Brick Assembly Networks: An Effective Network for Incremental Learning Problems



Abstract
1. Introduction
- BAN is the first network architecture that provides a capability of a trained neural network to assemble (add) and dismantle (remove) labels without retraining the neural network.
- We introduce a truth labels-less loss function to train a network.
- We propose a way to train a network with only one label data. In other words, we can train BAN with a single label at a time.
- BAN does not include old labels’ datasets during the training phase when we add or remove a label from the network.
2. Related Work
3. Proposed Method
3.1. Preliminaries
3.2. Brick Assembly Network
3.3. Pseudo-Code of the Brick Assembly Network
| Algorithm 1. The pseudo-code of the Brick Assembly Network |
| Input: Image dataset D, distributed into l sub-datasets, where each sub-dataset consists of only one label data, Output: A converged BAN.
|
3.4. Parametric Characteristic Layer
| Algorithm 2. The pseudo-code of the parametric characteristic layer |
| Input: Image dataset D, distributes into l sub-datasets, each sub-dataset consists of only one label data, Output: A converged parametric characteristic layer.
|
4. Experiment Settings
Dataset
5. Experiment Results and Discussion
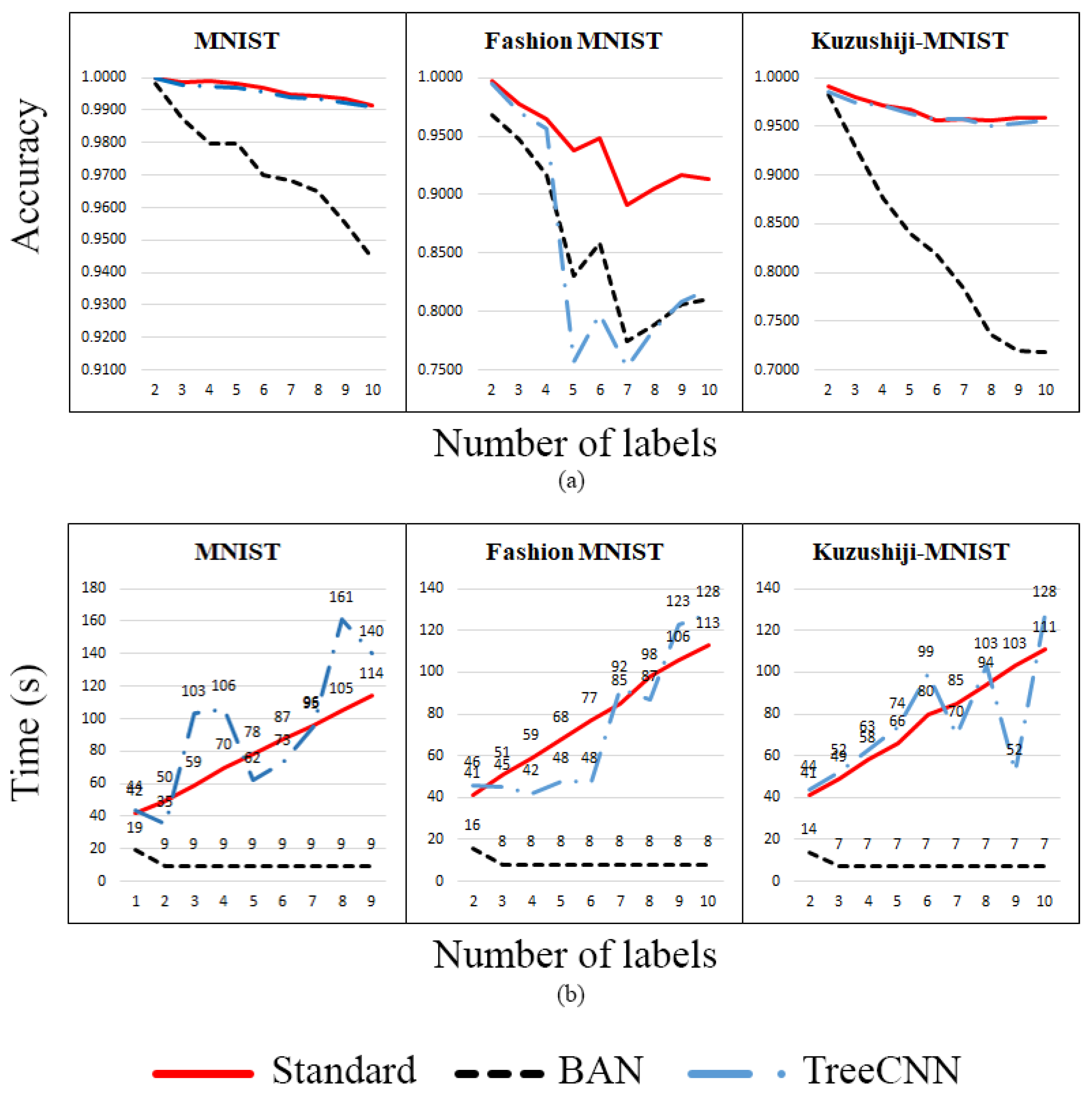
5.1. The Capability of Incrementally Adding New Label(s) on a Trained Network
5.1.1. Single Dataset
5.1.2. Multiple Datasets
5.2. The Capability of Changing Different Labels on a Network with a Mixture Dataset
5.3. Summary
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Chan, T.H.; Jia, K.; Gao, S.; Lu, J.; Zeng, Z.; Ma, Y. PCANet: A simple deep learning baseline for image classification? IEEE Trans. Image Process. 2015, 24, 5017–5032. [Google Scholar] [CrossRef] [PubMed]
- Li, S.; Song, W.; Fang, L.; Chen, Y.; Ghamisi, P.; Benediktsson, J.A. Deep learning for hyperspectral image classification: An overview. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6690–6709. [Google Scholar] [CrossRef]
- Perez, L.; Wang, J. The effectiveness of data augmentation in image classification using deep learning. arXiv 2017, arXiv:1712.04621. [Google Scholar]
