
Evaluation of Feature Selection Methods for Object-Based Land Cover Mapping of Unmanned Aerial Vehicle Imagery Using Random Forest and Support Vector Machine Classifiers



 ,
,  ,
,
Abstract
:1. Introduction
2. Methods
2.1. Study Area and Data Set
2.2. Segmentation and Features
2.3. Feature Selection Algorithms
2.4. Classification Procedure
2.4.1. Sampling and Validation
2.4.2. Classification Techniques
2.5. Statistical Inference
3. Results and Discussion
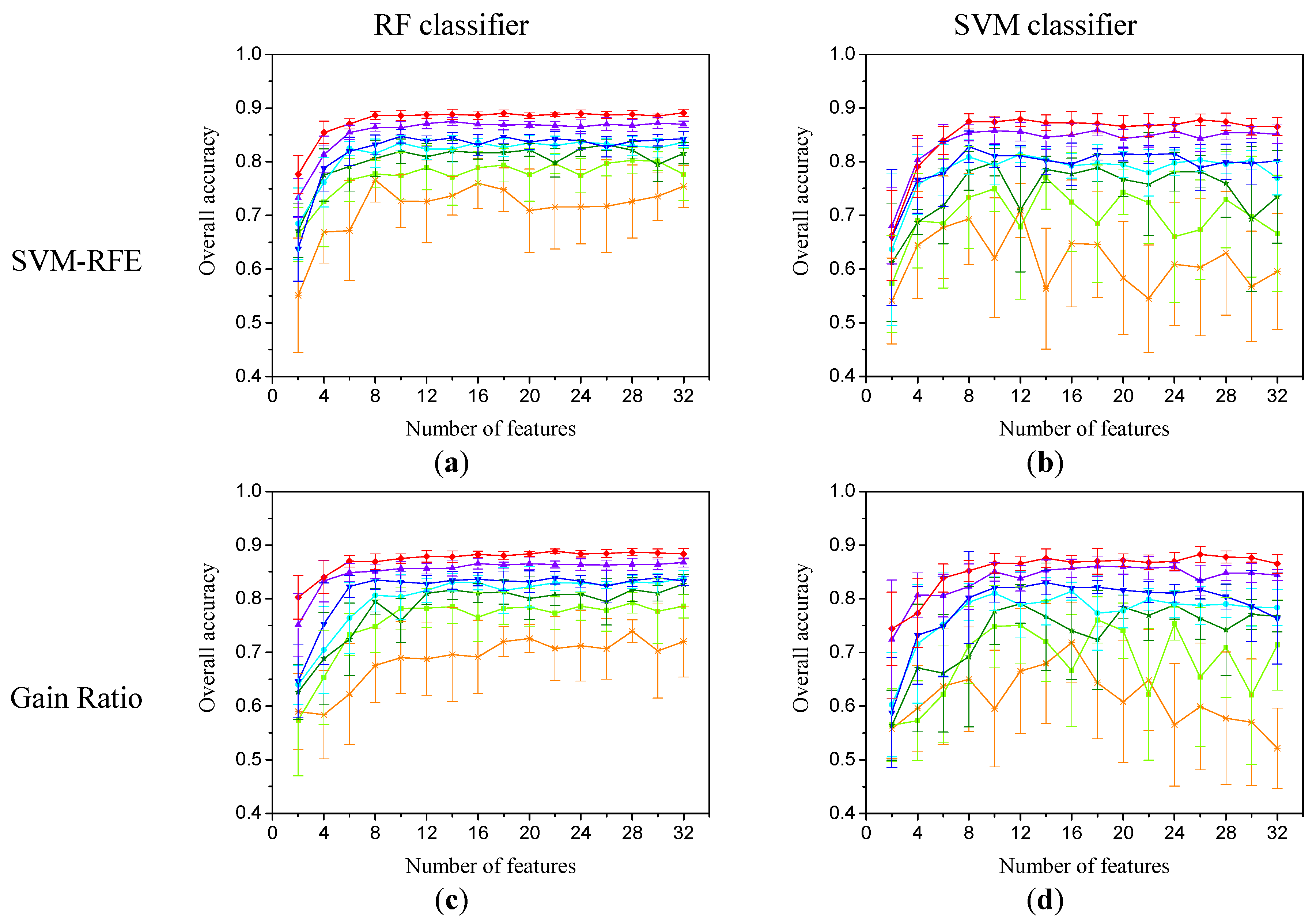
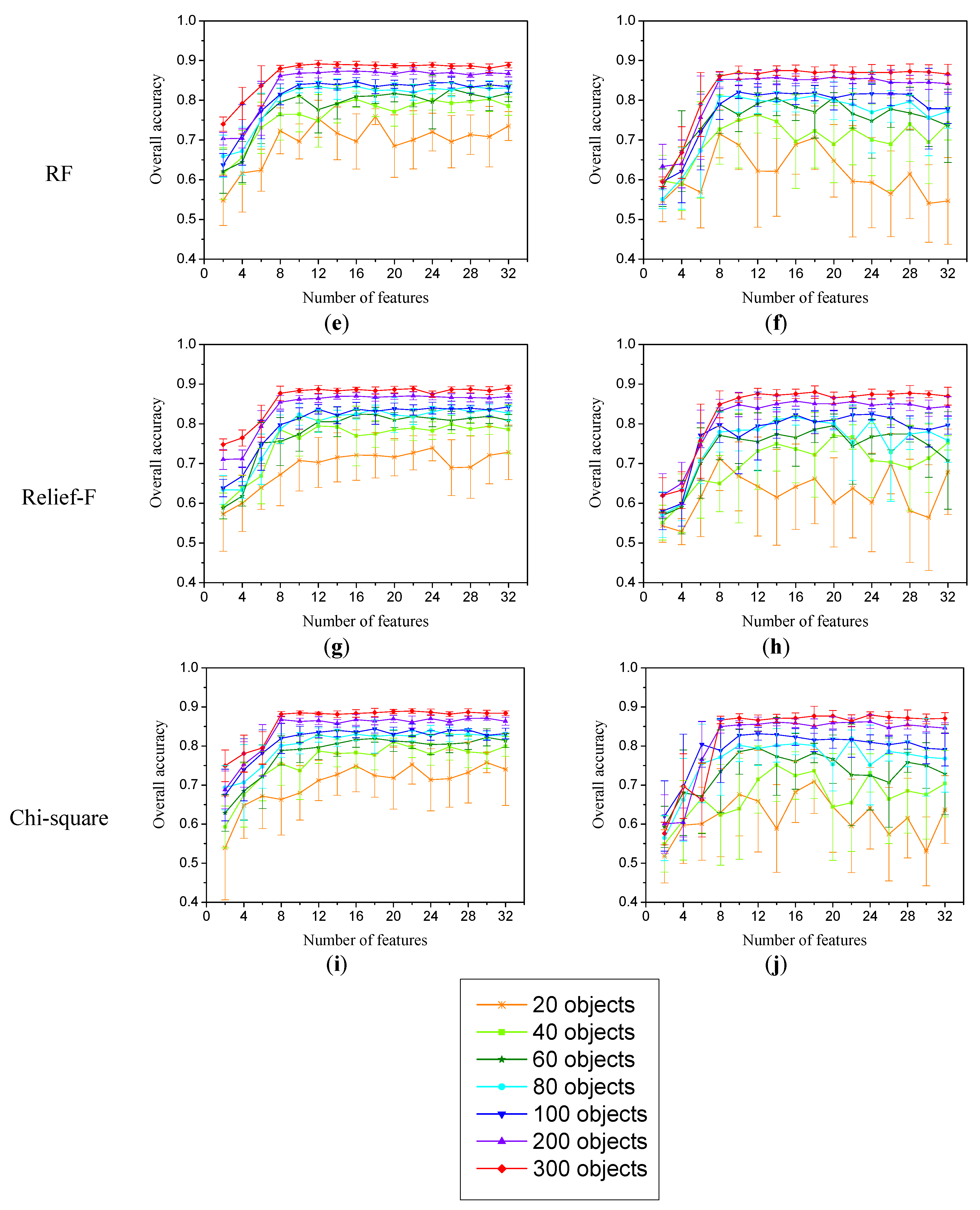
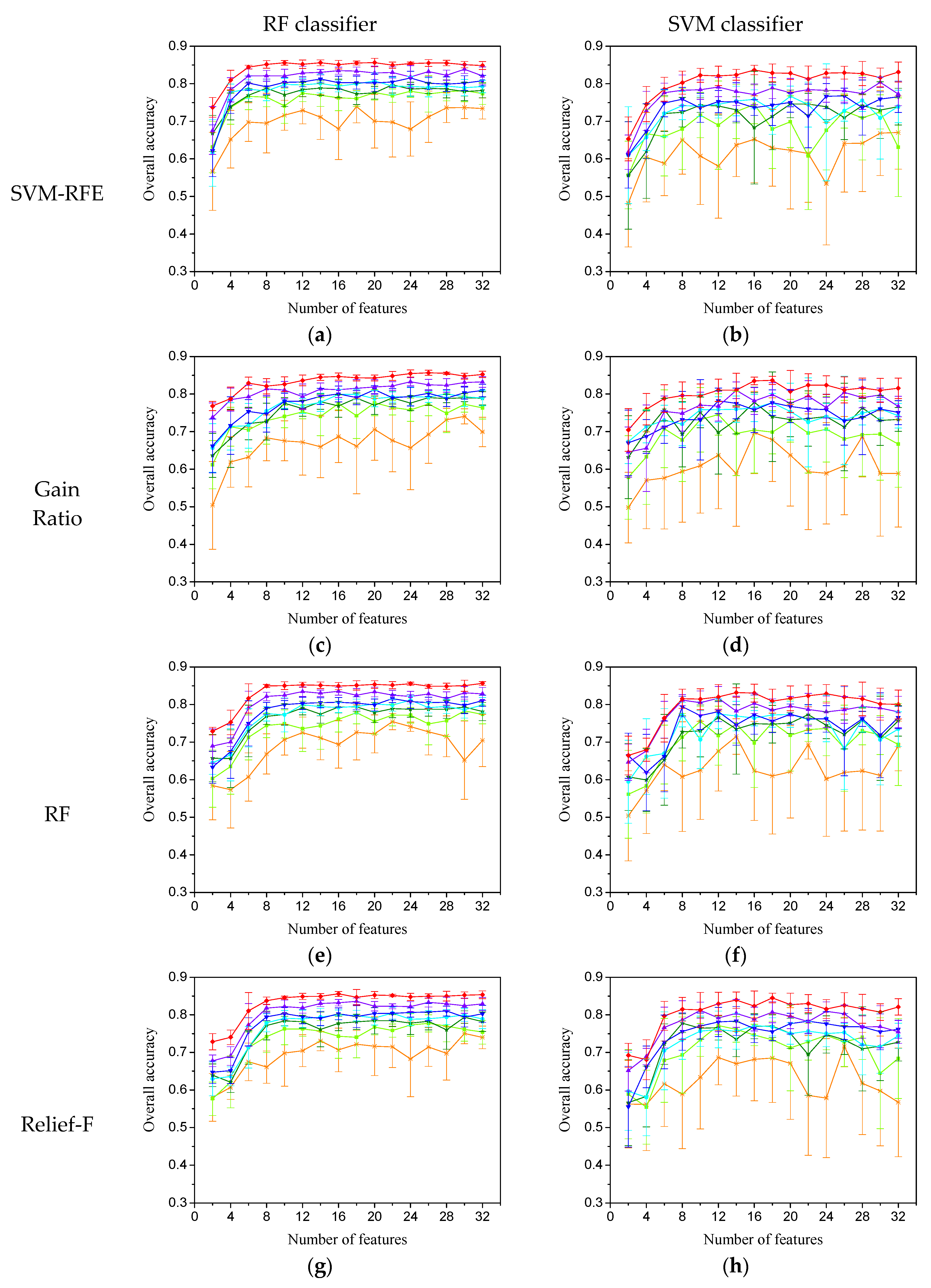
3.1. Evaluation of Feature-Importance-Evaluation Methods
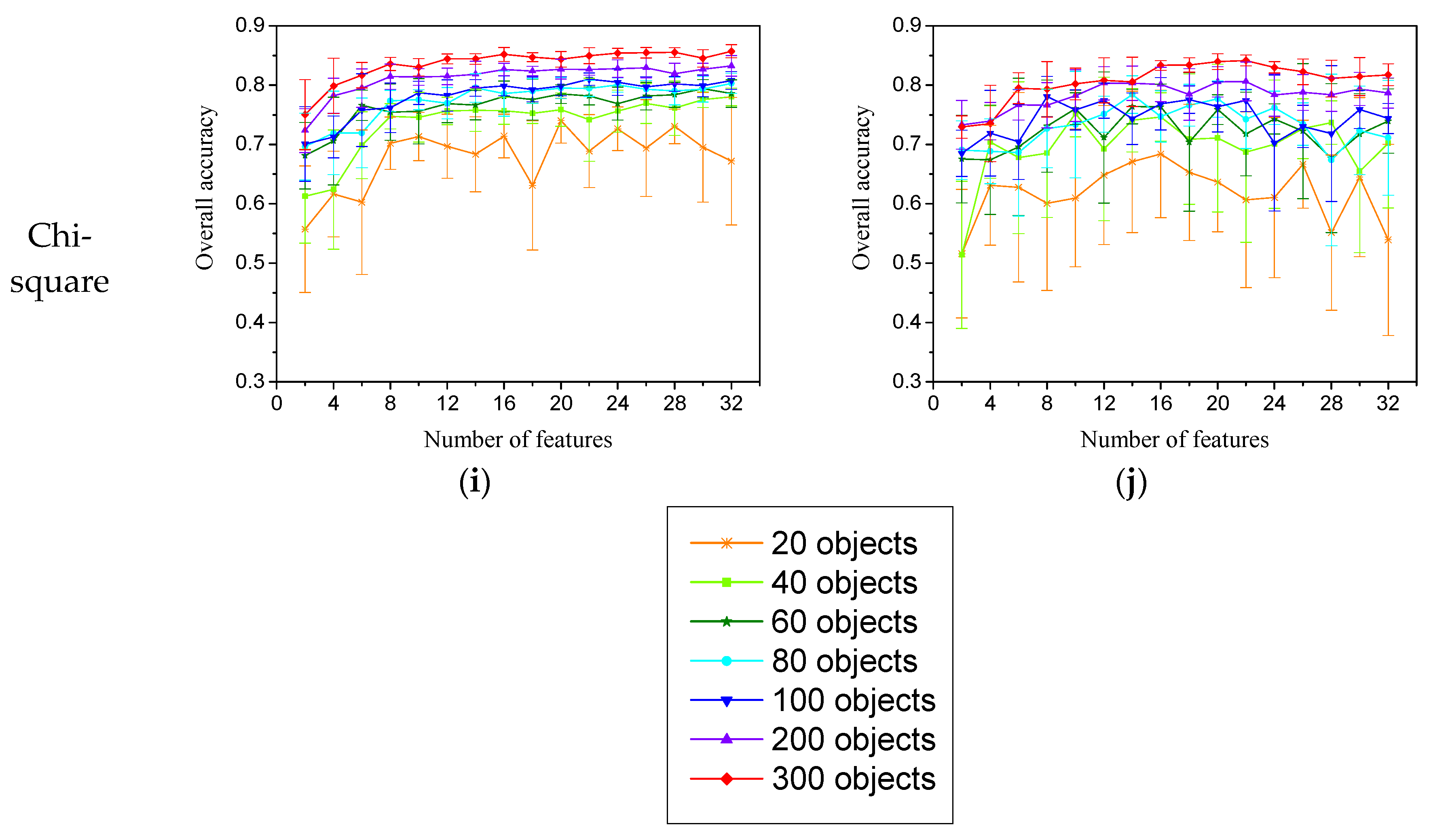
3.2. Evaluation for Feature-Subset-Evaluation Methods
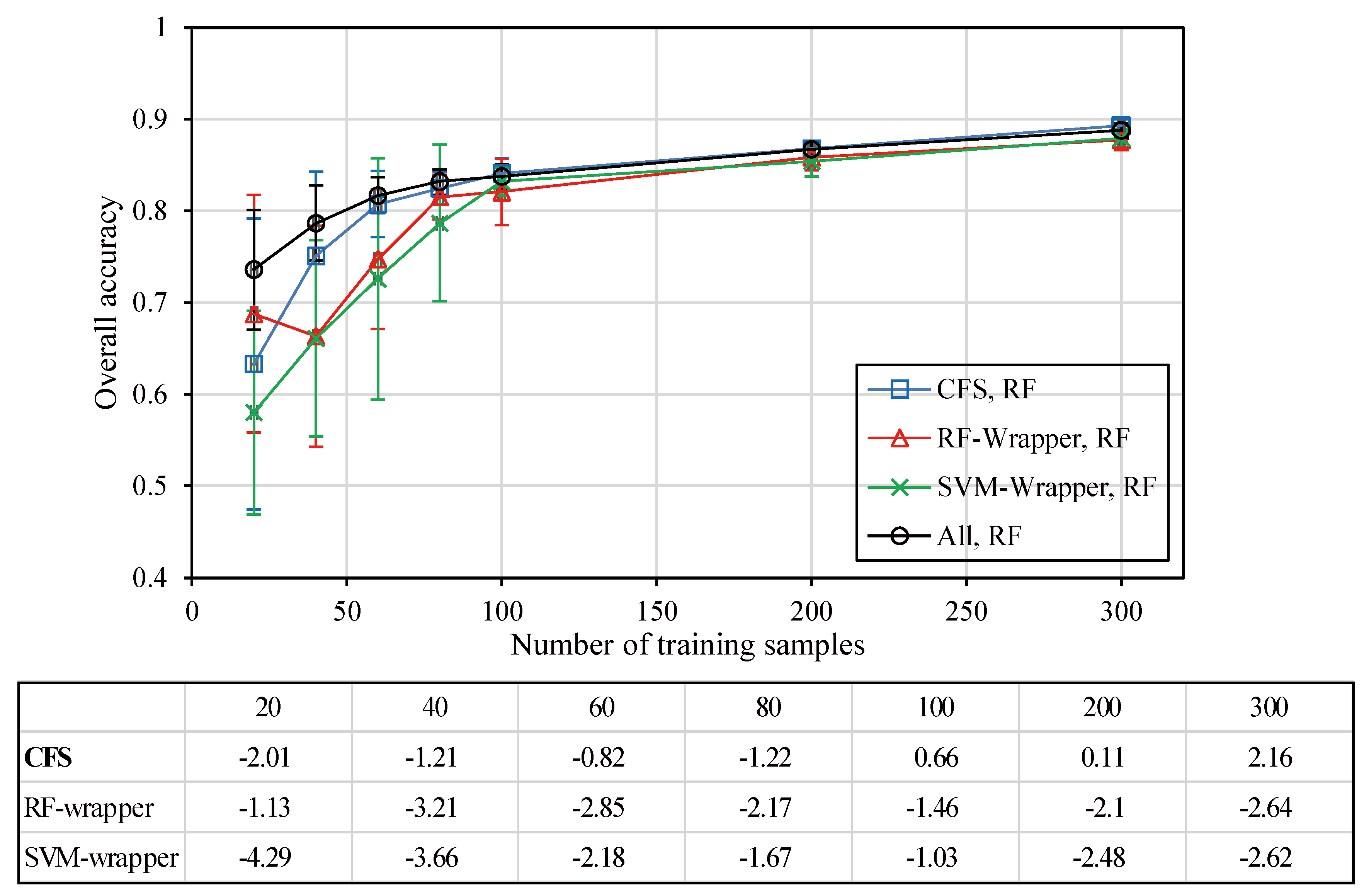
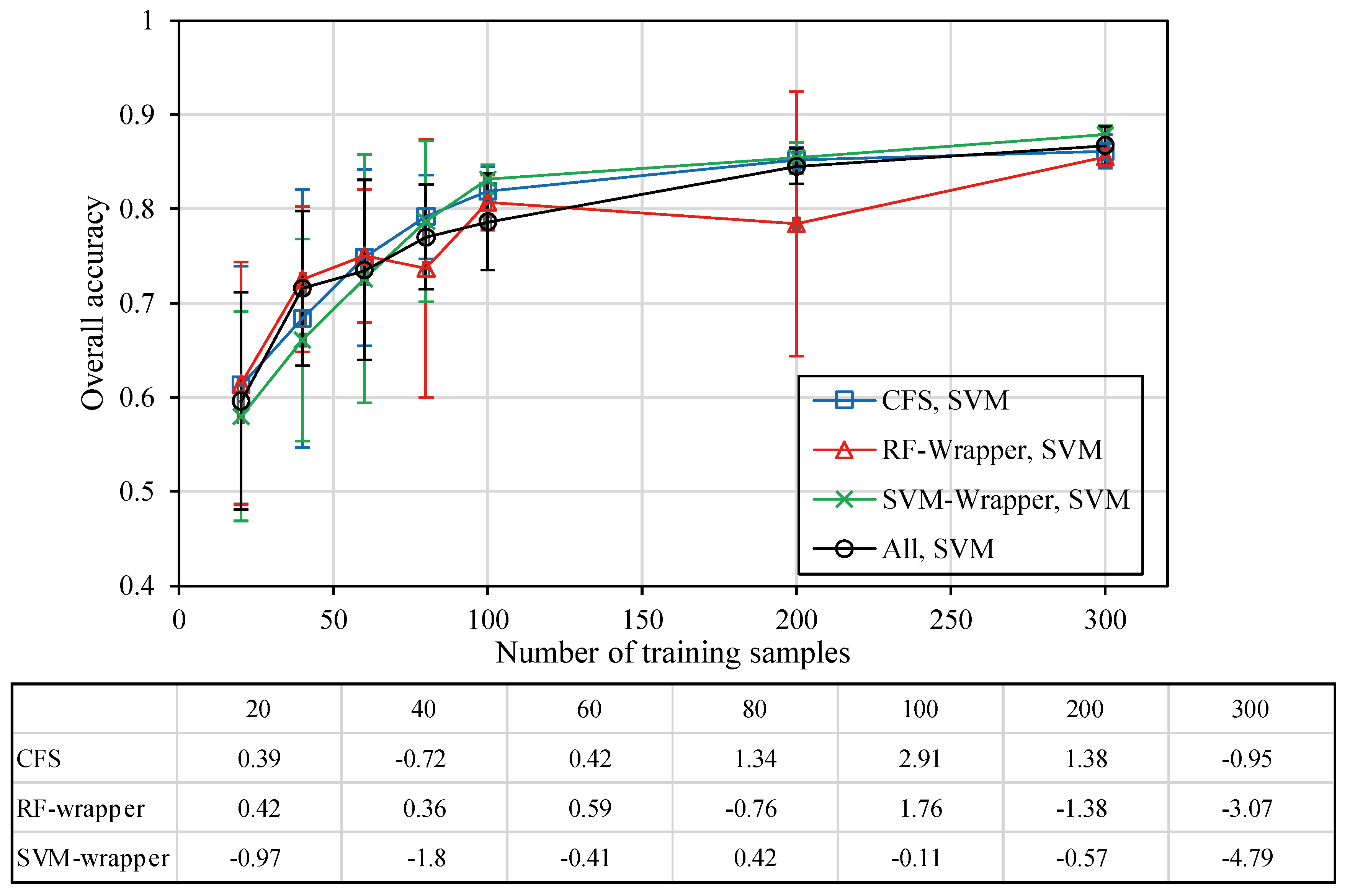
3.3. Comprehensive Evaluation for All Feature Selection Methods
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Pedergnana, M.; Marpu, P.R.; Dalla Mura, M.; Benediktsson, J.A.; Bruzzone, L. A novel technique for optimal feature selection in attribute profiles based on genetic algorithms. IEEE Trans. Geosci. Remote Sens. 2013, 51, 3514–3528. [Google Scholar] [CrossRef]
- Novack, T.; Esch, T.; Kux, H.; Stilla, U. Machine learning comparison between worldview-2 and quickbird-2-simulated imagery regarding object-based urban land cover classification. Remote Sens. 2011, 3, 2263–2282. [Google Scholar] [CrossRef]
- Topouzelis, K.; Psyllos, A. Oil spill feature selection and classification using decision tree forest on SAR image data. ISPRS J. Photogramm. Remote Sens. 2012, 68, 135–143. [Google Scholar] [CrossRef]
- Melgani, F.; Bruzzone, L. Classification of hyperspectral remote sensing images with support vector machines. IEEE Trans. Geosci. Remote Sens. 2004, 42, 1778–1790. [Google Scholar] [CrossRef]
- Pal, M.; Foody, G.M. Feature selection for classification of hyperspectral data by SVM. IEEE Trans. Geosci. Remote Sens. 2010, 48, 2297–2307. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J. A survey on object detection in optical remote sensing images. ISPRS J. Photogramm. Remote Sens. 2016, 117, 11–28. [Google Scholar] [CrossRef]
- Laliberte, A.S.; Browning, D.; Rango, A. A comparison of three feature selection methods for object-based classification of sub-decimeter resolution ultracam-l imagery. Int. J. Appl. Earth Obs. Geoinf. 2012, 15, 70–78. [Google Scholar] [CrossRef]
