
Recursive Feature Elimination with Cross-Validation with Decision Tree: Feature Selection Method for Machine Learning-Based Intrusion Detection Systems

Abstract
:1. Introduction
- An overview of the intrusion detection problem in the UNSW-NB15 dataset, highlighting the importance and challenges associated with this specific dataset.
- A detailed literature review of existing NIDSs and their limitations and shortcomings, focusing on those that adopted the recursive feature elimination (RFE) method and those that utilized UNSW-NB15.
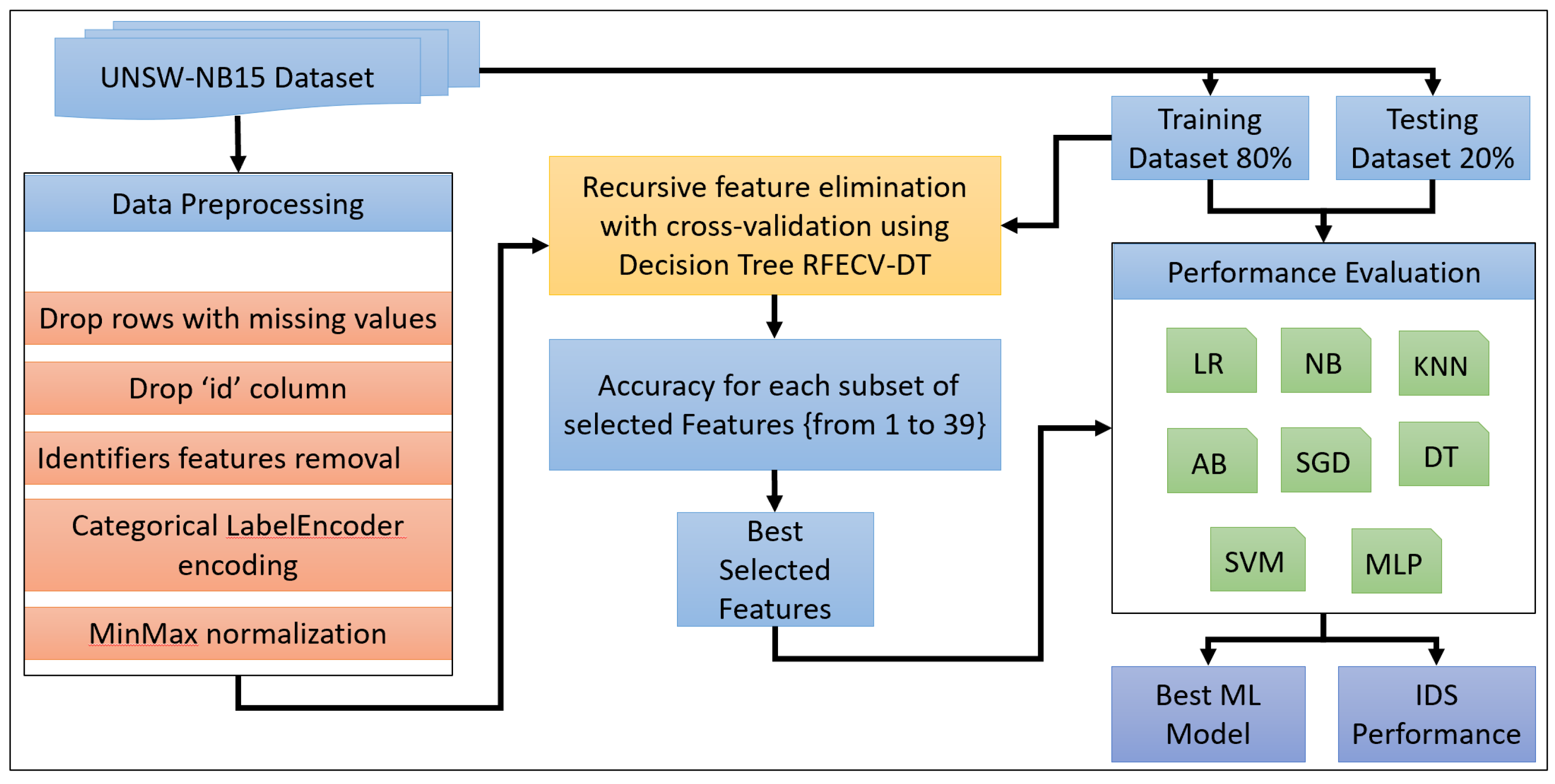
- Proposed a recursive feature elimination with cross-validation (RFECV) approach using binary decision tree classification for machine learning-based intrusion detection systems.