- Zhao, W.; Du, S. Spectral–spatial feature extraction for hyperspectral image classification: A dimension reduction and deep learning approach. IEEE Trans. Geosci. Remote Sens. 2016, 54, 4544–4554. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems Conference, Montreal, QC, Canada, 8–13 November 2014; pp. 2672–2680. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Wang, H.; Wang, J.; Wang, J.; Zhao, M.; Zhang, W.; Zhang, F.; Xie, X.; Guo, M. Graphgan: Graph representation learning with generative adversarial nets. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Yu, L.; Zhang, W.; Wang, J.; Yu, Y. Seqgan: Sequence generative adversarial nets with policy gradient. In Proceedings of the Thirty-First, AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Amodei, D.; Ananthanarayanan, S.; Anubhai, R.; Bai, J.; Battenberg, E.; Case, C.; Casper, J.; Catanzaro, B.; Cheng, Q.; Chen, G.; et al. Deep speech 2: End-to-end speech recognition in english and mandarin. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; pp. 173–182. [Google Scholar]
- Hannun, A.; Case, C.; Casper, J.; Catanzaro, B.; Diamos, G.; Elsen, E.; Prenger, R.; Satheesh, S.; Sengupta, S.; Coates, A.; et al. Deep speech: Scaling up end-to-end speech recognition. arXiv 2014, arXiv:1412.5567. [Google Scholar]
- Zhang, Z.; Geiger, J.; Pohjalainen, J.; Mousa, A.E.D.; Jin, W.; Schuller, B. Deep learning for environmentally robust speech recognition: An overview of recent developments. ACM Trans. Intell. Syst. Technol. (TIST) 2018, 9, 1–28. [Google Scholar] [CrossRef]
- He, X.; Deng, L. Deep learning for image-to-text generation: A technical overview. IEEE Signal Process. Mag. 2017, 34, 109–116. [Google Scholar] [CrossRef]
- Marcheggiani, D.; Perez-Beltrachini, L. Deep graph convolutional encoders for structured data to text generation. arXiv 2018, arXiv:1810.09995. [Google Scholar]
- Shrivastava, P. Challenges in Deep Learning. Available online: https://hackernoon.com/challenges-in-deep-learning-57bbf6e73bb (accessed on 10 February 2020).
