1. Introduction
Graphical models [
1,
2] provide a natural tool for dealing with two problems that occur throughout applied mathematics and engineering: uncertainty and complexity. The two most common types of graphical models are directed graphical models (also called Bayesian networks) [
3,
4] and undirected graphical models (also called Markov networks) [
5]. A Bayesian network (BN) is a type of statistical model consisting of a set of conditional probability distributions and a directed acyclic graph (DAG), in which the nodes denote a set of random variables and arcs describing conditional (in)dependence relationship between them. Therefore, BNs can be used to predict the consequences of intervention. The conditional dependencies in the graph are often estimated using known statistical and computational methods.
Supervised classification is an outstanding task in data analysis and pattern recognition. It requires the construction of a classifier, that is a function that assigns a class label to instances described by a set of variables. There are numerous classifier paradigms, among which Bayesian classifiers [
6–
11], based on probabilistic graphical models (PGMs) [
2], are well known and very effective in domains with uncertainty. Given class variable
C and a set of attributes
X = {X
1,
X2, ⋯,
Xn}, the aim of supervised learning is to predict from a training set the class of a testing instance
x = {
x1, ⋯,
xn}, where
xi is the value of the
i-th attribute. We wish to precisely estimate the conditional probability of
P(
c|
x) by selecting argmaxC
P(
c|
x), where
P(•) is a probability distribution function and c ∈ {
c1, ⋯,
ck} are the
k classes. By applying Bayes’ theorem, the classification process can be done in the following way with the BNs:
This kind of classifier is known as generative, and it forms the most common approach in the BN literature for classification [
6–
11].
Many scoring functions, e.g., maximum likelihood (ML) [
12], Bayesian information criterion (BIC) [
13], minimum description length (MDL) [
14] and Akaike information criterion (AIC) [
15], were proposed to evaluate whether the learned BN best fits the dataset. For BN, all attributes (including class variable) are treated equally, while for Bayesian classifiers, the class variable is treated as a distinguished one. Additionally, these scoring functions do not work well for Bayesian classifiers [
9]. In this paper, we limit our attention to a class of network structures, restricted Bayesian classifiers, which require that the class variable
C be a parent of every attribute and no attribute be the parent of C. P(c,
x) can be rewritten in terms of the product of a set of conditional distributions, which is also known as the chain rule of joint probability distribution.
where
Pai denotes a set of parent attributes of the node
Xi, except the class variable,
i.e., Pai = {
X1,
⋯,
Xi–1}. Each node
Xi has a conditional probability distribution (CPD) representing
P(
xi|Pai,
c). If the Bayesian classifier can be constructed based on
Equation (2), the corresponding model is “optimal”, since all conditional dependencies implicated in the joint probability distribution are fully described, and the main term determining the classification will take every attribute into account.
From
Equation (2), the order of attributes {X
1, ⋯,
Xn} is fixed in such a way that an arc between two attributes {
Xl, Xh} always goes from the lower ordered attribute
Xl to the higher ordered attribute
Xh. That is, the network can only contain arcs
Xl → Xh where
l <
h. The first few lower ordered attributes are more important than the higher ordered ones, because
Xl may be possible parent attributes of
Xh, but
Xh cannot be possible parent attributes of
Xl. One attribute may be dependent on several other attributes, and this dependence relationship will propagate to the whole attribute set. A slight move in one part may affect the whole situation. Finding an optimal order requires searching the space of all possible network structures for one that best describes the data. Without restrictive assumptions, learning Bayesian networks from data is NP-hard [
16]. Because of the limitation of time and space complexity, only a limited number of conditional probabilities can be encoded in the network. Additionally, precise estimation of
P(
xi|Pai,
c) is non-trivial when given too many parent attributes. One of the most important features of BNs is the fact that they provide an elegant mathematical structure for modeling complicated relationships, while keeping a relatively simple visualization of these relationships. If the network can capture all or at least the most important dependencies that exist in a database, we would expect a classifier to achieve optimal prediction accuracy. If the structure complexity is restricted to some extent, higher dependence cannot be represented. The restricted Bayesian classifier family can offer different tradeoffs between structure complexity and prediction performance. The simplest model is the naive Bayes [
6,
7], where
C is the parent of all predictive attributes, and there are no dependence relationships among them. On the basis of this, we can progressively increase the level of dependence, giving rise to a extension family of naive Bayes models, e.g., tree-augmented naive Bayes (TAN) [
8] or
K-dependence Bayesian network (KDB) [
10,
11].
