

Effective Natural Language Processing Algorithms for Early Alerts of Gout Flares from Chief Complaints
 ,
,
Abstract
:1. Introduction
1.1. Gout as a Global Health Burden
1.2. Early Detection of Gout at Emergency Department
1.3. Rationale for Using Large Language Models
1.4. Gaps and Limitations of Current Literature
1.5. Our Contributions
2. Materials and Methods
2.1. Data Collection
2.2. Feature Extraction
2.3. Large Language Models
2.3.1. Discriminative Models
2.3.2. Generative Models
2.4. Fine-Tuning
2.4.1. Fine-Tuning of Discriminative LLMs
2.4.2. Fine-Tuning of Generative LLMs
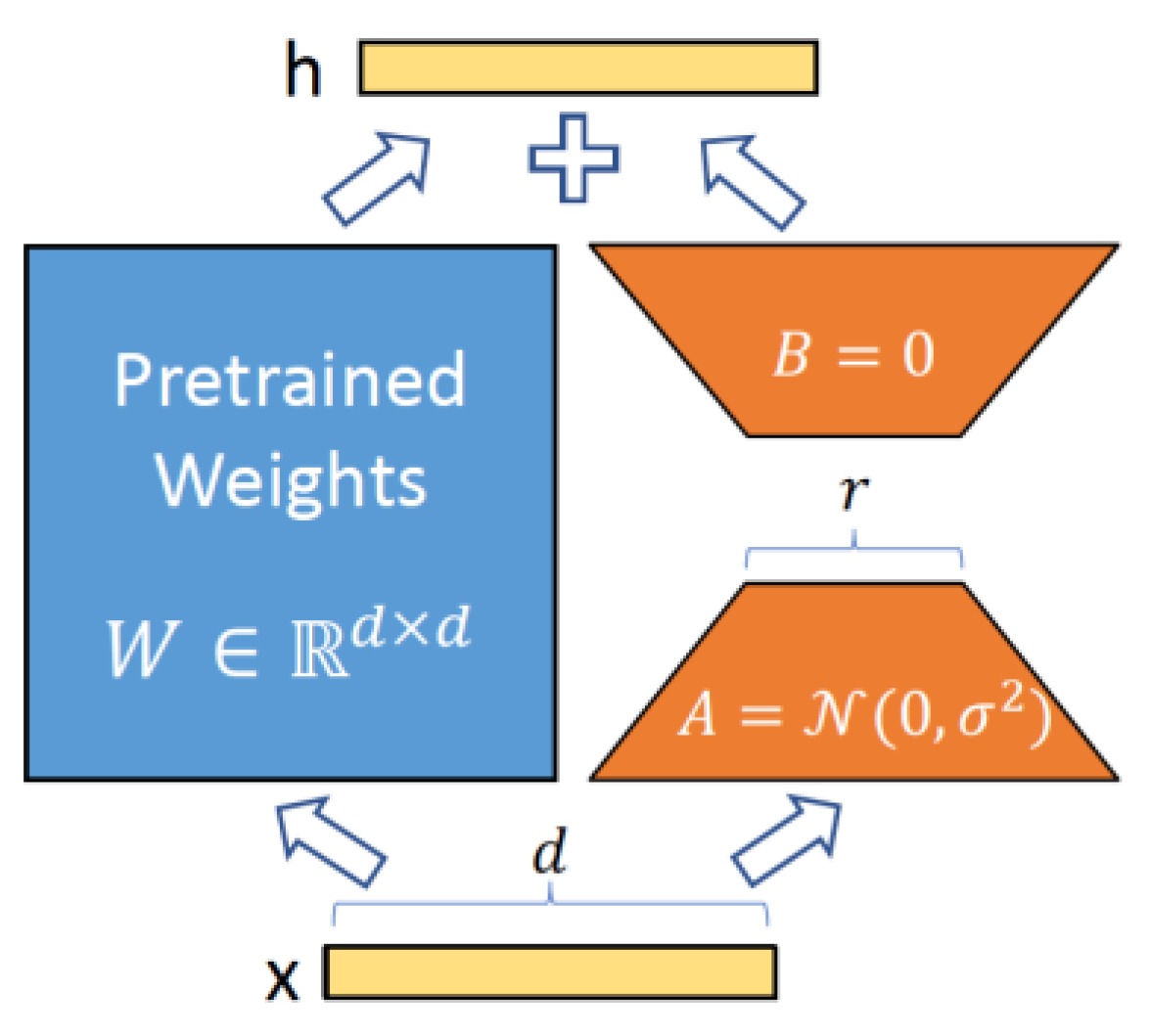
- The rank () of and was set to 8.
