


Reduction in Data Imbalance for Client-Side Training in Federated Learning for the Prediction of Stock Market Prices

Abstract
:1. Introduction
- A novel approach comprising balanced federated learning (Bal-fed) has been proposed for implementation on the FL setting to achieve a class balance to increase the training accuracy with lower computation costs.
- The proposed approach harnesses class estimation and balancing to train a linear regression (LR) machine learning algorithm in an FL setting. To assess its applicability, this approach is implemented on stock market data (text and numerical data).
- This approach has been shown to enhance the accuracy of the model in FL settings by demonstrating an accuracy rate exceeding 95% in the FL environment, even after mitigating the issue of data imbalance.
2. Related Work
3. Materials and Methods
3.1. Model Training on the Client Side
| Algorithm 1: Class Balancing Algorithm |
| Initialize Set St = ∅ and Rtotal = ∅ k0 = arg maxk rˆk St←St ∪ {k0} while |St| < K do Select kmin = arg mink DKL ((Rtotal+R¯k)||U) for k ∈ K\St Set St←St ∪ {kmin}, Rtotal←Rtotal + R¯k min. end while Outputs: St |
- A calculation of the deviation of the observed y-values from the predicted y-values for each corresponding x-value.
- A calculation of the square of each of these distances.
- A calculation of the mean for each of the squared distances.
3.2. Federated Averaging (FedAvg) for Model Aggregation
| Algorithm 2: FedAvg (Federated Averaging). There are n clients, B is the local minibatch size, E is the number of local epochs per communication round, ⴄ is the learning rate, and ƒᵢ is the local loss function. |
