
Predicting Compressive Strength of High-Performance Concrete Using Hybridization of Nature-Inspired Metaheuristic and Gradient Boosting Machine

Abstract
:1. Introduction
2. Research Significance
- (i)
- An integrated model, named DFP-XGBoost, is proposed to deal with the nonlinear and multivariate functional mapping between the CS of HPC mixes and their influencing factors. Notably, DFP, as a metaheuristic optimizer, is employed to assist the learning phase of the regressor. An integration of these two computational intelligence approaches for the task of interest has not yet been investigated.
- (ii)
- An innovative objective function is designed for DFP to express the two goals of model building: minimizing the prediction error and maximizing the generalization property. With the help of the DFP metaheuristic, it is able to automate the model’s construction phase. Therefore, the newly developed DFP-XGBoost can be easily applied and updated by practitioners without in-depth domain knowledge in machine learning and metaheuristic.
- (iii)
- A dataset, including 400 samples, is collected from laboratory testing results. This dataset is used to train and verify the proposed hybrid method. Besides the curing age, the contents of cement, fly ash, silica fume, ground granulated blast furnace slag, fine aggregate, coarse aggregate, water, and a water-reducing agent are employed as predictor variables. Different from previous studies [16,23], the gathered dataset has taken into account the effect of silica fume, which is a crucial ingredient in HPC [5,13,14].
- (iv)
- In addition to prediction accuracy, reliability is also a major concern in CS estimation [38,39]. Restriction of overestimation is an important task in model building. However, improving the reliability of the estimation has rarely been addressed in the case of HPC. The current work is an attempt to fill this gap in the literature. An asymmetric loss function is utilized in the training phase of the XGBoost regressor to express the bias against overestimations. By doing so, the number of overestimated CS values can be reduced, and the model’s reliability is enhanced accordingly. Additionally, XGBoost-based quantile regression is used to derive the prediction interval of the CS values.
- (v)
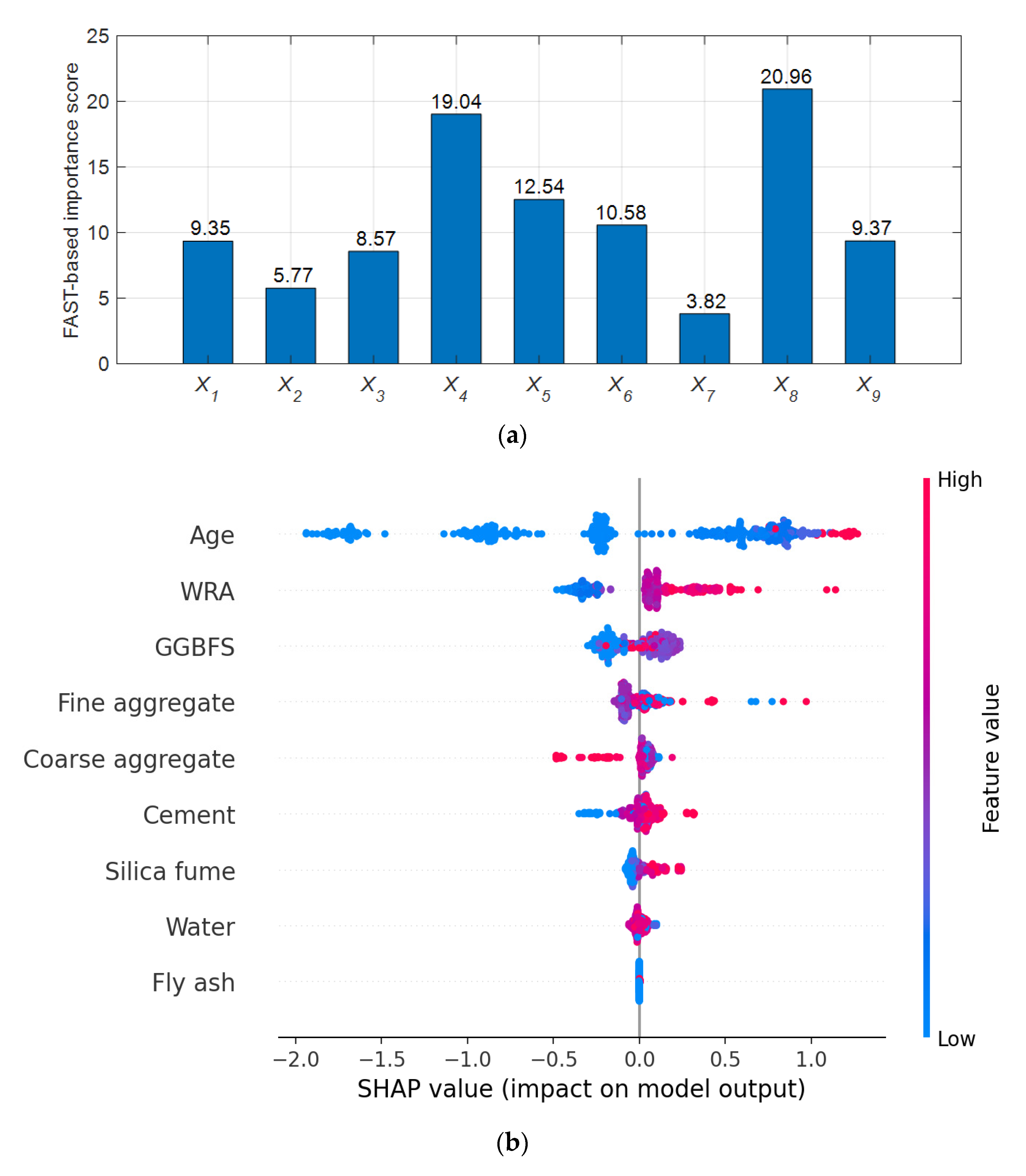
- To assess the contribution of predictor variables to the model’s output, this study resorts to the Fourier Amplitude Sensitivity Test. This is a variance-based global sensitivity analysis approach for computing the effects of the input factors on the CS of HPC. This test helps identify the constituents that considerably affect the response.
