1. Introduction
Time series data are characterized as datasets aligned in a chronological sequence over a specified temporal interval [
1]. Such data are frequently utilized in temporal analyses of events to discern trends or patterns, which may facilitate the forecasting or informed projection of future occurrences [
2]. The incorporation of contextual data associated with the time series, such as seasonal variations or events that trigger fluctuations in metrics like sales, can further elucidate factors influencing the observed variables over time [
3]. This comprehensive approach enables a more nuanced understanding of the dynamic interplay between the time series data and their external influences [
4].
Given that time is one of the axes of time series datasets, they can become somewhat cumbersome to analyze manually, depending on the intervals at which the tracked data are measured [
5]. Therefore, they would benefit from being analyzed through machine learning (ML) models. Machine learning approaches can significantly reduce the time needed to analyze large datasets [
6]. Some problems that can be solved using time series analysis through machine learning are forecasting, anomaly detection, imputation, and classification [
7]:
Forecasting: Predicting future values of the time series data based on historical data from the same time series.
Anomaly Detection: Identifying abnormal moments in the time series data that could possibly indicate that there is a problem with the data or room for improvement with the attribute being measured (i.e., selling jackets in the summertime).
Imputation: Replace missing data in time series datasets with calculated values based on the trends of surrounding data.
Classification: Prediction of categorical outcomes from the given time series data.
The use of ML algorithms for time series analysis has become increasingly important in a wide range of applications [
7], from finance and economics to weather forecasting and industrial production [
8]. However, building effective ML models for time series can be challenging [
9], especially for non-experts who may not have the necessary knowledge of ML algorithms or programming skills [
10].
In the field of machine learning, achieving the best performance often requires extensive knowledge, experience, and effort from humans [
11]. One of the most challenging and time-consuming tasks is selecting the right tool for a specific dataset [
12].
To address this challenge, AutoML has emerged as a set of techniques and frameworks that aim to automate the process of building and optimizing ML [
13]. AutoML tools automate various steps involved in constructing ML models, including data preprocessing, feature engineering, model selection, and hyperparameter tuning. This automation helps to simplify the ML process. With simplification, it becomes easier and faster for non-experts to create effective ML models. AutoML tools also often integrate with popular programming languages and machine learning libraries, such as Python and TensorFlow, making them accessible to a wide range of users [
14].
There are many types of AutoML tools, each with varying capabilities and features that allow them to solve different challenges in the ML pipeline [
13]. Some of the most common capabilities of AutoML tools include data preparation, model selection, and hyperparameter tuning:
Automated Data Preparation: These tools are designed to automate the process of cleaning and preparing data for machine learning [
15]. This includes tasks such as data preprocessing, feature selection, and data augmentation. Automated data preparation tools can save time and reduce the risk of errors that can occur during manual data preparation [
16].
Automated Model Selection: These tools are designed to automatically select the best ML model for a given problem. They accomplish this by automatically comparing the performance of multiple models and selecting the one that performs the best on the given dataset. Automated model selection tools can save time and provide models with the highest tested accuracy [
16].
Automated Hyperparameter Tuning: Hyperparameters are parameters that the ML model cannot learn during the training [
17]. They can be adjusted to improve the performance of ML models, but they must be tuned by the user, not the model itself [
18]. Automated hyperparameter tuning tools are designed to automate the tedious task of finding the best hyperparameters for a given model. This can save time and improve the accuracy of ML models [
19].
AutoML has recently seen significant advancements as well as increased popularity amongst the public, leading to a demand for automated systems that can support both experts and novices in creating ML applications quickly and efficiently [
20].
Certain AutoML tools are engineered to automate the complete ML pipeline, encompassing stages from data preparation to model deployment, proving beneficial for entities lacking a specialized ML team or the expertise to construct and deploy these models [
21]. These tools offer a rapid pathway for prototyping models or concepts, allowing for exploration prior to a significant investment of time and resources [
22]. This automation facilitates efficiency and accessibility in ML processes, especially for organizations with limited ML capabilities [
23].
