In this section, we present some numerical results to show the usefulness of including interactions in linear regression models. In particular, we will compare the performance of the linear regression models with and without interactions.
5.1. Experimental Setup
As mentioned in
Section 3, metamodeling has two major components: an experimental design method and a metamodel. The experimental design method is used to select representative VA contracts. The metamodel is first fitted to the representative VA contracts and then used to predict the fair market values of all the VA contracts in the portfolio.
Since this paper focuses on metamodels that include and do not include interactions, we just use random sampling as the experimental design method to minimize the effect of experimental design on the accuracy of the metamodel.
Another important factor to consider in metamodeling is the number of representative VA contracts. There is a trade-off between accuracy and speed. If only a few representative VA contracts are used, then it takes less time to run Monte Carlo valuation for the representative VA contracts. However, the fitted metamodel might not be accurate. If a lot of representative VA contracts are used, then the fitted metamodel performs well in terms of prediction accuracy. However, in this case it takes more time to run Monte Carlo simulation. In this paper, we follow the strategy used in previous studies (e.g.,
Gan and Lin 2015) to determine the number of representative VA contracts, that is, we use 10 times the number of predictors, including the dummy variables converted from categorical variables. Since there are 34 predictors, we start with 340 representative VA contracts. We also use 680 representative VA contracts to see the impact of the number of representative VA contracts on the performance of the metamodels.
