Beyond Spatial Proximity—Classifying Parks and Their Visitors in London Based on Spatiotemporal and Sentiment Analysis of Twitter Data

 ,
,  ,
,  ,
, 
Abstract
1. The Importance of Urban Green Areas and Ways to Analyze Their Role or Characteristics in the Urban System
- Spatial aspects: What are the spatial characteristics of the selected users’ tweeting behavior and how do these characteristics relate to their park visits? In terms of parks, how far do the visitors travel on average to visit a given park from their center of activity?
- Content aspects: Are tweets in parks more positive than in other urban areas? What feelings do the visitors have when spending time in a park? How does this vary between parks?
- Temporal aspects: How do the spatial and sentiment characteristics vary over time? Are there any significant differences during the day, week or year?
- Profiles: What types of parks and park visitors can we classify based on the identified spatial, temporal, and sentiment characteristics? What do we learn about them?
2. The Core Data Sets of the Analyses
2.1. Input Data Sets
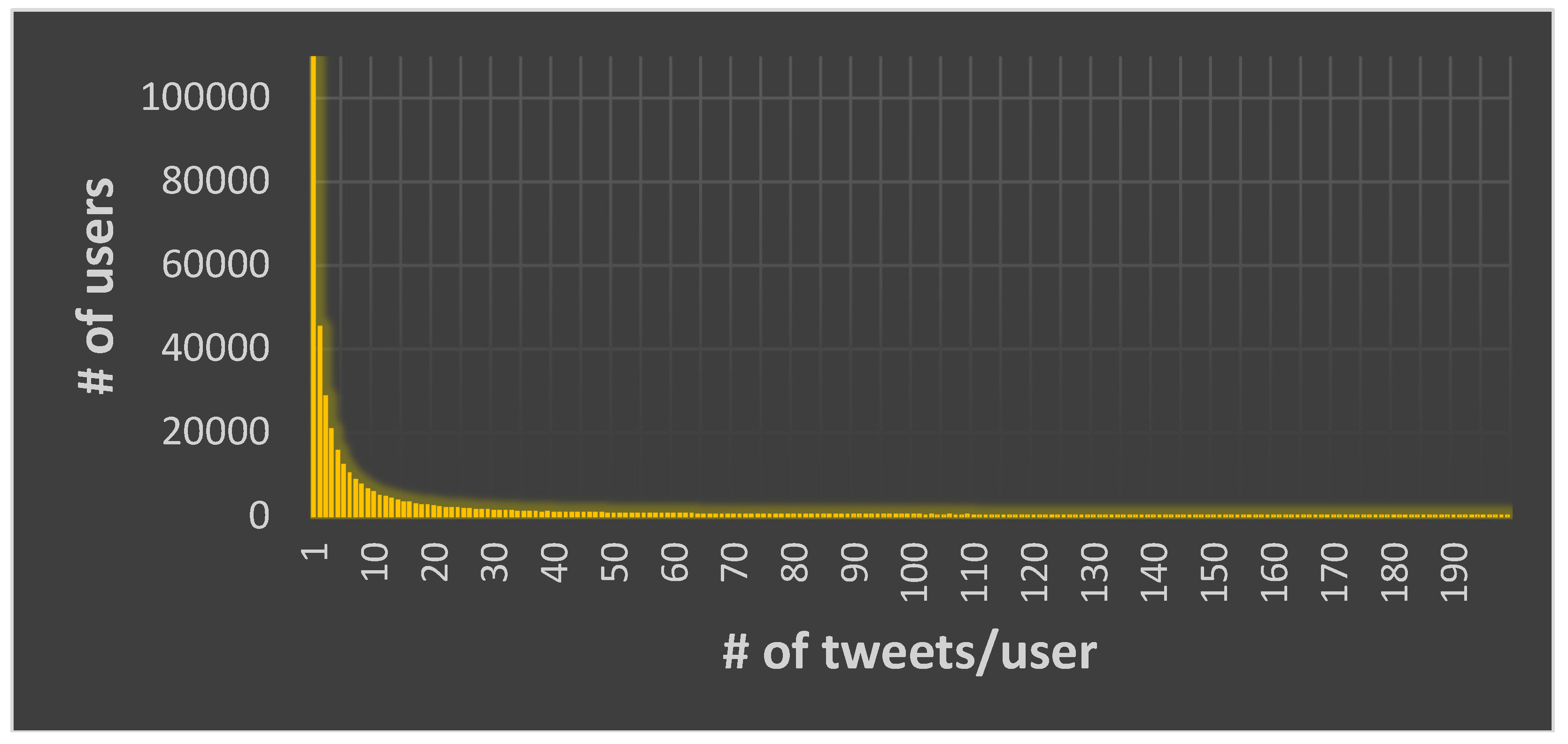
2.2. Preprocessing of the Data
3. Methodology
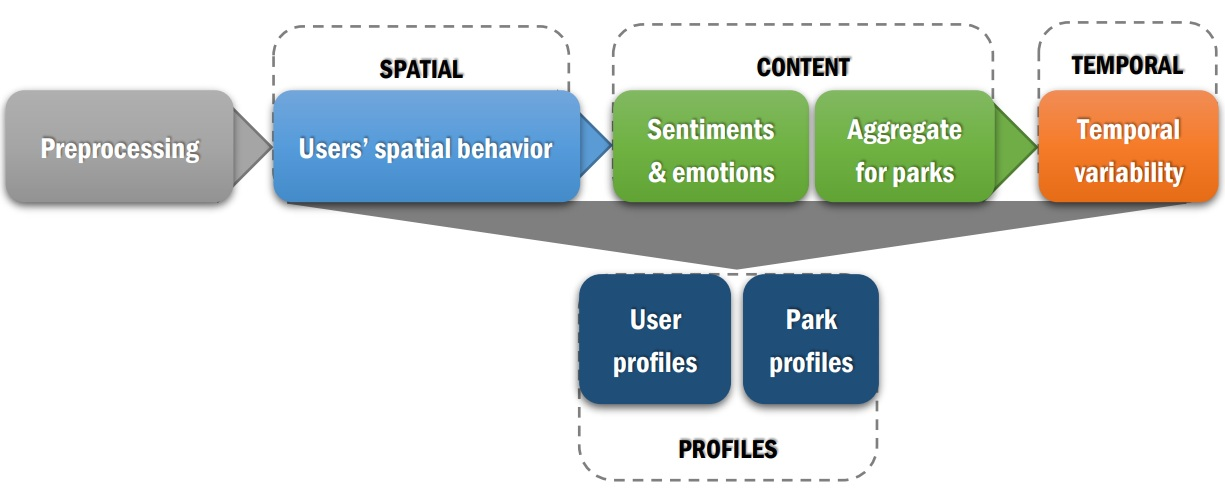
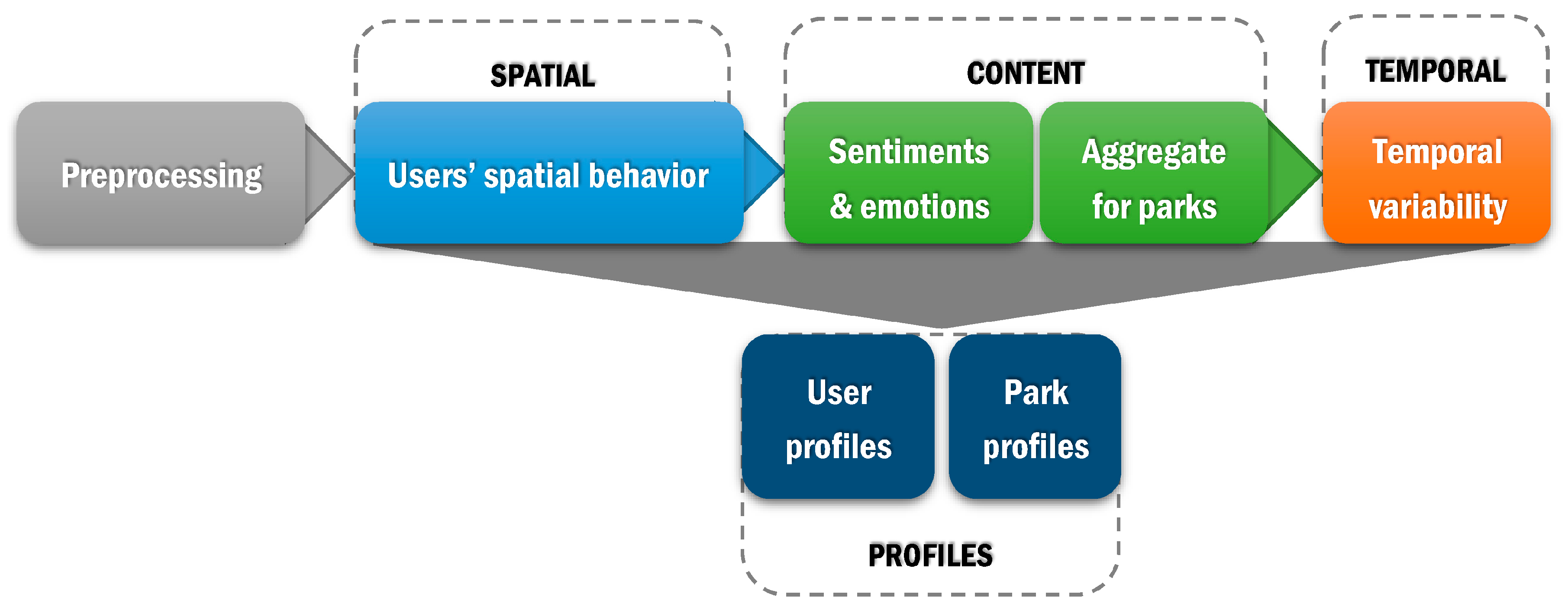
3.1. Overview
3.2. Spatial Analysis
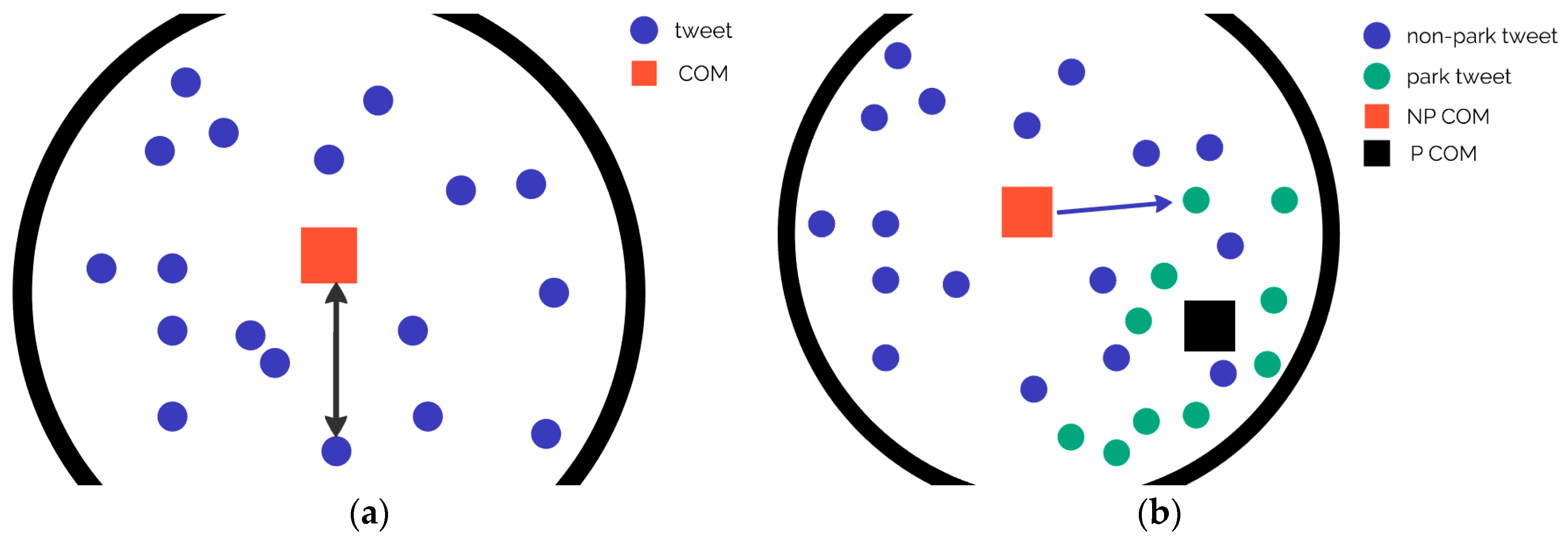
- To describe the main characteristics of the relevant users’ spatial behavior: Where is their main center of activity based on their tweets? What is the average distance between this center and each tweet from the same user?
