1. Introduction
Modern business processes use industrial control systems (ICSs) to manage and regulate industrial processes and machinery, and a variety of businesses and sectors rely on ICSs. Keeping complicated machinery and processes running smoothly, safely, and reliably is the goal of these monitoring and control systems, which are vulnerable to cybersecurity risks due to their digitization and interconnection. ICS engineers manage computer networks, mechanical and electrical equipment, and human and automated tasks in an ICS. In the present scenario, production, power utilities, water storage systems, gas pipelines, and various other industries can use ICSs for a more robust and innovative environment [
1]. ICS attacks can interrupt activities, disable machinery, undermine industrial procedures, and even endanger people. To protect these networks from attacks via the internet, they must be identified and fixed. Vulnerability studies and implementation must identify and generate commercial management system assaults. Analyzing ICSs involves methods of communication and ways to be attacked. Security experts and system administrators can improve critical network safety by analyzing risks and locations for attacks. Commercial control mechanisms are complex, making vulnerability and attack channel identification difficult. In contrast to standard IT systems, ICS settings have long lifespans with outdated equipment and older applications that may lack security patches. It is also important to comprehend ICS networks’ specialized methods of communication and technologies [
2].
Multi-faceted testing is needed to find ICS flaws and weaknesses. This method combines risk assessments, hacking tests, and ICS architecture analysis. Vulnerability evaluations detect software, network structure, and system setting weaknesses. Security experts can assess security and detect attack points using machine learning techniques and human evaluation. Ethical hacking—penetration testing—simulates practical problems and attacks [
3,
4]. This entails exploiting flaws to access important systems. Penetration analysis evaluates safety measures, ICS-responsive features, and possibilities for growth [
5,
6]. Threat sources, intelligence, and internal evaluations are needed to stay abreast of new corporate control system assault methods [
7,
8]. Threat analysis informs about ICS-specific risks, viruses, and attack operations. Industries can prevent cyberattacks and strengthen security by tracking threats and comprehending their methods. Importantly, ICSs support healthcare devices, cards with sensors, smart dwellings, and connected cities. ICS assets include commercial digital equipment. These electronics include SCADA, HMIs, RTUs, and PLCs. Smart technology and the IoT revolutionize ICSs, but they also raise cybersecurity concerns. ICSs have programs, configuration, and privacy issues [
9,
10]. The internet and physical risks, challenges to wireless and wired ICS innovations, business threats, architectural and technological risks, networking and information technology risks, and errors made by people (e.g., fraud and social technology) all go after ICSs. Malware, DoS, DDoS, identity compromise, memory overrun, exploiting style strings, brute force attempts, suxnet assaults, and more can target ICSs. Internet connections make the entire globe a battlefield. Criminals can be found all over the globe and in different legal frameworks. Electrical and health hazards can cause significant damage quickly. Despite technical developments, ICSs are becoming more susceptible [
11,
12].
An ICS exists in every essential facility; hence, it must be secure [
13]. Today, humanity’s economics, welfare, safety, and security as a whole rely on control system security. An ICS was safe while physically separated; therefore, the only approach to breaching it was to force your way into it. Because of their ease, technologies are increasingly integrating into networks that are wireless, bridge innovations, and already established parts, which compromise ICS safety.
The present paper explores ICS detection of breaches using testbeds. ICS identification of anomalies also uses deep learning (DL). For theoretical structures and the approach, this study investigates deep learning, variational self-encoding, and Wasserstein generative networks of adversarial networks. When it comes to developing classifications from complex data, deep learning approaches and multi-layer neural networks in particular really shine. Because of this, they can be used for many different applications, such as NLP, RL, and image identification. Because of their ability to handle enormous datasets and complicated problems at scale, deep learning models are frequently used to solve real-world problems. In many applications, deep learning models have outperformed and even eclipsed more conventional forms of machine learning. To produce new data samples, generative models like variational autoencoders can be trained. They can be used for things like creating images and cleaning up noisy data. To enable logical and continual interpolations between data points, VAEs map data into an ongoing latent space. Because of this, they are helpful for things like photo enhancement and clothing swapping. VAEs are helpful for applications where knowing model uncertainty is critical, such as medical diagnosis, because of their ability to assess uncertainty in their predictions. Some of the problems with classic generative adversarial networks’ (GANs’) training stability are resolved in Wasserstein GANs (WGANs) [
14,
15]. By switching to a loss function that is based on Wasserstein distance, training is made more consistent and robust. Samples generated using WGANs are typically of greater quality and more consistent than those generated using other GAN variations. Because of this, they are useful for projects like creating new images, copying existing ones, and enhancing existing data. Mode collapse is a typical issue in GANs when the generator produces little variability in generated samples, while WGANs are less susceptible to this issue. Kullback–Leibler divergence and Jensen–Shannon divergence are two topics that are studied in probability theory. Other topics include designing graphical elements for written and produced designs, fully developed artificial neural network architectures, simulations of latent variations, variational autoencoders, the generative approach in adversarial networks, and procedural methods like Modhus [
16,
17,
18].
The authors of this paper first modeled gas network and water holding tank SCADA systems. They then used Ian Turnipseed’s upgraded gas pipeline datasets as a substitute. Sensors, which are controls, an interaction network, and management controls comprise the dataset’s gas piping system.
Attack detection and deep relic networks are also covered. We discuss data-generating neural networks and their design. We test the system’s design with MNIST. Using the generated data, they categorize attacks. After identifying vulnerabilities and attack vectors, we build breaches and practice situations for the attack. This entails generating attack programs, malware samples, and exploit tools that mimic real-world attackers. Security experts can test security policies, response to incidents, and system resilience by simulating these assaults. Attack data helps industrial control system security designers [
14,
19]. It helps businesses assess prospective threats, identify defense flaws, and design mitigation plans. Simulated attacks can also help security and system operators create realistic training scenarios to improve their skills and response times. In one word, identifying and producing assaults in industrial management systems is essential to their resilience and safety against changing risks related to cybersecurity. Organizations can strengthen the safety of vital infrastructure by knowing hostile actors’ weaknesses, assault paths, and methods. Security evaluations, penetration tests, threat analysis, and mock attacks provide an extensive structure for proactive cyber security of industrial control systems. Businesses may protect vital facilities by regularly assessing and improving ICS security [
20,
21].
The primary contributions of this work are
The development of a dependable system for detecting security breaches, specifically in industrial control systems, including power systems, freshwater tanks, and gas pipelines.
The introduction of an effective neural network model that boasts enhanced performance over conventional models.
A case study was conducted to analyze the comprehensive threat posed to industrial control systems.
Objectives of This Paper
To understand the risks and security concerns in industry with the help of ICSs.
Build a cybersecurity system with the help of an industrial control system using residual neural networks.
Develop cybersecurity best practices to protect industrial control systems.
The paper is divided into sections: an introduction that talks about cyberattacks on ICSs and how they were found and then made to raise awareness about security; a literature review that talks about the background of this research and related work. A methodology that uses generative tools such as adaptive autoencoders and Wasserstein adversarial networks; and finally, a
Section 4 that talks about the results and compares the real dataset to the generated dataset. The
Section 5, “Conclusions” summarizes the entire project and makes suggestions for what comes next.
