
Data-Driven Framework for Uncovering Hidden Control Strategies in Evolutionary Analysis

1
Laboratoire de Mathématiques Blaise Pascal, University of Clermont Auvergne, CNRS, 63000 Clermont-Ferrand, France
2
Department of Statistical Modeling, Institute of Statistical Mathematics, 10-3 Midori-cho, Tachikawa 190-8562, Tokyo, Japan
*
Author to whom correspondence should be addressed.
†
These authors contributed equally to this work.
Math. Comput. Appl. 2023, 28(5), 103; https://doi.org/10.3390/mca28050103
Submission received: 22 August 2023
/
Revised: 4 October 2023
/
Accepted: 13 October 2023
/
Published: 20 October 2023
(This article belongs to the Collection Mathematical Modelling of COVID-19)
Abstract
:We devised a data-driven framework for uncovering hidden control strategies used by an evolutionary system described by an evolutionary probability distribution. This innovative framework enables deciphering of the concealed mechanisms that contribute to the progression or mitigation of such situations as the spread of COVID-19. Novel algorithms are used to estimate the optimal control in tandem with the parameters for evolution in general dynamical systems, thereby extending the concept of model predictive control. This marks a significant departure from conventional control methods, which require knowledge of the system to manipulate its evolution and of the controller’s strategy or parameters. We use a generalized additive model, supplemented by extensive statistical testing, to identify a set of predictor covariates closely linked to the control. Using real-world COVID-19 data, we delineate the descriptive behaviors of the COVID-19 epidemics in five prefectures in Japan and nine countries. We compare these nine countries and group them on the basis of shared profiles, providing valuable insights into their pandemic responses. Our findings underscore the potential of our framework as a powerful tool for understanding and managing complex evolutionary processes.
1. Introduction
The evolution of natural dynamical systems is a complex process where the dynamics are influenced by a multitude of factors, including epidemic evolution, environmental changes, and various exogenous random events. The traditional methods of studying evolutionary processes often involve creating simplified models that may not fully capture this complexity. When it comes to influencing or controlling this evolution, optimal control theory (OCT) is a powerful and flexible tool. This provides valuable insights into the likely paths of evolution and the factors that may affect it. The aim of this work is to investigate an evolutionary process, such as epidemic evolution, from the perspective of OCT in order to uncover the hidden mechanisms that lead to deterioration or improvement of the situation. We assume that the evolutionary process is described by a controlled system via a hidden mechanism to which we do not have access and that we cannot change directly; we can only observe its effects through measurements related to its evolution. We also assume that this hidden control mechanism is affected by an infinite number of random parameters related to the behavior and characteristics of societies and populations. We start from a simple linear control model based on Kalman-type filtering. We aim to jointly determine the parameters of the spatial-temporal process and the active optimal control that leads to the observed evolution. The determination of the appropriate parameters is based on the best proximity between the observed data and that generated by the simple model.
Given that the objects in evolution are probability distributions, various customized distance measures are employed to evaluate their proximity. The Hellinger distance is, thus, preferred due to its superior numerical performance, inherited from its link to the -norm. The coronavirus disease 2019 (COVID-19) is being examined using the principles of OCT. For instance, Péni et al. suggest an optimal control strategy based on model predictive control (MPC) theory for a compartmental epidemic model that depicts the dynamics of COVID-19 virus transmission. Péni and Szederkényi explore the application of the MPC approach to a nonlinear compartmental model. The COVID-19 outbreak in Germany is being studied using the epidemiological SIDARTH model to determine the best feedback control approach using MPC. Carli et al. present a unique feedback control mechanism using an epidemiological SIR (susceptible, infectious, and recovered or removed)-based model and the MPC approach to help policymakers effectively mitigate the effects of the COVID-19 pandemic in numerous regions, including Italy, where the pandemic reaches its peak. The SIR model is being explored by Morato et al. in relation to MPC strategies to control COVID-19 infections in Brazil. All of these studies use MPC to simulate epidemiological models such as the SIR model. However, using simulation to investigate the COVID-19 pandemic is challenging due to the simplistic assumptions and limitations of the models, such as their inability to represent treatments, their fixed parameters, and their uncertainty resulting from data quality concerns. We, thus, aim to identify the variables affecting the spread of COVID-19 by using a data-driven model and a simple controlled Kalman-type dynamical system.
Our goal in this work is to make a simple assumption about the dynamics of COVID-19 virus transmission and then utilize the data to determine the parameters governing it. An extensive initial analysis of Japanese data is being performed to understand the dynamics of the epidemic in diverse prefectures (Tokyo, Osaka, Hokkaido, Fukuoka, and Okinawa). Their differing characteristics are compared and linked via a generalized additive model (GAM) to different socio-demographic structures and the related policies that are adopted in each prefecture.
After validating our data-driven model on the Japanese data, we examine whether it can be applied to other countries or geographical regions with different population structures and dynamics. We do this by applying an MPC-like procedure, as we do for the Japan data, to simultaneously obtain the dynamics and control parameters that contribute to the observed evolution of the epidemic in each country. We then perform a comparative analysis between the countries based on their management strategies, such as for vaccinations and lockdowns.
- Descriptive behavior of epidemic by country: Using the epidemic’s fitted controlling parameters for each country or region, we attempt to clarify the relationship between the parameters and various socio-demographic indicators, as well as the various policies that governments implemented to reduce the epidemic’s spread.
- Comparative analysis and clustering: Using the contrasting characteristics and indicators of the various countries, we group them on the basis of the similarities in their profiles. We then look at the key variables that led to countries being grouped together. We also conduct additional investigations for each group to determine which factors contributed most to the grouping.
Our contributions are summarized below:
- We propose using a hidden controller framework in which the optimal control and the parameters for evolution in general dynamical systems, including the COVID-19 epidemic dynamical system, are simultaneously estimated. This transforms the linear evolution scheme into a nonlinear problem.
- We present an efficient optimization algorithm from the practical point of view that is based on a classical optimization algorithm, e.g., fmincon in MATLAB (https://www.mathworks.com/products/matlab.html, 22 August 2023).
- We present the results of a comparative analysis between prefectures and regions of Japan with differing population structures and epidemic management policies that were obtained using our hidden controller framework.
- We show that generalizing the model using our hidden controller framework to other countries (Australia, Germany, Italy, Brazil, South Africa, and so on) can reveal the effect of different policies and population structures on the evolution of the epidemic.
We discuss in detail the methodology we used, as well as the related work in Section 2. In Section 3, we describe our experiments, along with the application of our proposed model to real-world datasets. In Section 4, we discuss our results and the importance of our study. We conclude in Section 5 with a summary of the key points.