| Server Executes initialize Ꞷ0; for each round t = 0, 1,…do for each client i = 0,…, n − 1 in parallel Ꞷt←ClientUpdate(i, Ꞷt) t+1 k Ꞷt+1 ClientUpdate (i, Ꞷ): //Run on client i for each local epoch e from 0,…, E − 1 do for each minibatch b of size B do Ꞷe+1←Ꞷe − ⴄσ ƒᵢ(Ꞷe; b) return ꞶE to server |
3.3. Implementation
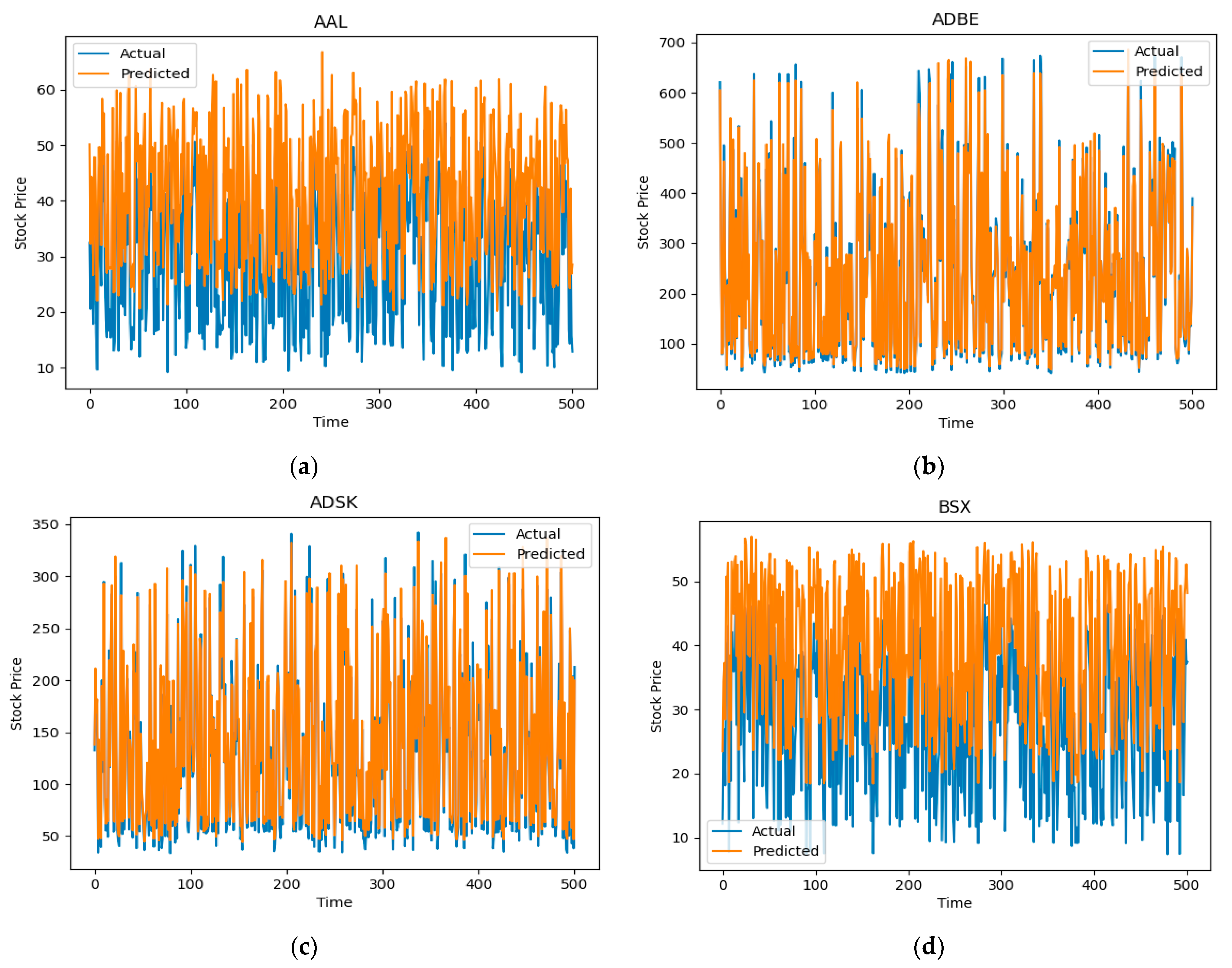
4. Results and Discussion
4.1. Evaluation Measure
4.2. Analysis of Results
4.3. Comparative Analysis

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Evaluation Measure | Result with LR-Employed Bal-Fed | Result without Estimation |
|---|---|---|
| Accuracy | 95.01% | 79.6% |
| Data loss | 19 | 43 |
| Training time in seconds | 14 | 10.7 |
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Lionel, V. Internet of Things (IoT) and non-IoT Active Device Connections Worldwide from 2010 to 2025(in billions). 2022. Available online: https://www.statista.com/statistics/1101442/iot-number-of-connected-devices-worldwide/#:~:text=The%20total%20installed%20base%20of,that%20are%20expected%20in%202021 (accessed on 30 November 2023).
- Petroc, T. Volume of Data/Information Created, Captured, Copied, and Consumed Worldwide from 2010 to 2020, with Forecasts from 2021 to 2025. 2023. Available online: https://www.statista.com/statistics/871513/worldwide-data-created/ (accessed on 30 November 2023).
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication efficient learning of deep networks from decentralized data. In Artificial Intelligence and Statistics; 2017; pp. 1273–1282. Available online: https://proceedings.mlr.press/v54/mcmahan17a.html (accessed on 30 November 2023).
