
Current Trends in Fluid Research in the Era of Artificial Intelligence: A Review

 ,
, 
 , , and
, , and
Abstract
:1. Introduction
1.1. Data Science
1.2. AI/ML in Fluid Research
1.3. Reviews and Perspectives on Fluid Research and ML
1.4. Aim and Objectives
2. Bridging across Scales
3. Fluid Properties Extraction
4. Physics-Based CFD
5. Algorithms for Fluid Flows
5.1. Multiple Linear Regression
5.2. Ridge Regression
5.3. Lasso Regression
5.4. Support Vector Machines
5.5. Gaussian Process Regression
5.6. k-Nearest Neighbors
5.7. Decision Trees
5.8. Random Forest
5.9. Gradient Boosting
5.10. Artificial Neural Networks
5.11. Symbolic Regression
5.12. Performance Metrics
6. Comparative Investigation
7. Conclusions and Future Perspectives
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Nomenclature
| English Symbols | |
| bias term | |
| B | number of decision trees in RF method |
| D | diffusion coefficient |
| external driving force | |
| DT function estimation | |
| gi | ith sample size of data for k-NN regression |
| g | the result of query point prediction for k-NN regression |
| channel width | |
| (x) | function for GBR method |
| DT indicator function | |
| k | number of neighbors for k-NN regression |
| kB | Boltzmann constant |
| m | particle mass |
| MAE | Mean Absolute Error |
| MSE | Mean Squared Error |
| N | number of particles |
| weight for GBR method | |
| coefficient of determination | |
| distance vector between ith and jth atom | |
| T | temperature |
| LJ potential of atom i with atom j | |
| weight of the variable | |
| X’ | number of unknown scenarios in RF method |
| input variable | |
| predicted variable | |
| Yb | decision tree in RF method |
| mean expected output | |
| mean predicted output | |
| Greek Symbols | |
| penalized residual sum for Ridge regression | |
| shrinkage factor | |
| Lasso regression estimate | |
| ε | energy parameter in the LJ potential |
| DT decision path | |
| λ | thermal conductivity |
| μ | coefficient of shear viscosity |
| ρ | fluid density |
| σ | length parameter in the LJ potential |
References
- Agrawal, A.; Choudhary, A. Perspective: Materials Informatics and Big Data: Realization of the “Fourth Paradigm” of Science in Materials Science. APL Mater. 2016, 4, 053208. [Google Scholar] [CrossRef] [Green Version]
- Agrawal, A.; Deshpande, P.D.; Cecen, A.; Basavarsu, G.P.; Choudhary, A.N.; Kalidindi, S.R. Exploration of Data Science Techniques to Predict Fatigue Strength of Steel from Composition and Processing Parameters. Integr. Mater. Manuf. Innov. 2014, 3, 90–108. [Google Scholar] [CrossRef] [Green Version]
- Wei, J.; Chu, X.; Sun, X.; Xu, K.; Deng, H.; Chen, J.; Wei, Z.; Lei, M. Machine Learning in Materials Science. InfoMat 2019, 1, 338–358. [Google Scholar] [CrossRef]
- Paulson, N.H.; Zomorodpoosh, S.; Roslyakova, I.; Stan, M. Comparison of Statistically-Based Methods for Automated Weighting of Experimental Data in CALPHAD-Type Assessment. Calphad 2020, 68, 101728. [Google Scholar] [CrossRef]
- Frank, M.; Drikakis, D.; Charissis, V. Machine-Learning Methods for Computational Science and Engineering. Computation 2020, 8, 15. [Google Scholar] [CrossRef] [Green Version]
- Wang, T.; Zhang, C.; Snoussi, H.; Zhang, G. Machine Learning Approaches for Thermoelectric Materials Research. Adv. Funct. Mater. 2020, 30, 1906041. [Google Scholar] [CrossRef]
- Alexiadis, A. Deep Multiphysics: Coupling Discrete Multiphysics with Machine Learning to Attain Self-Learning in-Silico Models Replicating Human Physiology. Artif. Intell. Med. 2019, 98, 27–34. [Google Scholar] [CrossRef]
- Brenner, M.P.; Eldredge, J.D.; Freund, J.B. Perspective on Machine Learning for Advancing Fluid Mechanics. Phys. Rev. Fluids 2019, 4, 100501. [Google Scholar] [CrossRef]
- Schmid, M.; Altmann, D.; Steinbichler, G. A Simulation-Data-Based Machine Learning Model for Predicting Basic Parameter Settings of the Plasticizing Process in Injection Molding. Polymers 2021, 13, 2652. [Google Scholar] [CrossRef]
- Goh, G.D.; Sing, S.L.; Yeong, W.Y. A Review on Machine Learning in 3D Printing: Applications, Potential, and Challenges. Artif. Intell. Rev. 2021, 54, 63–94. [Google Scholar] [CrossRef]