2. Methods
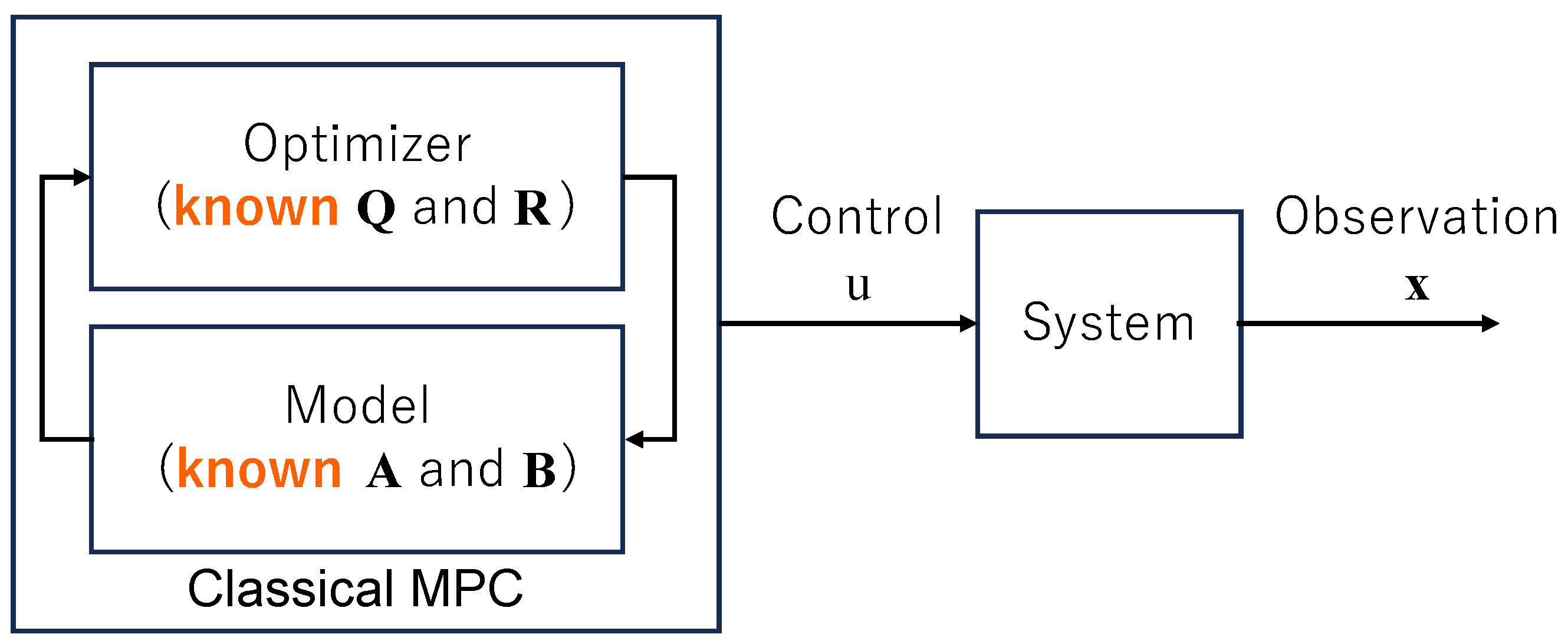
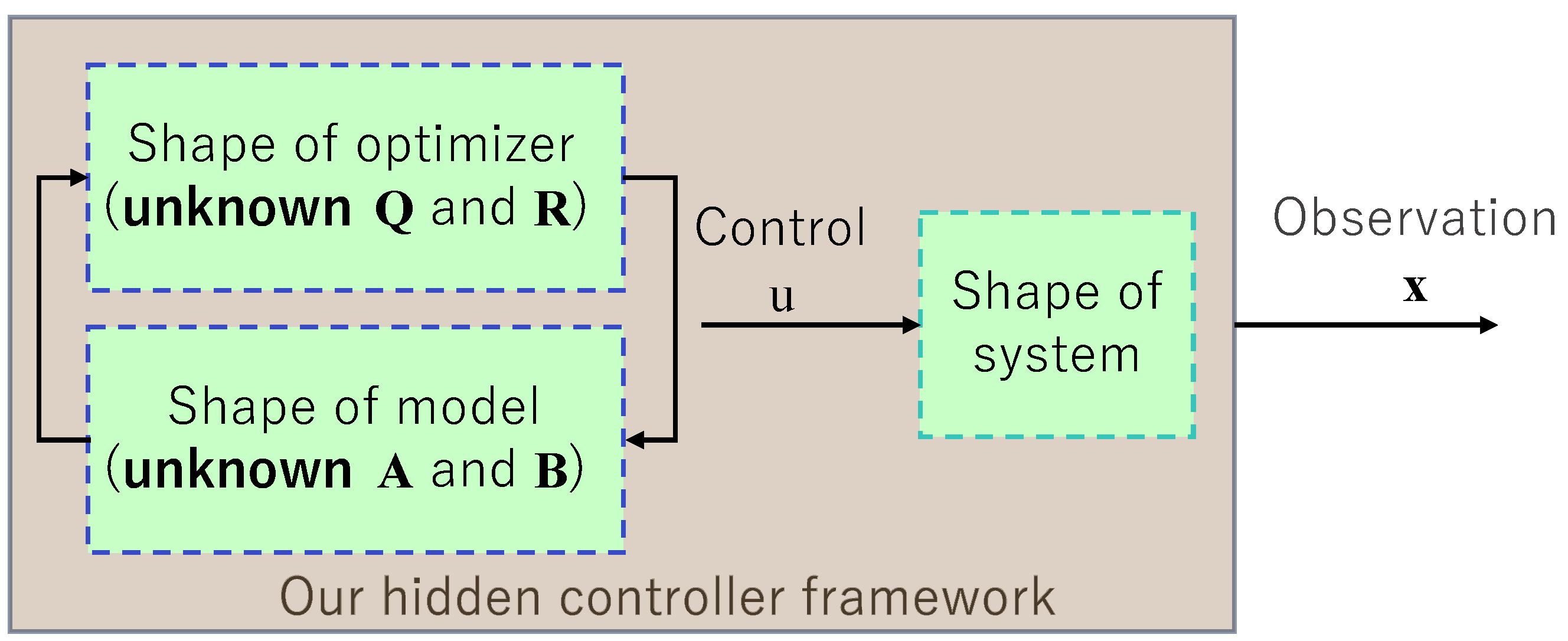
The most commonly used data-driven control technique is based on MPC (Figure 1). It enables the controller or user to interact with a dynamical system and affect its evolution by applying a specific control variable at selected times or epochs depending on the predicted horizon. Our approach was inspired by this technique but differs in two key aspects: we do not have direct access to the system, so we cannot manipulate its evolution, and we do not have any insight into the controller’s strategy or parameters. (Here we focus on a Kalman-type dynamical system, but our approach can be applied to any parametric/non-parametric dynamical system). Our knowledge is limited to the fact that the controller or the system uses a model from a specific system family (here, for example, one in the form of Equation (2)). That is, we have access to only the observed final output data. This idea is sketched in Figure 2.
This section is organized as follows; We begin by reviewing the related work and classical optimal control techniques in Section 2.1 and Section 2.2. In Section 2.3 and Section 2.6, we describe our proposed hidden control framework.
2.1. Targeted Control Problem and Its Formalism
We assume a discrete-time context in which decision-makers (e.g., government agencies) observe the distribution of the disease variable (e.g., the numbers of weekly infected, recovered, and deceased individuals), possibly with observational inaccuracy, for a given time period (day, week, month, etc.). For each sub-population , the observed distribution is generally estimated empirically from the data, which we denote . The estimated evolutionary distributions for the whole population can be represented as
Since can be expressed as , we are interested in the dynamical evolution of the discrete n-dimensional probability vector . Because we estimate the optimal control by sub-population, we omit the suffix i hereafter to simplify the description (e.g., is represented as and a column of as ). This simplified description represents the state vector of the disease distribution at time k. To model the evolution, we propose using a discrete Kalman-like controlled system:
where
- The term is an m-dimensional vector describing the unknown optimal control. This unknown control is the hidden mechanism that led to the observed shape of the evolution.
- The deterministic state matrix , defined in and describing the logical evolution of when no control is applied, is also unknown.
- The unknown control matrix , defined in , describes how the control is applied to the system to bring it to its targeted state.
The idea is to use only observed data , in Equation (1), to simultaneously estimate all the unknown objects of this control problem, namely, matrices , and the control term , which leads to the observed shape of the data. When A and B are known, the optimal control can be obtained using classical techniques that have been widely discussed in the literature (e.g., [1,2,3]). In our case, these parameters are unknown and should be estimated from the observed data. Our strategy is to use the optimal control results obtained using an iterative algorithm that minimizes a cost function.
2.2. Control Algorithm and Related Work
For given deterministic matrices A and B, the solution of the discrete-time optimal control problem, Equation (2), of a linear system is described in [1,3]. It consists of using a linear optimization scheme, Equation (2), and finding the optimal control that minimizes the objective or cost function:
where exponent represents the transpose, and , and S are cost matrices defined as follows.
- is a positive definite weighting matrix associated with the state vector. It is linked to the relative importance assigned to state vector in cost function . In other words, a higher value in the diagonal of this matrix indicates a bigger penalty or greater emphasis placed on minimizing the related state vector .
- is a positive definite weighting matrix affecting the relative relevance or weight assigned to control in cost function . It specifies how much emphasis the control algorithm should place on minimizing the control effort. A higher value in its diagonal, similar to that in the Q matrix, indicates a higher penalty or greater importance placed on reducing the control input.
- S is a positive definite weighing matrix linked to the final state vector. It is a cross-weighting matrix used by cost function to penalize discrepancies between the inputs from state and control . It is aimed at identifying any cross-dependencies between the states and control inputs. We are not interested in the final state here, so we suppose that .
