

LaANIL: ANIL with Look-Ahead Meta-Optimization and Data Parallelism
 , , and
, , and 
Abstract
:1. Introduction
- Real-world relevance: We chose few-shot image classification to demonstrate LaANIL’s ability to learn from a limited number of examples, which mimics real-world scenarios where acquiring extensive labeled data is often unfeasible.
- Generalization and adaptability: Few-shot image classification tasks require models to quickly adapt to new classes with only a small number of examples per class. This demonstrates the model’s ability to generalize from limited information, a crucial attribute for incremental learning algorithms like LaANIL, which are designed to assimilate and accommodate new knowledge iteratively.
- Robustness and flexibility: The use of few-shot image classification as the evaluation metric highlights the importance of models being able to learn from minimal data, which is in line with the fundamental goals of incremental learning frameworks.
- Benchmarking against state-of-the-art: Few-shot image classification tasks are used as a standardized benchmark to evaluate the performance of new algorithms. LaANIL was subjected to this benchmark to effectively compare its performance against state-of-the-art few-shot learning methods and assess its effectiveness in handling limited-data scenarios.
- Addressing model bias and overfitting: Few-shot image classification requires models to effectively combat overfitting and bias due to the limited training samples, which may lead to skewed representations.
2. Background
2.1. Meta-Learning
2.2. Model-Agnostic Meta-Learning (MAML)
2.3. MAML Using Head of the Inner Loop (ANIL)
3. Our Proposal: LaANIL
3.1. Data Parallelism in LaANIL
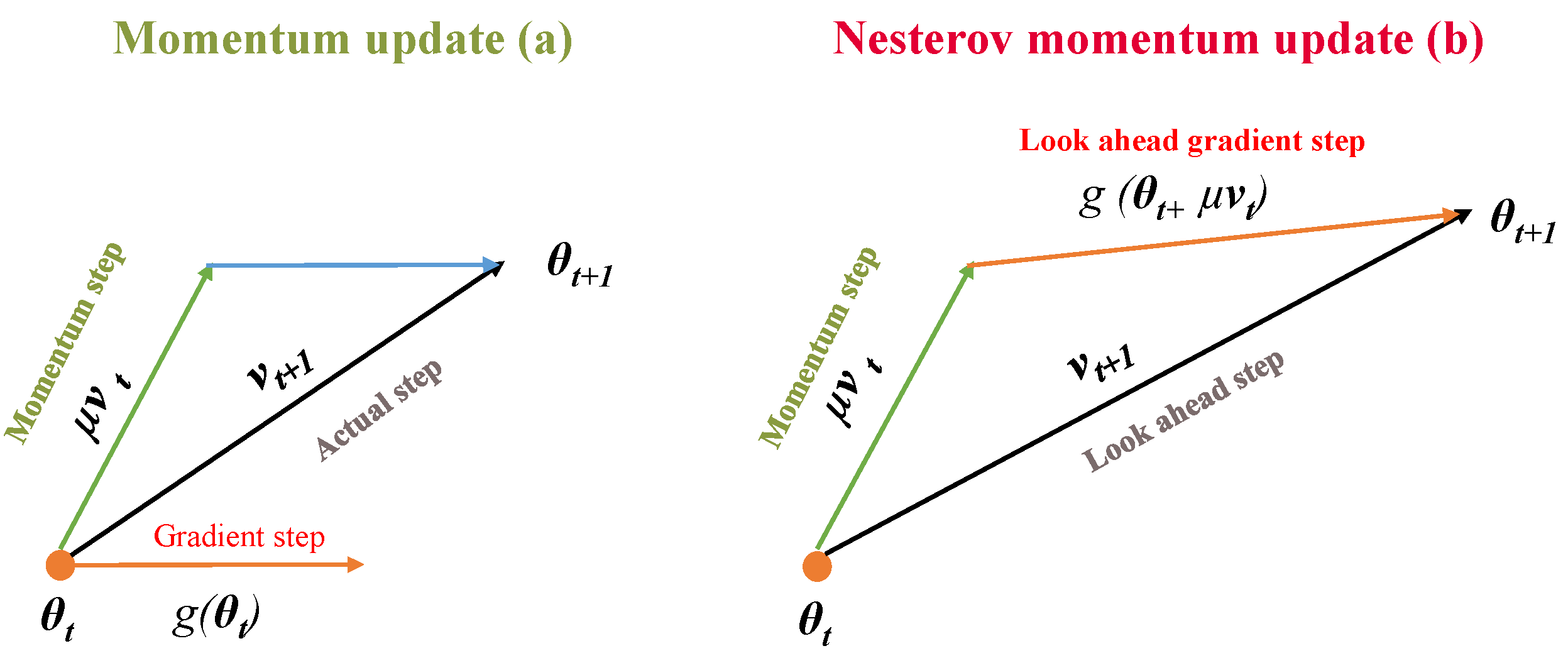
3.2. Gradient Calculation in LaANIL
- Decay constant
- Momentum vector m
- Learning rate
- Parameter set of LaANIL
- Velocity term
- Norm vector n
4. Experiment Setup
| Algorithm 1 LaANIL ANIL with Look-Ahead Meta-Optimization and Data Parallelism [3] |
|
| Algorithm 2 MAML with almost no inner loop (ANIL) [3] |
|
4.1. Datasets and Pre-Processing
4.2. Model Configuration
- Install the required libraries, including torch, numpy, random, and l2l, among others.
- Set up the datasets: FC100 CIFAR-FS, Mini-ImageNet, CUBirds-200-2011, and Tiered-ImageNet are downloaded and separated into train, validation, and test datasets using l2l.vision.datasets module.
- Define the model: Create LaANIL by using l2l.vision.models.CNN4 from the l2l library. Set the output size to the number of ways and hidden size, embedding size, and number of layers to the desired values.
- Define the head of the model using l2l.algorithms.MAML and define the learning rate to fast-lr.