- Beltrán, E.T.M.; Pérez, M.Q.; Sánchez, P.M.S.; Bernal, S.L.; Bovet, G.; Pérez, M.G.; Pérez, G.M.; Celdrán, A.H. Decentralized Federated Learning: Fundamentals, State of the Art, Frameworks, Trends, and Challenges. IEEE Commun. Surv. Tutor. 2023, 25, 2983–3013. [Google Scholar] [CrossRef]
- Dinh, C.T.; Tran, N.H.; Nguyen, M.N.; Hong, C.S.; Bao, W.; Zomaya, A.Y.; Gramoli, V. Federated learning over wireless networks: Convergence analysis and resource allocation. IEEE/ACM Trans. Netw. 2020, 29, 398–409. [Google Scholar] [CrossRef]
- Luping, W.; Wei, W.; Bo, L. Cmfl: Mitigating communication overhead for federated learning. In Proceedings of the 2019 IEEE 39th International Conference on Distributed Computing Systems (ICDCS), Dallas, TX, USA, 7–9 July 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 954–964. [Google Scholar]
- Arsalan, A.; Umer, T.; Rehman, R.A. 3 Federated Learning Technique in Enabling Data-Driven Design for Wireless Communication. In Data-Driven Intelligence in Wireless Networks: Concepts, Solutions, and Applications; CRC Press: Boca Raton, FL, USA, 2023; p. 23. [Google Scholar]
- Paragliola, G. Evaluation of the trade-off between performance and communication costs in federated learning scenario. Future Gener. Comput. Syst. 2022, 136, 282–293. [Google Scholar] [CrossRef]
- Paragliola, G.; Coronato, A. Definition of a novel federated learning approach to reduce communication costs. Expert Syst. Appl. 2022, 189, 116109. [Google Scholar] [CrossRef]
- Paragliola, G. Application of Federated Learning Approaches for Time-Series Classification in eHealth Domain. Procedia Comput. Sci. 2022, 207, 3545–3552. [Google Scholar] [CrossRef]
- Shaheen, M.; Farooq, M.S.; Umer, T.; Kim, B.-S. Applications of federated learning; taxonomy, challenges, and research trends. Electronics 2022, 11, 670. [Google Scholar] [CrossRef]
- Phyu, H.P.; Stanica, R.; Naboulsi, D. Multi-slice privacy-aware traffic forecasting at RAN level: A scalable federated-learning approach. IEEE Trans. Netw. Serv. Manag. 2023, 20, 5038–5052. [Google Scholar] [CrossRef]
- Paragliola, G. A federated learning-based approach to recognize subjects at a high risk of hypertension in a non-stationary scenario. Inf. Sci. 2023, 622, 16–33. [Google Scholar] [CrossRef]
- Rahman, A.; Hasan, K.; Kundu, D.; Islam, M.J.; Debnath, T.; Band, S.S.; Kumar, N. On the ICN-IoT with federated learning integration of communication: Concepts, security-privacy issues, applications, and future perspectives. Future Gener. Comput. Syst. 2023, 138, 61–88. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhao, J.; Jiang, L.; Tan, R.; Niyato, D. Mobile Edge Computing, Blockchain and Reputation-based Crowdsourcing IoT Federated Learning: A Secure, Decentralized and Privacy-preserving System. arXiv 2019, arXiv:1906.10893. [Google Scholar]
- Lu, Y.; Huang, X.; Zhang, K.; Maharjan, S.; Zhang, Y. Communication-efficient federated learning for digital twin edge networks in industrial IoT. IEEE Trans. Ind. Inform. 2020, 17, 5709–5718. [Google Scholar] [CrossRef]
- Pokhrel, S.R.; Choi, J. Federated Learning with Blockchain for Autonomous Vehicles: Analysis and Design Challenges. IEEE Trans. Commun. 2020, 68, 4734–4746. [Google Scholar] [CrossRef]
- Li, L.; Qin, J.; Luo, J. A Blockchain-Based Federated-Learning Framework for Defense against Backdoor Attacks. Electronics 2023, 12, 2500. [Google Scholar] [CrossRef]
- Farooq, M.S.; Tehseen, R.; Qureshi, J.N.; Omer, U.; Yaqoob, R.; Tanweer, H.A.; Atal, Z. FFM: Flood forecasting model using federated learning. IEEE Access 2023, 11, 24472–24483. [Google Scholar] [CrossRef]
- Tehseen, R.; Farooq, M.S.; Abid, A. A framework for the prediction of earthquake using federated learning. PeerJ Comput. Sci. 2021, 7, e540. [Google Scholar] [CrossRef]