The optimal control problem has been widely studied (e.g., [1,2]). In our case, a linear quadratic regulator variant is used to minimize, Equation (3). The solution of the state space, Equation (2), of a discrete time-invariant linear system is given in a more general framework [4] for :
This equation expresses state vector in terms of the initial state vector and a sequence of control vectors, , that are implicitly dependent: A, B, and weighting matrices Q, R. In this setting, the controlled system, Equation (2), with dimension K is controllable if the controllability matrix,
has column rank K (i.e., K linearly independent columns). Under these conditions on parameters A, B, the optimal control solution [4] is given by
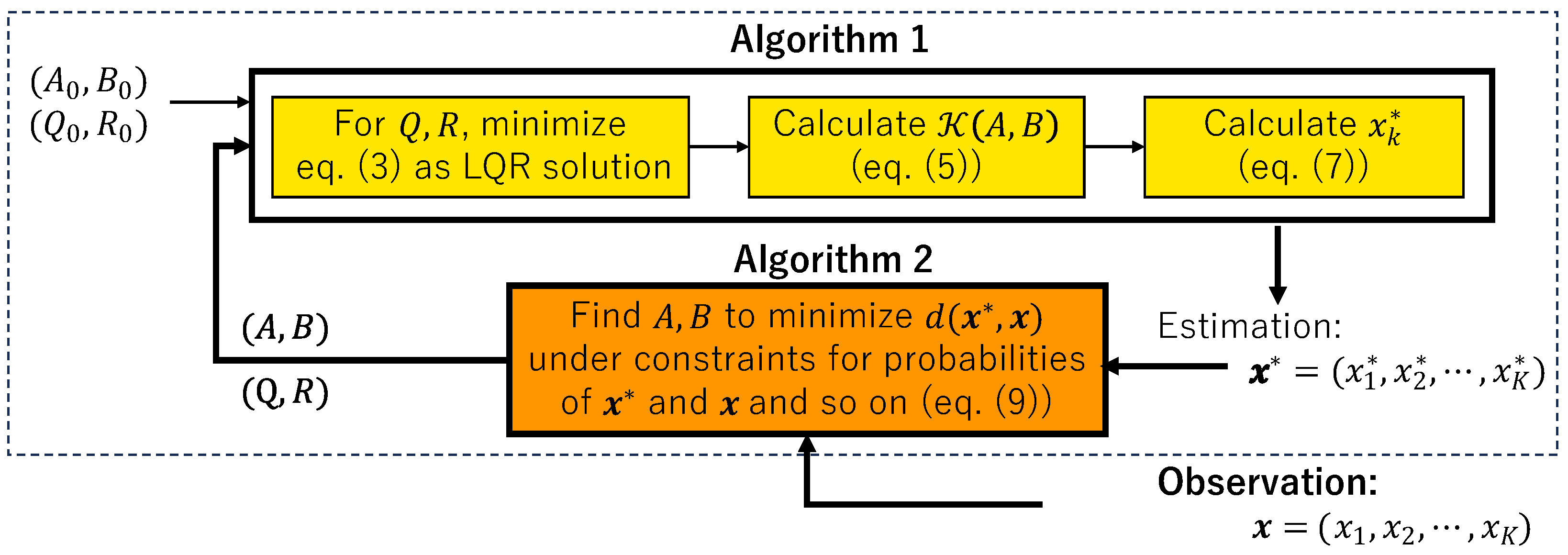
In this setting, the closed-form expression of the gain matrix is obtained using a linear quadratic regulator (LQR). This is performed iteratively in two steps using a backward approach, as detailed in Algorithm 1:
- Gain matrix is calculated from evolutionary parameter matrices A, B, Q, and R via at step k:
- is obtained from the solution of the Riccati equation [5]:
By combining Equations (2) and (6), we can write the evolutionary structure of the controlled system in Equation (2) recursively:
In the general framework of optimal control, the parameters are known and fixed. In our study, we are dealing with unknown parameters. Therefore, our objective becomes the estimation of these unidentified matrices in the Kalman filter parameters, namely, A, B, as well as weighting matrices Q, R.
| Algorithm 1: Computing optimal control and its corresponding trajectory (see Figure 3) |
|
2.3. Our Hidden Controller Framework
Instead of the traditional objects found in control problems, our methodology relies on using discrete probability distributions as the dynamic system object, as shown in Equation (2), to characterize the system’s behavior. A further distinguishing characteristic of our methodology is its ability to estimate both the parameters of the model and their corresponding optimal control, relying exclusively on observed data. To determine unknown parameters A and B, our approach utilizes two interrelated optimization steps:
- The first step is to find optimal control features and , as shown in Equation (9) under controllability conditions on A and B.
- The second step is to minimize a suitable distance that was adapted to probability distributions between and observation under two constraints: is a discrete probability distribution calculated from observed data , and the system is controllable. This leads to the following minimization problem:The constrained minimum is taken over all A and B such that the system is controllable, as detailed in Algorithm 2.
| Algorithm 2: Estimating hidden control parameters and trajectory |
|
In accordance with the concept of the probability distribution, distance in Equation (10) determines the degree of similarity between two probability distributions. A variety of metrics and distances that have been used in different circumstances and scenarios have been reported. We next discuss five of them.
2.4. Metrics and Distances
- The total variation distance measures the maximum difference between the probabilities that two distributions assign to an event. Therefore, it gives a worst-case measure of the difference between the two distributions, which makes it a conservative discrepancy measure. It is given byFor the discrete case, the right-hand side of Equation (11) can be expressed as the distance. Despite its frequent usage, the TV distance metric has certain disadvantages. It is sensitive to absolute differences between probabilities, which can lead to misleading results when applied to large event sets. Though it satisfies several metric properties such as non-negativity, symmetry, and triangle inequality, it is not a “proper” metric as it can assign a distance of zero to non-identical distributions. The TV distance also lacks the ability to capture dependencies among variables in multivariate distributions and does not provide information about the ‘location’ and ‘spread’ of differences. Furthermore, it is not a differentiable function, posing challenges for optimization algorithms. Finally, its computational complexity increases substantially for continuous distributions, especially in high-dimensional scenarios.
- Kullback–Leibler (KL) divergence quantifies the information loss when distribution is used to approximate :The KL divergence has several advantages and disadvantages when used as a measure of the difference between two probability distributions. Among its advantages are its high sensitivity to discrepancies in probability distributions, including those occurring in distribution tails, and its widespread application across multiple fields, such as information theory and machine learning. It also has a deep connection with maximum likelihood estimation, which enhances its value for theoretical analysis. The disadvantages include its lack of symmetry; that is, the divergence from distribution to is not the same as that from to , which can make it counterintuitive as a “distance” measure. Furthermore, it is not a metric as it does not satisfy properties such as symmetry and the triangle inequality. Another critical disadvantage is its undefined nature for non-overlapping distributions. Finally, when probability distributions are estimated from the data, KL divergence can be excessively sensitive to the sample size, leading to potentially unreliable estimates for smaller sample sizes.
- The Wasserstein distance, also known as the earth mover’s distance, measures the minimum amount of work needed to transform one pile into another pile. For continuous or discrete probability distributions and , the p-Wasserstein distance () is defined asThe inf bound is taken over all random variable couples such that the distribution of X is and the distribution of Y is . It offers an intuitive geometric interpretation, acting as a measure of the minimum cost required to transform one distribution into another. In addition, it captures shifts in location, a property not captured by other metrics, making it advantageous in cases in which location is important. Moreover, unlike measures such as KL divergence, the Wasserstein distance remains defined even for non-overlapping distributions and exhibits robustness to noise. However, its computation can be resource-intensive due to the underlying optimization problem. It, thus, poses challenges, particularly in higher dimensions. The distance also depends on the choice of a cost function, which may not always have an evident best choice and can affect the distance calculation. Although sensitivity to location shifts can be beneficial, in instances where location is irrelevant, this sensitivity could capture unnecessary differences. Finally, as many other measures, the Wasserstein metric faces scalability issues with high-dimensional data, demanding dimension reduction techniques to be effective.
- The Hellinger distance measures the total difference between the square roots of the probabilities in the two distributions:The Hellinger distance has several advantages. It possesses metric properties including symmetry and the satisfaction of the triangle inequality, making it a true metric. It is less sensitive to outliers due to the comparison of square roots of probabilities instead of the probabilities themselves. Its fixed range, typically between 0 and 1, aids in comparing distances across various distribution pairs. Moreover, its simplicity when comparing Gaussian distributions offers computational efficiency. However, the Hellinger distance is not without drawbacks. Its structure, rooted in square roots of probabilities, makes it less sensitive to differences in distribution tail behavior. It measures global dissimilarity, often failing to capture local differences effectively. Finally, unlike KL divergence, it does not quantify information loss when one distribution approximates another, a property that may be desirable in certain contexts.
- The distance is the sum of the squared differences between the two distributions, divided by the first distribution. It is not symmetric.
Each of these metrics comes with its own strengths and limitations. For instance, KL divergence () and the chi-squared distance () are non-symmetric, making them less intuitive for certain applications. On the other hand, metrics such as the TV distance () tend to be more conservative. In this study, our primary objective was to ensure robust convergence and computational efficiency in the optimization process. To identify the most suitable metric, we conducted comprehensive experiments testing these distances on our dataset. We encountered challenges regarding convergence and stability during the optimal control and estimation processes, as shown in Equation (10). Our experiments revealed that the Hellinger distance () exhibits superior performance in terms of convergence, stability, and efficiency. This can be attributed to its connection with the Euclidean norm, which provides certain computational advantages. Therefore, it is the primary distance measure we used in this study.
2.5. Our Parameter Estimation
To prepare for the calculation of matrix parameters of the hidden closed-loop Equation (9) on the basis of observed data, we vectorize them: . Furthermore, we assume that the hidden controller uses weighting matrices Q and R to calculate the gain matrix in Equation (7). There is no systematic way to make this choice as it depends only on the user’s preferences in terms of control over parameters A and B. Most often, the weighting matrices Q and R are chosen to be diagonal. Without a loss of generality, and due to the small number of observations, we use and . We then rearrange all the free parameters in a vector: . Let us now consider the objective cost function:
where is one of the distances , , , , or , and
- is the statistically estimated distribution for population segment i at observation time k. (Index i is omitted for and to simplify the description, as mentioned in Section 2.1).
