1. Introduction
Jumping spiders are known for their impressive hunting behavior, in which they jump accurately to catch their prey. Recently, it has been shown that jumping spiders, more precisely
Hasarius adansoni, estimate the distances to their prey based on monocular defocus cues in their anterior median eyes [
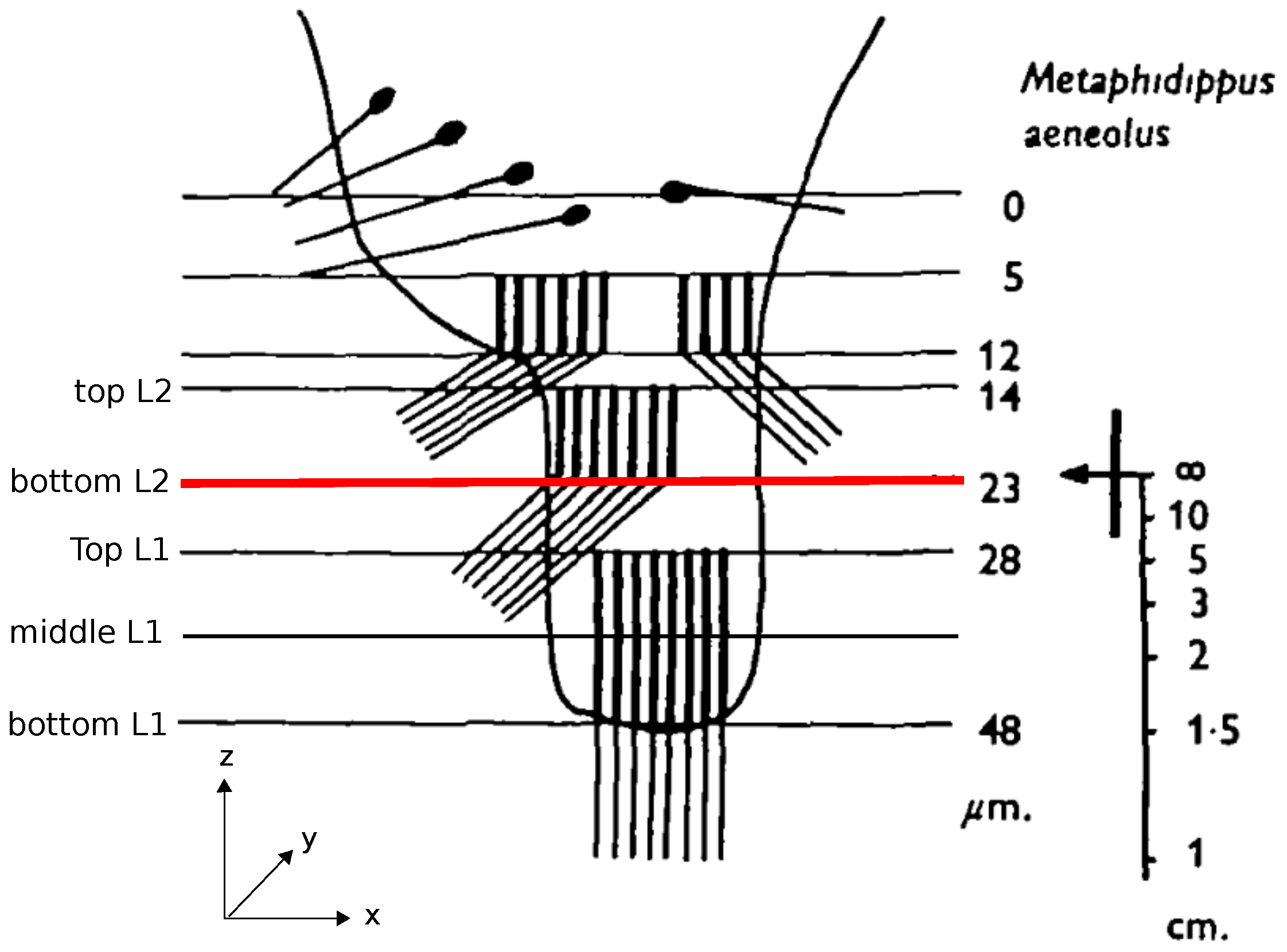
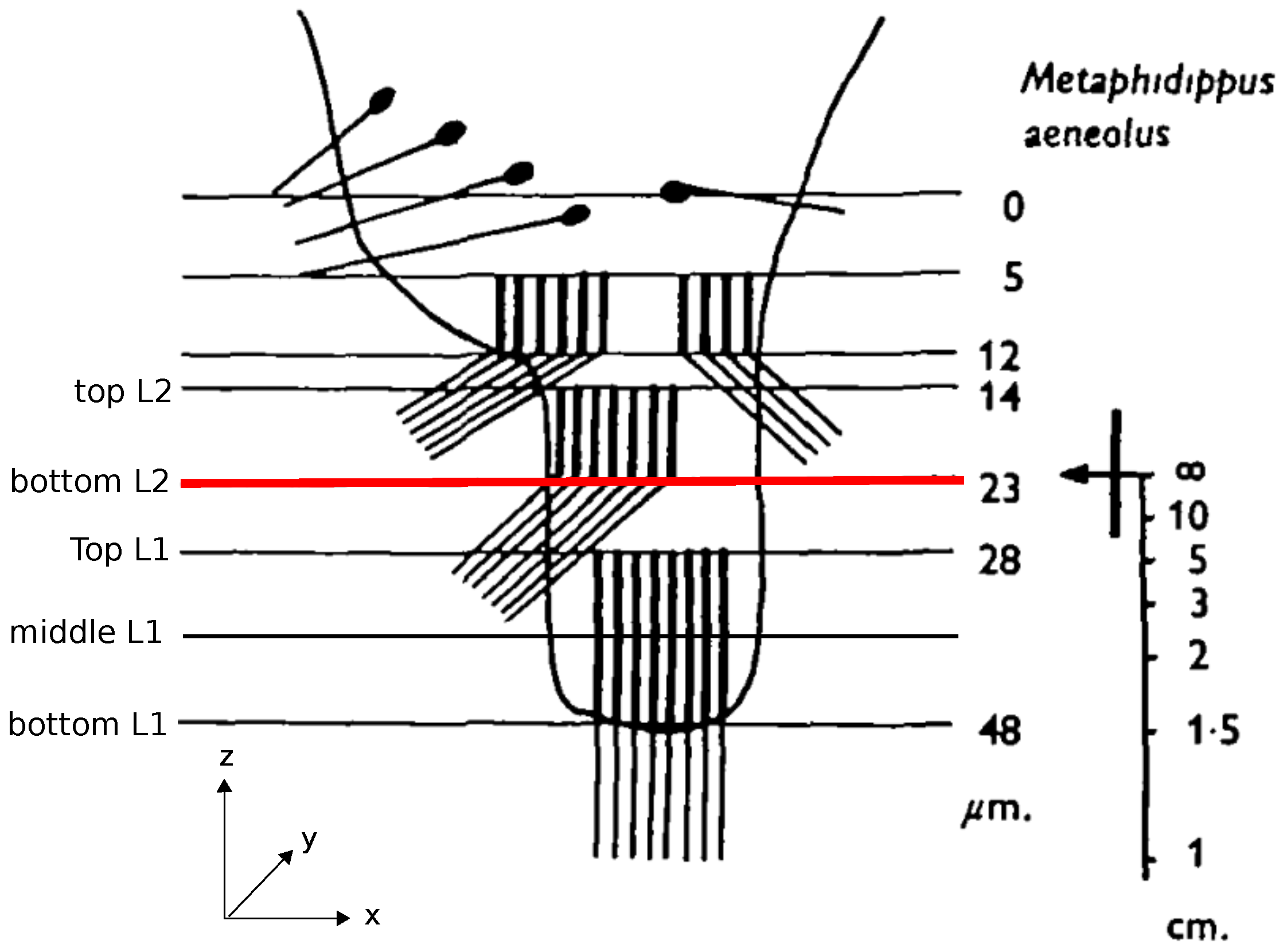
1]. The retinae of these eyes have a peculiar structure consisting of photoreceptors distributed over four vertically stacked layers (
Figure 1). Analyzing the optics of the eye and the spectral sensitivities of the photoreceptors, Nagata et al. [
1] and Land [
2] showed that only the bottom two layers, L1 and L2, are relevant for depth estimation (
Figure 1). When an object is projected onto these two layers of the retina, the projected images differ in the amount to which they are in or out of focus due to the spatial separation of the layers. For example, if the image projected on the deepest layer (L1) is in focus, the projection on the adjacent layer (L2) must be blurry. Because of the achromatic aberrations of the spider’s lens, the light of different wavelengths has different focal lengths so that the same amount of blur on e.g., L2, could be caused by an object at distance
d viewed in red light or the same object at a closer distance
viewed in green light (cf. Figure 3 in [
1]). In the spider’s natural environment, green light is more prevalent than red light and also the receptors in L1 and L2 are most sensitive to green light, therefore considerably less responsive to red light. In an experiment where all but one of the anterior median eyes were occluded, Nagata et al. could show that the spiders significantly underestimated the distance to their prey in red light, consistently jumping too short a distance, while performing the task with high accuracy under green light [
1]. This means, that, in the red light condition, the spider must have assumed the prey to be located at the closer distance
, which would have been the correct estimation based on the blur in the more natural green light scenario. Accordingly, this also means that the amount of defocus in the projections onto L1 and L2 must be the relevant cue from which jumping spiders deduce distances. However, the underlying mechanism and neuronal realizations of how these defocus cues are transferred to depth estimates remain unknown. In computer vision (CV), however, this method of estimating distances from defocused images of a scene is well known under the term depth-from-defocus (DFD). The main idea of computer vision depth-from-defocus (CV-DFD) algorithms is to estimate the blur levels in a scene and then to use known camera parameters or properties of the scene to recover depth information. The first basic algorithms were proposed in the late 1980s and have been subsequently expanded upon in various ways, mainly for creating accurate depth maps of whole scenes [
3,
4,
5].
