
Estimation of Error Variance in Regularized Regression Models via Adaptive Lasso


1
Department of Applied Mathematics, Beijing Jiaotong University, Beijing 100044, China
2
Department of Statistics, University of Manitoba, Winnipeg, MB R3T 2N2, Canada
*
Author to whom correspondence should be addressed.
Mathematics 2022, 10(11), 1937; https://doi.org/10.3390/math10111937
Submission received: 24 April 2022
/
Revised: 30 May 2022
/
Accepted: 30 May 2022
/
Published: 6 June 2022
(This article belongs to the Special Issue Statistical Methods for High-Dimensional and Massive Datasets)
Abstract
:Estimation of error variance in a regression model is a fundamental problem in statistical modeling and inference. In high-dimensional linear models, variance estimation is a difficult problem, due to the issue of model selection. In this paper, we propose a novel approach for variance estimation that combines the reparameterization technique and the adaptive lasso, which is called the natural adaptive lasso. This method can, simultaneously, select and estimate the regression and variance parameters. Moreover, we show that the natural adaptive lasso, for regression parameters, is equivalent to the adaptive lasso. We establish the asymptotic properties of the natural adaptive lasso, for regression parameters, and derive the mean squared error bound for the variance estimator. Our theoretical results show that under appropriate regularity conditions, the natural adaptive lasso for error variance is closer to the so-called oracle estimator than some other existing methods. Finally, Monte Carlo simulations are presented, to demonstrate the superiority of the proposed method.
Keywords:
high-dimensional linear model; variance estimation; natural adaptive lasso; mean squared error bound; regularized regressionMSC:
62F10; 62J05; 62J101. Introduction
Consider linear regression model , where is the response variable, is the predictor variable, is the unknown regression parameter and is the random error satisfying . Given an random sample , , the model can be written in the matrix form as , where , and . In this paper, we are mainly interested in the high-dimensional sparse model, where .
Regularized methods for simultaneous model selection and parameter estimation have been intensively studied in the literature, e.g., the lasso [1], smoothly clipped absolute deviation (SCAD) [2], adaptive lasso [3], bridge [4], adaptive elastic net [5], and minimax concave penalty (MCP) [6], as well as the Dantzig selector [7]. In addition, screening rules for dimension reduction are proposed, e.g., the sure independent screening method and iteratively sure independent screening method [8], lasso-based screening rules [9,10,11], etc.
However, most of these works focus on selection and estimation, with respect to regression parameters, and few studies deal with estimation of error variance, although it is a fundamental and crucial problem in statistical inference and regression analysis. In conventional linear models, the common estimator, based on residuals, plays an important role in statistical inferences and model checking. In high-dimensional models, however, variance estimation becomes a difficult problem, mainly due to two reasons. One is that the traditional residual-based methods may perform poorly or, even, fail, as, for example, the ordinary least squares method does not work when the number of covariates is greater than the sample size. The other reason is that it is difficult to select the true model, accurately, since in practice the selected model, often, contains spurious variables that are correlated with the residuals, resulting in significant underestimation of error variance (e.g., [12,13]).
Next, we provide some examples, where model error variance is involved and plays an important role.
Example 1
(Model selection). Penalization is a common approach to model selection and parameter estimation, in high-dimensional linear models. The efficiency and accuracy of such methods depend on certain tuning parameters that are chosen using some criteria, such as Mallows’s , Akaike’s information criterion (AIC) and the Bayesian information criterion (BIC). For example, the AIC and BIC for the lasso [14] are given by
and
respectively, where is the lasso estimator with tuning parameter and the degrees of freedom is equal to the number of non-zero elements in . It is easy to see that these criteria rely on error variance.
Example 2
(Confidence intervals). For a least-squares-based penalized estimator , let be its index set, corresponding to non-vanishing parameters. If has the oracle property, then for each , the confidence interval for is given by
where is the -th quantile of the standard normal distribution and is the i-th diagonal element of the matrix . It is clear that the above intervals depend on the variance parameter.
Example 3
(Penalized second-order least squares estimation). The second-order least squares method, in [15], extends the ordinary least squares method by, simultaneously, minimizing the first two order distances
and yields the joint estimators for the regression and variance parameters. Under general conditions, the second-order least squares estimator has been shown to be, asymptotically, more efficient than the ordinary least squares estimator, if the model error has a nonzero third moment, and they are equivalent otherwise. The regularized version of this method can be used in high-dimensional models.
1.1. Literature Review
Variance estimation in high-dimensional models has attracted increasing attention in recent years. Here, we briefly review some important advances in this area. First, if the true parameter vector was known, then the ideal variance estimator, called the oracle estimator, is . Correspondingly, the estimator , based on some estimator for , is called a naive estimator. Since the naive estimator is downward biased, a modified unbiased estimator is given by , where is the number of nonzero elements in . Unfortunately, when p is much larger than n, even a small change in will cause huge fluctuation in , if .
To overcome this problem, Ref. [16] estimated the mean and variance parameters jointly, by maximizing a reparameterized likelihood with penalty:
where , and . Moreover, they proposed a generalized EM algorithm for the numerical optimization.
A refitted cross-validation (RCV) method, to derive a variance estimator, was proposed in [12], and its asymptotic properties were studied. The main idea of RCV is to attenuate the influence of irrelevant variables with high spurious correlations, via a data-splitting technique. Ref. [12], also, discussed the asymptotic properties of the lasso-based estimator and SCAD-based estimator , where and are the least squares estimator, with penalty [1] and SCAD penalty [2], respectively; and .
Further, a scaled lasso was proposed in [17], for simultaneous estimation of regression and variance parameters. Their model can be written as
Under some regularity conditions, Ref. [17] proved the oracle inequalities for prediction and their estimators.
