
Acoustic Similarity Predicts Vowel Phoneme Detection in an Unfamiliar Regional Accent: Evidence from Monolinguals, Bilinguals and Second-Language Learners

Abstract
:1. Introduction
1.1. Acoustic Similarity in Speech Perception by Inexperienced and L2 Listeners
1.2. Speech Perception in Monolingual and Multilingual Populations
1.3. Present Study
2. Experiment 1: L2 Learners
2.1. Participants
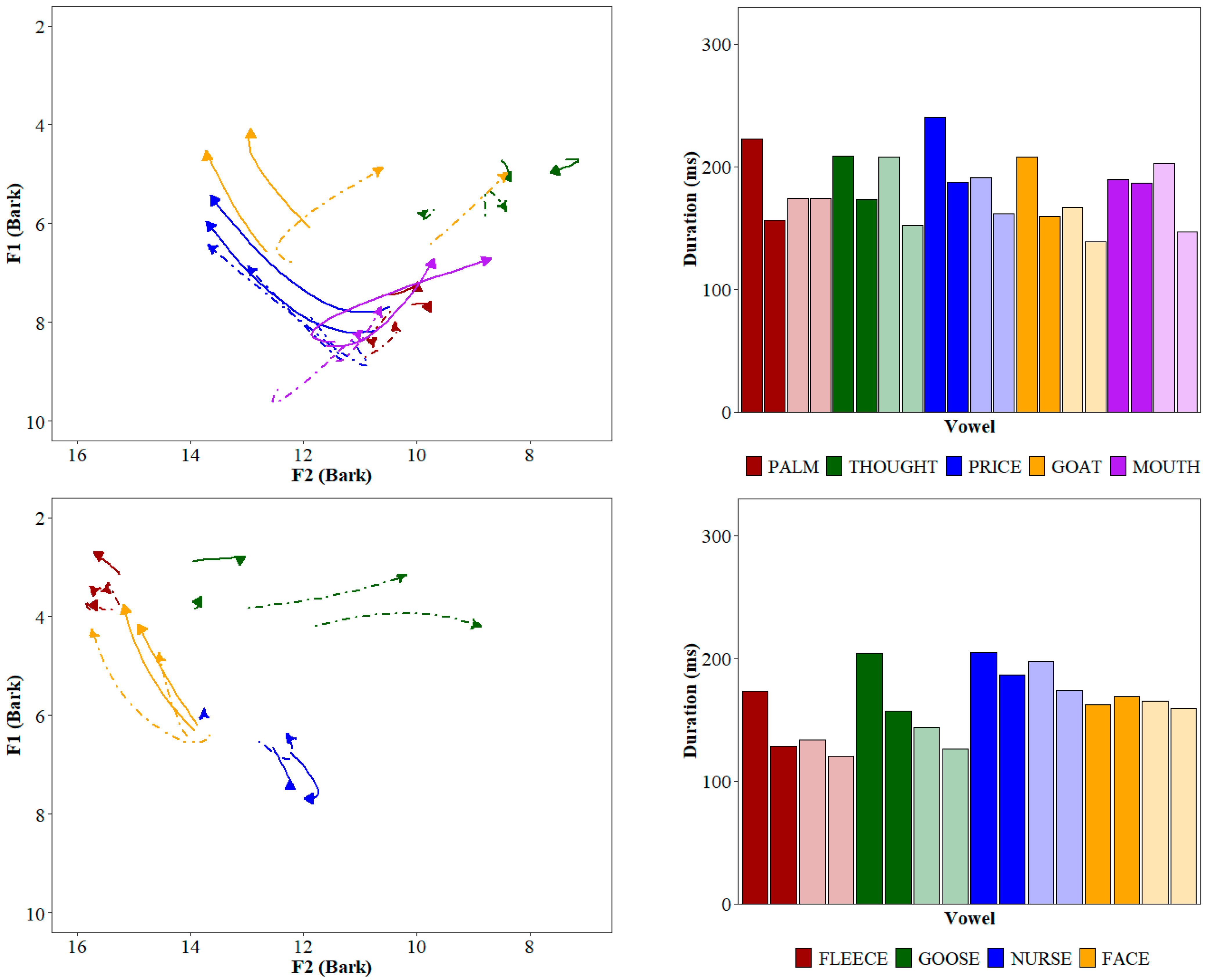
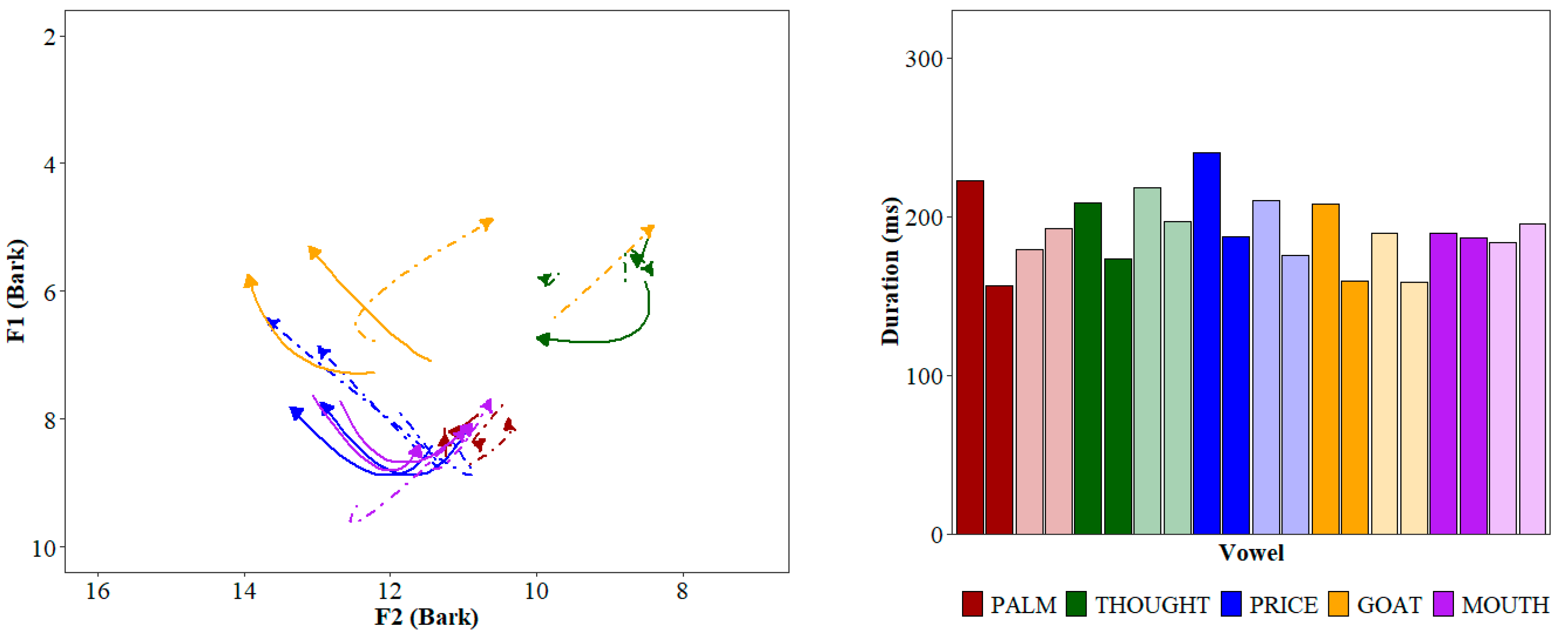
2.2. Auditory Syllables and Acoustic Similarity Procedure
2.3. Experiment Items
2.4. Experiment Procedure
2.5. Signal Detection Theory
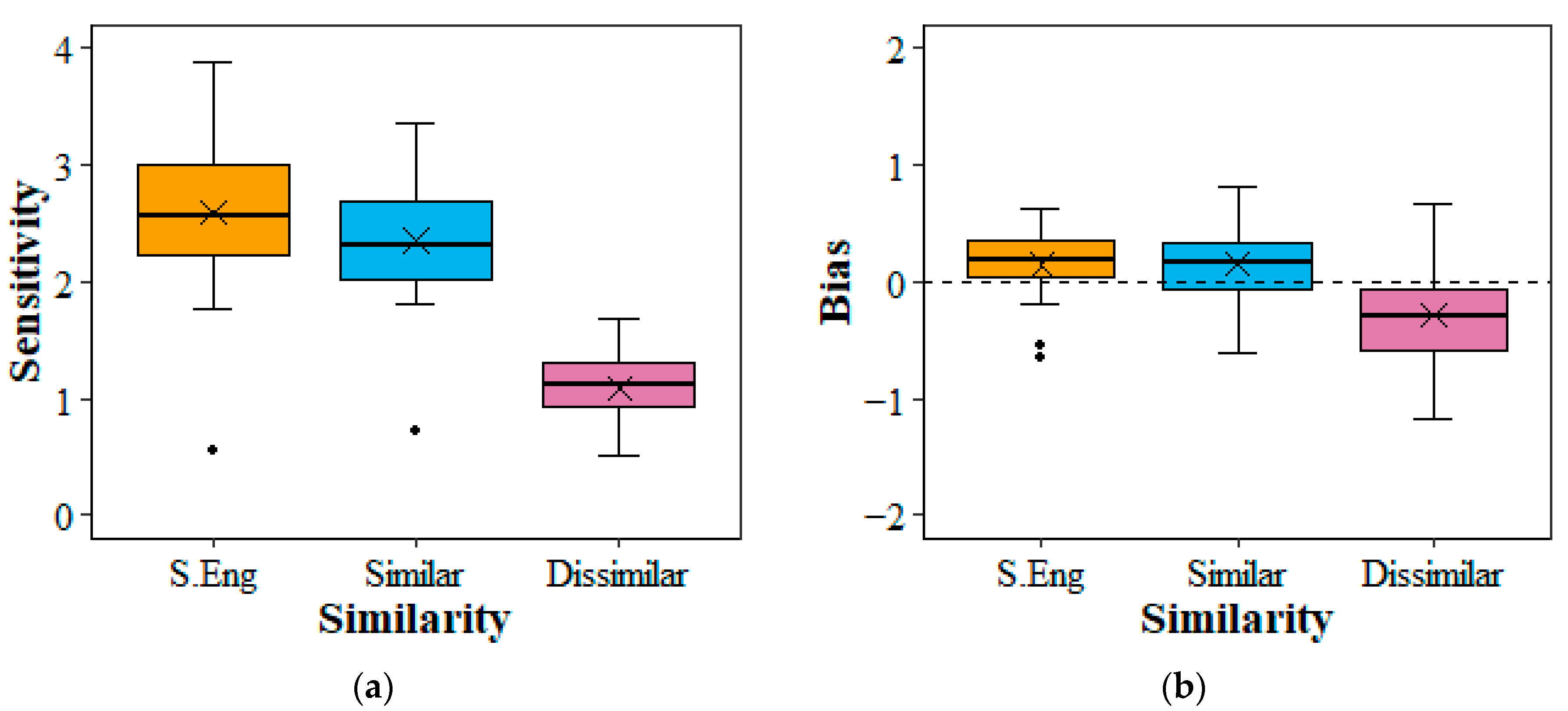
2.6. Results
3. Experiment 2: Monolinguals and Experienced Bilinguals
3.1. Participants
3.2. Auditory Syllables
3.3. Experiment Items
3.4. Experiment Procedure
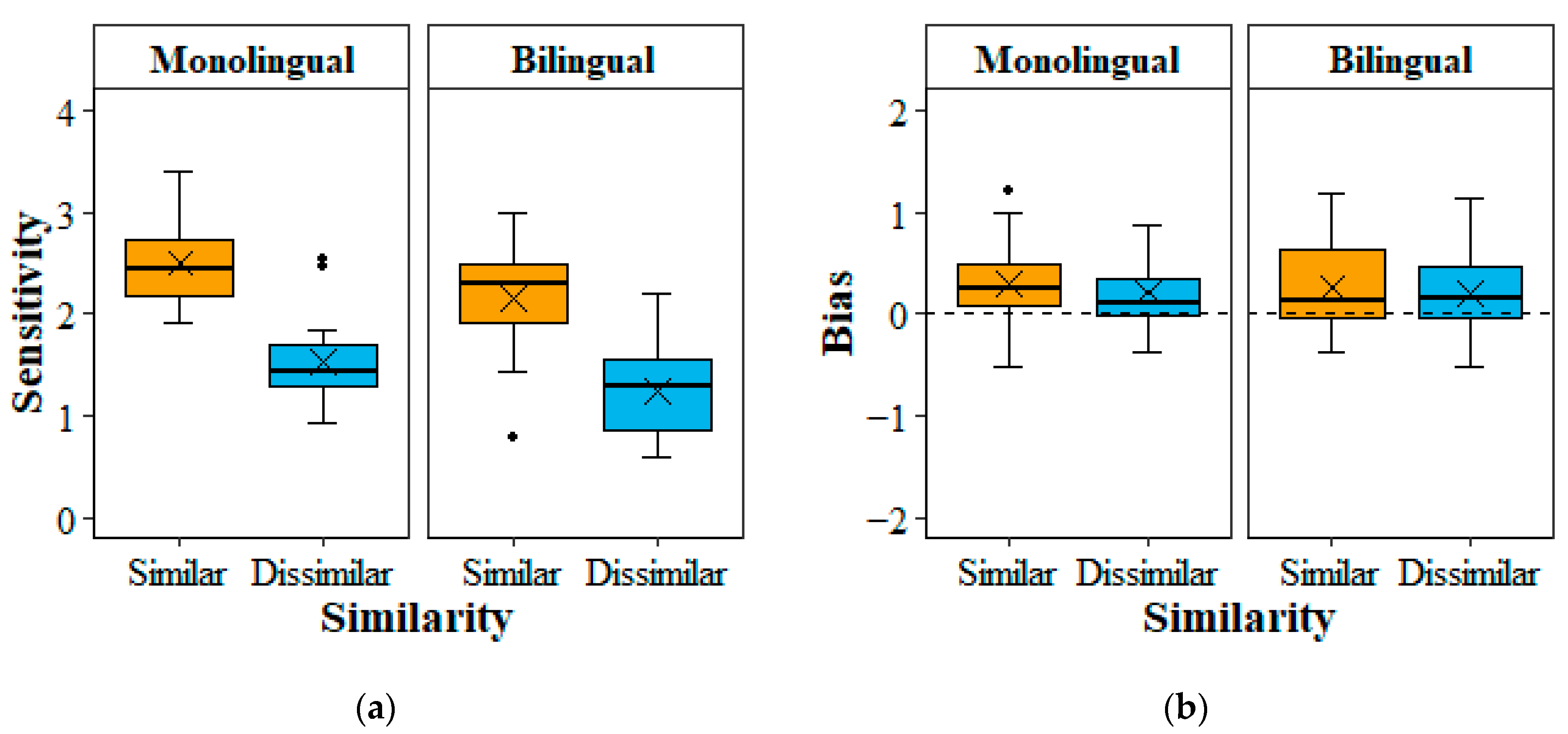
3.5. Results
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Frame | Phonemic Category | Speaker | |||||||
|---|---|---|---|---|---|---|---|---|---|
| S.Eng1 | S.Eng2 | N.Eng1 | N.Eng2 | ||||||
| Prob. | Group | Prob. | Group | Prob. | Group | Prob. | Group | ||
| /bVp/ | palm | 1.00 | Sim. | 1.00 | Sim. | 0.90 | Sim. | 0.15 | Dis. |
| thought | 1.00 | Sim. | 1.00 | Sim. | 0.45 | Dis. | 0.01 | Dis. | |
| price | 1.00 | Sim. | 1.00 | Sim. | 1.00 | Sim. | 0.85 | Sim. | |
| goat | 1.00 | Sim. | 0.89 | Sim. | 0.00 | Dis. | 0.02 | Dis. | |
| mouth | 1.00 | Sim. | 1.00 | Sim. | 0.90 | Sim. | 0.94 | Sim. | |
| /dVk/ | fleece | 0.99 | Sim. | 0.59 | Sim. | 0.44 | Dis. | 0.93 | Sim. |
| goose | 1.00 | Sim. | 0.98 | Sim. | 0.00 | Dis. | 0.03 | Dis. | |
| nurse | 1.00 | Sim. | 0.99 | Sim. | 0.99 | Sim. | 0.20 | Dis. | |
| face | 1.00 | Sim. | 1.00 | Sim. | 0.99 | Sim. | 1.00 | Sim. | |
| /fVf/ | kit | 0.99 | Sim. | 0.92 | Sim. | 0.97 | Sim. | 0.89 | Sim. |
| trap | 0.87 | Sim. | 1.00 | Sim. | 1.00 | Sim. | 0.83 | Sim. | |
| strut | 0.89 | Sim. | 1.00 | Sim. | 0.11 | Dis. | 0.59 | Sim. | |
| lot | 0.87 | Sim. | 0.94 | Sim. | 0.01 | Dis. | 0.00 | Dis. | |
| foot | 0.99 | Sim. | 1.00 | Sim. | 0.00 | Dis. | 0.00 | Dis. | |
Appendix B
