy and localization precision.
- The division of training and validation data: The study adopted a common random splitting method to ensure the randomness and representativeness of the data.
3.6.2. Software and Hardware Platform
3.6.3. Baseline Models
3.6.4. Experiment Metric
4. Results and Discussions
4.1. Fruit Fly Detection Results
4.2. Analysis of Visualization Results for Fruit Fly Detection
4.3. Ablation Study on the Step Attention Mechanism
4.4. Ablation Study on the Cross-Loss Function
4.5. Ablation Study on Preprocessing and Augmentation Method
4.6. Limitations and Future Work
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, Y.; Wa, S.; Zhang, L.; Lv, C. Automatic plant disease detection based on tranvolution detection network with GAN modules using leaf images. Front. Plant Sci. 2022, 13, 875693. [Google Scholar] [CrossRef] [PubMed]
- Lin, X.; Wa, S.; Zhang, Y.; Ma, Q. A dilated segmentation network with the morphological correction method in farming area image Series. Remote Sens. 2022, 14, 1771. [Google Scholar] [CrossRef]
- Cusumano, A.; Harvey, J.A.; Bourne, M.E.; Poelman, E.H.; G de Boer, J. Exploiting chemical ecology to manage hyperparasitoids in biological control of arthropod pests. Pest Manag. Sci. 2020, 76, 432–443. [Google Scholar] [CrossRef] [PubMed]
- Bajwa, A.A.; Farooq, M.; Al-Sadi, A.M.; Nawaz, A.; Jabran, K.; Siddique, K.H. Impact of climate change on biology and management of wheat pests. Crop Prot. 2020, 137, 105304. [Google Scholar] [CrossRef]
- Balagawi, S.; Drew, R.A.; Clarke, A.R. Comparative demography of a specialist and generalist fruit fly: Implications for host use and pest management. Ann. Appl. Biol. 2023, 182, 295–311. [Google Scholar] [CrossRef]
- Muriithi, B.W.; Gathogo, N.G.; Diiro, G.M.; Mohamed, S.A.; Ekesi, S. Potential adoption of integrated pest management strategy for suppression of mango fruit flies in East Africa: An ex ante and ex post analysis in Ethiopia and Kenya. Agriculture 2020, 10, 278. [Google Scholar] [CrossRef]
- Wang, J.; Chen, Y.; Hou, X.; Wang, Y.; Zhou, L.; Chen, X. An intelligent identification system combining image and DNA sequence methods for fruit flies with economic importance (Diptera: Tephritidae). Pest Manag. Sci. 2021, 77, 3382–3395. [Google Scholar] [CrossRef]
- Lello, F.; Dida, M.; Mkiramweni, M.; Matiko, J.; Akol, R.; Nsabagwa, M.; Katumba, A. Fruit fly automatic detection and monitoring techniques: A review. Smart Agric. Technol. 2023, 5, 100294. [Google Scholar] [CrossRef]
- Arkin, E.; Yadikar, N.; Xu, X.; Aysa, A.; Ubul, K. A survey: Object detection methods from CNN to transformer. Multimed. Tools Appl. 2023, 82, 21353–21383. [Google Scholar] [CrossRef]
- Zhang, Y.; Wa, S.; Liu, Y.; Zhou, X.; Sun, P.; Ma, Q. High-accuracy detection of maize leaf diseases CNN based on multi-pathway activation function module. Remote Sens. 2021, 13, 4218. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Han, T.; Sun, L.; Dong, Q. An Improved YOLO Model for Traffic Signs Small Target Image Detection. Appl. Sci. 2023, 13, 8754. [Google Scholar] [CrossRef]