A moment estimator for the error variance, based on the covariance matrix of the predictor variables, was studied in [18], where three cases were considered: , estimable and non-estimable . A maximum likelihood method for the normally distributed noise was developed in [19].
Moreover, Ref. [13] considered another re-parameterized likelihood, with lasso penalty
where , . In particular, they proposed two estimators: the natural lasso with and the organic lasso with .
Finally, Ref. [20] proposed a ridge-based method to estimate the error variance, under certain conditions, which is defined as follows:
where , and is the tuning parameter. This method performs well in low-dimensional cases, with weak signals, and it is suitable for sparse as well as non-sparse models.
1.2. Notation and Outline
Throughout the paper, let be the index set and be the number of the nonzero elements of , respectively. Given a design matrix and a subset of , denotes the i-th column vector of , and denotes the sub-matrix, consisting of the columns with indices in . For vectors , , denotes the Hadamard product. Moreover, let , , , , where
The rest of this paper is organized as follows: Section 2 defines and describes the proposed natural adaptive lasso, and Section 3 gives its asymptotic properties. Section 4 deals with the numerical optimization of the proposed estimators. Monte Carlo simulation studies of finite sample properties are provided in Section 5. The conclusions and discussion are given in Section 6, while the mathematical proofs are given in Section 7.
2. Natural Adaptive Lasso (NAL)
Some researchers, e.g., Refs. [13,16], used reparameterized likelihood to jointly estimate the mean and variance parameters in high-dimensional linear models. In particular, the method of [13] has good performance, and the associated numerical computation can be converted to some simple optimization procedures. However, the natural lasso in [13] always overestimates error variance, due to the over-selection of the covariates. This motivates us to consider the more generally adaptive lasso penalty, to further improve the properties of the estimators. Consider the following adaptively weighted -penalized likelihood
where is the reparameterized likelihood as (1), is the tuning parameter and is the adaptive weight vector. Given a solution of problem (2), the natural adaptive lasso estimators (NALE) for and are given by
It is easy to see that, when , the NALE reduces to the natural lasso estimator (NLE) of [13].
Note that the quality of the NALE depends on the weight vector . It follows from Proposition 1 in Section 3, that the weight in problem (2) plays the same role as in the adaptive lasso estimation of the regression coefficients only, which solves the following convex optimization problem:
where the weight depends on the initial estimator . As indicated by [3], any root-n consistent estimator can be used as the initial estimator for . For example, the least squares estimator can be used, and the weight vector is calculated as , . Ref. [4] discusses the selection of the initial estimators in linear models, with for some . They show that their marginal regression estimator can be used in the adaptive lasso, to yield the desirable selection and estimation properties. In addition, the weight in adaptive elastic-net [5], for moderate dimensional models (), can be constructed as , , where is the elastic-net estimator. In this paper, we use the following two-step procedure to calculate the weight vector.
Step 1: Solve the lasso problem to obtain the NLE , which is used as the initial estimator .
Step 2: Set with , where and is a folded-concave penalty function (such as SCAD, MCP or bridge).
Remark 1.
From [7,21,22], under some regularity conditions, the lasso is consistent with a near-oracle rate and has the sure-screening property, i.e.,
Further, based on the order of the bias of the lasso, under suitable conditions for the minimum signal strength (dee the first part of Condition 4 in Section 7) and the choice of tuning parameter, will be close, or even equal, to zero vector, when n is sufficiently larger, if a folded-concave penalty, such as SCAD, is used. These properties play an important role in some of the conclusions that follow.
3. Asymptotic Properties
In this section, we, first, establish the relationship between the NALE and the adaptive lasso, then analyze the asymptotic properties of the NALE for .
Proposition 1.
The results of Proposition 1 are instrumental in the derivation of the other theoretical results in this paper. Moreover, they, also, provide a method for calculating the NALE for and . It is well known that the adaptive lasso (4) is a convex optimization, and many existing optimization tools can be used to compute this problem.
Note that, since
and will be close or even equal to zero, for suitably chosen , the NALE for will be close to the naive estimator, if . As mentioned before, the naive estimator for , based on the adaptive lasso estimator , may work well when non-zero variables are selected, accurately. However, when more irrelevant variables are selected, the value of the penalty term will not be close to 0 in the finite sample, so that the naive estimator for will, always, underestimate the true error variance. In this case, the penalty term will mitigate the difference between the naive estimator and the true variance. Although the form of the natural lasso estimator of [13] is similar to (5), their method often tends to over-select predictors, due to the use of a lasso penalty. In addition, the value of the penalty term in [13] remains large because it is not controlled by the weight vector. These facts explain why the natural lasso estimator for tends to be larger than the true error variance in the simulation studies, in [13].
Next, we establish a key inequality for the NALE for .
Lemma 1.
If , then
The above inequality is deterministic, in that it does not rely on any statistical assumptions for and . Unlike Lemma 1 in [13], the proof of this result uses the fact that any vector provides an upper bound on and the convexity of the loss function. In addition, if and , Lemma 1 reduces to Lemma 1 in [13]. If is close or equal to zero, and , then the bound on the right-hand side of the inequality in Lemma 1 is lower than that for the natural lasso and organic lasso in [13].
3.1. Adaptive Lasso
It follows, from Lemma 1, that the error bound of the NALE for is controlled by the convergence rate of the adaptive-lasso estimator . Therefore, it is necessary to establish the asymptotic properties for . The results in this subsection are similar to that in [23]. All regularity conditions and proofs are given in Section 7.
Theorem 1.
Suppose Conditions 1–3 hold. Assume that
and , where is some positive constant and . Then, with probability at least , there exists unique minimizer of problem (4), such that and , where
with some constant , and are defined in the regularity conditions.
