Fluctuation Theory for Upwards Skip-Free Lévy Chains


Department of Mathematics, Faculty of Mathematics and Physics, University of Ljubljana, 1000 Ljubljana, Slovenia
Risks 2018, 6(3), 102; https://doi.org/10.3390/risks6030102
Submission received: 20 July 2018
/
Revised: 13 September 2018
/
Accepted: 16 September 2018
/
Published: 18 September 2018
(This article belongs to the Special Issue Exit Problems for Lévy and Markov Processes with One-Sided Jumps and Related Topics)
Abstract
:A fluctuation theory and, in particular, a theory of scale functions is developed for upwards skip-free Lévy chains, i.e., for right-continuous random walks embedded into continuous time as compound Poisson processes. This is done by analogy to the spectrally negative class of Lévy processes—several results, however, can be made more explicit/exhaustive in the compound Poisson setting. Importantly, the scale functions admit a linear recursion, of constant order when the support of the jump measure is bounded, by means of which they can be calculated—some examples are presented. An application to the modeling of an insurance company’s aggregate capital process is briefly considered.
1. Introduction
It was shown in Vidmar (2015) that precisely two types of Lévy processes exhibit the property of non-random overshoots: those with no positive jumps a.s., and compound Poisson processes, whose jump chain is (for some ) a random walk on , skip-free to the right. The latter class was then referred to as “upwards skip-free Lévy chains”. Also in the same paper it was remarked that this common property which the two classes share results in a more explicit fluctuation theory (including the Wiener-Hopf factorization) than for a general Lévy process, this being rarely the case (cf. (Kyprianou 2006, p. 172, sct. 6.5.4)).
Now, with reference to existing literature on fluctuation theory, the spectrally negative case (when there are no positive jumps, a.s.) is dealt with in detail in (Bertoin 1996, chp. VII); (Sato 1999, sct. 9.46) and especially (Kyprianou 2006, chp. 8). On the other hand, no equally exhaustive treatment of the right-continuous random walk seems to have been presented thus far, but see Brown et al. (2010); Marchal (2001); Quine (2004); (De Vylder and Goovaerts 1988, sct. 4); (Dickson and Waters 1991, sct. 7); (Doney 2007, sct. 9.3); (Spitzer 2001, passim).1 In particular, no such exposition appears forthcoming for the continuous-time analogue of such random walks, wherein the connection and analogy to the spectrally negative class of Lévy processes becomes most transparent and direct.
In the present paper, we proceed to do just that, i.e., we develop, by analogy to the spectrally negative case, a complete fluctuation theory (including theory of scale functions) for upwards skip-free Lévy chains. Indeed, the transposition of the results from the spectrally negative to the skip-free setting is mostly straightforward. Over and above this, however, and beyond what is purely analogous to the exposition of the spectrally negative case, (i) further specifics of the reflected process (Theorem 1-1), of the excursions from the supremum (Theorem 1-3) and of the inverse of the local time at the maximum (Theorem 1-4) are identified, (ii) the class of subordinators that are the descending ladder heights processes of such upwards skip-free Lévy chains is precisely characterized (Theorem 4), and (iii) a linear recursion is presented which allows us to directly compute the families of scale functions (Equations (20), (21), Proposition 9 and Corollary 1).
Application-wise, note that the classical continuous-time Bienaymé-Galton-Watson branching process is associated with upwards skip-free Lévy chains via a suitable time change (Kyprianou 2006, sct. 1.3.4). Besides, our chains feature as a natural continuous-time approximation of the more subtle spectrally negative Lévy family, that, because of its overall tractability, has been used extensively in applied probability (in particular to model the risk process of an insurance company; see the papers Avram et al. (2007); Chiu and Yin (2005); Yang and Zhang (2001) among others). This approximation point of view is developed in Mijatović et al. (2014, 2015). Finally, focusing on the insurance context, the chains may be used directly to model the aggregate capital process of an insurance company, in what is a continuous-time embedding of the discrete-time compound binomial risk model (for which see Avram and Vidmar (2017); Bao and Liu (2012); Wat et al. (2018); Xiao and Guo (2007) and the references therein). We elaborate on this latter point of view in Section 5.
The organisation of the rest of this paper is as follows. Section 2 introduces the setting and notation. Then Section 3 develops the relevant fluctuation theory, in particular details of the Wiener-Hopf factorization. Section 4 deals with the two-sided exit problem and the accompanying families of scale functions. Finally, Section 5 closes with an application to the risk process of an insurance company.
2. Setting and Notation
Let be a filtered probability space supporting a Lévy process (Kyprianou 2006, p. 2, Definition 1.1) X (X is assumed to be -adapted and to have independent increments relative to ). The Lévy measure (Sato 1999, p. 38, Definition 8.2) of X is denoted by . Next, recall from Vidmar (2015) (with denoting the support (Kallenberg 1997, p. 9) of a measure defined on the Borel -field of some topological space):
Definition 1 (Upwards skip-free Lévy chain).
X is an upwards skip-free Lévy chain, if it is a compound Poisson process (Sato 1999, p. 18, Definition 4.2), viz. if for and , and if for some , , whereas .
Remark 1.
Of course to say that X is a compound Poisson process means simply that it is a real-valued continuous-time Markov chain, vanishing a.s. at zero, with holding times exponentially distributed of rate and the law of the jumps given by (Sato 1999, p. 18, Theorem 4.3).
In the sequel, X will be assumed throughout an upwards skip-free Lévy chain, with () and characteristic exponent (). In general, we insist on (i) every sample path of X being càdlàg (i.e., right-continuous, admitting left limits) and (ii) satisfying the standard assumptions (i.e., the -field is -complete, the filtration is right-continuous and contains all -null sets). Nevertheless, we shall, sometimes and then only provisionally, relax assumption (ii), by transferring X as the coordinate process onto the canonical space of càdlàg paths, mapping , equipping with the -algebra and natural filtration of evaluation maps; this, however, will always be made explicit. We allow to be exponentially distributed, mean one, and independent of X; then define ().
Furthermore, for , introduce , the first entrance time of X into . Please note that is an -stopping time (Kallenberg 1997, p. 101, Theorem 6.7). The supremum or maximum (respectively infimum or minimum) process of X is denoted (respectively ) (). is the overall infimum.
With regard to miscellaneous general notation we have:
- The nonnegative, nonpositive, positive and negative real numbers are denoted by , , and , respectively. Then , , and are the nonnegative, nonpositive, positive and negative integers, respectively.
- Similarly, for : , , and are the apposite elements of .
- The following introduces notation for the relevant half-planes of ; the arrow notation is meant to be suggestive of which half-plane is being considered: , , and . , , and are then the respective closures of these sets.
- and are the positive and nonnegative integers, respectively. () is the ceiling function. For : and .
