
Enhancing Child Safety in Online Gaming: The Development and Application of Protectbot, an AI-Powered Chatbot Framework

_Karamitsos.jpg)

Abstract
:1. Introduction
- The development of Protectbot as a robust AI-driven framework for the real-time detection of predatory behavior, aimed at safeguarding children in online gaming environments.
- The achievement of superior detection performance through extensive training and evaluation on the PAN12 dataset, marking a significant advancement in AI-based child protection methodologies.
- The validation of our model’s effectiveness and its practical applicability, as demonstrated by its performance on a unique dataset of 71 predatory conversations sourced from the PJ website [22].
- Interactive Chatbot Initiation: Protectbot utilizes an interactive chatbot as the initial interface with users. This novel application of chatbot technology as a preventive tool diverges from the passive, analytical roles chatbots typically play in existing solutions.
- Advanced Conversational Modeling: By integrating the DialoGPT framework, Protectbot achieves a high level of conversational realism. This framework allows for the generation of contextually relevant responses, ensuring the chatbot can engage in meaningful and natural dialogues. This capability is critical for maintaining engagement without arousing suspicion, a distinct advantage over more rudimentary interaction models.
- Sophisticated ML Classification: Following interactions, chat logs are subjected to detailed scrutiny using an advanced ML classification model. This model is finely tuned to pick up on nuanced linguistic and behavioral cues that may suggest predatory intent, demonstrating a significant improvement in identifying potential threats.
- Automated Reporting for Rapid Intervention: Unique among its peers, Protectbot includes an automated reporting feature designed to alert law enforcement agencies swiftly. This functionality facilitates a faster response to identified threats, effectively closing the gap between detection and action, an area where prior research has shown limitations.
2. Related Work
3. Methodology
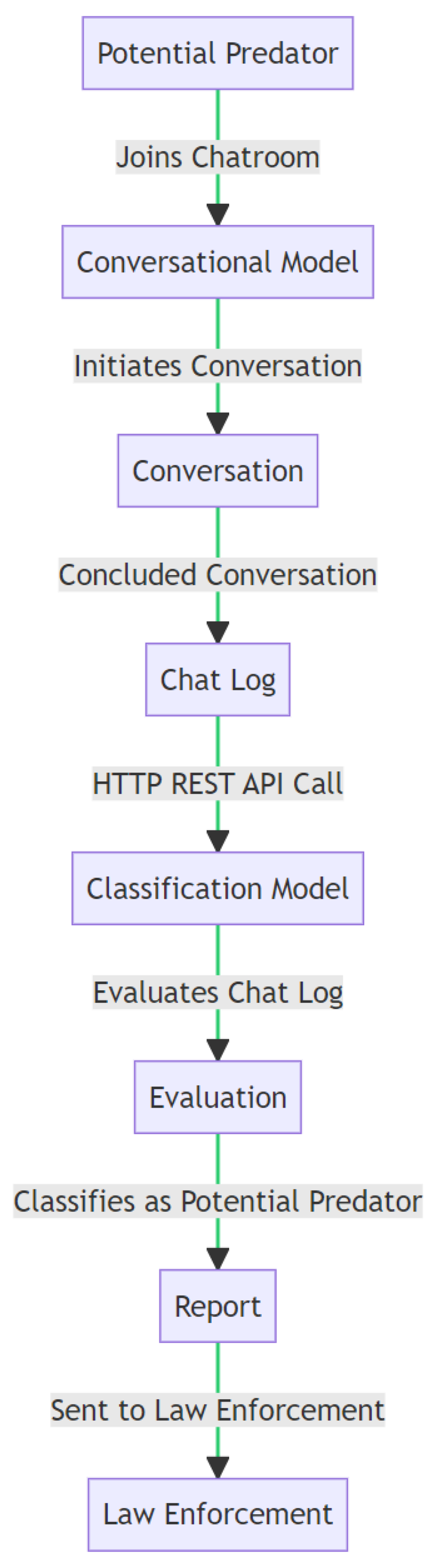
- Step 1: Initiation of Chat. The process begins when a user engages in conversation with Protectbot, marking the initial phase of the detection process.
- Step 2: Chat Sent to the Conversational Model. Chats are immediately processed by a conversational model utilizing the DialoGPT framework, selected for its superior ability to generate context-aware, human-like responses. The choice of DialoGPT, trained on diverse internet-based dialogues, ensures the generation of responses that are indistinguishably similar to human interactions, essential for maintaining the predator’s engagement.
- Step 3: Generated Response Sent to the Chatbot. Responses crafted by the conversational model are relayed back to Protectbot, which then continues the dialogue with the user. This step is critical for providing a seamless and realistic conversation flow, encouraging the predator to reveal their intentions without suspicion.
- Step 4: Response Sent to the Potential Predator. The conversation progresses with Protectbot sending the generated responses back to the user, meticulously maintaining the dialogue’s natural and fluid exchange.
- Step 5: Chat Logs Sent to the Classification Model. Upon concluding the conversation, chat logs are analyzed by an ML classification model. This model scrutinizes the dialogue for specific linguistic and behavioral indicators of predatory intent, such as grooming techniques or attempts to elicit personal information. The model’s training emphasizes the identification of nuanced predatory patterns, balancing sensitivity to predatory cues with the necessity to minimize false positives, thereby ensuring ethical considerations regarding privacy and accuracy are upheld.