- Marulli, F.; Verde, L.; Marrore, S.; Campanile, L. A Federated Consensus-Based Model for Enhancing Fake News and Misleading Information Debunking. In Proceedings of the Intelligent Decision Technologies: Proceedings of the 14th KES-IDT 2022 Conference, Rhodes, Greece, 22 June 2022; Springer Nature: Singapore, 2022; pp. 587–596. [Google Scholar]
- Marulli, F.; Verde, L.; Marrone, S.; Barone, R.; De Biase, M.S. Evaluating efficiency and effectiveness of federated learning approaches in knowledge extraction tasks. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–22 July 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–6. [Google Scholar]
- Mehta, S.; Kukreja, V.; Yadav, R. Advanced Mango Leaf Disease Detection and Severity Analysis with Federated Learning and CNN. In Proceedings of the 2023 3rd International Conference on Intelligent Technologies (CONIT), Hubli, India, 23–25 June 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–6. [Google Scholar]
- Silva, S.; Gutman, B.A.; Romero, E.; Thompson, P.M.; Altmann, A.; Lorenzi, M. Federated learning in distributed medical databases: Meta-analysis of large-scale subcortical brain data. In Proceedings of the International Symposium on Biomedical Imaging, Venice, Italy, 8–11 April 2019; Volume 2019, pp. 270–274. [Google Scholar]
- Antunes, R.S.; André da Costa, C.; Küderle, A.; Yari, I.A.; Eskofier, B. Federated learning for healthcare: Systematic review and architecture proposal. ACM Trans. Intell. Syst. Technol. (TIST) 2022, 13, 1–23. [Google Scholar] [CrossRef]
- Li, X.L.S.; Lv, L.; Ding, Z. Mobile app start-up prediction based on federated learning and attributed heterogeneous network embedding. Future Internet 2021, 13, 256. [Google Scholar] [CrossRef]
- Guendouzi, B.S.; Ouchani, S.; Assaad, H.E.; Zaher, M.E. A systematic review of federated learning: Challenges, aggregation methods, and development tools. J. Netw. Comput. Appl. 2023, 220, 103714. [Google Scholar] [CrossRef]
- Ye, M.; Fang, X.; Du, B.; Yuen, P.C.; Tao, D. Heterogeneous federated learning: State-of-the-art and research challenges. ACM Comput. Surv. 2023, 56, 1–44. [Google Scholar] [CrossRef]
- Liu, Y.; Ma, Z.; Liu, X.; Ma, S.; Nepal, S.; Deng, R. Boosting Privately: Privacy-Preserving Federated Extreme Boosting for Mobile Crowdsensing. arXiv 2019, arXiv:1907.10218. [Google Scholar]
- Yang, M.; Wang, X.; Zhu, H.; Wang, H.; Qian, H. Federated learning with class imbalance reduction. In Proceedings of the 2021 29th European Signal Processing Conference (EUSIPCO), Dublin, Ireland, 23–27 August 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 2174–2178. [Google Scholar]
- Wang, L.; Xu, S.; Wang, X.; Zhu, Q. Addressing class imbalance in federated learning. In Proceedings of the AAAI Conference on Artificial Intelligence, virtual, 2–9 February 2021; Volume 35, pp. 10165–10173. [Google Scholar]
- Yen, S.J.; Lee, Y.S. Under-sampling approaches for improving prediction of the minority class in an imbalanced dataset. In Proceedings of the Intelligent Control and Automation: International Conference on Intelligent Computing, ICIC 2006, Kunming, China, 16–19 August 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 731–740. [Google Scholar]
- Lin, W.C.; Tsai, C.F.; Hu, Y.H.; Jhang, J.S. Clustering-based undersampling in class-imbalanced data. Inf. Sci. 2017, 409, 17–26. [Google Scholar] [CrossRef]
- Seol, M.; Kim, T. Performance Enhancement in Federated Learning by Reducing Class Imbalance of Non-IID Data. Sensors 2023, 23, 1152. [Google Scholar] [CrossRef] [PubMed]
- Duan, M.; Liu, D.; Chen, X.; Tan, Y.; Ren, J.; Qiao, L.; Liang, L. Astraea: Selfbalancing federated learning for improving classification accuracy of mobile deep learning applications. In Proceedings of the 2019 IEEE International Conference on Computer Design, ICCD, Abu Dhabi, UAE, 17–20 November 2019; pp. 246–254. [Google Scholar]
