
A Comprehensive Survey of Transformers for Computer Vision



1
Department of Electronics Engineering, Sejong University, Seoul 05006, Republic of Korea
2
Department of Computer Engineering, Sejong University, Seoul 05006, Republic of Korea
*
Authors to whom correspondence should be addressed.
Drones 2023, 7(5), 287; https://doi.org/10.3390/drones7050287
Submission received: 24 March 2023
/
Revised: 19 April 2023
/
Accepted: 23 April 2023
/
Published: 25 April 2023
(This article belongs to the Special Issue Intelligent Image Processing and Sensing for Drones)
Abstract
:As a special type of transformer, vision transformers (ViTs) can be used for various computer vision (CV) applications. Convolutional neural networks (CNNs) have several potential problems that can be resolved with ViTs. For image coding tasks such as compression, super-resolution, segmentation, and denoising, different variants of ViTs are used. In our survey, we determined the many CV applications to which ViTs are applicable. CV applications reviewed included image classification, object detection, image segmentation, image compression, image super-resolution, image denoising, anomaly detection, and drone imagery. We reviewed the state of the-art and compiled a list of available models and discussed the pros and cons of each model.
1. Introduction
Vision transformers (ViTs) are designed for tasks related to vision, including image recognition [1]. Originally, transformers were used to process natural language (NLP). Bidirectional encoder representations from transformers (BERT) [2] and generative pretrained transformer 3 (GPT-3) [3] were the pioneers of transformer models for natural language processing. In contrast, classical image processing systems use convolutional neural networks (CNNs) for different computer vision (CV) tasks. The most common CNN models are AlexNet [4,5], ResNet [6], VGG [7], GoogleNet [8], Xception [9], Inception [10,11], DenseNet [12], and EfficientNet [13].
To track attention links between two input tokens, transformers are used. With an increasing number of tokens, the cost rises inexorably. The pixel is the most basic unit of measurement in photography, but calculating every pixel relationship in a normal image would be time-consuming; memory-intensive [14]. ViTs, however, take several steps to do this, as described below:
- ViTs divide the full image into a grid of small image patches.
- ViTs apply linear projection to embed each patch.
- Then, each embedded patch becomes a token, and the resulting sequence of embedded patches is passed to the transformer encoder (TE).
- Then, TE encodes the input patches, and the output is given to the multilayer perceptron (MLP) head, with the output of the MLP head being the input class.
Figure 1 shows the primary illustration of ViTs. In the beginning, the input image is divided into smaller patches. Each patch is then embedded using linear projection. Tokens are created from embedded patches that are given to the TE as inputs. Multihead attention and normalization are used by the TE to encode the information embedded in patches. The TE output is given to the MLP head, and the MLP head output is the input image class.
For image classification, the most popular architecture uses the TE to convert multiple input tokens. However, the transformer’s decoder can also be used for other purposes. As described in 2017, transformers have rapidly spread across NLP, becoming one of the most widely used and promising designs [15].
For CV tasks, ViTs were applied in 2020 [16]. The aim was to construct a sequence of patches that, once reconstructed into vectors, are interpreted as words by a standard transformer. Imagine that the attention mechanism of NLP transformers was designed to capture the relationships between different words within the text. In this case, the CV takes into account how the different patches of the image relate to one another.
In 2020, a pure transformer outperformed CNNs in image classification [16]. Later, a transformer backend was added to the conventional ResNet, drastically lowering costs while enhancing accuracy [17,18].
In the same year, several key ViT versions were released. These variants were more efficient, accurate, or applicable to specific regions. Swin transformers are the most prominent variants [19]. Using a multistage approach and altering the attention mechanism, the Swin transformer achieved cutting-edge performance on object detection datasets. There is also the TimeSformer, which was proposed for video comprehension issues and may capture spatial and temporal information through divided space–time attention [20].
ViT performance is influenced by decisions such as optimizers, dataset-specific hyperparameters, and network depth. Optimizing a CNN is significantly easier. Even when trained on data quantities that are not as large as those required by ViTs, CNNs perform admirably. Apparently, CNNs exhibit this distinct behavior because of some inductive biases that they can use to comprehend the particularities of images more rapidly, even if they end up restricting them, making it more difficult for them to recognize global connections. ViTs, on the other hand, are devoid of these biases, allowing them to capture a broader and more global set of relationships at the expense of more difficult data training [21].
ViTs are also more resistant to input visual distortions such as hostile patches and permutations [22]. Conversely, preferring one architecture over another may not be the best choice. The combination of convolutional layers with ViTs has been shown to yield excellent results in numerous CV tasks [23,24,25].
To train these models, alternate approaches were developed due to the massive amount of data required. It is feasible to train a neural network virtually autonomously, allowing it to infer the characteristics of a given issue without requiring a large dataset or precise labeling. It might be the ability to train ViTs without a massive vision dataset that makes this novel architecture so appealing.
ViTs have been employed in numerous CV jobs with outstanding and, in some cases, cutting-edge outcomes. The following are some of the important application areas:
- Image classification;
- Anomaly detection;
- Object detection;
- Image compression;
- Image segmentation;
- Video deepfake detection;
- Cluster analysis.
Figure 2 shows that the percentage of the application of ViTs for image classification, object detection, image segmentation, image compression, image super-resolution, image denoising, and anomaly detection is 50%, 40%, 3%, less than 1%, less than 1%, 2%, and 3% respectively.
ViTs have been widely utilized in CV tasks. ViTs can solve the problems faced by CNNs. Different variants of ViTs are used for image compression, super-resolution, denoising, and segmentation. With the advancement in the ViTs for CV applications, a state-of-the-art survey is needed to demonstrate the performance advantage of ViTs over current CV application approaches.
Our approach was to classify CV applications where ViTs are used, such as in image classification, object detection, image segmentation, image compression, image super-resolution, image denoising, and anomaly detection. Then we surveyed the state-of-the-art in each CV application and tabulated the existing ViT-based models, discussing the pros and cons of each model and lessons learned for each model. We also analyzed the advanced transformers and summarized open-source ViTs, briefly discussing drone imagery using ViTs.
The remainder of this paper is structured as follows: In Section 2, we discuss related work, while in Section 3, we present the application of ViTs in CV. In Section 4, we analyze advanced transformers. In Section 5, we summarize the open-source ViTs and their CV applications. In Section 6, we discuss ViT applications in drone imagery. In Section 7, we examine open research challenges and future directions. In Section 8, we conclude our survey with final thoughts on ViTs in place of CV applications and the results of our survey. A complete organization of the survey is shown in Figure 3.
2. Related Work
A number of surveys have been conducted on ViTs in the literature. The authors of [26] review the theoretical concepts, foundation, and applications of the transformer for memory efficiency. They also discussed the applications of efficient transformers in NLP. CV tasks, however, were not included. A similar study, ref. [27], examined the theoretical aspects of the ViTs, the foundations of transformers, the role of multihead attention in transformers, and the applications of transformers in image classification, segmentation, super-resolution, and object detection. The survey did not include applications of transformers for image denoising or compression.
In [28], the authors describe the architectures of transformers for segmenting, classifying, and detecting objects in images. Their survey did not include tasks such as image super-resolution, denoising, or compression associated with CV and image processing.
Lin et al. in [29] summarized different architectures of NLP. Their survey, however, did not include any applications of transformers for CV tasks. In [30], the authors discuss different architectures of transformers for computational visual media, including the application of transformers for low-level vision and generation, such as image colorization, image super-resolution, image generation, and text-to-image conversion. Additionally, the survey focused on high-level vision tasks such as segmentation and object detection. However, the survey did not discuss the transformer for image compression and classification.
Han et al. in [31] surveyed the application of transformers in high-, mid-, and low-level vision and video processing. They also provided a comprehensive discussion of self-attention and the role of transformers in real-device-based applications, and the survey did not discuss the transformer for image compression.
Table 1 summarizes all existing surveys on the ViTs. As a result of an analysis of Table 1, it is evident that the survey is needed to provide insight into the latest developments in ViTs for several image processing and CV tasks, including classification, detection, segmentation, compression, denoising, and super-resolution.
2.1. Bibliometric Analysis and Methodology
We used Google Scholar, Web of Science, IEEE Xplore, and ScienceDirect as the databases to select papers.
2.1.1. Bibliometric Analysis
We considered papers published between 2017 and 2023. In 2017, a total of 21 articles were published on transformers in CV, while 24 papers were published in 2018. A total of 44 papers were published in 2019. Additionally, in 2020, 2021, 2022, and 2023, a total of 52, 418, 494, and 8 papers were published, respectively. Figure 4 shows the number of publications per year from 2017 to 2023.
In terms of publishers, the Institute of Electrical and Electronics Engineers (IEEE) has published 527 publications on transformers in CV. Springer Nature, Multidisciplinary Digital Publishing Institute (MDPI), and Elsevier published 177, 104, and 82 papers, respectively. Assoc Computing Machinery (ACM) published the least number of publications on transformers in CV, which is 25. Figure 5 displays the number of publications by different publishers from 2017 to 2023.
In terms of topic popularity in different countries, we present a world map showing the top countries working on transformers in CV. From 2017 to 2023, China published 517 publications on transformers in CV. United States of America (USA), England, and South Korea published 242, 64, and 55 papers, respectively, from 2017 to 2023. Figure 6 shows which countries are leading in learning-driven image compression.
2.1.2. Methodology
Based on the following criteria as described in Algorithm 1 and Figure 7, 100 papers were selected for analysis:
| Algorithm 1 Article Selection Criteria |
| Require: Search on databases Ensure: Article from 2017 to 2023 while keyword—transformers in computer vision do if Discuss new architectures of ViTs | Evaluate performance of ViTs | Variants of ViTs then Consider for analysis else if Does not discuss ViTs architectures in vision then Exclude from the analysis end if end while |
3. Applications of ViTs in CV
In addition to classical ViTs, modified versions of classical ViTs are used for object detection, image segmentation, compression, super-resolution, denoising, and anomaly detection. Figure 8 shows the organization of Section 3.
3.1. ViTs for Image Classification
In image classification, the image is initially divided into patches; these patches are fed linearly to the transformer encoder, where MLP, normalization, and multihead attention are applied to create embedded patches. Embedded patches are fed to the MLP head, which predicts the output class. These classical ViTs have been used by many researchers to classify visual objects.
In [32], the authors proposed CrossViT-15, CrossViT-18, CrossViT-9†, CrossViT-15†, and CrossViT-18† for image classification. They used the ImageNet1K, CIFAR10, CIFAR100, pet, crop disease, and ChestXRay8 datasets to evaluate the different variants of CrossViT. They achieved 77.1% accuracy on the ImageNet1K dataset by using CrossViT-9†. Similarly, they attained 82.3% and 82.8% accuracy on ImageNet1K dataset using CrossViT-15† and CrossViT-18†, respectively. Similarly, the authors obtained an 99.0% and 99.11% accuracy with CrossViT-15 and CrossViT-18, respectively, on the CIFAR10 dataset. However, they obtained 90.77% and 91.36% accuracy on the CIFAR100 dataset using CrossViT-15 and CrossViT-18, respectively. The authors also used CrossViT for pet classification, crop disease classification, and chest X-ray classification. They observed the highest accuracy of 95.07% with CrossViT-18 for the pet classification. Similarly, they achieved the highest accuracy of 99.97% with CrossViT-15 and CrossViT-18 for the crop diseases classification. Moreover, they achieved the highest accuracy of 55.94% using CrossViT-18 for the chest X-ray classification.
Deng et al. in [33], proposed a combined CNN and ViT model named CTNet for the classification of high-resolution remote sensing images. To evaluate the model, they used the aerial image dataset (AID) and Northwestern Polytechnical University (NWPU)-RESISC45 dataset. CTNet obtained an accuracy of 97.70% and 95.49% using the AID and NWPU-RESISC45 datasets, respectively. Yu et al. in [34], presented multiple instance-enhanced ViT (MIL-ViT) for fundus image classification. They used APTOS 2019 blindness detection and the 2020 retinal fundus multidisease image dataset (RFMiD2020). MIL-ViT yielded an accuracy of 97.9% on the APTOS2019 dataset and 95.9% on the RFMiD2020 dataset. Similarly, Graham et al. in [35] proposed LeViT for fast inference image classification.