- Step 6: Report Generation for Law Enforcement Agencies. In instances where predatory behavior is detected, an automated report is generated and dispatched to law enforcement agencies. This report contains detailed insights from the conversation, structured to expedite the authorities’ review and action. The collaboration with law enforcement is built on established protocols to ensure rapid and appropriate responses to the identified threats.
3.1. Conversational Language Generation Model
Adaptability and Scalability
3.2. Machine Learning Classification Model
3.2.1. User Privacy and Data Security Measures
3.2.2. Data Acquisition
PAN12 Dataset
PJ Website Dataset
3.2.3. Text Cleaning and Prefiltering
3.2.4. Preprocessing
- Removal of Non-Textual Elements: URLs, punctuation marks, and special characters, including symbols like $, &, #, +, and =, were systematically removed from the dataset. Numerical values, which are often irrelevant to the context of predatory behavior analysis, were also excluded.
- Exclusion of Stop Words: Commonly occurring stop words, including but not limited to is, are, the, and a, were removed from the dataset. These words, while prevalent in natural language, typically do not contribute to the semantic richness required for text mining and were thus omitted to streamline the dataset for more efficient processing.
- Retention of Original Textual Features: Notably, our preprocessing did not involve stemming or lemmatization processes. These techniques, while useful for reducing words to their root forms, were omitted to preserve the integrity and informational value of the original text. The decision to forgo these steps was made to ensure that the dataset retained the maximum possible amount of relevant information, acknowledging that the unique linguistic characteristics present in chat messages might hold key insights into predatory behaviors.
3.2.5. Word Embeddings and Classification
Generating Sentence Vectors