- Define the optimization using torch.optim.NAdam. Set the parameters in the model and the learning rate to meta-lr.
- Train the model by iterating over the number of tasks in meta-bsz (batch size) and computing the meta-training, meta-validation, and meta-testing loss and accuracy. Use the fast-adapt function to adapt the model to the current task.
- Compute the gradients and optimize the model by averaging the accumulated gradients and calling optimizer.step().
- Evaluate the model by printing the metrics for each iteration in the outer loop.
- Finally, assess LaANIL with different back bones on the meta-test set by randomly selecting tasks and calculating the average and validation accuracy for all mentioned datasets [40].
5. Results and Discussion
5.1. Rapid Adaptation
5.2. Better Generalization
5.3. Low Variance
5.4. Edge Compatibility of New Model
5.5. Ablation Studies
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Khan, I.; Zhang, X.; Rehman, M.; Ali, R. A literature survey and empirical study of meta-learning for classifier selection. IEEE Access 2020, 8, 10262–10281. [Google Scholar] [CrossRef]
- Chen, Y.; Liu, Z.; Xu, H.; Darrell, T.; Wang, X. Meta-Baseline: Exploring Simple Meta-Learning for Few-Shot Learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 9062–9071. [Google Scholar]
- Finn, C.; Abbeel, P.; Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the International Conference on Machine Learning, PMLR, Sydney, NSW, Australia, 6–11 August 2017; pp. 1126–1135. [Google Scholar]
- Raghu, A.; Raghu, M.; Bengio, S.; Vinyals, O. Rapid learning or feature reuse? Towards understanding the effectiveness of maml. arXiv 2019, arXiv:1909.09157. [Google Scholar]
- Tian, P.; Li, W.; Gao, Y. Consistent meta-regularization for better meta-knowledge in few-shot learning. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 7277–7288. [Google Scholar] [CrossRef] [PubMed]
- Fan, Y.; Zhang, J.; Zhao, N.; Ren, Y.; Wan, J.; Zhou, L.; Shen, Z.; Wang, J.; Zhang, J.; Wei, Z. Model aggregation method for data parallelism in distributed real-time machine learning of smart sensing equipment. IEEE Access 2019, 7, 172065–172073. [Google Scholar] [CrossRef]
- Sun, C.M.; Chen, Z.; Lin, L. Counterfactual Balancing Feature Alignment for Few-Shot Cross-Domain Scene Parsing. IEEE Access 2023. [Google Scholar] [CrossRef]
- Zhao, S.; Li, F.; Chen, X.; Guan, X.; Jiang, J.; Huang, D.; Qing, Y.; Wang, S.; Wang, P.; Zhang, G.; et al. vpipe: A virtualized acceleration system for achieving efficient and scalable pipeline parallel dnn training. IEEE Trans. Parallel Distrib. Syst. 2021, 33, 489–506. [Google Scholar] [CrossRef]
- Goddard, H.; Shamir, L. SVMnet: Non-Parametric Image Classification Based on Convolutional Ensembles of Support Vector Machines for Small Training Sets. IEEE Access 2022, 10, 24029–24038. [Google Scholar] [CrossRef]