2. Literature Review
An ICS has a complex architecture with field equipment, a front-side processor, interaction gateways, a database, the historian program, a technical workstation, a smart electrical device, a portable termination unit, and configurable logic controllers. Each ICS element is built so that cybercriminals cannot hack or harm it [
22,
23]. The verification of input protects ICS applications from gaining access and unwanted performance. Incorrect input validation can impair ICS control and data flow. Unsecured code is low-quality. It requires careful development and maintenance. Hackers may take advantage of ICS application code weaknesses. A safe environment for development produces vulnerability-free code. Authorization and privileges regulate ICS access. ICS attackers may capitalize on missing or poor entitlements, rights, and entry controls. Identification checks ICS commands and clients for validity and authorization [
24]. However, many ICS distant components do not authorize commands executing unauthorized ones. The ICS can acknowledge invalid data if protocols and programs do not validate the data source or authenticity. CSRF attacks may result. Most ICS cryptography packages are weak. Accessibility to ICS information is also likely due to weak encryption. Clear-text accounts transferred across the internet expose the ICS to fraudulent usage of genuine login information. Network sniffing devices let cybercriminals log in with users’ credentials. ICSs are vulnerable to platform shortcomings, misconfigurations, and neglect. The operating system, along with application upgrades, can reduce risks. ICS products and applications have been thoroughly researched for vulnerabilities. A different theory examined PLCs and HMIs’ similar security flaws. They found basic credentials, unsecured remote administration connections, and insufficient encryption. These flaws allow hackers to take over vital systems, putting ICSs in danger [
25].
Related research by Gautam [
26] indicates that a system capable of identifying cyberattacks and network anomalies exists for intrusion detection. In order to combat IDS, many methods have been created. The current trend indicates that the deep learning (DL) method is superior to more conventional methods for IDS. In these studies, we introduced a novel, deep learning-based hybrid model consisting of a long short-term memory-gated recurrent unit–recurrent neural network. The proposed model outperformed other existing classifiers while using only 58% of the dataset’s features. Additionally, the study shows that LSTM and GRU with an RNN work well on their own.
For the creation of an IDS, Nagaraju et al. [
27] suggested a paradigm. Their method consists of two distinct phases. To begin, they used a GA (genetic algorithm) to optimize features, and then they used the RNN framework of deep learning to perform classification. The LSTM unit sequence was introduced to an RNN to improve its performance. Their model’s efficacy was measured using data from the NSL-KDD dataset. The results of their study demonstrate that GA can improve the accuracy of classification in both binary and multiclass settings. Additionally, when it comes to multiclass classification, their suggested model is more cutting-edge than both the support vector machine and the random forest in terms of accuracy. For attack detection against DDoS and DoS, Shurman et al. [
28] presented the deep learning model RNN using the long short-term memory (LSTM) architecture. They suggested two LSTM models with different numbers of LSTM layers. They stated that the three-layer LSTM model outperforms the competition. In a report by Savanovi, despite the IoT’s rapid progress, a major problem inside the IoT continues to restrict deeper integration. The goal of sustainable healthcare, enabled by the Internet of Things, is to provide people with organized healthcare that does not negatively impact the environment. Because security is crucial to the longevity of Internet of Things (IoT) systems, early detection and remediation are essential to meeting the sustainability problems that must be met [
29,
30,
31]. An enhanced configuration application for IoT structures is used to build a synthetic dataset, which is then used in experiments. All the analyses and comparisons show that the specified problem can be solved significantly better than before.
Hathaliya et al. [
32] undertook an intriguing analysis, summarizing the progression from Healthcare 1.0 to 4.0. They underlined that vulnerabilities in healthcare 4.0 methods can expose sensitive patient information. Sensitive information, such as email addresses, medical records of patients, messages between users and relevant parties, and more, might be compromised by an attack. The authors also discovered that the efficiency of data interchange could benefit from this technique. Savanovic argued that recent advances in IoT technology have resulted in the widespread adoption of connected devices. The healthcare industry is a prime example of one that might greatly benefit from the implementation of a system for active real-time monitoring. The ability to handle nondeterministic polynomial time-hard problem (NP-hard) issues in realistic time and without accuracy is crucial for long-term viability in any sector, especially in healthcare, which is where metaheuristic methods have made a significant contribution to sustainability [
33]. An enhanced setup application for IoT structures is used to build a synthetic dataset, which is then used in experiments. All of the analyses and comparisons show that the specified problem can be solved significantly better than before.
Research by Alferaidi [
34] showed that intrusion detection is becoming increasingly crucial as a vital detection tool for the security of data as 5G and other technologies become increasingly prevalent in the Internet of Vehicles. Conventional detection methods cannot guarantee their accuracy and real-time needs and are unable to be immediately applied to the Internet of Automobiles because of the quick changes in the framework of the IoV, the huge data circulation, and the complex and various kinds of intrusion. To detect infiltration in a car network and unearth anomalous activity, the cluster combines a deep-learning convolutional neural network (CNN) with an extending temporary memory (LSTM) network to extract elements and data from massive amounts of car network data traffic. According to Chen et al. [
35], who contrasted traditional methods with recent developments in deep learning, the field of deep learning has recently gained a lot of attention. Chen et al., using deep learning’s smart features, built an intelligent intrusion detection system. A method for finding suspicious intrusions using a mixed MLP and CNN was presented by Vijayanand et al. [
36]. Network intrusion detection was the focus of a study by Parimala and Kayalvizhi [
37], who created a method based on deep learning. In order to determine the various forms of invasion, the KDD-CUP99 dataset was analyzed using the BP neural network. In order to reduce the high complexity of network data, Karatas et al. [
38] devised an intrusion detection method using deep convolutional neural networks. Training and recognition can improve detection accuracy, false-positive rate, and detection throughput. To classify diverse attacks with supervised deep learning, Raschka et al. [
39] used Keras on top of TensorFlow, with the best accuracy being reached with RNN deep learning technology.
A study [
40] was performed to establish a web of dependence between various players. In order to comprehend the behavior of this type of service system, which may be considered a complex social system, it is possible to analyze the patterns of trust in dependence networks, as research has shown that trust is the fundamental coordinating mechanism in community-based organizations. Through his studies, he established a framework for the behavior and interaction among cognitive agents in their natural environment. Based on this design, we build a framework for agent-based simulation that can be used to study the interplay among various service systems’ informational and cooperative dynamics. The authors [
41,
42] discussed the intricate webs of finance. Extremely volatile financial markets are notoriously difficult to capture due to their unique structural characteristics. Researchers have turned to tail dependency networks as a possible solution to this issue. According to his findings, tail-dependent networks perform better than Pearson correlation ones on a global scale. According to a further examination of the connections in the upper- and lower-tail dependent networks, European markets have more sway over the economy in both prosperous and downturn economic conditions than their Asian and African counterparts. Furthermore, the two tail dependency networks have distinct cliques. This research shows that neighboring markets will feel the effects of financial risks.
The promise of machine learning models was demonstrated in tests where outstanding classification accuracy was attained, for example, 99.13% in anticipating attacks. For example, water reservoir monitoring and Internet of Things (IoT) device security in healthcare are only two areas where machine learning approaches have been successfully used in previous studies. The innovative use of deep learning and adapted metaheuristics to tackle hard security problems is a prime example of this. Certain models had trouble correctly categorizing attacks, suggesting they had certain limits in terms of coverage and generalizability [
43,
44,
45]. The models may have limited utility if they are tailored to fit just certain types of data, such as those collected from water reservoirs or Internet of Things devices. The difficulty in evaluating the relative performance of different research projects stems from the fact that many of them lacked comparative evaluations with other state-of-the-art methodologies [
46]. To overcome the constraints of past studies, we need models that are able to adapt well to new attack scenarios and datasets. While claims of high accuracy are encouraging, further statistical investigation is needed to determine the relevance of the gains. Real-time intrusion detection can be improved with further study, particularly in complex systems like the Internet of Vehicles. In order to close these knowledge gaps, this current research endeavors to conduct a comprehensive comparative analysis, statistically validate advancements, and center its attention on the extrapolation of intrusion detection models across a variety of settings. Our study significantly improves upon prior research efforts by helping to design more reliable and broadly useful intrusion detection systems by addressing these constraints. In conclusion, our study not only improves upon the strengths of previous work but also overcomes its shortcomings by offering a more exhaustive and statistically proven approach to intrusion detection [
47,
48,
49].