There are plenty of AutoML tools available for public use, either free or paid [
24]. As with any tool, the one you choose can specialize in specific fields of ML approaches and models [
25]. Since this study is looking into evaluating how the AutoML tools function when trained for time series data, the options were narrowed to choose the following AutoML tools that are better equipped for time series: H
2O ai [
26], TPOT [
27], AutoTS [
28], MLJAR [
29], Kedro [
30], AutoGluon [
31], Azure Machine Learning [
32], Amazon Forecast [
33], PyCaret [
34].
Given the large number of Automated Machine Learning tools available for time series analysis, it is important to conduct a rigorous comparison and evaluation of these different tools to discern their merits and limitations. The main objective of this paper is to comprehensively evaluate the leading AutoML tools used in the field of time series analysis. We quantify the adequacy of these tools by subjecting them to scrutiny using three datasets characterized by different properties while employing a large number of performance metrics. By undertaking this endeavor, our goal is to provide valuable insights into optimal strategies for the judicious selection and effective use of AutoML tools tailored to the requirements of time series analysis.
Time series data are a ubiquitous component of modern-day analysis in numerous fields, including finance, economics, meteorology, and traffic management. Analyzing these data and making informed forecasts is of significant importance. Although various models, including linear modeling and deep learning, are utilized for predictive forecasting, AutoML frameworks have attracted considerable attention due to their ability to autonomously identify and optimize models. Our investigation seeks to contribute to the existing literature on AutoML for time series data analysis by providing contemporary insights and analyses on the topic.
3. Methodology
To evaluate AutoML tools for time series, we reviewed the available AutoML tools for public use and selected three. In the following sections, we first introduce the selected AutoML tools and our selection criteria. We then introduce the selected datasets and their properties. Following this, we review the metrics that will be used to numerically evaluate the tools. Finally, we discuss the methods for utilizing the tools and how they are prepared.
3.1. AutoML Tools to Be Evaluated
Our criteria for choosing the AutoML tools include whether they can handle time series data as well as their popularity, performance, ease of use, open-source nature, and active development. We present the details of the selected three AutoML tools below:
AutoGluon automates many of the tasks in machine learning, including data preparation, feature engineering, model selection, and hyperparameter selection using advanced tuning algorithms [
35]. With AutoGluon, users can achieve state-of-the-art performance in image classification, object detection, text classification, and traditional tasks like classification and regression. Experts can also customize the process by specifying certain hyperparameter ranges or using AutoGluon to tune their own custom models. Additionally, AutoGluon can distribute its computation across multiple machines to return trained models more quickly.
AutoGluon fits various models ranging from off-the-shelf boosted trees to customized neural networks. The models are combined in a distinctive approach where they are stacked in various layers and trained layer by layer. This technique guarantees that the unprocessed data can be converted into accurate and reliable predictions within a specific time limit.
Auto-Sklearn 2.0 is an open-source library for Automated Machine Learning that builds upon the success of its predecessor, Auto-Sklearn. It offers a powerful framework for solving a wide range of ML problems, including classification, regression, and time series forecasting. It provides a range of preprocessing techniques, feature selection, and model selection strategies, including deep learning models.
Auto-Sklearn 2.0 also includes state-of-the-art ensemble methods, such as stacking and blending, that improve the accuracy of predictions. These features make Auto-Sklearn 2.0 a valuable tool for practitioners and researchers alike, as it simplifies the process of ML by automating many of the manual steps required for building models. Additionally, Auto-Sklearn 2.0 offers significant performance improvements over manual methods, which can save time and resources [
36].