In [36], the authors proposed excellent teacher-guiding small networks (ES-GSNet) for the classification of the remote sensing image scenes. They used four datasets: AID, NWPU-RESISC45, UC-Mered Land use dataset (UCM), and OPTIMAL-31. They obtained accuracies of 96.88%, 94.50%, 99.29%, and 96.45% for the AID, NWPU-RESISC45, UCM, and OPTIMAL-31 datasets, respectively.
Xue et al. in [37] proposed deep hierarchical ViT (DHViT) for the hyperspectral and light detection and ranging (LiDAR) data classification. The authors used the Trento, Houston 2013, and Houston 2018 datasets and obtained accuracies of 99.58%, 99.55%, and 96.40%, respectively.
In [38], the authors elaborated on the use of ViT for the satellite imagery multilabel classification and proposed ForestViT. ForestViT demonstrated an accuracy of 94.28% on planet understanding of the Amazon from space (PUAS) dataset. In [39], the researchers put forward the concept of LeViT for pavement image classification. They used Chinese asphalt pavement and German asphalt pavement to evaluate the model’s performance. They obtained an accuracy of 91.56% using the Chinese asphalt pavement dataset and 99.17% using the German asphalt pavement dataset.
In [40], the authors used ViT to distinguish malicious drones from airplanes, birds, drones, and helicopters. They demonstrated the efficiency of ViT for the classification over several CNNs such as AlexNet [4], ResNet-50 [41], MobileNet-V2 [42], ShuffleNet [43], SqueezeNet [44], and EfficicentNetb0 [45]. The ViT model achieved 98.3% accuracy on the malicious drones dataset.
Tanzi et al. in [46] applied ViT for the classification of the femur fracture. They used a dataset of real X-rays. The model achieved an accuracy of 83% with 77% precision, 76% recall, and 77% F1-score. In [47], the authors modified the classical ViT and proposed SeedViT for the classification of maize seed quality. They used a custom dataset. The model outperformed CNN and achieved a 96.70% accuracy.
Similarly, in [48], the researchers put forward double output ViT (DOViT) for the classification of air quality and its measurement. They used two datasets named get AQI in one shot-1 (GAOs-1) and get AQI in one shot-2 (GAOs-2). The model achieved a 90.32% accuracy for the GAOs-1 dataset and 92.78% accuracy for the GAOs-2 dataset. In [49], the authors developed a novel multi-instance ViT called MITformer for remote sensing scene classification. They evaluated their model on three different datasets. The model achieved 99.83% accuracy for the UCM dataset, 97.96% accuracy for the AID dataset, and 95.93% accuracy for the NWPU dataset.
Table 2 shows the summary of the application of ViT for image classification.
Key Takeaways—Transformers in image classification show better performance than do CNNs and use an attention mechanism [50] instead of convolution. However, the major drawback of using transformers in image classification is the requirement of a huge dataset for training [51]. thus, ViT is the best choice for image classification in cases where a huge dataset is easily available.
3.2. ViTs for Object Detection
The effort to tame pretrained vanilla ViT for object detection has never stopped since the evolution of transformer [15] to CV [16]. Beal et al. [52] were the first to use a faster region-based convolutional neural network (R-CNN) detector with a supervised pretrained ViT for object detection. You only look at one sequence (YOLOS) [53] suggests simply using a pretrained ViT encoder to conduct object detection in a pure sequence-to-sequence manner. Li et al. [54] were the first to complete a large-scale study of vanilla ViT on object detection using sophisticated masked image modeling (MIM) pretrained representations [55,56], confirming vanilla ViT’s promising potential and capacity in object-level recognition.
In [57], the authors proposed the unsupervised learning-based technique using ViT for the detection of the manipulation in the satellite images. They used two different datasets for the evaluation of the framework. The ViT model with postprocessing (ViT-PP) achieved an F1-score of 0.354 and a Jaccord index (JI) of 0.275 for dataset 2. The F1-score and JI can be calculated by Equations (1) and (2) respectively.
where , , and denote true positive, false positive, and false negative, respectively.
In [58], the authors proposed a bridged transformer (BrT) for the 3D object detection. The model was applied for the vision and point cloud 3D object detection. They used the ScanNet-V2 [59] and SUN RGB-D [60] datasets to validate their model. The model demonstrated the mean average precision (mAP)@0.5 of 52.8 for the ScanNet-V2 dataset and 55.2 for the SUN RGB-D dataset.
Similarly, in [61], the authors proposed a transformer-based framework for the detection of 3D objects using point cloud data. They used the ScanNet-V2 [59] and SUN RGB-D [60] datasets to validate their model. The model demonstrated a mean average precision (mAP)@0.5 of 52.8 for the ScanNet-V2 dataset and 45.2 for the SUN RGB-D dataset.
Table 3 shows the application of ViT for object detection.
Key Takeaways—Transformers are used for object detection in three different ways: (a) Feature extraction with transformers and detection with R-CNN as in [62], (b) feature extraction with CNN and detection head based on transformers as in [63,64], and (c) a complete end-to-end pure transformer-based object detection as in [53]. The third method is more feasible and requires more effort to create more end-to-end object detection models using ViTs.
3.3. ViTs for Image Segmentation
Image segmentation can also be performed using transformers. A combination of ViT and U-Net was used in [65] to segment medical images. The authors replaced the encoder part of the classical U-Net with a transformer. A multi-atlas abdomen-labeling challenge dataset from MICCAI 2015 was used. By using images with a resolution of 224, the TransUNet achieved an average dice score of 77.48%, and while using images of resolution 512, it achieved an average dice score of 84.36%.
In [66], the authors proposed a “ViT for biomedical image segmentation (ViTBIS)” for medical image segmentation. Transformers were used for both encoders and decoders in their transformer-based model. In addition, the MICCAI 2015 multi-atlas abdomen-labeling challenge dataset and the Brain Tumor Segmentation (BraTS 2019) challenge dataset were used. The evaluation metric used was dice score and Hausdorff distance (HD) [67]. According to the MICCAI 2015 dataset, the average dice scores were 80.45%, and the average HDs were 21.24%.
In [68], the authors proposed a novel “language-aware ViT (LAVT)” for image segmentation. They used four different datasets for the evaluation of the model. The datasets were RefCOCO [69], RefCOCO+ [69], G-Ref (UMD partition) [70], and G-Ref (Google partition) [71]. They used intersection over union (IoU) as the performance metric. The value of IoU for the RefCOCO dataset was 72.73%, and for RefCOCO+, the IoU was 62.14%. Similarly, for G-Ref (UMD partition), the IoU was 61.24%, and for G-Ref (Google partition), the IoU was 60.50%. Similarly, another work [72] proposed high-resolution ViT for semantic segmentation. The authors of this work used several branch block co-optimization techniques and achieved good results for the semantic segmentation on the ADE20K and Cityscapes datasets.
Cheng et al. in [73] proposed MaskFormer for image segmentation. This model outperformed state-of-the-art semantic [19,74,75,76,77,78] and panoptic [79] segmentation models.
Hatamizadeh et al. in [80] proposed UNetFormer for medical image segmentation. The model contained a transformer-based encoder, decoder, and bottleneck part. They used the medical segmentation decathlon (MSD) [81] and BraTS 2021 [82] dataset to test UNetFormer. They evaluated dice scores and HD. The dice score using the MSD dataset was 96.03% for the liver and 59.16% for the tumor, whereas the value of HD was 7.21% for the liver and 8.49% for the tumor. Moreover, the average dice score on the BraTS 2021 dataset was 91.54%.
Table 4 shows the application of ViT for image segmentation.
3.4. ViTs for Image Compression
In recent years, learning-based image compression has been a major focus of research. For lossy image compression based on learning, different CNN-based architectures have proven effective [85,86]. As ViTs evolved, learning-based image compression has also been performed using transformer-based models. In [87], the authors modified the entropy module of the Ballé 2018 mode [88] with the ViT. Due to the fact that the entropy module used a transformer, this model was called Entroformer. Entroformer effectively captured long-range dependencies in probability distribution estimation. On the Kodak dataset, they demonstrated the performance of the Entroformer. When the model was optimized for the mean squared error (MSE) loss function, the average peak signal-to-noise ratio (PSNR) and multiscale structural similarity (MS-SSIM) were 27.63 dB and 0.90132, respectively. Similarly, in [89], the authors proposed Contextformer and achieved 11% bit savings over Versatile Video Coding (VVC) [90].
3.5. ViTs for Image Super-Resolution
CNN has been used to perform image super-resolution. With ViT’s superiority over CNN, image super-resolution can also be achieved by transformers. Spatio-temporal ViT, a transformer-based model for the super-resolution of microscopic images, was developed in [92]. Additionally, the model addressed the problem of video super-resolution. To test the model’s performance, the authors used a video dataset. PSNR was calculated for static and dynamic videos. Static, medium, fast, and extreme motions were considered. The PSNR for static was 34.74 dB, whereas the PSNR for medium, fast, and extreme was 30.15 dB, 26.04 dB, and 22.95 dB, respectively.
3.6. ViTs for Image Denoising
Denoising images has also been a challenging problem for researchers. In spite of this, ViT has found a solution. A transformer was used to denoise CT images in [93]. In this work, the authors proposed a model called TED-Net for low-dose CT denoising. The authors used a transformer for both the encoder and decoder parts. Using the AAPM-Mayo clinic LDCT Grand Challenge dataset, they obtained a structural similarity (SSIM) of 0.9144 and a root mean square error (RMSE) of 8.7681.
Luthra et al. in [94] proposed Eformer for medical image denoising. Eformer was based on edge enhancement and incorporated the Sobel operator. They evaluated the model on AAPM-Mayo Clinic Low-Dose CT Grand Challenge Dataset [95]. Eformer achieved a PSNR of 43.487, an RMSE of 0.0067, and an SSIM of 0.9861.
In [96], the authors combined UNet [97] and Swin transformer [19] to propose SUNet for image denoising. The model was evaluated on CBSD68 [98] and Kodak24 [99] dataset. The model achieved a PSNR of 27.85 and SSIM of 0.799 for the CBSD68 dataset when the noise level () was 50. Similarly, the model achieved a PSNR of 29.54 and SSIM of 0.810 for the Kodak24 dataset when the was kept at 50.
In [100], the authors proposed DenSformer for image denoising. The DenSformer was composed of three modules, preprocessing, feature extraction, and reconstruction. The model achieved a PSNR of 39.68 and an SSIM of 0.958 on the SIDD dataset [101]. Similarly, the model yielded a PSNR of 39.87 and an SSIM of 0.955 on the Dnd dataset [102].
Xu et al. in [103] proposed the CUR transformer for image denoising.The CUR transformer was deduced from the convolutional unbiased regional transformer. Similarly, in [104,105,106], the combined transformers and CNN for image denoising and achieved better performance. In [107], the authors proposed Hider, a transformer-based model for image denoising. The model was designed for hyperspectral images. The authors in [108] proposed CSformer for image denoising. The model was based on cross-scale feature fusion. The model was evaluated on Set12 [109], BSD68 [98] and General100 [110] dataset. The model outperformed DnCNN [109], FDnCNN [109], FFDNet [111], IRCNN [112], DRUnet [113], Uformer [114], and SwinIR [115] in terms of PSNR and SSIM.
Key Takeaways—Transformer models can be used for image denoising either in standalone fashion, i.e., end-to-end, or hybrid, i.e., combined with CNN. Standalone models have relatively better performance than do hybrid models.
