Globally Consistent Indoor Mapping via a Decoupling Rotation and Translation Algorithm Applied to RGB-D Camera Output

Abstract
1. Introduction
- A 3D reconstruction algorithm is proposed, which decouples the estimation of the rotation and absolute translation of the camera poses. Note that we do not decouple the rotation and arbitrary translation completely, as we use these as the initial values for further processing.
- We incorporate the constraints between planes and points in the estimation problem, which contributes to the robustness of the algorithm.
- The qualitative and quantitative comparisons on various datasets show that the proposed 3D reconstruction algorithm is accurate, robust and effective.
2. Related Work
3. Methods
3.1. Visual Feature Detection
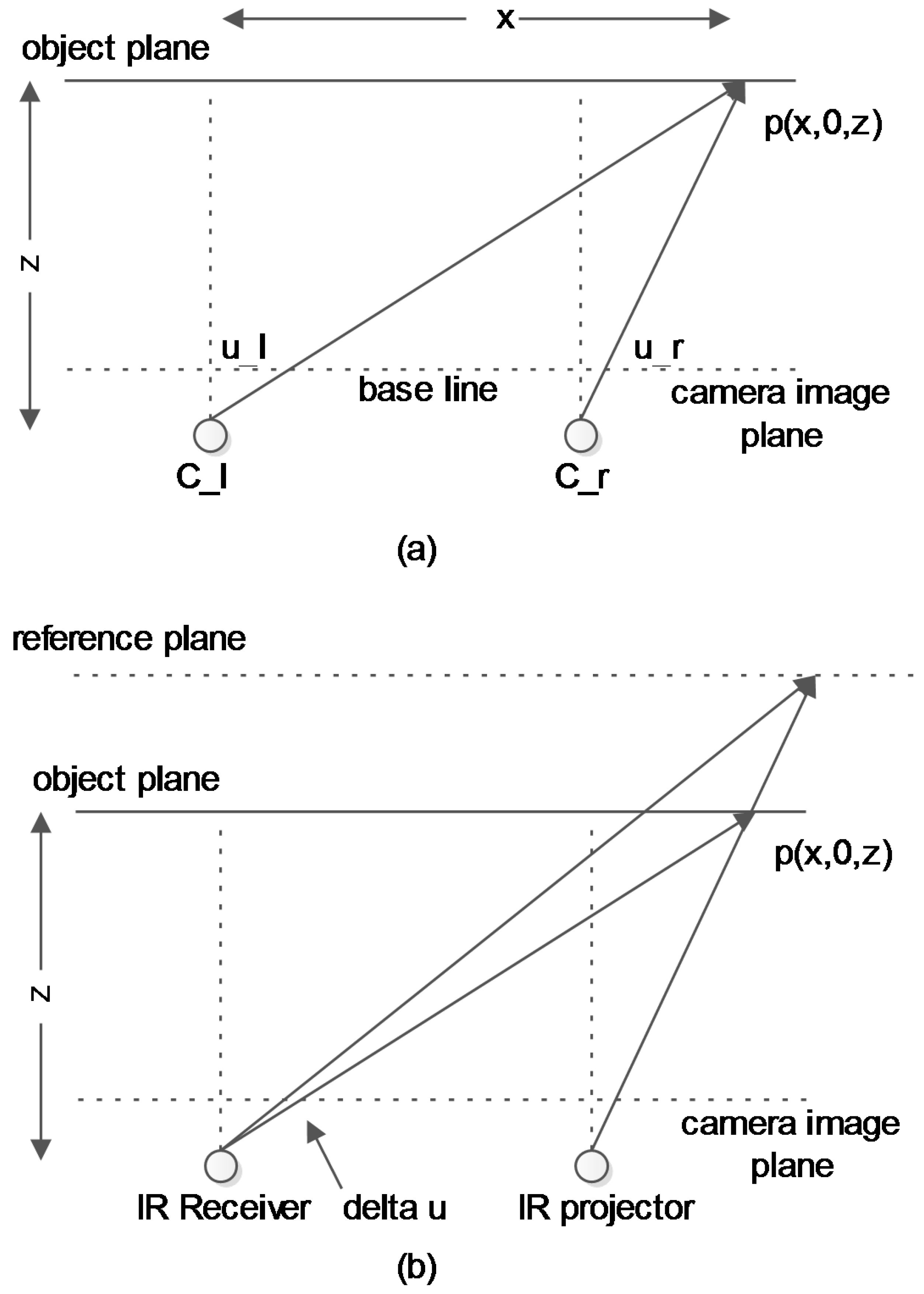
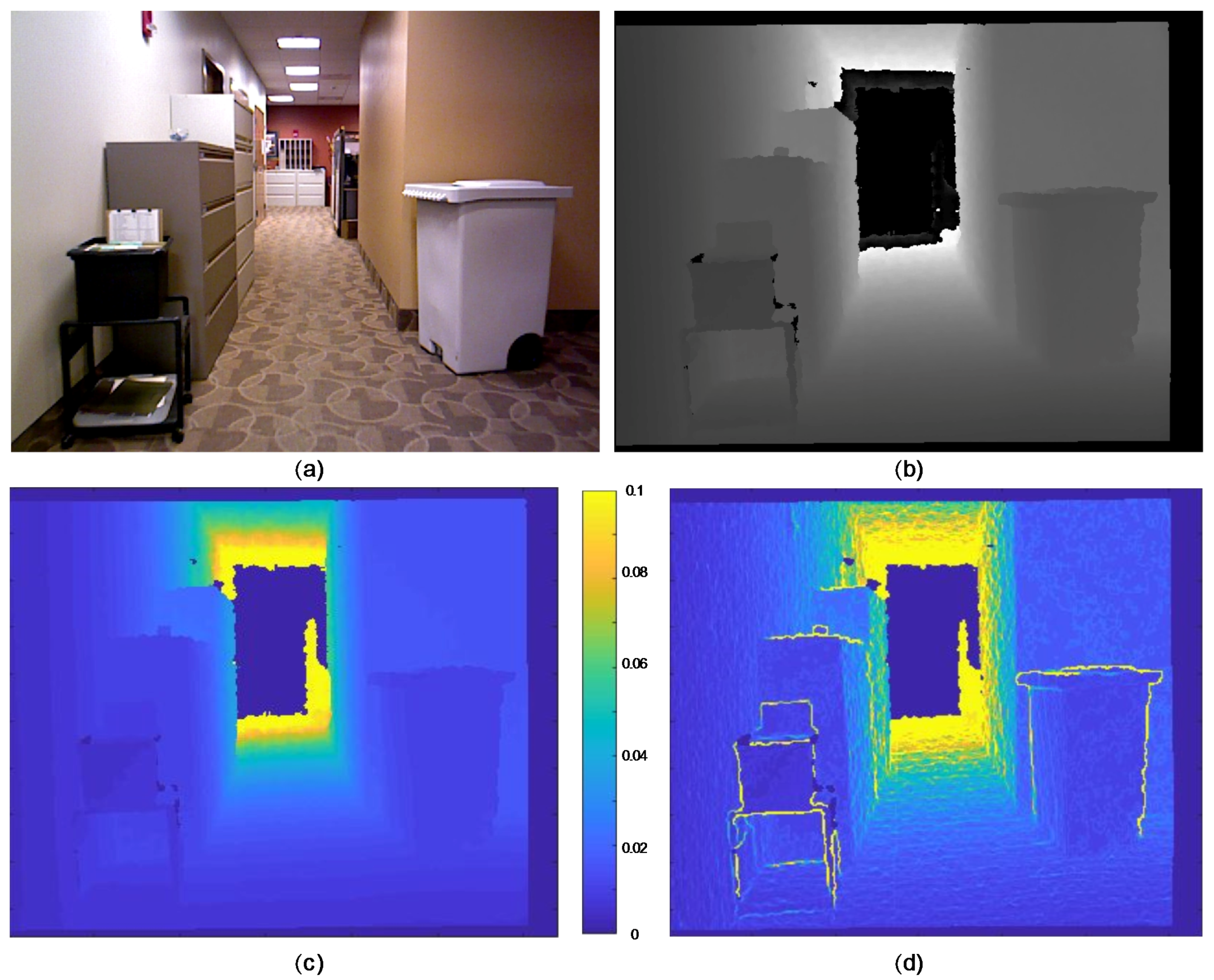
3.2. Uncertainty of Depth Measurements
3.3. Rotation Solving
3.4. Absolute Translation Recovery
3.4.1. Back Projection Associations
3.4.2. Solve Translation
3.5. Plane Constraints
3.5.1. Plane Extraction
3.5.2. Plane Points’ Associations
3.5.3. Plane Constraints
3.6. Joint Optimization
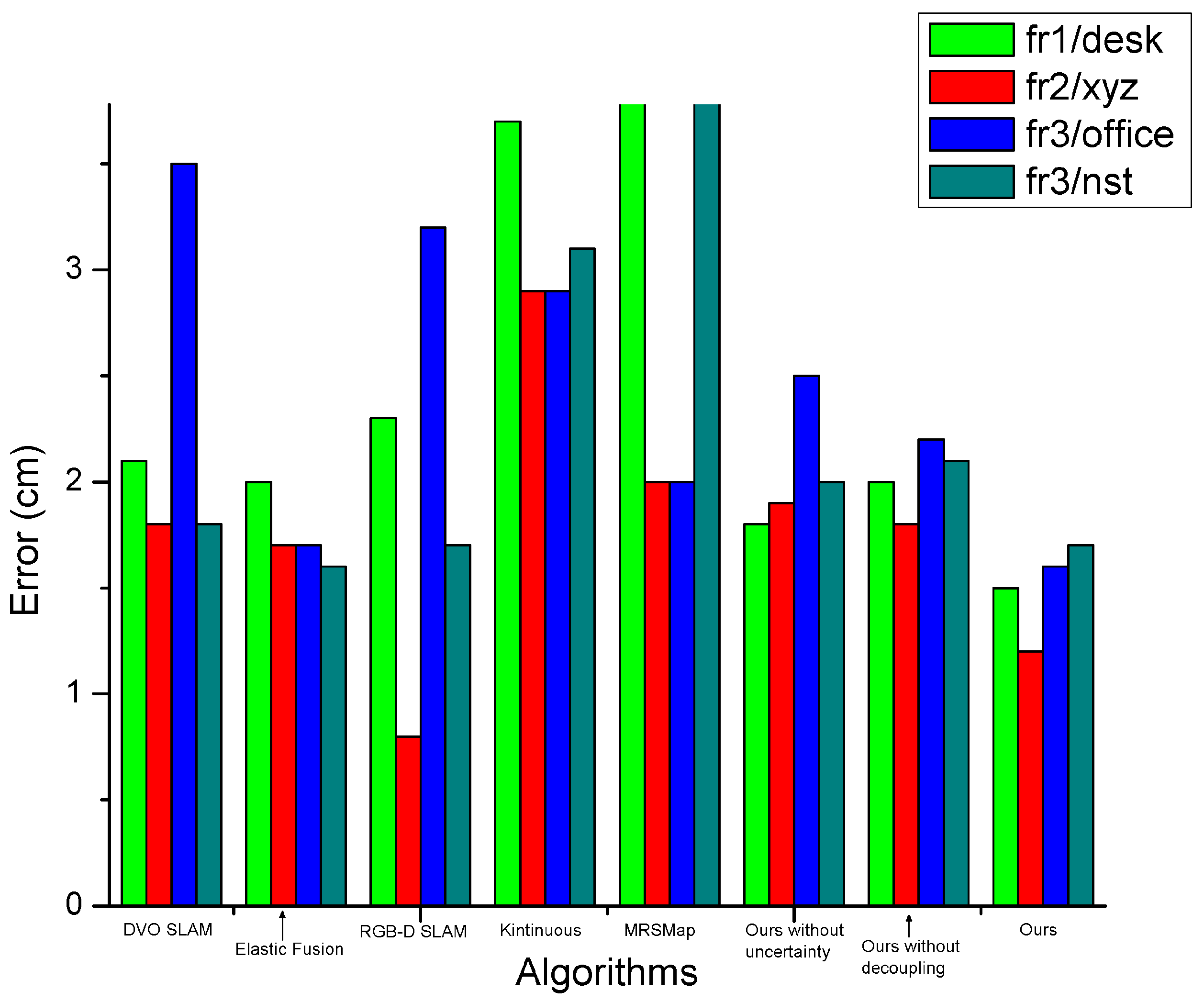
4. Experimental Section
5. Conclusions and Future Work
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Hijazi, I.H.; Ehlers, M.; Zlatanova, S. NIBU: A new approach to representing and analysing interior utility networks within 3D geo-information systems. Int. J. Digit. Earth 2012, 5, 22–42. [Google Scholar] [CrossRef]
- Thill, J.C.; Dao, T.H.D.; Zhou, Y. Traveling in the three-dimensional city: Applications in route planning, accessibility assessment, location analysis and beyond. J. Transp. Geogr. 2011, 19, 405–421. [Google Scholar] [CrossRef]
- Loch-Dehbi, S.; Dehbi, Y.; Plümer, L. Estimation of 3D Indoor Models with Constraint Propagation and Stochastic Reasoning in the Absence of Indoor Measurements. ISPRS Int. J. Geo-Inf. 2017, 6, 90. [Google Scholar] [CrossRef]
- Sternberg, H.; Keller, F.; Willemsen, T. Precise indoor mapping as a basis for coarse indoor navigation. J. Appl. Geodesy 2013, 7, 231–246. [Google Scholar] [CrossRef]
