
Is Catchment Classification Possible by Means of Multiple Model Structures? A Case Study Based on 99 Catchments in Germany


Abstract
:1. Introduction
2. Materials and Methods
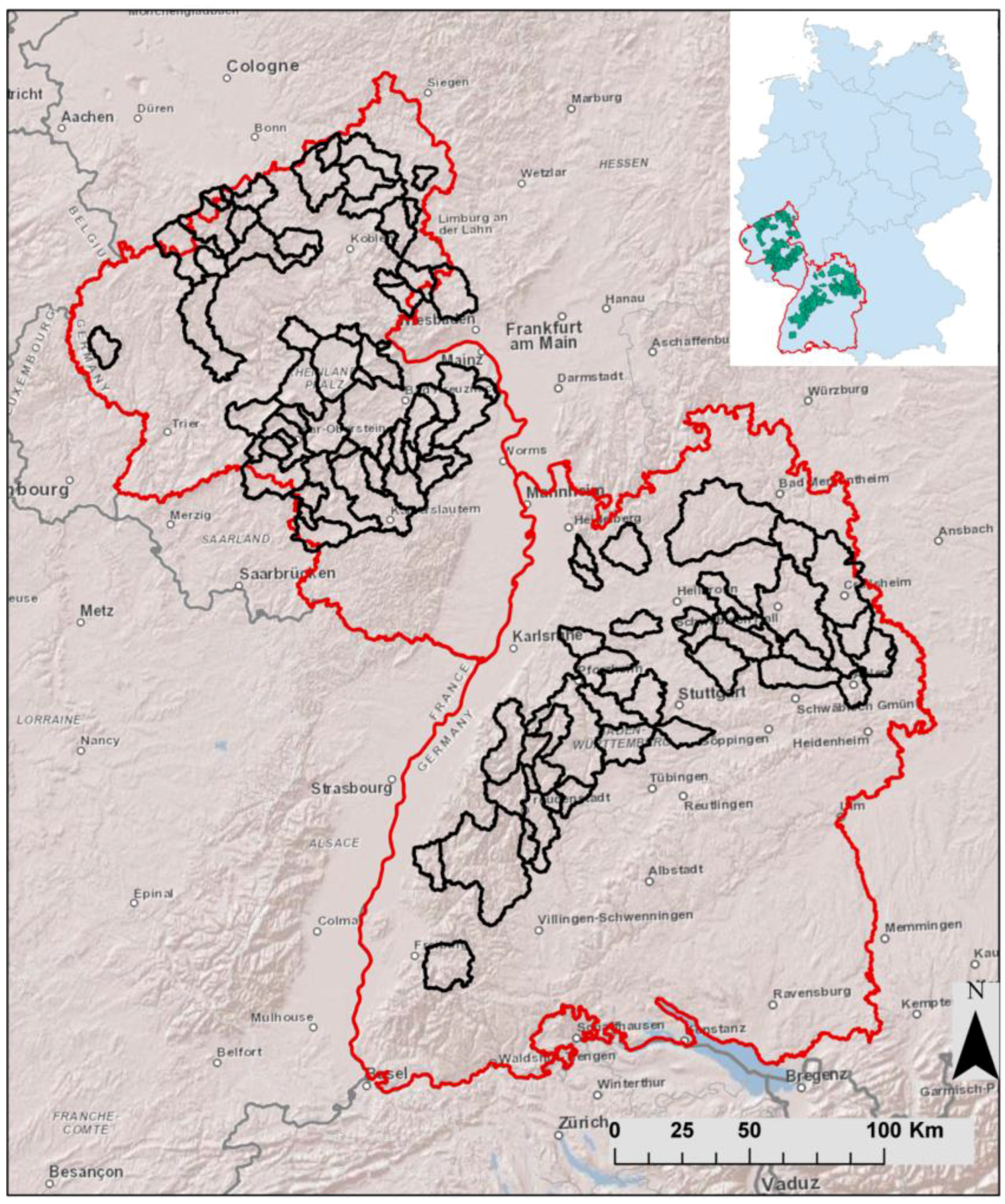
2.1. Study Area
2.2. Data
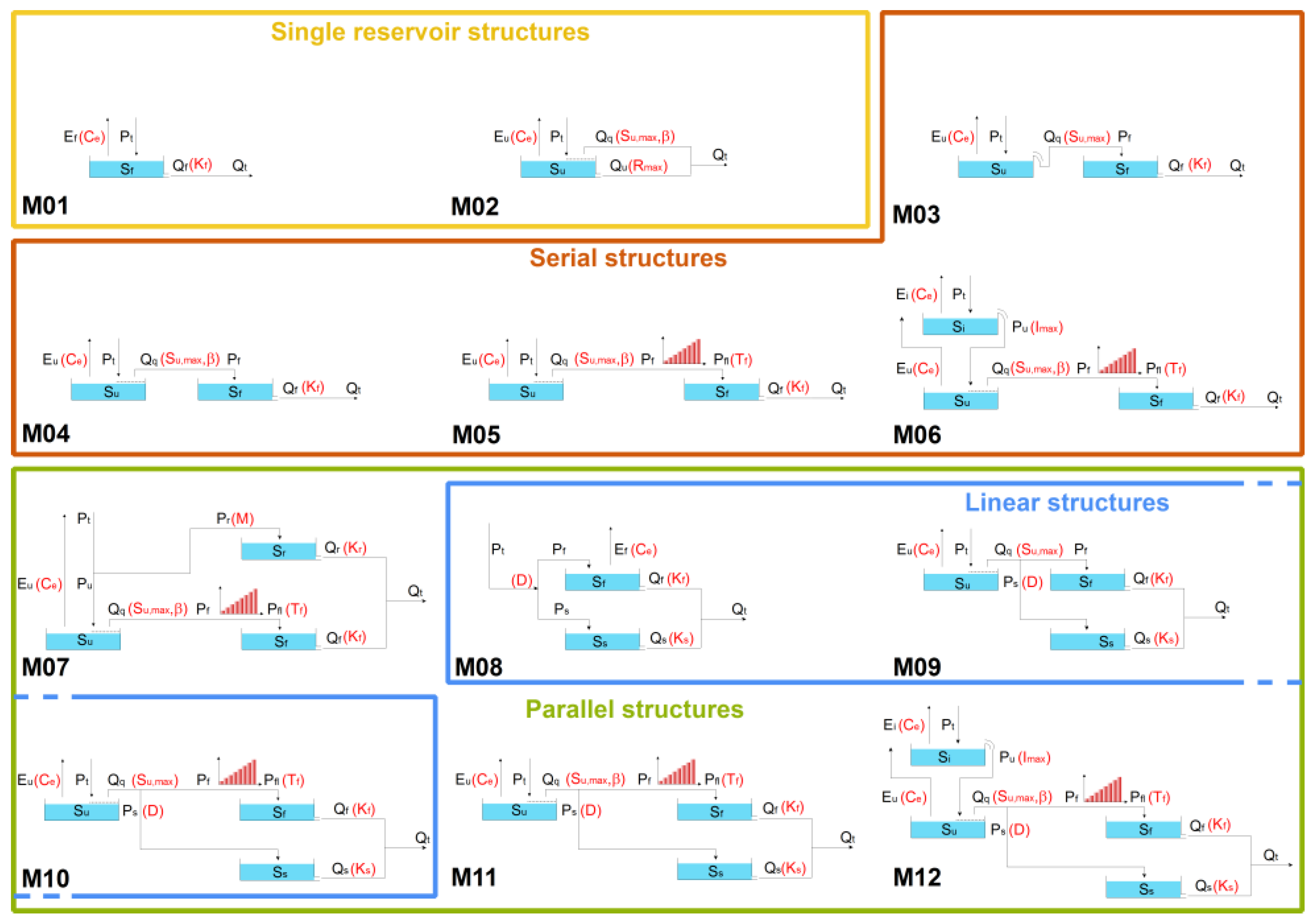
2.3. Methods
2.3.1. Calibration
2.3.2. Model Evaluation: Identification of Acceptable Models