3.7. ViTs for Anomaly Detection
Additionally, ViT is used for anomaly detection. A novel ViT network for image anomaly detection and localization (VT-ADL) was developed in [116]. In this study, the authors used a real-world dataset called BTAD. The model was also tested on two publicly available datasets, MNIST and MVTec [117]. For all three datasets, they calculated the model’s per region overlap (PRO) score. A mean PRO score of 0.984 was obtained for the MNIST dataset, 0.807 for the MVTec dataset, and 0.89 for the BTAD dataset.
Similarly, in [118], the authors proposed AnoViT for the detection and localization of anomalies. The MNIST, CIFAR, and MVTecAD datasets were used by the authors. Based on the MINST, CIFAR, and MVTecAD datasets, the mean area under the region operating characteristics (AUROC) curve was 92.4, 60.1, and 78, respectively.
Yuan et al. in [119] proposed TransAnomaly, a video ViT and U-Net-based framework for the detection of the anomalies in the videos. They used three datasets, Pred1, Pred2, and Avenue. The calculated area under the curve (AUC) for three datasets, achieving 84.0%, 96.10%, and 85.80%, respectively, without using the sliding windows method (swm). With the swm, the model yielded an AUC of 86.70%, 96.40%, and 87.00% for the Pred1, Pred2, and Avenue datasets, respectively.
Table 5 shows the summary of the ViT for anomaly detection.
4. Advanced ViTs
In addition to their promising use in vision, some transformers have been particularly designed to perform a specific task or to solve a particular problem. In this section, we analyze the different advanced transformer models by categorizing them into the following categories:
- Task-based ViTs;
- Problem-based ViTs.
4.1. Task-Based ViTs
In this subsection, we summarize task-based ViTs. Task-based ViTs are those ViTs that are designed for a specific task and perform exceptionally well for that task. Lee et al. in [120] proposed the multipath ViT (MPViT) for dense prediction by embedding features of the same sequence length with the patches of the different scales. The model achieved superior performance for classification, object detection, and segmentation. However, the model is specific to dense prediction.
In [121], the authors proposed the coarse-to-fine ViT (C2FViT) for medical image registration. C2FViT uses convolutional ViT [24,122] an ad multiresolution strategy [123] to learn global affine for image registration. The model was specifically designed for affine medical image registration. Similarly, in [124], the authors proposed TransMorph for medical image registration and achieved state-of-the-art results. However, these models are task-specific, which is why they are categorized as task-based ViTs here.
4.2. Problem-Based ViTs
In this subsection, we present problem-based ViTs. Problem-based ViTs are those ViTs which are proposed to solve a particular problem that cannot be solved by pure ViTs. These types of ViTs are not dependent on tasks but rather on problems. For example, ViTs are not flexible. To make a ViT more flexible and to reduce its complexity, the authors in [125] proposed a messenger (MSG) transformer. They used specialized MSG tokens for each region. By manipulating these tokens, one can flexibly exchange visual information across the regions. This reduces the computational complexity of ViTs.
Similarly, it has been discovered that mixup-based augmentation works well for generalizing models during training, especially for ViTs because they are prone to overfitting. However, the basic presumption of earlier mixup-based approaches is that the linearly interpolated ratio of targets should be maintained constantly with the percentage suggested by input interpolation. As a result, there may occasionally be no valid object in the mixed image due to the random augmentation procedure, but there is still a response in the label space. Chen et al. in [126] proposed TransMix for bridging this gap between the input and label spaces. TransMix blends labels based on the attention maps of ViTs.
In ViTs, global attention is computationally expensive, whereas local attention provides limited interactions between tokens. To solve this problem, the authors in [127] proposed the CSWin transformer based on the cross-shaped window self-attention. This provided efficient computation of self-attention and achieved better results than did the pure ViTs.
5. Open Source ViTs
This section summarizes the available open-source ViTs with potential CV applications. We also provide the links to the source codes of each model discussed. Table 6 presents the comprehensive summary of the open-source ViTs for the different applications of CV such as image classification, object detection, instance segmentation, semantic segmentation, video action classification, and robustness evaluation.
6. ViTs and Drone Imagery
In drone imagery, unmanned aerial vehicles (UAVs) or drones capture images or videos. Images of this type can provide a birds-eye view of a particular area, which can be useful for various applications, such as land surveys, disaster management, agricultural planning, and urban development.
Initially, DL models such as CNNs [137], recurrent neural networks (RNNs) [138], fully convolutional networks (FCNs) [139], and generative adversarial networks (GANs) [140] were widely used for tasks in which drone image processing was involved. CNNs are commonly used for image classification and object detection using drone images. These are particularly useful, as these models can learn to detect features such as buildings, roads, and other objects of interest. Similarly, RNNs are commonly used for processing time-series data, such as drone imagery. These models are able to learn to detect changes in the landscape over time. These are useful for tasks such as crop monitoring and environmental monitoring.
FCNs are mainly used for semantic segmentation tasks, such as identifying different types of vegetation in drone imagery. These can be used to create high-resolution maps of the landscape, which can be useful for various applications.
GANs are commonly used for image synthesis tasks, such as generating high-resolution images of the landscape from low-resolution drone imagery. These can also be used for data augmentation, which can help to improve the performance of other DL models.
When it comes to drone imagery, ViTs can be used for a variety of tasks because of the advantages of ViTs over traditional DL models [26,27,28,31]. ViTs use a self-attention mechanism that allows these models to focus on relevant parts of the input data [21]. This is particularly useful when processing drone imagery, which may contain a lot of irrelevant information, such as clouds or trees, that can distract traditional DL models. By selectively attending to relevant parts of the image, transformers can improve their accuracy. Similarly, traditional DL models typically process data in a sequential manner, which is slow and inefficient, especially when dealing with large amounts of data. ViTs, on the other hand, can process data in parallel, making them much faster and more efficient. Another advantage of ViTs over traditional DL models is efficient transfer learning ability [141], as ViTs are pretrained on large amounts of data, allowing them to learn general features that can be applied to a wide range of tasks. This means that they can be easily fine-tuned for specific tasks, such as processing drone imagery, with relatively little training data. Moreover, one of the most important advantages is the ability to handle variable-length input as drone imagery can vary in size and shape, making it difficult for traditional DL models to process. ViTs, on the other hand, can handle variable-length input, making them better suited for processing drone imagery.
Similarly, another main advantage of using ViTs for drone imagery analysis is their ability to handle long sequences of inputs. This is particularly useful for drone imagery, where large images or video frames must be processed. Additionally, ViTs can learn complex spatial relationships between different image features, leading to more accurate results than those produced with other DL models.
ViTs are used for object detection, disease detection, prediction, classification, and segmentation using drone imagery. This section briefly summarizes the applications of ViT using drone imagery.
In [142], the authors proposed TransVisDrone, which is a spatio-temporal transformer for the detection of drones in aerial videos. The model obtained state-of-the-art performance on the NPS [143], FLDrones [144], and Airborne Object Tracking (AOT) datasets.
Liu et al. [145] reported the use of ViT for drone crowd counting. The dataset used in the challenge was collected by drones.
In [146], the authors used unmanned aerial vehicle (UAV) images of date palm trees to investigate the reliability and efficiency of various deep-ViTs. They used different ViTs such as Segformer [147], the Segmeter [148], the UperNet-Swin transformer, and dense prediction transformers (DPT) [149]. Based on the comprehensive experimental analysis, Segformer achieved the highest performance.
Zhu et al. [150], proposed TPH-YOLOv5 for which they replaced the original prediction head of YOLOv5 with the transformer prediction head (TPH) to overcome the challenges of objection in the drone-captured images.
In [151], the authors summarized the results of the challenger VisDrone-DET2021 in which the proponents used different transformers, such as Scaled-YOLOv4 with transformer and BiFPN (SOLOER), Swin-transformer (Swin-T), stronger visual information for tiny object detection (VistrongerDet), and EfficientDet for object detection in the drone imagery. Thai et al. [152] demonstrated the use of ViT for cassava leaf disease classification and achieved better performance than did the CNNs. A detailed summary of the existing ViTs for drone imagery data is presented in Table 7.
7. Open Research Challenges and Future Directions
Despite showing promising results for different image coding and CV tasks, in addition to high computational costs, large training datasets, neural architecture search, interpretability of transformers, and efficient hardware designs, ViTs implementation still faces challenges. The purpose of this section is to explain the challenges and future directions of ViTs.
7.1. High Computational Cost
There are millions of parameters in ViT-based models. Computers with high computational power are needed to train these models. Due to their high cost, these high-performance computers increase the computational cost of ViTs. In comparison to CNN, ViT performs better; however, its computational cost is much higher. One of the biggest challenges researchers face is reducing the computational cost of ViTs. In [153], the authors proposed the glance-and-gaze ViT to reduce the memory consumption and computational cost of the ViT. However, this critical issue needs more attention and research to make ViTs more effective in terms of computational cost.
7.2. Large Training Dataset
The training of ViTs requires a large amount of data. With a small training dataset, ViTs perform poorly [154]. A ViT trained with the ImageNet1K dataset was found to perform worse than did ResNet, but a ViT trained with ImageNet21K performed better than did ResNet [16]. However, in [51], the authors trained ViT on a small dataset, but the model could not be generalized. Similarly, other authors [155] demonstrated the method to train ViT on 2040 images. Chen et al. in [136] proposed Visformer to reduce the model’s complexity and train ViTs on a small dataset. Despite these efforts from researchers, training a ViT with a small dataset to achieve remarkable performance is still challenging.
7.3. Neural Architecture Search (NAS)
There has been a great deal of exploration of NAS for CNNs [156,157,158,159]. In contrast, NAS has not yet been fully explored for ViTs. In [160], the authors surveyed several NAS techniques for ViTs. To the best of our knowledge, there are limited studies on the NAS exploration in ViTs [161,162,163,164,165,166], and more attention is needed in the future. The NAS exploration for ViTs may a new direction for young investigators in the future.
7.4. Interpretability of the Transformers
It is difficult to visualize the relative contribution of input tokens to the final predictions with ViTs since the attention that originates in each layer is intermixed in succeeding layers. In [167,168], the authors demonstrated the interpretability of the transformers to some extent. However, the problem remains unresolved.
7.5. Hardware-Efficient Designs
Power and processing requirements can make large-scale ViTs networks unsuitable for edge devices and resource-constrained contexts such as the Internet of Things (IoT). In [169], the authors proposed a framework for low-bit ViTs. However, the issue is still unresolved.
7.6. Large CV Model
With the advancement of technologies such as green communication [170], digital twins [171], and usage of ViTs, researchers have started to focus on large CV models and large language models [172] with billions of parameters. A large model can be used as a basis for transfer learning and fine-tuning, so there is interest in developing increasingly high-performance models. Google ViT-22B [173] paves the way for new large transformers and to revolutionizing CV. It consists of 22 billion parameters and is trained on four billion images. It can be used for image classification, video classification, semantic segmentation, and depth estimation. Inspired by Google ViT-22B, the authors in [174] proposed the EVA-02 model with 304 M parameters. Despite the remarkable performance of large models, retraining these models on new datasets is a daunting task, but one approach to solving this problem is the usage of a pretrained model. The researchers in [175] demonstrated that continual learning (CL) can help pretrained vision-language models efficiently adapt to new or undertrained data distributions without retraining. Although they achieved good performance, this problem still needs to be explored in future research.
8. Conclusions
It is becoming more common to use ViTs for image coding and CV instead of CNNs. The use of ViTs for classification, detection, segmentation, compression, and image super-resolution has risen dramatically since the introduction of the classical ViT for image classification. This survey presented the existing surveys on ViTs in the literature. This survey highlighted the applications of different variants of ViTs in CV and further examined the use of ViTs for image classification, object detection, image segmentation, image compression, image super-resolution, image denoising, and anomaly detection. We also presented the lessons learned in each category. From the detailed analysis, we observed that ViTs are replacing traditional DL models for CV applications. Significant achievement has been made in image classification and object detection, where ViTs are widely used because of the self-attention mechanism and effective transfer learning. Additionally, we discussed the open research challenges faced by researchers during the implementation of ViTs, which include the high computational costs, large training datasets, interpretability of transformers, and hardware efficiency. By providing future directions, we offer young researchers a new perspective. Recently, large CV models have attracted the focus of the research community as Google’s ViT22B has paved the way for future research in this direction.