- The Laplace transform of a measure on , concentrated on , is denoted by : (for all such that this integral is finite). To a nondecreasing right-continuous function , a measure may be associated in the Lebesgue-Stieltjes sense.
The geometric law with success parameter has (), is then the failure parameter. The exponential law with parameter is specified by the density . A function is said to be of exponential order, if there are , such that (); , when this limit exists. DCT (respectively MCT) stands for the dominated (respectively monotone) convergence theorem. Finally, increasing (respectively decreasing) will mean strictly increasing (respectively strictly decreasing), nondecreasing (respectively nonincreasing) being used for the weaker alternative; we will understand for .
3. Fluctuation Theory
In the following section, to fully appreciate the similarity (and eventual differences) with the spectrally negative case, the reader is invited to directly compare the exposition of this subsection with that of (Bertoin 1996, sct. VII.1) and (Kyprianou 2006, sct. 8.1).
3.1. Laplace Exponent, the Reflected Process, Local Times and Excursions from the Supremum, Supremum Process and Long-Term Behaviour, Exponential Change of Measure
Since the Poisson process admits exponential moments of all orders, it follows that and, in particular, for all . Indeed, it may be seen by a direct computation that for , , , where is the Laplace exponent of X. Moreover, is continuous (by the DCT) on and analytic in (use the theorems of Cauchy (Rudin 1970, p. 206, 10.13 Cauchy’s theorem for triangle), Morera (Rudin 1970, p. 209, 10.17 Morera’s theorem) and Fubini).
Next, note that tends to as over the reals, due to the presence of the atom of at h. Upon restriction to , is strictly convex, as follows first on by using differentiation under the integral sign and noting that the second derivative is strictly positive, and then extends to by continuity.
Denote then by the largest root of . Indeed, 0 is always a root, and due to strict convexity, if , then 0 and are the only two roots. The two cases occur, according as to whether or , which is clear. It is less obvious, but nevertheless true, that this right derivative at 0 actually exists, indeed . This follows from the fact that is nonincreasing as for and hence the monotone convergence applies. Continuing from this, and with a similar justification, one also gets the equality (where we agree if ). In any case, is continuous and increasing, it is a bijection and we let be the inverse bijection, so that .
With these preliminaries having been established, our first theorem identifies characteristics of the reflected process, the local time of X at the maximum (for a definition of which see e.g., (Kyprianou 2006, p. 140, Definition 6.1)), its inverse, as well as the expected length of excursions and the probability of an infinite excursion therefrom (for definitions of these terms see e.g., (Kyprianou 2006, pp. 140–47); we agree that an excursion (from the maximum) starts immediately after X leaves its running maximum and ends immediately after it returns to it; by its length we mean the amount of time between these two time points).
Theorem 1 (Reflected process; (inverse) local time; excursions).
Let for and .
- The generator matrix of the Markov process on is given by (with ): , unless , in which case we have .
- For the reflected process Y, 0 is a holding point. The actual time spent at 0 by Y, which we shall denote L, is a local time at the maximum. Its right-continuous inverse , given by (for ; otherwise), is then a (possibly killed) compound Poisson subordinator with unit positive drift.
- Assuming that to avoid the trivial case, the expected length of an excursion away from the supremum is equal to ; whereas the probability of such an excursion being infinite is .
- Assume again to avoid the trivial case. Let N, taking values in , be the number of jumps the chain makes before returning to its running maximum, after it has first left it (it does so with probability 1). Then the law of is given by (for ):In particular, has a killing rate of , Lévy mass and its jumps have the probability law on given by the length of a generic excursion from the supremum, conditional on it being finite, i.e., that of an independent N-fold sum of independent -distributed random variables, conditional on N being finite. Moreover, one has, for , , where the coefficients satisfy the initial conditions:the recursions:and may be interpreted as the probability of X reaching level 0 starting from level for the first time on precisely the k-th jump ().
Proof.
Theorem 1-1 is clear, since, e.g., Y transitions away from 0 at the rate at which X makes a negative jump; and from to 0 at the rate at which X jumps up by s or more etc.
Theorem 1-2 is standard (Kyprianou 2006, p. 141, Example 6.3 & p. 149, Theorem 6.10).
We next establish Theorem 1-3. Denote, provisionally, by the expected excursion length. Furthermore, let the discrete-time Markov chain W (on the state space ) be endowed with the initial distribution for , ; and transition matrix P, given by , whereas for : , if ; , if ; and otherwise (W jumps down with probability p, up i steps with probability , , until it reaches 0, where it gets stuck). Further let N be the first hitting time for W of , so that a typical excursion length of X is equal in distribution to an independent sum of N (possibly infinite) -random variables. It is Wald’s identity that . Then (in the obvious notation, where indicates the sum is inclusive of ∞), by Fubini: , where is the mean hitting time of for W, if it starts from , as in (Norris 1997, p. 12). From the skip-free property of the chain W it is moreover transparent that , , for some (with the usual convention ). Moreover we know (Norris 1997, p. 17, Theorem 1.3.5) that is the minimal solution to and (). Plugging in , the last system of linear equations is equivalent to (provided ) , where . Thus, if , the minimal solution to the system is , , from which follows at once. If , clearly we must have , hence and thus .
To establish the probability of an excursion being infinite, i.e., , where , we see that (by the skip-free property) , , and by the strong Markov property, for , . It follows that , i.e., . Hence, by Theorem 2-2, whose proof will be independent of this one, (since , if and only if X drifts to ).
Finally, Theorem 1-4 is straightforward. ☐
We turn our attention now to the supremum process . First, using the lack of memory property of the exponential law and the skip-free nature of X, we deduce from the strong Markov property applied at the time , that for every , : In particular, for any : And since for , (-a.s.) one has (for ): . Therefore .
Next, to identify , , observe that (for , ): and hence is an -martingale by stationary independent increments of X, for each . Then apply the optional sampling theorem at the bounded stopping time () to get:
Please note that and converges to (-a.s.) as on . It converges to on the complement of this event, -a.s., provided . Therefore we deduce by dominated convergence, first for and then also for , by taking limits:
Before we formulate our next theorem, recall also that any non-zero Lévy process either drifts to , oscillates or drifts to (Sato 1999, pp. 255–56, Proposition 37.10 and Definition 37.11).
Theorem 2 (Supremum process and long-term behaviour).
- The failure probability for the geometrically distributed is ().
- X drifts to , oscillates or drifts to according as to whether is positive, zero, or negative. In the latter case has a geometric distribution with failure probability .
- is a discrete-time increasing stochastic process, vanishing at 0 and having stationary independent increments up to the explosion time, which is an independent geometric random variable; it is a killed random walk.
Remark 2.
Unlike in the spectrally negative case (Bertoin 1996, p. 189), the supremum process cannot be obtained from the reflected process, since the latter does not discern a point of increase in X when the latter is at its running maximum.
Proof.