2.3.3. Comparing Model Performances
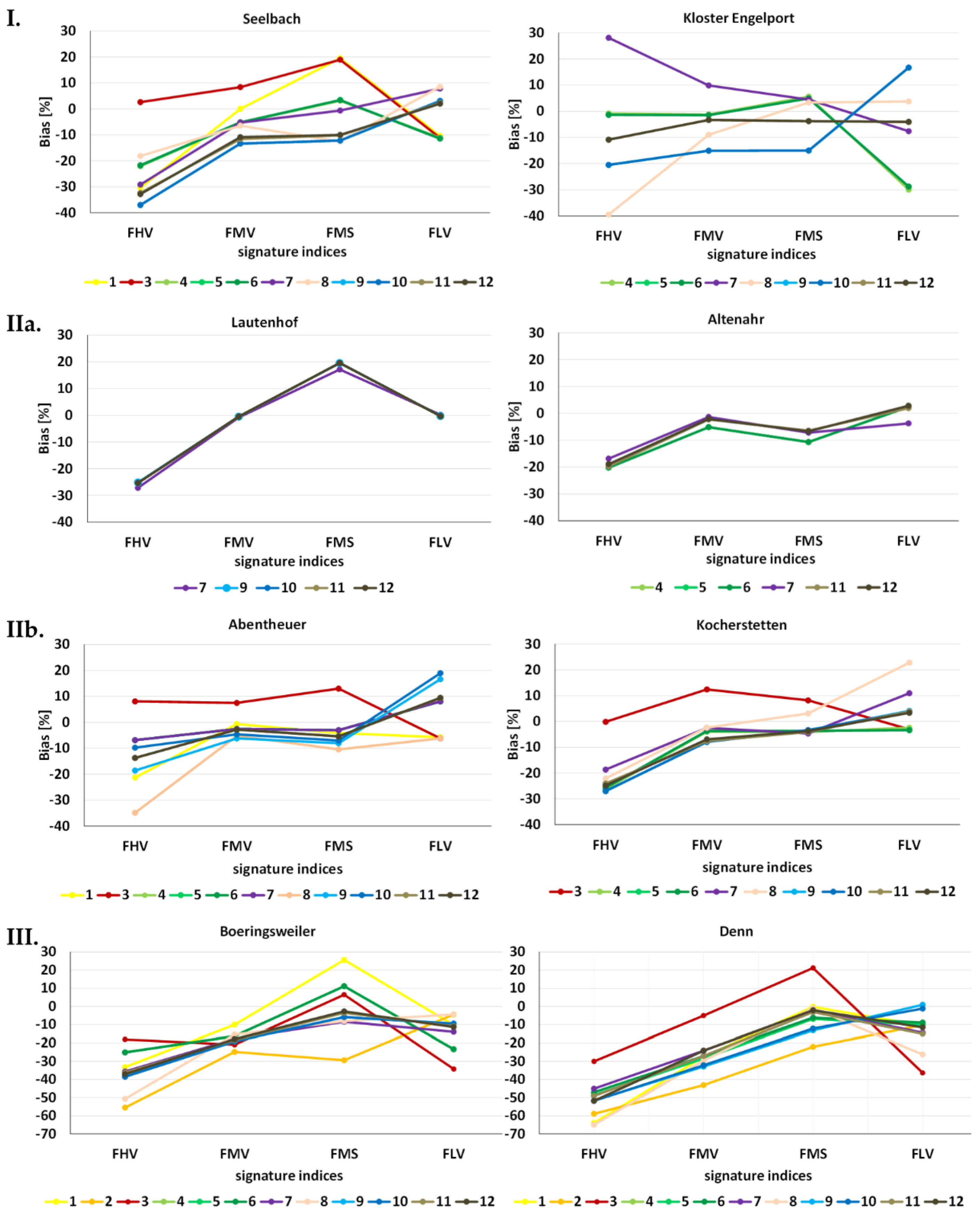
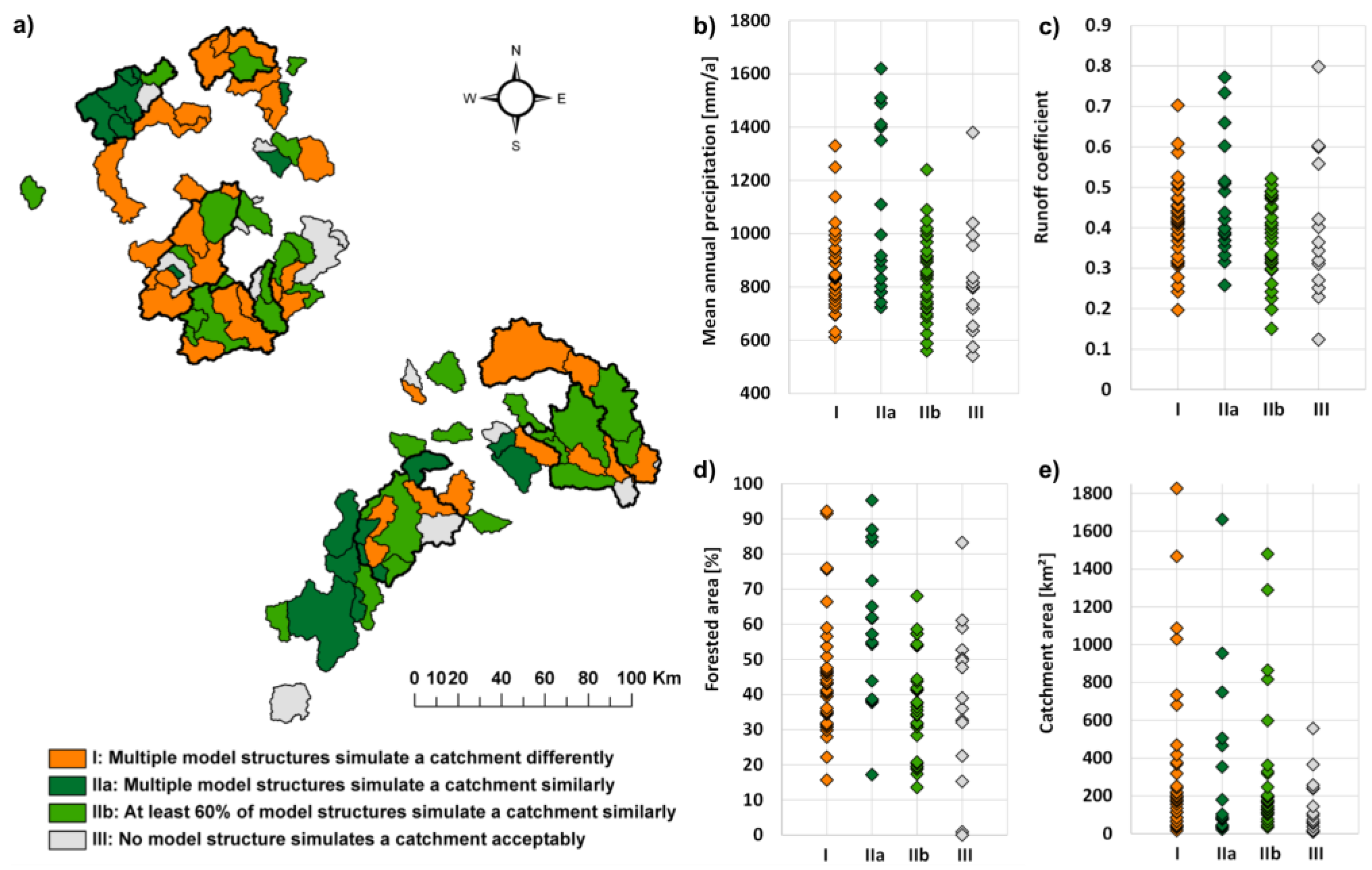
- Multiple model structures simulate a catchment differently. The identification of a best performing model is possible. The model structure can be tentatively connected to the catchment behavior. If there are catchments with only one acceptable model, they belong to this group too.
