Building a Taiwan Law Ontology Based on Automatic Legal Definition Extraction


Department of Computer Science & Information Engineering, National Chung Cheng University, No.168, Sec. 1, University Rd., Minhsiung, Chiayi 62102, Taiwan
*
Author to whom correspondence should be addressed.
Appl. Syst. Innov. 2018, 1(3), 22; https://doi.org/10.3390/asi1030022
Submission received: 2 April 2018
/
Revised: 22 June 2018
/
Accepted: 24 June 2018
/
Published: 27 June 2018
Abstract
:Term extraction is an important task that automatically extracts relative terms from the texts in a given domain. A significant number of web applications need to model information for specific topics. In particular, we have explored a Taiwan government website that maintains the Laws & Regulations Database of the Republic of China (R.O.C) to provide the current Chinese law text to the public. However, the main issue is that there is no efficient structured method to handle such a large number of law texts. Therefore, in this paper, we propose a novel approach to extract legal as well as domain-relative terms, and then build a law ontology. We used the current Chinese law text from the Laws & Regulations Database as the data source. We then utilized natural language processing tools and data mining techniques to extract legal keywords and their definitions automatically. Subsequently, we constructed a Taiwan law ontology with the legal keywords and relative definitions. We have extracted 1114 legal keywords with definitions. With the characteristics of an ontology, users can view one keyword with its information and the associated keywords. Furthermore, we provide a service, which includes both the graphical and text interfaces to users on the web, such that a user can readily access the legal information on the Internet.
1. Introduction
With the prevalence of the Internet, people tend to search information, for example, that concerning laws on the Web. However, it may take users a lot of time to acquire the "right" information since there is a lack of structured methods to effectively express the information. Furthermore, the content of some specific domain knowledge is too hard for users to fully understand. In those countries governed by law, law involves a legal compelling force to secure civil rights. Law systems can be classified into two categories: common law and continental law. Taiwan adopts the continental law system whereby law is a social norm, and numbers of laws and regulations have been enacted to deal with possible arguments or conflicts that people may encounter in their daily life. Therefore, it is important for people to know the definitions of legal terms as they are used in specific laws.
In Taiwan’s legal system, there are rules to name laws and regulations. According to Articles 2 and 3 of the Central Regulation Standard Act [1], statutes are named as acts, penal acts, special acts or comprehensive acts. Other ordinances publicized by a government agency according to their properties are named organic rules, norm rules, enforcement rules, directive rules, guidance rules, standard rules or canon rules. Currently, there are over six thousand laws and regulations, classified as acts or rules, in Taiwan. The Laws & Regulations Database of the Republic of China (Taiwan) is a legal platform on the Internet designed to provide the latest news and a query function [2]. It is convenient for people to acquire legal information; however, understanding this legislation still requires a certain level of knowledge on the part of the public. Hence, organizing and identifying professional knowledge by technical methods, and providing an easy and convenient service for users have become a potential issue of knowledge retrieval. Considering that the number of laws is huge and they are mostly expressed in a descriptive way without proper structural form, it is difficult for users to understand the legislation immediately. Thus, the goal of this paper is to develop a tool that facilitates expressing knowledge related to Taiwan’s laws and making the legal information more accessible to users.
In the field of knowledge engineering, the semantic web is an extension of the web through standards by the World Wide Web Consortium (W3C); these standards promote common data formats and exchange protocols on the Web [3]. Ontology is a knowledge representation method in the semantic web, which originated in the field of philosophy and which concerns what entities exist or can be said to exist [4]. In computer science, ontology is a practical application of philosophical ontology, which defines the types, properties, and interrelationships of the entities that really or fundamentally exist in particular domain knowledge [5]. In this paper, based on the current legal database, words can be analyzed by extracted keywords [6] and Chinese word segmentation tools. Chinese is more complex than English in terms of natural language processing (NLP) [7] because it does not use spaces to separate words. Therefore, using a Chinese word segmentation tool to pre-process the Chinese text is necessary. The legal keywords and their relative definitions from statutes can then be extracted using an automatic method. In our previous work [6], support vector machine (SVM) and expertise knowledge were used to automatically extract legal keywords from Taiwan’s law database. Based on the extracted legal keywords, we proceed to find the existing relationships between the keywords. To make our ontology closer to the characteristics of laws, we compared the existing elements of the ontologies from different domains, and established the elements of the ontology which are suitable for the field of law. There were also a number of issues that needed to be addressed. First, it is a challenge to figure out the related attributes and the relationships between each keyword. Second, it is also a challenge to identify and label the important keywords from a large number of keywords in statutes. The third issue is how to provide a graphical way to display the law ontology.