- Kailkhura, B.; Gallagher, B.; Kim, S.; Hiszpanski, A.; Han, T.Y.-J. Reliable and Explainable Machine-Learning Methods for Accelerated Material Discovery. Npj Comput. Mater. 2019, 5, 108. [Google Scholar] [CrossRef]
- Sofos, F. A Water/Ion Separation Device: Theoretical and Numerical Investigation. Appl. Sci. 2021, 11, 8548. [Google Scholar] [CrossRef]
- Roscher, R.; Bohn, B.; Duarte, M.F.; Garcke, J. Explainable Machine Learning for Scientific Insights and Discoveries. IEEE Access 2020, 8, 42200–42216. [Google Scholar] [CrossRef]
- Vasudevan, R.K.; Choudhary, K.; Mehta, A.; Smith, R.; Kusne, G.; Tavazza, F.; Vlcek, L.; Ziatdinov, M.; Kalinin, S.V.; Hattrick-Simpers, J. Materials Science in the Artificial Intelligence Age: High-Throughput Library Generation, Machine Learning, and a Pathway from Correlations to the Underpinning Physics. MRS Commun. 2019, 9, 821–838. [Google Scholar] [CrossRef] [Green Version]
- Craven, G.T.; Lubbers, N.; Barros, K.; Tretiak, S. Machine Learning Approaches for Structural and Thermodynamic Properties of a Lennard-Jones Fluid. J. Chem. Phys. 2020, 153, 104502. [Google Scholar] [CrossRef]
- Sun, W.; Zheng, Y.; Yang, K.; Zhang, Q.; Shah, A.A.; Wu, Z.; Sun, Y.; Feng, L.; Chen, D.; Xiao, Z.; et al. Machine Learning-Assisted Molecular Design and Efficiency Prediction for High-Performance Organic Photovoltaic Materials. Sci. Adv. 2019, 5, eaay4275. [Google Scholar] [CrossRef] [Green Version]
- Zhang, W.-W.; Noack, B.R. Artificial Intelligence in Fluid Mechanics. Acta Mech. Sin. 2022, 1–3. [Google Scholar] [CrossRef]
- Raissi, M.; Perdikaris, P.; Karniadakis, G.E. Physics-Informed Neural Networks: A Deep Learning Framework for Solving Forward and Inverse Problems Involving Nonlinear Partial Differential Equations. J. Comput. Phys. 2019, 378, 686–707. [Google Scholar] [CrossRef]
- Papastamatiou, K.; Sofos, F.; Karakasidis, T.E. Machine Learning Symbolic Equations for Diffusion with Physics-Based Descriptions. AIP Adv. 2022, 12, 025004. [Google Scholar] [CrossRef]
- Brunton, S.L.; Noack, B.R.; Koumoutsakos, P. Machine Learning for Fluid Mechanics. Annu. Rev. Fluid Mech. 2020, 52, 477–508. [Google Scholar] [CrossRef] [Green Version]
- Brunton, S.L. Applying Machine Learning to Study Fluid Mechanics. Acta Mech. Sin. 2022, 1–9. [Google Scholar] [CrossRef]
- Jirasek, F.; Hasse, H. Perspective: Machine Learning of Thermophysical Properties. Fluid Phase Equilib. 2021, 549, 113206. [Google Scholar] [CrossRef]
- Arief, H.A.; Wiktorski, T.; Thomas, P.J. A Survey on Distributed Fibre Optic Sensor Data Modelling Techniques and Machine Learning Algorithms for Multiphase Fluid Flow Estimation. Sensors 2021, 21, 2801. [Google Scholar] [CrossRef]
- Pandey, S.; Schumacher, J.; Sreenivasan, K.R. A Perspective on Machine Learning in Turbulent Flows. J. Turbul. 2020, 21, 567–584. [Google Scholar] [CrossRef]
- Botu, V.; Ramprasad, R. Learning Scheme to Predict Atomic Forces and Accelerate Materials Simulations. Phys. Rev. B Condens. Matter Mater. Phys. 2015, 92, 094306. [Google Scholar] [CrossRef] [Green Version]
- Behler, J.; Parrinello, M. Generalized Neural-Network Representation of High-Dimensional Potential-Energy Surfaces. Phys. Rev. Lett. 2007, 98, 146401. [Google Scholar] [CrossRef] [PubMed]
- Noé, F.; Olsson, S.; Köhler, J.; Wu, H. Boltzmann Generators: Sampling Equilibrium States of Many-Body Systems with Deep Learning. Science 2019, 365, eaaw1147. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sofos, F.; Karakasidis, T.E.; Liakopoulos, A. Fluid Flow at the Nanoscale: How Fluid Properties Deviate from the Bulk. Nanosci. Nanotechnol. Lett. 2013, 5, 457–460. [Google Scholar] [CrossRef]
- Sofos, F.; Karakasidis, T.E.; Giannakopoulos, A.E.; Liakopoulos, A. Molecular Dynamics Simulation on Flows in Nano-Ribbed and Nano-Grooved Channels. Heat Mass Transf./Waerme Stoffuebertragung 2016, 52, 153–162. [Google Scholar] [CrossRef]
- Mueller, T.; Hernandez, A.; Wang, C. Machine Learning for Interatomic Potential Models. J. Chem. Phys. 2020, 152, 050902. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Krems, R.V. Bayesian Machine Learning for Quantum Molecular Dynamics. Phys. Chem. Chem. Phys. 2019, 21, 13392–13410. [Google Scholar] [CrossRef] [Green Version]