PyCaret is a Python-based ML library that is available as an open-source library and facilitates low-code development. This library automates machine learning workflows and serves as an end-to-end machine learning and model management tool. With PyCaret, users can increase productivity by quickly experimenting with different algorithms and settings, compare the performance of different models, and generate insights from the data without requiring a deep understanding of ML theory or programming [
37]. PyCaret can automatically perform many of the tedious and time-consuming tasks involved in machine learning, such as data preprocessing, feature selection, model selection, and hyperparameter tuning. Overall, PyCaret’s AutoML capabilities help abstract machine learning, making it more accessible and usable for a wider range of users [
38].
The similarities and differences between AutoGluon, Auto-Sklearn 2.0, and PyCaret in several key areas are listed in
Table 1 and are further explained as follows:
Flexibility: AutoGluon and PyCaret support a wider range of ML tasks and algorithms, while Auto-Sklearn 2.0 focuses on classification and regression tasks only. AutoGluon also provides more flexibility in terms of customization and user-defined constraints.
Ease of Use: All three frameworks are designed to be easy to use and require minimal programming knowledge. AutoGluon and PyCaret are designed to be accessible to non-experts, with user friendly interfaces and tutorials.
Methodology: AutoGluon and Auto-Sklearn 2.0 are designed to maximize the performance of ML models, using a combination of meta-learning, ensemble methods, and other techniques. PyCaret is designed to be a high-performance library that can quickly and efficiently process large datasets and build accurate ML models.
Open Source: All three frameworks are open source, which means that they are freely available for anyone to use and modify. AutoGluon, Auto-Sklearn 2.0, and PyCaret are developed by researchers.
Community: All three frameworks have active communities of developers and users, with resources such as tutorials, documentation, and forums available to users.
In summary, while AutoGluon, Auto-Sklearn 2.0, and PyCaret share many similarities as they are all AutoML frameworks, they also have their unique strengths and weaknesses. Depending on the specific needs of the user, one framework may be more suitable than the others.
3.2. Datasets
We selected three types of time-series datasets, Bitcoin, COVID-19, and weather, which present different challenges for the selected AutoML tools. We explain the properties of these datasets below:
The highly volatile and variable nature of Bitcoin prices demanded an exceptional analytical tool that could disentangle complex historical patterns and prognosticate future trends. AutoML tools provide a fast, precise, and efficient approach to analyzing the intricate and inherently uncertain nature of Bitcoin data.
AutoML technology promises exceptional efficacy in dissecting historical data and making precise projections about Bitcoin’s future value and helps uncover previously hidden, latent patterns that are crucial in decision-making processes to acquire, divest, or retain Bitcoin assets.
In the study of Bitcoin data, it is important to be cautious and consider all relevant factors when conducting analyses or making predictions. This involves using data from multiple sources, including cryptocurrency market news, trading volume, investor attitudes, and broader economic factors such as interest rates and inflation rates. The time series analysis showed significant patterns in Bitcoin’s value over time, notably initial increases that have since leveled off. Our research indicates that using an AutoML-based method improves the accuracy and usefulness of our forecasts, offering valuable insights into upcoming trends.
We based our predictions on a training dataset of 2509 instances, with a testing dataset comprising 280 instances. Our principal objective was to anticipate ‘adj close’ values, representing a holistic predictive endeavor.