Different Bayesian classifiers correspond to different factorizations of
P(
x|c). However, few studies have proposed to learn Bayesian classifiers from the perspective of the chain rule. This paper first establishes the mapping relationship between conditional probability distribution and mutual information, then proposes to evaluate the rationality of the Bayesian classifier from the perspective of information quantity. To build an optimal Bayesian classifier, the key point is to achieve the largest sum of mutual information that corresponds to the largest
a posteriori probability. The working mechanisms of three classical restricted Bayesian classifiers,
i.e., NB, TAN and KDB, are analyzed and evaluated from the perspectives of the chain rule and information quantity implicated in the graphical structure. On the basis of this, the proposed learning algorithm, the flexible
K-dependence Bayesian (FKDB) classifier, applies greedy search of the mutual information space to represent high-dependence relationships. The optimal attribute order is determined dynamically during the learning procedure. The experimental results on the UCImachine learning repository [
17] validate the rationality of the FKDB classifier from the viewpoints of zero-one loss and information quantity.
3. Restricted Bayesian Classifier Analysis
In the following discussion, we will analyze and summarize the working mechanisms of some popular Bayesian classifiers to clarify their rationality from the viewpoints of information theory and probability theory.
NB: NB simplified the estimation of P(
x|
c) by conditional independence assumption:
Then, the following equation is often calculated in practice, rather than
Equation (2).
As
Figure 2 shows, the NB classifier can be considered as a BN with a fixed network structure, where every attribute
Xi has the class variable as its only parent attribute,
i.e., Pai will be restricted to being null. NB can only represent a zero-dependence relationship between predictive attributes. There exists no information flow, but that between predictive attributes and the class variable.
TAN: The disadvantage of the NB classifier is that it assumes that all attributes are conditionally independent given the class, while this often is not a realistic assumption. As
Figure 3 shows, TAN introduces more dependencies by allowing each attribute to have an extra parent from the other attributes,
i.e., Pai can contain at most one attribute. TAN is based on the Chow–Liu algorithm [
20] and can achieve global optimization by building a maximal spanning tree (MST). This algorithm is quadratic in the number of attributes.