- Multiple model structures simulate the catchment similarly. Model equifinality [12,18,43] makes it difficult to connect model structure and catchment structure or behavior. Catchments of this group are further divided into:
- catchments where all acceptable models simulate the runoff similarly; and
- catchments where at least 60% but not all acceptable models simulate runoff similarly.
Catchments without an acceptable model result constitute an additional group: - No model structure simulates the catchment acceptably. All structures fail to capture catchment behavior.
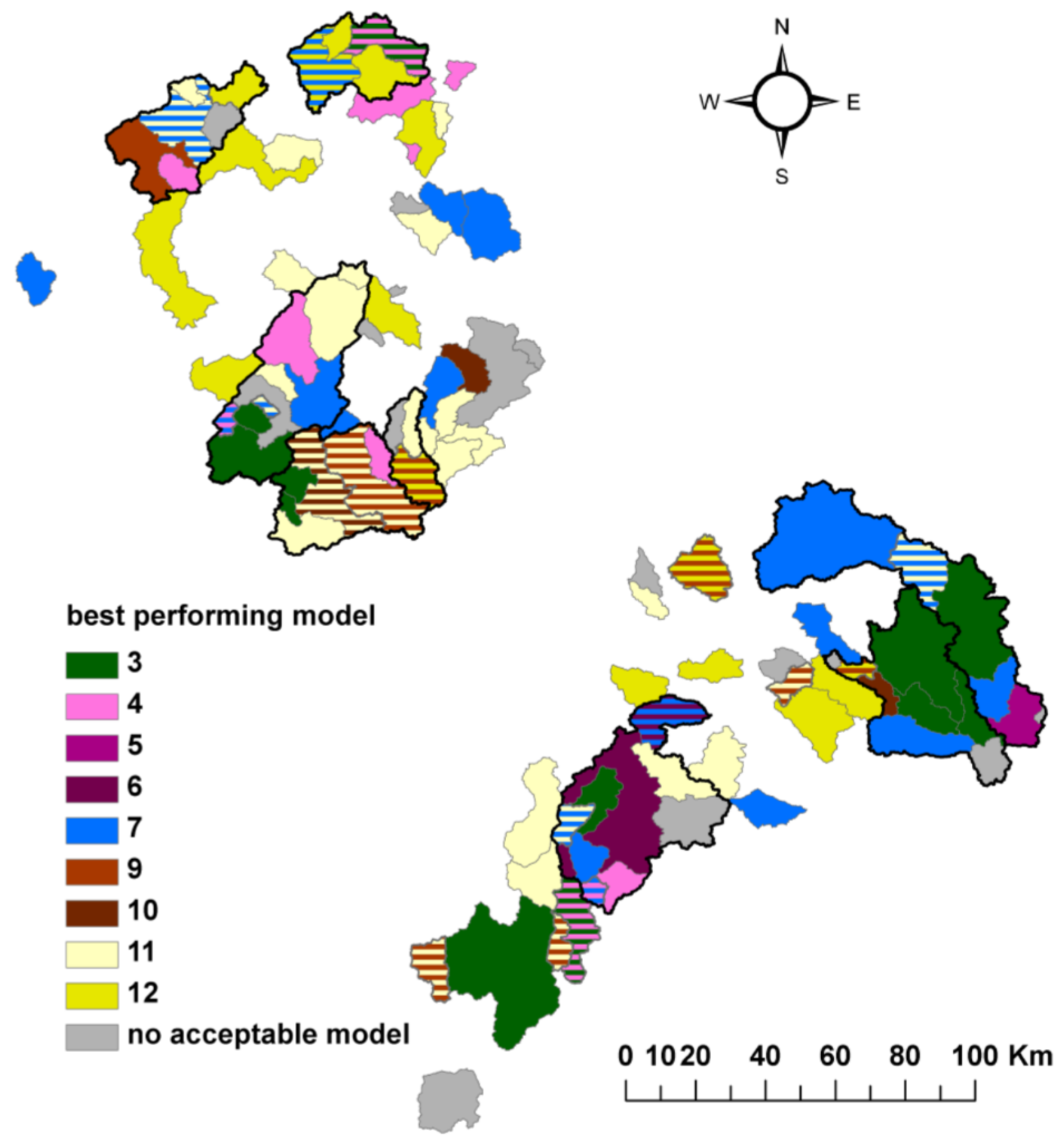
2.3.4. Identification of Best Performing Models
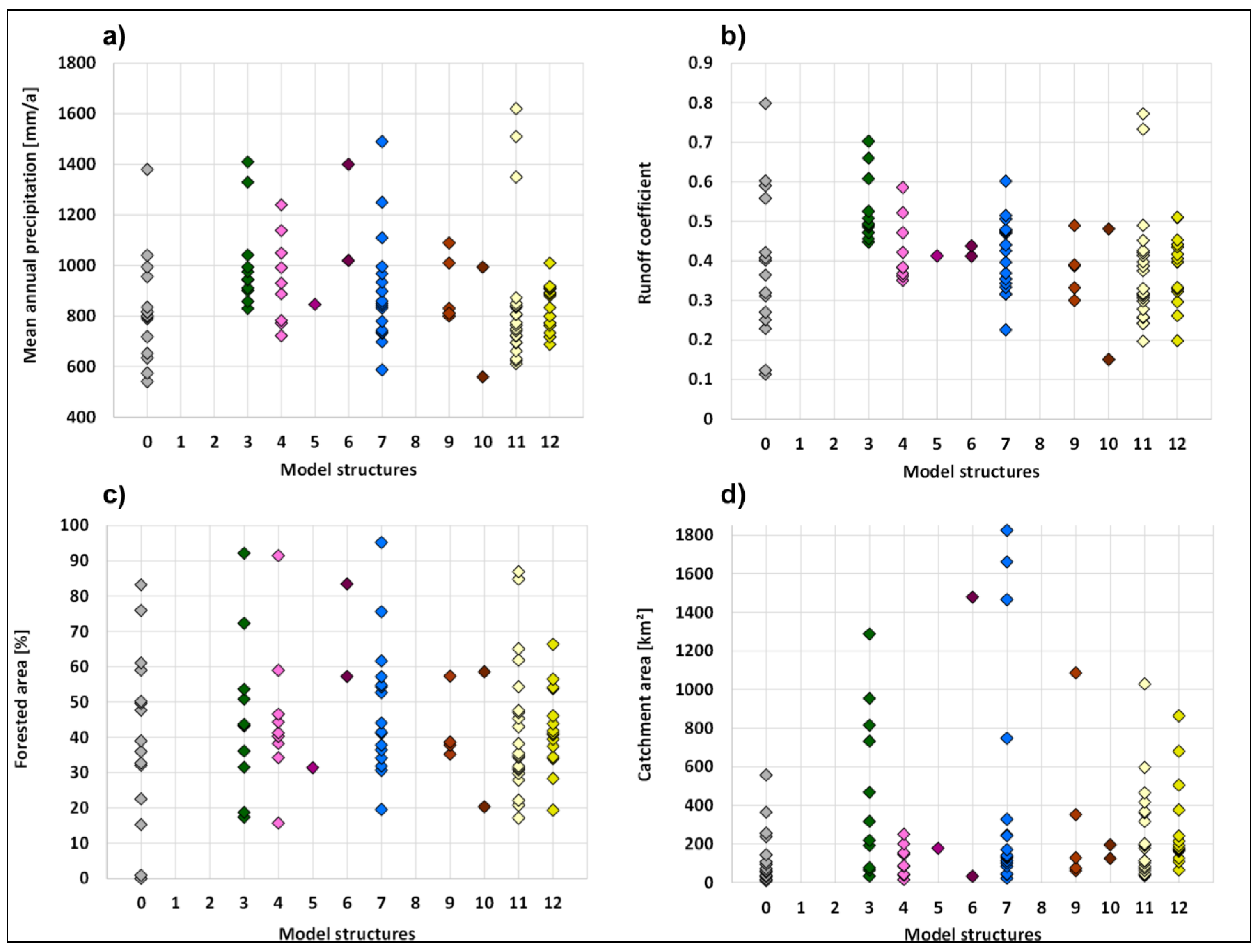
2.3.5. Correlation with Catchment Properties
3. Results
3.1. Calibration
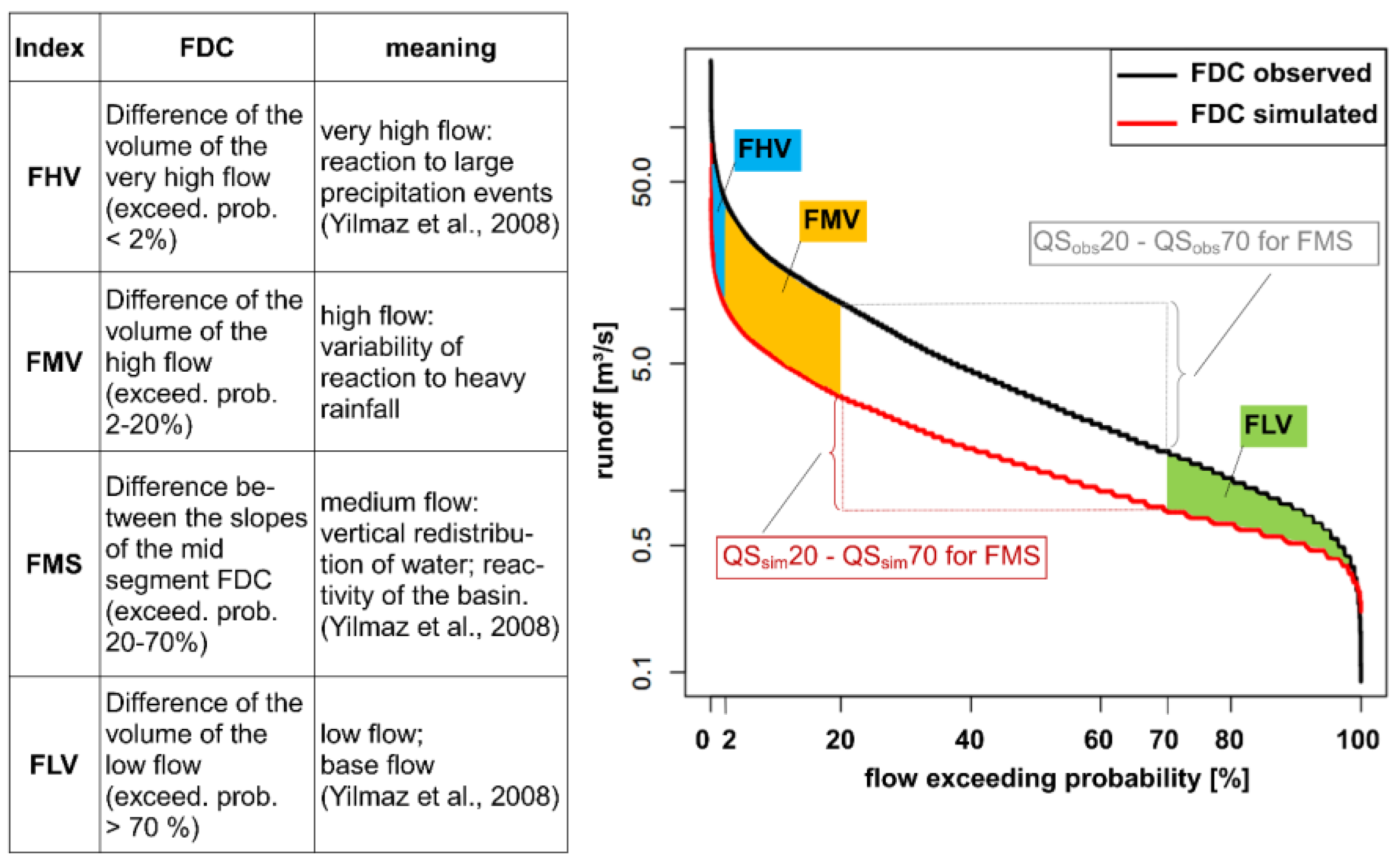
3.2. Signature Indices
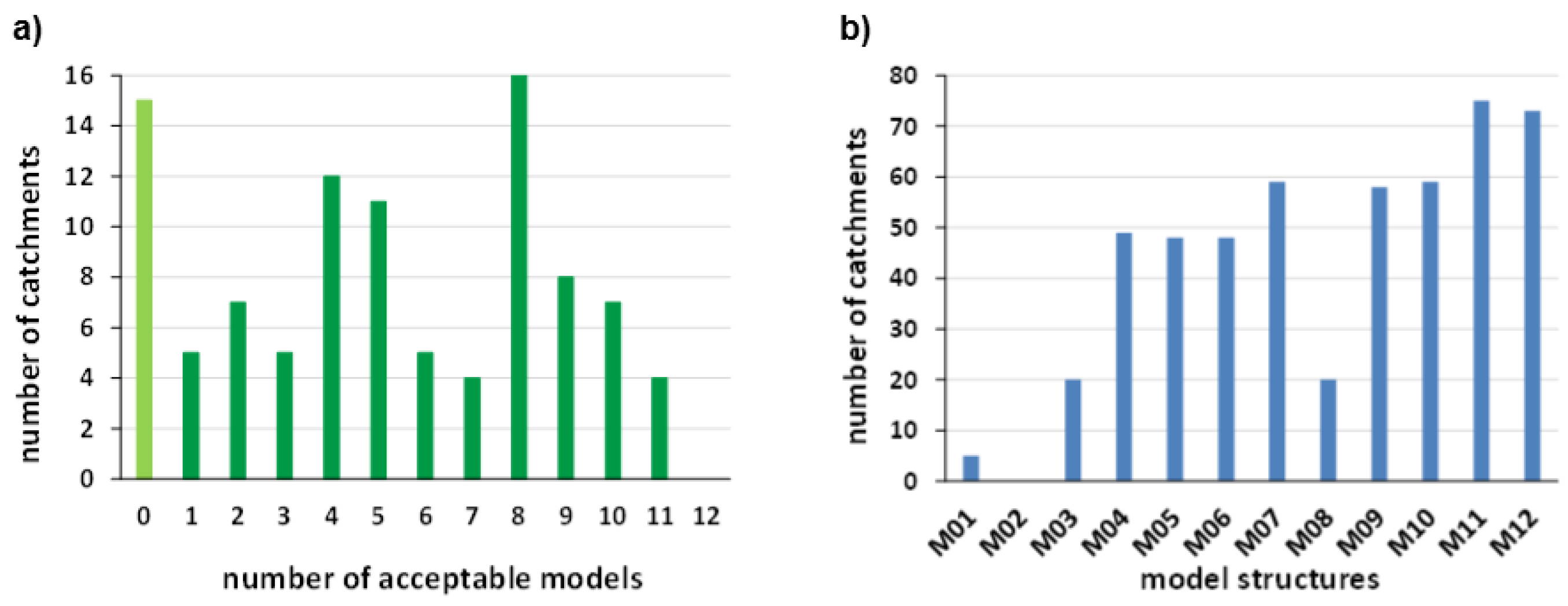
3.3. Acceptable Models
3.4. Comparing Model Performances
- I
- Multiple model structures simulate a catchment differently. The two example catchments (Figure 6I) show different patterns of signature indices.For 30 catchments of the study area (Table A1), multiple model structures produce different simulations, even though few models show related patterns of signature indices.Additionally, we include in this group the five catchments with only one acceptable model because of differentiated simulation results (Table A1).
- IIa
- IIb
- III
3.5. Best Performing Models
3.6. Correlations with Catchment Properties
4. Discussion
5. Conclusions
- For about 15% of the catchments, no model had a suitable performance, which indicates model structural errors or data errors.
- For about 50% of the catchments, large parts of the models display a similar performance and thus demonstrate strong equifinality. About 35% of the catchments show no strong equifinality.
- Most of the catchments can be classified by a clear best performing model, which indicates that models may perform differently in different regions.
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Catchment Name | State | Size (km2) | Urban Area (%) | Forest Area (%) | River Length (km) | Mean Prec. (mm/year) | RC | AI | Best | Group |
|---|---|---|---|---|---|---|---|---|---|---|
| Abentheuer | RLP | 39 | 0 | 91 | 13 | 1139 | 0.59 | 2.05 | 4; 7 | I |
| Abtsgmuend | BW | 246 | 5 | 36 | 46 | 968 | 0.51 | 1.61 | 7 | IIb |
| Albisheim | RLP | 113 | 5 | 30 | 22 | 631 | 0.28 | 0.97 | 11 | I |
| Altenahr | RLP | 748 | 2 | 55 | NaN | 780 | 0.35 | 1.19 | 7; 11 | IIa |
| Altenbamberg | RLP | 318 | 4 | 31 | 51 | 662 | 0.30 | 1.03 | 11 | IIb |
| Altensteig | BW | 135 | 2 | 76 | 24 | 1250 | 0.47 | 2.24 | 7 | I |
| Argenschwang | RLP | 31 | 0 | 76 | 13 | 790 | 0.41 | 1.10 | 0 | I |
| Bad Bodendorf | RLP | 864 | 3 | 54 | NaN | 773 | 0.33 | 1.17 | 12 | IIb |
| Böhringsweiler | BW | 17 | 8 | 48 | 6 | 1040 | 0.56 | 1.45 | 0 | III |
| Bad Rotenfels | BW | 466 | 5 | 85 | 64 | 1510 | 0.73 | 2.53 | 11 | IIa |
| Denkendorf | BW | 128 | 29 | 14 | 26 | 744 | 0.48 | 1.12 | 7 | IIb |
| Denn | RLP | 95 | 0 | 83 | 18 | 817 | 0.40 | 1.20 | 0 | III |
| Doerzbach | BW | 1029 | 5 | 32 | 112 | 835 | 0.41 | 1.31 | 11; 7 | I |
| Ebnet | BW | 257 | 3 | 61 | 26 | 1380 | 0.60 | 2.16 | 0 | III |
| Elpershofen | BW | 816 | 6 | 32 | 84 | 830 | 0.45 | 1.32 | 3 | IIb |