To fit linear models to the data, we use the R function lm from the stats package. To fit the overlapped group-lasso, we use the R function glinternet.cv with default settings from the glinternet package developed by
Lim and Hastie (
2018). We use 10-fold cross-validation to select the best value of
in Equation (
5).
5.2. Validation Measures
To compare the prediction accuracy of the metamodels, we use the following three validation measures: the percentage error at the portfolio level, the
(
Frees 2009), and the concordance correlation coefficient (
Lin 1989).
Let
denote the fair market value of the
ith VA policy in the portfolio that is calculated by Monte Carlo simulation method. Let
denote the fair market value predicted by a metamodel. Then the percentage error (
) at the portfolio level is defined as
where
n is the number of VA policies in the portfolio. Between two metamodels, the one producing a PE that is closer to zero is better.
The
is calculated as
where
is the average of
. Between two metamodels, the one that produces a lower MSE is better.
The concordance correlation coefficient (
) is used to measure the agreement between two variables. It is defined as follows (
Lin 1989):
where
is the correlation between
and
,
and
are the standard deviation and the mean of
, respectively, and
and
are the standard deviation and the mean of
,
, …,
, respectively. Between two metamodels, the one that produces a higher CCC is considered a better model. In particular, a value of 1 indicates perfect agreement between the two models.
5.3. Results
To demonstrate the benefit of including interactions in regression models, we fitted a multiple linear regression model without interactions and the first-order interaction model defined in Equation (
2) to the representative VA contracts. We conducted our experiments on a Laptop computer with a Windows operating system and 8 GB memory.