- is the closed-loop state of the controlled system. The computation of vector for is shown in Equation (9). It is implicitly dependent on the parameters in vector Y. This step is nested inside the general optimization problem, Equation (10). Vector Y should satisfy two constraints, and , on the one hand, to comply with both the controllability constraints on A and B and the positive definiteness of Q and R and, on the other hand, to satisfy the probability structure of state vector .
- C1:
- Vector Y should verify the constraint that A and B lead to a controllable system by verifying Equation (5). Moreover, the unknown weighting matrices Q and R must be positive definite. For instance, in simulations and experiments, we selected Q and R as diagonal matrices, which necessitates that their diagonal elements be positive. This implies that all elements and are positive.
- C2:
- For all k, vector calculated using Equation (9) should satisfy a probability structure, meaning that all its elements should be positive and their sum is less than 1.
The final optimal parameter vector, , is then obtained by solving the nonlinear optimization problem under constraints:
From the practical point of view and to reduce the relative error in estimating the unknown coefficients of the parameters, we assume that the hidden controller resets vector to the observed value each time when calculating it for interval K. To implement this assumption, we divide the range of time-ordered observations by a pre-selected value T (e.g., for the COVID-19 dataset, (three days) or (one week)) and denote the number of observation groups formed by , where is the integer part. We then consider the partition group on all the observations ordered in accordance with time: the observations in group being , those in group being , and those in the last group being , for example. For any , we take vector as follows:
- for . Thus, we reset vector to the first observed value in each group.
- for all .
For the solution of the nonlinear optimization problem (10), we use sequential quadratic programming, which is an efficient and widely used technique [6,7,8,9], Moreover, it is readily available in the MATLAB software used for the optimization part of this work.
The results produced by Algorithm are dependent on the outcomes from Algorithm 1. To secure reliability in the results, Algorithm is configured to perform repeated calculations, utilizing different initial values, until it successfully converges to an optimal solution. In cases where convergence is not readily achieved, a systematic approach is employed to modify initial values, thus, facilitating the necessary conditions for convergence, and thereby ensuring the robustness of the results obtained.
These algorithms were applied to each segment of the population. The trajectories estimated using these algorithms and the observed data for different countries are plotted in Figure 5.
2.6. Interpretation of Control Parameters
In accordance with the preceding discussions, we computed the controlled part, denoted here as , of the resulting dynamical system. This computation enabled us to estimate the hidden parameters and, in turn, uncover the controller’s strategy. Another key accomplishment of this study was correlating these controlling elements with the characteristics of the corresponding population. The next step is to, a posteriori, explore how these elements affected the evolution of the dynamical system. To this end, we fit the derived controlled part to the observed population characteristics as illustrated in Figure 3. For each population segment , this was performed using a multivariate GAM. Such models are well-known for their adaptability in dealing with various forms of data and their capacity to model nonlinear relationships. We conducted extensive statistical testing on the GAM output to identify the set of variables closely linked with the control part.
Multivariate GAM
Let us consider a multivariate GAM in which the response is vector and denote as the dependent covariables describing the characteristics of the population. As shown in Table 1, we consider six characteristic COVID-19 variables specific to Japanese prefectures. The responses and covariates (predictors) are observed at times .
The functions are flexible smooth functions and can fit complex patterns in the data that would not be captured by a linear model. At the same time, they maintain interpretability: the fitted functions can be plotted and easily interpreted. The specifics of fitting a GAM depend on the type of response variable (whether it is binary, count data, continuous, etc.), the chosen link function, and the chosen form for the nonlinear functions . This model has been well studied, and many software packages are available for fitting GAMs, such as Mixed GAM Computation Vehicle with Automatic Smoothness Estimation (mgcv) in R [10,11]. As depicted in Figure 4, the application of the GAM yields an array of newly minted comprehensible features designated as . These features serve to quantify the intensity of the association between the control and corresponding population characteristics, thereby offering a method to gauge the extent of a particular population characteristic’s effect on the control of the hidden dynamical system.
These new features provide valuable information for investigating the dynamical system’s behavior across various population segments. This facilitates the identification of similarities among segments for which the system exhibits identical behavior. Various classification techniques have been explored to achieve this functionality. More details, illustrative figures, and discussion can be found below on the experiments performed on the actual COVID-19 data.
3. Experiments and Application to Real Data
3.1. Data Description
We used two sets of observed COVID-19 data: (i) data from five prefectures in Japan provided by JX PRESS Corporation and (ii) data from nine countries sourced from a “worldwide epidemiological database for COVID-19” [12] and the “COVID-19 data hub” [13]. Using our hidden controller framework, we estimate the unknown parameters , and the gain matrix K of the closed-loop system (9) to capture the dynamic behavior of COVID-19.
The prefectural data used in this study comprised the proportion of weekly infected individuals in prefecture i (), the proportion of weekly recovered individuals (), the proportion of weekly deceased individuals (), and the proportion of all other people who never had contact with the virus (. The proportions were estimated from weekly counts of numbers reported daily for 32 weeks from 1 April 2021 to 10 November 2021, coinciding with the vaccination campaign in Japan. The five prefectures () comprise Tokyo, Osaka, Hokkaido, Fukuoka, and Okinawa, respectively. These prefectures are representative of Japanese populations for which there were a sufficient number of cases for statistical analysis. For each prefecture, the data are represented as a matrix, with the weekly observations in the columns. The candidate weekly predictor covariates listed in Table 1 are for the period two weeks prior. Factors such as increases in driving and public transport (“transit”) in Tokyo, which are considered to affect the rate of new infections, are included. We used a two-week delay between measurement and onset in accordance with previous findings [14].
We selectively used data from nine countries, having complete data in our experiments: Australia (AUS), Brazil (BRA), Chile (CHL), Colombia (COL), Czech Republic (CZE), Germany (DEU), Lithuania (LTU), South Africa (ZAF), and Japan (JPN). The proportion of weekly infected individuals in country i (), the proportion of weekly recovered individuals (), and the proportion of weekly deceased individuals () were calculated from the data on “confirmed” (cumulative number of confirmed cases), “deaths” (cumulative number of deaths), and “recovered” (cumulative number of patients released from hospitals or reported recovered) [12,13]. For the sake of comparison, the period was the same as for dataset (i): the 32 weeks from 1 April 2021 to 10 November 2021. The candidate predictor covariates for these nine countries are shown in Table 2. Four of them represent governmental policy measures: government_response_index, stringency_index, containment_health_index, and economic_support_index. Since these policy measures are correlated and the ranges of the index scores vary between countries, we first categorized the policy measures into three levels—low (L: 0–50 percentile), middle (M: 50–90 percentile), and high (H: 90–100 percentile), using the Japanese data as a reference. We then applied multiple correspondence analysis and hierarchical clustering on principal components to the categorized data and obtained three groups of policy measures, as shown in Table 3. We again used a two-week delay between measurement and onset in accordance with the previous findings [14].
3.2. Experimental Conditions
To calculate parameters from Equation (13) on the basis of the observed COVID-19 data for the five Japanese prefectures (i) and nine countries (ii), we first defined , representing the unknown coefficients of parameters . We then set the Hellinger distance (described in Section 2.3) to , where the term represents the estimated COVID-19 dynamics, and the other term represents the observed COVID-19 dynamics on the day.
The proportions were calculated using the total population of Japan and the population ratios of each prefecture as of January 2021. We used the fmincon programming solver in MATLAB and selected the interior-point algorithm, for which the parameters of the termination tolerances on first-order optimality, function value, and input matrices were set to . The function optimized in fmincon was estimated for each window with a length of 3 using the -norm. We used mgcv in R [10,11] to interpret the control parameters (Section 2.6).
The code and data pertaining to the nine countries are accessible via our GitHub repository: https://github.com/ismstat/hidden-controller-framework.git, accessed on 22 August 2023.