- Mishin, Y. Machine-Learning Interatomic Potentials for Materials Science. Acta Mater. 2021, 214, 116980. [Google Scholar] [CrossRef]
- Veit, M.; Jain, S.K.; Bonakala, S.; Rudra, I.; Hohl, D.; Csányi, G. Equation of State of Fluid Methane from First Principles with Machine Learning Potentials. J. Chem. Theory Comput. 2019, 15, 2574–2586. [Google Scholar] [CrossRef] [Green Version]
- Peng, G.C.Y.; Alber, M.; Buganza Tepole, A.; Cannon, W.R.; De, S.; Dura-Bernal, S.; Garikipati, K.; Karniadakis, G.; Lytton, W.W.; Perdikaris, P.; et al. Multiscale Modeling Meets Machine Learning: What Can We Learn? Arch. Comput. Methods Eng. 2021, 28, 1017–1037. [Google Scholar] [CrossRef] [Green Version]
- Tchipev, N.; Seckler, S.; Heinen, M.; Vrabec, J.; Gratl, F.; Horsch, M.; Bernreuther, M.; Glass, C.W.; Niethammer, C.; Hammer, N.; et al. TweTriS: Twenty Trillion-Atom Simulation. Int. J. High Perform. Comput. Appl. 2019, 33, 838–854. [Google Scholar] [CrossRef] [Green Version]
- Mortazavi, B.; Podryabinkin, E.V.; Roche, S.; Rabczuk, T.; Zhuang, X.; Shapeev, A.V. Machine-Learning Interatomic Potentials Enable First-Principles Multiscale Modeling of Lattice Thermal Conductivity in Graphene/Borophene Heterostructures. Mater. Horiz. 2020, 7, 2359–2367. [Google Scholar] [CrossRef]
- Holland, D.M.; Lockerby, D.A.; Borg, M.K.; Nicholls, W.D.; Reese, J.M. Molecular Dynamics Pre-Simulations for Nanoscale Computational Fluid Dynamics. Microfluid. Nanofluid. 2015, 18, 461–474. [Google Scholar] [CrossRef] [Green Version]
- Lin, C.; Li, Z.; Lu, L.; Cai, S.; Maxey, M.; Karniadakis, G.E. Operator Learning for Predicting Multiscale Bubble Growth Dynamics. J. Chem. Phys. 2021, 154, 104118. [Google Scholar] [CrossRef]
- Wang, Y.; Ouyang, J.; Wang, X. Machine Learning of Lubrication Correction Based on GPR for the Coupled DPD–DEM Simulation of Colloidal Suspensions. Soft Matter 2021, 17, 5682–5699. [Google Scholar] [CrossRef]
- Sofos, F.; Chatzoglou, E.; Liakopoulos, A. An Assessment of SPH Simulations of Sudden Expansion/Contraction 3-D Channel Flows. Comput. Part. Mech. 2022, 9, 101–115. [Google Scholar] [CrossRef]
- Albano, A.; Alexiadis, A. A Smoothed Particle Hydrodynamics Study of the Collapse for a Cylindrical Cavity. PLoS ONE 2020, 15, e0239830. [Google Scholar] [CrossRef] [PubMed]
- Bai, J.; Zhou, Y.; Rathnayaka, C.M.; Zhan, H.; Sauret, E.; Gu, Y. A Data-Driven Smoothed Particle Hydrodynamics Method for Fluids. Eng. Anal. Bound. Elem. 2021, 132, 12–32. [Google Scholar] [CrossRef]
- Wang, J.; Olsson, S.; Wehmeyer, C.; Pérez, A.; Charron, N.E.; De Fabritiis, G.; Noé, F.; Clementi, C. Machine Learning of Coarse-Grained Molecular Dynamics Force Fields. ACS Cent. Sci. 2019, 5, 755–767. [Google Scholar] [CrossRef] [Green Version]
- Wang, W.; Gómez-Bombarelli, R. Coarse-Graining Auto-Encoders for Molecular Dynamics. npj Comput. Mater. 2019, 5, 125. [Google Scholar] [CrossRef] [Green Version]
- Scherer, C.; Scheid, R.; Andrienko, D.; Bereau, T. Kernel-Based Machine Learning for Efficient Simulations of Molecular Liquids. J. Chem. Theory Comput. 2020, 16, 3194–3204. [Google Scholar] [CrossRef] [PubMed]
- Ye, H.; Xian, W.; Li, Y. Machine Learning of Coarse-Grained Models for Organic Molecules and Polymers: Progress, Opportunities, and Challenges. ACS Omega 2021, 6, 1758–1772. [Google Scholar] [CrossRef] [PubMed]
- Moradzadeh, A.; Aluru, N.R. Transfer-Learning-Based Coarse-Graining Method for Simple Fluids: Toward Deep Inverse Liquid-State Theory. J. Phys. Chem. Lett. 2019, 10, 1242–1250. [Google Scholar] [CrossRef] [PubMed]
- Noé, F.; Tkatchenko, A.; Müller, K.-R.; Clementi, C. Machine Learning for Molecular Simulation. Annu. Rev. Phys. Chem. 2020, 71, 361–390. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Giannakopoulos, A.E.; Sofos, F.; Karakasidis, T.E.; Liakopoulos, A. A Quasi-Continuum Multi-Scale Theory for Self-Diffusion and Fluid Ordering in Nanochannel Flows. Microfluid. Nanofluid. 2014, 17, 1011–1023. [Google Scholar] [CrossRef]
- Allers, J.P.; Garzon, F.H.; Alam, T.M. Artificial Neural Network Prediction of Self-Diffusion in Pure Compounds over Multiple Phase Regimes. Phys. Chem. Chem. Phys. 2021, 23, 4615–4623. [Google Scholar] [CrossRef] [PubMed]
