Structured Knowledge Base as Prior Knowledge to Improve Urban Data Analysis

 ,
,
Abstract
:1. Introduction
- (1)
- We propose a method to learn the structured knowledge representation from raw urban data and build an urban knowledge graph containing domain prior knowledge that is helpful for decision-making when there are few instances and may help improve the prediction of other applications by transfer learning. UKG-NN employs convolution-based neural network by considering global, propagation-specific, and locale-specific features automatically generated from an urban knowledge graph as well as manually extracted features from raw urban data.
- (2)
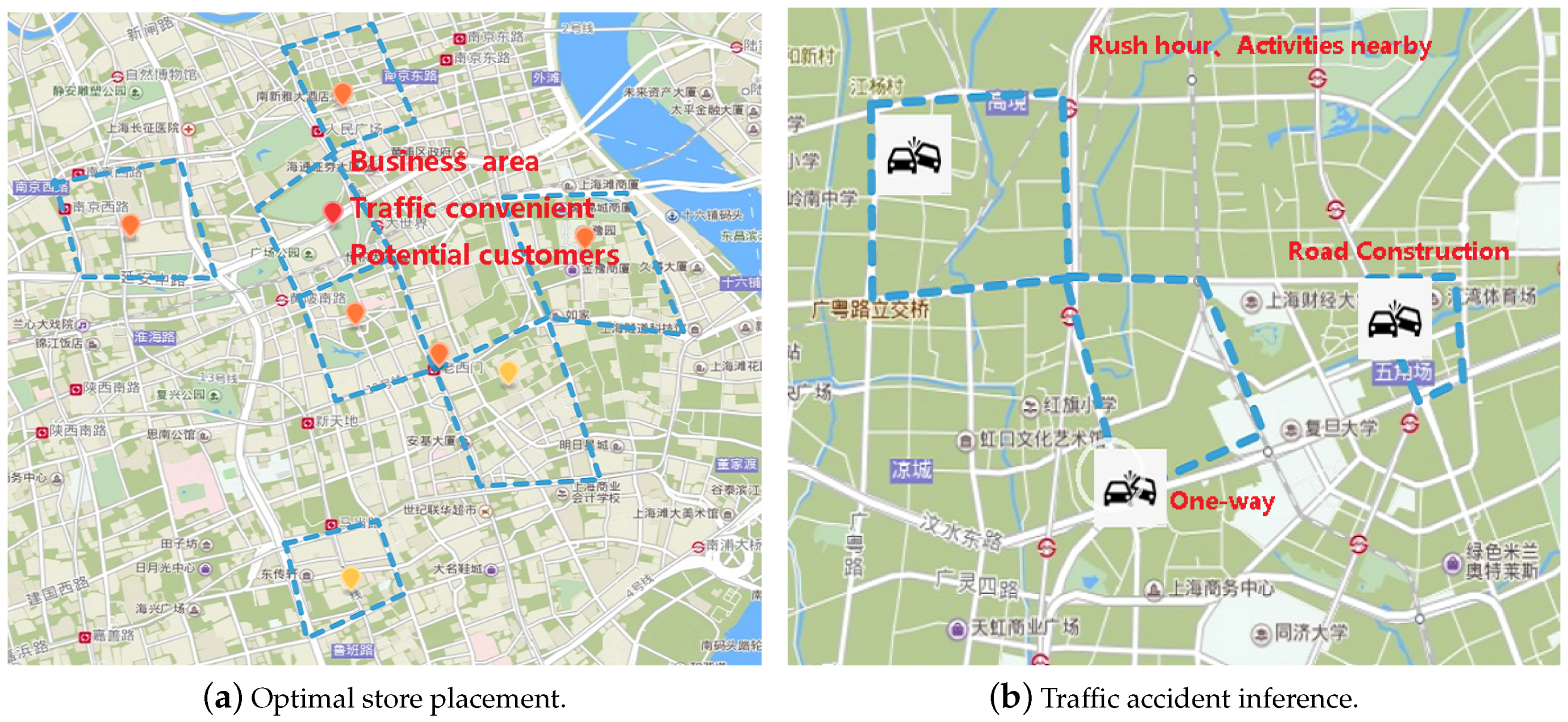
- We apply the UKG-NN to optimal store placement and traffic accident inference using a noisy urban knowledge graph and manually extracted features.
- (3)
- The UKG-NN has the ability to explain some results of store placement and traffic accident inference as model interpretability is a requirement in many applications in which crucial decisions are made by users relying on a model’s outputs.
- (4)
- We evaluated our method using real user comments, taxicabs, meteorological data, and human flow data in Shanghai. The results showed that our approach outperforms the baseline methods.
