
A Rank Analysis and Ensemble Machine Learning Model for Load Forecasting in the Nodes of the Central Mongolian Power System

 ,
,  , ,
, ,
Abstract
:1. Introduction
- Regulatory methods (methods of “direct counting”) are based on the use of energy consumption standards for the main types of products and sectors of the economy. The use of regulatory methods presupposes the prediction of specific power consumption rates per unit of production [6]. From the point of view of the proposed model, the advantages of this method include the fact that it is quite simple and does not require any complex calculations.
- Technological methods take into account the policy of energy saving, efficient use of energy, justification of rational types of energy carriers, and modes of operation of electric receivers. The complexity of such accounting limits the scope of application of these methods by individual enterprises, while regulatory methods can be applied to relatively large territorial units (network nodes and energy districts). Difficulties in predicting specific indicators of electricity consumption constrain the use of both of the above methods [7].
- Methods of processing consumer applications, for example, for connecting additional loads, are effective for individual substations but are much less effective for energy districts [8]. In other words, the comparative effectiveness of this method decreases with the enlargement of the territorial division, that is, with the increase in the number of consumers.
- Forecasting methods based on mathematical models, including trend extrapolation methods (simple regression models) consist of establishing an analytical relationship between a certain modeled indicator (power consumption, load, balance indicators, etc.) and a set of parameters affecting it. The tasks of regression analysis are establishing the form of dependence, selecting a regression model, and evaluating model parameters. Note that there is no minimally necessary data set that is required to prepare a reliable model [9]. However, the above listed methods rely on data obtained from consumers or on some standards obtained empirically, while others are based on statistical data processing using various mathematical methods or their combinations. Regression models and time series models should be noted as the most successful.
- Economic–statistical and econometric methods have the main purpose of identifying future tendencies for predicting the load for the time period under consideration. The method studies and makes provisions for seasonal changes in energy consumption, the reduction of electricity consumption of large consumers due to the suspension of factories, equipment repairs, temperature factors, the shutdown of energy-intensive industries, and consumer withdrawal from the unified energy system due to high tariffs, as well as the reduction of electricity consumption by large enterprises, etc.
- -
- For the first time, a methodology was proposed to make load profile forecasts for the nodes of the EPS of Mongolia with hourly resolution. It can improve the accuracy of planning the EPS’s operation.
- -
- In contrast to existing studies on forecasting the power consumption of large energy systems, it was proposed to divide the power system into zones for predicting their power consumptions using rank analysis. This approach allows us to increase the forecasting accuracy for each zone, improve the quality of management, and create more favorable conditions for the development of distributed generation.
- -
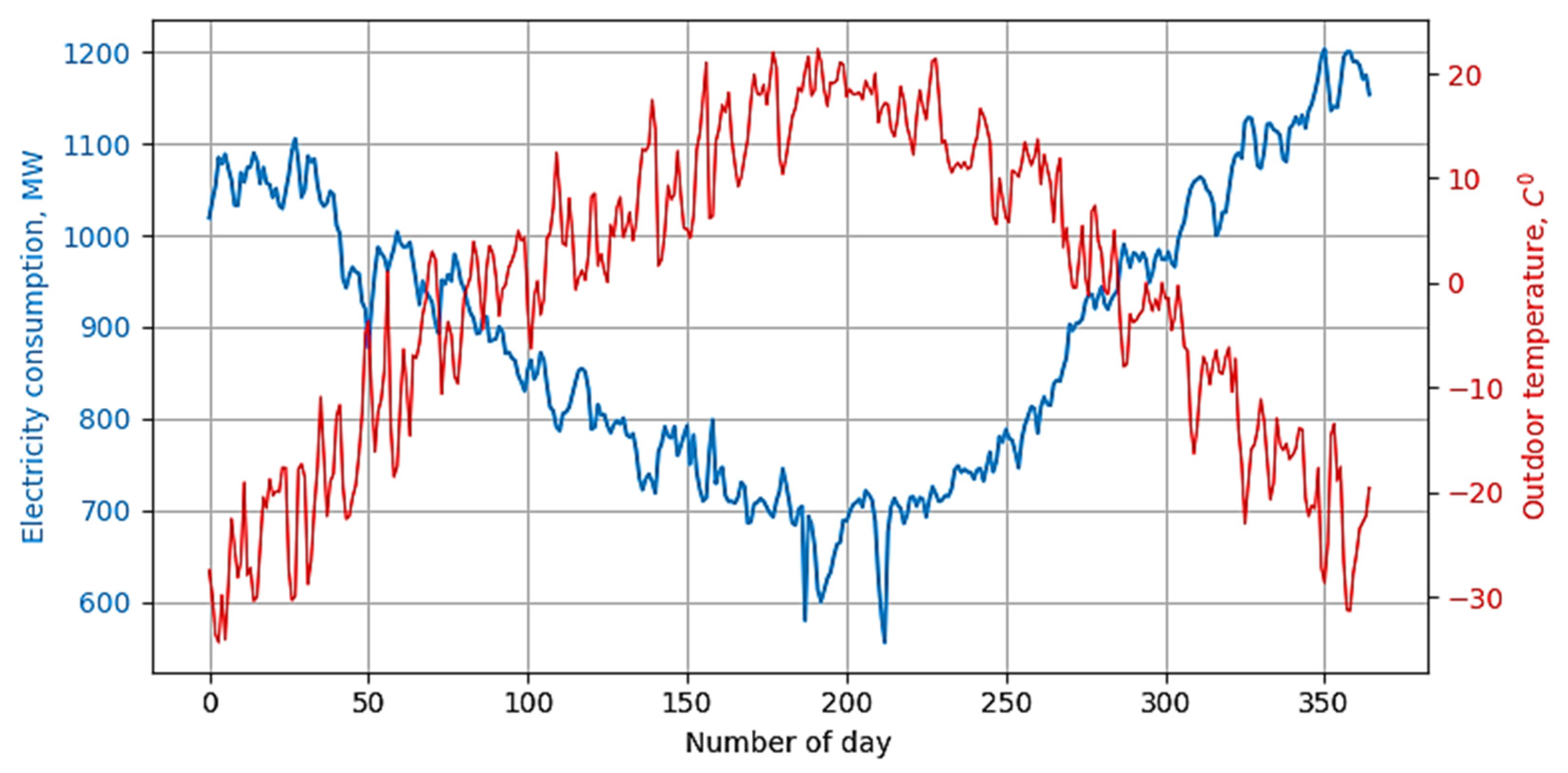
- It has been established that the accurate prediction of power consumption in Mongolia requires the use of temperature forecasting; other meteorological factors have little influence on consumption.
