
Harnessing Test-Oriented Knowledge Graphs for Enhanced Test Function Recommendation

1
School of Computer Science and Engineering, Beihang University, Beijing 100191, China
2
CLOUD BU, Huawei Technologies Co., Ltd., Beijing 100191, China
*
Author to whom correspondence should be addressed.
Electronics 2024, 13(8), 1547; https://doi.org/10.3390/electronics13081547
Submission received: 8 March 2024
/
Revised: 3 April 2024
/
Accepted: 16 April 2024
/
Published: 18 April 2024
(This article belongs to the Section Computer Science & Engineering)
Abstract
:Application Programming Interfaces (APIs) have become common in contemporary software development. Many automated API recommendation methods have been proposed. However, these methods suffer from a deficit of using domain knowledge, giving rise to challenges like the “cold start” and “semantic gap” problems. Consequently, they are unsuitable for test function recommendation, which recommends test functions for test engineers to implement test cases formed with various test steps. This paper introduces an approach named TOKTER, which recommends test functions leveraging test-oriented knowledge graphs. Such a graph contains domain concepts and their relationships related to the system under test and the test harness, which is constructed from the corpus data of the concerned test project. TOKTER harnesses the semantic associations between test steps (or queries) and test functions by considering literal descriptions, test function parameters, and historical data. We evaluated TOKTER with an industrial dataset and compared it with three state-of-the-art approaches. Results show that TOKTER significantly outperformed the baseline by margins of at least 36.6% in mean average precision (MAP), 19.6% in mean reciprocal rank (MRR), and 1.9% in mean recall (MR) for the top-10 recommendations.
1. Introduction
Utilizing Application Programming Interfaces (APIs) is common in software development. Studies indicate that approximately half of the method calls in Java projects are API-related [1]. Harnessing the power of APIs for programming is of great value. Nevertheless, it is difficult for developers to master the knowledge of all APIs in a library. Therefore, to find proper APIs to use, engineers must study API documentation and other relevant documents and even search for online help. The study in [2] shows that effective understanding and use of APIs depend on domain concepts, API usage patterns, and API execution facts such as inputs, outputs, and side-effects [2]. Most existing API recommendation methods utilize API usage patterns [3,4,5] and API execution facts [6] that are collected from historical data sets. Some API recommendation studies are called with knowledge graphs [7,8] but only utilize Mashup-API co-invocation patterns and service category attributes [7] or properties of the third-party libraries (e.g., version, groupID and language) [8]. These studies do not use domain knowledge, such as domain concepts and the semantic relations among them, while these are the key concerns in knowledge-graph-based tasks [9,10].
Like API recommendations, test function recommendations focus on recommending test function(s) to realize a given test step as a query. However, there exist fundamental differences between recommending test functions and APIs. First, test functions are used in a confined domain, i.e., for testing a specific System Under Test (SUT), whereas APIs (e.g., standard and third-party libraries) are used in a more open application context. Second, test functions embody domain knowledge in more implicit ways; as discussed in our previous study [11], test functions from industrial datasets have significantly fewer words to describe their functionalities than methods from standard API libraries, and a test function library is not intended to be used externally for testing other systems.
Since test functions are used in more confined domains and are usually developed to test a specific software product, as opposed to using APIs from libraries for programming, test engineers often search for test functions by reading through existing test scripts or obtaining helps from senior peers. Hence, test function recommendations usually face the challenge called “cold start”, a phenomenon where effective inferences are hindered by insufficient historical data. Numerous API recommendation methods depend on historical data, e.g., feature request history [3], Stack Overflow posts [4], and clickthrough data from search engines [12]. These methods work well when historical data are abundant; otherwise, their performances significantly degrade. According to the study reported in [4], utilizing only API documentation as a data source is 16.9% as effective as compared to utilizing both Stack Overflow posts and API documentation. Since domain knowledge can compensate for the insufficiency of historical data effectively [13,14], it is a valuable solution to overcome the “cold start” challenge.
The second challenge is called “semantic gap”, which denotes that gaps exist between the description of a test step and the description(s) of test function(s) implementing the test step [4,11]. One of the main causes of the semantic gap is that different engineers express concepts or test behaviors in different words, though they are equivalent in semantics. For example, “Synchronous Digital Hierarchy” and its abbreviation “SDH” are both used in the test step and test function description. Recommending testing functions becomes difficult without such domain knowledge that “SDH” and “Synchronous Digital Hierarchy” are synonymous. The other reason is that the words or phrases used in test steps and test function descriptions are different but semantically related. For example, as we observed in the Huawei data set, the test step “create an EPL service” is implemented by test function “create_eth” whose description is “create an Ethernet service”. Misunderstanding might happen when a test engineer does not know that the “EPL service” is a type of “Ethernet service”. In the past, efforts have been made to overcome the semantic gap using latent semantic analysis but still failed to recommend test functions accurately due to the lack of historical data [11].
To address the aforementioned two challenges, we propose an approach named TOKTER for a test function recommendation based on a test-oriented knowledge graph capturing domain knowledge about the system under test (SUT) and test harness. The domain knowledge about SUT comprises domain concepts that specify its functionalities, business flows, data definitions, etc., and their relations (e.g., synonymy, hyponymy, and association). The domain knowledge about the test harness refers to the structure in which a specific testing project is developed and managed, e.g., test cases, test steps, test functions and their parameters, and the relations among these artifacts. TOKTER first constructs a test-oriented knowledge graph using the corpus data of a given test project, then recommends test functions based on the constructed knowledge graph by using the semantic relations between test steps (i.e., query) and test functions according to the literal descriptions, test function parameters, and historical occurrences.
To evaluate TOKTER, we choose BIKER [4], CLEAR [5], and SRTEF [11] as the comparison baselines and employ an industrial dataset from our industrial partner Huawei. We use the metrics of Mean Reciprocal Rank (MRR), Mean Average Precision (MAP), and Mean Recall (MR) to evaluate their performance. Results show that TOKTER achieved 0.743 in MAP, 0.824 in MRR, and 0.804 in MR for the top-10 recommendation results and significantly outperformed the baselines by more than 36.6% in MAP, 19.6% in MRR, and 1.9% in MR.
Contributions. (1) We propose a knowledge-graph-based test function recommendation approach, which utilizes both domain knowledge about the SUT and test harness; (2) we propose three types of meta-paths explicitly designed for test-oriented knowledge graphs, description-based, parameter-based, and history-based meta-paths, to discover candidate test functions from different perspectives; (3) we implement TOKTER as an open-source tool (https://anonymous.4open.science/r/TOKTER-78DE (accessed on 7 March 2024)); and (4) we evaluate TOKTER with an industrial dataset and demonstrate that it is practically useful and advances all the baselines.
2. Background
Knowledge graph offers a practical and effective way for capturing and representing concepts and relations among concepts, which is often specified with the Resource Description Framework (RDF) standard, whereby a node corresponds to an entity or concept, and an edge between two nodes denotes a relation between the corresponding entities or concepts. Its formal definition is given as follows.
Definition 1
(Knowledge Graph). A knowledge graph is a directed graph where is the set of entities and is the set of edges among entities. Each edge has the form of (head entity, relation, tail entity) (denoted as ), indicating a relation of r from entity to entity .
For example, (cat, kind of, mammal) declares that a cat is a kind of mammal. As a heterogeneous network, a knowledge graph can contain multiple types of entities and relations. Knowledge graphs have been widely applied, for instance, in search engines [10,15], recommending systems [16,17], and question answering systems [9,18], etc.
There are two kinds of knowledge graphs: cross-domain (or generic) ones, e.g., Freebase [19], DBpedia [20], and YAGO [21], and domain-specific ones, e.g., MovieLens [22]. The test function recommendation needs a domain-specific knowledge graph to capture the links between domain knowledge and a confined specific test project instead of these public cross-domain knowledge graphs. In current studies of constructing domain-specific knowledge graphs, despite the adoption of complex, trained linguistic analyzers (e.g., dependency parser), manual work by domain experts is still indispensable to achieve good results [23,24,25].
To facilitate the construction of a knowledge graph, a network schema has been introduced to specify the structure of a knowledge graph at a meta-level (schema-level) [26] and to define types of entities and relations. Its formal definition is provided as follows.
Definition 2
(Network Schema). A network schema, denoted as , is a meta template for a knowledge graph with the entity-type mapping and the relation-type mapping , which is a directed graph defined over entity types , with edges as relations from .