| Frame | Phonemic Category | Speaker | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Aus.Eng1 | Aus.Eng2 | N.Eng1 | N.Eng2 | ||||||
| Prob. | Group | Prob. | Group | Prob. | Group | Prob. | Group | ||
| /bVp/ | palm | 0.78 | Sim. | 0.99 | Sim. | 0.63 | Sim. | 1.00 | Sim. |
| thought | 1.00 | Sim. | 0.99 | Sim. | 0.92 | Sim. | 1.00 | Sim. | |
| price | 1.00 | Sim. | 1.00 | Sim. | 0.99 | Sim. | 1.00 | Sim. | |
| goat | 0.96 | Sim. | 0.82 | Sim. | 0.64 | Sim. | 0.01 | Dis. | |
| mouth | 0.84 | Sim. | 0.97 | Sim. | 0.11 | Dis. | 0.21 | Dis. | |
| /dVk/ | fleece | 0.99 | Sim. | 0.97 | Sim. | 1.00 | Sim. | 1.00 | Sim. |
| goose | 1.00 | Sim. | 0.81 | Sim. | 0.01 | Dis. | 0.02 | Dis. | |
| nurse | 0.98 | Sim. | 0.99 | Sim. | 0.95 | Sim. | 0.97 | Sim. | |
| face | 0.81 | Sim. | 0.97 | Sim. | 0.25 | Dis. | 0.88 | Sim. | |
| /fVf/ | kit | 0.99 | Sim. | 1.00 | Sim. | 1.00 | Sim. | 0.99 | Sim. |
| trap | 0.94 | Sim. | 0.87 | Sim. | 0.85 | Sim. | 0.47 | Dis. | |
| strut | 0.97 | Sim. | 0.93 | Sim. | 0.01 | Dis. | 0.00 | Dis. | |
| lot | 0.97 | Sim. | 0.98 | Sim. | 0.01 | Dis. | 0.00 | Dis. | |
| foot | 0.90 | Sim. | 0.94 | Sim. | 0.95 | Sim. | 0.90 | Sim. | |
| 1 | The 14 syllables formed meaningless non-words with three potential exceptions. First, a variant common in North America for the English word duke, ‘nobleman’, corresponds to the syllable /dVk/, in which V is the goose vowel. Second, the syllable /dVk/, in which V is the nurse vowel corresponds to the regional word dirk, ‘dagger’, found in some Scottish dialects. Third, the syllable /fVf/, in which V is the trap vowel corresponds to the regional word faff, ‘unnecssary effort’, in informal British English. It is uncertain whether native German L2 learners residing in Germany or Aus.Eng listeners residing in Australia would be aware of these possible semantic associations. |
References
- Adank, Patti, Bronwen G. Evans, Jane Stuart-Smith, and Sophie K. Scott. 2009. Comprehension of familiar and unfamiliar native accents under adverse listening conditions. Journal of Experimental Psychology: Human Perception and Performance 35: 520–29. [Google Scholar]