3. Material and Methods
The theoretical background for this paper is presented in this portion of the paper with Equations (1)–(9). The concepts behind machine learning, including adaptive autoencoders and Wasserstein adversarial networks that are generative will be discussed.
3.1. Jensen–Shannon with Kullback–Leibler Divergences
KL divergence and Jensen–Shannon divergence measure the resemblance between distributions of probabilities. p and q are probability distributions. KL divergence quantifies p-q divergence. DKL is 0 when p(x) = q(x). The predicted shock from applying q as a framework when the actual range is p is the KL deviation of p off q. KL divergence is asymmetric and violates the triangle inequality.
DKL(p∣∣q): This is the value that stands in for the KL divergence between the p and q distributions of probabilities. The distance between p and q is measured.
Log (∫xp(x)log(p(x)/q(x))dx: The KL divergence is found by performing an integral (a computation analogous to finding the dimension under a curve).
The KL divergence measures how different p and q are in terms of information content. On average, it informs us how much “extra” information we would need to code p if we utilized the best coding for q. If ( ) = 0 and DKL (pq) = 0, then p and q are coincident (i.e., their probability distributions are the same). If () DKL (pq) is non-zero, then p and q are not identical; a bigger value indicates a larger gap between the two sets.
A further comparable measure for probability distributions is [0,1]. Despite KL divergence, Jensen–Shannon is symmetric. This equation can be used to calculate the Jensen–Shannon (JS) divergence of two probability distributions, p and q, with the notation D JS (pq). The Kullback–Leibler (KL) divergence is symmetric and smoothed down to create this. The JS divergence is the median of two KL divergences, one measuring the dissimilarity between p and the mean of p and q and the other measuring the dissimilarity between q and the mean of p and q. The symmetrical and usually positive JS divergence is a result of the 1/2 weighting. With a value of 0, the JS divergence indicates that p and q have the same distribution, while bigger values indicate greater dissimilarity. It is a standard measure for contrasting and grouping probability distributions in the fields of probability theory, statistics, and data analysis. The formula is:
3.2. Statistical Predictive Model
This method used neural networks with deep layers to estimate the probable density of a function. The true design probability is p ∗ (x). Randomly sampled processes x machine learning models have to maximize parameters. The equation p (x) p (x) serves as an approximation in an effort to as closely approximate the true or desired distribution p (x). In a nutshell, the objective of many data-driven and modeling tasks is to have the modeled or learned variable p (x) resemble the target variable p (x) as closely as is humanly possible. Thus, deep learning seeks the following:
A probabilistic model should discover the variables that best match the method’s probability function. A probabilistic model lacks the parameter p(x). Due to excessive unknowns. The notation p (yx), where y and x are both functions of some unknown factors, denotes a contingent probability distribution. It is frequently used in the context of quantitative modeling and machine learning, where x stands for the parameters of the model and p (yx) stands for the distribution of y given the value of x. In simple terms, it is the result of a model’s attempt to predict y from x. The real or ideal dependent probability for the variable y given x is denoted as p (yx). The conditional distribution is the one we want to come as close to as possible. When p (yx) is a close approximation of p (yx), we write to denote this. The purpose of several branches of science, including statistics, machine learning, and scientific modeling, is to train or design a model (parameterized by) so that p (yx) closely matches p (yx). Maximum likelihood calculation, Bayesian inference, and training neural networks are common techniques for this purpose, although they vary with the modeling framework. Thus, a probability model remains conditional, as follows:
A case study of this would be a model that classifies a visual representation of the numerical value 2 as the number 2. The present one is simpler than the other. Predicting p(x,y) is more difficult. A user inputs 2, and the representation outputs a 2 image [
50,
51]. Neural networks are networks that parametrize probability functions. Softmax probability output: _i = 1. Neural network variables are all biased and weighted parameters.
Categorical (y); p = p (yx)
p (yx): This is a representation of the probability distribution of y given x, which is a parameter of the distribution. The probabilities of various outcomes or classes of y predicted with the model given input x are denoted by () p (yx).
Distinctive characters
Categorical (y; p): In this notation, y is a categorical random value standing in for various classes, and p is a vector of probabilities corresponding to those classes. For each y category, the model predicts a certain probability, denoted by p. For instance:
If p = neural net (x), then neural net (x) is equivalent to p. The results of a neural network are shown here. The problem at hand determines whether or not it is a vector or one value. The initial equation stands for the odds that various classes of y will be produced from the given input x.
Artificial neural networks: NeuralNet (x) vs. the result of feeding the neural network the value x as input is indicated here. Various features of the data, such as probability distributions, can be modeled by feeding them into the neural network and using the output.
3.3. Models in Graphical Directions
Visual probabilistic models express independent conditions on a graph. Edges represent conditional independence relations between vertices, which represent unknown variables. G is a DAG with V = (X_1, …, X_d). V = (1, …, d) also works. If G describes P, then P is Related to G.
A solution to the equation 1 p(x) = j = 1 d p(x j x j) can be written as follows:
The sum of the conditional probabilities for the elements of the random vector x reflects the probability distribution p (x). The combined probability distribution of a group of random variables can be modeled using this equation by decomposing it into conditional values that describe the interdependencies and relationships among the variables. In other words, every p (x j x j) can be interpreted as a local conditional probability distribution that accounts for pertinent information or context (x j). For each component x j, simplifying the modeling of complex joint distributions.
x_j’s parents are _(x_j). M(G) represents G’s distributions. The conditional probability distribution of x given x is equal to the conditional probability distribution of x given, where both are parameterized according to the equation = P (x x) = P (x). This equation may be useful in a variety of disciplines, including statistics, machine learning, and Bayesian modeling. This means that the model’s x-based behavior remains unchanged regardless of whether the equation is used. Neural networks may simply define the following functions:
3.4. Goals of Study Findings
ICS records are rarely released due to their economic and worldwide effects on industries. The data sector has worries about the privacy of organizational data. The study will benefit from real-world industry datasets, but if they end up in inappropriate hands, the outcome will be terrible. Hackers can target system weaknesses. Cybersecurity methods for ICSs detect anomalies that can harm organizational data. This paper seeks to address the lack of ICS data needed for neural network model development. “Limited supply” does not equal no data. ICS situations involving attacks lack data, whereas normal operation does not. Most data are typical ICS operations, whereas scenarios involving attacks make up less than 10%. Additionally, attack scenarios include DoS, man-in-the-middle, injection, and other attacks. Occasionally, just 1% of the data is attributed to a single assault type [
52].
A major problem with the detection of intrusions is the high rate of false positives, which can overwhelm security teams with false alarms and squander valuable time and resources. Organizations use a variety of approaches to counteract this problem. One common practice is to adjust the sensitivity of intrusion detection systems. Detection criteria and thresholds must be fine-tuned to the specific network architecture. In addition, sophisticated methods like identifying anomalies and machine learning are utilized by businesses to better recognize out-of-the-ordinary patterns of behavior. Maintaining and updating an intrusion detection system on a regular basis is essential for keeping it up-to-date with the latest fingerprints and patches, which in turn improves its accuracy. To obtain a fuller picture of network activity, security teams combine malware detection with additional safety features like SIEM platforms, taking advantage of context and correlation in the process. They can discover and prioritize warnings with less chance of false positives by looking at the bigger picture. Overall, a multi-pronged strategy including rule customization, improved detection algorithms, frequent updates, and the incorporation of contextual information is necessary to overcome the problem of false alarms in intrusion detection. This all-encompassing approach allows businesses to improve their security posture by simultaneously detecting more actual threats and reducing the number of false positives [
53,
54].