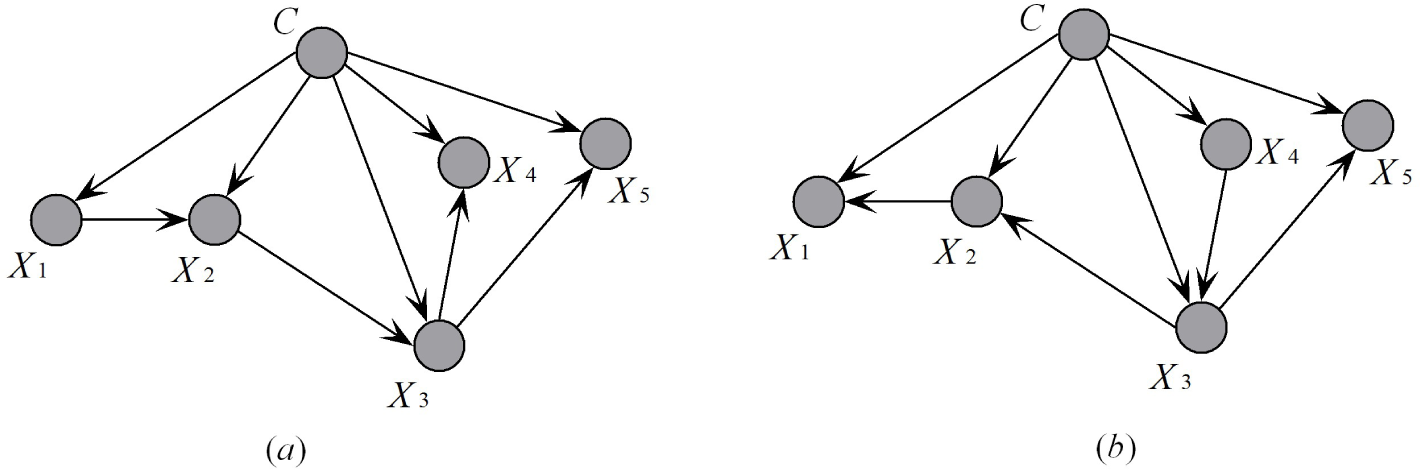
As a one-dependence Bayesian classifier, TAN is optimal. Different attribute orders provide the same undirected Bayesian network, which is the basis of TAN. When a different attribute is selected as the root node, the direction of some arcs may reverse. For example,
Figure 3a,b represents the same dependence relationship while
X1 and
X4 are selected as the root nodes, respectively. Additionally, corresponding chain rules are described as:
and:
Sum_MI is the same for
Figure 3a, b. That is the main reason why TAN performs almost the same, while the causal relationships implicated in the network structure differ. To achieve diversity, Ma and Shi [
21] proposed the RTAN algorithm, the output of which is TAN ensembles. Each sub-classifier is trained with different training subsets sampled from the original instances, and the final decision is generated by a majority of votes.
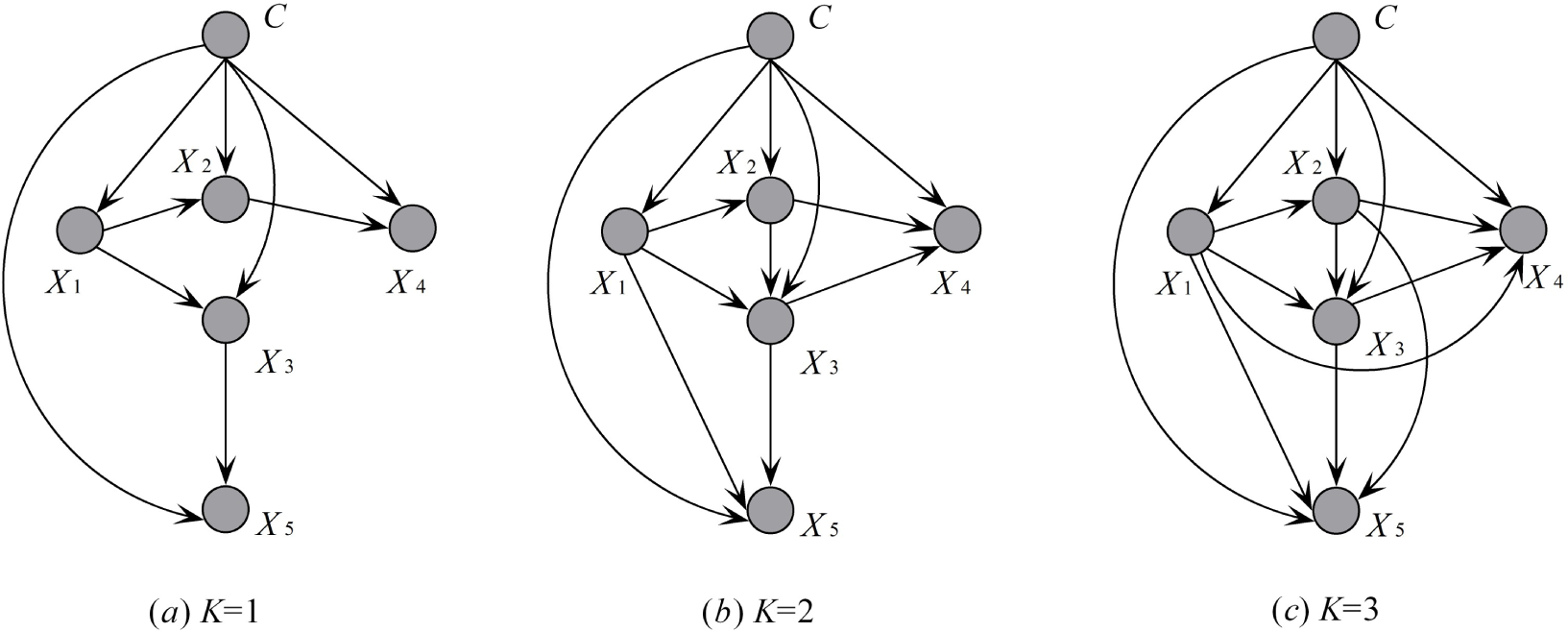
KDB: In KDB, the probability of each attribute value is conditioned by the class variable and, at most, K predictive attributes. The KDB algorithm adopts a greedy strategy in order to identify the graphical structure of the resulting classifier. KDB sets the order of attributes by calculating mutual information and achieves the weights of the relationship between attributes by calculating conditional mutual information. For example, given five predictive attributes {X1, X2, X3, X4, X5} and supposing that I(X1;C) > I(X2; C) > I(X3;C) > I(X4; C) > I(X5; C), the attribute order is {X1, X2, X3, X4, X5} by comparing mutual information.
From the chain rule of joint probability distribution, there will be:
Obviously, with more attributes to be considered as possible parent attributes, more causal relationships will be represented, and
Sum_MI will be larger correspondingly. However, because of the time and space complexity overhead, only a limited number of attributes will be considered. For KDB, each predictive attribute can select at most
K attributes as parent attributes.
Figure 4 gives an example to show corresponding KDB models when given different
K values.