For example, the bibliographic information network is a typical knowledge graph, also known as a heterogeneous information network [26]. It contains four types of entities: papers (P), venues (i.e., conferences/journals) (C), authors (A), and terms (T). Each paper has links to a set of authors, a venue, a set of words as terms in the title, a set of citing papers, and a set of cited papers. The network schema for this bibliographic information network is shown in Figure 1a.
In a knowledge graph, a meta-path is a sequence of relations connecting more than two entities. As shown in Figure 1b, the author and paper can be connected via path. For a given author, this meta-path identifies papers published in the same venue as the author’s publications. In this meta-path, represents the category of entities rather than individual authors; then, such a path is called a meta-path. Its formal definition is given below.
Definition 3
(Meta-path). A meta-path is a path defined on the graph of network schema . A meta-path defines a new composite relation between type and , where and for . Informative meta-paths in a knowledge graph are often engineered manually based on domain knowledge or expertise [27].
3. Approach
As shown in Figure 2, TOKTER first constructs the test-oriented knowledge graph based on the corpus data, e.g., test function and SUT documentations and historical test cases (Section 3.1) from a given test project. Then, TOKTER links the query to the knowledge graph and finds path instances with meta-paths defined in the network schema. After computing scores between the query and test functions within the path instances, TOKTER ranks candidate test functions as recommendation results (Section 3.2). After introducing TOKTER, we use an illustrative example to describe the process of a testing function recommendation (Section 3.3).
3.1. Constructing the Test-Oriented Knowledge Graph
3.1.1. Specification
In this section, we define the network schema of the test-oriented knowledge graph, as shown in Figure 3. This test-oriented knowledge graph captures the domain knowledge about the SUT and test harness. The domain knowledge about the SUT refers to domain concepts and their relations in the SUT domain, e.g., synonymy, hyponymy, and association, which have been extensively used in the literature [28,29]. A synonymy relation of two words indicates whether the senses of the two words represent the near identity. For example,“SDH” and “Synchronous Digital Hierarchy” are both domain concept entities in a knowledge graph. Although they differ in the description text, both refer to the same type of equipment. It is easy for humans with domain knowledge to determine that “SDH” is an abbreviation of “Synchronous Digital Hierarchy”, and there is a synonymous relation between these two entities (Table 1). However, it is very difficult for a recommendation algorithm to identify such synonymy relations automatically. A hyponymy relation of two entities A and B is the inclusiveness sense relation that means A is a kind or type of B. For example, because “Java code” is a kind of “program code”, we can identify the hyponymy relation between these two entities. An association relation between two domain concept entities indicates that they are semantically related and can have certain interactions in the domain. For example, there is an association relation between two domain concept entities: “precomputing” and “business path”. That means the domain concepts of “precomputing” and “business path” may interact in the testing domain, e.g., “precomputing the business paths for the ETH service”.
Test-harness domain knowledge refers to connected test artifacts, e.g., test functions and their parameters, test steps of historical test cases, and relations among these artifacts. TOKTER captures three types of entities: the test step, test function, and function parameter. Since test functions implement test behaviors of test steps, there exist implementation relations between test functions and test steps. A test function has a relation of containment with function parameters, which are the necessary part of the test function specification.
Moreover, relations need to be established between domain concept entities from the SUT domain and entities of test steps, test functions, and function parameters from the test harness, which are named related_to_dc relations where “dc” abbreviates “domain concept”.
3.1.2. Overall Process
Constructing a test-oriented knowledge graph involves entity recognition and relation extraction (Figure 2). The process’s input includes test function and SUT documentations, and historical test cases. Test function documentation describes test functions and their parameters. SUT documentation provides the necessary information about functional interfaces, data definitions, and operations of the SUT so that tests can be conducted. A historical test case has been used to test the SUT and has sequential literal test steps. Each test step has the test function(s) that implement its test behavior. For instance, as shown in Table 2, the test case aims to test the creation, querying, and deletion of two SDH services via five test steps. Each test step describes the test behavior in natural language and a test function that implements the behavior. Based on such information, TOKTER recognizes entities and extracts relations among the recognized entities.
3.1.3. Entity Recognition
Since test engineers have already implemented the test functions and specified the test function documentation, test function entities and function parameter entities can be accurately identified by parsing the test function documentation. Similarly, test step entities can be identified by parsing the provided historical test cases.
The recognition of domain concepts from SUT documentation, on the other hand, is a typical NLP problem in domain-specific knowledge-graph construction [23,30,31,32]. We first use mutual information and branch entropy to obtain a list of domain concept candidates and then, with the aid of domain experts, filter out irrelevant domain concepts and supplement the necessary ones that are not identified or even not present in SUT documentation. Mutual information refers to the degree of correlation between word x and word y in the same phrase w [33], which can be computed with the following formula:
where , represent the probability of word x, y appearing in the corpus, respectively; represents the probability of words x and y appearing in the corpus together. A greater mutual information value between words x and y indicates a greater correlation and a greater possibility that phrase w can be treated as a domain phrase.
Branch entropy measures the diversity and complexity of domain phrases by calculating the entropy of their adjacent words [34]. A domain phrase has left-branch and right-branch entropy to specify the diversity of its left and right adjacent words, respectively. The minimal one is chosen as its branch entropy of a domain phrase, a common way for calculating branch entropy [34], as shown below:
The left-branch entropy and right-branch entropy can be computed with the following formula:
where (or ) denotes the set of left (or right) adjacent words of w; (or ) denotes the probability that (or ) is the left (or right) adjacent word of domain phrase w. A bigger branch entropy tells more various words adjacent to w, thus a greater possibility that w is a domain phrase. After calculating and , we use the formula below to calculate scores of candidate domain phrase w:
Ranking by makes it easier for domain experts to validate if candidate domain phrases are true domain concepts during a review process. Domain experts can also supplement domain concepts when needed.
3.1.4. Relation Extraction
As summarized in Table 1, TOKTER needs to extract six types of relations: synonymy, hyponymy, association, related_to_dc, implementation, and containment. We use a rule-based approach to extract them from the corpus, i.e., the test functions and SUT documentations, and the historical test cases. In relation extraction, we treat these corpus data as unstructured texts as we use the dependency parser to obtain dependency trees from sentences in the corpus, a common practice in ontology construction [35,36].
A synonymy relation means that the two domain concepts are synonymous. The most commonly applied synonymy knowledge base is BabelNet [37], which is a semantic network connecting about 22 million entities, with each entity expressing a given meaning and its related synonyms. Synonymy relations are across different languages, making it more suitable for situations where both Chinese and English words exist. TOKTER first uses BabelNet to obtain all synonyms of the domain concept entities identified in the entity extraction phase. Note that synonyms of domain concept entities also need to be domain concept entities.
A hyponymy relation means that one domain concept is a type of the other. An association relation is a relation between two domain concept entities, denoting a communication path (also called a link) between them. In this paper, the extraction of hyponymy and association relations uses the same rule based on the results of a dependency parser, which identifies the dependencies between words in a sentence [38]. The two domain concept entities, and , have a hyponymy relation when they satisfy the following rule:
This rule tells that if has and and is , there should be an amod (adjectival modifier) or nn (noun compound modifier) grammatical relation between and , then a hyponymy relation can be identified between and . Notice that the amod and nn grammatical relations are widely used in knowledge-graph construction [10,39,40].
Figure 4 shows the dependency tree of the sentence “Create a static tunnel and specify the interface type as ETH subinterface”. In this dependency tree, three hyponymy relations can be extracted based on the above rule: , , and .
Two domain concept entities and can have an association relation () if there is a (direct object) or (nominal subject) grammatical relation between them. They are widely used grammatical relations in knowledge graph construction [10,39,40].
Figure 5 shows the dependency trees of two sentences: “delete the SDH service” (Figure 5a) and “confirm whether the service was created successfully” (Figure 5b). In the dependency trees, two association relations can be extracted based on the following dobj and nsubj grammatical relations: and .
Relation indicates whether an entity of test function (TF), test step (TS), or function parameter (FP) is related to a domain concept entity (DC). TOKTER segments the descriptions of test steps, test functions, and function parameters at first into a set of phrases by using the word segmentation tool HanLP [41]. For any segmented phrase , if there is a domain concept entity matches, i.e., is literally identical to the name of , then a related_to_dc relation between and would be constructed.
Implementation relation and containment relation are explicitly specified and can be extracted from the historical test cases and test function documentation for a given test project directly.