| Enzweiler | RLP | 22.9 | 6 | 62 | 11 | 899 | 0.32 | 1.36 | 7; 11 | IIa |
| Erzgrube | BW | 34 | 2 | 83 | 10 | 1400 | 0.44 | 2.44 | 6 | IIa |
| Eschelbronn | BW | 193 | 6 | 28 | 27 | 893 | 0.45 | 1.16 | 9; 12 | IIb |
| Eschenau | RLP | 597 | 9 | 34 | 57 | 841 | 0.39 | 1.40 | 10; 11 | IIb |
| Friedrichsthal | RLP | 681 | 6 | 41 | 91 | 908 | 0.42 | 1.38 | 12; 7 | I |
| Gaildorf | BW | 733 | 6 | 51 | 76 | 945 | 0.49 | 1.53 | 3 | I |
| Gaugrehweiler | RLP | 41 | 1 | 43 | 15 | 694 | 0.26 | 0.99 | 11 | I |
| Gensingen | RLP | 196 | 5 | 20 | 45 | 560 | 0.15 | 0.82 | 10 | IIb |
| Gerach | RLP | 63 | 4 | 54 | 20 | 850 | 0.38 | 1.33 | 11 | IIb |
| Gondelsheim | BW | 127 | 8 | 34 | 22 | 800 | 0.20 | 1.06 | 12 | IIb |
| Hausen | BW | 109 | 8 | 19 | 22 | 763 | 0.32 | 1.04 | 12 | IIb |
| Heddesheim | RLP | 164 | 5 | 54 | 31 | 718 | 0.26 | 1.03 | 12 | IIb |
| Heimbach | RLP | 318 | 6 | 43 | 29 | 1042 | 0.70 | 1.65 | 3 | I |
| Hoefen | BW | 219 | 2 | 92 | 33 | 1330 | 0.61 | 2.04 | 3 | I |
| Hopfau | BW | 201 | 5 | 41 | 30 | 1240 | 0.52 | 2.03 | 3; 4 | IIb |
| Hüttlingen | BW | 107 | 13 | 50 | 23 | 956 | 0.80 | 1.44 | 0 | III |
| Imsweiler | RLP | 171 | 6 | 37 | 24 | 688 | 0.30 | 1.09 | 9; 12 | IIb |
| Iselshausen | BW | 147 | 5 | 44 | 24 | 992 | 0.36 | 1.55 | 4 | IIb |
| Isenburg | RLP | 155 | 6 | 47 | 35 | 888 | 0.37 | 1.34 | 4 | I |
| Jagstzell | BW | 329 | 6 | 41 | 41 | 850 | 0.43 | 1.32 | 7 | IIb |
| Kallenfels | RLP | 251 | 4 | 40 | 42 | 773 | 0.35 | 1.20 | 4 | I |
| KArnstein | RLP | 113 | 2 | 41 | 33 | 735 | 0.32 | 1.06 | 7 | IIb |
| Kautenmuehle | RLP | 37 | 11 | 17 | 15 | 873 | 0.40 | 1.39 | 11 | IIa |
| KEhrenstein | RLP | 66 | 1 | 34 | 21 | 910 | 0.44 | 1.31 | 12 | I |
| Kellenbach | RLP | 362 | 2 | 35 | 49 | 721 | 0.33 | 1.11 | 11 | IIb |
| KEngelport | RLP | 113 | 2 | 48 | NaN | 774 | 0.32 | 1.20 | 11 | I |
| Kirmutscheid | RLP | 88 | 3 | 38 | 21 | 781 | 0.38 | 1.25 | 4 | IIa |
| Kocherstetten | BW | 1289 | 6 | 44 | 120 | 911 | 0.47 | 1.47 | 3 | IIb |
| Kreuzberg | RLP | 45 | 1 | 62 | NaN | 742 | 0.26 | 1.06 | 11 | IIa |
| Kronweiler | RLP | 65 | 3 | 54 | 17 | 976 | 0.46 | 1.51 | 3 | I |
| Lahr | BW | 130 | 6 | 68 | 26 | 1090 | 0.31 | 1.52 | 9; 11 | IIb |
| Lautenhof | BW | 84 | 1 | 95 | 20 | 1490 | 0.60 | 2.55 | 7; 9 | IIa |
| Lippach | BW | 10 | 1 | 39 | 7 | 835 | 0.42 | 1.31 | 0 | III |
| Loellbach | RLP | 45 | 0 | 32 | 16 | 699 | 0.33 | 1.13 | 7 | IIb |
| Martinstein | RLP | 1467 | 5 | 44 | 79 | 842 | 0.47 | 1.31 | 7 | I |
| Miehlen | RLP | 102 | 2 | 38 | 17 | 724 | 0.42 | 1.03 | 11 | IIa |
| Mittelrot | BW | 126 | 4 | 59 | 31 | 994 | 0.48 | 1.60 | 10 | IIb |
| Monsheim | RLP | 198 | 5 | 21 | 30 | 625 | 0.24 | 0.91 | 11 | IIb |
| Muesch | RLP | 353 | 2 | 39 | NaN | 759 | 0.33 | 1.27 | 9 | IIa |
| Murr | BW | 505 | 8 | 44 | 48 | 918 | 0.51 | 1.37 | 12 | IIa |
| Nanzdietschw. | RLP | 201 | 8 | 34 | 30 | 838 | 0.43 | 1.48 | 11 | I |
| Nettegut | RLP | 368 | 10 | 31 | 65 | 697 | 0.31 | 0.98 | 11 | I |
| Neuenstadt | BW | 142 | 5 | 38 | 33 | 859 | 0.40 | 1.28 | 7 | IIb |
| Niederelbert | RLP | 16.4 | 6 | 59 | 8 | 930 | 0.42 | 1.35 | 4 | I |
| Nierstein | RLP | 37 | 14 | 0 | 13 | 575 | 0.12 | 0.78 | 0 | III |
| Oberingelheim | RLP | 365 | 8 | 1 | 62 | 542 | 0.11 | 0.79 | 0 | III |
| Obermoschel | RLP | 61 | 1 | 15 | 20 | 653 | 0.25 | 0.97 | 0 | III |