Improving cybersecurity in critical facilities requires a methodologically sound approach, one that may be achieved by the painstaking construction of a breach framework based on the careful research of parts of industrial control systems (ICSs), communication mechanisms, and probable attack sources. Businesses are able to better safeguard their critical facilities, reduce the risk of compromises, and be more prepared for cyberattacks by taking measures such as recognizing ICS elements, analyzing ways to communicate, conducting a risk assessment, implementing countermeasures, continuously monitoring and testing, collaborating, identifying possible attack sources, and creating the breach framework, which includes attack vectors, areas of attack, exploitation methods, an impact analysis, and an incident response plan. Given the gravity of the risks associated with ICS breaches, it is imperative to take preventative and all-encompassing measures to safeguard these systems. Kullback–Leibler and Jensen–Shannon are common practices in data analysis and machine learning to compare and contrast different probability distributions, and the book Divergences: Likely outlines one such mathematical or statistical method for doing so. It might be used to check how closely a theoretical model matches up with the distribution of data that has been collected. A statistical predictive model probably relates to creating or using such a model. Predictions and inferences about the relationships between variables may be derived from this model, and these in turn may be associated with one or more of the research topics. It would appear that the book “Models in Graphical Directions” addresses the topic of visual models, which are frequently used to depict intricate interrelationships among variables. The data related to the study topics could be visualized or analyzed using these models [
55,
56].
An anomaly identification method (such as an autoencoder) may detect “attack” and “average operation” with <1% of the data, but it cannot distinguish between different forms of assault. Classifying assaults requires a model. Classification approaches use several data pieces to identify distinct attacks. Even with a huge amount of actual data for the study, industrial control systems