- Bag of Words (BoW): Utilized extensively for generating sentence vectors, BoW creates a vocabulary from a corpus and assigns an index to each word in a high-dimensional vector space. The presence of words within a text is marked by non-zero entries in the corresponding vector, with values representing binary occurrences, term counts, or term frequency-inverse document frequency (TF-IDF) scores. However, BoW’s limitations are its inability to capture semantic relationships between words and the impracticality of managing large, sparse vectors for extensive corpora.
- Word Embeddings: This approach overcomes BoW’s shortcomings by mapping words with similar meanings to proximate points in the vector space, thus preserving semantic relationships. Popular methods include Word2Vec [57], GloVe [58], and fastText [59], with each employing distinct mechanisms for generating word vectors. Word2Vec and GloVe rely on contextual relationships or co-occurrence matrices, while fastText, innovatively, uses character n-grams to accommodate out-of-vocabulary words. This characteristic enables fastText to generate meaningful vectors for previously unseen words, showcasing its versatility and superior performance in various comparative studies [60,61].
Application to Predatory Behavior Detection
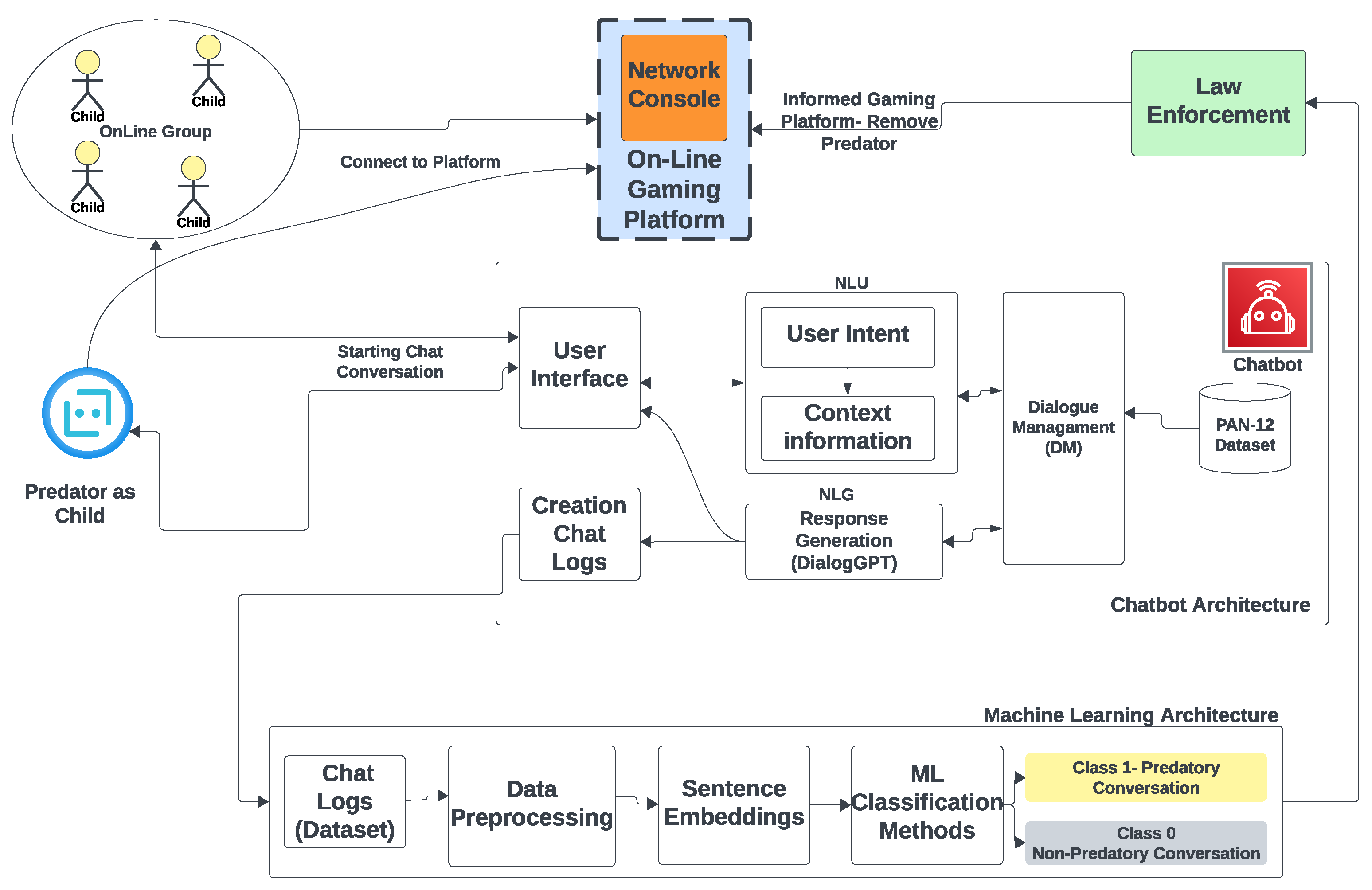
3.3. System Integration
3.3.1. Real-World Deployment and Feedback
Interface for Model Communication
Classification and Response
Actionable Outcomes
Visualizing System Integration
4. Results
4.1. Classification Performance
4.2. Loss Metrics Evaluation
4.3. Comparative Analysis with State of the Art
4.4. Overfitting Assessment and Model Generalization
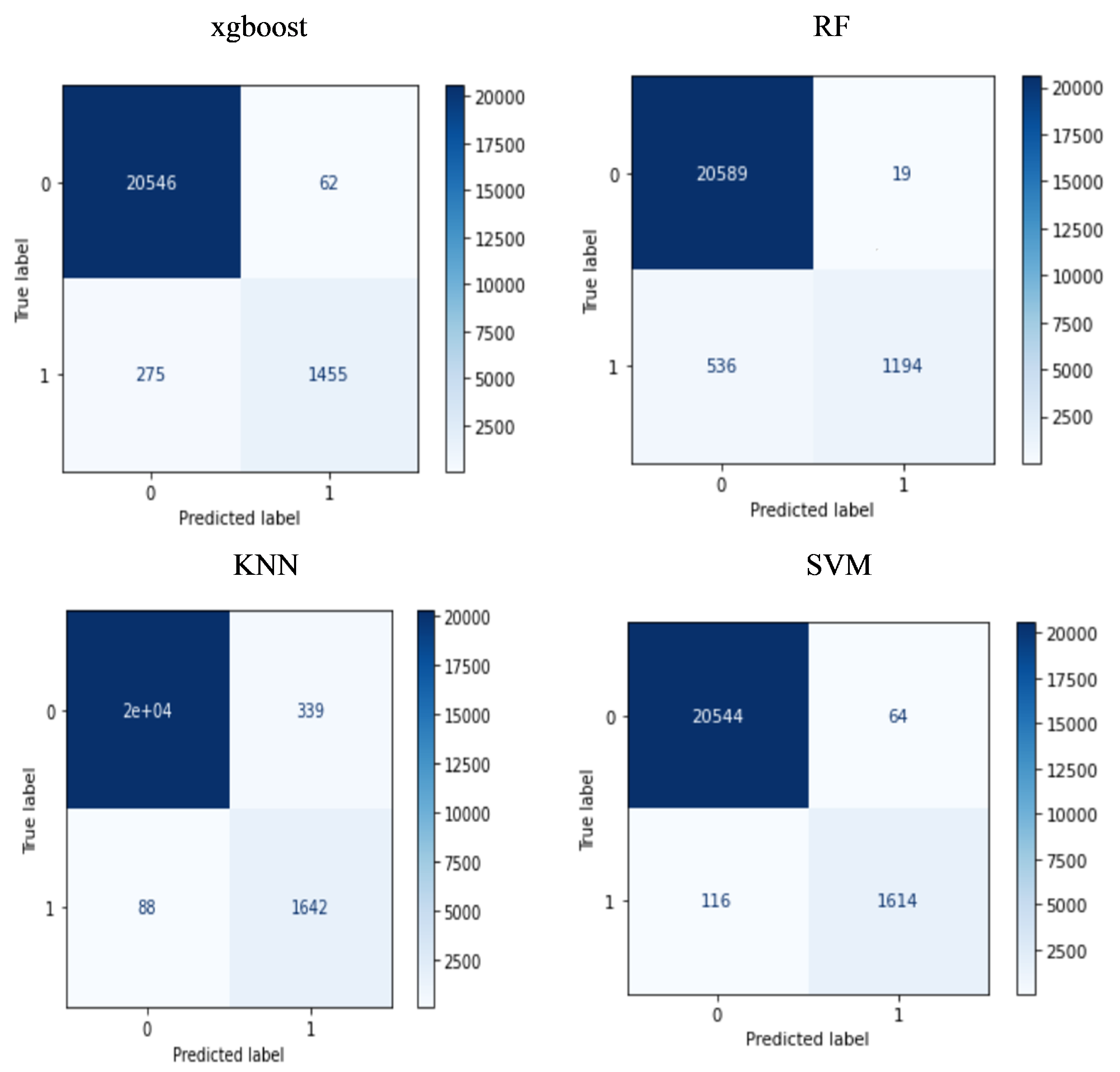
4.5. Confusion Matrix Analysis
4.6. Validation on Curated Dataset
4.7. Discussion
- Advanced Text Classification for Online Child Safety: Our SVM classifier’s exceptional performance underscores a significant leap in text classification methodologies aimed at online child safety. Achieving metrics of accuracy, precision, recall, -score, and -score at approximately 0.99 for all, the SVM classifier not only validates the efficacy of our text classifier in identifying predatory behavior, but also positions our approach as a leading methodology within the realm of AI-based child protection. This aligns with our contribution towards enhancing child safety through advanced AI techniques.