- Gu, P.; Tian, S.; Chen, Y. Iterative learning control based on Nesterov accelerated gradient method. IEEE Access 2019, 7, 115836–115842. [Google Scholar] [CrossRef]
- Chen, X.W.; Lin, X. Big data deep learning: Challenges and perspectives. IEEE Access 2014, 2, 514–525. [Google Scholar] [CrossRef]
- Luo, X.; Xu, J.; Xu, Z. Channel Importance Matters in Few-Shot Image Classification. In Proceedings of the 39th International Conference on Machine Learning, PMLR, Baltimore, MD, USA, 17–23 July 2022; Chaudhuri, K., Jegelka, S., Song, L., Szepesvari, C., Niu, G., Sabato, S., Eds.; Proceedings of Machine Learning Research: New York, NY, USA, 2022; Volume 162, pp. 14542–14559. [Google Scholar]
- Hutter, F.; Kotthoff, L.; Vanschoren, J. Automated Machine Learning: Methods, Systems, Challenges; Springer Nature: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Tian, Y.; Zhao, X.; Huang, W. Meta-learning approaches for learning-to-learn in deep learning: A survey. Neurocomputing 2022, 494, 203–223. [Google Scholar] [CrossRef]
- Lee, T.; Yoo, S. Augmenting few-shot learning with supervised contrastive learning. IEEE Access 2021, 9, 61466–61474. [Google Scholar] [CrossRef]
- Wang, Y.; Gui, G.; Lin, Y.; Wu, H.C.; Yuen, C.; Adachi, F. Few-shot specific emitter identification via deep metric ensemble learning. IEEE Internet Things J. 2022, 9, 24980–24994. [Google Scholar] [CrossRef]
- Fu, K.; Zhang, T.; Zhang, Y.; Yan, M.; Chang, Z.; Zhang, Z.; Sun, X. Meta-SSD: Towards fast adaptation for few-shot object detection with meta-learning. IEEE Access 2019, 7, 77597–77606. [Google Scholar] [CrossRef]
- Lu, S.; Cui, X.; Squillante, M.S.; Kingsbury, B.; Horesh, L. Decentralized bilevel optimization for personalized client learning. In Proceedings of the ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; pp. 5543–5547. [Google Scholar]
- He, Y.; Luo, F.; Ranzi, G. Transferrable model-agnostic meta-learning for short-term household load forecasting with limited training data. IEEE Trans. Power Syst. 2022, 37, 3177–3180. [Google Scholar] [CrossRef]
- Chua, K.; Lei, Q.; Lee, J.D. How fine-tuning allows for effective meta-learning. In Proceedings of the Advances in Neural Information Processing Systems, Virtual, 6–14 December 2021; Volume 34, pp. 8871–8884. [Google Scholar]
- Wu, M.; Jiang, F.; Liu, J.; Peng, Y. Application of C1DAE-ANIL in End-to-End Communication of IRS-Assisted UAV System. IEEE Access 2022, 10, 80703–80713. [Google Scholar] [CrossRef]
- Collins, L.; Mokhtari, A.; Oh, S.; Shakkottai, S. Maml and anil provably learn representations. In Proceedings of the International Conference on Machine Learning, PMLR, Baltimore, MD, USA, 17–23 July 2022; pp. 4238–4310. [Google Scholar]
