
Lightweight UAV Object-Detection Method Based on Efficient Multidimensional Global Feature Adaptive Fusion and Knowledge Distillation
Abstract
:1. Introduction
- (1)
- To address the challenges faced by UAVs in practical applications, we propose the MGFAFNET, a network specifically designed for UAV images. This method aims to enable devices with limited computational capabilities to meet the requirements of UAV applications in various complex scenarios.
- (2)
- To tackle the complex backgrounds and object-occlusion issues in UAV scenarios, we construct a DBMA Backbone Network. DBMA encodes more effective global feature representations from complex environments and successfully overcomes the high-latency challenges posed by self-attention token mixers.
- (3)
- We introduce a DSPF network that utilizes multi-layer adaptive fusion to suppress irrelevant features. After the data passes through an FRM to enhance multi-scale detection capabilities, the network ultimately incorporates a 3D small-object-detection layer to improve the detection results for small objects.
- (4)
- We design an LCDD distillation method tailored to UAV images. LCDD utilizes the local and global fusion features from the teacher and student networks, adjusting spatial and channel dimensions through adaptive feature masks. The student network comprehensively learns richer encoded information from the larger teacher network.
- (5)
- We constructed a UAV object-detection platform and validated the effectiveness of the proposed method using a self-constructed dataset. Additionally, we performed further validation of the MGFAFNET on the VisDrone2021 dataset [20].
2. Related Work
2.1. UAV Detection Methods
2.2. KD for Object Detection
3. Methodology
3.1. UAV Object-Detection Platform
3.2. MGFAFNET
3.3. DBMA Backbone
3.4. DSPF Neck
3.5. LCDD Knowledge Distillation
3.6. Loss Function
4. Experimental Results and Analysis
4.1. Implementation Details
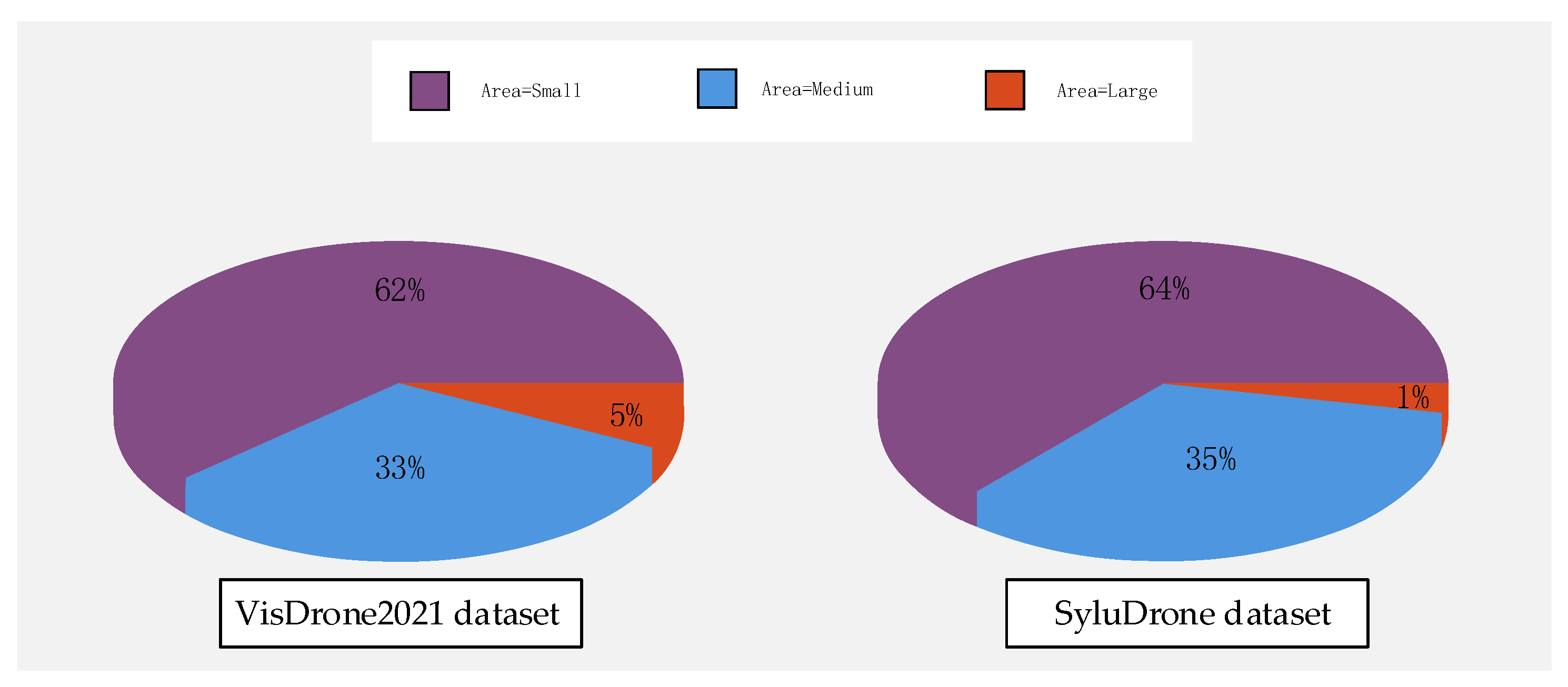
4.2. Dataset Preparation
4.3. Evaluation Metrics
4.4. Comparisons with SOTA Method
4.5. Ablation Study
4.6. Module Analysis
4.7. Analysis of Visualization Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ke, R.; Li, Z.; Tang, J.; Pan, Z.; Wang, Y. Real-time traffic flow parameter estimation from UAV video based on ensemble classifier and optical flow. IEEE Trans. Intell. Transp. Syst. 2018, 20, 54–64. [Google Scholar] [CrossRef]
- Su, J.; Zhu, X.; Li, S.; Chen, W.-H. AI meets UAVs: A survey on AI empowered UAV perception systems for precision agriculture. Neurocomputing 2023, 518, 242–270. [Google Scholar] [CrossRef]