- Nuanced Classifier Selection Based on Application Needs: Highlighting the KNN classifier’s superior recall rate for predatory conversations points to its effectiveness in scenarios where the cost of missing a potential threat is high. This finding supports our contribution of presenting a nuanced, application-specific approach to classifier selection, emphasizing that platforms prioritizing the reduction of false negatives might find KNN more suitable, despite its slightly lower overall accuracy compared to SVM.
- Insights from Loss Metrics on Model Generalization: Our detailed analysis of loss metrics, specifically Mean Absolute Error (MAE) and Mean Squared Logarithmic Error (MSLE), provides critical insights into the models’ ability to generalize. SVM’s consistently low error rates across both training and testing phases highlight its robustness and reliability, crucial for deployment in unpredictable real-world settings. This supports our contribution of refining text classification strategies for child safety, showcasing the importance of model generalization in practical applications.
- Comparative Analysis with State-of-the-Art Models: The combination of pre-trained FastText embeddings with the SVM classifier demonstrates significant advantages in detecting predatory behavior, marking a notable advancement in the field. This performance not only affirms the effectiveness of our methods, but also paves the way for future explorations into enhancing AI-driven child safety solutions. Our contribution in this area highlights the potential for innovative embedding techniques combined with classical ML models to improve online child protection.
- Challenges and Future Directions in Predator Detection: The validation process on the curated dataset illuminated the inherent challenges in accurately identifying predatory behavior, revealing the complex nature of this task. The variable performance of SVM and KNN on this dataset points to the potential benefits of employing hybrid models or adaptive techniques to enhance accuracy and reliability in predator detection. This discussion emphasizes our commitment to future research aimed at overcoming these challenges, aligning with our initial contribution towards advancing the field of AI in child online safety.
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- American Psychological Association Resolution on Violent Video Games. Available online: http://www.apa.org/about/policy/violent-video-games.aspx (accessed on 4 March 2024).
- Faraz, A.; Mounsef, J.; Raza, A.; Willis, S. Child Safety and Protection in the Online Gaming Ecosystem. IEEE Access 2022, 10, 115895–115913. [Google Scholar] [CrossRef]
- Digital 2021: Global Overview Report. Available online: https://datareportal.com/reports/digital-2021-global-overview-report (accessed on 4 March 2024).
- Stalker, P.; Livingstone, S.; Kardefelt-Winthe, D.; Saeed, M. Growing up in a Connected World; UNICEF Office of Research–Innocenti: Firenze, Italiy, 2019. [Google Scholar]
- Child Rights and Online Gaming: Opportunities & Challenges for Children and the Industry. Available online: https://www.unicef-irc.org/files/upload/documents/UNICEF_CRBDigitalWorldSeriesOnline_Gaming.pdf (accessed on 4 March 2024).
- Helbing, D.; Brockmann, D.; Chadefaux, T.; Donnay, K.; Blanke, U.; Woolley-Meza, O.; Moussaid, M.; Johansson, A.; Krause, J.; Schutte, S.; et al. Saving Human Lives: What Complexity Science and Information Systems can Contribute. J. Stat. Phys. 2015, 158, 735–781. [Google Scholar] [CrossRef]
- Perc, M.; Ozer, M.; Hojnik, J. Social and Juristic Challenges of Artificial Intelligence. Palgrave Commun. 2019, 5, 61. [Google Scholar] [CrossRef]
- Agarwal, N.; Ünlü, T.; Wani, M.A.; Bours, P. Predatory Conversation Detection Using Transfer Learning Approach. In Proceedings of the 7th International Conference on Machine Learning, Optimization, and Data Science (LOD), Grasmere, UK, 4–8 October 2021; Springer: Berlin/Heidelberg, Germany, 2021; Volume 13163, pp. 488–499. [Google Scholar]
- Anderson, P.; Zuo, Z.; Yang, L.; Qu, Y. An Intelligent Online Grooming Detection System Using AI Technologies. In Proceedings of the International Conference on Fuzzy Systems (FUZZ-IEEE), New Orleans, LA, USA, 23–26 June 2019; IEEE: New York, NY, USA, 2019; pp. 1–6. [Google Scholar]
- Andleeb, S.; Ahmed, R.; Ahmed, Z.; Kanwal, M. Identification and Classification of Cybercrimes using Text Mining Technique. In Proceedings of the International Conference on Frontiers of Information Technology (FIT), Islamabad, Pakistan, 16–18 December 2019; IEEE: New York, NY, USA, 2019; pp. 227–232. [Google Scholar]
- Borj, P.R.; Bours, P. Predatory Conversation Detection. In Proceedings of the International Conference on Cyber Security for Emerging Technologies (CSET), Doha, Qatar, 27–29 October 2019; IEEE: New York, NY, USA, 2019; pp. 1–6. [Google Scholar]
- Borj, P.R.; Raja, K.B.; Bours, P. Detecting Sexual Predatory Chats by Perturbed Data and Balanced Ensembles Effects. In Proceedings of the 20th International Conference of the Biometrics Special Interest Group (BIOSIG), Digital Conference, 15–17 September 2021; Gesellschaft für Informatik e.V.: Hamburg, Germany, 2021; Volume P-315, pp. 245–252. [Google Scholar]
- Bours, P.; Kulsrud, H. Detection of Cyber Grooming in Online Conversation. In Proceedings of the International Workshop on Information Forensics and Security (WIFS), Delft, The Netherlands, 9–12 December 2019; IEEE: New York, NY, USA, 2019; pp. 1–6. [Google Scholar]
- Fauzi, M.A.; Bours, P. Ensemble Method for Sexual Predators Identification in Online Chats. In Proceedings of the 8th International Workshop on Biometrics and Forensics (IWBF), Porto, Portugal, 29–30 April 2020; IEEE: New York, NY, USA, 2020; pp. 1–6. [Google Scholar]
- Gunawan, F.E.; Ashianti, L.; Sekishita, N. A Simple Classifier for Detecting Online Child Grooming Conversation. Telkomnika (Telecommun. Comput. Electron. Control) 2018, 16, 1239–1248. [Google Scholar] [CrossRef]
- Kick Ass Open Web Technologies IRC Logs. Available online: https://krijnhoetmer.nl/irc-logs/ (accessed on 4 March 2024).