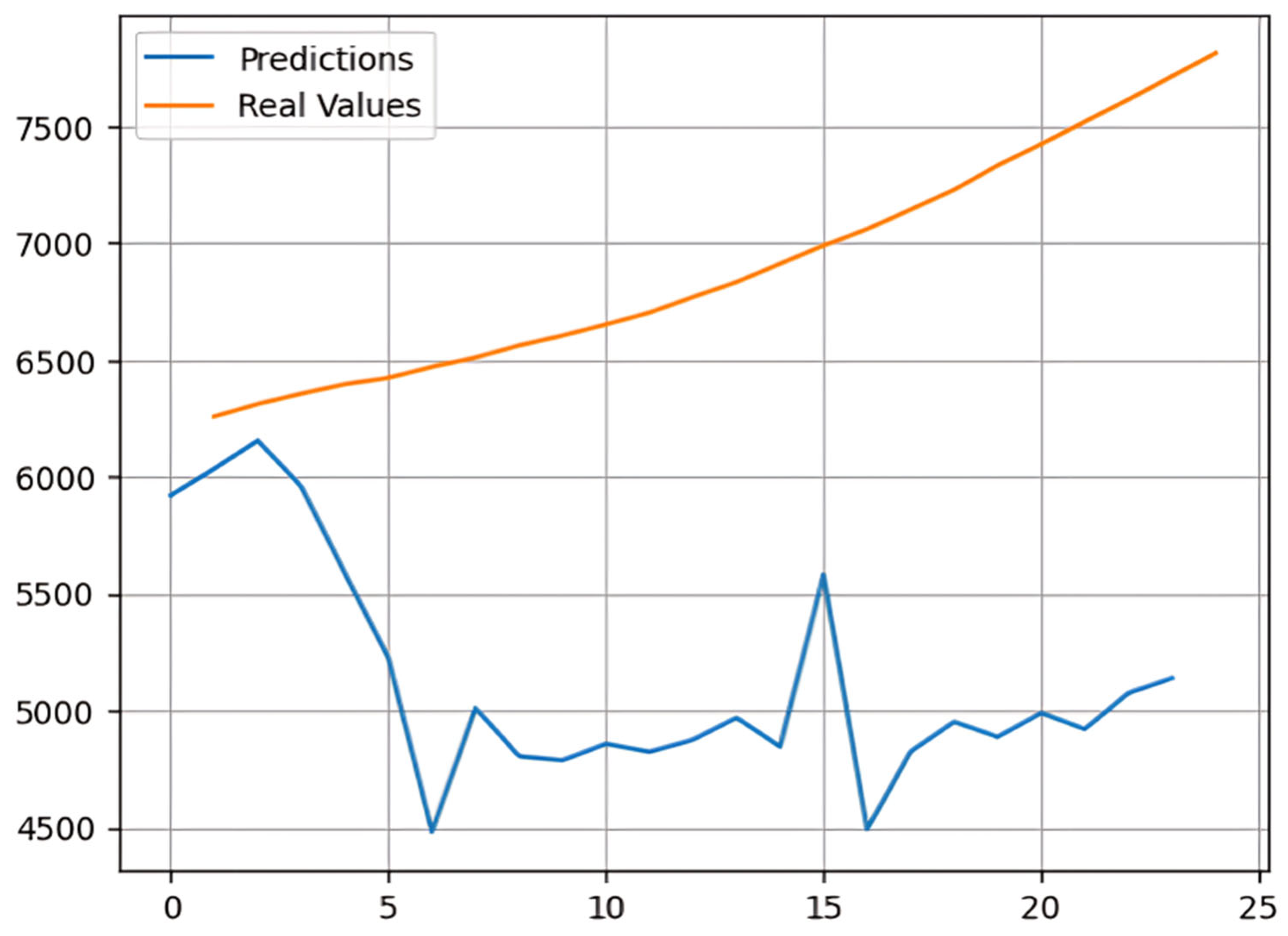
Figure 1 plots the values of the Adjacent Close between 2014 and 2022. Our analysis of Bitcoin’s price history revealed intricate patterns that could inform sound investment decisions. By leveraging AutoML technology and exercising judicious circumspection in incorporating all pertinent determinants, it is possible to generate insights that would be instrumental in optimizing the investment portfolios in Bitcoin and other cryptocurrencies.
Delhi’s COVID-19 dataset is suitable for time series analysis due to its impact on the public, temporal trends, non-stationarity, policy implications, and predictive power. Time series analysis can help understand how the virus spreads, the impact of interventions and vaccination efforts, and inform future policy decisions. It can also be used to forecast future case counts, hospitalizations, and deaths for public health planning and resource allocation.