- The LoRA regularization coefficient α was set to 16.
- To prevent overfitting and enhancing model generalisation, we applied a LoRA dropout rate of 0.1.
- A learning rate of 3 × 10−4 was used, enabling efficient convergence during training.
2.5. Classification
2.6. Optimisation
2.6.1. Class Weights
2.6.2. Oversampling
2.6.3. Focal Loss
3. Results
3.1. Fine-Tuned LLM
3.2. Frozen LLMs as Feature Extractors
3.3. Sparse Text Representation
3.4. Comparative Analysis
4. Discussion
4.1. Potential and Limitations
4.2. Generalisability
4.3. Ethical Issues
4.4. Future Directions
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- National Institute of Health. Gout (Health Topic). Available online: https://www.niams.nih.gov/health-topics/gout (accessed on 27 February 2024).
- He, Q.; Mok, T.N.; Sin, T.H.; Yin, J.; Li, S.; Yin, Y.; Ming, W.K.; Feng, B. Global, Regional, and National Prevalence of Gout From 1990 to 2019: Age-Period-Cohort Analysis With Future Burden Prediction. JMIR Public Health Surveill 2023, 9, e45943. [Google Scholar] [CrossRef]
- Chen, X.M.; Yokose, C.; Rai, S.K.; Pillinger, M.H.; Choi, H.K. Contemporary Prevalence of Gout and Hyperuricemia in the United States and Decadal Trends: The National Health and Nutrition Examination Survey, 2007–2016. Arthritis Rheumatol. 2019, 71, 991–999. [Google Scholar] [CrossRef]
- Zhang, J.; Jin, C.; Ma, B.; Sun, H.; Chen, Y.; Zhong, Y.; Han, C.; Liu, T.; Li, Y. Global, regional and national burdens of gout in the young population from 1990 to 2019: A populationbased study. RMD Open 2023, 9, e003025. [Google Scholar] [CrossRef]
- Hirsch, J.D.; Terkeltaub, R.; Khanna, D.; Singh, J.; Sarkin, A.; Shieh, M.; Kavanaugh, A.; Lee, S.J. Gout disease specific quality of life and the association with gout characteristics. Patient Relat. Outcome Meas. 2010, 1, 1–8. [Google Scholar] [CrossRef]
- Safiri, S.; Kolahi, A.A.; Cross, M.; Carson-Chahhoud, K.; Hoy, D.; Almasi-Hashiani, A.; Sepidarkish, M.; Ashrafi-Asgarabad, A.; Moradi-Lakeh, M.; Mansournia, M.A.; et al. Prevalence, Incidence, and Years Lived With Disability Due to Gout and Its Attributable Risk Factors for 195 Countries and Territories 1990–2017: A Systematic Analysis of the Global Burden of Disease Study 2017. Arthritis Rheumatol. 2020, 72, 1916–1927. [Google Scholar] [CrossRef]
- Singh, J.A.; Yu, S. Time Trends, Predictors, and Outcome of Emergency Department Use for Gout: A Nationwide US Study. J. Rheumatol. 2016, 43, 1581–1588. [Google Scholar] [CrossRef]
- Osborne, J.D.; Booth, J.S.; O’Leary, T.; Mudano, A.; Rosas, G.; Foster, P.J.; Saag, K.G.; Danila, M.I. Identification of Gout Flares in Chief Complaint Text Using Natural Language Processing. AMIA Annu. Symp. Proc. 2020, 2020, 973–982. [Google Scholar] [PubMed]
- Hossain, E.; Rana, R.; Higgins, N.; Soar, J.; Barua, P.D.; Pisani, A.R. Natural Language Processing in Electronic Health Records in relation to healthcare decision-making: A systematic review. Comput. Biol. Med. 2023, 155, 106649. [Google Scholar] [CrossRef] [PubMed]
- Zheng, C.; Rashid, N.; Wu, Y.L.; Koblick, R.; Lin, A.T.; Levy, G.D.; Cheetham, T.C. Using Natural Language Processing and Machine Learning to Identify Gout Flares From Electronic Clinical Notes. Arthritis Care Res. 2014, 66, 1740–1748. [Google Scholar] [CrossRef] [PubMed]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, (NAACL-HLT’2019), Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. In Advances in Neural Information Processing Systems; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M.F., Lin, H., Eds.; Curran Associates Inc.: Red Hook, NY, USA, 2020; Volume 33, pp. 1877–1901. Available online: https://papers.nips.cc/paper/2020/hash/1457c0d6bfcb4967418bfb8ac142f64a-Abstract.html (accessed on 29 February 2024).