- To measure the average distance between a park visitor’s main activity center and a given park: What is the median and mean distance from the activity center of the users who tweeted from the given park?
3.3. Semantic Content Analysis
3.3.1. Sentiment Scores
3.3.2. Emotion Detection
3.4. Temporal Analysis
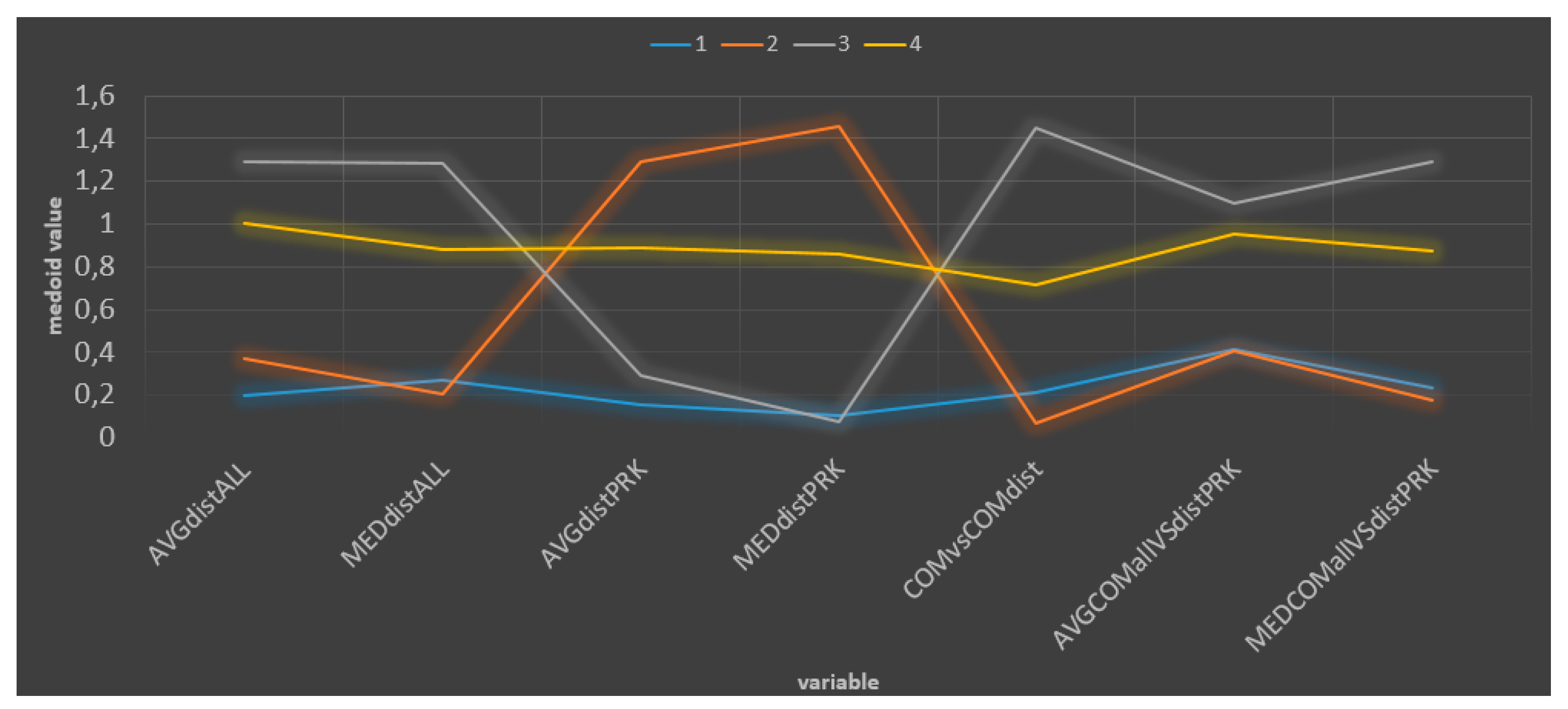
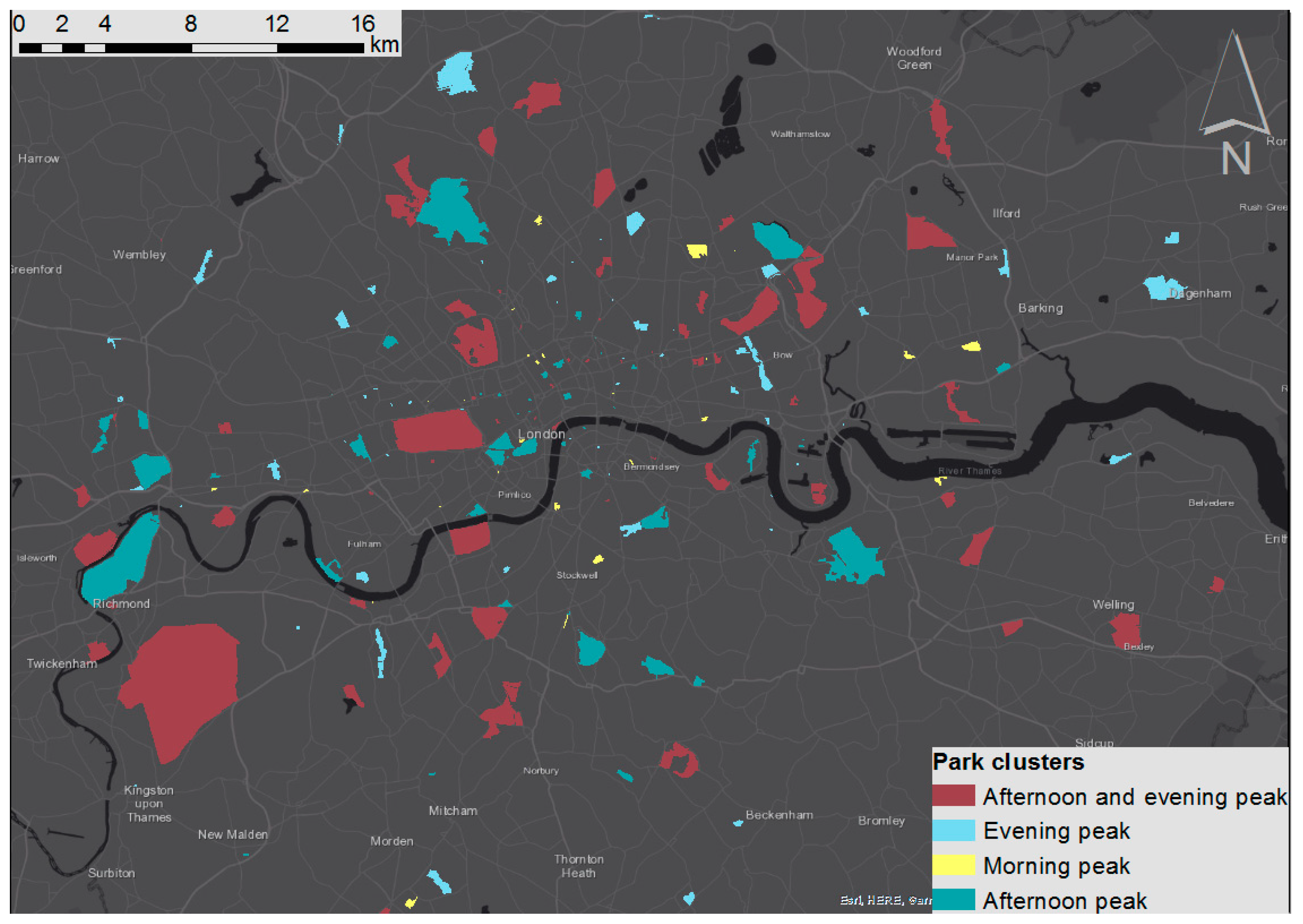
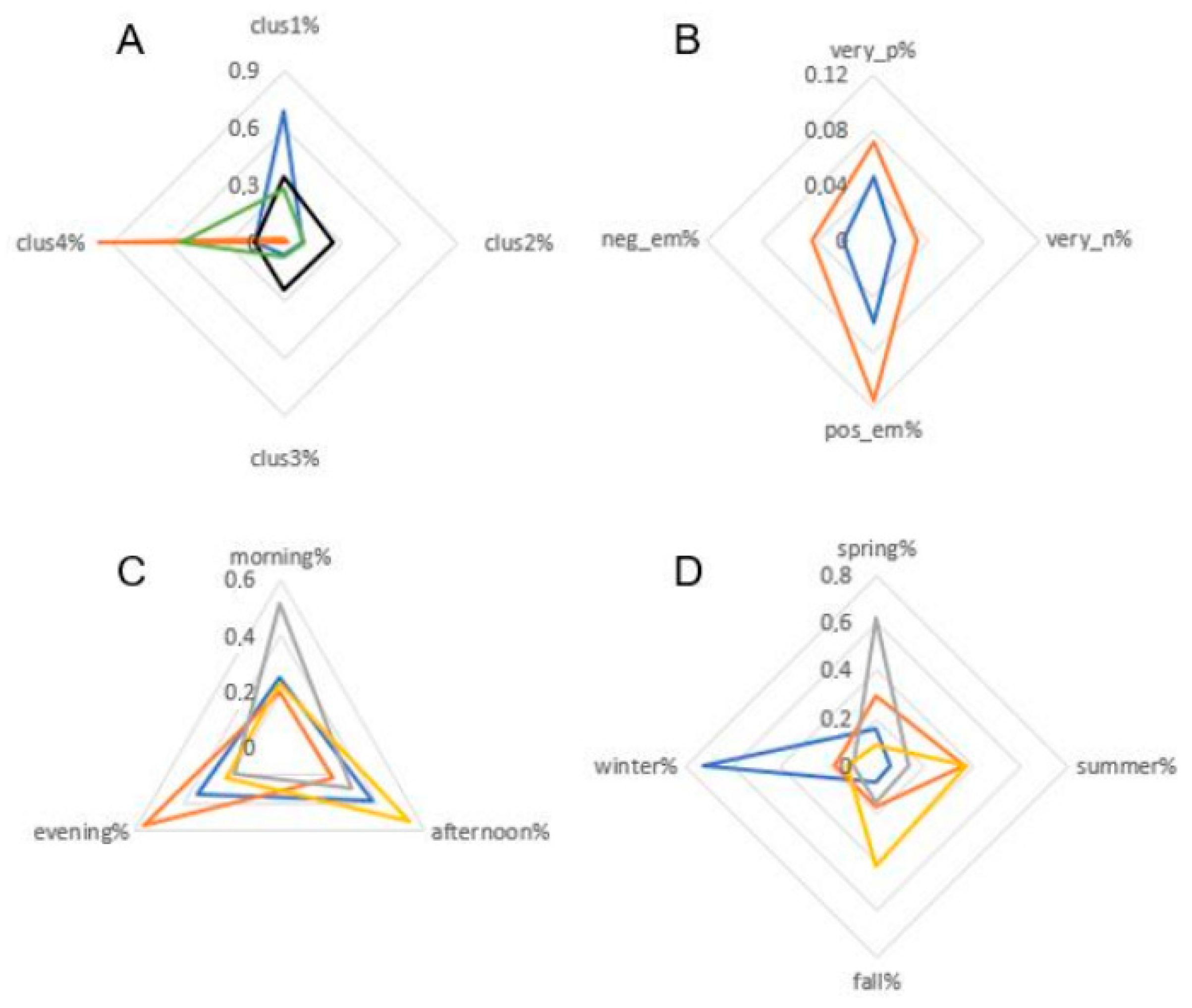
3.5. Profiles
4. Results
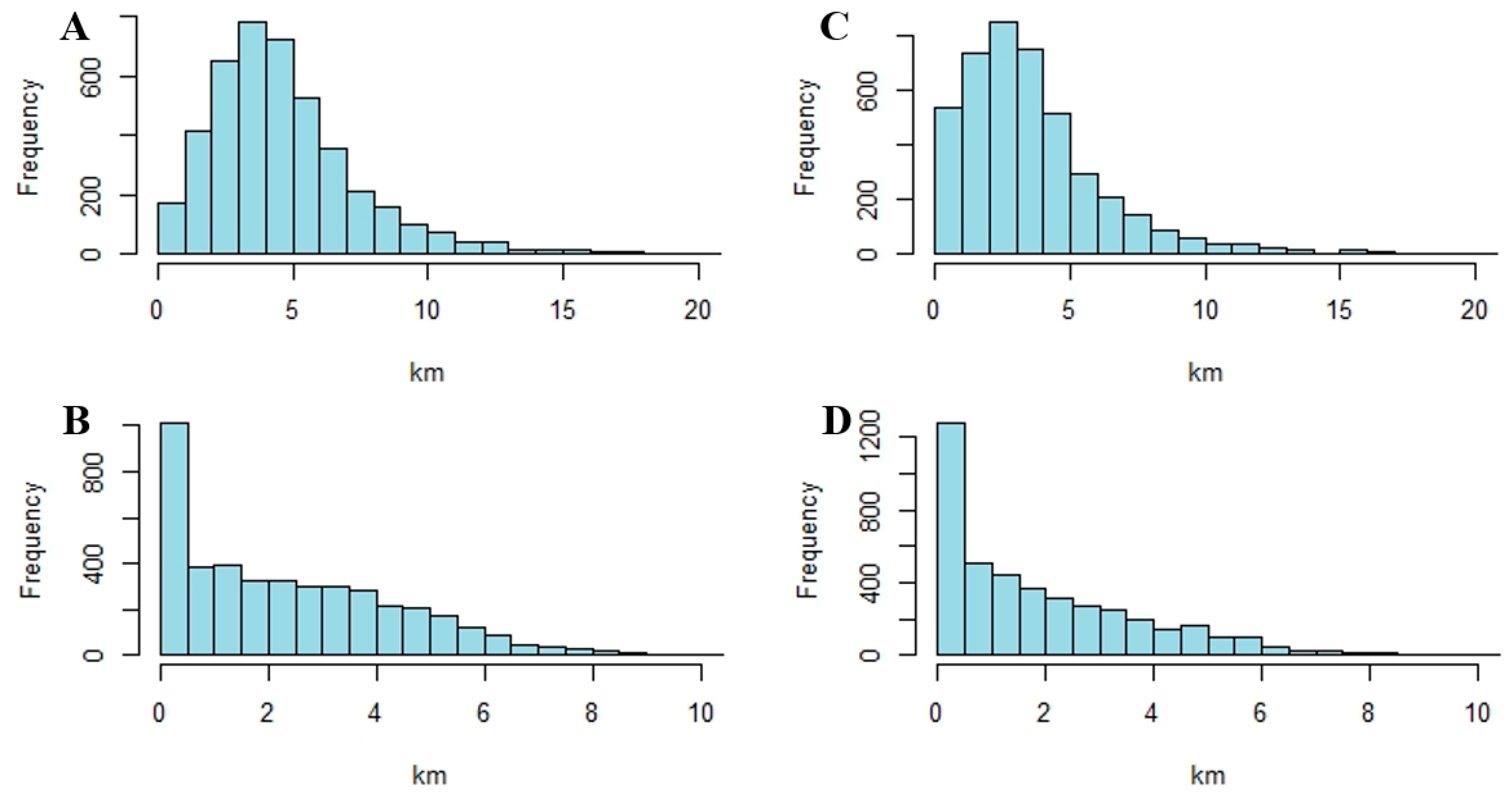
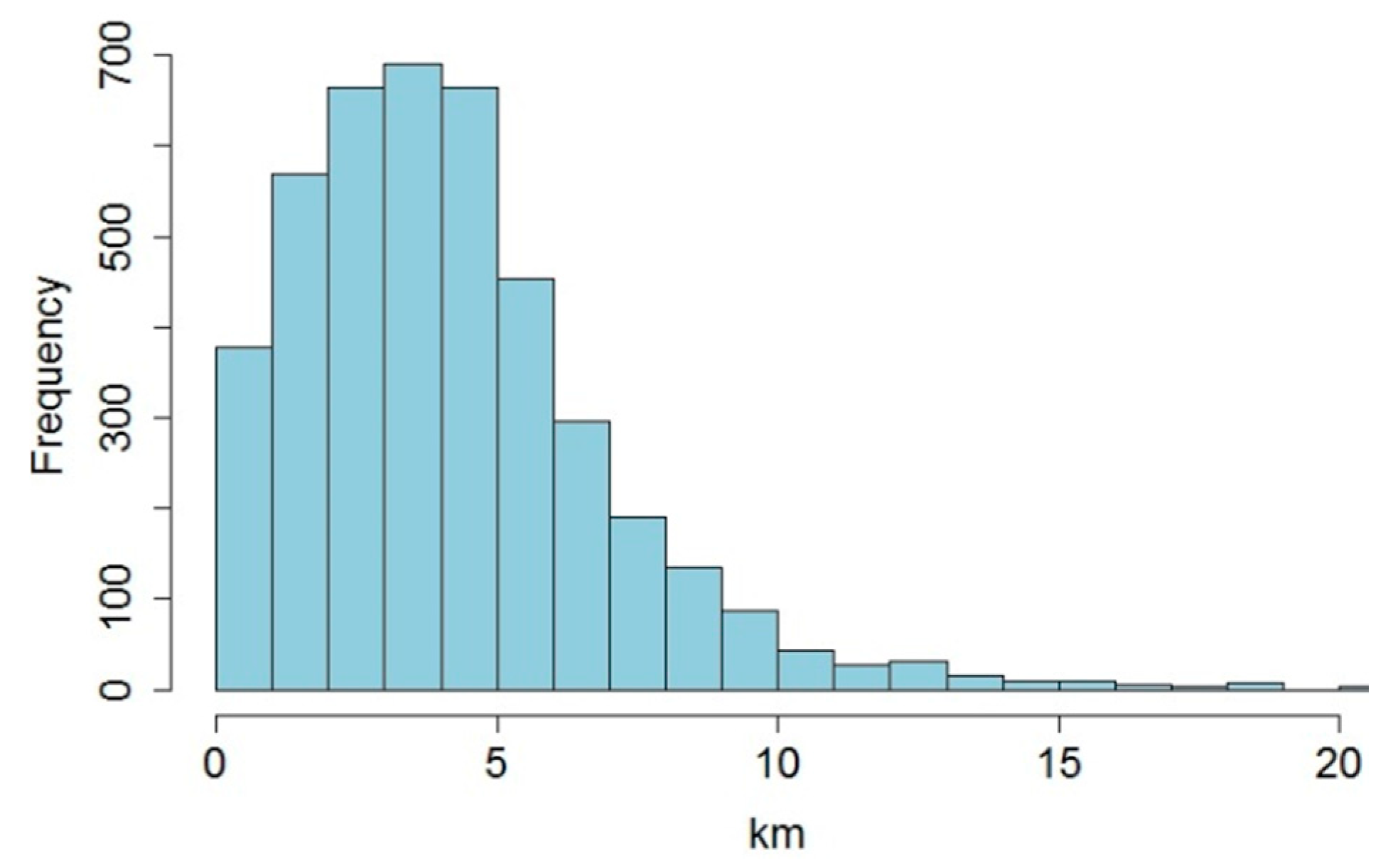
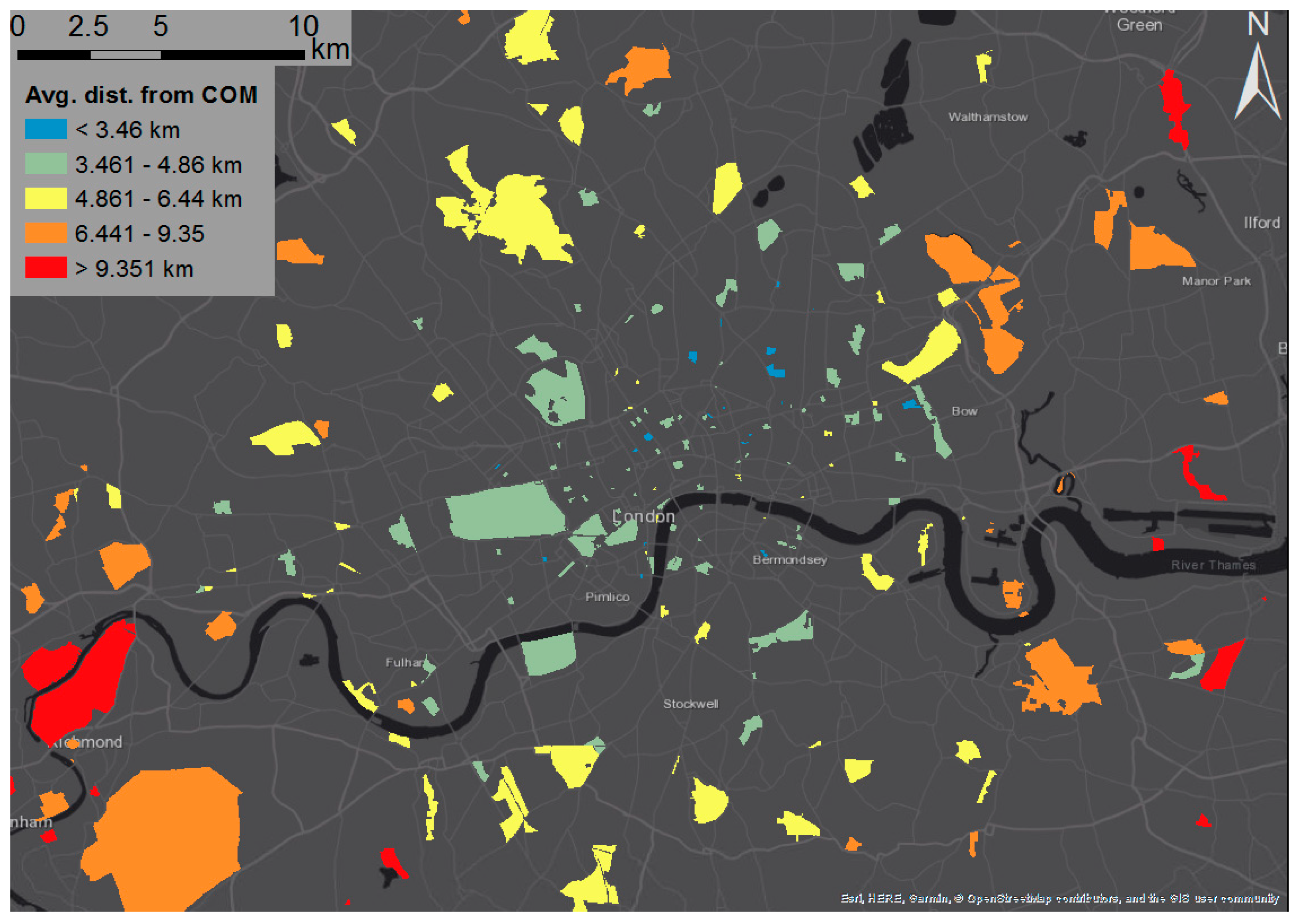
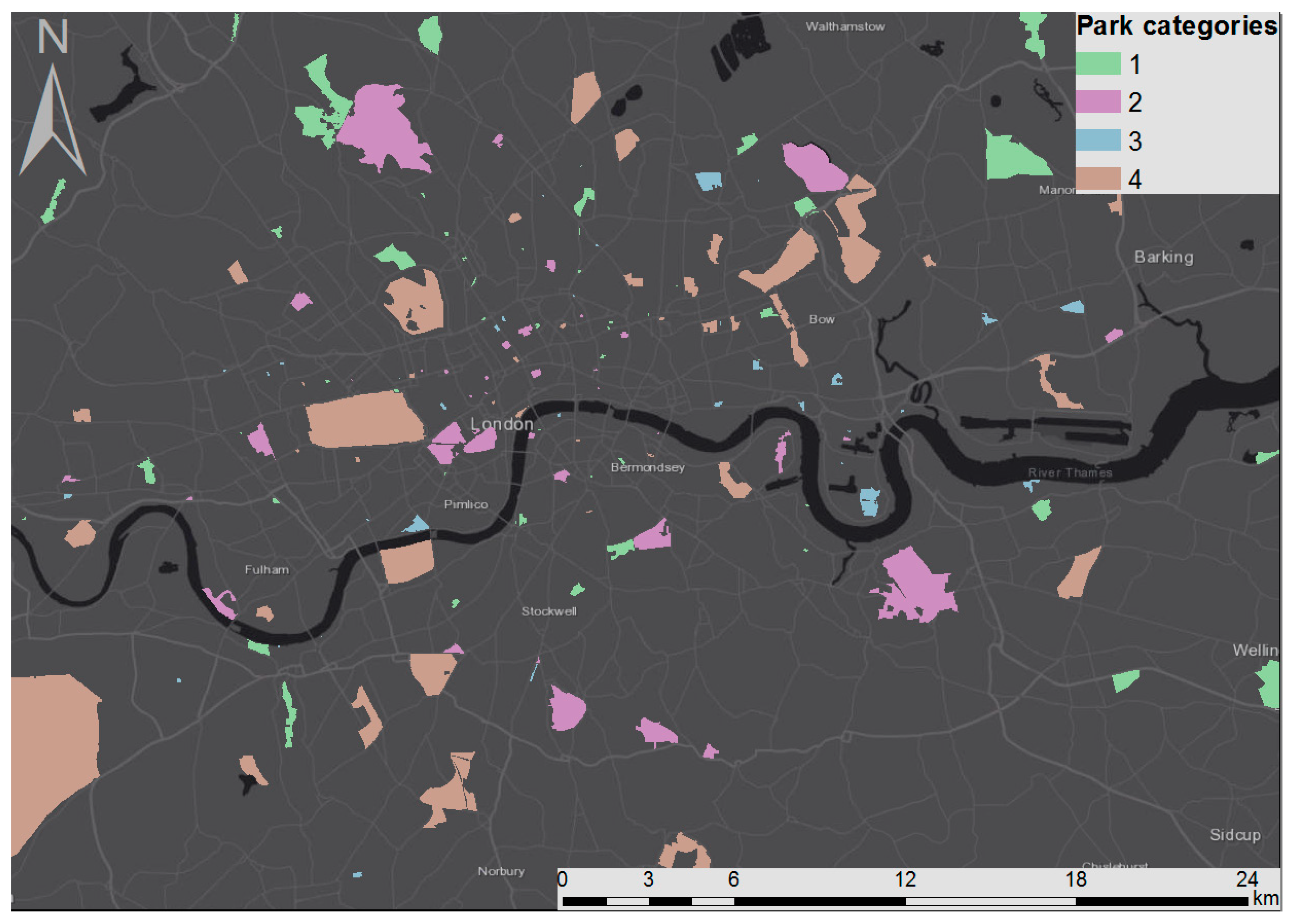
4.1. Spatial Profiles
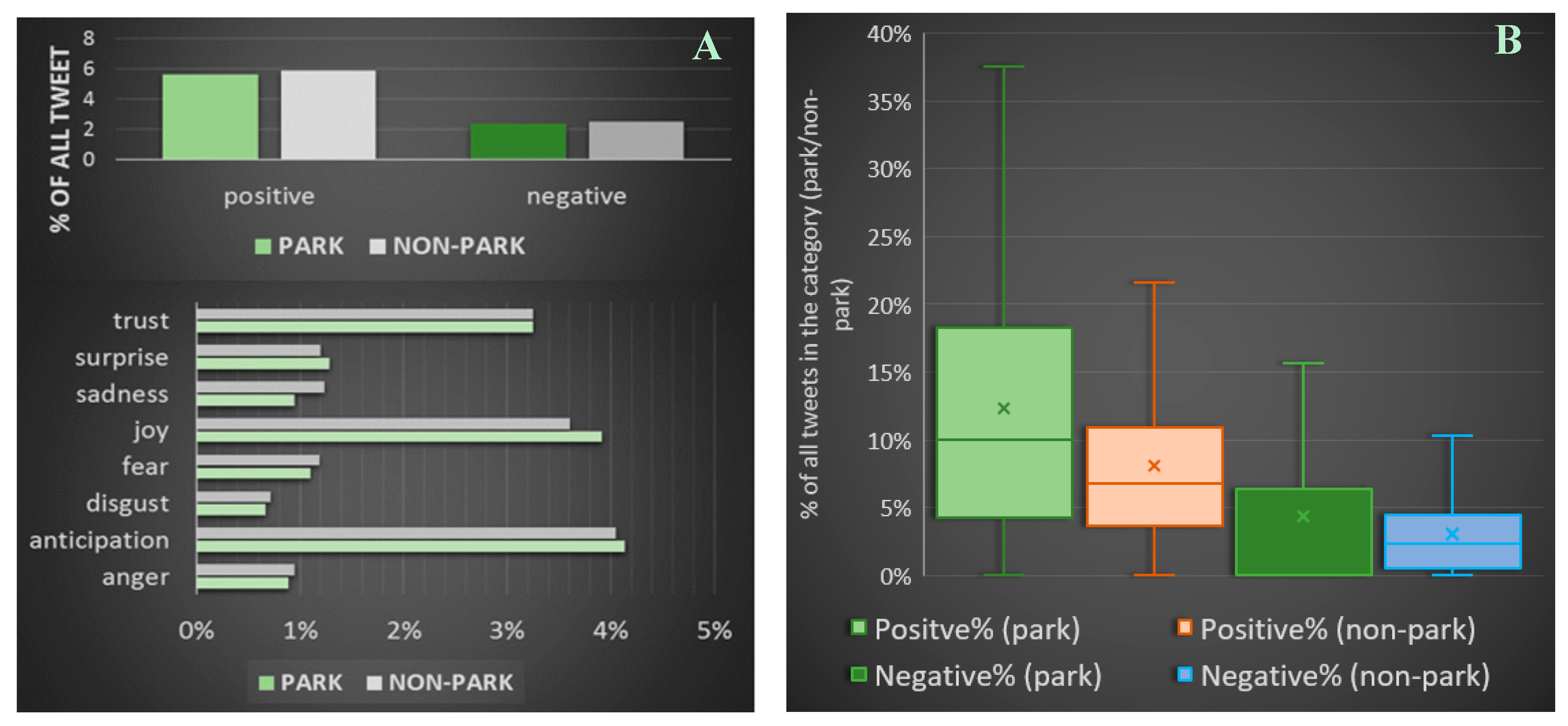
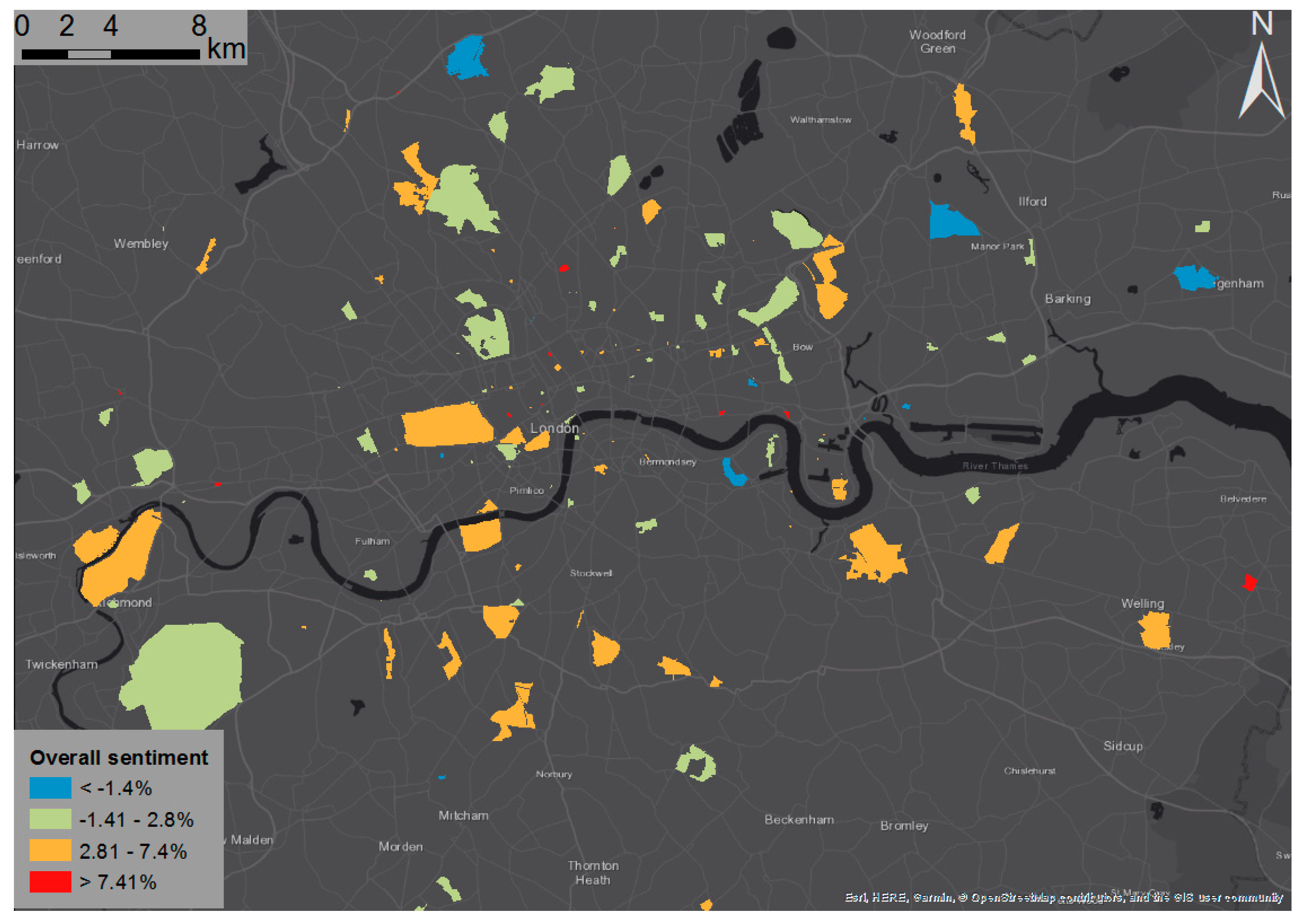
4.2. Sentiments and Emotions
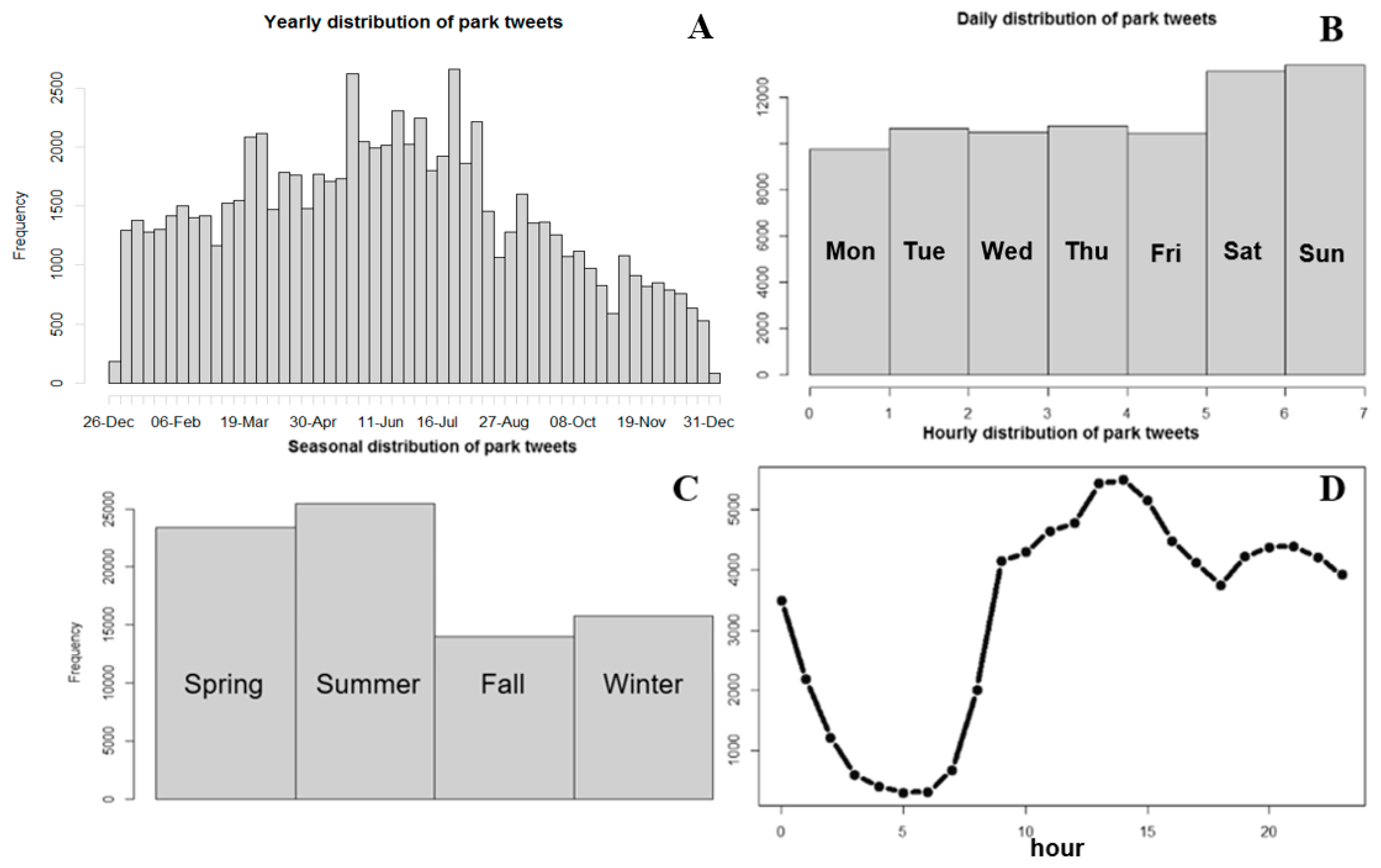
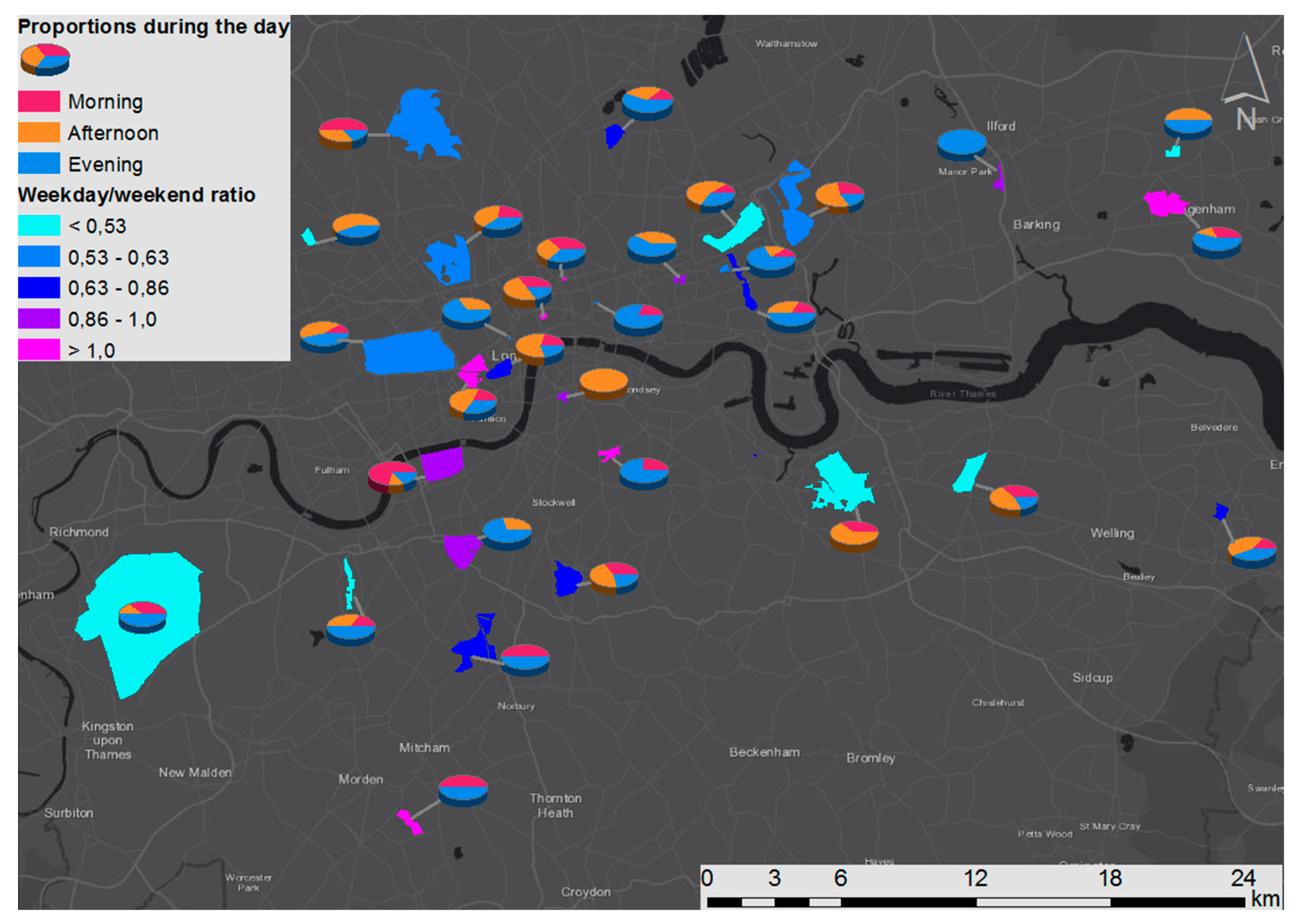
4.3. Temporal Variability of the Results
4.3.1. Number of Tweets
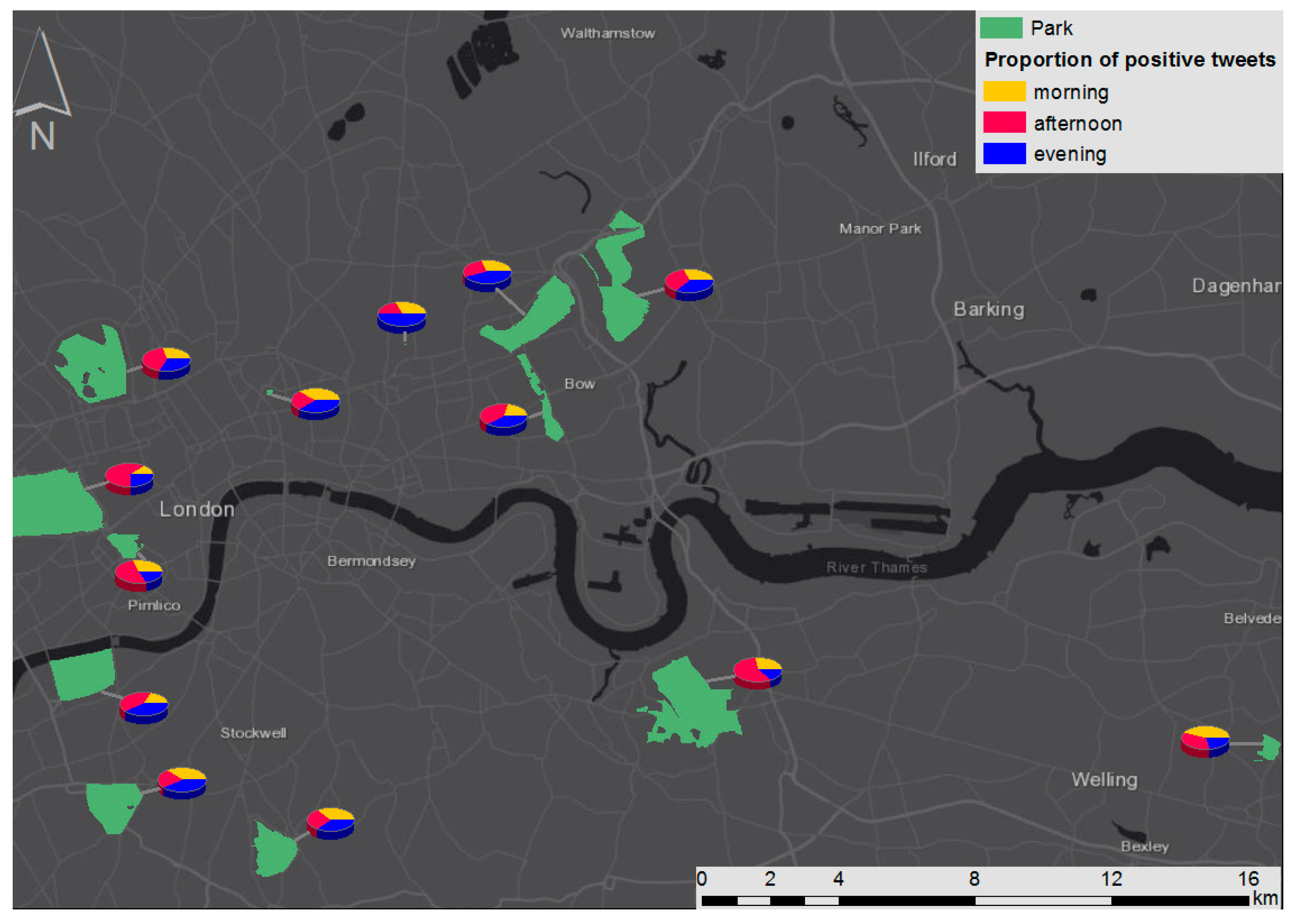
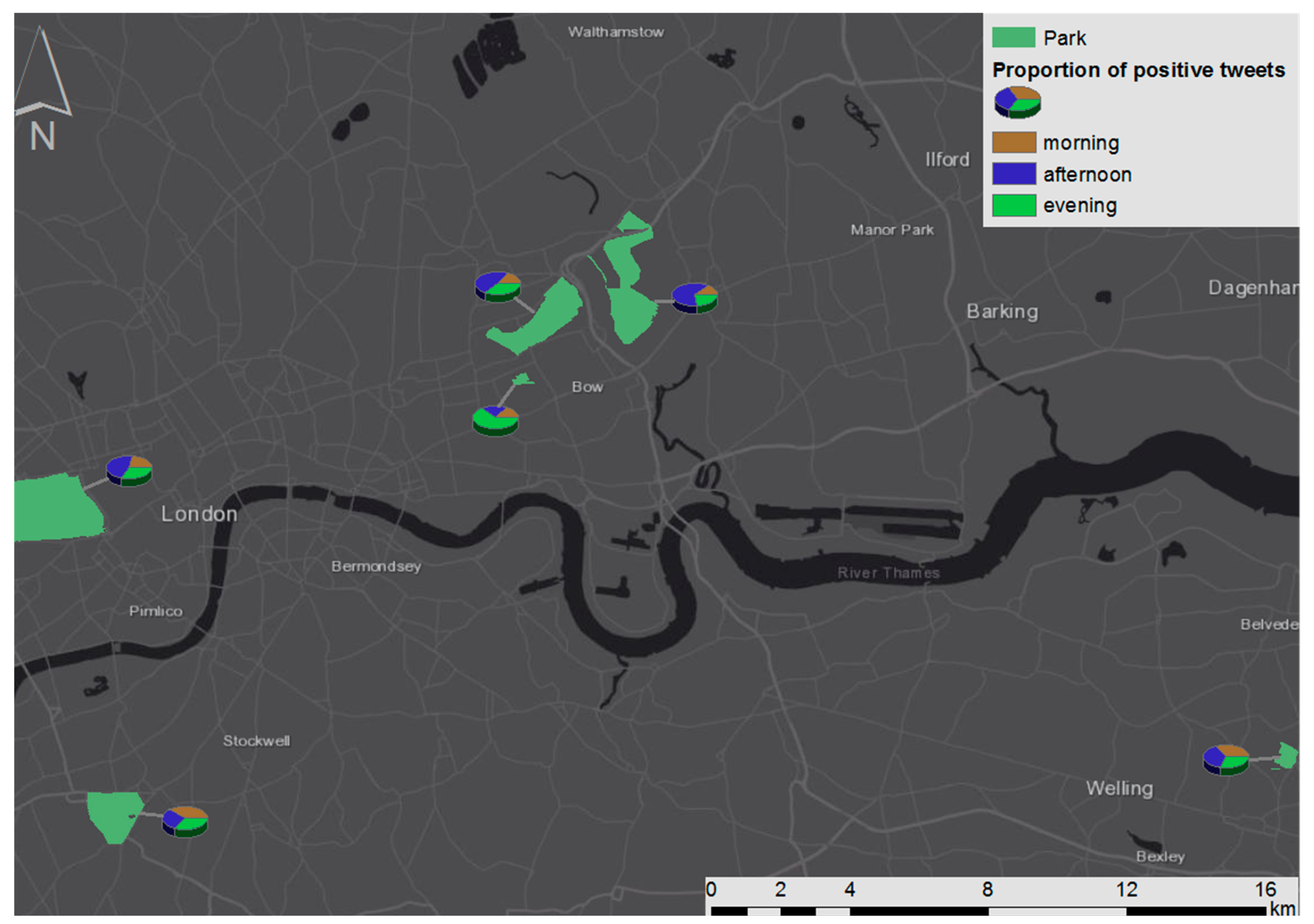
4.3.2. Temporal Patterns of Positive Tweets
4.3.3. Temporal Patterns of Emotions
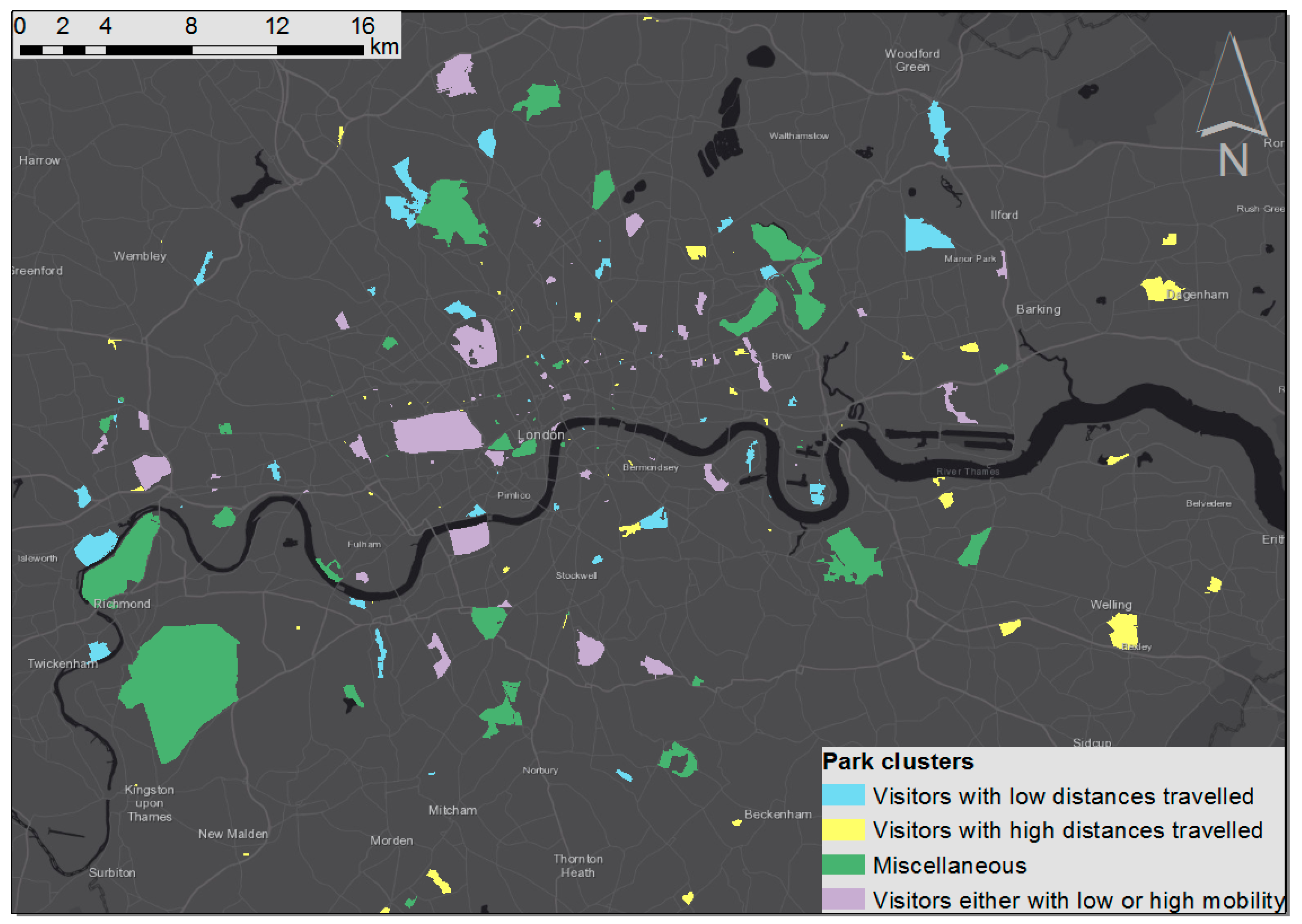
4.4. Comprehensive Park Profiles
5. Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Batty, M. The New Science of Cities; MIT Press: Cambridge, MA, USA, 2013; ISBN 9780262019521. [Google Scholar]