- Freitas, L.; Martins, V.; de Aguiar, M.; de Brisolara, L.; Ferreira, P. Deep Learning Embedded into Smart Traps for Fruit Insect Pests Detection. ACM Trans. Intell. Syst. Technol. 2022, 14, 1–24. [Google Scholar] [CrossRef]
- Victoriano, M.; Oliveira, L.; Oliveira, H.P. Automated Detection and Identification of Olive Fruit Fly Using YOLOv7 Algorithm. In Proceedings of the Iberian Conference on Pattern Recognition and Image Analysis, Alicante, Spain, 27–30 June 2023; Springer: Berlin/Heidelberg, Germany, 2023; pp. 211–222. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 1–11. [Google Scholar]
- Tetko, I.V.; Karpov, P.; Van Deursen, R.; Godin, G. State-of-the-art augmented NLP transformer models for direct and single-step retrosynthesis. Nat. Commun. 2020, 11, 5575. [Google Scholar] [CrossRef] [PubMed]
- Adarsh, P.; Rathi, P.; Kumar, M. YOLO v3-Tiny: Object Detection and Recognition using one stage improved model. In Proceedings of the 2020 6th International Conference on Advanced Computing and Communication Systems (ICACCS), Coimbatore, India, 6–7 March 2020; pp. 687–694. [Google Scholar]
- Zhang, Y.; Yang, X.; Liu, Y.; Zhou, J.; Huang, Y.; Li, J.; Zhang, L.; Ma, Q. A time-series neural network for pig feeding behavior recognition and dangerous detection from videos. Comput. Electron. Agric. 2024, 218, 108710. [Google Scholar] [CrossRef]
- Zhang, Y.; Lv, C. TinySegformer: A lightweight visual segmentation model for real-time agricultural pest detection. Comput. Electron. Agric. 2024, 218, 108740. [Google Scholar] [CrossRef]
- Qi, F.; Chen, G.; Liu, J.; Tang, Z. End-to-end pest detection on an improved deformable DETR with multihead criss cross attention. Ecol. Inf. 2022, 72, 101902. [Google Scholar] [CrossRef]
- Li, H.; Li, S.; Yu, J.; Han, Y.; Dong, A. Plant disease and insect pest identification based on vision transformer. In Proceedings of the International Conference on Internet of Things and Machine Learning (IoTML 2021), Harbin, China, 16–18 December 2022; Volume 12174, pp. 194–201. [Google Scholar]
- Dai, M.; Dorjoy, M.M.H.; Miao, H.; Zhang, S. A New Pest Detection Method Based on Improved YOLOv5m. Insects 2023, 14, 54. [Google Scholar] [CrossRef]
- Jiang, P.; Ergu, D.; Liu, F.; Cai, Y.; Ma, B. A Review of Yolo algorithm developments. Procedia Comput. Sci. 2022, 199, 1066–1073. [Google Scholar] [CrossRef]
- Ahmad, T.; Ma, Y.; Yahya, M.; Ahmad, B.; Nazir, S.; Haq, A.u. Object detection through modified YOLO neural network. Sci. Program. 2020, 2020, 8403262. [Google Scholar] [CrossRef]
- Diwan, T.; Anirudh, G.; Tembhurne, J.V. Object detection using YOLO: Challenges, architectural successors, datasets and applications. Multimed. Tools Appl. 2023, 82, 9243–9275. [Google Scholar] [CrossRef]