- Xu, B.; Gil-Jardiné, C.; Thiessard, F.; Tellier, E.; Avalos, M.; Lagarde, E. Pre-training A Neural Language Model Improves The Sample Efficiency of an Emergency Room Classification Model. In Proceedings of the Thirty-Third International FLAIRS Conference (FLAIRS-33), North Miami Beach, FL, USA, 17–20 May 2020; Available online: https://aaai.org/papers/264-flairs-2020-18444/ (accessed on 29 February 2024).
- Veladas, R.; Yang, H.; Quaresma, P.; Gonçalves, T.; Vieira, R.; Sousa Pinto, C.; Martins, J.P.; Oliveira, J.; Cortes Ferreira, M. Aiding Clinical Triage with Text Classification. In Progress in Artificial Intelligence, Lecture Notes in Computer Science; Marreiros, G., Melo, F.S., Lau, N., Lopes Cardoso, H., Reis, L.P., Eds.; Springer International Publishing: Berlin/Heidelberg, Germany, 2021; Volume 12981, pp. 83–96. [Google Scholar] [CrossRef]
- Ding, L.; Zhang, Z.; Liu, H.; Li, J.; Yu, G. Automatic Keyphrase Extraction from Scientific Chinese Medical Abstracts Based on Character-Level Sequence Labeling. J. Data Inf. Sci. 2021, 6, 35–57. [Google Scholar] [CrossRef]
- Ding, L.; Zhang, Z.; Zhao, Y. Bert-Based Chinese Medical Keyphrase Extraction Model Enhanced with External Features. In Towards Open and Trustworthy Digital Societies, Lecture Notes in Computer Science; Ke, H.R., Lee, C.S., Sugiyama, K., Eds.; Springer International Publishing: Berlin/Heidelberg, Germany, 2021; Volume 13133, pp. 167–176. [Google Scholar] [CrossRef]
- Han, L.; Erofeev, G.; Sorokina, I.; Gladkoff, S.; Nenadic, G. Investigating Massive Multilingual Pre-Trained Machine Translation Models for Clinical Domain via Transfer Learning. In Proceedings of the 5th Clinical Natural Language Processing Workshop (ClinicalNLP’2019), Minneapolis, MN, USA, 7 June 2019; pp. 31–40. [Google Scholar] [CrossRef]
- Tang, L.; Sun, Z.; Idnay, B.; Nestor, J.G.; Soroush, A.; Elias, P.A.; Xu, Z.; Ding, Y.; Durrett, G.; Rousseau, J.F.; et al. Evaluating Large Language Models on Medical Evidence Summarization. npj Digit. Med. 2003, 6, 158. [Google Scholar] [CrossRef] [PubMed]
- Osborne, J.D.; O’Leary, T.; Mudano, A.; Booth, J.; Rosas, G.; Peramsetty, G.S.; Knighton, A.; Foster, J.; Saag, K.; Danila, M.I. Gout Emergency Department Chief Complaint Corpora, version 1.0; PhysioNet: Bristol, UK, 2020. [Google Scholar] [CrossRef]
- Manning, C.D.; Raghavan, P.; Schütze, H. Introduction to Information Retrieval; Cambridge University Press: Cambridge, UK, 2008. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is All you Need. In Advances in Neural Information Processing Systems; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30, pp. 5998–6008. Available online: https://papers.nips.cc/paper_files/paper/2017/hash/3f5ee243547dee91fbd053c1c4a845aa-Abstract.html (accessed on 29 February 2024).
- Lewis, P.; Ott, M.; Du, J.; Stoyanov, V. Pretrained Language Models for Biomedical and Clinical Tasks: Understanding and Extending the State-of-the-Art. In Proceedings of the 3rd Clinical Natural Language Processing Workshop (ClinicalNLP’2020), Online, 19 November 2020; pp. 146–157. [Google Scholar] [CrossRef]
- Kanakarajan, K.R.; Kundumani, B.; Sankarasubbu, M. BioELECTRA: Pretrained Biomedical Text Encoder using Discriminators. In Proceedings of the 20th Workshop on Biomedical Language Processing (BioNLP’2021), Online, 16 August 2021; pp. 143–154. [Google Scholar] [CrossRef]
- Yuan, H.; Yuan, Z.; Gan, R.; Zhang, J.; Xie, Y.; Yu, S. BioBART: Pretraining and Evaluation of A Biomedical Generative Language Model. In Proceedings of the 21st Workshop on Biomedical Language Processing (BioNLP’2022), Dublin, Ireland, 6 May 2022; pp. 97–109. [Google Scholar] [CrossRef]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. Available online: http://arxiv.org/abs/1907.11692 (accessed on 29 February 2024).