Author Contributions
Conceptualization, S.J. and M.J.P.; methodology, S.J.; formal analysis, S.J.; investigation, M.J.P.; resources, O.-J.K.; data curation, S.J.; writing—original draft preparation, S.J.; writing—review and editing, M.J.P. and O.-J.K.; visualization, S.J.; supervision, M.J.P.; project administration, O.-J.K.; funding acquisition, O.-J.K. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| AID | Aerial image dataset |
| AP | Average precision |
| AQI | Air quality index |
| AUC | Area under the curve |
| AUROC | Area under receiver operating characteristic curve |
| Box average precision | |
| BERT | Bidirectional encoder representations from transformers |
| bpp | Bits per pixel |
| BrT | Bridged transformer |
| BTAD | BeanTech anomaly detection |
| CIFAR | Canadian Institute for Advanced Research |
| CV | Computer vision |
| CNN | Convolutional neural network |
| DHViT | Deep hierarchical ViT |
| DOViT | Double output ViT |
| ES-GSNet | Excellent teacher guiding small networks |
| GAOs-1 | Get AQI in one shot-1 |
| GAOs-2 | Get AQI in one shot-2 |
| GPT-3 | Generative pretrained transformer 3 |
| HD | Hausdorff distance |
| IoU | Intersection over union |
| JI | Jaccord index |
| LiDAR | Light detection and ranging |
| mAP | Mean average precision |
| MLP | Multilayer perceptron |
| MIL-ViT | Multiple instance-enhanced ViT |
| MIM | Masked image modeling |
| MITformer | Multi-instance ViT |
| MSE | Mean squared error |
| MS-SSIM | Multiscale structural similarity |
| NLP | Natural language processing |
| NWPU | Northwestern Polytechnical University |
| PSNR | Peak signal to noise ratio |
| PRO | Per region overlap |
| PUAS | Planet Understanding the Amazon from Space |
| RFMiD2020 | 2020 retinal fundus multidisease image dataset |
| R-CNN | Region-based convolutional neural network |
| RMSE | Root mean square error |
| SSIM | Structural similarity |
| TE | Transformer encoder |
| UCM | UC-Mered land use dataset |
| ViTs | Vision transformers |
| VT-ADL | ViT network for image anomaly detection and localization |
| ViT-PP | ViT with postprocessing |
| YOLOS | You only look at one sequence |
References
- Heo, B.; Yun, S.; Han, D.; Chun, S.; Choe, J.; Oh, S.J. Rethinking spatial dimensions of vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision; IEEE: New York, NY, USA, 2021; pp. 11936–11945. [Google Scholar]
- Tenney, I.; Das, D.; Pavlick, E. BERT rediscovers the classical NLP pipeline. arXiv 2019, arXiv:1905.05950. [Google Scholar]
- Floridi, L.; Chiriatti, M. GPT-3: Its nature, scope, limits, and consequences. Minds Mach. 2020, 30, 681–694. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Jamil, S.; Rahman, M.; Ullah, A.; Badnava, S.; Forsat, M.; Mirjavadi, S.S. Malicious UAV detection using integrated audio and visual features for public safety applications. Sensors 2020, 20, 3923. [Google Scholar] [CrossRef]
- Wu, Z.; Shen, C.; Van Den Hengel, A. Wider or deeper: Revisiting the resnet model for visual recognition. Pattern Recognit. 2019, 90, 119–133. [Google Scholar] [CrossRef]
- Hammad, I.; El-Sankary, K. Impact of approximate multipliers on VGG deep learning network. IEEE Access 2018, 6, 60438–60444. [Google Scholar] [CrossRef]
- Yao, X.; Wang, X.; Karaca, Y.; Xie, J.; Wang, S. Glomerulus classification via an improved GoogLeNet. IEEE Access 2020, 8, 176916–176923. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Wang, C.; Chen, D.; Hao, L.; Liu, X.; Zeng, Y.; Chen, J.; Zhang, G. Pulmonary image classification based on inception-v3 transfer learning model. IEEE Access 2019, 7, 146533–146541. [Google Scholar] [CrossRef]
- Jamil, S.; Fawad; Abbas, M.S.; Habib, F.; Umair, M.; Khan, M.J. Deep learning and computer vision-based a novel framework for himalayan bear, marco polo sheep and snow leopard detection. In Proceedings of the 2020 International Conference on Information Science and Communication Technology (ICISCT), Karachi, Pakistan, 8–9 February2020; pp. 1–6. [Google Scholar]
- Zhang, K.; Guo, Y.; Wang, X.; Yuan, J.; Ding, Q. Multiple feature reweight densenet for image classification. IEEE Access 2019, 7, 9872–9880. [Google Scholar] [CrossRef]
- Wang, J.; Yang, L.; Huo, Z.; He, W.; Luo, J. Multi-label classification of fundus images with efficientnet. IEEE Access 2020, 8, 212499–212508. [Google Scholar] [CrossRef]
- Hossain, M.A.; Nguyen, V.; Huh, E.N. The trade-off between accuracy and the complexity of real-time background subtraction. IET Image Process. 2021, 15, 350–368. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. Available online: https://proceedings.neurips.cc/paper_files/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf (accessed on 18 April 2023).
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Wu, B.; Xu, C.; Dai, X.; Wan, A.; Zhang, P.; Yan, Z.; Tomizuka, M.; Gonzalez, J.; Keutzer, K.; Vajda, P. Visual transformers: Token-based image representation and processing for computer vision. arXiv 2020, arXiv:2006.03677. [Google Scholar]
- Xiao, T.; Singh, M.; Mintun, E.; Darrell, T.; Dollár, P.; Girshick, R. Early convolutions help transformers see better. Adv. Neural Inf. Process. Syst. 2021, 34, 30392–30400. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision; IEEE: New York, NY, USA, 2021; pp. 10012–10022. [Google Scholar]
- Bertasius, G.; Wang, H.; Torresani, L. Is space-time attention all you need for video understanding? In ICML; PMLR, 2021; Volume 2, p. 4. Available online: https://proceedings.mlr.press/v139/bertasius21a.html (accessed on 18 April 2023).
- Raghu, M.; Unterthiner, T.; Kornblith, S.; Zhang, C.; Dosovitskiy, A. Do vision transformers see like convolutional neural networks? Adv. Neural Inf. Process. Syst. 2021, 34, 12116–12128. [Google Scholar]
- Naseer, M.M.; Ranasinghe, K.; Khan, S.H.; Hayat, M.; Shahbaz Khan, F.; Yang, M.H. Intriguing properties of vision transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 23296–23308. [Google Scholar]
- Dai, Z.; Liu, H.; Le, Q.V.; Tan, M. Coatnet: Marrying convolution and attention for all data sizes. Adv. Neural Inf. Process. Syst. 2021, 34, 3965–3977. [Google Scholar]
- Wu, H.; Xiao, B.; Codella, N.; Liu, M.; Dai, X.; Yuan, L.; Zhang, L. Cvt: Introducing convolutions to vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision; IEEE: New York, NY, USA, 2021; pp. 22–31. [Google Scholar]
- Coccomini, D.A.; Messina, N.; Gennaro, C.; Falchi, F. Combining efficientnet and vision transformers for video deepfake detection. In International Conference on Image Analysis and Processing; Springer: Cham, Switzerland, 2022; pp. 219–229. [Google Scholar]
- Tay, Y.; Dehghani, M.; Bahri, D.; Metzler, D. Efficient transformers: A survey. ACM Comput. Surv. (CSUR) 2020, 55, 1–28. [Google Scholar] [CrossRef]
- Khan, S.; Naseer, M.; Hayat, M.; Zamir, S.W.; Khan, F.S.; Shah, M. Transformers in vision: A survey. ACM Comput. Surv. (CSUR) 2022, 54, 1–41. [Google Scholar] [CrossRef]
- Liu, Y.; Zhang, Y.; Wang, Y.; Hou, F.; Yuan, J.; Tian, J.; Zhang, Y.; Shi, Z.; Fan, J.; He, Z. A survey of visual transformers. arXiv 2021, arXiv:2111.06091. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.; Wang, Y.; Liu, X.; Qiu, X. A survey of transformers. AI Open 2022, 3, 111–132. [Google Scholar] [CrossRef]
- Xu, Y.; Wei, H.; Lin, M.; Deng, Y.; Sheng, K.; Zhang, M.; Tang, F.; Dong, W.; Huang, F.; Xu, C. Transformers in computational visual media: A survey. Comput. Vis. Media 2022, 8, 33–62. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y.; et al. A survey on vision transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 87–110. [Google Scholar] [CrossRef] [PubMed]
- Chen, C.F.R.; Fan, Q.; Panda, R. Crossvit: Cross-attention multi-scale vision transformer for image classification. In Proceedings of the IEEE/CVF International Conference on Computer Vision; IEEE: New York, NY, USA, 2021; pp. 357–366. [Google Scholar]
- Deng, P.; Xu, K.; Huang, H. When CNNs meet vision transformer: A joint framework for remote sensing scene classification. IEEE Geosci. Remote. Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Yu, S.; Ma, K.; Bi, Q.; Bian, C.; Ning, M.; He, N.; Li, Y.; Liu, H.; Zheng, Y. Mil-vt: Multiple instance learning enhanced vision transformer for fundus image classification. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Cham, Switzerland, 2021; pp. 45–54. [Google Scholar]
- Graham, B.; El-Nouby, A.; Touvron, H.; Stock, P.; Joulin, A.; Jégou, H.; Douze, M. Levit: A vision transformer in convnet’s clothing for faster inference. In Proceedings of the IEEE/CVF International Conference on Computer Vision; IEEE: New York, NY, USA, 2021; pp. 12259–12269. [Google Scholar]
- Xu, K.; Deng, P.; Huang, H. Vision transformer: An excellent teacher for guiding small networks in remote sensing image scene classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Xue, Z.; Tan, X.; Yu, X.; Liu, B.; Yu, A.; Zhang, P. Deep Hierarchical Vision Transformer for Hyperspectral and LiDAR Data Classification. IEEE Trans. Image Process. 2022, 31, 3095–3110. [Google Scholar] [CrossRef]
- Kaselimi, M.; Voulodimos, A.; Daskalopoulos, I.; Doulamis, N.; Doulamis, A. A Vision Transformer Model for Convolution-Free Multilabel Classification of Satellite Imagery in Deforestation Monitoring. IEEE Trans. Neural Netw. Learn. Syst. 2022; Online ahead of print. [Google Scholar]
- Chen, Y.; Gu, X.; Liu, Z.; Liang, J. A Fast Inference Vision Transformer for Automatic Pavement Image Classification and Its Visual Interpretation Method. Remote Sens. 2022, 14, 1877. [Google Scholar] [CrossRef]
- Jamil, S.; Abbas, M.S.; Roy, A.M. Distinguishing Malicious Drones Using Vision Transformer. AI 2022, 3, 260–273. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6848–6856. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and< 0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In International Conference on Machine Learning; PMLR: Cambridge, MA, USA, 2019; pp. 6105–6114. [Google Scholar]
- Tanzi, L.; Audisio, A.; Cirrincione, G.; Aprato, A.; Vezzetti, E. Vision Transformer for femur fracture classification. Injury 2022, 53, 2625–2634. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.; Luo, T.; Wu, J.; Wang, Z.; Zhang, H. A Vision Transformer network SeedViT for classification of maize seeds. J. Food Process. Eng. 2022, 45, e13998. [Google Scholar] [CrossRef]