- Keniger, L.E.; Gaston, K.J.; Irvine, K.N.; Fuller, R.A. What are the benefits of interacting with nature? Int. J. Environ. Res. Public Health 2013, 10, 913–935. [Google Scholar] [CrossRef] [PubMed]
- Costanza, R.; D’Arge, R.; De Groot, R.; Farber, S.; Grasso, M.; Hannon, B.; Limburg, K.; Naeem, S.; O’Neill, R.V.; Paruelo, J.; et al. The value of the world’s ecosystem services and natural capital. Nature 1997, 387, 253–260. [Google Scholar] [CrossRef]
- Sturm, R.; Cohen, D. Proximity to urban parks and mental health. J. Ment. Health Policy Econ. 2014, 17, 19–24. [Google Scholar] [PubMed]
- Van den Berg, M.; Wendel-Vos, W.; van Poppel, M.; Kemper, H.; van Mechelen, W.; Maas, J. Health benefits of green spaces in the living environment: A systematic review of epidemiological studies. Urban For. Urban Green. 2015, 14, 806–816. [Google Scholar] [CrossRef]
- Wolch, J.R.; Byrne, J.; Newell, J.P. Urban green space, public health, and environmental justice: The challenge of making cities “just green enough”. Landsc. Urban Plan. 2014, 125, 234–244. [Google Scholar] [CrossRef]
- Chiesura, A. The role of urban parks for the sustainable city. Landsc. Urban Plan. 2004, 68, 129–138. [Google Scholar] [CrossRef]
