
Automated Grading of Angelica sinensis Using Computer Vision and Machine Learning Techniques

 , , and
, , and
Abstract
:1. Introduction
2. Materials and Methods
2.1. Samples Preparation
2.2. Image Acquisition
2.3. Pre-Processing and Segmentation
2.4. Feature Extraction
2.4.1. Extraction of Shape Features
2.4.2. Extraction of Color Features
2.4.3. Extraction of Texture Features
2.5. Classification Model for AS Grades
2.5.1. The BPNN Model
2.5.2. The GO Algorithm
2.5.3. The GOBPNN Model
- (1)
- Collected the AS images, and extracted features of AS images. Then selected features that were used for model training. Defined the architecture of the BPNN and network training parameters were configured, such as the maximum number of training epochs (epochs), learning rate (lr), target error (goal), display frequency (show), momentum factor (mc), minimum performance gradient (min_grad), and maximum number of failures (max_fail).
- (2)
- Initialized parameters, including population size (N), population dimension (D), iteration count (FEs), maximum iteration count (MaxFEs), upper bound of the search space (ub), and lower bound of the search space (lb).
- (3)
- Initialized the population (X) based on N, D, ub, and lb. The population represented a set of individuals, where an individual’s elements denoted crucial parameters (e.g., weights and biases). An individual was a row vector with D columns, forming an N row by D column matrix. The error between the output value and the target value of the neural network was used to calculate the fitness. The individual with the minimum fitness was defined as the optimal individual, gbestX.