4. Results and Discussion
4.1. Evaluating Predictive Power of Hidden Controller Framework
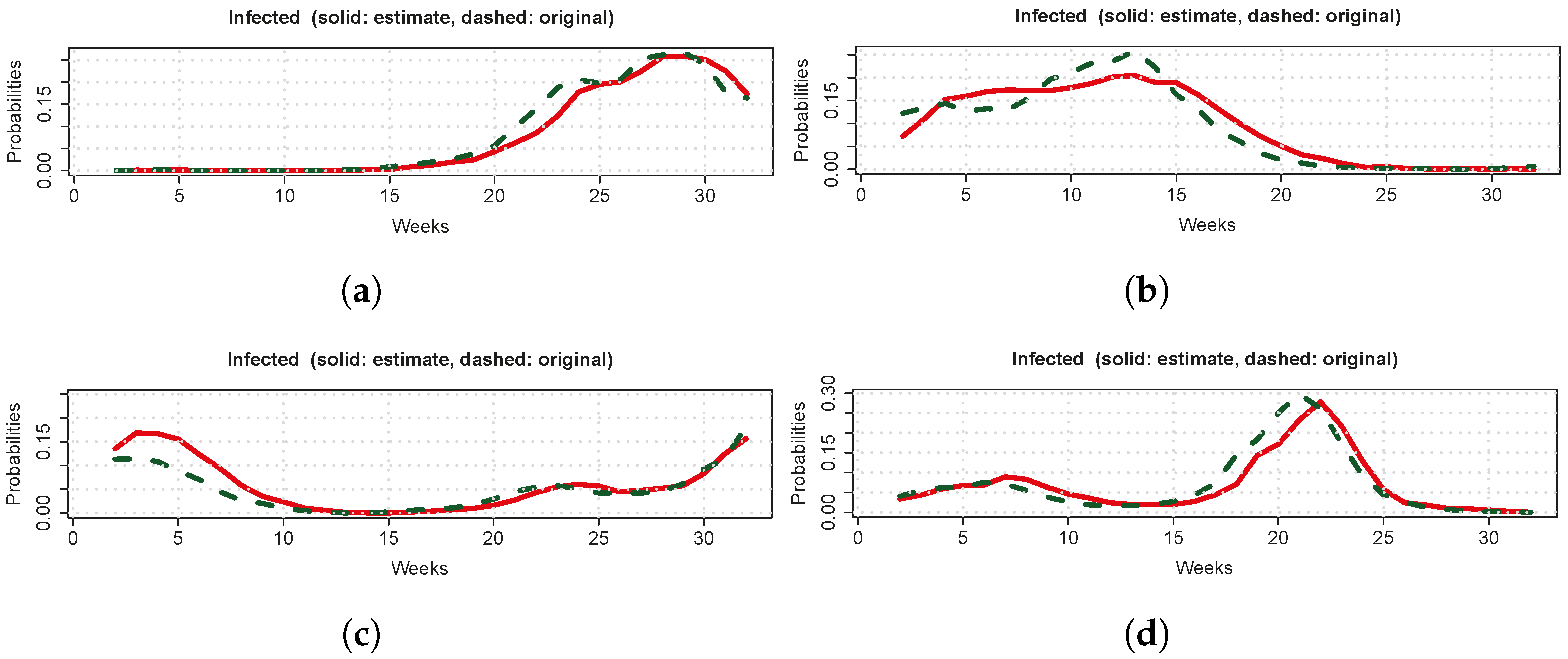
Figure 5 shows comparisons between our hidden controller framework’s prediction () and the observed for Australia, Colombia, Germany, and Japan based on the data for nine countries (data set (ii)). The predictions are reasonably accurate, suggesting that model parameters were well-estimated. Similar results were observed for the other five countries, as detailed in Appendix A. These results underscore the predictive capacity of our hidden controller framework. Furthermore, control feedback can be effectively used in subsequent data analyses.
4.2. Predictor Covariates Aimed at Halving the Number of Infected and Deceased Individuals
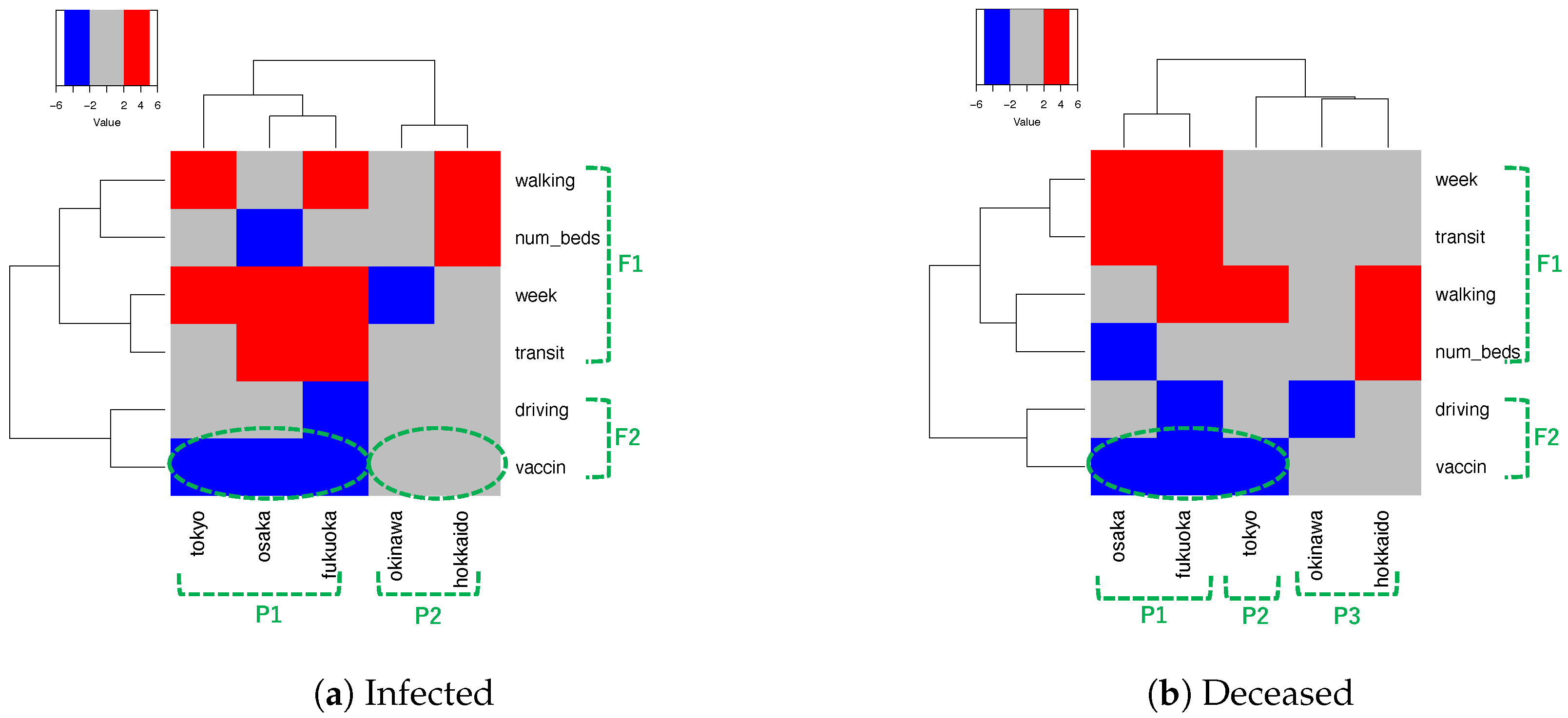
To analyze which predictor covariates effectively reduce the number of infected and deceased individuals, we applied our hidden controller framework (Section 2.3) and a multivariate GAM (Section 2.6) to a dataset in which the number of infected and deceased individuals was halved (dataset (i)). Figure 6 shows heatmaps depicting the z-scores of the predictor covariates associated with the numbers of (a) infected and (b) deceased individuals. Since z-scores approximately follow a Student’s t-distribution and transition to a normal distribution when the degree of freedom becomes large, we calculated the z-scores at a significance level of 0.05, assuming a normal distribution. We color-coded the heatmaps blue for smaller z-scores, representing positive effects in decreasing the number of infected and deceased individuals, and red for larger z-scores, representing negative effects that increase these numbers.
We roughly categorized the predictor covariates into two groups, F1 and F2. F1 includes “week”, “transit”, “walking”, and “num_beds”, which generally had negative effects. In contrast, the predictor covariates in F2 (“driving” and “vaccination”) had positive effects. These results suggest that, in Japan, traveling by automobile and getting vaccinated effectively reduced the number of infected and deceased individuals.
We can classify the prefectures into two groups: the major metropolises of Tokyo, Osaka, and Fukuoka and the tourist cities in Okinawa and Hokkaido. The data suggest that vaccination in metropolitan areas is highly effective.