- Roe, J.J.; Ward Thompson, C.; Aspinall, P.A.; Brewer, M.J.; Duff, E.I.; Miller, D.; Mitchell, R.; Clow, A. Green space and stress: Evidence from cortisol measures in deprived urban communities. Int. J. Environ. Res. Public Health 2013, 10, 4086–4103. [Google Scholar] [CrossRef] [PubMed]
- Akpinar, A.; Barbosa-Leiker, C.; Brooks, K.R. Does green space matter? Exploring relationships between green space type and health indicators. Urban For. Urban Green. 2016, 20, 407–418. [Google Scholar] [CrossRef]
- Lee, A.C.K.; Maheswaran, R. The health benefits of urban green spaces: A review of the evidence. J. Public Health 2011, 33, 212–222. [Google Scholar] [CrossRef] [PubMed]
- Takano, T.; Nakamura, K.; Watanabe, M. Urban residential environments and senior citizens’ longevity in megacity areas: The importance of walkable green spaces. J. Epidemiol. Community Health 2002, 56, 913–918. [Google Scholar] [CrossRef] [PubMed]
- Hartig, T.; Mitchell, R.; de Vries, S.; Frumkin, H. Nature and Health. Annu. Rev. Public Health 2014, 35, 207–228. [Google Scholar] [CrossRef] [PubMed]
- Liu, H.L.; Shen, Y.S. The impact of green space changes on air pollution and microclimates: A case study of the taipei metropolitan area. Sustainability 2014, 6, 8827–8855. [Google Scholar] [CrossRef]
- Maimaitiyiming, M.; Ghulam, A.; Tiyip, T.; Pla, F.; Latorre-Carmona, P.; Halik, Ü.; Sawut, M.; Caetano, M. Effects of green space spatial pattern on land surface temperature: Implications for sustainable urban planning and climate change adaptation. ISPRS J. Photogramm. Remote Sens. 2014, 89, 59–66. [Google Scholar] [CrossRef]