We have for every :
Thus Theorem 2-1 obtains.
For Theorem 2-2 note that letting in (2), we obtain (-a.s.), if and only if , which is equivalent to . If so, is geometrically distributed with failure probability and then (and only then) does X drift to .
It remains to consider the case of drifting to (the cases being mutually exclusive and exhaustive). Indeed, X drifts to , if and only if is finite for each (Bertoin 1996, p. 172, Proposition VI.17). Using again the nondecreasingness of in , we deduce from (1), by the monotone convergence, that one may differentiate under the integral sign, to get . So the are finite, if and only if (so that -a.s.) and . Since is the inverse of , this is equivalent to saying .
Finally, Theorem 2-3 is clear. ☐
Table 1 briefly summarizes for the reader’s convenience some of our main findings thus far.
We conclude this section by offering a way to reduce the general case of an upwards skip-free Lévy chain to one which necessarily drifts to . This will prove useful in the sequel. First, there is a pathwise approximation of an oscillating X, by (what is again) an upwards skip-free Lévy chain, but drifting to infinity.
Remark 3.
Suppose X oscillates. Let (possibly by enlarging the probability space to accommodate for it) N be an independent Poisson process with intensity 1 and () so that is a Poisson process with intensity ϵ, independent of X. Define . Then, as , converges to X, uniformly on bounded time sets, almost surely, and is clearly an upwards skip-free Lévy chain drifting to .
The reduction of the case when X drifts to is somewhat more involved and is done by a change of measure. For this purpose assume until the end of this subsection, that X is already the coordinate process on the canonical space , equipped with the -algebra and filtration of evaluation maps (so that coincides with the law of X on and , while for , , where , for ). We make this transition in order to be able to apply the Kolmogorov extension theorem in the proposition, which follows. Note, however, that we are no longer able to assume the standard conditions on . Notwithstanding this, remain -stopping times, since by the nature of the space , for , , .
Proposition 1 (Exponential change of measure).
Let . Then, demanding:
this introduces a unique measure on . Under the new measure, X remains an upwards skip-free Lévy chain with Laplace exponent , drifting to , if , unless . Moreover, if is the new Lévy measure of X under , then and λ-a.e. in . Finally, for every -stopping time T, on restriction to , and:
Proof.
That is introduced consistently as a probability measure on follows from the Kolmogorov extension theorem (Parthasarathy 1967, p. 143, Theorem 4.2). Indeed, is a nonnegative martingale (use independence and stationarity of increments of X and the definition of the Laplace exponent), equal identically to 1 at time 0.
Furthermore, for all , and :
An application of the Functional Monotone Class Theorem then shows that X is indeed a Lévy process on and its Laplace exponent under is as stipulated (that -a.s. follows from the absolute continuity of with respect to on restriction to ).
Next, from the expression for , the claim regarding follows at once. Then clearly X remains an upwards skip-free Lévy chain under , drifting to , if .
Finally, let and . Then , and by the Optional Sampling Theorem:
Using the MCT, letting , we obtain the equality . ☐
Proposition 2 (Conditioning to drift to +∞).
Assume and denote (see (3)). We then have as follows.
- For every , .
- For every , the stopped process is identical in law under the measures and on the canonical space .
Proof.
With regard to Proposition 2-1, we have as follows. Let . By the Markov property of X at time t, the process is identical in law with X on and independent of under . Thus, letting (), one has for and , by conditioning:
since . Next, noting that :
The second term clearly converges to as . The first converges to 0, because by (2) , as , and we have the estimate .
We next show Proposition 2-2. Note first that X is -progressively measurable (in particular, measurable), hence the stopped process is measurable as a mapping into (Karatzas and Shreve 1988, p. 5, Problem 1.16).
Furthermore, by the strong Markov property, conditionally on , is independent of the future increments of X after , hence also of for any . We deduce that the law of is the same under as it is under for any . Proposition 2-2 then follows from Proposition 2-1 by letting tend to , the algebra being sufficient to determine equality in law by a /-argument. ☐
3.2. Wiener-Hopf Factorization
Definition 2.
We define, for , , i.e., -a.s., is the last time in the interval that X attains a new maximum. Similarly we let be, -a.s., the last time on of attaining the running infimum ().
While the statements of the next proposition are given for the upwards skip-free Lévy chain X, they in fact hold true for the Wiener-Hopf factorization of any compound Poisson process. Moreover, they are (essentially) known in Kyprianou (2006). Nevertheless, we begin with these general observations, in order to (a) introduce further relevant notation and (b) provide the reader with the prerequisites needed to understand the remainder of this subsection. Immediately following Proposition 3, however, we particularize to our the skip-free setting.
Proposition 3.
Let . Then:
- The pairs and are independent and infinitely divisible, yielding the factorisation:where for ,Duality: is equal in distribution to . and are the Wiener-Hopf factors.
- The Wiener-Hopf factors may be identified as follows:andfor .
- Here, in terms of the law of X,andfor , and some constants .
Proof.
These claims are contained in the remarks regarding compound Poisson processes in (Kyprianou 2006, pp. 167–68) pursuant to the proof of Theorem 6.16 therein. Analytic continuations have been effected in part Proposition 3-3 using properties of zeros of holomorphic functions (Rudin 1970, p. 209, Theorem 10.18), the theorems of Cauchy, Morera and Fubini, and finally the finiteness/integrability properties of q-potential measures (Sato 1999, p. 203, Theorem 30.10(ii)). ☐
Remark 4.
- (Kyprianou 2006, pp. 157, 168) is also the Laplace exponent of the (possibly killed) bivariate descending ladder subordinator , where is a local time at the minimum, and the descending ladder heights process (on ; otherwise) is X sampled at its right-continuous inverse :
- As for the strict ascending ladder heights subordinator (on ; otherwise), being the right-continuous inverse of , and denoting the amount of time X has spent at a new maximum, we have, thanks to the skip-free property of X, as follows. Since , X stays at a newly achieved maximum each time for an -distributed amount of time, departing it to achieve a new maximum later on with probability , and departing it, never to achieve a new maximum thereafter, with probability . It follows that the Laplace exponent of is given by:(where ). In other words, is a killed Poisson process of intensity and with killing rate .
Again thanks to the skip-free nature of X, we can expand on the contents of Proposition 3, by offering further details of the Wiener-Hopf factorization. Indeed, if we let and (, ) then clearly are the arrival times of a renewal process (with a possibly defective inter-arrival time distribution) and is the ‘number of arrivals’ process. One also has the relation: , (-a.s.). Thus the random variables entering the Wiener-Hopf factorization are determined in terms of the renewal process .