- Blaschke, T.; Hay, G.J.; Kelly, M.; Lang, S.; Hofmann, P.; Addink, E.; Feitosa, R.Q.; Meer, F.V.D.; Werff, H.V.D.; Coillie, F.V. Geographic object-based image analysis—Towards a new paradigm. ISPRS J. Photogramm. Remote Sens. 2014, 87, 180–191. [Google Scholar] [CrossRef] [PubMed]
- Ma, L.; Cheng, L.; Li, M.; Liu, Y.; Ma, X. Training set size, scale, and features in geographic object-based image analysis of very high resolution unmanned aerial vehicle imagery. ISPRS J. Photogramm. Remote Sens. 2015, 102, 14–27. [Google Scholar] [CrossRef]
- Duro, D.C.; Franklin, S.E.; Dubé, M.G. Multi-scale object-based image analysis and feature selection of multi-sensor earth observation imagery using random forests. Int. J. Remote Sens. 2012, 33, 4502–4526. [Google Scholar] [CrossRef]
- Stumpf, A.; Kerle, N. Object-oriented mapping of landslides using random forests. Remote Sens. Environ. 2011, 115, 2564–2577. [Google Scholar] [CrossRef]
- Puissant, A.; Rougier, S.; Stumpf, A. Object-oriented mapping of urban trees using random forest classifiers. Int. J. Appl. Earth Obs. Geoinf. 2014, 26, 235–245. [Google Scholar] [CrossRef]
- Han, J.; Pei, J.; Kamber, M. Data Mining: Concepts and Techniques; Elsevier: Amsterdam, The Netherlands, 2011. [Google Scholar]
- Chubey, M.S.; Franklin, S.E.; Wulder, M.A. Object-based analysis of Ikonos-2 imagery for extraction of forest inventory parameters. Photogramm. Eng. Remote Sens. 2006, 72, 383–394. [Google Scholar] [CrossRef]
- Laliberte, A.S.; Rango, A. Texture and scale in object-based analysis of subdecimeter resolution unmanned aerial vehicle (UAV) imagery. IEEE Trans. Geosci. Remote Sens. 2009, 47, 761–770. [Google Scholar] [CrossRef]
- Vieira, M.A.; Formaggio, A.R.; Rennó, C.D.; Atzberger, C.; Aguiar, D.A.; Mello, M.P. Object based image analysis and data mining applied to a remotely sensed landsat time-series to map sugarcane over large areas. Remote Sens. Environ. 2012, 123, 553–562. [Google Scholar] [CrossRef]
- Peña-Barragán, J.M.; Ngugi, M.K.; Plant, R.E.; Six, J. Object-based crop identification using multiple vegetation indices, textural features and crop phenology. Remote Sens. Environ. 2011, 115, 1301–1316. [Google Scholar] [CrossRef]
