Extraction of Tourist Destinations and Comparative Analysis of Preferences Between Foreign Tourists and Domestic Tourists on the Basis of Geotagged Social Media Data


Abstract
:1. Introduction
- (RQ1): How can the locations of tourist destinations be extracted?
- (RQ2): How can the preferences of foreign tourists and those of domestic tourists be compared?
- We propose a method to extract the locations of tourist destinations by using geotagged data from Twitter. This method infers the attractiveness of each location by applying a gravity model to locational data and infers the originality of each location by analyzing text data from Twitter. It then extracts locations that have both high attractiveness and originality, and the extracted locations are regarded as tourist destinations.
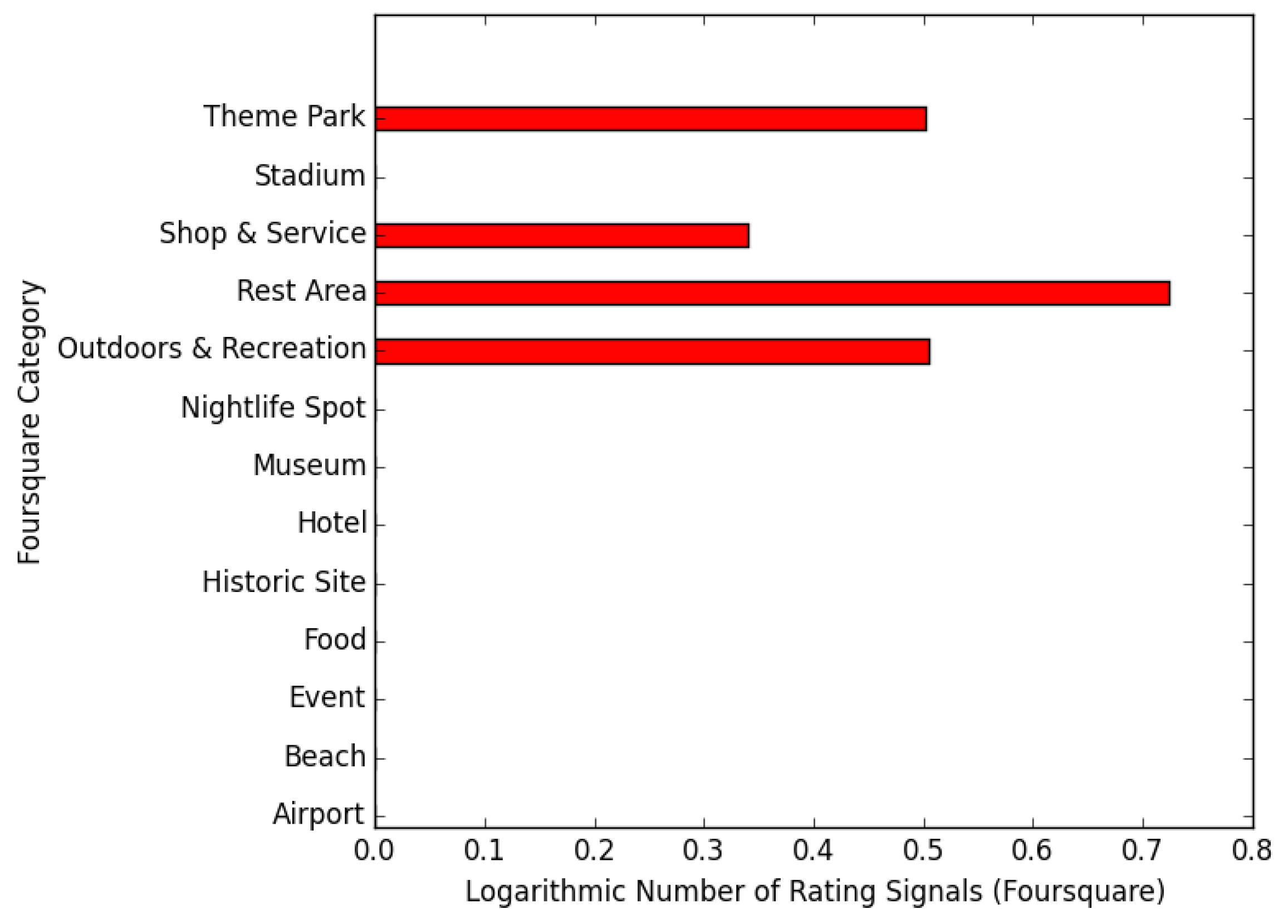
- We propose a method of identifying the differences in the preferences of foreign tourists and those of domestic tourists by using data from Twitter and Foursquare. The data from Foursquare have information about POIs. These data are utilized to characterize each location. The characterization results indicate that compared to domestic tourists, foreign tourists in Japan expect night-life spots such as pubs and clubs to be located near tourist attractions.
2. Related Works
- Separating the locations of tourist destinations from those of merely popular locations (e.g., shopping centers).
- Evaluating the attractiveness of destinations on the basis of both the number of tourist arrivals and the distance from tourists’ places of residence.
- Understanding what characteristics of each location contribute to the number of domestic tourist arrivals and that of foreign tourist arrivals.
3. Extraction of Tourist Destinations
3.1. Identifying Hotspots of Touristic Destinations
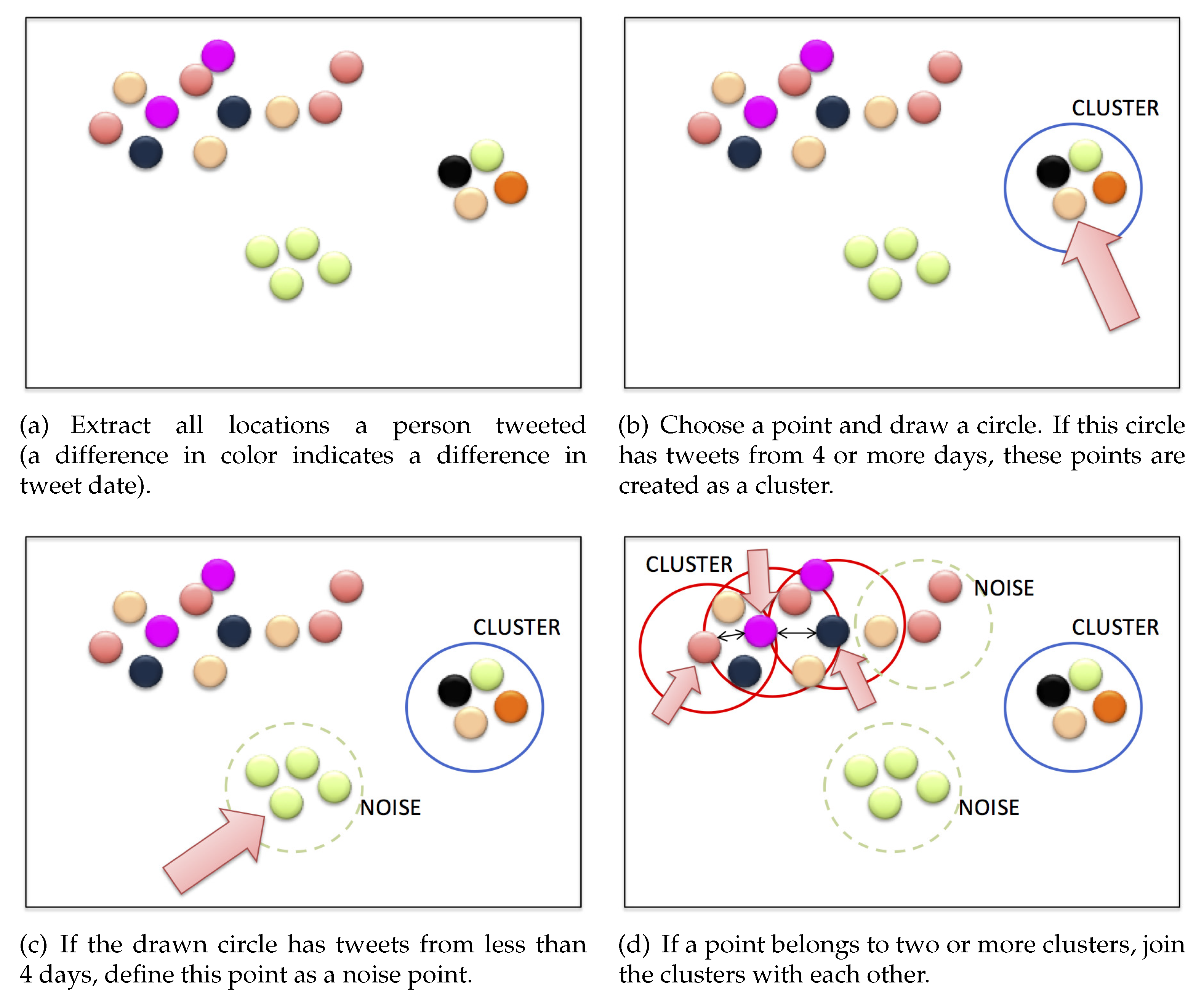
- Extract all locations where a person tweeted. Figure 1a illustrates a person’s tweet locations. A difference in color indicates a difference in tweet date.
- Choose a tweet and draw a circle centered on the tweet’s location. The radius can be set to an arbitrary length; here, we set the radius to 4 km. If this circle contains tweets of 4 days or more, we define the group of these tweets in this circle as a cluster. The numbers of days can also be set arbitrarily. In Figure 1b, a circle is drawn around a point indicated by an arrow. This circle contains tweets from 4 days, so these points are created as a new cluster.