3.2. Recommending Test Functions
3.2.1. Meta-Paths
To enable test function recommendation with test-oriented knowledge graphs, we design three types of meta-paths based on the defined schema, description-based, parameter-based, and history-based meta-paths, to capture semantic links from a query to test functions (Table 3).
Using description-based meta-paths, we can recommend semantically similar test functions regarding function descriptions. The starting node and target node of a description-based meta-path are the query Q and the test function , respectively, which remain unchanged. Domain concept entities are in-between nodes, which entail semantics between the query and the test function. In this paper, we categorize the use of domain concept entities as 1-hop and 2-hop, common configurations in the literature [42]. is a 1-hop description-based meta-path as it only uses a single domain concept entity to connect Q and . is a 2-hop description-based meta-path as it sequentially uses two different domain concept entities to connect Q and , and the relation between these two entities can be synonymy, hyponymy, or association, which is represented with the “*”.
For parameter-based and history-based meta-paths, domain concept entities connect the query Q to function parameters and test steps , respectively. The use of domain concept entities is also categorized into 1-hop and 2-hop configurations. With parameter-based meta-paths, we can recommend test functions whose parameters are semantically related to the query. With history-based meta-paths, we can recommend test functions that have previously implemented some test steps similar to the given query.
3.2.2. Test Function Recommendation with Meta-Paths
In recommending test functions, TOKTER first segments a given query (i.e., a literal test step) into a set of query phrases. If any query phrase matches a domain concept entity in the knowledge graph, a related_to_dc relation between it and the query is constructed, implying that the query is linked to the knowledge graph. After that, all such links can be identified such that path instances of meta-paths , donated as P, are retrieved from the knowledge graph to connect a given query Q to a given test function . TOKTER then calculates the score between Q and the test function with the following formula to decide its ranking:
where and are the total numbers of domain concept entities linked to query Q and test function in the knowledge graph, respectively; is a search process that would return path instances P matched with meta-paths according to Q and , as shown in Algorithm 1. The function calculates the maximum length of all meta-paths M. returns the end node of path p. returns all neighboring nodes of in the knowledge graph G. is used to determine whether the path matches one of the meta-paths M. This algorithm belongs to depth-first traversal algorithms, incorporating pruning techniques.
| Algorithm 1 Path Instances Search Algorithm |
| Identifier: PathSearch(G, M, Q, , p) Input: knowledge graph G, mate-paths M, query Q, test function , temporary path p Output: path instances P
|
is the total weights of relations captured in P. and only count the numbers of domain concept entities linked to Q and which appear in path set P, respectively. calculates relation weights for path set P with the formula below:
where is the number of path instances in P, is the set of all relations that appeared in path p, and denotes the weight for relation in . Indeed, different types of relations do not have the same semantic importance. For the relations listed in Table 1, since the related_to_dc relation is extracted when two entities have the same text and the implementation and containment relations are explicitly specified in documents, these three ones have the least uncertainty and thus have the biggest weights. The other three relations (i.e., synonymy, hyponymy, and association relations) are difficult to extract with 100% certainty due to the use of NLP techniques. In particular, the association relation is inherently uncertain since it would be extracted only when a or grammatical relation is present in a dependency tree. Therefore, we give relations of the synonymy and hyponymy relations smaller weights and the association relation the smallest weight, as shown below:
In the end, we rank any test function for given query Q by using the score function and obtain the top-10 test functions as recommendation results.
3.3. Example
In order to describe the process of test function recommendation more clearly, we give a small illustrative example containing all types of entities and relations, as shown in Figure 6. The example contains 8 domain concept entities, 4 test function entities, 1 test step entity, and 1 function parameter entity. Furthermore, there are 1 synonym relation, 2 hyponymy relations, 1 association relation, 13 related_to_dc relations, 1 implementation relation, and 1 containment relation among these entities.
For the given test step “create an SDH service” (Q), three related_to_dc relations (, , and ) can be established with the test-oriented knowledge graph after word segmentation. After that, TOKTER searches all path instances of meta-paths from given query Q to each test function . For example, from the query Q to the test function “create_sdh” (), there are five different path instances that conform to the meta-paths as shown in Table 4. According to the (Equation (8)), we can calculate that the score between Q and the test function “create_sdh” () is 0.733. Similarly, we can calculate the score between Q and the other three test functions (“create_eth”, “create_eth_path” and “query_sdh”) to be 0.407, 0.407, and 0.714. Thus, we can obtain the list of recommendation results by sorting the scores. The test function “create_sdh” with the highest score is exactly the ground truth.
4. Experiment Design
Baseline. To evaluate TOKTER, we select three baselines. BIKER [4] is a classic approach in API recommendation and is often used as a baseline in the literature [5,11,43]. BIKER exploits Stack Overflow posts and API documentation and tackles the task-API knowledge gap. BIKER uses a word embedding model to represent question (query) text and API description text. CLEAR [5] embeds the whole sentence of queries and Stack Overflow posts with a Bidirectional Encoder Representation from Transformers (BERT) model that can preserve the semantic-related sequential information. CLEAR is a state-of-the-art approach in API recommendation. We select CLEAR because it uses BERT and, hence, ensembles the performance of Large Language Models (LLM) on test function recommendations. We implemented and trained CLEAR according to the model settings described in [5]. SRTEF [11] exclusively recommends test functions based on weighted description similarity and scenario similarity. The former employs the Deep Structured Semantic Model (DSSM) to assess the relatedness between test steps and test functions based on their literal descriptions. The scenario similarity is calculated by considering both test scenarios and test function usage scenarios. We selected SRTEF as one of the baselines because it is the closest to TOKTER as both focus on test function recommendation.
Dataset. The dataset we use is from our industrial partner Huawei. The collaboration context is about testing a Network Cloud Engine-Transport (Huawei, Shenzhen, China) product, one of the components enabling the transformation of a transport network towards modern software-defined networking. The dataset consists of historical test cases, test function documentation, and SUT documentation. There are 6514 historical test cases implemented in Ruby, and each test case has 8.7 test steps on average. Since some test steps are included in more than one test case, there are, in total, 9924 unique test steps. Each test step contains one or several sentences written in Chinese embedded with some English terms and is implemented by 2.9 test functions on average. Table 5 shows the number of test functions used to realize a test step. According to the statistics, we randomly select 500 test steps with the corresponding test functions proportionally as testing data to evaluate TOKTER, including 180 test steps implemented by one test function, 102 test steps implemented by two test functions, 70 test steps implemented by three test functions, 53 test steps implemented by four test functions, and 95 test steps implemented by more than five test functions. The test set is exactly the same as in our previous study SRTEF [11].
The test function documentation contains 967 test functions. Each test function has a corresponding description in Chinese to explain its functionality and usage. There are a total of five documents related to the SUT. These documents encompass interface descriptions and functionality usages. We consider them as unstructured texts, which contain, in total, 109,978 sentences comprising 728,065 words.
Metrics. To compare TOKTER with the baseline approaches in terms of their effectiveness, we employ three metrics, Mean Average Precision (MAP), Mean Reciprocal Rank (MRR), and Mean Recall (MR), which are the classical metrics for information retrieval [44] and have been frequently used in software engineering studies [3,4,45,46,47,48,49]. MAP can be calculated with the following formula:
where represents the set of test functions that actually implement the test step (corresponding to query q), and is the size of the test function set. represents the position or order at which the ith test function of appears in the recommendation list. For MAP, represents all queries, and is the number of those queries. For each query q in , the average precision is calculated using Equation (11), and Equation (12) computes the mean of the of all queries.
MRR can be calculated with the following formula:
where is the ranking of the first test function in for query q.
MR can be calculated with the following formula:
where is the number of test functions for query q, and is the number of test functions that actually implement q.
Since in recommendation tasks, top-matched results are of great interest in practice, we evaluate TOKTER and the baselines with their top-10 recommendation results, which is commonly applied in API recommendation studies [3,45].
Statistical Test. We use the non-parametric Wilcoxon signed-rank test [50], which has been widely used in API recommendation studies [4,5] to test whether there are statistically significant differences in the effectiveness and time cost of different approaches or strategies, with a significance level of 0.05. We also use the Spearman correlation analysis to assess the correlation between recommendation time and the number of domain concept entities connected to the query.