- (vi)
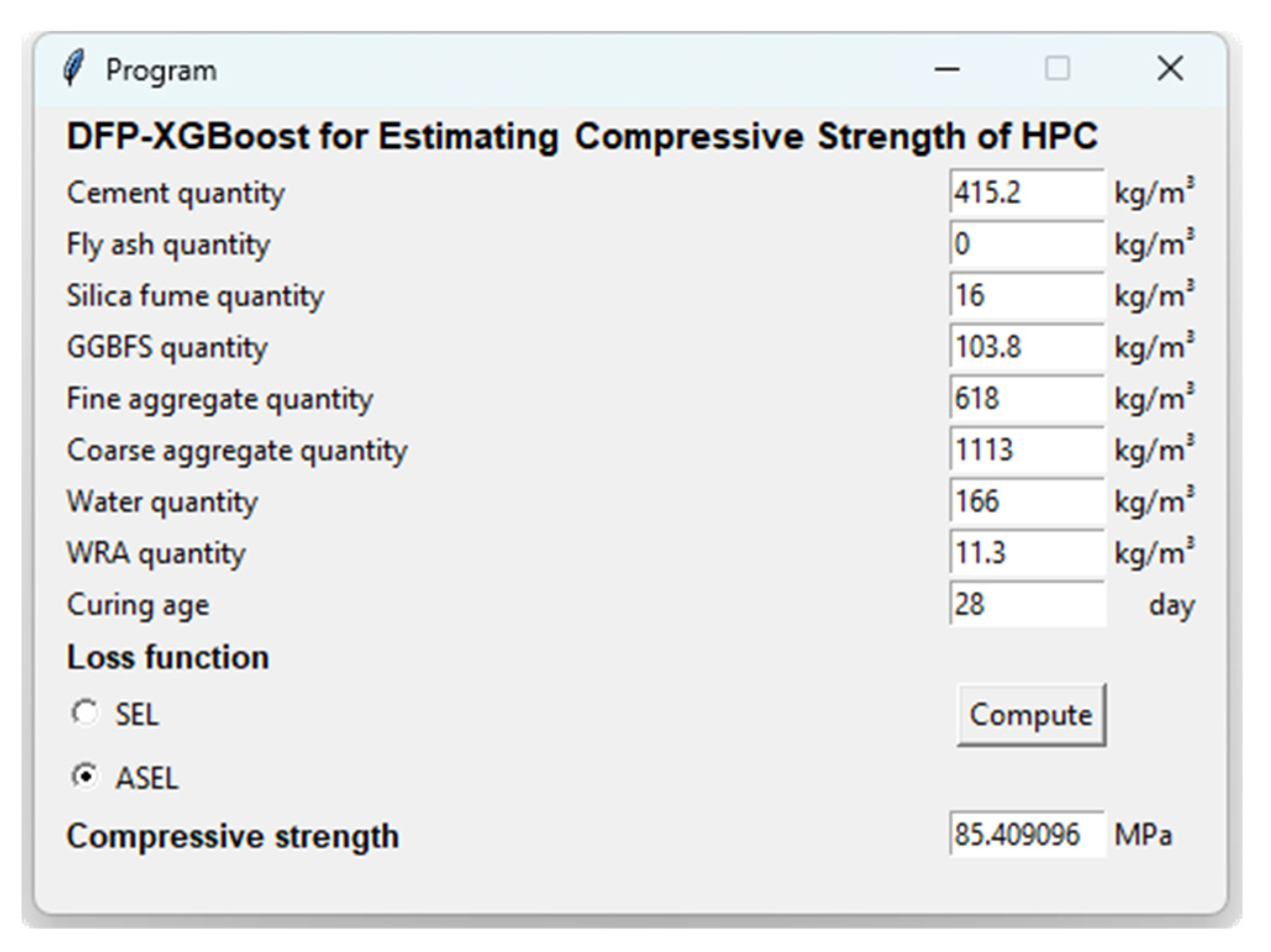
- A program based on DFP-XGBoost with a graphical user interface has been developed in Python to ease the implementation of the model. Using this program, the user can obtain a prediction of the CS of untested HPC mixes.