It follows from inequality (18) that the extra term in is due to the bias of the initial estimator . When tends to zero, the order of the extra term is . Thus, under some general conditions, the convergence rate of is . Usually, the order of L is .
We, now, present the asymptotic normality of the adaptive-lasso estimator .
Theorem 2.
Assume that conditions of Theorem 1 hold. Let for any satisfying . Then, under Conditions 1–4, with probability at least , the minimizer in Theorem 1 satisfies
where .
The result of Theorem 2 is consistent with the asymptotic normality, for the bridge estimator of in [4]. The only difference is in the form of the penalty function.
Next, we consider the convergence performance of the specific adaptive-lasso estimator , with a weight vector decided by the SCAD penalty [23], which is defined by
where is a given constant and . Usually, the order of is . By definition, it holds , and Condition 4 is satisfied when . Thus, we have the following result.
Corollary 1.
Assume that the conditions of Theorem 1 hold. Then, under Conditions 1–4, with probability at least , there exists unique minimizer of problem (4), such that
Furthermore, satisfies
where for any satisfying .
The rate of convergence of the estimators in Theorem 1 and Corollary 1 is controlled by the distribution of random error and predictor matrix. Moreover, these results can be generalized for other situations, where random error follows sub-Gaussian or sub-exponential distributions.
3.2. Error Bounds of NALE
In this subsection, we establish the error bound for the NALE of . It follows from (14) that, under the conditions of Theorem 1, holds, with probability . Since , we have . Thus, in order to establish the asymptotic properties of NALE for , we still need to determine the order of . By Condition 2 and Theorem 1, we have
Thus, we have the following result on the error bound of the NALE for .
Theorem 3.
Under the conditions of Theorem 1, the NALE for has the following error bound, with probability at least :
where .
The proof of the above result follows, straightforwardly, from Lemma 1 and Theorem 1, so it is omitted. Since , is close or equal to zero, and the order of for the adaptive lasso is , we have . It follows that when , the error bound of NALE for is smaller than that of the NLE, OLE and SLE, when n is sufficiently large. In the following, we analyze the mean squared error bound for the NALE of .
Theorem 4.
Under the conditions of Theorem 1, for any and , the NALE for satisfies
Note that the above mean squared error bound of NALE for is lower than that for the NLE, OLS and SLE estimators. Finally, we consider the case using the SCAD penalty. Then, by Theorem 3 and the fact that , under the condition on minimum signal strength, we have the following result.
Corollary 2.
Under the conditions of Corollary 1, the NALE for using the SCAD has the following error bound, with probability at least :
Further, by Theorem 4 and Corollary 2, we have the mean squared error bound of the NALE for using the SCAD.
Corollary 3.
Under the conditions of Corollary 1, for any , the NALE for using SCAD with satisfies the following relative mean squared error bound:
4. Numerical Optimization
In this section, we study the optimization method for the NALE. Proposition 1 provides an easy way to calculate the NALE for , through existing optimization tools, to compute the adaptive lasso (4). Given the tuning parameter , we consider the proximal gradient algorithm (PGA) to calculate this problem, which has the following steps:
- Initialization: take initial value , .
- Iterative step: .
In the above framework, is taken to be the Lipschitz constant of , , such that for any , ,
Usually, . In addition, by the definition of proximal mapping,
By simple calculation,
Finally, the PGA is terminated, when either the sequence meets the criterion
or the maximum number of iterations is reached.
5. Numerical Simulations
In this section, we carry out Monte Carlo simulations to study the finite-sample performance of the NALE, with the weight calculated by using the SCAD penalty. Further, we compare the NALE with the square-root/scaled lasso (SLE) [17], the natural lasso (NLE) [13], the organic lasso (OLE) [13] and the ridge-based estimator (RBE) [20]. We, also, include the oracle estimator (OE) , as a benchmark in the comparisons. All numerical computation was done using Matlab. The programs are available upon request, from the first author of this paper or Supplementary Materials.
5.1. Simulation Settings
Following [23], throughout the simulations we use the sample size and parameter dimension . Further, each row of the design matrix is generated from the multivariate normal distribution , with and . The sparsity of is set to be the largest integer less than or equal to , and the locations of the nonzero elements in are determined randomly. We consider various parameter values, , and , and use the following true regression parameter vectors
We have, also, considered other variance settings, such as , however, the simulation results are similar to that of the above settings and, therefore, are not included. To assess the performances of the estimators, we calculate the average mean squared error (MSE) and the average relative error (RE) , based on 100 Monte Carlo runs.
5.2. Selection of Tuning Parameters
Usually, five-fold cross-validation can be used, to select tuning parameters for each estimation, which is fairly expensive. In order to reduce the computational cost, we consider the following methods, with a fixed choice of tuning parameters for all estimators, except for the NLE and NALE.
For the SLE, we consider three penalty levels , , which is similar to Example 1 in [17]. Then, the best estimator is selected as the final SLE estimator. Indeed, Ref. [17] found that works very well for SLE. By the simulation results of [13], the OLE with and performed very well, where . From [20,24], the tuning parameter used in RBE is calculated by setting with .
5.3. Simulation Results
In each simulation, 100 runs are carried out to calculate the average of the performance measures. The results are presented in Table 1, Table 2, Table 3 and Table 4. These results show that, overall, both the MSE and RE of the NALE are very close to that of the OE, and are remarkably better than the other estimators, in most of the cases. However, in a few cases, such as and with both and , the NALE has a slightly larger MSE than the NLE, although it has smaller RE than the latter. As expected, the NLE often overestimates the true value, due to the bias and over-selection of the lasso. Moreover, in the cases where the NLE has a relatively large MSE, the NALE tends to have a large MSE as well, indicating that the poor performance of the NLE will impact the performance of the NALE, since it is used as the initial estimator. Finally, Ref. [20] reported that the RBE performs well in the cases with relatively small p and weak signals, however, it performs poorly and is, even, ineffective in the settings of our simulations.