- Hussain, M. YOLO-v1 to YOLO-v8, the Rise of YOLO and Its Complementary Nature toward Digital Manufacturing and Industrial Defect Detection. Machines 2023, 11, 677. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Yang, L.; Chen, G.; Ci, W. Multiclass objects detection algorithm using DarkNet-53 and DenseNet for intelligent vehicles. EURASIP J. Adv. Signal Process. 2023, 2023, 85. [Google Scholar] [CrossRef]
- Gong, Y.; Yu, X.; Ding, Y.; Peng, X.; Zhao, J.; Han, Z. Effective fusion factor in FPN for tiny object detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual, 5–9 January 2021; pp. 1160–1168. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12993–13000. [Google Scholar]
- Kang, D.; Lai, J.; Han, Y. Improving surface defect detection with context-guided asymmetric modulation networks and confidence-boosting loss. Expert Syst. Appl. 2023, 225, 120121. [Google Scholar] [CrossRef]
- Ridnik, T.; Ben-Baruch, E.; Zamir, N.; Noy, A.; Friedman, I.; Protter, M.; Zelnik-Manor, L. Asymmetric loss for multi-label classification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021; pp. 82–91. [Google Scholar]
- Liu, M.; Wang, X.; Zhou, A.; Fu, X.; Ma, Y.; Piao, C. Uav-yolo: Small object detection on unmanned aerial vehicle perspective. Sensors 2020, 20, 2238. [Google Scholar] [CrossRef]
- Su, Y.; Li, D.; Chen, X. Lung nodule detection based on faster R-CNN framework. Comput. Methods Programs Biomed. 2021, 200, 105866. [Google Scholar] [CrossRef] [PubMed]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Xu, X.; Zhao, M.; Shi, P.; Ren, R.; He, X.; Wei, X.; Yang, H. Crack detection and comparison study based on faster R-CNN and mask R-CNN. Sensors 2022, 22, 1215. [Google Scholar] [CrossRef] [PubMed]
- Qiao, L.; Zhao, Y.; Li, Z.; Qiu, X.; Wu, J.; Zhang, C. Defrcn: Decoupled faster r-cnn for few-shot object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021; pp. 8681–8690. [Google Scholar]
- Xiao, Y.; Wang, X.; Zhang, P.; Meng, F.; Shao, F. Object detection based on faster R-CNN algorithm with skip pooling and fusion of contextual information. Sensors 2020, 20, 5490. [Google Scholar] [CrossRef]
- Xu, X.; Feng, Z.; Cao, C.; Li, M.; Wu, J.; Wu, Z.; Shang, Y.; Ye, S. An improved swin transformer-based model for remote sensing object detection and instance segmentation. Remote Sens. 2021, 13, 4779. [Google Scholar] [CrossRef]
- Graterol, W.; Diaz-Amado, J.; Cardinale, Y.; Dongo, I.; Lopes-Silva, E.; Santos-Libarino, C. Emotion detection for social robots based on NLP transformers and an emotion ontology. Sensors 2021, 21, 1322. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; Lu, X.; Cao, G.; Yang, Y.; Jiao, L.; Liu, F. ViT-YOLO: Transformer-based YOLO for object detection. In Proceedings of the IEEE/CVF international Conference on Computer Vision, Virtual, 11–17 October 2021; pp. 2799–2808. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 213–229. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Talaat, F.M.; ZainEldin, H. An improved fire detection approach based on YOLO-v8 for smart cities. Neural Comput. Appl. 2023, 35, 20939–20954. [Google Scholar] [CrossRef]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE international Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Jiang, D.; Li, G.; Tan, C.; Huang, L.; Sun, Y.; Kong, J. Semantic segmentation for multiscale target based on object recognition using the improved Faster-RCNN model. Future Gener. Comput. Syst. 2021, 123, 94–104. [Google Scholar] [CrossRef]