Moreover, we can proceed to calculate explicitly the Wiener-Hopf factors as well as and . Let . First, since is a geometrically distributed random variable, we have, for any :
Note here that for all . On the other hand, using conditioning (for any ):
Now, conditionally on , is independent of and has the same distribution as . Therefore, by (1) and the theorem of Fubini:
We identify from (4) for any : and therefore for any : We identify from (5) for any : Therefore, multiplying the last two equalities, for and , the equality:
obtains. In particular, for and , we recognize for some constant : . Next, observe that by independence and duality (for and ):
Therefore:
Both sides of this equality are continuous in and analytic in . They agree on , hence agree on by analytic continuation. Therefore (for all , ):
i.e., for all and for which one has:
Moreover, for the unique , for which , one can take the limit in the above to obtain: . We also recognize from (7) for and with , and some constant : . With one can take the limit in the latter as to obtain: .
In summary:
Theorem 3 (Wiener-Hopf factorization for upwards skip-free Lévy chains).
We have the following identities in terms of ψ and Φ:
- For every and :and(the latter whenever ; for the unique such that , i.e., for , one has the right-hand side given by ).
- For some and then for every and :and(the latter whenever ; for the unique such that , i.e., for , one has the right-hand side given by ).
☐
As a consequence of Theorem 3-1, we obtain the formula for the Laplace transform of the running infimum evaluated at an independent exponentially distributed random time:
(and ). In particular, if , then letting in (8), one obtains by the DCT:
We obtain next from Theorem 3-2 (recall also Remark 4-1), by letting therein, the Laplace exponent of the descending ladder heights process :
where we have set for simplicity , by insisting on a suitable choice of the local time at the minimum. This gives the following characterization of the class of Laplace exponents of the descending ladder heights processes of upwards skip-free Lévy chains (cf. (Hubalek and Kyprianou 2011, Theorem 1)):
Theorem 4.
Let , , and , with . Then:
if and only if the following conditions are satisfied:There exists (in law) an upwards skip-free Lévy chain X with values in and with (i) γ being the killing rate of its strict ascending ladder heights process (see Remark 4-2), and (ii) , , being the Laplace exponent of its descending ladder heights process.
- .
- Setting x equal to 1, when , or to the unique solution of the equation:on the interval , otherwise2; and then defining , , ; it holds:
Such an X is then unique (in law), is called the parent process, its Lévy measure is given by , and .
Remark 5.
Condition Theorem 4-2 is actually quite explicit. When (equivalently, the parent process does not drift to ), it simply says that the sequence should be nonincreasing. In the case when the parent process X drifts to (equivalently, (hence )), we might choose first, then , and finally γ.
Proof.
Please note that with , , and comparing the respective Fourier components of the left and the right hand-side, (10) is equivalent to:
- .
- .
- , .
Moreover, the killing rate of the strict ascending ladder heights processes expresses as , whereas (1) and (3) alone, together imply .
Necessity of the conditions. Remark that the strict ascending ladder heights and the descending ladder heights processes cannot simultaneously have a strictly positive killing rate. Everything else is trivial from the above (in particular, we obtain that such an X, when it exists, is unique, and has the stipulated Lévy measure and ).
Sufficiency of the conditions. The compound Poisson process X whose Lévy measure is given by (and whose Laplace exponent we shall denote , likewise the largest zero of will be denoted ) constitutes an upwards skip-free Lévy chain. Moreover, since , unless , we obtain either way that with , . Substituting in this relation , we obtain at once that if (so ), that then X drifts to , , and hence is the killing rate of the strict ascending ladder heights process. On the other hand, when , then , and a direct computation reveals . So X does not drift to , and , whence (again) . Also in this case, the killing rate of the strict ascending ladder heights process is . Finally, and regardless of whether is strictly positive or not, compared with (10), we conclude that is indeed the Laplace exponent of the descending ladder heights process of X. ☐
4. Theory of Scale Functions
Again the reader is invited to compare the exposition of the following section with that of (Bertoin 1996, sct. VII.2) and (Kyprianou 2006, sct. 8.2), which deal with the spectrally negative case.
4.1. The Scale Function W
It will be convenient to consider in this subsection the times at which X attains a new maximum. We let , and so on, denote the depths (possibly zero, or infinity) of the excursions below these new maxima. For , it is agreed that if the process X never reaches the level . Then it is clear that for , (cf. (Bühlmann 1970, p. 137, para. 6.2.4(a)) (Doney 2007, sct. 9.3)):
where we have introduced (up to a multiplicative constant) the scale function:
(When convenient, we extend W by 0 on .)
Remark 6.
If needed, we can of course express , , in terms of the usual excursions away from the maximum. Thus, let be the depth of the first excursion away from the current maximum. By the time the process attains a new maximum (that is to say h), conditionally on this event, it will make a total of N departures away from the maximum, where (with the first jump time of X, , ) . So, denoting , one has , .
The following theorem characterizes the scale function in terms of its Laplace transform.
Theorem 5 (The scale function).
For every and one has:
and is (up to a multiplicative constant) the unique right-continuous and piecewise continuous function of exponential order with Laplace transform:
Proof.
(For uniqueness see e.g., (Engelberg 2005, p. 14, Theorem 10). It is clear that W is of exponential order, simply from the definition (11).)
Suppose first X tends to . Then, letting in (12) above, we obtain . Here, since the left-hand side limit exists by the DCT, is finite and non-zero at least for all large enough x, so does the right-hand side, and .
Therefore and hence the Laplace-Stieltjes transform of W is given by (9)—here we consider W as being extended by 0 on :
Since (integration by parts (Revuz and Yor 1999, chp. 0, Proposition 4.5)) ,
Suppose now that X oscillates. Via Remark 3, approximate X by the processes , . In (14), fix , carry over everything except for , divide both sides by , and then apply this equality to . Then on the left-hand side, the quantities pertaining to will converge to the ones for the process X as by the MCT. Indeed, for , and (in the obvious notation): , since , uniformly on bounded time sets, almost surely as . (It is enough to have convergence for , as this implies convergence for all , W being the right-continuous piecewise constant extension of .) Thus we obtain in the oscillating case, for some which is the limit of the right-hand side as :
Finally, we are left with the case when X drifts to . We treat this case by a change of measure (see Proposition 1 and the paragraph immediately preceding it). To this end assume, provisionally, that X is already the coordinate process on the canonical filtered space . Then we calculate by Proposition 2-2 (for , ):
where the third equality uses the fact that is a measurable transformation. Here is the scale function corresponding to X under the measure , with Laplace transform:
Please note that the equality remains true if we revert back to our original X (no longer assumed to be in its canonical guise). This is so because we can always go from X to its canonical counter-part by taking an image measure. Then the law of the process, hence the Laplace exponent and the probability do not change in this transformation.
Remark 7.
Henceforth the normalization of the scale function W will be understood so as to enforce the validity of (13).
Proposition 4.
, and if . If , then .
Proof.