Tool Implementation. The tool contains two functionalities, test-oriented knowledge graph construction and test function recommendation, both implemented in Python. For the construction of the test-oriented knowledge graph, TOKTER utilizes the NLP tool HanLP [41] for segmentation and dependency parsing, along with the NetworkX tool [51] for representing and storing knowledge graphs. For the test function recommendation, TOKTER implements the algorithm that searches for path instances matching the meta-path on the constructed knowledge graph in Python. It then ranks and recommends all test functions based on the scores of all path instances. We implement TOKTER as an open-source tool.
Experiment Execution. For training the CLEAR baseline, we utilized cloud computing resources (running about 20 h on NVIDIA V100 GPU (Nvidia Corporation, Santa Clara, CA, USA) and Intel Golden 6240 CPU (Intel Corporation, Santa Clara, CA, USA) with CentOS 7.6 system). Due to the substantial scale of the BERT model used in CLEAR, fine-tuning the pre-trained BERT model on the dataset is time-consuming. The process of recommending test functions using the four methods was conducted on a PC equipped with AMD Ryzen 7 1700X CPU (AMD, Santa Clara, CA, USA), running Windows 10 (64-bit).
Research Questions (RQs). RQ1: How effective is TOKTER compared with the three baseline approaches? These baselines use different models (i.e., word embedding, BERT, and DSSM) to measure the semantic similarity between two sentences (e.g., queries, test steps) and improve the recommendation effectiveness with historical data. TOKTER relies on a test-oriented knowledge graph and uses meta-paths to recommend test functions. With RQ1, we aim to assess TOKTER’s effectiveness in recommending test functions, which justifies the need to employ a knowledge graph and the meta-paths.
RQ2: How is the time performance of TOKTER compared with the three baselines? To test the efficiency of TOKTER, we compared its time performance with the three baseline approaches. Furthermore, we discussed the factors that influence recommendation time.
RQ3: How does the size of the knowledge graph affect the effectiveness and time cost of TOKTER? Recall that TOKTER relies on domain experts to select relevant candidates of domain concept entities automatically identified by TOKTER and identify those missed by TOKTER. Consequently, the size of the test-oriented knowledge graph, to a certain extent, relates to the manual effort required from domain experts. Hence, we propose this RQ to study how the size of the knowledge graph affects the effectiveness of TOKTER.
RQ4: How effective are different meta-paths at contributing to TOKTER? Recall that TOKTER uses different types of meta-paths: description-based, parameter-based, and history-based meta-paths. With this RQ, we aim to investigate how using different meta-paths can influence the test function recommendation effectiveness and time cost of TOKTER.
5. Results and Analyses
In this section, we first describe the test-oriented knowledge graph generated by TOKTER (Section 5.1), followed by answering each RQ in Section 5.2, Section 5.3, Section 5.4 and Section 5.5.
5.1. Test-Oriented Knowledge Graph Generated with TOKTER
Descriptive statistics of the generated test-oriented knowledge graph are summarized in Table 6. From the table, we can see that, after extracting entities and relations from the test function library, we obtained, in total, 967 test functions with 3038 function parameters. From the test case library (historical test cases), TOKTER extracted 9924 unique test steps, 500 of which were used as testing data. Hence, the remaining 9424 test steps were incorporated as test step entities in the test-oriented knowledge graph.
TOKTER initially acquired 8931 candidates of domain concept entities (Section 3.1.3). After a review process by two domain experts, 1536 suitable cases were selected, and 142 were added. In fact, the ranking metric ( defined in Formula (5)) has been very helpful for filtering domain concept entities. Domain experts selected 56 domain concepts from the top 100 candidates and 474 domain concepts from the top 1000 candidates. The average for the selected 1536 domain concepts is 1469.27, while the average for all candidates is 658.559. Eventually, we obtained 1678 (1536 + 142) domain concept entities. The review process took two days, which is acceptable to our industrial partner. We also want to point out that this review process is a one-time effort. When the knowledge graph needs to be updated, it is just about updating the domain concepts in the knowledge graph (mostly adding new domain concepts), followed by the automatic extraction of relations with TOKTER.
After entity recognition, TOKTER extracts relations (Section 3.1.4), which resulted in 203 synonymy, 290 hyponymy, 6750 association, 57,462 related_to_dc, 26,238 implementation, and 3038 containment relations. Note that domain experts do not need to check these relations manually.
5.2. RQ1: Evaluating TOKTER’s Effectiveness
To answer this RQ, we evaluated TOKTER with all meta-paths applied by comparing it with the three baselines in terms of their performance on the same industrial dataset (Section 4). Results are presented in Table 7.
From Table 7, we observe that TOKTER performed the best, followed by SRTEF and CLEAR with comparable performance, and BIKER, which performed the worst. This is because BIKER’s word embedding model is weaker in capturing semantics than the DSSM model employed by SRTEF and the BERT model used by CLEAR. We conducted the Wilcoxon signed-rank test to compare the performances of TOKTER and the baselines with the 500 queries (we used the SPSS tool to perform these tests, and the results were also put into the open source repository). Results show that TOKTER achieves significantly better performance than all baselines (p < 0.05). The standard deviations of the average precision (AP) metric for the BIKER, SRTEF, CLEAR, and TOKTER methods on 500 test queries are 0.121, 0.122, 0.132, and 0.134, respectively, which are quite small. TOKTER performed the best (0.743 in MAP, 0.824 in MRR, and 0.804 in MR) because it explores semantic relations between queries and test functions by utilizing domain knowledge capturing relations among domain concepts from the SUT and test steps, test functions, and their parameters of a test project. Moreover, TOKTER searches for semantically matched test functions comprehensively from descriptions, function parameters, and historical data via the meta-paths.
5.3. RQ2: Evaluating TOKTER’s Time Performance
To answer this RQ, we collected time spent by TOKTER and the three baselines on preparation and recommendation. Results are presented in Table 8.
During the setup phase, the primary task for the three baselines is training their respective models. In the case of TOKTER, the time cost for setup is mainly about caching all paths in the test-oriented knowledge graph to accelerate the recommendation. As shown in Table 8, TOKTER took a shorter setup time than CLEAR and SRTEF. CLEAR’s training time is the longest due to the significantly large scale of the BERT model (with 134 million parameters) used in CLEAR.
Regarding the recommendation time, from the table, we can see that TOKTER, SRTEF, and CLEAR took less than one second per query, while BIKER took 2.4 s per query. The main reason is that BIKER transforms each word in a text description into a word vector using its word embedding model, which requires a looped comparison for each word in the sentence. SRTEF and CLEAR, instead, represent queries, test steps, and test functions as vectors, and comparing vectors is computationally efficient. TOKTER searches for relevant test functions through the test-oriented knowledge graph, which requires a bit longer time than SRTEF and CLEAR. However, 0.6 s per query is acceptable in industrial practice.
The distribution of recommendation time for each query is shown in Figure 7. We can observe from the figure that TOKTER is relatively consistent, with recommendation time clustering around 0.4–0.8 s. Only 10 out of 500 cases have 1.2–2.0 s spent. We notice that there are 53 cases for which TOKTER performed very efficiently (within the range of 0.2–0.4 s). After carefully checking these cases, we noticed that there are relatively few connections between queries and domain concept entities in the test-oriented knowledge graph.
Furthermore, we conducted a Spearman’s Rank Correlation analysis between recommendation time and the number of nodes linked to Q, i.e., , in the knowledge graph, which are all domain concept entities, ranging from 1 to 17. The correlation coefficient is 0.891 (p-value < 0.05), indicating a significant and very strong positive correlation. It is also easy to understand that the more entities connected to a query, the more paths need to be searched, resulting in a longer recommendation time.
5.4. RQ3: Impact of the Knowledge Graph Size
To answer this RQ, we evaluate the effectiveness and time cost of TOKTER when being configured with test-oriented knowledge graphs at different scales. As shown in Table 6, among the four types of entities in the knowledge graph, the proportion of domain concept entities is roughly 11%, which is the smallest. Once the test function library and historical test cases are determined, the quantities of test functions, parameters, and test steps remain constant across different knowledge graphs. Therefore, knowledge graph construction’s quality and time cost depend solely on the domain concept entities. Thus, variations in the size of the knowledge graph are reflected in the number of included domain concept entities.
In real projects, it is often seen that some domain concepts are more frequently used than others. In the domain of the SUT of this work, the minimum frequency of domain concepts is 9; the maximum is 48,547; the average is 530.01; and the median is 102. The frequency distribution of domain concepts is shown in Figure 8. More frequently used domain concepts are typically given priority in the construction of knowledge graphs. Therefore, we sort all valid domain concepts in descending order of the frequencies of their occurrences in the corpus. After that, we sequentially selected the top 10%, top 20%, …, and 100% of the domain concepts to form 10 test-oriented knowledge graphs.