The previous methods of ontology construction usually required extensive involvement of experts in the field, which takes a great deal of human resources and time. In this paper, an automatic tool is proposed to construct the law ontology from Taiwan’s law database. With this automatic tool, we believe it would be beneficial to both law experts, such as law professors, judges, and lawyers, and to the general public. Therefore, the expected contributions of this paper are listed as follows:
- We design an efficient approach to structuring law information and extracting legal keywords and their relative definitions automatically using data mining and automatic methods.
- A user-friendly, graphical user interface (GUI) that adopts our proposed approach is implemented to allow users to access legal keywords effectively.
- We consider the related attributes and relationships among keywords to retrieve not only the legal terms, but also the relevant definitions by integrating the patterns discovered by law experts into our extraction process.
- The proposed method aims to enhance the usage of legal knowledge by using ontology technology. In the evaluation section, we show that our approach compared with the conventional methods which only provide keyword searching in statutes is able to provide in-depth legal term retrievals.
The rest of this paper is organized as follows: Section 2 explores related works on ontology and the semantic web. Section 3 illustrates our approaches to automatically building the Taiwan law ontology. The implementation and evaluation are described in Section 4. The discussion of this paper is presented in Section 5, and the conclusions are also presented in Section 5.
2. Related Work
The survey of current approaches, algorithms and tools are related to our approach. The details are given in the following section.
2.1. Chinese Word Segmentation
In this paper, we propose an approach to automatically extract law terms and their definitions so as to construct a law ontology. Much current state-of-the-art research has explored automation strategies [8,9,10,11] to support various online applications. In the following sections, we describe the related work in terms of Chinese word segmentation and ontology.
2.2. Chinese Word Segmentation
NLP, an active research area in artificial intelligence, aims to enable computers to understand human language. There are many challenging tasks in NLP, such as sentence segmentation, word segmentation [12], and part-of-speech tagging [13]. Word segmentation is the process of dividing continuous text into meaningful units. In English and many other written languages, the space is a good punctuation mark for delimiting words. However, the Chinese written language does not mark word boundaries in such a fashion. As a consequence, when processing Chinese text, word segmentation is an important process that separates continuous sentences into separate words. There are many Chinese word segmentation tools including CKIP [14], ICTCLAS [15], etc. Taking Chinese text as inputs, these tools are able to mark the boundaries from the Chinese text to Chinese meaning units and even add part-of-speech tagging (POS tagging) to each unit. This POS tagging is very helpful for computers to determine the grammatical type of the word.
2.3. Ontology
2.3.1. The Definition of Ontology
In knowledge engineering, the most popular definition of ontology was proposed by Gruber in 1993 [16]: "An ontology is an explicit specification of a conceptualization". Ontology is a formal description of the concepts and relationships that can represent the knowledge of a specific domain. Furthermore, an ontology can be regarded as the set of terms in the field of particular domain knowledge. To represent concepts that belong to the domain knowledge, each term is described by its attributes and relationships to other terms. Ontology already has several mature applications in many domains. These ontologies are available for public use. For example, WordNet is a lexical database of the English language [17]; it groups English words into synonyms called synsets. WordNet has been administered by George Armitage Miller of the Cognitive Science Laboratory of Princeton University since 1985. In recent years, WordNet has been widely extended from English to other languages. Another application of ontology is Gene Ontology (GO) [18] which provides an ontology of defined terms representing gene product properties. Gene Ontology aims to provide an efficient way to store and display complicated biological information, saving searching time. Yet another application of ontology is BabelNet [19], a multilingual lexicalized semantic network. For learners, BabelNet is a language learning tool that provides a search engine for multiple languages. The ontology applications mentioned above are aimed at building general ontologies for common knowledge in each language. These ontologies are designed for some specific domains; nevertheless, when they are used to express domain-specific knowledge, they might not be available to describe that specific knowledge accurately. In this paper, we construct an ontology for legal domain knowledge with the objective of precisely expressing the legal knowledge. Although ontologies are applied in different fields, contemporary ontologies share similar structures. Figure 1 is a good example from the Protege Ontology 101 page [20]. It describes the category, the place of production and much information about wine to integrate a wine ontology. In Figure 1, the black and red boxes represent classes and instances, respectively, while the links represent the relationships between classes and instances. An ontology consists of the following common components:
- Classes, also called sets, collections, or concepts, are the core component of an ontology. Classes present the concepts in the field.
- Attributes, also called aspects, properties, features, characteristics, or parameters, actually act as conceptual components of class.
- Individuals are also called instances or objects. An individual is a thing or entity in reality.
- Relations are used by classes or individuals to relate to one another.
Since ontologies are made up of these ontology components, sharing ontologies becomes more convenient and formal.
2.3.2. The Ontology Construction Methods