3. Research Method
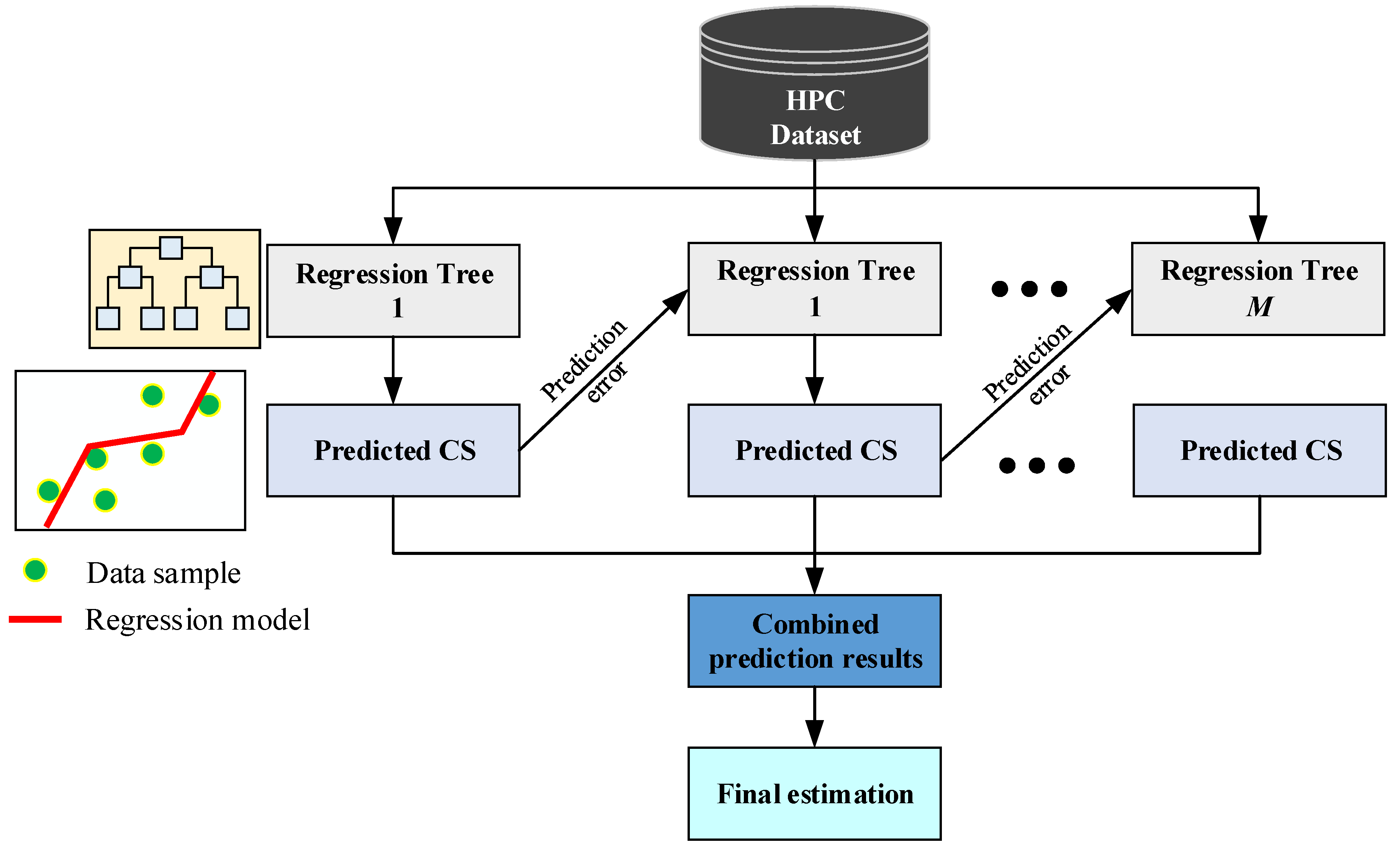
3.1. Extreme Gradient Boosting Machine Regressor
3.2. Differential Flower Pollination
3.3. The Collected Dataset
3.4. Benchmark Methods
3.4.1. Artificial Neural Network
3.4.2. Support Vector Regression
4. Result and Discussion
4.1. Experimental setting
4.2. Prediction Results and Performance Comparison
4.3. Sensitivity Analysis-Based Assessment of Feature Importance
4.4. Interval Prediction of Compressive Strength Based on Quantile Regression
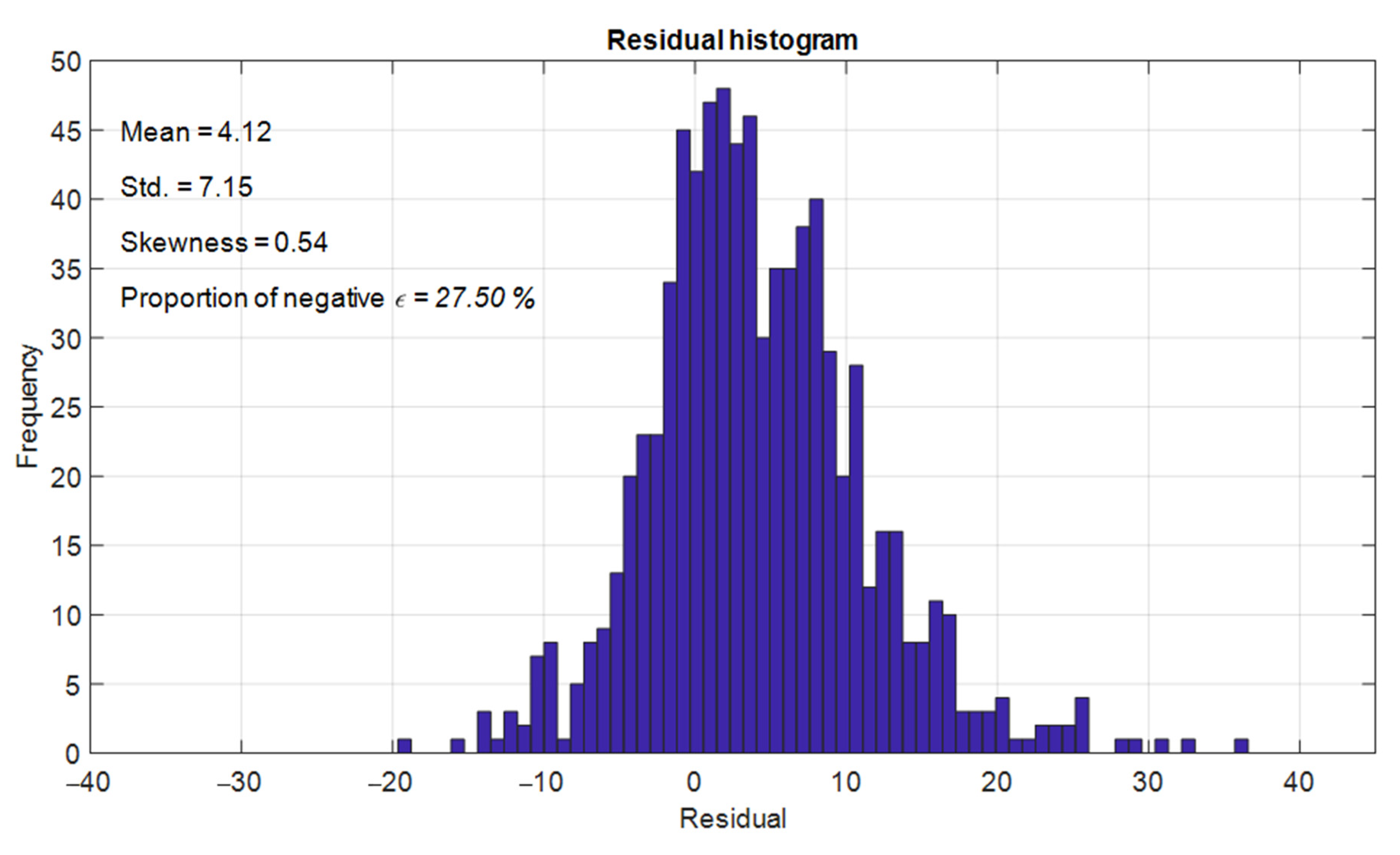
4.5. Reduction in Overestimations Committed by XGBoost Regressor
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

References
- Van Damme, H. Concrete material science: Past, present, and future innovations. Cem. Concr. Res. 2018, 112, 5–24. [Google Scholar] [CrossRef]
- Gagg, C.R. Cement and concrete as an engineering material: An historic appraisal and case study analysis. Eng. Fail. Anal. 2014, 40, 114–140. [Google Scholar] [CrossRef]
- Chou, J.-S.; Pham, A.-D. Enhanced artificial intelligence for ensemble approach to predicting high performance concrete compressive strength. Constr. Build. Mater. 2013, 49, 554–563. [Google Scholar] [CrossRef]
- Akhnoukh, A.K.; Buckhalter, C. Ultra-high-performance concrete: Constituents, mechanical properties, applications and current challenges. Case Stud. Constr. Mater. 2021, 15, e00559. [Google Scholar] [CrossRef]
- Neville, A.; Aïtcin, P.-C. High performance concrete—An overview. Mater. Struct. 1998, 31, 111–117. [Google Scholar] [CrossRef]
- Videla, C.; Gaedicke, C. Modeling portland blast-furnace slag cement high-performance concrete. ACI Mater. J. 2004, 101, 365–375. [Google Scholar]
- Wu, L.; Farzadnia, N.; Shi, C.; Zhang, Z.; Wang, H. Autogenous shrinkage of high performance concrete: A review. Constr. Build. Mater. 2017, 149, 62–75. [Google Scholar] [CrossRef]
- Xue, J.; Briseghella, B.; Huang, F.; Nuti, C.; Tabatabai, H.; Chen, B. Review of ultra-high performance concrete and its application in bridge engineering. Constr. Build. Mater. 2020, 260, 119844. [Google Scholar] [CrossRef]
- Ben Chaabene, W.; Flah, M.; Nehdi, M.L. Machine learning prediction of mechanical properties of concrete: Critical review. Constr. Build. Mater. 2020, 260, 119889. [Google Scholar] [CrossRef]
- Li, Q.-F.; Song, Z.-M. High-performance concrete strength prediction based on ensemble learning. Constr. Build. Mater. 2022, 324, 126694. [Google Scholar] [CrossRef]
- Azkune, M.; Puente, I.; Santilli, A. Shore overloads during shoring removal. Eng. Struct. 2010, 32, 3629–3638. [Google Scholar] [CrossRef]
- Lee, S.; Nguyen, N.-H.; Karamanli, A.; Lee, J.; Vo, T.P. Super learner machine-learning algorithms for compressive strength prediction of high performance concrete. Struct. Concr. 2023, 24, 2208–2228. [Google Scholar] [CrossRef]
