1. Introduction
Cardiovascular disease (CVD) poses a significant public health challenge, with profound implications for both individuals and communities, resulting in substantial mortality rates and societal impact. A range of cardiovascular disorders, including coronary artery disease, myocardial infarction (heart attacks), strokes, arrhythmias, heart failure, and atherosclerosis, present a substantial menace to human health [
1]. These conditions disrupt the normal function of the heart and blood vessels, impairing blood and oxygen delivery and causing significant damage to various bodily systems [
2]. Consider the impact of narrowed arteries depriving the heart of oxygen and nutrients in coronary artery disease, the irregular electrical signals leading to arrhythmias, or the weakened pumping ability of the heart in heart failure, leaving individuals struggling to breathe. A stroke, characterized by a sudden interruption of blood flow to the brain, can strip individuals of language, movement, and essential functions. Meanwhile, atherosclerosis, operating silently, accumulates plaque in arteries, constricts blood flow, and increases the risk of events [
3].
Cardiovascular diseases (CVDs) do not arise from isolated factors but rather from a complex network of interconnected risk elements. High blood pressure, cholesterol, and diabetes often collaborate, intensifying each other’s adverse impacts [
4]. We require a multi-faceted strategy that addresses all contributing factors collectively rather than addressing each risk element in isolation. Engaging in unhealthy behaviors, such as poor diet, smoking, and excessive alcohol consumption, exacerbates the risk of CVD [
5,
6,
7]. Individual choices and behaviors play a pivotal role in determining cardiovascular health outcomes. The solution rests in adopting healthier behaviors: consuming balanced diets, engaging in regular physical activity, quitting smoking, and moderating alcohol intake. However, prevention alone is insufficient. Detecting cardiovascular diseases (CVDs) at an early stage allows for timely intervention to prevent their severe impact.
Early detection poses a significant challenge in combating cardiovascular diseases (CVDs) [
8,
9,
10]. Unlike diseases with clear and recognizable symptoms, CVDs often present as subtle signs, such as fatigue, chest discomfort, or general stress—easily dismissed in the hustle of daily life. These ambiguous indicators often fail to prompt proactive medical intervention, leading to disease. Compounding this challenge, certain CVDs progress gradually. Atherosclerosis, for example, deposits plaque in arteries, obstructing blood flow and revealing its destructive consequences much later on. Effective screening tools do exist but often require specialized equipment and trained professionals, resources that are not readily available in regions with limited resources. This reality means that essential examinations, such as electrocardiograms, blood tests, and cardiac ultrasounds, become inaccessible, further reducing the likelihood of early detection.
The accurate prediction of cardiovascular diseases (CVDs) can help healthcare professionals identify high-risk individuals before the onset of clinical symptoms. By analyzing a comprehensive set of CVD risk factors, predictive models can be constructed to estimate an individual’s susceptibility to this often silent condition [
11,
12,
13,
14]. This method empowers clinicians to prioritize patient monitoring and implement preventative measures. Tailored medical interventions and personalized health management recommendations can then be established for each patient. Early detection through such predictive models provides a valuable opportunity for treatment, facilitating interventions such as targeted lifestyle modifications (e.g., diet and exercise programs) and stress management strategies [
15]. By adopting these proactive measures, individuals identified as high-risk can significantly reduce their CVD risk and take greater control of their overall well-being.
Additionally, pharmacological interventions become viable options, further lowering the risk of cardiovascular events [
16]. Ultimately, early prediction not only minimizes the incidence and severity of CVD but also empowers individuals to become active participants in their cardiovascular health. The effect of CVD prediction fosters public health awareness, prompting individuals to take ownership of their heart health. Understanding their susceptibility can prompt people to make positive changes, such as incorporating regular exercise, choosing healthier diets, and scheduling preventive check-ups with their doctors. This approach can significantly reduce their risk of developing health problems. This shift in behavior translates to a healthier population, placing less strain on healthcare systems. Predictive models empower healthcare professionals to become efficient stewards of limited resources. By anticipating demand and developing targeted prevention and treatment plans, we can optimize resource allocation, reduce hospitalization times, and minimize healthcare costs [
17]. The early identification of high-risk individuals coupled with effective interventions alleviates the pressure on healthcare systems, creating a virtuous cycle of improved health outcomes and reduced long-term financial burdens.