With the spread of the application of ontologies, previous studies have built ontologies in various domains. In addition, previous research has promoted automatic [21] or semi-automatic [22,23] construction methods to enhance the efficiency of ontology construction. One study [23] extracted health records from a database and encoded them into ontological structured data for constructing a health ontology system, which shares the information within the healthcare community. Another work [24] constructed a law enforcement ontology by collecting thousands of sanitized emails between law enforcement investigators over a three-year period as its data source. In order to improve the ability to describe law enforcement events, the research defined the domain-specific ontology components. Another work [25] created an ontology of maritime information in Chinese. When extracting terms from Chinese text, this research calculated the weight of each term. A term has a higher weight when it is regarded as a proper term in the maritime area. As a consequence, those terms with a high weight are considered as a suitable class in maritime ontology. The above-mentioned construction methods aim to build domain ontologies efficiently. On the other hand, another work [26] focused on providing web services and visualization for law ontology related to the domestic law of Korea. It also supports associated search functions, providing an easy and convenient service from the user’s perspective. Although there are many ontology construction methods, there is a lack of an ontology for the legal domain in Taiwan. In order to build a law ontology, we cooperated with Taiwanese law experts as well as using the laws and regulations of Taiwan as the data source. In other words, we aimed to identify the features in law statutes using an automatic method to construct a law ontology for Taiwan.
2.3.3. Ontology Language and Ontology Editor
An ontology is a formal way to describe knowledge expression, and can be applied in a wide range of fields. There are many traditional syntax ontology languages, such as CycL [27], and DOGMA [28]. To provide a unified standard of constructed ontology, the W3C defines the standard of the Ontology Language, called OWL [29]. The OWL language is a family of knowledge representation languages for authoring ontologies in the semantic web, providing common frameworks that allow data to be shared and reused.
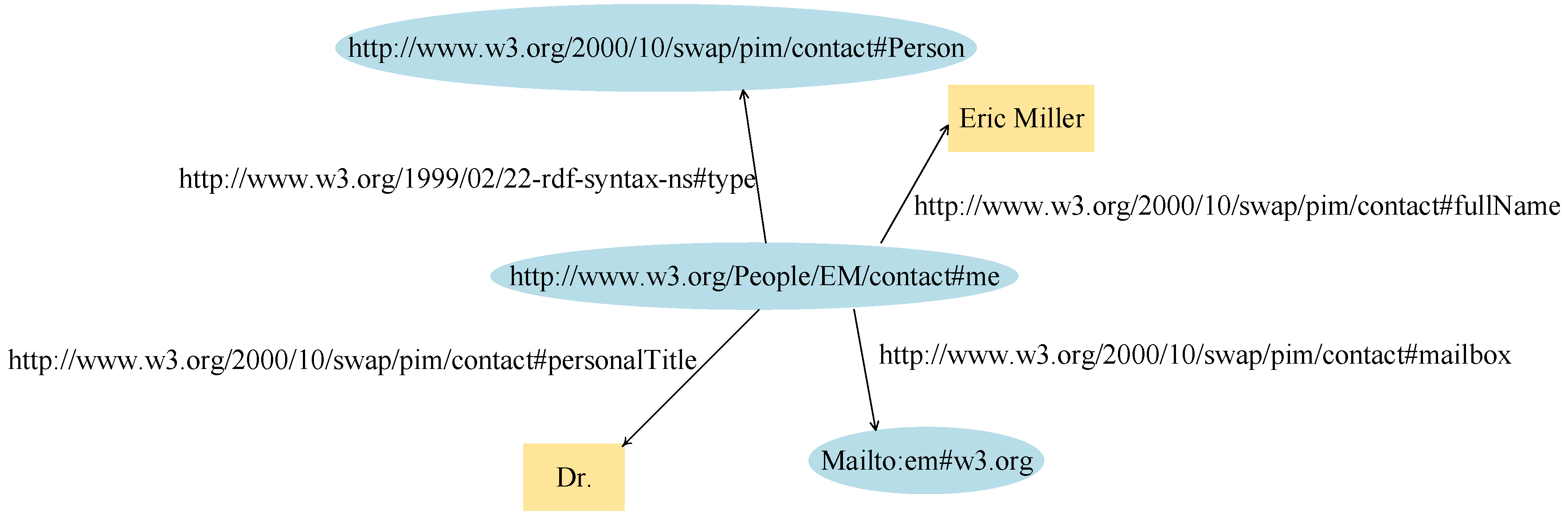
The OWL languages are characterized by formal semantics including SHOE [30], DAML + OIL [31], the Web Ontology Language [32], etc. They are built upon a W3C Extensible Markup Language (XML) [33] standard for objects called the Resource Description Framework (RDF) [34]. Extending from the RDF is the RDF Schema (Resource Description Framework Schema, variously abbreviated as RDFS, RDF(S), RDF-S, or RDF/S) [35], which is an extensible knowledge representation data model. The following example is taken from the W3C website [36] and describes the personal profile of a person whose name is Eric Miller, whose email address is e.miller123@example (changed for security purposes), and whose title is Doctor (Figure 2).
The resource [37] is a subject that includes the following objects:
- "Eric Miller" (with a predicate "whose name is").
- "mailto:e.miller123@example" (with a predicate "whose email address is").
- "Dr." (with a predicate "whose title is").
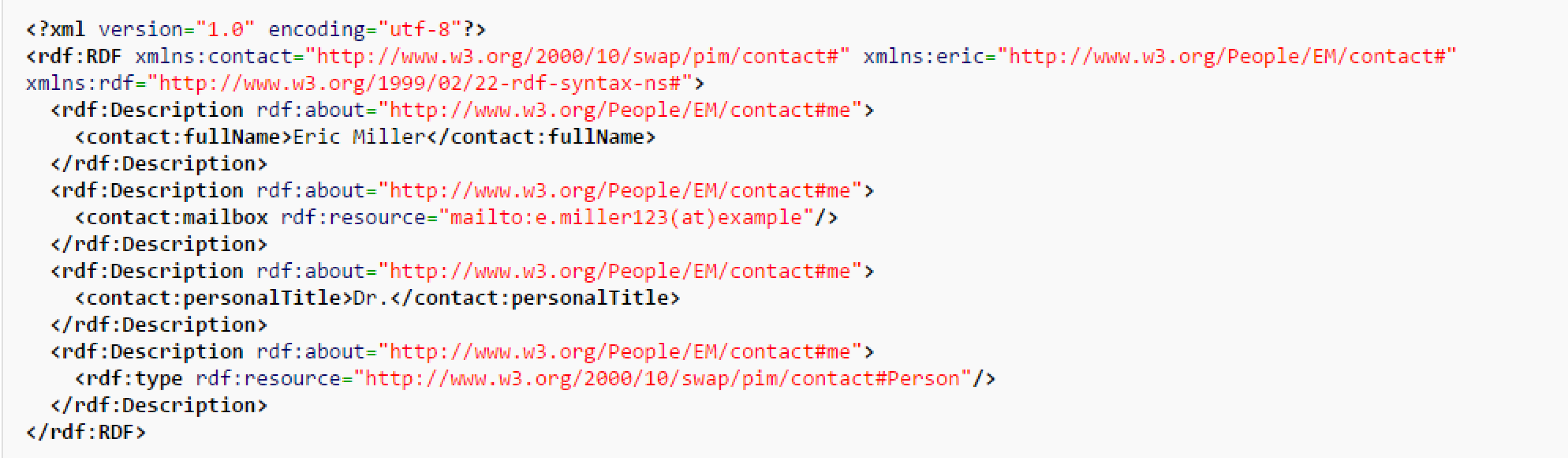
This information can also be written in RDF/XML format (Figure 3).
These RDF resources can be saved in a triple-store and searched by the query language SPARQL (a recursive acronym for SPARQL Protocol and RDF Query Language) [38]. Figure 4 shows the structure of the OWL languages.
The OWL languages aim to produce readable data for both humans and machines, but the huge number of labels makes it inconvenient for humans to read. There are many kinds of ontology editors: Protége [39], Knoodl [40], and OntoEdit [41], for instance. Ontology editors are applications designed to assist in the creation or manipulation of ontologies. Some of them also provide the function of exporting to other ontology languages. These ontology editors provide a user interface for experts to establish their domain ontology. However, these editors are not able to automatically create ontologies. In this paper, by automatic extraction of legal terms, definitions, and relations, we aim to build a law ontology automatically using Apache Jena, a Java Semantic Web framework [42], as the presentation tool. Apache Jena provides many application programming interfaces (APIs) for Java to write RDF graphs, such as RDF API [43] and Ontology API [44]. It also provides the Apache Jena Fesuki [45], which is a SPARQL server providing OWL data by JSON, XML and many other formats. In this paper, we use the Ontology API and Apache Jena Fesuki server to design the user interface for querying the law ontology.
3. System Architecture
Section 3.1 introduces our proposed system overview. Section 3.2 introduces the method of pre-processing the Chinese law text. Section 3.3 introduces the patterns found by law experts. Section 3.4 introduces how to classify the ontology using the Taiwan Six Codes structure. Section 3.5 describes our proposed ontology data model for constructing the Taiwan Law Ontology.
3.1. System Overview
The objective of this paper was to automatically construct a Taiwan law ontology based on Taiwan’s statutes. In particular, an automatic extraction mechanism was developed which extracts the definitions of legal keywords from various statutes. In this paper, we used the current Chinese law text from the Taiwan law database as the data source. The data sources of the statutes include acts, penal acts, special acts, and comprehensive acts. These acts are named according to Article two in the Central Regulation Standard Act [1]. There are 585 acts included in our data source. The number of statutes under each act is shown in Table 1.
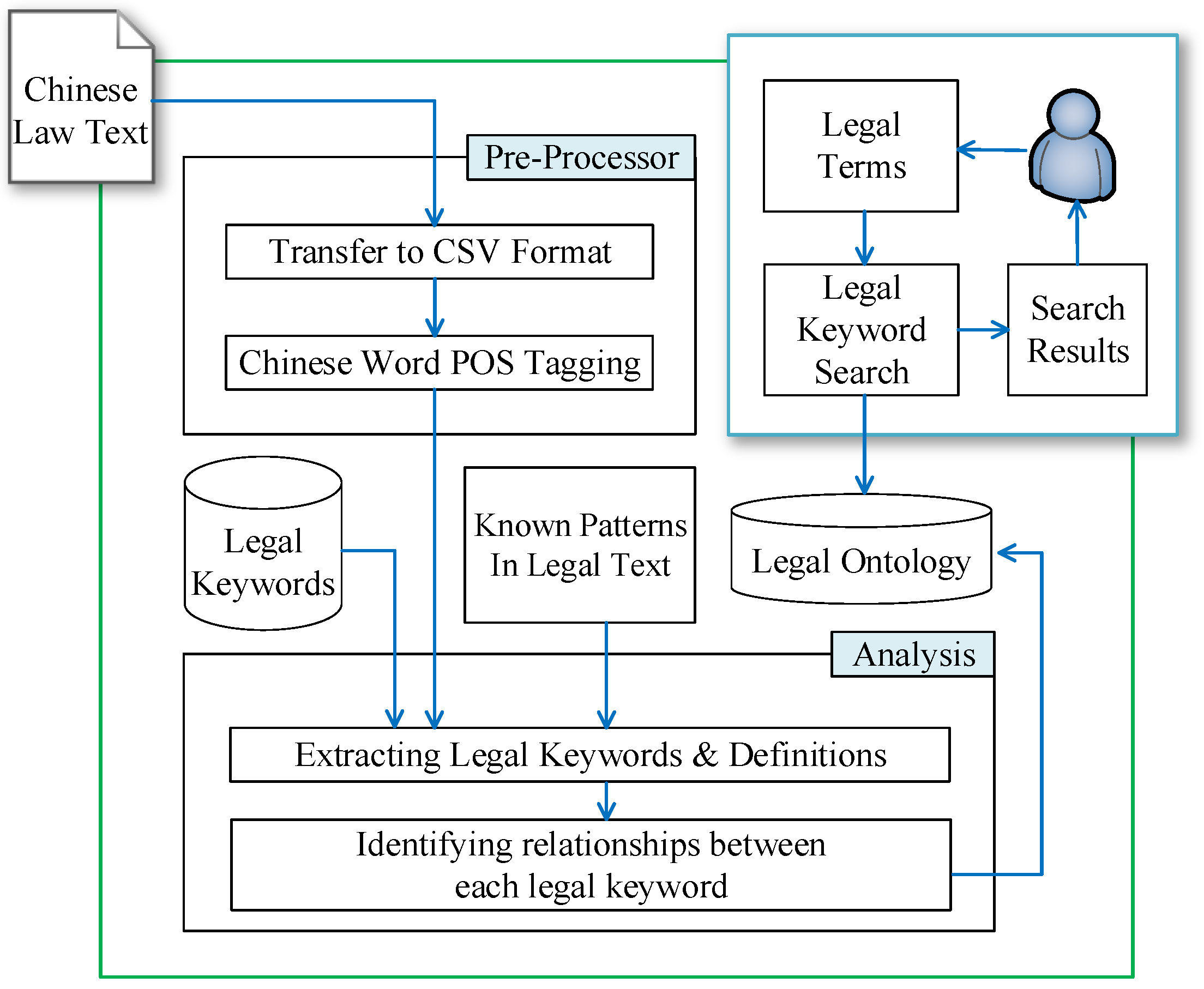