- Clark, K.; Luong, M.T.; Le, Q.V.; Manning, C.D. ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators. In Proceedings of the Eighteenth International Conference on Learning Representations (ICLR’2020), Online, 27–30 April 2020; Available online: https://openreview.net/forum?id=r1xMH1BtvB (accessed on 29 February 2024).
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Zettlemoyer, L. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL’2020), Online, 5–10 July 2020; pp. 7871–7880. [Google Scholar] [CrossRef]
- Johnson, A.E.; Pollard, T.J.; Shen, L.; Lehman, L.W.H.; Feng, M.; Ghassemi, M.; Moody, B.; Szolovits, P.; Anthony Celi, L.; Mark, R.G. MIMIC-III, a freely accessible critical care database. Sci. Data 2016, 3, 160035. [Google Scholar] [CrossRef] [PubMed]
- Luo, R.; Sun, L.; Xia, Y.; Qin, T.; Zhang, S.; Poon, H.; Liu, T.Y. BioGPT: Generative pre-trained transformer for biomedical text generation and mining. Brief. Bioinform. 2022, 23, bbac409. [Google Scholar] [CrossRef]
- Wu, C.; Lin, W.; Zhang, X.; Zhang, Y.; Wang, Y.; Xie, W. PMC-LLaMA: Towards Building Open-source Language Models for Medicine. arXiv 2023, arXiv:2305.10415. Available online: https://arxiv.org/abs/2304.14454 (accessed on 29 February 2024).
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language Models are Unsupervised Multitask Learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. LLaMA: Open and Efficient Foundation Language Models. arXiv 2023, arXiv:2302.13971. Available online: https://arxiv.org/abs/2302.13971 (accessed on 29 February 2024).
- Touvron, H.; Martin, L.; Stone, K.; Albert, P.; Almahairi, A.; Babaei, Y.; Bashlykov, N.; Batra, S.; Bhargava, P.; Bhosale, S.; et al. Llama 2: Open Foundation and Fine-Tuned Chat Models. arXiv 2023, arXiv:2307.0928. Available online: http://arxiv.org/abs/2307.09288 (accessed on 29 February 2024).
- Gao, L.; Biderman, S.; Black, S.; Golding, L.; Hoppe, T.; Foster, C.; Phang, J.; He, H.; Thite, A.; Nabeshima, N.; et al. The Pile: An 800GB Dataset of Diverse Text for Language Modeling. arXiv 2021, arXiv:2101.00027. Available online: http://arxiv.org/abs/2101.00027 (accessed on 29 February 2024).
- Lo, K.; Wang, L.L.; Neumann, M.; Kinney, R.; Weld, D. S2ORC: The Semantic Scholar Open Research Corpus. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL’2020), Online, 5–10 July 2020; pp. 4969–4983. [Google Scholar] [CrossRef]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. In Proceedings of the Seventh International Conference on Learning Representations (ICLR’2019), New Orleans, LA, USA, 6–9 May 2019; Available online: https://openreview.net/pdf?id=Bkg6RiCqY7 (accessed on 29 February 2024).
- Hu, E.J.; Shen, Y.; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, S.; Wang, L.; Chen, W. LoRA: Low-Rank Adaptation of Large Language Models. In Proceedings of the Ninth International Conference on Learning Representations (ICLR’2021), Online, 3–7 May 2021; Available online: https://openreview.net/forum?id=nZeVKeeFYf9 (accessed on 29 February 2024).