- Smarzewski, P. Influence of silica fume on mechanical and fracture properties of high performance concrete. Procedia Struct. Integr. 2019, 17, 5–12. [Google Scholar] [CrossRef]
- Mazloom, M.; Ramezanianpour, A.A.; Brooks, J.J. Effect of silica fume on mechanical properties of high-strength concrete. Cem. Concr. Compos. 2004, 26, 347–357. [Google Scholar] [CrossRef]
- Yeh, I.C. Modeling of strength of high-performance concrete using artificial neural networks. Cem. Concr. Res. 1998, 28, 1797–1808. [Google Scholar] [CrossRef]
- Bilim, C.; Atiş, C.D.; Tanyildizi, H.; Karahan, O. Predicting the compressive strength of ground granulated blast furnace slag concrete using artificial neural network. Adv. Eng. Softw. 2009, 40, 334–340. [Google Scholar] [CrossRef]
- Erdal, H.I. Two-level and hybrid ensembles of decision trees for high performance concrete compressive strength prediction. Eng. Appl. Artif. Intell. 2013, 26, 1689–1697. [Google Scholar] [CrossRef]
- González, S.; García, S.; Del Ser, J.; Rokach, L.; Herrera, F. A practical tutorial on bagging and boosting based ensembles for machine learning: Algorithms, software tools, performance study, practical perspectives and opportunities. Inf. Fusion 2020, 64, 205–237. [Google Scholar] [CrossRef]
- Gómez-Ríos, A.; Luengo, J.; Herrera, F. A Study on the Noise Label Influence in Boosting Algorithms: AdaBoost, GBM and XGBoost. In Hybrid Artificial Intelligent Systems; Springer International Publishing: Cham, Switzerland, 2017; pp. 268–280. [Google Scholar]
- Chithra, S.; Kumar, S.R.R.S.; Chinnaraju, K.; Alfin Ashmita, F. A comparative study on the compressive strength prediction models for High Performance Concrete containing nano silica and copper slag using regression analysis and Artificial Neural Networks. Constr. Build. Mater. 2016, 114, 528–535. [Google Scholar] [CrossRef]
- Yu, Y.; Li, W.; Li, J.; Nguyen, T.N. A novel optimised self-learning method for compressive strength prediction of high performance concrete. Constr. Build. Mater. 2018, 184, 229–247. [Google Scholar] [CrossRef]
- Kaloop, M.R.; Kumar, D.; Samui, P.; Hu, J.W.; Kim, D. Compressive strength prediction of high-performance concrete using gradient tree boosting machine. Constr. Build. Mater. 2020, 264, 120198. [Google Scholar] [CrossRef]
- Nguyen, H.; Vu, T.; Vo, T.P.; Thai, H.-T. Efficient machine learning models for prediction of concrete strengths. Constr. Build. Mater. 2021, 266, 120950. [Google Scholar] [CrossRef]
- Chou, J.-S.; Chen, L.-Y.; Liu, C.-Y. Forensic-based investigation-optimized extreme gradient boosting system for predicting compressive strength of ready-mixed concrete. J. Comput. Des. Eng. 2022, 10, 425–445. [Google Scholar] [CrossRef]
- Li, Z.; Yoon, J.; Zhang, R.; Rajabipour, F.; Srubar Iii, W.V.; Dabo, I.; Radlińska, A. Machine learning in concrete science: Applications, challenges, and best practices. npj Comput. Mater. 2022, 8, 127. [Google Scholar] [CrossRef]