- Wang, Z.; Yang, Y.; Yue, S. Air Quality Classification and Measurement Based on Double Output Vision Transformer. IEEE Internet Things J. 2022, 9, 20975–20984. [Google Scholar] [CrossRef]
- Sha, Z.; Li, J. MITformer: A Multi-Instance Vision Transformer for Remote Sensing Scene Classification. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Kim, K.; Wu, B.; Dai, X.; Zhang, P.; Yan, Z.; Vajda, P.; Kim, S.J. Rethinking the self-attention in vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision; IEEE: New York, NY, USA, 2021; pp. 3071–3075. [Google Scholar]
- Lee, S.H.; Lee, S.; Song, B.C. Vision transformer for small-size datasets. arXiv 2021, arXiv:2112.13492. [Google Scholar]
- Beal, J.; Kim, E.; Tzeng, E.; Park, D.H.; Zhai, A.; Kislyuk, D. Toward transformer-based object detection. arXiv 2020, arXiv:2012.09958. [Google Scholar]
- Fang, Y.; Liao, B.; Wang, X.; Fang, J.; Qi, J.; Wu, R.; Niu, J.; Liu, W. You only look at one sequence: Rethinking transformer in vision through object detection. Adv. Neural Inf. Process. Syst. 2021, 34, 26183–26197. [Google Scholar]
- Li, Y.; Xie, S.; Chen, X.; Dollar, P.; He, K.; Girshick, R. Benchmarking detection transfer learning with vision transformers. arXiv 2021, arXiv:2111.11429. [Google Scholar]
- Bao, H.; Dong, L.; Wei, F. Beit: Bert pre-training of image transformers. arXiv 2021, arXiv:2106.08254. [Google Scholar]
- He, K.; Chen, X.; Xie, S.; Li, Y.; Dollár, P.; Girshick, R. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June2022; pp. 16000–16009. [Google Scholar]
- Horváth, J.; Baireddy, S.; Hao, H.; Montserrat, D.M.; Delp, E.J. Manipulation detection in satellite images using vision transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 1032–1041. [Google Scholar]
- Wang, Y.; Ye, T.; Cao, L.; Huang, W.; Sun, F.; He, F.; Tao, D. Bridged Transformer for Vision and Point Cloud 3D Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12114–12123. [Google Scholar]
- Dai, A.; Chang, A.X.; Savva, M.; Halber, M.; Funkhouser, T.; Nießner, M. Scannet: Richly-annotated 3d reconstructions of indoor scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5828–5839. [Google Scholar]
- Song, S.; Lichtenberg, S.P.; Xiao, J. Sun rgb-d: A rgb-d scene understanding benchmark suite. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 567–576. [Google Scholar]
- Liu, Z.; Zhang, Z.; Cao, Y.; Hu, H.; Tong, X. Group-free 3D object detection via transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision; IEEE: New York, NY, USA, 2021; pp. 2949–2958. [Google Scholar]
- Prangemeier, T.; Reich, C.; Koeppl, H. Attention-based transformers for instance segmentation of cells in microstructures. In Proceedings of the 2020 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Seoul, Republic of Korea, 16–19 December 2020; pp. 700–707. [Google Scholar]
- Chen, T.; Saxena, S.; Li, L.; Fleet, D.J.; Hinton, G. Pix2seq: A language modeling framework for object detection. arXiv 2021, arXiv:2109.10852. [Google Scholar]
- Wang, Y.; Zhang, X.; Yang, T.; Sun, J. Anchor detr: Query design for transformer-based detector. AAAI Conf. Artif. Intell. 2022, 36, 2567–2575. [Google Scholar] [CrossRef]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. Transunet: Transformers make strong encoders for medical image segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- Sagar, A. Vitbis: Vision transformer for biomedical image segmentation. In Clinical Image-Based Procedures, Distributed and Collaborative Learning, Artificial Intelligence for Combating COVID-19 and Secure and Privacy-Preserving Machine Learning; Springer: Cham, Switzerland, 2021; pp. 34–45. [Google Scholar]
- Huttenlocher, D.P.; Klanderman, G.A.; Rucklidge, W.J. Comparing images using the Hausdorff distance. IEEE Trans. Pattern Anal. Mach. Intell. 1993, 15, 850–863. [Google Scholar] [CrossRef]
- Yang, Z.; Wang, J.; Tang, Y.; Chen, K.; Zhao, H.; Torr, P.H. LAVT: Language-Aware Vision Transformer for Referring Image Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 18155–18165. [Google Scholar]
- Yu, L.; Poirson, P.; Yang, S.; Berg, A.C.; Berg, T.L. Modeling context in referring expressions. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 69–85. [Google Scholar]
- Nagaraja, V.K.; Morariu, V.I.; Davis, L.S. Modeling context between objects for referring expression understanding. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 792–807. [Google Scholar]
- Mao, J.; Huang, J.; Toshev, A.; Camburu, O.; Yuille, A.L.; Murphy, K. Generation and comprehension of unambiguous object descriptions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 11–20. [Google Scholar]
- Gu, J.; Kwon, H.; Wang, D.; Ye, W.; Li, M.; Chen, Y.H.; Lai, L.; Chandra, V.; Pan, D.Z. Multi-scale high-resolution vision transformer for semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12094–12103. [Google Scholar]
- Cheng, B.; Schwing, A.; Kirillov, A. Per-pixel classification is not all you need for semantic segmentation. Adv. Neural Inf. Process. Syst. 2021, 34, 17864–17875. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In European Conference on Computer Vision (ECCV); Springer: Cham, Switzerland, 2018; pp. 801–818. [Google Scholar]
- Xiao, T.; Liu, Y.; Zhou, B.; Jiang, Y.; Sun, J. Unified perceptual parsing for scene understanding. In European Conference on Computer Vision (ECCV); Springer: Cham, Switzerland, 2018; pp. 418–434. [Google Scholar]
- Yuan, Y.; Chen, X.; Wang, J. Object-contextual representations for semantic segmentation. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part VI 16. Springer: Cham, Switzerland, 2020; pp. 173–190. [Google Scholar]
- Yuan, Y.; Huang, L.; Guo, J.; Zhang, C.; Chen, X.; Wang, J. OCNet: Object context for semantic segmentation. Int. J. Comput. Vis. 2021, 129, 2375–2398. [Google Scholar] [CrossRef]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.H.; et al. Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 6881–6890. [Google Scholar]
- Wang, H.; Zhu, Y.; Adam, H.; Yuille, A.; Chen, L.C. Max-deeplab: End-to-end panoptic segmentation with mask transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 5463–5474. [Google Scholar]
- Hatamizadeh, A.; Xu, Z.; Yang, D.; Li, W.; Roth, H.; Xu, D. UNetFormer: A Unified Vision Transformer Model and Pre-Training Framework for 3D Medical Image Segmentation. arXiv 2022, arXiv:2204.00631. [Google Scholar]
- Antonelli, M.; Reinke, A.; Bakas, S.; Farahani, K.; Kopp-Schneider, A.; Landman, B.A.; Litjens, G.; Menze, B.; Ronneberger, O.; Summers, R.M.; et al. The medical segmentation decathlon. Nat. Commun. 2022, 13, 4128. [Google Scholar] [CrossRef]
- Baid, U.; Ghodasara, S.; Mohan, S.; Bilello, M.; Calabrese, E.; Colak, E.; Farahani, K.; Kalpathy-Cramer, J.; Kitamura, F.C.; Pati, S.; et al. The rsna-asnr-miccai brats 2021 benchmark on brain tumor segmentation and radiogenomic classification. arXiv 2021, arXiv:2107.02314. [Google Scholar]
- Zhao, H.; Jia, J.; Koltun, V. Exploring self-attention for image recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10076–10085. [Google Scholar]
- Ramachandran, P.; Parmar, N.; Vaswani, A.; Bello, I.; Levskaya, A.; Shlens, J. Stand-alone self-attention in vision models. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Mishra, D.; Singh, S.K.; Singh, R.K. Deep architectures for image compression: A critical review. Signal Process. 2022, 191, 108346. [Google Scholar] [CrossRef]
- Jamil, S.; Piran, M. Learning-Driven Lossy Image Compression; A Comprehensive Survey. arXiv 2022, arXiv:2201.09240. [Google Scholar]
- Qian, Y.; Lin, M.; Sun, X.; Tan, Z.; Jin, R. Entroformer: A Transformer-based Entropy Model for Learned Image Compression. arXiv 2022, arXiv:2202.05492. [Google Scholar]
- Ballé, J.; Minnen, D.; Singh, S.; Hwang, S.J.; Johnston, N. Variational image compression with a scale hyperprior. arXiv 2018, arXiv:1802.01436. [Google Scholar]
- Koyuncu, A.B.; Gao, H.; Boev, A.; Gaikov, G.; Alshina, E.; Steinbach, E. Contextformer: A Transformer with Spatio-Channel Attention for Context Modeling in Learned Image Compression. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2022; pp. 447–463. [Google Scholar]
- Bross, B.; Wang, Y.K.; Ye, Y.; Liu, S.; Chen, J.; Sullivan, G.J.; Ohm, J.R. Overview of the versatile video coding (VVC) standard and its applications. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 3736–3764. [Google Scholar] [CrossRef]
- Lu, M.; Guo, P.; Shi, H.; Cao, C.; Ma, Z. Transformer-based image compression. arXiv 2021, arXiv:2111.06707. [Google Scholar]
- Christensen, C.N.; Lu, M.; Ward, E.N.; Lio, P.; Kaminski, C.F. Spatio-temporal Vision Transformer for Super-resolution Microscopy. arXiv 2022, arXiv:2203.00030. [Google Scholar]
- Wang, D.; Wu, Z.; Yu, H. Ted-net: Convolution-free t2t vision transformer-based encoder-decoder dilation network for low-dose ct denoising. In International Workshop on Machine Learning in Medical Imaging; Springer: Cham, Switzerland, 2021; pp. 416–425. [Google Scholar]
- Luthra, A.; Sulakhe, H.; Mittal, T.; Iyer, A.; Yadav, S. Eformer: Edge enhancement based transformer for medical image denoising. arXiv 2021, arXiv:2109.08044. [Google Scholar]
- McCollough, C.H.; Bartley, A.C.; Carter, R.E.; Chen, B.; Drees, T.A.; Edwards, P.; Holmes, D.R., III; Huang, A.E.; Khan, F.; Leng, S.; et al. Low-dose CT for the detection and classification of metastatic liver lesions: Results of the 2016 low dose CT grand challenge. Med. Phys. 2017, 44, e339–e352. [Google Scholar] [CrossRef]
- Fan, C.M.; Liu, T.J.; Liu, K.H. SUNet: Swin Transformer UNet for Image Denoising. arXiv 2022, arXiv:2202.14009. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Martin, D.; Fowlkes, C.; Tal, D.; Malik, J. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In Proceedings of the Eighth IEEE International Conference on Computer Vision. ICCV 2001, Vancouver, BC, Canada, 7–14 July 2001; Volume 2, pp. 416–423. [Google Scholar]
- Franzen, R. Kodak Lossless True Color Image Suite. 1999, Volume 4. Available online: http://r0k.us/graphics/kodak (accessed on 19 April 2023).