- Kim, J.; Kim, Y.J.; Behzadi, M.; Harris, I.G. Analysis of Online Conversations to Detect Cyberpredators Using Recurrent Neural Networks. In Proceedings of the 1st International Workshop on Social Threats in Online Conversations: Understanding and Management (STOC@LREC), Marseille, France, 12–13 May 2020; European Language Resources Association: Paris, France, 2020; pp. 15–20. [Google Scholar]
- Kirupalini, S.; Baskar, A.; Ramesh, A.; Rengarajan, G.; Gowri, S.; Swetha, S.; Sangeetha, D. Prevention of Emotional Entrapment of Children on Social Media. In Proceedings of the International Conference on Emerging Techniques in Computational Intelligence (ICETCI), Hyderabad, India, 25–27 August 2021; IEEE: New York, NY, USA, 2021; pp. 95–100. [Google Scholar]
- Laorden, C.; Galán-García, P.; Santos, I.; Sanz, B.; Hidalgo, J.M.G.; Bringas, P.G. Negobot: A Conversational Agent Based on Game Theory for the Detection of Paedophile Behaviour. In Proceedings of the International Joint Conference CISIS’12-ICEUTE’12-SOCO’12, Ostrava, Czech Republic, 5–7 September 2012; Springer: Berlin/Heidelberg, Germany, 2012; Volume 189, pp. 261–270. [Google Scholar]
- Ngejane, C.H.; Eloff, J.H.P.; Sefara, T.J.; Marivate, V.N. Digital Forensics Supported by Machine Learning for the Detection of Online Sexual Predatory Chats. Forensic Sci. Int. Digit. Investig. 2021, 36, 301109. [Google Scholar] [CrossRef]
- Pardo, F.M.R.; Rosso, P.; Koppel, M.; Stamatatos, E.; Inches, G. Overview of the Author Profiling Task at PAN 2013. In Proceedings of the Working Notes for CLEF Conference, CEUR-WS.org, Valencia, Spain, 23–26 September 2013; Volume 1179. [Google Scholar]
- Perverted Justice Foundation. Available online: http://www.perverted-justice.com/ (accessed on 4 March 2024).
- Ringenberg, T.R.; Misra, K.; Rayz, J.T. Not So Cute but Fuzzy: Estimating Risk of Sexual Predation in Online Conversations. In Proceedings of the International Conference on Systems, Man and Cybernetics (SMC), Bari, Italy, 6–9 October 2019; IEEE: New York, NY, USA, 2019; pp. 2946–2951. [Google Scholar]
- Rodríguez, J.I.; Durán, S.R.; Díaz-López, D.; Pastor-Galindo, J.; Mármol, F.G. C3-Sex: A Conversational Agent to Detect Online Sex Offenders. Electronics 2020, 9, 1779. [Google Scholar] [CrossRef]
- Sulaiman, N.R.; Siraj, M.M. Classification of Online Grooming on Chat Logs Using Two Term Weighting Schemes. Int. J. Innov. Comput. 2019, 9. [Google Scholar] [CrossRef]
- Triviño, J.M.; Rodríguez, S.M.; López, D.O.D.; Mármol, F.G. C3-Sex: A Chatbot to Chase Cyber Perverts. In Proceedings of the International Conference on Dependable, Autonomic and Secure Computing, International Conference on Pervasive Intelligence and Computing, International Conference on Cloud and Big Data Computing, International Conference on Cyber Science and Technology Congress (DASC/PiCom/CBDCom/CyberSciTech), Fukuoka, Japan, 5–8 August 2019; IEEE: New York, NY, USA, 2019; pp. 50–57. [Google Scholar]
- Wani, M.A.; Agarwal, N.; Bours, P. Sexual-predator Detection System based on Social Behavior Biometric (SSB) Features. In Proceedings of the 5th International Conference on Arabic Computational Linguistics (ACLING), Virtual Event, 4–5 June 2021; Procedia Computer Science. Volume 189, pp. 116–127. [Google Scholar]