Despite the appeal of early CVD prediction, the potential for erroneous outcomes cannot be overlooked. In the context of early CVD prediction, a misclassification of patients as high-risk can trigger a sequence of unwarranted interventions, resource misallocation, and psychological distress [
18]. Considering the potential for undergoing extraneous medical procedures, the associated financial strain, and the consequent psychological burden, a cautious approach to early CVD prediction is warranted [
19]. The converse scenario presents an equally significant challenge: the missed identification of genuinely high-risk individuals. This can lead to a critical delay in implementing essential interventions, potentially allowing for the disease to progress unabated. Furthermore, inaccurate predictions breed skepticism. This public distrust can hamper efforts to promote preventative measures and ultimately weaken the entire system [
20]. Therefore, the pursuit of highly accurate CVD prediction is not just a scientific endeavor but an ethical imperative. We must strive to minimize false positives and negatives, ensuring the benefits outweigh the risks and upholding public trust in this invaluable tool.
Scholars such as Arroyo and Delima (2022) [
21] have harnessed genetic algorithms to fine-tune artificial intelligence, boosting prediction accuracy by 5.08%. Kim (2021) [
22] demonstrated the potential of smartwatch-derived data for CVD prevalence prediction, achieving promising results with a machine-learning approach utilizing support vector machines (SVMs). Khan et al. (2023) [
23] investigated the efficacy of machine learning algorithms, specifically random forest, for CVD prediction. Their findings demonstrated promising performance in terms of both accuracy and sensitivity. Building on previous work, Moon et al. (2023) [
24] achieved a breakthrough in cardiovascular disease (CVD) susceptibility prediction. Their approach, which combined advanced AI techniques such as the literature embedding with machine learning, not only delivered 96% accuracy but also shed light on the underlying genes and factors contributing to individual risk.
Cardiovascular disease (CVD) prediction has made significant strides in recent years, but achieving high accuracy with limited resources remains a challenge. This study tackles the critical barrier of computational costs in accurate cardiovascular disease (CVD) prediction. The proposed method empowers individuals by significantly reducing computing needs while maintaining high accuracy, thereby achieving the goal of real-time, individualized CVD risk stratification that is readily accessible to users, enabling