To construct the Taiwan law ontology, legal keywords were used as classes of this topology. The legal keywords used in this paper were obtained based on our previous work on the automatic extraction of legal keywords from Taiwan’s statutes [6]. Figure 5 shows the system architecture that consists of five steps to automatically construct the Taiwan law ontology. First, the Chinese legal texts are imported to the system and stored in csv format. Second, ICTCLAS, a Chinese word segmentation tool, is used to divide Chinese sentences into meaningful units (segments). In addition, it also adds the POS tag to each unit. The word segmentation and POS tagging performed in this step are critical to the following steps, especially the accuracy of the keyword definition and class relation in the ontology. Third, examples of patterns of legal definitions in the statutes were defined by law experts first. Based on these examples, patterns of legal definitions were transformed into regular expressions to facilitate the finding of legal definitions by string matching. By searching all statutes, all pairs of (keyword, legal definition) were automatically extracted, and each pair was associated with one or more originating statutes. Fourth, with the legal keywords, their relations with acts, statutes, and legal definition, the Taiwan law ontology data model was constructed with the aim of expressing the legal knowledge. Finally, we classify the classes of the ontology using the Taiwan Six Codes structure [46] and describe the ontology using the OWL Language. After we finished the law ontology construction, we built a web platform to provide a visualized presentation of the law Ontology information, which also has a search function. In the following, we describe the technical details of each step.
3.2. The Pre-Processing of the Data
In order to use Taiwan statutes as the data source for automatic topology construction, pre-processing the raw data obtained from the website of the Ministry of Justice, Taiwan was necessary to facilitate later processing. Taiwan’s acts are formed with articles, but each article might contain one or more statute sentences. Thus, storing each article in csv format could ease the processing of the articles sentence by sentence, and extracting the legal keywords and definitions. With csv format, when there are multiple statute sentences in the article, they will be separated by a special character: the half-width colon. As a consequence, it becomes much easier for computers to identify and process one single statute sentence at a time. After each sentence has been properly separated, the next issue is dividing the Chinese sentences into meaningful units and adding POS tags. As previously mentioned, ICTCLAS was used for this purpose. In addition to these steps, the pre-processing step also needs to determine the number of column-type items as well as remove polished words in statute sentences.
3.3. Patterns of Legal Definitions
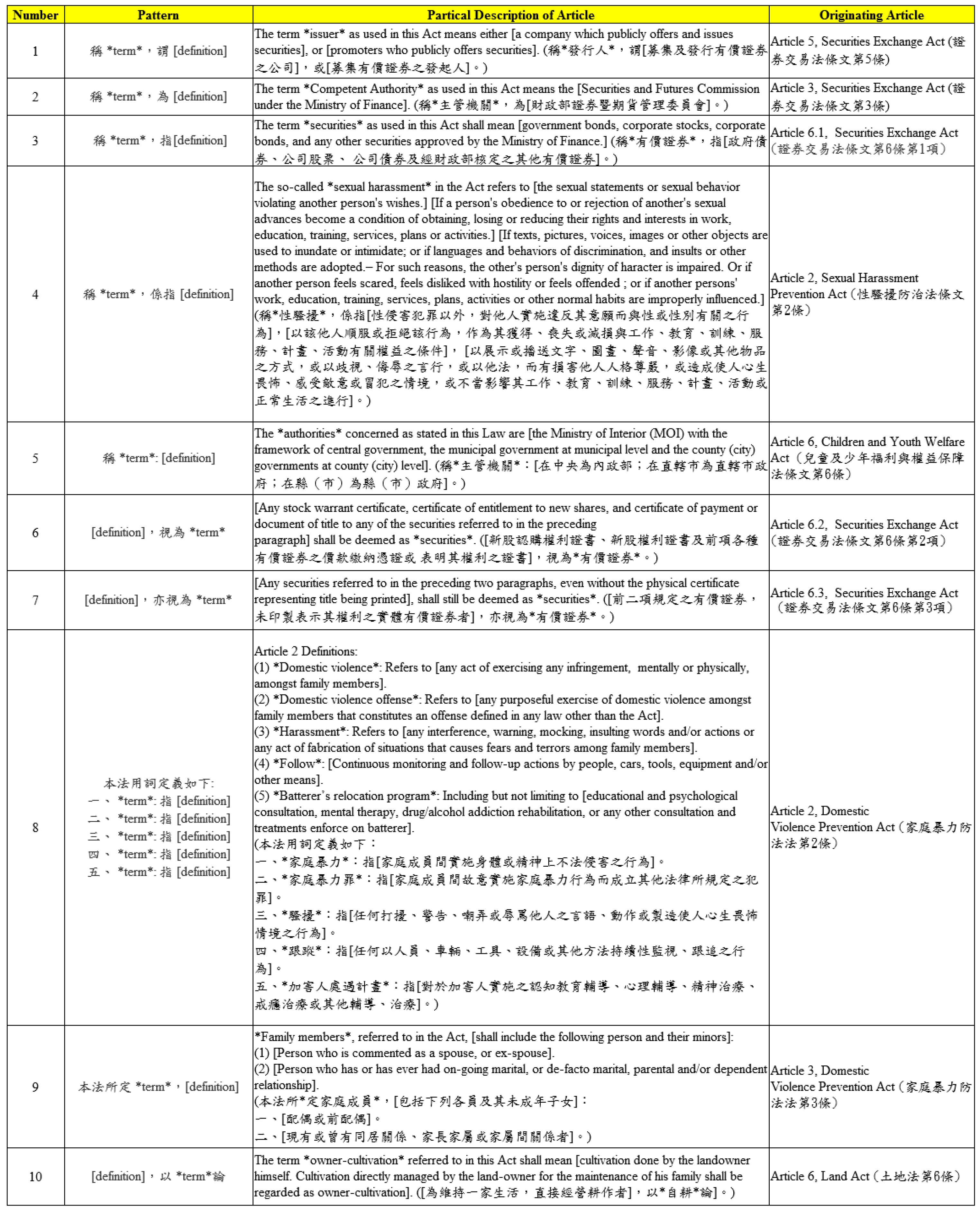
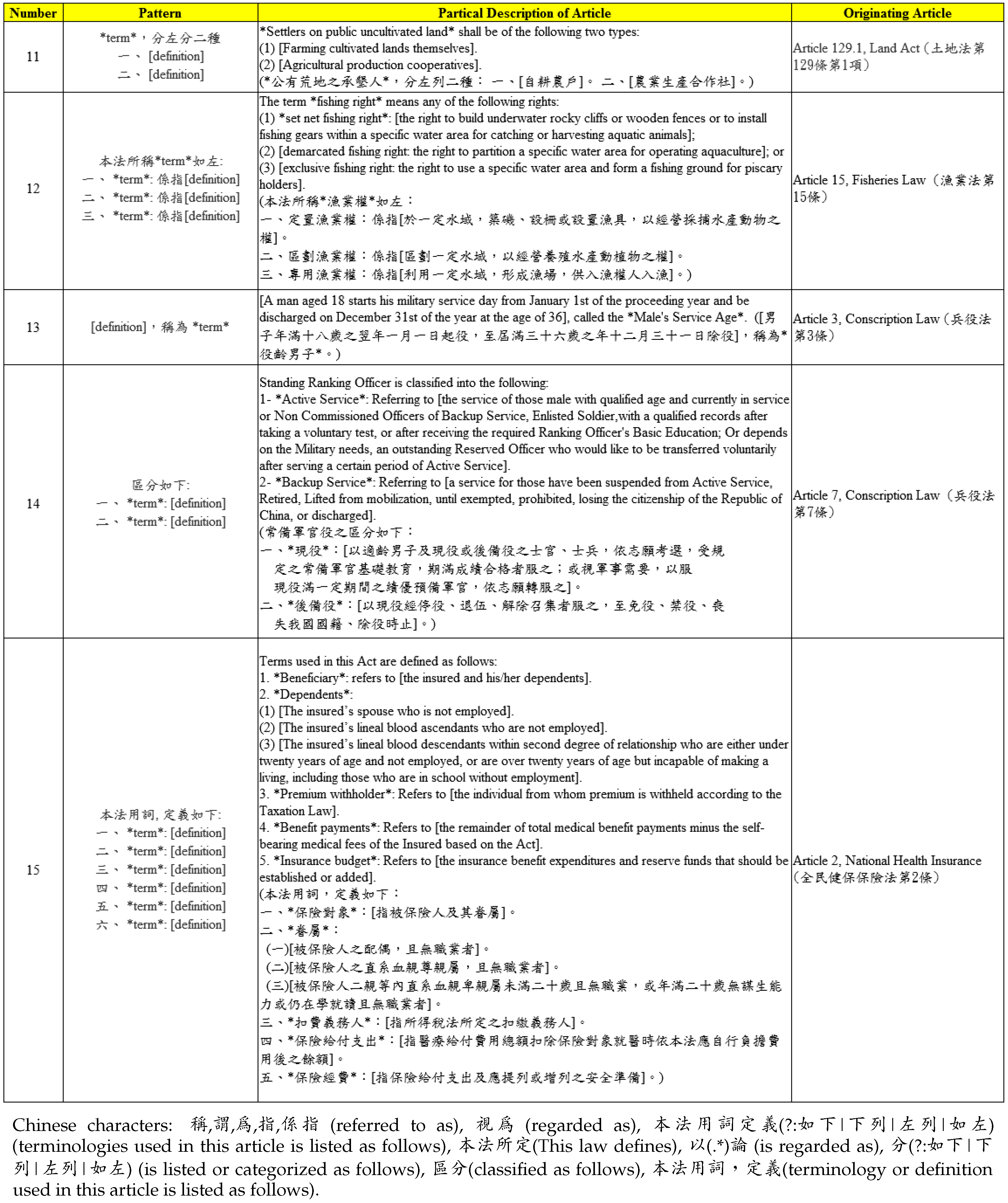
In order to extract the legal definitions of legal keywords, we first had law experts collect example patterns of legal definitions appearing in Taiwan statutes. Figure 6 shows the legal definition patterns found by the law experts. These patterns are given in the format of (pattern, partial sentence, originating article). The pattern consists of some special Chinese characters and grammar. The partial sentence gives an example of how a keyword is defined by this pattern. In total, the law experts found 15 patterns are listed in Figure 6. These patterns were then transformed into regular expressions. Due to the power of regular expression, we were able to merge two or three patterns into a single regular expression. The final regular expressions we derived are shown in Table 2.
3.4. The Taiwan Six Codes Structure
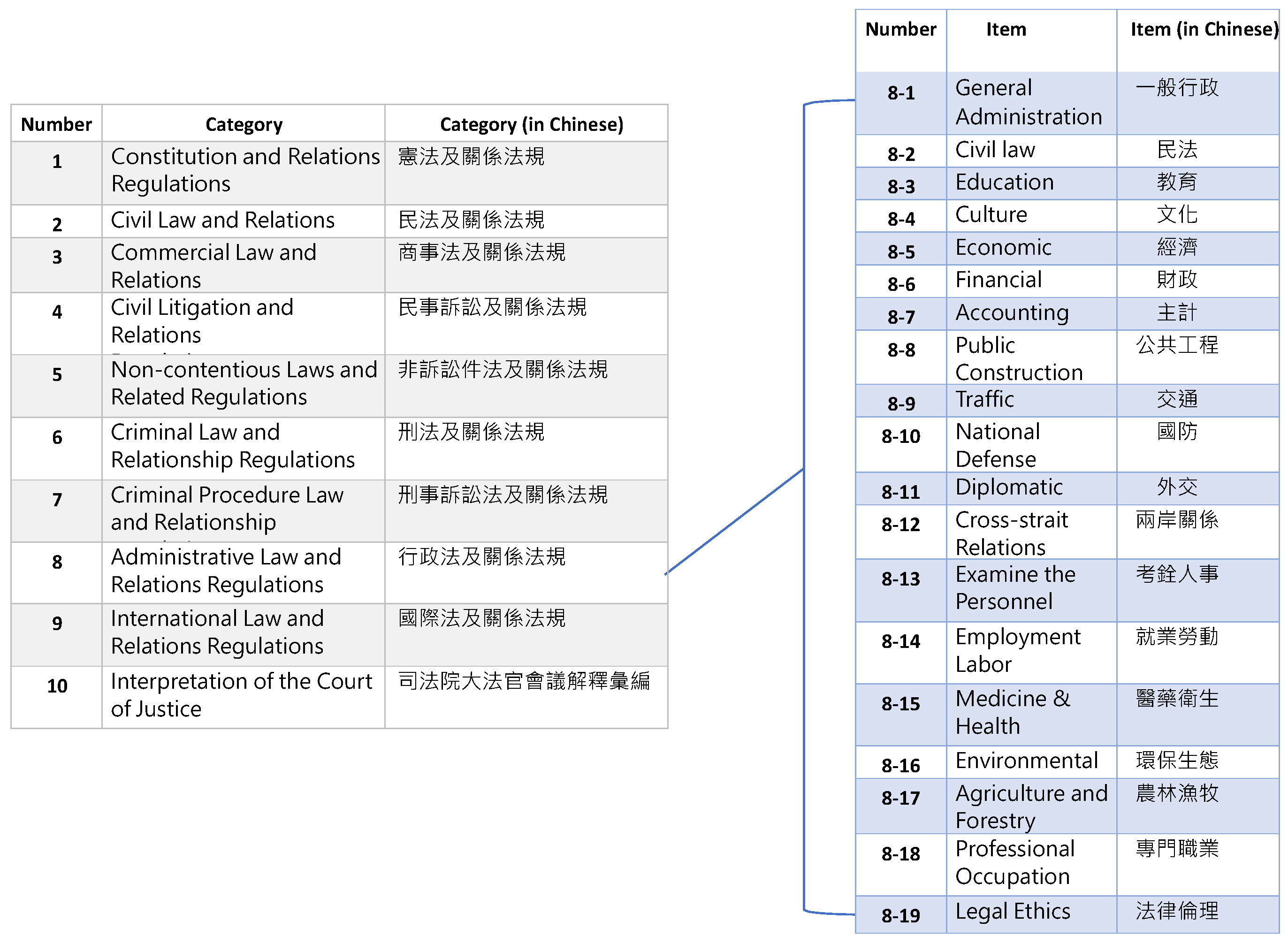
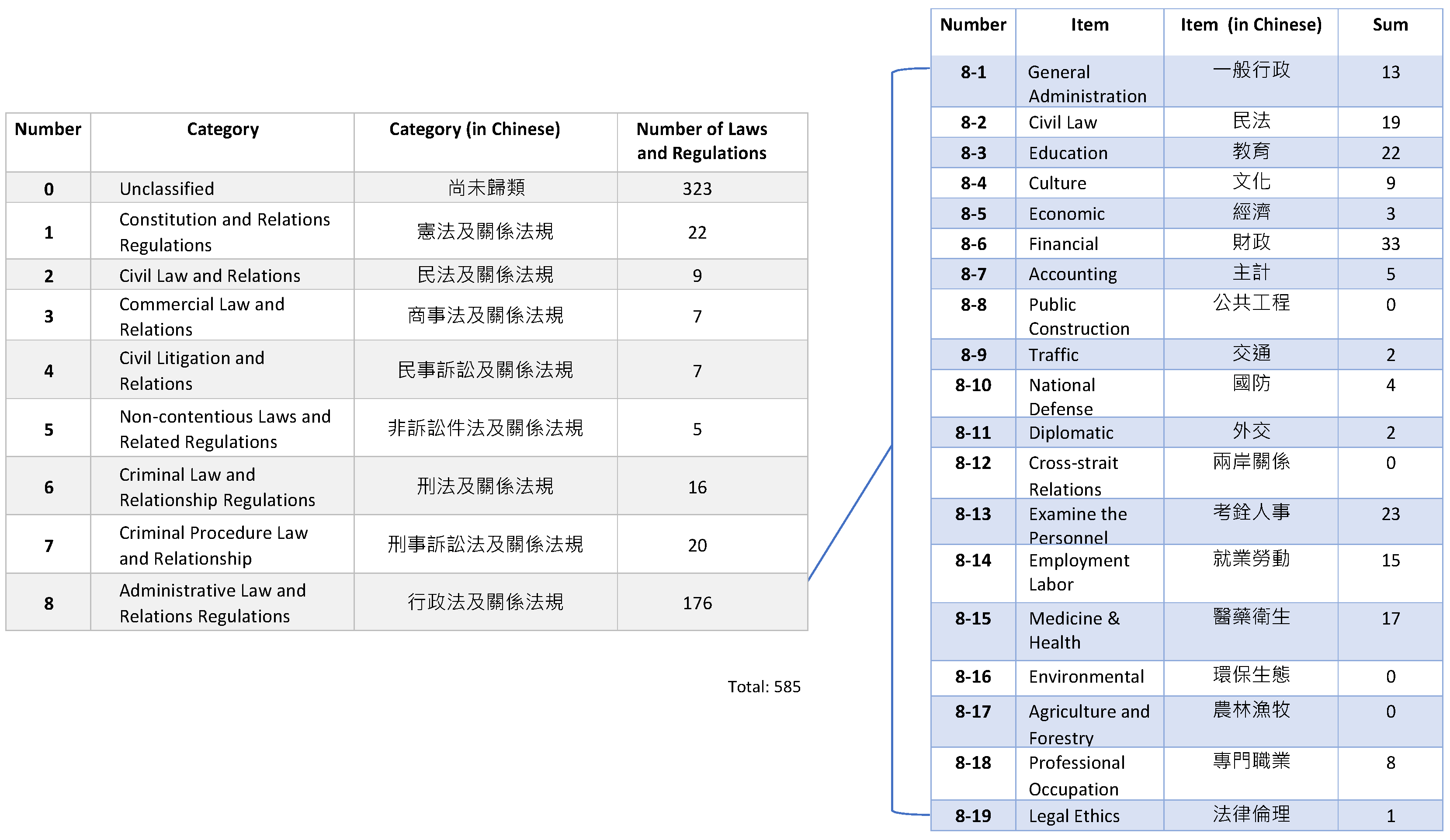
There are many laws and regulations; furthermore, the lack of a categorization structure makes it difficult to sort them systematically. To categorize the laws and regulations clearly, we adopted the Taiwan Six Codes structure, the W.N. structure, which was proposed by the Wu-Nan Culture Enterprise. Figure 7 shows the W.N. structure in which the laws and regulations are divided into 10 categories.
However, the W.N. structure could not categorize the laws and regulations completely. After consulting with several law experts, we modified the classification structure as follows:
- Remove category 9 and category 10 which are unsuitable for our classification structure.
- Add category 0 to collect those laws and regulations that cannot be classified into any other category. For example, The Indigenous People’s Basic Law (原住民基本法) cannot to be classified into any of the existing categories, so it can be categorized into category 0.
The proposed classification structure is more suitable for categorization, and is shown in the following figure (Figure 8). We developed the classification classes in our law ontology based on this classification structure. The classification classes are described in detail in Section 3.5.
3.5. Ontology Data Model
The Taiwan law ontology we built consists of the following components: class, instance, relation, and attributes. In this topology, classes are concepts or categories. Specifically, each legal keyword extracted automatically from the statutes/articles is defined as a class. Furthermore, the classifications from the Taiwan Six Codes structure are also defined as classes.
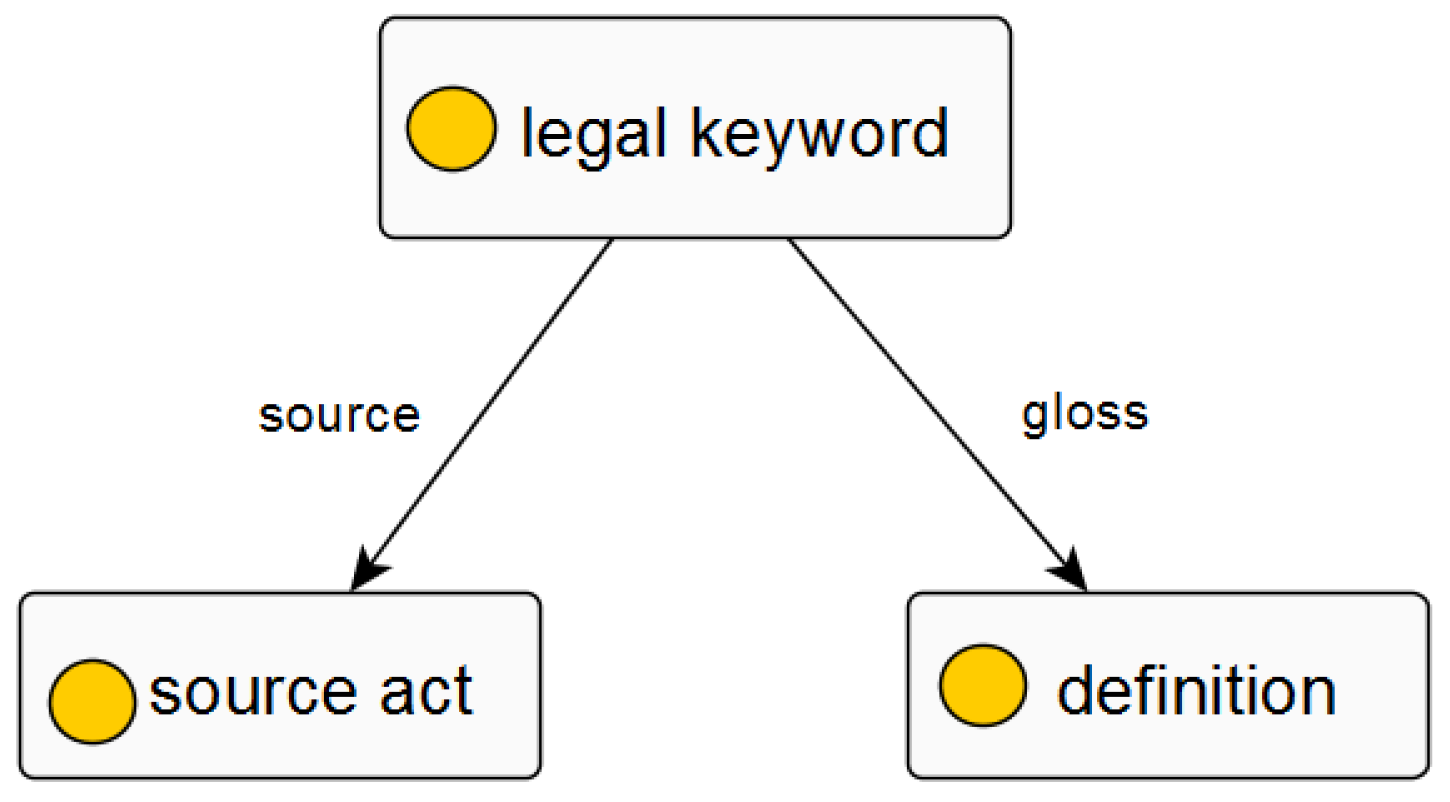
Each class may have the following attributes: , , . The attribute describes from which statute and article number the class was extracted. The attribute is the key contribution of this paper which gives the automatic extracted legal definition for the class by using the aforementioned definition pattern. Figure 9 shows a basic class with its attributes and .The attribute is used to describe a concrete object of the class. Notably, since each legal keyword may appear in more than one statute and has more than one legal definition, each of these source statutes and definitions is described by separate attributes. In other words, each class may have multiple , , or attributes.