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2009, 22, 1345–1359. [Google Scholar] [CrossRef]
- Roy, D.; Panda, P.; Roy, K. Tree-CNN: A hierarchical deep convolutional neural network for incremental learning. Neural Netw. 2020, 121, 148–160. [Google Scholar] [CrossRef] [PubMed]
- Castro, F.M.; Marín-Jiménez, M.J.; Guil, N.; Schmid, C.; Alahari, K. End-to-end incremental learning. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 233–248. [Google Scholar]
- Rosenblatt, F. The Perceptron, a Perceiving and Recognizing Automaton Project Para; Cornell Aeronautical Laboratory: Buffalo, NY, USA, 1957. [Google Scholar]
- Oza, P.; Patel, V.M. One-class convolutional neural network. IEEE Signal Process. Lett. 2018, 26, 277–281. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Danielsson, P.E. Euclidean distance mapping. Comput. Graph. Image Process. 1980, 14, 227–248. [Google Scholar] [CrossRef]
- Xiao, H.; Rasul, K.; Vollgraf, R. Fashion-mnist: A novel image dataset for benchmarking machine learning algorithms. arXiv 2017, arXiv:1708.07747. [Google Scholar]
- Clanuwat, T.; Bober-Irizar, M.; Kitamoto, A.; Lamb, A.; Yamamoto, K.; Ha, D. Deep learning for classical japanese literature. arXiv 2018, arXiv:1812.01718. [Google Scholar]
- Maas, A.L.; Hannun, A.Y.; Ng, A.Y. Rectifier nonlinearities improve neural network acoustic models. In Proceedings of the International Conference on Machine Learning, Atlanta, GA, USA, 17–19 June 2013; Volume 30, p. 3. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| True Label | Predicted Label | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
| 0 | 0.000186 | 0.007645 | 0.000471 | 0.000762 | 0.000796 | 0.000489 | 0.000520 | 0.001993 | 0.000610 | 0.000903 |
| 1 | 0.001541 | 0.000065 | 0.000215 | 0.000376 | 0.000252 | 0.000256 | 0.000426 | 0.001012 | 0.000179 | 0.000555 |
| 2 | 0.000988 | 0.001925 | 0.000213 | 0.000612 | 0.000867 | 0.000743 | 0.000732 | 0.005793 | 0.000721 | 0.001876 |
| 3 | 0.000853 | 0.001601 | 0.000367 | 0.000210 | 0.001054 | 0.000345 | 0.001081 | 0.001764 | 0.000463 | 0.001134 |
| 4 | 0.001074 | 0.002564 | 0.000505 | 0.000553 | 0.000155 | 0.000490 | 0.000866 | 0.000816 | 0.000438 | 0.000615 |
| 5 | 0.000825 | 0.001596 | 0.000607 | 0.000694 | 0.000759 | 0.000179 | 0.000875 | 0.002095 | 0.000373 | 0.001011 |
| 6 | 0.000905 | 0.003593 | 0.000469 | 0.000959 | 0.000768 | 0.000756 | 0.000151 | 0.009304 | 0.000868 | 0.002458 |
| 7 | 0.001447 | 0.001962 | 0.001191 | 0.000452 | 0.000477 | 0.000541 | 0.002470 | 0.000161 | 0.000638 | 0.000412 |
| 8 | 0.000796 | 0.001359 | 0.000435 | 0.000522 | 0.000540 | 0.000393 | 0.000765 | 0.001318 | 0.000212 | 0.000645 |
| 9 | 0.001167 | 0.001794 | 0.000797 | 0.000397 | 0.000265 | 0.000379 | 0.001572 | 0.000331 | 0.000371 | 0.000163 |
| True Label | Predicted Label | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
| 0 | 0.000135 | 0.001707 | 0.000247 | 0.000494 | 0.000479 | 0.003169 | 0.000168 | 0.101183 | 0.000382 | 0.003559 |
| 1 | 0.000329 | 0.000125 | 0.000450 | 0.000336 | 0.000495 | 0.001480 | 0.000391 | 0.020732 | 0.000565 | 0.001418 |