- Generated an optimal set of features selected from the UNSW-NB15 dataset using RFECV with a decision tree model as the estimator. Then, we evaluated their performance prediction capability via multiple well-known machine learning classifier models.
- Applied data preprocessing techniques on the UNSW-NB15 dataset to address overfitting and biasing issues. This included removing duplicate rows and eliminating identifier features such as IP and port-related features and TTL-based features that were deemed unrealistically correlated with the label features and could cause bias.
- Experimental findings using the UNSW-NB15 dataset demonstrated that the proposed model reduced the feature dimension from 42 to 15 while gaining a prediction accuracy of 95.30% compared to 95.56% with the original dataset and maintaining a similar F1-score (95.29% compared to 95.55%).
2. Related Work
3. Proposed Methodology
3.1. Data Preprocessing
3.1.1. Drop Rows with Missing Values
3.1.2. Drop id Column
3.1.3. Identifiers Features Removal
3.1.4. Categorical LabelEncoder Encoding
3.1.5. MinMax Normalization
3.2. RFECV Using DT for Features Selection
3.2.1. Decision Tree
3.2.2. Recursive Feature Elimination with Cross-Validation
| Algorithm 1 RFECV with DT |
| Require: Training set X Ensure: Ranked features
|
3.3. Classification Using Machine Learning Algorithms
3.3.1. Logistic Regression
3.3.2. Naive Bayes
3.3.3. Stochastic Gradient Descent
3.3.4. Random Forest
3.3.5. AdaBoost
3.3.6. Multi-Layer Perceptron
4. Experiments and Results
4.1. Hardware and Environment Setting
4.2. Unsw-Nb15 Dataset
4.3. Evaluation Metrics
- Begin a timer function before calling the fit() method of the classifier.
- Call the fit() method, passing in the training data.
- Stop the timer function after the fit() method completes.
- Calculate the duration of the fit() method by subtracting the start time from the stop time.
4.4. Experiments Results
4.5. Comparison with Others
5. Conclusions and Future Research Prospects
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- The Growth in Connected IoT Devices Is Expected to Generate 79.4 ZB of Data in 2025, According to a New IDC Forecast. 2019. Available online: https://www.businesswire.com/news/home/20190618005012/en/The-Growth-in-Connected-IoT-Devices-is-Expected-to-Generate-79.4ZB-of-Data-in-2025-According-to-a-New-IDC-Forecast (accessed on 20 May 2022).
- Rose, K.; Eldridge, S.; Chapin, L. The internet of things: An overview. Internet Soc. (ISOC) 2015, 80, 1–50. [Google Scholar]
- Radanliev, P.; De Roure, D.; Burnap, P.; Santos, O. Epistemological equation for analysing uncontrollable states in complex systems: Quantifying cyber risks from the internet of things. Rev. Socionetw. Strateg. 2021, 15, 381–411. [Google Scholar] [CrossRef] [PubMed]
- Al-Fawa’reh, M.; Al-Fayoumi, M.; Nashwan, S.; Fraihat, S. Cyber threat intelligence using PCA-DNN model to detect abnormal network behavior. Egypt. Inform. J. 2022, 23, 173–185. [Google Scholar] [CrossRef]
- Haq, N.F.; Onik, A.R.; Hridoy, M.A.K.; Rafni, M.; Shah, F.M.; Farid, D.M. Application of machine learning approaches in intrusion detection system: A survey. IJARAI-Int. J. Adv. Res. Artif. Intell. 2015, 4, 9–18. [Google Scholar]
- Moualla, S.; Khorzom, K.; Jafar, A. Improving the Performance of Machine Learning-Based Network Intrusion Detection Systems on the UNSW-NB15 Dataset. Comput. Intell. Neurosci. 2021, 2021, 5557577. [Google Scholar] [CrossRef] [PubMed]