the optimization of preventative interventions and transforming health surveillance. Moreover, the proposed method, enabled by a resource-efficient artificial neural network model, allows for precise individual risk assessment, facilitating timely interventions that improve quality of life and overall cardiovascular health. Whether at the doctor’s office or even at home, this further achieves the goal of accurate CVD prediction at the point of care.
4. Discussion
Accurately predicting cardiovascular disease (CVD) risk is crucial for early intervention and improved patient outcomes. This study proposes a novel framework, TPTM-HANN-GA, that continuously optimizes hyperparameters for an ANN model to enhance CVD prediction precision.
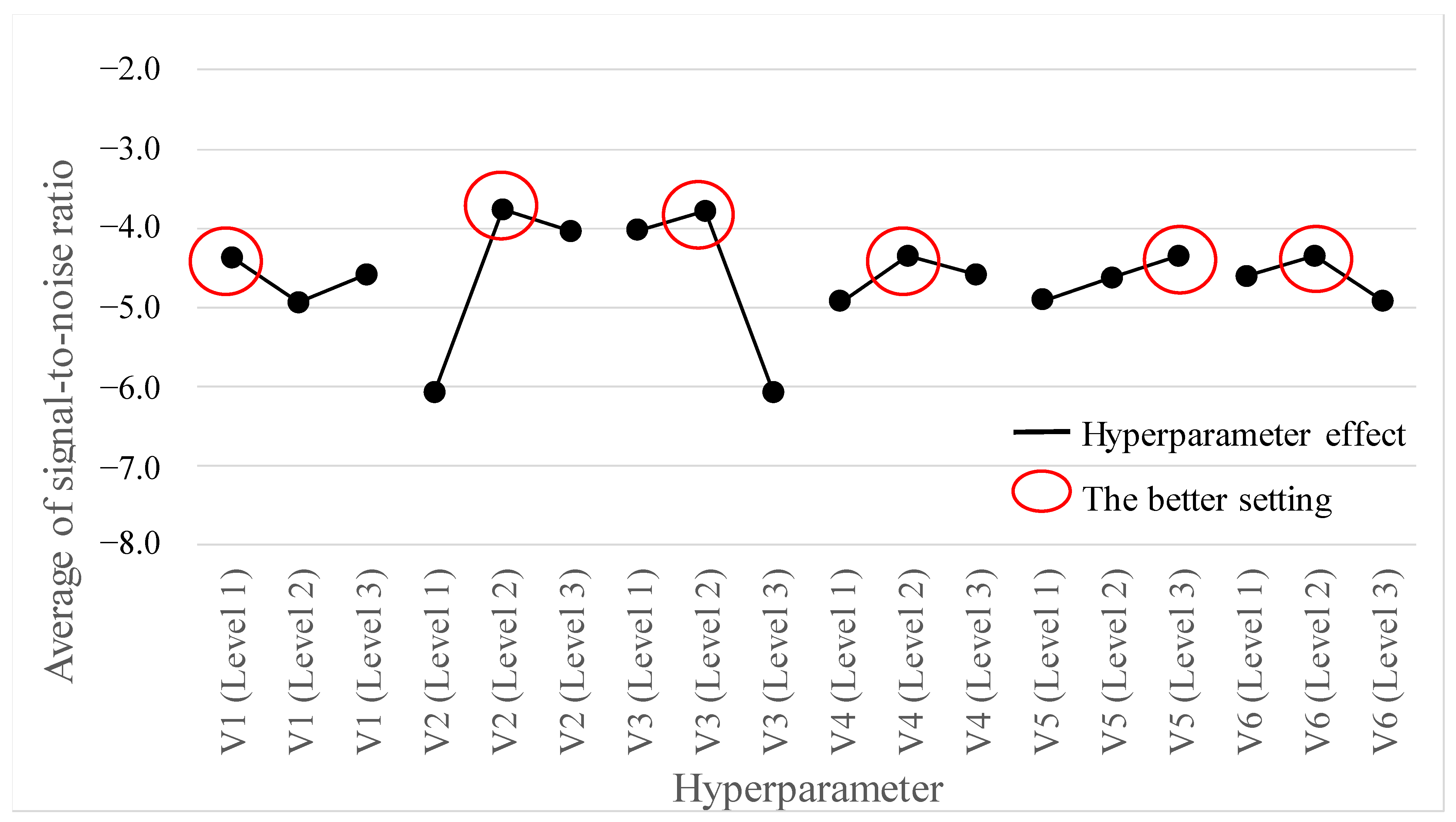
This study addressed the crucial challenge of improving prediction accuracy for cardiovascular disease (CVD). We proposed the TPTM-HANN-GA framework to fine-tune an ANN model for better CVD risk assessment. This method also revealed the relative impact of each hyperparameter (V2 > V3 > V6 > V4 > V5 > V1), guiding further optimization. Our analysis led to these optimal hyperparameter settings for the ANN model: V1 (HL) = 4, V2 (AF) = tanh, V3 (OP) = sgd, V4 (LR) = 0.3, V5 (MR) = 0.9, and V6 (HN) = 8.
In the subsequent phase, we refined the three hyperparameters’ predicted accuracies using the Taguchi method L9(34). This method facilitated the identification of optimal configurations with fewer trials. We then added the Monte Carlo method with a normal distribution probabilistic model into the second-stage Taguchi method of TSTO to increase the number of modeling data points. By employing the Monte Carlo method, this study aimed to construct a hyperparameter artificial neural network (HANN) model using a larger and more diverse dataset, theoretically enhancing the overall performance of the given dataset.
Table 9 serves as the data source for the HANN model, with V
4 (LR), V
5 (MR), and V
6 (HN) acting as input variables for predicting cardiovascular accuracy. The model boasts a single hidden layer for efficient learning. An amount of 80% of the dataset fuels the training process, while the remaining 20% is reserved for testing. To identify the optimal hyperparameter combination, we employed a grid search, evaluating various learning rates, momentum rates, and hidden node configurations. After 1000 training iterations, the search yielded these winning settings: learning rate = 0.25, moment rate = 0.9, and hidden nodes = 7. This configuration translates to a 3-7-1 HANN model architecture chosen based on minimizing the root mean square error (RMSE) on the test dataset.