Let us examine an example which shows the need for multiple attributes. Figure 10 shows Article 6 in the Consumer Protection Law [D3JSDOC]. The phrase "competent authorities" is identified as a legal keyword by our system. The article also matches one of the legal definition patterns. However, with the ICTCLAS tool, the auto extraction system is able to identify that the definition part consists of three sub-sentences, each of which defines a different level of administrative authority, namely, central government level, municipal level and county/city level. Consequently, the "competent authorities" class will be constructed with attributes as shown in Figure 11. The attribute indicates that its source article is "Article 6 in the Consumer Protection Law". We give the an additional tag to differentiate which level of the instance. Specifically, , , indicates the administrative authority at the county/city, municipal, and central level, respectively. In addition, in order to distinguish different components in the ontology graph, different colors and symbols are used to represent different components. The classes and attributes are represented by yellow circles and the instances are illustrated by purple diamonds.
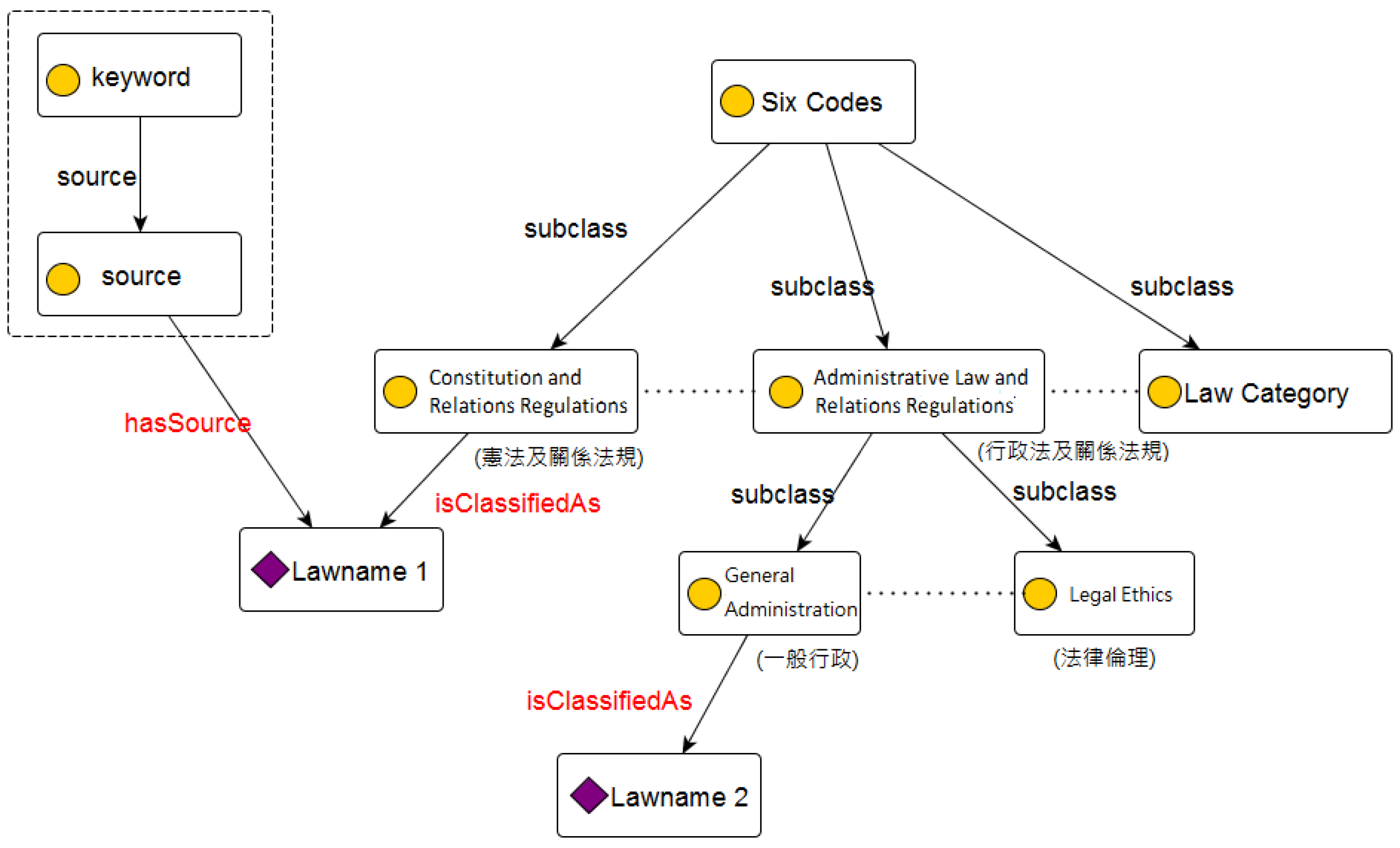
There are six types of relations between two classes: , , , , , and . First, the relation, denoted by a pointed arrow between two classes describes that the origin class is the superclass of the pointed class. It is also often referred to as . Second, the relation means that the pointed class appears in the legal definition of the origin class of the pointed arrow. This relation is a specially designed relation for the purpose of this topology. Third, the relation between two classes means that they share the same source statute. Fourth, the relation, which is also denoted by a pointed arrow between two classes indicates that the origin class can be divided into the pointed classes. Each pointed class is a part of the origin class. The origin class might have multiple relations with multiple pointed classes. All the pointed classes constitute the definition of the origin class. Fifth, the relation between a class and an instance is used in the Taiwan Six Code classification classes. This relation means that the instance belongs to the classification class. Finally, the relation between an attribute and an instance links the attribute to the relative instance. This relation indicates that the class can be classified into the Taiwan Six Code classification class. Figure 12 shows an example of the relations and .
4. Approach Implementation and Evaluation
In this section, we describe the various steps that were required to create the Taiwan law ontology, including extracting the keywords and definitions from the statutes, constructing the ontology, and storing the ontology in the RDF storage. Finally, the web-based interface is presented which makes the ontology more convenient for users to access the professional legal knowledge. We performed the data pre-processing, extraction of the legal keywords and definitions, and the ontology construction with Jena API [44,45,46] in Java. We constructed the Web-based Services using PHP and JavaScript, and implemented the method for accessing the database using SPARQL.
4.1. Extracting Legal Keywords and Definitions
This paper aims to design and implement the Taiwan law ontology based on extracted legal keywords and definitions automatically. The first step is to gather the legal keywords and relative definitions. As with the aforementioned methods in Section 3.2 and Section 3.3, our data sources are the pre-processed laws and relations. We use the segmentation tool (ICTCLAS) as well as the 15 patterns in the regular expression format to assist in the process. The first statistics shown in Table 3 indicate the number of definitions found in the regular expression for each keyword. After inspecting the 15 patterns, we find that there are some patterns with more than one keyword and definition in the article, for example, pattern number 8 and pattern number 15 in Table 2. These kinds of statutes might contain multiple keywords and definitions. After adjusting the judgment program, we obtained the second set of statistics. In Table 3, there are dramatic improvements in the second set of statistics for pattern number 8 and pattern number 15.
4.2. Law Ontology Construction and Storage
In this step, we utilize those extracted data from Section 4.1 to implement the law ontology. The first step is to extract the keywords from the patterns or judged from the statutes by SVM [6], then convert them into classes with their attributes. When constructing the attributes of the class, the relative definition was created as the and the law article source was created as the . The attribute format needs to contain the referenced statute’s name and the article number in detail. That will make it clear for users to look up the whole article content at a glance in the source statutes. The format is: "", as in the example: "" (消費者保護法–第六條). By verifying the keyword, if it is equal to or contains the words "competent authorities" (主管機關or 主辦機關) at the end of the keyword string, it may have the attribute in the statutes. Therefore, we have to identify out the different level competent authorities, create these competent authorities as instances, and give additional tags to differentiate which level of the instance it is.
When converting those keywords into classes, we notice that the definitions of several keywords vary according to the different sources. In this case, we create one keyword as a unique class with multiple attributes and . Thus, we have 1333 keywords and their definitions, but the number of classes in the ontology will be 1114 after the combination. However, the "competent authorities" keywords are not used in this situation. Although the "competent authorities" keywords may be the same in words, they represent different administrative units in different statutes. The following table shows the statistical number of the ontology class and the competent authorities class (Table 4).
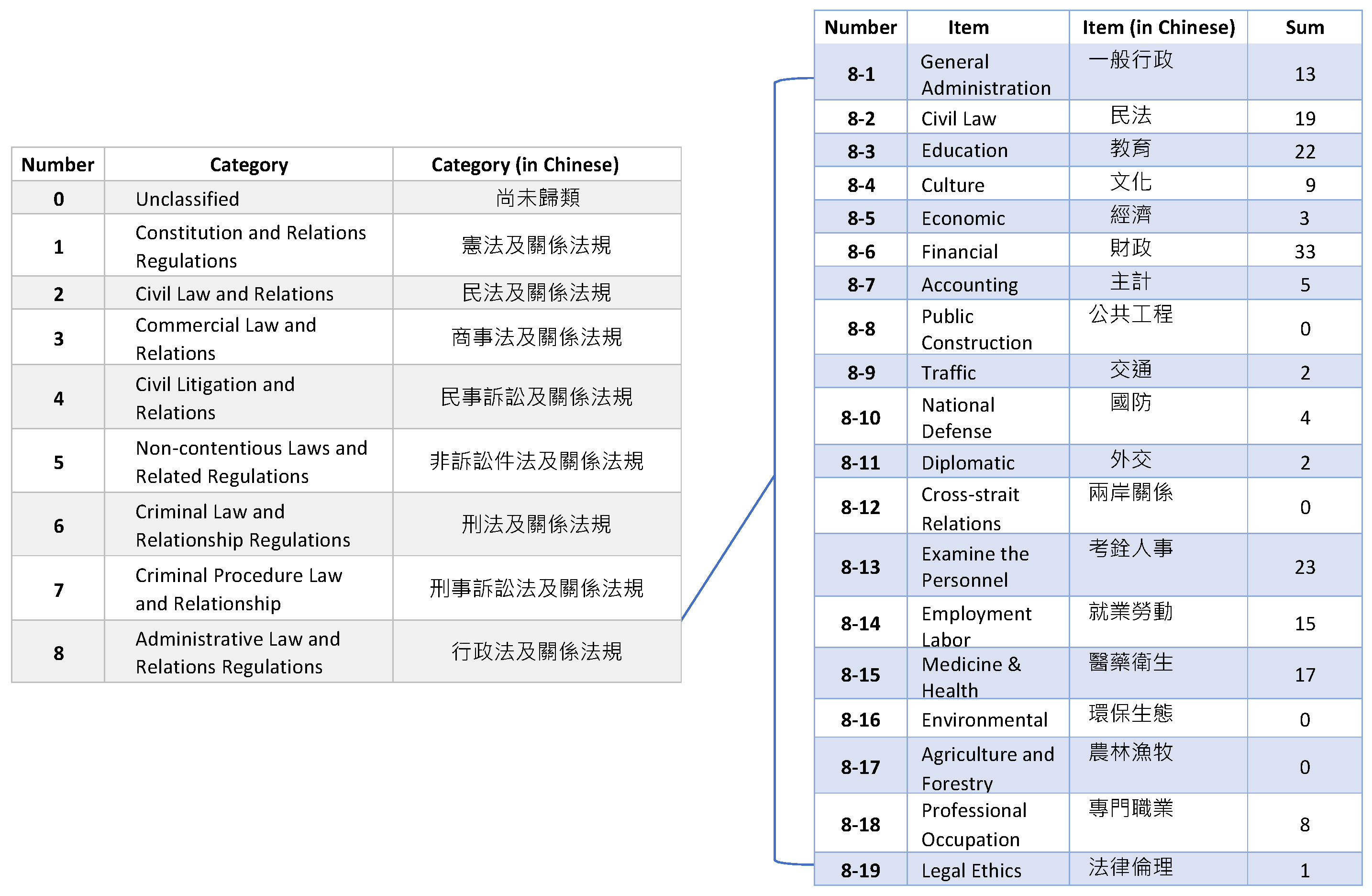
The second step is to construct the Six Code classification classes that have already been described in detail in Section 3.4. Figure 13 shows the number of laws and regulations in each classification.