- -
- It has been discovered that despite the cyclic nature of power consumption, statistical methods, such as ARIMA, are inferior to machine learning algorithms that are able to take into consideration additional factors, such as the type of day (weekends, holidays) and temperature.
2. Research Methods
2.1. Autoregressive Integrated Moving Average (ARIMA) Model
2.2. Ensemble Models
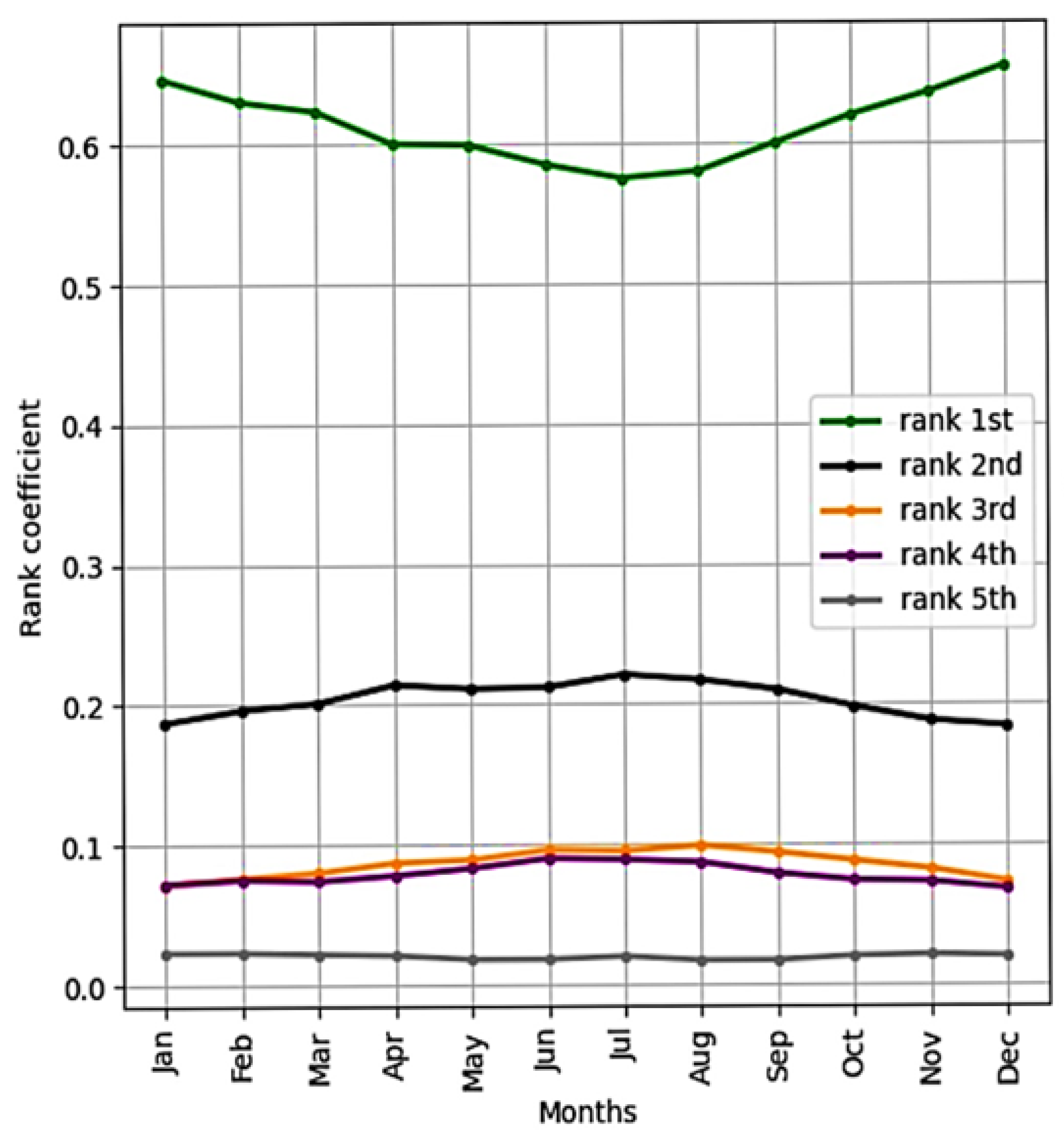
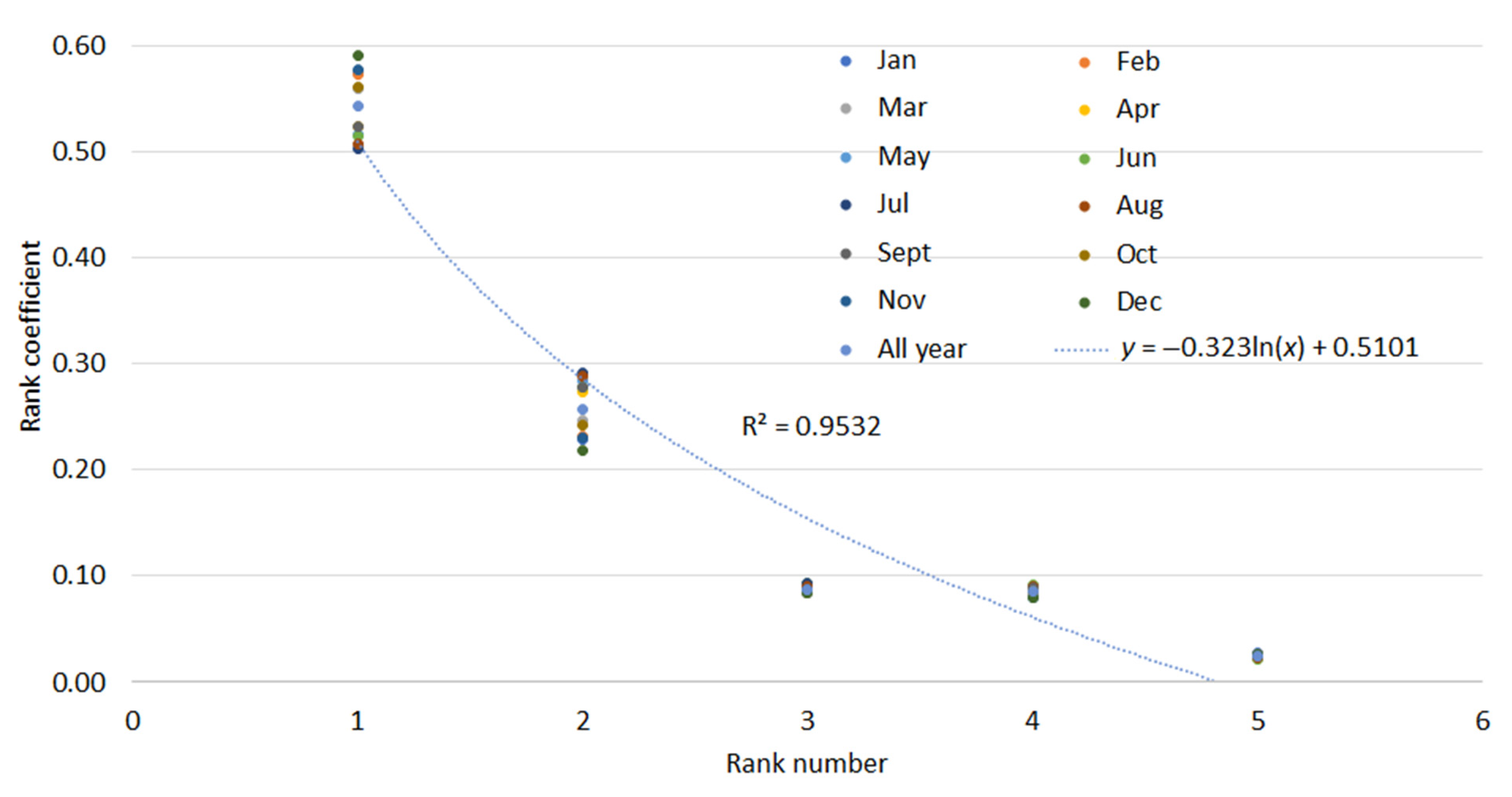
2.3. Rank Models
3. Results
3.1. The Result of the Autoregressive Integrated Moving Average Model
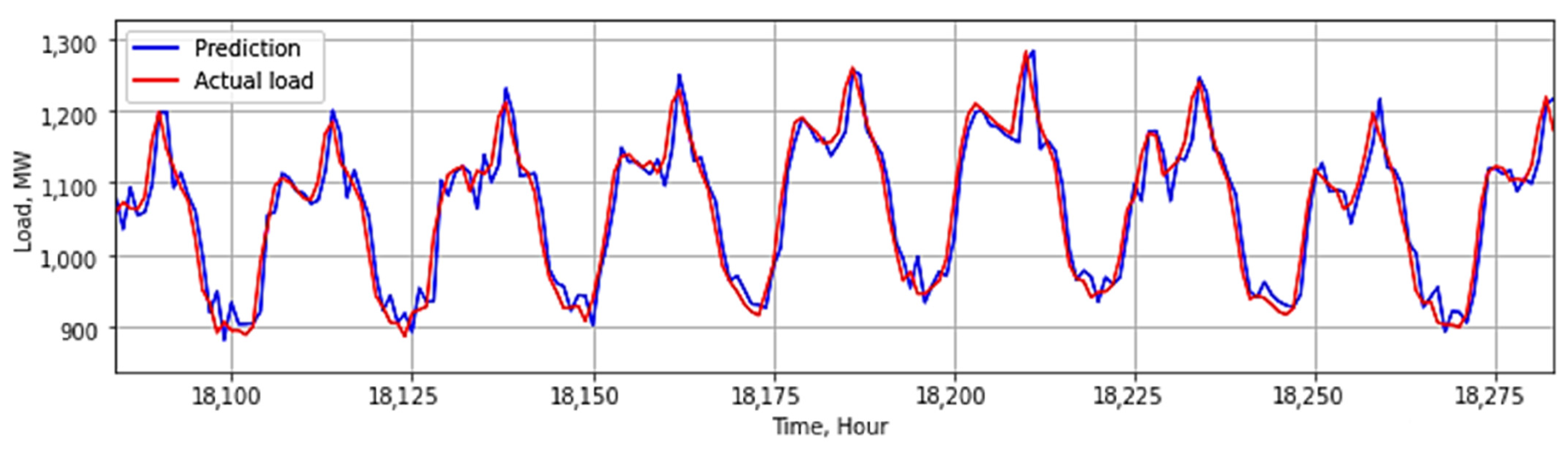
3.2. The Result of Ensemble Models
3.3. Consumption Forecasting in the Nodes of the Energy System
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kychkin, A.V.; Chasparis, G.C. Feature and model selection for day-ahead electricity-load forecasting in residential buildings. Energy Build. 2021, 249, 111200. [Google Scholar] [CrossRef]
- Alfares, H.K.; Nazeeruddin, M. Electric load forecasting: Literature survey and classification of methods. Int. J. Syst. Sci. 2002, 33, 23–34. [Google Scholar] [CrossRef]
- Ghalehkhondabi, I.; Ardjmand, E.; Weckman, G.R.; Young, W.A. An overview of energy demand forecasting methods published in 2005–2015. Energy Syst. 2017, 2, 411–447. [Google Scholar] [CrossRef]
- Abdurahmanov, A.; Volodin, M.; Zybin, E.; Ryabchenko, V. Forecasting methods in electricity distribution networks (review). Russ. Internet J. Electr. Eng. 2016, 3, 3–23. [Google Scholar] [CrossRef]
- Patel, H.; Shah, M. Energy Consumption and Price Forecasting Through Data-Driven Analysis Methods: A Review. SN Comput. Sci. 2021, 2, 315. [Google Scholar] [CrossRef]
- Makoklyuev, B.I. Analysis and Planning of Electricity Consumption; Energoatomizdat: Moscow, Russia, 2008. [Google Scholar]
- Matrenin, P.; Antonenkov, D.; Arestova, A. Energy Efficiency Improvement of Industrial Enterprise Based on Machine Learning Electricity Tariff Forecasting. In Proceedings of the 2021 15th International Scientific-Technical Conference on Actual Problems of Electronic Instrument Engineering, APEIE 2021, Novosibirsk, Russia, 19–21 November 2021. [Google Scholar] [CrossRef]