To identify the optimal configuration of input variables for the HANN model, we employed a genetic algorithm (GA), leveraging a population size of 25. This work prioritizes individuals within the population for reproduction based on their predicted accuracy. Individuals exhibiting superior predictive performance are assigned a higher probability of selection. Crossover and mutation rates were set at 0.9 and 0.05, respectively, balancing exploration and stability. After 500 iterations, the GA identified the ultimate hyperparameter configuration: V4 (LR) = 0.23425849, V5 (MR) = 0.75462782, and V6 (HN) = 7. To validate these findings, we conducted confirmation experiments and achieved an average accuracy of 74.25%. This underscores the effectiveness of the GA-optimized HANN model.
The proposed TPTM-HANN-GA framework achieved a 0.11% higher accuracy in predicting cardiovascular disease risk compared to the leading TSTO-ANN model. This indicates its ability to correctly identify an additional 77 patients from the 70,000 data points in the Kaggle Cardiovascular Disease dataset. It highlights the potential to enhance patient survival rates. In addition, TPTM-HANN-GA can perform a continuous value search for each continuous variable. This method has a larger search space and is more general than the discrete search method of the TSTO-ANN model, which is more likely to find the optimal solution. The GA used in this paper performed eight-digit and single-digit searches for LR (learning rate), MR (moment rate), and HN (hidden nodes), respectively.
The TPTM-HANN-GA framework offers several advantages over traditional grid search methods, notably by substantially reducing computational demands while maintaining the ideal accuracy.
In this study, we applied the HANN method to the GA to search for optimal settings of continuous hyperparameters. In contrast to the TSTO method, which only allows for discrete parameter searches (e.g., learning rate choices limited to 0.2, 0.3, and 0.4), HANN-TPTM-GA enables the simultaneous use of discrete and continuous variables. For instance, the learning rate can be selected continuously within the range of 0.2 to 0.4. Theoretically, it allows for an infinite number of learning rate choices. In our study, the identified optimal learning rate was 0.23425849. Consequently, the expanded search range makes it easier to find optimal solutions compared to TSTO-ANN. In our research, the achieved accuracy of 74.25% surpasses the 74.14% accuracy obtained with TSTO-ANN.
In the initial phase of the Taguchi method, experiments for model training were performed using the Taguchi orthogonal array L18(21 × 37) involving 54 runs, which required a total computation time of 33.9 min on a personal computer, translating to an average of about 0.63 min per run. Comparatively, considering the traditional grid search involving 2187 runs, this study did not execute all runs but estimated that at 0.63 min per run, completing the full set of 2187 runs would likely demand around 1373.8 min. The initial-phase Taguchi method enables a reduction in computation time by approximately 40 times.
In the second phase of the Taguchi method, a traditional grid search with three levels for each hyperparameter, repeated three times, would necessitate 81 trials, taking approximately 50.9 min to complete. Conversely, employing the Taguchi orthogonal array L9(34) reduced the number of experiments to 27, with an approximate total time requirement of 16.9 min. The second-phase Taguchi method enables a reduction in computation time by approximately three times.
In the final step, we applied a genetic algorithm to identify optimal hyperparameter configurations for accurate CVD Risk Prediction. This involved testing a total of 25 initial populations over 500 iterations, resulting in 12,500 tests. In contrast, if a traditional grid search were employed, it would entail 108 × 108 × 10 = 1017 tests, leading to an impractical consumption of time resources.
Our approach significantly mitigates computational demands, rendering it well-suited for low-power computers and edge artificial intelligence (edge AI) devices, which can achieve the goal of point-of-care testing (POCT), providing individuals a way to take charge of their heart health.
While the identified hyperparameters are tailored to the specific dataset used, exploring the adaptability of TPTM-HANN-GA to other medical domains could reveal significant potential. Additionally, relying solely on a single dataset limits generalizability. Incorporating independent datasets from diverse healthcare organizations in future research can enhance the technique’s validity. Furthermore, validating its efficacy with datasets from various sources will increase its credibility and generalizability.
In future work, the proposed TPTM-HANN-GA framework could be extended to address other deep learning-based medical image disease detection tasks, including pathological, CT, and X-ray images. The TPTM-HANN-GA framework is particularly suitable for application in clinical edge AI devices, which will provide more efficient training and accurate inference results for medical image disease detection tasks with limited computing resources.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}