- De Pablo, J.J.; Jackson, N.E.; Webb, M.A.; Chen, L.Q.; Moore, J.E.; Morgan, D.; Jacobs, R.; Pollock, T.; Schlom, D.G.; Toberer, E.S.; et al. New Frontiers for the Materials Genome Initiative. npj Comput. Mater. 2019, 5, 41. [Google Scholar] [CrossRef]
- Jakob, J.; Gross, M.; Günther, T. A fluid flow data set for machine learning and its application to neural flow map interpolation. IEEE Trans. Vis. Comput. Graph. 2020, 27, 1279–1289. [Google Scholar] [CrossRef]
- Curtarolo, S.; Setyawan, W.; Hart, G.L.W.; Jahnatek, M.; Chepulskii, R.V.; Taylor, R.H.; Wang, S.; Xue, J.; Yang, K.; Levy, O.; et al. AFLOW: An Automatic Framework for High-Throughput Materials Discovery. Comput. Mater. Sci. 2012, 58, 218–226. [Google Scholar] [CrossRef] [Green Version]
- Draxl, C.; Scheffler, M. NOMAD: The FAIR Concept for Big Data-Driven Materials Science. MRS Bull. 2018, 43, 676–682. [Google Scholar] [CrossRef] [Green Version]
- Jain, A.; Ong, S.P.; Hautier, G.; Chen, W.; Richards, W.D.; Dacek, S.; Cholia, S.; Gunter, D.; Skinner, D.; Ceder, G.; et al. The Materials Project: A Materials Genome Approach to Accelerating Materials Innovation. APL Mater. 2013, 1, 011002. [Google Scholar] [CrossRef] [Green Version]
- Wang, W.; Xu, M.; Xu, X.; Zhou, W.; Shao, Z. Perovskite Oxide Based Electrodes for High-Performance Photoelectrochemical Water Splitting. Angew. Chem. Int. Ed. 2020, 59, 136–152. [Google Scholar] [CrossRef]
- Allen, M.P.; Tildesley, D.J. Computer Simulation of Liquids, 2nd ed.; Oxford University Press: Oxford, UK, 2017; ISBN 9780198803195. [Google Scholar]
- Allers, J.P.; Harvey, J.A.; Garzon, F.H.; Alam, T.M. Machine Learning Prediction of Self-Diffusion in Lennard-Jones Fluids. J. Chem. Phys. 2020, 153, 034102. [Google Scholar] [CrossRef]
- Udrescu, S.-M.; Tan, A.; Feng, J.; Neto, O.; Wu, T.; Tegmark, M. AI Feynman 2.0: Pareto-Optimal Symbolic Regression Exploiting Graph Modularity. In Proceedings of the 34th Conference on Neural Information Processing Systems (NeurIPS 2020), Vancouver, BC, Canada, 6–12 December 2020; pp. 1–12. [Google Scholar]
- Ye, H.F.; Wang, J.; Zheng, Y.G.; Zhang, H.W.; Chen, Z. Machine Learning for Reparameterization of Four-Site Water Models: TIP4P-BG and TIP4P-BGT. Phys. Chem. Chem. Phys. 2021, 23, 10164–10173. [Google Scholar] [CrossRef]
- Liu, Y.; Hong, W.; Cao, B. Machine Learning for Predicting Thermodynamic Properties of Pure Fluids and Their Mixtures. Energy 2019, 188, 116091. [Google Scholar] [CrossRef]
- Boobier, S.; Hose, D.R.J.; Blacker, A.J.; Nguyen, B.N. Machine Learning with Physicochemical Relationships: Solubility Prediction in Organic Solvents and Water. Nat. Commun. 2020, 11, 5753. [Google Scholar] [CrossRef]
- Wang, K.; Xu, H.; Yang, C.; Qiu, T. Machine Learning-Based Ionic Liquids Design and Process Simulation for CO2 Separation from Flue Gas. Green Energy Environ. 2021, 6, 432–443. [Google Scholar] [CrossRef]
- Saldana, D.A.; Starck, L.; Mougin, P.; Rousseau, B.; Ferrando, N.; Creton, B. Prediction of Density and Viscosity of Biofuel Compounds Using Machine Learning Methods. Energy Fuels 2012, 26, 2416–2426. [Google Scholar] [CrossRef]
- Wu, H.; Lorenson, A.; Anderson, B.; Witteman, L.; Wu, H.; Meredig, B.; Morgan, D. Robust FCC Solute Diffusion Predictions from Ab-Initio Machine Learning Methods. Comput. Mater. Sci. 2017, 134, 160–165. [Google Scholar] [CrossRef] [Green Version]
- Amsallem, D.; Farhat, C. Interpolation Method for Adapting Reduced-Order Models and Application to Aeroelasticity. AIAA J. 2008, 46, 1803–1813. [Google Scholar] [CrossRef] [Green Version]
- Amsallem, D.; Deolalikar, S.; Gurrola, F.; Farhat, C. Model Predictive Control under Coupled Fluid-Structure Constraints Using a Database of Reduced-Order Models on a Tablet. In Proceedings of the 21st AIAA Computational Fluid Dynamics Conference, Fluid Dynamics and Co-located Conferences, American Institute of Aeronautics and Astronautics, San Diego, CA, USA, 24–27 June 2013. [Google Scholar]
- Ooi, C.; Le, Q.T.; Dao, M.H.; Nguyen, V.B.; Nguyen, H.H.; Ba, T. Modeling Transient Fluid Simulations with Proper Orthogonal Decomposition and Machine Learning. Int. J. Numer. Methods Fluids 2021, 93, 396–410. [Google Scholar] [CrossRef]