- Miller, S.S.; Mocanu, P.T. Second order differential inequalities in the complex plane. J. Math. Anal. Appl. 1978, 65, 289–305. [Google Scholar] [CrossRef]
- Sun, S.; Cao, Z.; Zhu, H.; Zhao, J. A survey of optimization methods from a machine learning perspective. IEEE Trans. Cybern. 2019, 50, 3668–3681. [Google Scholar] [CrossRef] [PubMed]
- Aimen, A.; Sidheekh, S.; Madan, V.; Krishnan, N.C. Stress testing of meta-learning approaches for few-shot learning. In Proceedings of the AAAI Workshop on Meta-Learning and MetaDL Challenge, PMLR, Virtual, 9 February 2021; pp. 38–44. [Google Scholar]
- Fan, Q.; Peng, J.; Li, H.; Lin, S. Convergence of a gradient-based learning algorithm with penalty for ridge polynomial neural networks. IEEE Access 2020, 9, 28742–28752. [Google Scholar] [CrossRef]
- Wang, B.; Wang, D. Plant leaves classification: A few-shot learning method based on siamese network. IEEE Access 2019, 7, 151754–151763. [Google Scholar] [CrossRef]
- Zhao, Y.; Gao, X.; Shumailov, I.; Fusi, N.; Mullins, R. Rapid Model Architecture Adaption for Meta-Learning. In Proceedings of the Advances in Neural Information Processing Systems, New Orleans, LA, USA, 28 November–9 December 2022; Volume 35, pp. 18721–18732. [Google Scholar]
- Ye, H.J.; Sheng, X.R.; Zhan, D.C. Few-shot learning with adaptively initialized task optimizer: A practical meta-learning approach. Mach. Learn. 2020, 109, 643–664. [Google Scholar] [CrossRef]
- Chen, M. Analysis of Data Parallelism Methods with Deep Neural Network. In Proceedings of the 2022 6th International Conference on Electronic Information Technology and Computer Engineering, Xiamen, China, 21–23 October 2022; pp. 1857–1861. [Google Scholar]
- Tang, S.; Shen, C.; Wang, D.; Li, S.; Huang, W.; Zhu, Z. Adaptive deep feature learning network with Nesterov momentum and its application to rotating machinery fault diagnosis. Neurocomputing 2018, 305, 1–14. [Google Scholar] [CrossRef]
- Dozat, T. Incorporating Nesterov Momentum into Adam. In Proceedings of the ICLR 2016 Workshop, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Zaheer, M.; Reddi, S.; Sachan, D.; Kale, S.; Kumar, S. Adaptive methods for nonconvex optimization. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 3–8 December 2018; Volume 31. [Google Scholar]
- Xiao, B.; Liu, Y.; Xiao, B. Accurate state-of-charge estimation approach for lithium-ion batteries by gated recurrent unit with ensemble optimizer. IEEE Access 2019, 7, 54192–54202. [Google Scholar] [CrossRef]
- Korkmaz, E. Nesterov momentum adversarial perturbations in the deep reinforcement learning domain. In Proceedings of the International Conference on Machine Learning, ICML, Virtual, 13–18 July 2020. [Google Scholar]
