6.1. Definitions
In this section, we recall the xNES and pure rank-μ CMA-ES, and we describe them in the IGO framework, thus allowing a reasonable comparison with the GIGO algorithms.
6.1.1. xNES
We recall a restriction of the xNES algorithm, introduced in [
19] (this restriction is sufficient to describe the numerical experiments in [
19]).
Definition 9 (xNES algorithm).
The xNES algorithm with sample size N, weights wi and learning rates ημ and ηΣ updates the parameters μ ∈ ℝ
d, A ∈ Md(ℝ)
with the following rule: At each step, N points x1, …,
xN are sampled from the distribution..
Without loss of generality, we assume f(
x1)
< … < f(
xN)
. The parameter is updated according to:where, setting zi =
A−1(
xi − μ)
: The more general version decomposes the matrix
A as
σB, where det
B = 1, and uses two different learning rates for
σ and for
B. We gave the version where these two learning rates are equal (in particular, for the default parameters in [
19], these two learning rates are equal). This restriction of the xNES algorithm can be described in the IGO framework, provided all of the learning rates are equal (most of the elements of the proof can be found in [
19] (the proposition below essentially states that xNES is a natural gradient update) or in [
1]):
Proposition 6 (xNES as IGO).
The xNES algorithm with sample size N, weights wi and learning rates ημ =
ηΣ =
δt coincides with the IGO algorithm with sample size N, weights wi, step size δt and in which, given the current position (
μt, At)
, the set of Gaussians is parametrized by:with δ ∈ ℝ
m and M ∈ Sym(ℝ
m).
The parameters maintained by the algorithm are (μ, A), and the xi are sampled from.
Proof. Let us compute the IGO update in the parametrization
: we have
δt = 0,
Mt = 0, and by using Proposition 1, we can see that for this parametrization, the Fisher information matrix at (0, 0) is the identity matrix. The IGO update is therefore,
where:
and:
Since tr(
M) = log(det(exp(
M))), we have:
and a straightforward computation yields:
and:
Therefore, the IGO update is:
or, in terms of mean and covariance matrix:
or:
This is the xNES update. □
6.1.2. Using a Square Root of the Covariance Matrix
Firstly, we recall that the IGO framework (on
, for example) emphasizes the Riemannian manifold structure on
. All of the algorithms studied here (including GIGO, which is not strictly speaking an IGO algorithm) define a trajectory in
(a new point for each step), and to go from a point θ to the next one (θ′), we follow some curve
, with γ(0) = θ, γ(δt) = θ′ and
given by the natural gradient
.
To be compatible with this point of view, an algorithm giving an update rule for a square root (any matrix A such that Σ = AAT: since we do not force A to be symmetric, the decomposition is not unique) of the covariance matrix A has to satisfy the following condition: for a given initial speed, the covariance matrix Σt+δt after one step must depend only on Σt and not on the square root At chosen for Σt.
The xNES algorithm does satisfy this condition: consider two xNES algorithms, with the same learning rates, respectively, at
and
, with
(i.e., they define the same Σt), using the same samples xi to compute the natural gradient update, then we will have
. Using the definitions of Section 6.3, we have just shown that what we will call the “xNES trajectory” is well defined.
It is also important to notice that, in order to be well defined, a natural gradient algorithm updating a square root of the covariance matrix has to specify more conditions than simply following the natural gradient.
The reason for this is that the natural gradient is a vector tangent to
: it lives in a space of dimension d(d + 3)/2 (the dimension of
), whereas the vector (μ, A) lives in a space of dimension d(d + 1) (the dimension of ℝn × GLn(ℝ)), which is too large: there exists infinitely many applications t ↦At, such that a given curve
can be written
. This is why Theorem 5 is simply an implication, whereas Theorem 4 is an equivalence.
More precisely, let us consider A in GLd(ℝ) and vA,
two infinitesimal updates of A. Since Σ = AAT, the infinitesimal update of Σ corresponding to
(resp.
) is
(resp.
It is now easy to see that vA and
define the same direction for Σ (i.e.,
) if and only if AMT + MAT = 0, where
. This is equivalent to A−1M antisymmetric.
For any
A ∈ M
d(ℝ), let us denote by
TA the space of the matrices
M, such that
A−1M is antisymmetric or, in other words,
TA :=
{u ∈ M
d(ℝ)
, AuT +
uAT = 0}. Having a subspace
SA in direct sum with
TA for all
A is sufficient (but not necessary) to have a well-defined update rule. Namely, consider the (linear) application:
sending an infinitesimal update of
A to the corresponding update of Σ. It is not bijective, but as we have seen before, Ker
ϕA =
TA, and therefore, if we have, for some
UA,
then
φA|UA is an isomorphism. Let
vΣ be an infinitesimal update of Σ. We choose the following update of
A corresponding to
vΣ:
Any
UA, such that
UA ⊕ TA = M
d(ℝ), is a reasonable choice to pick
vA for a given
vΣ. The choice
SA = {
u ∈ M
d(ℝ)
, AuT − uAT = 0} has an interesting additional property; it is the orthogonal of
TA for the norm:
and consequently, it can be defined without referring to the parametrization, which makes it a canonical choice. To prove this, remark that
TA = {
M ∈ M
d(ℝ),
A−1M antisymmetric} and
SA = {
M ∈ M
d(ℝ),
A−1M symmetric} and that if
M is symmetric and
N is antisymmetric, then
Let us now show that this is the choice made by xNES and GIGO-A (which are well-defined algorithms updating a square root of the covariance matrix).
Proposition 7. Let A ∈ Mn(ℝ). The vA given by the xNES and GIGO-A algorithms lies in SA = {u ∈ Md(ℝ), AuT − uAT = 0} = SA.