- Mittal, P.; Singh, R.; Sharma, A. Deep learning-based object detection in low-altitude UAV datasets: A survey. Image Vis. Comput. 2020, 104, 104046. [Google Scholar] [CrossRef]
- Yu, J.; Gao, H.; Chen, Y.; Zhou, D.; Liu, J.; Ju, Z. Adaptive spatiotemporal representation learning for skeleton-based human action recognition. IEEE Trans. Cogn. Dev. Syst. 2021, 14, 1654–1665. [Google Scholar] [CrossRef]
- Yu, J.; Gao, H.; Zhou, D.; Liu, J.; Gao, Q.; Ju, Z. Deep temporal model-based identity-aware hand detection for space human–robot interaction. IEEE Trans. Cybern. 2021, 52, 13738–13751. [Google Scholar] [CrossRef]
- Yu, J.; Gao, H.; Chen, Y.; Zhou, D.; Liu, J.; Ju, Z. Deep object detector with attentional spatiotemporal LSTM for space human–robot interaction. IEEE Trans. Hum.-Mach. Syst. 2022, 52, 784–793. [Google Scholar] [CrossRef]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE international Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 7464–7475. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Yu, J.; Xu, Y.; Chen, H.; Ju, Z. Versatile Graph Neural Networks Toward Intuitive Human Activity Understanding. IEEE Trans. Neural Netw. Learn. Syst. 2022, 1–13. [Google Scholar] [CrossRef]
- Yu, J.; Zheng, W.; Chen, Y.; Zhang, Y.; Huang, R. Surrounding-aware representation prediction in Birds-Eye-View using transformers. Front. Neurosci. 2023, 17, 1219363. [Google Scholar] [CrossRef]
- Yang, C.; Huang, Z.; Wang, N. QueryDet: Cascaded sparse query for accelerating high-resolution small object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 13668–13677. [Google Scholar]
- Du, B.; Huang, Y.; Chen, J.; Huang, D. Adaptive Sparse Convolutional Networks with Global Context Enhancement for Faster Object Detection on Drone Images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 13435–13444. [Google Scholar]
- Zhou, W.; Min, X.; Hu, R.; Long, Y.; Luo, H. Faster-X: Real-Time Object Detection Based on Edge GPUs for UAV Applications. arXiv 2022, arXiv:2209.03157. [Google Scholar]
- Lu, W.; Lan, C.; Niu, C.; Liu, W.; Lyu, L.; Shi, Q.; Wang, S. A CNN-Transformer Hybrid Model Based on CSWin Transformer for UAV Image Object Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 1211–1231. [Google Scholar] [CrossRef]
- Yang, G.; Tang, Y.; Wu, Z.; Li, J.; Xu, J.; Wan, X. DMKD: Improving Feature-based Knowledge Distillation for Object Detection Via Dual Masking Augmentation. arXiv 2023, arXiv:2309.02719. [Google Scholar]
- Jang, Y.; Shin, W.; Kim, J.; Woo, S.; Bae, S.H. GLAMD: Global and Local Attention Mask Distillation for Object Detectors. In European Conference on Computer Vision; Springer Nature Switzerland: Cham, Switzerland, 2022; pp. 460–476. [Google Scholar]