do not get hacked enough to build a reliable categorization system. This paper addresses attack data shortages. Generative networks are used to generate new information about attacks on ICS data, which is scarce. Our research contains three specific objectives for this major objective: a new ICS categorization model, checking ICS data generation, and training an automatic classification model with data that were generated using semi-supervised machine learning [
57,
58,
59].
3.5. Collecting Data
A number of different academics have previously collected the datasets used in this work. We aimed for a comprehensive collection of datasets covering a wide range of commercial sectors. We drew on the power system, freshwater tank, and gas pipeline datasets in our analysis. Each of the three categories of industries stands in for a wide range of everyday situations where anomalous behavior identification and attack categorization techniques can be invaluable [
60].
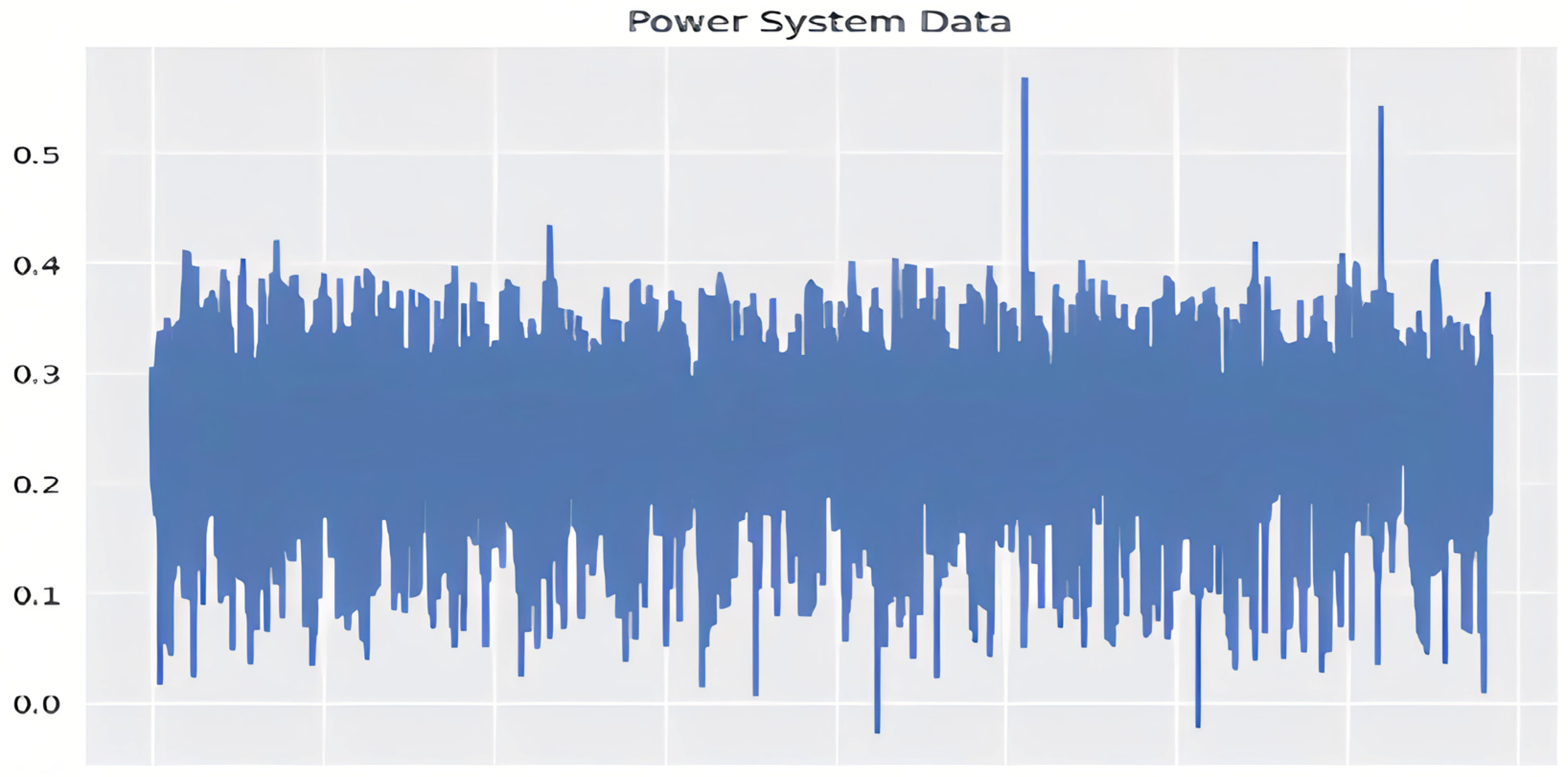
3.6. Energy Network Statistics
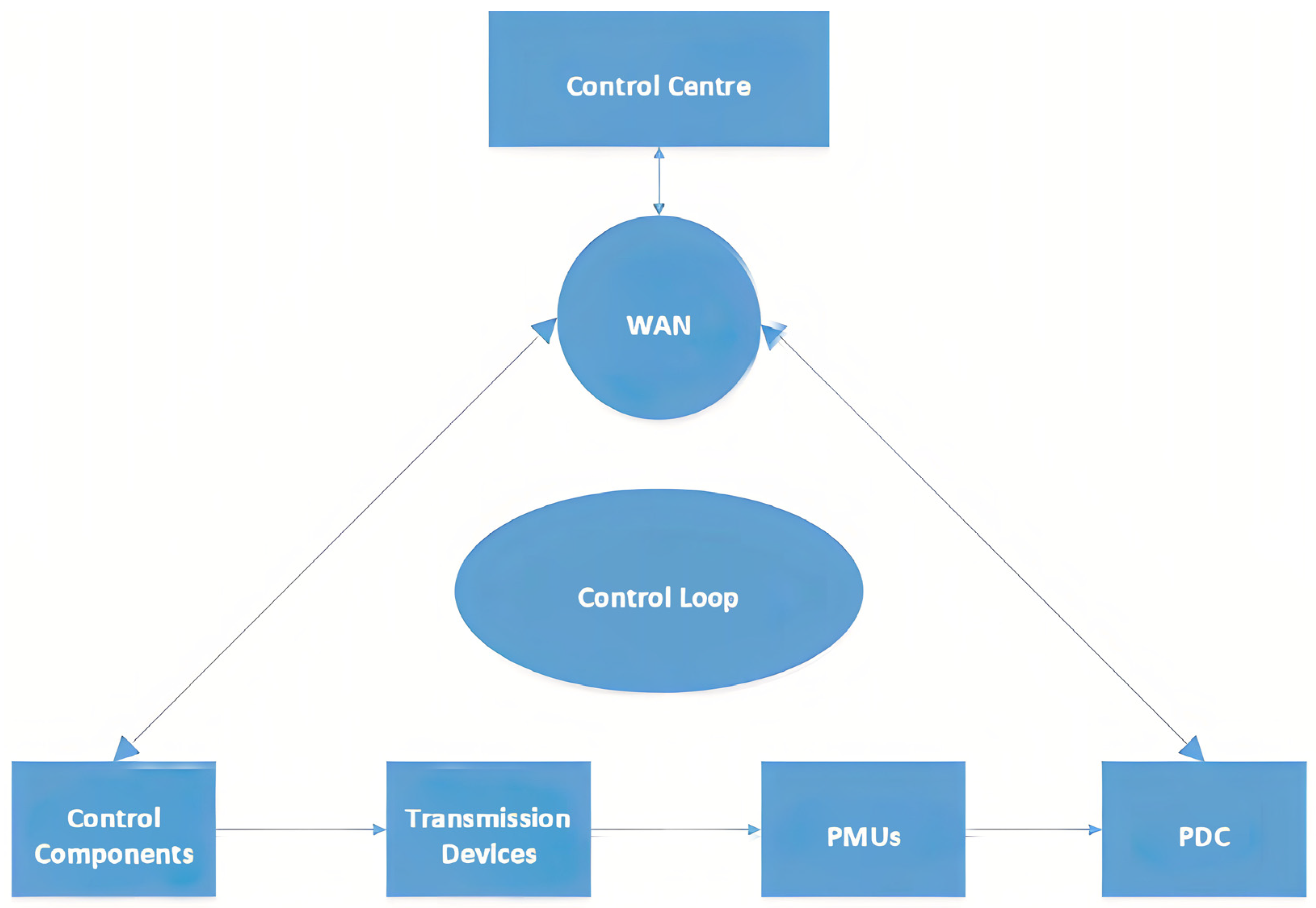
Power systems have four sections. Transmission, distribution, consumption, and transmission are the energy system’s foundation. It transmits power from the generator to the consumption center, often across miles and miles. Field detectors monitor the transmission network’s breakers and transformers. In Synchrophasor systems, field sensing uses PMUs. GPS signals are used to synchronize PMU data to UTC for continuous tracking. Phasor data concentration devices (PDCs) use WANs to transport Synchrophasor observations from temPMUs to the control center. Synchrophasor-based WAMS require PDCs and other PMUs. SCADA field sensors collect data every few seconds. WAMS use Synchrophasor technology to measure the data transfer system at 30–120 samples per second, quicker than SCADA. PDCs gather high-resolution measurement data for system status evaluation. The control facility uses complex algorithms to make actual time-field element control decisions. Controlling the loop ellipse centralized control lets system protection components detect and respond to disturbances [
61]. Field sensors monitor transmission system components like breakers and transformers. A Synchrophasor system, in this particular case as shown in