- Aghajanyan, A.; Zettlemoyer, L.; Gupta, S. Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (ACL-IJCNLP’2020), Online, 1–6 August 2020; pp. 7319–7328. [Google Scholar] [CrossRef]
- Messem, A.V. Support vector machines: A robust prediction method with applications in bioinformatics. Handb. Stat. 2020, 43, 391–466. [Google Scholar] [CrossRef]
- Cyran, K.A.; Kawulok, J.; Kawulok, M.; Stawarz, M.; Michalak, M.; Pietrowska, M.; Widłak, P.; Polańska, J. Support Vector Machines in Biomedical and Biometrical Applications. In Emerging Paradigms in Machine Learning. Smart Innovation, Systems and Technologies; Ramanna, S., Jain, L., Howlett, R., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; Volume 13. [Google Scholar] [CrossRef]
- He, J.; Cheng, X. Weighting Methods for Rare Event Identification from Imbalanced Datasets. Front. Big Data 2021, 4, 715320. [Google Scholar] [CrossRef] [PubMed]
- Singh, K. How to Improve Class Imbalance using Class Weights in Machine Learning? Analytics Vidhya. Available online: https://www.analyticsvidhya.com/blog/2020/10/improve-class-imbalance-class-weights (accessed on 29 January 2024).
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef]
- Abdennour, G.B.; Gasmi, K.; Ejbali, R. Ensemble Learning Model for Medical Text Classification. In Web Information Systems Engineering—WISE 2023; Lecture Notes in Computer Science; Zhang, F., Wang, H., Barhamgi, M., Chen, L., Zhou, R., Eds.; Springer: Singapore, 2023; Volume 14306. [Google Scholar] [CrossRef]
- Duarte, J.M.; Berton, L. A review of semi-supervised learning for text classification. Artif. Intell. Rev. 2023, 56, 9401–9469. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Sohn, S.; Liu, S.; Shen, F.; Wang, L.; Atkinson, E.J.; Amin, S.; Liu, H. A clinical text classification paradigm using weak supervision and deep representation. BMC Med. Inform. Decis. Mak. 2019, 19, 1. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
| Dataset Name | GF-POS (Positive) | GF-NEG (Negative) | GF-UNK (Unknown) | Review | Agreement | Cohen’s κ |
|---|---|---|---|---|---|---|
| GOUT-CC-2019-CORPUS | 93 | 194 | 13 | CC | 0.883 | 0.825 |
| GOUT-CC-2019-CORPUS * | 70 | 118 | 9 | Chart | 0.849 | 0.774 |
| GOUT-CC-2020-CORPUS | 14 | 7992 | 129 | CC | 0.977 | 0.965 |
| GOUT-CC-2020-CORPUS * | 25 | 232 | 7 | Chart | 0.904 | 0.856 |
| Chief Complaint Text * | Predicted ** | Actual *** |
|---|---|---|
| AMS, lethargy, increasing generalized weakness over 2 weeks. Hx: ESRD on hemodialysis at home, HTN, DM, gout, neuropathy | No | No |
| “I started breathing hard” hx-htn, gout, anxiety, | No | No |
| R knee pain × 8 years. pmh: gout, arthritis | Unknown | No |
| Doc N Box DX pt w/R hip FX on sat. Pt states no falls or injuries. PMH: gout | Unknown | No |
| out of gout medicine | Yes | Yes |
| sent from boarding home for increase BP and bilateral knee pain for 1 week. Hx of HTN, gout. | Yes | Yes |
| Model Name | RoBERTa-Large-PM-M3-Voc | BioELECTRA | BioBART |
|---|---|---|---|
| Model Size | 355M Parameters | --- | 139M Parameters |
| Hidden Size | 1024 | 768 | 768 |
| Model Size | 24 Layers, 16 heads | 12 Layers, 12 heads | 12 Layers, 12 heads |
| Base Model | RoBERTa-large | Electra Base | BART Base |
| Training Data | PubMed articles and MIMIC-III corpora [28] | PubMed articles | PubMed abstracts and articles |
| Model | BioGPT | BioMedLM | PMC_LLaMA_7B |
|---|---|---|---|