- Yao, C.; Jin, S.; Liu, M.; Ban, X. Dense residual Transformer for image denoising. Electronics 2022, 11, 418. [Google Scholar] [CrossRef]
- Abdelhamed, A.; Lin, S.; Brown, M.S. A high-quality denoising dataset for smartphone cameras. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1692–1700. [Google Scholar]
- Plotz, T.; Roth, S. Benchmarking denoising algorithms with real photographs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1586–1595. [Google Scholar]
- Xu, K.; Li, W.; Wang, X.; Wang, X.; Yan, K.; Hu, X.; Dong, X. CUR Transformer: A Convolutional Unbiased Regional Transformer for Image Denoising. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2022, 19, 1–22. [Google Scholar] [CrossRef]
- Xue, T.; Ma, P. TC-net: Transformer combined with cnn for image denoising. Appl. Intell. 2022, 53, 6753–6762. [Google Scholar] [CrossRef]
- Zhao, M.; Cao, G.; Huang, X.; Yang, L. Hybrid Transformer-CNN for Real Image Denoising. IEEE Signal Process. Lett. 2022, 29, 1252–1256. [Google Scholar] [CrossRef]
- Pang, L.; Gu, W.; Cao, X. TRQ3DNet: A 3D Quasi-Recurrent and Transformer Based Network for Hyperspectral Image Denoising. Remote Sens. 2022, 14, 4598. [Google Scholar] [CrossRef]
- Chen, H.; Yang, G.; Zhang, H. Hider: A Hyperspectral Image Denoising Transformer With Spatial–Spectral Constraints for Hybrid Noise Removal. IEEE Trans. Neural Netw. Learn. Syst. 2022; Early Access. [Google Scholar]
- Yin, H.; Ma, S. CSformer: Cross-Scale Features Fusion Based Transformer for Image Denoising. IEEE Signal Process. Lett. 2022, 29, 1809–1813. [Google Scholar] [CrossRef]
- Zhang, K.; Zuo, W.; Chen, Y.; Meng, D.; Zhang, L. Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising. IEEE Trans. Image Process. 2017, 26, 3142–3155. [Google Scholar] [CrossRef] [PubMed]
- Dong, C.; Loy, C.C.; Tang, X. Accelerating the super-resolution convolutional neural network. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 391–407. [Google Scholar]
- Zhang, K.; Zuo, W.; Zhang, L. FFDNet: Toward a fast and flexible solution for CNN-based image denoising. IEEE Trans. Image Process. 2018, 27, 4608–4622. [Google Scholar] [CrossRef]
- Zhang, K.; Zuo, W.; Gu, S.; Zhang, L. Learning deep CNN denoiser prior for image restoration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3929–3938. [Google Scholar]
- Zhang, K.; Li, Y.; Zuo, W.; Zhang, L.; Van Gool, L.; Timofte, R. Plug-and-play image restoration with deep denoiser prior. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 6360–6376. [Google Scholar] [CrossRef]
- Wang, Z.; Cun, X.; Bao, J.; Zhou, W.; Liu, J.; Li, H. Uformer: A general u-shaped transformer for image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 17683–17693. [Google Scholar]
- Liang, J.; Cao, J.; Sun, G.; Zhang, K.; Van Gool, L.; Timofte, R. Swinir: Image restoration using swin transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision; IEEE: New York, NY, USA, 2021; pp. 1833–1844. [Google Scholar]
- Mishra, P.; Verk, R.; Fornasier, D.; Piciarelli, C.; Foresti, G.L. VT-ADL: A vision transformer network for image anomaly detection and localization. In Proceedings of the 2021 IEEE 30th International Symposium on Industrial Electronics (ISIE), Kyoto, Japan, 20–23 June 2021; pp. 1–6. [Google Scholar]
- Bergmann, P.; Fauser, M.; Sattlegger, D.; Steger, C. MVTec AD–A comprehensive real-world dataset for unsupervised anomaly detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9592–9600. [Google Scholar]
- Lee, Y.; Kang, P. AnoViT: Unsupervised Anomaly Detection and Localization With Vision Transformer-Based Encoder-Decoder. IEEE Access 2022, 10, 46717–46724. [Google Scholar] [CrossRef]
- Yuan, H.; Cai, Z.; Zhou, H.; Wang, Y.; Chen, X. TransAnomaly: Video Anomaly Detection Using Video Vision Transformer. IEEE Access 2021, 9, 123977–123986. [Google Scholar] [CrossRef]
- Lee, Y.; Kim, J.; Willette, J.; Hwang, S.J. MPViT: Multi-path vision transformer for dense prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 7287–7296. [Google Scholar]
- Mok, T.C.; Chung, A. Affine Medical Image Registration with Coarse-to-Fine Vision Transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 20835–20844. [Google Scholar]
- Yuan, K.; Guo, S.; Liu, Z.; Zhou, A.; Yu, F.; Wu, W. Incorporating convolution designs into visual transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision; IEEE: New York, NY, USA, 2021; pp. 579–588. [Google Scholar]
- Sun, W.; Niessen, W.J.; Klein, S. Hierarchical vs. simultaneous multiresolution strategies for nonrigid image registration. In International Workshop on Biomedical Image Registration; Springer: Berlin/Heidelberg, Germany, 2012; pp. 60–69. [Google Scholar]
- Chen, J.; Frey, E.C.; He, Y.; Segars, W.P.; Li, Y.; Du, Y. TransMorph: Transformer for unsupervised medical image registration. Med. Image Anal. 2022, 82, 102615. [Google Scholar] [CrossRef] [PubMed]
- Fang, J.; Xie, L.; Wang, X.; Zhang, X.; Liu, W.; Tian, Q. Msg-transformer: Exchanging local spatial information by manipulating messenger tokens. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12063–12072. [Google Scholar]
- Chen, J.N.; Sun, S.; He, J.; Torr, P.H.; Yuille, A.; Bai, S. Transmix: Attend to mix for vision transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12135–12144. [Google Scholar]
- Dong, X.; Bao, J.; Chen, D.; Zhang, W.; Yu, N.; Yuan, L.; Chen, D.; Guo, B. Cswin transformer: A general vision transformer backbone with cross-shaped windows. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12124–12134. [Google Scholar]
- Liu, Z.; Hu, H.; Lin, Y.; Yao, Z.; Xie, Z.; Wei, Y.; Ning, J.; Cao, Y.; Zhang, Z.; Dong, L.; et al. Swin transformer v2: Scaling up capacity and resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12009–12019. [Google Scholar]
- Wang, Y.; Huang, R.; Song, S.; Huang, Z.; Huang, G. Not all images are worth 16x16 words: Dynamic transformers for efficient image recognition. Adv. Neural Inf. Process. Syst. 2021, 34, 11960–11973. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision; IEEE: New York, NY, USA, 2021; pp. 568–578. [Google Scholar]
- Chu, X.; Tian, Z.; Wang, Y.; Zhang, B.; Ren, H.; Wei, X.; Xia, H.; Shen, C. Twins: Revisiting the design of spatial attention in vision transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 9355–9366. [Google Scholar]
- Mehta, S.; Rastegari, M. Mobilevit: Light-weight, general-purpose, and mobile-friendly vision transformer. arXiv 2021, arXiv:2110.02178. [Google Scholar]
- Zhou, D.; Shi, Y.; Kang, B.; Yu, W.; Jiang, Z.; Li, Y.; Jin, X.; Hou, Q.; Feng, J. Refiner: Refining self-attention for vision transformers. arXiv 2021, arXiv:2106.03714. [Google Scholar]
- Zhou, D.; Kang, B.; Jin, X.; Yang, L.; Lian, X.; Jiang, Z.; Hou, Q.; Feng, J. Deepvit: Towards deeper vision transformer. arXiv 2021, arXiv:2103.11886. [Google Scholar]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jégou, H. Training data-efficient image transformers & distillation through attention. In International Conference on Machine Learning; PMLR: Cambridge, MA, USA, 2021; pp. 10347–10357. [Google Scholar]
- Chen, Z.; Xie, L.; Niu, J.; Liu, X.; Wei, L.; Tian, Q. Visformer: The vision-friendly transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision; IEEE: New York, NY, USA, 2021; pp. 589–598. [Google Scholar]
- Zhang, L.; Zhang, L.; Du, B. Deep learning for remote sensing data: A technical tutorial on the state of the art. IEEE Geosci. Remote. Sens. Mag. 2016, 4, 22–40. [Google Scholar] [CrossRef]
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.S.; Zhang, L.; Xu, F.; Fraundorfer, F. Deep learning in remote sensing: A comprehensive review and list of resources. IEEE Geosci. Remote. Sens. Mag. 2017, 5, 8–36. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Jozdani, S.; Chen, D.; Pouliot, D.; Johnson, B.A. A review and meta-analysis of generative adversarial networks and their applications in remote sensing. Int. J. Appl. Earth Obs. Geoinf. 2022, 108, 102734. [Google Scholar] [CrossRef]
- Zhou, H.Y.; Lu, C.; Yang, S.; Yu, Y. ConvNets vs. Transformers: Whose visual representations are more transferable? In Proceedings of the IEEE/CVF International Conference on Computer Vision; IEEE: New York, NY, USA, 2021; pp. 2230–2238. [Google Scholar]