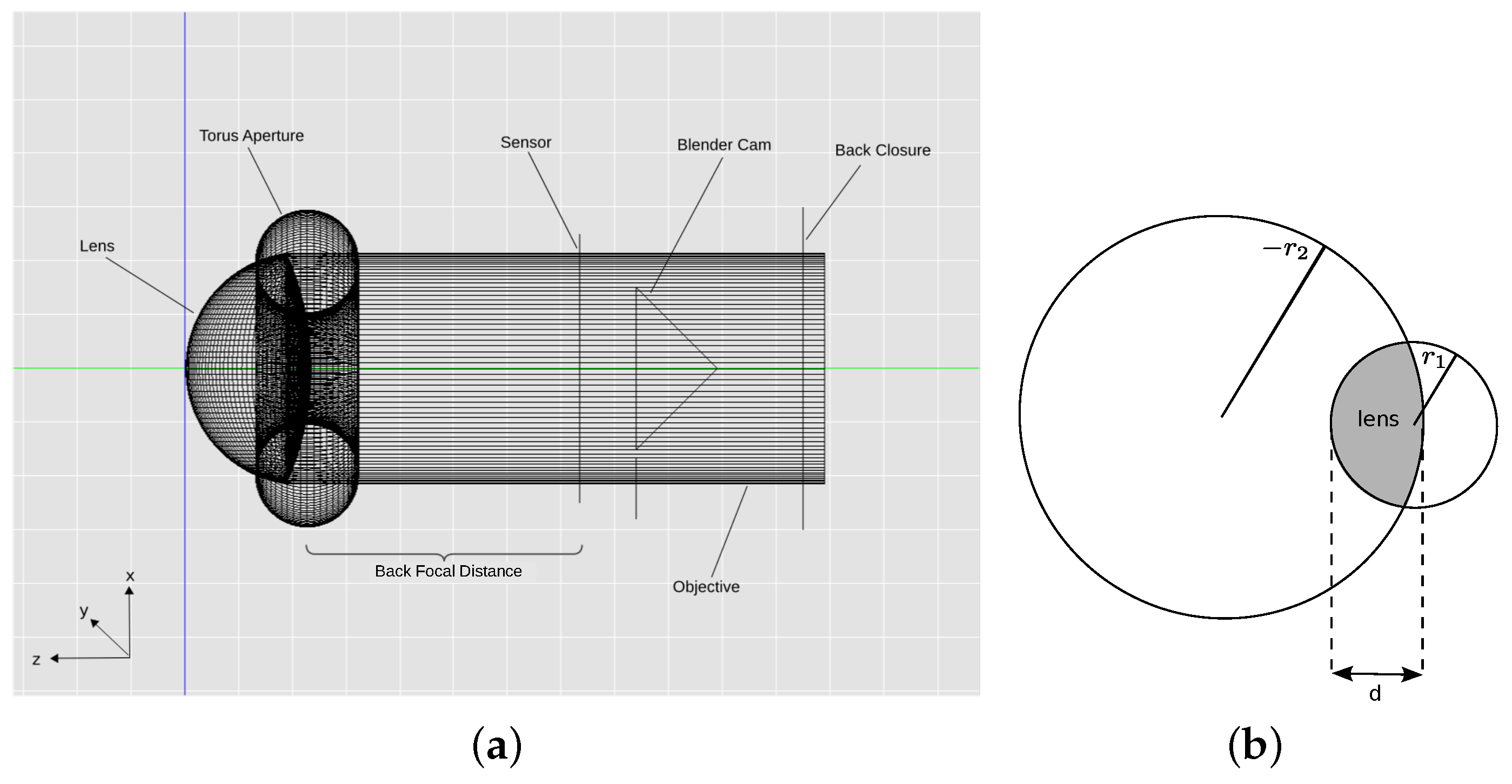
In contrast to the spider eye which has a thick lens, CV-DFD is concerned with thin lenses or corrected lens systems. Projections through thick lenses show varying amounts of blur due to the lens’ spherical and achromatic aberration, while theoretical thin lenses or corrected lens systems result in less complex blur profiles. Therefore, some interesting questions arise: either the spider’s depth estimation mechanism is functionally different to the mechanisms underlying CV-DFD algorithms, or the CV-DFD algorithms are also applicable for the spider’s thick lens setup. In the former case, investigating the spider eye might result in findings which might inspire new algorithms which are also applicable for thick lenses.