- Choose another tweet that has not previously been chosen and draw a circle centered on the tweet’s location. If this circle does not contain tweets from 4 days, the tweet is defined as a noise point. In Figure 1c, a circle is drawn around a point indicated by an arrow. This circle contains tweets from only 1 day, so this point is regarded as a noise point.
- When a point belongs to two or more clusters, the clusters are combined. In Figure 1d, three circles are drawn around the points indicated by the arrows, and the points within each circle form a cluster. Since the points indicated by the arrows are reachable from each other, these three clusters form a single cluster.
- Finally, we obtain the person’s noise points and clusters. The clusters extracted from the person’s tweet data are the person’s personally important places (home, workplace, school). The noise points are locations that are rarely visited by the person. We infer the cluster with tweets on the greatest number of days as this person’s home location. If the person has no cluster, we ignore this person’s data.
3.2. Evaluation of the Attractiveness of Each Location Using the Gravity Model
- : Attractiveness of destination e (unknown variable)
- : Distance between origin s and destination e (known variable)
- : Distance coefficient (unknown variable)
- : Sum of the attractiveness of all points divided by the distance to the origin s (unknown variable)
- K: A set of all origins
- L: A set of all destinations
- : The number of visits from origin s to destination e based on the Twitter data (known variable)
3.3. Evaluation of the Originality of Each Location Using Term Frequency-Inverse Document Frequency (TF-IDF)
- : A set of whose TF-IDF indicates the word is in the top 10% of the words in document d.
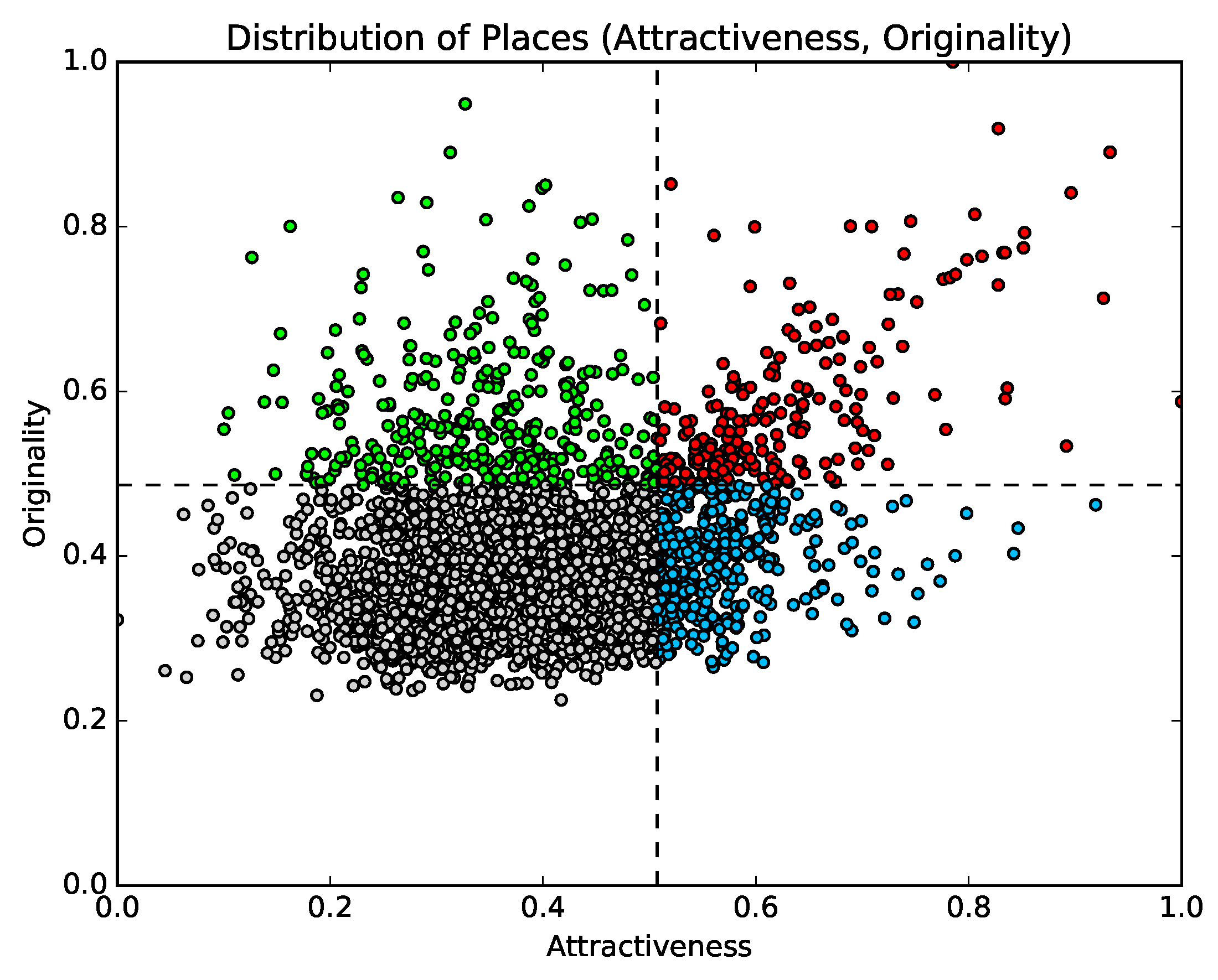
3.4. Results
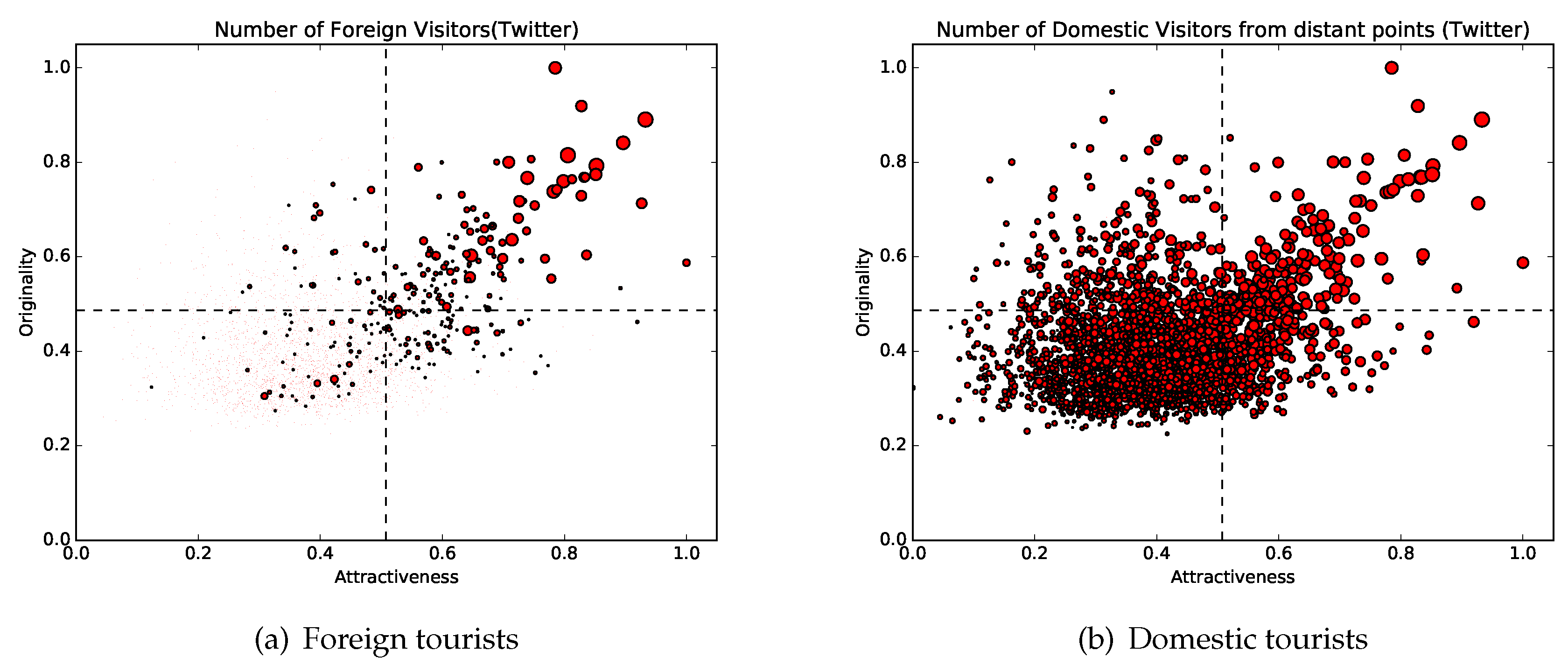
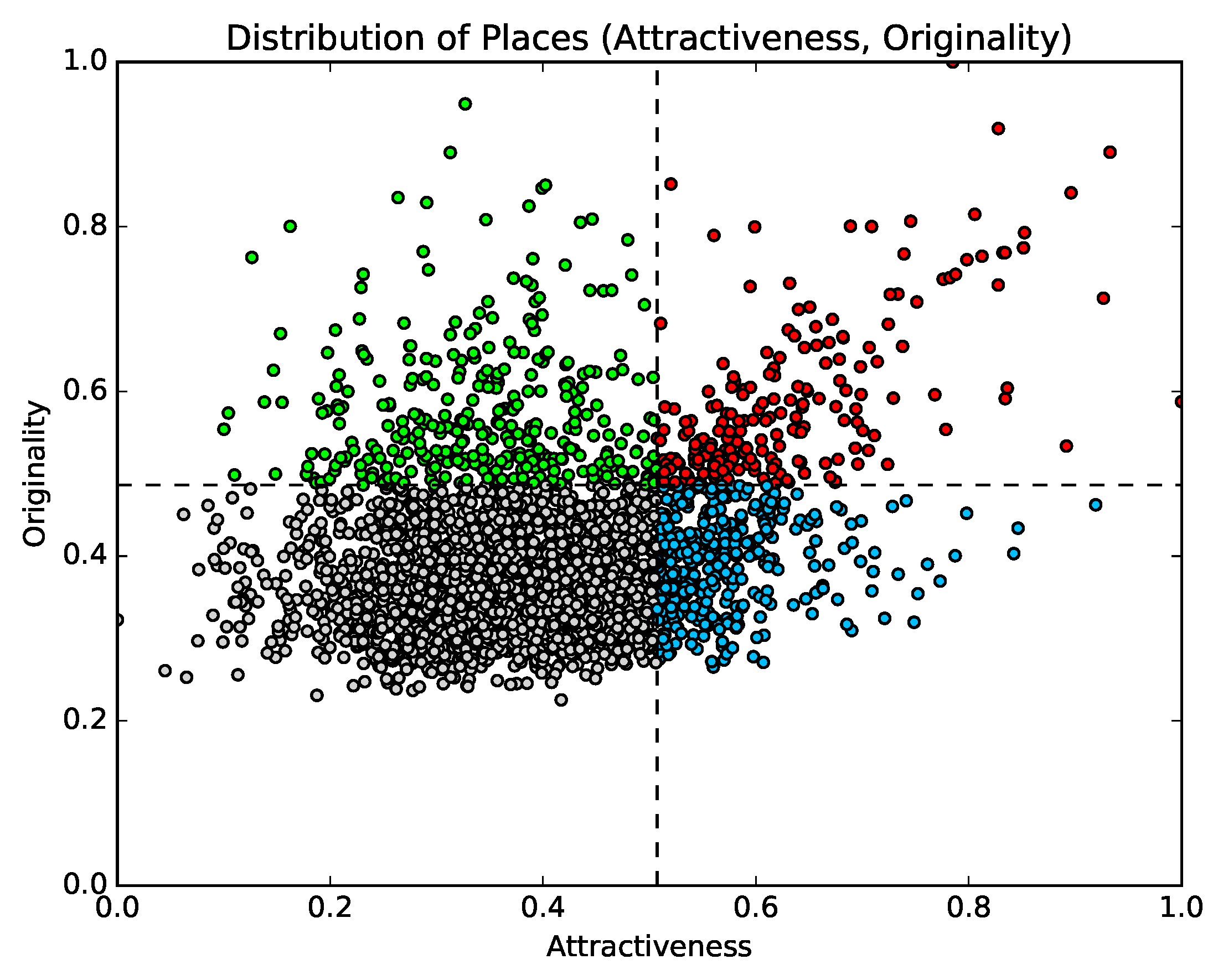
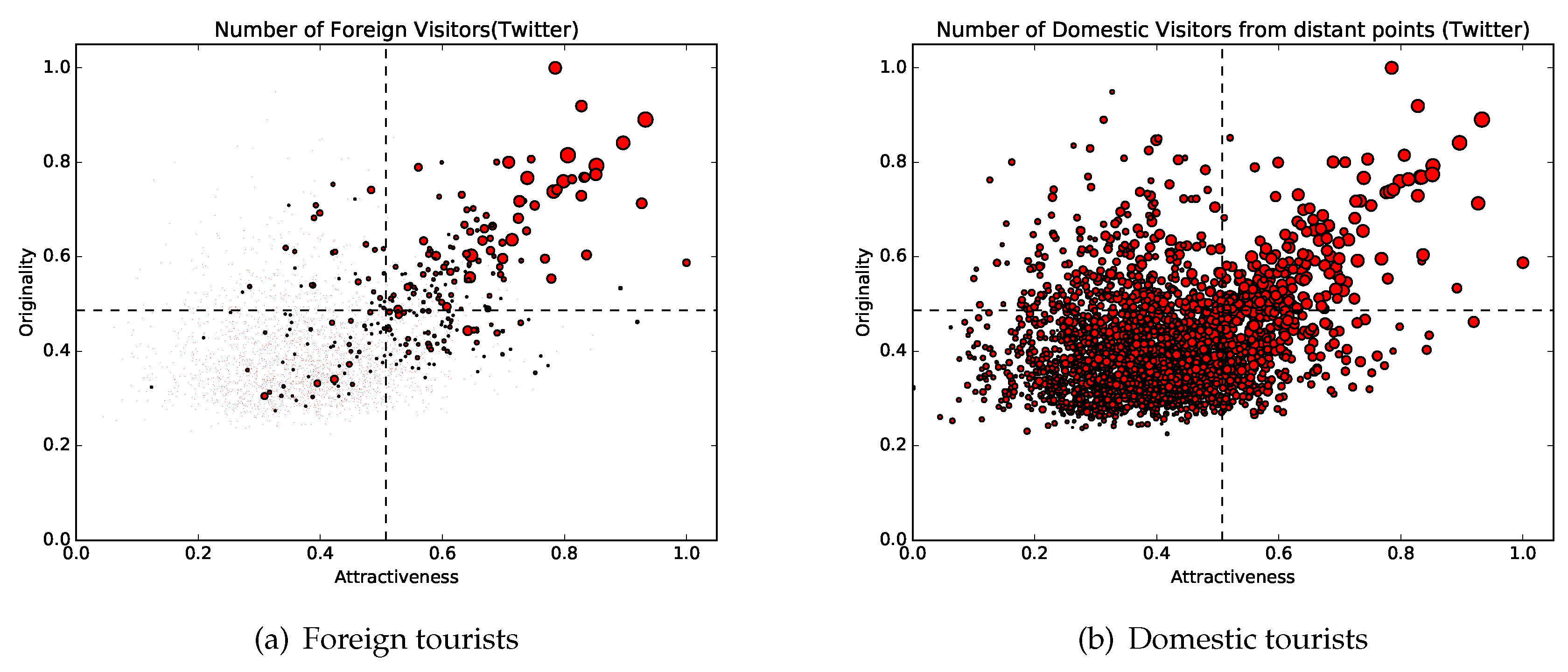
- Red points (attractiveness: top 20%; originality: top 20%)This group includes various types of tourist destinations, such as amusement parks, famous mountains, bustling shopping and entertainment districts, and historic sites. Moreover, this cluster contains locations where seasonal events, such as summer rock festivals, are held. On the other hand, the cluster also includes airports, which cannot be recognized as tourist destinations. Airports are included in the group because many people visit airports from distant locations and stay for a brief duration. However, as a whole, most of the locations in this group are regarded as tourist destinations. Twenty-eight of the locations listed on Trip Advisor’s list of the thirty best places in Japan are included in this group [33].
- Blue points (attractiveness: top 20%; originality: bottom 80%)This group includes locations in urban areas with few touristic attractions and many shopping centers.
- Green points (attractiveness: bottom 80%; originality: top 20%)This group includes transit points, such as rest areas and ferry stands. The reason these locations have high originality is that topics the users post are very limited (since people do not stay at these locations for long periods of time).