| 2 | 0.000272 | 0.001305 | 0.000125 | 0.000618 | 0.000231 | 0.002530 | 0.000161 | 0.083569 | 0.000411 | 0.003803 |
| 3 | 0.000246 | 0.000573 | 0.000298 | 0.000159 | 0.000342 | 0.001338 | 0.000255 | 0.024446 | 0.000432 | 0.001430 |
| 4 | 0.000272 | 0.000949 | 0.000144 | 0.000449 | 0.000142 | 0.001996 | 0.000151 | 0.054401 | 0.000356 | 0.003784 |
| 5 | 0.001058 | 0.007484 | 0.000895 | 0.002885 | 0.001812 | 0.000184 | 0.000840 | 0.001232 | 0.000667 | 0.000889 |
| 6 | 0.000250 | 0.001342 | 0.000203 | 0.000526 | 0.000395 | 0.002419 | 0.000160 | 0.059214 | 0.000387 | 0.003245 |
| 7 | 0.000718 | 0.006877 | 0.000664 | 0.001859 | 0.001288 | 0.000131 | 0.000617 | 0.000093 | 0.000367 | 0.000430 |
| 8 | 0.000666 | 0.005456 | 0.000606 | 0.001954 | 0.002104 | 0.001598 | 0.000527 | 0.023552 | 0.000221 | 0.003303 |
| 9 | 0.000940 | 0.006535 | 0.000878 | 0.001860 | 0.002020 | 0.000275 | 0.000698 | 0.000972 | 0.000468 | 0.000144 |
| True Label | Predicted Label | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
| 0 | 0.000278 | 0.000918 | 0.000849 | 0.000477 | 0.000442 | 0.000424 | 0.000719 | 0.000605 | 0.000579 | 0.000553 |
| 1 | 0.000723 | 0.000238 | 0.000418 | 0.000501 | 0.000403 | 0.000431 | 0.000344 | 0.000590 | 0.000318 | 0.000388 |
| 2 | 0.000596 | 0.000444 | 0.000297 | 0.000447 | 0.000386 | 0.000399 | 0.000366 | 0.000570 | 0.000384 | 0.000395 |
| 3 | 0.000555 | 0.001015 | 0.000971 | 0.000265 | 0.000469 | 0.000487 | 0.000527 | 0.000766 | 0.000675 | 0.000626 |
| 4 | 0.000465 | 0.000527 | 0.000551 | 0.000448 | 0.000293 | 0.000445 | 0.000411 | 0.000598 | 0.000455 | 0.000460 |
| 5 | 0.000504 | 0.000413 | 0.000469 | 0.000350 | 0.000326 | 0.000168 | 0.000323 | 0.000412 | 0.000314 | 0.000370 |
| 6 | 0.000672 | 0.000384 | 0.000399 | 0.000446 | 0.000370 | 0.000389 | 0.000227 | 0.000537 | 0.000333 | 0.000433 |
| 7 | 0.000551 | 0.000734 | 0.000700 | 0.000571 | 0.000484 | 0.000555 | 0.000550 | 0.000488 | 0.000659 | 0.000521 |
| 8 | 0.000646 | 0.000454 | 0.000527 | 0.000496 | 0.000452 | 0.000469 | 0.000431 | 0.000705 | 0.000253 | 0.000464 |
| 9 | 0.000572 | 0.000532 | 0.000524 | 0.000527 | 0.000454 | 0.000508 | 0.000532 | 0.000614 | 0.000601 | 0.000299 |
| # of Label | Accuracy | Retrain | Training Time (s) | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Standard | BAN | TreeCNN | Standard | BAN | TreeCNN | Standard | BAN | TreeCNN | ||
| 1 | 9 | 0.9433 | 0.8460 | 0.9165 | Yes | No | Yes | 121 | - | 176 |
| 2 | 8 | 0.9440 | 0.8550 | 0.9188 | Yes | No | Yes | 120 | - | 178 |
| 3 | 7 | 0.9652 | 0.9021 | 0.9454 | Yes | No | Yes | 120 | - | 163 |
| 4 | 6 | 0.9776 | 0.9186 | 0.9588 | Yes | No | Yes | 126 | - | 142 |
| 5 | 5 | 0.9901 | 0.9551 | 0.9784 | Yes | No | Yes | 120 | - | 143 |
| 6 | 4 | 0.9911 | 0.9657 | 0.9825 | Yes | No | Yes | 119 | - | 143 |
| 7 | 3 | 0.9909 | 0.9659 | 0.9837 | Yes | No | Yes | 123 | - | 143 |
| 8 | 2 | 0.9947 | 0.9708 | 0.9890 | Yes | No | Yes | 127 | - | 143 |
| 9 | 1 | 0.9933 | 0.9599 | 0.9860 | Yes | No | Yes | 119 | - | 144 |