| Oberrot | BW | 62 | 5 | 57 | 19 | 1010 | 0.49 | 1.58 | 9; 12 | IIb |
| Oberstein | RLP | 557 | 6 | 50 | 55 | 995 | 0.60 | 1.56 | 0 | III |
| Odenbach | RLP | 1087 | 9 | 35 | 78 | 784 | 0.38 | 1.30 | 9; 11 | I |
| Odenbach Steinbruch | RLP | 85 | 2 | 16 | 25 | 723 | 0.38 | 1.10 | 4 | I |
| Oppenweiler | BW | 181 | 4 | 66 | 23 | 1010 | 0.51 | 1.56 | 12 | I |
| Papiermühle | RLP | 170 | 3 | 57 | NaN | 818 | 0.44 | 1.35 | 12 | I |
| Pforzheim-E | BW | 1479 | 8 | 57 | 94 | 1020 | 0.41 | 1.61 | 6 | IIb |
| Pforzheim-W | BW | 418 | 13 | 35 | 52 | 806 | 0.32 | 1.21 | 11 | I |
| Planig | RLP | 171 | 4 | 20 | 44 | 588 | 0.23 | 0.87 | 7 | IIb |
| Platten | RLP | 377 | 5 | 46 | NaN | 834 | 0.40 | 1.40 | 12 | I |
| Rammelsbach | RLP | 78 | 7 | 17 | 18 | 901 | 0.49 | 1.42 | 3 | IIb |
| Rheindiebach | RLP | 10 | 0 | 59 | 7 | 635 | 0.23 | 1.04 | 0 | III |
| Schafhausen | BW | 238 | 16 | 33 | 23 | 802 | 0.36 | 1.21 | 0 | III |
| Schenkenzell | BW | 76 | 4 | 65 | 19 | 1350 | 0.49 | 2.24 | 9; 11 | IIa |
| Schulmuehle | RLP | 145 | 2 | 36 | 26 | 719 | 0.31 | 1.01 | 0 | III |
| Schwabsberg | BW | 178 | 4 | 31 | 27 | 846 | 0.41 | 1.31 | 5 | I |
| Schwaibach | BW | 954 | 3 | 72 | 69 | 1410 | 0.66 | 1.84 | 3 | IIa |
| Schwarzenberg | BW | 179 | 4 | 87 | 30 | 1620 | 0.77 | 2.86 | 11 | IIa |
| Seelbach | RLP | 193 | 6 | 36 | 41 | 994 | 0.51 | 1.53 | 3; 4 | I |
| Seifen | RLP | 176 | 6 | 42 | 43 | 917 | 0.41 | 1.38 | 12 | IIb |
| Sinspelt | RLP | 101 | 1 | 34 | NaN | 934 | 0.48 | 1.48 | 7 | IIb |
| Stausee Ohmb. | RLP | 34 | 4 | 19 | 15 | 858 | 0.49 | 1.42 | 3 | IIb |
| Steinbach | RLP | 46 | 0 | 47 | 11 | 750 | 0.45 | 1.13 | 11 | I |
| Steinheim | BW | 76 | 8 | 38 | 18 | 831 | 0.39 | 1.30 | 9; 11 | IIa |
| Talhausen | BW | 192 | 17 | 28 | 40 | 764 | 0.24 | 1.09 | 11 | I |
| Talheim | BW | 73 | 8 | 32 | 19 | 816 | 0.32 | 1.20 | 0 | III |
| Uffhofen | RLP | 85 | 3 | 45 | 22 | 612 | 0.20 | 0.88 | 11 | I |
| Untergriesheim | BW | 1826 | 5 | 31 | 168 | 832 | 0.44 | 1.27 | 7 | I |
| Vaihingen | BW | 1662 | 8 | 54 | 122 | 996 | 0.51 | 1.09 | 6; 7 | IIa |
| Voerbach | BW | 44 | 4 | 57 | 10 | 1110 | 0.37 | 1.74 | 4; 7 | IIa |
| Weinaehr | RLP | 215 | 13 | 41 | 38 | 887 | 0.40 | 1.34 | 12 | I |
| Wernerseck | RLP | 242 | 5 | 39 | 56 | 734 | 0.33 | 1.07 | 12 | I |
| Westerburg | RLP | 44 | 13 | 34 | 13 | 1049 | 0.47 | 1.80 | 4 | IIb |
| Wiesloch_W | BW | 55 | 9 | 23 | 18 | 797 | 0.27 | 1.05 | 0 | III |
| Wiesloch_L | BW | 114 | 10 | 22 | 21 | 808 | 0.31 | 1.03 | 11 | I |
| Woellstein | BW | 468 | 7 | 43 | 51 | 943 | 0.53 | 1.52 | 3 | I |
| Zollhaus | RLP | 243 | 4 | 53 | NaN | 734 | 0.34 | 1.05 | 7 | III |
References
- McDonnell, J.J.; Woods, R. On the need for catchment classification. J. Hydrol. 2004, 299, 2–3. [Google Scholar] [CrossRef]
- Gupta, H.V.; Perrin, C.; Blöschl, G.; Montanari, A.; Kumar, R.; Clark, M.; Andreassian, V. Large-sample hydrology: A need to balance depth with breadth. Hydrol. Earth Syst. Sci. 2014, 18, 463–477. [Google Scholar] [CrossRef]
- Bárdossy, A. Calibration of hydrological model parameters for ungauged catchments. Hydrol. Earth Syst. Sci. 2007, 11, 703–710. [Google Scholar] [CrossRef]