In summary, from the viewpoint of probability theory, all of these algorithms can be regarded as different variations of the chain rule. Different algorithms tried to get different levels of tradeoff between computational complexity and classification accuracy. One advantage of NB is avoiding model selection, because selecting between alternative models can be expected to increase variance and allow a learning system to overfit the training data. However, the conditional independence assumption makes NB neglect the conditional mutual information between predictive attributes. Thus, NB is zero-dependence based and performs the worst among the three algorithms. TAN proposes to achieve global optimization by building MST to weigh the one-dependence causal relationships,
i.e., TAN can only have at most one parent, except the class variable. Thus, only a limited number of dependencies or a limited information quantity can be represented in TAN. KDB allows for higher dependence to represent much more complicated relationships between attributes and can have at most
K parent attributes. However, KDB is guided by a rigid ordering obtained by using the mutual information between the predictive attribute and the class variable. Mutual information does not consider the interaction between predictive attributes, and this marginal knowledge may result in sub-optimal order. Suppose
K = 2 and
I(
C; X1)
> I(
C; X2)
> I(
C; X3) >
I(
C; X4)
> I(
C; X5);
X3 will use
X2 as the parent attribute, even if they are independent of each other. When
K = 1, KDB performs poorer than TAN, because it can only achieve a local optimal network structure. Besides, as described in
Equation (9)I(
Xi;
Xj|C) can only partially measure the dependence between
Xi and {
Xj,
C}.
4. The Flexible K-Dependence Bayesian Classifier
To retain the privileges of TAN and KDB, i.e., global optimization and higher dependence representation, we presently give an algorithm, i.e., FKDB, which also allows one to construct K-dependence classifiers along the attribute dependence spectrum. To achieve the optimal attribute order, FKDB considers not only the dependence between the predictive attribute and the class variable, but also the dependencies among predictive attributes. As the learning procedure proceeds, the attributes will be put into order one by one. Thus, the order is determined dynamically.
