


Appl. Sci. 2025, 15(14), 7833; https://doi.org/10.3390/app15147833 - 12 Jul 2025
Cited by 4 | Viewed by 7688
Abstract
►
Show Figures
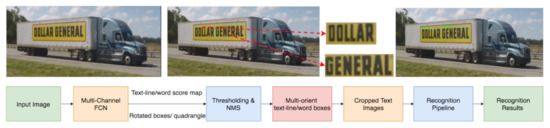
Automatic license plate recognition (ALPR) plays an important role in applications such as intelligent traffic systems, vehicle access control in specific areas, and law enforcement. The main novelty brought by the present research consists in the development of an automatic vehicle license plate
[...] Read more.
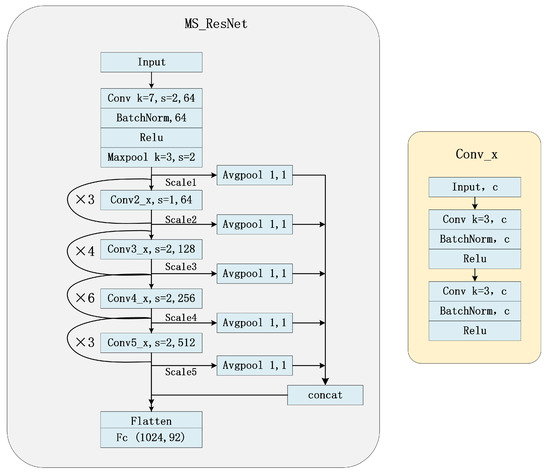
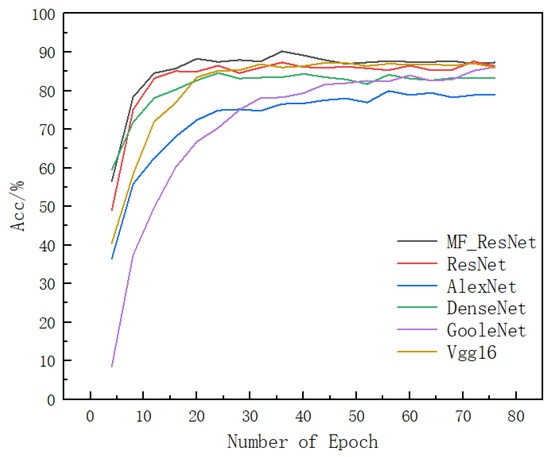
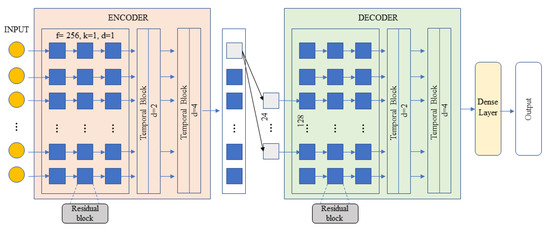
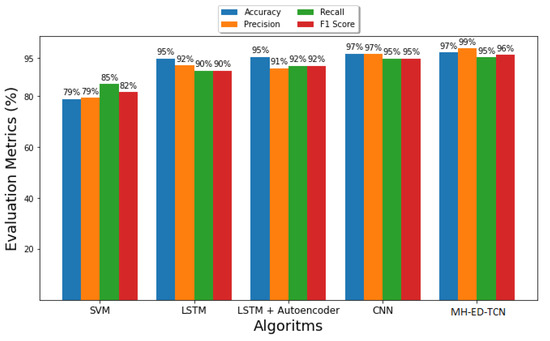
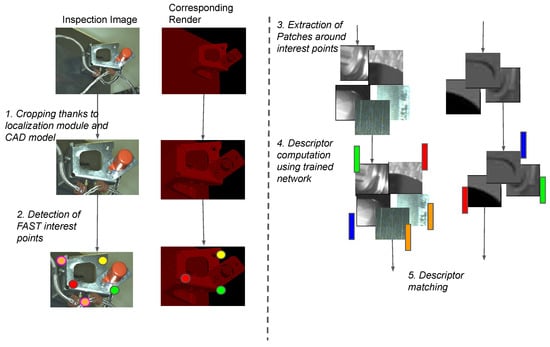
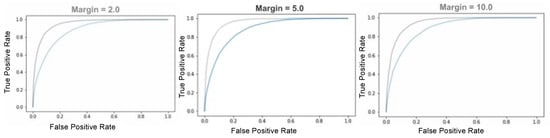
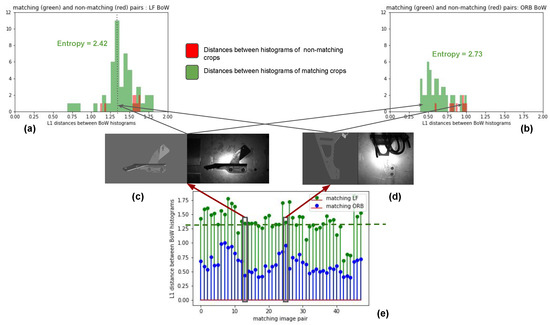
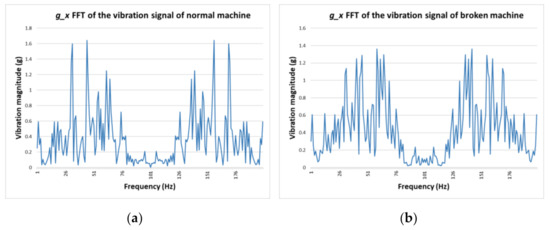
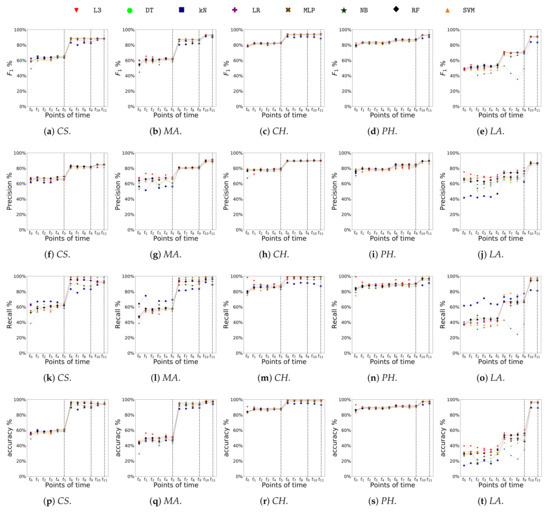
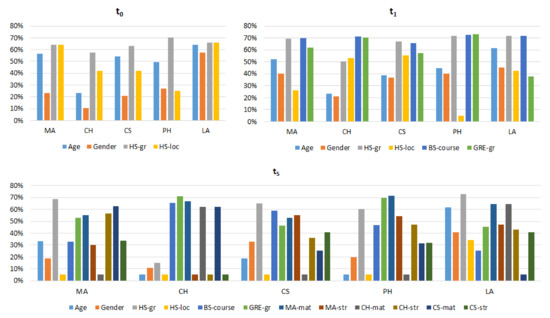
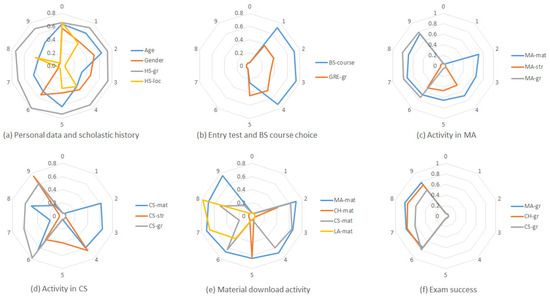
Automatic license plate recognition (ALPR) plays an important role in applications such as intelligent traffic systems, vehicle access control in specific areas, and law enforcement. The main novelty brought by the present research consists in the development of an automatic vehicle license plate recognition system adapted to the Romanian context, which integrates the YOLOv12 detection architecture with the PaddleOCR library while also providing functionalities for recognizing the type of vehicle on which the license plate is mounted and identifying the county of registration. The integration of these functionalities allows for an extension of the applicability range of the proposed solution, including for addressing issues related to restricting access for certain types of vehicles in specific areas, as well as monitoring vehicle traffic based on the county of registration. The dataset used in the study was manually collected and labeled using the makesense.ai platform and was made publicly available for future research. It includes 744 images of vehicles registered in Romania, captured in real traffic conditions (the training dataset being expanded by augmentation). The YOLOv12 model was trained to automatically detect license plates in images with vehicles, and then it was evaluated and validated using standard metrics such as precision, recall, F1 score, mAP@0.5, mAP@0.5:0.95, etc., proving very good performance. Experimental results demonstrate that YOLOv12 achieved superior performance compared to YOLOv11 for the analyzed issue. YOLOv12 outperforms YOLOv11 with a 2.3% increase in precision (from 97.4% to 99.6%) and a 1.1% improvement in F1 score (from 96.7% to 97.8%).
Full article

Figure 1













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}