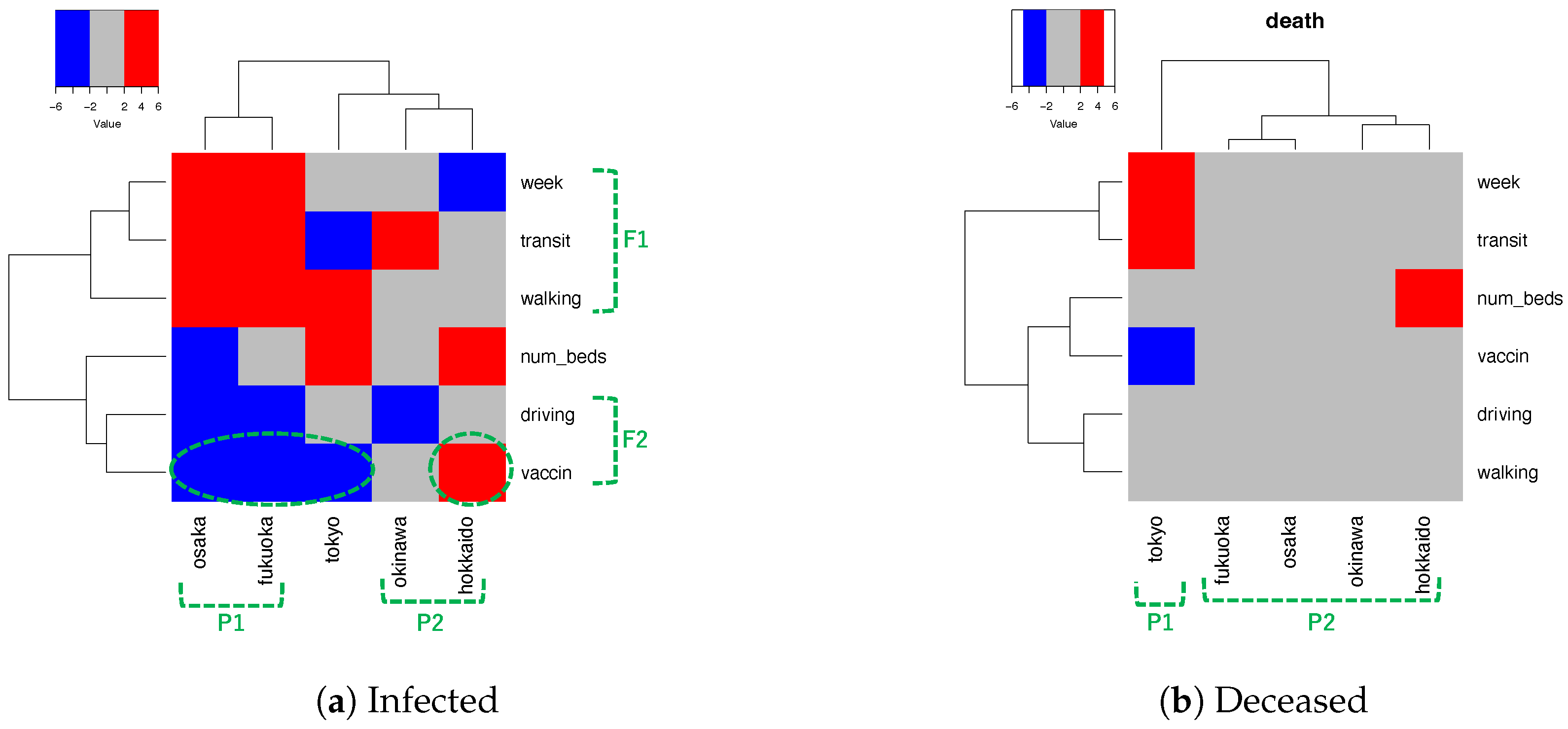
To further investigate the positive and negative effects on reducing the number of infected and deceased individuals, we analyzed the difference in z-scores for predictor covariates associated with both categories, with the goal of halving each compared with the observed numbers. Figure 7 presents heatmaps illustrating these differences in z-scores. For the infected category, vaccination was highly effective in the metropolises of Tokyo, Osaka, and Fukuoka. For the deceased category, vaccination was particularly effective in Tokyo.
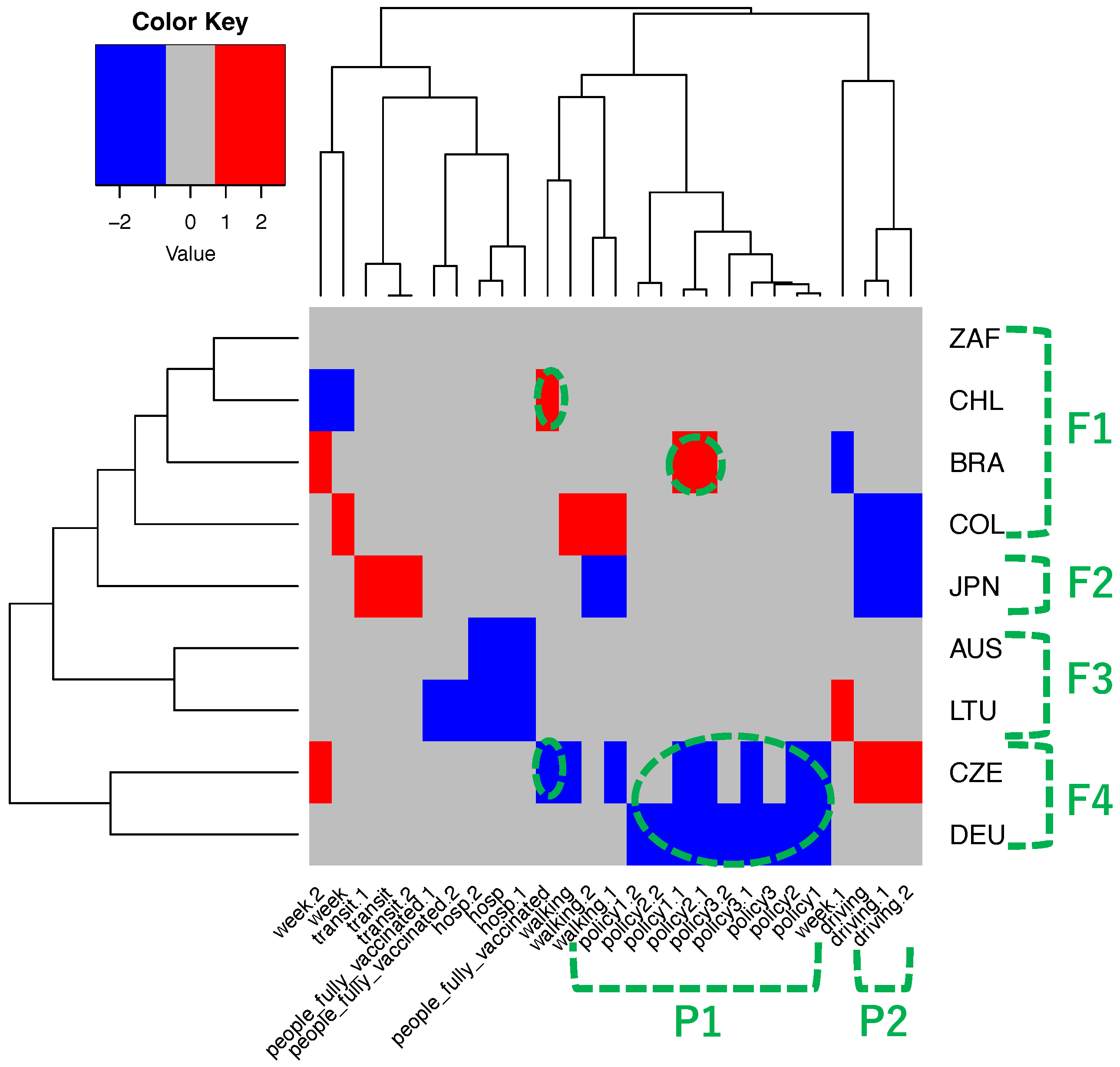
4.3. Differences in Predictor Covariates across Countries
Figure 8 presents a heatmap of z-scores for predictor covariates associated with the number of infected, deceased, and recovered individuals across the nine countries. As an illustration of the classification of characteristics based on control (Section 2.6), the countries can be broadly categorized into four clusters: F1 includes South Africa, Chile, Brazil, and Colombia; F2 is comprised solely of Japan; F3 encompasses Australia and Lithuania; and F4 contains the Czech Republic and Germany. For group F4, three policy measures in Table 3 (P1 as indicated in the figure) and vaccination (P2) seem to effectively control the number of infected, deceased, and recovered individuals. However, for countries in group F1, the opposite effects were observed.