- (4)
- Commenced the iterative process. Calculated the fitness of each individual in the population, sorted the fitness to find the current best individual (Best_X) and worst individual (Worst_X), continuously updated the best individual (Best_X) during iteration, and updated gbestX after each evaluation.
- (5)
- Learning phase: For the i-th individual, selected Better_X and Worst_X to participate in the learning process. Additionally, Best_X contributed to the learning process of individual i, updating the real-time global optimal solution gbestX during each iteration. Recorded the number of evaluations using FEs.
- (6)
- Reflection phase: For the j-th dimension of the i-th individual, the algorithm refined the dimension using three specific methods. The first maintained the original dimension, the second involved a higher-level individual guiding the j-th dimension of the i-th individual, and the third reconstructed the j-th dimension with a small probability based on the second method. Updated the i-th individual and real-time updated the global optimal solution gbestX.
- (7)
- Termination criterion: If the current iteration count (Fes) equaled the maximum iteration count (MaxFEs), the program stopped, and the output global optimal solution was fed into the BPNN for training and testing. Otherwise, returned to step (4).
2.6. Evaluation of Recognition Performance
2.7. Statistical Analyses
3. Results and Discussion
3.1. Selection of Feature Parameters of AS Images
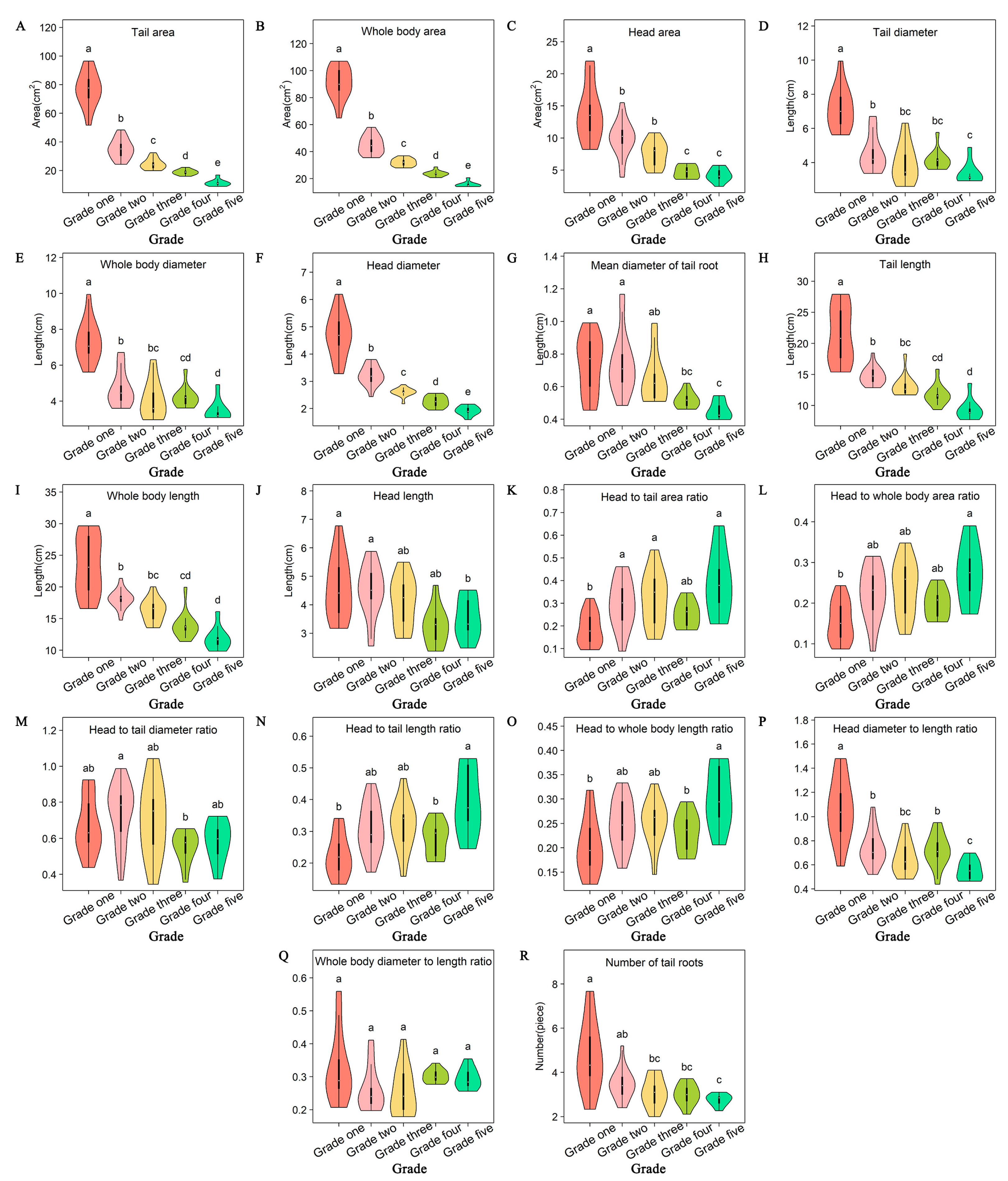
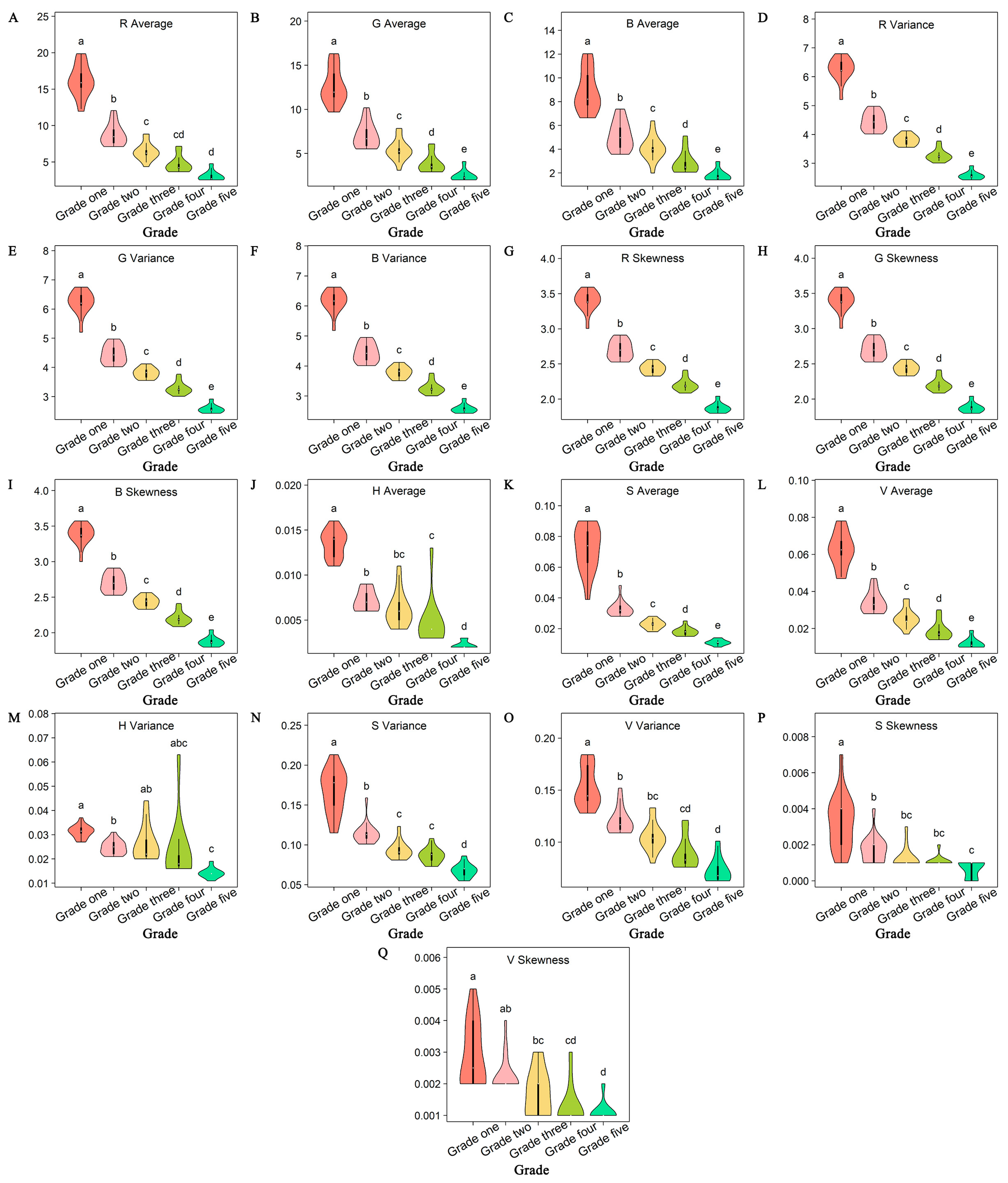
3.1.1. Difference Analysis of Appearance Feature Parameters among Different Grades
3.1.2. Correlation Analysis
3.1.3. Comprehensive Analysis
3.2. Classification of AS Grades
3.2.1. Determination of the Optimal Number of Hidden Neurons
3.2.2. Determination of the Optimal Feature
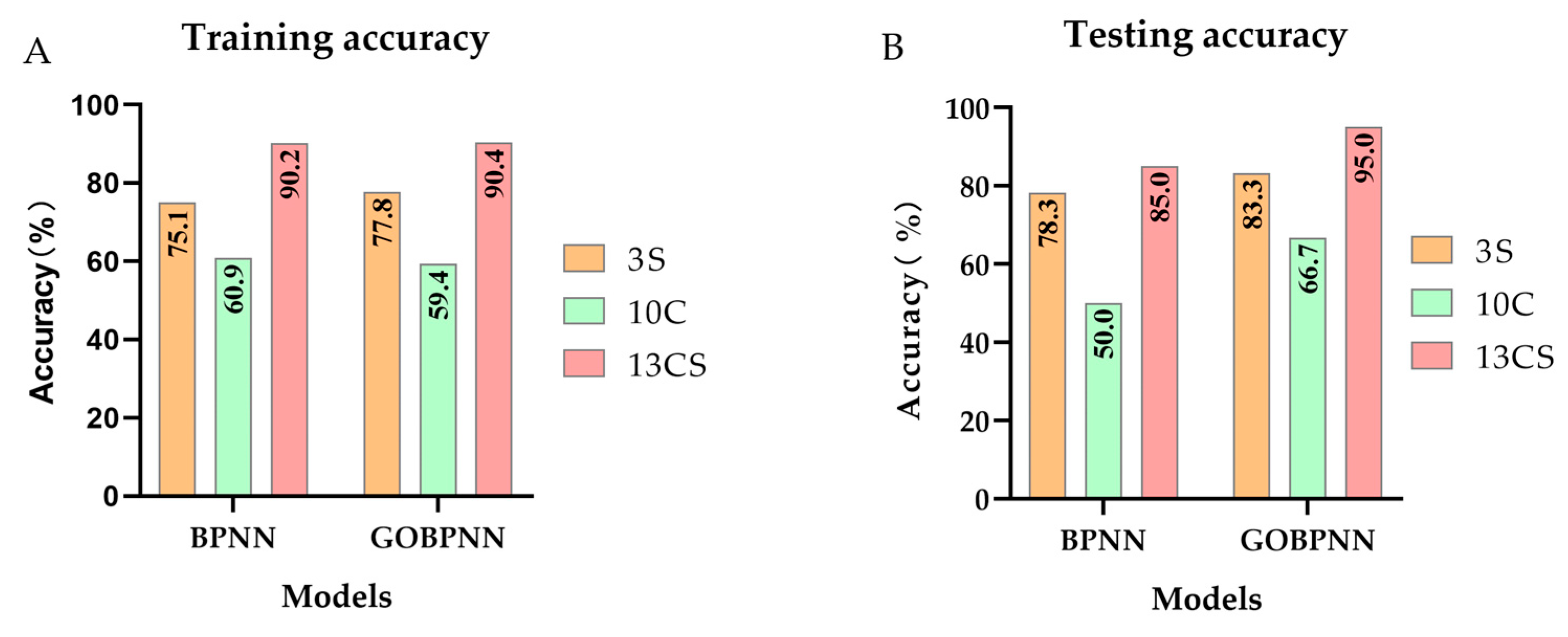
3.2.3. Determination of the Optimal Model
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Batiha, G.E.; Shaheen, H.M.; Elhawary, E.A.; Mostafa, N.M.; Eldahshan, O.A.; Sabatier, J. Phytochemical Constituents, Folk Medicinal Uses, and Biological Activities of Genus Angelica: A Review. Molecules 2023, 28, 267. [Google Scholar] [CrossRef]
- Commission, C.P. Pharmacopoeia of the People’s Republic of Chin 1; China Medical Science and Technology Press: Beijing, China, 2020; p. 1902. ISBN 978-7-5214-1574-2. [Google Scholar]
- Long, Y.; Li, D.; Yu, S.; Shi, A.; Deng, J.; Wen, J.; Li, X.Q.; Ma, Y.; Zhang, Y.L.; Liu, S.Y.; et al. Medicine–food herb:Angelica sinensis, a potential therapeutic hope for Alzheimer’s disease and related complications. Food Funct. 2022, 13, 8783–8803. [Google Scholar] [CrossRef]