Figure 2 displays the number of deaths in Delhi during the COVID-19 pandemic. The training data include 216 rows, and the test data include 24 rows.
In the dataset, there is an unexpected decrease in reported COVID-19-related deaths in Delhi on 24 July 2020. The exact cause of this dip is uncertain, but it may be attributed to factors such as reporting delays, health policy changes, or updates in data collection methods. Such anomalies underscore the complexities of interpreting time-series health data and highlight the need for careful analysis. The potential reasons provided here need further investigation and emphasize the dynamic nature of pandemic data reporting.
The COVID-19 dataset is too small to have a good prediction; however, that is the problem for many cases, so it is interesting to see how AutoML tools will perform with this dataset. The dataset has multiple columns; however, for this experiment, ‘Date’ is used as the index, and ‘Deaths’ is used to predict the number of deaths. The selection of the COVID-19 dataset was based on its relatively low number of rows and consistent pattern of data. This dataset never had any decrease in deaths; it was a cumulative total and not just a day-to-day count.
We selected the weather change dataset for time series analysis based on the availability and reliability of the dataset, the significance of weather change as a global issue, and its possibility of obtaining insights about the weather dataset patterns. The weather dataset is the most stable dataset compared to the other datasets used in this study. The weather has similar outcomes throughout the years with a small variation, which makes it easier to predict what the temperature will be over time. The training data include 1315 rows, and the test data include 148 rows. The objective is to forecast the “average temperature” values.
Figure 3 presents a plot of the datasets over several years.
The weather dataset is a valuable source of information for time series analysis for several reasons:
Temporal Dependence: Time series analysis is well-suited for analyzing data with a temporal dependence, i.e., how much previous data influence the future data. Such dependence can be seen in the weather change dataset, which records changes in temperature, pressure, humidity, precipitation, and other weather variables over time.
Short-term forecasting: Time series analysis can be used to forecast future weather patterns, such as temperature, rainfall, or snowfall, which can be used to inform short-term planning and decision-making, such as in agricultural production or transportation logistics.
Seasonality: The weather change dataset exhibits strong seasonality, with cyclic patterns of variation across different seasons, months, and years. Time series analysis can be used to identify and model these patterns, which can be used to make more accurate predictions about future weather trends.
Trend Analysis: Time series analysis can be used to identify long-term trends in the weather change dataset, such as increasing global temperatures or changes in precipitation patterns.
3.5. Steps to Use the AutoML Tools
We utilized Google Colab for benchmarking all three AutoML tools to ensure fair computing power. The steps and the methodology followed during the evaluation of the AutoML tools are described next.
AutoGluon (version 0.7.0), like other AutoML software, has specific requirements for data structure and presentation of its predictor functions. The data should consist of at least three columns: a unique ID (integer or string), a compatible timestamp indicating the analyzed value’s time, and the numeric value of the time series. Although the column names are not crucial, they should be specified when constructing a ‘Time Series Data Frame’ for AutoGluon’s prediction. Failure to match the required format will result in an exception and the failure to execute.
Table 3 presents an example of the correct dataset format.
To create the necessary data structure ‘TimeSeriesDataFrames’ for AutoGluon, the dataset must be loaded into pandas dataframes for both training and testing. The ‘TimeSeriesDataFrame.from_data_frame’ function is utilized to construct a ‘TimeSeriesDataFrame’ by specifying parameters such as the data frame, ID column name, and timestamp column name. The same format is employed for the conversion of test data.
AutoGluon employs ‘TimeSeriesPredictor’ objects to forecast future values of time series data. These predictor objects have essential parameters for customizing the forecasting model, including the prediction length, the path for saving trained models, the target column to track, and the evaluation metric used for model fitting. The ‘fit()’ function requires parameters such as the ‘TimeSeriesDataFrame’ of the training data, a quality preset, and a preferred time limit.