- Matrenin, P.V.; Manusov, V.Z.; Khalyasmaa, A.I.; Antonenkov, D.V.; Eroshenko, S.A.; Butusov, D.N. Improving Accuracy and Generalization Performance of Small-Size Recurrent Neural Networks Applied to Short-Term Load Forecasting. Mathematics 2020, 8, 2169. [Google Scholar] [CrossRef]
- Kamalov, F.; Smail, L.; Gurrib, I. Stock price forecast with deep learning. In Proceedings of the 2020 International Conference on Decision Aid Sciences and Application (DASA), Sakheer, Bahrain, 8–9 November 2020; pp. 1098–1102. [Google Scholar]
- Chen, Y.; Tang, Y.; Zhang, S.; Liu, G.; Liu, T. Weather Sensitive Residential Load Forecasting Using Neural Networks. In Proceedings of the 2023 IEEE 6th International Electrical and Energy Conference (CIEEC), Hefei, China, 12–14 May 2023. [Google Scholar] [CrossRef]
- Xu, F.; Xu, W.; Qiu, Y.; Wu, M.; Wang, R.; Li, Y.; Fan, P.; Yang, J. A Short-term Load Forecasting Model Based on Neural Network Considering Weather Features. In Proceedings of the 2021 IEEE 4th International Conference on Automation, Electronics and Electrical Engineering (AUTEEE), Shenyang, China, 19–21 November 2021. [Google Scholar] [CrossRef]
- Chodakowska, E.; Nazarko, J.; Nazarko, Ł. ARIMA Models in Electrical Load Forecasting and Their Robustness to Noise. Energies 2021, 14, 7952. [Google Scholar] [CrossRef]
- López, J.C.; Rider, M.J.; Wu, Q. Parsimonious Short-Term Load Forecasting for Optimal Operation Planning of Electrical Distribution Systems. IEEE Trans. Power Syst. 2019, 34, 1427–1437. [Google Scholar] [CrossRef]
- Sun, X.; Luh, P.B.; Cheung, K.W.; Guan, W.; Michel, L.D.; Venkata, S.S.; Miller, M.T. An efficient approach to short-term load forecasting at the distribution level. IEEE Trans. Power Syst. 2015, 31, 2526–2537. [Google Scholar] [CrossRef]
- Fernandes, K.C.; Sardinha, R.; Rebelo, S.; Singh, R. Electric load analysis and forecasting using artificial neural networks. In Proceedings of the 2019 3rd International Conference on Trends in Electronics and Informatics (ICOEI), Tirunelveli, India, 23–25 April 2019; pp. 1274–1278. [Google Scholar] [CrossRef]
- Alobaidi, M.H.; Chebana, F.; Meguid, M.A. Robust ensemble learning framework for day—Ahead forecasting of household based energy consumption. Appl. Energy 2018, 212, 997–1012. [Google Scholar] [CrossRef]