Table 9 summarizes the effectiveness and time cost of TOKTER with test-oriented knowledge graphs of various sizes. Results show that with 10% of domain concepts, TOKTER only achieved ≈0.11 MAP, MRR, and MR. As the size of the graph increases, TOKTER’s effectiveness rapidly improves, implying that the completeness of the domain concepts in the knowledge graph has a great impact on TOKTER’s recommendation. Regarding the time cost (i.e., recommendation time), along with the increase in the number of domain concept entities in the knowledge graph, TOKTER’s recommendation time gets longer. This is because queries can be connected to more domain concept entities, leading to a growth in the number of path instances from the queries to test functions based on meta-paths, which need to be calculated.
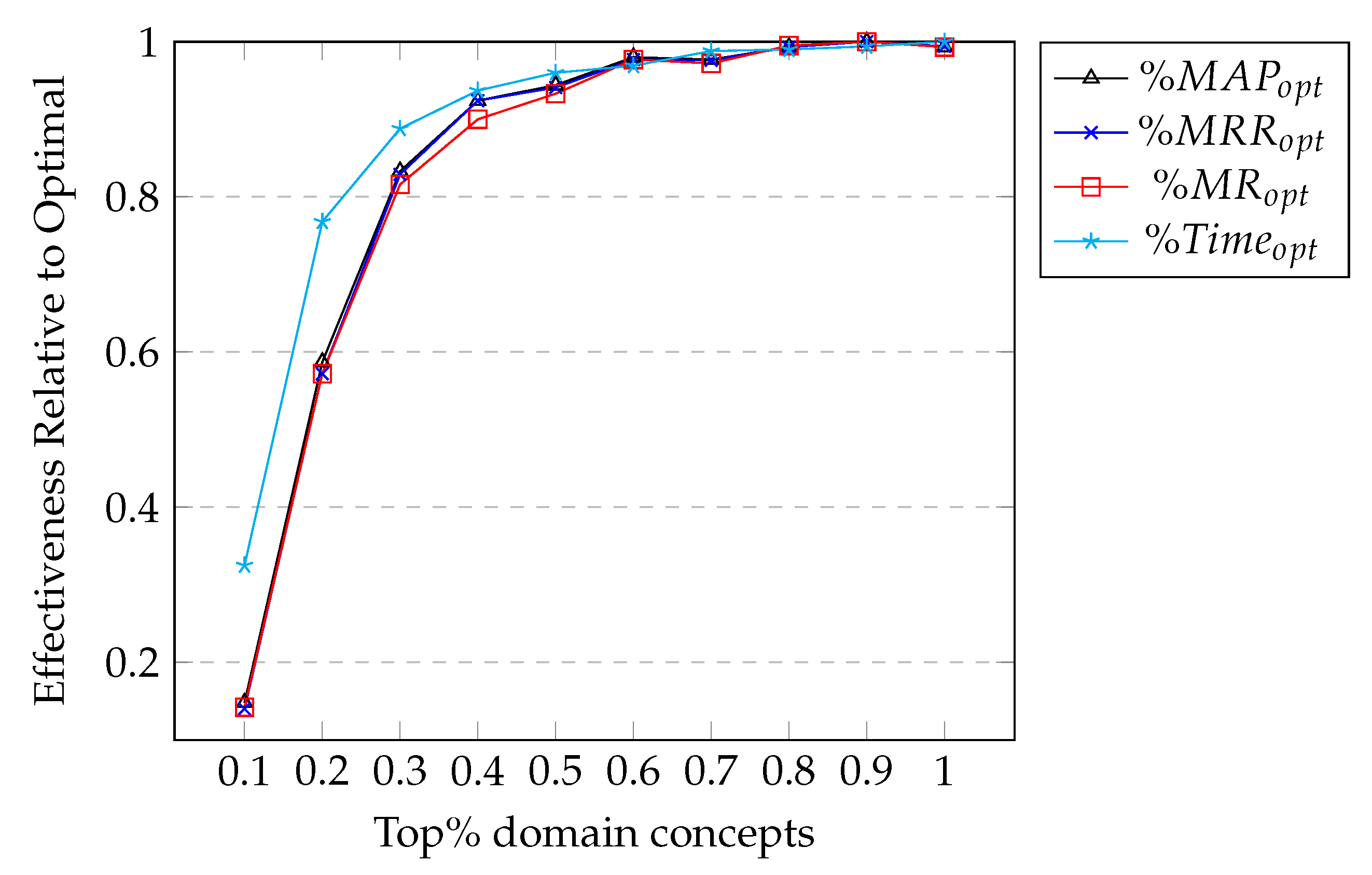
From Figure 9, we can easily notice that the size of the knowledge graph increases to ≈60%, TOKTER’s effectiveness and time cost gains stabilize. We further conducted the Wilcoxon signed-rank test to compare the difference in the effectiveness and time cost of TOKTER when being combined with the knowledge graphs of two adjacent sizes (e.g., 0.2 and 0.3 of Top% domain concepts). Results show that once the size of the knowledge graph increases to ≈60%, the change in recommendation effectiveness is no longer significant. However, the recommendation time increases significantly with the increase in the knowledge graph’s scale. This message is important as it implies that there is a diminishing marginal benefit of continuously enriching the domain concepts in the test-oriented knowledge graph. Specifically, with ≈30% of the domain concepts, TOKTER can already achieve 83.3% of the optimal results in MAP, MRR, and MR. This observation is close to the Pareto principle, also known as the 80–20 rule, specifying that 80% of consequences come from 20% of the causes. This observation is useful as it helps determine the sufficiency level of the domain concepts while constructing the test-oriented knowledge graph, especially considering that manual effort from domain experts is required to verify domain concepts automatically extracted by TOKTER.
5.5. RQ4: Meta-Paths’ Contributions to TOKTER’s Performance
To answer this RQ, we set up TOKTER with seven various meta-path strategies, which are all possible combinations of one, two, or all three meta-path types, as listed in Table 10.
Table 10 shows that using any type of meta-paths alone is less effective than using all. In comparing the use of a single type of meta-paths, TOKTER with the parameter-based meta-path alone achieved the worst recommendation result, and TOKTER with only history-based meta-path achieved the best. We further conducted the Wilcoxon signed-rank test on data collected from the 500 queries. Results show that using all meta-paths is significantly better than all other strategies; the history-based strategy contributes statistically significantly more than the parameter-based and description-based strategies regarding all effectiveness metrics; and introducing the description-based strategy leads to a significant improvement in TOKTER’s effectiveness. Moreover, introducing the parameter-based strategy does not lead to a significant improvement because function parameters complement function descriptions, and the parameter-based meta-paths are expected to be combined with description-based ones to create positive effects on TOKTER’s performance. Regarding the time cost, TOKTER with the history-based strategy used significantly more time than those without, as expected.
5.6. Threats to Validity
Internal validity. TOKTER’s test-oriented knowledge graph construction heavily relies on NLP techniques, such as segmentation and dependency parsing. These tools, including HanLP we used, do not achieve 100% accuracy. However, TOKTER still remains highly effective because NLP techniques are relatively mature, and their inaccuracies are generally minimal. Outputs that are not precise still fall within the acceptable range in practice. Moreover, TOKTER is robust, as evidenced by the results for RQ3 (Section 5.4); when slightly reducing the size of the knowledge graph, there is minimal effect on the effectiveness of the recommendations.
External validity. In our experiment, we only employed one dataset of one domain, i.e., Network Cloud Engine-Transport. However, the methodology of TOKTER itself is general; it can be applied for other domains as long as three types of data are available: test function documentation, SUT documentation, and historical test cases. Though TOKTER only supports processing texts in Chinese, as the entity recognition and rule-based relation extraction in the knowledge graph construction process are language-independent, and the metrics (e.g., mutual information and branch entropy) and rules involved are language-agnostic, TOKTER can easily support other natural languages, as long as proper segmentation tools and dependency parsers are available.
6. Related Work
In the literature, SRTEF [11] is presented for recommending test functions based on the weighted description and scenario similarity. However, due to the absence of domain knowledge utilization, SRTEF fails to address the challenges of “cold start” and “semantic gap” (see Section 1), especially when dealing with insufficient historical data.