- Marulli, F.; Bellini, E.; Marrone, S. A security-oriented architecture for federated learning in cloud environments. In Proceedings of the Web, Artificial Intelligence and Network Applications: Proceedings of the Workshops of the 34th International Conference on Advanced Information Networking and Applications (WAINA-2020), Caserta, Italy, 15–17 April 2020; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 730–741. [Google Scholar]
- Rahman, A.; Hossain, M.S.; Muhammad, G.; Kundu, D.; Debnath, T.; Rahman, M.; Khan, M.S.I.; Tiwari, P.; Band, S.S. Federated learning-based AI approaches in smart healthcare: Concepts, taxonomies, challenges and open issues. Clust. Comput. 2023, 26, 2271–2311. [Google Scholar] [CrossRef] [PubMed]
- Subramanian, M.; Rajasekar, V.; V.E., S.; Shanmugavadivel, K.; Nandhini, P.S. Effectiveness of Decentralized Federated Learning Algorithms in Healthcare: A Case Study on Cancer Classification. Electronics 2022, 11, 4117. [Google Scholar] [CrossRef]
- Cremonesi, F.; Vesin, M.; Cansiz, S.; Bouillard, Y.; Balelli, I.; Innocenti, L.; Silva, S.; Ayed, S.S.; Taiello, R.; Kameni, L. Fed-BioMed: Open, Transparent and Trusted Federated Learning for Real-world Healthcare Applications. arXiv 2023, arXiv:2304.12012. [Google Scholar]
- Farooq, M.S.; Younas, H.A. Beta Thalassemia Carriers detection empowered federated Learning. arXiv 2023, arXiv:2306.01818. [Google Scholar]
- Nguyen, D.C.; Ding, M.; Pathirana, P.N.; Seneviratne, A.; Zomaya, A.Y. Federated learning for COVID-19 detection with generative adversarial networks in edge cloud computing. IEEE Internet Things J. 2021, 9, 10257–10271. [Google Scholar] [CrossRef]
- Berghout, T.; Benbouzid, M.; Bentrcia, T.; Lim, W.H.; Amirat, Y. Federated Learning for Condition Monitoring of Industrial Processes: A Review on Fault Diagnosis Methods, Challenges, and Prospects. Electronics 2023, 12, 158. [Google Scholar] [CrossRef]
- Yang, L.; Huang, J.; Lin, W.; Cao, J. Personalized federated learning on non-IID data via group-based meta-learning. ACM Trans. Knowl. Discov. Data 2023, 17, 1–20. [Google Scholar] [CrossRef]
- Zhao, Y.; Li, M.; Lai, L.; Suda, N.; Civin, D.; Chandra, V. Federated learning with non-iid data. arXiv 2018, arXiv:1806.00582. [Google Scholar] [CrossRef]
- Li, T.; Sahu, A.K.; Zaheer, M.; Sanjabi, M.; Talwalkar, A.; Smith, V. Federated opti mization in heterogeneous networks. arXiv 2020, arXiv:1812.06127. [Google Scholar]
- Li, T.; Sahu, A.K.; Talwalkar, A.; Smith, V. Federated learning: Challenges, methods, and future directions. IEEE Signal Process. Mag. 2020, 37, 50–60. [Google Scholar] [CrossRef]
- Verma, D.C.; White, G.; Julier, S.; Pasteris, S.; Chakraborty, S.; Cirincione, G. Approaches to address the data skew problem in federated learning. In Artificial Intelligence and Machine Learning for Multi-Domain Operations Applications; International Society for Optics and Photonics: Bellingham, WA, USA, 2019; Volume 11006, p. 110061I. [Google Scholar]
- Konečný, J.; McMahan, H.B.; Yu, F.X.; Richtárik, P.; Suresh, A.T.; Bacon, D. Federated learning: Strategies for improving communication efficiency. arXiv 2016, arXiv:1610.05492. [Google Scholar]
- Wu, X.; Yao, X.; Wang, C.L. FedSCR: Structure-based communication reduction for federated learning. IEEE Trans. Parallel Distrib. Syst. 2020, 32, 1565–1577. [Google Scholar] [CrossRef]
- Rothchild, D.; Panda, A.; Ullah, E.; Ivkin, N.; Stoica, I.; Braverman, V.; Gonzalez, J.; Arora, R. Fetchsgd: Communication-efficient federated learning with sketching. In Proceedings of the International Conference on Machine Learning, virtual, 12–18 July 2020; 119, pp. 8253–8265. Available online: https://proceedings.mlr.press/v119/rothchild20a.html (accessed on 30 November 2023).