Proof. For xNES, let us write
and
. We have
, and therefore, forcing
M (and
GM) to be symmetric in xNES is equivalent to
A−1 υA = (
A−1 υA)
T, which can be rewritten as
. For GIGO-
A,
Equation (40) shows that
is symmetric, and with this fact in mind,
Equation (42) shows that we have
. □
6.1.3. Pure Rank-μ CMA-ES
We now recall the pure rank-
μ CMA-ES algorithm. The general CMA-ES algorithm is described in [
21].
Definition 10 (Pure rank-
μ CMA-ES algorithm).
The pure rank-μ CMA-ES algorithm with sample size N, weights wi and learning rates ημ and ηΣ is defined by the following update rule: At each step, N points x1,
…, xN are sampled from the distribution.
Without loss of generality, we assume f)
x1)
< … < f(
xN).
The parameter is updated according to: The pure rank-
μ CMA-ES can also be described in the IGO framework; see, for example, [
20].
Proposition 8 (Pure rank-μ CMA-ES as IGO). The pure rank-μ CMA-ES algorithm with sample size N, weights wi and learning rates ημ = ηΣ = δt coincides with the IGO algorithm with sample size N, weights wi, step size δt and the parametrization (μ, Σ).
6.2. Twisting the Metric
As we can see, the IGO framework does not allow one to recover the learning rates for xNES and pure rank-
μ CMA-ES, which is a problem, since usually, the covariance learning rate is set much smaller than the mean learning rate (see either [
19] or [
21]).
A way to recover these learning rates is to incorporate them directly into the metric (see also blockwise GIGO, in Section 6.4). More precisely:
Definition 11 (Twisted Fisher metric).
Let ημ, ηΣ ∈ ℝ,
and let (
Pθ)
θ∈Θ be a family of normal probability distributions: Pθ =
N (
μ(
θ), Σ(
θ))
, with μ and Σ
C1. We call the “(
ημ,
ηΣ)
-twisted Fisher metric” the metric defined by: All of the remainder of this section is simply a rewriting of the work in Section 2 with the twisted Fisher metric instead of the regular Fisher metric. We will use the term “twisted geodesic” instead of “geodesic for the twisted metric”.
This approach seems to be somewhat arbitrary: arguably, the mean and the covariance play a “different role” in the definition of a Gaussian (only the covariance can affect diversity, for example), but we lack a reasonable intrinsic characterization that would make this choice of twisting more natural. This construction can be slightly generalized (see the
Appendix).
The IGO flow and the IGO algorithms can be modified to take into account the twisting of the metric; the (
ημ, ηΣ)-twisted IGO flow reads:
The only difference with
(9) is that
I−1(
θ) has been replaced by
I(
ημ,
ηΣ)
−1(
θ).
This leads us to the twisted IGO algorithms.
Definition 12. The (
ημ, ηΣ)
-twisted IGO algorithm associated with parametrization θ, sample size N, step size δt and selection scheme w is given by the following update rule: Definition 13. The (
ημ,
ηΣ)
-twisted geodesic IGO algorithm associated with sample size N, step size δt and selection scheme w is given by the following update rule:where: By definition, the twisted geodesic IGO algorithm does not depend on the parametrization (but it does depend on ημ and ηΣ).
There is some redundancy between δt, ημ and ηΣ: the only values actually appearing in the equations are δtημ and δtηΣ. More formally:
Proposition 9. Let k, d, N ∈ N, ημ, ηΣ, δt, λ1, λ2 ∈ ℝ and w : [0; 1] → ℝ.
The (ημ, ηΣ)-twisted IGO algorithm with sample size N, step size δt and selection scheme w coincides with the (λ1ημ, λ1ηΣ)-twisted IGO algorithm with sample size N, step size λ2δt and selection scheme. The same is true for geodesic IGO.
In order to obtain the twisted algorithms, the Fisher metric in IGO has to be replaced by the metric from Definition 11. In practice, the equations found by twisting the metric are exactly the equations without twisting, except that we have “forced” the learning rates ημ, ηΣ to appear by multiplying the increments of μ and Σ by ημ and ηΣ.
We can now describe pure rank-μ CMA-ES and xNES with separate learning rates as twisted IGO algorithms:
Proposition 10 (xNES as IGO).
The xNES algorithm with sample size N, weights wi and learning rates ημ, ησ =
ηB =
ηΣ coincides with the,
-twisted IGO algorithm with sample size N, weights wi, step size δt and in which, given the current position (
μt, At)
, the set of Gaussians is parametrized by:with δ ∈ ℝ
m and M ∈ Sym(ℝ
m).
The parameters maintained by the algorithm are (μ, A), and the xi are sampled from N (μ, AAT).
Proposition 11 (Pure rank-μ CMA-ES as IGO). The pure rank-μ CMA-ES algorithm with sample size N, weights wi and learning rates ημ and ηΣ coincides with the-twisted IGO algorithm with sample size N, weights wi, step size δt and the parametrization (μ, Σ).
The proofs of these two statements are an easy rewriting of their non-twisted counterparts: one can return to the non-twisted metric (up to a ηΣ factor) by changing μ to
.
We give the equations of the twisted geodesics of
in the
Appendix.