- Al Yamani, W.H.; Ghunimat, D.M.; Bisharah, M.M. Modeling and predicting the sensitivity of high-performance concrete compressive strength using machine learning methods. Asian J. Civ. Eng. 2023, 24, 1943–1955. [Google Scholar] [CrossRef]
- Nguyen, T.-D.; Cherif, R.; Mahieux, P.-Y.; Lux, J.; Aït-Mokhtar, A.; Bastidas-Arteaga, E. Artificial intelligence algorithms for prediction and sensitivity analysis of mechanical properties of recycled aggregate concrete: A review. J. Build. Eng. 2023, 66, 105929. [Google Scholar] [CrossRef]
- Singh, S.; Patro, S.K.; Parhi, S.K. Evolutionary optimization of machine learning algorithm hyperparameters for strength prediction of high-performance concrete. Asian J. Civ. Eng. 2023, 24, 3121–3143. [Google Scholar] [CrossRef]
- Rathakrishnan, V.; Beddu, S.B.; Ahmed, A.N. Predicting compressive strength of high-performance concrete with high volume ground granulated blast-furnace slag replacement using boosting machine learning algorithms. Sci. Rep. 2022, 12, 9539. [Google Scholar] [CrossRef]
- Hoang, N.D.; Tran, D.V. Machine learning-based estimation of concrete compressive strength: A multi-model and multi-dataset study. Civ. Eng. Infrastruct. J. 2023. [Google Scholar] [CrossRef]
- Al Adwan, J.; Alzubi, Y.; Alkhdour, A.; Alqawasmeh, H. Predicting Compressive Strength of Concrete Using Histogram-Based Gradient Boosting Approach for Rapid Design of Mixtures. Civ. Eng. Infrastruct. J. 2023, 56, 159–172. [Google Scholar] [CrossRef]
- Ranjbar, I.; Toufigh, V.; Boroushaki, M. A combination of deep learning and genetic algorithm for predicting the compressive strength of high-performance concrete. Struct. Concr. 2022, 23, 2405–2418. [Google Scholar] [CrossRef]
- Ben Seghier, M.E.A.; Golafshani, E.M.; Jafari-Asl, J.; Arashpour, M. Metaheuristic-based machine learning modeling of the compressive strength of concrete containing waste glass. Struct. Concr. 2023, 24, 5417–5440. [Google Scholar] [CrossRef]
- Huang, Y.; Lei, Y.; Luo, X.; Fu, C. Prediction of compressive strength of rice husk ash concrete: A comparison of different metaheuristic algorithms for optimizing support vector regression. Case Stud. Constr. Mater. 2023, 18, e02201. [Google Scholar] [CrossRef]
- Mohammadizadeh, M.R.; Esfandnia, F. Predicting Compression Strength of Reinforced Concrete Columns Confined by FRP Using Meta-Heuristic Methods. Civ. Eng. Infrastruct. J. 2022, 55, 1–17. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar] [CrossRef]
- Hoang, N.-D.; Tien Bui, D.; Liao, K.-W. Groutability estimation of grouting processes with cement grouts using Differential Flower Pollination Optimized Support Vector Machine. Appl. Soft Comput. 2016, 45, 173–186. [Google Scholar] [CrossRef]