Figure 1.
The control center sends command data, and the IDEs send time-synchronized audit data. It is a finite-state machine. A control center command documented in the control center panel will induce a system state shift later. Breakers, relays that operate, and cables for transmission alter behavior over time, which changes the system state. Hardware logs record every modification. Temporal-state transitions are observed and measured data changes [
62,
63].
3.7. The Freshwater Reservoir
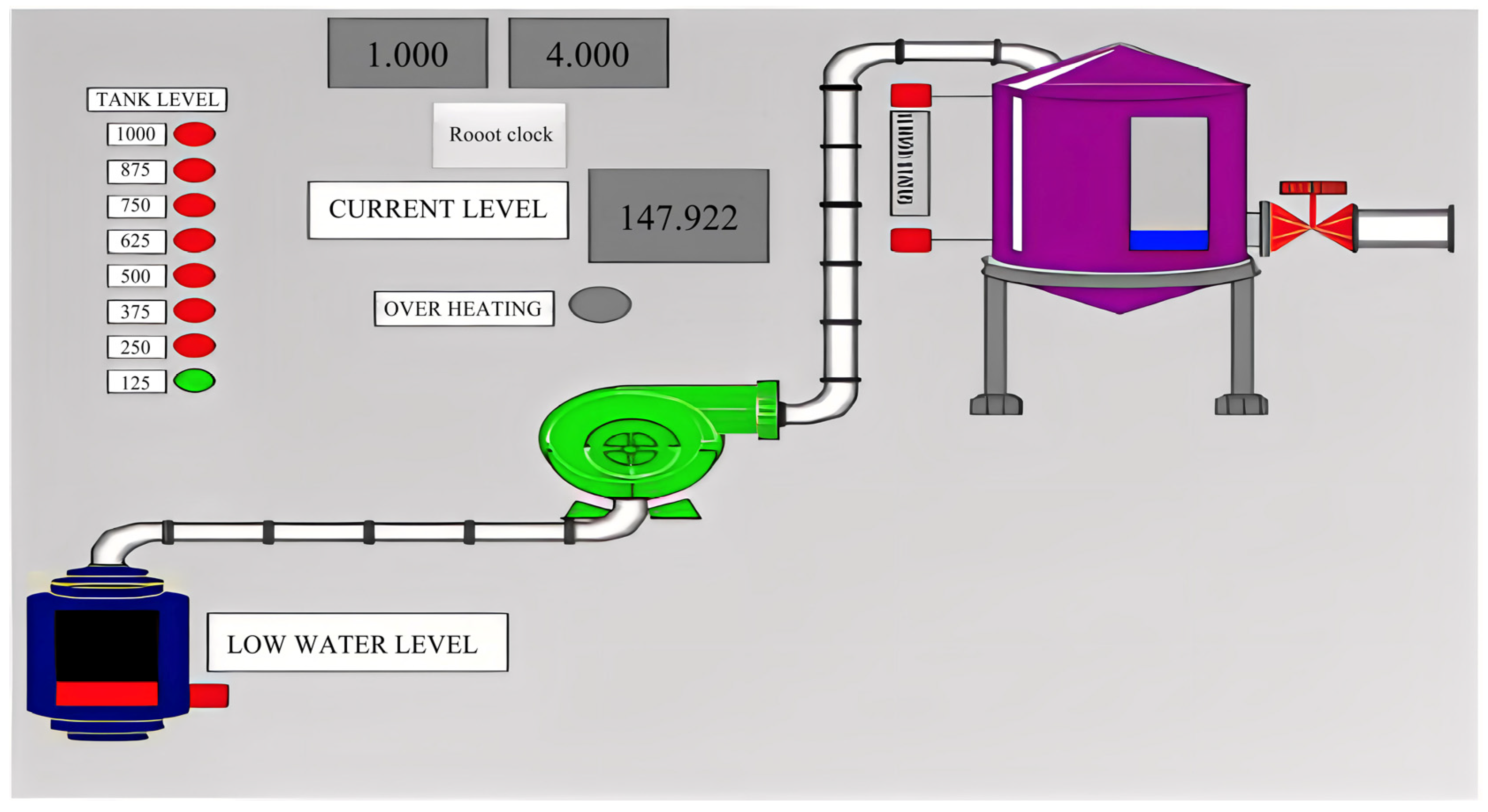
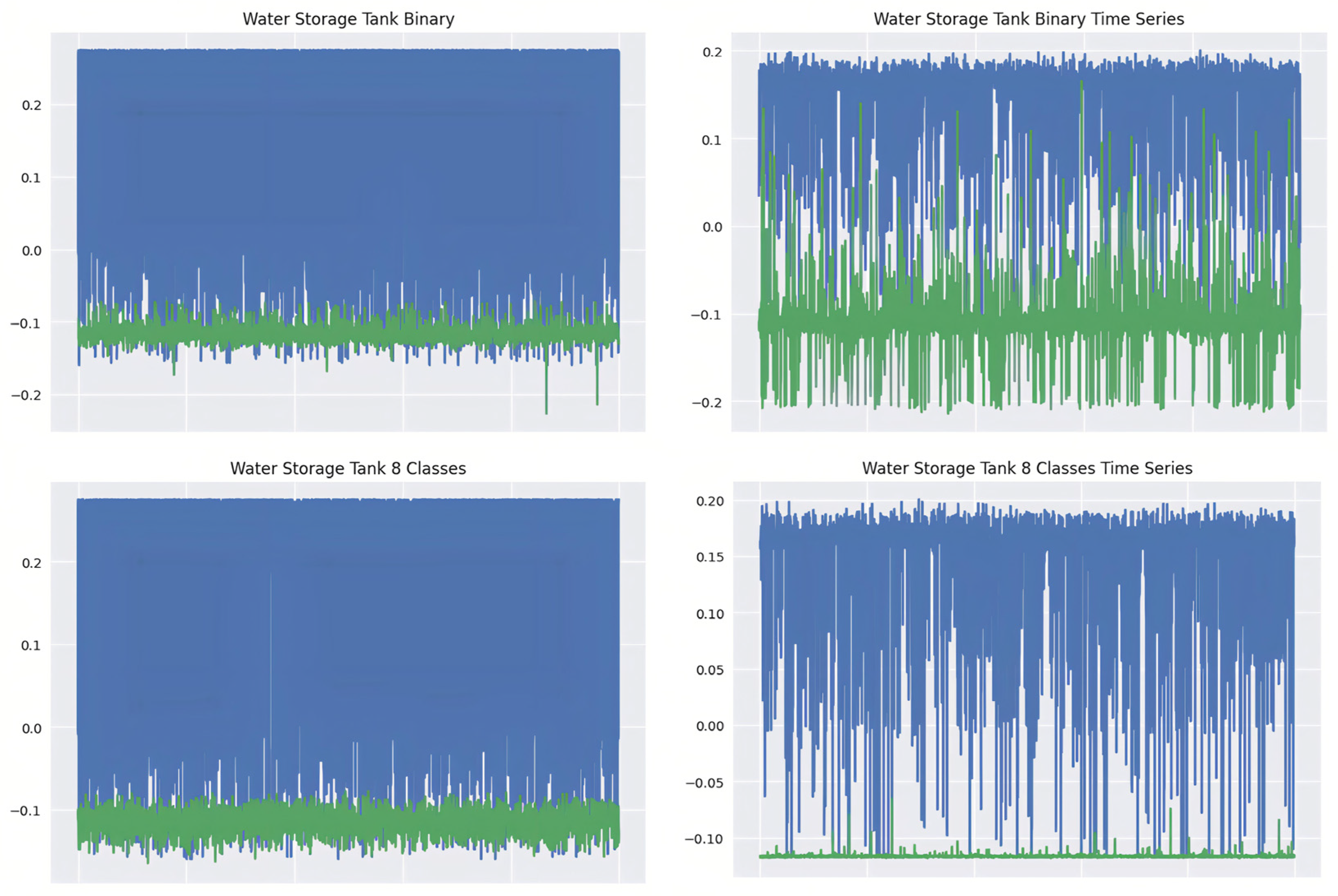
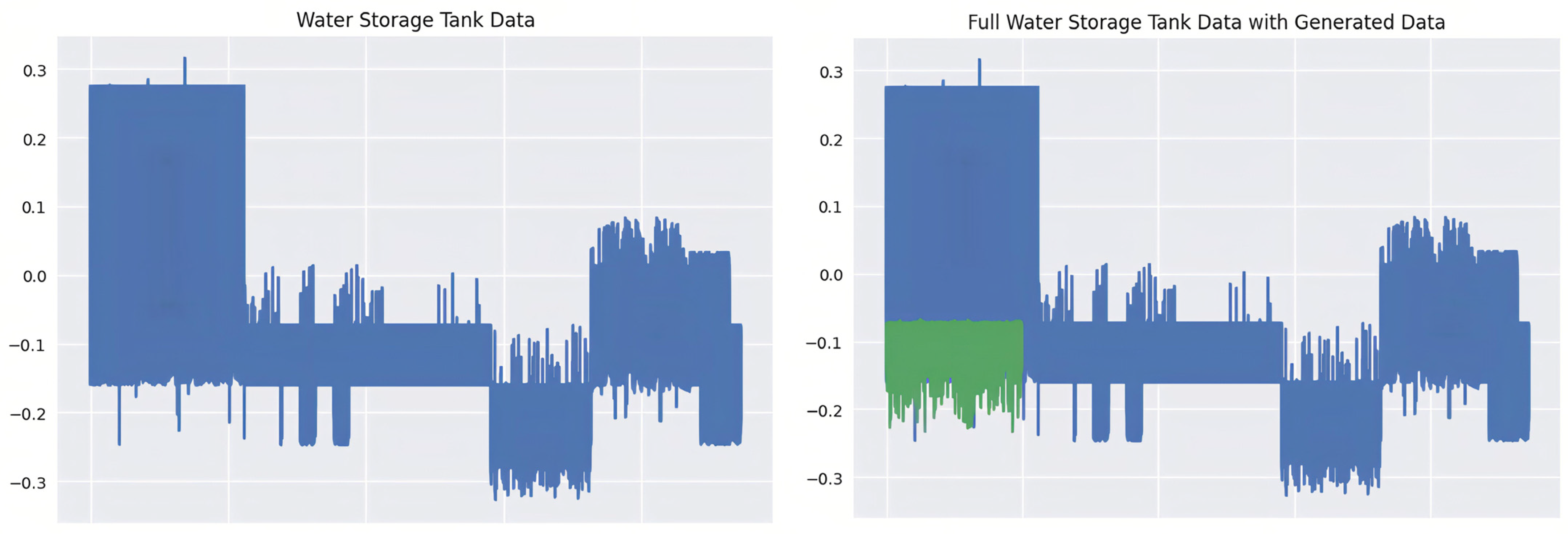
An RS-232 network data logger monitored and stored MODBUS traffic from the liquid storage vessel record. The authors of this paper first modeled gas pipeline functionality and water-holding container SCADA networks. Instead, we apply Ian Turnipseed’s upgraded gas pipeline dataset. The water reservoir’s management system mimics petrochemical manufacturing sector storage vessels for oil because the water-filled tank was developed for oil storage facilities. The tank has a main holding tank, an additional reservoir for the water container, and a pump that is used to move fluid out of the secondary reservoir to the main tank. A gravity-operated manually operated relief valve operates to allow liquid to pass from the main tank to the supplementary tank. In addition, a gauge is provided to measure the main tank’s capacity. Water exits the main tank and fills the additional tank. It uses closed-loop reservoir control. The water-holding system control method and factors of the system work correctly if the answer code for a function matches the given command’s functional code. Error response sub-function codes are the command function code plus 0 × 80. The system measures the water reservoir level. The unsophisticated and advanced malicious response injection assaults changed the predicted measuring results. During the test, a pump maintains the desired amount of water. The pump modes are on and off.
Human–machine interfacing (HMI) and the water reservoir system used by researchers are shown in
Figure 2. The water tank was originally intended for oil storage. Moreover, its control system is based on those used in the petrochemical sector.