6.3. Trajectories of Different IGO Steps
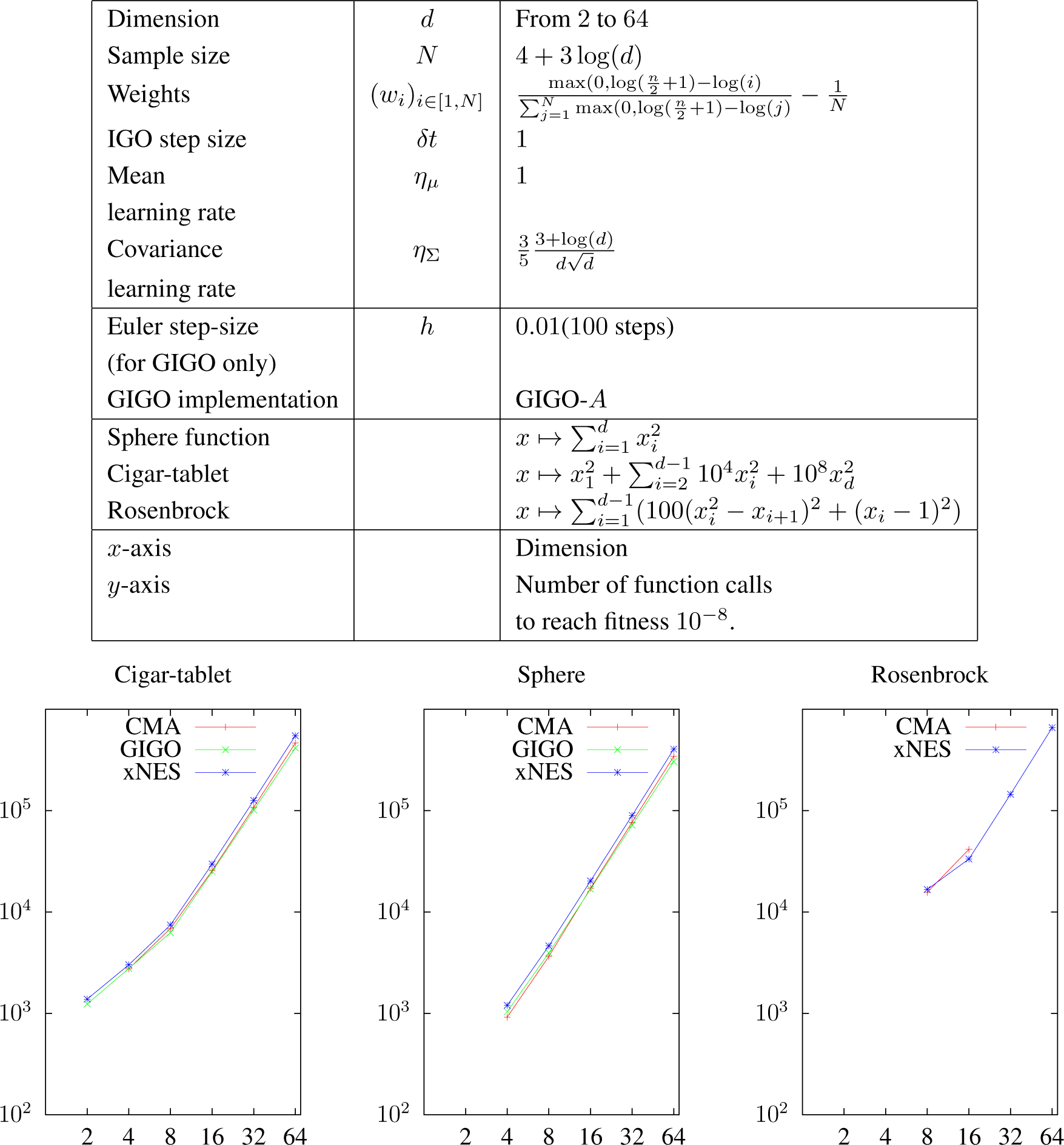
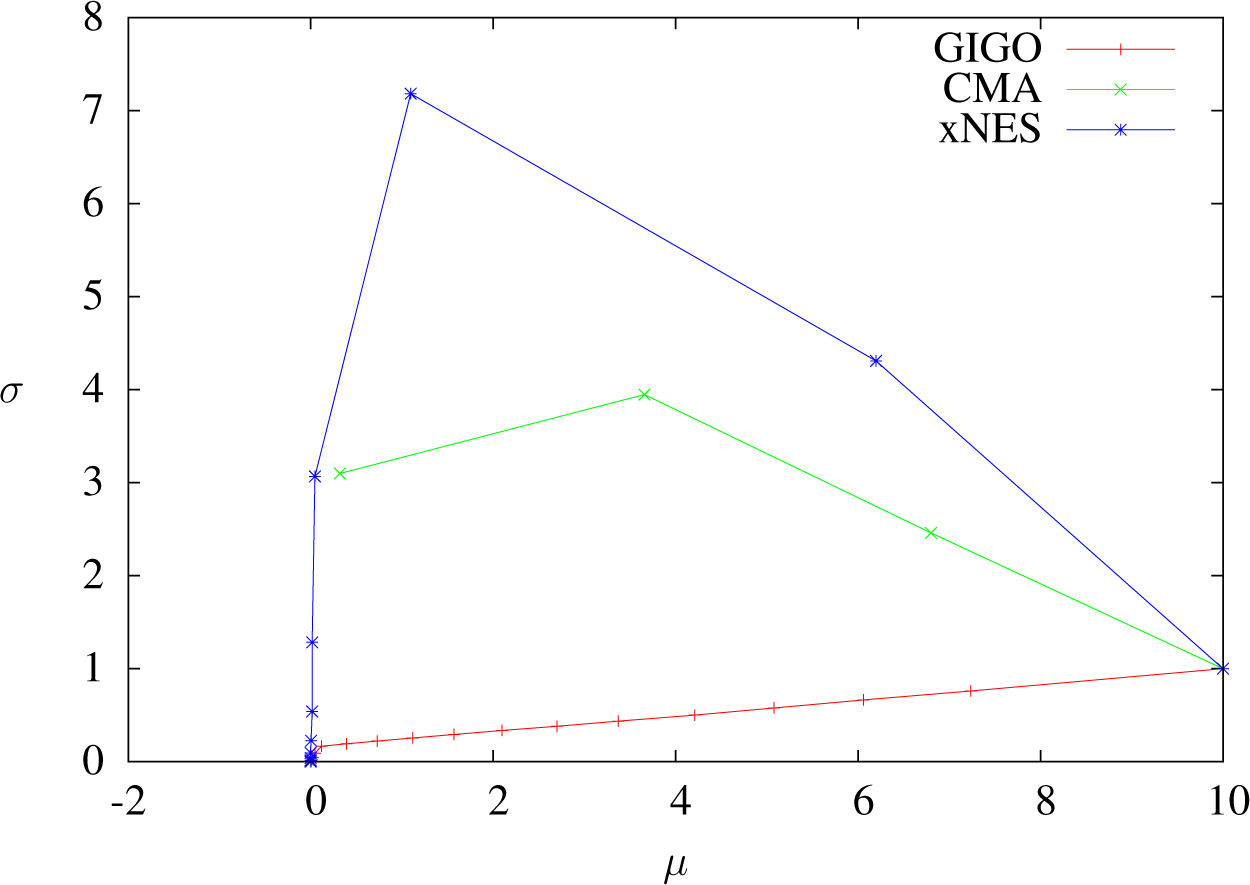
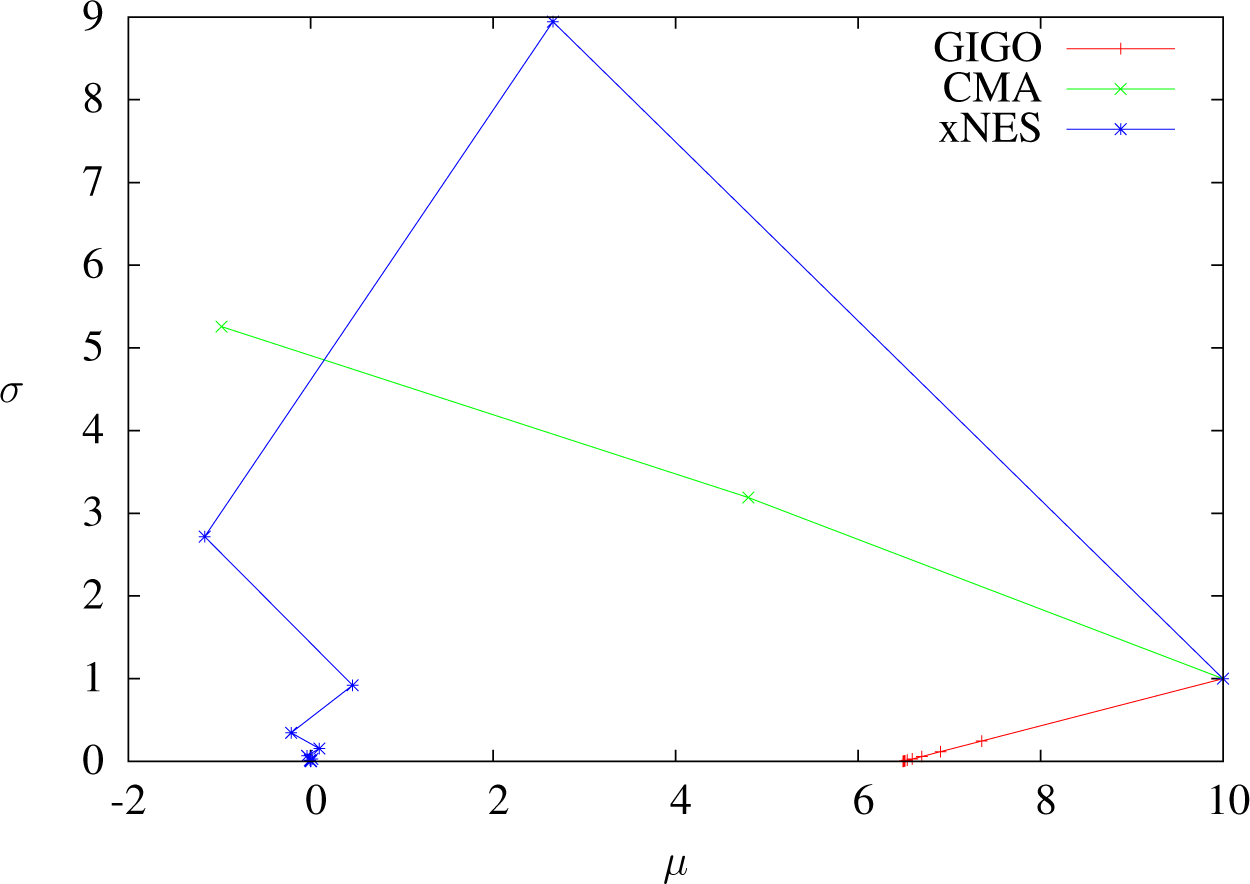
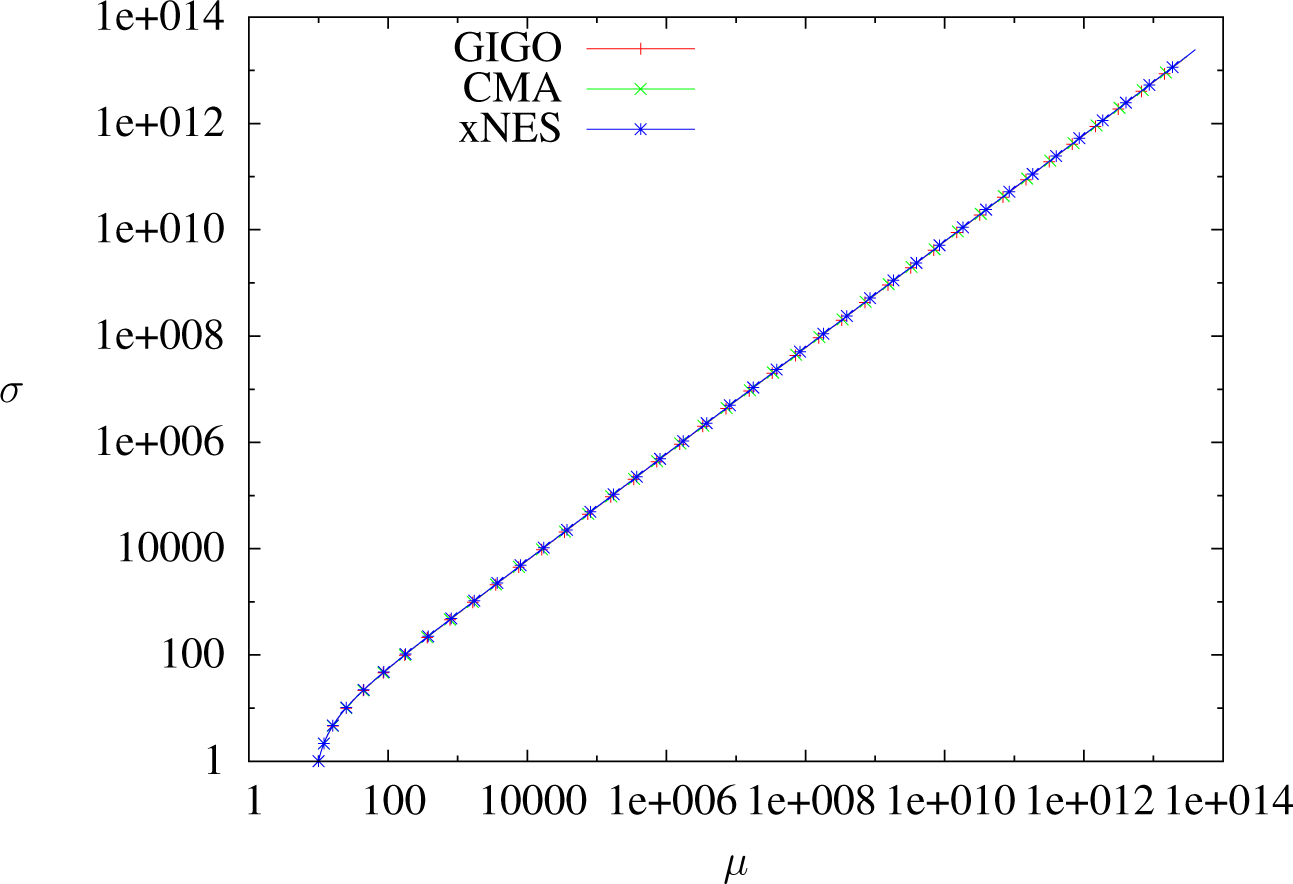
As we have seen, two different IGO algorithms (or an IGO algorithm and the GIGO algorithm) coincide at first order in δt when δt → 0. In this section, we study the differences between pure rank-μ CMA-ES, xNES and GIGO by looking at the second order in δt, and in particular, we show that xNES and GIGO do not coincide in the general case.
We view the updates done by one step of the algorithms as paths on the manifold
, from (μ(t), Σ(t)) to (μ(t + δt), Σ(t + δt)), where δt is the time step of our algorithms, seen as IGO algorithms. More formally:
Definition 14. (1) We call the GIGO update trajectory the application: (exp is the exponential of the Riemannian manifold)
(2) We call the xNES update trajectory the application:with AAT = Σ