- Yu, Q.; Gong, P.; Clinton, N.; Biging, G.; Kelly, M.; Schirokauer, D. Object-based detailed vegetation classification with airborne high spatial resolution remote sensing imagery. Photogramm. Eng. Remote Sens. 2006, 72, 799–811. [Google Scholar] [CrossRef]
- Li, M.; Ma, L.; Blaschke, T.; Cheng, L.; Tiede, D. A systematic comparison of different object-based classification techniques using high spatial resolution imagery in agricultural environments. Int. J. Appl. Earth Obs. Geoinf. 2016, 49, 87–98. [Google Scholar] [CrossRef]
- Pal, M.; Mather, P. Some issues in the classification of dais hyperspectral data. Int. J. Remote Sens. 2006, 27, 2895–2916. [Google Scholar] [CrossRef]
- Van Coillie, F.M.; Verbeke, L.P.; De Wulf, R.R. Feature selection by genetic algorithms in object-based classification of IKONOS imagery for forest mapping in flanders, Belgium. Remote Sens. Environ. 2007, 110, 476–487. [Google Scholar] [CrossRef]
- Weston, J.; Mukherjee, S.; Chapelle, O.; Pontil, M.; Poggio, T.; Vapnik, V. Feature selection for SVMS. Adv. Neural Inf. Process. Syst. 2000, 13, 668–674. [Google Scholar]
- Guyon, I.; Weston, J.; Barnhill, S.; Vapnik, V. Gene selection for cancer classification using support vector machines. Mach. Learn. 2002, 46, 389–422. [Google Scholar] [CrossRef]
- Duro, D.C.; Franklin, S.E.; Dubé, M.G. A comparison of pixel-based and object-based image analysis with selected machine learning algorithms for the classification of agricultural landscapes using SPOT-5 HRG imagery. Remote Sens. Environ. 2012, 118, 259–272. [Google Scholar] [CrossRef]
- Ma, L.; Cheng, L.; Han, W.; Zhong, L.; Li, M. Cultivated land information extraction from high-resolution unmanned aerial vehicle imagery data. J. Appl. Remote Sens. 2014, 8, 1–25. [Google Scholar] [CrossRef]
- Peña, J.M.; Torres-Sánchez, J.; de Castro, A.I.; Kelly, M.; López-Granados, F. Weed mapping in early-season maize fields using object-based analysis of unmanned aerial vehicle (UAV) images. PLoS ONE 2013, 8, e77151. [Google Scholar]
- Ma, L.; Wang, Y.; Li, M.; Tong, L.; Cheng, L. Using high-resolution imagery acquired with an autonomous unmanned aerial vehicle for urban construction and planning. In Proceedings of the International Conference on Remote Sensing, Environment and Transportation Engineering, Najing, China, 26–28 July 2013.
