1. Introduction
Soot emission from combustion systems can be a substantial threat to human health and to the environment [
1]. Increasingly strict emissions regulations (e.g., the EURO 6 standard) are emerging to combat the negative effects of soot emission, leaving designers with two major avenues-experiments and numerical simulations—to model, understand, and reduce soot formation in combustion systems. A general advance in the knowledge and capabilities of the soot modelling community has allowed a push past empirical or semi-empirical soot models and into robust soot models inspired by the underlying physico-chemical processes of soot formation. These high-fidelity soot models (e.g., [
2]) generally give detailed consideration to phenomena such as nucleation from polycyclic aromatic hydrocarbons (PAHs), PAH condensation, physical coagulation, surface growth by the hydrogen-abstraction-carbon-addition (HACA) mechanism, oxidation, and oxidation-induced fragmentation on soot formation and evolution. Recent advancements, including reversible nucleation [
3] and condensation [
4,
5] models, detailed models to track soot maturity [
6] and internal structure [
7], and the consideration of chemical bond formation in the inception process [
8], have greatly advanced high-fidelity CFD models. However, many knowledge gaps, particularly in the inception step [
9], still remain in CFD soot modelling.
In general, the consideration of the above-mentioned phenomena is extremely time-consuming, especially as the sub-models become more detailed and physically realistic. The cumbersome nature of high-fidelity models has pushed many industries to use semi-empirical soot models which, although faster, may sacrifice a good deal of accuracy compared to their high-fidelity counterparts (relative errors of 1–2 orders of magnitude in soot volume fraction prediction [
10,
11,
12,
13]). To circumvent the clash between accuracy and cost in traditional soot modelling methods, a novel computational concept called the “soot estimator” has been recently introduced [
14,
15,
16,
17]. In the soot estimator concept, only a validated combustion model is needed, and the soot characteristics are estimated without solving the soot-related terms and equations. In a practical context, relieving the need to calculate the soot-related terms will save valuable computational time and may greatly facilitate the design process in industry. The soot estimator approach is essentially a soot post-processing tool that is linked to computational fluid dynamics (CFD) simulations of combustion environments. In this approach, gas-related properties such as temperature and species mass fractions are obtained from the solution of gas-phase conservation equations (mass, momentum, energy and species mass fractions). The gas properties are then used to estimate the soot characteristics, such as soot volume fraction
:
where
T is the gas temperature,
is the mass fraction of species
i,
P is the pressure, and
t is the time. Bozorgzadeh [
14], who first introduced the soot estimator concept in 2014, reasoned that the larger timescales of soot formation and destruction relative to those of flow and gas-phase chemistry implied that the residence time of the soot particles should be considered. Therefore, Bozorgzadeh suggested that local instantaneous soot properties such as soot volume fraction should be a function of the temporal (time-integrated) histories of the above-mentioned gas-related variables. Temporal integration was performed over the pathlines of the soot particles, which were extracted from CFD using the Lagrangian approach. Equation (
1) then becomes:
where the subscript
h represents the time-integrated history of the corresponding variable. To keep true to the premise of a low-cost (yet accurate) soot estimator, it was necessary to select key variables to track, so as to limit the dimensionality and reduce computational cost. For example, Equation (
3) below:
would attempt to relate the soot volume fraction in the flame to selected gas parameters, namely: the histories of temperature, mixture fraction, and H
2 concentration, respectively. The relationship between the soot characteristics and the gas-related parameters (i.e., the function
f in Equation (
3)) is central to the soot estimator concept and was a major focus in previous developments [
14,
15,
16,
17].
In [
14,
15,
16,
17], previous versions of the soot estimator were used to estimate the soot characteristics of steady coflow laminar diffusion flames at atmospheric pressure. In these studies, the CFD code called CoFlame [
2] was used to generate the required data, i.e., the gas parameters such as temperature and species concentrations. In the work of Bozorgzadeh [
14], polynomial functions were used to link the CFD results to the desired soot characteristic. At first, soot concentration was related to temperature history, and later to both temperature and acetylene histories. The author found that in both cases, polynomial functions were not able to reproduce the soot concentration accurately. The addition of other parameters such as
(which can be considered an indicator of oxidation and soot reduction) helped increase the estimation accuracy. However, this increase in the dimensionality of the function was accompanied by a steep increase in computational cost, leading to a new estimation approach in [
15,
16]—tabulating the relationships between the histories of gas-related variables and the soot concentration.
To generate the lookup tables (also referred to as the libraries), Alexander et al. [
15] and Zimmer et al. [
16] grouped the histories of the gas-related variables into bins. Each variable is a “dimension” of the table and each dimension has a certain number of bins. In [
16], 4D tables (i.e.,
and the histories of three variables) were generated for steady laminar diffusion flames using 300 bins in each dimension. In these studies, the number of dimensions and the number of bins were very sensitive parameters. An increase in the number of dimensions or bins could result in a disproportionate increase in memory requirement and computational time. In addition, the variable selection had a large impact on the results. For example, Zimmer et al. [
16] showed that changing the variables in the table from [
,
,
] to [
,
),
] increased the error (measured relative to model predictions) in
estimation by around 57%. Furthermore, the tabular scheme may not scale well to more complex problems. As originally discussed by Zimmer et al. [
16], the dimensionality issues become more significant when the tool is extended to transient and turbulent diffusion flames, where the the amount of required data can be much larger than in steady laminar flame simulations.
The above-mentioned limitations inspired the deep learning approach recently developed by Jadidi et al. [
17]. As in many fields, the use of deep learning and artificial neural networks (ANN) is becoming increasingly pervasive in combustion research. As far back as the mid 1990s, Christo et al. [
18,
19] used an ANN to estimate the reaction chemistry in turbulent flames. Christo et al. [
18] found that the ANN can yield predictions of “reasonable” accuracy (absolute errors on the order of
) in a computational time that was one order of magnitude less than the direct integration approach. The authors went on to stress that the accuracy of the ANN model was strongly dependent on the selection of the training data sets and that a broad, dynamic range of training samples can improve the accuracy and generality of the ANN. In the recent work of Ranade et al. [
20], an ANN was used to develop a computationally inexpensive chemical kinetics model. As the authors explain, an ANN may be applied to relieve some of the complexity and computational requirements inherent in the development of a detailed chemistry model. In [
20], a shallow ANN was used to fit temporal profiles of fuel fragments, and a deep ANN was used to predict chemical reaction rates during pyrolysis. The ANN approach showed reasonable agreement with the detailed chemistry results.
These works, and a selection of others (e.g., [
21,
22,
23,
24,
25,
26,
27]), show that an ANN is a versatile tool that can be used to reduce computational time at the expense of a minor decrease in accuracy (compared to traditional tools). As such, a handful of recent works have applied ANNs to the field of soot estimation [
17,
28,
29,
30,
31]. The work of Talebi-Moghaddam et al. [
28] used an ANN to efficiently and accurately estimate the light scattering kernel that is used in experiments to infer the morphological characteristics of soot particles. Furthermore, a handful of studies [
29,
30,
31] have used ANNs to couple engine operational parameters such as crank angle or fuel consumption to the soot emissions from engines. In [
29], a shallow (1 hidden layer) multilayer perceptron ANN was used to predict the soot,
, and
emissions from a direct injection diesel engine. The study used the CFD-computed quantities of crank angle, temperature, pressure, liquid mass evaporated, equivalence ratio, and
concentration as input to the ANN. The optimal ANN architecture achieved a mean squared error on the order of
for the soot,
, and
predictions (soot,
, and
predictions on the order of
,
, and
, respectively). The study of Ghazikhani and Mirzaii [
30] used a shallow multilayer perceptron ANN to predict the soot density in the exhaust of a turbo-charged diesel engine. Six experimentally measured parameters (inlet manifold pressure, inlet manifold temperature, inlet air mass flow rate, fuel consumption, engine torque, and speed) were used as input to the neural network and the network achieved a mean absolute percent error of about 6% relative to experimental measurements.