The last step is to link the six types of relations between the classes in the ontology. The rule of each type relation has been described in detail in Section 3.5. The table below shows the number of each type of relation in the law ontology (Table 5). After the ontology construction, we use the Jena TDB dataset storage to store the ontology [46]. When storing the ontology in Jena TDB, we name each class with its own URI. Therefore, we can utilize the Apache Jena Fuseki Server [45] with the SPARQL query language and the class’s URI to access the class and its related information in the law ontology, which is provided to users via the Web.
4.3. The Web-Based Service
4.3.1. Query Processing Engine
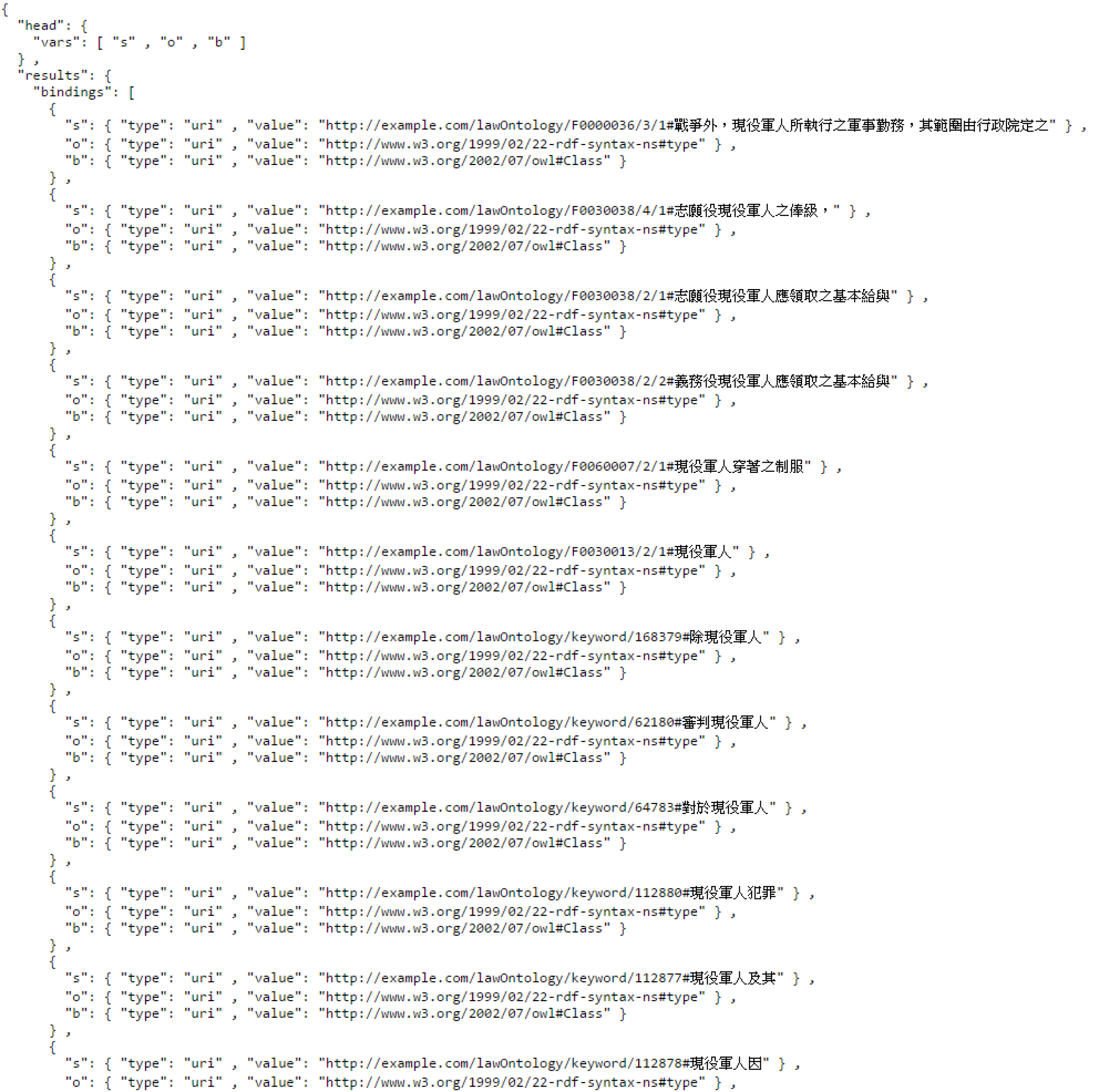
In this paper, we used the Apache Jena Fuseki Server connected to the Apache Jena TDB dataset. Fuseki is a SPARQL server via which we can access the data using the SPARQL protocol over HTTP. Following is a sample of the SPARQL query language (Table 6). With this type of query, we are able to obtain the search information in JSON format (In Figure 14, we enter "in-active-service soldiers (現役軍人).
4.3.2. The Graphical Interface
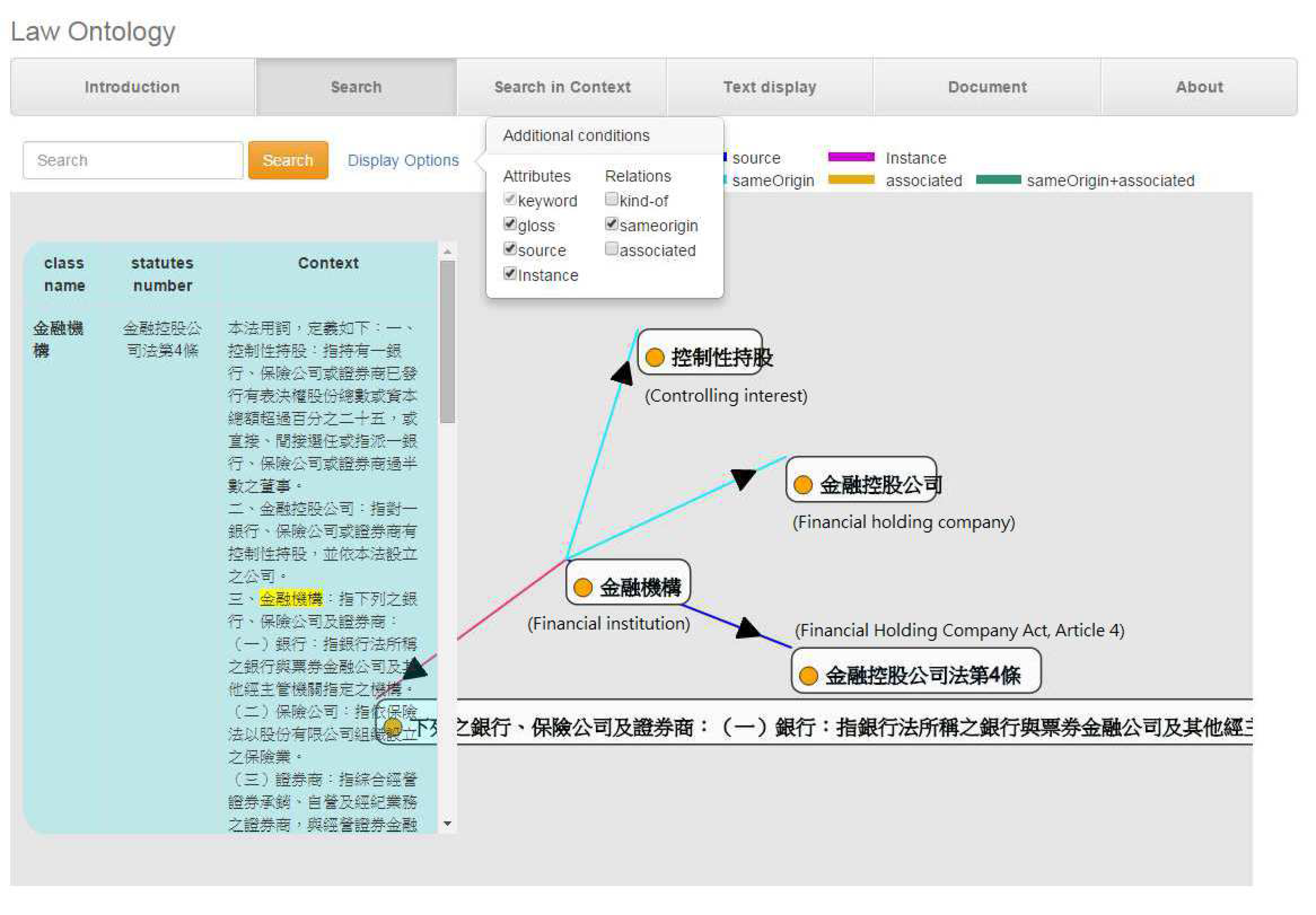
In the graphical interface, we used D3.js (Data-Driven Documents), which is a JavaScript library [47]. We transform the returned JSON data into an SVG graph and present the ontology-based data in the graphical interface. The classes, attributes and instances are represented by squares. Pointed arrows with different colors denote different types of relationships in the ontology. As we provide two view options, when the user enters the search keyword, he/she can also select the view option, either graphical or text. The graphical interface shows the ontology as a graph and lists the complete article in the left column. The graphical interface is illustrated in Figure 15, which shows the search result of using "financial institutions" (金融機構) as the search keyword.
4.3.3. The Text Interface
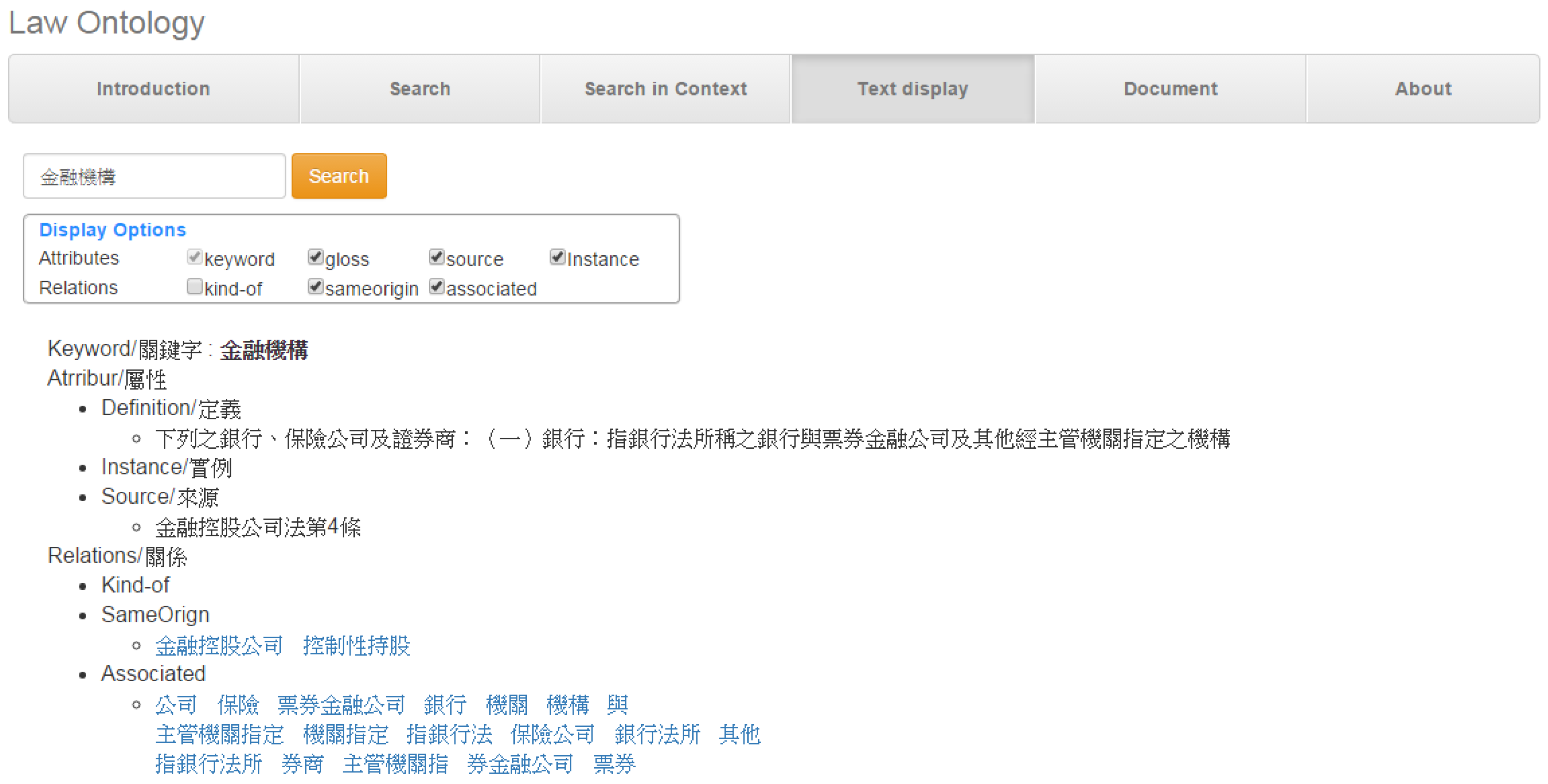
We also provide a text interface which only lists the ontology class and its detailed information. When users only need the text context, it is a succinct way to show the class and other relevant information. Figure 16 illustrates the text interface and shows the search result using "financial institutions" (金融機構) as the search keyword. Users can choose the most suitable interface to inspect the legal information. Both interfaces provide the search words with basic information (definitions, sources) and furthermore show the related legal keywords. Users can click on the related legal keywords which will show the detailed information using the same format.
4.4. The Evaluation of Keyword Extraction
After automatically extracting legal keywords and relative definitions, we invited a number of law experts to analyze the results manually. The total number of legal keywords and relative definitions is 1114. There are 681 legal keywords with correct definitions. On the other hand, there are 315 keywords with correct definitions, but these keywords are not regarded as legal keywords. Instead, they are just further explanations of some terms which appear in the statutes. Only 82 legal keywords are considered as having incorrect definitions. Furthermore, we collected the statistical number of patterns in different cases. The statistics are listed in the following table (Table 7). We found that pattern numbers 6, 9, 12, and 14 have a higher percentage of generating incorrect definitions, especially a large number of legal terms that are not keywords are generated by pattern numbers 6 and 9.
5. Discussion and Conclusions
We propose a novel approach to automatically extracting legal and domain-relevant terms and definitions by utilizing natural language processing tools and data mining techniques. We used a Taiwan’s Laws & Regulations Database as the data source, and cooperated with legal experts to make the information more useful via leveraging the automatically found legal keywords and definitions to construct the Taiwan law ontology. With the characteristics of an ontology which is also implemented as an application with both the graphical and text user interfaces, users can view one keyword with its information and the associated keywords. When examining the results of the automatically captured legal keywords and definitions, we identified some research directions for future works. First, the Chinese law text is unlexicalized, and there are more than 15 patterns in Taiwan laws and regulations. We can therefore increase the number of patterns, which will allow us to find more keywords and definitions. Second, we found that there were some results which could not be regarded as legal keywords and definitions. Rather, they were just some terms and further explanations used in the laws. To solve this situation, we can add the attributes and relations in our law ontology, and then the legal information can be expressed more completely. Finally, yet most importantly, although the automatic methods are convenient and rapid, the results still need manual verification by experts to ensure that they match their domain knowledge. We will enhance our approach by adopting deep learning techniques.
Author Contributions
R.-H.H.: conception and method design, data analysis, manuscript writing, final approval of manuscript; Y.-L.H.: conception and method design, manuscript writing, final approval of manuscript; Y.-T.C.: implementation, manuscript writing, final approval of manuscript.
Funding
This research received no external funding.
Acknowledgments
This research has been funded in part by the National Science Council under the Grants No. MOST 106-2221-E-194-021-MY3 and No. MOST 106-2221-E-194-047-MY2.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Central Regulation Standard Act. Available online: http://law.moj.gov.tw/eng/LawClass/LawAll.aspx?PCode=A0030133 (accessed on 20 June 2018).
- Laws & Regulations Database of The Republic of China. Available online: http://law.moj.gov.tw/Eng/ (accessed on 20 June 2018).
- Semantic Web. Available online: http://en.wikipedia.org/wiki/Semantic_Web#cite_note-1 (accessed on 20 June 2018).
- Ontology. Available online: http://en.wikipedia.org/wiki/Ontology (accessed on 20 June 2018).
- Ontology (Information Science). Available online: http://en.wikipedia.org/wiki/Ontology_(information_science) (accessed on 20 June 2018).