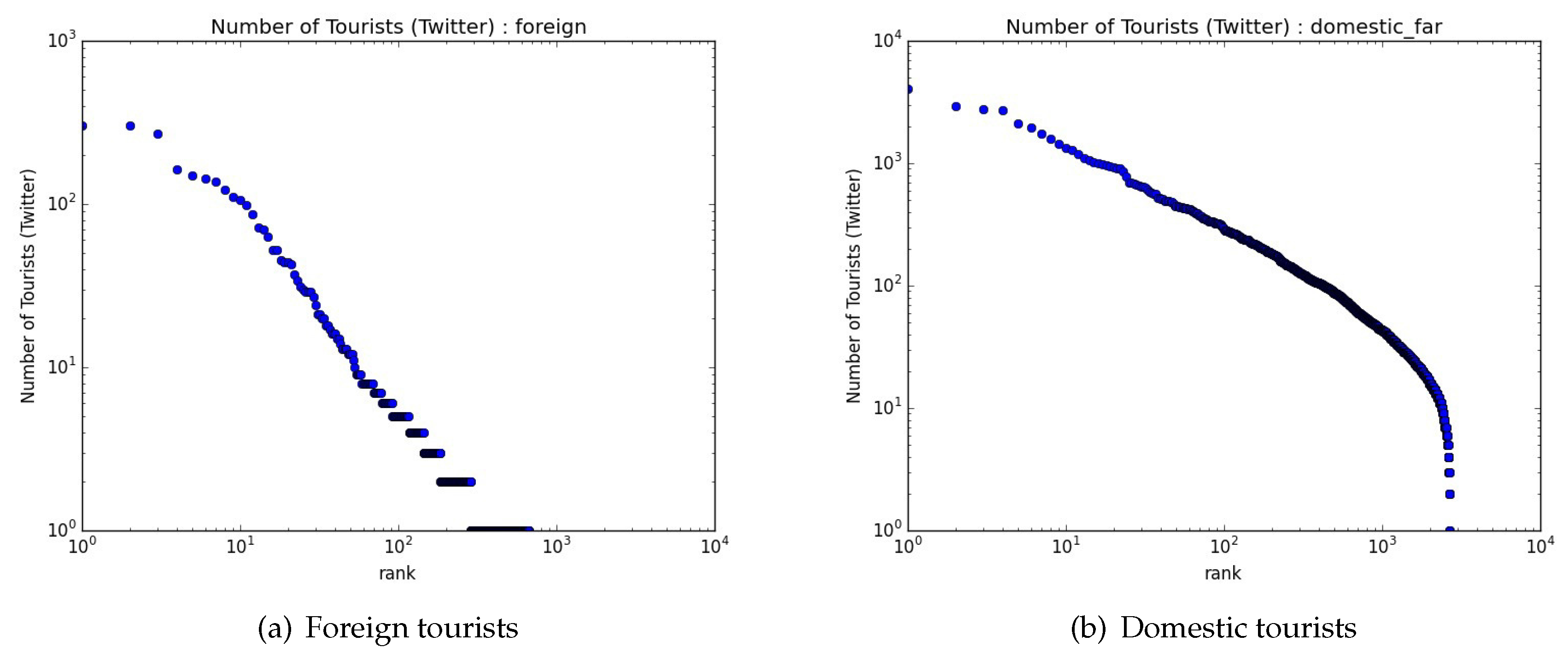
4. Comparison of the Preferences of Domestic Tourists and Foreign Tourists
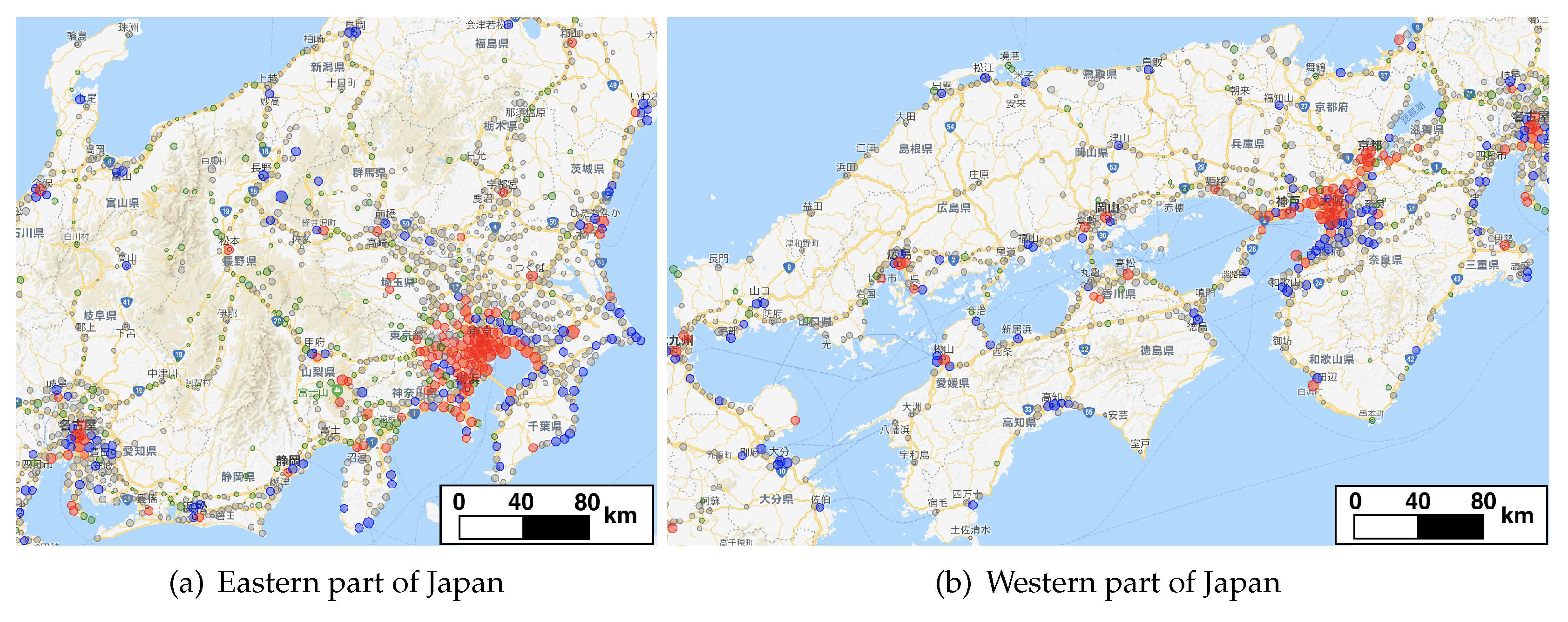
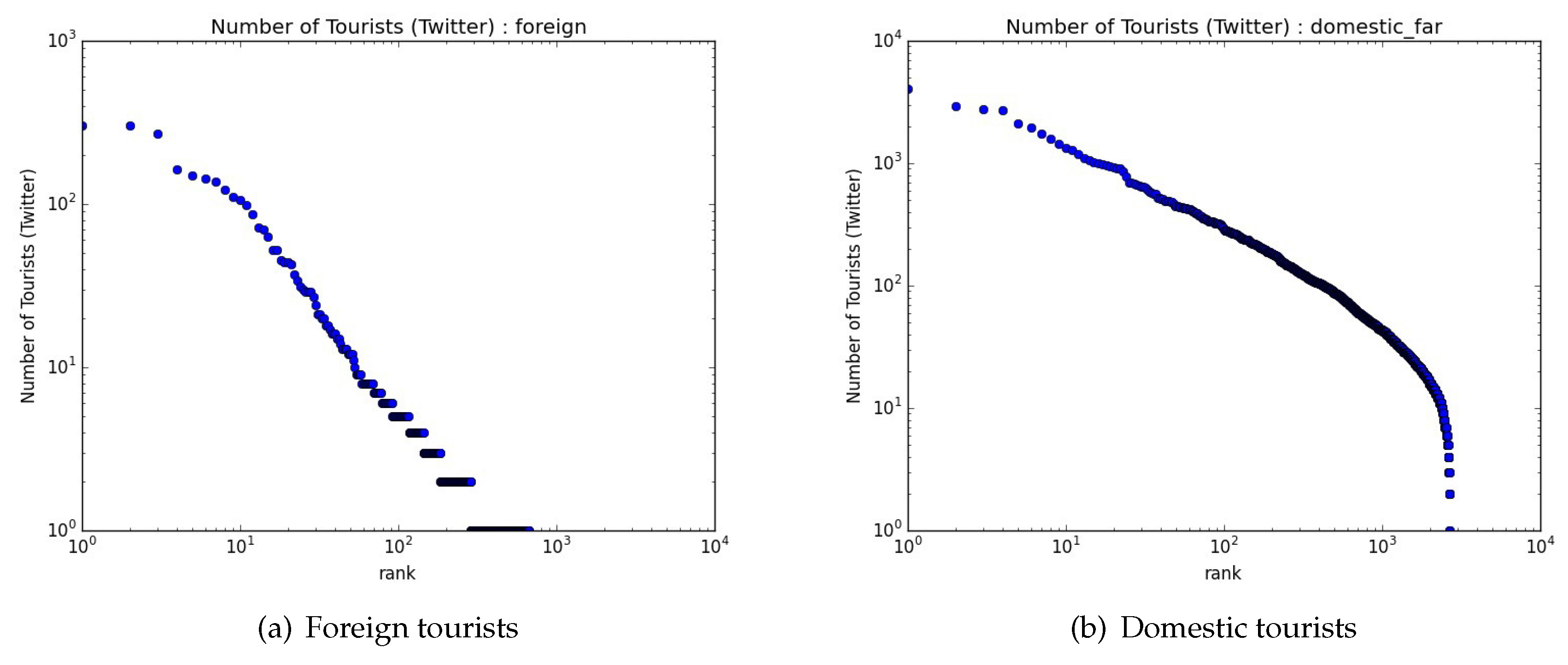
4.1. Distribution of Places Visited by Tourists
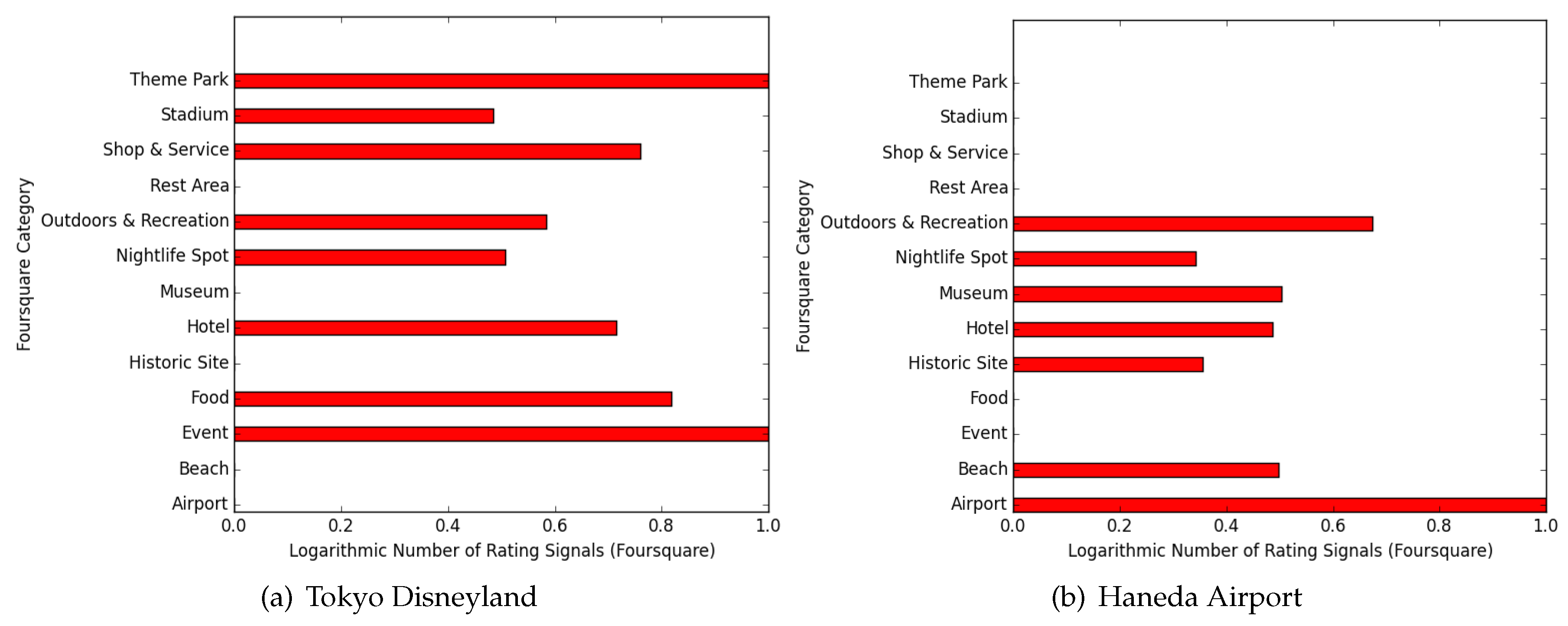
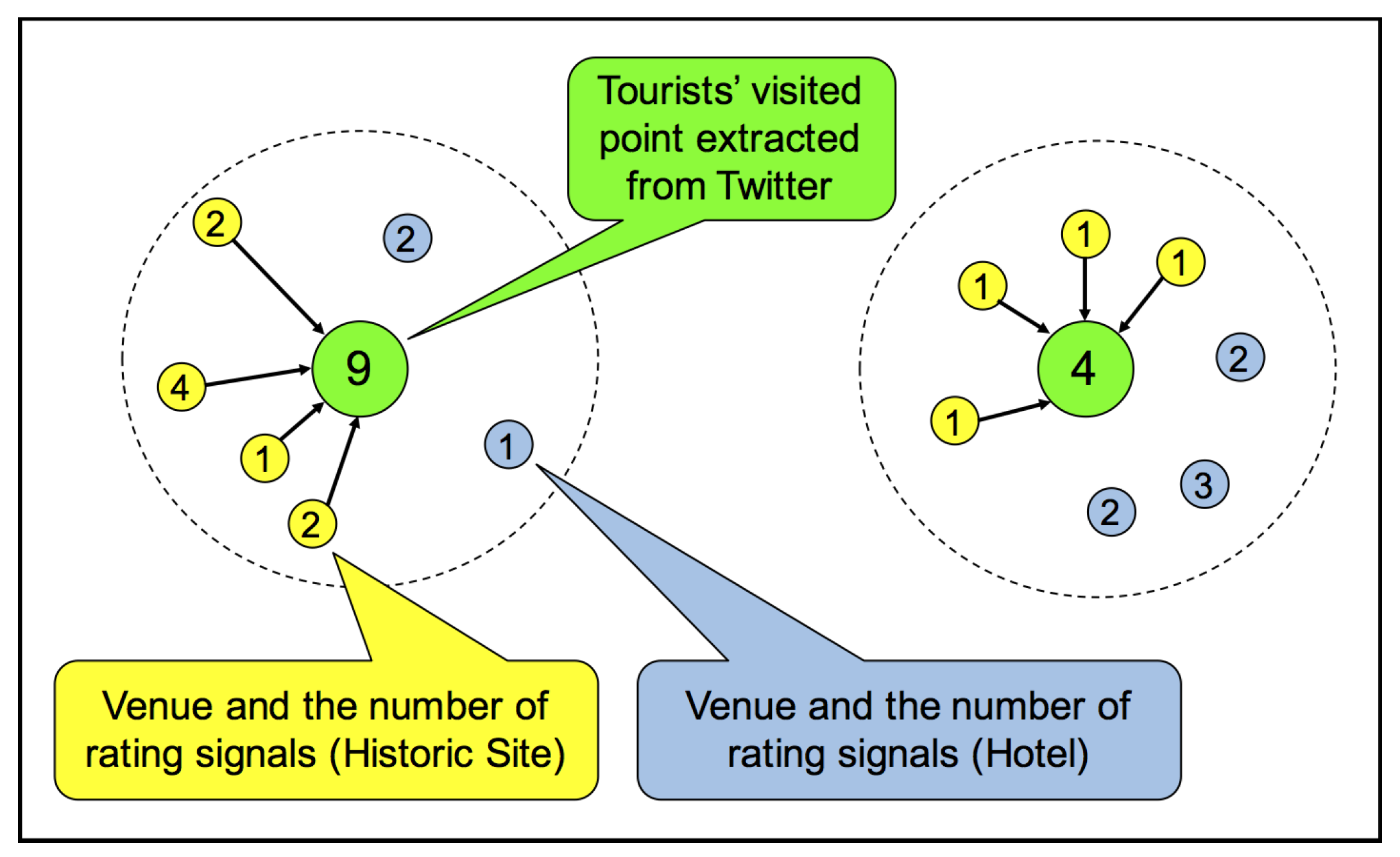
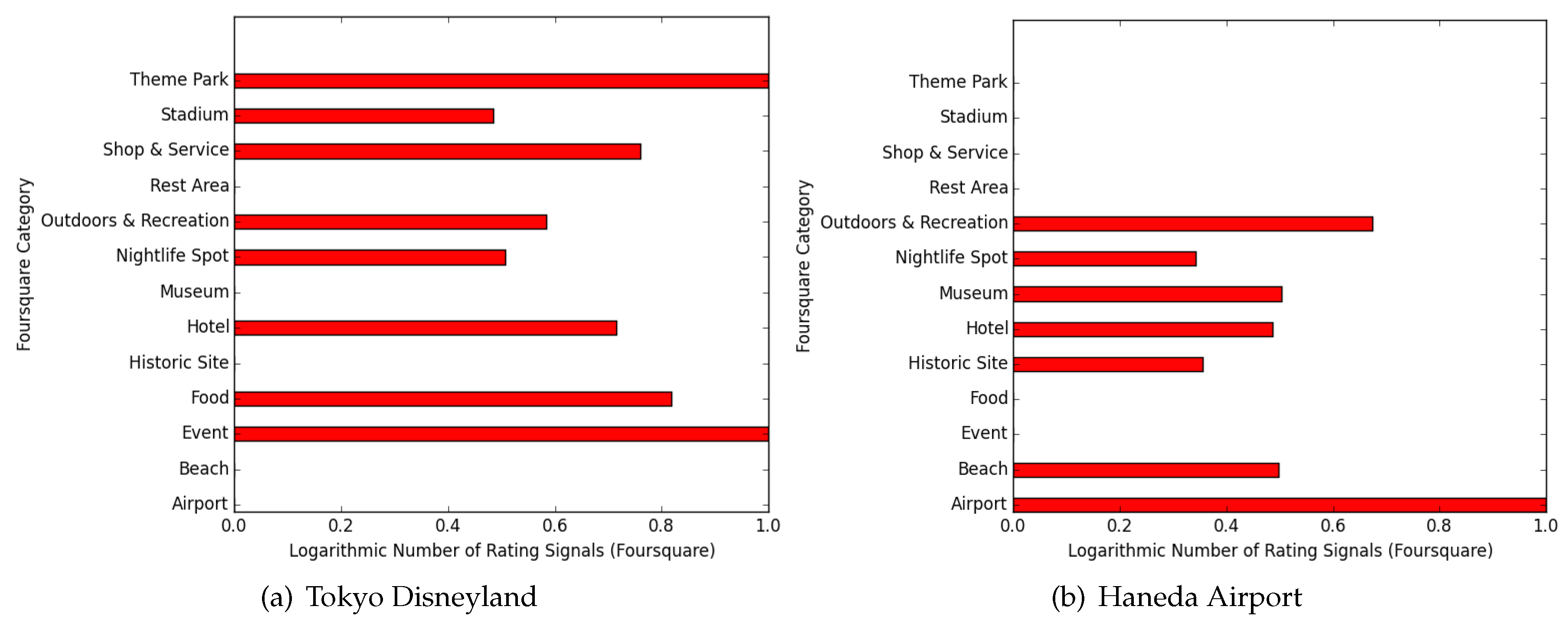
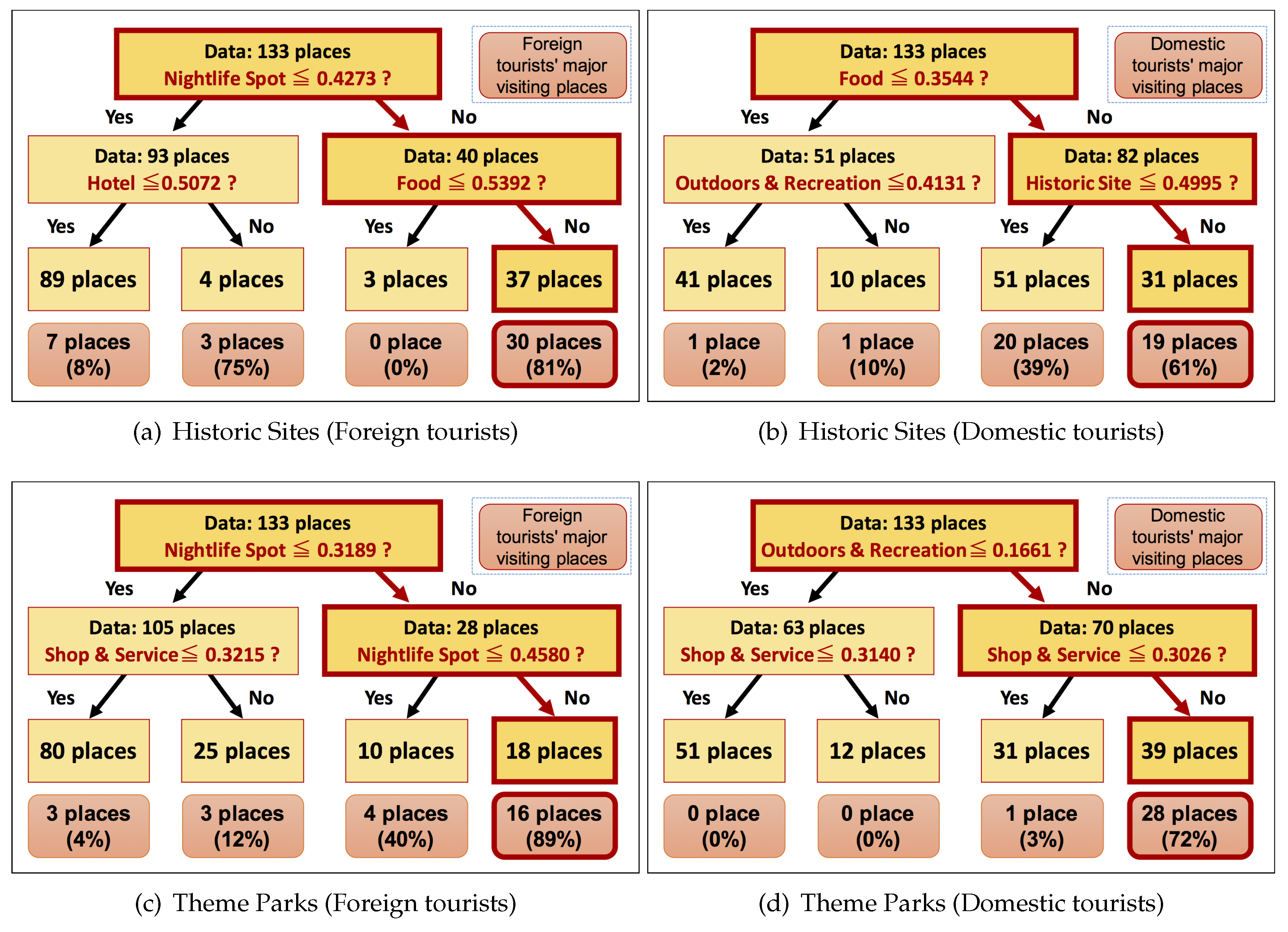
4.2. Characterization of Each Location
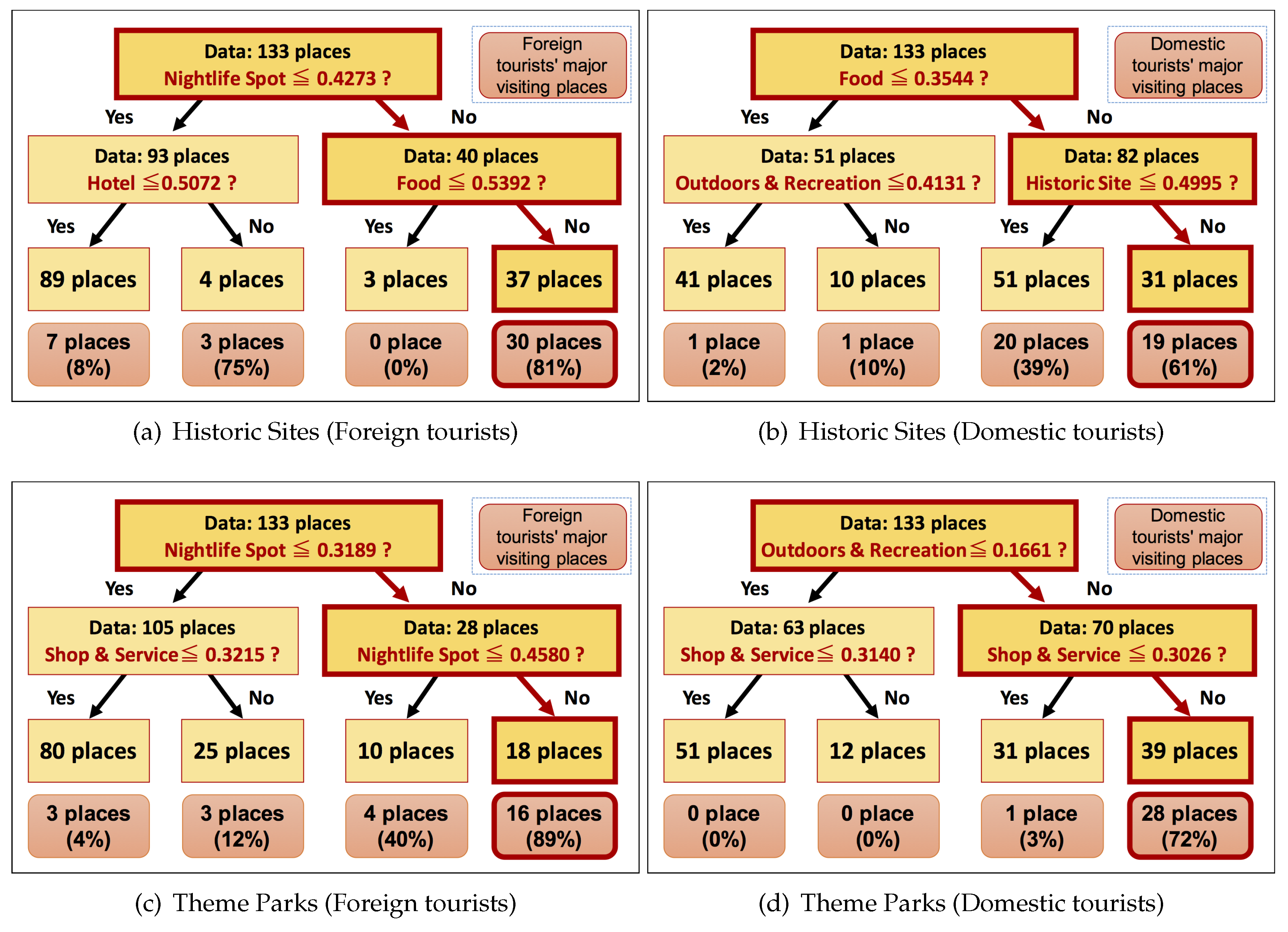
4.3. Results
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Abbreviations
| DBSCAN | density-based spatial clustering algorithm with noise |
| IDF | inverse document frequency |
| LBSN | location-based social networks |
| POI | point of interest |
| TF | term frequency |
| UNWTO | United Nations World Tourism Organization |
References
- Maeda, T.N.; Yoshida, M.; Toriumi, F.; Ohashi, H. Decision Tree Analysis of Tourists’ Preferences Regarding Tourist Attractions Using Geotag Data from Social Media. In Proceedings of the Second International Conference on IoT in Urban Space, Tokyo, Japan, 24–25 May 2016. [Google Scholar]
- United Nations World Tourism Organization. UNWTO Tourism Highlights 2016 Edition; United Nations World Tourism Organization: Madrid, Spain, 2016. [Google Scholar]
- Paci, R.; Marrocu, E. Tourism and regional growth in Europe. Pap. Reg. Sci. 2013, 93, S25–S50. [Google Scholar] [CrossRef]
- Kostakis, I.; Theodoropoulou, E. Spatial analysis of the nexus between tourism–human capital–economic growth. Tourism Economics 2017, 23, 1523–1534. [Google Scholar] [CrossRef]
- Crandall, D.J.; Backstrom, L.; Huttenlocher, D.; Kleinberg, J. Mapping the World’s Photos. In Proceedings of the 18th International Conference on World Wide Web, Madrid, Spain, 20–24 April 2009. [Google Scholar]
- Yang, Y.; Gong, Z.; Hou U, L. Identifying Points of Interest by Self-tuning Clustering. In Proceedings of the 34th International ACM SIGIR Conference on Research and Development in Information Retrieval, Beijing, China, 24–28 July 2011. [Google Scholar]
- Zhou, X.; Xu, C.; Kimmons, B. Detecting tourism destinations using scalable geospatial analysis based on cloud computing platform. Comput. Environ. Urban Syst. 2015, 54, 144–153. [Google Scholar] [CrossRef]
- Wei, L.Y.; Zheng, Y.; Peng, W.C. Constructing Popular Routes from Uncertain Trajectories. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Beijing, China, 12–16 August 2012. [Google Scholar]