- Alispahic, Samra, Karen E. Mulak, and Paola Escudero. 2017. Acoustic properties predict perception of unfamiliar Dutch vowels by adult Australian English and Peruvian Spanish listeners. Frontiers in Psychology 8: 52. [Google Scholar] [CrossRef] [PubMed]
- Baigorri, Miriam, Luca Campanelli, and Erika S. Levy. 2019. Perception of American–English vowels by early and late Spanish–English bilinguals. Language and Speech 62: 681–700. [Google Scholar] [CrossRef] [PubMed]
- Barr, Dale J., Roger Levy, Christoph Scheepers, and Harry J. Tily. 2013. Random effects structure for confirmatory hypothesis testing: Keep it maximal. Journal of Memory and Language 68: 255–78. [Google Scholar] [CrossRef] [PubMed]
- Best, Catherine T. 1995. A direct realist view of cross-language speech perception. In Speech Perception and Linguistic Experience: Issues in Cross-language Speech Research. Edited by Winifred Strange. Baltimore: York Press, pp. 171–203. [Google Scholar]
- Best, Catherine T., and Michael D. Tyler. 2007. Nonnative and second-language speech perception: Commonalities and complementarities. In Language Experience in Second Language Speech Learning: In Honor of James Emil Flege. Edited by Ocke-Schwen Bohn and Murray J. Munro. Amsterdam and Philadelphia: John Benjamins, pp. 13–34. [Google Scholar]
- Best, Catherine T., Gerald W. McRoberts, and Elizabeth Goodell. 2001. Discrimination of non-native consonant contrasts varying in perceptual assimilation to the listener’s native phonological system. Journal of the Acoustical Society of America 109: 775–94. [Google Scholar] [CrossRef] [PubMed]
- Bohn, Ocke-Schwen, and James Emil Flege. 1992. The production of new and similar vowels by adult German learners of English. Studies in Second Language Acquisition 14: 131–58. [Google Scholar] [CrossRef]
- Bradlow, Ann R., and Tessa Bent. 2002. The clear speech effect for non-native listeners. Journal of the Acoustical Society of America 112: 272–84. [Google Scholar] [CrossRef] [PubMed]