2. Related Work
2.1. Urban Computing
2.2. Knowledge Graph
3. Approach
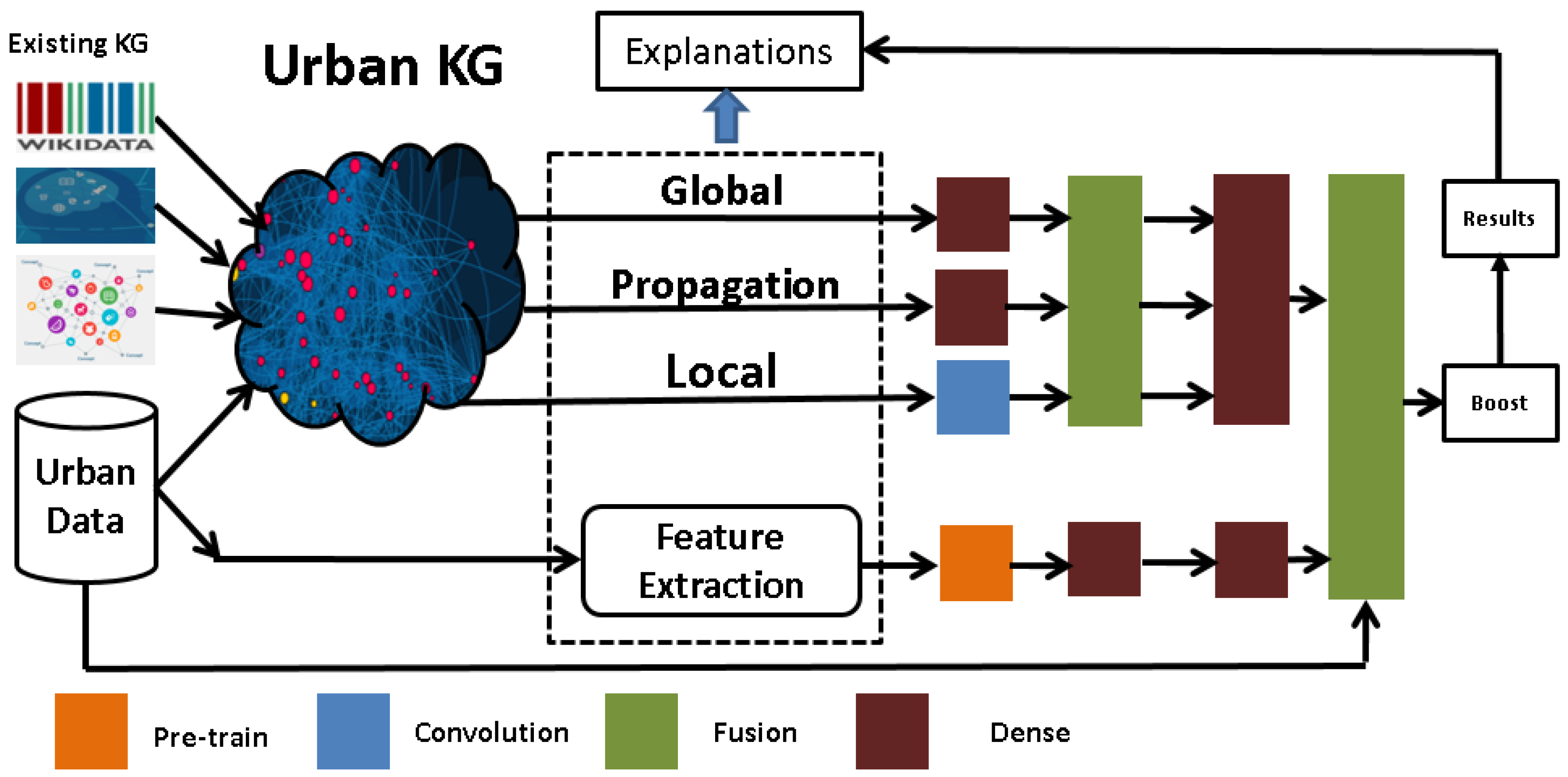
3.1. Overview
3.2. Notations and Problem Formulation