- Yang, M.J.; Wang, Y.G.; Liu, X.F.; Wu, J.; Qian, J.L. Study on Angelica sinensis Endophytic Fungi and its Antibacterial Activity. Adv. Mater. Res. 2013, 641, 816–819. [Google Scholar] [CrossRef]
- Xu, S.; Wan, H.; Zhao, X.; Zhang, Y.; Yang, J.; Jin, W.; He, Y. Optimization of extraction and purification processes of six flavonoid components from Radix Astragali using BP neural network combined with particle swarm optimization and genetic algorithm. Ind. Crop. Prod. 2022, 178, 114556. [Google Scholar] [CrossRef]
- Bi, S.J.; Fu, R.J.; Li, J.J.; Chen, Y.Y.; Tang, Y.P. The Bioactivities and Potential Clinical Values of Angelica Sinensis Polysaccharides. Nat. Prod. Commun. 2021, 16, 1934578X2199732. [Google Scholar] [CrossRef]
- Nai, J.; Zhang, C.; Shao, H.; Li, B.; Li, H.; Gao, L.; Dai, M.; Zhu, L.; Sheng, H. Extraction, structure, pharmacological activities and drug carrier applications of Angelica sinensis polysaccharide. Int. J. Biol. Macromol. 2021, 183, 2337–2353. [Google Scholar] [CrossRef]
- Qu, Y.; Liu, H.S.; Hu, J.J.; Zhang, B.H. Study on Commercial Specification Grades Standard and Quality Evaluation of Momordica cochinchinensis. Shi Zhen Chin. Med. 2022, 33, 238–243. [Google Scholar]
- T/CACM 1021.5-2018; Commercial Grades for Chinese Materia Medica Angelica sinensis Radix. Chinese Association of Traditional Chinese Medicine: Hongkong, China, 2018.