The quality preset impacts model complexity and training time in AutoGluon fitting. Dataset size and hardware also influence training time. The ‘fit()’ function takes a time limit parameter for maximum fitting duration. It guides AutoGluon to avoid new fittings exceeding the remaining time. Without a time limit, all models for the specified model preset are trained. AutoGluon outputs trained models, fitting duration, best model, and its score.
Following the model fitting process, the AutoGluon predictor generates future time series forecasts for the provided dataset. By default, it utilizes the model with the highest score on the validation set. Forecasts initiate from the end of the training data, aligning with the specified number of predictions. The ‘predict()’ function requires the ‘TimeSeriesDataFrame’ training dataset as input and delivers predictions in a corresponding format. The forecasts are probabilistic, encompassing a range of outcomes spanning a 10% to 90% likelihood. The mean, signifying the expected value, emerges as the most influential outcome, denoting the average likelihood.
AutoGluon offers several presets, allowing for the easy comparison of its models. Higher-quality presets generally yield more accurate predictions but require longer training times and result in less computationally efficient models. After generating the forecasted values, AutoGluon offers visualization and evaluation tools for analysis.
AutoGluon’s leaderboard() function allows the evaluation of each trained model’s performance by displaying test scores, which compare predictions to the test data, and validation scores derived from an internal validation set.
There is no need to manipulate the dataset when using Auto-Sklearn to train a model, as the platform automatically handles the organization of datetime values. During the pre-training phase, only the date and label values are selected. It is crucial to specify both the training and testing datasets and to separate the label from the dataset. The training set comprises the first 90% of the data, while the test set contains the remaining 10%.
During the training, we utilized autosklearn.regression class’s AutoSklearnRegressor() method using the default parameters, with the exception of ‘time_left_for_this_task’ and ‘n_jobs’. The former parameter defines the time_limit in seconds for searching suitable models while increasing its value enhances the likelihood of obtaining better models. The latter parameter specifies the number of jobs to run in parallel for fit (), where −1 denotes the utilization of all processors. ‘n_jobs’ was utilized to expedite the process, while ‘time_left_for_this_task’ was used to monitor how the training success depends on the duration of the model search. The remaining parameters were kept as default values, given that the purpose was to observe how the tool handles the data with its default settings.
PyCaret offers well-documented tutorials and examples for various scenarios. However, it requires users to have some knowledge of ML to prepare the dataset in the required format. PyCaret provides several functions that simplify the forecasting process. The following functions were used: (1) initialization: setup(), (2) training: compare_models(), (3) analysis: plot_model() and evaluate_model().
The setup() function in PyCaret allows customization of the preprocessing pipeline and ML workflow. It requires two parameters: the dataset and the target variable. It must be called before executing other functions.
PyCaret trains multiple models and ranks them from best to worst based on performance metrics. The compare_models() function outputs the models organized by their scores, which can take varying amounts of time depending on the dataset size and type.
PyCaret includes the plot_model() function, which allows for visualization of the performance of trained ML models. It provides graphical representations of performance metrics and diagnostics, aiding in the interpretation and understanding of the model’s behavior.
5. Discussion
As technology evolves, new methodologies and tools for predictive forecasting using time series data will continue to emerge. AutoML frameworks are among the most promising methodologies that provide considerable potential for automated data processing and the optimization of predictive models. The incorporation of contemporary frameworks with an empirical study of their efficacy has significant implications for time series data analysis, predictive forecasting, and other associated fields. Next, we continue our discussion focusing on each dataset.
The reason why each tool produces different scores can be attributed to several factors, such as the following:
Algorithm selection: Each tool uses different algorithms to train models on the given dataset. For example, PyCaret uses a decision tree regressor, while Auto-Sklearn 2.0 and AutoGluon use gradient boosting and ensemble models, respectively. Different algorithms can have varying strengths and weaknesses and may be better suited for different types of data.