- Kang, H.K.; Li, K.J. A Standard Indoor Spatial Data Model—OGC IndoorGML and Implementation Approaches. ISPRS Int. J. Geo-Inf. 2017, 6, 116. [Google Scholar] [CrossRef]
- Atila, U.; Karas, I.; Turan, M.; Rahman, A. Automatic generation of 3D networks in CityGML and design of an intelligent individual evacuation model for building fires within the scope of 3D GIS. In Innovations in 3D Geo-Information Sciences; Springer: Berlin, Germany, 2014; pp. 123–142. [Google Scholar]
- Zhang, L.; Wang, Y.; Shi, H.; Zhang, L. Modeling and analyzing 3D complex building interiors for effective evacuation simulations. Fire Saf. J. 2012, 53, 1–12. [Google Scholar] [CrossRef]
- Biljecki, F.; Stoter, J.; Ledoux, H.; Zlatanova, S.; Çöltekin, A. Applications of 3D city models: State of the art review. ISPRS Int. J. Geo-Inf. 2015, 4, 2842–2889. [Google Scholar] [CrossRef]
- Yeh, M.; Chou, Y.; Yang, L. The Evaluation of GPS techniques for UAV-based Photogrammetry in Urban Area. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, 41. [Google Scholar] [CrossRef]
- Endres, F.; Hess, J.; Engelhard, N.; Sturm, J.; Cremers, D.; Burgard, W. An evaluation of the RGB-D SLAM system. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation (ICRA), Saint Paul, MN, USA, 14–18 May 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 1691–1696. [Google Scholar]
- Newcombe, R.A.; Izadi, S.; Hilliges, O.; Molyneaux, D.; Kim, D.; Davison, A.J.; Kohi, P.; Shotton, J.; Hodges, S.; Fitzgibbon, A. KinectFusion: Real-time dense surface mapping and tracking. In Proceedings of the 2011 10th IEEE International Symposium on Mixed and Augmented Reality (ISMAR), Basel, Switzerland, 26–29 October 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 127–136. [Google Scholar]
- Whelan, T.; Kaess, M.; Johannsson, H.; Fallon, M.; Leonard, J.J.; McDonald, J. Real-time large-scale dense RGB-D SLAM with volumetric fusion. Int. J. Robot. Res. 2015, 34, 598–626. [Google Scholar] [CrossRef]
- Litomisky, K. Consumer RGB-D Cameras and Their Applications; Rapport Technique; University of California: Oakland, CA, USA, 2012; Volume 20. [Google Scholar]
- Khoshelham, K.; Elberink, S.O. Accuracy and resolution of kinect depth data for indoor mapping applications. Sensors 2012, 12, 1437–1454. [Google Scholar] [CrossRef] [PubMed]