- Zuo, Z.; Li, J.; Anderson, P.; Yang, L.; Naik, N. Grooming Detection using Fuzzy-Rough Feature Selection and Text Classification. In Proceedings of the International Conference on Fuzzy Systems (FUZZ-IEEE), Rio de Janeiro, Brazil, 8–13 July 2018; IEEE: New York, NY, USA, 2018; pp. 1–8. [Google Scholar]
- Zuo, Z.; Li, J.; Wei, B.; Yang, L.; Chao, F.; Naik, N. Adaptive Activation Function Generation for Artificial Neural Networks through Fuzzy Inference with Application in Grooming Text Categorisation. In Proceedings of the International Conference on Fuzzy Systems (FUZZ-IEEE), New Orleans, LA, USA, 23–26 June 2019; IEEE: New York, NY, USA, 2019; pp. 1–6. [Google Scholar]
- Inches, G.; Crestani, F. Overview of the International Sexual Predator Identification Competition at PAN-2012. In Proceedings of the CLEF 2012 Evaluation Labs and Workshop, CEUR-WS.org, Rome, Italy, 17–20 September 2012; CEUR Workshop Proceedings. Volume 1178. [Google Scholar]
- Verma, K.; Davis, B.; Milosevic, T. Examining the Effectiveness of Artificial Intelligence-Based Cyberbullying Moderation on Online Platforms: Transparency Implications. AoIR Sel. Pap. Internet Res. 2022. [Google Scholar] [CrossRef]
- Halder, D. PUBG Ban and Issues of Online Child Safety during COVID-19 Lockdown in India: A Critical Review from the Indian Information Technology Act Perspectives. Temida 2021, 24, 303–327. [Google Scholar] [CrossRef]
- Rita, M.N.; Shava, F.B.; Chitauro, M. Tech4Good: Artificial Intelligence Powered Chatbots with Child Online Protection in Mind. Inf. Syst. Emerg. Technol. 2022, 35. Available online: https://www.researchgate.net/profile/Abubakar-Saidu-Arah-Phd/publication/372992925_Information_and_Communication_Technologies_Readiness_and_Acceptance_among_Teachers_in_Vocational_Enterprises_Institutions_in_Abuja_Nigeria/links/64d37471b684851d3d92fcbd/Information-and-Communication-Technologies-Readiness-and-Acceptance-among-Teachers-in-Vocational-Enterprises-Institutions-in-Abuja-Nigeria.pdf#page=49 (accessed on 4 March 2024).
- Mohasseb, A.; Bader-El-Den, M.; Kanavos, A.; Cocea, M. Web Queries Classification Based on the Syntactical Patterns of Search Types. In Proceedings of the 19th International Conference on Speech and Computer (SPECOM), Hatfield, UK, 12–16 September 2017; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2017; Volume 10458, pp. 809–819. [Google Scholar]
- Mohasseb, A.; Kanavos, A. Grammar-Based Question Classification Using Ensemble Learning Algorithms. In Proceedings of the 18th International Conference on Web Information Systems and Technologies (WEBIST), Valletta, Malta, 25–27 October 2022; Lecture Notes in Business Information Processing. Springer: Berlin/Heidelberg, Germany, 2022; Volume 494, pp. 84–97. [Google Scholar]
- Zambrano, P.; Sánchez, M.; Torres, J.; Fuertes, W. BotHook: An Option against Cyberpedophilia. In Proceedings of the 1st Cyber Security in Networking Conference (CSNet), Janeiro, Brazil, 18–20 October 2017; IEEE: New York, NY, USA, 2017; pp. 1–3. [Google Scholar]
- Urbas, G. Legal Considerations in the Use of Artificial Intelligence in the Investigation of Online Child Exploitation. In ANU College of Law Research Paper; 2021; Available online: https://ssrn.com/abstract=3978325 (accessed on 4 March 2024).