- Kochkov, D.; Smith, J.A.; Alieva, A.; Wang, Q.; Brenner, M.P.; Hoyer, S. Machine Learning–Accelerated Computational Fluid Dynamics. Proc. Natl. Acad. Sci. USA 2021, 118, e2101784118. [Google Scholar] [CrossRef] [PubMed]
- Fukami, K.; Fukagata, K.; Taira, K. Assessment of Supervised Machine Learning Methods for Fluid Flows. Theor. Comput. Fluid Dyn. 2020, 34, 497–519. [Google Scholar] [CrossRef] [Green Version]
- Shukla, K.; Jagtap, A.D.; Karniadakis, G.E. Parallel Physics-Informed Neural Networks via Domain Decomposition. J. Comput. Phys. 2021, 447, 110683. [Google Scholar] [CrossRef]
- Zhu, Q.; Liu, Z.; Yan, J. Machine Learning for Metal Additive Manufacturing: Predicting Temperature and Melt Pool Fluid Dynamics Using Physics-Informed Neural Networks. Comput. Mech. 2021, 67, 619–635. [Google Scholar] [CrossRef]
- Rudy, S.H.; Brunton, S.L.; Proctor, J.L.; Kutz, J.N. Data-Driven Discovery of Partial Differential Equations. Sci. Adv. 2017, 3, e1602614. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Raissi, M.; Yazdani, A.; Karniadakis, G.E. Hidden Fluid Mechanics: Learning Velocity and Pressure Fields from Flow Visualizations. Science 2020, 367, 1026–1030. [Google Scholar] [CrossRef]
- Wan, Z.Y.; Sapsis, T.P. Machine Learning the Kinematics of Spherical Particles in Fluid Flows. J. Fluid Mech. 2018, 857, R2. [Google Scholar] [CrossRef] [Green Version]
- Seong, Y.; Park, C.; Choi, J.; Jang, I. Surrogate Model with a Deep Neural Network to Evaluate Gas–Liquid Flow in a Horizontal Pipe. Energies 2020, 13, 968. [Google Scholar] [CrossRef] [Green Version]
- Rastogi, A.; Fan, Y. Machine Learning Augmented Two-Fluid Model for Segregated Flow. Fluids 2022, 7, 12. [Google Scholar] [CrossRef]
- Hanna, B.N.; Dinh, N.T.; Youngblood, R.W.; Bolotnov, I.A. Machine-Learning Based Error Prediction Approach for Coarse-Grid Computational Fluid Dynamics (CG-CFD). Prog. Nucl. Energy 2020, 118, 103140. [Google Scholar] [CrossRef]
- Amini, S.; Mohaghegh, S. Application of Machine Learning and Artificial Intelligence in Proxy Modeling for Fluid Flow in Porous Media. Fluids 2019, 4, 126. [Google Scholar] [CrossRef] [Green Version]
- Tian, J.; Qi, C.; Sun, Y.; Yaseen, Z.M.; Pham, B.T. Permeability Prediction of Porous Media Using a Combination of Computational Fluid Dynamics and Hybrid Machine Learning Methods. Eng. Comput. 2021, 37, 3455–3471. [Google Scholar] [CrossRef]
- Kutz, J.N. Deep Learning in Fluid Dynamics. J. Fluid Mech. 2017, 814, 1–4. [Google Scholar] [CrossRef] [Green Version]
- Li, B.; Yang, Z.; Zhang, X.; He, G.; Deng, B.-Q.; Shen, L. Using Machine Learning to Detect the Turbulent Region in Flow Past a Circular Cylinder. J. Fluid Mech. 2020, 905, A10. [Google Scholar] [CrossRef]
- Pathak, J.; Mustafa, M.; Kashinath, K.; Motheau, E.; Kurth, T.; Day, M. Using Machine Learning to Augment Coarse-Grid Computational Fluid Dynamics Simulations. arXiv 2020, arXiv:2010.00072. [Google Scholar]
- Dubois, P.; Gomez, T.; Planckaert, L.; Perret, L. Machine Learning for Fluid Flow Reconstruction from Limited Measurements. J. Comput. Phys. 2022, 448, 110733. [Google Scholar] [CrossRef]
- Ghasemi, F.; Mehridehnavi, A.; Pérez-Garrido, A.; Pérez-Sánchez, H. Neural Network and Deep-Learning Algorithms Used in QSAR Studies: Merits and Drawbacks. Drug Discov. Today 2018, 23, 1784–1790. [Google Scholar] [CrossRef] [PubMed]
- Vinuesa, R.; Brunton, S.L. The Potential of Machine Learning to Enhance Computational Fluid Dynamics. arXiv 2021, arXiv:2110.02085. [Google Scholar]
- Zhang, J.; Lei, Y.-K.; Zhang, Z.; Chang, J.; Li, M.; Han, X.; Yang, L.; Yang, Y.I.; Gao, Y.Q. A Perspective on Deep Learning for Molecular Modeling and Simulations. J. Phys. Chem. A 2020, 124, 6745–6763. [Google Scholar] [CrossRef] [PubMed]
- Hoerl, A.E.; Kannard, R.W.; Baldwin, K.F. Ridge Regression: Some Simulations. Commun. Stat. 1975, 4, 105–123. [Google Scholar] [CrossRef]
- Hoerl, A.E.; Kennard, R.W. Ridge Regression: Biased Estimation for Nonorthogonal Problems. Technometrics 1970, 12, 55–67. [Google Scholar] [CrossRef]
- Gareth, J.D.W.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning: With Applications in R; Springer: New York, NY, USA, 2013. [Google Scholar]