- Zheng, Y.; Zhang, L.; Xie, X.; Ma, W.Y. Mining Interesting Locations and Travel Sequences from GPS Trajectories. In Proceedings of the 18th International Conference on World Wide Web, Madrid, Spain, 20–24 April 2009. [Google Scholar]
- Kurashima, T.; Iwata, T.; Irie, G.; Fujimura, K. Travel Route Recommendation Using Geotags in Photo Sharing Sites. In Proceedings of the 19th ACM International Conference on Information and Knowledge Management, Toronto, ON, Canada, 26–30 October 2010. [Google Scholar]
- Majid, A.; Chen, L.; Chen, G.; Mirza, H.T.; Hussain, I.; Woodward, J. A context-aware personalized travel recommendation system based on geotagged social media data mining. Int. J. Geogr. Inf. Sci. 2013, 27, 662–684. [Google Scholar] [CrossRef]
- Vu, H.Q.; Li, G.; Law, R.; Ye, B.H. Exploring the travel behaviors of inbound tourists to Hong Kong using geotagged photos. Tour. Manag. 2015, 46, 222–232. [Google Scholar] [CrossRef]
- Paldino, S.; Bojic, I.; Sobolevsky, S.; Ratti, C.; González, M.C. Urban magnetism through the lens of geo-tagged photography. EPJ Data Sci. 2015, 4, 5. [Google Scholar] [CrossRef]
- Vu, H.Q.; Li, G.; Law, R.; Zhang, Y. Travel Diaries Analysis by Sequential Rule Mining. J. Travel Res. 2018, 57, 399–413. [Google Scholar] [CrossRef]
- Spinsanti, L.; Berlingerio, M.; Pappalardo, L. Mobility and Geo-Social Networks. In Mobility Data: Modeling, Management, and Understanding; Renso, C., Spaccapietra, S., Zimányi, E., Eds.; Cambridge University Press: Cambridge, UK, 2013; pp. 315–333. [Google Scholar]
- Hawelka, B.; Sitko, I.; Beinat, E.; Sobolevsky, S.; Kazakopoulos, P.; Ratti, C. Geo-located Twitter as proxy for global mobility patterns. Cartogr. Geogr. Inf. Sci. 2014, 41, 260–271. [Google Scholar] [CrossRef] [PubMed]
- Bassolas, A.; Lenormand, M.; Tugores, A.; Gonçalves, B.; Ramasco, J.J. Touristic site attractiveness seen through Twitter. EPJ Data Sci. 2016, 5, 12. [Google Scholar] [CrossRef]
- Sobolevsky, S.; Bojic, I.; Belyi, A.; Sitko, I.; Hawelka, B.; Arias, J.M.; Ratti, C. Scaling of City Attractiveness for Foreign Visitors through Big Data of Human Economical and Social Media Activity. In Proceedings of the 2015 IEEE International Congress on Big Data, Santa Clara, CA, USA, 29 October–1 November 2015. [Google Scholar]