Hyperparameter tuning: Each algorithm used by these tools has several hyperparameters that need to be tuned to achieve optimal performance. Different tools use different approaches to optimize these hyperparameters. For example, PyCaret uses a combination of grid search and random search, while Auto-Sklearn 2.0 uses Bayesian optimization. The effectiveness of these methods in finding optimal hyperparameters can vary.
Time spent training: The amount of time spent training can also affect the RMSE score. With more time, the models can potentially be trained to a higher level of accuracy. As we can see from the metrics, Auto-Sklearn 2.0 and AutoGluon achieved a decrease in RMSE values when given more time to train.
Dataset characteristics: The performance of ML models is heavily influenced by the characteristics of the dataset, such as the size, complexity, and distribution of the data. Different algorithms and hyperparameters may perform better or worse on different types of data.
In summary, the differences in RMSE/MAPE scores among the tools studied can be traced back to differences in algorithms, hyperparameter optimization methods, training time, and specific traits of the dataset. A close look at the RMSE scores related to the Bitcoin dataset shows that PyCaret achieves the lowest value of 10,311, followed by Auto-Sklearn 2.0 and AutoGluon. This highlights PyCaret’s ability to provide the most accurate forecasts according to the chosen metric, a finding that is also reflected in the MAPE values.
It is important to note that the RMSE/MAPE scores from Auto-Sklearn 2.0 and AutoGluon are also relatively moderate, especially when longer training times are employed. This supports the idea that these tools can also be effective in modeling the Bitcoin dataset, although other factors like ease of use and computational resources should be considered when choosing a tool.
Given the volatile nature of the Bitcoin dataset, it is reasonable to assume that model accuracy may decline over time due to market changes. Therefore, ongoing evaluation and improvement are essential to maintain the reliability and usefulness of these models, ensuring their long-term effectiveness.
PyCaret uses a range of ML algorithms to automatically train and evaluate models on a given dataset. In this case, PyCaret achieved an RMSE score of 3.10 and a MAPE score of 0.10 using the extra trees regressor algorithm. The extra trees algorithm is a type of decision tree that uses randomization to improve the accuracy and stability of the model. The specific hyperparameters chosen by PyCaret, as well as the size and complexity of the dataset, may have contributed to the specific RMSE score achieved.
Auto-Sklearn 2.0 is a tool that uses Bayesian optimization to select the best combination of ML algorithms and hyperparameters for a given dataset. In this case, Auto-Sklearn 2.0 achieved the lowest RMSE score of 2.07 after 3600 s of training and achieved the lowest MAPE score of 0.07 using the gradient boosting algorithm. Gradient boosting is an ensemble learning technique that combines multiple weak models to create a more accurate overall model. The use of Bayesian optimization allows Auto-Sklearn 2.0 to efficiently explore the space of possible models and hyperparameters to find the best combination for the given dataset.
AutoGluon achieved low RMSE/MAPE scores across a range of quality levels, with the lowest score achieved at the highest quality level using an ensemble model. Like gradient boosting, ensemble models combine multiple models to create a more accurate overall model. The specific hyperparameters chosen by AutoGluon, as well as the size and complexity of the dataset, may have contributed to the specific RMSE/MAPE scores achieved.
Overall, Auto-Sklearn 2.0 achieved the lowest RMSE/MAPE score and appears to have found the most accurate model for the weather in Delhi dataset. AutoGluon also achieved relatively low scores across a range of quality levels, while PyCaret achieved a reasonable score but was not as accurate as the other tools. However, it is worth noting that the specific hyperparameters chosen by each tool, as well as the size and complexity of the dataset, likely contribute to the specific RMSE/MAPE scores achieved, and other metrics such as accuracy and precision should also be considered when selecting an ML model.
PyCaret achieved a low RMSE/MAPE score using the orthogonal matching pursuit algorithm for predicting COVID-19 deaths.
Auto-Sklearn 2.0 struggled to find an accurate model for the high complexity of COVID-19 data, and a large number of variables might have impacted the prediction of the number of deaths.