Table 5 shows the values of the validation measures for the linear models with and without interactions when 340 representative VA contracts were used. All the validation measures show that the linear model with interactions outperformed the one without interactions in terms of accuracy. At the portfolio level, for example, the percentage error of the linear model with interactions is around −0.4%, while the percentage error of the linear model without interactions is around 2.1%, which is higher. Since we used 10-fold cross validation to select the optimal tuning parameter
in the overlapped group-lasso, the runtime used to fit the linear model with interactions is higher.
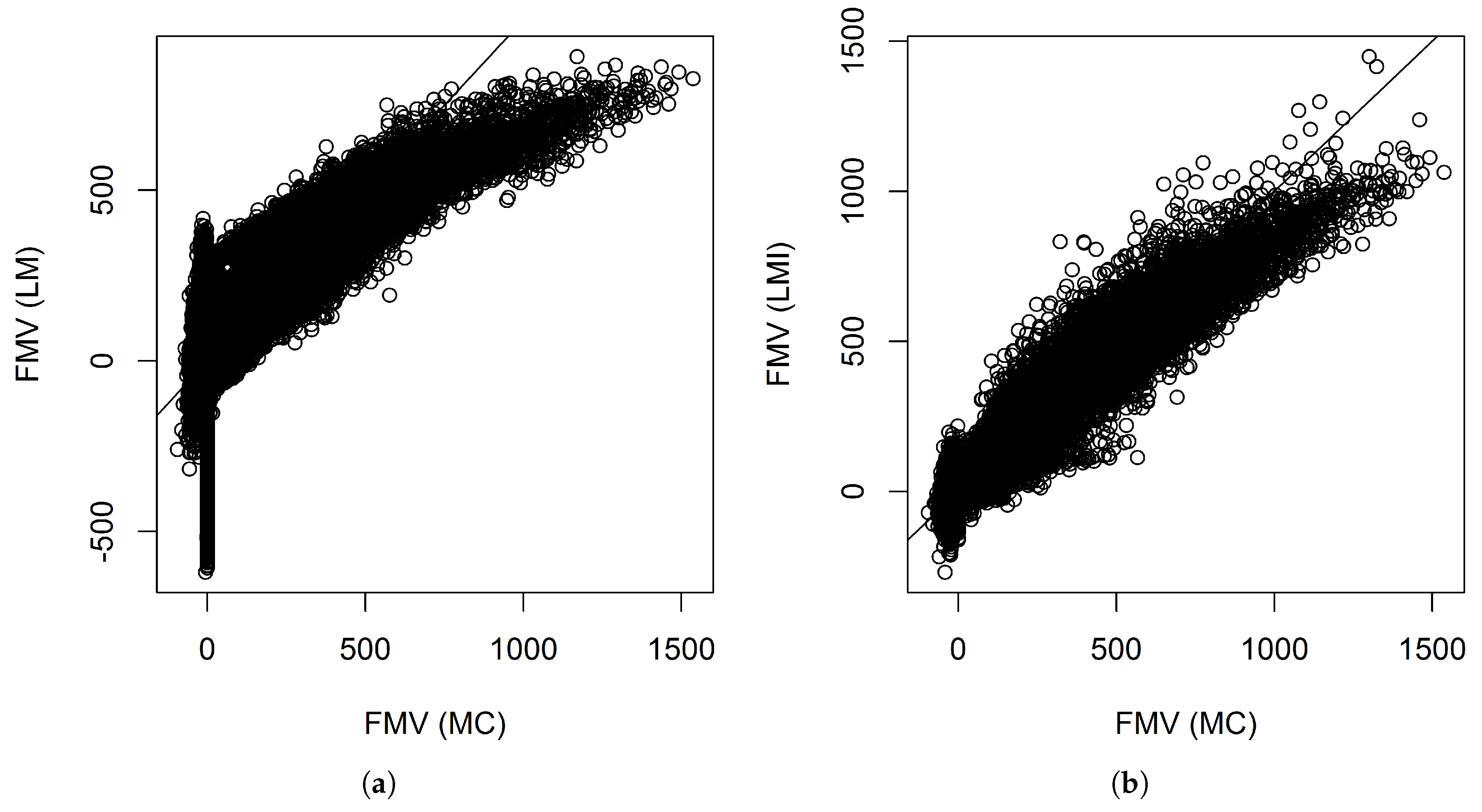
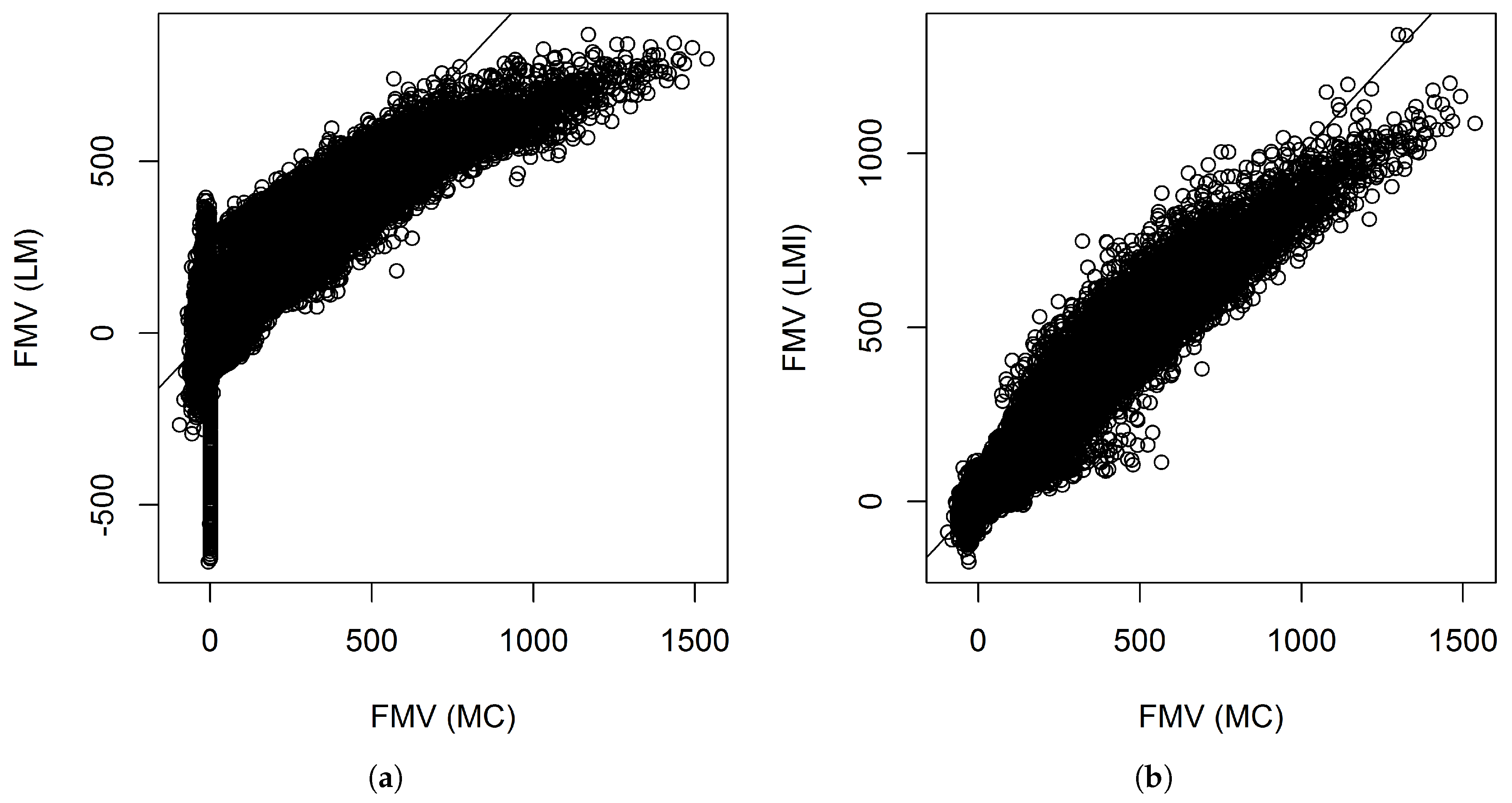
Figure 3 shows the scatter plots between the fair market values calculated by Monte Carlo and those predicted by the linear models with and without interactions when 340 representative VA contracts were used. The figures show that the linear model without interactions did not fit the tails well. For example, many of the contracts have near zero fair market values. However, their fair market values predicted by the linear model without interactions ranges from less than −
$500 thousand to near
$500 thousand.
Table 6 shows some summary statistics of the prediction errors of individual VA contracts. From the table, we see that prediction errors of the linear model with interactions have a more symmetric distribution.
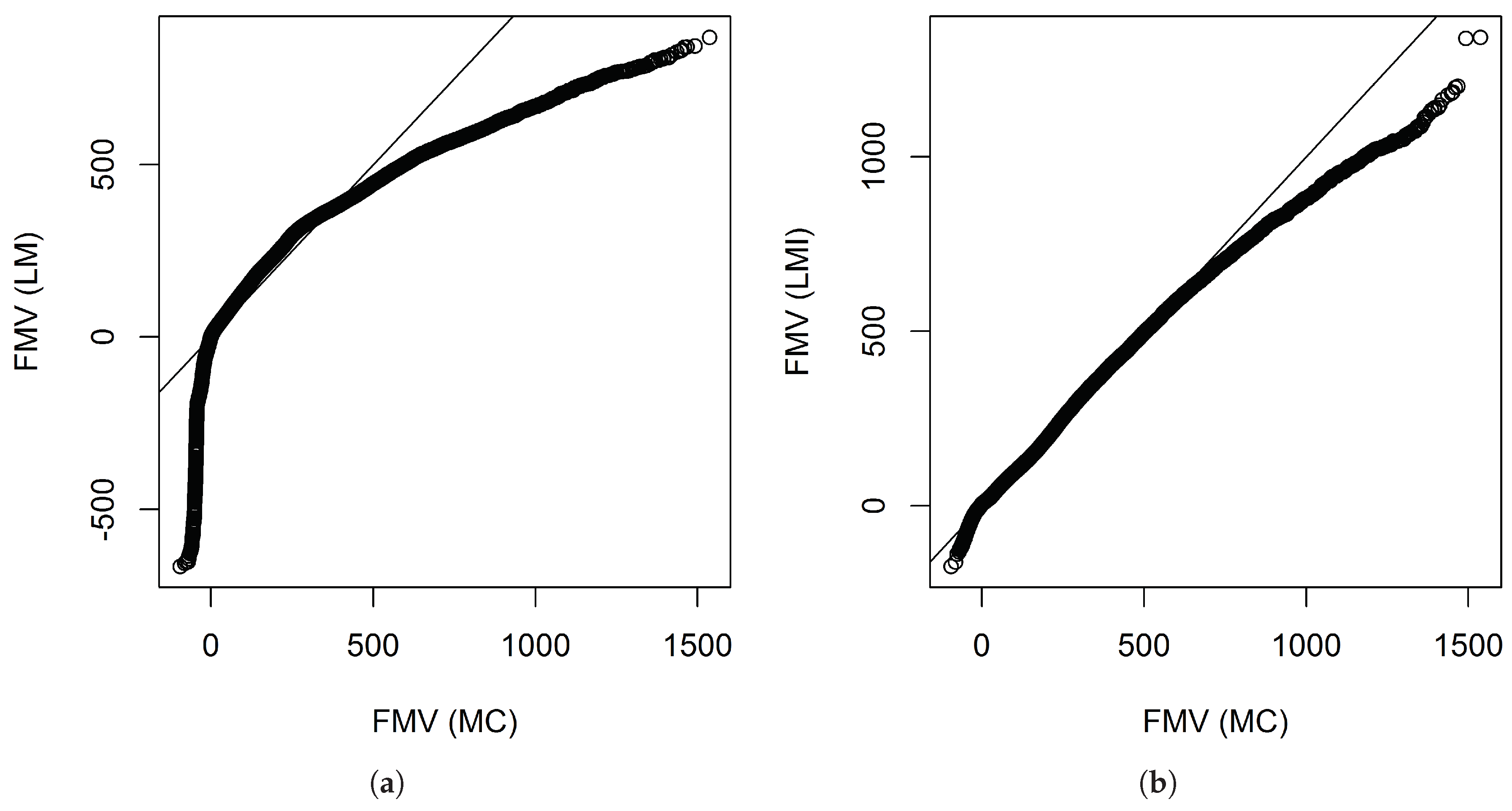
Figure 4 shows the QQ plots produced by the linear model with interactions found by the overlapped group-lasso and the linear model without interactions. If we look at these plots, we see that the linear model with interactions worked pretty well, although the fitting at the tails is a little bit off.