Integration by parts and the DCT yield . (13) and another application of the DCT then show that . Similarly, integration by parts and the MCT give the identity . The conclusion is then immediate from (13) when . If , then the right-hand side of (13) tends to infinity as and thus, by the MCT, necessarily . ☐
4.2. The Scale Functions ,
Definition 3.
For , let (), where plays the role of W but for the process (; see Proposition 1). Please note that . When convenient we extend by 0 on .
Theorem 6.
For each , is the unique right-continuous and piecewise continuous function of exponential order with Laplace transform:
Moreover, for all and :
Proof.
The claim regarding the Laplace transform follows from Proposition 1, Theorem 5 and Definition 3 as it did in the case of the scale function W (cf. final paragraph of the proof of Theorem 5). For the second assertion, let us calculate (moving onto the canonical space as usual, using Proposition 1 and noting that on ):
☐
Proposition 5.
For all : and .
Proof.
As in Proposition 4, . Since , also follows at once from the expression for . ☐
Moreover:
Proposition 6.
For :
- If or , then .
- If (hence ), then , but . Indeed, , if and , if .
Proof.
The first claim is immediate from Proposition 4, Definition 3 and Proposition 1. To handle the second claim, let us calculate, for the Laplace transform of the measure , the quantity (using integration by parts, Theorem 5 and the fact that (since ) ):
For:
by the MCT, since is nonincreasing on (the latter can be checked by comparing derivatives). The claim then follows by the Karamata Tauberian Theorem (Bingham et al. 1987, p. 37, Theorem 1.7.1 with ρ = 1). ☐
4.3. The Functions ,
Definition 4.
For each , let (). When convenient we extend these functions by 1 on .
Definition 5.
For , let .
Proposition 7.
In the sense of measures on the real line, for every :
where is the normalized counting measure on , is the law of under , and for Borel subsets A of .
Theorem 7.
For each ,
when , and . The Laplace transform of , , is given by:
Proofs of Proposition 7 and Theorem 7. First, with regard to the Laplace transform of , we have the following derivation (using integration by parts, for every ):
Next, to prove Proposition 7, note that it will be sufficient to check the equality of the Laplace transforms (Bhattacharya and Waymire 2007, p. 109, Theorem 8.4). By what we have just shown, (8), integration by parts, and Theorem 6, we then only need to establish, for :
which is clear.
Finally, let . For , evaluate the measures in Proposition 7 at , to obtain:
whence the claim follows. On the other hand, when , the following calculation is straightforward: (we have passed to the limit in (12) and used the DCT on the left-hand side of this equality). ☐
Proposition 8.
Let , , . Then:
Proof.
Observe that , -a.s. The case when is immediate and indeed contained in Theorem 5, since, -a.s., . For we observe that by the strong Markov property, Theorem 6 and Theorem 7:
which completes the proof. ☐
4.4. Calculating Scale Functions
In this subsection it will be assumed for notational convenience, but without loss of generality, that . We define:
Fix . Then denote, provisionally, , and , where and note that, thanks to Theorem 6, for all . Now, . Moreover, by the strong Markov property, for each , by conditioning on and then on , where J is the time of the first jump after (so that, conditionally on , ):
Upon division by , we obtain:
Put another way, for all :
Coupled with the initial condition (from Proposition 5 and Proposition 4), this is an explicit recursion scheme by which the values of obtain (cf. (De Vylder and Goovaerts 1988, sct. 4, eq. (6) & (7)) (Dickson and Waters 1991, sct. 7, eq. (7.1) & (7.5)) (Marchal 2001, p. 255, Proposition 3.1)). We can also see the vector as a suitable eigenvector of the transition matrix P associated with the jump chain of X. Namely, we have for all : .
Now, with regard to the function , its values can be computed directly from the values of by a straightforward summation, (). Alternatively, (20) yields immediately its analogue, valid for each (make a summation and multiply by q, using Fubini’s theorem for the last sum):
i.e., for all :
Again this can be seen as an eigenvalue problem. Namely, for all : . In summary:
Proposition 9 (Calculation of and ).
Corollary 1.
We have for all :
and for ,
Proof.
Recursion (23) obtains from (20) as follows (cf. also (Asmussen and Albrecher 2010, (proof of) Proposition XVI.1.2)):
Now, given these explicit recursions for the calculation of the scale functions, searching for those Laplace exponents of upwards skip-free Lévy chains (equivalently, their descending ladder heights processes, cf. Theorem 4), that allow for an inversion of (16) in terms of some or another (more or less exotic) special function, appears less important. This is in contrast to the spectrally negative case, see e.g., Hubalek and Kyprianou (2011).
That said, when the scale function(s) can be expressed in terms of elementary functions, this is certainly note-worthy. In particular, whenever the support of is bounded from below, then (20) becomes a homogeneous linear difference equation with constant coefficients of some (finite) order, which can always be solved for explicitly in terms of elementary functions (as long as one has control over the zeros of the characteristic polynomial). The minimal example of this situation is of course when X is skip-free to the left also. For simplicity let us only consider the case .
- Skip-free chain. Let . Then , unless , in which case , .