Let S represent the attribute set, and predictive attributes will be added to S in a sequential order. The newly-added attribute Xj must select parent attributes from S. To achieve global optimization, Xj should have the strongest relationship with its parent attributes on average, i.e., the largest mutual information should be between Xj and {Paj,C}. Once selected, Xj will be added to S as possible parent attributes of the following attribute. FKDB applies greedy search of the mutual information space to find an optimal ordering of all of the attributes, which may help to fully describe the interaction between attributes.
Algorithm 1.
Algorithm FKDB.
Algorithm 1.
Algorithm FKDB.
| Input: a database of pre-classified instances, DB, and the K value for the maximum allowable degree of attribute dependence. |
| Output: a K-dependence Bayesian classifiers with conditional probability tables determined from the input data. |
Let the used attribute list, S, be empty. Select attribute Xroot that corresponds to the largest value I(Xi; C), and add it to S. Add an arc from C to Xroot. Repeat until S includes all domain attributes • Select attribute Xi, which is not in S and corresponds to the largest sum value:
where Xj ∈ S and q = min(| S|; K). • Add a node to BN representing Xi. • Add an arc from C to Xi in BN. • Add q arcs from q distinct attributes Xj in S to Xi. • Add Xi to S. Compute the conditional probability tables inferred by the structure of BN using counts from DB, and output BN.
|
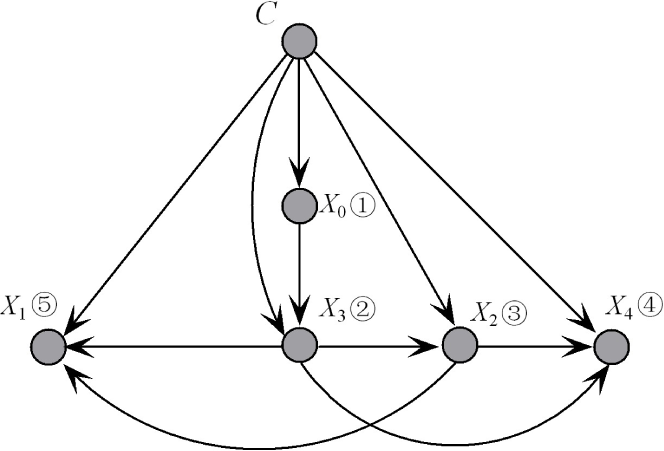
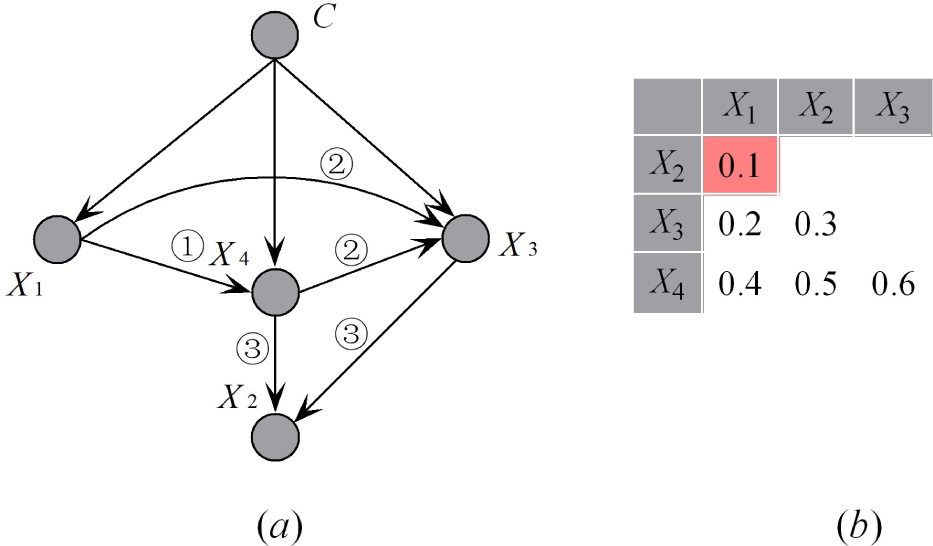
FKDB requires that at most
K parent attributes can be selected for each new attribute. To make the working mechanism of FKDB clear, we set
K = 2 in the following discussion. Because
I(
Xi;
Xj|C)
= I(
Xj; Xi|C), we describe the relationships between attributes using an upper triangular matrix of conditional mutual information. The format and one example with five predictive attributes {X
0,X
1,X
2,X
3,X
4} are shown in
Figure 5a,b, respectively. Suppose that
I(
X0;
C) >
I(
X3;
C)
> I(
X2;
C)
> I(
X4;
C)
> I(
X1;
C),
X0 is added into
S as the root node.