. The application above does not depend on the choice of a square root A. (3) We call the CMA-ES update trajectory the application: These applications map the set of tangent vectors to (to the curves in.
We will also use the following notation: μGIGO := ϕμ○TGIGO, μxNES := ϕμ○TxNES, μCMA := ϕμ○TCMA, ΣGIGO := ϕΣ ○ TGIGO, ΣxNES := ϕΣ ○ TxNES and ΣCMA := ϕΣ ○ TCMA, where ϕμ (resp. ϕΣ) extracts the μ-component (resp. the Σ-component) of a curve.
In particular, Im(ϕμ) ⊂ ℝd and Im(ϕΣ) ⊂ Pd, where Pd (the set of real symmetric positive-definitematrices of dimension d) is seen as a subset of ℝd2.
For instance, TGIGO(μ, Σ, vμ, vΣ)(δt) gives the position (mean and covariance matrix) of the GIGO algorithm after a step of size δt, while μGIGO and ΣGIGO give, respectively, the mean component and the covariance component of this position.
This formulation ensures that the trajectories we are comparing had the same initial position and the same initial speed, which is the case provided the sampled points (the values directly sampled from
, not from
and transformed) are the same.
Different IGO algorithms coincide at first order in δt. The following proposition gives the second order expansion of the trajectories of the algorithms.
Proposition 12 (Second derivatives of the trajectories).
We have: Proof. We can immediately see that the second derivatives of
μxNES,
μCMA and Σ
CMA are zero. Next, we have:
The expression of ΣxNES(μ, Σ, vμ, vΣ)″(0) follows.
Now, for GIGO, let us consider the geodesic starting at (
μ0, Σ
0) with initial speed (
ημvμ, ηΣvΣ). By writing
Jμ(0) =
Jμ(
t), we find
. We then easily have
In other words:
Finally, by using Theorem 4 and differentiating, we find:
In order to interpret these results, we will look at what happens in dimension one. In higher dimensions, we can suppose that the algorithms exhibit a similar behavior, but an exact interpretation is more difficult for GIGO in
.