- Bibas, K.; Fogel, Y.; Feder, M. A New Look at an Old Problem: A Universal Learning Approach to Linear Regression. In Proceedings of the 2019 IEEE International Symposium on Information Theory (ISIT), Paris, France, 7–12 July 2019; pp. 2304–2308. [Google Scholar]
- Zhao, J.; Zhao, C.; Zhang, F.; Wu, G.; Wang, H. Water Quality Prediction in the Waste Water Treatment Process Based on Ridge Regression Echo State Network. IOP Conf. Ser. Mater. Sci. Eng. 2018, 435, 012025. [Google Scholar] [CrossRef] [Green Version]
- Wang, T.; Zhang, K.; Thé, J.; Yu, H. Accurate Prediction of Band Gap of Materials Using Stacking Machine Learning Model. Comput. Mater. Sci. 2022, 201, 110899. [Google Scholar] [CrossRef]
- Mansour, R.F. Evolutionary Computing Enriched Ridge Regression Model for Craniofacial Reconstruction. Multimed. Tools Appl. 2020, 79, 22065–22082. [Google Scholar] [CrossRef]
- Tibshirani, R. Regression Shrinkage and Selection via the Lasso. J. R. Stat. Soc. Ser. B (Methodol.) 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning; Springer Series in Statistics; Springer: New York, NY, USA, 2001. [Google Scholar]
- Moon, C.; Mitchell, S.A.; Heath, J.E.; Andrew, M. Statistical Inference Over Persistent Homology Predicts Fluid Flow in Porous Media. Water Resour. Res. 2019, 55, 9592–9603. [Google Scholar] [CrossRef]
- Behesht Abad, A.R.; Tehrani, P.S.; Naveshki, M.; Ghorbani, H.; Mohamadian, N.; Davoodi, S.; Aghdam, S.K.; Moghadasi, J.; Saberi, H. Predicting Oil Flow Rate through Orifice Plate with Robust Machine Learning Algorithms. Flow Meas. Instrum. 2021, 81, 102047. [Google Scholar] [CrossRef]
- Callaham, J.L.; Maeda, K.; Brunton, S.L. Robust Flow Reconstruction from Limited Measurements via Sparse Representation. Phys. Rev. Fluids 2019, 4, 103907. [Google Scholar] [CrossRef] [Green Version]
- Li, X.; Zhou, J.; Li, H.; Zhang, S.; Chen, Y. Computational Intelligent Methods for Predicting Complex Ithologies and Multiphase Fluids. Pet. Explor. Dev. 2012, 39, 261–267. [Google Scholar] [CrossRef]
- Chen, H.; Zhang, C.; Jia, N.; Duncan, I.; Yang, S.; Yang, Y. A Machine Learning Model for Predicting the Minimum Miscibility Pressure of CO2 and Crude Oil System Based on a Support Vector Machine Algorithm Approach. Fuel 2021, 290, 120048. [Google Scholar] [CrossRef]
- Samadianfard, S.; Jarhan, S.; Salwana, E.; Mosavi, A.; Shamshirband, S.; Akib, S. Support Vector Regression Integrated with Fruit Fly Optimization Algorithm for River Flow Forecasting in Lake Urmia Basin. Water 2019, 11, 1934. [Google Scholar] [CrossRef] [Green Version]
- Morita, Y.; Rezaeiravesh, S.; Tabatabaei, N.; Vinuesa, R.; Fukagata, K.; Schlatter, P. Applying Bayesian Optimization with Gaussian Process Regression to Computational Fluid Dynamics Problems. J. Comput. Phys. 2022, 449, 110788. [Google Scholar] [CrossRef]
- Deringer, V.L.; Bartók, A.P.; Bernstein, N.; Wilkins, D.M.; Ceriotti, M.; Csányi, G. Gaussian Process Regression for Materials and Molecules. Chem. Rev. 2021, 121, 10073–10141. [Google Scholar] [CrossRef] [PubMed]
- Lee, T.R.; Wood, W.T.; Phrampus, B.J. A Machine Learning (KNN) Approach to Predicting Global Seafloor Total Organic Carbon. Glob. Biogeochem. Cycles 2019, 33, 37–46. [Google Scholar] [CrossRef]
- Rahman, J.; Ahmed, K.S.; Khan, N.I.; Islam, K.; Mangalathu, S. Data-Driven Shear Strength Prediction of Steel Fiber Reinforced Concrete Beams Using Machine Learning Approach. Eng. Struct. 2021, 233, 111743. [Google Scholar] [CrossRef]
- Adithiyaa, T.; Chandramohan, D.; Sathish, T. Optimal Prediction of Process Parameters by GWO-KNN in Stirring-Squeeze Casting of AA2219 Reinforced Metal Matrix Composites. Mater. Today Proc. 2020, 21, 1000–1007. [Google Scholar] [CrossRef]
- Khosravi, P.; Vergari, A.; Choi, Y.; Liang, Y.; Van den Broeck, G. Handling Missing Data in Decision Trees: A Probabilistic Approach. In Proceedings of the The Art of Learning with Missing Values Workshop at ICML (Artemiss), Online, 17 July 2020. [Google Scholar]
- Winkler, D.; Haltmeier, M.; Kleidorfer, M.; Rauch, W.; Tscheikner-Gratl, F. Pipe Failure Modelling for Water Distribution Networks Using Boosted Decision Trees. Struct. Infrastruct. Eng. 2018, 14, 1402–1411. [Google Scholar] [CrossRef] [Green Version]