For distance estimation in practice, a thick lens DFD is a promising technique. Particularly from a hardware perspective, a DFD sensor mimicking the spider eye setup by using only a single uncorrected lens and two photo sensors would be cheaper and more robust than the expensive and fragile corrected lens systems commonly used for DFD. In addition, when considering other widely used distance sensing equipment like laser detection and ranging systems (LADAR), sound navigation and ranging systems (SONAR) and stereo vision systems, (spider-inspired) DFD sensors seem worthy of advancing. Not requiring any mechanical or moving parts prone to malfunction, they would be much more robust and lower in maintenance. Due to the absence of moving parts and thus power-consuming actuators, energy would only be needed for the computational hardware resulting in a sensor that would be low in energy consumption. All of these properties would result in a sensor that would be cheap and, in turn, would allow for redundant employment or utilization as an assisting or fall-back option for other methods, making the sensor highly usable for unmanned aerial vehicles (UAVs), micro air vehicles (MAVs), and U-class spacecraft (CubeSats).
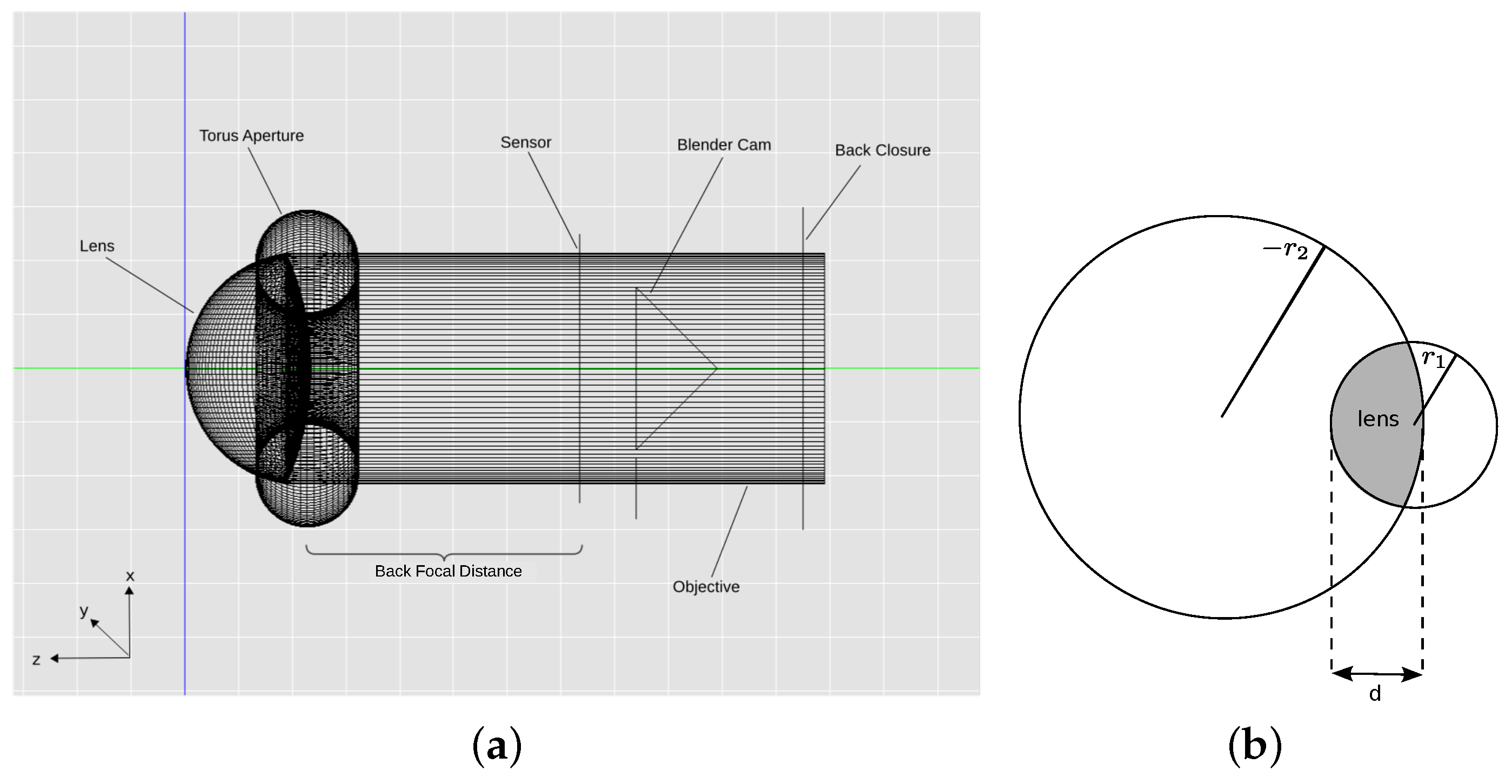
To investigate if we can learn from the spider for the creation of such a basic DFD sensor and to answer the question of whether CV-DFD algorithms are suitable for the spider’s thick lens setup, we created a computer model of the anterior median eye of the spider
Metaphidippus aeneolus, a species for which the relevant parameters of the anterior median eye are well described in the literature [
2]. For a structure as small and fragile as a spider eye, a computer model was preferred over an experimental approach, as experimental approaches have many more physical and experimental limitations rendering measurement of what the spider sees