Indeed one can in general reverse-engineer the Lévy measure, so that the zeros of the characteristic polynomial of (20) (with ) are known a priori, as follows. Choose as being ; as representing the probability of an up-jump; and then the numbers , …, (real, or not), in such a way that the polynomial (in x) coincides with the characteristic polynomial of (20) (for ):
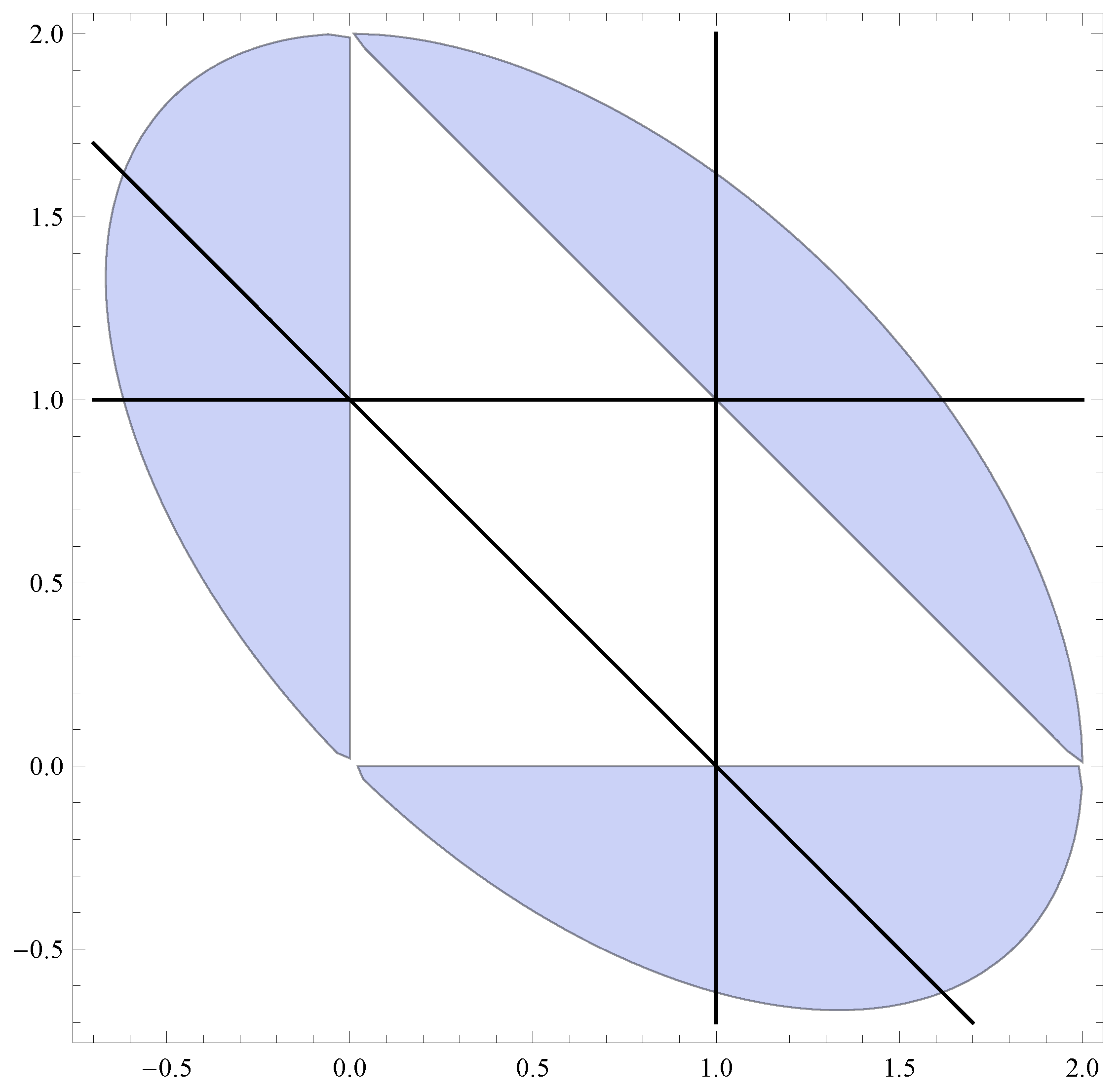
of some upwards skip-free Lévy chain, which can jump down by at most (and does jump down by) l units (this imposes some set of algebraic restrictions on the elements of ). A priori one then has access to the zeros of the characteristic polynomial, and it remains to use the linear recursion in order to determine the first values of W, thereby finding (via solving a set of linear equations of dimension ) the sought-after particular solution of (20) (with ), that is W. A particular parameter set for the zeros is depicted in Figure 1 and the following is a concrete example of this procedure.
- “Reverse-engineered” chain. Let , and, with reference to (the caption of) Figure 1, , , . Then this corresponds (in the sense that has been made precise above) to an upwards skip-free Lévy chain with and with , for all , for some . Choosing (say) , we have from Proposition 4, ; and then from (20), , . This renders , , .
An example in which the support of is not bounded, but one can still obtain closed form expressions in terms of elementary functions, is the following.
- “Geometric” chain. Assume , take an , and let for . Then (20) implies for that , i.e., for the relation , a homogeneous second order linear difference equation with constant coefficients. Specialize now to and take . Solving the difference equation with the initial conditions that are got from the known values of and leads to , . This example is further developed in Section 5, in the context of the modeling of the capital surplus process of an insurance company.
Beyond this “geometric” case it seems difficult to come up with other Lévy measures for X that have unbounded support and for which W could be rendered explicit in terms of elementary functions.
We close this section with the following remark and corollary (cf. (Biffis and Kyprianou 2010, eq. (12)) and (Avram et al. 2004, Remark 5), respectively, for their spectrally negative analogues): for them we no longer assume that .
Remark 8.
Corollary 2.
For each , the stopped processes Y and Z, defined by and , , are nonnegative -martingales with respect to the natural filtration of X.
Proof.
We argue for the case of the process Y, the justification for Z being similar. Let , , be the sequence of jump times of X (where, possibly by discarding a -negligible set, we may insist on all of the , , being finite and increasing to as ). Let , . By the MCT it will be sufficient to establish for , , that:
On the left-hand (respectively right-hand) side of (25) we may now replace (respectively ) by (respectively ) and then harmlessly insist on . Moreover, up to a completion, . Therefore, by a /-argument, we need only verify (25) for sets A of the form: , , Borel subsets of , , . Due to the presence of the indicator , we may also take, without loss of generality, and hence . Furthermore, is independent of and then , -a.s. (as follows at once from (22) of Proposition 9), whence (25) obtains. ☐
5. Application to the Modeling of an Insurance Company’s Risk Process
Consider an insurance company receiving a steady but temporally somewhat uncertain stream of premia—the uncertainty stemming from fluctuations in the number of insurees and/or simply from the randomness of the times at which the premia are paid in—and which, independently, incurs random claims. For simplicity assume all the collected premia are of the same size and that the claims incurred and the initial capital are all multiples of h. A possible, if somewhat simplistic, model for the aggregate capital process of such a company, net of initial capital, is then precisely the upwards skip-free Lévy chain X of Definition 1.
Fix now the X. We retain the notation of the previous sections, and in particular of Section 4.4, assuming still that (of course this just means that we are expressing all monetary sums in the unit of the sizes of the received premia).
As an illustration we may then consider the computation of the Laplace transform (and hence, by inversion, of the density) of the time until ruin of the insurance company, which is to say of the time .