- Henry, P.; Krainin, M.; Herbst, E.; Ren, X.; Fox, D. RGB-D mapping: Using Kinect-style depth cameras for dense 3D modeling of indoor environments. Int. J. Robot. Res. 2012, 31, 647–663. [Google Scholar] [CrossRef]
- Chen, K.; Lai, Y.K.; Hu, S.M. 3D indoor scene modeling from RGB-D data: A survey. Comput. Vis. Media 2015, 1, 267–278. [Google Scholar] [CrossRef]
- Dai, A.; Nießner, M.; Zollhöfer, M.; Izadi, S.; Theobalt, C. BundleFusion: Real-time Globally Consistent 3D Reconstruction using On-the-fly Surface Reintegration. ACM Trans. Graph. (TOG) 2017, 36, 24. [Google Scholar] [CrossRef]
- Haene, C.; Zach, C.; Cohen, A.; Pollefeys, M. Dense Semantic 3D Reconstruction. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1730–1743. [Google Scholar] [CrossRef] [PubMed]
- Dos Santos, D.R.; Basso, M.A.; Khoshelham, K.; de Oliveira, E.; Pavan, N.L.; Vosselman, G. Mapping indoor spaces by adaptive coarse-to-fine registration of RGB-D data. IEEE Geosci. Remote Sens. Lett. 2016, 13, 262–266. [Google Scholar] [CrossRef]
- Khoshelham, K.; Dos Santos, D.; Vosselman, G. Generation and weighting of 3D point correspondences for improved registration of RGB-D data. Proc. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2013, 5, 127–132. [Google Scholar] [CrossRef]
- Chow, J.C.; Lichti, D.D.; Hol, J.D.; Bellusci, G.; Luinge, H. Imu and multiple RGB-D camera fusion for assisting indoor stop-and-go 3D terrestrial laser scanning. Robotics 2014, 3, 247–280. [Google Scholar] [CrossRef]
- Pavan, N.L.; dos Santos, D.R. A Global Closed-Form Refinement for Consistent TLS Data Registration. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1131–1135. [Google Scholar] [CrossRef]
- Pathak, K.; Birk, A.; Vaskevicius, N.; Pfingsthorn, M.; Schwertfeger, S.; Poppinga, J. Online three-dimensional SLAM by registration of large planar surface segments and closed-form pose-graph relaxation. J. Field Robot. 2010, 27, 52–84. [Google Scholar] [CrossRef]
- Theiler, P.W.; Wegner, J.D.; Schindler, K. Globally consistent registration of terrestrial laser scans via graph optimization. ISPRS J. Photogramm. Remote Sens. 2015, 109, 126–138. [Google Scholar] [CrossRef]