- Raki, H.; Aalaila, Y.; Taktour, A.H.; Peluffo-Ordóñez, D. Combining AI Tools with Non-Destructive Technologies for Crop-Based Food Safety: A Comprehensive Review. Foods 2024, 13, 11. [Google Scholar] [CrossRef]
- Xin, N.; Luo, C.; Mo, Y. Comparison of ferulic acid content in different grades of Angelica sinensis. J. Chin. Med. Mater. 2001, 4, 244–245. [Google Scholar] [CrossRef]
- Zhao, W. Study on the Correlation between the Commercial Specification Grades and Quality of Gansu Angelica Sinensis Radix; Gansu University of Chinese Medicine: Lan Zhou, China, 2018. [Google Scholar]
- Ruan, H.; Liu, X.; Song, P.; Zhao, D.; Zhao, J.; Yong-Hui, D.; Lu, J.; Lin, R. Rational analysis of Angelica product grades divided by chemical and weight indicators. Chin. J. Tradit. Chin. Med. 2013, 28, 2453–2456. [Google Scholar]
- Ewa, R.; Justyna, S. The Estimation of Chemical Properties of Pepper Treated with Natural Fertilizers Based on Image Texture Parameters. Foods 2023, 12, 2123. [Google Scholar] [CrossRef]
- Kakani, V.; Nguyen, V.H.; Kumar, B.P.; Kim, H.; Pasupuleti, V. A critical review on computer vision and artificial intelligence in food industry. J. Agric. Food Res. 2020, 2, 100033. [Google Scholar] [CrossRef]
- Ding, H.; Tian, J.; Yu, W.; Wilson, D.; Young, B.; Cui, X.; Xin, X.; Wang, Z.; Li, W. The Application of Artificial Intelligence and Big Data in the Food Industry. Foods 2023, 12, 4511. [Google Scholar] [CrossRef]
- Liu, C.; Wang, Q.; Ma, M.; Zhu, Z.; Lin, W.; Liu, S.; Fan, W. Single-View Measurement Method for Egg Size Based on Small-Batch Images. Foods 2023, 12, 936. [Google Scholar] [CrossRef]
- Zhao, S.; Bai, Z.; Wang, S.; Gu, Y. Research on Automatic Classification and Detection of Mutton Multi-Parts Based on Swin-Transformer. Foods 2023, 12, 1642. [Google Scholar] [CrossRef]
- Zhou, W.; Song, C.; Song, K.; Wen, N.; Sun, X.; Gao, P. Surface Defect Detection System for Carrot Combine Harvest Based on Multi-Stage Knowledge Distillation. Foods 2023, 12, 793. [Google Scholar] [CrossRef]
- Kim, S.M.; Kim, C.S.; Lee, C.H.; Kim, M.H.; Park, S.J. Nondestructive Evaluation System for White Ginseng Quality Using Image Processing Technique. Key Eng. Mater. 2006, 321, 1225–1228. [Google Scholar] [CrossRef]
- Cui, Y.; Liu, R.; Lin, Z.; Chen, P.; Wang, L.; Wang, Y.; Chen, S. Quality evaluation based on color grading: Quality discrimination of the Chinese medicine Corni Fructus by an E-eye. Sci. Rep. 2019, 9, 17006. [Google Scholar] [CrossRef]
- Wang, J.; Zeng, L.; Zang, Q.; Gong, Q.; Li, B.; Zhang, X.; Chu, X.; Zhang, P.; Zhao, Y.; Xiao, X.; et al. Colorimetric grading scale can promote the standardization of experiential and sensory evaluation in quality control of traditional Chinese medicines. PLoS ONE 2012, 7, e48887. [Google Scholar] [CrossRef]
- Zhu, Y.; Zhang, F.; Li, L.; Lin, Y.; Zhang, Z.; Shi, L.; Tao, H.; Qin, T. Research on Classification Model of Panax notoginseng Taproots Based on Machine Vision Feature Fusion. Sensors 2021, 21, 7945. [Google Scholar] [CrossRef]
- She, B.; Hu, J.; Huang, L.; Zhu, M.; Yin, Q. Mapping Soybean Planting Areas in Regions with Complex Planting Structures Using Machine Learning Models and Chinese GF-6 WFV Data. Agriculture 2024, 14, 231. [Google Scholar] [CrossRef]