- Yue, K.; Deng, J.; Zhou, F. Matching guided distillation. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XV 16; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 312–328. [Google Scholar]
- Yang, G.; Tang, Y.; Li, J.; Xu, J.; Wan, X. AMD: Adaptive Masked Distillation for Object Detection. In Proceedings of the 2023 International Joint Conference on Neural Networks (IJCNN), Gold Coast, Australia, 18–23 June 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–8. [Google Scholar]
- Cao, Y.; He, Z.; Wang, L.; Wang, W.; Yuan, Y.; Zhang, D.; Zhang, J.; Zhu, P.; Van Gool, L.; Han, J.; et al. VisDrone-DET2021: The vision meets drone object detection challenge results. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021; pp. 284–2854. [Google Scholar]
- Ye, T.; Qin, W.; Li, Y.; Wang, S.; Zhang, J.; Zhao, Z. Dense and small object detection in UAV-vision based on a global-local feature enhanced network. IEEE Trans. Instrum. Meas. 2022, 71, 1–13. [Google Scholar] [CrossRef]
- Zhang, Y.; Wu, C.; Guo, W.; Zhang, T.; Li, W. CFANet: Efficient Detection of UAV Image Based on Cross-layer Feature Aggregation. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–11. [Google Scholar] [CrossRef]
- Liao, J.; Piao, Y.; Su, J.; Cai, G.; Huang, X.; Chen, L.; Huang, Z.; Wu, Y. Unsupervised cluster guided object detection in aerial images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 11204–11216. [Google Scholar] [CrossRef]
- Deng, S.; Li, S.; Xie, K.; Song, W.; Liao, X.; Hao, A.; Qin, H. A global-local self-adaptive network for drone-view object detection. IEEE Trans. Image Process. 2020, 30, 1556–1569. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Li, W.; Wang, X.; Xia, X.; Wu, J.; Xiao, X.; Zheng, M.; Wen, S. Sepvit: Separable vision transformer. arXiv 2022, arXiv:2203.15380. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Wang, J.; Chen, Y.; Zheng, Z.; Li, X.; Cheng, M.M.; Hou, Q. CrossKD: Cross-Head Knowledge Distillation for Dense Object Detection. arXiv 2023, arXiv:2306.11369. [Google Scholar]
- Yang, L.; Zhou, X.; Li, X.; Qiao, L.; Li, Z.; Yang, Z.; Wang, G.; Li, X. Bridging Cross-task Protocol Inconsistency for Distillation in Dense Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 17175–17184. [Google Scholar]
- Romero, A.; Ballas, N.; Kahou, S.E.; Chassang, A.; Gatta, C.; Bengio, Y. Fitnets: Hints for thin deep nets. arXiv 2014, arXiv:1412.6550. [Google Scholar]