The study of Alcan et al. [
31] used a gated recurrent unit (GRU) neural network (which is similar to the long short-term memory neural network used in the present study) to estimate the soot emission from a diesel engine. The network inputs were experimentally determined and consisted of engine speed, total injected fuel quantity, main start of injection, rail pressure, and intake oxygen ratio. The results showed accuracies of 77% on the training data and 57% on the validation data. Finally, the study of Yang et al. [
32] used a long short-term memory (LSTM) neural network—the same type of neural network used in the present study—to predict
emissions from coal burners. The study used 35 experimentally measured parameters that are relevant to
emissions from a coal burner as input to the LSTM. The authors concluded that the LSTM could give reasonably accurate
estimations, with 54% of the test data showing a relative error less than 0.01 and an overall root mean squared error of 2.271 (for
emission levels on the order of
). While these studies have laid the groundwork for the present objective of devising a more broadly applicable ANN system of soot prediction, each of them considers one or few specific operating configurations. By contrast, the present work is a step toward developing an ANN to predict soot characteristics in a broad range of conditions and configurations.
In the recent work of Jadidi et al. [
17], the authors used a multilayer perceptron ANN to pair the combustion conditions (the input) to the resulting soot characteristics (the target). As in the previous studies [
14,
15,
16], CoFlame [
2] was used to generate the flame data. After generation of the combustion data, the Lagrangian histories of soot-containing fluid parcels were calculated using the approach developed by Zimmer et al. [
16]. Subsequently, eight parameters, selected due to their significant influence on soot formation, were fed to the network as the input dataset. These eight parameters were the temperature history (
), mixture fraction history (
), oxygen history (
), carbon monoxide history (
), carbon dioxide history (
), hydrogen history (
), hydroxide history (
), and acetylene history (
). The soot volume fraction was the output of the network. Overall, the ANN approach of Jadidi et al. [
17] was successful; the authors found that the network could estimate the shape of the soot regions as well as the values of soot concentration very well and with low computational cost. Additionally, the use of eight parameters highlighted the network’s ability to handle a high-dimensional input, providing a degree of flexibility that was not present in the previous studies [
14,
15,
16] (i.e., the amount of dimensions can be changed depending on the accuracy and computational requirements).
While the multilayer perceptron ANN of [
17] was applicable to a steady flame, there exist more complex and versatile neural network architectures (namely, recurrent neural networks or RNNs) that were designed specially for time-series data. Therefore, as practical combustion devices are inherently transient, the main objective of the current study is to extend the capability of the ANN-based soot estimator to time-dependent flames. Ultimately, the aim of this and future works is to develop the ANN-based soot estimator into a tool for industry end use that quickly and accurately estimates soot characteristics without requiring a large amount of computing resources. In the present study, a time-varying, laminar, ethylene/air coflow diffusion flame with 20 Hz periodic fluctuation on the fuel velocity and a 50% amplitude of modulation, the same as [