- Chen, C. Automatic Keyword Extraction and Chinese-English Word Alignment based on Law Database. Master’s Thesis, National Chung Cheng University, Chia-Yi, Taiwan, 2014. [Google Scholar]
- Natural Language Processing. Available online: http://en.wikipedia.org/wiki/Natural_language_processing (accessed on 20 June 2018).
- Huh, J.-H.; Seo, K. Hybrid advanced metering infrastructure design for micro grid using the game theory model. Int. J. Softw. Eng. Appl. 2015, 9, 257–268. [Google Scholar] [CrossRef]
- Huh, J.-H.; Otgonchimeg, S.; Seo, K. Advanced metering infrastructure design and test bed experiment using intelligent agents: Focusing on the plc network base technology for smart grid system. J. Supercomput. 2016, 72, 1862–1877. [Google Scholar] [CrossRef]
- Huh, J.-H. Smart grid framework test bed using opnet and power line communication. Adv. Comput. Electr. Eng. IGI Glob. USA 2017, 1–425. [Google Scholar] [CrossRef]
- Huh, J.-H. Plc-based design of monitoring system for ict-integrated vertical fish farm. Hum.-Cent. Comput. Inf. Sci. 2017, 7, 1–19. [Google Scholar] [CrossRef]
- Text Segmentation. Available online: http://en.wikipedia.org/wiki/Text_segmentation (accessed on 20 June 2018).
- Part-of-Speech Tagging. Available online: http://en.wikipedia.org/wiki/Part-of-speech_tagging (accessed on 20 June 2018).
- CKIP. Available online: http://ckip.iis.sinica.edu.tw/CKIP/index.htm (accessed on 20 June 2018).
- ICTCLAS. Available online: http://ictclas.nlpir.org/ (accessed on 20 June 2018).
- Gruber, T.R. A translation approach to portable ontology specifications. Knowl. Acquis. 1993, 5, 199–220. [Google Scholar] [CrossRef] [Green Version]
- WordNet. Available online: http://wordnet.princeton.edu/ (accessed on 20 June 2018).
- The Gene Ontology. Available online: http://www.geneontology.org/ (accessed on 20 June 2018).
- BabelNet. Available online: http://lcl.uniroma1.it/babelnet/ (accessed on 20 June 2018).
- Ontology Development 101: A Guide to Creating Your First Ontology. Available online: http://protege.stanford.edu/publications/ontology_development/ontology101-noy-mcguinness.html (accessed on 20 June 2018).
- Huh, J.-H. Big data analysis for personalized health activities: Machine learning processing for automatic keyword extraction approach. Symmetry 2018, 10, 1–30. [Google Scholar] [CrossRef]
- Ghosh, M.E.; Naja, H.; Abdulrab, H.; Khalil, M. Ontology learning process as a bottom-up strategy for building domain-specific ontology from legal texts. In Proceedings of the 9th International Conference on Agents and Artificial Intelligence (ICAART), Porto, Portugal, 24–26 February 2017. [Google Scholar]
- Kiong, Y.C.; Palaniappan, S.; Yahaya, N.A. Health ontology system. In Proceedings of the 2011 IEEE 7th International Conference on Information Technology in Asia (CITA 11), Sarawak, Malaysia, 12–13 July 2011; pp. 1–4. [Google Scholar]
- Johnson, J.R.; Miller, A.; Khan, L. Law enforcement ontology for identification of related information of interest across free text dcouments. In Proceedings of the 2011 IEEE European Intelligence and Security Informatics Conference (EISIC), Athens, Greece, 12–14 September 2011; pp. 19–27. [Google Scholar]
- Deng, L.; Wang, X. Context-based semantic approach to ontology creation of maritime information in Chinese. In Proceedings of the IEEE International Conference on Granular Computing (GrC), San Jose, CA, USA, 14–16 August 2010; pp. 133–138. [Google Scholar]
- Jo, D.W.; Kim, M.H. Web-based semantic web retrieval service for law ontology. In Proceedings of the 2013 IEEE 10th International Conference on High Performance Computing and Communications & 2013 IEEE International Conference on Embedded and Ubiquitous Computing (HPCC_EUC), Zhangjiajie, China, 13–15 November 2013; pp. 666–673. [Google Scholar]
- CycL. Available online: http://en.wikipedia.org/wiki/CycL (accessed on 20 June 2018).
- DOGMA, Short for Developing Ontology-Grounded Methods and Applications. Available online: http://en.wikipedia.org/wiki/DOGMA#References (accessed on 20 June 2018).
- Ontology Language. Available online: http://en.wikipedia.org/wiki/Ontology_language (accessed on 20 June 2018).
- SHOE Base Ontology. Available online: http://www.w3.org/2000/04shoe-swell/base-ns.html (accessed on 20 June 2018).
- DAML + OIL Web Ontology Language. Available online: http://www.w3.org/Submission/2001/12/ (accessed on 20 June 2018).
- OWL Web Ontology Language. Available online: http://www.w3.org/TR/owl-guide/ (accessed on 20 June 2018).
- Extensible Markup Language (XML). Available online: http://www.w3.org/XML/ (accessed on 20 June 2018).
- Resource Description Framework (RDF). Available online: http://www.w3.org/RDF/ (accessed on 20 June 2018).[Green Version]
- RDF Schema. Available online: http://www.w3.org/TR/rdf-schema/ (accessed on 20 June 2018).
- RDF Primer. Available online: http://www.w3.org/TR/rdf-primer/ (accessed on 20 June 2018).
- Eric Miller Contact Infromation. Available online: http://www.w3.org/People/EM/contact#me (accessed on 20 June 2018).
- SPARQL Protocol and RDF Query Language. Available online: http://www.w3.org/TR/rdf-sparql-query/ (accessed on 20 June 2018).
- Protégé. Available online: http://protege.stanford.edu/ (accessed on 20 June 2018).
- Knoodl. Available online: http://semanticweb.org/wiki/Knoodl. (accessed on 20 June 2018).
- OntoEdit. Available online: http://www.lt-world.org/kb/ipr-and-products/products/obj_76702 (accessed on 20 June 2018).
- Apache Jena. Available online: https://jena.apache.org/index.html (accessed on 20 June 2018).
- The Core RDF API. Available online: https://jena.apache.org/documentation/rdf/index.html (accessed on 20 June 2018).
- Jena Ontology API. Available online: https://jena.apache.org/documentation/ontology/ (accessed on 20 June 2018).
- Apache Jena Fuseki. Available online: https://jena.apache.org/documentation/fuseki2/index.html (accessed on 20 June 2018).
- Apache Jena TDB. Available online: https://jena.apache.org/documentation/tdb/ (accessed on 20 June 2018).
- D3.js (Data-Driven Documents). Available online: http://d3js.org/ (accessed on 20 June 2018).
Figure 1.
Some classes, instances, and their relationships in the wine domain [20].
Figure 1.
Some classes, instances, and their relationships in the wine domain [20].