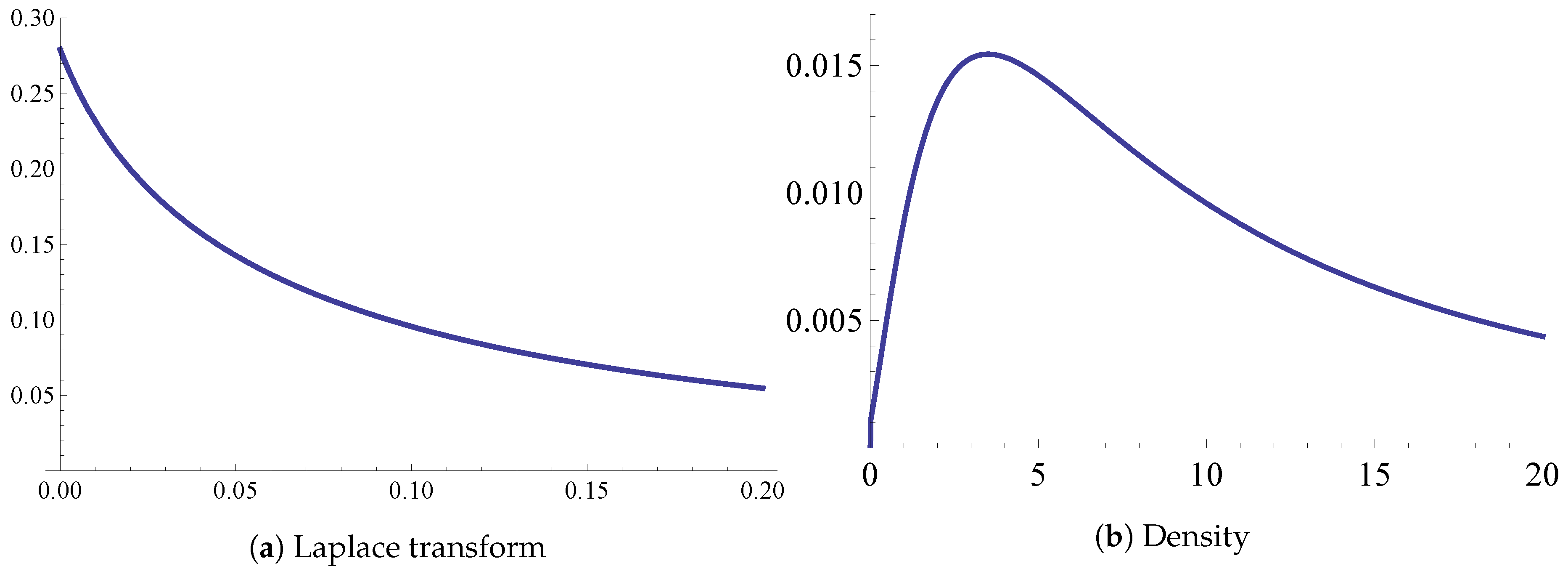
To make it concrete let us take the parameters as follows. The masses of the Lévy measure on the down jumps: , ; mass of Lévy measure on the up jump: /positive “safety loading” /; initial capital: . This is a special case of the “geometric” chain from Section 4.4 with , and (see p. 20 for a). Setting, for , produces the following difference equation: , . The initial conditions are and . Finishing the tedious computation with the help of Mathematica produces the results reported in Figure 2.
On a final note, we should point out that the assumptions made above concerning the risk process are, strictly speaking, unrealistic. Indeed (i) the collected premia will typically not all be of the same size, and, moreover, (ii) the initial capital, and incurred claims will not be a multiple thereof. Besides, there is no reason to believe (iii) that the times that elapse between the accrual of premia are (approximately) i.id. exponentially distributed. Nevertheless, these objections can be reasonably addressed to some extent. For (ii) one just need to choose h small enough so that the error committed in “rounding off” the initial capital and the claims is negligible (of course even a priori the monetary units are not infinitely divisible, but e.g., , may not be the most computationally efficient unit to consider in this context). Concerning (i) and (iii) we would typically prefer to see a premium drift (with slight stochastic deviations). This can be achieved by taking sufficiently large: we will then be witnessing the arrival of premia with very high-intensity, which by the law of large numbers on a large enough time scale will look essentially like premium drift (but slightly stochastic), interdispersed with the arrivals of claims. This is basically an approximation of the Cramér-Lundberg model in the spirit of Mijatović et al. (2015), which however (because we are not ultimately effecting the limits , ) retains some stochasticity in the premia. Keeping this in mind, it would be interesting to see how the upwards skip-free model behaves when fitted against real data, but this investigation lies beyond the intended scope of the present text.
Funding
The support of the Slovene Human Resources Development and Scholarship Fund under contract number 11010-543/2011 is acknowledged.
Acknowledgments
I thank Andreas Kyprianou for suggesting to me some of the investigations in this paper. I am also grateful to three anonymous Referees whose comments and suggestions have helped to improve the presentation as well as the content of this paper. Finally my thanks goes to Florin Avram for inviting me to contribute to this special issue of Risks.
Conflicts of Interest
The author declares no conflict of interest.
References
- Asmussen, Søren, and Hansjörg Albrecher. 2010. Ruin Probabilities. Advanced series on statistical science and applied probability; Singapore: World Scientific. [Google Scholar]
- Avram, Florin, Andreas E. Kyprianou, and Martijn R. Pistorius. 2004. Exit Problems for Spectrally Negative Lévy Processes and Applications to (Canadized) Russian Options. The Annals of Applied Probability 14: 215–38. [Google Scholar]
- Avram, Florin, Zbigniew Palmowski, and Martijn R. Pistorius. 2007. On the optimal dividend problem for a spectrally negative Lévy process. The Annals of Applied Probability 17: 156–80. [Google Scholar] [CrossRef]
- Avram, Florin, and Matija Vidmar. 2017. First passage problems for upwards skip-free random walks via the Φ, W, Z paradigm. arXiv, arXiv:1708.0608. [Google Scholar]
- Bao, Zhenhua, and He Liu. 2012. The compound binomial risk model with delayed claims and random income. Mathematical and Computer Modelling 55: 1315–23. [Google Scholar] [CrossRef]
- Bertoin, Jean. 1996. Lévy Processes. Cambridge Tracts in Mathematics. Cambridge: Cambridge University Press. [Google Scholar]
- Bhattacharya, Rabindra Nath, and Edward C. Waymire. 2007. A Basic Course in Probability Theory. New York: Springer. [Google Scholar]
- Biffis, Enrico, and Andreas E. Kyprianou. 2010. A note on scale functions and the time value of ruin for Lévy insurance risk processes. Insurance: Mathematics and Economics 46: 85–91. [Google Scholar]
- Bingham, Nicholas Hugh, Charles M. Goldie, and Jozef L. Teugels. 1987. Regular Variation. Encyclopedia of Mathematics and its Applications. Cambridge: Cambridge University Press. [Google Scholar]
- Brown, Mark, Erol A. Peköz, and Sheldon M. Ross. 2010. Some results for skip-free random walk. Probability in the Engineering and Informational Sciences 24: 491–507. [Google Scholar] [CrossRef]
- Bühlmann, Hans. 1970. Mathematical Methods in Risk Theory. Grundlehren der mathematischen Wissenschaft: A series of comprehensive studies in mathematics; Berlin/ Heidelberg: Springer. [Google Scholar]
- Chiu, Sung Nok, and Chuancun Yin. 2005. Passage times for a spectrally negative Lévy process with applications to risk theory. Bernoulli 11: 511–22. [Google Scholar] [CrossRef]
- De Vylder, Florian, and Marc J. Goovaerts. 1988. Recursive calculation of finite-time ruin probabilities. Insurance: Mathematics and Economics 7: 1–7. [Google Scholar] [CrossRef]
- Dickson, David C. M., and Howard R. Waters. 1991. Recursive calculation of survival probabilities. ASTIN Bulletin 21: 199–221. [Google Scholar] [CrossRef]
- Doney, Ronald A. 2007. Fluctuation Theory for Lévy Processes: Ecole d’Eté de Probabilités de Saint-Flour XXXV-2005. Edited by Jean Picard. Number 1897 in Ecole d’Eté de Probabilités de Saint-Flour. Berlin/Heidelberg: Springer. [Google Scholar]
- Engelberg, Shlomo. 2005. A Mathematical Introduction to Control Theory. Series in Electrical and Computer Engineering; London: Imperial College Press, vol. 2. [Google Scholar]
- Hubalek, Friedrich, and Andreas E. Kyprianou. 2011. Old and New Examples of Scale Functions for Spectrally Negative Lévy Processes. In Seminar on Stochastic Analysis, Random Fields and Applications VI. Edited by Robert Dalang, Marco Dozzi and Francesco Russo. Basel: Springer, pp. 119–45. [Google Scholar]