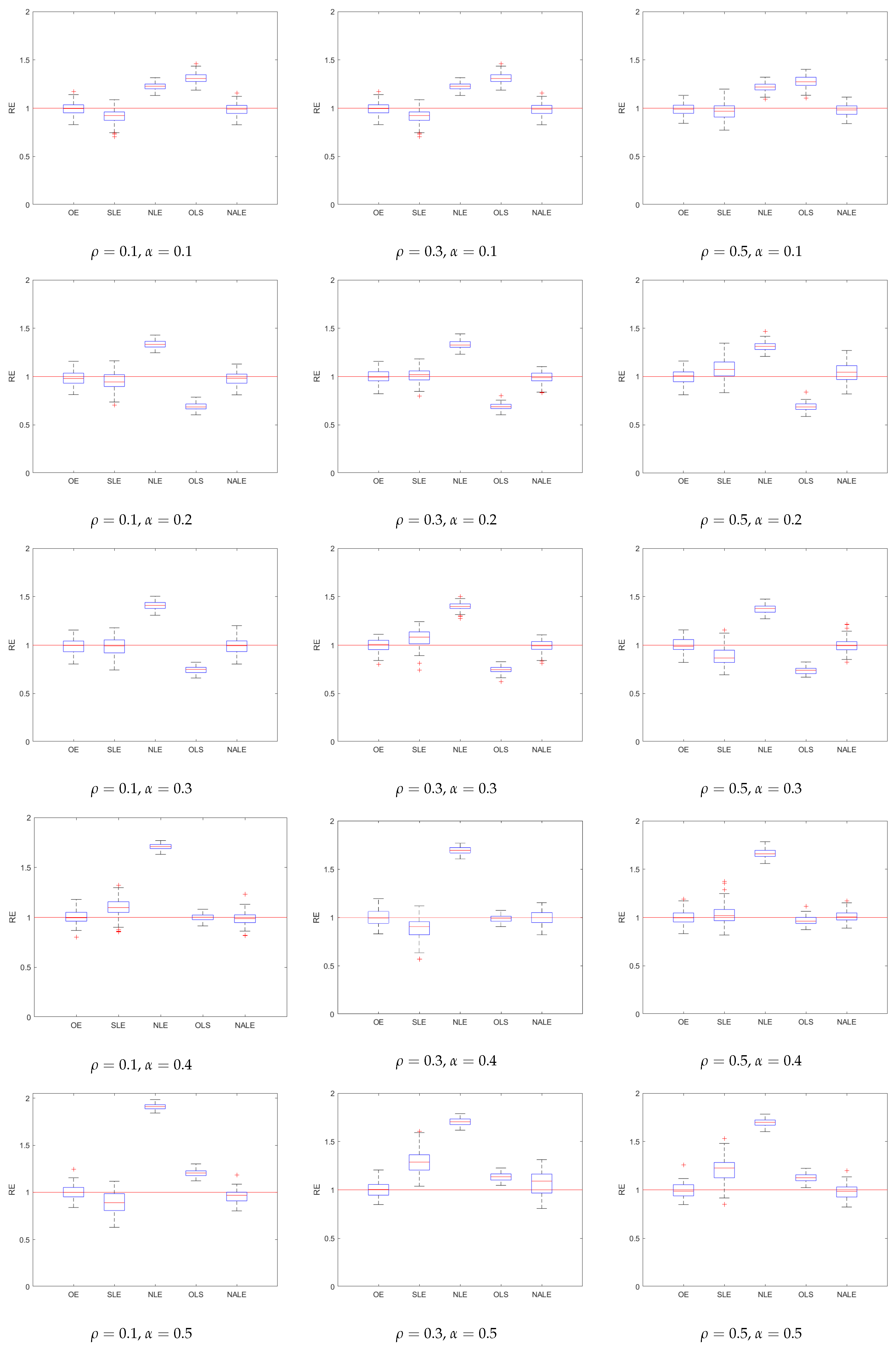
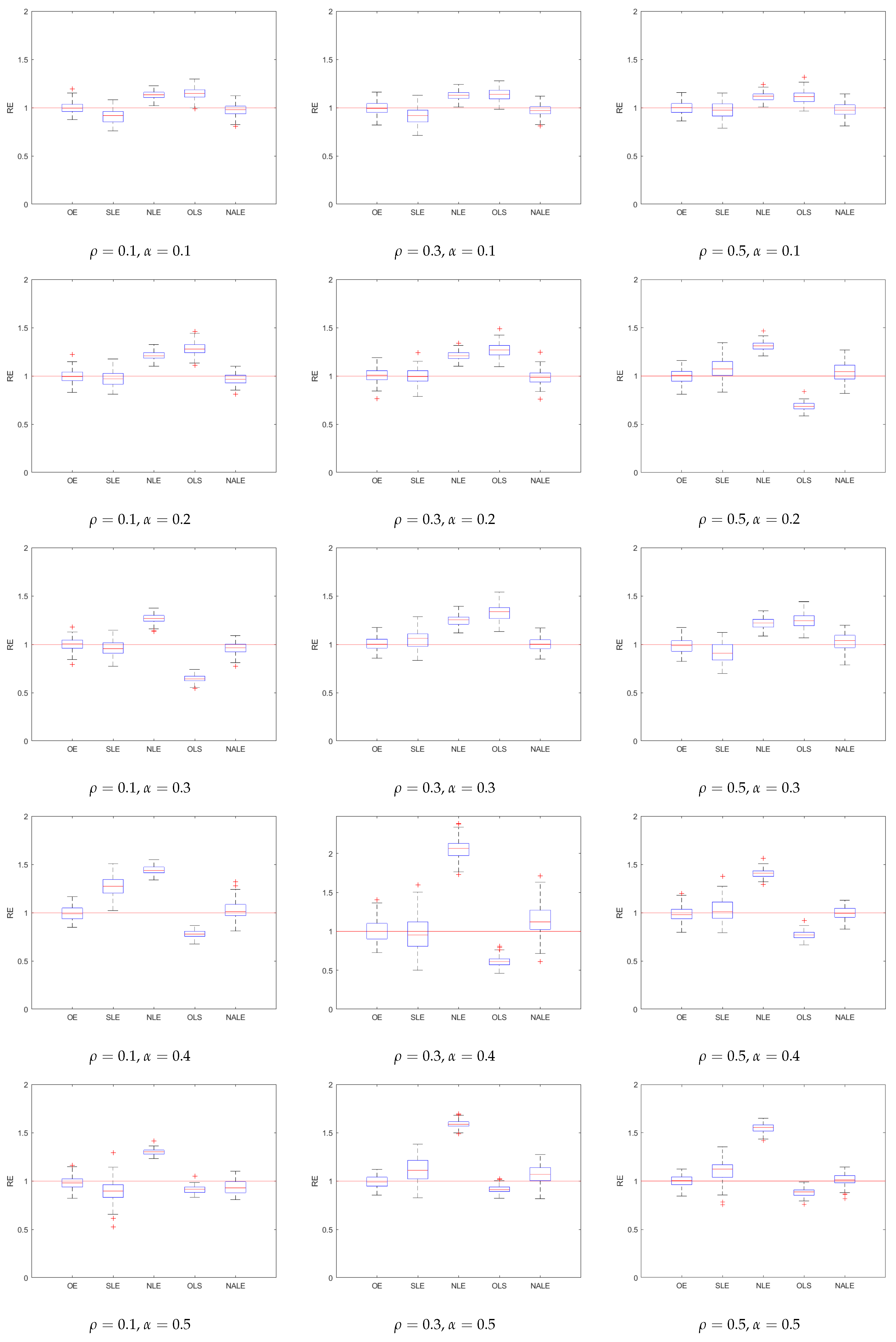
We, further, summarize the performances of various methods using boxplots, in Figure 1 and Figure 2. As one can easily see, the NALE is accurate and stable in all cases, while the OLE is less accurate, although it is, still, fairly stable. Further, the NALE performs well in extremely sparse scenarios. Another interesting point is that the NALE inherits the variable selection and parameter estimation of the adaptive lasso. Although we focus on the variance estimation in this work, the method performs well in estimating the regression coefficients as well.
6. Conclusions and Discussion
We proposed a novel approach for variance estimation that combines the reparameterized log-likelihood function and adaptive-lasso penalization. We have established the asymptotic properties of the NALE. The theory in this paper shows that the NALE converges at a faster rate than some other existing estimators, including the NLE, OLE and SLE. In addition, the NAL is closely related to the adaptive lasso, which makes its numerical calculation straightforward. We have used the PGA to obtain the NALE in numerical simulations. Our simulation results show that the NALE performs well and favorably against other existing methods, in most finite sample situations, especially in extremely sparse scenarios. However, the quality of the NALE depends on that of the initial estimator used in its numerical optimization, and the poor performance of the initial estimator may result in the poor performance of the NALE.
7. Regularity Conditions and Proofs
This section provides theoretical proofs. We first state the following regularity conditions.
Condition 1.
With probability approaching one, the initial estimator satisfies .
Condition 2.
is non-increasing in and is Lipschitz with constant , that is,
for any , . Moreover, for sufficiently large n, where is defined in Condition 1.
Condition 3.
There exist positive constants , such that
and
where , , is defined in Theorem 1.
Condition 4.
The true coefficients satisfy . Moreover, it holds for any and .