X3 = argmax (
I(
Xi;
C) +
I(
X0;
Xi|
C)) (
Xi ∉
S); thus,
X3 is added to
S; and
S = {
X0,
X3}.
X2 = argmax (
I(
Xi;
C) +
I(
X0;
Xi|
C) +
I(
X3;
Xi|C)) (
Xi ∉
S); thus,
X2 is added into
S; and
S = {X
0,X
2,X
3}. Similarly,
X4 = argmax (
I(
Xi;
C) +
I(
Xj,Xi|C) +
I(
Xk,
Xi|C)) (
Xi ∉
S, Xj,
Xk ∈
S); thus,
X4 is added into
S, and
X1 will be the last one in the order. Thus, the whole attribute order and causal relationship can be achieved simultaneously. The final network structures is illustrated in
Figure 6.
Optimal attribute order and high dependence representation are two key points for learning KDB. Note that KDB achieves these two goals in different steps. KDB first computes and compares mutual information to get an attribute order before structured learning. Then, during the structured learning procedure, each predictive attribute Xi can select at most K attributes as parent attributes by comparing conditional mutual information (CMI). Because these two steps are separate, the attribute order cannot ensure that the first K strongest dependencies between Xi and other attributes should be represented. On the other hand, to achieve the optimal attribute order, FKDB considers not only the dependence between predictive attribute and class variable, but also the dependencies among predictive attributes. As the learning procedure proceeds, the attributes will be put into order one by one. Thus, the order is determined dynamically. That is why the classifier is named “flexible”.
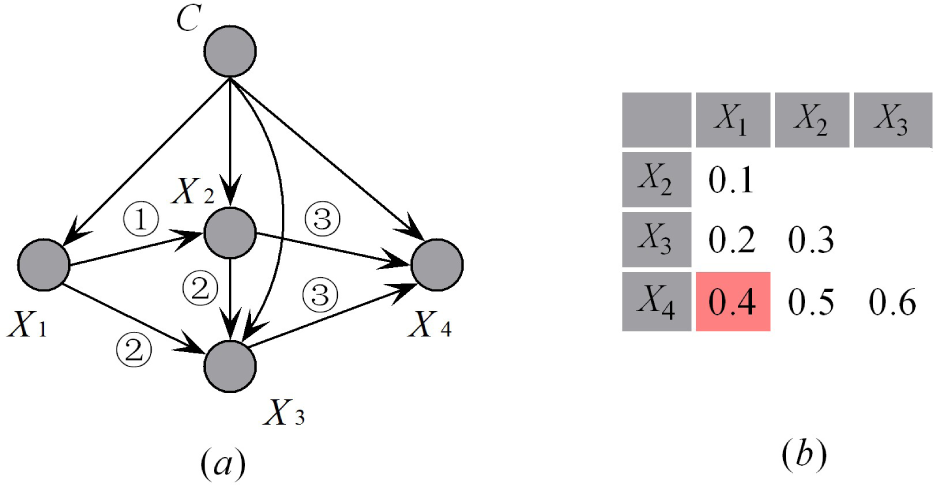
We will further compare KDB and FKDB with an example. Suppose that for KDB, the attribute order is {
X1,
X2,
X3,
X4};
Figure 7 shows the corresponding network structure of KDB when
K = 2 corresponds to the CMI matrix shown in
Figure 7b, and the learning steps are annotated. The weight of dependencies between attributes are depicted in
Figure 7b. Although the dependence relationship between
X2 and
X1 is the weakest,
X1 is selected as the parent attribute of
X2; whereas the strong dependence between
X4 and
X1 is neglected. Suppose that for FKDB, the mutual information
I(
Xi;
C) is the same for all predictive attributes.