- Sangam, T.; Dave, I.R.; Sultani, W.; Shah, M. Transvisdrone: Spatio-temporal transformer for vision-based drone-to-drone detection in aerial videos. arXiv 2022, arXiv:2210.08423. [Google Scholar]
- Li, J.; Ye, D.H.; Chung, T.; Kolsch, M.; Wachs, J.; Bouman, C. Multi-target detection and tracking from a single camera in Unmanned Aerial Vehicles (UAVs). In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Republic of Korea, 9–14 October 2016; pp. 4992–4997. [Google Scholar]
- Rozantsev, A.; Lepetit, V.; Fua, P. Detecting flying objects using a single moving camera. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 879–892. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; He, Z.; Wang, L.; Wang, W.; Yuan, Y.; Zhang, D.; Zhang, J.; Zhu, P.; Van Gool, L.; Han, J.; et al. VisDrone-CC2021: The vision meets drone crowd counting challenge results. In Proceedings of the IEEE/CVF International Conference on Computer Vision; IEEE: New York, NY, USA, 2021; pp. 2830–2838. [Google Scholar]
- Gibril, M.B.A.; Shafri, H.Z.M.; Al-Ruzouq, R.; Shanableh, A.; Nahas, F.; Al Mansoori, S. Large-Scale Date Palm Tree Segmentation from Multiscale UAV-Based and Aerial Images Using Deep Vision Transformers. Drones 2023, 7, 93. [Google Scholar] [CrossRef]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and efficient design for semantic segmentation with transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar]
- Strudel, R.; Garcia, R.; Laptev, I.; Schmid, C. Segmenter: Transformer for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision; IEEE: New York, NY, USA, 2021; pp. 7262–7272. [Google Scholar]
- Ranftl, R.; Bochkovskiy, A.; Koltun, V. Vision transformers for dense prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision; IEEE: New York, NY, USA, 2021; pp. 12179–12188. [Google Scholar]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 based on transformer prediction head for object detection on drone-captured scenarios. In Proceedings of the IEEE/CVF International Conference on Computer Vision; IEEE: New York, NY, USA, 2021; pp. 2778–2788. [Google Scholar]
- Cao, Y.; He, Z.; Wang, L.; Wang, W.; Yuan, Y.; Zhang, D.; Zhang, J.; Zhu, P.; Van Gool, L.; Han, J.; et al. VisDrone-DET2021: The vision meets drone object detection challenge results. In Proceedings of the IEEE/CVF International Conference on Computer Vision; IEEE: New York, NY, USA, 2021; pp. 2847–2854. [Google Scholar]
- Thai, H.T.; Tran-Van, N.Y.; Le, K.H. Artificial cognition for early leaf disease detection using vision transformers. In Proceedings of the 2021 International Conference on Advanced Technologies for Communications (ATC), Ho Chi Minh City, Vietnam, 14–16 October 2021; pp. 33–38. [Google Scholar]
- Yu, Q.; Xia, Y.; Bai, Y.; Lu, Y.; Yuille, A.L.; Shen, W. Glance-and-gaze vision transformer. Adv. Neural Inf. Process. Syst. 2021, 34, 12992–13003. [Google Scholar]
- Bai, J.; Yuan, L.; Xia, S.T.; Yan, S.; Li, Z.; Liu, W. Improving Vision Transformers by Revisiting High-frequency Components. arXiv 2022, arXiv:2204.00993. [Google Scholar]
- Cao, Y.H.; Yu, H.; Wu, J. Training vision transformers with only 2040 images. arXiv 2022, arXiv:2201.10728. [Google Scholar]
- Liu, Y.; Sun, Y.; Xue, B.; Zhang, M.; Yen, G.G.; Tan, K.C. A survey on evolutionary neural architecture search. IEEE Trans. Neural Netw. Learn. Syst. 2021, 34, 550–570. [Google Scholar] [CrossRef]
- Ren, P.; Xiao, Y.; Chang, X.; Huang, P.Y.; Li, Z.; Chen, X.; Wang, X. A comprehensive survey of neural architecture search: Challenges and solutions. ACM Comput. Surv. (CSUR) 2021, 54, 1–34. [Google Scholar] [CrossRef]
- Hu, Y.Q.; Yu, Y. A technical view on neural architecture search. Int. J. Mach. Learn. Cybern. 2020, 11, 795–811. [Google Scholar] [CrossRef]
- Elsken, T.; Metzen, J.H.; Hutter, F. Neural architecture search: A survey. J. Mach. Learn. Res. 2019, 20, 1997–2017. [Google Scholar]
- Chitty-Venkata, K.T.; Emani, M.; Vishwanath, V.; Somani, A.K. Neural Architecture Search for Transformers: A Survey. IEEE Access 2022, 10, 108374–108412. [Google Scholar] [CrossRef]
- Chen, B.; Li, P.; Li, C.; Li, B.; Bai, L.; Lin, C.; Sun, M.; Yan, J.; Ouyang, W. Glit: Neural architecture search for global and local image transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision; IEEE: New York, NY, USA, 2021; pp. 12–21. [Google Scholar]
- Li, C.; Tang, T.; Wang, G.; Peng, J.; Wang, B.; Liang, X.; Chang, X. Bossnas: Exploring hybrid cnn-transformers with block-wisely self-supervised neural architecture search. In Proceedings of the IEEE/CVF International Conference on Computer Vision; IEEE: New York, NY, USA, 2021; pp. 12281–12291. [Google Scholar]
- Gong, C.; Wang, D.; Li, M.; Chen, X.; Yan, Z.; Tian, Y.; Chandra, V. NASViT: Neural Architecture Search for Efficient Vision Transformers with Gradient Conflict aware Supernet Training. In Proceedings of the International Conference on Learning Representations, Vienna, Austria, 4–8 May 2021. [Google Scholar]
- Liu, Z.; Li, D.; Lu, K.; Qin, Z.; Sun, W.; Xu, J.; Zhong, Y. Neural architecture search on efficient transformers and beyond. arXiv 2022, arXiv:2207.13955. [Google Scholar]
- Wu, B.; Li, C.; Zhang, H.; Dai, X.; Zhang, P.; Yu, M.; Wang, J.; Lin, Y.; Vajda, P. Fbnetv5: Neural architecture search for multiple tasks in one run. arXiv 2021, arXiv:2111.10007. [Google Scholar]
- Ni, B.; Meng, G.; Xiang, S.; Pan, C. NASformer: Neural Architecture Search for Vision Transformer. In Asian Conference on Pattern Recognition; Springer: Cham, Switzerland, 2022; pp. 47–61. [Google Scholar]
- Chefer, H.; Gur, S.; Wolf, L. Transformer interpretability beyond attention visualization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 782–791. [Google Scholar]
- Rigotti, M.; Miksovic, C.; Giurgiu, I.; Gschwind, T.; Scotton, P. Attention-based Interpretability with Concept Transformers. In Proceedings of the International Conference on Learning Representations, Vienna, Austria, 4–8 May 2021; Available online: https://openreview.net/forum?id=Qaw16njk6L (accessed on 18 April 2023).
- Sun, M.; Ma, H.; Kang, G.; Jiang, Y.; Chen, T.; Ma, X.; Wang, Z.; Wang, Y. VAQF: Fully Automatic Software-hardware Co-design Framework for Low-bit Vision Transformer. arXiv 2022, arXiv:2201.06618. [Google Scholar]
- Jamil, S.; Abbas, M.S.; Umair, M.; Hussain, Y. A review of techniques and challenges in green communication. In Proceedings of the 2020 International Conference on Information Science and Communication Technology (ICISCT), Karachi, Pakistan, 8–9 February 2020; pp. 1–6. [Google Scholar]
- Jamil, S.; Rahman, M. A Comprehensive Survey of Digital Twins and Federated Learning for Industrial Internet of Things (IIoT), Internet of Vehicles (IoV) and Internet of Drones (IoD). Appl. Syst. Innov. 2022, 5, 56. [Google Scholar] [CrossRef]
- Hu, E.J.; Shen, Y.; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, S.; Wang, L.; Chen, W. Lora: Low-rank adaptation of large language models. arXiv 2021, arXiv:2106.09685. [Google Scholar]
- Dehghani, M.; Djolonga, J.; Mustafa, B.; Padlewski, P.; Heek, J.; Gilmer, J.; Steiner, A.; Caron, M.; Geirhos, R.; Alabdulmohsin, I.; et al. Scaling vision transformers to 22 billion parameters. arXiv 2023, arXiv:2302.05442. [Google Scholar]
- Fang, Y.; Sun, Q.; Wang, X.; Huang, T.; Wang, X.; Cao, Y. EVA-02: A Visual Representation for Neon Genesis. arXiv 2023, arXiv:2303.11331. [Google Scholar]
- Zheng, Z.; Ma, M.; Wang, K.; Qin, Z.; Yue, X.; You, Y. Preventing Zero-Shot Transfer Degradation in Continual Learning of Vision-Language Models. arXiv 2023, arXiv:2303.06628. [Google Scholar]
Figure 1.
ViT for Image Classification.

Figure 2.
Use of ViTs for CV applications.

Figure 3.
Organization of the survey.

Figure 4.
Number of publications in each year from 2017 to 2023 based on Web of Science.

Figure 5.
Number of publications by different publishers from 2017 to 2023 based on Web of Science.

Figure 6.
Leading countries working on transformers in CV based on Web of Science.

Figure 7.
Article Selection Algorithm

Figure 8.
Organization of the Section 3.
Figure 8.
Organization of the Section 3.


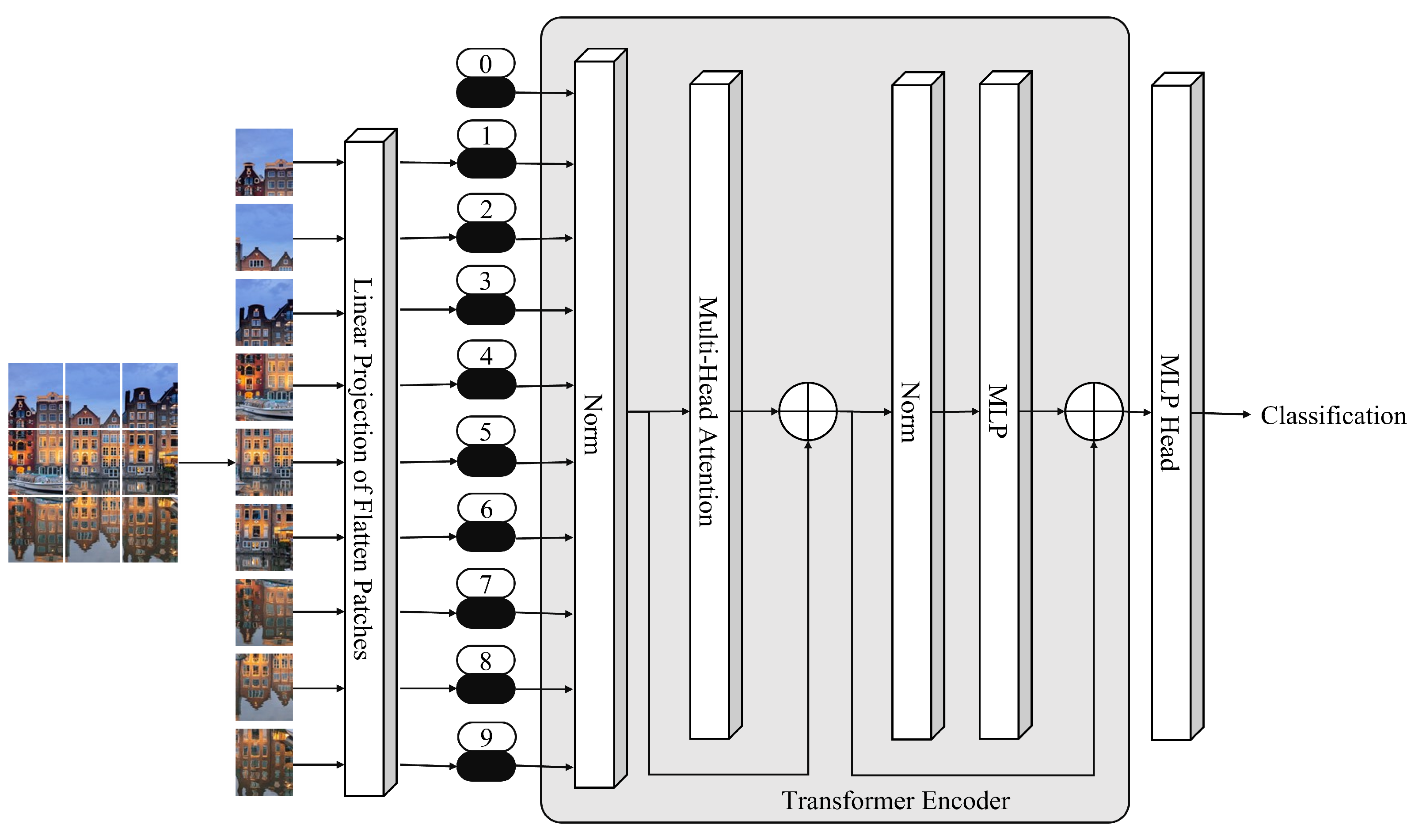{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
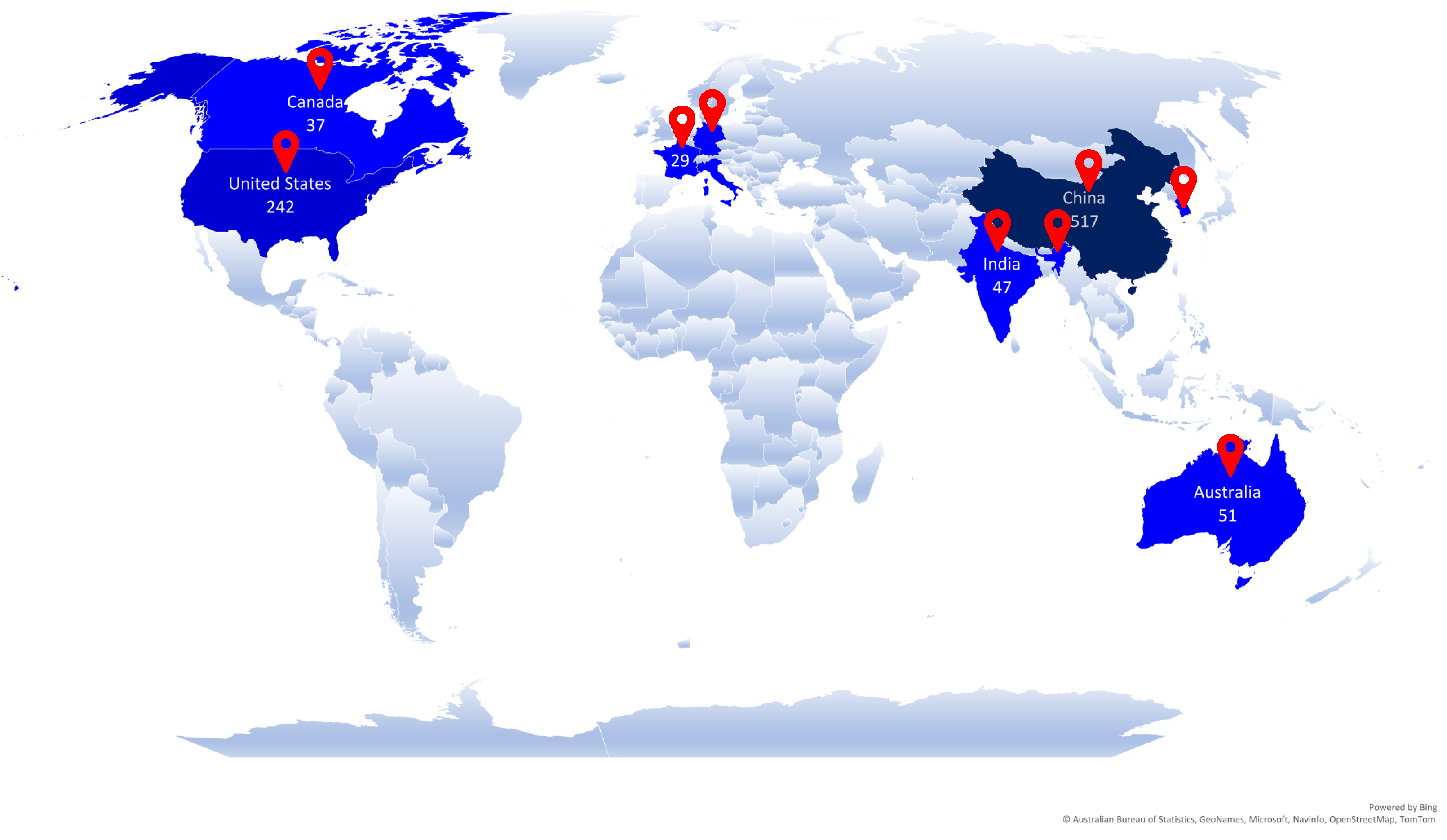{kind=link}
{kind=link}
{kind=link}
Table 1.