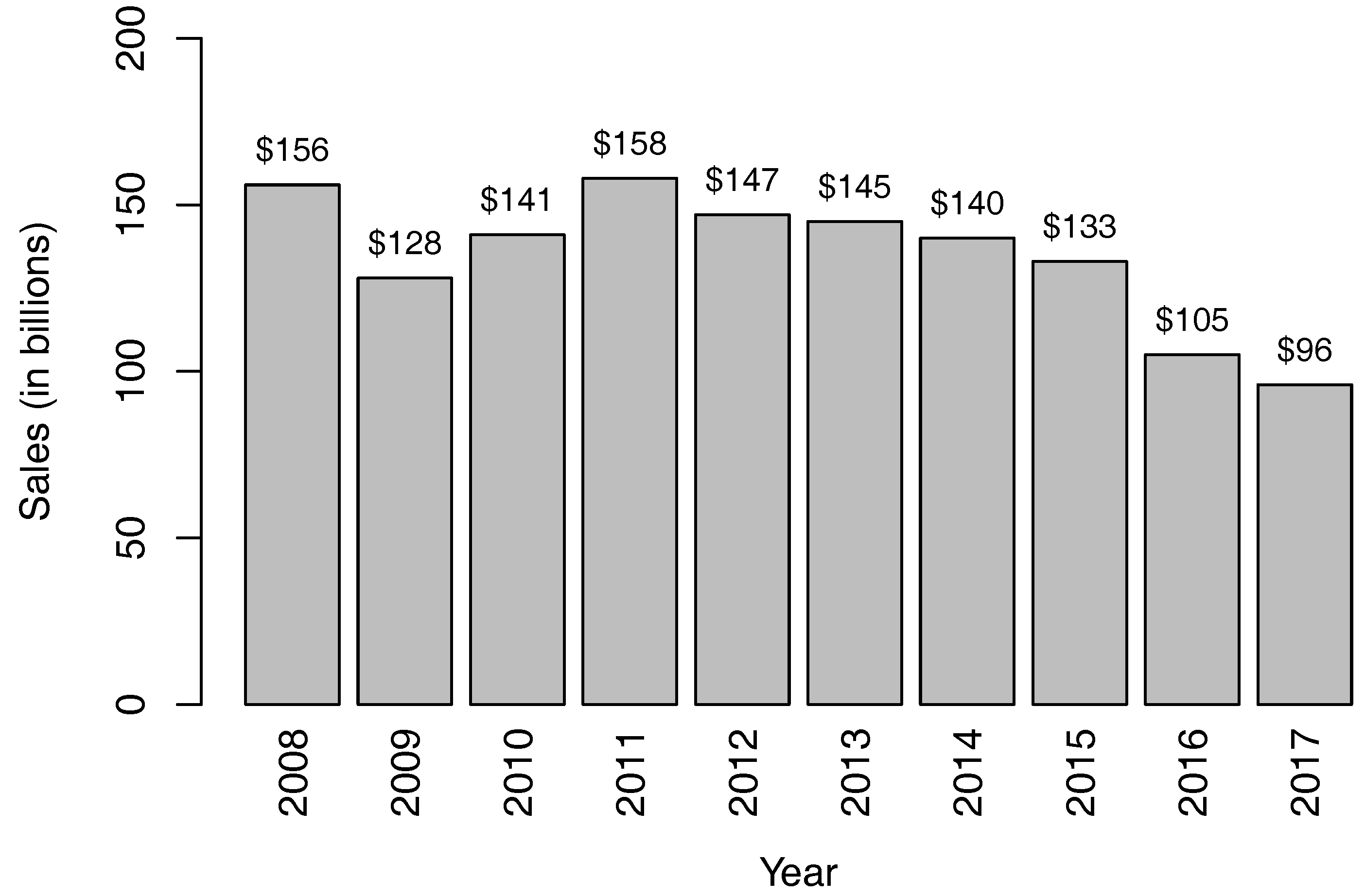
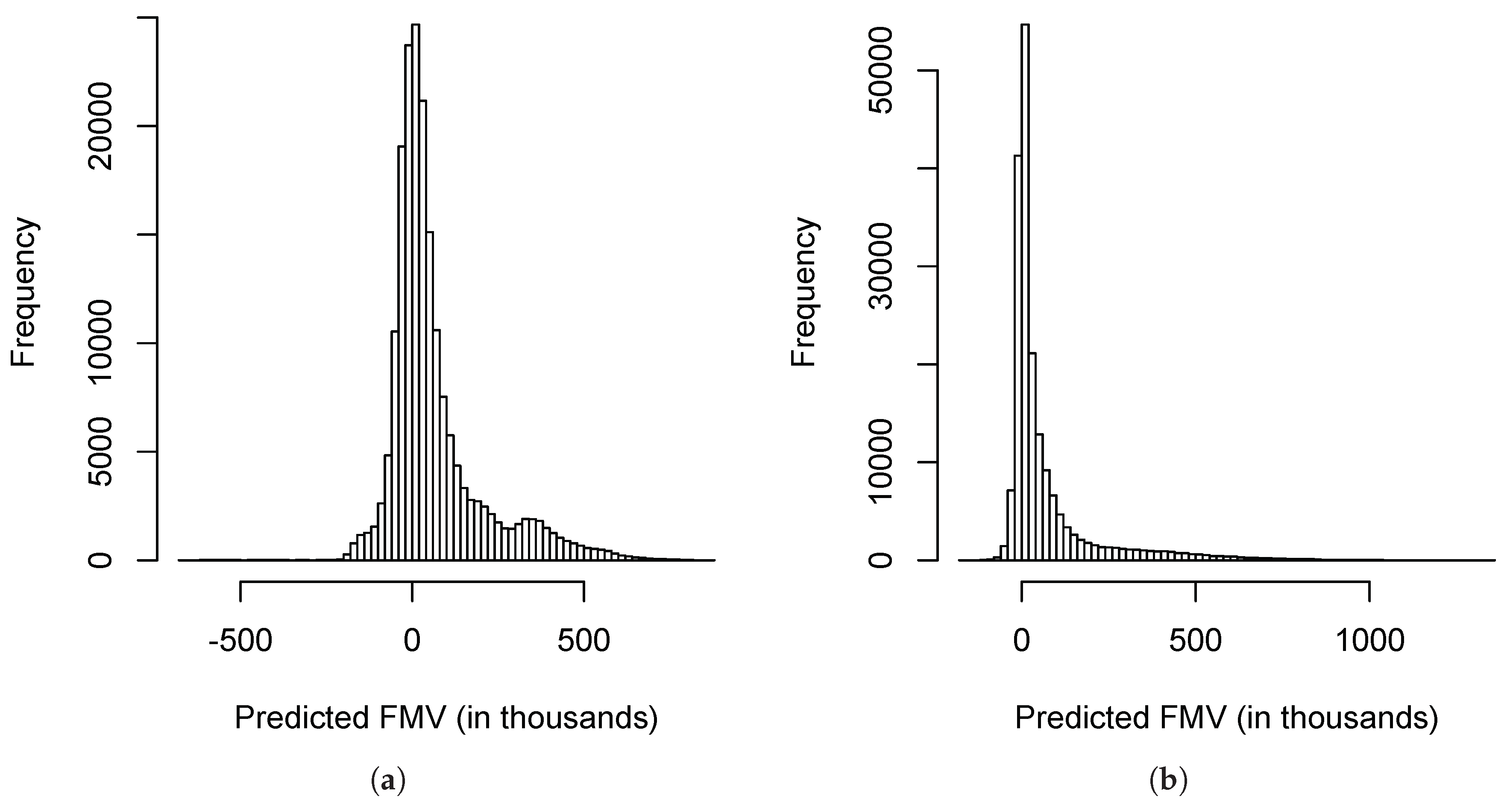
Figure 5 shows the histograms of the fair market values predicted by the linear models with and without interactions. Between the two histograms, the histogram produced by the linear model with interactions is more similar to the histogram of the data shown in
Figure 2.