| # of Label | Accuracy | Retrain | Training Time (s) | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Standard | BAN | TreeCNN | Standard | BAN | TreeCNN | Standard | BAN | TreeCNN | ||
| 1 | 9 | 0.9605 | 0.7208 | 0.9226 | Yes | No | Yes | 115 | - | 144 |
| 2 | 8 | 0.9696 | 0.7541 | 0.9373 | Yes | No | Yes | 117 | - | 146 |
| 3 | 7 | 0.9792 | 0.7689 | 0.9498 | Yes | No | Yes | 116 | - | 151 |
| 4 | 6 | 0.9826 | 0.7515 | 0.9560 | Yes | No | Yes | 111 | - | 146 |
| 5 | 5 | 0.9890 | 0.7793 | 0.9657 | Yes | No | Yes | 118 | - | 146 |
| 6 | 4 | 0.9921 | 0.8001 | 0.9761 | Yes | No | Yes | 116 | - | 146 |
| 7 | 3 | 0.9916 | 0.8529 | 0.9765 | Yes | No | Yes | 117 | - | 144 |
| 8 | 2 | 0.9930 | 0.8958 | 0.9855 | Yes | No | Yes | 116 | - | 152 |
| 9 | 1 | 0.9940 | 0.9409 | 0.9884 | Yes | No | Yes | 117 | - | 150 |
| # of Label | Accuracy | Retrain | Training Time (s) | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Standard | BAN | TreeCNN | Standard | BAN | TreeCNN | Standard | BAN | TreeCNN | ||
| 1 | 9 | 0.9616 | 0.7363 | 0.9370 | Yes | No | Yes | 119 | - | 139 |
| 2 | 8 | 0.9654 | 0.7629 | 0.9428 | Yes | No | Yes | 122 | - | 140 |
| 3 | 7 | 0.9718 | 0.8025 | 0.9566 | Yes | No | Yes | 110 | - | 140 |
| 4 | 6 | 0.9667 | 0.8013 | 0.9514 | Yes | No | Yes | 123 | - | 139 |
| 5 | 5 | 0.9543 | 0.7888 | 0.9375 | Yes | No | Yes | 119 | - | 139 |
| 6 | 4 | 0.9632 | 0.8169 | 0.9406 | Yes | No | Yes | 120 | - | 142 |
| 7 | 3 | 0.9277 | 0.7694 | 0.8967 | Yes | No | Yes | 116 | - | 141 |
| 8 | 2 | 0.9235 | 0.8127 | 0.9023 | Yes | No | Yes | 117 | - | 138 |
| 9 | 1 | 0.9221 | 0.8223 | 0.9159 | Yes | No | Yes | 121 | - | 141 |
| Standard | BAN | TreeCNN | |
|---|---|---|---|
| # of Parameters | Low | High | High |
| Usage of Memory | Low | High | High |
| Train Individually | Not possible | Possible | Not possible |
| Re-usability | Not possible | Possible | Not possible |
| Retraining Time | High | Low/None | High |
| Old Dataset | Required | Not required | Required |
| Training Effort [17] | High | Low | Medium |
| Accuracy | High | Medium | High |
| Add New Labels | Retrain Entire Network | Train Separately and Merge | Retrain only specific nodes |
| Requirement in loss function | True Label | Characteristic Layer | True Label |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ho, J.; Kang, D.-K. Brick Assembly Networks: An Effective Network for Incremental Learning Problems. Electronics 2020, 9, 1929. https://doi.org/10.3390/electronics9111929
Ho J, Kang D-K. Brick Assembly Networks: An Effective Network for Incremental Learning Problems. Electronics. 2020; 9(11):1929. https://doi.org/10.3390/electronics9111929
Chicago/Turabian StyleHo, Jiacang, and Dae-Ki Kang. 2020. "Brick Assembly Networks: An Effective Network for Incremental Learning Problems" Electronics 9, no. 11: 1929. https://doi.org/10.3390/electronics9111929
APA StyleHo, J., & Kang, D.-K. (2020). Brick Assembly Networks: An Effective Network for Incremental Learning Problems. Electronics, 9(11), 1929. https://doi.org/10.3390/electronics9111929