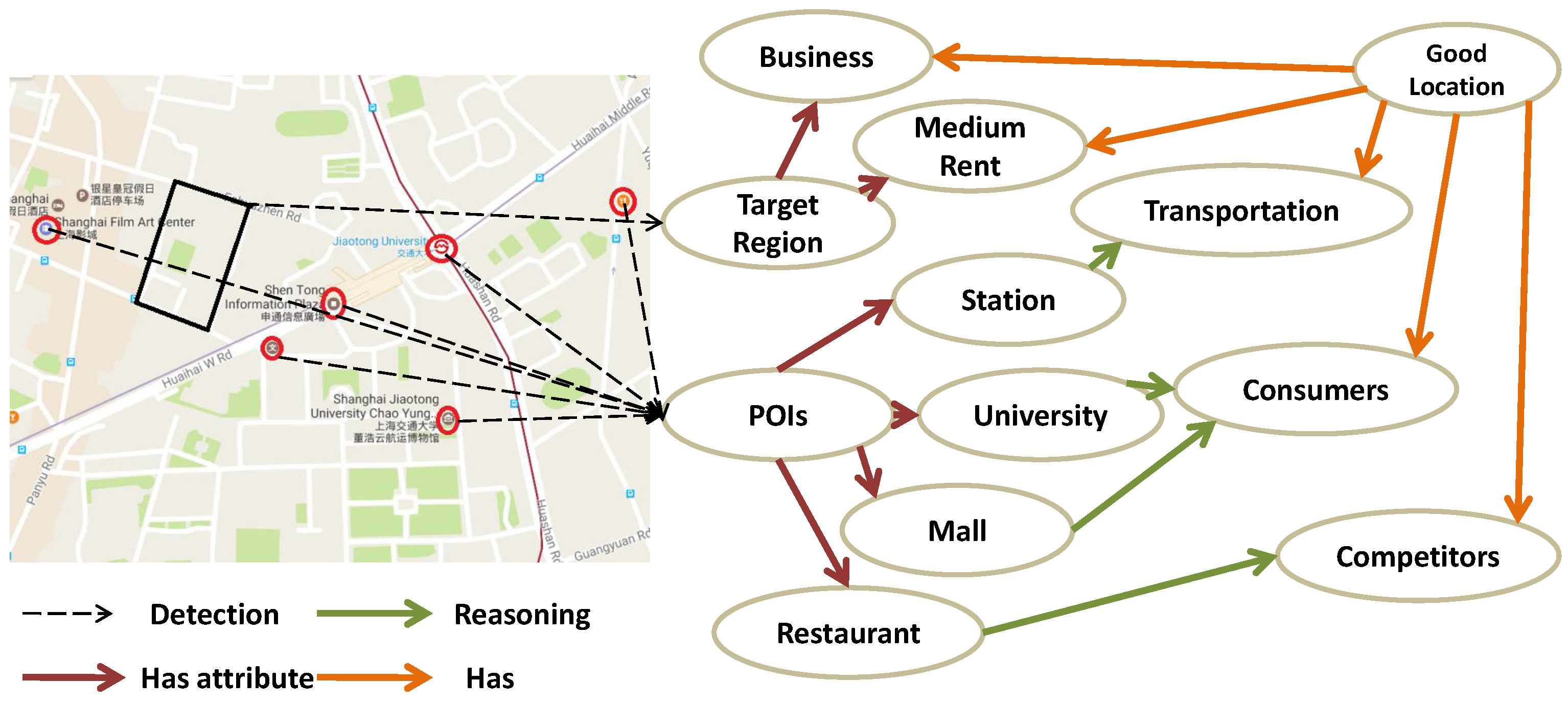
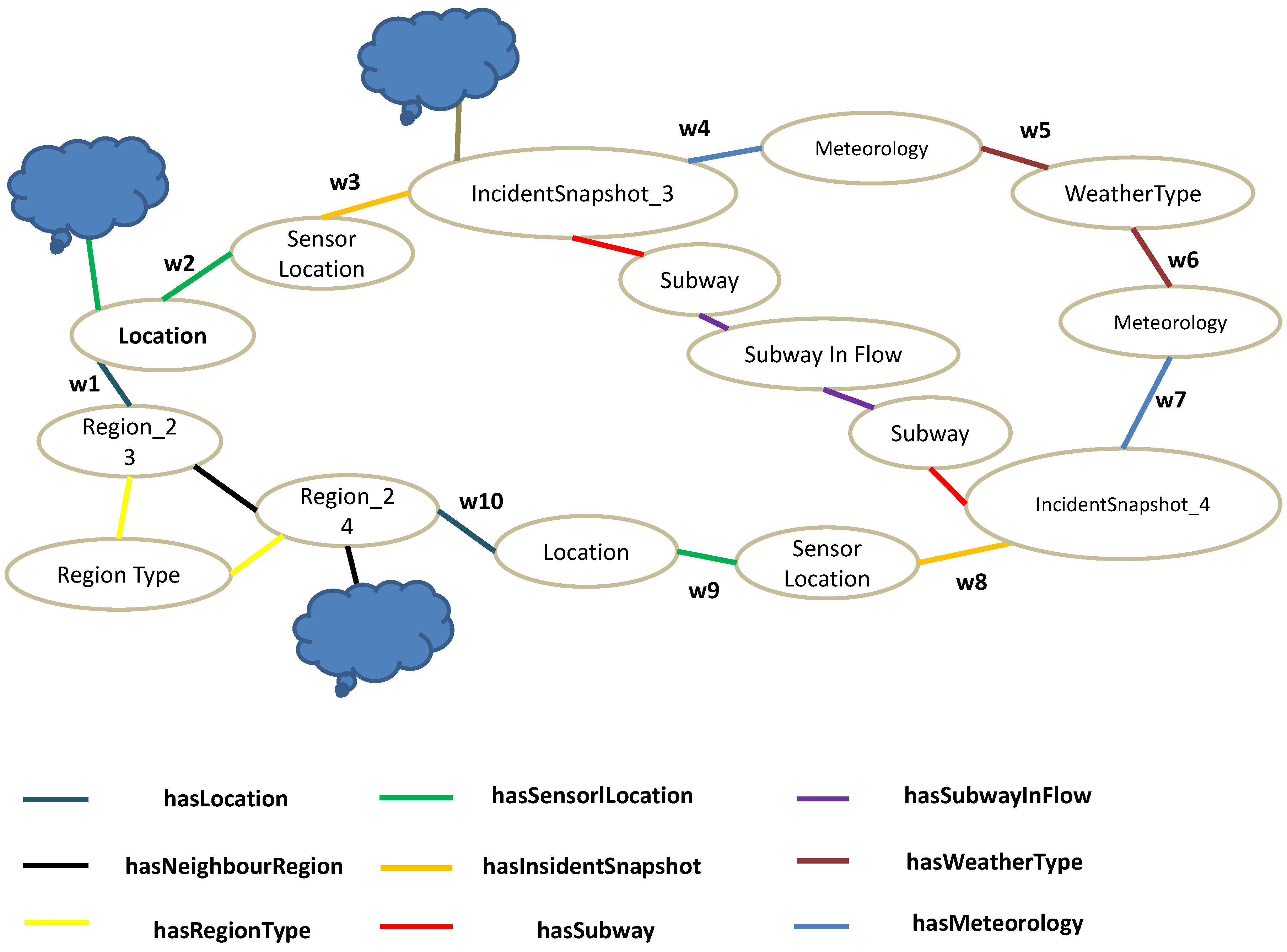
3.3. Urban Knowledge Graph
3.4. Manual Feature Extraction
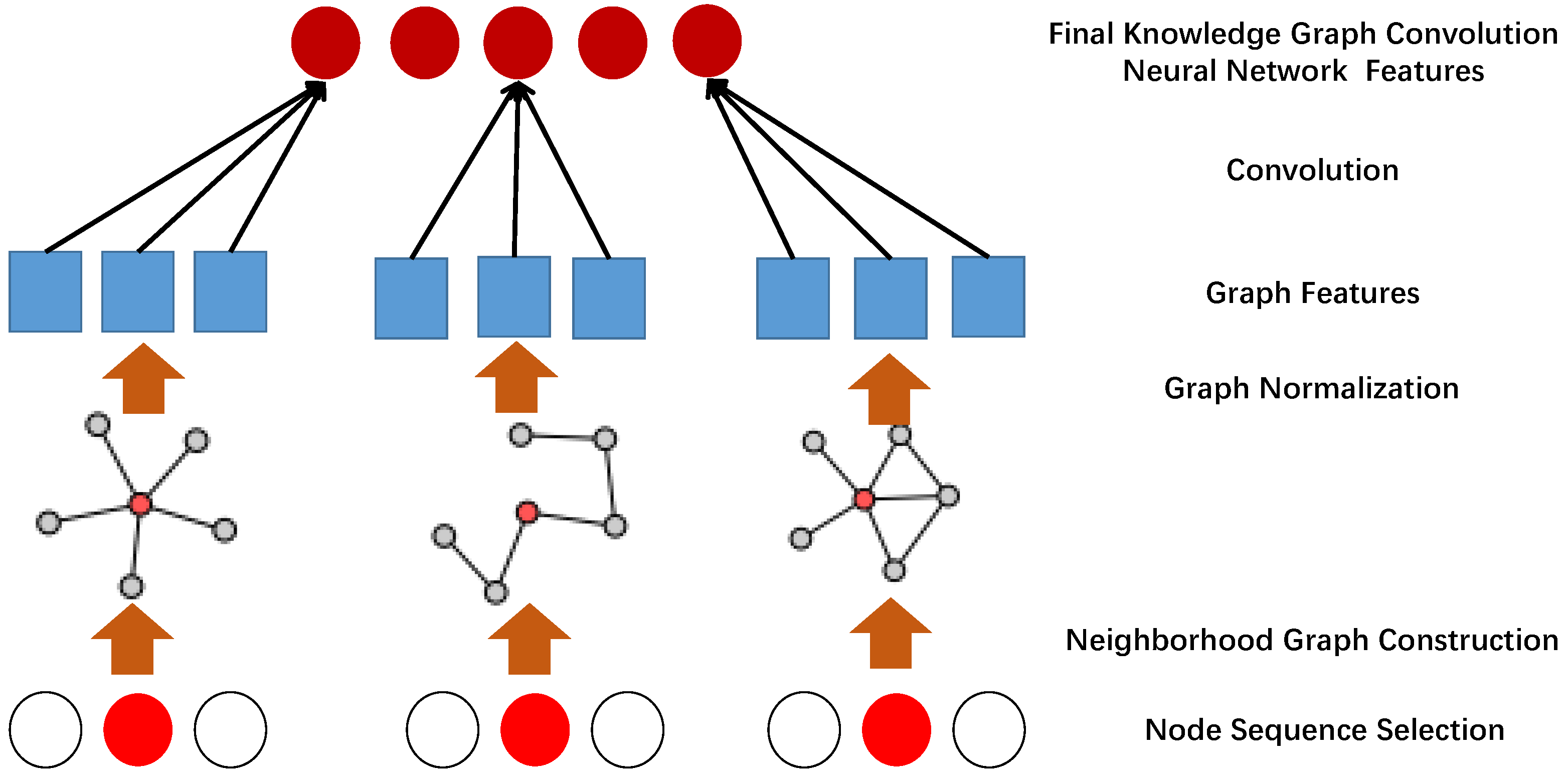
3.5. Graph Feature Extraction
3.6. Model
4. Experiments
4.1. Settings
4.1.1. Datasets
4.1.2. Baselines
- Linear. We used the linear regression algorithm Lasso, where the regularization parameter were .