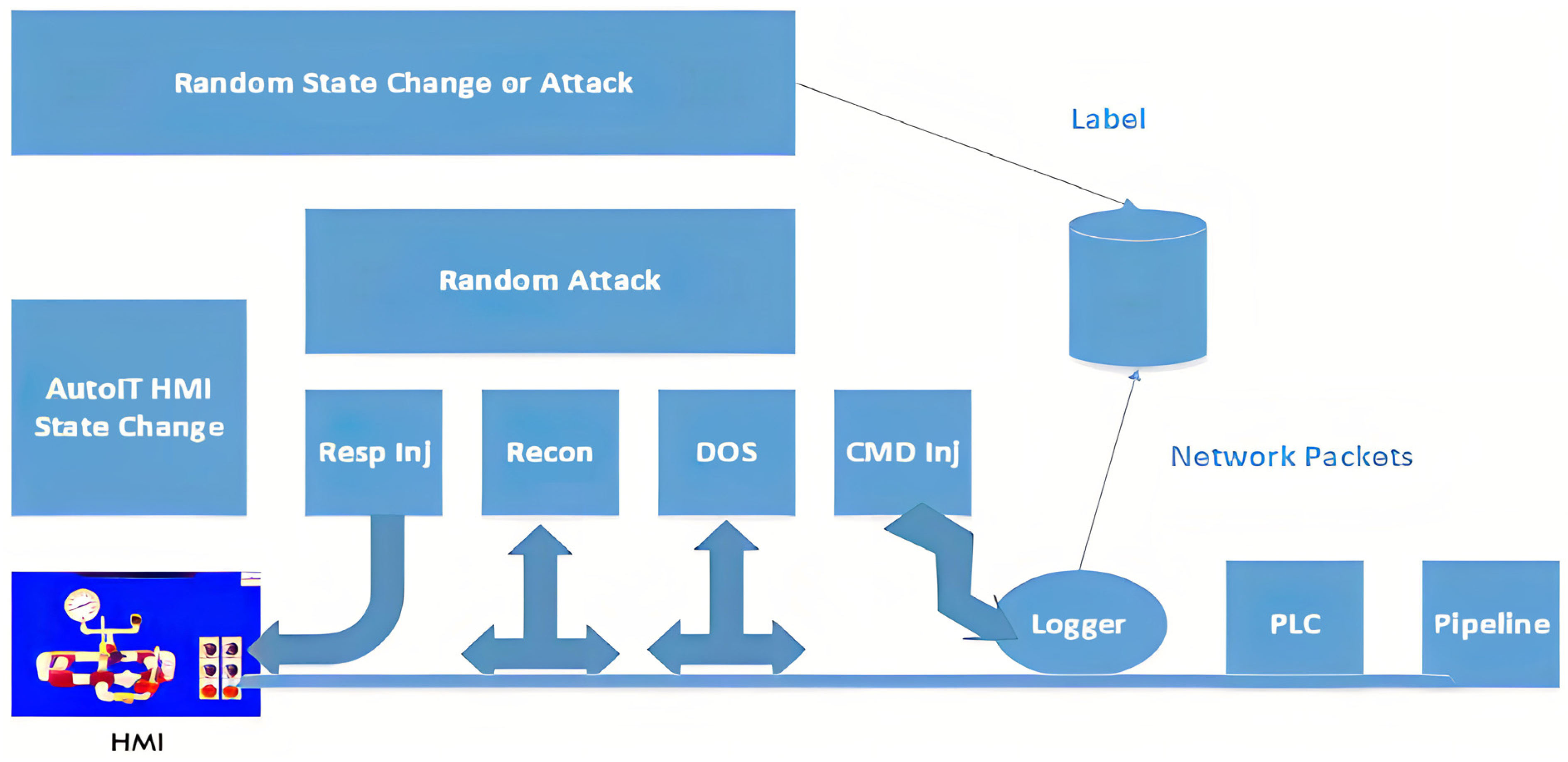
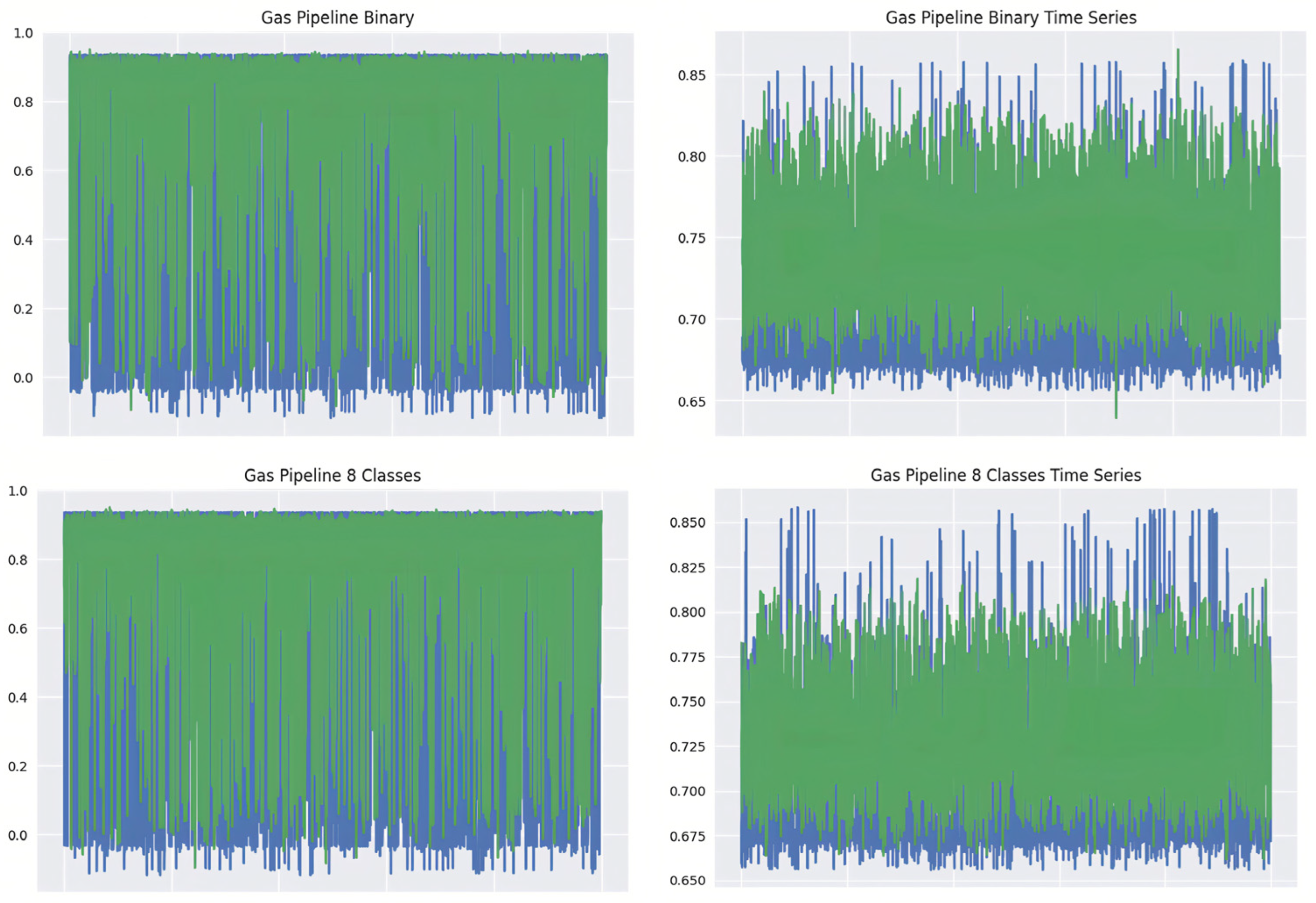
3.8. Gas Piping Statistics
Sensors are device controls, an interaction system, and management controls that comprise this dataset’s gaseous pipeline structure. This paper illustrates the gas pipeline network that generated the information being studied and the HMI that controls it. Gas pipelines have two actuators and a type of pressure sensor. A hydraulic pump and solenoid govern the entire system’s mechanical process, while supervisory controls regulate pressure. Pipelines that carry gas are manual and automated. Managerial controls choose two pressure-maintenance systems in automated mode, as shown in
Figure 3. First, the pumping mode setting controls pipeline pressure with the pump on/off controls. This approach maintains the system load. The solenoid mode is first. Solenoid-controlled relief valves regulate pressure in this system. This paper used a parametric and randomized approach to gather statistics. The threats were man-in-the-middle. The payload data includes gas pipeline state, options, and variables. These show system performance. These data are capable of identifying system outages and critical states. The dataset has 274,627 occurrences. Many aspects are uncertain since Modbus packets offer various details.