- Hausmann, A.; Toivonen, T.; Slotow, R.; Tenkanen, H.; Moilanen, A.; Heikinheimo, V.; Di Minin, E. Social Media Data Can Be Used to Understand Tourists’ Preferences for Nature-Based Experiences in Protected Areas. Conserv. Lett. 2017, 11, e12343. [Google Scholar] [CrossRef]
- Keeler, B.L.; Wood, S.A.; Polasky, S.; Kling, C.; Filstrup, C.T.; Downing, J.A. Recreational demand for clean water: Evidence from geotagged photographs by visitors to lakes. Front. Ecol. Environ. 2015, 13, 76–81. [Google Scholar] [CrossRef]
- Kurashima, T.; Iwata, T.; Hoshide, T. Geo topic model: Joint modeling of user’s activity area and interests for location recommendation. In Proceedings of the Sixth ACM International Conference on Web Search and Data Mining, Rome, Italy, 4–8 February 2013. [Google Scholar]
- Hu, B.; Ester, M. Spatial Topic Modeling in Online Social Media for Location Recommendation. In Proceedings of the 7th ACM Conference on Recommender Systems, Hong Kong, China, 12–16 October 2013. [Google Scholar]
- Philander, K.; Zhong, Y.Y. Twitter sentiment analysis: Capturing sentiment from integrated resort tweets. Int. J. Hosp. Manag. 2016, 55, 16–24. [Google Scholar] [CrossRef]
- Shi, B.; Zhao, J.; Chen, P.J. Exploring urban tourism crowding in Shanghai via crowdsourcing geospatial data. Curr. Issues Tour. 2017, 20, 1186–1209. [Google Scholar] [CrossRef]
- Zhu, Y.; Newsam, S. Spatio-temporal Sentiment Hotspot Detection Using Geotagged Photos. In Proceedings of the 24th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Francisco Bay Area, CA, USA, 31 October–3 November 2016. [Google Scholar]
- Miah, S.J.; Vu, H.Q.; Gammack, J.; McGrath, M. A Big Data Analytics Method for Tourist Behaviour Analysis. Inf. Manag. 2016, 54, 771–785. [Google Scholar] [CrossRef]
- Georgiev, P.; Noulas, A.; Mascolo, C. Where businesses thrive: Predicting the impact of the Olympic games on local retailers through location-based services data. In Proceedings of the 8th International AAAI Conference on Weblogs and Social Media, Ann Arbor, MI, USA, 1–4 June 2014. [Google Scholar]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining, Portland, Oregon, 2–4 August 1996; pp. 226–231. [Google Scholar]
- Zipf, G.K. The P1P2/D Hypothesis: On the Intercity Movement of Persons. Am. Sociol. Rev. 1946, 11, 677–686. [Google Scholar] [CrossRef]