- RF. RF stands for random forests. The number of trees was 10, and the minimum number of samples required to split an internal node was set to 2. The function to measure the quality of a split was the mean squared error.
- GBR. GBR is short for gradient boosting for regression (GBR), where the loss function to be optimized was least-squares regression, and the number of boosting stages was 100.
- SVR (Support Vector Regression). The kernel function we used was also an RBF. The penalty parameter of the error term was set to 1.0, and the kernel coefficient was set to 0.1.
- SVC (Support Vector Classification). The kernel function we used was also an RBF. The penalty parameter of the error term was set to 1.5 and the kernel coefficient to 0.2.
- LambdaMART. The number of boosting stages was 100, and the learning rate was 0.1; the minimum loss required to make a further partition was 1.0.
- Huff Gravity Model. We used both manual features graph features in the Huff Gravity Model.
- Geo-spotting. We used both manual features graph features in the Geo-spotting model.
4.1.3. Preprocessing
4.1.4. Hyperparameters
4.1.5. Evaluation Metric
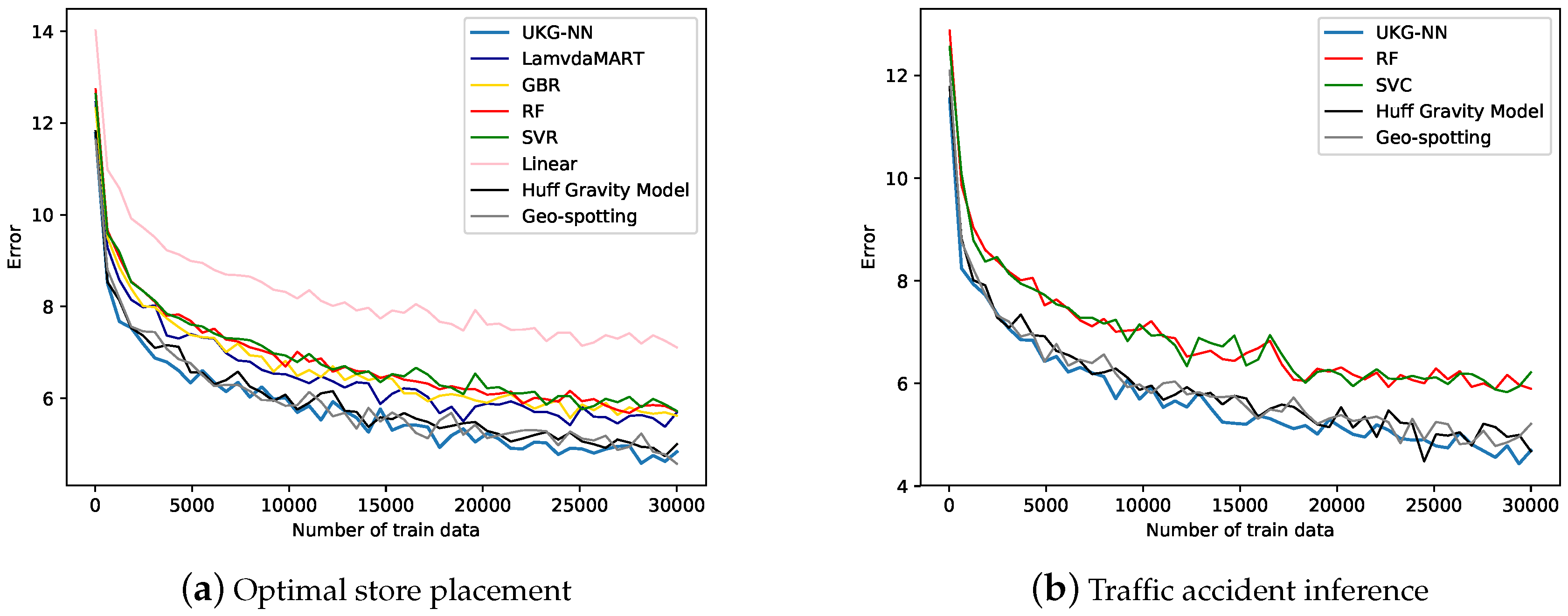
4.2. Results
Ablation Study
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| KG | Knowledge Graph |
| GGNN | Gated Graph Neural Network |
| SFE | Sub-graph Feature Extraction |
| IoT | Internet of Things |
| OWL | Web Ontology Language |
| POI | Point of Interest |
| RF | Random Forests |
| GBR | Gradient Boosting for Regression |
References
- Gomez-Perez, J.M.; Pan, J.Z.; Vetere, G.; Wu, H. Enterprise KnowledgeGraph: An Introduction. In Exploiting Linked Data and Knowledge Graphs in Large Organisations; Springer: Heidelberg/Berlin, Germany, 2017; pp. 1–14. [Google Scholar]
- Pan, J.Z.; Vetere, G.; Gomez-Perez, J.M.; Wu, H. Exploiting Linked Data and Knowledge Graphs in Large Organisations; Springer: Heidelberg/Berlin, Germany, 2017. [Google Scholar]
- Chen, X.; Shrivastava, A.; Gupta, A. Neil: Extracting visual knowledge from web data. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 1409–1416. [Google Scholar]
- Mitchell, T.; Fredkin, E. Never ending language learning. In Proceedings of the 2014 IEEE International Conference on Big Data, Washington, DC, USA, 27–30 October 2014. [Google Scholar]
- Miller, G.A. WordNet: A lexical database for English. Commun. ACM 1995, 38, 39–41. [Google Scholar] [CrossRef]
- Vrandečić, D.; Krötzsch, M. Wikidata: A free collaborative knowledgebase. Commun. ACM 2014, 57, 78–85. [Google Scholar] [CrossRef]
- Liu, H.; Singh, P. ConceptNet—A practical commonsense reasoning tool-kit. BT Technol. J. 2004, 22, 211–226. [Google Scholar] [CrossRef]
- Lao, N.; Minkov, E.; Cohen, W.W. Learning Relational Features with Backward Random Walks; Atlantic Container Line: Westfield, NJ, USA, 2015; pp. 666–675. [Google Scholar]
- Gardner, M.; Mitchell, T.M. Efficient and Expressive Knowledge Base Completion Using Subgraph Feature Extraction. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 1488–1498. [Google Scholar]
- Li, Y.; Tarlow, D.; Brockschmidt, M.; Zemel, R. Gated graph sequence neural networks. arXiv, 2015; arXiv:1511.05493. [Google Scholar]
- Niepert, M.; Ahmed, M.; Kutzkov, K. Learning convolutional neural networks for graphs. In Proceedings of the 33rd Annual International Conference on Machine Learning, Orlando, FL, USA, 4–8 December 2017. [Google Scholar]