- Hoang, N.-D. Compressive Strength Estimation of Rice Husk Ash-Blended Concrete Using Deep Neural Network Regression with an Asymmetric Loss Function. Iran. J. Sci. Technol. Trans. Civ. Eng. 2022, 47, 1547–1565. [Google Scholar] [CrossRef]
- Pham, A.-D.; Hoang, N.-D.; Nguyen, Q.-T. Predicting Compressive Strength of High-Performance Concrete Using Metaheuristic-Optimized Least Squares Support Vector Regression. J. Comput. Civ. Eng. 2016, 30, 06015002. [Google Scholar] [CrossRef]
- Hoang, N.-D. A novel ant colony-optimized extreme gradient boosting machine for estimating compressive strength of recycled aggregate concrete. Multiscale Multidiscip. Model. Exp. Design. 2023, 7, 375–394. [Google Scholar] [CrossRef]
- Bentéjac, C.; Csörgő, A.; Martínez-Muñoz, G. A Comparative Analysis of XGBoost. arXiv 2019, arXiv:1911.01914. [Google Scholar]
- Storn, R.; Price, K. Differential Evolution—A Simple and Efficient Heuristic for global Optimization over Continuous Spaces. J. Glob. Optim. 1997, 11, 341–359. [Google Scholar] [CrossRef]
- Yang, X.-S. Flower Pollination Algorithm for Global Optimization. In Unconventional Computation and Natural Computation; Springer: Berlin/Heidelberg, Germany, 2012; pp. 240–249. [Google Scholar]
- Tien Bui, D.; Hoang, N.-D.; Samui, P. Spatial pattern analysis and prediction of forest fire using new machine learning approach of Multivariate Adaptive Regression Splines and Differential Flower Pollination optimization: A case study at Lao Cai province (Viet Nam). J. Environ. Manag. 2019, 237, 476–487. [Google Scholar] [CrossRef]
- Pavlů, T.; Fořtová, K.; Mariaková, D.; Řepka, J.; Vlach, T.; Hájek, P. High-performance concrete with fine recycled concrete aggregate: Experimental assessment. Struct. Concr. 2023, 24, 1868–1878. [Google Scholar] [CrossRef]
- Fallah-Valukolaee, S.; Mousavi, R.; Arjomandi, A.; Nematzadeh, M.; Kazemi, M. A comparative study of mechanical properties and life cycle assessment of high-strength concrete containing silica fume and nanosilica as a partial cement replacement. Structures 2022, 46, 838–851. [Google Scholar] [CrossRef]
- Li, J.; Tian, P. Effect of slag and silica fume on mechanical properties of high strength concrete. Cem. Concr. Res. 1997, 27, 833–837. [Google Scholar] [CrossRef]
- Wang, L.; Yu, Z.; Liu, B.; Zhao, F.; Tang, S.; Jin, M. Effects of Fly Ash Dosage on Shrinkage, Crack Resistance and Fractal Characteristics of Face Slab Concrete. Fractal Fract. 2022, 6, 335. [Google Scholar] [CrossRef]
- Sun, Y.; Liu, Z.; Ghorbani, S.; Ye, G.; De Schutter, G. Fresh and hardened properties of alkali-activated slag concrete: The effect of fly ash as a supplementary precursor. J. Clean. Prod. 2022, 370, 133362. [Google Scholar] [CrossRef] [PubMed]
- Reddy, P.V.R.K.; Ravi Prasad, D. A study on workability, strength and microstructure characteristics of graphene oxide and fly ash based concrete. Mater. Today Proc. 2022, 62, 2919–2925. [Google Scholar] [CrossRef]