- Baatz, M.; Schäpe, A. Multiresolution segmentation: An optimization approach for high quality multi-scale image segmentation. In Angewandte Geographische Informationsverarbeitung XII; Strobl, J., Blaschke, T., Griesebner, G., Eds.; Herbert Wichmann Verlag: Berlin, Germany, 2000; Volume 58, pp. 12–23. [Google Scholar]
- Hall, M.; Frank, E.; Holmes, G.; Pfahringer, B.; Reutemann, P.; Witten, I.H. The weka data mining software: An update. ACM SIGKDD Explor. Newsl. 2009, 11, 10–18. [Google Scholar] [CrossRef]
- Zhao, Z.; Morstatter, F.; Sharma, S.; Alelyani, S.; Anand, A.; Liu, H. Advancing Feature Selection Research: Asu Feature Selection Repository; TR-10-007; School of Computing, Informatics, and Decision Systems Engineering, Arizona State University: Tempe, AZ, USA, 2007. [Google Scholar]
- Liu, H.; Setiono, R. Chi2: Feature selection and discretization of numeric attributes. In Proceedings of the Seventh IEEE International Conference on Tools with Artificial Intelligence, Herndon, VA, USA, 29–31 May 1995; pp. 388–391.
- Gilad-Bachrach, R.; Navot, A.; Tishby, N. Margin based feature selection-theory and algorithms. In Proceedings of the Twenty-First International Conference on Machine Learning, Banff, AB, Canada, 4–8 July 2004; ACM: New York, NY, USA; p. 43.
- Robnik-Šikonja, M.; Kononenko, I. Theoretical and empirical analysis of relieff and rrelieff. Mach. Learn. 2003, 53, 23–69. [Google Scholar] [CrossRef]
- Verikas, A.; Gelzinis, A.; Bacauskiene, M. Mining data with random forests: A survey and results of new tests. Pattern Recogn. 2011, 44, 330–349. [Google Scholar] [CrossRef]
- Hall, M.A.; Holmes, G. Benchmarking attribute selection techniques for discrete class data mining. IEEE Trans. Knowl. Data Eng. 2003, 15, 1437–1447. [Google Scholar] [CrossRef]
- Phuong, T.M.; Lin, Z.; Altman, R.B. Choosing SNPS using feature selection. J. Bioinf. Comput. Biol. 2006, 4, 241–257. [Google Scholar] [CrossRef]
- Kohavi, R.; John, G.H. Wrappers for feature subset selection. Artif. Intell. 1997, 97, 273–324. [Google Scholar] [CrossRef]
- Maldonado, S.; Weber, R. A wrapper method for feature selection using support vector machines. Inf. Sci. 2009, 179, 2208–2217. [Google Scholar] [CrossRef]
- Rodin, A.S.; Litvinenko, A.; Klos, K.; Morrison, A.C.; Woodage, T.; Coresh, J.; Boerwinkle, E. Use of wrapper algorithms coupled with a random forests classifier for variable selection in large-scale genomic association studies. J. Comput. Biol. 2009, 16, 1705–1718. [Google Scholar] [CrossRef] [PubMed]