33], is considered. An LSTM neural network, a type of RNN, will be used for the soot estimator tool. The numerical simulation of this flame, which was performed and validated by Dworkin et al. [
33], is used as the LSTM neural network’s training and testing data. The use of an
LSTM neural network for soot estimation is, to the authors’ knowledge, novel. Further novelty (relative to the above-mentioned ANN/soot studies) of the present work (as well as [
17]) stems from the soot estimator tool being trained using a detailed CFD model. The ANN is trained using inputs that are fundamental to the soot inception, growth, and oxidation processes (such as
and
mass fractions), thereby training the ANN to recognize the foundational relationships between the gas phase and soot concentration.
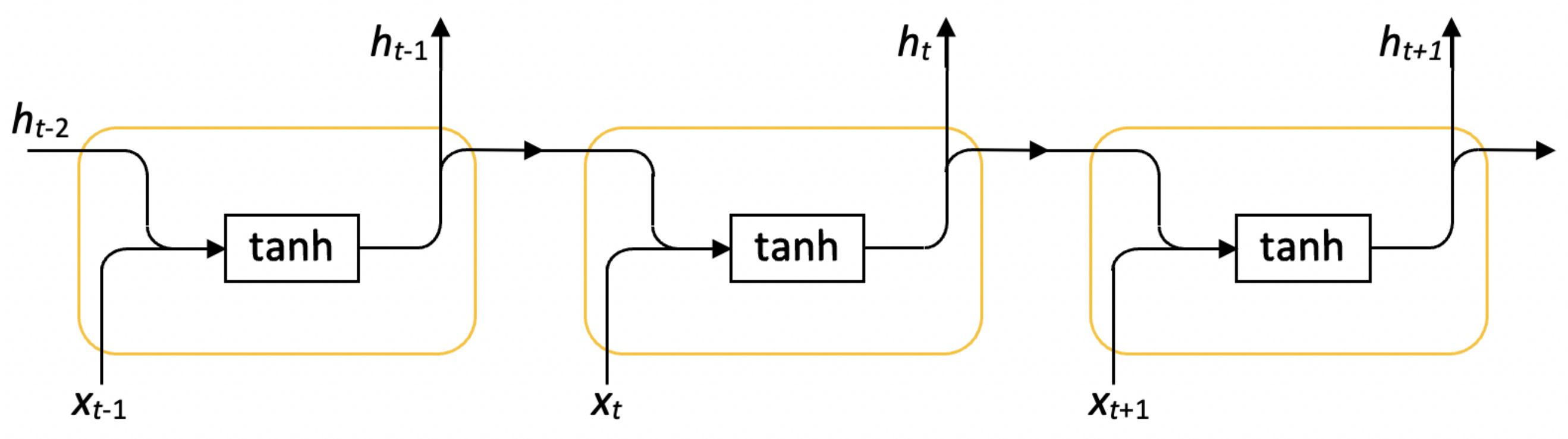
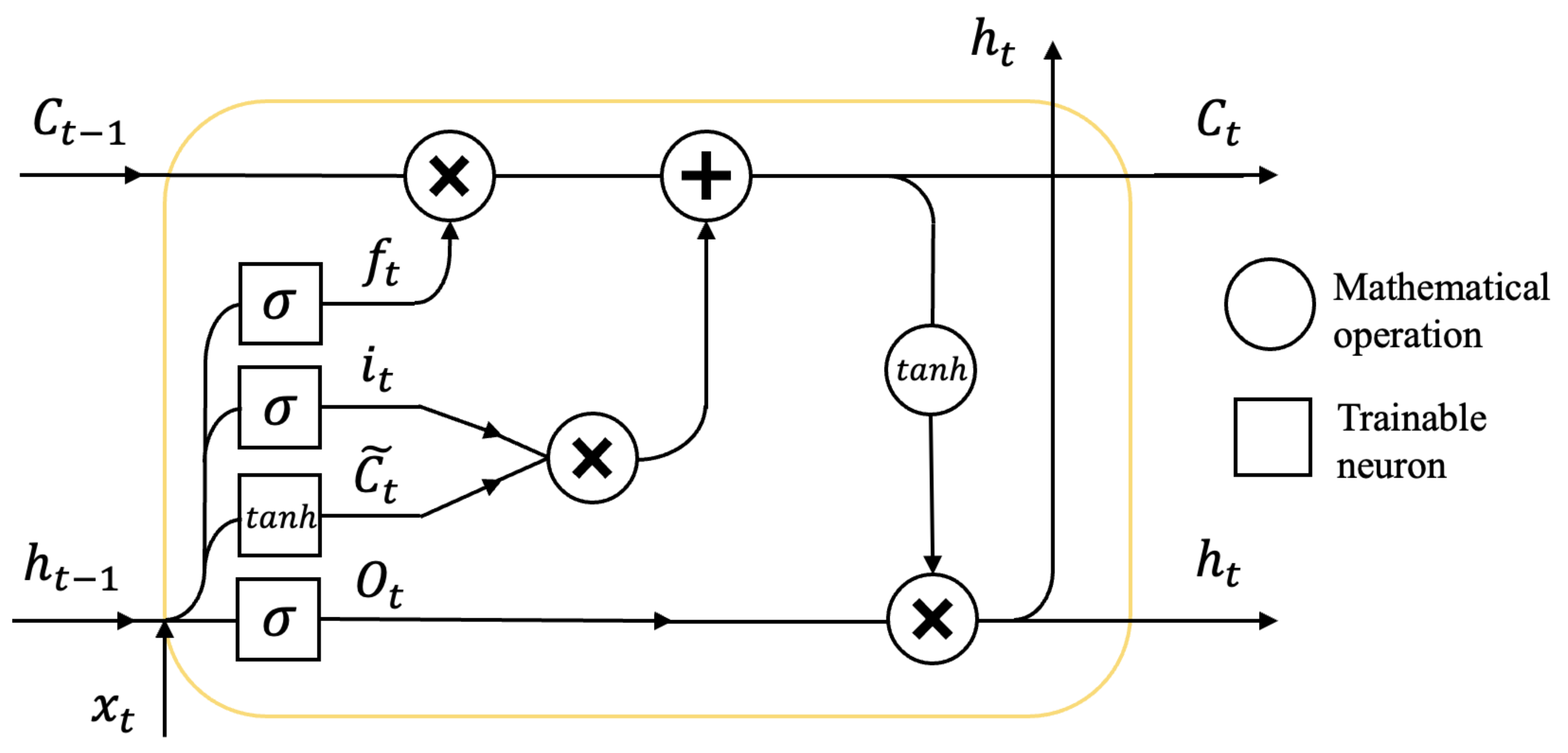
An LSTM network is better-suited for transient flame predictions, compared to a multilayer perceptron ANN, due to the LSTM’s inherent ability to learn long-term temporal interdependencies between time steps of sequential data [
32]. Furthermore, the use of an LSTM will eliminate assumptions and potential sources of error that were present in the previous works. In the previous implementations of the soot estimator tool [
16,
17], it was necessary to (1) calculate the pathlines of soot containing fluid parcels, (2) compute the history of a given variable (i.e., the time integration of the variable over its lifetime), and (3) perform linear interpolation to distribute the estimated
values from the pathlines onto the
r-z coordinate system [
17]. In the present work, the gas-related variables computed by CFD can be fed directly to the LSTM (eliminating the need for steps 1–3), since the LSTM inherently considers time-dependence. By design, the LSTM learns the temporal relationships between the input and output data. Therefore, the widely varying characteristic time scales between combustion kinetics and soot formation are accounted for without issue. Previously, step 2 assumed, without validation, the simplest form of the time integration, i.e., it assumed that the history of a variable had a linear relationship with the variable itself, with an implied weighting function of unity. The use of the LSTM network eliminates the need for that assumption and the potential error associated with it.
In the following section, the CFD simulations, flame conditions, and LSTM fundamentals are explained. Subsequently, the data preprocessing, network architecture, and the LSTM’s performance and error relative to CFD are discussed.
3. Results and Discussion
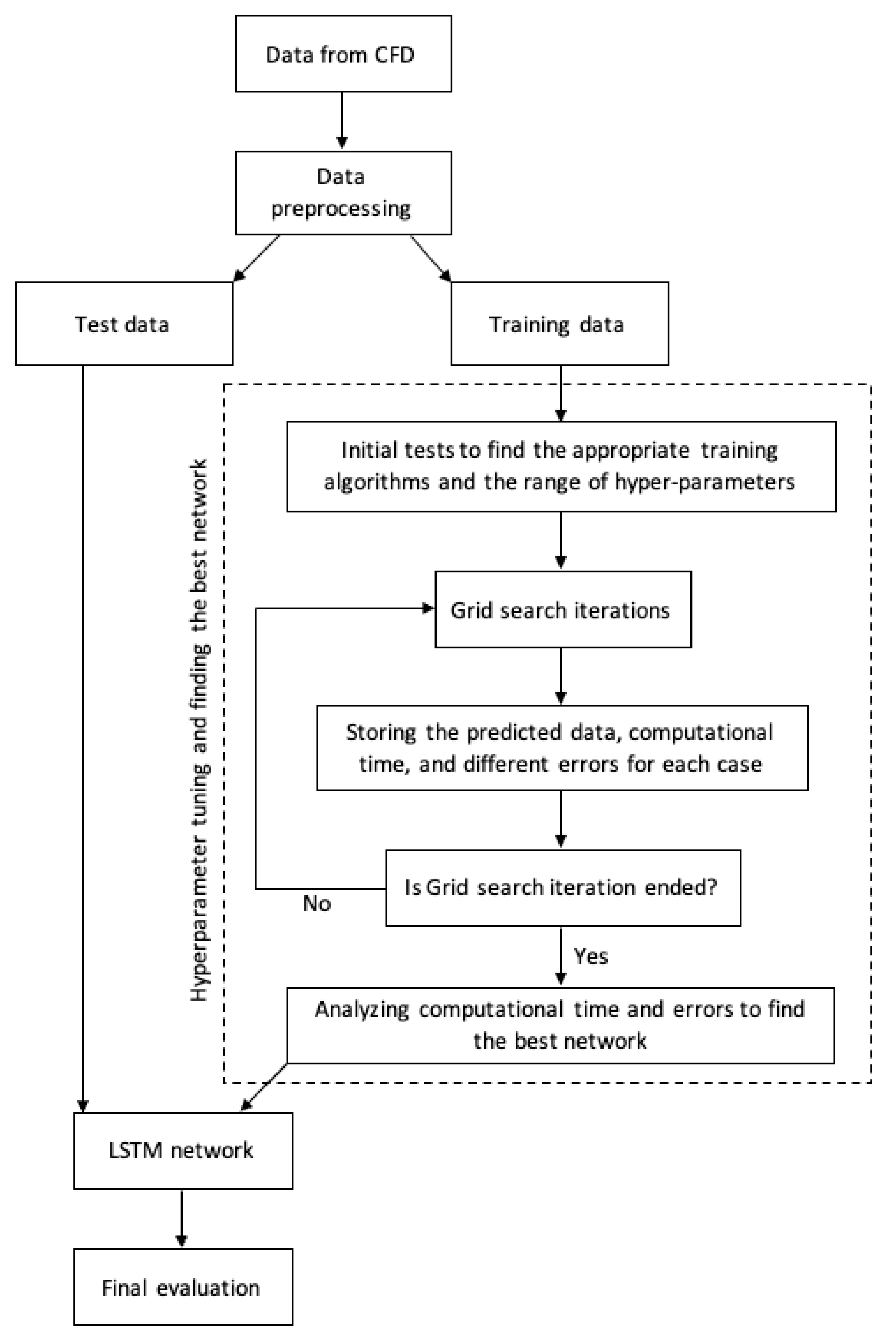
Given as a generalized algorithm, developing a model on the basis of an ANN should proceed as follows: (1) identification and collection of input/output data pairs (which in the present study are CFD-obtained gas parameters and soot volume fraction), (2) data preprocessing, (3) testing and optimization of the network architecture, (4) training the network, (5) testing the network, and (6) evaluation of the network predictions.