3.9. Analysis Techniques
Data classification and generation using deep neural networks are the primary topics of this study. Common metrics for ICS identification of anomalies studies include precision, accuracy, recollection, F1-score, and the false-positive rate, all of which we examined. The generated network is a crucial component of our study. The generative network first generates samples of data based on its learned distribution of the probability of the original dataset. The next step is to assess the degree of similarity between the generated data and the source data.
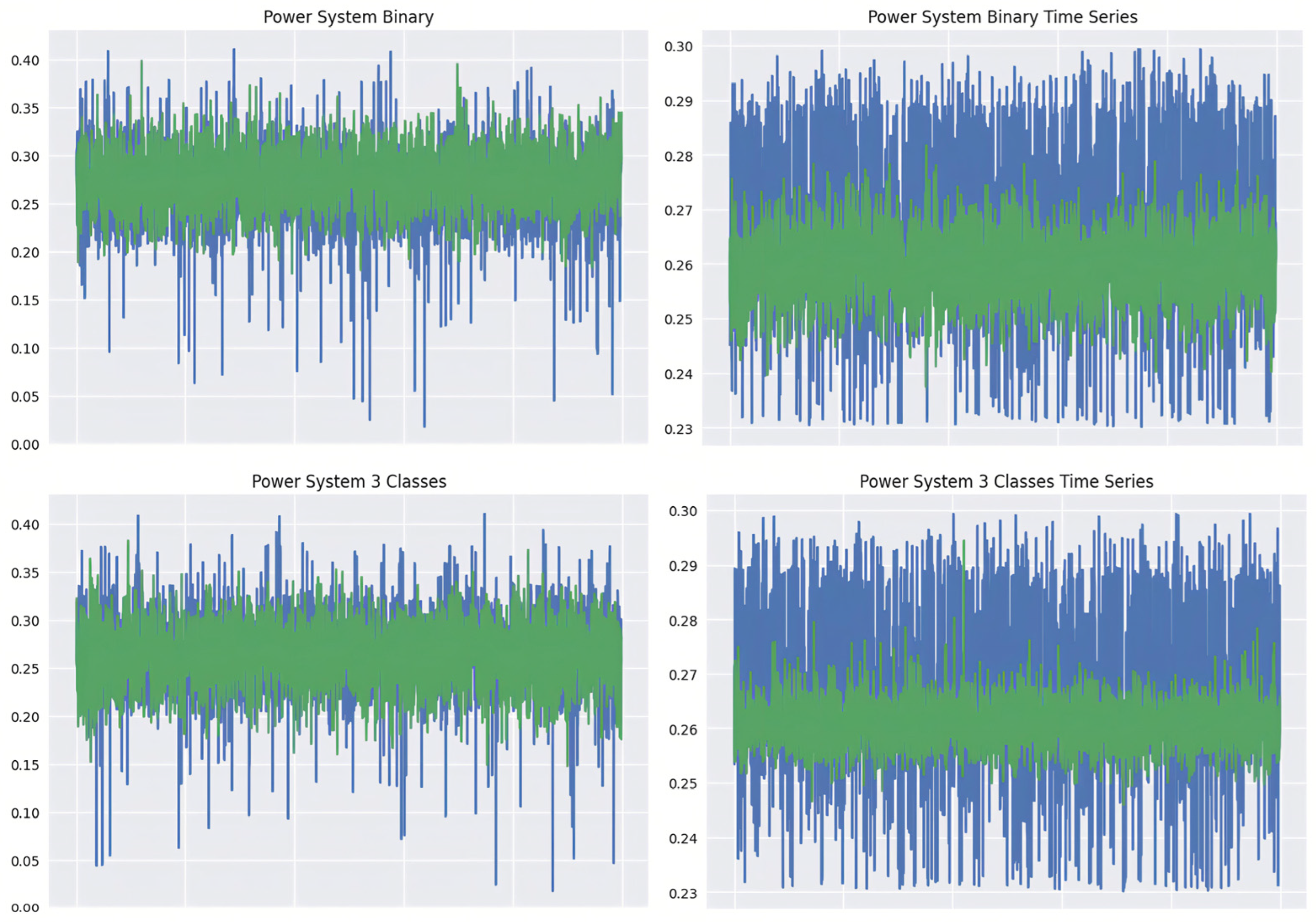
We will compare the produced and original datasets using statistical measures like mean and variance. This is because, during model training, the mean serves as the loss function for the generator. A zero-mean, one-variance Gaussian noise was utilized to generate the dataset. The second method involves taking a random sample of 5000 data points and plotting them against 5000 original datasets. This will provide a visual summary of the created data’s resemblance to the original data [
64].
This report focuses on major industries, including the electric power industry and water storage facilities. These fields rely substantially on ICS for their operations, and they are vital parts of society’s crucial infrastructure. This study prioritizes the protection of critical services by tackling cybersecurity concerns within these domains while also minimizing potential risks. A dedication to using cutting-edge technologies to deal with ICS risks is also reflected in the emphasis on developing and deploying neural systems in cybersecurity, in particular, residual neural networks. The detection of anomalies and breaches in ICS settings can benefit from residual neural networks’ superior performance in deep learning tasks. This exemplifies the authors’ commitment to leading the field of cybersecurity and using cutting-edge methods to safeguard vital networks and systems. Overall, this paper’s emphasis on key sectors and the utilization of cutting-edge technology like neural networks demonstrate a proactive approach to protecting ICS, which is essential in the face of constantly shifting cyber threats.
5. Conclusions
This research concluded that the manufacturing industry’s essential area of controlling processes is increasingly at risk due to the widespread adoption of low-power sensors and Internet of Things (IoT) solutions. Cyberattacks on these industries have been highlighted, as has the lack of effective security systems, which leaves our electronic gadgets and infrastructure open to assault. Our approach combined data from three databases that track critically important infrastructure: those that keep track of power plants, water reservoirs, and gas lines. Key discoveries arose as we analyzed the collected dataset and performed preliminary statistical evaluations. In the scenario of electric power systems, where time-series information is unavailable, one of the important discoveries is that supplementing the dataset cannot always enhance the efficiency of systems already battling difficulties in the initial dataset. In addition, this study used information about water reservoirs to emphasize the significance of information accuracy when using more recent types of systems to generate samples. The fact that the created data replicated inconsistencies found in the original water reservoir dataset brought attention to the need for precise and reliable data. Finally, this study proved that feeding more data into neural networks greatly improved the effectiveness of the dataset. Overall performance often improves after being exposed to a wider variety of scenarios, including edge cases.
However, the scope of this endeavor has limitations that must be taken into account. For example, the study’s conclusions may not be readily transferable to other sectors due to its narrow focus on infrastructure. More research is needed on this important subject because this study did not even touch on the topic of implementing particular security mechanisms against cyberattacks. The goal of future research in this area should be to create and evaluate effective cybersecurity solutions that address the specific threats posed by low-power sensing and Internet of Things technologies in industrial settings.



 and
and 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}