- Nilsson, A.; Smith, S.; Ulm, G.; Gustavsson, E.; Jirstrand, M. A performance evaluation of federated learning algorithms. In Proceedings of the Second Workshop on Distributed Infrastructures for Deep Learning, Rennes, France, 10–11 December 2018; pp. 1–8. [Google Scholar]
- Wang, H.; Wu, Z.; Xing, E.P. Removing confounding factors associated weights in deep neural networks improves the prediction accuracy for healthcare applications. In Proceedings of the BIOCOMPUTING 2019: Proceedings of the Pacific Symposium, San Diego, CA, USA, 29 October–4 November 2018; World Scientific: Singapore, 2018; pp. 54–65. [Google Scholar]
- Nori, M.K.; Yun, S.; Kim, I.M. Fast federated learning by balancing communication trade-offs. IEEE Trans. Commun. 2021, 69, 5168–5182. [Google Scholar] [CrossRef]
- Xu, J.; Glicksberg, B.S.; Su, C.; Walker, P.; Bian, J.; Wang, F. Federated learning for healthcare informatics. J. Healthc. Inform. Res. 2021, 5, 1–19. [Google Scholar] [CrossRef] [PubMed]
- Sattler, F.; Muller, K.-R.; Samek, W. Clustered federated learning: Model-agnostic distributed multitask optimization under privacy constraints. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 3710–3722. [Google Scholar] [CrossRef]
- Sattler, F.; Müller, K.R.; Wiegand, T.; Samek, W. On the Byzantine Robustness of Clustered Federated Learning. In Proceedings of the ICASSP 2020–2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 8861–8865. [Google Scholar] [CrossRef]
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated machine learning: Concept and applications. ACM Trans. Intell. Syst. Technol. (TIST) 2019, 10, 1–19. [Google Scholar] [CrossRef]
- Lim, W.Y.B.; Luong, N.C.; Hoang, D.T.; Jiao, Y.; Liang, Y.C.; Yang, Q.; Niyato, D.; Miao, C. Federated learning in mobile edge networks: A comprehensive survey. IEEE Commun. Surv. Tutor. 2020, 22, 2031–2063. [Google Scholar] [CrossRef]
- Mohri, M.; Sivek, G.; Suresh, A.T. Agnostic federated learning. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 4615–4625. [Google Scholar]
- Bonawitz, K.; Eichner, H.; Grieskamp, W.; Huba, D.; Ingerman, A.; Ivanov, V.; Kiddon, C.; Konečný, J.; Mazzocchi, S.; McMahan, B.; et al. Towards federated learning at scale: System design. In Proceedings of the Machine Learning and Systems, Stanford, CA, USA, 31 March–2 April 2019; Volume 1, pp. 374–388. [Google Scholar]
- Abadi, M.; Chu, A.; Goodfellow, I.; McMahan, H.B.; Mironov, I.; Talwar, K.; Zhang, L. Deep learning with differential privacy. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016; pp. 308–318. [Google Scholar]
- Xiao, C.; Wang, S. Triplets Oversampling for Class Imbalanced Federated Datasets. In Proceedings of the Machine Learning and Knowledge Discovery in Databases: Research Track: European Conference, ECML PKDD 2023, Turin, Italy, 18–22 September 2023; Koutra, D., Plant, C., Rodriguez, M.G., Baralis, E., Bonchi, F., Eds.; Proceedings, Part II (1 ed., pp. 368–383). (Lecture Notes in Computer Science; Volume 14170). Springer: Berlin/Heidelberg, Germany, 2023; pp. 368–383. [Google Scholar]
- Zhang, J.; Li, A.; Tang, M.; Sun, J.; Chen, X.; Zhang, F.; Chen, C.; Chen, Y.; Li, H. Fed-cbs: A heterogeneity-aware client sampling mechanism for federated learning via class-imbalance reduction. In Proceedings of the International Conference on Machine Learning, Honolulu, HI, USA, 23–29 July 2023; pp. 41354–41381. [Google Scholar]
- Ma, Z.; Zhao, M.; Cai, X.; Jia, Z. Fast-convergent federated learning with class-weighted aggregation. J. Syst. Archit. 2021, 117, 102125. [Google Scholar] [CrossRef]