- Divekar, A.; Parekh, M.; Savla, V.; Mishra, R.; Shirole, M. Benchmarking datasets for Anomaly-based Network Intrusion Detection: KDD CUP 99 alternatives. In Proceedings of the 2018 IEEE 3rd International Conference on Computing, Communication and Security (ICCCS), Kathmandu, Nepal, 25–27 October 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Kuhn, M.; Johnson, K. Applied Predictive Modeling; Springer: Berlin/Heidelberg, Germany, 2013; Volume 26. [Google Scholar]
- Itoo, F.; Meenakshi; Singh, S. Comparison and analysis of logistic regression, Naïve Bayes and KNN machine learning algorithms for credit card fraud detection. Int. J. Inf. Technol. 2021, 13, 1503–1511. [Google Scholar] [CrossRef]
- Berrar, D. Bayes’ theorem and naive Bayes classifier. Encycl. Bioinform. Comput. Biol. ABC Bioinform. 2018, 403, 412. [Google Scholar]
- Li, X.; Orabona, F. On the convergence of stochastic gradient descent with adaptive stepsizes. In Proceedings of the 22nd International Conference on Artificial Intelligence and Statistics PMLR, Naha, Japan, 16–18 April 2019; pp. 983–992. [Google Scholar]
- Speiser, J.L.; Miller, M.E.; Tooze, J.; Ip, E. A comparison of random forest variable selection methods for classification prediction modeling. Expert Syst. Appl. 2019, 134, 93–101. [Google Scholar] [CrossRef] [PubMed]
- Shahraki, A.; Abbasi, M.; Haugen, Ø. Boosting algorithms for network intrusion detection: A comparative evaluation of Real AdaBoost, Gentle AdaBoost and Modest AdaBoost. Eng. Appl. Artif. Intell. 2020, 94, 103770. [Google Scholar] [CrossRef]
- Taud, H.; Mas, J. Multilayer perceptron (MLP). In Geomatic Approaches for Modeling Land Change Scenarios; Springer: Berlin/Heidelberg, Germany, 2018; pp. 451–455. [Google Scholar]
- Al-Zewairi, M.; Almajali, S.; Awajan, A. Experimental evaluation of a multi-layer feed-forward artificial neural network classifier for network intrusion detection system. In Proceedings of the 2017 International Conference on New Trends in Computing Sciences (ICTCS), Amman, Jordan, 11–13 October 2017; IEEE: New York, NY, USA, 2017; pp. 167–172. [Google Scholar]
- Zhang, H.; Wu, C.Q.; Gao, S.; Wang, Z.; Xu, Y.; Liu, Y. An Effective Deep Learning Based Scheme for Network Intrusion Detection. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 682–687. [Google Scholar] [CrossRef]
- Gharaee, H.; Hosseinvand, H. A new feature selection IDS based on genetic algorithm and SVM. In Proceedings of the 2016 8th International Symposium on Telecommunications (IST), Tehran, Iran, 27–28 September 2016; IEEE: New York, NY, USA, 2016; pp. 139–144. [Google Scholar]
- Salman, T.; Bhamare, D.; Erbad, A.; Jain, R.; Samaka, M. Machine learning for anomaly detection and categorization in multi-cloud environments. In Proceedings of the 2017 IEEE 4th International Conference on Cyber Security and Cloud Computing (CSCloud), New York, NY, USA, 26–28 June 2017; IEEE: New York, NY, USA, 2017; pp. 97–103. [Google Scholar]
- Yin, Y.; Jang-Jaccard, J.; Xu, W.; Singh, A.; Zhu, J.; Sabrina, F.; Kwak, J. IGRF-RFE: A hybrid feature selection method for MLP-based network intrusion detection on UNSW-NB15 Dataset. J. Big Data 2023, 10, 1–26. [Google Scholar] [CrossRef]
- Alissa, K.; Alyas, T.; Zafar, K.; Abbas, Q.; Tabassum, N.; Sakib, S. Botnet Attack Detection in IoT Using Machine Learning. Comput. Intell. Neurosci. 2022, 2022, 4515642. [Google Scholar] [CrossRef] [PubMed]
- Mulyanto, M.; Faisal, M.; Prakosa, S.W.; Leu, J.S. Effectiveness of focal loss for minority classification in network intrusion detection systems. Symmetry 2020, 13, 4. [Google Scholar] [CrossRef]
- Tama, B.A.; Comuzzi, M.; Rhee, K.H. TSE-IDS: A two-stage classifier ensemble for intelligent anomaly-based intrusion detection system. IEEE Access 2019, 7, 94497–94507. [Google Scholar] [CrossRef]