- Bürkner, Paul-Christian. 2017. brms: An R package for Bayesian multilevel models using Stan. Journal of Statistical Software 80: 1–28. [Google Scholar] [CrossRef]
- Bürkner, Paul-Christian. 2018. Advanced Bayesian multilevel modeling with the R Package brms. The R Journal 10: 395–411. [Google Scholar] [CrossRef]
- Colantoni, Laura, Paola Escudero, Victoria Marrero-Aguiar, and Jeffrey Steele. 2021. Evidence-based design principles for Spanish pronunciation teaching. Frontiers in Communication 6: 639889. [Google Scholar] [CrossRef]
- Cutler, Anne, Andrea Weber, Roel Smits, and Nicole Cooper. 2004. Patterns of English phoneme confusions by native and non-native listeners. Journal of the Acoustical Society of America 116: 3668–78. [Google Scholar] [CrossRef]
- DeCarlo, Lawrence T. 1998. Signal detection theory and generalized linear models. Psychological Methods 3: 186–205. [Google Scholar] [CrossRef]
- Elvin, Jaydene, Daniel Williams, and Paola Escudero. 2016. Dynamic acoustic properties of monophthongs and diphthongs in Western Sydney Australian English. Journal of the Acoustical Society of America 140: 576–81. [Google Scholar] [CrossRef] [PubMed]
- Elvin, Jaydene, Paola Escudero, and Polina Vasiliev. 2014. Spanish is better than English for discriminating Portuguese vowels: Acoustic similarity versus vowel inventory size. Frontiers in Psychology 5: 1188. [Google Scholar] [CrossRef]
- Escudero, Paola, and Daniel Williams. 2012. Native dialect influences second-language vowel perception: Peruvian versus Iberian Spanish learners of Dutch. Journal of the Acoustical Society of America 131: EL406–12. [Google Scholar] [CrossRef] [PubMed]
- Escudero, Paola, and Polina Vasiliev. 2011. Cross-language acoustic similarity predicts perceptual assimilation of Canadian English and Canadian French vowels. Journal of the Acoustical Society of America 130: EL277–83. [Google Scholar] [CrossRef]
- Escudero, Paola. 2005. Linguistic Perception and Second Language Acquisition: Explaining the Attainment of Optimal Phonological Categorization. Utrecht: LOT. [Google Scholar]