As we pointed out in Remark 1, the lasso estimator satisfies Condition 1. Condition 2 affects the bound between and and is used in the proof of Theorem 1. Further, it determines the bound between and . The first part of Condition 3 is a very common regularity condition (see [4,12,23]) in high-dimensional regression. The remaining part is similar to Condition 3 in [23], which is used in the proofs of Theorems 1 and 2. Condition 4 is needed in the analysis of Corollary 1.
Proof of Lemma 1.
From Proposition 1, we have
Since the loss function in the adaptive lasso is convex, we have
Proof of Theorem 1.
Since problem (4) is a convex optimization, by Theorem 1 of [25], it suffices to show that, with probability tending to 1, there exists a minimizer of problem (4) that satisfies
where .
Let and . Since and , it follows from Corollary 4.3 in [26] that, for any ,
Now we show that there exists a minimizer of problem (4) satisfies conditions (11)–(13).
Equation (11): Consider the minimizer of problem (4) in the subspace . Let , where with , , and is some large enough constant. Note that
where , . For , by (14), we have
where the last inequality holds, due to . For , we have
By the two-steps procedure of weight vector and Condition 2, it holds that
Taking a large enough C, we have obtained, with probability tending to one,
It follows, immediately, that, with probability approaching one, there exists a minimizer of problem (4), subject to subspace , such that , with some constant . Therefore, equality (11) holds, by the optimality theory.
Inequality (12): It remains to be proven that with asymptotic probability 1, (12) holds. Then, by optimality theory, is the unique global minimizer of problem (4).
By triangle inequality, we have
Further, by Condition 1, we have with probability approaching one, where . Moreover, by the definition of the fold-concave penalty function,
Therefore, by Condition 2 and inequality (20), we conclude that
Thus, for the first term of the right hand of inequality (19), by (14) and the condition that , with probability approaching one,
Proof of Theorem 2.