- Nawir, M.; Amir, A.; Lynn, O.B.; Yaakob, N.; Badlishah Ahmad, R. Performances of machine learning algorithms for binary classification of network anomaly detection system. J. Physics Conf. Ser. 2018, 1018, 012015. [Google Scholar] [CrossRef]
- Thakkar, A.; Lohiya, R. Fusion of statistical importance for feature selection in Deep Neural Network-based Intrusion Detection System. Inf. Fusion 2023, 90, 353–363. [Google Scholar] [CrossRef]
- Liu, Z.; Shi, Y. A hybrid IDS using GA-based feature selection method and random forest. Int. J. Mach. Learn. Comput. 2022, 12, 43–50. [Google Scholar]
- Eunice, A.D.; Gao, Q.; Zhu, M.Y.; Chen, Z.; LV, N. Network Anomaly Detection Technology Based on Deep Learning. In Proceedings of the 2021 IEEE 3rd International Conference on Frontiers Technology of Information and Computer (ICFTIC), Virtual, 12–14 November 2021; pp. 6–9. [Google Scholar] [CrossRef]
- Barkah, A.S.; Selamat, S.R.; Abidin, Z.Z.; Wahyudi, R. Impact of Data Balancing and Feature Selection on Machine Learning-based Network Intrusion Detection. Int. J. Inform. Vis. 2023, 7, 241–248. [Google Scholar] [CrossRef]
- Kumar, V.; Sinha, D.; Das, A.K.; Pandey, S.C.; Goswami, R.T. An integrated rule based intrusion detection system: Analysis on UNSW-NB15 data set and the real time online dataset. Clust. Comput. 2020, 23, 1397–1418. [Google Scholar] [CrossRef]
- Kasongo, S.M.; Sun, Y. Performance analysis of intrusion detection systems using a feature selection method on the UNSW-NB15 dataset. J. Big Data 2020, 7, 1–20. [Google Scholar] [CrossRef]
- Alazzam, H.; Sharieh, A.; Sabri, K.E. A feature selection algorithm for intrusion detection system based on pigeon inspired optimizer. Expert Syst. Appl. 2020, 148, 113249. [Google Scholar] [CrossRef]
- Sarhan, M.; Layeghy, S.; Portmann, M. Towards a standard feature set for network intrusion detection system datasets. Mob. Netw. Appl. 2022, 27, 357–370. [Google Scholar] [CrossRef]
- Sarhan, M.; Layeghy, S.; Portmann, M. Feature Analysis for Machine Learning-based IoT Intrusion Detection. arXiv 2021, arXiv:2108.12732. [Google Scholar]
- Megantara, A.A.; Ahmad, T. Feature importance ranking for increasing performance of intrusion detection system. In Proceedings of the 2020 3rd International Conference on Computer and Informatics Engineering (IC2IE), Yogyakarta, Indonesia, 15–16 September 2020; IEEE: New York, NY, USA, 2020; pp. 37–42. [Google Scholar]
- Ustebay, S.; Turgut, Z.; Aydin, M.A. Intrusion detection system with recursive feature elimination by using random forest and deep learning classifier. In Proceedings of the 2018 International Congress on Big Data, Deep Learning and Fighting Cyber Terrorism (IBIGDELFT), Ankara, Turkey, 3–4 December 2018; IEEE: New York, NY, USA, 2018; pp. 71–76. [Google Scholar]
- Sharma, N.V.; Yadav, N.S. An optimal intrusion detection system using recursive feature elimination and ensemble of classifiers. Microprocess Microsyst. 2021, 85, 104293. [Google Scholar] [CrossRef]
- Tonni, Z.A.; Mazumder, R. A Novel Feature Selection Technique for Intrusion Detection System Using RF-RFE and Bio-inspired Optimization. In Proceedings of the 2023 57th Annual Conference on Information Sciences and Systems (CISS), Baltimore, MD, USA, 22–24 March 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Ren, K.; Zeng, Y.; Cao, Z.; Zhang, Y. ID-RDRL: A deep reinforcement learning-based feature selection intrusion detection model. Sci. Rep. 2022, 12, 15370. [Google Scholar] [CrossRef] [PubMed]