- Escudero, Paola, Catherine T. Best, Christine Kitamura, and Karen E. Mulak. 2014. Magnitude of phonetic distinction predicts success at early word learning in native and non-native accents. Frontiers in Psychology 5: 1059. [Google Scholar] [CrossRef]
- Escudero, Paola, Ellen Simon, and Holger Mitterer. 2012. The perception of English front vowels by North Holland and Flemish listeners: Acoustic similarity predicts and explains cross-linguistic and L2 perception. Journal of Phonetics 40: 280–88. [Google Scholar] [CrossRef]
- Ferragne, Emmanuel, and François Pellegrino. 2010. Formant frequencies of vowels in 13 accents of the British Isles. Journal of the International Phonetic Association 40: 1–34. [Google Scholar] [CrossRef]
- Flege, James Emil, and Ian R. A. MacKay. 2004. Perceiving vowels in a second language. Studies in Second Language Acquisition 26: 1–34. [Google Scholar] [CrossRef]
- Flege, James Emil, and Ocke-Schwen Bohn. 2021. The revised speech learning model (SLM-r). In Second Language Speech Learning: Theoretical and Empirical Progress. Edited by Ratree Wayland. Cambridge: Cambridge University Press, pp. 3–83. [Google Scholar]
- Flege, James Emil, and Serena Liu. 2001. The effect of experience on adults’ acquisition of a second language. Studies in Second Language Acquisition 23: 527–52. [Google Scholar] [CrossRef]
- Fox, Robert Allen, and Ewa Jacewicz. 2009. Cross-dialectal variation in formant dynamics of American English vowels. Journal of the Acoustical Society of America 126: 2603–18. [Google Scholar] [CrossRef] [PubMed]
- Gelman, Andrew, Aleks Jakulin, Maria Grazia Pittau, and Yu-Sung Su. 2008. A weakly informative default prior distribution for logistic and other regression models. Annals of Applied Statistics 2: 1360–83. [Google Scholar] [CrossRef]
- Georgiou, Georgios P. 2022. The acquisition of /ɪ/–/iː/ is challenging: Perceptual and production evidence from Cypriot Greek speakers of English. Behavioral Sciences 12: 469. [Google Scholar] [CrossRef] [PubMed]
- Georgiou, Georgios P. 2023. Comparison of the prediction accuracy of machine learning algorithms in crosslinguistic vowel classification. Scientific Reports 13: 15594. [Google Scholar] [CrossRef] [PubMed]