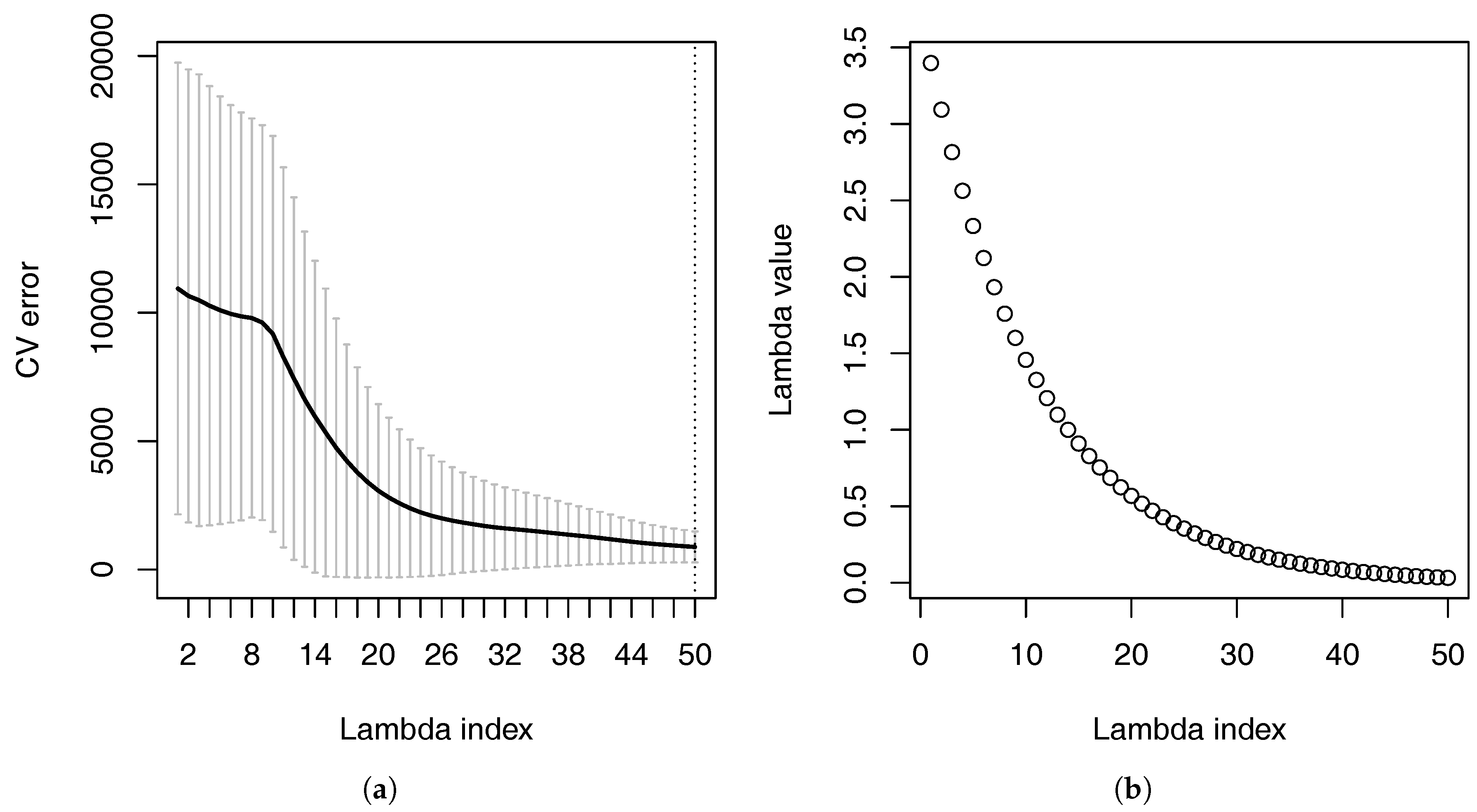
Figure 6a shows the cross-validation errors of the linear model with interactions at different values of the tuning parameter
.
Figure 6b shows the these values of
. When the value of
is large, many of the coefficients are forced to be zero because of the penalty. When many of the coefficients are zero, the linear model with interactions produces large cross-validation errors. When the value of
decreases, the cross-validation error also decreases.