- Alahmed, S.; Alasad, Q.; Hammood, M.M.; Yuan, J.; Alawad, M. Mitigation of Black-Box Attacks on Intrusion Detection Systems-Based ML. Computers 2022, 11, 115. [Google Scholar] [CrossRef]
- Fraihat, S.; Makhadmeh, S.; Awad, M.; Al-Betar, M.A.; Al-Redhaei, A. Intrusion detection system for large-scale IoT NetFlow networks using machine learning with modified Arithmetic Optimization Algorithm. Internet Things 2023, 22, 100819. [Google Scholar] [CrossRef]
- Bisong, E.; Bisong, E. Introduction to Scikit-learn. In Building Machine Learning and Deep Learning Models on Google Cloud Platform: A Comprehensive Guide for Beginners; Springer: Berlin/Heidelberg, Germany, 2019; pp. 215–229. [Google Scholar]
- Jackson, E.; Agrawal, R. Performance Evaluation of Different Feature Encoding Schemes on Cybersecurity Logs; IEEE: New York, NY, USA, 2019. [Google Scholar]
- Raju, V.G.; Lakshmi, K.P.; Jain, V.M.; Kalidindi, A.; Padma, V. Study the influence of normalization/transformation process on the accuracy of supervised classification. In Proceedings of the 2020 Third International Conference on Smart Systems and Inventive Technology (ICSSIT), Tirunelveli, India, 20–22 August 2020; IEEE: New York, NY, USA, 2020; pp. 729–735. [Google Scholar]
- Batra, M.; Agrawal, R. Comparative analysis of decision tree algorithms. In Nature Inspired Computing: Proceedings of CSI 2015; Springer: Berlin/Heidelberg, Germany, 2018; pp. 31–36. [Google Scholar]
- Elaidi, H.; Benabbou, Z.; Abbar, H. A comparative study of algorithms constructing decision trees: Id3 and c4.5. In Proceedings of the International Conference on Learning and Optimization Algorithms: Theory and Applications, Rabat, Morocco, 2–5 May 2018; pp. 1–5. [Google Scholar]
- Lin, C.L.; Fan, C.L. Evaluation of CART, CHAID, and QUEST algorithms: A case study of construction defects in Taiwan. J. Asian Archit. Build. Eng. 2019, 18, 539–553. [Google Scholar] [CrossRef]
- Canete-Sifuentes, L.; Monroy, R.; Medina-Perez, M.A. A review and experimental comparison of multivariate decision trees. IEEE Access 2021, 9, 110451–110479. [Google Scholar] [CrossRef]
- Scikit Learn, Machine Learning in Python. Available online: https://scikit-learn.org (accessed on 20 April 2023).
- Moustafa, N.; Slay, J. UNSW-NB15: A comprehensive data set for network intrusion detection systems (UNSW-NB15 network data set). In Proceedings of the 2015 Military Communications and Information Systems Conference (MilCIS), Canberra, Australia, 10–12 November 2015; IEEE: New York, NY, USA, 2015; pp. 1–6. [Google Scholar]
- Moustafa, N.; Slay, J. The evaluation of Network Anomaly Detection Systems: Statistical analysis of the UNSW-NB15 data set and the comparison with the KDD99 data set. Inf. Secur. J. Glob. Perspect. 2016, 25, 18–31. [Google Scholar] [CrossRef]
- Powers, D.M. Evaluation: From precision, recall and F-measure to ROC, informedness, markedness and correlation. arXiv 2020, arXiv:2010.16061. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Training Dataset | Testing Dataset |
|---|---|---|
| Normal | 56,000 | 37,000 |
| Generic | 40,000 | 18,871 |
| Exploits | 33,393 | 11,132 |
| Fuzzers | 18,184 | 6062 |
| DoS | 12,264 | 4089 |
| Reconnaissance | 10,491 | 3496 |
| Analysis | 2000 | 667 |
| Backdoor | 1746 | 583 |
| Shellcode | 1133 | 378 |
| Worms | 130 | 44 |
| Total | 175,341 | 82,332 |
| No. | Feature | Format | Description |
|---|---|---|---|
| 1 | dur | Float | Duration of the connection |
| 2 | proto | Categorical | Protocol type of the connection |
| 3 | service | Categorical | Network service on the destination machine |
| 4 | state | Categorical | State of the connection |