By equality (11), Since , we have
Therefore,
By the first part of Condition 4 and the bound of in Theoroem 1, we have . Then, . In addition, by the second part in condition 4,
where and lie on the line segment . It follows that . Further, since
we have, for the second term of the left hand of (24),
Finally, the result follows, by verifying the conditions of the Lindeberg–Feller central limit theorem, in the same way as in the proof of Theorem 2 in [4]. □
Supplementary Materials
The following supporting information can be downloaded at: https://www.mdpi.com/article/10.3390/math10111937/s1, The programs in numerical simulations are available in supplementary materials.
Author Contributions
Methodology, X.W., L.K. and L.W.; software, X.W.; writing—original draft, X.W., L.K. and L.W.; validation, X.W., L.K. and L.W. All authors have read and agreed to the published version of the manuscript.
Funding
The National Natural Science Foundation of China (12071022) and the 111 Project of China (B16002).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
The authors thank the editor and the three anonymous reviewers, for their helpful comments and suggestions.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Tibshirani, R. Regression shrinkage and selection via the lasso. J. R. Stat. Soc. Ser. B 1996, 73, 273–282. [Google Scholar] [CrossRef]
- Fan, J.; Li, Y. Variable selection via nonconcave penalized likelihood and its oracle properties. J. Am. Stat. Assoc. 2001, 96, 1348–1360. [Google Scholar] [CrossRef]
- Zou, H. The adaptive lasso and its oracle properties. J. R. Stat. Soc. Ser. B 2006, 101, 1418–1429. [Google Scholar] [CrossRef] [Green Version]
- Huang, J.; Horowitz, J.L.; Ma, S. Asymptotic properties of bridge estimators in sparse high-dimensional regression models. Ann. Stat. 2008, 36, 587–613. [Google Scholar] [CrossRef]
- Zou, H.; Zhang, H.H. On the adaptive elastic-net with a diverging number of parameters. Ann. Stat. 2009, 37, 1733–1751. [Google Scholar] [CrossRef] [Green Version]
- Zhang, C.H. Nearly unbiased variable selection under minimax concave penalty. Ann. Stat. 2010, 38, 894–942. [Google Scholar] [CrossRef] [Green Version]
- Candes, E.; Tao, T. The Dantzig selector: Statistical estimation when p is much larger than n. Ann. Stat. 2007, 35, 2313–2351. [Google Scholar]
- Fan, J.; Lv, J. Sure independence screening for ultrahigh dimensional feature space. J. R. Stat. Soc. Ser. B 2008, 70, 849–911. [Google Scholar] [CrossRef] [Green Version]
- Ghaoui, L.E.; Viallon, V.; Rabbani, T. Safe feature elimination in sparse supervised learning. Pac. J. Optim. 2012, 8, 667–698. [Google Scholar]
- Wang, J.; Wonka, P.; Ye, j. Lasso screening rules via dual polytope projection. J. Mach. Learn. Res. 2015, 16, 1063–1101. [Google Scholar]
- Xiang, Z.J.; Wang, Y.; Ramadge, P.J. Safe feature elimination in sparse supervised learning. IEEE Trans. Pattern Anal. 2017, 39, 1008–1027. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fan, J.; Guo, S.; Hao, N. Variance estimation using refitted cross-validation in ultrahigh dimensional regression. J. R. Stat. Soc. Ser. B 2012, 74, 37–65. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yu, G.; Bien, J. Estimating the error variance in a high-dimensional linear model. Biometrika 2019, 106, 533–546. [Google Scholar] [CrossRef]
- Zou, H.; Hastie, T.; Tibshirani, R. On the “Degrees of freedom” of the lasso. Ann. Stat. 2007, 35, 2173–2192. [Google Scholar] [CrossRef]
- Wang, L.; Leblanc, A. Second-order nonlinear least squares estimation. Ann. Inst. Stat. Math. 2008, 60, 883–900. [Google Scholar] [CrossRef]
- Stadler, N.; Bühlmann, P. ℓ1-penalization for mixture regression models. Test 2010, 19, 209–256. [Google Scholar] [CrossRef] [Green Version]
- Sun, T.; Zhang, C.H. Scaled sparse linear regression. Biometrika 2012, 99, 879–898. [Google Scholar] [CrossRef] [Green Version]
- Dicker, L.H. Variance estimation in high-dimensional linear models. Biometrika 2014, 101, 269–284. [Google Scholar] [CrossRef]
- Dicker, L.H.; Erdogdu, M.A. Maximum likelihood for variance estimation in high-dimensional linear models. In Proceedings of the 19th International Conference on Artificial Intelligence and Statistics, Cadiz, Spain, 9–11 May 2016; pp. 159–167. [Google Scholar]
- Liu, X.; Zheng, S.; Feng, X. Estimation of error variance via ridge regression. Biometrika 2020, 107, 481–488. [Google Scholar] [CrossRef]
- Zhang, C.H.; Huang, J. The sparsity and bias of the lasso selection in high-dimensional linear regression. Ann. Stat. 2008, 36, 1567–1594. [Google Scholar] [CrossRef]
- Bickel, P.J.; Ritov, Y.A.; Tsybakov, A.B. Simultaneous analysis of lasso and dantzig selector. Ann. Stat. 2009, 37, 1705–1732. [Google Scholar] [CrossRef]
- Fan, J.; Fan, Y.; Barut, E. Adaptive robust variable selection. Ann. Stat. 2014, 42, 324–351. [Google Scholar] [CrossRef] [PubMed]
- Friedman, J.; Hastie, T.; Tibshirani, R. Regularization paths for generalized linear models via coordinate descent. J. Stat. Softw. 2010, 33, 1–22. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fan, J.; Lv, J. Non-concave penalized likelihood with np-dimensionality. IEEE Trans. Inform. Theory 2011, 57, 5467–5484. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Giraud, C. Introduction to High-Dimensional Statistics, 1st ed.; Chapman and Hall/CRC: New York, NY, USA, 2014. [Google Scholar]
Figure 1.