AutoGluon used an ensemble approach, combining the predictions of multiple models to achieve higher accuracy. Its low RMSE/MAPE scores across a range of quality levels suggest that it is well-suited for predicting COVID-19 deaths.
Overall, PyCaret achieved the lowest RMSE score and appears to have found the most accurate model for the COVID-19 dataset. AutoGluon obtained relatively low scores across various quality levels in root mean square error (RMSE), and it exhibited the lowest Mean Absolute Percentage Error (MAPE) score when trained with the ‘best quality’, while Auto-Sklearn 2.0 achieved higher scores and was not as accurate for this dataset. While comparing the RMSE/MAPE scores between these tools can provide some insight into their performance, it is important to keep in mind that the hyperparameters chosen and the size and complexity of the dataset can have a significant impact on the results. Therefore, it may be necessary to consider other metrics, such as accuracy and precision, in addition to RMSE/MAPE, when selecting an ML model for a particular task.
One limitation we faced was the highly specialized and rapidly evolving nature of the field. The field of AutoML is advancing rapidly, with new techniques, algorithms, and tools being developed at a fast pace. This dense and dynamic nature of the field presented challenges in terms of keeping up with the latest advancements, understanding the nuances of different AutoML techniques, and thoroughly evaluating the performance of various AutoML tools.
While metrics are commonly used to evaluate model performance, they may not always accurately identify a good model, as they may not fully capture the complexities of real-world scenarios, may prioritize different aspects of performance, and may not align with project requirements or domain-specific considerations. It is important to interpret the results of performance metrics with caution and consider other relevant factors when evaluating the quality of AutoML models.
Another limitation of our study was the significant impact of the datasets used for training and testing the AutoML. The size and characteristics of the datasets can greatly affect the performance and accuracy of the AutoML models. When using large datasets, training the models can be time-consuming and resource-intensive. This can sometimes result in having to stop the training prematurely without obtaining meaningful results. Additionally, large datasets may pose challenges in terms of formatting and handling and may require additional preprocessing steps to make them compatible with the AutoML tools.
On the other hand, small datasets, such as the COVID-19 dataset we used, can also present challenges. With limited data points, the AutoML models may struggle to make accurate predictions, as they may not have enough examples from which they can learn. Additionally, the nature of the data, such as the exponential growth in COVID-19 deaths, can also pose challenges for the models to capture the patterns effectively.
Furthermore, some datasets, such as the Bitcoin dataset, may be inherently volatile and unpredictable, making it difficult for AutoML to generate meaningful predictions. In such cases, the limitations of the dataset itself can hinder the performance of the models generated by the AutoML tool or any ML model that was created manually.
This paper evaluates multiple AutoML tools regarding how well they perform in analyzing time series datasets. The chosen tools were tested on metrics explained previously in the methodology, but there are other metrics that need examination as well [
39]. These other metrics are not the scores given as to how accurately they are predicted. Instead, they are how polished and well-made the tools are for every kind of user. Not only the tool itself but also the documentation and ease of use are to be evaluated since that is something for which AutoML is made. AutoML is made to alleviate the burden of knowing how to create and train an ML model, something that the average user/customer would not know how to accomplish. New studies started to emerge providing open-source code for the quick adaptation and comparison of AutoML tools [
40].
In our research, we operated under the assumption that the developers behind each AutoML tool had already optimized the hyperparameters to enhance performance. Therefore, we refrained from tweaking these presets, positing that they were calibrated for peak efficiency. Our assessments were carried out with each tool in its default state, mirroring the common use case for individuals with limited ML expertise. This approach provided us with valuable insights into how each tool performs out of the box, which is especially relevant for users unfamiliar with the intricacies of ML fine-tuning. Considering the vast customization capabilities of AutoML tools, attempting to standardize their settings across different algorithms would be unnecessarily complicated and typically unfeasible.



 and
and 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}