- Clark, M.P.; Slater, A.G.; Rupp, D.E.; Woods, R.A.; Jasper, A.V.; Gupta, H.V.; Wagener, T.; Hay, L.E. Framework for Understanding Structural Errors (FUSE): A modular framework to diagnose differences between hydrological models. Water Resour. Res. 2008. [Google Scholar] [CrossRef]
- Hrachowitz, M.; Savenije, H.H.G.; Blöschl, G.; McDonnell, J.J.; Sivapalan, M.; Pomeroy, J.W.; Arheimer, B.; Blume, T.; Clark, M.P.; Ehret, U.; et al. A decade of Predictions in Ungauged Basins (PUB)–A review. Hydrol. Sci. J. 2013, 58, 1–58. [Google Scholar] [CrossRef]
- Coxon, G.; Freer, J.; Wagener, T.; Odoni, N.A.; Clark, M. Diagnostic evaluation of multiple hypotheses of hydrological behaviour in a limits-of-acceptability framework for 24 UK catchments. Hydrol. Process. 2014, 28, 6135–6150. [Google Scholar] [CrossRef]
- McDonnell, J.J. Where does water go when it rains? Moving beyond the variable source area concept of rain fall-runoff response. Hydrol. Process. 2003, 17, 1869–1875. [Google Scholar] [CrossRef]
- Savenije, H.H.G. HESS opinions “The art of hydrology”. Hydrol. Earth Syst. Sci. 2009, 13, 157–161. [Google Scholar] [CrossRef]
- Fenicia, F.; McDonnell, J.J.; Savenije, H.H.G. Learning from model improvement: On the contribution of complementary data to process understanding. Water Resour. Res. 2008. [Google Scholar] [CrossRef]
- Fenicia, F.; Kavetski, D.; Savenije, H.H.G. Elements of a flexible approach for conceptual hydrological modeling: 1. Motivation and theoretical development. Water Resour. Res. 2011. [Google Scholar] [CrossRef]
- Van Dijk, A.I.J.M. Selection of an appropriately simple storm runoff model. Hydrol. Earth Syst. Sci. 2010, 14, 447–458. [Google Scholar] [CrossRef]
- Perrin, C.; Michel, C.; Anréassian, V. Does a large number of parameters enhance model performance? Comparative assessment of common catchment model structures on 429 catchments. J. Hydrol. 2001, 242, 275–301. [Google Scholar] [CrossRef]
- Staudinger, M.; Stahl, K.; Seibert, J.; Clark, M.P.; Tallaksen, L.M. Comparison of hydrological model structures based on recession an low flow simulations. Hydrol. Earth Syst. Sci. 2011, 15, 3447–3459. [Google Scholar] [CrossRef] [Green Version]
- Lee, H.; McIntyre, N.; Wheater, H.; Young, A. Selection of conceptual models for regionalisation of the rainfall-runoff relationship. J. Hydrol. 2005, 312, 125–147. [Google Scholar] [CrossRef]
- Wagener, T.; McIntyre, N. Hydrological catchment classification using a data-based mechanistic strategy. In System Identification, Environmental Modelling, and Control System Design; Springer: London, UK, 2012. [Google Scholar]
- Van Esse, W.R.; Perrin, C.; Booij, M.J.; Augutsijen, D.C.M.; Fenicia, F.; Lobligeois, F. The influence of conceptual model structure on model performance: A comparative study for 237 French catchments. Hydrol. Earth Syst. Sci. 2013, 17, 4227–4239. [Google Scholar] [CrossRef] [Green Version]
- Fenicia, F.; Kavetski, D.; Savenije, H.H.G.; Clark, M.P.; Schoups, G.; Pfister, L.; Freer, J. Catchment properties, function, and conceptual model representation: Is there a correspondence? Hydrol. Process. 2014, 28, 2451–2467. [Google Scholar] [CrossRef]
- Beven, K. Prophecy, reality and uncertainty in distributed hydrological modelling. Adv. Water Resour. 1993, 16, 41–51. [Google Scholar] [CrossRef]