Boxplots of 100 RE values for five estimators, true .

Figure 2.
Boxplots of 100 RE values for five estimators, true .


{kind=link}
{kind=link}
Table 1.
Average RE of various estimators, true .
| OE | NALE | SLE | SLE | SLE | NLE | OLE | OLE | RBE | |
|---|---|---|---|---|---|---|---|---|---|
| 0.1 | 0.004 | 0.004 | 0.692 | 0.081 | 0.013 | 0.052 | 0.098 | 0.152 | 1.034 |
| 0.2 | 0.005 | 0.005 | 0.723 | 0.080 | 0.011 | 0.115 | 0.283 | 0.097 | 1.799 |
| 0.3 | 0.006 | 0.006 | 0.758 | 0.076 | 0.010 | 0.170 | 0.474 | 0.067 | 2.043 |
| 0.4 | 0.005 | 0.005 | 0.817 | 0.059 | 0.018 | 0.503 | 1.998 | 0.001 | 3.758 |
| 0.5 | 0.005 | 0.006 | 0.730 | 0.022 | 0.164 | 0.830 | 3.405 | 0.044 | 5.769 |
| 0.1 | 0.005 | 0.005 | 0.621 | 0.069 | 0.008 | 0.051 | 0.086 | 0.150 | 0.655 |
| 0.2 | 0.005 | 0.004 | 0.642 | 0.053 | 0.005 | 0.111 | 0.242 | 0.098 | 0.765 |
| 0.3 | 0.004 | 0.004 | 0.585 | 0.043 | 0.014 | 0.161 | 0.383 | 0.067 | 1.249 |
| 0.4 | 0.006 | 0.006 | 0.598 | 0.024 | 0.081 | 0.483 | 1.616 | 0.002 | 3.431 |
| 0.5 | 0.006 | 0.006 | 0.721 | 0.015 | 0.536 | 0.790 | 2.848 | 0.003 | 4.896 |
| 0.1 | 0.004 | 0.005 | 0.458 | 0.056 | 0.008 | 0.049 | 0.079 | 0.147 | 0.485 |
| 0.2 | 0.005 | 0.013 | 0.422 | 0.035 | 0.015 | 0.099 | 0.184 | 0.099 | 1.214 |
| 0.3 | 0.005 | 0.005 | 0.425 | 0.023 | 0.043 | 0.142 | 0.283 | 0.070 | 0.878 |
| 0.4 | 0.005 | 0.004 | 0.392 | 0.013 | 0.219 | 0.438 | 1.228 | 0.003 | 3.062 |
| 0.5 | 0.017 | 0.018 | 0.810 | 0.066 | 1.703 | 2.854 | 6.952 | 0.040 | 15.446 |
Table 2.
Average RE of various estimators, true .
| OE | NALE | SLE | SLE | SLE | NLE | OLE | OLE | RBE | |
|---|---|---|---|---|---|---|---|---|---|
| 0.1 | 0.993 | 0.988 | 0.175 | 0.727 | 0.914 | 1.225 | 1.309 | 0.612 | 2.013 |
| 0.2 | 0.983 | 0.979 | 0.156 | 0.737 | 0.953 | 1.336 | 1.528 | 0.690 | 2.337 |
| 0.3 | 0.992 | 0.992 | 0.133 | 0.743 | 0.982 | 1.410 | 1.685 | 0.745 | 2.426 |
| 0.4 | 1.003 | 0.994 | 0.100 | 0.775 | 1.094 | 1.708 | 2.412 | 0.998 | 2.937 |
| 0.5 | 1.003 | 0.961 | 0.152 | 0.900 | 1.388 | 1.910 | 2.844 | 1.206 | 3.400 |
| 0.1 | 1.007 | 0.998 | 0.219 | 0.754 | 0.963 | 1.222 | 1.287 | 0.614 | 1.803 |
| 0.2 | 0.996 | 0.988 | 0.205 | 0.783 | 1.015 | 1.330 | 1.487 | 0.689 | 1.870 |
| 0.3 | 0.998 | 0.992 | 0.242 | 0.815 | 1.071 | 1.399 | 1.615 | 0.745 | 2.113 |
| 0.4 | 1.000 | 0.993 | 0.239 | 0.887 | 1.259 | 1.694 | 2.269 | 0.987 | 2.850 |
| 0.5 | 1.001 | 1.017 | 0.159 | 0.976 | 1.717 | 1.999 | 2.686 | 1.182 | 3.211 |
| 0.1 | 0.990 | 0.985 | 0.331 | 0.779 | 0.965 | 1.217 | 1.274 | 0.619 | 1.688 |
| 0.2 | 0.994 | 1.043 | 0.359 | 0.845 | 1.077 | 1.311 | 1.423 | 0.688 | 2.097 |
| 0.3 | 1.000 | 1.001 | 0.357 | 0.881 | 1.183 | 1.374 | 0.528 | 0.737 | 1.932 |
| 0.4 | 0.999 | 1.014 | 0.384 | 1.029 | 1.453 | 1.660 | 2.105 | 0.966 | 2.747 |
| 0.5 | 1.011 | 1.025 | 0.297 | 1.058 | 1.503 | 1.638 | 1.901 | 0.900 | 2.251 |
Table 3.