- Lau, B.P.L.; Wijerathne, N.; Ng, B.K.K.; Yuen, C. Sensor fusion for public space utilization monitoring in a smart city. IEEE Int. Things J. 2018, 5, 473–481. [Google Scholar] [CrossRef]
- Zhou, Y.; Lau, B.P.L.; Yuen, C.; Tunçer, B.; Wilhelm, E. Understand Urban Human Mobility through Crowdsensed Data. arXiv, 2018; arXiv:1805.00628. [Google Scholar]
- Zhang, N.; Chen, H.; Chen, X.; Chen, J. ELM Meets Urban Computing: Ensemble Urban Data for Smart City Application; Springer: Heidelberg/Berlin, Germany, 2016; pp. 51–63. [Google Scholar]
- Zhang, N.; Chen, H.; Chen, J.; Chen, X. Social media meets big urban data: A case study of urban waterlogging analysis. Comput. Intell. Neurosci. 2016, 2016. [Google Scholar] [CrossRef] [PubMed]
- Zhang, N.; Zheng, G.; Chen, H.; Chen, X.; Chen, J. Monitoring urban waterlogging disaster using social sensors. In Proceedings of the Chinese Semantic Web and Web Science Conference, Wuhan, China, 8–12 August 2014; Springer: Heidelberg/Berlin, Germany, 2014; pp. 227–236. [Google Scholar]
- Zhang, N.; Chen, H.; Chen, X.; Chen, J. Forecasting public transit use by crowdsensing and semantic trajectory mining: Case studies. ISPRS Int. J. Geo-Inf. 2016, 5, 180. [Google Scholar] [CrossRef]
- Zhang, N.; Chen, H.; Chen, X.; Chen, J. Semantic framework of internet of things for smart cities: Case studies. Sensors 2016, 16, 1501. [Google Scholar] [CrossRef] [PubMed]
- Hernandez, T.; Bennison, D. The art and science of retail location decisions. Int. J. Retail Distrib. Manag. 2000, 28, 357–367. [Google Scholar] [CrossRef]
- Kubis, A.; Hartmann, M. Analysis of location of large-area shopping centres. A probabilistic Gravity Model for the Halle–Leipzig area. Jahrbuch Regionalwissenschaft 2007, 27, 43–57. [Google Scholar] [CrossRef]
- Xiao, X.; Yao, B.; Li, F. Optimal location queries in road network databases. In Proceedings of the 2011 IEEE 27th International Conference on Data Engineering (ICDE), Hannover, Germany, 11–16 April 2011; pp. 804–815. [Google Scholar]
- Rogers, D. Site for store buys. New Perspect. 1997, 5, 14–17. [Google Scholar]
- Li, Y.; Zheng, Y.; Ji, S.; Wang, W.; Gong, Z. Location selection for ambulance stations: A data-driven approach. In Proceedings of the 23rd SIGSPATIAL International Conference on Advances in Geographic Information Systems, Seattle, WA, USA, 3–6 November 2015; p. 85. [Google Scholar]
- Graells-Garrido, E.; Peredo, O.; García, J. Sensing urban patterns with antenna mappings: The case of Santiago, Chile. Sensors 2016, 16, 1098. [Google Scholar] [CrossRef] [PubMed]
- Huang, T.; Bergman, D.; Gopal, R. Predictive and Prescriptive Analytics for Location Selection of Add-on Retail Products. arXiv, 2018; arXiv:1804.01182. [Google Scholar]
- Ching, W.; Chu, A.; Hin, M.; Chan, E. A Retail Gravity Model for Selecting the Optimal Store Location. In Proceedings of the 2017 World Transport Convention, Beijing, China, 3–6 June 2017. [Google Scholar]
- Chen, T.Y.; Chen, L.C.; Chen, Y.M. Mining Location-Based Service Data for Feature Construction in Retail Store Recommendation; Springer: Heidelberg/Berlin, Germany, 2017; pp. 68–77. [Google Scholar]