- Beven, K.; Freer, J. Equifinality, data assimilation and uncertainty estimation in mechanistic modelling of complex environmental systems using the GLUE methodology. J. Hydrol. 2001, 249, 11–29. [Google Scholar] [CrossRef]
- Buytaert, W.; Beven, K. Models as multiple working hypotheses: Hydrological simulation of tropical alpine wetlands. Hydrol. Process. 2011, 25, 1784–1799. [Google Scholar] [CrossRef]
- Clark, M.P.; Kavetski, D.; Fenicia, F. Pursuing the method of multiple working hypotheses for hydrological modeling. Water Resour. Res. 2011. [Google Scholar] [CrossRef]
- Gupta, H.V.; Wagener, T.; Liu, Y. Reconciling theory with observations: Elements of a diagnostic approach to model evaluation. Hydrol. Process. 2008, 22, 3802–3813. [Google Scholar] [CrossRef]
- Ley, R.; Hellebrand, H.; Casper, M.C.; Fenicia, F. Comparing classical performance measures with signature indices derived from flow duration curves to asses model structures as tools for catchment classification. Hydrol. Res. 2016, 47, 1–14. [Google Scholar]
- Gerlach, N. Intermet interpolation meteorologischer grössen. In Niederschlag-Abfluss-Modellierung zur Verlängerung des Vorhersagezeitraumes Operationeller Wasserstands-Und Abflussvorhersagen, Kolloquium am 27. September 2005 in Koblenz; Bundesanstalt für Gewässerkunde: Koblenz, Germany, 2006; p. 98. [Google Scholar]
- Ludwig, K.; Bremicker, M. The Water Balance Model LARSIM—Design, Content and Applications; Freiburger Schriften zur Hydrologie; Institut für Hydrologie, Universität Freiburg i. Br.: Freiburg, Germany, 2006. [Google Scholar]
- Hamon, W.R. Estimating potential evapotranspiration. J. Hydraul. Div. ASCE 1961, 87, 107–120. [Google Scholar]
- Klemeš, V. Operational testing of hydrological simulation-models. Hydrol. Sci. J. 1986, 13, 13–24. [Google Scholar] [CrossRef]
- Brutsaert, W.; Nieber, J.L. Regionalized drought flow hydrographs from a mature glaciated plateau. Water Resour. Res. 1977, 13, 637–643. [Google Scholar] [CrossRef]
- Kavetski, D.; Fenicia, F. Elements of a flexible approach for conceptual hydrological modeling: 2. Application and experimental insights. Water Resour. Res. 2011. [Google Scholar] [CrossRef]
- Nash, J.E.; Sutcliffe, J.V. River flow forecasting through conceptual models part I: A discussion of principles. J. Hydrol. 1970, 10, 282–290. [Google Scholar] [CrossRef]
- Vogel, R.M.; Fennessey, N.M. Flow-duration curves. I: New interpretation and confidence intervals. J. Water Resour. Plan. Manag. 1994, 120, 485–504. [Google Scholar] [CrossRef]
- Yilmaz, K.K.; Gupta, H.V.; Wagener, T. A process-based diagnostic approach to model evaluation: Application to the NWS distributed hydrologic model. Water Resour. Res. 2008. [Google Scholar] [CrossRef]
- Westerberg, I.K.; Guerro, J.-L.; Younger, P.M.; Beven, K.J.; Seibert, J.; Halldin, S.; Freer, J.E.; Xu, C.Y. Calibration of hydrological models using flow-duration curves. Hydrol. Earth Syst. Sci. 2011, 15, 2205–2227. [Google Scholar] [CrossRef] [Green Version]
- Legates, D.R.; McCabe, G.J., Jr. Evaluating the use of “goodness-of-fit” measures in hydrologic and hydroclimatic model validation. Water Resour. Res. 1999, 35, 233–241. [Google Scholar] [CrossRef]
- Schaefli, B.; Gupta, H.V. Do Nash values have value? Hydrol. Process. 2007, 21, 2075–2080. [Google Scholar] [CrossRef]