Figure 5 illustrates the general model development procedure when using a deep learning approach. As in the previous study [
17], data preprocessing was an essential step in obtaining satisfactory results. Recall that the core principle of training an artificial neural network is to update the network’s weights and biases such that the error between the network’s prediction and the actual outcome is minimized. Without some form of data preprocessing, differences in scale between the input and target data (potentially coupled with large variances within the data itself) may make the weights and biases hypersensitive to change. Updating the weights and biases in that kind of environment may lead to inaccuracies, low reproducibility, and inefficiency in the training process. Indeed, in the previous study [
17], the greatest enhancement to the network’s predictive accuracy was the inclusion of data preprocessing. Prior to data preprocessing, the data was highly skewed (far from a normal distribution) and the network was predicting nonphysical results. The application of a log transformation gave a much more symmetric, bell-shaped distribution [
17]. Similar results were obtained by Christo et al. [
19] upon the application of a log transformation to their data set. In the current study, the unprepared data (both the input and target data sets) was processed by applying a log transformation and by standardizing the data (i.e., ensuring a mean of 0 and a standard deviation of 1).
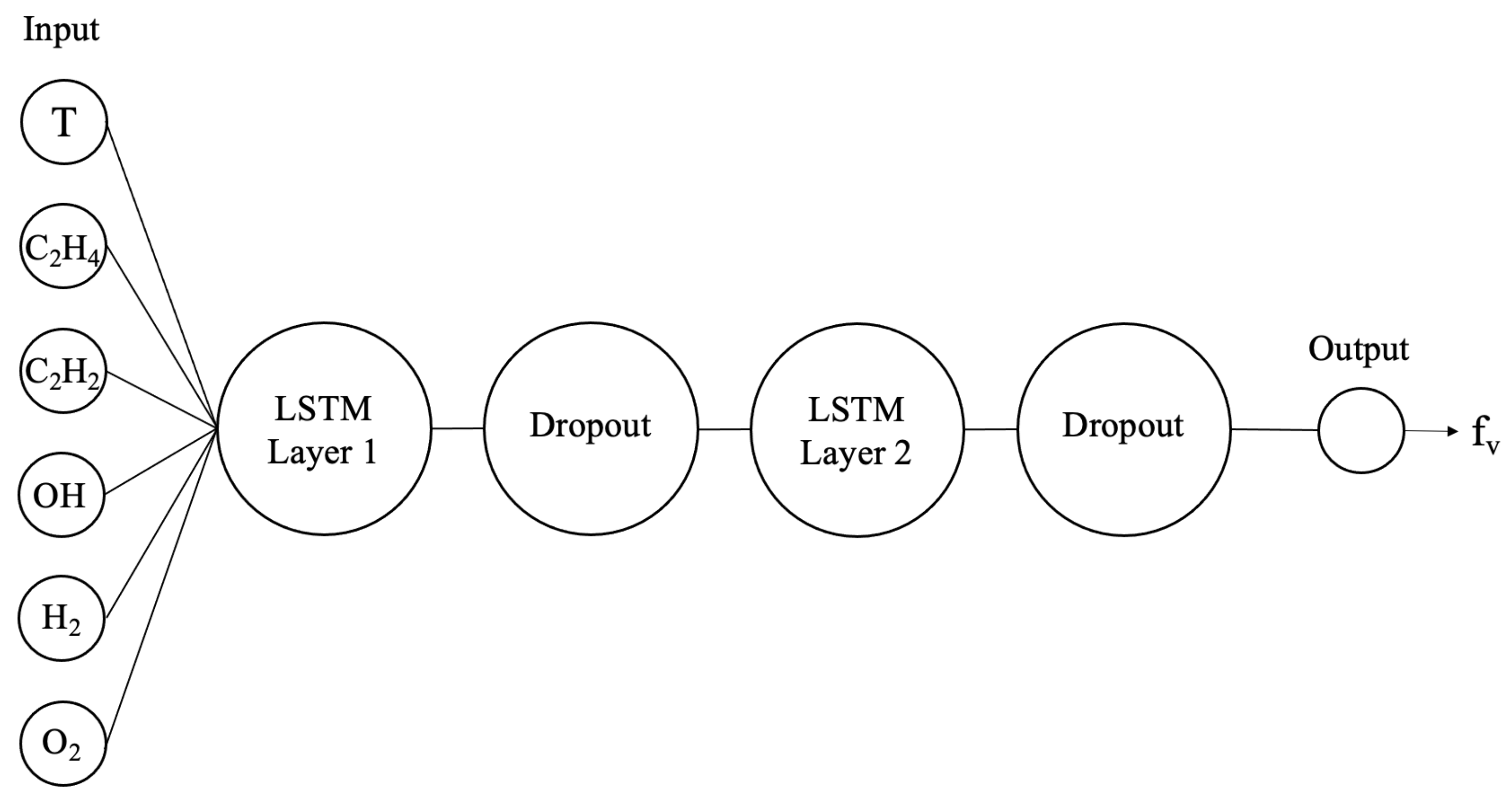
The network architecture has a significant impact on training time and predictive accuracy. The time-dependent nature of this problem implied that LSTM layers should be the core of the network. Beyond this initial framework, it is important to realize that there is no definitive way to determine the ideal features of the neural network. This is due to the inherent complexity of a neural network. For example, consider the learning rate parameter. The learning rate of the network is the rate at which the weights and biases of the network are updated. While it is clear that the learning rate should not be too high (or else there may be instability in the training process), the optimal value is not immediately clear for a given problem.
Overfitting, one of the most significant issues in the training and application of ANNs, is a common example of a phenomenon that the network architecture impacts in a vague manner. Overfitting is a network behaviour that occurs when the predictive accuracy is higher for the training data than for the test data. The amount of overfitting is regarded as a measure of the general applicability of the network (i.e., the range of problems the network can successfully handle) and is a result of the network being excessively tuned to noise or specific features in the training data. The problem of excessive training can occur when there are many more trainable parameters (weights and biases) than data points. Consequently, a neural network with more layers or nodes is not guaranteed to give an increase in predictive accuracy. It is for this reason that structural parameters such as the number of hidden layers and number of nodes per layer become subject to experimentation.
The dropout process [
39] is a regularization technique that is used to help reduce overfitting [
32]. Dropout refers to the removal of certain nodes during the training process. Essentially, some nodes in a layer (chosen randomly) are dropped out and the network is trained without them for that iteration [
32]. When the network is used after training, neurons are not dropped out. Rather, their output is scaled by
, where
p is the probability of being dropped out during training [
39]. Dropout may be thought of as an averaging process, where the final network has a predictive capability averaged over all the different networks from the training process (the networks with different nodes dropped out). Dropout aims to prevent the network from overemphasizing the importance of any specific piece of data in the training data set, hopefully broadening its range of use. In the current network, dropout is only applied between nodes transferring information in the same time step
t [
32], i.e., it is used in the vertical direction only (referring to
Figure 2). The percentage of nodes to be dropped out and the number of layers to apply dropout on are more characteristics that must be tested.