- Shi, J.; Wang, Z. A Hybrid Forecast Model for Household Electric Power by Fusing Landmark-Based Spectral Clustering and Deep Learning. Sustainability 2022, 14, 9255. [Google Scholar] [CrossRef]
- Huyghues-Beaufond, N.; Tindemans, S.; Falugi, P.; Sun, M.; Strbac, G. Robust and automatic data cleansing method for short-term load forecasting of distribution feeders. Appl. Energy 2020, 261, 114405. [Google Scholar] [CrossRef]
- Hayes, B.P.; Gruber, J.K.; Prodanovic, M. Multi-nodal short-term energy forecasting using smart meter data. IET Gener. Transm. Distrib. 2018, 12, 2988–2994. [Google Scholar] [CrossRef]
- Tan, M.; Hu, C.; Chen, J.; Wang, L.; Li, Z. Multi-node load forecasting based on multi-task learning with modal feature extraction. Eng. Appl. Artif. Intell. 2022, 112, 104856. [Google Scholar] [CrossRef]
- Tan, M.; Liu, Y.; Meng, B.; Su, Y. Multinodal forecasting of industrial power load using participation factor and ensemble learning. In Proceedings of the 2020 IEEE 4th Conference on Energy Internet and Energy System Integration (EI2), Wuhan, China, 30 October–1 November 2020; pp. 745–750. [Google Scholar] [CrossRef]
- Abreu, T.; Amorim, A.J.; Santos-Junior, C.R.; Lotufo, A.D.; Minussi, C.R. Multinodal load forecasting for distribution systems using a fuzzy-artmap neural network. Appl. Soft Comput. 2018, 71, 307–316. [Google Scholar] [CrossRef]
- Rai, S.; De, M. Effect of Load Contribution Factor on Multinodal Load Forecasting. In Proceedings of the IEEE EUROCON 2021—19th International Conference on Smart Technologies, Lviv, Ukraine, 6–8 July 2021; pp. 455–459. [Google Scholar] [CrossRef]
- Amorim, A.J.; Abreu, T.A.; Tonelli-Neto, M.S.; Minussi, C.R. A new formulation of multinodal short-term load forecasting based on adaptive resonance theory with reverse training. Electr. Power Syst. Res. 2020, 179, 106096. [Google Scholar] [CrossRef]
- Ferreira, A.B.A.; Minussi, C.R.; Lotufo, A.D.P.; Lopes, M.L.M.; Chavarette, F.R.; Abreu, T.A. Multinodal load forecast using euclidean ARTMAP Neural network. In Proceedings of the 2019 IEEE PES Innovative Smart Grid Technologies Conference-Latin America (ISGT Latin America), Gramado, Brazil, 15–18 September 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Stephen, B.; Telford, R.; Galloway, S. Non-Gaussian residual based short term load forecast adjustment for distribution feeders. IEEE Access 2020, 8, 10731–10741. [Google Scholar] [CrossRef]