- Dai, Z.; Cai, B.; Lin, Y.; Chen, J. Up-detr: Unsupervised pre-training for object detection with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2021; pp. 1601–1610. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Fruit Fly Species | Scientific Name | Family Name | Number of Images |
|---|---|---|---|
| Melon Fly | Bactrocera cucurbitae | Tephritidae | 193 |
| Mediterranean Fruit Fly | Ceratitis capitata | Tephritidae | 532 |
| Mexican Fruit Fly | Anastrepha ludens | Tephritidae | 419 |
| Oriental Fruit Fly | Bactrocera dorsalis | Tephritidae | 374 |
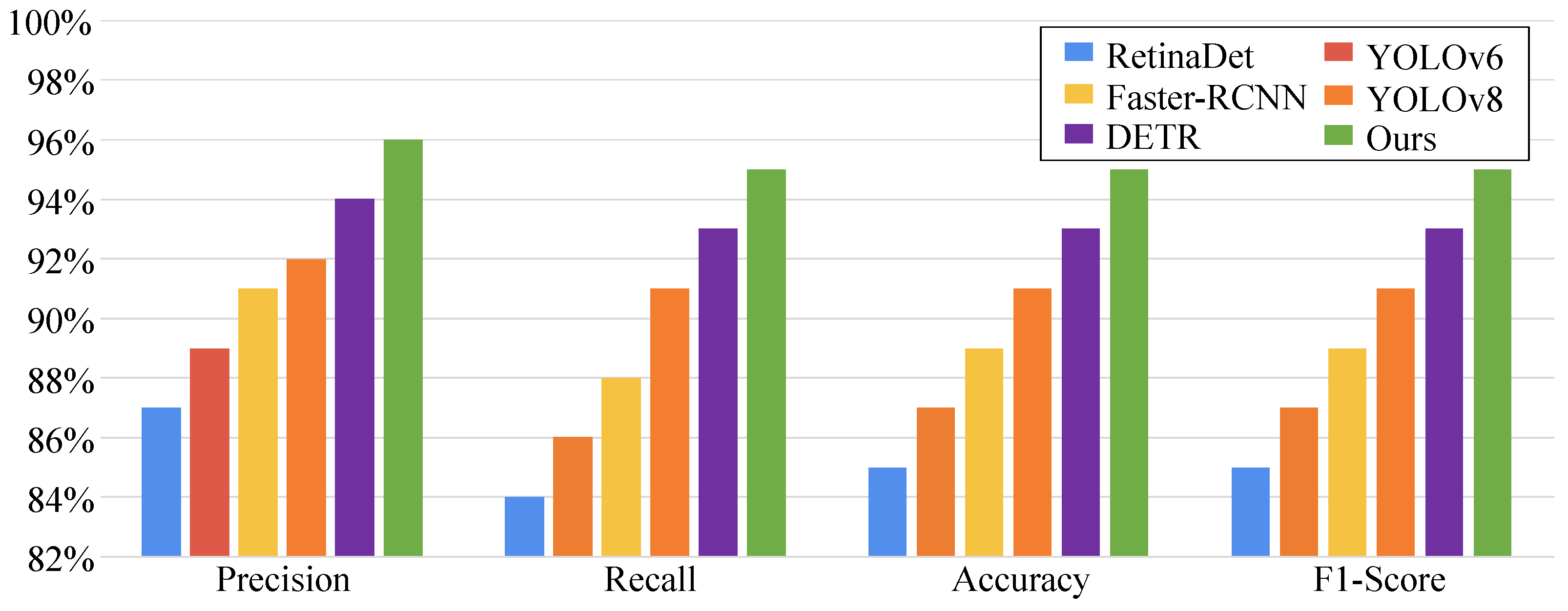
| Model | Precision | Recall | Accuracy | F1-Score |
|---|---|---|---|---|
| RetinaDet | 0.87 | 0.84 | 0.85 | 0.85 |
| YOLOv6 | 0.89 | 0.86 | 0.87 | 0.87 |
| Faster-RCNN | 0.91 | 0.88 | 0.89 | 0.89 |
| YOLOv8 | 0.92 | 0.91 | 0.91 | 0.91 |
| DETR | 0.94 | 0.93 | 0.93 | 0.93 |
| Ours | 0.96 | 0.95 | 0.95 | 0.95 |
| Model | Precision | Recall | Accuracy | F1-Score |
|---|---|---|---|---|
| Loss in YOLOv8 [46] | 0.92 | 0.91 | 0.91 | 0.91 |
| Loss in DETR [49] | 0.94 | 0.93 | 0.93 | 0.93 |
| Cross-loss | 0.96 | 0.95 | 0.95 | 0.95 |
| Rotation | Brightness | Cropping | Flipping | Contrast | P. | R. | Acc. | F1-Score |
|---|---|---|---|---|---|---|---|---|
| ✗ | ✗ | ✗ | ✗ | ✗ | 0.85 | 0.82 | 0.83 | 0.84 |
| ✓ | ✗ | ✗ | ✗ | ✗ | 0.91 | 0.88 | 0.90 | 0.90 |
| ✗ | ✓ | ✗ | ✗ | ✗ | 0.89 | 0.90 | 0.89 | 0.90 |
| ✗ | ✗ | ✓ | ✗ | ✗ | 0.92 | 0.93 | 0.92 | 0.93 |
| ✗ | ✗ | ✗ | ✓ | ✗ | 0.86 | 0.85 | 0.85 | 0.86 |
| ✗ | ✗ | ✗ | ✗ | ✓ | 0.87 | 0.85 | 0.86 | 0.86 |
| ✓ | ✓ | ✓ | ✓ | ✓ | 0.96 | 0.95 | 0.95 | 0.95 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, L.; Chen, K.; Zheng, L.; Liao, X.; Lu, F.; Li, Y.; Cui, Y.; Wu, Y.; Song, Y.; Yan, S. Enhancing Fruit Fly Detection in Complex Backgrounds Using Transformer Architecture with Step Attention Mechanism. Agriculture 2024, 14, 490. https://doi.org/10.3390/agriculture14030490
Zhang L, Chen K, Zheng L, Liao X, Lu F, Li Y, Cui Y, Wu Y, Song Y, Yan S. Enhancing Fruit Fly Detection in Complex Backgrounds Using Transformer Architecture with Step Attention Mechanism. Agriculture. 2024; 14(3):490. https://doi.org/10.3390/agriculture14030490
Chicago/Turabian StyleZhang, Lexin, Kuiheng Chen, Liping Zheng, Xuwei Liao, Feiyu Lu, Yilun Li, Yuzhuo Cui, Yaze Wu, Yihong Song, and Shuo Yan. 2024. "Enhancing Fruit Fly Detection in Complex Backgrounds Using Transformer Architecture with Step Attention Mechanism" Agriculture 14, no. 3: 490. https://doi.org/10.3390/agriculture14030490