In the present study, a grid search was performed to explore the parameter space and select the network with the best performance. The network’s accuracy and its computational time (time taken to train the network) are the major considerations in assessing network performance, with accuracy being the more dominant consideration. Readers are referred to the previous work [
17] for more detail on the selection of the network parameters. The accuracy of the network was evaluated using 3 metrics: the relative error in the peak
prediction, the relative error in the volume integral of
across the whole domain, and the root mean squared error (RMSE), where all errors are relative to the CFD predictions. The error in peak
measures the LSTM’s ability to predict the flame’s maximum soot concentration. The RMSE and error in the
volume integral approximately quantifies the LSTM’s ability to predict the shape and distribution of the whole
field. The errors for peak
, the volume integral, and the RMSE are defined below in Equations (
13,
14,
15), respectively. Note that in the discussion on the performance of the LSTM, Equations (
13,
14) are expressed in percentages.
where
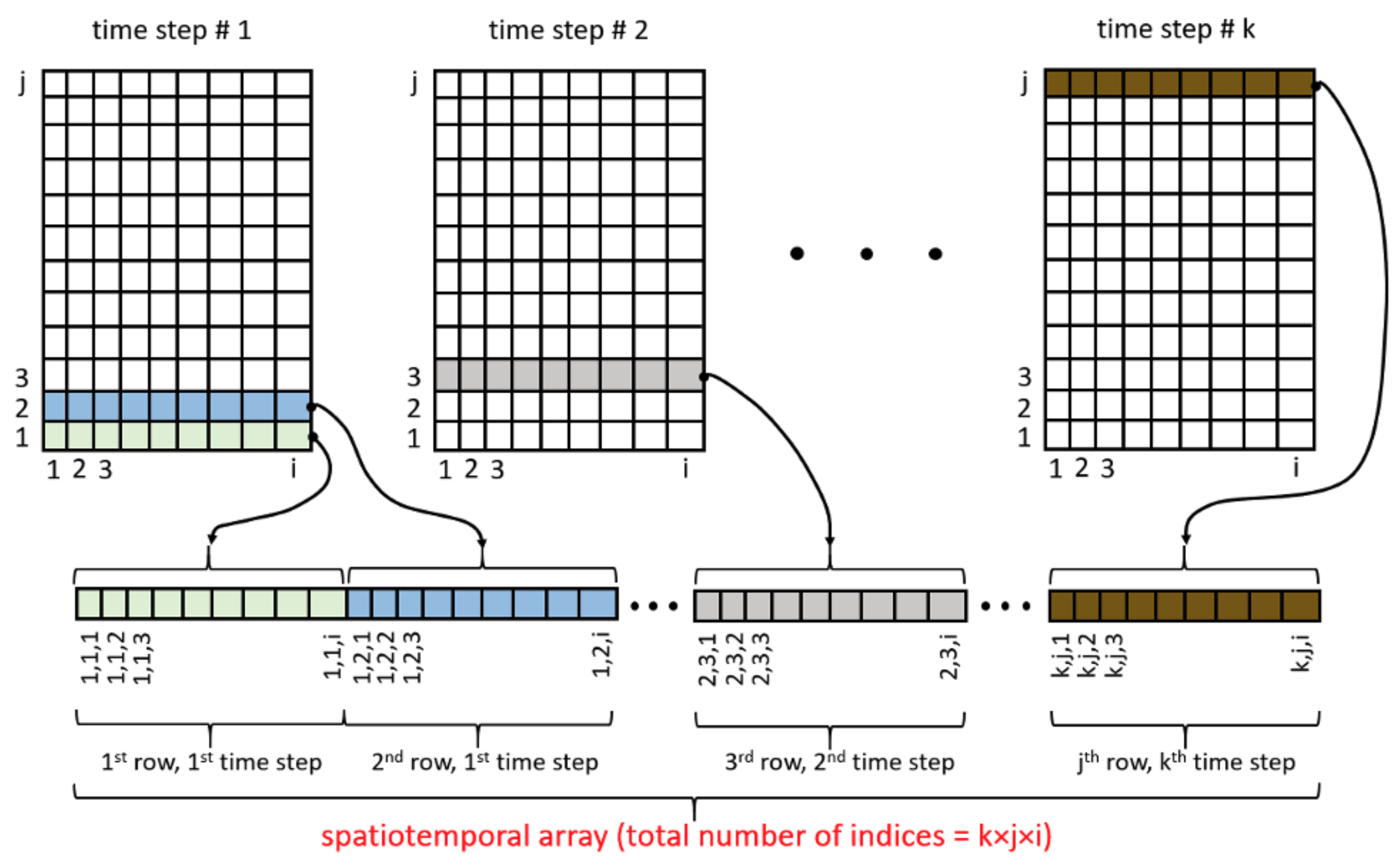
r and
z are the radial and axial coordinates in the 2D axisymmetric domain, respectively,
i represents the index in the spatiotemporal array, and
n is the total number of points in the spatiotemporal array.
The full list of hyperparameters and their tested values are shown in
Table 1, where the parameters of the selected network are shown in bold. The selected network exhibited the best balance between accuracy and computational time, taking about 1 h to train on an NVIDIA GeForce GTX 1660 desktop graphics processing unit (GPU) and displaying good accuracy (to be discussed in detail below). A visualization of the final network is shown in
Figure 6. Note that in
Table 1, a dropout layer is not actually a layer of nodes. Rather, it signals that dropout has been applied to the previous layer of nodes. After the LSTM layers, there is a fully connected layer containing one node. This was the output node that returned the soot volume fraction and therefore was not changed throughout the grid search. For further information regarding the training options for a neural network, the reader is referred to the Mathworks documentation [
40].