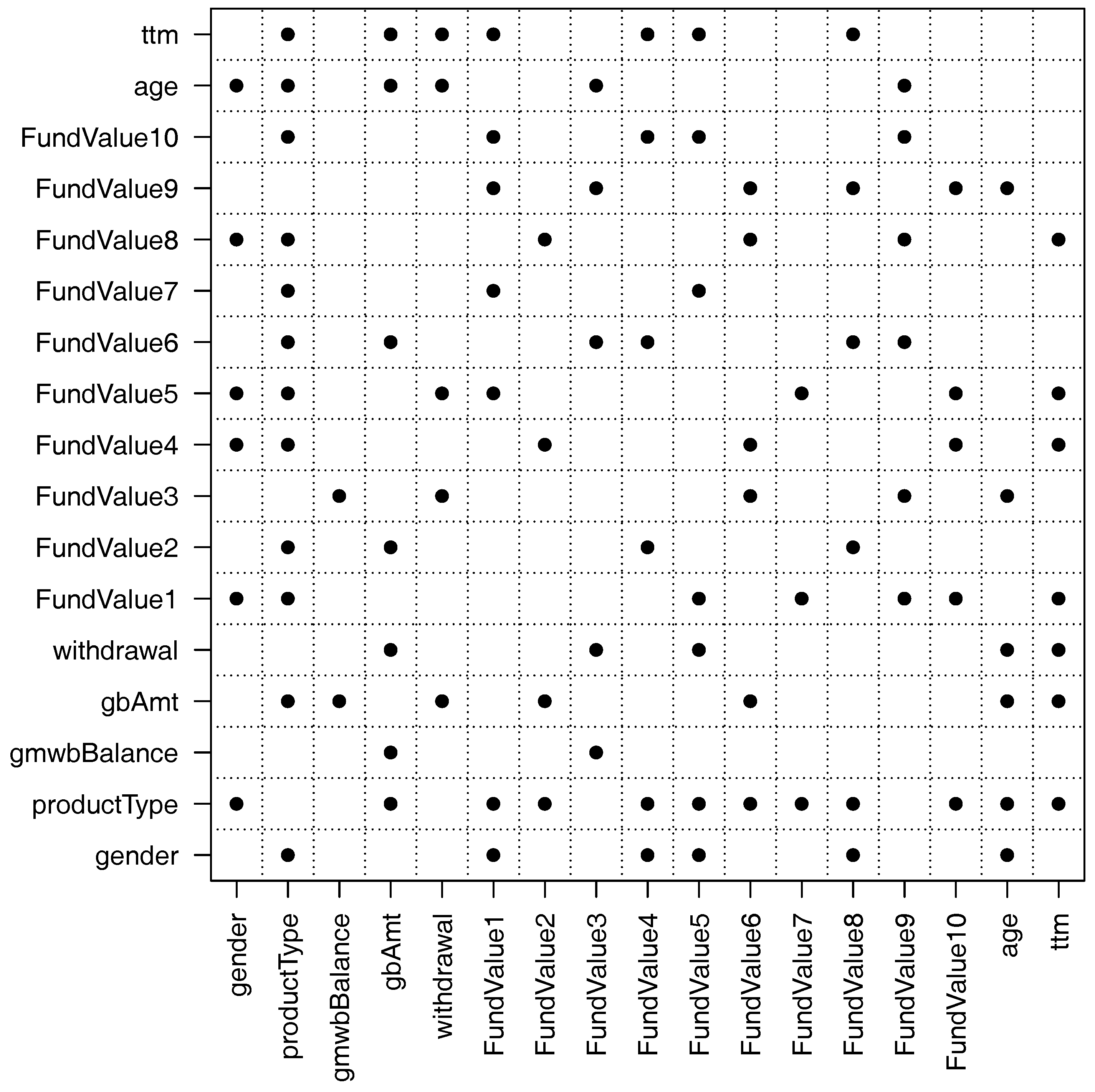
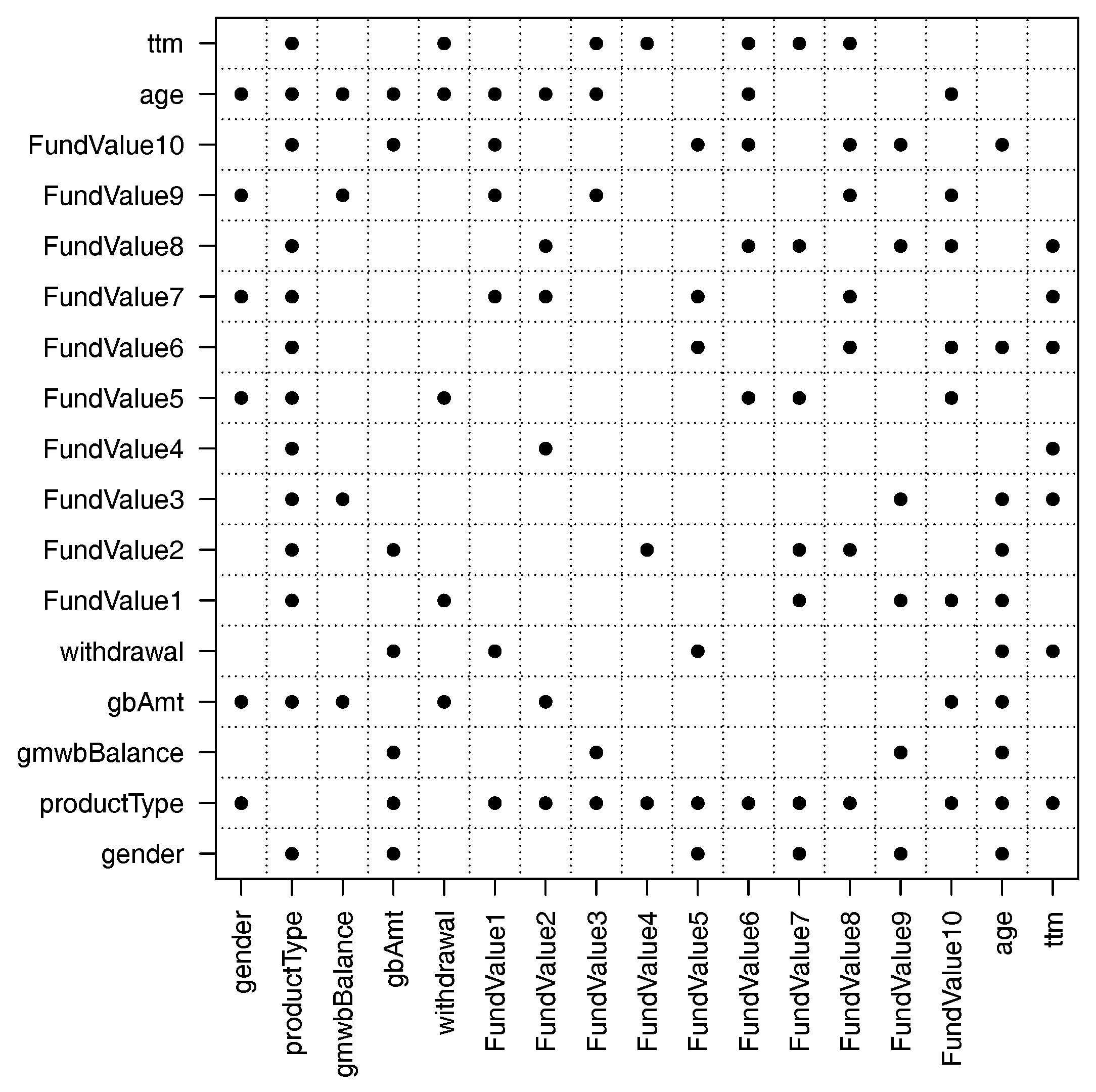
Figure 7 shows the important pairwise interactions found by the overlapped group-lasso. From the figure, we see that there are more than 50 pairwise interactions that are important. In particular, the variable productType has interactions with many other variables. This makes sense because the variable productType controls how the guarantee payoffs are calculated (see
Gan and Valdez 2017b for details). The variable gmwbBalance has the fewest interactions with other variables. It has interactions with only two variables: gbAmt and FundValue3. The reason is that the variable gmwbBalance is zero for all contracts that do not include the GMWB guarantee.
Now let us look at how the models perform when we double the number of representative VA contracts.
Table 7 shows the values of the validation measures and the runtime for the two models when 680 representative VA contracts were used. The values of the validation measures indicate that the linear model with interactions outperformed the linear model without interactions. The runtime shows that learning the important pairwise interactions takes some time. If we compare
Table 7 to
Table 5, we see that the performance of the linear model without interactions decreased when the number of representative contracts doubled. For example, the absolute value of the percentage error increased from 2.07% to 4.27% and the values of
and
also decreased slightly. This is counterintuitive because increasing the training samples usually leads to improvement in prediction accuracy. This might be related to the experimental design method we used. We used random sampling to select the representative VA contracts.
If we compare the values of the validation measures for the linear model with interactions in
Table 5 and
Table 7, we see that the accuracy of the linear model with interactions increased when we doubled the number of representative VA contracts. For example, the absolute value of the percentage error decreased from 0.36% to 0.23%, the
increased from 0.9441 to 0.9589, and the