- Zhang, L.; Ma, K. Improve object detection with feature-based knowledge distillation: Towards accurate and efficient detectors. In Proceedings of the International Conference on Learning Representations, Virtual, 26 April–1 May 2020. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Li, Z.; Peng, C.; Yu, G.; Zhang, X.; Deng, Y.; Sun, J. Light-head r-cnn: In defense of two-stage object detector. arXiv 2017, arXiv:1711.07264. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28. [Google Scholar]
- Li, Y.; Hu, J.; Wen, Y.; Evangelidis, G.; Salahi, K.; Wang, Y.; Tulyakov, S.; Ren, J. Rethinking vision transformers for mobilenet size and speed. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 16889–16900. [Google Scholar]
- Wang, A.; Chen, H.; Lin, Z.; Han, J.; Ding, G. Repvit: Revisiting mobile cnn from vit perspective. arXiv 2023, arXiv:2307.09283. [Google Scholar]
- Chen, J.; Kao, S.H.; He, H.; Zhuo, W.; Wen, S.; Lee, C.H.; Chan, S.H.G. Run, Don’t Walk: Chasing Higher FLOPS for Faster Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 12021–12031. [Google Scholar]
- Woo, S.; Debnath, S.; Hu, R.; Chen, X.; Liu, Z.; Kweon, I.S.; Xie, S. Convnext v2: Co-designing and scaling convnets with masked autoencoders. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 16133–16142. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Yang, G.; Lei, J.; Zhu, Z.; Cheng, S.; Feng, Z.; Liang, R. Afpn: Asymptotic feature pyramid network for object detection. arXiv 2023, arXiv:2306.15988. [Google Scholar]
- Jiang, Y.; Tan, Z.; Wang, J.; Sun, X.; Lin, M.; Li, H. GiraffeDet: A heavy-neck paradigm for object detection. arXiv 2022, arXiv:2202.04256. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Input Size | Params (M) | GFLOPs | AP (%) | AP50 (%) | FPS |
|---|---|---|---|---|---|---|
| Cascade-RCNN | 1536 × 1536 | — | — | 16.1 | 31.9 | — |
| Light-RCNN | 1536 × 1536 | — | — | 16.5 | 32.8 | — |
| FasterR-CNN | 1536 × 1536 | — | — | 12.1 | 23.5 | — |
| YOLOv5n | 640 × 640 | 1.8 | 4.2 | 14.2 | 27.3 | 158.6 |
| YOLOV5s | 640 × 640 | 7.0 | 15.8 | 18.6 | 33.6 | 130.6 |
| YOLOV6n | 640 × 640 | 4.6 | 11.34 | 14.0 | 25.0 | 211.0 |
| YOLOV7-tiny | 640 × 640 | 6.1 | 13.1 | 15.8 | 30.6 | 243.0 |
| YOLOv8n | 640 × 640 | 3.0 | 8.1 | 16.4 | 29.0 | 240.4 |
| YOLOv8s | 640 × 640 | 11.1 | 28.5 | 19.2 | 33.1 | 208.9 |
| YOLOv8m | 640 × 640 | 25.8 | 78.7 | 21.5 | 36.8 | 102.8 |
| MGFAFNET-N | 640 × 640 | 2.0 | 13.5 | 20.2 | 35.6 | 141.1 |
| MGFAFNET-S | 640 × 640 | 4.2 | 24.2 | 21.0 | 36.6 | 116.9 |
| MGFAFNET-M | 640 × 640 | 7.5 | 39.7 | 22.2 | 38.8 | 82.6 |
| Method | Input Size | Params (M) | GFLOPs | AP (%) | AP50 (%) | FPS |
|---|---|---|---|---|---|---|
| YOLOv5n | 640 × 640 | 1.77 | 4.1 | 31.0 | 79.6 | 158.1 |