- Moriasi, D.N.; Arnold, J.G.; van Liew, M.W.; Bingner, R.L.; Harmel, R.D.; Veith, T.L. Model evaluation guidelines for systematic quantification of accuracy in watershed simulations. Am. Soc. Agric. Biol. Eng. 2007, 50, 885–900. [Google Scholar]
- Oudin, L.; Andréassian, V.; Perrin, C.; Michel, C.; Moine, N.L. Spatial proximity, physical similarity, regression and ungaged catchments: A comparison of regionalization approaches based on 913 French catchments. Water Resour. Res. 2008. [Google Scholar] [CrossRef]
- Kohonen, T. Essentials of the self-organizing map. Neural Netw. 2013, 37, 52–65. [Google Scholar] [CrossRef]
- Kohonen, T. Self-Organizing Maps, 3rd ed.; Springer Series in Information Sciences; Springer-Verlag: Berlin, Germany, 2001. [Google Scholar]
- Ley, R.; Casper, M.C.; Hellebrand, H.; Merz, R. Catchment classification by runoff behaviour with self-organizing maps (SOM). Hydrol. Earth Syst. Sci. 2011, 115, 2947–2962. [Google Scholar] [CrossRef]
- Ley, R. Klassifikation von Pegel-Einzugsgebieten und Regionalisierung von Abfluss-Und Modell-Parametern unter Berücksichtigung des Abflussverhaltens, Hydroklimatischer und Physiogeografischer Gebietsmerkmale. Ph.D. Thesis, Universität Trier, Trier, Germany, 2014. [Google Scholar]
- Vesanto, J.; Alhoniemi, E. Clustering of the self-organizing map. IEEE Trans. Neural Netw. 2000, 11, 586–600. [Google Scholar] [CrossRef]
- Beven, K.J. Uncertainty in Environmental Modelling: A Manifesto for the Equifinality Thesis. In Proceedings of the international workshop on uncertainty, sensitivity and parameter estimation for multimedia environmental modelling, Rockville, MD, USA, 19–21 August 2003; pp. 103–105.
- Merz, R.; Blöschl, G. Regionalisation of catchment model parameters. J. Hydrol. 2004, 287, 95–123. [Google Scholar] [CrossRef]
- Samaniego, L.; Kumar, R.; Attinger, S. Multiscale parameter regionalization of a grid-based hydrologic model at the mesoscale. Water Resour. Res. 2010. [Google Scholar] [CrossRef]
- Fenicia, F.; Kavetski, D.; Savenije, H.H.G.; Pfister, L. From spatially variable streamflow to distributed hydrological models: Analysis of key modeling decisions. Water Resour. Res. 2016, 52, 1–36. [Google Scholar] [CrossRef]









| Parameter | Minimum | Maximum |
|---|---|---|
| Ce (-) | 0.01 | 30 |
| D (-) | 0 | 1 |
| Imax (mm) | 0.000001 | 20 |
| Kf (1/d) | 0.0000001 | 1 |
| Kr (1/d) | 0.00001 | 1 |
| Ks (1/d) | 0.0000001 | 1 |
| M (-) | 0 | 0.3 |
| Rmax (mm/day) | 0.001 | 30 |
| Sumax (mm) | 0.1 | 0.000001 |
| Tf (d) | 1 | 500 |
| β (-) | 0.001 | 50 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ley, R.; Hellebrand, H.; Casper, M.C.; Fenicia, F. Is Catchment Classification Possible by Means of Multiple Model Structures? A Case Study Based on 99 Catchments in Germany. Hydrology 2016, 3, 22. https://doi.org/10.3390/hydrology3020022
Ley R, Hellebrand H, Casper MC, Fenicia F. Is Catchment Classification Possible by Means of Multiple Model Structures? A Case Study Based on 99 Catchments in Germany. Hydrology. 2016; 3(2):22. https://doi.org/10.3390/hydrology3020022
Chicago/Turabian StyleLey, Rita, Hugo Hellebrand, Markus C. Casper, and Fabrizio Fenicia. 2016. "Is Catchment Classification Possible by Means of Multiple Model Structures? A Case Study Based on 99 Catchments in Germany" Hydrology 3, no. 2: 22. https://doi.org/10.3390/hydrology3020022