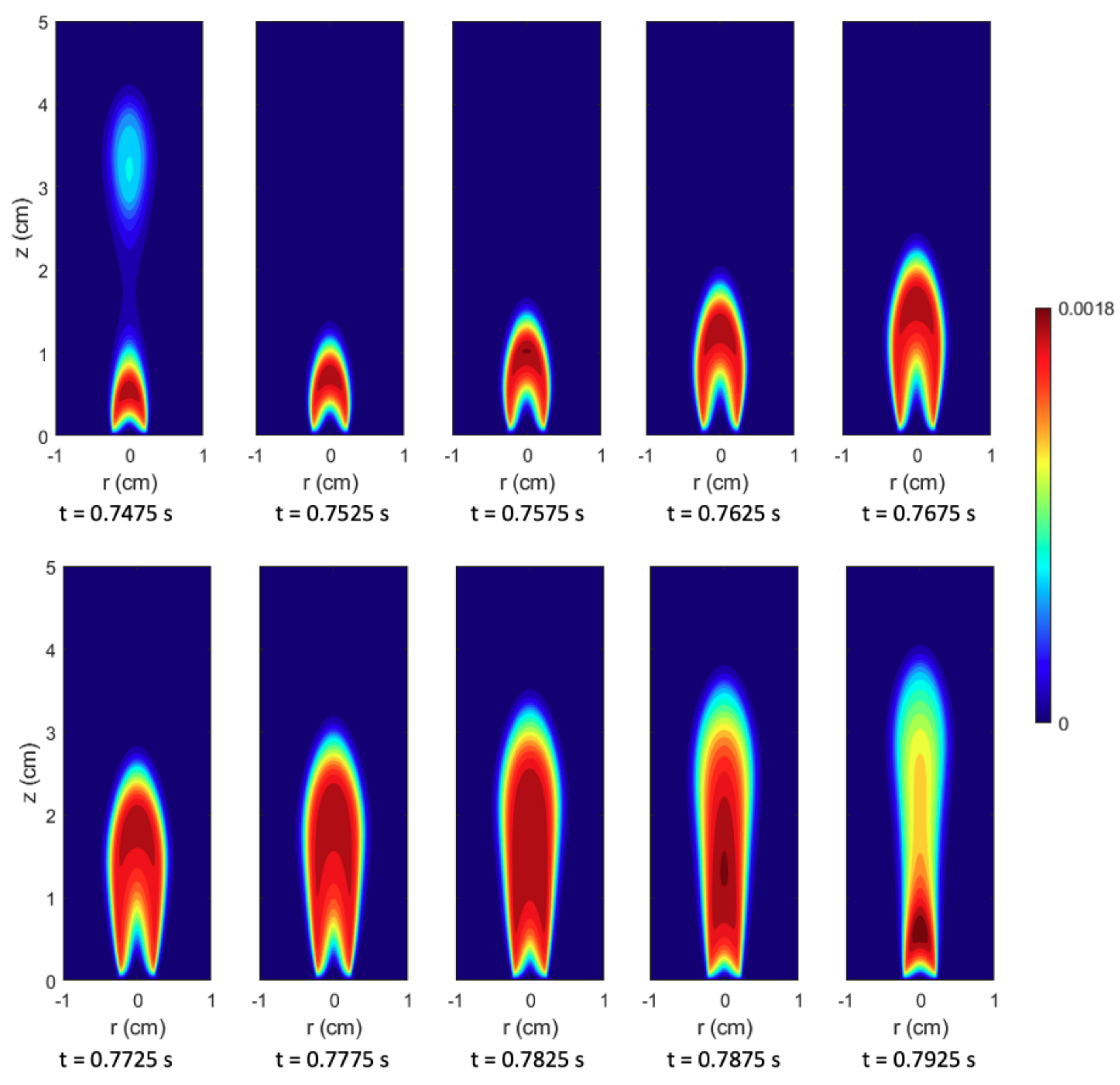
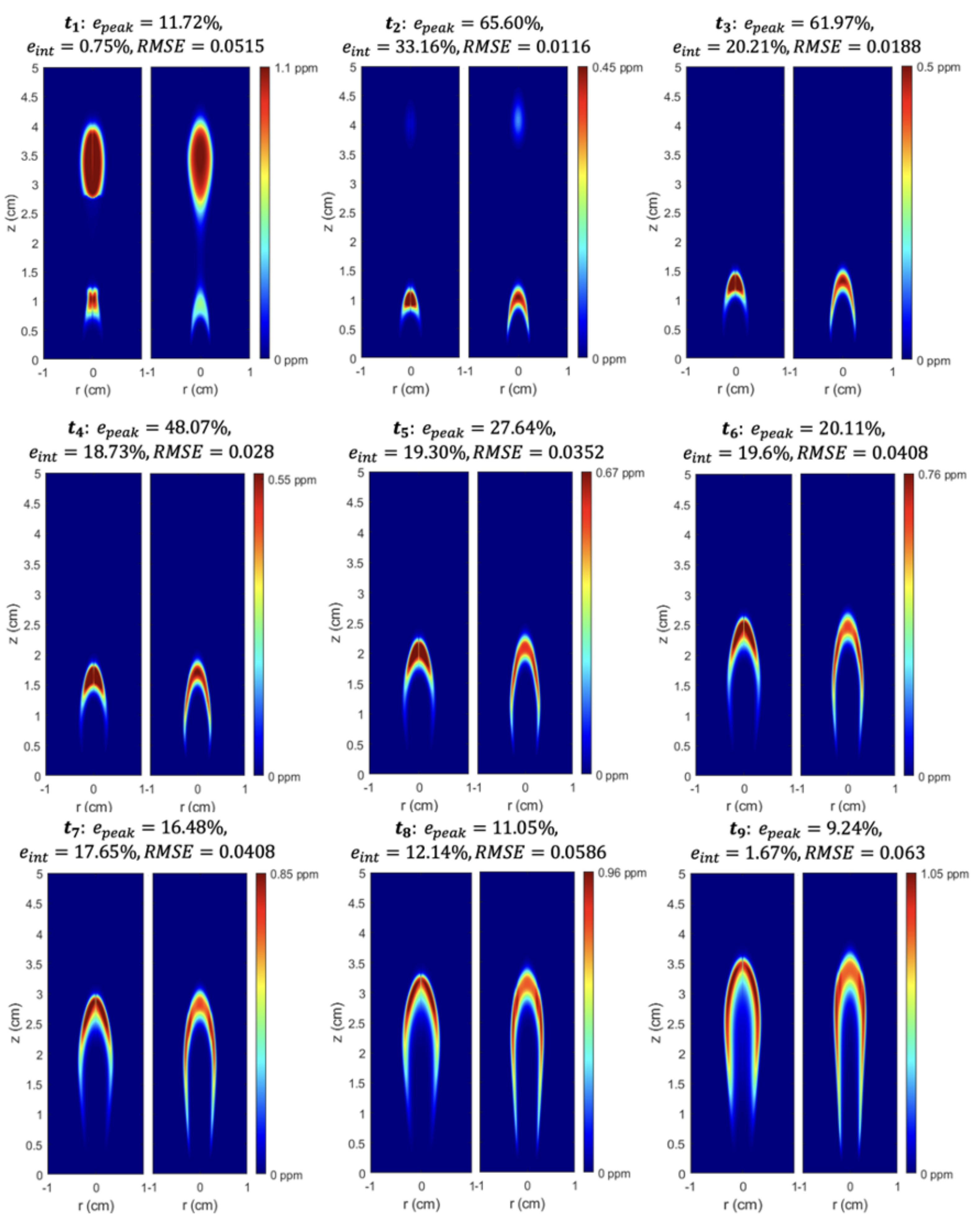
Figure 7 shows the predictions of the selected network compared to the CFD predictions. The images show the soot volume fraction at the 9 time steps in the training data set, where the left side is the prediction from the neural network and the right side is the CFD simulation. The network’s predictions on the training data match very well with the corresponding CFD prediction; the general shape and magnitude of the soot volume fraction contour is very similar between the CFD and the LSTM. The largest errors in
and
(defined above in Equations (
13) and (
14)) occur in the earlier time steps, with accuracy steadily increasing from
,
at
to
,
at
. Note that the color bar on the right hand side of each pair of images corresponds to the CFD prediction. For example, at
, the peak
prediction from CFD was 0.45 and the peak prediction from the neural network was 65.60% higher than that (0.75 ppm).
Table S1 in the
Supplementary Materials shows the values of
,
, and
for CFD and the LSTM for each time step (rather than expressing them in a relative error percentage). The approximately fivefold decrease in
between
and
may be because the overall shape of the
contour changes less rapidly at larger time steps, i.e., the change in
shape from
to
is more pronounced than from
to
. Effectively, this may mean that the weights and biases are more tuned to predict an
field that is similar to
than one that is similar to
(since there are more shapes in the training data that are similar to
than to
). This may be resolved by including more data in the training data set that resembles the shape of the
contour at
.