| 5 | spkts | Integer | Number of data packets sent from source to destination |
| 6 | dpkts | Integer | Number of data packets sent from destination to source |
| 7 | sbytes | Integer | Number of data bytes sent from source to destination |
| 8 | dbytes | Integer | Number of data bytes sent from destination to source |
| 9 | rate | Float | Transfer rate (packets/second) |
| 10 | sttl | Integer | Source TTL (Time to Live) |
| 11 | dttl | Integer | Destination TTL (Time to Live) |
| 12 | sload | Float | Source load (bytes/second) |
| 13 | dload | Float | Destination load (bytes/second) |
| 14 | sloss | Integer | Number of lost packets from source to destination |
| 15 | dloss | Integer | Number of lost packets from destination to source |
| 16 | sinpkt | Float | Interarrival time of packets sent from source |
| 17 | dinpkt | Float | Interarrival time of packets sent from destination |
| 18 | sjit | Float | Source jitter (variance of packet interarrival time) |
| 19 | djit | Float | Destination jitter (variance of packet interarrival time) |
| 20 | swin | Integer | Source TCP window size |
| 21 | stcpb | Integer | Source TCP base sequence number |
| 22 | dtcpb | Integer | Destination TCP base sequence number |
| 23 | dwin | Integer | Destination TCP window size |
| 24 | tcprtt | Float | TCP round-trip time |
| 25 | synack | Float | TCP SYN-ACK time |
| 26 | ackdat | Float | TCP ACK data time |
| 27 | smean | Integer | Mean of the packet sizes in the connection from source to destination |
| 28 | dmean | Integer | Mean of the packet sizes in the connection from destination to source |
| 29 | trans_depth | Integer | Transaction depth (if applicable) |
| 30 | response_body_len | Integer | Length of the response body (if applicable) |
| 31 | ct_srv_src | Integer | Number of connections to the same service and source IP |
| 32 | ct_state_ttl | Integer | Number of connections with the same state and source IP |
| 33 | ct_dst_ltm | Integer | Number of connections to the same destination IP in the last two minutes |
| 34 | ct_src_dport_ltm | Integer | Number of connections with the same source IP and destination port in the last two minutes |
| 35 | ct_dst_sport_ltm | Integer | Number of connections with the same destination IP and source port in the last two minutes |
| 36 | ct_dst_src_ltm | Integer | Number of connections with the same source and destination IP in the last two minutes |
| 37 | is_ftp_login | Binary | Indicates if the connection is an FTP login attempt (0 or 1) |
| 38 | ct_ftp_cmd | Integer | Number of FTP commands in the connection |
| 39 | ct _fw_http_mthd | Integer | Number of firewall and HTTP methods in the connection |
| 40 | ct_src_ltm | Integer | Number of connections with the same source IP in the last two minutes |
| 41 | ct_srv_dst | Integer | Number of connections to the same service and destination IP |
| 42 | is_sm_ips_ports | Binary | Indicates if the source IP and source port are the same (0 or 1) |
| Actual Class | |||
|---|---|---|---|
| Attack | Benign | ||
| Predicted Class | Attack | True Positives (TP) | False Positives (FP) |
| Benign | False Negatives (FN) | True Negatives (TN) | |
| Original Dataset (39 Features) | Original Dataset (Top 15 Features) | Selected Dataset (15 Features) | |
|---|---|---|---|
| Logistic Regression | 0.851122 | 0.701149 | 0.847957 |
| Naive Bayes | 0.789615 | 0.703457 | 0.847187 |
| Stochastic Gradient Descent | 0.403205 | 0.594228 | 0.805783 |
| Random Forest | 0.955602 | 0.872613 | 0.953007 |
| AdaBoost | 0.931278 | 0.801560 | 0.922011 |
| Multi-layer Perceptron | 0.872765 | 0.764357 | 0.897516 |