- Borrmann, D.; Elseberg, J.; Lingemann, K.; Nüchter, A.; Hertzberg, J. Globally consistent 3D mapping with scan matching. Robot. Auton. Syst. 2008, 56, 130–142. [Google Scholar] [CrossRef]
- Lu, F.; Milios, E. Globally consistent range scan alignment for environment mapping. Auton. Robots 1997, 4, 333–349. [Google Scholar] [CrossRef]
- Moulon, P.; Monasse, P.; Marlet, R. Global fusion of relative motions for robust, accurate and scalable structure from motion. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013; pp. 3248–3255. [Google Scholar]
- Reich, M.; Yang, M.Y.; Heipke, C. Global robust image rotation from combined weighted averaging. ISPRS J. Photogramm. Remote Sens. 2017, 127, 89–101. [Google Scholar] [CrossRef]
- Whelan, T.; Kaess, M.; Fallon, M.; Johannsson, H.; Leonard, J.; McDonald, J. Kintinuous: Spatially Extended KinectFusion; MIT-CSAIL-TR-2012-020; DSpace@MIT: Sydney, Australia, 9 July 2012. [Google Scholar]
- Mur-Artal, R.; Tardós, J.D. ORB-SLAM2: An Open-Source SLAM System for Monocular, Stereo, and RGB-D Cameras. IEEE Trans. Robot. 2017. [Google Scholar] [CrossRef]
- Concha, A.; Civera, J. RGBDTAM: A Cost-Effective and Accurate RGB-D Tracking and Mapping System. arXiv, 2017; arXiv:1703.00754. [Google Scholar]
- Angeli, A.; Filliat, D.; Doncieux, S.; Meyer, J.A. Fast and incremental method for loop-closure detection using bags of visual words. IEEE Trans. Robot. 2008, 24, 1027–1037. [Google Scholar] [CrossRef]
- Whelan, T.; Salas-Moreno, R.F.; Glocker, B.; Davison, A.J.; Leutenegger, S. ElasticFusion: Real-time dense SLAM and light source estimation. Int. J. Robot. Res. 2016, 35, 1697–1716. [Google Scholar] [CrossRef]
- Hou, Y.; Zhang, H.; Zhou, S. Convolutional neural network-based image representation for visual loop closure detection. In Proceedings of the 2015 IEEE International Conference on Information and Automation, Lijiang, China, 8–10 August 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 2238–2245. [Google Scholar]
- Xiao, J.; Owens, A.; Torralba, A. Sun3d: A database of big spaces reconstructed using sfm and object labels. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013; pp. 1625–1632. [Google Scholar]