- Li, C.; Wang, X.; Chen, L.; Zhao, X.; Li, Y.; Chen, M.; Liu, H.; Zhai, C. Grading and Detection Method of Asparagus Stem Blight Based on Hyperspectral Imaging of Asparagus Crowns. Agriculture 2023, 13, 1673. [Google Scholar] [CrossRef]
- Mcclelland, J.; Rumelhart, D. Parallel Distributed Processing; MIT Press: Cambridge, MA, USA, 1986. [Google Scholar]
- Li, C.H.; Park, S.C. Combination of modified BPNN algorithms and an efficient feature selection method for text categorization. Inf. Process. Manag. 2009, 45, 329–340. [Google Scholar] [CrossRef]
- Khan, A.; Bukhari, J.; Bangash, J.I.; Khan, A.; Imran, M.; Asim, M.; Ishaq, M.; Khan, A. Optimizing connection weights of functional link neural network using APSO algorithm for medical data classification. J. King Saud Univ. Comput. Inf. Sci. 2022, 34, 2551–2561. [Google Scholar] [CrossRef]
- Zhang, Q.; Gao, H.; Zhan, Z.; Li, J.; Zhang, H. Growth Optimizer: A powerful metaheuristic algorithm for solving continuous and discrete global optimization problems. Knowl. Based Syst. 2023, 261, 110206. [Google Scholar] [CrossRef]
- Deng, J.; Zhou, H.; Lv, X.; Yang, L.; Shang, J.; Sun, Q.; Zheng, X.; Zhou, C.; Zhao, B.; Wu, J.; et al. Applying convolutional neural networks for detecting wheat stripe rust transmission centers under complex field conditions using RGB-based high spatial resolution images from UAVs. Comput. Electron. Agric. 2022, 200, 107211. [Google Scholar] [CrossRef]
- Singh, S.; Mittal, N.; Singh, H.; Oliva, D. Improving the segmentation of digital images by using a modified Otsu’s between-class variance. Multimed. Tools Appl. 2023, 82, 40701–40743. [Google Scholar] [CrossRef]
- Chen, Y.; Li, Q.; Qiu, D. The Dynamic Accumulation Rules of Chemical Components in Different Medicinal Parts of Angelica sinensis by GC-MS. Molecules 2022, 27, 4617. [Google Scholar] [CrossRef]
- Chen, L.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Tamura, H.; Mori, S.; Yamawaki, T. Textural Features Corresponding to Visual Perception. IEEE Trans. Syst. Man Cybern. 1978, 8, 460–473. [Google Scholar] [CrossRef]
- Rafi, M.; Mukhopadhyay, S. Texture description using multi-scale morphological GLCM. Multimed. Tools Appl. 2018, 77, 30505–30532. [Google Scholar] [CrossRef]
- Zhu, L.; Yan, H.; Zhou, G.; Jiang, C.; Liu, P.; Yu, G.; Guo, S.; Wu, Q.; Duan, J. Insights into the mechanism of the effects of rhizosphere microorganisms on the quality of authentic Angelica sinensis under different soil microenvironments. Bmc Plant Biol. 2021, 21, 285. [Google Scholar] [CrossRef]
- Ogilvie, C.M.; Ashiq, W.; Vasava, H.B.; Biswas, A. Quantifying Root-Soil Interactions in Cover Crop Systems: A Review. Agriculture 2021, 11, 218. [Google Scholar] [CrossRef]
- Borden, K.A.; Anglaaere, L.C.N.; Owusu, S.; Martin, A.R.; Buchanan, S.W.; Addo-Danso, S.D.; Isaac, M.E. Soil texture moderates root functional traits in agroforestry systems across a climatic gradient. Agric. Ecosyst. Environ. 2020, 295, 106915. [Google Scholar] [CrossRef]
- Ling, L.; Ma, W.; Li, Z.; Jiao, Z.; Xu, X.; Lu, L.; Zhang, X.; Feng, J.; Zhang, J. Comparative study of the endophytic and rhizospheric bacterial diversity of Angelica sinensis in three main producing areas in Gansu, China. S. Afr. J. Bot. 2020, 134, 36–42. [Google Scholar] [CrossRef]