- Jung, W.S.; Wang, F.; Stanley, H.E. Gravity model in the Korean highway. EPL (Europhys. Lett.) 2008, 81, 48005. [Google Scholar] [CrossRef]
- Simini, F.; Gonzalez, M.C.; Maritan, A.; Barabasi, A.L. A universal model for mobility and migration patterns. Nature 2012, 484, 96–100. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Salton, G.; Buckley, C. Term-weighting approaches in automatic text retrieval. Inf. Process. Manag. 1988, 24, 513–523. [Google Scholar] [CrossRef]
- TripAdvisor. Trip Advisor’s List of the Thirty Best Places in Japan (Written in Japanese). Available online: https://www.tripadvisor.jp/pages/InboundAttraction_2014.html (accessed on 28 January 2018).
- Lee, R.; Wakamiya, S.; Sumiya, K. Urban area characterization based on crowd behavioral lifelogs over Twitter. Pers. Ubiquitous Comput. 2013, 17, 605–620. [Google Scholar] [CrossRef]
- Breiman, L.; Friedman, J.; Stone, C.J.; Olshen, R. Classification and Regression Trees; Chapman and Hall/CRC: Oxfordshire, UK, 1984. [Google Scholar]
- The Themed Entertainment Association. TEA/AECOM 2014 Theme Index and Museum Index. 2014. Available online: http://www.teaconnect.org/images/files/TEA_103_49736_150603.pdf (accessed on 13 March 2018).
- Japan Tourism Agency. Statistical Information. Available online: http://www.mlit.go.jp/kankocho/en/siryou/toukei/index.html (accessed on 28 January 2018).
- Henderson, J.C. Destination Development: Trends in Japan’s Inbound Tourism. Int. J. Tour. Res. 2017, 19, 89–98. [Google Scholar] [CrossRef]
- Ishida, Y.; Miyaki, M.; Fujisawa, Y.; Iwasaki, K. How does tourism differ among generations? Tourists from the United States and their willingness to visit Japan. Int. J. Tour. Sci. 2017, 17, 49–60. [Google Scholar] [CrossRef]
- Nikkei Shimbun. Inbound Tourists Enjoy Nightlife Attractions (Written in Japanese). Available online: https://www.nikkei.com/article/DGXMZO94100130X11C15A1H11A00/ (accessed on 28 January 2018).
- Japan Times. LDP Panel Eyes Extended Nightlife Hours to Boost Japan’s Economy. Available online: https://www.japantimes.co.jp/news/2017/12/19/business/economy-business/ldp-panel-eyes-extended-nightlife-hours-boost-japans-economy/ (accessed on 28 January 2018).
- NHK (Japan Broadcasting Corporation). Tourist Spending Exceeds US$40 Billion. Available online: https://www3.nhk.or.jp/nhkworld/nhknewsline/backstories/touristspendingexceeds/ (accessed on 28 January 2018).