- Liang, P.P.; Liu, T.; Ziyin, L.; Allen, N.B.; Auerbach, R.P.; Brent, D.; Salakhutdinov, R.; Morency, L.P. Think locally, act globally: Federated learning with local and global representations. arXiv 2020, arXiv:2001.01523. [Google Scholar]
- Wong, S.C.; Gatt, A.; Stamatescu, V.; McDonnell, M.D. Understanding data augmentation for classification: When to warp? In Proceedings of the 2016 International Conference on Digital Image Computing: Techniques and Applications (DICTA), Gold Coast, Australia, 30 November–2 December 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1–6. [Google Scholar]
- Dwork, C.; Roth, A. The algorithmic foundations of differential privacy. Found. Trends Theor. Comput. Sci. 2014, 9, 211–407. [Google Scholar] [CrossRef]
- Abay, N.C.; Zhou, Y.; Kantarcioglu, M.; Thuraisingham, B.; Sweeney, L. Privacy preserving synthetic data release using deep learning. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Dublin, Ireland, 10–14 September 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 510–526. [Google Scholar]
- Dwork, C.; McSherry, F.; Nissim, K.; Smith, A. Calibrating noise to sensitivity in private data analysis. J. Priv. Confidentiality 2016, 7, 17–51. [Google Scholar] [CrossRef]
- Augenstein, S.; McMahan, H.B.; Ramage, D.; Ramaswamy, S.; Kairouz, P.; Chen, M.; Mathews, R. Generative models for effective ml on private, decentralized datasets. arXiv 2019, arXiv:1911.06679. [Google Scholar]
- Bejjanki, K.K.; Gyani, J.; Gugulothu, N. Class imbalance reduction (CIR): A novel approach to software defect prediction in the presence of class imbalance. Symmetry 2020, 12, 407. [Google Scholar] [CrossRef]
- Anand, R.; Mehrotra, K.G.; Mohan, C.K.; Ranka, S. An improved algorithm for neural network classification of imbalanced training sets. IEEE Trans. Neural Netw. 1993, 4, 962–969. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T.M.; Furht, B. Text data augmentation for deep learning. J. Big Data 2021, 8, 1–34. [Google Scholar] [CrossRef]
- Pourroostaei Ardakani, S.; Du, N.; Lin, C.; Yang, J.C.; Bi, Z.; Chen, L. A federated learning-enabled predictive analysis to forecast stock market trends. J. Ambient. Intell. Human Comput. 2023, 14, 4529–4535. [Google Scholar] [CrossRef]
- Shaheen, M.; Awan, S.M.; Hussain, N.; Gondal, Z.A. Sentiment analysis on mobile phone reviews using supervised learning techniques. Int. J. Mod. Educ. Comput. Sci. 2019, 11, 32. [Google Scholar] [CrossRef]
- Ahmad, F.; Najam, A. Video-based face classification approach: A survey. In Proceedings of the 2012 International Conference of Robotics and Artificial Intelligence, Rawalpindi, Pakistan, 22–23 October 2012; IEEE: Piscataway, NJ, USA; pp. 179–186. [Google Scholar]
- Ahmad, F.; Najam, A.; Ahmed, Z. Image-based face detection and recognition: “state of the art”. arXiv 2013, arXiv:1302.6379. [Google Scholar]
- Ahmad, F.; Ahmed, Z.; Najam, A. Soft Biometric Gender Classification Using Face for Real Time Surveillance in Cross Dataset Environment; INMIC: Islamabad, Pakistan, 2013. [Google Scholar]
- Su, X.; Yan, X.; Tsai, C.L. Linear regression. Wiley Interdiscip. Rev. Comput. Stat. 2012, 4, 275–294. [Google Scholar] [CrossRef]
- Montgomery, D.C.; Peck, E.A.; Vining, G.G. Introduction to Linear Regression Analysis; John Wiley & Sons: Hoboken, NJ, USA, 2021. [Google Scholar]
- Maulud, D.; Abdulazeez, A.M. A review on linear regression comprehensive in machine learning. J. Appl. Sci. Technol. Trends 2020, 1, 140–147. [Google Scholar] [CrossRef]
- Li, X.; Huang, K.; Yang, W.; Wang, S.; Zhang, Z. On the convergence of fedavg on non-iid data. arXiv 2019, arXiv:1907.02189. [Google Scholar]
- Flower. Flower a Friendly Federated Learning Framework. 2022. Available online: https://fower.dev/ (accessed on 24 August 2022).