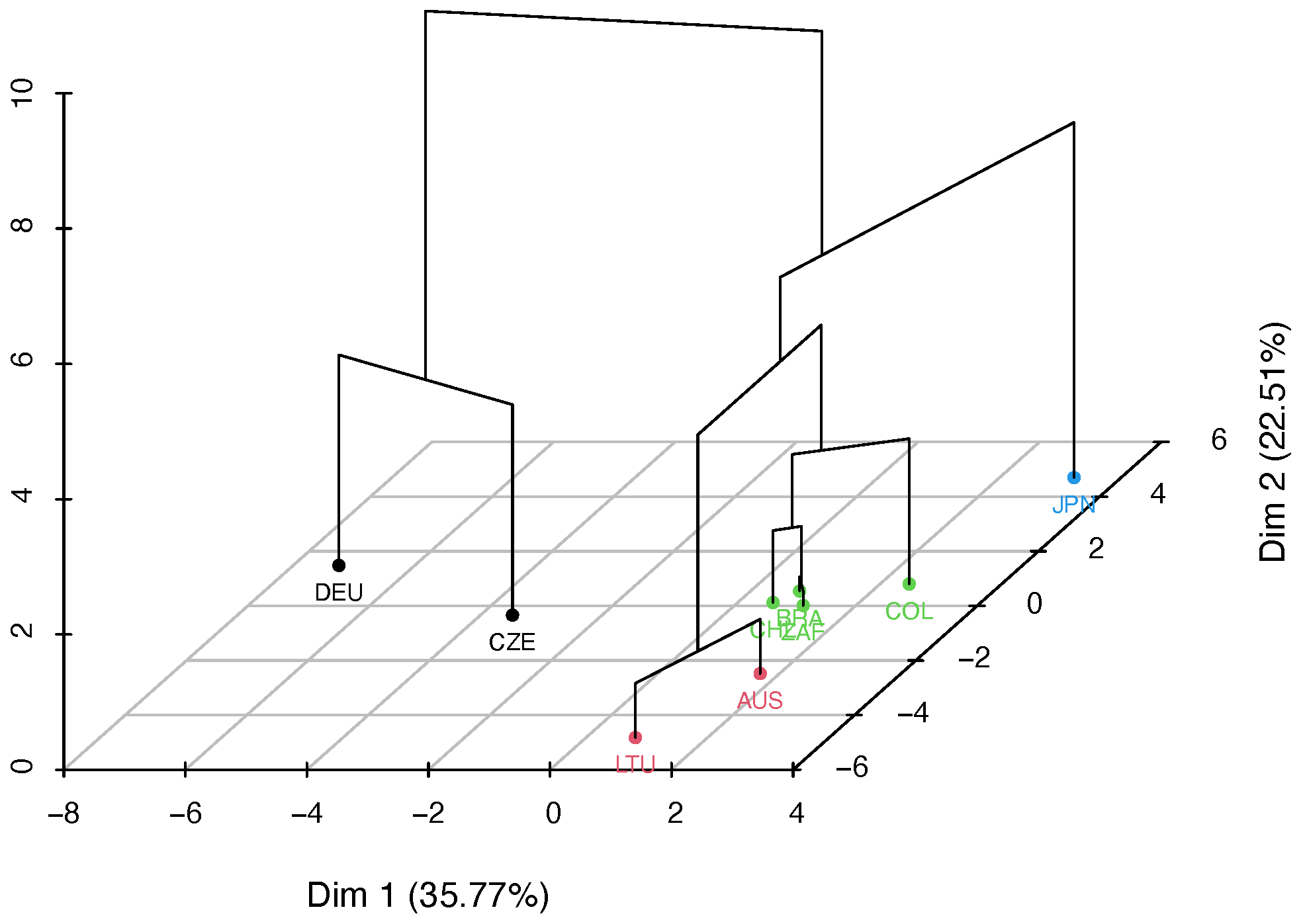
4.4. Clustering of Countries on the Basis of Policy Measures
Figure 9 illustrates the clustering of countries into four groups on the basis of the three categories of policy measures outlined in Table 3. These groups align with the ones determined by the z-scores in the previous section. This underscores the critical role of policy measures in controlling the number of infected, deceased, and recovered individuals.
5. Conclusions
We have presented a methodology that enables the correlation of various population characteristics with the evolution of a dynamically controlled system. We assume that the observed dynamical system is the result of the optimal control of a Kalman-type model, with no direct access to the various stages of this control. The choice of a Kalman-type model was made for simplicity, but this concept can be readily generalized to other models. We assume knowledge of only the model’s structure, not its parameters. Our approach, therefore, is to estimate what the controller has carried out to arrive at the observed data; the estimates of the control parameters are made a posteriori. Our innovation resides in providing a data-driven solution, obviating the need for complex modeling. Furthermore, a distinctive facet of our work lies in treating the evolutionary objects of the dynamical system as probability distributions. We delve into exploring how these distributions have evolved under various hidden controller settings. We have provided an algorithm for estimating the various parameters that control the evolution of these distributions, which are based solely on a posteriori observations.
Once the control parameters were obtained, we used a multivariate generalized additive model (GAM) to explore the potential relationships between the part that controls the system’s evolution and the various characteristics of the studied population. We applied this methodology to a COVID-19 database for five prefectures in Japan, considering various explanatory variables. We newly discovered that for the infected category, vaccination was highly effective in the metropolises of Tokyo, Osaka, and Fukuoka; while for the deceased category, vaccination exhibited particular effectiveness in Tokyo. This approach was generalized to nine countries in order to explore the effects of the various policies they follow. Our findings illustrate that countries can be broadly grouped into four clusters, with each group demonstrating varied effectiveness of policy measures and vaccination efforts.
From the GAM, we extracted indicators to quantify the degrees of association between the different explanatory variables. These new indicators enable the analysis and visualization of groups with similar and different evolutionary profiles. The aim is to explain the reasons for these differences. This work provides a novel perspective on understanding and managing complex evolutionary processes.
Author Contributions
Conceptualization, N.A.; Methodology, T.M. and N.A.; Software, T.M.; Validation, T.M. and N.A.; Formal analysis, T.M.; Investigation, T.M. and N.A.; Data curation, D.M.; Writing—original draft, T.M. and N.A.; Writing—review & editing, D.M.; Visualization, D.M. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Acknowledgments
This research was supported by a “Strategic Programs” grant from ROIS (Research Organization of Information and Systems), Japan.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Additional Results for Predictive Power of Hidden Controller Framework
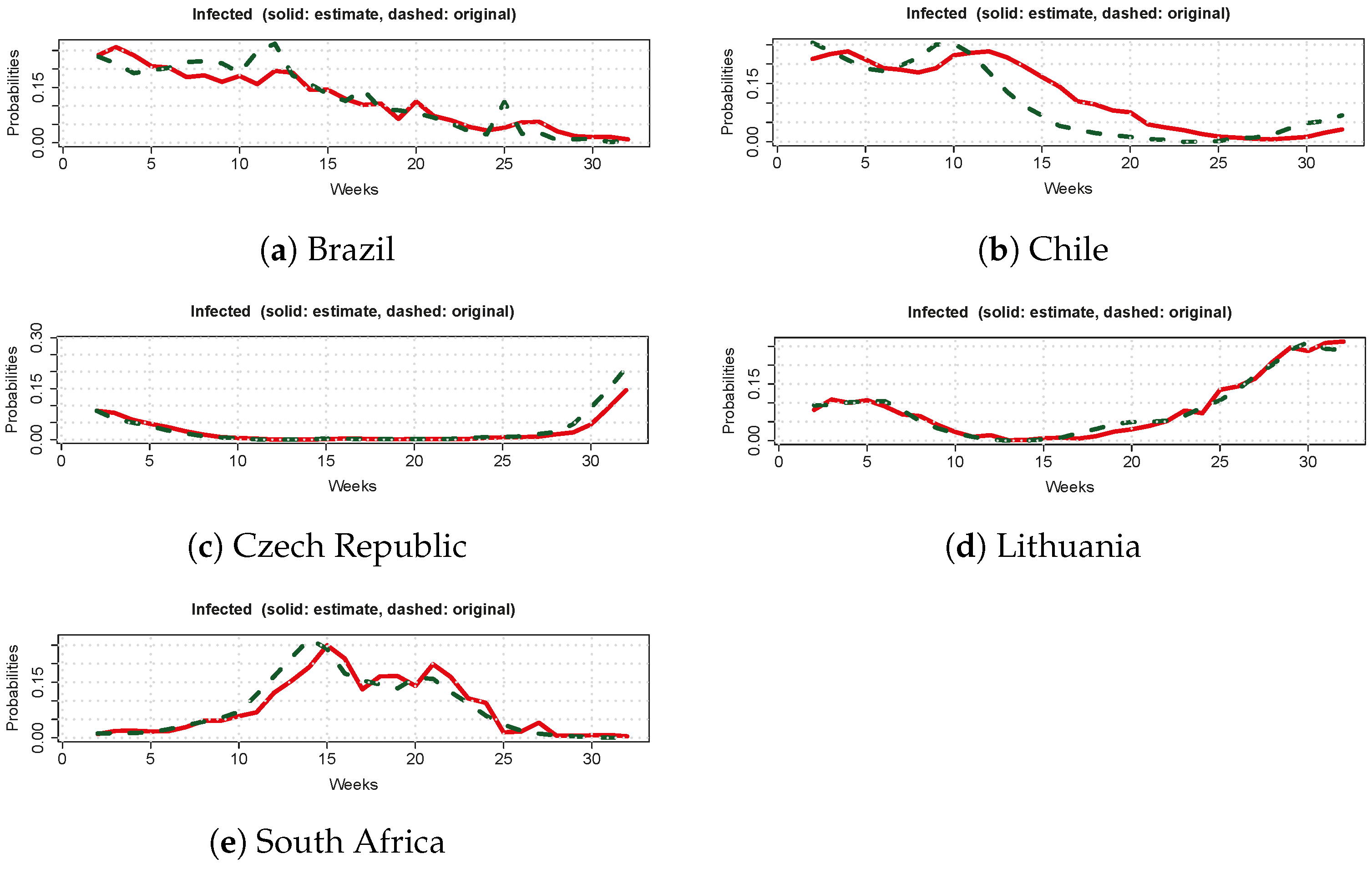
Figure A1 presents a comparison between the predictions made by our hidden controller framework and the observed data for five countries. Consistent with the results in Section 4.1, our hidden controller framework performed well.