- Platt, J.C. 12 fast training of support vector machines using sequential minimal optimization. In Advances in Kernel Methods: Support Vector Learning; MIT Press: Cambridge, MA, USA, 1999; pp. 185–208. [Google Scholar]
- Whiteside, T.G.; Maier, S.W.; Boggs, G.S. Area-based and location-based validation of classified image objects. Int. J. Appl. Earth Obs. Geoinf. 2014, 28, 117–130. [Google Scholar] [CrossRef]
- Stefanski, J.; Mack, B.; Waske, B. Optimization of object-based image analysis with random forests for land cover mapping. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2013, 6, 2492–2504. [Google Scholar] [CrossRef]
- Pal, M. Random forest classifier for remote sensing classification. Int. J. Remote Sens. 2005, 26, 217–222. [Google Scholar] [CrossRef]
- Rodriguez-Galiano, V.F.; Ghimire, B.; Rogan, J.; Chica-Olmo, M.; Rigol-Sanchez, J.P. An assessment of the effectiveness of a random forest classifier for land-cover classification. ISPRS J. Photogramm. Remote Sens. 2012, 67, 93–104. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Zhou, P.; Guo, L. Multi-class geospatial object detection and geographic image classification based on collection of part detectors. ISPRS J. Photogramm. Remote Sens. 2014, 98, 119–132. [Google Scholar] [CrossRef]
- Mountrakis, G.; Im, J.; Ogole, C. Support vector machines in remote sensing: A review. ISPRS J. Photogramm. Remote Sens. 2011, 66, 247–259. [Google Scholar] [CrossRef]
- Chang, C.-C.; Lin, C.-J. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. (TIST) 2011, 2, 27. [Google Scholar] [CrossRef]
- Shao, Y.; Lunetta, R.S. Comparison of support vector machine, neural network, and cart algorithms for the land-cover classification using limited training data points. ISPRS J. Photogramm. Remote Sens. 2012, 70, 78–87. [Google Scholar] [CrossRef]
- Ghosh, A.; Joshi, P. A comparison of selected classification algorithms for mapping bamboo patches in lower gangetic plains using very high resolution worldview 2 imagery. Int. J. Appl. Earth Obs. Geoinf. 2014, 26, 298–311. [Google Scholar] [CrossRef]
- Fassnacht, F.; Hartig, F.; Latifi, H.; Berger, C.; Hernández, J.; Corvalán, P.; Koch, B. Importance of sample size, data type and prediction method for remote sensing-based estimations of aboveground forest biomass. Remote Sens. Environ. 2014, 154, 102–114. [Google Scholar] [CrossRef]