Figure 8a shows the network structure of FKDB corresponding to the CMI matrix shown in
Figure 8b, and learning steps are also annotated. The weights of causal relationships are depicted in
Figure 8b, from which we can see that all strong causal relationships are implicated in the final network structure.
5. Experimental Study
In order to verify the efficiency and effectiveness of the proposed FKDB (
K = 2), we conduct experiments on 45 datasets from the UCI machine learning repository.
Table 1 summarizes the characteristics of each dataset, including the numbers of instances, attributes and classes. Missing values for qualitative attributes are replaced with modes, and those for quantitative attributes are replaced with means from the training data. For each benchmark dataset, numeric attributes are discretized using MDL discretization [
22]. The following algorithms are compared:
NB, standard naive Bayes.
TAN [
23], tree-augmented naive Bayes applying incremental learning.
RTAN [
21], tree-augmented naive Bayes ensembles.
KDB (K = 2), standard K-dependence Bayesian classifier.
All algorithms were coded in MATLAB 7.0 (MathWorks, Natick, MA, USA) on a Pentium 2.93 GHz/1 G RAM computer. Base probability estimates
P(
c),
P(
c,
xi) and
P(
c,
xi,
xj) were smoothed using the Laplace estimate, which can be described as follows:
where
F(·) is the frequency with which a combination of terms appears in the training data,
M is the number of training instances for which the class value is known,
Mi is the number of training instances for which both the class and attribute
Xi are known and
Mij is the number of training instances for which all of the class and attributes
Xi and
Xj are known.
m is the number of attribute values of class
C; m
i is the number of attribute value combinations of
C and
Xi; and
mij is the number of attribute value combinations of
C, Xj and
Xi.In the following experimental study, functional dependencies (FDs) [
24] are used to detect redundant attribute values and to improve model interpretability. To maintain the
K-dependence restriction,
P(
xi|x1, ⋯,
xk,
c) will be used as an approximate estimation of
P(
xi|x1, ⋯,
xi–1,
c) when
i > K. Obviously,
P(
xi|x1,
⋯,
xk+1, c) will be more accurate than
P(
xi|x1, ⋯, xk, c). If there exists FD:
x2 → x1, then
x2 functionally determines
x1 and
x1 is extraneous for classification. According to the augmentation rule of probability [
24],
Correspondingly, in practice, FKDB uses P(xi|x2, ⋯ ,xk+1, c) instead, which still maintains K-dependence restriction, whereas it represents more causal relationships.
FDs use the following criterion:
to infer that
xi → xj, where
Count(
xi) is the number of training cases with value
xi,
Count(
xi,
xj) is the number of training cases with both values and
l is a user-specified minimum frequency. A large number of deterministic attributes, which are on the left side of the FD, will increase the risk of incorrect inference and, at the same time, needs more computer memory to store credible FDs. Consequently, only the one-one FDs are selected in our current work. Besides, as no formal method has been used to select an appropriate value for
l, we use the setting that
l = 100, which is achieved from empirical studies.