Many works have been proposed in API recommendation. For instance, Thung et al. [3] proposed to learn from issue management and version control systems and compare the literal description of a requested feature with the literal description of the API method. Rahman et al. [45] proposed recommending a ranked list of API classes for a given query in natural language based on keyword-API mappings mined from Stack Overflow questions and corresponding answers. Rahman et al. [52] further proposed NLP2API to automatically identify relevant API categories for queries in natural language, such that a query statement can be organized with the obtained API categories to improve API recommendation performance. Raghothaman et al. [12] proposed the tool SWIM to rank APIs with a statistical word alignment model based on the clickthrough data from the Bing search engine and provide code snippets to illustrate the usage of ranked APIs. Gu et al. [53] proposed DeepAPI, which adapts a Recurrent Neural Network (RNN) Encoder–Decoder model to transfer a word sequence (a user query) into a fixed-length context vector based on which a sequence of APIs will be recommended.
Works have been proposed to use knowledge graphs for API recommendation. For instance, Wang et al. [7] proposed an unsupervised API recommendation approach utilizing deep random walks on a knowledge graph constructed from Mashup-API co-invocation patterns and service category attributes. Zhao et al. [8] proposed KG2Lib, which leverages a knowledge-graph-based convolutional network and utilizes libraries called by projects to make recommendations. The knowledge graph in KG2Lib only includes properties of the third-party libraries (e.g., version, groupID). Kwapong et al. [54] presented a knowledge-graph framework built from web API and mashup data as side information for API recommendation. These entities (e.g., tags, categories) and relationships (e.g., “belongs_to”, “invokes”) in their knowledge graph are extracted from structured information and do not involve domain knowledge.
All these related works do not incorporate domain knowledge. TOKTER, however, greatly benefits from incorporating domain knowledge, allowing for more precise recommendations of test functions.
7. Conclusions and Future Work
In this paper, we introduce TOKTER, an approach designed to automatically recommend suitable test functions for natural language test steps using a test-oriented knowledge graph. This knowledge graph captures the domain knowledge of the software under test and its test harness. To recommend test functions, TOKTER has three types of meta-paths, i.e., description-based, parameter-based, and history-based meta-paths. We compared TOKTER’s performance with three state-of-the-art approaches with a real industrial dataset from Huawei. The results indicate that TOKTER significantly outperforms all baselines and has a practically acceptable recommendation time. We found that as the size of the knowledge graph increases, TOKTER’s effectiveness rapidly improves, implying that the completeness of the domain concepts in the knowledge graph has a great impact on TOKTER’s recommendation. As the size of the knowledge graph increases to about 60%, TOKTER’s effectiveness gains stabilize. We found that a few high-frequency domain concepts play a very significant role in the test function recommendation. Specifically, with about 30% of the high-frequency domain concepts, TOKTER can already achieve 83.3% of the optimal results in MAP, MRR, and MR. This observation is valuable as it aids in assessing the adequacy of domain concepts when constructing the test-oriented knowledge graph. Furthermore, we observed that TOKTER achieves optimal results with all types of meta-paths, and history-based meta-paths contribute the most to the cost-effectiveness of TOKTER. TOKTER requires manual effort from domain experts, as well as corpus data about SUT, which is the more preferable scenario. In the future, we plan to distill knowledge from LLMs to aid in constructing the knowledge graph, thus reducing the workload of domain experts.
Author Contributions
Conceptualization, K.L. and J.W.; Data curation, R.W.; Formal analysis, K.L. and Q.S.; Investigation, K.L.; Methodology, K.L. and Q.S.; Resources, R.W.; Software, K.L.; Supervision, K.L.; Validation, K.L., J.W., Q.S., and H.Y.; Visualization, H.Y.; Writing—original draft, K.L.; Writing—review and editing, J.W. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
Data are contained within the article.
Conflicts of Interest
Author Ruiyuan Wan is affiliated with Huawei Technologies Co., Ltd. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
- Qiu, D.; Li, B.; Leung, H. Understanding the API usage in Java. Inf. Softw. Technol. 2016, 73, 81–100. [Google Scholar] [CrossRef]
- Thayer, K.; Chasins, S.E.; Ko, A.J. A theory of robust API knowledge. ACM Trans. Comput. Educ. (TOCE) 2021, 21, 1–32. [Google Scholar] [CrossRef]
- Thung, F.; Wang, S.; Lo, D.; Lawall, J. Automatic recommendation of API methods from feature requests. In Proceedings of the 2013 28th IEEE/ACM International Conference on Automated Software Engineering (ASE), Silicon Valley, CA, USA, 11–15 November 2013; pp. 290–300. [Google Scholar]
- Huang, Q.; Xia, X.; Xing, Z.; Lo, D.; Wang, X. API method recommendation without worrying about the task-API knowledge gap. In Proceedings of the 2018 33rd IEEE/ACM International Conference on Automated Software Engineering (ASE), Montpellier, France, 3–7 September 2018; pp. 293–304. [Google Scholar]
- Wei, M.; Harzevili, N.S.; Huang, Y.; Wang, J.; Wang, S. Clear: Contrastive learning for api recommendation. In Proceedings of the 44th International Conference on Software Engineering, Pittsburgh, PA, USA, 21–29 May 2022; pp. 376–387. [Google Scholar]
- Thummalapenta, S.; Xie, T. Parseweb: A programmer assistant for reusing open source code on the web. In Proceedings of the Twenty-Second IEEE/ACM International Conference on Automated Software Engineering, Atlanta, GA, USA, 5–9 November 2007; pp. 204–213. [Google Scholar]
- Wang, X.; Liu, X.; Liu, J.; Chen, X.; Wu, H. A novel knowledge graph embedding based API recommendation method for Mashup development. World Wide Web 2021, 24, 869–894. [Google Scholar] [CrossRef]
- Zhao, J.z.; Zhang, X.; Gao, C.; Li, Z.d.; Wang, B.l. KG2Lib: Knowledge-graph-based convolutional network for third-party library recommendation. J. Supercomput. 2023, 79, 1–26. [Google Scholar] [CrossRef]
- Bao, J.; Duan, N.; Yan, Z.; Zhou, M.; Zhao, T. Constraint-based question answering with knowledge graph. In Proceedings of the COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers, Osaka, Japan, 11–16 December 2016; pp. 2503–2514. [Google Scholar]
- Zhao, X.; Chen, H.; Xing, Z.; Miao, C. Brain-inspired search engine assistant based on knowledge graph. IEEE Trans. Neural Netw. Learn. Syst. 2021, 34, 4386–4400. [Google Scholar] [CrossRef] [PubMed]
- Liu, K.; Wu, J.; Yang, H.; Sun, Q.; Wan, R. SRTEF: Test Function Recommendation With Scenarios and Latent Semantic for Implementing Stepwise Test Case. IEEE Trans. Reliab. 2022, 71, 1127–1140. [Google Scholar] [CrossRef]
- Raghothaman, M.; Wei, Y.; Hamadi, Y. Swim: Synthesizing what i mean-code search and idiomatic snippet synthesis. In Proceedings of the 2016 IEEE/ACM 38th International Conference on Software Engineering (ICSE), Singapore, 3–7 September 2016; pp. 357–367. [Google Scholar]
- Mirbakhsh, N.; Ling, C.X. Improving top-n recommendation for cold-start users via cross-domain information. ACM Trans. Knowl. Discov. Data (TKDD) 2015, 9, 1–19. [Google Scholar] [CrossRef]
- Panda, D.K.; Ray, S. Approaches and algorithms to mitigate cold start problems in recommender systems: A systematic literature review. J. Intell. Inf. Syst. 2022, 59, 341–366. [Google Scholar] [CrossRef]
- Xiong, C.; Power, R.; Callan, J. Explicit semantic ranking for academic search via knowledge graph embedding. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017; pp. 1271–1279. [Google Scholar]
- Wang, H.; Zhang, F.; Wang, J.; Zhao, M.; Li, W.; Xie, X.; Guo, M. Ripplenet: Propagating user preferences on the knowledge graph for recommender systems. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, Torino, Italy, 22–26 October 2018; pp. 417–426. [Google Scholar]
- Wang, H.; Zhao, M.; Xie, X.; Li, W.; Guo, M. Knowledge graph convolutional networks for recommender systems. In Proceedings of the The World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 3307–3313. [Google Scholar]