- Zhou, Y.; Ye, Q.; Lv, J. Communication-efficient federated learning with compensated overlap-fedavg. IEEE Trans. Parallel Distrib. Syst. 2021, 33, 192–205. [Google Scholar] [CrossRef]
- Patro, V.M.; Patra, M.R. Augmenting weighted average with confusion matrix to enhance classification accuracy. Trans. Mach. Learn. Artif. Intell. 2014, 2, 77–91. [Google Scholar]
- Das, K.; Jiang, J.; Rao, J.N.K. Mean squared error of empirical predictor. Ann. Stat. 2004, 32, 818–840. [Google Scholar] [CrossRef]
- Willmott, C.J.; Matsuura, K. Advantages of the mean absolute error (MAE) over the root mean square error (RMSE) in assessing average model performance. Clim. Res. 2005, 30, 79–82. [Google Scholar] [CrossRef]
- Chicco, D.; Warrens, M.J.; Jurman, G. The coefficient of determination R-squared is more informative than SMAPE, MAE, MAPE, MSE and RMSE in regression analysis evaluation. PeerJ Comput. Sci. 2021, 7, e623. [Google Scholar] [CrossRef]






| Stock | Training Iterations | R-Squared | Mean Absolute Error | Mean Squared Error | Relative MSE | RMSE |
|---|---|---|---|---|---|---|
| AAL | 80 | 0.67 | 5.70 | 116.34 | 3.82 | 10.78 |
| 81 | 0.68 | 5.70 | 55.50 | 1.82 | 7.45 | |
| 82 | 0.69 | 6.86 | 55.0 | 1.81 | 11.04 | |
| ADBE | 80 | 0.98 | 15.07 | 691.52 | 2.94 | 26.29 |
| 81 | 0.98 | 17.8 | 457.35 | 3.01 | 26.59 | |
| 82 | 0.98 | 17.95 | 436.03 | 1.94 | 21.38 | |
| ADSK | 80 | 0.97 | 9.93 | 189.43 | 1.41 | 13.76 |
| 81 | 0.98 | 7.77 | 184.26 | 1.37 | 13.57 | |
| 82 | 0.98 | 6.77 | 182.78 | 1.36 | 13.51 | |
| BSX | 80 | 0.98 | 5.02 | 35.60 | 1.21 | 5.92 |
| 81 | 0.98 | 13.84 | 34.60 | 1.21 | 5.88 | |
| 82 | 0.98 | 5.02 | 34.50 | 1.21 | 5.87 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shaheen, M.; Farooq, M.S.; Umer, T. Reduction in Data Imbalance for Client-Side Training in Federated Learning for the Prediction of Stock Market Prices. J. Sens. Actuator Netw. 2024, 13, 1. https://doi.org/10.3390/jsan13010001
Shaheen M, Farooq MS, Umer T. Reduction in Data Imbalance for Client-Side Training in Federated Learning for the Prediction of Stock Market Prices. Journal of Sensor and Actuator Networks. 2024; 13(1):1. https://doi.org/10.3390/jsan13010001
Chicago/Turabian StyleShaheen, Momina, Muhammad Shoaib Farooq, and Tariq Umer. 2024. "Reduction in Data Imbalance for Client-Side Training in Federated Learning for the Prediction of Stock Market Prices" Journal of Sensor and Actuator Networks 13, no. 1: 1. https://doi.org/10.3390/jsan13010001
APA StyleShaheen, M., Farooq, M. S., & Umer, T. (2024). Reduction in Data Imbalance for Client-Side Training in Federated Learning for the Prediction of Stock Market Prices. Journal of Sensor and Actuator Networks, 13(1), 1. https://doi.org/10.3390/jsan13010001