- Stephen, B.; Tang, X.; Harvey, P.R.; Galloway, S.; Jennett, K.I. Incorporating practice theory in sub-profile models for short term aggregated residential load forecasting. IEEE Trans. Smart Grid 2015, 8, 1591–1598. [Google Scholar] [CrossRef]
- Wang, J.; Zhu, W.; Zhang, W.; Sun, D. A trend fixed on firstly and seasonal adjustment model combined with the ε-SVR for short-term forecasting of electricity demand. Energy Policy 2009, 37, 4901–4909. [Google Scholar] [CrossRef]
- Çevik, H.H.; Çunkaş, M. Short-term load forecasting using fuzzy logic and ANFIS. Neural Comput. Appl. 2015, 26, 1355–1367. [Google Scholar] [CrossRef]
- Lahouar, A.; Slama, J.B.H. Day-ahead load forecast using random forest and expert input selection. Energy Convers. Manag. 2015, 103, 1040–1051. [Google Scholar] [CrossRef]
- Moon, J.; Kim, Y.; Son, M.; Hwang, E. Hybrid short-term load forecasting scheme using random forest and multilayer perceptron. Energies 2018, 11, 3283. [Google Scholar] [CrossRef]
- Lahouar, A.; Slama, J.B.H. Hour-ahead wind power forecast based on random forest. Renew. Energy 2017, 109, 529–541. [Google Scholar] [CrossRef]
- Barrows, C.; Bloom, A.; Ehlen, A.; Ikaheimo, J.; Jorgenson, J.; Krishnamurthy, D.; Lau, J.; McBennett, B.; O’Connell, M.; Preston, E. The IEEE reliability test system: A proposed 2019 update. IEEE Trans. Power Syst. 2019, 35, 119–127. [Google Scholar] [CrossRef]
- Saranchimeg, S.; Nair, N.K.C. A novel framework for integration analysis of large-scale photovoltaic plants into weak grids. Appl. Energy 2021, 282, 116141. [Google Scholar] [CrossRef]
- Rusina, A.G.; Sidorkin, Y.M.; Kalinin, A.E. Application of rank models for structural forecasting. In Proceedings of the 2016 11th International Forum on Strategic Technology (IFOST 2016), Novosibirsk, Russia, 1–3 June 2016; pp. 271–275. [Google Scholar] [CrossRef]
- Velasco, L.C.P.; Polestico, D.L.L.; Macasieb, G.P.O.; Reyes, M.B.V.; Vasquez, F.B., Jr. Load forecasting using autoregressive integrated moving average and artificial neural network. Int. J. Adv. Comput. Sci. Appl. 2018, 9, 23–29. [Google Scholar] [CrossRef]
- Kamalov, F. A note on time series differencing. Gulf J. Math. 2021, 10, 50–56. [Google Scholar] [CrossRef]