Figure A1.
Comparison between the predictions made by our hidden controller framework (green dashed lines) and the observed data (red solid lines) for the remaining five countries.
Figure A1.
Comparison between the predictions made by our hidden controller framework (green dashed lines) and the observed data (red solid lines) for the remaining five countries.

References
- Brogan, W.L. Modern Control Theory; Pearson Education India: Chennai, India, 1991. [Google Scholar]
- Bryson, A.E.; Ho, Y.C. Applied Optimal Control: Optimization, Estimation, and Control; Routledge: London, UK, 2018. [Google Scholar]
- Chen, C.T. Linear System Theory and Design; Saunders College Publishing: Philadelphia, PA, USA, 1984. [Google Scholar]
- Fadali, M.S.; Visioli, A. Digital Control Engineering: Analysis and Design; Academic Press: Cambridge, MA, USA, 2012. [Google Scholar]
- Bittanti, S.; Laub, A.J.; Willems, J.C. The Riccati Equation; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- de Gouvêa, M.; Odloak, D. Dealing with Inconsistent Quadratic Programs in a SQP Based Algorithm. Braz. J. Chem. Eng. 1997, 14, 63–80. [Google Scholar] [CrossRef]
- Wright, S.; Nocedal, J. Numerical Optimization; Springer Science: New York, NY, USA, 1999; Volume 35, p. 7. [Google Scholar]
- Fletcher, R. Practical Methods of Optimization; John Wiley & Sons: Hoboken, NJ, USA, 2013. [Google Scholar]
- Schittkowski, K.; Zillober, C. Nonlinear programming: Algorithms, software, and applications. In Proceedings of the IFIP Conference on System Modeling and Optimization, Sophia Antipolis, France, 21–25 July 2003; pp. 73–107. [Google Scholar]
- Wood, S.N. Fast stable restricted maximum likelihood and marginal likelihood estimation of semiparametric generalized linear models. J. R. Stat. Soc. (B) 2011, 73, 3–36. [Google Scholar] [CrossRef]
- Wood, S.N.; Pya, N.; Säfken, B. Smoothing parameter and model selection for general smooth models (with discussion). J. Am. Stat. Assoc. 2016, 111, 1548–1575. [Google Scholar] [CrossRef]
- Guidotti, E. A worldwide epidemiological database for COVID-19 at fine-grained spatial resolution. Sci. Data 2022, 9, 112. [Google Scholar] [CrossRef] [PubMed]
- Guidotti, E.; Ardia, D. COVID-19 Data Hub. J. Open Source Softw. 2020, 5, 2376. [Google Scholar] [CrossRef]
- Matsui, T.; Azzaoui, N.; Murakami, D. Analysis of COVID-19 evolution based on testing closeness of sequential data. Jpn. J. Stat. Data Sci. 2022, 5, 321–338. [Google Scholar] [CrossRef] [PubMed]
- Hale, T.; Angrist, N.; Goldszmidt, R.; Kira, B.; Petherick, A.; Phillips, T.; Webster, S.; Cameron-Blake, E.; Hallas, L.; Majumdar, S.; et al. A global panel database of pandemic policies (Oxford COVID-19 Government Response Tracker). Nat. Hum. Behav. 2021, 5, 529–538. [Google Scholar] [CrossRef] [PubMed]
Figure 1.
In the MPC framework, users can access and manipulate (i.e., change or control) the system parameters.
Figure 1.
In the MPC framework, users can access and manipulate (i.e., change or control) the system parameters.

Figure 2.
In our framework, users do not have access to the items in the shaded area; they know only the shapes of the optimizer, model, and system and are unable to act on that information.
Figure 2.
In our framework, users do not have access to the items in the shaded area; they know only the shapes of the optimizer, model, and system and are unable to act on that information.

Figure 3.
Structure of main algorithm for estimating hidden control process.

Figure 4.
For each population segment, the link between control terms , and , which describe the characteristic variables (covariates, predictors) of the population segment, was fitted to a GAM. The z-score output of the GAM was used for classification to identify how these predictors contributed to the control of the system.
Figure 4.
For each population segment, the link between control terms , and , which describe the characteristic variables (covariates, predictors) of the population segment, was fitted to a GAM. The z-score output of the GAM was used for classification to identify how these predictors contributed to the control of the system.

Figure 5.
Comparison between predictions made by our hidden controller framework (green dashed lines) and observed data (red solid lines) for (a) Australia, (b) Colombia, (c) Germany, and (d) Japan.
Figure 5.
Comparison between predictions made by our hidden controller framework (green dashed lines) and observed data (red solid lines) for (a) Australia, (b) Colombia, (c) Germany, and (d) Japan.

Figure 6.
Heatmaps depicting z-scores of predictor covariates associated with numbers of (a) infected and (b) deceased individuals, with a goal of reducing the counts in both categories by half.
Figure 6.
Heatmaps depicting z-scores of predictor covariates associated with numbers of (a) infected and (b) deceased individuals, with a goal of reducing the counts in both categories by half.

Figure 7.
Heatmaps illustrating difference in z-scores for predictor covariates associated with numbers of (a) infected and (b) deceased individuals, aimed at reducing each category by half compared with the observed numbers.
Figure 7.
Heatmaps illustrating difference in z-scores for predictor covariates associated with numbers of (a) infected and (b) deceased individuals, aimed at reducing each category by half compared with the observed numbers.

Figure 8.
Heatmap of z-scores for predictor covariates (cov) associated with the number of infected ({cov}.1), deceased ({cov}.2), and recovered individuals ({cov}.3) for nine countries.
Figure 8.
Heatmap of z-scores for predictor covariates (cov) associated with the number of infected ({cov}.1), deceased ({cov}.2), and recovered individuals ({cov}.3) for nine countries.

Figure 9.
Dendrogram illustrating clustering of countries on the basis of policy measures.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Candidate weekly predictor covariates for five Japanese prefectures.
| Predictor Covariate | Description |
|---|---|
| week | Time point (weekly ID) |
| driving | Vehicle increase rate (provided by Apple Inc.; compared with 13 January 2020) |
| transit | Public transport increase rate (provided by Apple Inc.; compared with 13 January 2020) |
| walking | Pedestrian increase rate (provided by Apple Inc.; compared with 13 January 2020) |
| num_beds | Number of available beds in hospitals in Tokyo (provided by Ministry of Health, Labour and Welfare) |
| vaccine | Number of people vaccinated in Tokyo (provided by Ministry of Health, Labour and Welfare) |
| Predictor Covariate | Description |
|---|---|
| week | Time point (weekly ID) |
| driving | Vehicle increase rate (provided by Apple Inc.; compared with 13 January 2020) |
| transit | Public transport increase rate (provided by Apple Inc.; compared with 13 January 2020) |
| walking | Pedestrian increase rate (provided by Apple Inc.; compared with 13 January 2020) |
| hosp | Number of hospitalized patients |
| people_fully_vaccinated | Number of people who received all doses prescribed by vaccination protocol |
| government_response_index | Index of how government response varied over all indicators in Oxford COVID-19 Government Response Tracker database [15], becoming stronger or weaker over the course of the outbreak |
| stringency_index | Index of strictness of ‘lockdown’-related policies that restricted people’s behavior |
| containment_health_index | Index combining ‘lockdown’ restrictions and closures with measures such as testing policy, contact tracing, short term investment in healthcare, and investment in vaccines |
| economic_support_index | Index representing such factors as income support and debt relief |
Table 3.
Main categorical levels consisting of three groups of policy measures.
| Index | Government _Response | Stringency | Containment _Health | Economic _Support |
|---|---|---|---|---|
| policy 1 | H | - | H | L |
| policy 2 | M | H | - | M |
| policy 3 | L | - | L | - |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Azzaoui, N.; Matsui, T.; Murakami, D. Data-Driven Framework for Uncovering Hidden Control Strategies in Evolutionary Analysis. Math. Comput. Appl. 2023, 28, 103. https://doi.org/10.3390/mca28050103
AMA Style
Azzaoui N, Matsui T, Murakami D. Data-Driven Framework for Uncovering Hidden Control Strategies in Evolutionary Analysis. Mathematical and Computational Applications. 2023; 28(5):103. https://doi.org/10.3390/mca28050103
Chicago/Turabian StyleAzzaoui, Nourddine, Tomoko Matsui, and Daisuke Murakami. 2023. "Data-Driven Framework for Uncovering Hidden Control Strategies in Evolutionary Analysis" Mathematical and Computational Applications 28, no. 5: 103. https://doi.org/10.3390/mca28050103