- Karamshuk, D.; Noulas, A.; Scellato, S.; Nicosia, V.; Mascolo, C. Geo-spotting: mining online location-based services for optimal retail store placement. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 11–14 August 2013; pp. 793–801. [Google Scholar]
- Xie, Z.; Yan, J. Detecting traffic accident clusters with network kernel density estimation and local spatial statistics: An integrated approach. J. Trans. Geogr. 2013, 31, 64–71. [Google Scholar] [CrossRef]
- Bíl, M.; Andrášik, R.; Janoška, Z. Identification of hazardous road locations of traffic accidents by means of kernel density estimation and cluster significance evaluation. Accid. Anal. Prev. 2013, 55, 265–273. [Google Scholar] [CrossRef] [PubMed]
- Malisiewicz, T.; Efros, A. Beyond Categories: The Visual Memex Model for Reasoning about Object Relationships. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 7–10 December 2009; pp. 1222–1230. [Google Scholar]
- Zhu, Y.; Fathi, A.; Fei-Fei, L. Reasoning about Object Affordances in a Knowledge Base Representation; Springer: Heidelberg/Berlin, Germany, 2014; pp. 408–424. [Google Scholar]
- Road Network Segementation. Available online: https://github.com/zxlzr/Segment-Maps (accessed on 5 July 2018).
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems, Lake Tahoe, Nevada, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Bengio, Y. Learning deep architectures for AI. Found. Trends Mach. Learn. 2009, 2, 1–127. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Soda Data of Shanghai. Available online: http://soda.datashanghai.gov.cn/ (accessed on 5 July 2018).
- Wikidata. Available online: http://www.wikidata.org (accessed on 5 July 2018).
- ConceptNet5. Available online: http://github.com/commonsense/conceptnet5 (accessed on 5 July 2018).
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A System for Large-Scale Machine Learning. arXiv, 2016; arXiv:1605.08695v2. [Google Scholar]
- Chollet, F. Keras. Available online: https://github.com/keras-team/keras (accessed on 5 July 2018).
- Järvelin, K.; Kekäläinen, J. Cumulated gain-based evaluation of IR techniques. ACM Trans. Inf. Syst. 2002, 20, 422–446. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Deshpande, A. Consensus answers for queries over probabilistic databases. In Proceedings of the Twenty-Eighth ACM SIGMOD-SIGACT-SIGART Symposium on Principles of Database System, Providence, RI, USA, 29 June–1 July 2009; pp. 259–268. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Baselines | Manual Features | Graph Features |
|---|---|---|
| Linear | All | GCNN + SFE + s-GGNN |
| RF | All | GCNN + SFE + s-GGNN |
| GBR | All | GCNN + SFE + s-GGNN |
| SVR/SVC | All | GCNN + SFE + s-GGNN |
| LambdaMART | All | GCNN + SFE + s-GGNN |
| Huff Gravity Model | All | GCNN + SFE + s-GGNN |
| Geo-spotting | All | GCNN + SFE + s-GGNN |
| Model | Starbucks | Home-Inn | ||
|---|---|---|---|---|
| nDCG@10 | nSD@10 | nDCG@10 | nSD@10 | |
| Linear | 0.454 | 0.91 | 0.532 | 0.97 |
| RF | 0.743 | 0.70 | 0.710 | 0.87 |
| GBR | 0.754 | 0.88 | 0.745 | 0.87 |
| SVR | 0.643 | 0.91 | 0.675 | 0.95 |
| LambdaMART | 0.762 | 0.81 | 0.734 | 0.67 |
| Huff Gravity Model | 0.810 | 0.79 | 0.702 | 0.59 |
| Geo-spotting | 0.800 | 0.80 | 0.683 | 0.71 |
| Ours | ||||
| UKG-NN | 0.812 | 0.60 | 0.781 | 0.50 |
| Model | 9:00 | 10:00 | 18:00 | 19:00 |
|---|---|---|---|---|
| RF | 0.56 | 0.54 | 0.53 | 0.44 |