- Kamalov, F. A note on the autocovariance of p-series linear process. Gulf J. Math. 2020, 9, 40–45. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 4, 5–32. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. Available online: https://arxiv.org/abs/1603.02754 (accessed on 22 May 2023).
- Drucker, H. Improving Regressors Using Boosting Techniques. Available online: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.31.314&rep=rep1&type=pdf (accessed on 22 May 2023).
- Matrenin, P.V.; Osgonbaatar, T.; Sergeev, N.N. Overview of Renewable Energy Sources in Mongolia. In Proceedings of the 2022 IEEE International Multi-Conference on Engineering, Computer and Information Sciences (SIBIRCON), Yekaterinburg, Russia, 11–13 November 2022. [Google Scholar] [CrossRef]
- Bumtsend, U.; Safaraliev, M.; Ghulomzoda, A.; Ghoziev, B.; Ahyoev, J.; Ghulomabdolov, G. The Unbalanced Modes Analyze of Traction Loads Network. In Proceedings of the 2020 Ural Symposium on Biomedical Engineering, Radioelectronics and Information Technology (USBEREIT), Yekaterinburg, Russia, 14–15 May 2020; pp. 0456–0459. [Google Scholar] [CrossRef]
- Manusov, V.Z.; Bumtsend, U.; Demin, Y.V. Analysis of the power quality impact in power supply system of Urban railway passenger transportation—The city of Ulaanbaatar. IOP Conf. Ser. Earth Environ. Sci. 2018, 177, 012024. [Google Scholar]
- Vivas, E.; Allende-Cid, H.; Salas, R. A Systematic Review of Statistical and Machine Learning Methods for Electrical Power Forecasting with Reported MAPE Score. Entropy 2020, 22, 1412. [Google Scholar] [CrossRef]
- Rusina, A.G.; Tuvshin, O.; Matrenin, P.V. Forecasting the daily energy load schedule of working days using meteofactors for the central power system of Mongolia. Power Eng. Res. Equip. Technol. 2022, 24, 98–107. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
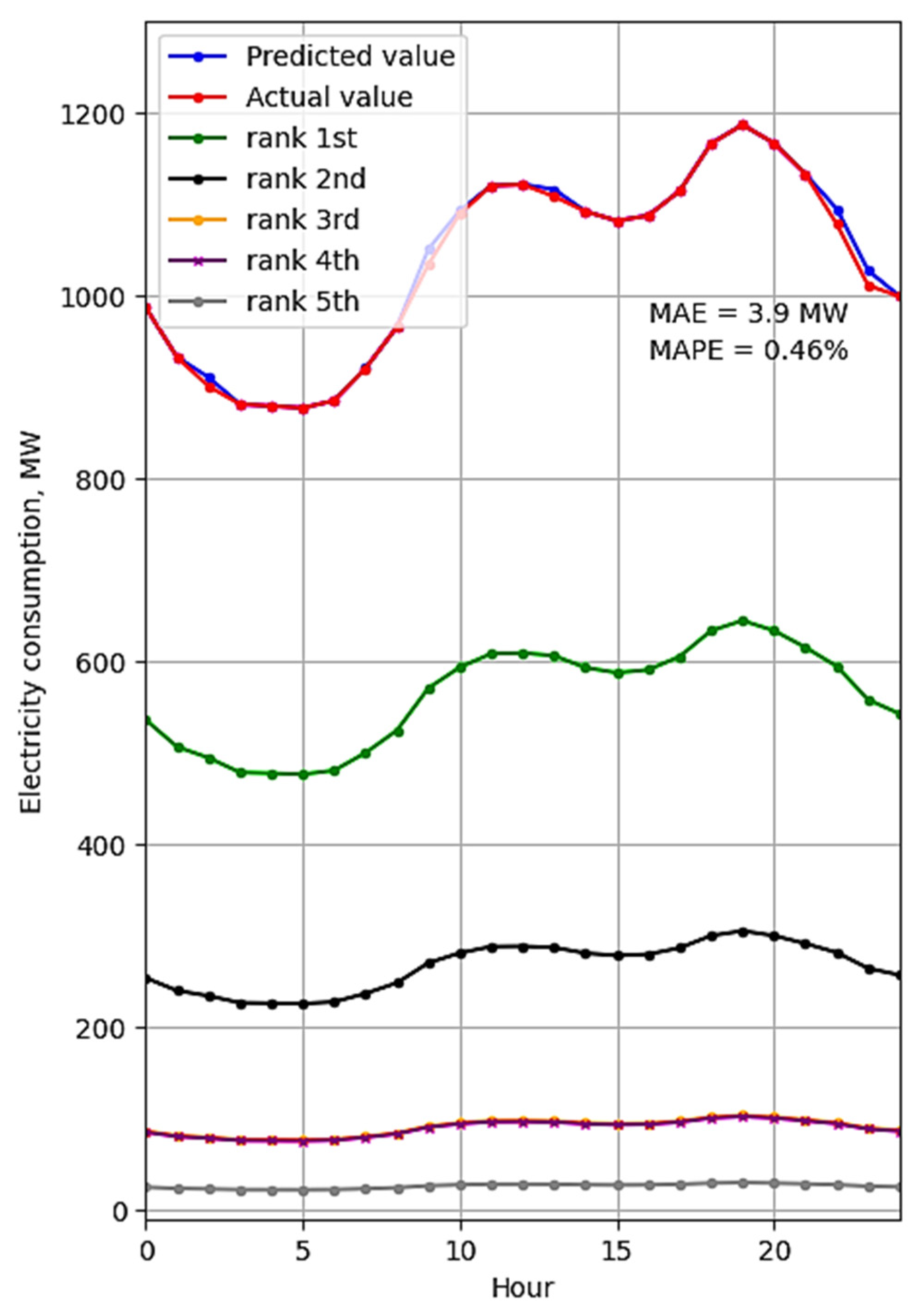{kind=link}
{kind=link}
| Year | Month | Day | Hour | Wd | Wh | Temp | Hum | Wind | Load-7 | Load-6 | … | Load-1 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2019 | 1 | 8 | 0 | 2 | 1 | −33 | 67 | 3 | 947 | 894 | … | 917 |
| 2019 | 1 | 8 | 1 | 3 | 1 | −31 | 68 | 5 | 888 | 838 | … | 850 |
| 2019 | 1 | 8 | 2 | 3 | 1 | −29 | 68 | 4 | 825 | 825 | … | 819 |
| 2019 | 1 | 8 | 3 | 3 | 1 | −33 | 67 | 4 | 795 | 811 | … | 813 |