| YOLOV5s | 640 × 640 | 7.03 | 15.8 | 34.3 | 83.3 | 130.2 |
| YOLOV6n | 640 × 640 | 4.63 | 11.34 | 31.6 | 82.8 | 210.6 |
| YOLOV7-tiny | 640 × 640 | 6.05 | 13.0 | 45.6 | 87.8 | 242.0 |
| YOLOv8n | 640 × 640 | 3.00 | 8.1 | 45.4 | 85.0 | 239.9 |
| YOLOv8s | 640 × 640 | 11.12 | 28.4 | 46.9 | 86.1 | 207.1 |
| YOLOv8m | 640 × 640 | 25.84 | 78.7 | 48.3 | 86.8 | 103.1 |
| MGFAFNET-N | 640 × 640 | 2.09 | 13.5 | 50.1 | 90.2 | 141.2 |
| MGFAFNET-S | 640 × 640 | 4.28 | 24.2 | 51.6 | 92.4 | 116.6 |
| MGFAFNET-M | 640 × 640 | 7.56 | 39.7 | 52.7 | 93.6 | 82.4 |
| Visdrone Dataset | |||||||||||||
| Baseline | DBMA | DSPF | LCDD | Params (M) | GFLOPs | AP (%) | AP50 (%) | APS (%) | APM (%) | APL (%) | FPS (GPU) | FPS (Xavier nx) | Memory (G) |
| √ | 3.00 | 8.1 | 16.4 | 29.0 | 6.1 | 23.8 | 34.8 | 241.0 | 35.3 | 1.6 | |||
| √ | √ | 2.95 | 8.9 | 17.6 | 31.4 | 7.2 | 25.6 | 38.1 | 183.2 | 30.6 | 1.6 | ||
| √ | √ | 2.17 | 12.7 | 17.5 | 31.0 | 7.9 | 24.4 | 35 | 164.2 | 28.4 | 1.6 | ||
| √ | √ | √ | 2.09 | 13.5 | 19.4 | 34.5 | 9.2 | 26.8 | 34.6 | 143.5 | 27.2 | 1.6 | |
| √ | √ | √ | √ | 2.09 | 13.5 | 20.2 | 35.6 | 9.7 | 28.6 | 36.1 | 143.5 | 27.2 | 1.7 |
| SyluDrone Dataset | |||||||||||||
| Baseline | DBMA | DSPF | LCDD | Params (M) | GFLOPs | AP (%) | AP50 (%) | APS (%) | APM (%) | APL(%) | FPS (GPU) | FPS (Xavier nx) | Memory (G) |
| √ | 3.00 | 8.1 | 45.4 | 85.0 | 34.1 | 55.2 | 55.9 | 241.0 | 35.2 | 1.6 | |||
| √ | √ | 2.95 | 8.9 | 46.6 | 86.8 | 36.5 | 55.9 | 47.5 | 182.2 | 30.4 | 1.6 | ||
| √ | √ | 2.17 | 12.7 | 47.6 | 87.9 | 37.8 | 57.7 | 51.6 | 162.8 | 28.4 | 1.6 | ||
| √ | √ | √ | 2.09 | 13.5 | 48.8 | 88.4 | 38.1 | 58.8 | 53.1 | 144.1 | 27.1 | 1.6 | |
| √ | √ | √ | √ | 2.09 | 13.5 | 50.1 | 90.2 | 38.9 | 60.4 | 56.8 | 144.1 | 27.1 | 1.7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, J.; Gao, H.; Yan, Z.; Qi, X.; Yu, J.; Ju, Z. Lightweight UAV Object-Detection Method Based on Efficient Multidimensional Global Feature Adaptive Fusion and Knowledge Distillation. Electronics 2024, 13, 1558. https://doi.org/10.3390/electronics13081558
Sun J, Gao H, Yan Z, Qi X, Yu J, Ju Z. Lightweight UAV Object-Detection Method Based on Efficient Multidimensional Global Feature Adaptive Fusion and Knowledge Distillation. Electronics. 2024; 13(8):1558. https://doi.org/10.3390/electronics13081558
Chicago/Turabian StyleSun, Jian, Hongwei Gao, Zhiwen Yan, Xiangjing Qi, Jiahui Yu, and Zhaojie Ju. 2024. "Lightweight UAV Object-Detection Method Based on Efficient Multidimensional Global Feature Adaptive Fusion and Knowledge Distillation" Electronics 13, no. 8: 1558. https://doi.org/10.3390/electronics13081558