| SVC | 0.53 | 0.53 | 0.58 | 0.64 |
| Huff Gravity Model | 0.60 | 0.61 | 0.61 | 0.63 |
| Geo-spotting | 0.59 | 0.61 | 0.60 | 0.59 |
| Ours | ||||
| UKG-NN | 0.61 | 0.65 | 0.65 | 0.60 |
| Relation Path | Mean Weight |
|---|---|
| (hasNeighbourRegion, hasNeighbourRegion) | 0.2 |
| (hasLocation, hasSensorlLocation, hasInsidentSnapshot, hasMeteorology, hasWeatherType, hasMeteorology, hasIncidentSnapshot, hasSensorlLocation, hasLocation) | 2.13 |
| (hasLocation, hasSensorlLocation, hasInsidentSnapshot, hasSubway, hasSubwayInFlow, hasSubway, hasIncidentSnapshot, hasSensorlLocation, hasLocation) | 1.53 |
| (hasRegionType, hasRegionType) | 1.83 |
| Top Weights Node | Hidden Variable |
|---|---|
| RegionType | (0.3, 0.1, 0.1, 0.5, 1.3) |
| WeatherType | (2.3, 2.5, 2.6, 2.5, 1.9) |
| SubwayInFlow | (3.3, 2.4, 2.5, 2.1, 2.9) |
| HumanFlow | (1.3, 1.3, 1.6, 1.5, 1.9) |
| Relation Path | Mean Weight |
|---|---|
| (hasNeighbourRegion, hasNeighbourRegion) | 8.2 |
| (hasLocation, hasSensorlLocation, hasInsidentSnapshot, hasMeteorology, hasWeatherType, hasMeteorology, hasIncidentSnapshot, hasSensorlLocation, hasLocation) | 2.13 |
| (hasLocation, hasSensorlLocation, hasInsidentSnapshot, hasSubway, hasSubwayInFlow, hasSubway, hasIncidentSnapshot, hasSensorlLocation, hasLocation) | 11.53 |
| (hasRegionType, hasRegionType) | 9.83 |
| Top Weights Node | Hidden Variable |
|---|---|
| RegionType | (5.3, 3.1, 5.1, 11.5, 3.3) |
| WeatherType | (1.3, 1.5, 1.6, 1.5, 1.2) |
| SubwayInFlow | (3.3, 2.4, 5.5, 9.1, 3.9) |
| HumanFlow | (7.3, 6.3, 6.6, 6.5, 6.9) |
| Model | Starbucks | Home-Inn | ||
|---|---|---|---|---|
| nDCG@10 | nSD@10 | nDCG@10 | nSD@10 | |
| UKG-NN | 0.812 | 0.60 | 0.781 | 0.50 |
| FC | 0.644 | 0.70 | 0.674 | 0.86 |
| FC + Boost | 0.691 | 0.67 | 0.699 | 0.73 |
| GCNN + FC | 0.686 | 0.67 | 0.707 | 0.81 |
| GCNN + SFE + FC | 0.743 | 0.66 | 0.731 | 0.74 |
| GCNN + SFE + s-GGNN + FC | 0.781 | 0.62 | 0.760 | 0.55 |
| Model | 9:00 a.m. | 10:00 a.m. | 6:00 p.m. | 7:00 p.m. |
|---|---|---|---|---|
| UKG-NN | 0.61 | 0.65 | 0.65 | 0.60 |
| FC | 0.46 | 0.44 | 0.46 | 0.49 |
| FC + Boost | 0.49 | 0.49 | 0.47 | 0.51 |
| GCNN + FC | 0.45 | 0.49 | 0.48 | 0.52 |
| GCNN + SFE + FC | 0.55 | 0.50 | 0.51 | 0.55 |
| GCNN + SFE + s-GGNN + FC | 0.57 | 0.51 | 0.55 | 0.57 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, N.; Deng, S.; Chen, H.; Chen, X.; Chen, J.; Li, X.; Zhang, Y. Structured Knowledge Base as Prior Knowledge to Improve Urban Data Analysis. ISPRS Int. J. Geo-Inf. 2018, 7, 264. https://doi.org/10.3390/ijgi7070264
Zhang N, Deng S, Chen H, Chen X, Chen J, Li X, Zhang Y. Structured Knowledge Base as Prior Knowledge to Improve Urban Data Analysis. ISPRS International Journal of Geo-Information. 2018; 7(7):264. https://doi.org/10.3390/ijgi7070264
Chicago/Turabian StyleZhang, Ningyu, Shumin Deng, Huajun Chen, Xi Chen, Jiaoyan Chen, Xiaoqian Li, and Yiyi Zhang. 2018. "Structured Knowledge Base as Prior Knowledge to Improve Urban Data Analysis" ISPRS International Journal of Geo-Information 7, no. 7: 264. https://doi.org/10.3390/ijgi7070264
APA StyleZhang, N., Deng, S., Chen, H., Chen, X., Chen, J., Li, X., & Zhang, Y. (2018). Structured Knowledge Base as Prior Knowledge to Improve Urban Data Analysis. ISPRS International Journal of Geo-Information, 7(7), 264. https://doi.org/10.3390/ijgi7070264