- Kallenberg, Olav. 1997. Foundations of Modern Probability. Probability and Its Applications. New York and Berlin/Heidelberg: Springer. [Google Scholar]
- Karatzas, Ioannis, and Steven E. Shreve. 1988. Brownian Motion and Stochastic Calculus. Graduate Texts in Mathematics. New York: Springer. [Google Scholar]
- Kyprianou, Andreas E. 2006. Introductory Lectures on Fluctuations of Lévy Processes with Applications. Berlin/ Heidelberg: Springer. [Google Scholar]
- Marchal, Philippe. 2001. A Combinatorial Approach to the Two-Sided Exit Problem for Left-Continuous Random Walks. Combinatorics, Probability and Computing 10: 251–66. [Google Scholar] [CrossRef]
- Mijatović, Aleksandar, Matija Vidmar, and Saul Jacka. 2014. Markov chain approximations for transition densities of Lévy processes. Electronic Journal of Probability 19: 1–37. [Google Scholar] [CrossRef]
- Mijatović, Aleksandar, Matija Vidmar, and Saul Jacka. 2015. Markov chain approximations to scale functions of Lévy processes. Stochastic Processes and their Applications 125: 3932–57. [Google Scholar] [CrossRef]
- Norris, James R. 1997. Markov Chains. Cambridge series in statistical and probabilistic mathematics; Cambridge: Cambridge University Press. [Google Scholar]
- Parthasarathy, Kalyanapuram Rangachari. 1967. Probability Measures on Metric Spaces. New York and London: Academic Press. [Google Scholar]
- Quine, Malcolm P. 2004. On the escape probability for a left or right continuous random walk. Annals of Combinatorics 8: 221–23. [Google Scholar] [CrossRef]
- Revuz, Daniel, and Marc Yor. 1999. Continuous Martingales and Brownian Motion. Berlin/Heidelberg: Springer. [Google Scholar]
- Rudin, Walter. 1970. Real and Complex Analysis. International student edition. Maidenhead: McGraw-Hill. [Google Scholar]
- Sato, Ken-iti. 1999. Lévy Processes and Infinitely Divisible Distributions. Cambridge studies in advanced mathematics. Cambridge: Cambridge University Press. [Google Scholar]
- Spitzer, Frank. 2001. Principles of Random Walk. Graduate texts in mathematics. New York: Springer. [Google Scholar]
- Vidmar, Matija. 2015. Non-random overshoots of Lévy processes. Markov Processes and Related Fields 21: 39–56. [Google Scholar]
- Wat, Kam Pui, Kam Chuen Yuen, Wai Keung Li, and Xueyuan Wu. 2018. On the compound binomial risk model with delayed claims and randomized dividends. Risks 6: 6. [Google Scholar] [CrossRef]
- Xiao, Yuntao, and Junyi Guo. 2007. The compound binomial risk model with time-correlated claims. Insurance: Mathematics and Economics 41: 124–33. [Google Scholar] [CrossRef]
- Yang, Hailiang, and Lianzeng Zhang. 2001. Spectrally negative Lévy processes with applications in risk theory. Advances in Applied Probability 33: 281–91. [Google Scholar] [CrossRef]
| 1. | However, such a treatment did eventually become available (several years after this manuscript was essentially completed, but before it was published), in the preprint Avram and Vidmar (2017). |
| 2. | It is part of the condition, that such an x should exist (automatically, given the preceding assumptions, there is at most one). |
Figure 1.
Consider the possible zeros , and of the characteristic polynomial of (20) (with ), when and . Straightforward computation shows they are precisely those that satisfy (o) ; (i) and (ii) & . In the plot one has as the abscissa, as the ordinate. The shaded area (an ellipse missing the closed inner triangle) satisfies (ii), the black lines verify (i). Then and .
Figure 1.
Consider the possible zeros , and of the characteristic polynomial of (20) (with ), when and . Straightforward computation shows they are precisely those that satisfy (o) ; (i) and (ii) & . In the plot one has as the abscissa, as the ordinate. The shaded area (an ellipse missing the closed inner triangle) satisfies (ii), the black lines verify (i). Then and .

Figure 2.
(a): The Laplace transform for the parameter set described in the body of the text, on the interval . The probability of ruin is and the mean ruin time conditionally on ruin is (graphically this is one over where the tangent to l at zero meets the abscissa); (b): Density of on , plotted on the interval , and obtained by means of numerically inverting the Laplace transform l (the Lebesgue integral of this density on is equal to ).
Figure 2.
(a): The Laplace transform for the parameter set described in the body of the text, on the interval . The probability of ruin is and the mean ruin time conditionally on ruin is (graphically this is one over where the tangent to l at zero meets the abscissa); (b): Density of on , plotted on the interval , and obtained by means of numerically inverting the Laplace transform l (the Lebesgue integral of this density on is equal to ).


{kind=link}
{kind=link}
Table 1.
Connections between the quantities , , , the behaviour of X at large times, and the behaviour of its excursions away from the running supremum (the latter when ).
Table 1.
Connections between the quantities , , , the behaviour of X at large times, and the behaviour of its excursions away from the running supremum (the latter when ).
| Long-Term Behaviour | Excursion Length | |||
|---|---|---|---|---|
| 0 | drifts to | finite expectation | ||
| 0 | 0 | oscillates | a.s. finite with infinite expectation | |
| drifts to | infinite with a positive probability |
© 2018 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Vidmar, M. Fluctuation Theory for Upwards Skip-Free Lévy Chains. Risks 2018, 6, 102. https://doi.org/10.3390/risks6030102
AMA Style
Vidmar M. Fluctuation Theory for Upwards Skip-Free Lévy Chains. Risks. 2018; 6(3):102. https://doi.org/10.3390/risks6030102
Chicago/Turabian StyleVidmar, Matija. 2018. "Fluctuation Theory for Upwards Skip-Free Lévy Chains" Risks 6, no. 3: 102. https://doi.org/10.3390/risks6030102
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.