- Sun, J.; Kong, K.H.; Lye, C.Q.; Quek, S.T. Effect of ground granulated blast furnace slag on cement hydration and autogenous healing of concrete. Constr. Build. Mater. 2022, 315, 125365. [Google Scholar] [CrossRef]
- Aggarwal, C.C. Neural Networks and Deep Learning; Springer: Berlin/Heidelberg, Germany, 2018; ISBN 978-3-319-94463-0. [Google Scholar]
- Ly, H.-B.; Nguyen, M.H.; Pham, B.T. Metaheuristic optimization of Levenberg–Marquardt-based artificial neural network using particle swarm optimization for prediction of foamed concrete compressive strength. Neural Comput. Appl. 2021, 33, 17331–17351. [Google Scholar] [CrossRef]
- Nazari, A.; Sanjayan, J.G. Modelling of compressive strength of geopolymer paste, mortar and concrete by optimized support vector machine. Ceram. Int. 2015, 41 Pt B, 12164–12177. [Google Scholar] [CrossRef]
- XGBoost XGBoost Documentation. Available online: https://xgboostreadthedocsio/en/stable/indexhtml (accessed on 30 December 2021).
- Beale, M.H.; Hagan, M.T.; Demuth, H.B. Neural Network Toolbox User’s Guide. The MathWorks, Inc. 2018. Available online: https://www.mathworks.com/help/pdf_doc/nnet/nnet_ug.pdf (accessed on 28 April 2018).
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Wong, T.; Yeh, P. Reliable Accuracy Estimates from k-Fold Cross Validation. IEEE Trans. Knowl. Data Eng. 2020, 32, 1586–1594. [Google Scholar] [CrossRef]
- Conover, W.J. Practical Nonparametric Statistics; John Wiley & Sons, Inc.: New York, NY, USA, 1999; ISBN 0-471-16068-7. [Google Scholar]
- McRae, G.J.; Tilden, J.W.; Seinfeld, J.H. Global sensitivity analysis—A computational implementation of the Fourier Amplitude Sensitivity Test (FAST). Comput. Chem. Eng. 1982, 6, 15–25. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.-I. A unified approach to interpreting model predictions. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Herman, J.; Usher, W. SALib: An open-source Python library for sensitivity analysis. J. Open Source Softw. 2017, 2, 97. [Google Scholar] [CrossRef]
- Lundberg, S. An Introduction to Explainable AI with Shapley Values. 2018. Available online: https://shapreadthedocsio/en/latest/indexhtml (accessed on 27 February 2024).
- Koenker, R.; Bassett, G. Regression Quantiles. Econometrica 1978, 46, 33–50. [Google Scholar] [CrossRef]
- Meinshausen, N. Quantile Regression Forests. J. Mach. Learn. Res. 2006, 7, 983–999. [Google Scholar]
- Fahrmeir, L.; Kneib, T.; Lang, S.; Marx, B. Regression: Models, Methods and Applications; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar] [CrossRef]
- Khosravi, A.; Nahavandi, S.; Creighton, D. Construction of Optimal Prediction Intervals for Load Forecasting Problems. IEEE Trans. Power Syst. 2010, 25, 1496–1503. [Google Scholar] [CrossRef]
- Python Tkinter—Python Interface to Tcl/Tk. 2023. Available online: https://docs.python.org/3/library/tkinter.html (accessed on 7 May 2023).