- Budruk, M.; Thomas, H.; Tyrrell, T. Urban green spaces: A study of place attachment and environmental attitudes in India. Soc. Nat. Resour. 2009, 22, 824–839. [Google Scholar] [CrossRef]
- Kim, J.; Kaplan, R. Physical and psychological factors in sense of community: New urbanist Kentlands and nearby orchard village. Environ. Behav. 2004, 36, 313–340. [Google Scholar] [CrossRef]
- Tyrväinen, L.; Ojala, A.; Korpela, K.; Lanki, T.; Tsunetsugu, Y.; Kagawa, T. The influence of urban green environments on stress relief measures: A field experiment. J. Environ. Psychol. 2014, 38, 1–9. [Google Scholar] [CrossRef]
- Anguluri, R.; Narayanan, P. Role of green space in urban planning: Outlook towards smart cities. Urban For. Urban Green. 2017, 25, 58–65. [Google Scholar] [CrossRef]
- Hartig, T.; Kahn, P.H. Living in cities, naturally. Science 2016, 352, 938–940. [Google Scholar] [CrossRef] [PubMed]
- Schetke, S.; Qureshi, S.; Lautenbach, S.; Kabisch, N. What determines the use of urban green spaces in highly urbanized areas?—Examples from two fast growing Asian cities. Urban For. Urban Green. 2016, 16, 150–159. [Google Scholar] [CrossRef]