difficult, time-consuming and potentially inaccurate. In contrast, light tracing in optical systems is fully understood, meaning that results obtained from simulations are expected to be more accurate than measurements in an experimental setup. Using a generated computer model, we created a data set of images representing projections through the spider eye onto different locations on the retina and tested if a basic and well known CV-DFD algorithm [
3], Subbarao’s algorithm, can estimate distances correctly based on these images.
3. Results
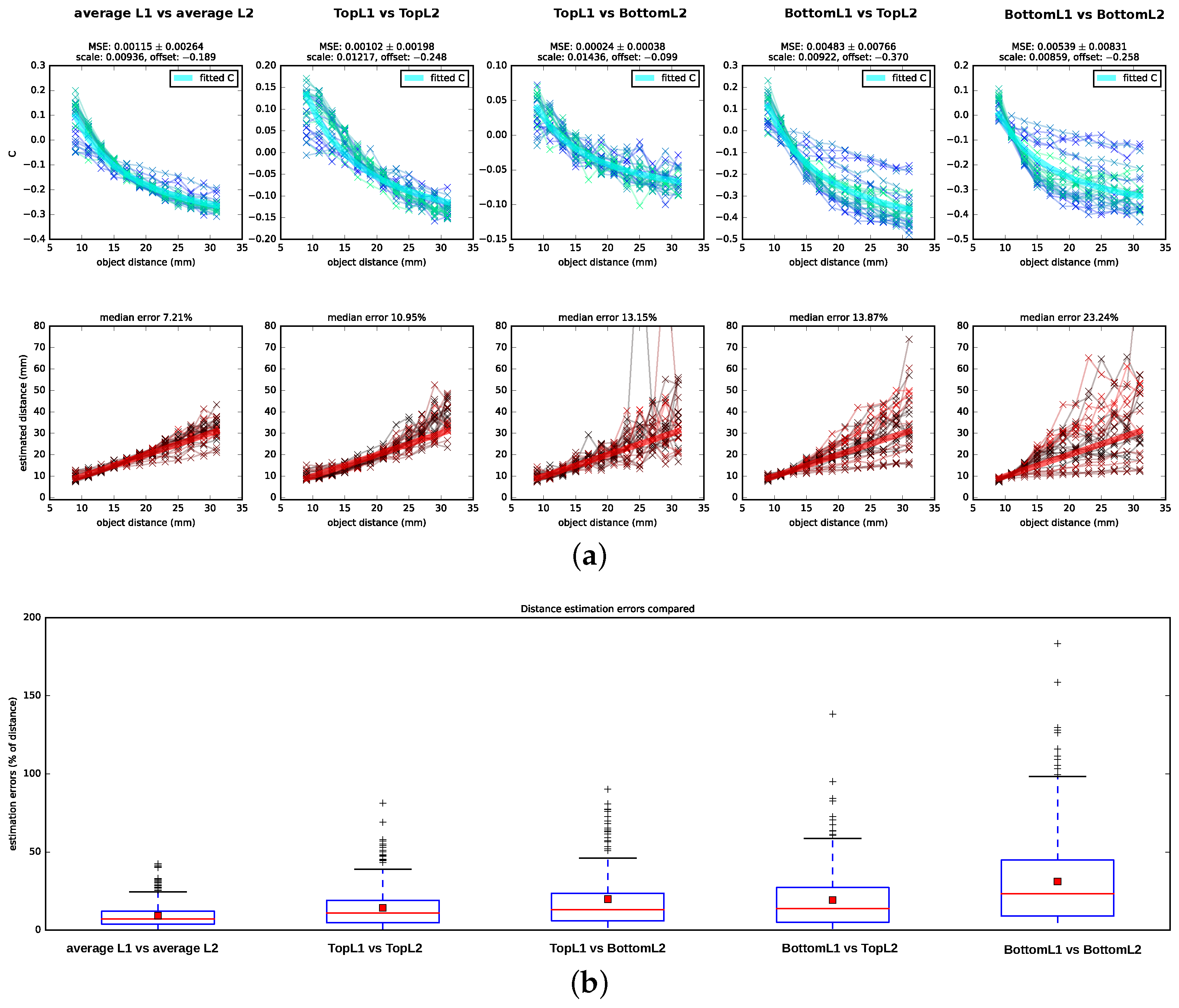
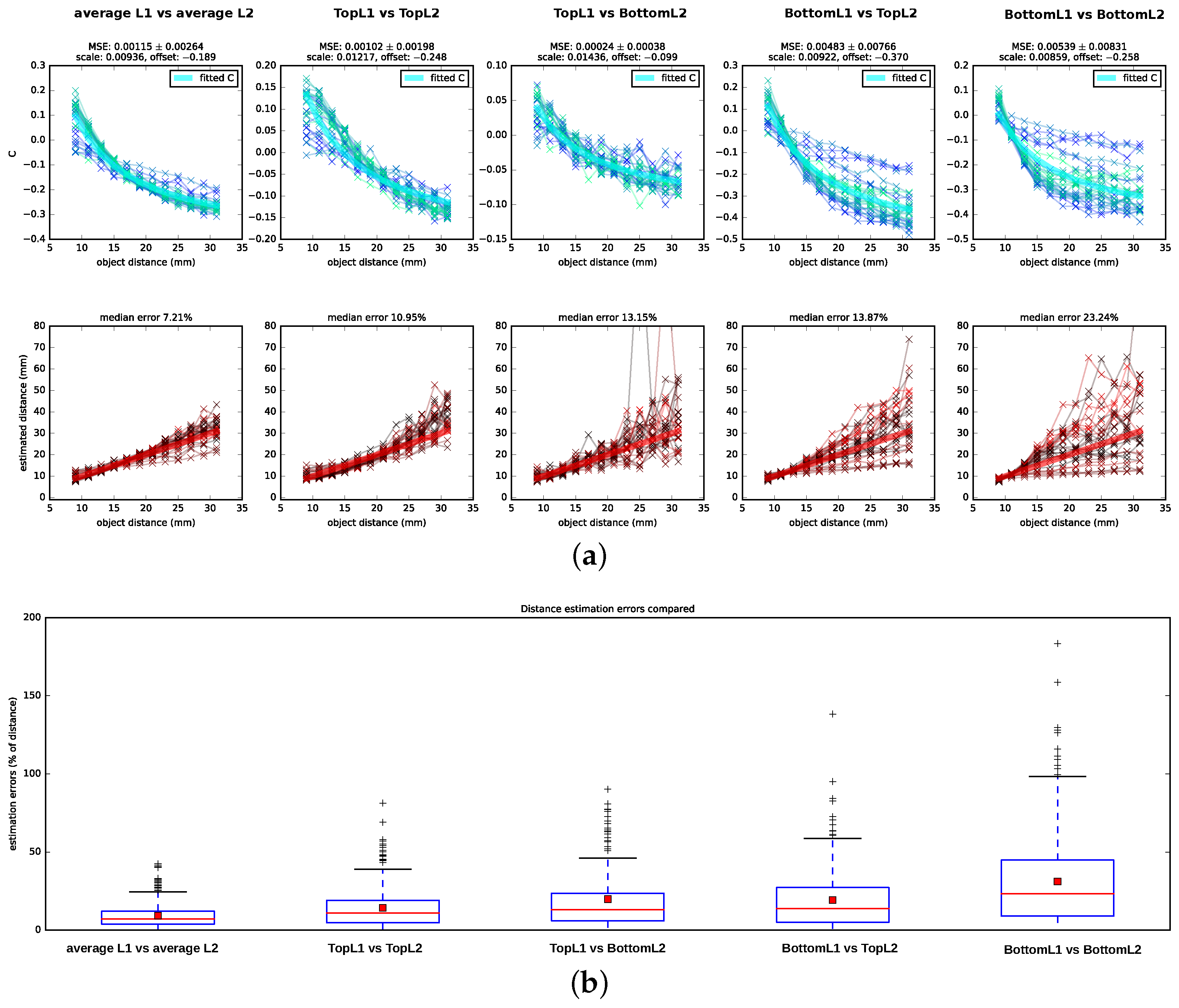
We tested Subbarao’s algorithm on the data set described in
Section 2.2 by testing five different hypotheses of which retina planes might be used for the depth estimation: a combination of planes located at different depths of L1 and L2—namely, TopL1 vs. TopL2, BottomL1 vs. BottomL2, TopL2 vs. BottomL1, and BottomL1 vs. TopL2, (cf.