Summary of the available surveys on ViTs.
| Survey | Year | Scope | Contributions and Limitations | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Class. | Det. | Seg. | Com. | Super Res. | Den. | AD. | |||
| [26] | 2020 |  |  | | | | | |
|
| [27] | 2022 |  | | | | | | |
|
| [28] | 2021 | | | | | | | |
|
| [30] | 2022 | | | | | | | |
|
| [31] | 2022 | | | | | | | |
|
| Our survey | 2023 | | | | | | | |
|
Class.—classification; Det.—detection; Seg.—segmentation; Com.—compression; Super Res.—super-resolution; AD.—anomaly detection; ![Drones 07 00287 i001]() —fully explained;
—fully explained; ![Drones 07 00287 i002]() —partially explained;
—partially explained; ![Drones 07 00287 i003]() —not explained.
—not explained.
—fully explained; —partially explained; —not explained.Table 2.
ViT for Image Classification.
| Research | Model | Dataset | Objective Classification | Accuracy |
|---|---|---|---|---|
| [32] | CrossViT-9† | ImageNet1K | Image | 77.100% |
| CrossViT-15† | 82.300% | |||
| CrossViT-18† | 82.800% | |||
| CrossViT-15 | CIFAR10 | Image | 99.000% | |
| CIFAR100 | 90.770% | |||
| Pet | Pet classification | 94.550% | ||
| Crop Diseases | Crop disease classification | 99.970% | ||
| ChestXRay8 | Chest X-ray classification | 55.890% | ||
| CrossViT-18 | CIFAR10 | Image | 99.110% | |
| CIFAR100 | 91.360% | |||
| Pet | Pet classification | 95.070% | ||
| Crop Diseases | Crop diseases | 99.970% | ||
| ChestXRay8 | Chest X-rays | 55.940% | ||
| [33] | CTNet | AID | Remote sensing scene | 97.700% |
| NWPU-RESISC45 | 95.490% | |||
| [34] | MIL-ViT | APTOS2019 | Fundus image | 97.900% |
| RFMiD2020 | 95.900% | |||
| [36] | ET-GSNet | AID | Remote sensing images | 96.880% |
| NWPU-RESISC45 | 94.500% | |||
| UCM | 99.290% | |||
| OPTIMAL-31 | 96.450% | |||
| [37] | DHViT | Trento | Hyperspectral & LiDAR | 99.580% |
| Houston 2013 | 99.550% | |||
| Houston 2018 | 96.400% | |||
| [38] | ForestViT | PUAS | Satellite imagery multilabel | 94.280% |
| [39] | LeViT | Chinese asphalt pavement | Pavement image | 91.560% |
| German asphalt pavement | 99.170% | |||
| [40] | ViT | Malicious drone | Malicious drones | 98.300% |
| [46] | ViT | Real X Rays | Femur fracture | 83.000% |
| [47] | SeedViT | Maize seeds | Maize seed quality | 96.700% |
| [48] | DOViT | GAOs-1 | Air quality | 90.320% |
| GAOs-2 | 92.780% | |||
| [49] | MITformer | UCM | Remote sensing scene | 99.830% |
| AID | 97.960% | |||
| NWPU | 95.930% |
https://github.com/IBM/CrossViT (accessed on 19 April 2023); https://github.com/greentreeys/MIL-VT (accessed on 19 April 2023); https://github.com/facebookresearch/LeViT (accessed on 19 April 2023).
Table 3.
ViT for Object Detection.
| Research | Model | Dataset | Objective | Perf. Metric | Value |
|---|---|---|---|---|---|
| [53] | YOLOS | COCO | Object detection | 42.000 | |
| [57] | ViT | Satellite images | Manipulation detection | F1-score | 0.354 |
| JI | 0.275 | ||||
| [58] | BrT | ScanNet-V2 | 3D object detection | [email protected] | 55.200 |
| SUN RGB-D | 48.100 | ||||
| [61] | ViT | ScanNet-V2 | 3D object detection | [email protected] | 52.800 |
| SUN RGB-D | 45.200 |
https://github.com/hustvl/YOLOS (accessed on 19 April 2023); https://github.com/zeliu98/Group-Free-3D (accessed on 19 April 2023).
Table 4.
ViT for Image Segmentation.
| Research | Model | Dataset | Objective | Performance Metric | Value |
|---|---|---|---|---|---|
| [65] | TransUNet | MICCAI 2015 | Medical image segmentation | Dice score | 77.480% |
| [66] | ViTBIS | MICCAI 2015 | Medical image segmentation | Dice score | 80.450% |
| HD | 21.240% | ||||
| [68] | LAVT | RefCOCO | Image segmentation | IoU | 72.730% |
| RefCOCO+ | 62.140% | ||||
| G-Ref (UMD partition) | 61.240% | ||||
| G-Ref (Google partition) | 60.500% | ||||
| [80] | UNetFormer | MSD | Liver segmentation | Dice score | 96.030% |
| HD | 7.210% | ||||
| Tumor segmentation | Dice score | 59.160% | |||
| HD | 8.490% | ||||
| BraTS 2021 | Brain tumor segmentation | Dice score | 91.540% |
https://github.com/Beckschen/TransUNet (accessed on 19 April 2023); https://github.com/Project-MONAI/research-contributions (accessed on 19 April 2023).
Table 5.
ViT for Anomaly Detection.
| Research | Model | Dataset | Objective | Perf. Metric | Value |
|---|---|---|---|---|---|
| [116] | VT-ADL | MNIST | Anomaly detection | PRO | 0.984 |
| MVTec | 0.807 | ||||
| BTAD | 0.890 | ||||
| [118] | AnoViT | MNIST | Anomaly detection | AUROC | 92.400% |
| CIFAR | 60.100% | ||||
| MVTec | 78.000% | ||||
| [119] | TransAnomaly | Pred1 | Anomaly detection | AUC | 84.000% |
| Pred2 | 96.100% | ||||
| Avenue | 85.800% | ||||
| TransAnomaly | Pred1 | 86.700% | |||
| Pred2 | 96.400% | ||||
| Avenue | 87.000% |
https://github.com/pankajmishra000/VT-ADL (accessed on 19 April 2023); https://github.com/tkdleksms/LG_ES_anomaly (accessed on 19 April 2023).
Table 6.
Summary of the open-source ViTs present in the literature for different applications of CV.
Table 6.
Summary of the open-source ViTs present in the literature for different applications of CV.
| Research | Year | Model Name | CV Application | Source Code |
|---|---|---|---|---|
| [1] | 2021 | PiT |
| https://github.com/naver-ai/pit (accessed on 19 April 2023) |
| [16] | 2020 | ViT |
| https://github.com/google-research/vision_transformer (accessed on 19 April 2023) |
| [19] | 2021 | Swin Transformer |
| https://github.com/microsoft/Swin-Transformer (accessed on 19 April 2023) |
| [32] | 2021 | Cross-ViT |
| https://github.com/IBM/CrossViT (accessed on 19 April 2023) |
| [122] | 2021 | CeiT |
| https://github.com/rishikksh20/CeiT-pytorch (accessed on 19 April 2023) |
| [128] | 2022 | Swin Transformer V2 |
| https://github.com/microsoft/Swin-Transformer (accessed on 19 April 2023) |
| [129] | 2021 | DVT |
| https://github.com/blackfeather-wang/Dynamic-Vision-Transformer (accessed on 19 April 2023) |
| [130] | 2021 | PVT |
| https://github.com/whai362/PVT (accessed on 19 April 2023) |
| [131] | 2021 | Twins |
| https://github.com/Meituan-AutoML/Twins (accessed on 19 April 2023) |
| [132] | 2021 | Mobile-ViT |
| https://github.com/apple/ml-cvnets (accessed on 19 April 2023) |
| [133] | 2021 | Refiner |
| https://github.com/zhoudaquan/Refiner_ViT (accessed on 19 April 2023) |
| [134] | 2021 | DeepViT |
| https://github.com/zhoudaquan/dvit_repo (accessed on 19 April 2023) |
| [135] | 2021 | DeiT |
| https://github.com/facebookresearch/deit (accessed on 19 April 2023) |
| [136] | 2021 | Visformer |
| https://github.com/danczs/Visformer (accessed on 19 April 2023) |
Pooling-based Vision Transformer, Vision transformer, Dynamic vision transformer, Pyramid vision transformer, Deeper vision transformer, Data-efficient image Transformer, Convolution-enhanced image Transformer; Image classification, Detection, Segmentation, Video action classification, e Robustness evaluation.
Table 7.
ViTs for drone imagery.
| Ref. | Model | Dataset | Objective | Perf. Metric | Value |
|---|---|---|---|---|---|
| [142] | TransVisDrone |
| Drone detection | [email protected] |
|
| [146] |
| Date palm trees | Segmentation | mIoU |
|
| [146] |
| Date palm trees | Segmentation | mF-Score |
|
| [146] |
| Date palm trees | Segmentation | mAcc |
|
| [150] | TPH-YOLOv5 | VisDrone2021 | Object detection | mAP |
|
| [151] |
| VisDrone-DET2021 | Object detection | AP |
|
https://github.com/tusharsangam/TransVisDrone (accessed on 19 April 2023), https://github.com/cv516Buaa/tph-yolov5 (accessed on 19 April 2023); mean intersection over union, mean F-Score, mean accuracy, mean average precision. red color text: Worst performing model, green color text: best-performing model.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Jamil, S.; Jalil Piran, M.; Kwon, O.-J. A Comprehensive Survey of Transformers for Computer Vision. Drones 2023, 7, 287. https://doi.org/10.3390/drones7050287
AMA Style
Jamil S, Jalil Piran M, Kwon O-J. A Comprehensive Survey of Transformers for Computer Vision. Drones. 2023; 7(5):287. https://doi.org/10.3390/drones7050287
Chicago/Turabian StyleJamil, Sonain, Md. Jalil Piran, and Oh-Jin Kwon. 2023. "A Comprehensive Survey of Transformers for Computer Vision" Drones 7, no. 5: 287. https://doi.org/10.3390/drones7050287