- Cui, Y.; Wang, L.; Duan, L.; Chen, S. Quality evaluation based on color grading—Relationship between chemical susbtances and commercial grades by machine version in Corni fructus. Trop. J. Pharm. Res. 2020, 19, 1495–1501. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Grade | Number of AS | Weight of Each AS (g) |
|---|---|---|
| Grade one | 49 | >60 |
| Grade two | 140 | 25~60 |
| Grade three | 110 | 15~25 |
| Grade four | 44 | 10~15 |
| Grade five | 54 | <10 |
| Total | 397 |
| Feature Parameters | Correlation Coefficient (r) | Feature Parameters | Correlation Coefficient (r) |
|---|---|---|---|
| Tail area | −0.963 ** | G variances | −0.972 ** |
| Whole body area | −0.976 ** | B variances | −0.971 ** |
| Head diameter | −0.950 ** | R skewness | −0.972 ** |
| G average | −0.929 ** | G skewness | −0.972 ** |
| B average | −0.905 ** | B skewness | −0.972 ** |
| R variances | −0.972 ** | S average | −0.968 ** |
| V variances | −0.939 ** |
| Features | Number of Hidden Neurons | Training Accuracy (%) | Number of Hidden Neurons | Training Accuracy (%) |
|---|---|---|---|---|
| 3S | 3 | 69.9% | 8 | 76.4% |
| 4 | 75.5% | 9 | 74.3% | |
| 5 | 72.3% | 10 | 77.1% | |
| 6 | 73.2% | 11 | 76.5% | |
| 7 | 75.1% | 12 | 74.9% | |
| 10C | 4 | 62.5% | 9 | 62.0% |
| 5 | 57.9% | 10 | 56.6% | |
| 6 | 60.0% | 11 | 53.4% | |
| 7 | 60.9% | 12 | 56.0% | |
| 8 | 60.9% | 13 | 59.7% | |
| 13CS | 5 | 85.3% | 10 | 90.0% |
| 6 | 87.7% | 11 | 87.2% | |
| 7 | 90.3% | 12 | 89.3% | |
| 8 | 87.5% | 13 | 88.4% | |
| 9 | 90.2% | 14 | 86.8% |
| Model | Feature | Training Time (s) | Testing Time (s) |
|---|---|---|---|
| BPNN | 3S | 0.615 | 0.017 |
| 10C | 0.648 | 0.014 | |
| 13CS | 1.639 | 0.016 | |
| GOBPNN | 3S | 603.717 | 0.016 |
| 10C | 474.880 | 0.015 | |
| 13CS | 678.454 | 0.015 |
| Model | Evaluation Index | Grade One | Grade Two | Grade Three | Grade Four | Grade Five | Average Value | Average Growth |
|---|---|---|---|---|---|---|---|---|
| BPNN | Precision (%) | 83.3 | 87.5 | 75.0 | 66.7 | 100.0 | 82.5 | |
| Recall (%) | 100.0 | 95.5 | 75.0 | 66.7 | 78.6 | 83.2 | ||
| F-score (%) | 90.9 | 91.3 | 75.0 | 66.7 | 88.0 | 82.4 | ||
| Accuracy (%) | 85.0 | |||||||
| GOBPNN | Precision (%) | 100.0 | 91.7 | 93.8 | 100.0 | 100.0 | 97.1 | 17.7 |
| Recall (%) | 100.0 | 100.0 | 88.2 | 100.0 | 91.7 | 95.9 | 15.4 | |
| F-score (%) | 100.0 | 95.7 | 90.9 | 100.0 | 95.7 | 96.5 | 17.1 | |
| Accuracy (%) | 95.0 | 11.8 | ||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Z.; Xiao, J.; Wang, W.; Zielinska, M.; Wang, S.; Liu, Z.; Zheng, Z. Automated Grading of Angelica sinensis Using Computer Vision and Machine Learning Techniques. Agriculture 2024, 14, 507. https://doi.org/10.3390/agriculture14030507
Zhang Z, Xiao J, Wang W, Zielinska M, Wang S, Liu Z, Zheng Z. Automated Grading of Angelica sinensis Using Computer Vision and Machine Learning Techniques. Agriculture. 2024; 14(3):507. https://doi.org/10.3390/agriculture14030507
Chicago/Turabian StyleZhang, Zimei, Jianwei Xiao, Wenjie Wang, Magdalena Zielinska, Shanyu Wang, Ziliang Liu, and Zhian Zheng. 2024. "Automated Grading of Angelica sinensis Using Computer Vision and Machine Learning Techniques" Agriculture 14, no. 3: 507. https://doi.org/10.3390/agriculture14030507