- Wieland, M.; Pittore, M. Performance evaluation of machine learning algorithms for urban pattern recognition from multi-spectral satellite images. Remote Sens. 2014, 6, 2912–2939. [Google Scholar] [CrossRef]
- Chan, J.C.-W.; Paelinckx, D. Evaluation of random forest and adaboost tree-based ensemble classification and spectral band selection for ecotope mapping using airborne hyperspectral imagery. Remote Sens. Environ. 2008, 112, 2999–3011. [Google Scholar] [CrossRef]
- Huang, X.; Zhang, L. An svm ensemble approach combining spectral, structural, and semantic features for the classification of high-resolution remotely sensed imagery. IEEE Trans. Geosci. Remote Sens. 2013, 51, 257–272. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Guo, L.; Liu, Z.; Bu, S.; Ren, J. Effective and efficient midlevel visual elements-oriented land-use classification using VHR remote sensing images. IEEE Trans. Geosci. Remote Sens. 2015, 53, 4238–4249. [Google Scholar] [CrossRef]
- Sun, L.; Schulz, K. Response to johnson ba scale issues related to the accuracy assessment of land use/land cover maps produced using multi-resolution data: Comments on “the improvement of land cover classification by thermal remote sensing”. Remote Sens. 2015, 7, 13440–13447. [Google Scholar] [CrossRef]
- Johnson, B.A. Scale issues related to the accuracy assessment of land use/land cover maps produced using multi-resolution data: Comments on “the improvement of land cover classification by thermal remote sensing”. Remote Sens. 2015, 7, 13436–13439. [Google Scholar] [CrossRef]
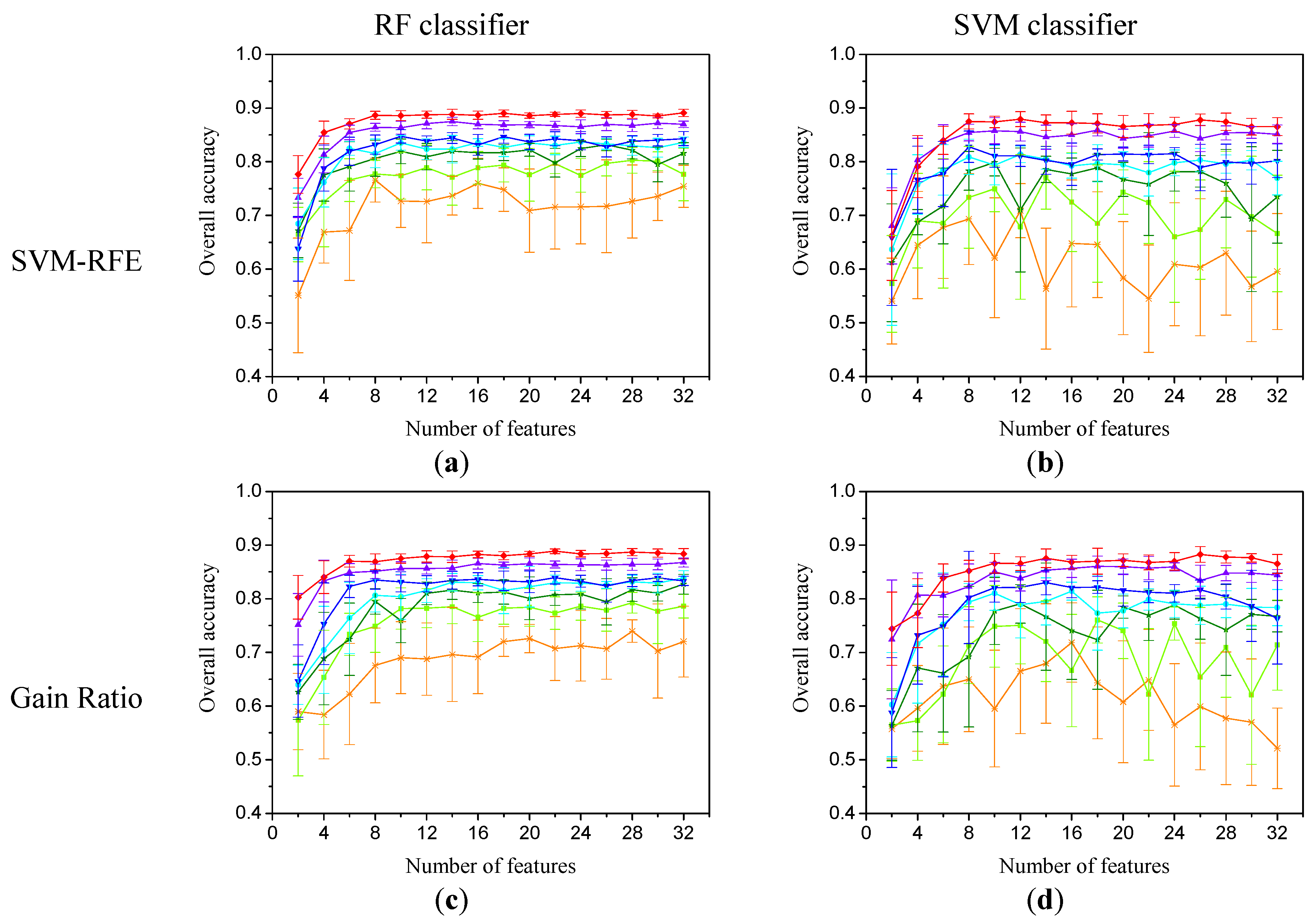
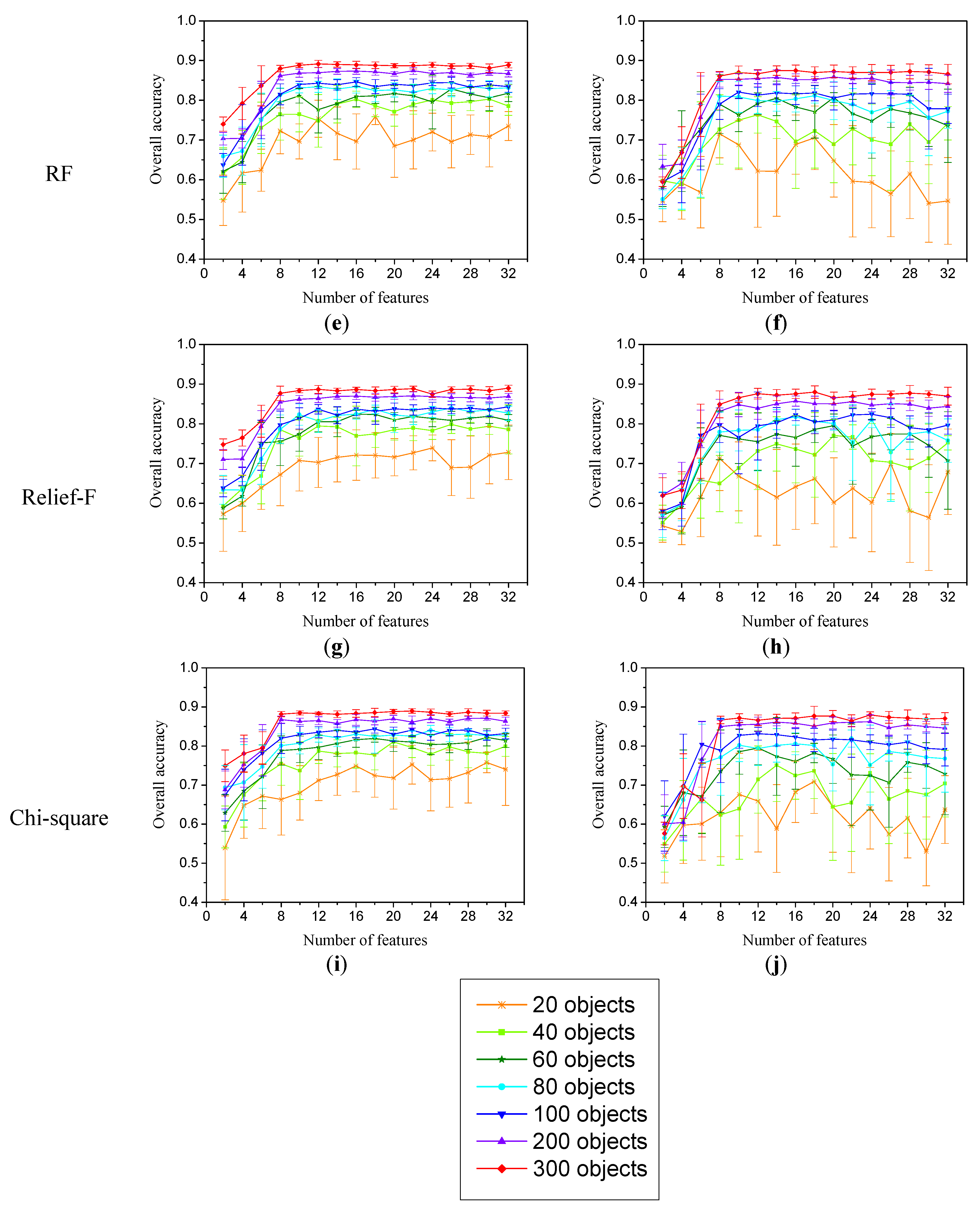
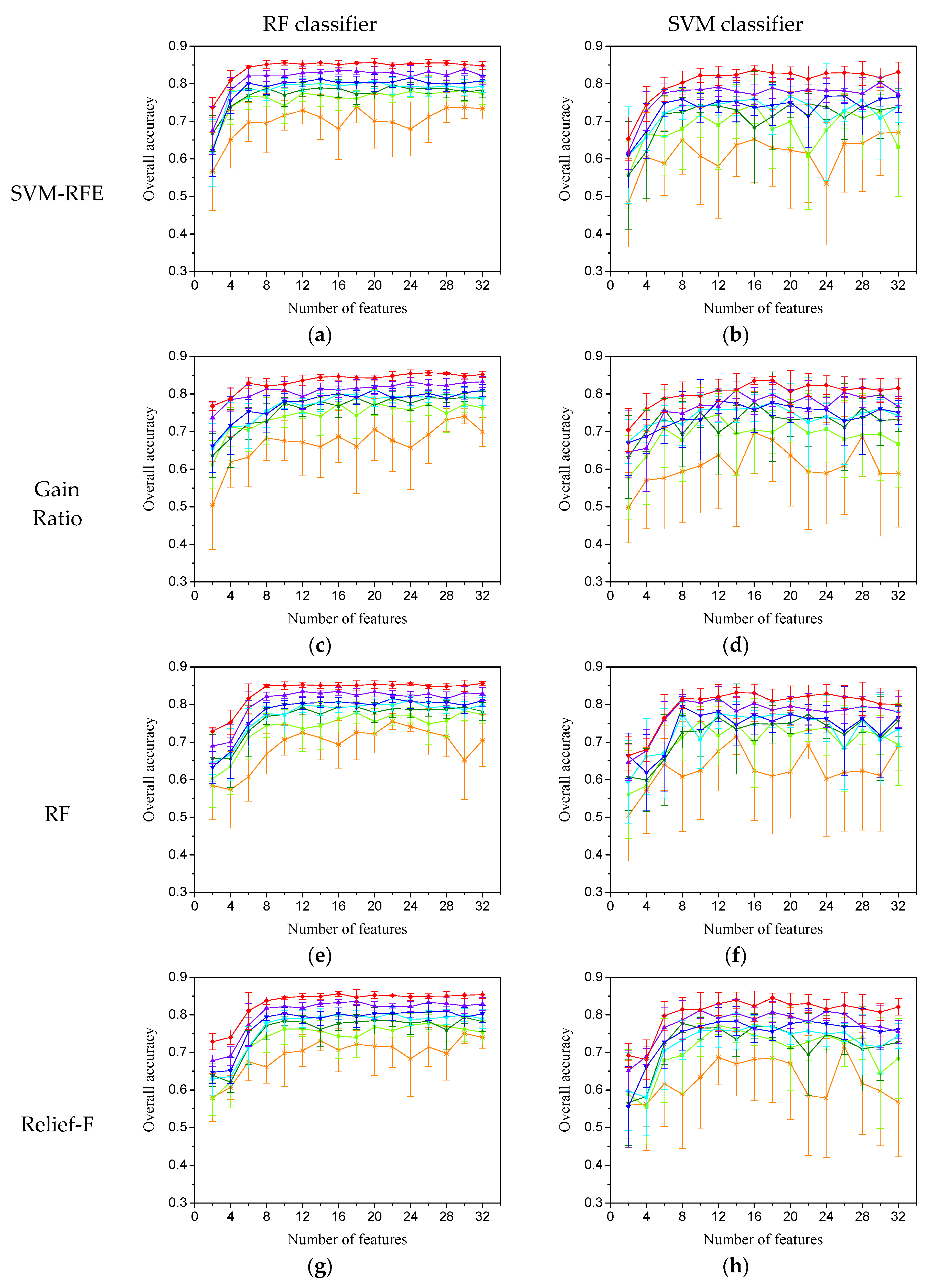



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Type | Feature Names | Description |
|---|---|---|
| Spectral | Mean blue, mean green, mean red, max difference, standard deviation (std. dev.) blue, std. dev. green, std. dev. red, brightness | Spectral features were used to evaluate the first (mean), second (standard deviation) of an image object’s pixel value. |
| Texture | GLCM (Gray-Level Co-occurrence Matrix) homogeneity, GLCM contrast, GLCM dissimilarity, GLCM entropy, GLCM std. dev., GLCM correlation, GLCM ang. 2nd moment, GLCM mean, GLDV (Gray-Level Difference Vector) ang. 2nd moment, GLDV entropy, GLDV mean, GLDV contrast | Texture features are derived from texture after Haralick based on the Gray-Level Co-occurrence Matrix or Gray-Level Difference Vector. |