- Halber, M.; Funkhouser, T. Fine-To-Coarse Global Registration of RGB-D Scans. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Vestena, K.; Dos Santos, D.; Oilveira, F., Jr.; Pavan, N.; Khoshelham, K. A Weighted Closed-Form Solution for RGB-D Data Registration. In Proceedings of the 2016 23th ISPRS Congres, the International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences, Prague, Czech Republic, 12–19 July 2016. [Google Scholar]
- Oehler, B.; Stueckler, J.; Welle, J.; Schulz, D.; Behnke, S. Efficient multi-resolution plane segmentation of 3D point clouds. In Proceedings of the 4th International Conference on Intelligent Robotics and Applications, Aachen, Germany, 6–8 December 2011; pp. 145–156. [Google Scholar]
- Lowe, D.G. Object recognition from local scale-invariant features. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999; IEEE: Piscataway, NJ, USA, 1999; Volume 2, pp. 1150–1157. [Google Scholar]
- Bay, H.; Tuytelaars, T.; Van Gool, L. Surf: Speeded up robust features. In Proceedings of the Computer vision–ECCV 2006, Graz, Austria, 7–13 May 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 404–417. [Google Scholar]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the 2011 IEEE international conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 2564–2571. [Google Scholar]
- Hartley, R.; Zisserman, A. Multiple View Geometry in Computer Vision; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Rusu, R.B.; Blodow, N.; Marton, Z.C.; Beetz, M. Close-range Scene Segmentation and Reconstruction of 3D Point Cloud Maps for Mobile Manipulation in Domestic Environments. In Proceedings of the 2009 IEEE/RSJ International Conference on Intelligent Robots and Systems, St. Louis, MO, USA, 10–15 October 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 1–6. [Google Scholar]
- Handa, A.; Whelan, T.; McDonald, J.; Davison, A.J. A benchmark for RGB-D visual odometry, 3D reconstruction and SLAM. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 1524–1531. [Google Scholar]