| 2019 | 1 | 8 | 4 | 3 | 1 | −33 | 67 | 5 | 773 | 808 | … | 804 |
| Wd | Wh | Wind | Hum | Temp | Load-7 | Load-6 | Load-5 | Load-4 | Load-3 | Load-2 | Load-1 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| load | 0.004 | 0.05 | 0.15 | −0.03 | −0.59 | 0.96 | 0.96 | 0.96 | 0.97 | 0.97 | 0.97 | 0.98 |
| Random Forest | AdaBoost | XGBoost | |
|---|---|---|---|
| Depth of trees | 12 | 12 | 12 |
| Number of trees | 100 | 100 | 100 |
| MAPE [%] | 2.44 | 2.38 | 2.35 |
| Month | Naive | AR | ARIMA | Random Forest | AdaBoost | XG Boost | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MAE [MW] | MAPE [%] | MAE [MW] | MAPE [%] | MAE [MW] | MAPE [%] | MAE [MW] | MAPE [%] | MAE [MW] | MAPE [%] | MAE [MW] | MAPE [%] | |
| January | 20.90 | 1.97 | 26.11 | 2.45 | 19.90 | 1.90 | 10.24 | 0.92 | 10.82 | 1.04 | 5.84 | 0.55 |
| February | 26.54 | 2.70 | 23.12 | 2.21 | 33.70 | 3.05 | 16.67 | 1.63 | 13.73 | 1.33 | 11.38 | 1.11 |
| March | 20.53 | 2.23 | 31.29 | 3.26 | 25.86 | 2.64 | 25.04 | 2.66 | 11.70 | 1.23 | 9.38 | 0.97 |
| April | 20.22 | 2.45 | 26.42 | 3.17 | 20.06 | 2.22 | 9.80 | 1.32 | 10.45 | 1.26 | 8.75 | 1.02 |
| May | 22.76 | 2.98 | 29.51 | 3.98 | 28.26 | 3.88 | 16.62 | 2.26 | 11.08 | 1.47 | 9.43 | 1.26 |
| June | 27.04 | 3.67 | 11.68 | 1.69 | 28.25 | 4.06 | 7.69 | 1.17 | 12.65 | 1.80 | 12.03 | 1.70 |
| July | 30.19 | 5.54 | 11.73 | 1.78 | 19.91 | 3.05 | 11.20 | 1.66 | 8.64 | 1.31 | 6.89 | 1.06 |
| August | 22.69 | 3.21 | 33.18 | 4.52 | 15.06 | 2.08 | 8.87 | 1.21 | 19.36 | 2.64 | 9.25 | 1.24 |
| September | 24.09 | 2.98 | 23.78 | 3.03 | 17.21 | 2.14 | 8.91 | 1.08 | 16.64 | 2.17 | 15.54 | 2.09 |
| October | 19.64 | 2.07 | 43.28 | 4.61 | 21.81 | 2.46 | 11.93 | 1.27 | 18.39 | 1.93 | 17.48 | 1.79 |
| November | 22.51 | 2.14 | 21.76 | 2.18 | 18.61 | 1.93 | 14.31 | 1.37 | 15.52 | 1.58 | 14.83 | 1.48 |
| December | 20.29 | 1.78 | 30.53 | 2.83 | 17.39 | 1.66 | 9.20 | 0.87 | 10.69 | 0.96 | 8.33 | 0.76 |
| Result | 23.14 | 2.81 | 26.03 | 2.96 | 22.17 | 2.59 | 12.54 | 1.45 | 13.26 | 1.56 | 10.76 | 1.25 |
| Name of the Energy Supply Zone | Name of the Calculation | Rank Number | Percentage of the Total Power Load Participation Rate, % |
|---|---|---|---|
| Ulaanbaatar | ‘U’ | I | 54.34 |
| Erdenet-Bulgan | ‘H’ | II | 25.73 |