- Georgiou, Georgios P., and Dimitra Dimitriou. 2023. Perception of Dutch vowels by Cypriot Greek listeners: To what extent can listeners’ patterns be predicted by acoustic and perceptual similarity? Attention, Perception, & Psychophysics 85: 2459–74. [Google Scholar]
- Georgiou, Georgios P., Natalia V. Perfilieva, and Maria Tenizi. 2020. Vocabulary size leads to better attunement to L2 phonetic differences: Clues from Russian learners of English. Language Learning and Development 16: 382–98. [Google Scholar] [CrossRef]
- Gilichinskaya, Yana D., and Winifred Strange. 2010. Perceptual assimilation of American English vowels by inexperienced Russian listeners. Journal of the Acoustical Society of America 128: EL80–85. [Google Scholar] [CrossRef]
- Grosjean, François. 2001. The bilingual’s language modes. In One Mind, Two Languages: Bilingual Language Processing. Edited by Janet Nicol. Oxford: Blackwell, pp. 37–66. [Google Scholar]
- Hillenbrand, James, Laura A. Getty, Michael J. Clark, and Kimberlee Wheeler. 1995. Acoustic characteristics of American English vowels. Journal of the Acoustical Society of America 97: 3099–111. [Google Scholar] [CrossRef]
- Holt, Lori L., and Andrew J. Lotto. 2010. Speech perception as categorization. Attention, Perception, & Psychophysics 72: 1218–27. [Google Scholar]
- Iverson, Paul, and Bronwen G. Evans. 2007. Learning English vowels with different first-language vowel systems: Perception of formant targets, formant movement, and duration. Journal of the Acoustical Society of America 122: 2842–54. [Google Scholar] [CrossRef] [PubMed]
- Iverson, Paul, Patricia K. Kuhl, Reiko Akahane-Yamada, Eugen Diesch, Andreas Kettermann, and Claudia Siebert. 2003. A perceptual interference account of acquisition difficulties for non-native phonemes. Cognition 87: B47–57. [Google Scholar] [CrossRef] [PubMed]
- Keating, Pat. 2005. D-Prime (Signal Detection) Analysis. UCLA Phonetics Laboratory. Available online: http://phonetics.linguistics.ucla.edu/facilities/statistics/dprime.htm (accessed on 1 November 2023).