Figure 2.
The RDF graph describing Eric Miller.

Figure 3.
The RDF/XML format describing Eric Miller.

Figure 4.
The structure of the OWL languages.

Figure 5.
The procedure of building and using the law ontology.

Figure 6.
The patterns of legal definitions.


Figure 7.
The W.N. structure of Taiwan six codes.

Figure 8.
The proposed structure of Taiwan six codes.

Figure 9.
The general class model.

Figure 10.
The sample statutes.

Figure 11.
The competent authorities class model.

Figure 12.
The example shows the and relation, as well as the Taiwan Six Codes Classification Class0.
Figure 12.
The example shows the and relation, as well as the Taiwan Six Codes Classification Class0.

Figure 13.
The number of laws and regulations in each classification.

Figure 14.
The query result in JSON format.

Figure 15.
The Law Ontology Search with graphical interface.

Figure 16.
The Law Ontology Search with text interface.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
The number of laws under each type of act.
| Type | Act | Penal Act | Special Act | Comprehensive Act |
|---|---|---|---|---|
| Laws | 353 | 0 | 216 | 16 |
Table 2.
The final regular expressions of each pattern.
| Regular Expression | Pattern Number |
|---|---|
| ⌃稱(.*),(?:謂|為|指|係指)(.*) | 1.2.3.4 |
| ⌃稱(.*?):(.*) | 5 |
| (.*),(?:|亦)視為(.*) | 6.7 |
| ⌃本法用詞定義(?:如下|下列|左列|如左):(.*) | 8 |
| 本法所定(.*?),(.*) | 9 |
| (.*),以(.*)論 | 10 |
| (.*),分(?:如下|下列|左列|如左)(?:一|二|三|四| 五|六|七|八|九|十)種:(.*) | 11 |
| ⌃稱(.*)(?:如下|下列|左列|如左):(.*) | 12 |
| (.*),稱為(.*) | 13 |
| (.*)區分(?:如下|下列|左列|如左):(.*) | 14 |
| ⌃本法用詞,定義(?:如下|下列|左列|如左):(.*) | 15 |
Chinese characters: 稱,謂,為,指,係指(referred to as), 視為(regarded as), 本法用詞定義(?:如下|下列|左列|如左) (terminologies used in this article is listed as follows), 本法所定(This law defines), 以(.*)論(is regarded as), 分(?:如下|下列|左列|如左) (is listed or categorized as follows), 區分(classified as follows), 本法用詞,定義(terminology or definition used in this article is listed as follows).
Table 3.
The statistics of each pattern.
| Pattern Number | Regular Expression | First Statistics | Second Statistics |
|---|---|---|---|
| 1 | ⌃稱(.*),謂(.*) | 138 | 138 |
| 2 | ⌃稱(.*),為(.*) | 17 | 17 |
| 3 | ⌃稱(.*),指(.*) | 188 | 188 |
| 4 | ⌃稱(.*),係指(.*) | 101 | 101 |
| 5 | ⌃稱(.*?):(.*) | 95 | 95 |
| 6 | (.*),視為(.*) | 393 | 393 |
| 7 | (.*),亦視為(.*) | 2 | 2 |
| 8 | ⌃本法用詞定義(?:如下|下列|左列|如左):(.*) | 20 | 99 |
| 9 | 本法所定(.*?),(.*) | 141 | 141 |
| 10 | (.*),以(.*)論 | 0 | 0 |
| 11 | (.*),分(?:如下|下列|左列|如左)(?:一|二|三|四|五|六|七|八|九|十)種:(.*) | 2 | 2 |
| 12 | ⌃稱(.*)(?:如下|下列|左列|如左):(.*) | 20 | 20 |
| 13 | (.*),稱為(.*) | 16 | 16 |
| 14 | (.*)區分(?:如下|下列|左列|如左):(.*) | 15 | 15 |
| 15 | ⌃本法用詞,定義(?:如下|下列|左列|如左):(.*) | 25 | 106 |
| Total | 1173 | 1333 | |
Chinese characters: 稱,謂,為,指,係指(referred to as), 視為(regarded as), 本法用詞定義(?:如下|下列|左列|如左) (terminologies used in this article is listed as follows), 本法所定(This law defines), 以(.*)論(is regarded as), 分(?:如下|下列|左列|如左) (is listed or categorized as follows), 區分(classified as follows), 本法用詞,定義(terminology or definition used in this article is listed as follows).
Table 4.
The statistical number of ontology classes.
| The Ontology Class | Number of Classes |
|---|---|
| Definition patterns extracted class | 1114 |
| Competent authorities class | 81 |
| SVM judged keyword class | 168,020 |
| Classes in law ontology | 169,215 |
Table 5.
The number of each type of relation in the law ontology.
| The Type of Relation | The Number of Relation |
|---|---|
| <kind-of> | 10 |
| <associated> | 27,412 |
| <same-origin> | 1100 |
| <sub-class> | 28 |
| <is-Classified-As> | 585 |
| <has-Source> | 1319 |
Table 6.
Sample SPARQL query language.
| SPARQL | SELECT * WHERE { ?s ?o ?b . FILTER regex(str(?s), “the search words”). } |
Table 7.
The statistical number of patterns in different cases.
| Pattern Number | Total | Correct | Not Regarded | Incorrect |
|---|---|---|---|---|
| 1 | 138 | 127 | 6 | 5 |
| 2 | 17 | 17 | 0 | 0 |
| 3 | 188 | 178 | 6 | 4 |
| 4 | 101 | 95 | 2 | 4 |
| 5 | 95 | 85 | 6 | 4 |
| 6 | 393 | 152 | 220 | 21 |
| 7 | 2 | 2 | 0 | 0 |
| 8 | 99 | 98 | 1 | 0 |
| 9 | 141 | 52 | 75 | 14 |
| 10 | 0 | 0 | 0 | 0 |
| 11 | 2 | 0 | 2 | 0 |
| 12 | 20 | 3 | 15 | 2 |
| 13 | 16 | 12 | 1 | 3 |
| 14 | 15 | 4 | 9 | 2 |
| 15 | 106 | 102 | 0 | 4 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Hwang, R.-H.; Hsueh, Y.-L.; Chang, Y.-T. Building a Taiwan Law Ontology Based on Automatic Legal Definition Extraction. Appl. Syst. Innov. 2018, 1, 22. https://doi.org/10.3390/asi1030022
AMA Style
Hwang R-H, Hsueh Y-L, Chang Y-T. Building a Taiwan Law Ontology Based on Automatic Legal Definition Extraction. Applied System Innovation. 2018; 1(3):22. https://doi.org/10.3390/asi1030022
Chicago/Turabian StyleHwang, Ren-Hung, Yu-Ling Hsueh, and Yu-Ting Chang. 2018. "Building a Taiwan Law Ontology Based on Automatic Legal Definition Extraction" Applied System Innovation 1, no. 3: 22. https://doi.org/10.3390/asi1030022