| Shape | Area, compactness, density, roundness, main direction, rectangular fit, elliptic fit, asymmetry, border index, shape index | Shape features refer to the geometry information of meaningful objects, which is calculated from the pixels that form it. An accurate segmentation of the map is necessary to ensure the use of these features successfully. |
| Number of Features | Gain Ratio | Relief-F | RF | SVM-RFE | Chi-Square | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| RF | SVM | RF | SVM | RF | SVM | RF | SVM | RF | SVM | |
| 2 | 5.81 | 5.15 | 26.32 | 15.11 | 23.35 | 29.82 | 9.68 | 7.14 | 9.87 | 27.13 |
| 4 | 4.09 | 4.13 | 17.51 | 13.82 | 7.05 | 8.54 | 4.95 | 3.72 | 6.53 | 6.17 |
| 6 | 2.82 | 2.5 | 6.05 | 3.54 | 3.06 | 2.72 | 5.26 | 2.52 | 6.33 | 6.52 |
| 8 | 2.49 | 1.47 | 1.98 | 1.53 | 2.39 | 0.55 | 1.37 | −1.35 | 0.82 | 0.64 |
| 10 | 2.01 | −0.13 | 1.94 | 0.48 | 0.15 | −0.38 | 1.35 | −1.34 | −0.23 | −0.15 |
| 12 | 1.04 | −0.06 | 0.76 | −0.69 | −0.74 | −0.08 | 1.05 | −1.94 | 0.34 | 0.7 |
| 14 | 1.14 | −1.27 | 1.96 | −0.29 | −0.46 | −0.98 | 0.67 | −0.98 | 0.8 | −0.02 |
| 16 | 0.32 | −0.46 | 1.06 | −0.67 | −0.11 | −0.94 | 1.24 | −0.81 | 0.23 | −0.08 |
| 18 | 0.86 | −0.51 | 1.54 | −1.1 | 0.16 | −0.39 | 0.32 | −0.71 | −0.35 | −0.65 |
| 20 | 0.03 | −0.99 | 0.87 | 0.5 | 0.52 | −0.7 | 1.85 | −0.02 | −1.5 | −0.91 |
| 22 | −1.33 | −0.36 | 0.4 | 0.09 | 0.41 | −0.46 | 0.99 | −0.27 | −2.07 | 0.85 |
| 24 | −0.03 | −0.57 | 4.09 | −0.53 | −0.19 | −0.36 | 0.42 | −0.57 | −0.72 | −1.58 |
| 26 | −0.15 | −2.31 | 1.02 | −0.55 | 0.84 | −0.42 | 1.2 | −1.89 | 0.92 | −0.43 |
| 28 | −0.76 | −1.83 | 0.73 | −0.74 | 0.6 | −0.66 | 0.85 | −1.16 | −0.62 | −0.13 |
| 30 | −0.32 | −1.75 | 1.47 | −0.59 | 1.82 | −0.52 | 2.22 | 0.02 | 0.03 | 0.18 |
| 20 Objects | 40 Objects | 60 Objects | 100 Objects | 200 Objects | 300 Objects | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RF | SVM | RF | SVM | RF | SVM | RF | SVM | RF | SVM | RF | SVM | |
| Gain Ratio | 0.35(28) | 4.2(16) | 0.69(28) | 2.4(18) | 0.0084(28) | 3.1(12) | 0.46(22) | 4.2(14) | −0.52(16) | 2.2(18) | 0.63(22) | 2.7(26) |
| Relief-F | 0.26(24) | 3.7(8) | 1.2(26) | 3.1(20) | 1.8(16) | 3.6(20) | 0.49(24) | 4.4(24) | 0.89(22) | 2.4(16) | 0.35(22) | 2.1(18) |