- Schmidt, J.; Marques, M.R.G.; Botti, S.; Marques, M.A.L. Recent Advances and Applications of Machine Learning in Solid-State Materials Science. npj Comput. Mater. 2019, 5, 83. [Google Scholar] [CrossRef]
- Sofos, F.; Karakasidis, T.E. Nanoscale Slip Length Prediction with Machine Learning Tools. Sci. Rep. 2021, 11, 12520. [Google Scholar] [CrossRef]
- Wei, Z.; Yu, J.; Lu, Y.; Han, J.; Wang, C.; Liu, X. Prediction of Diffusion Coefficients in Fcc, Bcc and Hcp Phases Remained Stable or Metastable by the Machine-Learning Methods. Mater. Des. 2021, 198, 109287. [Google Scholar] [CrossRef]
- Bentéjac, C.; Csörgő, A.; Martínez-Muñoz, G. A Comparative Analysis of Gradient Boosting Algorithms. Artif. Intell. Rev. 2021, 54, 1937–1967. [Google Scholar] [CrossRef]
- Qian, N.; Wang, X.; Fu, Y.; Zhao, Z.; Xu, J.; Chen, J. Predicting Heat Transfer of Oscillating Heat Pipes for Machining Processes Based on Extreme Gradient Boosting Algorithm. Appl. Therm. Eng. 2020, 164, 114521. [Google Scholar] [CrossRef]
- Bikmukhametov, T.; Jäschke, J. Oil Production Monitoring Using Gradient Boosting Machine Learning Algorithm. IFAC-PapersOnLine 2019, 52, 514–519. [Google Scholar] [CrossRef]
- Ma, B.; Meng, F.; Yan, G.; Yan, H.; Chai, B.; Song, F. Diagnostic Classification of Cancers Using Extreme Gradient Boosting Algorithm and Multi-Omics Data. Comput. Biol. Med. 2020, 121, 103761. [Google Scholar] [CrossRef]
- Kim, S.; Lu, P.Y.; Mukherjee, S.; Gilbert, M.; Jing, L.; Ceperic, V.; Soljacic, M. Integration of Neural Network-Based Symbolic Regression in Deep Learning for Scientific Discovery. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 4166–4177. [Google Scholar] [CrossRef]
- Udrescu, S.-M.; Tegmark, M. AI Feynman: A Physics-Inspired Method for Symbolic Regression. Sci. Adv. 2020, 6, eaay2631. [Google Scholar] [CrossRef] [Green Version]
- Loftis, C.; Yuan, K.; Zhao, Y.; Hu, M.; Hu, J. Lattice Thermal Conductivity Prediction Using Symbolic Regression and Machine Learning. J. Phys. Chem. A 2021, 125, 435–450. [Google Scholar] [CrossRef]
- Wadekar, D.; Villaescusa-Navarro, F.; Ho, S.; Perreault-Levasseur, L. Modeling Assembly Bias with Machine Learning and Symbolic Regression. arXiv 2020, arXiv:2012.00111. [Google Scholar]
- Reinbold, P.A.K.; Kageorge, L.M.; Schatz, M.F.; Grigoriev, R.O. Robust Learning from Noisy, Incomplete, High-Dimensional Experimental Data via Physically Constrained Symbolic Regression. Nat. Commun. 2021, 12, 3219. [Google Scholar] [CrossRef] [PubMed]
- Sofos, F.; Karakasidis, T.E.; Liakopoulos, A. Surface Wettability Effects on Flow in Rough Wall Nanochannels. Microfluid. Nanofluid. 2012, 12, 25–31. [Google Scholar] [CrossRef]
- Meier, K.; Laesecke, A.; Kabelac, S. Transport Coefficients of the Lennard-Jones Model Fluid. II Self-Diffusion. J. Chem. Phys. 2004, 121, 9526–9535. [Google Scholar] [CrossRef] [PubMed]
- Hess, B. Determining the Shear Viscosity of Model Liquids from Molecular Dynamics Simulations. J. Chem. Phys. 2002, 116, 209–217. [Google Scholar] [CrossRef]
- Bugel, M.; Galliero, G. Thermal Conductivity of the Lennard-Jones Fluid: An Empirical Correlation. Chem. Phys. 2008, 352, 249–257. [Google Scholar] [CrossRef] [Green Version]
- Sofos, F.; Karakasidis, T.E. Machine Learning Techniques for Fluid Flows at the Nanoscale. Fluids 2021, 6, 96. [Google Scholar] [CrossRef]
- Zhu, Y.; Lu, X.; Zhou, J.; Wang, Y.; Shi, J. Prediction of Diffusion Coefficients for Gas, Liquid and Supercritical Fluid: Application to Pure Real Fluids and Infinite Dilute Binary Solutions Based on the Simulation of Lennard–Jones Fluid. Fluid Phase Equilib. 2002, 194, 1141–1159. [Google Scholar] [CrossRef]
- Zolotukhin, A.B.; Gayubov, A.T. Machine Learning in Reservoir Permeability Prediction and Modelling of Fluid Flow in Porous Media. IOP Conf. Ser. Mater. Sci. Eng. 2019, 700, 012023. [Google Scholar] [CrossRef]
- Usman, A.; Rafiq, M.; Saeed, M.; Nauman, A.; Almqvist, A.; Liwicki, M. Machine Learning Computational Fluid Dynamics. In Proceedings of the 2021 Swedish Artificial Intelligence Society Workshop (SAIS), Lulea, Sweden, 14–15 June 2021; pp. 1–4. [Google Scholar]