increased from 0.9697 to 0.9785. The validation measures show that the impact of experimental design is not material when interactions are included. If we use a higher number of representative VA contracts, however, the runtime will increase due to the cross-validation.
Figure 8 shows the scatter plots between the fair market value calculated by Monte Carlo and those predicted by the linear models with and without interactions when 680 representative VA contracts were used. We see similar patterns as before when 340 representative VA contracts were used. Without interactions, the linear model did not fit the tails well.
Table 8 shows some summary statistics of the prediction errors of individual VA contracts when 680 representative VA contracts were used. From the table, we again see that prediction errors of the linear model with interactions have a more symmetric distribution.
Figure 9 shows the QQ plots obtained by the linear models with and without interactions when 680 representative VA contracts were used. However,
Figure 9b shows that even interactions were included, the fitting at the tails are a little bit off. The reason is that the distribution of the fair market values is highly skewed as shown in
Figure 2.
Figure 10 shows the histograms produced by the linear models with and without interaction effects where 680 representative VA contracts were used. The histograms also show that the linear model with interactions outperforms the linear model without interactions.
Figure 11 and
Figure 12 show respectively the cross-validation errors at different values of
and the important pairwise interactions found by the overlapped group-lasso when 680 representative VA contracts were used. We see similar patterns as before when 340 representative VA contracts were used. For example, the cross-validation error decreases when the value of
increases. The variable productType has interactions with many other variables. If we compare
Figure 12 to
Figure 7, however, we see that more interactions are found by the overlapped group-lasso when the number of representative VA contracts doubled.
In summary, our numerical results presented above show that including interactions in linear regression models is able to improve the prediction accuracy significantly.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