- Kriengwatana, Buddhamas, Josephine Terry, Kateřina Chládková, and Paola Escudero. 2016. Speaker and accent variation are handled differently: Evidence in native and non-Native Listeners. PLoS ONE 11: e0156870. [Google Scholar] [CrossRef] [PubMed]
- Kruschke, John. 2014. Doing Bayesian Data Analysis: A Tutorial with R, JAGS, and Stan. London: Academic Press. [Google Scholar]
- Kuhl, Patricia K. 1993. Innate predispositions and the effects of experience in speech perception: The native language magnet theory. In Developmental Neurocognition: Speech and Face Processing in the First Year of Life. Edited by Bénédicte de Boysson-Bardies, Scania de Schonen, Peter Jusczyk, Peter MacNeilage and John Morton. Dordrecht: Springer, pp. 259–74. [Google Scholar]
- Lado, Robert. 1957. Linguistics across Cultures: Applied Linguistics for Language Teachers. Ann Arbor: University of Michigan Press. [Google Scholar]
- Lecumberri, Maria Luisa Garcia, Martin Cooke, and Anne Cutler. 2010. Non-native speech perception in adverse conditions: A review. Speech Communication 52: 864–86. [Google Scholar] [CrossRef]
- Le, Jennifer T., Catherine T. Best, Michael D. Tyler, and Christian Kroos. 2007. Effects of non-native dialects on spoken word recognition. In Eighth Annual Conference of the International Speech Communication Association: Interspeech 2007. Adelaide: Causal Productions, pp. 1592–98. [Google Scholar]
- MacKay, Ian R. A., James Emil Flege, Thorsten Piske, and Carlo Schirru. 2001. Category restructuring during second-language speech acquisition. Journal of the Acoustical Society of America 110: 516–28. [Google Scholar] [CrossRef] [PubMed]
- Macmillan, Neil A., and C. Douglas Creelman. 1991. Detection Theory: A User’s Guide. Cambridge: Cambridge University Press. [Google Scholar]
- Makowski, Dominique, Mattan S. Ben-Shachar, S. H. Annabel Chen, and Daniel Lüdecke. 2019. Indices of Effect Existence and Significance in the Bayesian Framework. Frontiers in Psychology 10: 2767. [Google Scholar] [CrossRef]
- Mattys, Sven L., Matthew H. Davis, Ann R. Bradlow, and Sophie K. Scott. 2013. Speech recognition in adverse conditions: A review. Language and Cognitive Processes 27: 953–78. [Google Scholar] [CrossRef]
- Maye, Jessica, Richard N. Aslin, and Michael K. Tanenhaus. 2008. The weckud wetch of the wast: Lexical adaptation to a novel accent. Cognitive Science 32: 543–62. [Google Scholar] [CrossRef]
- Mayo, Lynn Hansberry, Mary Florentine, and Søren Buus. 1997. Age of second-language acquisition and perception of speech in noise. Journal of Speech, Language, and Hearing Research 40: 686–93. [Google Scholar] [CrossRef]
- Meador, Diane, James E. Flege, and Ian R. A. MacKay. 2000. Factors affecting the recognition of words in a second language. Bilingualism: Language and Cognition 3: 55–67. [Google Scholar] [CrossRef]
- Middlebrooks, John C., Jonathan Z. Simon, Arthur N. Popper, and Richard R. Fay. 2017. The Auditory System at the Cocktail Party. New York: Springer. [Google Scholar]
- Quené, Hugo, and L. E. Van Delft. 2010. Non-native durational patterns decrease speech intelligibility. Speech Communication 52: 911–18. [Google Scholar] [CrossRef]
- R Core Team. 2021. R: A Language and Environment for Statistical Computing (Version 4.1.2). Available online: https://www.R-project.org/ (accessed on 9 January 2022).
- Rogers, Catherine L., Jennifer J. Lister, Dashielle M. Febo, Joan M. Besing, and Harvey B. Abrams. 2006. Effects of bilingualism, noise, and reverberation on speech perception by listeners with normal hearing. Applied Psycholinguistics 27: 465–85. [Google Scholar] [CrossRef]
- Scharenborg, Odette, and Marjolein van Os. 2019. Why listening in background noise is harder in a non-native language than in a native language: A review. Speech Communication 108: 53–64. [Google Scholar] [CrossRef]
- Schmidtke, Jens. 2016. The bilingual disadvantage in speech understanding in noise is likely a frequency effect related to reduced language exposure. Frontiers in Psychology 7: 678. [Google Scholar] [CrossRef] [PubMed]
- Shaw, Jason A., Paul Foulkes, Jennifer Hay, Bronwen G. Evans, Gerard Docherty, Karen E. Mulak, and Catherine T. Best. 2023. Revealing perceptual structure through input variation: Cross-accent categorization of vowels in five accents of English. Laboratory Phonology 14: 1–38. [Google Scholar] [CrossRef]
- Stan Development Team. 2022. Stan User’s Guide and Stan Language Reference Manual. Available online: https://mc-stan.org/ (accessed on 19 October 2023).