- Korteby, Y.; Kristó, K.; Sovány, T.; Regdon, G. Use of Machine Learning Tool to Elucidate and Characterize the Growth Mechanism of an In-Situ Fluid Bed Melt Granulation. Powder Technol. 2018, 331, 286–295. [Google Scholar] [CrossRef] [Green Version]
- Ling, J.; Templeton, J. Evaluation of Machine Learning Algorithms for Prediction of Regions of High Reynolds Averaged Navier Stokes Uncertainty. Phys. Fluids 2015, 27, 085103. [Google Scholar] [CrossRef]
- Gul, S. Machine Learning Applications in Drilling Fluid Engineering: A Review. In Proceedings of the ASME 2021 40th International Conference on Ocean, Offshore and Arctic Engineering—OMAE2021, Online, 21 June 2021; Volume 10: Petroleum Technology. [Google Scholar]
- Zhu, L.-T.; Tang, J.-X.; Luo, Z.-H. Machine Learning to Assist Filtered Two-Fluid Model Development for Dense Gas–Particle Flows. AlChE J. 2020, 66, e16973. [Google Scholar] [CrossRef]











{kind=link}
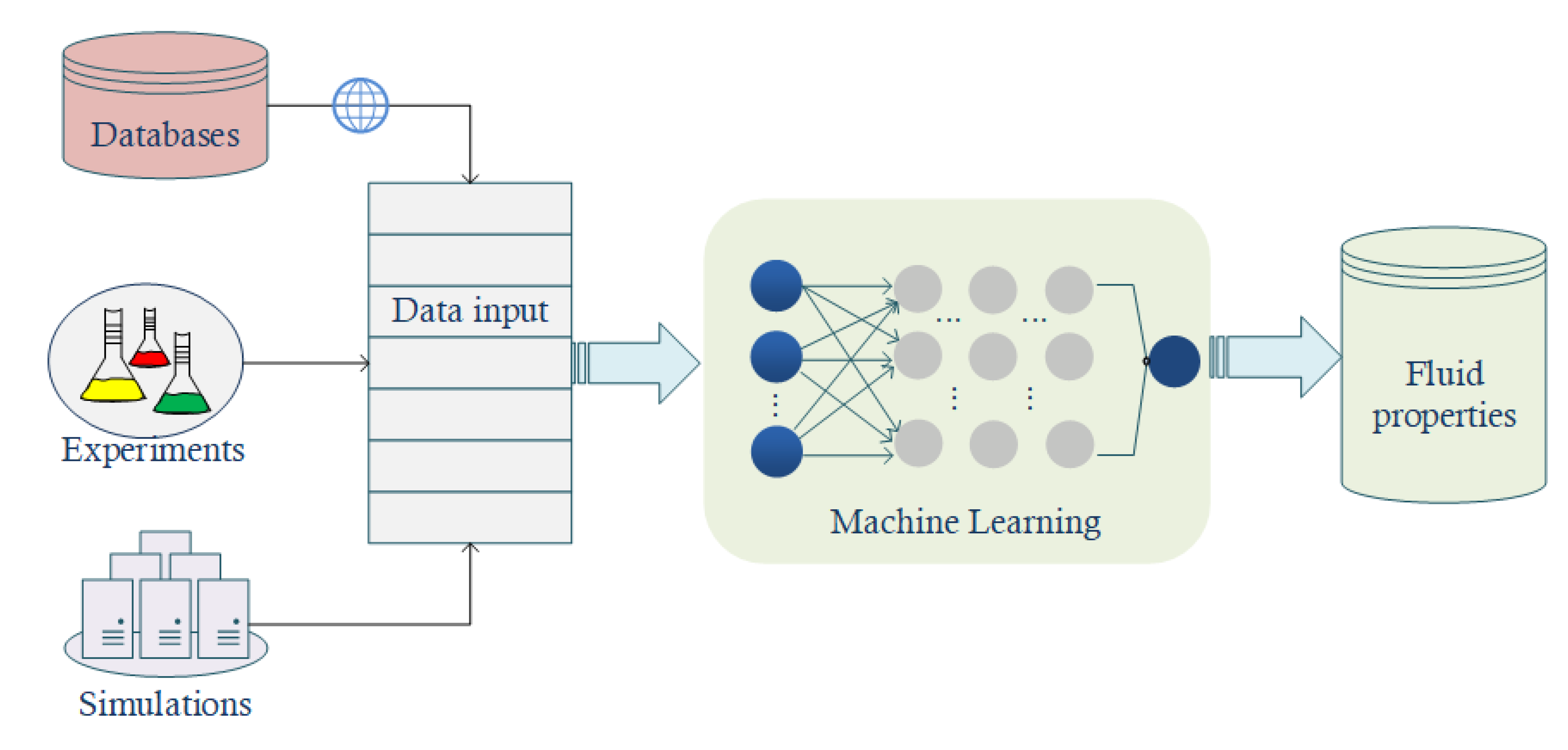{kind=link}
{kind=link}
{kind=link}
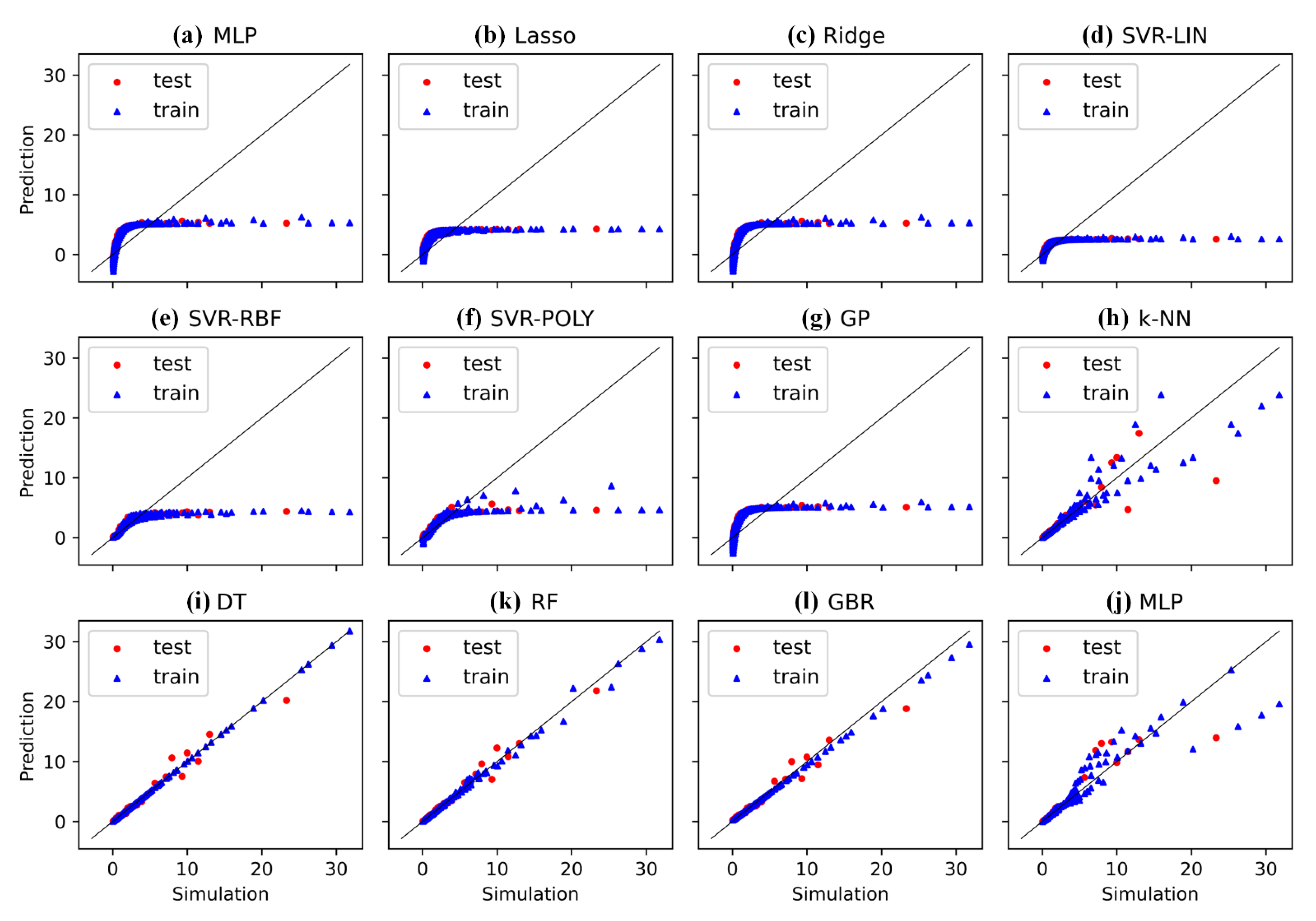{kind=link}
{kind=link}
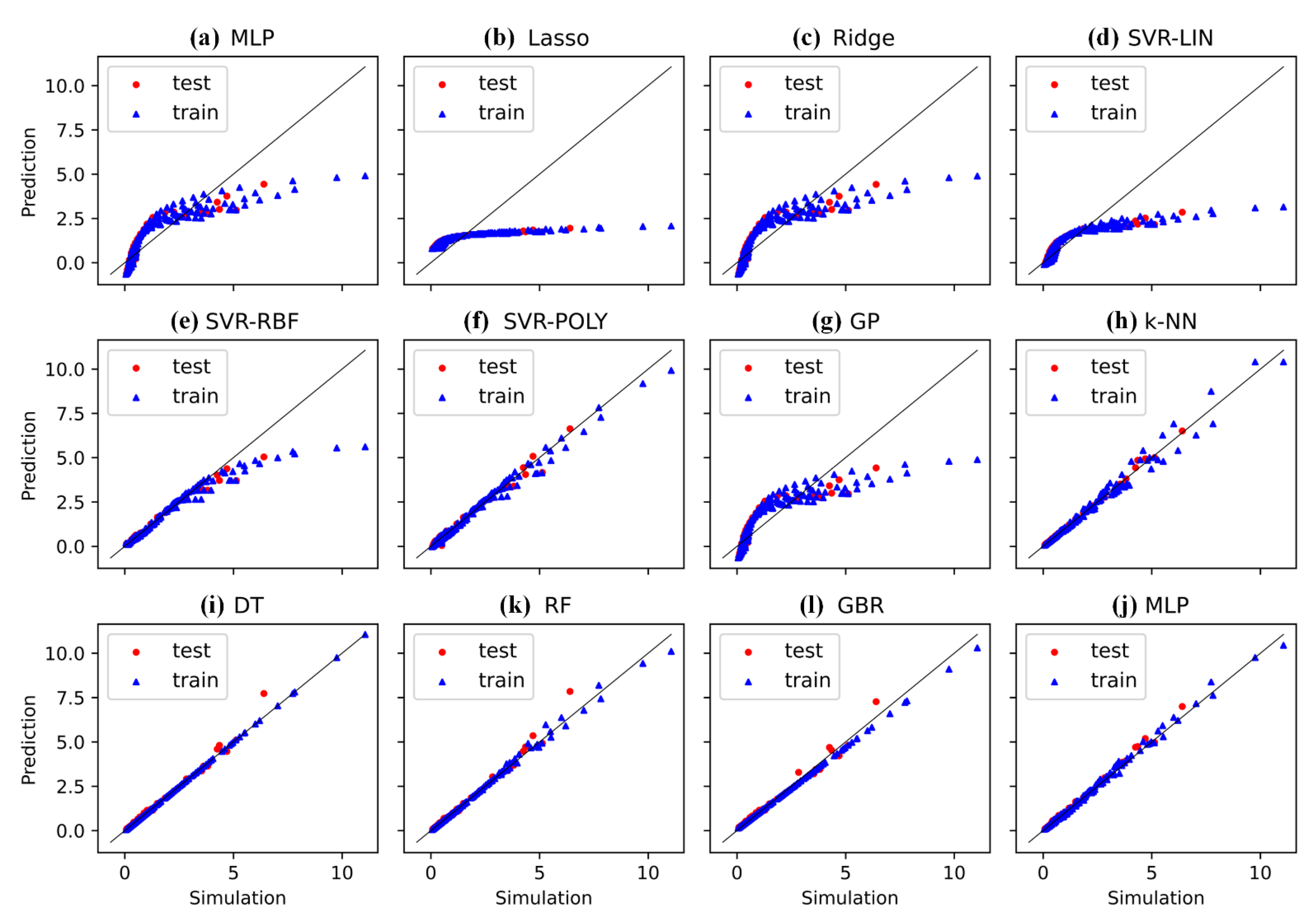{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Db | Dc | |||||
|---|---|---|---|---|---|---|
| R2 | MAE | MSE | R2 | MAE | MSE | |
| MLR | 0.371 | 1.936 | 9.767 | 0.882 | 0.418 | 0.593 |
| Lasso | 0.299 | 1.990 | 10.877 | 0.409 | 1.135 | 2.963 |
| Ridge | 0.371 | 1.934 | 9.768 | 0.878 | 0.433 | 0.610 |
| SVR-LIN | 0.204 | 1.465 | 12.358 | 0.864 | 0.472 | 0.682 |
| SVR-RBF | 0.410 | 1.037 | 9.155 | 0.587 | 0.874 | 2.070 |
| SVR-POLY | 0.450 | 1.060 | 8.530 | 0.962 | 0.246 | 0.191 |
| GP | 0.369 | 1.903 | 9.801 | 0.881 | 0.422 | 0.597 |
| k-NN | 0.716 | 0.587 | 4.405 | 0.916 | 0.260 | 0.421 |
| DT | 0.971 | 0.284 | 0.446 | 0.564 | 0.766 | 2.185 |
| RF | 0.982 | 0.203 | 0.281 | 0.708 | 0.589 | 1.462 |
| GB | 0.962 | 0.385 | 0.595 | 0.913 | 0.331 | 0.435 |
| MLP | 0.878 | 0.395 | 1.901 | 0.943 | 0.284 | 0.287 |
| R2 | MAE | MSE | R2 | MAE | MSE | |
|---|---|---|---|---|---|---|
| MLR | 0.697 | 0.661 | 0.578 | 0.111 | 0.236 | 0.075 |
| Lasso | 0.327 | 0.849 | 1.285 | −0.368 | 0.283 | 0.116 |
| Ridge | 0.698 | 0.659 | 0.577 | 0.126 | 0.233 | 0.074 |
| SVR-LIN | 0.626 | 0.505 | 0.714 | 0.013 | 0.250 | 0.083 |
| SVR-RBF | 0.958 | 0.132 | 0.080 | 0.067 | 0.164 | 0.079 |
| SVR-POLY | 0.983 | 0.115 | 0.032 | −0.726 | 0.278 | 0.146 |
| GP | 0.698 | 0.660 | 0.577 | 0.114 | 0.236 | 0.075 |
| k-NN | 0.997 | 0.031 | 0.006 | −0.022 | 0.166 | 0.086 |
| DT | 0.973 | 0.080 | 0.052 | 0.730 | 0.072 | 0.023 |
| RF | 0.978 | 0.067 | 0.042 | 0.831 | 0.079 | 0.014 |
| GB | 0.984 | 0.109 | 0.031 | 0.859 | 0.061 | 0.012 |
| MLP | 0.996 | 0.051 | 0.008 | 0.296 | 0.159 | 0.059 |
| R2 | MAE | MSE | R2 | MAE | MSE | |
|---|---|---|---|---|---|---|
| MLR | 0.489 | 1.617 | 3.466 | 0.327 | 0.150 | 0.032 |
| Lasso | −0.000 | 2.127 | 6.787 | −0.250 | 0.220 | 0.059 |
| Ridge | 0.483 | 1.632 | 3.509 | 0.337 | 0.149 | 0.031 |
| SVR-LIN | 0.348 | 1.629 | 4.424 | 0.249 | 0.157 | 0.035 |
| SVR-RBF | 0.640 | 0.700 | 2.442 | 0.808 | 0.088 | 0.009 |
| SVR-POLY | 0.735 | 0.639 | 1.798 | 0.621 | 0.114 | 0.018 |
| GP | 0.450 | 1.700 | 3.734 | 0.328 | 0.150 | 0.032 |
| k-NN | 0.649 | 0.517 | 2.379 | 0.802 | 0.051 | 0.009 |
| DT | 0.960 | 0.332 | 0.271 | 0.996 | 0.004 | 0.000 |
| RF | 0.980 | 0.182 | 0.135 | 0.960 | 0.024 | 0.002 |
| GB | 0.949 | 0.404 | 0.347 | 0.994 | 0.015 | 0.000 |
| MLP | 0.988 | 0.208 | 0.083 | 0.741 | 0.090 | 0.012 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sofos, F.; Stavrogiannis, C.; Exarchou-Kouveli, K.K.; Akabua, D.; Charilas, G.; Karakasidis, T.E. Current Trends in Fluid Research in the Era of Artificial Intelligence: A Review. Fluids 2022, 7, 116. https://doi.org/10.3390/fluids7030116
Sofos F, Stavrogiannis C, Exarchou-Kouveli KK, Akabua D, Charilas G, Karakasidis TE. Current Trends in Fluid Research in the Era of Artificial Intelligence: A Review. Fluids. 2022; 7(3):116. https://doi.org/10.3390/fluids7030116
Chicago/Turabian StyleSofos, Filippos, Christos Stavrogiannis, Kalliopi K. Exarchou-Kouveli, Daniel Akabua, George Charilas, and Theodoros E. Karakasidis. 2022. "Current Trends in Fluid Research in the Era of Artificial Intelligence: A Review" Fluids 7, no. 3: 116. https://doi.org/10.3390/fluids7030116