- Lindberg, M.; Schipperijn, J. Active use of urban park facilities–Expectations versus reality. Urban For. Urban Green. 2015, 14, 909–918. [Google Scholar] [CrossRef]
- Goličnik, B.; Ward Thompson, C. Emerging relationships between design and use of urban park spaces. Landsc. Urban Plan. 2010, 94, 38–53. [Google Scholar] [CrossRef]
- Ives, C.D.; Oke, C.; Hehir, A.; Gordon, A.; Wang, Y.; Bekessy, S.A. Capturing residents’ values for urban green space: Mapping, analysis and guidance for practice. Landsc. Urban Plan. 2017, 161, 32–43. [Google Scholar] [CrossRef]
- Bedimo-Rung, A.L. The Significance of Parks to Physical Activity and Public Health: A Conceptual Model. Am. J. Prev. Med. 2005, 28 (Suppl. S2), 159–168. [Google Scholar] [CrossRef]
- Kothencz, G.; Blaschke, T. Urban parks: Visitors’ perceptions versus spatial indicators. Land Use Policy 2017, 64, 233–244. [Google Scholar] [CrossRef]
- Ode Sang, Å.; Knez, I.; Gunnarsson, B.; Hedblom, M. The effects of naturalness, gender, and age on how urban green space is perceived and used. Urban For. Urban Green. 2016, 18, 268–276. [Google Scholar] [CrossRef]
- United Nations General Assembly Transforming Our World: The 2030 Agenda for Sustainable Development. 2015. Available online: https://sustainabledevelopment.un.org/content/documents/7891Transforming%20Our%20World.pdf (accessed on 26 June 2018).