- Hashemi, S.R.; Salehi, S.S.M.; Erdogmus, D.; Prabhu, S.P.; Warfield, S.K.; Gholipour, A. Asymmetric loss functions and deep densely-connected networks for highly-imbalanced medical image segmentation: Application to multiple sclerosis lesion detection. IEEE Access 2018, 7, 1721–1735. [Google Scholar] [CrossRef]
- Khan, M.U.; Jawad, M.; Khan, S.U. Adadb: Adaptive diff-batch optimization technique for gradient descent. IEEE Access 2021, 9, 99581–99588. [Google Scholar] [CrossRef]
- Jamal, M.A.; Qi, G.J. Task agnostic meta-learning for few-shot learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 11719–11727. [Google Scholar]
- Patowary, G.; Agarwalla, M.; Agarwal, S.; Sarma, M.P. A lightweight CNN architecture for land classification on satellite images. In Proceedings of the 2020 International Conference on Computational Performance Evaluation (ComPE), Shillong, India, 2–4 July 2020; pp. 362–366. [Google Scholar]
- Karami, A.; Crawford, M.; Delp, E.J. Automatic plant counting and location based on a few-shot learning technique. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2020, 13, 5872–5886. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, Y.; Liu, X. Tapnet: Enhancing trajectory prediction with auxiliary past learning task. In Proceedings of the 2021 IEEE Intelligent Vehicles Symposium (IV), Nagoya, Japan, 11–17 July 2021; pp. 421–426. [Google Scholar]
- Mauro, G.; Chmurski, M.; Servadei, L.; Pegalajar-Cuellar, M.; Morales-Santos, D.P. Few-shot user-definable radar-based hand gesture recognition at the edge. IEEE Access 2022, 10, 29741–29759. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sno | Dataset | Base Model Validation Accuracy (ANIL) | Our Model Validation Accuracy (LaANIL) |
|---|---|---|---|
| 1 | FC-100% | 95% | 98% |
| 2 | CIFAR-FS | 93% | 95% |
| 3 | Mini-ImageNet | 96% | 99% |
| 4 | CUBirds-200-2011 | 95% | 99% |
| 5 | Tiered-ImageNet | 98% | 99% |
| Sno | Dataset | Base Model Validation Accuracy (ANIL) | Our Model LaANIL Validation Accuracy | Varience ANIL | Varience LaANIL |
|---|---|---|---|---|---|
| 1 | FC-100 | 71% | 78% | 21 ± 3% | 6 ± 1% |
| 2 | CIFAR-FS | 63% | 68% | 21.6 ± 3% | 5 ± 1% |
| 3 | Mini-ImageNet | 65% | 72% | 20 ± 2% | 5 ± 1% |
| 4 | CUBirds-200-2011 | 66% | 74% | 23 ± 2% | 7 ± 1% |
| 5 | Tiered-ImageNet | 64% | 73% | 25 ± 4% | 8 ± 1% |
| Sno | Dataset | Base Model Validation Accuracy (ANIL) | Our Model LaANIL Validation Accuracy | Varience ANIL | Varience LaANIL |
|---|---|---|---|---|---|
| 1 | FC-100 | 47% | 52% | 15 ± 1% | 4 ± 0.7% |
| 2 | CIFAR-FS | 58% | 62% | 13 ± 1.5% | 4 ± 0.8% |
| 3 | Mini-ImageNet | 59% | 63% | 14 ± 1% | 3 ± 0.5% |
| 4 | CUBirds-200-2011 | 58% | 63% | 13 ± 1% | 5 ± 0.9% |
| 5 | Tiered-ImageNet | 63% | 66% | 15 ± 1.5% | 6 ± 1% |