| Darkhan-Selenge | ‘T’ | III | 8.75 |
| Frog | ‘B’ | IV | 8.63 |
| Gobi | ‘G’ | V | 2.55 |
| Rank Number | Zone U | Zone H | Zone B | Zone T | Zone G | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| MAE [MW] | MAPE [%] | MAE [MW] | MAPE [%] | MAE [MW] | MAPE [%] | MAE [MW] | MAPE [%] | MAE [MW] | MAPE [%] | |
| January | 2.81 | 0.37 | 0.83 | 0.37 | 0.41 | 0.48 | 0.38 | 0.49 | 0.29 | 1.38 |
| February | 7.70 | 1.24 | 2.52 | 1.27 | 1.04 | 1.21 | 0.86 | 1.18 | 0.31 | 1.46 |
| March | 3.69 | 0.58 | 1.16 | 0.56 | 0.49 | 0.56 | 0.54 | 0.70 | 0.23 | 1.29 |
| April | 8.05 | 1.66 | 3.36 | 1.65 | 1.66 | 1.83 | 1.15 | 1.68 | 0.24 | 1.86 |
| May | 1.38 | 0.32 | 0.60 | 0.34 | 0.30 | 0.40 | 0.25 | 0.41 | 0.15 | 1.43 |
| June | 2.55 | 0.66 | 1.18 | 0.70 | 0.57 | 0.78 | 0.48 | 0.69 | 0.16 | 1.46 |
| July | 5.05 | 1.43 | 2.41 | 1.43 | 0.90 | 1.34 | 0.94 | 1.37 | 0.18 | 1.48 |
| August | 6.73 | 1.58 | 2.46 | 1.59 | 1.14 | 1.58 | 1.11 | 1.60 | 0.30 | 2.12 |
| September | 1.37 | 0.32 | 0.62 | 0.37 | 0.29 | 0.41 | 0.24 | 0.35 | 0.22 | 1.78 |
| October | 3.56 | 0.80 | 1.44 | 0.80 | 0.58 | 0.84 | 0.55 | 0.86 | 0.22 | 1.41 |
| November | 6.68 | 1.39 | 2.65 | 1.41 | 1.06 | 1.37 | 0.95 | 1.40 | 0.33 | 1.79 |
| December | 1.77 | 0.31 | 0.72 | 0.36 | 0.35 | 0.46 | 0.37 | 0.49 | 0.23 | 1.10 |
| Result | 4.2 | 0.88 | 1.66 | 0.90 | 0.73 | 0.93 | 0.65 | 0.93 | 0.23 | 1.54 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Osgonbaatar, T.; Matrenin, P.; Safaraliev, M.; Zicmane, I.; Rusina, A.; Kokin, S. A Rank Analysis and Ensemble Machine Learning Model for Load Forecasting in the Nodes of the Central Mongolian Power System. Inventions 2023, 8, 114. https://doi.org/10.3390/inventions8050114
Osgonbaatar T, Matrenin P, Safaraliev M, Zicmane I, Rusina A, Kokin S. A Rank Analysis and Ensemble Machine Learning Model for Load Forecasting in the Nodes of the Central Mongolian Power System. Inventions. 2023; 8(5):114. https://doi.org/10.3390/inventions8050114
Chicago/Turabian StyleOsgonbaatar, Tuvshin, Pavel Matrenin, Murodbek Safaraliev, Inga Zicmane, Anastasia Rusina, and Sergey Kokin. 2023. "A Rank Analysis and Ensemble Machine Learning Model for Load Forecasting in the Nodes of the Central Mongolian Power System" Inventions 8, no. 5: 114. https://doi.org/10.3390/inventions8050114