| RF | 2.02(18) | 4.6(8) | 1.4(30) | 2.5(12) | 1.9(26) | 5.1(20) | 2.3(16) | 3.8(10) | 2.1(22) | 2.6(20) | 1.2(12) | 1.5(14) |
| SVM-RFE | 1.83(8) | 4.8(12) | 1.6(28) | 2.4(14) | 3.3(26) | 4(10) | 2.2(10) | 3.4(8) | 2.7(14) | 3(18) | 1.1(18) | 2.2(12) |
| Chi-square | 1.74(30) | 3.6(18) | 3.7(20) | 1.1(14) | 0.69(30) | 3.1(12) | 1.7(18) | 5(12) | 1.8(30) | 2.6(24) | 1.1(22) | 3.1(24) |
| CFS | −2.01(2.9) | 0.39(3) | −1.21(4.6) | −0.72(4.6) | −0.82(5.4) | 0.42(5.9) | 0.66(7.5) | 2.91(6.3) | 0.11(8.1) | 1.38(8.4) | 2.16(9) | −0.95(9.2) |
| RF wrapper | −1.13(3) | 0.42(2.5) | −3.21(3.8) | 0.36(3.9) | −2.85(3.2) | 0.59(3.5) | −1.46(5.4) | 1.76(4.4) | −2.1(5.6) | −1.38(5.2) | −2.64(6.2) | −3.07(5.6) |
| SVM wrapper | −4.29(3) | −0.97(2) | −3.66(3.8) | −1.8(3.7) | −2.18(4.1) | −0.41(5.1) | −1.03(7) | −0.11(6) | −2.48(6.7) | −0.57(6.4) | −2.62(6.9) | −4.79(6.1) |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license ( http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, L.; Fu, T.; Blaschke, T.; Li, M.; Tiede, D.; Zhou, Z.; Ma, X.; Chen, D. Evaluation of Feature Selection Methods for Object-Based Land Cover Mapping of Unmanned Aerial Vehicle Imagery Using Random Forest and Support Vector Machine Classifiers. ISPRS Int. J. Geo-Inf. 2017, 6, 51. https://doi.org/10.3390/ijgi6020051
Ma L, Fu T, Blaschke T, Li M, Tiede D, Zhou Z, Ma X, Chen D. Evaluation of Feature Selection Methods for Object-Based Land Cover Mapping of Unmanned Aerial Vehicle Imagery Using Random Forest and Support Vector Machine Classifiers. ISPRS International Journal of Geo-Information. 2017; 6(2):51. https://doi.org/10.3390/ijgi6020051
Chicago/Turabian StyleMa, Lei, Tengyu Fu, Thomas Blaschke, Manchun Li, Dirk Tiede, Zhenjin Zhou, Xiaoxue Ma, and Deliang Chen. 2017. "Evaluation of Feature Selection Methods for Object-Based Land Cover Mapping of Unmanned Aerial Vehicle Imagery Using Random Forest and Support Vector Machine Classifiers" ISPRS International Journal of Geo-Information 6, no. 2: 51. https://doi.org/10.3390/ijgi6020051
APA StyleMa, L., Fu, T., Blaschke, T., Li, M., Tiede, D., Zhou, Z., Ma, X., & Chen, D. (2017). Evaluation of Feature Selection Methods for Object-Based Land Cover Mapping of Unmanned Aerial Vehicle Imagery Using Random Forest and Support Vector Machine Classifiers. ISPRS International Journal of Geo-Information, 6(2), 51. https://doi.org/10.3390/ijgi6020051