Overall, the shape of the soot volume fraction contours predicted by the LSTM are very similar to the CFD contours. Early on ( to ), the neural network does not predict enough soot in the “tails”; however, this issue seemed to decrease as time increased (likely for the reasons stated in the previous paragraph). Even at , which is notably different than the rest of the time steps, the shape of the profile is fairly similar between the LSTM and CFD.
The average relative errors across all time steps in the training data were: , , and . Despite the errors in peak for and , the accuracy of the network is beyond satisfactory when one considers the massive reduction in computational time awarded by the neural network. As mentioned above, the selected neural network only took about 1 h to train on a desktop GPU, which is orders-of-magnitude less than the time it took to obtain a converged solution with CFD. The CFD calculations take on the order of 1 week to converge using approximately 400 CPUs. Furthermore, once the network was trained, it took seconds to run on the test data. This incredible speed-up, accompanied only by an average error of ∼30% in peak (relative to a high-fidelity CFD code) may be very valuable in an industry setting. In an industry use-case, high-fidelity CFD tools may not be practical and the designer may turn to semi-empirical soot models that are generally inaccurate yet expedient. Therefore, the availability of a soot estimating tool that can replicate a high-fidelty CFD model to within ∼30% in and ∼15% in may not only facilitate the design cycle (through fast predictions), but provide an increase in accuracy relative to a semi-empirical model.
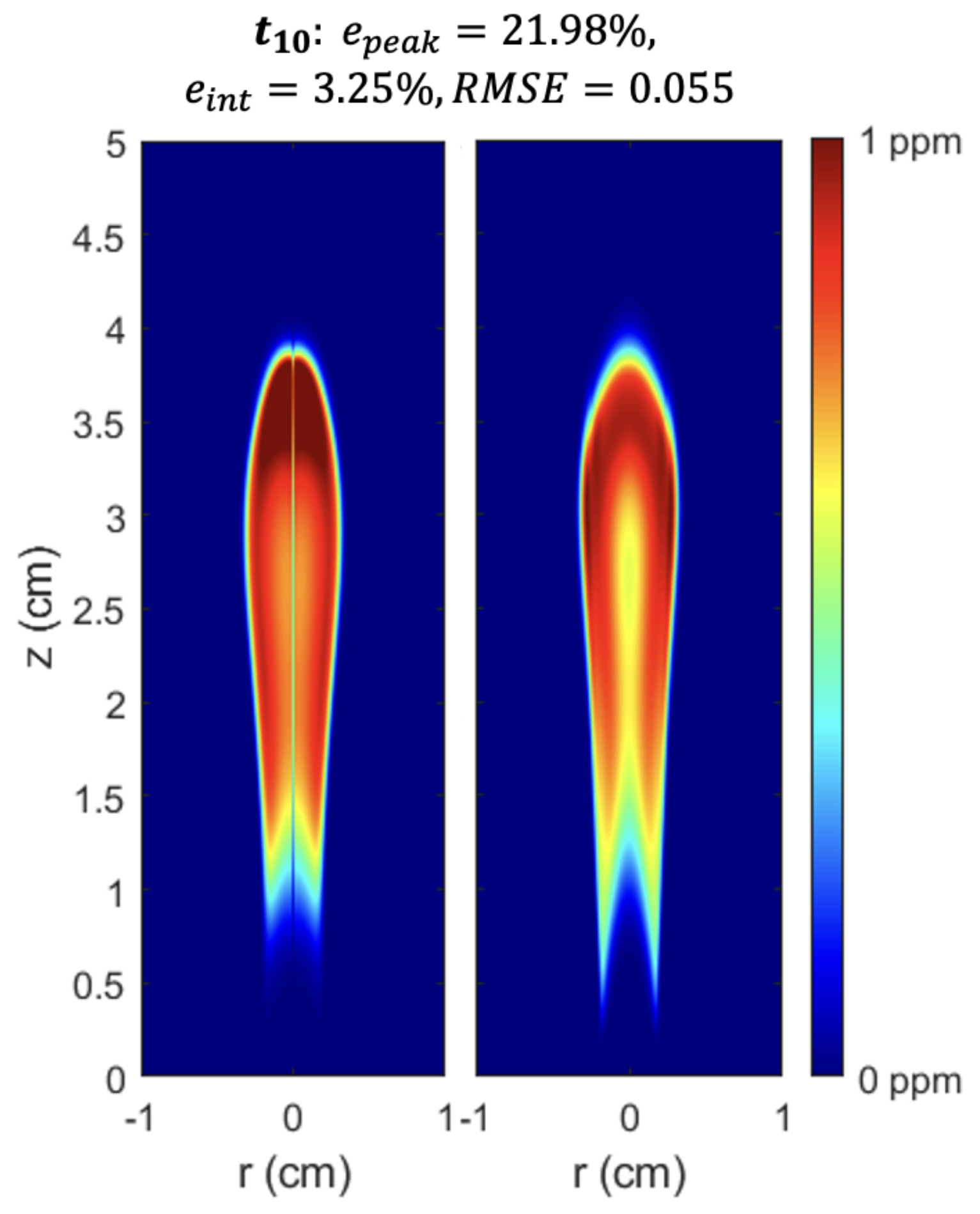
Figure 8 compares the prediction of the LSTM to CFD on the test data set (the
time step). Recall that the test data was not used to update the weights and biases of the neural network and therefore represents an independent measure of the network’s accuracy and general applicability. The results on the test data were very reasonable:
,
, and
. The error with the LSTM predictions in the present study is comparable to the error in a recent study that used an LSTM to predict
emissions from a coal burner [
32]; in both studies, the
values were approximately 1–2 orders of magnitude lower than the magnitudes of the predicted quantities (i.e., soot and
). In the results on the test data, there is perhaps some under-prediction of
in the tails of the flame and some over-prediction of
in the center and top; however, the overall shape and distribution of the
field is quite similar between CFD and the LSTM.
The test results are encouraging because (1) and were similar to and from the training data set, indicating negligible overfitting and (2) the test results were fairly accurate despite the challenges associated with the contour at being qualitatively dissimilar to the contour from to . The fact that the network can still give reasonable accuracy (compared to CFD) for a contour that is dissimilar to the contours in the training data set indicates that it could potentially be applied to a wide range of problems. As in many problems that involve neural networks, the best way to increase the network’s general applicability is to broaden the training data set. Therefore, improvement to this network will involve an expansion of the training data set. Additional changes may be made to try to improve the accuracy of the prediction tool in future uses, including the use of a deeper network (more hidden layers) and an exploration of more advanced deep learning techniques (such as attention).
Given the novelty of the soot estimator and its potential application over a wide range of
, it is appropriate to discuss different types of error. Equation (
16) below was developed in [
17] to analyze the absolute error for the soot estimator and will be applied here.
Equation (
16) is only a function of
z (axial height) because it is averaged in the radial direction. The averaging process in the radial direction reduces the error fluctuations significantly and makes the presentation and interpretation clearer. The error is averaged over
r ∈ [0,1] because it covers the sooting region for all time steps.