- Roberts, H.; Sadler, J.; Chapman, L. Using Twitter to investigate seasonal variation in physical activity in urban green space. Geo Geogr. Environ. 2017, 4, e00041. [Google Scholar] [CrossRef]
- Roberts, H.V. Using Twitter data in urban green space research: A case study and critical evaluation. Appl. Geogr. 2017, 81, 13–20. [Google Scholar] [CrossRef]
- Roberts, H.; Sadler, J.; Chapman, L. The value of Twitter data for determining the emotional responses of people to urban green spaces: A case study and critical evaluation. Urban Stud. 2018. [Google Scholar] [CrossRef]
- Lee, G.; Hong, I. Measuring spatial accessibility in the context of spatial disparity between demand and supply of urban park service. Landsc. Urban Plan. 2013, 119, 85–90. [Google Scholar] [CrossRef]
- La Rosa, D. Accessibility to greenspaces: GIS based indicators for sustainable planning in a dense urban context. Ecol. Indic. 2014, 42, 122–134. [Google Scholar] [CrossRef]
- Kolcsár, R.A.; Szilassi, P. Assessing accessibility of urban green spaces based on isochrone maps and street resolution population data through the example of Zalaegerszeg, Hungary. Carpath. J. Earth Environ. Sci. 2018, 13, 31–36. [Google Scholar] [CrossRef]
- Cohen, D.A.; McKenzie, T.L.; Sehgal, A.; Williamson, S.; Golinelli, D.; Lurie, N. Contribution of public parks to physical activity. Am. J. Public Health 2007, 97, 509–514. [Google Scholar] [CrossRef] [PubMed]
- Maas, J.; Verheij, R.A.; De Vries, S.; Spreeuwenberg, P.; Schellevis, F.G.; Groenewegen, P.P. Morbidity is related to a green living environment. J. Epidemiol. Community Health 2009, 63, 967–973. [Google Scholar] [CrossRef] [PubMed]
- Scott, M.M.; Evenson, K.R.; Cohen, D.A.; Cox, C.E. Comparing perceived and objectively measured access to recreational facilities as predictors of physical activity in adolescent girls. J. Urban Heal. 2007, 84, 346–359. [Google Scholar] [CrossRef] [PubMed]
- Wang, D.; Brown, G.; Liu, Y. The physical and non-physical factors that influence perceived access to urban parks. Landsc. Urban Plan. 2015, 133, 53–66. [Google Scholar] [CrossRef]
- Kaczynski, A.T.; Potwarka, L.R.; Saelens, B.E. Association of park size, distance, and features with physical activity in neighborhood parks. Am. J. Public Health 2008, 98, 1451–1456. [Google Scholar] [CrossRef] [PubMed]
- Dony, C.C.; Delmelle, E.M.; Delmelle, E.C. Re-conceptualizing accessibility to parks in multi-modal cities: A Variable-width Floating Catchment Area (VFCA) method. Landsc. Urban Plan. 2015, 143, 90–99. [Google Scholar] [CrossRef]
- Gupta, K.; Roy, A.; Luthra, K.; Maithani, S. Mahavir GIS based analysis for assessing the accessibility at hierarchical levels of urban green spaces. Urban For. Urban Green. 2016, 18, 198–211. [Google Scholar] [CrossRef]
- Ekkel, E.D.; de Vries, S. Nearby green space and human health: Evaluating accessibility metrics. Landsc. Urban Plan. 2017, 157, 214–220. [Google Scholar] [CrossRef]
- Bauman, A.E.; Bull, F.C. Environmental Correlates of Physical Activity and Walking in Adults and Children: A Review of Reviews; National Institute of Health and Clinical Excellence: Loughborough, UK, 2007. [Google Scholar]
- Kashef, M. Urban livability across disciplinary and professional boundaries. Front. Archit. Res. 2016, 5, 239–253. [Google Scholar] [CrossRef]
- IMCL. The Value of Rankings and the Meaning of Livablity. Available online: http://www.livablecities.org/blog/value-rankings-and-meaning-livability (accessed on 19 April 2017).
- Salzano, E. Seven Aims for the Livable City. In Making Cities Livable—Wege zur Menschlichen Stadt; Lennard, S.H.C., von Ungern-Sternberg, S., Lennard, H.L., Eds.; Gondolier Press: Carmel, CA, USA, 1997; pp. 18–20. ISBN 0-937824-08-1. [Google Scholar]
- Veenhoven, R. The Four Qualities of Life. J. Happiness Stud. 2000, 1, 1–39. [Google Scholar] [CrossRef]
- Lim, K.H.; Lee, K.E.; Kendal, D.; Rashidi, L.; Naghizade, E.; Winter, S.; Vasardani, M. The grass is greener on the other side: Understanding the effects of green spaces on Twitter user sentiments. In Proceedings of the WWW ’18 Companion, The Web Conference 2018, Lyon, France, 23–27 April 2018; pp. 275–282. [Google Scholar] [CrossRef]
- Martí, P.; Serrano-Estrada, L.; Nolasco-Cirugeda, A. Using locative social media and urban cartographies to identify and locate successful urban plazas. Cities 2017, 64, 66–78. [Google Scholar] [CrossRef]
- Crooks, A.; Pfoser, D.; Jenkins, A.; Croitoru, A.; Stefanidis, A.; Smith, D.; Karagiorgou, S.; Efentakis, A.; Lamprianidis, G. Crowdsourcing urban form and function. Int. J. Geogr. Inf. Sci. 2015, 29, 720–741. [Google Scholar] [CrossRef]
- Hasan, S.; Ukkusuri, S.V. Urban activity pattern classification using topic models from online geo-location data. Transp. Res. Part C Emerg. Technol. 2014, 44, 363–381. [Google Scholar] [CrossRef]
- Ciuccarelli, P.; Lupi, G.; Simeone, L. Visualizing the Data City–Social Media as a Source of Knowledge for Urban Planning and Management, 1st ed.; Springer International Publishing: Berlin, Germany, 2014; ISBN 978-3-319-02194-2. [Google Scholar]
- Wu, L.; Zhi, Y.; Sui, Z.; Liu, Y. Intra-urban human mobility and activity transition: Evidence from social media check-in data. PLoS ONE 2014, 9, e97010. [Google Scholar] [CrossRef] [PubMed]
- Aubrecht, C.; Ungar, J.; Freire, S. Exploring the potential of volunteered geographic information for modeling spatio-temporal characteristics of urban population: A case study for Lisbon Metro using foursquare check-in data. In Proceedings of the 7th International Conference Virtual Cities and Territories, Lisbon, Portugal, 11–13 October 2011. [Google Scholar]
- Fujisaka, T.; Lee, R.; Sumiya, K. Exploring urban characteristics using movement history of mass mobile microbloggers. In Proceedings of the Eleventh Workshop on Mobile Computing Systems & Applications—HotMobile ’10, Annapolis, MD, USA, 22–23 February 2010; pp. 13–18. [Google Scholar]
- Fujisaka, T.; Lee, R.; Sumiya, K. Discovery of user behavior patterns from geo-tagged micro-blogs. In Proceedings of the 4th International Conference on Ubiquitous Information Management and Communication—ICUIMC ’10, Suwon, Korea, 14–15 January 2010; p. 36. [Google Scholar]
- Hawelka, B.; Sitko, I.; Beinat, E.; Sobolevsky, S.; Kazakopoulos, P.; Ratti, C. Geo-located Twitter as proxy for global mobility patterns. Cartogr. Geogr. Inf. Sci. 2014, 41, 260–271. [Google Scholar] [CrossRef] [PubMed]
- Blanford, J.I.; Huang, Z.; Savelyev, A.; MacEachren, A.M. Geo-located tweets. Enhancing mobility maps and capturing cross-border movement. PLoS ONE 2015, 10, e0129202. [Google Scholar] [CrossRef] [PubMed]
- Cranshaw, J.; Hong, J.I.; Sadeh, N. The Livehoods Project: Utilizing Social Media to Understand the Dynamics of a City. In Proceedings of the Sixth International AAAI Conference on Weblogs and Social Media, Dublin, Ireland, 4–8 June 2012. [Google Scholar]
- Longley, P.A.; Adnan, M. Geo-temporal Twitter demographics. Int. J. Geogr. Inf. Sci. 2016, 30, 369–389. [Google Scholar] [CrossRef]
- Shelton, T.; Poorthuis, A.; Zook, M. Social media and the city: Rethinking urban socio-spatial inequality using user-generated geographic information. Landsc. Urban Plan. 2015, 142, 198–211. [Google Scholar] [CrossRef]
- Cheng, Z.; Caverlee, J.; Lee, K. You Are Where You Tweet: A Content-Based Approach to Geo-locating Twitter Users. In Proceedings of the 19th ACM International Conference on Information and Knowledge Management, Toronto, ON, Canada, 26–30 October 2010; pp. 759–768. [Google Scholar] [CrossRef]
- Kinsella, S.; Murdock, V.; Hare, N.O. “I’ m Eating a Sandwich in Glasgow”: Modeling Locations with Tweets. In Proceedings of the 3rd International Workshop on Search and Mining User-Generated Contents, Glasgow, UK, 28 October 2011; pp. 61–68. [Google Scholar]
- Birkin, M.; Harland, K.; Malleson, N. The classification of space-time behaviour patterns in a British city from crowd-sourced data. In Computational Science and Its Applications—ICCSA 2013; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2013; pp. 179–192. [Google Scholar]
- Frank, M.R.; Mitchell, L.; Dodds, P.S.; Danforth, C.M. Happiness and the Patterns of Life: A Study of Geolocated Tweets. Sci. Rep. 2013, 3, 2625. [Google Scholar] [CrossRef] [PubMed]
- Mitchell, L.; Frank, M.R.; Harris, K.D.; Dodds, P.S.; Danforth, C.M. The Geography of Happiness: Connecting Twitter Sentiment and Expression, Demographics, and Objective Characteristics of Place. PLoS ONE 2013, 8, e64417. [Google Scholar] [CrossRef] [PubMed]
- Quercia, D.; Seaghdha, D.O.; Crowcroft, J. Talk of the City: Our Tweets, Our Community Happiness. In Proceedings of the Sixth International AAAI Conference on Weblogs and Social Media, Dublin, Ireland, 4–8 June 2012; pp. 555–558. [Google Scholar]
- Quercia, D.; Ellis, J.; Capra, L.; Crowcroft, J. Tracking “gross community happiness” from tweets. In Proceedings of the ACM 2012 Conference on Computer Supported Cooperative Work—CSCW ’12, Seattle, WA, USA, 11–15 February 2012; p. 965. [Google Scholar]
- Resch, B.; Summa, A.; Zeile, P.; Strube, M. Citizen-Centric Urban Planning through Extracting Emotion Information from Twitter in an Interdisciplinary Space-Time-Linguistics Algorithm. Urban Plan. 2016, 1, 114–127. [Google Scholar] [CrossRef]
- Nguyen, Q.C.; Kath, S.; Meng, H.W.; Li, D.; Smith, K.R.; VanDerslice, J.A.; Wen, M.; Li, F. Leveraging geotagged Twitter data to examine neighborhood happiness, diet, and physical activity. Appl. Geogr. 2016, 73, 77–88. [Google Scholar] [CrossRef] [PubMed]