Average MSE of various estimators, true .
| OE | NALE | SLE | SLE | SLE | NLE | OLE | OLE | RBE | |
|---|---|---|---|---|---|---|---|---|---|
| 0.1 | 0.004 | 0.004 | 0.740 | 0.090 | 0.013 | 0.019 | 0.025 | 0.200 | 0.347 |
| 0.2 | 0.005 | 0.005 | 0.731 | 0.074 | 0.006 | 0.005 | 0.083 | 0.155 | 0.455 |
| 0.3 | 0.005 | 0.005 | 0.759 | 0.081 | 0.008 | 0.074 | 0.161 | 0.127 | 0.600 |
| 0.4 | 0.004 | 0.008 | 0.748 | 0.043 | 0.038 | 0.043 | 0.592 | 0.041 | 1.479 |
| 0.5 | 0.005 | 0.009 | 0.834 | 0.028 | 0.223 | 0.091 | 1.021 | 0.009 | 1.934 |
| 0.1 | 0.005 | 0.005 | 0.655 | 0.087 | 0.015 | 0.018 | 0.023 | 0.201 | 0.266 |
| 0.2 | 0.005 | 0.006 | 0.642 | 0.063 | 0.008 | 0.045 | 0.074 | 0.153 | 0.457 |
| 0.3 | 0.005 | 0.005 | 0.597 | 0.048 | 0.012 | 0.065 | 0.116 | 0.131 | 0.478 |
| 0.4 | 0.005 | 0.015 | 0.621 | 0.015 | 0.128 | 0.192 | 0.404 | 0.049 | 1.101 |
| 0.5 | 0.004 | 0.016 | 0.667 | 0.026 | 0.356 | 0.349 | 0.856 | 0.010 | 1.811 |
| 0.1 | 0.004 | 0.005 | 0.476 | 0.054 | 0.007 | 0.016 | 0.017 | 0.193 | 0.141 |
| 0.2 | 0.005 | 0.007 | 0.414 | 0.028 | 0.012 | 0.036 | 0.044 | 0.156 | 0.275 |
| 0.3 | 0.006 | 0.009 | 0.357 | 0.017 | 0.030 | 0.049 | 0.064 | 0.134 | 0.345 |
| 0.4 | 0.005 | 0.004 | 0.398 | 0.015 | 0.108 | 0.169 | 0.325 | 0.055 | 0.868 |
| 0.5 | 0.004 | 0.004 | 0.490 | 0.023 | 0.237 | 0.306 | 0.722 | 0.016 | 1.328 |
Table 4.
Average RE of various estimators, true .
| OE | NALE | SLE | SLE | SLE | NLE | OLE | OLE | RBE | |
|---|---|---|---|---|---|---|---|---|---|
| 0.1 | 1.002 | 0.977 | 0.144 | 0.711 | 0.914 | 1.131 | 1.148 | 0.555 | 1.581 |
| 0.2 | 0.999 | 0.964 | 0.149 | 0.742 | 0.969 | 1.211 | 1.279 | 0.608 | 1.667 |
| 0.3 | 1.003 | 0.964 | 0.133 | 0.726 | 0.963 | 1.268 | 1.394 | 0.636 | 1.767 |
| 0.4 | 1.003 | 0.940 | 0.141 | 0.818 | 1.176 | 1.205 | 1.766 | 0.801 | 2.212 |
| 0.5 | 0.981 | 0.937 | 0.091 | 0.891 | 1.459 | 1.300 | 2.007 | 0.913 | 2.387 |
| 0.1 | 0.994 | 0.971 | 0.197 | 0.720 | 0.913 | 1.125 | 1.137 | 0.553 | 1.506 |
| 0.2 | 1.005 | 0.987 | 0.207 | 0.767 | 0.997 | 1.207 | 1.263 | 0.610 | 1.669 |
| 0.3 | 1.007 | 1.000 | 0.234 | 0.804 | 1.054 | 1.251 | 1.331 | 0.640 | 1.684 |
| 0.4 | 1.001 | 1.068 | 0.219 | 0.982 | 1.342 | 1.436 | 1.632 | 0.783 | 2.048 |
| 0.5 | 0.993 | 1.068 | 0.193 | 1.111 | 1.584 | 1.589 | 1.922 | 0.912 | 2.341 |
| 0.1 | 1.001 | 0.980 | 0.316 | 0.783 | 0.977 | 1.118 | 1.113 | 0.562 | 1.364 |
| 0.2 | 1.000 | 1.016 | 0.362 | 0.862 | 1.065 | 1.183 | 1.200 | 0.607 | 1.514 |
| 0.3 | 0.987 | 1.028 | 0.412 | 0.911 | 1.146 | 1.215 | 1.242 | 0.636 | 1.580 |
| 0.4 | 0.990 | 0.996 | 0.381 | 1.026 | 1.310 | 1.408 | 1.566 | 0.771 | 1.926 |
| 0.5 | 1.000 | 1.011 | 0.310 | 1.100 | 1.473 | 1.551 | 1.846 | 0.882 | 2.148 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Wang, X.; Kong, L.; Wang, L. Estimation of Error Variance in Regularized Regression Models via Adaptive Lasso. Mathematics 2022, 10, 1937. https://doi.org/10.3390/math10111937
AMA Style
Wang X, Kong L, Wang L. Estimation of Error Variance in Regularized Regression Models via Adaptive Lasso. Mathematics. 2022; 10(11):1937. https://doi.org/10.3390/math10111937
Chicago/Turabian StyleWang, Xin, Lingchen Kong, and Liqun Wang. 2022. "Estimation of Error Variance in Regularized Regression Models via Adaptive Lasso" Mathematics 10, no. 11: 1937. https://doi.org/10.3390/math10111937
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.