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Source | Number of Laboratory Tests | Proportion (%) | Type of Specimens | Reference |
|---|---|---|---|---|
| 1 | 100 | 25.00 | 150 × 150 × 150 mm cube | [16] |
| 2 | 4 | 1.00 | 100 × 200 mm cylinder | [46] |
| 3 | 16 | 4.00 | 100 × 100 × 100 mm cube | [47] |
| 4 | 52 | 13.00 | 100 × 100 × 100 mm cube | [10] |
| 5 | 28 | 7.00 | 100 × 100 × 100 mm cube | [14] |
| 6 | 200 | 50.00 | 150 × 300 mm cylinder | [6] |
| Specimen | Cube | Cube | Cylinder | Cylinder |
|---|---|---|---|---|
| Dimension (mm) | 150 × 150 × 150 | 100 × 100 × 100 | 100 × 200 | 150 × 300 |
| Correlation factor | 1.119 | 1.000 | 1.020 | 1.063 |
| Variables | Unit | Notation | Min | Average | Std | Skewness | Max |
|---|---|---|---|---|---|---|---|
| Cement content | kg/m3 | X1 | 80.00 | 378.16 | 103.28 | −1.38 | 527.20 |
| Fly ash content | kg/m3 | X2 | 0.00 | 6.42 | 22.56 | 3.51 | 123.50 |
| Silica fume content | kg/m3 | X3 | 0.00 | 19.93 | 21.63 | 0.71 | 75.00 |
| GGBFS content | kg/m3 | X4 | 0.00 | 96.40 | 84.87 | 1.19 | 360.00 |
| Fine-aggregate content | kg/m3 | X5 | 488.00 | 649.20 | 79.25 | 0.07 | 804.96 |
| Coarse-aggregate content | kg/m3 | X6 | 915.20 | 1129.35 | 48.23 | −1.33 | 1203.00 |
| Water content | kg/m3 | X7 | 120.00 | 161.13 | 14.45 | −1.52 | 180.00 |
| WRA content | kg/m3 | X8 | 1.30 | 9.42 | 4.18 | −0.07 | 18.00 |
| Age | day | X9 | 1.00 | 48.68 | 91.37 | 2.93 | 400.00 |
| Compressive strength | MPa | Y | 22.54 | 69.66 | 22.13 | −0.06 | 120.86 |
| Phase | Performance Measurement Indices | DFP-XGBoost | ANN | SVR | |||
|---|---|---|---|---|---|---|---|
| Mean | Std | Mean | Std | Mean | Std | ||
| Training | RMSE | 3.710 | 0.148 | 6.746 | 2.649 | 7.424 | 0.106 |
| MAPE (%) | 4.780 | 0.183 | 8.857 | 4.040 | 9.852 | 0.164 | |
| R2 | 0.972 | 0.003 | 0.893 | 0.076 | 0.887 | 0.004 | |
| Testing | RMSE | 5.270 | 0.834 | 8.823 | 1.990 | 10.461 | 1.204 |
| MAPE (%) | 6.740 | 1.360 | 11.836 | 3.350 | 15.212 | 2.037 | |
| R2 | 0.942 | 0.020 | 0.820 | 0.096 | 0.763 | 0.053 | |
| Phase | Performance Measurement Indices | DFP-XGBoost Using SEL | DFP-XGBoost Using ASEL | ||
|---|---|---|---|---|---|
| Mean | Std | Mean | Std | ||
| Training | RMSE | 3.710 | 0.148 | 6.280 | 0.648 |
| MAPE (%) | 4.780 | 0.183 | 7.290 | 0.855 | |
| R2 | 0.972 | 0.003 | 0.919 | 0.017 | |
| Testing | RMSE | 5.270 | 0.834 | 8.130 | 1.360 |
| MAPE (%) | 6.740 | 1.360 | 9.570 | 1.630 | |
| R2 | 0.942 | 0.020 | 0.852 | 0.054 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hoang, N.-D.; Tran, V.-D.; Tran, X.-L. Predicting Compressive Strength of High-Performance Concrete Using Hybridization of Nature-Inspired Metaheuristic and Gradient Boosting Machine. Mathematics 2024, 12, 1267. https://doi.org/10.3390/math12081267
Hoang N-D, Tran V-D, Tran X-L. Predicting Compressive Strength of High-Performance Concrete Using Hybridization of Nature-Inspired Metaheuristic and Gradient Boosting Machine. Mathematics. 2024; 12(8):1267. https://doi.org/10.3390/math12081267
Chicago/Turabian StyleHoang, Nhat-Duc, Van-Duc Tran, and Xuan-Linh Tran. 2024. "Predicting Compressive Strength of High-Performance Concrete Using Hybridization of Nature-Inspired Metaheuristic and Gradient Boosting Machine" Mathematics 12, no. 8: 1267. https://doi.org/10.3390/math12081267