- Huang, X.; Zhang, J.; Li, D.; Li, P. Knowledge graph embedding based question answering. In Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining, Melbourne, VIC, Australia, 11–15 February 2019; pp. 105–113. [Google Scholar]
- Bollacker, K.; Evans, C.; Paritosh, P.; Sturge, T.; Taylor, J. Freebase: A collaboratively created graph database for structuring human knowledge. In Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data, Vancouver, BC, Canada, 9–12 June 2008; pp. 1247–1250. [Google Scholar]
- Auer, S.; Bizer, C.; Kobilarov, G.; Lehmann, J.; Cyganiak, R.; Ives, Z. Dbpedia: A nucleus for a web of open data. In Proceedings of the International Semantic Web Conference, Busan, Republic of Korea, 11–15 November 2007; pp. 722–735. [Google Scholar]
- Suchanek, F.M.; Kasneci, G.; Weikum, G. Yago: A large ontology from wikipedia and wordnet. J. Web Semant. 2008, 6, 203–217. [Google Scholar] [CrossRef]
- Harper, F.M.; Konstan, J.A. The movielens datasets: History and context. ACM Trans. Interact. Intell. Syst. 2015, 5, 1–19. [Google Scholar] [CrossRef]
- Shang, J.; Liu, J.; Jiang, M.; Ren, X.; Voss, C.R.; Han, J. Automated phrase mining from massive text corpora. IEEE Trans. Knowl. Data Eng. 2018, 30, 1825–1837. [Google Scholar] [CrossRef] [PubMed]
- Liu, J.; Shang, J.; Wang, C.; Ren, X.; Han, J. Mining quality phrases from massive text corpora. In Proceedings of the 2015 ACM SIGMOD International Conference on Management of Data, Melbourne, VIC, Australia, 1–4 June 2015; pp. 1729–1744. [Google Scholar]
- Nassif, M.; Robillard, M.P. Identifying Concepts in Software Projects. IEEE Trans. Softw. Eng. 2023, 49, 3660–3674. [Google Scholar] [CrossRef]
- Sun, Y.; Han, J.; Yan, X.; Yu, P.S.; Wu, T. Pathsim: Meta path-based top-k similarity search in heterogeneous information networks. Proc. VLDB Endow. 2011, 4, 992–1003. [Google Scholar] [CrossRef]
- Noori, A.; Li, M.M.; Tan, A.L.; Zitnik, M. metapaths: Similarity search in heterogeneous knowledge graphs via meta paths. Bioinformatics 2023, 39, btad297. [Google Scholar] [CrossRef] [PubMed]
- Murphy, M.L. Semantic Relations and the Lexicon: Antonymy, Synonymy and Other Paradigms; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Wang, P.; Hu, J.; Zeng, H.J.; Chen, Z. Using Wikipedia knowledge to improve text classification. Knowl. Inf. Syst. 2009, 19, 265–281. [Google Scholar] [CrossRef]
- Siu, A.; Nguyen, D.B.; Weikum, G. Fast Entity Recognition in Biomedical Text. In Proceedings of the Workshop on Data Mining for Healthcare at the 19th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 11 August 2013. [Google Scholar]
- Huang, S.; Wan, X. AKMiner: Domain-specific knowledge graph mining from academic literatures. In Proceedings of the Web Information Systems Engineering–WISE 2013: 14th International Conference, Nanjing, China, 13–15 October 2013; pp. 241–255. [Google Scholar]
- Li, F.L.; Chen, H.; Xu, G.; Qiu, T.; Ji, F.; Zhang, J.; Chen, H. AliMeKG: Domain knowledge graph construction and application in e-commerce. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, Virtual Event, Ireland, 19–23 October 2020; pp. 2581–2588. [Google Scholar]
- Veyrat-Charvillon, N.; Standaert, F.X. Mutual information analysis: How, when and why? In Proceedings of the International Workshop on Cryptographic Hardware and Embedded Systems, Lausanne, Switzerland, 6–9 September 2009; pp. 429–443. [Google Scholar]
- Huang, J.H.; Powers, D. Chinese word segmentation based on contextual entropy. In Proceedings of the 17th Pacific Asia Conference on Language, Information and Computation, Singapore, 1–3 October 2003; pp. 152–158. [Google Scholar]
- Rios-Alvarado, A.B.; Lopez-Arevalo, I.; Sosa-Sosa, V.J. Learning concept hierarchies from textual resources for ontologies construction. Expert Syst. Appl. 2013, 40, 5907–5915. [Google Scholar] [CrossRef]
- Rei, M.; Briscoe, T. Looking for hyponyms in vector space. In Proceedings of the Eighteenth Conference on Computational Natural Language Learning, Baltimore, MD, USA, 26–27 June 2014; pp. 68–77. [Google Scholar]
- Navigli, R.; Ponzetto, S.P. BabelNet: Building a very large multilingual semantic network. In Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics, Uppsala, Sweden, 11–16 July 2010; pp. 216–225. [Google Scholar]
- Chen, D.; Manning, C.D. A fast and accurate dependency parser using neural networks. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 740–750. [Google Scholar]
- Simov, K.; Popov, A.; Osenova, P. Improving word sense disambiguation with linguistic knowledge from a sense annotated treebank. In Proceedings of the International Conference Recent Advances in Natural Language Processing, Hissar, Bulgaria, 7–9 September 2015; pp. 596–603. [Google Scholar]
- Zhang, H.; Liu, X.; Pan, H.; Song, Y.; Leung, C.W.K. ASER: A large-scale eventuality knowledge graph. In Proceedings of the Web Conference 2020, Taipei, Taiwan, 20–24 April 2020; pp. 201–211. [Google Scholar]
- He, H.; Choi, J.D. The Stem Cell Hypothesis: Dilemma behind Multi-Task Learning with Transformer Encoders. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Online and Punta Cana, Dominican Republic, 7–11 November 2021; pp. 5555–5577. [Google Scholar]
- Fu, T.y.; Lee, W.C.; Lei, Z. Hin2vec: Explore meta-paths in heterogeneous information networks for representation learning. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, Singapore, 6–10 November 2017; pp. 1797–1806. [Google Scholar]
- Sworna, Z.T.; Islam, C.; Babar, M.A. Apiro: A framework for automated security tools api recommendation. ACM Trans. Softw. Eng. Methodol. 2023, 32, 1–42. [Google Scholar] [CrossRef]
- Schütze, H.; Manning, C.D.; Raghavan, P. Introduction to Information Retrieval; Cambridge University Press: Cambridge, UK, 2008; Volume 39. [Google Scholar]
- Rahman, M.M.; Roy, C.K.; Lo, D. Rack: Automatic api recommendation using crowdsourced knowledge. In Proceedings of the 2016 IEEE 23rd International Conference on Software Analysis, Evolution, and Reengineering (SANER), Osaka, Japan, 14–18 March 2016; Volume 1, pp. 349–359. [Google Scholar]
- Ye, X.; Shen, H.; Ma, X.; Bunescu, R.; Liu, C. From word embeddings to document similarities for improved information retrieval in software engineering. In Proceedings of the 38th International Conference on Software Engineering, Austin, TX, USA, 14–22 May 2016; pp. 404–415. [Google Scholar]
- Ye, X.; Bunescu, R.; Liu, C. Learning to rank relevant files for bug reports using domain knowledge. In Proceedings of the 22nd ACM SIGSOFT International Symposium on Foundations of Software Engineering, Hong Kong, China, 16–21 November 2014; pp. 689–699. [Google Scholar]
- Saha, R.K.; Lease, M.; Khurshid, S.; Perry, D.E. Improving bug localization using structured information retrieval. In Proceedings of the 2013 28th IEEE/ACM International Conference on Automated Software Engineering (ASE), Silicon Valley, CA, USA, 11–15 November 2013; pp. 345–355. [Google Scholar]
- Guo, J.; Cheng, J.; Cleland-Huang, J. Semantically enhanced software traceability using deep learning techniques. In Proceedings of the 2017 IEEE/ACM 39th International Conference on Software Engineering (ICSE), Buenos Aires, Argentina, 20–28 May 2017; pp. 3–14. [Google Scholar]
- Wilcoxon, F. Individual comparisons by ranking methods. In Breakthroughs in Statistics: Methodology and Distribution; Springer: Berlin/Heidelberg, Germany, 1992; pp. 196–202. [Google Scholar]
- Hagberg, A.; Swart, P.; S Chult, D. Exploring Network Structure, Dynamics, and Function Using NetworkX; Technical Report; Los Alamos National Laboratory (LANL): Los Alamos, NM, USA, 2008. [Google Scholar]
- Rahman, M.M.; Roy, C. Effective reformulation of query for code search using crowdsourced knowledge and extra-large data analytics. In Proceedings of the 2018 IEEE International Conference on Software Maintenance and Evolution (ICSME), Madrid, Spain, 23–29 September 2018; pp. 473–484. [Google Scholar]
- Gu, X.; Zhang, H.; Zhang, D.; Kim, S. Deep API learning. In Proceedings of the 2016 24th ACM SIGSOFT International Symposium on Foundations of Software Engineering, Seattle, WA, USA, 13–18 November 2016; pp. 631–642. [Google Scholar]
- Kwapong, B.; Fletcher, K. A knowledge graph based framework for web API recommendation. In Proceedings of the 2019 IEEE World Congress on Services (SERVICES), Milan, Italy, 8–13 July 2019; pp. 115–120. [Google Scholar]
Figure 1.