Figure 1)—as well as an additional condition in which we averaged over all planes in a layer (TopL2 and BottomL2 vs. TopL1, MiddleL1 and BottomL1) and used the resulting average images as input for the algorithm (for details on image preprocessing refer to
Appendix C). We showed the computed
C-values (Equation (
11)), including scaled and shifted ground truth
C-values as determined by least square fitting (cf.
Section 2.3.2), as well as the distances that are determined from the
C-values and the camera parameters in
Figure 5 alongside the corresponding ground truth values. Following the DFD literature, we reported the estimation errors for the distances in percentage of the ground truth distance. We found that the algorithm performs best on the averaged images with a median distance error of
. In addition, when using image pairs that are projected onto the surface planes, TopL2 and TopL1, the distance recovery is acceptable but considerably worse with a median squared error of
. For the other layer combinations, the distance estimation is less consistent: the number of outliers and hereby also the variances increase, and, particularly for distances further from the lens, the estimated
C-values show a large amount of spread around the theoretical
C-values.
4. Discussion
Subbarao’s algorithm yields good distance estimates ( median error) on images that integrate the information available for each layer by averaging over the images formed on the top, (middle—only L1) and bottom receptor planes. For images formed on the surfaces of the receptor layers (TopL1 vs. TopL2), depths can still be estimated with a median error of . For all other combinations of input layers, the C-values show a spread that is too large around the ground truth C-curve, which results in incoherent distance estimates.
The good performance in the two reported cases is surprising, as Subbarao’s algorithm assumes an ideal thin lens. A thick lens like in the spider eye might introduce strong artifacts due to spherical aberrations, like e.g., a variation of the blur strength dependent on the location relative to the optical axis, which could mislead the algorithm. It seems likely that the image planes for which the algorithm fails are located at distances relative to the lens where these aberrations have a more severe impact for most object distances and that the top surfaces of L2 and L1 are located relative to the lens and to each other such that the impact of the overall aberrations is either low or canceled out. If incoming photons are more likely to be absorbed towards the distal part of the receptors, it would make sense that the surfaces of the layers are located optimally instead of the middle or bottom of these layers.
However, the distance estimation on the averaged images is considerably more accurate than when using the surfaces’ layers. This may indicate that the considerable depth of the receptor layers (10
m for L2 and 20
m for L1) plays an additional role in depth estimation. Indeed, the receptor layer thickness might have a stabilizing effect, enhancing the depth estimation. When considering the performance in
Figure 5 for TopL1 vs. TopL2 in more detail, the spread of the estimated
C-values is higher for distances closer to the lens and varies least for object distances at about 2 cm. However, for the BottomL1 vs. the BottomL2 case, it is vice versa: the estimated
C-values show a small spread for distances close to the lens and a very large spread for distances further away. Therefore, it may be possible that the thickness of the layers compensates in capturing the best suitable projection in both cases: towards the bottom of the layers for closer distances and towards the surfaces of the layers for intermediate and further distances.