| Sno | Dataset | Base Model Validation Accuracy (ANIL) | Our Model LaANIL Validation Accuracy | Varience ANIL | Varience LaANIL |
|---|---|---|---|---|---|
| 1 | FC-100 | 68% | 72% | 6 ± 0.5% | 2 ± 0.4% |
| 2 | CIFAR-FS | 64% | 70% | 4.6 ± 3% | 2 ± 0.5% |
| 3 | Mini-ImageNet | 63% | 69% | 7 ± 0.8% | 3 ± 0.5% |
| 4 | CUBirds-200-2011 | 66% | 73% | 8 ± 1% | 2 ± 0.6% |
| 5 | Tiered-ImageNet | 68% | 72% | 8 ± 1% | 2.5 ± 0.7% |
| Dataset | Model | Back Bone | Test Accuracy | Validation Accuracy | Varience (Validation) |
|---|---|---|---|---|---|
| mini ImageNet (5W5S) | ANIL | VGG | 61.7 ± 1.77% | 59.3 ± 2.27% | ±17.5% |
| CNN4 | 62.7 ± 1.87% | 59.0 ± 1.97% | ±14.5% | ||
| ResNet12 | 62.7 ± 0.87% | 59.3 ± 1.57% | ±15.7% | ||
| MAML | VGG | 61.2 ± 1.1% | 58.3 ± 2.17% | ±17.5% | |
| CNN4 | 62.8 ± 1.87% | 60.0 ± 1.35% | ±13.3% | ||
| ResNet12 | 63.16 ± 0.47% | 60.5 ± 1.27% | ±15.2% | ||
| ProtoNet | VGG | 61.5 ± 1.1% | 59.3 ± 2.17% | ±14.5% | |
| CNN4 | 62.0 ± 2.57% | 60.0 ± 1.37% | ±13.8% | ||
| ResNet12 | 63.5 ± 0.77% | 61.3 ± 1.57% | ±18.1% | ||
| LaANIL | VGG | 62.5 ± 1.27% | 62.3 ± 1.77% | ±6.5% | |
| CNN4 | 65.2 ± 0.57% | 64.3 ± 0.67% | ±3.8% | ||
| ResNet12 | 64.8 ± 0.87% | 63.3 ± 1.17% | ±5.5% |
| Dataset | Model | Back Bone | Test Accuracy | Validation Accuracy | Varience (Validation) |
|---|---|---|---|---|---|
| Tiered ImageNet (2W2S) | ANIL | VGG | 73.7 ± 1.77% | 68.3 ± 1.2% | ±22.1% |
| CNN4 | 77.7 ± 1.87% | 71.0 ± 1.37% | ±21.5% | ||
| ResNet12 | 78.7 ± 0.87% | 70.3 ± 1.27% | ±21.7% | ||
| MAML | VGG | 80.2 ± 1.1% | 70.3 ± 2.17% | ±30.5% | |
| CNN4 | 82.8 ± 1.87% | 73.0 ± 1.25% | ±28.3% | ||
| ResNet12 | 83 ± 1.47% | 74.5 ± 1.27% | ±33.2% | ||
| ProtoNet | VGG | 79.5 ± 1.13% | 72 ± 2.17% | ±28.5% | |
| CNN4 | 82.0 ± 1.57% | 71.0 ± 1.37% | ±23.8% | ||
| ResNet12 | 82.5 ± 0.77% | 70.5 ± 1.57% | ±21.1% | ||
| LaANIL | VGG | 80.5 ± 0.87% | 74.3 ± 1.16% | ±7.5% | |
| CNN4 | 84.2 ± 0.57% | 78.3 ±0.67% | ±6.1% | ||
| ResNet12 | 84.8 ± 1.27% | 73.6 ± 1.17% | ±7.7% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tammisetti, V.; Bierzynski, K.; Stettinger, G.; Morales-Santos, D.P.; Cuellar, M.P.; Molina-Solana, M. LaANIL: ANIL with Look-Ahead Meta-Optimization and Data Parallelism. Electronics 2024, 13, 1585. https://doi.org/10.3390/electronics13081585
Tammisetti V, Bierzynski K, Stettinger G, Morales-Santos DP, Cuellar MP, Molina-Solana M. LaANIL: ANIL with Look-Ahead Meta-Optimization and Data Parallelism. Electronics. 2024; 13(8):1585. https://doi.org/10.3390/electronics13081585
Chicago/Turabian StyleTammisetti, Vasu, Kay Bierzynski, Georg Stettinger, Diego P. Morales-Santos, Manuel Pegalajar Cuellar, and Miguel Molina-Solana. 2024. "LaANIL: ANIL with Look-Ahead Meta-Optimization and Data Parallelism" Electronics 13, no. 8: 1585. https://doi.org/10.3390/electronics13081585