- Al-Garadi, M.A.; Hussain, M.R.; Khan, N.; Murtaza, G.; Nweke, H.F.; Ali, I.; Mujtaba, G.; Chiroma, H.; Khattak, H.A.; Gani, A. Predicting Cyberbullying on Social Media in the Big Data Era Using Machine Learning Algorithms: Review of Literature and Open Challenges. IEEE Access 2019, 7, 70701–70718. [Google Scholar] [CrossRef]
- Fire, M.; Goldschmidt, R.; Elovici, Y. Online Social Networks: Threats and Solutions. IEEE Commun. Surv. Tutor. 2014, 16, 2019–2036. [Google Scholar] [CrossRef]
- Jevremovic, A.; Veinovic, M.; Cabarkapa, M.; Krstic, M.; Chorbev, I.; Dimitrovski, I.; Garcia, N.; Pombo, N.; Stojmenovic, M. Keeping Children Safe Online With Limited Resources: Analyzing What is Seen and Heard. IEEE Access 2021, 9, 132723–132732. [Google Scholar] [CrossRef]
- de Morentin, J.I.M.; Lareki, A.; Altuna, J. Risks Associated with Posting Content on the Social Media. Rev. Iberoam. Tecnol. Del Aprendiz. 2021, 16, 77–83. [Google Scholar]
- Murshed, B.A.H.; Abawajy, J.H.; Mallappa, S.; Saif, M.A.N.; Al-Ariki, H.D.E. DEA-RNN: A Hybrid Deep Learning Approach for Cyberbullying Detection in Twitter Social Media Platform. IEEE Access 2022, 10, 25857–25871. [Google Scholar] [CrossRef]
- Pendar, N. Toward Spotting the Pedophile Telling victim from Predator in Text Chats. In Proceedings of the 1st International Conference on Semantic Computing (ICSC), Irvine, CA, USA, 17–19 September 2007; IEEE Computer Society: New York, NY, USA, 2007; pp. 235–241. [Google Scholar]
- McGhee, I.; Bayzick, J.; Kontostathis, A.; Edwards, L.; McBride, A.; Jakubowski, E. Learning to Identify Internet Sexual Predation. Int. J. Electron. Commer. 2011, 15, 103–122. [Google Scholar] [CrossRef]
- Nobata, C.; Tetreault, J.R.; Thomas, A.; Mehdad, Y.; Chang, Y. Abusive Language Detection in Online User Content. In Proceedings of the 25th International Conference on World Wide Web (WWW), Montreal, QC, Canada, 11–15 April 2016; ACM: New York, NY, USA, 2016; pp. 145–153. [Google Scholar]
- Isaza, G.A.; Muñoz, F.; Castillo, L.F.; Buitrago, F. Classifying Cybergrooming for Child Online Protection using Hybrid Machine Learning Model. Neurocomputing 2022, 484, 250–259. [Google Scholar] [CrossRef]
- Fadhil, I.M.; Sibaroni, Y. Topic Classification in Indonesian-language Tweets using Fast-Text Feature Expansion with Support Vector Machine (SVM). In Proceedings of the International Conference on Data Science and Its Applications (ICoDSA), Bandung, Indonesia, 6–7 July 2022; IEEE: New York, NY, USA, 2022; pp. 214–219. [Google Scholar]
- Lestari, S.D.; Setiawan, E.B. Sentiment Analysis Based on Aspects Using FastText Feature Expansion and NBSVM Classification Method. J. Comput. Syst. Inform. (JoSYC) 2022, 3, 469–477. [Google Scholar] [CrossRef]
- Preuß, S.; Bayha, T.; Bley, L.P.; Dehne, V.; Jordan, A.; Reimann, S.; Roberto, F.; Zahm, J.R.; Siewerts, H.; Labudde, D.; et al. Automatically Identifying Online Grooming Chats Using CNN-based Feature Extraction. In Proceedings of the 17th Conference on Natural Language Processing (KONVENS), Düsseldorf, Germany, 6–9 September 2021; pp. 137–146. [Google Scholar]
- Ma, W.; Yu, H.; Ma, J. Study of Tibetan Text Classification based on FastText. In Proceedings of the 3rd International Conference on Computer Engineering, Information Science & Application Technology (ICCIA), Chongqing, China, 30–31 May 2019; pp. 374–380. [Google Scholar]
- Kocon, J.; Cichecki, I.; Kaszyca, O.; Kochanek, M.; Szydlo, D.; Baran, J.; Bielaniewicz, J.; Gruza, M.; Janz, A.; Kanclerz, K.; et al. ChatGPT: Jack of all trades, master of none. Inf. Fusion 2023, 99, 101861. [Google Scholar] [CrossRef]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. 2018. Available online: https://www.mikecaptain.com/resources/pdf/GPT-1.pdf (accessed on 4 March 2024).
- Zhang, Y.; Sun, S.; Galley, M.; Chen, Y.C.; Brockett, C.; Gao, X.; Gao, J.; Liu, J.; Dolan, B. DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation. arXiv 2019, arXiv:1911.00536. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language Models are Unsupervised Multitask Learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Faraz, A. Curated PJ Dataset; IEEE Dataport: New York, NY, USA, 2023. [Google Scholar] [CrossRef]
- Borj, P.R.; Raja, K.B.; Bours, P. On Preprocessing the Data for Improving Sexual Predator Detection: Anonymous for review. In Proceedings of the 15th International Workshop on Semantic and Social Media Adaptation and Personalization (SMAP), Zakynthos, Greece, 29–30 October 2020; IEEE: New York, NY, USA, 2020; pp. 1–6. [Google Scholar]
- Church, K.W. Word2Vec. Nat. Lang. Eng. 2017, 23, 155–162. [Google Scholar] [CrossRef]