In [
19], it has been noted that xNES converges to quadratic minima slower than CMA-ES and that it is less subject to premature convergence. That fact can be explained by observing that the mean update is exactly the same for CMA-ES and xNES, whereas xNES tends to have a higher variance (Proposition 12 shows this at order two, and it is easy to see that in dimension one, for any
μ, Σ,
vμ,
vΣ, we have Σ
xNES(
μ, Σ
, vμ, vΣ) > Σ
CMA(
μ, Σ
, vμ, vΣ)).
At order two, GIGO moves the mean faster than xNES and CMA-ES if the standard deviation is increasing and more slowly if it is decreasing. This seems to be a reasonable behavior (if the covariance is decreasing, then the algorithm is presumably close to a minimum, and it should not leave the area too quickly). This remark holds only for isolated steps, because we do not take into account the evolution of the variance.
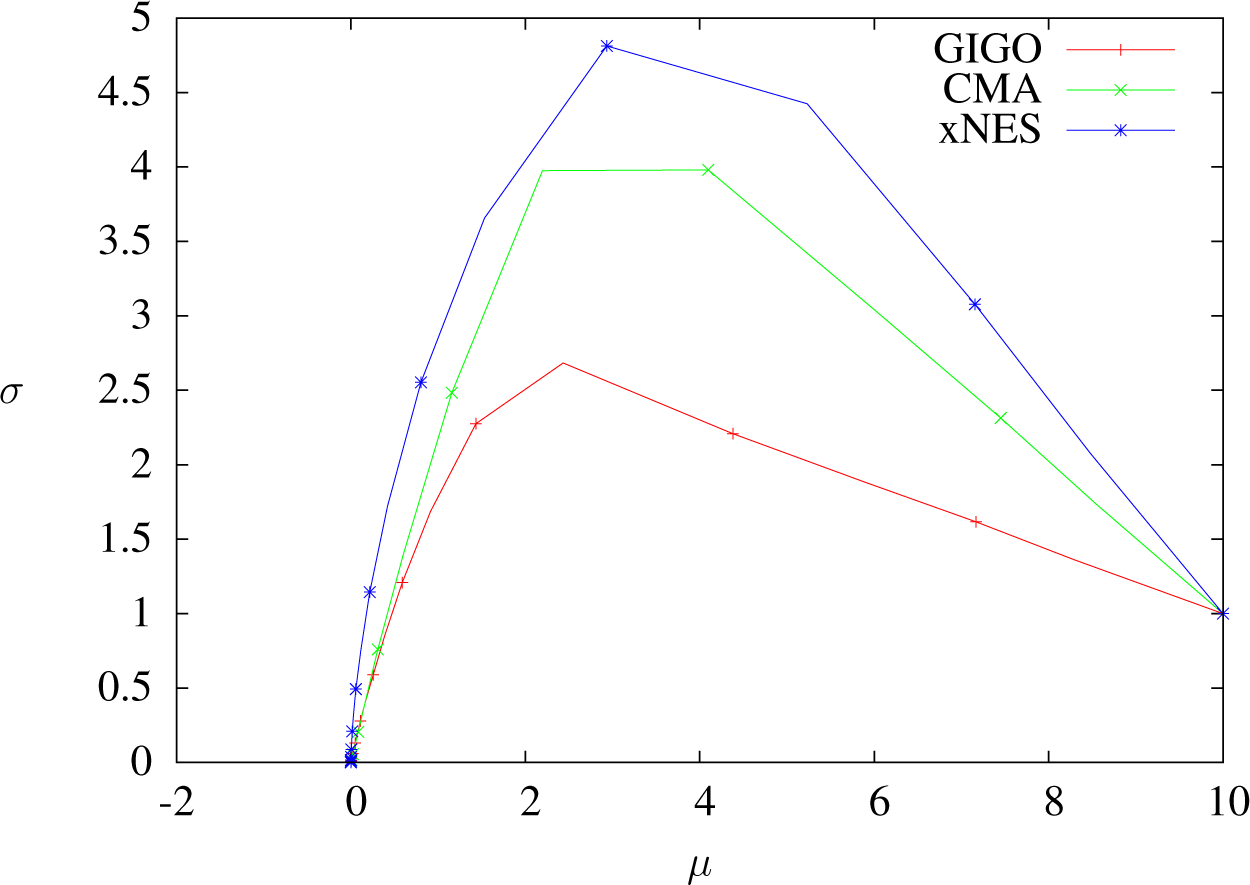
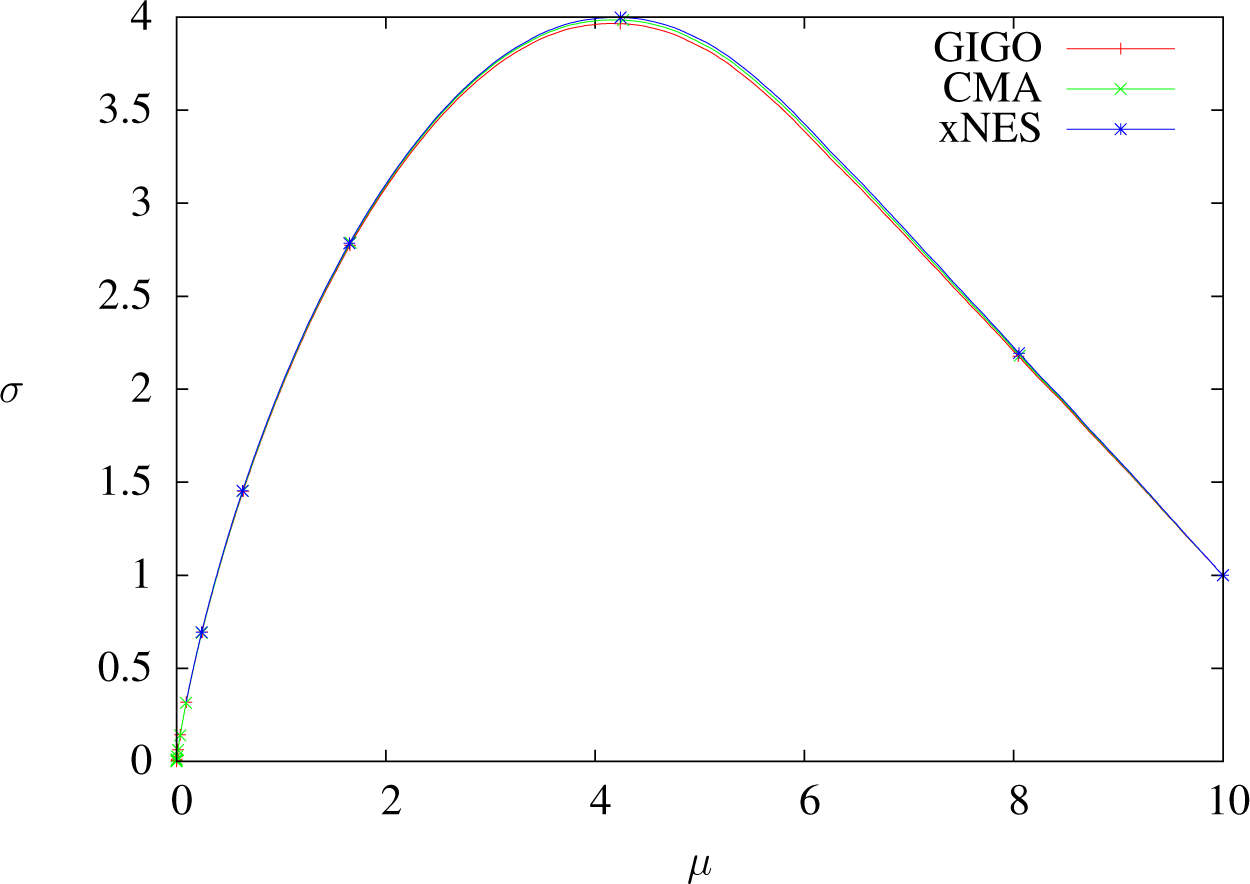
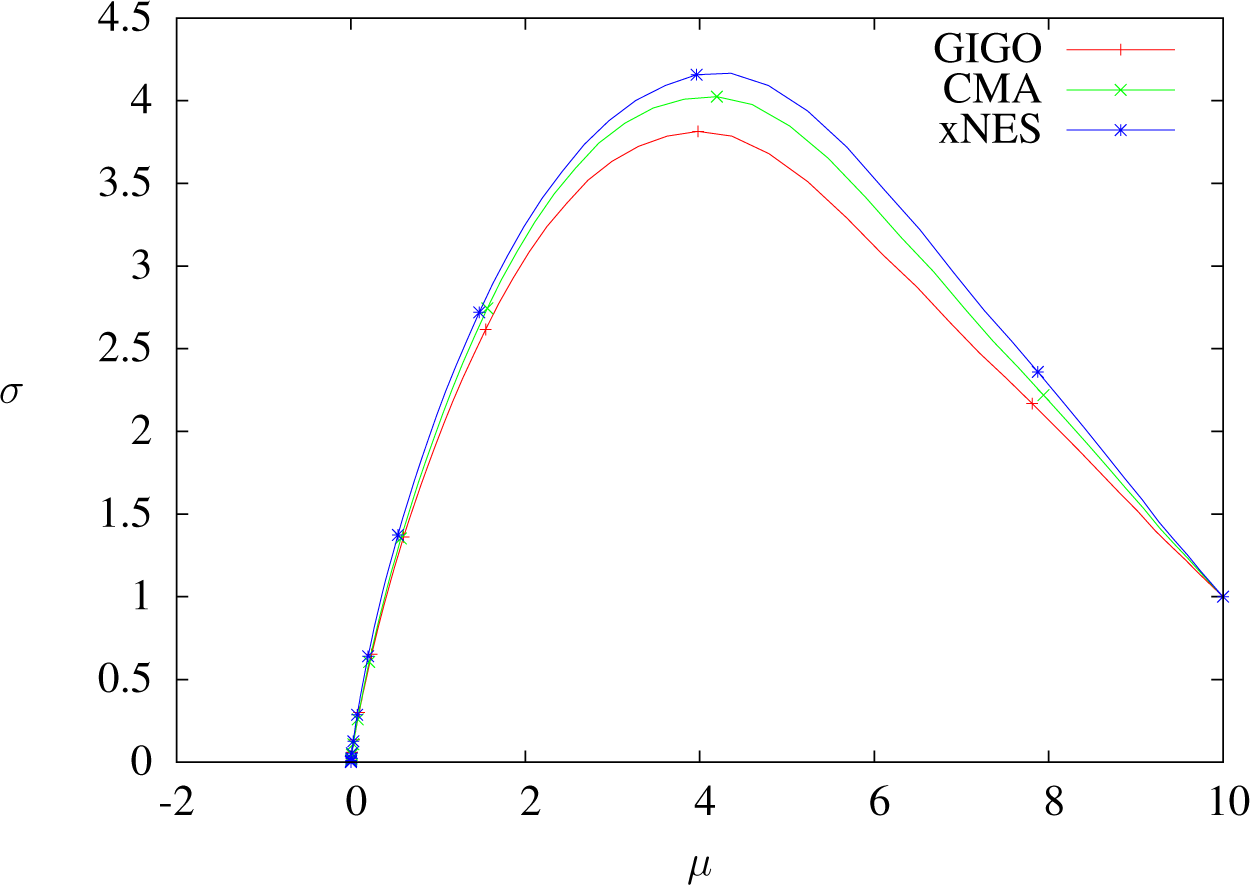
The geodesics of
are half-circles (see
Figure 2 below; we recall that
is the Poincaré half-plane). Consequently, if the mean is supposed to move (which always happens), then
σ → 0 when
δt → ∞. For example, a step whose initial speed has no component on the standard deviation will always decrease it. See also Proposition 15, about the optimization of a linear function.