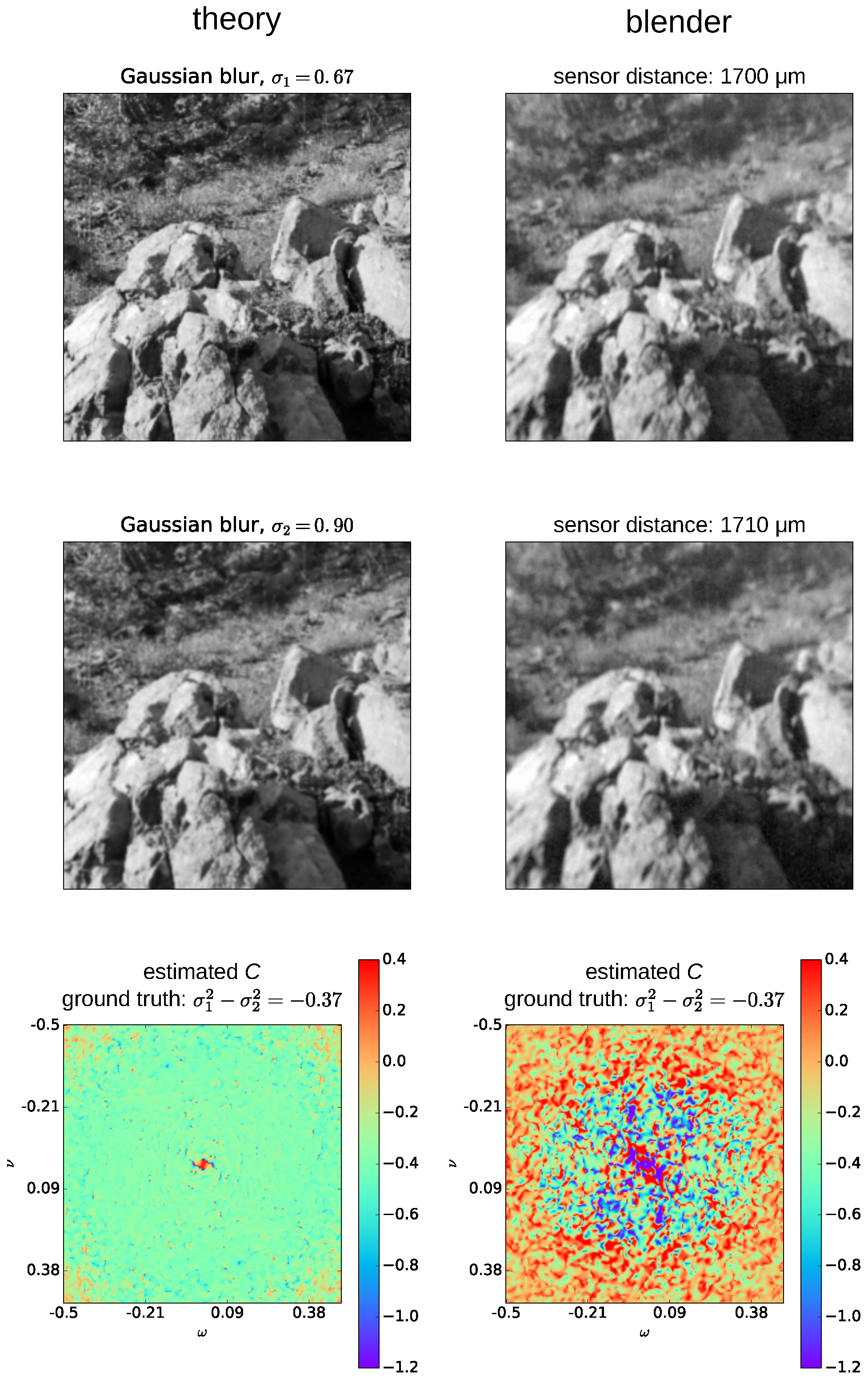
Taken together, the spider’s depth estimation capabilities can be reproduced to a large extent by the mechanism underlying Subbarao’s algorithm. However, the estimated distances are still not perfectly accurate. This is likely due to noise in the algorithm, most likely in the calculation of the
C-values, as the spectra are processed heuristically to discover the relevant values (shown in
Appendix D) or due to noise in the rendering process. An indication that either algorithm or rendering are responsible was also shown in earlier experiments that we conducted with a thin lens model (see
Appendix D), which resulted in a similar level of inaccuracy. Less likely, it may be that physiological parameters like lens shape and refractive indices may be used to construct the eye model are not completely accurate or that details in the physiology, like the exact spacing and layout of receptors, play additional functional roles. However, another possibility is that the spider’s performance could be even better explained by a more sophisticated DFD algorithm that is less sensitive to noise.


 and
and 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}