- Pennington, J.; Socher, R.; Manning, C.D. GloVe: Global Vectors for Word Representation. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Grave, E.; Bojanowski, P.; Gupta, P.; Joulin, A.; Mikolov, T. Learning Word Vectors for 157 Languages. arXiv 2018, arXiv:1802.06893. [Google Scholar]
- Dharma, E.M.; Gaol, F.L.; Warnars, H.L.H.S.; Soewito, B. The Accuracy Comparison among Word2Vec, Glove, and FastText towards Convolution Neural Network (CNN) Text Classification. J. Theor. Appl. Inf. Technol. 2022, 100, 31. [Google Scholar]
- Nguyen, H.N.; Teerakanok, S.; Inomata, A.; Uehara, T. The Comparison of Word Embedding Techniques in RNNs for Vulnerability Detection. In Proceedings of the 7th International Conference on Information Systems Security and Privacy (ICISSP), Virtual Event, 11–13 February 2021; pp. 109–120. [Google Scholar]
- Villatoro-Tello, E.; Juárez-González, A.; Escalante, H.J.; y Gómez, M.M.; Villasenor-Pineda, L. A Two-step Approach for Effective Detection of Misbehaving Users in Chats. In Proceedings of the CLEF (Online Working Notes/Labs/Workshop), Rome, Italy, 17–20 September 2012; Volume 1178. [Google Scholar]
- Singla, Y. Detecting Sexually Predatory Behavior on Open-Access Online Forums. In Research and Applications in Artificial Intelligence (RAAI); Advances in Intelligent Systems and Computing; Springer: Singapore, 2021; pp. 27–40. [Google Scholar]
- Ebrahimi, M.; Suen, C.Y.; Ormandjieva, O. Detecting Predatory Conversations in Social Media by Deep Convolutional Neural Networks. Digit. Investig. 2016, 18, 33–49. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metric | Training Dataset | Test Dataset |
|---|---|---|
| Total Conversations | 66,927 | 155,128 |
| Predatory Conversations | 2016 | 3737 |
| Identified Predators | 142 | 254 |
| Number of Conversations | Training Dataset | Test Dataset |
|---|---|---|
| Non-predatory Conversations | 8783 | 20,608 |
| Predatory Conversations | 973 | 1730 |
| Classifier | Class 0 (Non-Predatory) | Class 1 (Predatory) | Weighted Avg | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Accuracy | Recall | F1-Score | F0.5-Score | Accuracy | Recall | F1-Score | F0.5-Score | Accuracy | Recall | F1-Score | F0.5-Score | |
| XGBoost | 0.99 | 1 | 0.99 | 0.98 | 0.96 | 0.84 | 0.90 | 0.93 | 0.98 | 0.92 | 0.95 | 0.95 |
| KNN (n = 15, p = 2) | 1 | 0.98 | 0.99 | 0.99 | 0.83 | 0.95 | 0.88 | 0.85 | 0.92 | 0.97 | 0.94 | 0.92 |
| SVM (C = 10, = 1, kernel = rbf) | 0.99 | 1 | 1 | 0.99 | 0.96 | 0.93 | 0.95 | 0.95 | 0.98 | 0.97 | 0.98 | 0.97 |
| RF | 0.97 | 1 | 0.99 | 0.98 | 0.98 | 0.69 | 0.81 | 0.90 | 0.98 | 0.85 | 0.90 | 0.94 |
| Classifier | Training Set | Testing Set | ||
|---|---|---|---|---|
| MAE | MSLE | MAE | MSLE | |
| XGBoost | 0 | 0 | 0.015 | 0.007 |
| KNN | 0.023 | 0.011 | 0.019 | 0.009 |
| SVM | 0.008 | 0.004 | 0.008 | 0.003 |
| RF | 0 | 0 | 0.024 | 0.011 |
| Technique | Paper | Precision | Accuracy | Recall | -Score | -Score |
|---|---|---|---|---|---|---|
| BoW with TF-IDF Weighting + NN | [62] | 0.98 | - | 0.78 | 0.87 | 0.93 |
| BoW with TF-IDF Weighting + Linear SVM | [11] | - | 0.98 | - | - | - |
| Soft Voting: BoW with TF-IDF Weighting + SVM, | [14] | 1.0 | 0.99 | 0.95 | 0.98 | 0.99 |
| BoW with Binary Weighting + MNB, | ||||||
| BoW with Binary Weighting + LR | ||||||
| Word2Vec + CNN | [46] | 0.29 | 0.88 | 0.70 | 0.42 | - |
| Word2Vec + Class Imbalance + | [12] | - | 0.99 | - | 0.99 | 0.94 |
| Histogram Gradient Boosted DT | ||||||
| BoW + SVM + RF | [63] | 1 | - | 0.82 | - | 0.957 |
| CNN + Multilayer Perceptron | [49] | 0.46 | - | 0.72 | - | - |
| BERT + Feed Forward NN | [8] | 0.98 | - | 0.99 | 0.98 | 0.98 |
| TF-IDF + SVM | [56] | 0.92 | 0.91 | 0.89 | 0.91 | 0.91 |
| One-hot CNN | [64] | 0.92 | - | 0.72 | 0.81 | - |
| Pre-Trained FastText + SVM (Ours) | This Study | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 |
| Classifier | Correctly Classified | Incorrectly Classified | TP Rate | FN Rate |
|---|---|---|---|---|
| KNN | 66 | 5 | 0.92 | 0.08 |
| SVM | 48 | 23 | 0.68 | 0.32 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Faraz, A.; Ahsan, F.; Mounsef, J.; Karamitsos, I.; Kanavos, A. Enhancing Child Safety in Online Gaming: The Development and Application of Protectbot, an AI-Powered Chatbot Framework. Information 2024, 15, 233. https://doi.org/10.3390/info15040233
Faraz A, Ahsan F, Mounsef J, Karamitsos I, Kanavos A. Enhancing Child Safety in Online Gaming: The Development and Application of Protectbot, an AI-Powered Chatbot Framework. Information. 2024; 15(4):233. https://doi.org/10.3390/info15040233
Chicago/Turabian StyleFaraz, Anum, Fardin Ahsan, Jinane Mounsef, Ioannis Karamitsos, and Andreas Kanavos. 2024. "Enhancing Child Safety in Online Gaming: The Development and Application of Protectbot, an AI-Powered Chatbot Framework" Information 15, no. 4: 233. https://doi.org/10.3390/info15040233