Bibliographic network schema and meta-path. (a) Network schema. (b) Meta-path: Author–Paper–Author.
Figure 1.
Bibliographic network schema and meta-path. (a) Network schema. (b) Meta-path: Author–Paper–Author.

Figure 2.
Overview of TOKTER.

Figure 3.
Network schema of the test-oriented knowledge graph.

Figure 4.
Dependency tree of the sentence “Create a static tunnel and specify the interface type as ETH subinterface”.
Figure 4.
Dependency tree of the sentence “Create a static tunnel and specify the interface type as ETH subinterface”.

Figure 5.
Association relations extracted from dependency trees of two sentences. (a) dobj example. (b) nsubj example.
Figure 5.
Association relations extracted from dependency trees of two sentences. (a) dobj example. (b) nsubj example.

Figure 6.
An example of the test-oriented knowledge graph. The yellow circle represents the domain concept entity, the blue circle represents the test function entity, the green circle represents the function parameter entity and the gray square represents the test step entity.
Figure 6.
An example of the test-oriented knowledge graph. The yellow circle represents the domain concept entity, the blue circle represents the test function entity, the green circle represents the function parameter entity and the gray square represents the test step entity.

Figure 7.
Distribution of recommendation time.

Figure 8.
Frequency distribution of domain concepts.

Figure 9.
TOKTER’s performance changes when configured with 10 test-oriented knowledge graphs of various sizes. The Y-axis represents the performance measured in MAP, MRR, MR, and time relative to their optimal values or longest time achieved by TOKTER (i.e., 0.743, 0.824, 0.804, and 0.647 s, respectively, (see Table 7)).
Figure 9.
TOKTER’s performance changes when configured with 10 test-oriented knowledge graphs of various sizes. The Y-axis represents the performance measured in MAP, MRR, MR, and time relative to their optimal values or longest time achieved by TOKTER (i.e., 0.743, 0.824, 0.804, and 0.647 s, respectively, (see Table 7)).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Relations in the test-oriented knowledge graph.
| Relation | Description |
|---|---|
| Two domain concepts are synonymous. | |
| One domain concept is a type of the other. | |
| Two domain concepts are associated. | |
| A test function, test step, or function parameter is related to a domain concept. | |
| A test step is implemented by a test function. | |
| A test function contains a function parameter. |
Table 2.
An example test case.
| operate(“Select a port to create an SDH service.”) { |
| @sdh1= @sdh.create_sdh() |
| } |
| expect(“Confirm whether the service was created successfully.”) { |
| @sdh1.query_sdh() |
| } |
| operate(“Create another SDH service through the same port.”) { |
| @sdh2= @sdh.create_sdh() |
| } |
| expect(“Check if the service failed to be created.”) { |
| @sdh2.query_sdh() |
| } |
| operate(“Delete all SDH services.”) { |
| @sdh.delete_sdh() |
| } |
Table 3.
All types of meta-paths of TOKTER.
| Meta-Path | Semantics | Type |
|---|---|---|
| Extract test functions whose functional descriptions are semantically related to the query | description-based | |
| Extract test functions whose parameters are semantically related to the query | parameter-based | |
| Extract test functions historically used to implement some test steps that are semantically related to the query | history-based |
Table 4.
Path instances that conform to the meta-paths.
| Path Instance | Meta-Path |
|---|---|
Table 5.
The number of test functions to implement a test step.
| Test Functions for Implementing a Test Step | Test Step | Percentage |
|---|---|---|
| 1 | 3559 | 35.9% |
| 2 | 2030 | 20.4% |
| 3 | 1376 | 13.9% |
| 4 | 1064 | 10.7% |
| More than 4 | 1895 | 19.1% |
Table 6.
Descriptive statistics of the generated test-oriented knowledge graph.
| Item | Count |
|---|---|
| Test function entities | 967 |
| Function parameter entities | 3038 |
| Test step entities | 9424 |
| Domain concept entities | 1678 |
| Synonymy relations | 203 |
| Hyponymy relations | 290 |
| Association relations | 6750 |
| Related_to_dc relations | 57,462 |
| Implementation relations | 26,238 |
| Containment relations | 3038 |
Table 7.
Effectiveness of TOKTER and the baseline approaches.
| Approach | MAP | MRR | MR |
|---|---|---|---|
| BIKER | 0.365 | 0.518 | 0.602 |
| SRTEF | 0.544 | 0.689 | 0.753 |
| CLEAR | 0.527 | 0.603 | 0.789 |
| TOKTER | 0.743 | 0.824 | 0.804 |
Table 8.
Time cost of TOKTER and the baseline approaches—RQ2.
| Approach | Training/Caching | Recommendation |
|---|---|---|
| BIKER | 0.02 h | 2.4 s/query |
| SRTEF | 2.17 h | 0.041 s/query |
| CLEAR | 20 h | 0.057 s/query |
| TOKTER | 0.19 h | 0.647 s/query |
Table 9.
Effectiveness and time cost of TOKTER across 10 test-oriented knowledge graphs of various sizes.
Table 9.
Effectiveness and time cost of TOKTER across 10 test-oriented knowledge graphs of various sizes.
| Top% Domain Concepts | MAP | MRR | MR | Time * |
|---|---|---|---|---|
| 10% | 0.111 | 0.116 | 0.115 | 0.210 |
| 20% | 0.439 | 0.474 | 0.462 | 0.496 |
| 30% | 0.623 | 0.687 | 0.659 | 0.574 |
| 40% | 0.691 | 0.766 | 0.727 | 0.606 |
| 50% | 0.706 | 0.780 | 0.754 | 0.621 |
| 60% | 0.733 | 0.810 | 0.787 | 0.627 |
| 70% | 0.731 | 0.809 | 0.786 | 0.639 |
| 80% | 0.743 | 0.823 | 0.804 | 0.640 |
| 90% | 0.748 | 0.829 | 0.808 | 0.643 |
| 100% | 0.743 | 0.824 | 0.802 | 0.647 |
* Time is measured in seconds.
Table 10.
TOKTER’ performance with various meta-path strategies.
| Meta-Path Strategies | MAP | MRR | MR | Time * |
|---|---|---|---|---|
| Only description-based | 0.392 | 0.451 | 0.455 | 0.133 |
| Only parameter-based | 0.184 | 0.196 | 0.209 | 0.105 |
| Only history-based | 0.671 | 0.748 | 0.741 | 0.584 |
| Description- and parameter-based | 0.438 | 0.505 | 0.519 | 0.156 |
| Parameter- and history-based | 0.676 | 0.753 | 0.747 | 0.623 |
| Description- and history-based | 0.736 | 0.815 | 0.799 | 0.641 |
| All | 0.743 | 0.824 | 0.804 | 0.647 |
* Time is measured in seconds.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Liu, K.; Wu, J.; Sun, Q.; Yang, H.; Wan, R. Harnessing Test-Oriented Knowledge Graphs for Enhanced Test Function Recommendation. Electronics 2024, 13, 1547. https://doi.org/10.3390/electronics13081547
AMA Style
Liu K, Wu J, Sun Q, Yang H, Wan R. Harnessing Test-Oriented Knowledge Graphs for Enhanced Test Function Recommendation. Electronics. 2024; 13(8):1547. https://doi.org/10.3390/electronics13081547
Chicago/Turabian StyleLiu, Kaiqi, Ji Wu, Qing Sun, Haiyan Yang, and Ruiyuan Wan. 2024. "Harnessing Test-Oriented Knowledge Graphs for Enhanced Test Function Recommendation" Electronics 13, no. 8: 1547. https://doi.org/10.3390/electronics13081547
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.