- Campagna, M. The Geographic Turn in Social Media: Opportunities for Spatial Planning and Geodesign. In Computational Science and Its Applications—ICCSA 2014; Murgante, B., Misra, S., Rocha, A.M.A.C., Torre, C., Rocha, J.G., Falcão, M.I., Taniar, D., Apduhan, B.O., Gervasi, O., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 598–610. [Google Scholar]
- Sagl, G.; Resch, B.; Hawelka, B.; Beinat, E. From Social Sensor Data to Collective Human Behaviour Patterns—Analysing and Visualising Spatio-Temporal Dynamics in Urban Environments. In GI-Forum 2012: Geovisualization, Society and Learning; Jekel, T., Car, A., Strobl, J., Griesebner, G., Eds.; Wichmann Verlag: Salzburg, Austria, 2012; pp. 54–63. ISBN 978-3-87907-521-8. [Google Scholar]
- Lee, R.; Sumiya, K. Measuring geographical regularities of crowd behaviors for Twitter-based geo-social event detection. In Proceedings of the 2nd ACM SIGSPATIAL International Workshop on Location Based Social Networks—LBSN ’10, San Jose, CA, USA, 2 November 2010. [Google Scholar]
- Gupta, A.; Kumaraguru, P. Credibility ranking of tweets during high impact events. In Proceedings of the 1st Workshop on Privacy and Security in Online Social Media—PSOSM ’12, Lyon, France, 17 April 2012. [Google Scholar]
- Zhang, Z.; Ni, M.; He, Q.; Gao, J. Mining Transportation Information from Social Media for Planned and Unplanned Events; University at Buffalo, SUNY: Buffalo, NY, USA, 2016. [Google Scholar]
- Li, R.; Lei, K.H.; Khadiwala, R.; Chang, K.C.C. TEDAS: A twitter-based event detection and analysis system. In Proceedings of the 2012 IEEE 28th International Conference on Data Engineering, Washington, DC, USA, 1–5 April 2012. [Google Scholar]
- Weng, J.; Yao, Y.; Leonardi, E.; Lee, F. Event Detection in Twitter. In Proceedings of the Fifth International AAAI Conference on Weblogs and Social Media, Barcelona, Spain, 17–21 July 2011. [Google Scholar]
- Panteras, G.; Wise, S.; Lu, X.; Croitoru, A.; Crooks, A.; Stefanidis, A. Triangulating Social Multimedia Content for Event Localization using Flickr and Twitter. Trans. GIS 2015, 19, 694–715. [Google Scholar] [CrossRef]
- Fraustino, J.D.; Liu, B.; Yan, J. Social Media Use during Disasters: A Review of the Knowledge Base and Gaps; National Consortium for the Study of Terrorism and Responses to Terrorism: College Park, MD, USA, 2012. [Google Scholar]
- Resch, B.; Usländer, F.; Havas, C. Combining machine-learning topic models and spatiotemporal analysis of social media data for disaster footprint and damage assessment. Cartogr. Geogr. Inf. Sci. 2017, 45, 362–376. [Google Scholar] [CrossRef]
- Kovács-Győri, A.; Ristea, A.; Havas, C.; Resch, B.; Cabrera-Barona, P. #London2012: Towards citizen-contributed urban planning through sentiment analysis of twitter data. Urban Plan. 2018, 3, 75–99. [Google Scholar] [CrossRef]
- Jankowski, P.; Czepkiewicz, M.; Młodkowski, M.; Zwoliński, Z. Geo-questionnaire: A Method and Tool for Public Preference Elicitation in Land Use Planning. Trans. GIS 2016, 20, 903–924. [Google Scholar] [CrossRef]
- Brown, G.; Raymond, C.M. Methods for identifying land use conflict potential using participatory mapping. Landsc. Urban Plan. 2014, 122, 196–208. [Google Scholar] [CrossRef]
- Innes, J.E.; Booher, D.E. Reframing public participation: Strategies for the 21st century. Plan. Theory Pract. 2004, 5, 419–436. [Google Scholar] [CrossRef]
- Pietrzyk-Kaszyńska, A.; Czepkiewicz, M.; Kronenberg, J. Eliciting non-monetary values of formal and informal urban green spaces using public participation GIS. Landsc. Urban Plan. 2017, 160, 85–95. [Google Scholar] [CrossRef]
- Bluemke, M.; Resch, B.; Lechner, C.; Westerholt, R.; Kolb, J.-P.; Kolb, J.-P. Integrating Geographic Information into Survey Research: Current Applications, Challenges and Future Avenues. Surv. Res. Methods 2017, 11, 307–327. [Google Scholar] [CrossRef]
- Twitter Developers. Available online: https://developer.twitter.com/ (accessed on 21 February 2017).
- Steiger, E.; Resch, B.; Zipf, A. Exploration of spatiotemporal and semantic clusters of Twitter data using unsupervised neural networks. Int. J. Geogr. Inf. Sci. 2016, 30, 1694–1716. [Google Scholar] [CrossRef]
- Hu, M.; Liu, B. Mining and summarizing customer reviews. In Proceedings of the 2004 ACM SIGKDD International Conference on Knowledge Discovery and Data Mining—KDD ’04, Seattle, WA, USA, 22–25 August 2004. [Google Scholar]
- Breen, J.O. Mining Twitter for Airline Consumer Sentiment. In Practical Text Mining and Statistical Analysis for Non-Structured Text Data Applications; Academic Press: Orlando, FL, USA, 2012; ISBN 9780123869791. pp. 133–149. [Google Scholar] [CrossRef]
- Mohammad, S.M.; Turney, P.D. Emotions evoked by common words and phrases: Using mechanical turk to create an emotion lexicon. In Proceedings of the CAAGET ’10 NAACL HLT 2010 Workshop on Computational Approaches to Analysis and Generation of Emotion in Text, Los Angeles, CA, USA, 5 June 2010. [Google Scholar]
- Mohammad, S.M.; Turney, P.D. Crowdsourcing a word-emotion association lexicon. Comput. Intell. 2013, 29, 436–465. [Google Scholar] [CrossRef]
- Jockers, M. Syuzhet: Extracts Sentiment and Sentiment-Derived Plot Arcs from Text (Version 1.0.1). Available online: https://github.com/mjockers/syuzhet (accessed on 14 July 2018).
- Van der Laan, M.J.; Pollard, K.S.; Bryan, J. A new partitioning around medoids algorithm. J. Stat. Comput. Simul. 2003, 73, 575–584. [Google Scholar] [CrossRef]
- Lin, J.; Cromley, R.G. Inferring the home locations of Twitter users based on the spatiotemporal clustering of Twitter data. Trans. GIS 2018, 22, 82–97. [Google Scholar] [CrossRef]
- Abbasi, A.; Rashidi, T.H.; Maghrebi, M.; Waller, S.T. Utilising Location Based Social Media in Travel Survey Methods: Bringing Twitter Data into the Play. In Proceedings of the 8th ACM SIGSPATIAL International Workshop on Location-Based Social Networks, Bellevue, WA, USA, 3–6 November 2015. [Google Scholar]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Value | |
|---|---|
| Bounding box (WGS84) | 51.225808, −0.560455; 51.734863, 0.319181 |
| Total tweets | 11,372,967 |
| Total unique users | 374,700 |
| Temporal extent | 1 January 2012–31 December 2012 |
| Option 1 | Option 2 | Option 3 | |
|---|---|---|---|
| Quarter 1 (January–March) | ✓ | ✓ | |
| Quarter 2 (April–June) | ✓ | ||
| Quarter 3 (July–September) | ✓ | ||
| Quarter 4 (October–December) | ✓ | ✓ |
| Variable | Description |
|---|---|
| COM_all | Center of the coordinates of all tweets (per user) |
| COM_park | Center of the coordinates of all park tweets (per user) |
| COM shift | Distance between the two different COMs |
| COM to all distance | Distance between COM and all the tweets (average and median) |
| COM to park distance | Distance between COM and park tweets (average and median) |
| Sentiment or Emotion | Significance (p) | Result | Difference (%) |
|---|---|---|---|
| Sentiment polarity | 0.482183466 | Not significant | |
| Anger | <0.001 | less anger in parks | 0.50% |
| Anticipation | 0.170095853 | Not significant | |
| Disgust | 0.001601268 | less disgust in parks | 0.34% |
| Fear | <0.001 | less fear in parks | 1.19% |
| Joy | <0.001 | more joy in parks | 0.71% |
| Sadness | <0.001 | less sadness in parks | 1.49% |
| Surprise | <0.001 | more surprise in parks | 0.50% |
| Trust | 0.875638565 | Not significant | |
| Positive sentiment * | 0.015684988 | less positive in parks | 0.22% |
| Negative sentiment * | 0.00279889 | less negative in parks | 0.18% |
| Positive emotions | <0.001 | less positive in parks | 1.07% |
| Negative emotions | <0.001 | less negative in parks | 1.14% |
| Category | User Types | Sentiment and Emotions | Daily Pattern | Seasonal Pattern |
|---|---|---|---|---|
| 1 | Park COM to park distance is larger (Cl. 2) | Higher | Evening peak | Spring and summer higher |
| 2 | Every distance value is high except park to park COM (Cl. 3) | Lower | Afternoon peak | Spring and summer higher |
| 3 | Park COM to park distance is larger (Cl. 2) | Higher | Morning peak | Spring and fall higher |
| 4 | Every distance value is in the mid-range (Cl. 4) | Lower | Afternoon and evening peak | Spring and summer higher |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kovacs-Györi, A.; Ristea, A.; Kolcsar, R.; Resch, B.; Crivellari, A.; Blaschke, T. Beyond Spatial Proximity—Classifying Parks and Their Visitors in London Based on Spatiotemporal and Sentiment Analysis of Twitter Data. ISPRS Int. J. Geo-Inf. 2018, 7, 378. https://doi.org/10.3390/ijgi7090378
Kovacs-Györi A, Ristea A, Kolcsar R, Resch B, Crivellari A, Blaschke T. Beyond Spatial Proximity—Classifying Parks and Their Visitors in London Based on Spatiotemporal and Sentiment Analysis of Twitter Data. ISPRS International Journal of Geo-Information. 2018; 7(9):378. https://doi.org/10.3390/ijgi7090378
Chicago/Turabian StyleKovacs-Györi, Anna, Alina Ristea, Ronald Kolcsar, Bernd Resch, Alessandro Crivellari, and Thomas Blaschke. 2018. "Beyond Spatial Proximity—Classifying Parks and Their Visitors in London Based on Spatiotemporal and Sentiment Analysis of Twitter Data" ISPRS International Journal of Geo-Information 7, no. 9: 378. https://doi.org/10.3390/ijgi7090378
APA StyleKovacs-Györi, A., Ristea, A., Kolcsar, R., Resch, B., Crivellari, A., & Blaschke, T. (2018). Beyond Spatial Proximity—Classifying Parks and Their Visitors in London Based on Spatiotemporal and Sentiment Analysis of Twitter Data. ISPRS International Journal of Geo-Information, 7(9), 378. https://doi.org/10.3390/ijgi7090378