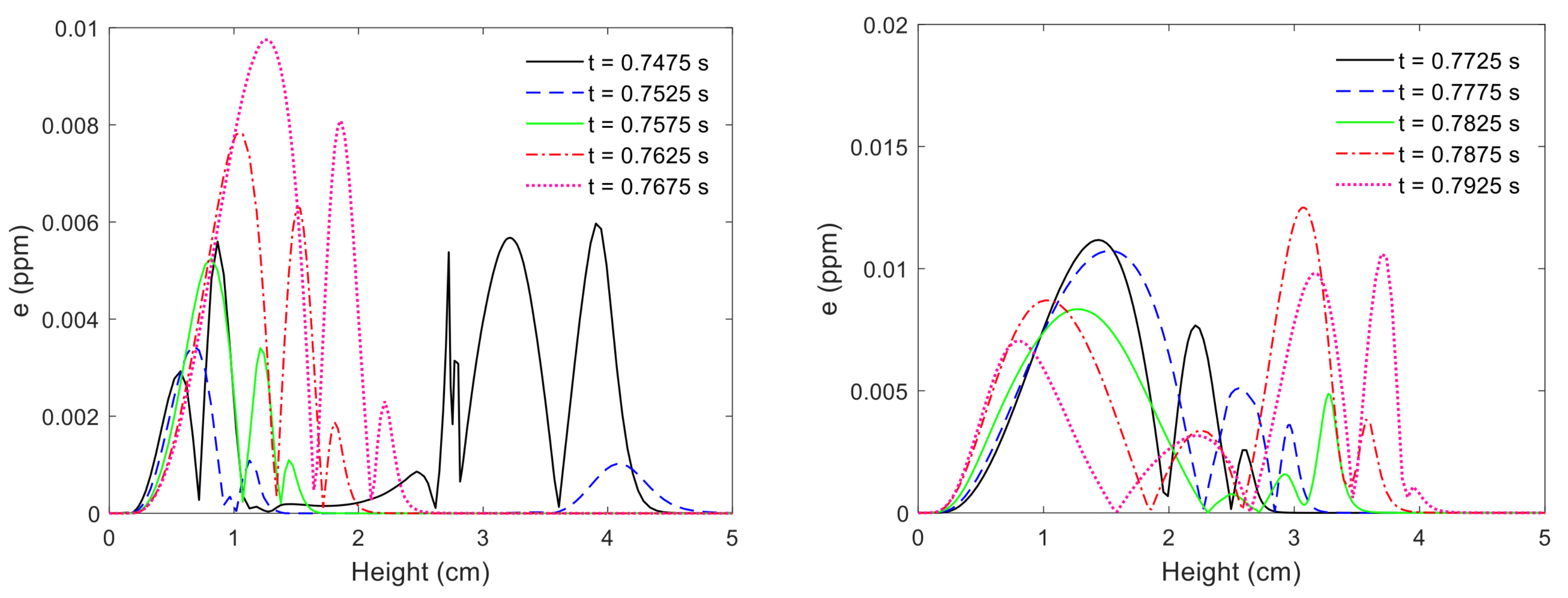
Figure 9 shows
e for all time steps in the training and test data (the test case is the largest time step). Interestingly, the largest values of
e are for the time steps where
and
are lowest, which indicates that the LSTM can give accurate predictions for all time steps if the predictions are averaged in the radial direction. Across all time steps, the maximum error is slightly over 0.012 ppm.
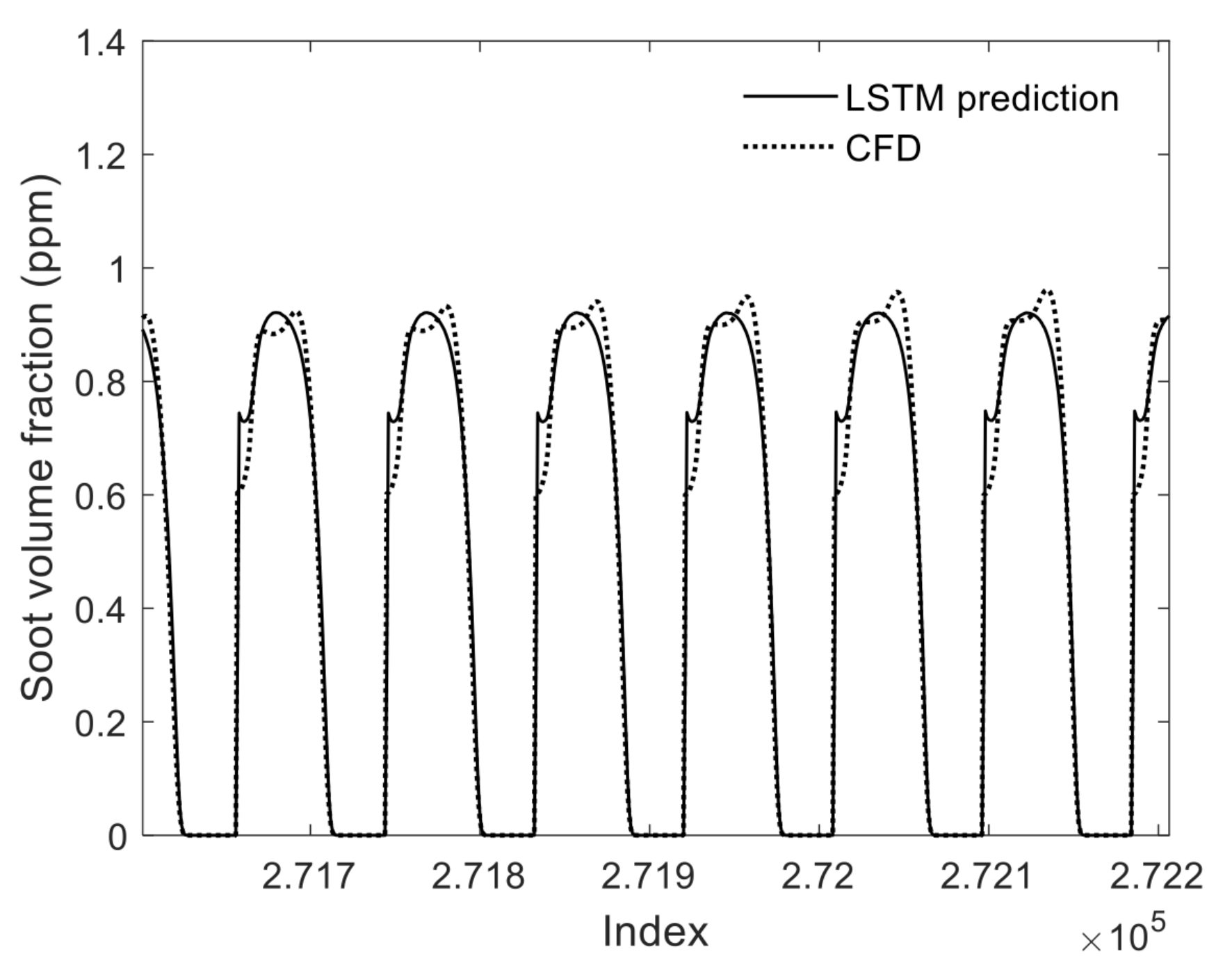
Figure 10 shows a graph of the LSTM and CFD predictions of soot volume fraction as a function of their index in the spatiotemporal array. Since the spatiotemporal arrays have tens of thousands of entries, the x-axis was limited to about 500 entries in order to improve readability.
Figure 10 shows that the neural network can follow the CFD data across rapid changes in
, which may bode well for its potential use in more complicated problems such as turbulent combustion. However, it remains to be seen whether this approach will thrive in a turbulent environment, where there may be many random or irregular changes in
or any of the input parameters. The application of this LSTM to complex problems like transient, turbulent diffusion flames may be the subject of future works.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}