For the same reason, for a given initial speed, the update of μ always stays bounded as a function of δt: it is not possible to make one step of the GIGO algorithm go further than a fixed point by increasing δt. Still, the geodesic followed by GIGO changes at each step, so the mean of the overall algorithm is not bounded.
We now show that xNES follows the geodesics of
if the mean is fixed, but that xNES and GIGO do not coincide otherwise.
Proposition 13 (xNES is not GIGO in the general case). Let μ, vμ ∈ ℝd, A ∈ GLd, vΣ ∈ Md.
Then, the GIGO and xNES updates starting at with initial speeds vμ and vΣ follow the same trajectory if and only if the mean remains constant. In other words: Proof. If vμ = 0, then we can compute the GIGO update by using Theorem 4: since Jμ = 0,
, and μ remains constant. Now, we have
; this is enough information to compute the update. Since this quantity is also preserved by the xNES algorithm (see, for example, the proof of Proposition 14), the two updates coincide.
Figure 2. One step of the geodesic IGO (GIGO) update.
If vμ ≠ 0, then
and, in particular, TGIGO(μ, Σ, vμ, vΣ) ≠ TxNES(μ, Σ, vμ, vΣ).
6.4. Blockwise GIGO
Although xNES is not GIGO, it is possible to define a family of algorithms extending GIGO and including xNES, by decomposing our family of probability distributions as a product and by following the restricted geodesics simultaneously.
Definition 15 (Splitting). Let Θ be a Riemannian manifold. A splitting of Θ is n manifolds Θ1, …, Θn and a diffeomorphism Θ ≅ Θ1 × … × Θn. If for all x ∈ Θ, for all 1 ≤ i < j ≤ n, we also have Ti,xM ⊥ Tj,xM as subspaces of TxM (see Notation 2), then the splitting is said to be compatible with the Riemannian structure. If the Riemannian manifold is not ambiguous, we will simply write a “compatible splitting”.
We now give some notation, and we define the blockwise GIGO update:
Notation 2. Let Θ
be a Riemannian manifold, Θ
1, …, Θ
n a splitting of Θ
, θ = (
θ1, …
, θn) ∈ Θ
, Y ∈
TθΘ
and 1 ≤
i ≤
n. Definition 16 (Blockwise GIGO update).
Let Θ
1, …, Θ
n be a compatible splitting. The blockwise GIGO algorithm in Θ
with splitting Θ
1, …, Θ
n associated with sample size N, step sizes δt1, …
, δtn and selection scheme w is given by the following update rule:where:with Yk the TΘ
θ,k-component of Y. This update only depends on the splitting (and not on the parametrization inside each Θ
k).
The compatibility condition ensures that the natural gradient of
(defined in Section 2.2) in the whole manifold Θ really is the sum of the gradients of this same function in the submanifolds Θ
k. A practical consequence is that the
Yk in
Equation (62) can be computed simply by taking the natural gradient in Θ
k:
where
Ik is the metric of Θ
k.
Since blockwise GIGO only depends on the splitting (and the tunable parameters: sample size, step sizes and selection scheme), it can be thought of as almost parametrization-invariant.
Notice that blockwise GIGO updates and twisted GIGO updates are two different things: firstly, blockwise GIGO can be defined on any manifold with a compatible splitting, whereas twisted GIGO (and twisted IGO) are only defined for Gaussians. However, even in
, with the splitting (
μ, Σ), these two algorithms are different: for instance, if
ημ =
ηΣ and
δt = 1, then the twisted GIGO is the regular GIGO algorithm, whereas blockwise GIGO is not (actually, we will prove that it is the xNES algorithm). The only thing blockwise GIGO and twisted GIGO have in common is that they are compatible with the (
ημ, ηΣ)-twisted IGO flow
Equation (57): a parameter
θt following these updates with
δt → 0 and
N → ∞ is a solution of
Equation (57).
We now have a new description of the xNES algorithm:
Proposition 14 (xNES is a Blockwise GIGO algorithm). The Blockwise GIGO algorithm in with splitting, sample size N, step sizes δtμ, δtΣ and selection scheme w coincides with the xNES algorithm with sample size N, weights wi and learning rates ημ = δtμ, ησ = ηB = δtΣ.
Proof. Firstly, notice that the splitting (μ, Σ) is compatible, by Proposition 1.
Now, let us compute the Blockwise GIGO update: we have
, where
Pd is the space of real positive-definite matrices of dimension
d. We have
. The induced metric on
is the Euclidean metric, so we have:
Since we have already shown (using the notation in Definition 9) that
Yμ =
AGμ (in the proof of Proposition 6), we find:
On Θ
θt,
2, we have the following Lagrangian for the geodesics:
By applying Noether’s theorem, we find that
is invariant along the geodesics of
, so they are defined by the equation
(and therefore, any update preserving the invariant
JΣ will satisfy this first-order differential equation and follow the geodesics of
. The xNES update for the covariance matrix is given by
A(
t) =
A0 exp(
tGM/2). Therefore, we have
,
and, finally,
. Therefore, xNES preserves
JΣ, and therefore, xNES follows the geodesics of
(notice that we had already proven this in Proposition 13, since we are looking at the geodesics of
with a fixed mean).
Although blockwise GIGO is somewhat “less natural” than GIGO, it can be easier to compute for some splittings (as we have just seen), and in the case of the Gaussian distributions, the mean-covariance splitting seems reasonable.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}