| Model Size | 347M Parameters | 2.7B Parameters | 7B Parameters |
| Hidden Size | 1024 | 2560 | 4096 |
| Model Size | 24 Layers, 16 heads | 32 Layers, 20 heads | 32 Layers, 32 heads |
| Base Model | GPT2-medium | GPT2 | LLaMA_7B |
| Training Data | 15M PubMed abstracts from scratch | All PubMed abstracts and full texts from The Pile benchmark [34]. | 4.8 million Biomedical publications from the S2ORC dataset [35]. |
| GOUT-CC-2019-CORPUS | GOUT-CC-2020-CORPUS | |||||
|---|---|---|---|---|---|---|
| Model | Precision | Recall | F1 Score | Precision | Recall | F1 Score |
| RoBERTa-large-PM-M3-Voc | 0.80 | 0.79 | 0.80 | 0.62 | 0.72 | 0.63 |
| BioELECTRA | 0.76 | 0.76 | 0.76 | 0.63 | 0.68 | 0.65 |
| BioBART | 0.74 | 0.73 | 0.73 | 0.65 | 0.70 | 0.67 |
| BioGPT | 0.62 | 0.59 | 0.60 | 0.82 | 0.88 | 0.85 |
| BioMedLM | 0.49 | 0.49 | 0.47 | 0.52 | 0.53 | 0.52 |
| GOUT-CC-2019-CORPUS | GOUT-CC-2020-CORPUS | |||||
|---|---|---|---|---|---|---|
| Algorithm | Precision | Recall | F1 Score | Precision | Recall | F1 Score |
| SVM with BioGPT Embeddings | 0.68 | 0.67 | 0.67 | 0.69 | 0.73 | 0.71 |
| SVM with BioMedLM Embeddings | 0.69 | 0.66 | 0.66 | 0.59 | 0.70 | 0.61 |
| SVM with PMC_LLaMA_7B Embeddings | 0.66 | 0.66 | 0.66 | 0.60 | 0.60 | 0.60 |
| GOUT-CC-2019-CORPUS | GOUT-CC-2020-CORPUS | |||||
|---|---|---|---|---|---|---|
| Algorithm | Precision | Recall | F1 Score | Precision | Recall | F1 Score |
| SVM with tf-idf | 0.75 | 0.75 | 0.75 | 0.82 | 0.74 | 0.77 |
| NAIVE-GF | 0.23 | 1.00 | 0.38 | 0.28 | 0.56 | 0.37 |
| SIMPLE-GF | 0.44 | 0.84 | 0.58 | 0.37 | 0.40 | 0.38 |
| BERT-GF | 0.71 | 0.48 | 0.56 | 0.79 | 0.47 | 0.57 |
| GOUT-CC-2019-CORPUS | GOUT-CC-2020-CORPUS | |||||
|---|---|---|---|---|---|---|
| Algorithm | Precision | Recall | F1 Score | Precision | Recall | F1 Score |
| RoBERTa-large-PM-M3-Voc | 0.80 | 0.79 | 0.80 | 0.62 | 0.72 | 0.63 |
| BioELECTRA | 0.76 | 0.76 | 0.76 | 0.63 | 0.68 | 0.65 |
| BioBART | 0.74 | 0.73 | 0.73 | 0.65 | 0.70 | 0.67 |
| BioGPT | 0.62 | 0.59 | 0.60 | 0.82 | 0.88 | 0.85 |
| BioMedLM | 0.49 | 0.49 | 0.47 | 0.52 | 0.53 | 0.52 |
| SVM with BioGPT Embeddings | 0.68 | 0.67 | 0.67 | 0.69 | 0.73 | 0.71 |
| SVM with BioMedLM Embeddings | 0.69 | 0.66 | 0.66 | 0.59 | 0.70 | 0.61 |
| SVM with PMC_LLaMA_7B Embeddings | 0.66 | 0.66 | 0.66 | 0.60 | 0.60 | 0.60 |
| SVM with tf-idf | 0.75 | 0.75 | 0.75 | 0.82 | 0.74 | 0.77 |
| NAIVE-GF | 0.23 | 1.00 | 0.38 | 0.28 | 0.56 | 0.37 |
| SIMPLE-GF | 0.44 | 0.84 | 0.58 | 0.37 | 0.40 | 0.38 |
| BERT-GF | 0.71 | 0.48 | 0.56 | 0.79 | 0.47 | 0.57 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Oliveira, L.L.; Jiang, X.; Babu, A.N.; Karajagi, P.; Daneshkhah, A. Effective Natural Language Processing Algorithms for Early Alerts of Gout Flares from Chief Complaints. Forecasting 2024, 6, 224-238. https://doi.org/10.3390/forecast6010013
Oliveira LL, Jiang X, Babu AN, Karajagi P, Daneshkhah A. Effective Natural Language Processing Algorithms for Early Alerts of Gout Flares from Chief Complaints. Forecasting. 2024; 6(1):224-238. https://doi.org/10.3390/forecast6010013
Chicago/Turabian StyleOliveira, Lucas Lopes, Xiaorui Jiang, Aryalakshmi Nellippillipathil Babu, Poonam Karajagi, and Alireza Daneshkhah. 2024. "Effective Natural Language Processing Algorithms for Early Alerts of Gout Flares from Chief Complaints" Forecasting 6, no. 1: 224-238. https://doi.org/10.3390/forecast6010013