- Stockwell, Robert P., J. Donald Bowen, and John W. Martin. 1965. The Grammatical Structures of English and Spanish. Chicago: University of Chicago Press. [Google Scholar]
- Strange, Winifred, Andrea Weber, Erika S. Levy, Valeriy Shafiro, Miwako Hisagi, and Kanae Nishi. 2007. Acoustic variability within and across German, French, and American English vowels: Phonetic context effects. Journal of the Acoustical Society of America 122: 1111–29. [Google Scholar] [CrossRef] [PubMed]
- Strange, Winifred, Miwako Hisagi, Reiko Akahane-Yamada, and Rieko Kubo. 2011. Cross-language perceptual similarity predicts categorial discrimination of American vowels by naïve Japanese listeners. Journal of the Acoustical Society of America 130: EL226–31. [Google Scholar] [CrossRef] [PubMed]
- Sumner, Meghan, and Arthur G. Samuel. 2009. The effect of experience on the perception and representation of dialect variants. Journal of Memory and Language 60: 487–501. [Google Scholar] [CrossRef]
- Tabri, Dollen, Kim Michelle Smith Abou Chacra, and Tim Pring. 2011. Speech perception in noise by monolingual, bilingual and trilingual listeners. International Journal of Language & Communication Disorders 46: 411–22. [Google Scholar]
- Tyler, Michael D., Catherine T. Best, Alice Faber, and Andrea G. Levitt. 2014. Perceptual assimilation and discrimination of non-native vowel contrasts. Phonetica 71: 4–21. [Google Scholar] [CrossRef] [PubMed]
- Van Hedger, Stephen C., and Ingrid S. Johnsrude. 2022. Speech perception under adverse listening conditions. In Speech Perception: Springer Handbook of Auditory Research. Edited by Lori L. Holt, Jonathan E. Peelle, Allison B. Coffin, Arthur N. Popper and Richard R. Fay. Cham: Springer International Publishing, pp. 141–71. [Google Scholar]
- Van Leussen, Jan-Willem, and Paola Escudero. 2015. Learning to perceive and recognize a second language: The L2LP model revised. Frontiers in Psychology 6: 1000. [Google Scholar] [CrossRef]
- Weiss, Deborah, and James J. Dempsey. 2008. Performance of bilingual speakers on the English and Spanish versions of the Hearing in Noise Test (HINT). Journal of the American Academy of Audiology 19: 5–17. [Google Scholar] [CrossRef]
- Wells, John C. 1982. Accents of English: Volume 1. Cambridge: Cambridge University Press, vol. 1. [Google Scholar]
- Werker, Janet F., and Chris E. Lalonde. 1988. Cross-language speech perception: Initial capabilities and developmental change. Developmental Psychology 24: 672–83. [Google Scholar] [CrossRef]
- Werker, Janet F., and Richard C. Tees. 1984. Cross-language speech perception: Evidence for perceptual reorganization during the first year of life. Infant Behavior and Development 7: 49–63. [Google Scholar] [CrossRef]
- Williams, Daniel, and Paola Escudero. 2014a. A cross-dialectal acoustic comparison of vowels in Northern and Southern British English. Journal of the Acoustical Society of America 136: 2751–61. [Google Scholar] [CrossRef]
- Williams, Daniel, and Paola Escudero. 2014b. Influences of listeners’ native and other dialects on cross-language vowel perception. Frontiers in Psychology 5: 1065. [Google Scholar] [CrossRef] [PubMed]
- Yazawa, Kakeru, James Whang, Mariko Kondo, and Paola Escudero. 2020. Language-dependent cue weighting: An investigation of perception modes in L2 learning. Second Language Research 36: 557–81. [Google Scholar] [CrossRef]
- Yazawa, Kakeru, James Whang, Mariko Kondo, and Paola Escudero. 2023. Feature-driven new sound category formation: Computational implementation with the L2LP model and beyond. Frontiers in Psychology 2: 1303511. [Google Scholar] [CrossRef]


| SDT Component | Predictor | Median | CI | PD | p |
|---|---|---|---|---|---|
| Response bias | Intercept | −0.08 | −0.32, 0.15 | 0.716 | 0.567 |
| Similarity-A * | 0.06 | −0.20, 0.32 | 0.651 | 0.698 | |
| Similarity-B ** | −0.55 | −0.77, −0.33 | 1.000 | <0.001 | |
| Sensitivity | Item type | 2.71 | 2.40, 3.01 | 1.000 | <0.001 |
| Similarity-A * × Item type | −0.13 | −0.67, 0.39 | 0.661 | 0.678 | |
| Similarity-B ** × Item type | −1.70 | −2.14, −1.24 | 1.000 | <0.001 |
| SDT Component | Predictor | Median | CI | PD | p |
|---|---|---|---|---|---|
| Response bias | Intercept | 0.27 | 0.11, 0.44 | 0.994 | 0.012 |
| Similarity | −0.06 | −0.23, 0.11 | 0.709 | 0.581 | |
| Group | −0.03 | −0.33, 0.25 | 0.569 | 0.862 | |
| Similarity × Group | −0.02 | −0.16, 0.10 | 0.606 | 0.788 | |
| Sensitivity | Item type | 2.30 | 2.08, 2.51 | 1.000 | <0.001 |
| Similarity × Item type | −0.99 | −1.32, −0.64 | 1.000 | <0.001 | |
| Group × Item type | −0.51 | −0.80, −0.21 | 0.996 | 0.007 | |
| Similarity × Group × Item type | 0.00 | −0.30, 0.30 | 0.507 | 0.986 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Williams, D.; Ağabeyoğlu, T.; Gafos, A.; Escudero, P. Acoustic Similarity Predicts Vowel Phoneme Detection in an Unfamiliar Regional Accent: Evidence from Monolinguals, Bilinguals and Second-Language Learners. Languages 2024, 9, 62. https://doi.org/10.3390/languages9020062
Williams D, Ağabeyoğlu T, Gafos A, Escudero P. Acoustic Similarity Predicts Vowel Phoneme Detection in an Unfamiliar Regional Accent: Evidence from Monolinguals, Bilinguals and Second-Language Learners. Languages. 2024; 9(2):62. https://doi.org/10.3390/languages9020062
Chicago/Turabian StyleWilliams, Daniel, Turgut Ağabeyoğlu, Adamantios Gafos, and Paola Escudero. 2024. "Acoustic Similarity Predicts Vowel Phoneme Detection in an Unfamiliar Regional Accent: Evidence from Monolinguals, Bilinguals and Second-Language Learners" Languages 9, no. 2: 62. https://doi.org/10.3390/languages9020062