- Sturm, J.; Engelhard, N.; Endres, F.; Burgard, W.; Cremers, D. A Benchmark for the Evaluation of RGB-D SLAM Systems. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robot Systems (IROS), Vilamoura, Portugal, 7–12 October 2012. [Google Scholar]
- Kerl, C.; Sturm, J.; Cremers, D. Dense visual SLAM for RGB-D cameras. In Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Tokyo, Japan, 3–7 November 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 2100–2106. [Google Scholar]
- Stückler, J.; Behnke, S. Model Learning and Real-Time Tracking using Multi-Resolution Surfel Maps. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI-12), Toronto, ON, Canada, 22–26 July 2012. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm/Evaluation | Whelan [33] | Endres [10] | Whelan [29] | Xiao [35] | Concha [31] | Halber [36] | Santos [19] | Vestena [37] |
|---|---|---|---|---|---|---|---|---|
| Features | Patches | Points | Points | Points | Points | Points Planes | Points Regions | Points |
| Real time | Yes | Yes | Yes | No | Yes | No | No | No |
| Uncertainty model | No | No | No | No | No | No | Yes | Yes |
| Decoupling | No | No | No | No | No | No | Yes | Yes |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Y.; Wang, J.; Song, J.; Song, Z. Globally Consistent Indoor Mapping via a Decoupling Rotation and Translation Algorithm Applied to RGB-D Camera Output. ISPRS Int. J. Geo-Inf. 2017, 6, 323. https://doi.org/10.3390/ijgi6110323
Liu Y, Wang J, Song J, Song Z. Globally Consistent Indoor Mapping via a Decoupling Rotation and Translation Algorithm Applied to RGB-D Camera Output. ISPRS International Journal of Geo-Information. 2017; 6(11):323. https://doi.org/10.3390/ijgi6110323
Chicago/Turabian StyleLiu, Yuan, Jun Wang, Jingwei Song, and Zihui Song. 2017. "Globally Consistent Indoor Mapping via a Decoupling Rotation and Translation Algorithm Applied to RGB-D Camera Output" ISPRS International Journal of Geo-Information 6, no. 11: 323. https://doi.org/10.3390/ijgi6110323
APA StyleLiu, Y., Wang, J., Song, J., & Song, Z. (2017). Globally Consistent Indoor Mapping via a Decoupling Rotation and Translation Algorithm Applied to RGB-D Camera Output. ISPRS International Journal of Geo-Information, 6(11), 323. https://doi.org/10.3390/ijgi6110323