- Cabinet Office, Government of Japan. Basic Policy on Economic and Fiscal Management and Reform 2017. Available online: http://www5.cao.go.jp/keizai-shimon/kaigi/cabinet/2017/2017_basicpolicies_en.pdf (accessed on 28 January 2018).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
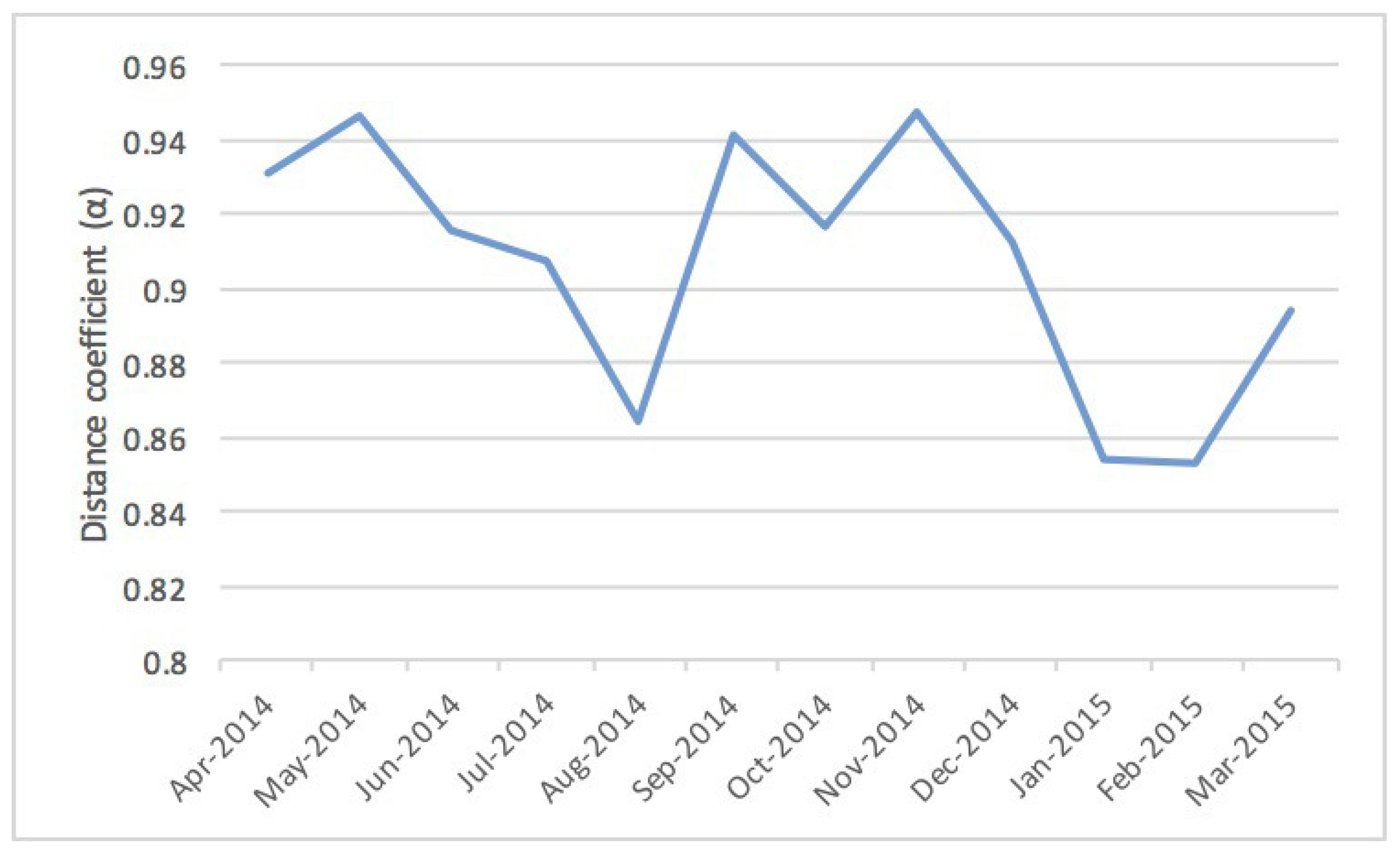
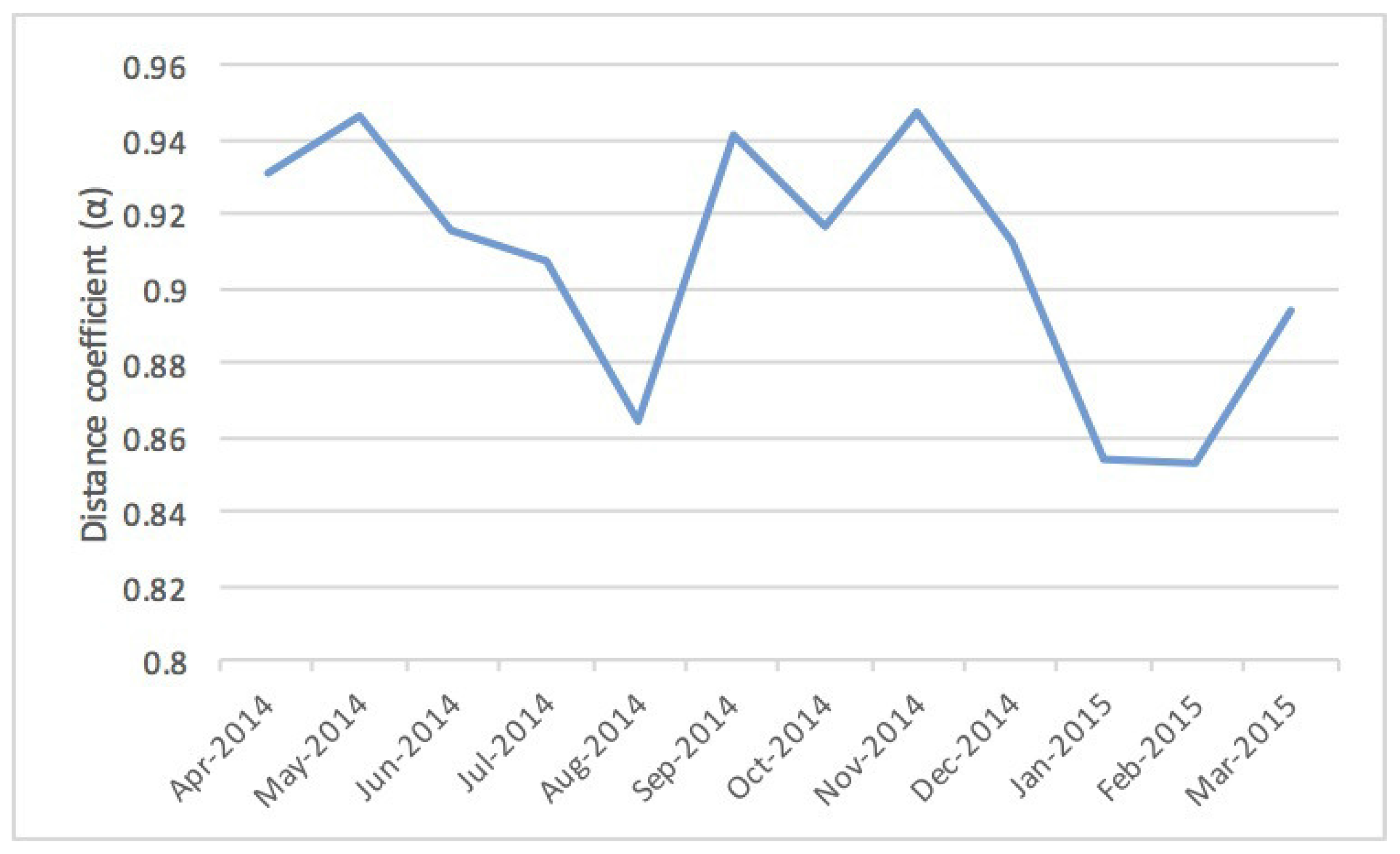
| Period | Number of Valid Users | Distance Coefficient () | |
|---|---|---|---|
| April 2014 | 81,115 | 0.75412 | 0.93051 |
| May 2014 | 79,870 | 0.75431 | 0.94589 |
| June 2014 | 86,167 | 0.77979 | 0.91594 |
| July 2014 | 93,809 | 0.77449 | 0.90771 |
| August 2014 | 107,418 | 0.72844 | 0.86430 |
| September 2014 | 95,723 | 0.73748 | 0.94081 |
| October 2014 | 85,012 | 0.75326 | 0.91642 |
| November 2014 | 83,743 | 0.74258 | 0.94743 |
| December 2014 | 106,951 | 0.74248 | 0.91262 |
| January 2015 | 105,444 | 0.74380 | 0.85424 |
| February 2015 | 99,846 | 0.76183 | 0.85350 |
| March 2015 | 124,954 | 0.73715 | 0.89403 |
| Foreign Tourists | Domestic Tourists | |
|---|---|---|
| Historic Site | The first tree | The second tree |
| Theme park | The third tree | The fourth tree |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Maeda, T.N.; Yoshida, M.; Toriumi, F.; Ohashi, H. Extraction of Tourist Destinations and Comparative Analysis of Preferences Between Foreign Tourists and Domestic Tourists on the Basis of Geotagged Social Media Data. ISPRS Int. J. Geo-Inf. 2018, 7, 99. https://doi.org/10.3390/ijgi7030099
Maeda TN, Yoshida M, Toriumi F, Ohashi H. Extraction of Tourist Destinations and Comparative Analysis of Preferences Between Foreign Tourists and Domestic Tourists on the Basis of Geotagged Social Media Data. ISPRS International Journal of Geo-Information. 2018; 7(3):99. https://doi.org/10.3390/ijgi7030099
Chicago/Turabian StyleMaeda, Takashi Nicholas, Mitsuo Yoshida, Fujio Toriumi, and Hirotada Ohashi. 2018. "Extraction of Tourist Destinations and Comparative Analysis of Preferences Between Foreign Tourists and Domestic Tourists on the Basis of Geotagged Social Media Data" ISPRS International Journal of Geo-Information 7, no. 3: 99. https://doi.org/10.3390/ijgi7030099
APA StyleMaeda, T. N., Yoshida, M., Toriumi, F., & Ohashi, H. (2018). Extraction of Tourist Destinations and Comparative Analysis of Preferences Between Foreign Tourists and Domestic Tourists on the Basis of Geotagged Social Media Data. ISPRS International Journal of Geo-Information, 7(3), 99. https://doi.org/10.3390/ijgi7030099