| Original Dataset (39 Features) | Selected Dataset (15 Features) | ||||||
|---|---|---|---|---|---|---|---|
| Precision | Recall | F1-Score | Precision | Recall | F1-Score | ||
| Logistic Regression | Class Benign | 0.8998 | 0.6007 | 0.7205 | 0.7859 | 0.7202 | 0.7516 |
| Class Attack | 0.8379 | 0.9686 | 0.8985 | 0.8737 | 0.9079 | 0.8905 | |
| macro avg | 0.8689 | 0.7847 | 0.8095 | 0.8298 | 0.8140 | 0.8210 | |
| weighted avg | 0.8577 | 0.8511 | 0.8417 | 0.8456 | 0.8480 | 0.8461 | |
| Naive Bayes | Class Benign | 0.6685 | 0.6768 | 0.6726 | 0.9011 | 0.5858 | 0.7100 |
| Class Attack | 0.8475 | 0.8426 | 0.8450 | 0.8331 | 0.9698 | 0.8963 | |
| macro avg | 0.7580 | 0.7597 | 0.7588 | 0.8671 | 0.7778 | 0.8031 | |
| weighted avg | 0.7903 | 0.7896 | 0.7900 | 0.8548 | 0.8472 | 0.8368 | |
| Stochastic Gradient Descent | Class Benign | 0.2899 | 0.5993 | 0.3908 | 0.7223 | 0.6366 | 0.6768 |
| Class Attack | 0.6234 | 0.3112 | 0.4151 | 0.8385 | 0.8852 | 0.8612 | |
| macro avg | 0.4566 | 0.4552 | 0.4030 | 0.7804 | 0.7609 | 0.7690 | |
| weighted avg | 0.5169 | 0.4032 | 0.4074 | 0.8014 | 0.8058 | 0.8023 | |
| Random Forest | Class Benign | 0.9354 | 0.9248 | 0.9301 | 0.9345 | 0.9171 | 0.9257 |
| Class Attack | 0.9649 | 0.9700 | 0.9675 | 0.9615 | 0.9698 | 0.9656 | |
| macro avg | 0.9502 | 0.9474 | 0.9488 | 0.9480 | 0.9435 | 0.9457 | |
| weighted avg | 0.9555 | 0.9556 | 0.9555 | 0.9528 | 0.9530 | 0.9529 | |
| AdaBoost | Class Benign | 0.9239 | 0.8553 | 0.8883 | 0.9422 | 0.8052 | 0.8683 |
| Class Attack | 0.9344 | 0.9669 | 0.9504 | 0.9144 | 0.9768 | 0.9446 | |
| macro avg | 0.9291 | 0.9111 | 0.9193 | 0.9283 | 0.8910 | 0.9065 | |
| weighted avg | 0.9310 | 0.9313 | 0.9305 | 0.9233 | 0.9220 | 0.9202 | |
| Multi-layer Perceptron | Class Benign | 0.9079 | 0.6696 | 0.7707 | 0.8838 | 0.7819 | 0.8297 |
| Class Attack | 0.8619 | 0.9681 | 0.9120 | 0.9029 | 0.9518 | 0.9267 | |
| macro avg | 0.8849 | 0.8188 | 0.8413 | 0.8934 | 0.8668 | 0.8782 | |
| weighted avg | 0.8766 | 0.8728 | 0.8668 | 0.8968 | 0.8975 | 0.8957 | |
| MLs | Original Dataset | Selected Features Dataset |
|---|---|---|
| Logistic Regression |  |  |
| Naive Bayes |  |  |
| Stochastic Gradient Descent |  |  |
| Random Forest |  |  |
| AdaBoost |  |  |
| Multi-layer Perceptron |  |  |
| Classifier | Feature Extraction Method | Number of Selected Features | Accuracy | F1-Score | |
|---|---|---|---|---|---|
| Thakkar and Lohiya, 2023 [24] | DNN | Statistical | 21 | 89.03 | 96.93 |
| Liu and Shi, 2022 [25] | DNN | GA | 30 | 76.70 | 93.83 |
| Kasongo and Sun, 2020 [29] | DT | XGBoost | 19 | 90.85 | 88.45 |
| Tama et al., 2019 [22] | DT | PSO-CO-GA | 19 | 91.27 | 91.44 |
| Eunice et al., 2021 [26] | RF | DNN | 20 | 82.1 | - |
| Proposed method | RF | DT-RFECV | 15 | 95.30 | 95.29 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Awad, M.; Fraihat, S. Recursive Feature Elimination with Cross-Validation with Decision Tree: Feature Selection Method for Machine Learning-Based Intrusion Detection Systems. J. Sens. Actuator Netw. 2023, 12, 67. https://doi.org/10.3390/jsan12050067
Awad M, Fraihat S. Recursive Feature Elimination with Cross-Validation with Decision Tree: Feature Selection Method for Machine Learning-Based Intrusion Detection Systems. Journal of Sensor and Actuator Networks. 2023; 12(5):67. https://doi.org/10.3390/jsan12050067
Chicago/Turabian StyleAwad, Mohammed, and Salam Fraihat. 2023. "Recursive Feature Elimination with Cross-Validation with Decision Tree: Feature Selection Method for Machine Learning-Based Intrusion Detection Systems" Journal of Sensor and Actuator Networks 12, no. 5: 67. https://doi.org/10.3390/jsan12050067