Kohavi and Wolpert [
25] presented a powerful tool from sampling theory statistics for analyzing supervised learning scenarios. Suppose c and c are the true class label and that generated by classifier
A, respectively, for the
i-th testing sample; the zero-one loss is defined as:
where
δ(
c,
ĉ) = 1 if
ĉ =
c and 0 otherwise.
Table 2 presents for each dataset the zero-one loss and the standard deviation, which are estimated by 10-fold cross-validation to give an accurate estimation of the average performance of an algorithm. Statistically, a win/draw/loss record (W/D/L) is calculated for each pair of competitors
A and
B with regard to a performance measure
M. The record represents the number of datasets in which
A respectively beats, loses to or ties with
B on
M. Small improvements may be attributable to chance. Runs with the various algorithms are carried out on the same training sets and evaluated on the same test sets. In particular, the cross-validation folds are the same for all of the experiments on each dataset. Finally, related algorithms are compared via a one-tailed binomial sign test with a 95 percent confidence level.
Table 3 shows the W/D/L records corresponding to zero-one loss. When dependence complexity increases, the performance of TAN gets better than that of NB. RTAN investigates the diversity of TAN by the
K statistic. The bagging mechanism helps RTAN to achieve superior performance to TAN. FKDB performs undoubtedly the best. However, surprisingly, as a 2-dependence Bayesian classifier, the advantage of KDB is not obvious when compared to 1-dependence classifiers, and it even performs poorer than RTAN in general. However, when the data size increases to a certain extent, e.g., 4177 (the size of dataset “Abalone”), as
Table 4 shows, the prediction performance of all restricted classifiers can be evaluated from the perspective of the dependence level. Two-dependence Bayesian classifiers, e.g., FKDB and KDB, perform the best. The one-dependence Bayesian classifier, e.g., TAN, performs better. Additionally, 0-dependence Bayesian classifiers, e.g., NB, perform the worst.
Friedman proposed a non-parametric measure [
28], the Friedman test, which compares the ranks of the algorithms for each dataset separately. The null-hypothesis is that all of the algorithms are equivalent, and there is no difference in average ranks. We can compute the Friedman statistic:
by using the chi-square distribution with
t – 1 degrees of freedom, where
and
is the rank of the j-th of
t algorithms on the
i-th of
N datasets. Thus, for any selected level of significance
α, we reject the null hypothesis if the computed value of
Fr is greater than
, the upper-tail critical value for the chi-square distribution having
t – 1 degrees of freedom. The critical value of
for
α = 0.05 is 1.8039. The Friedman statistic for 45 datasets and 17 large (size > 4177) datasets are 12 and 28.9, respectively. Additionally,
p < 0.001 for both cases. Hence, we reject the null-hypotheses.
The average ranks of zero-one loss of different classifiers on all and large datasets are {NB(3.978), TAN(2.778), RTAN(2.467), KDB(3.078), FKDB(2.811)} and {NB(4.853), TAN(3.118), RTAN(3), KDB(2.176) and FKDB(2)}, respectively. Correspondingly, the order of these algorithms is {RTAN, TAN, FKDB, KDB, NB} when comparing the experimental results on all datasets. The performance of FKDB is not obviously superior to other algorithms. However, when comparing the experimental results on large datasets, the order changes greatly and turns out to be {FKDB, KDB, RTAN, TAN, NB}.
When the class distribution is imbalanced, traditional classifiers are easily overwhelmed by instances from majority classes, while the minority classes instances are usually ignored [
26]. A classification system should, in general, work well for all possible class distribution and misclassification costs. This issue was successfully addressed in binary problems using ROC analysis and the area under the ROC curve (AUC) metric [
27]. Research on related topics, such as imbalanced learning problems, is highly focused on the binary class problem, while progress on multiclass problems is limited [
26]. Therefore, we select 16 datasets with binary class labels for comparison of the AUC. The AUC values are shown in
Table 5. With 5 algorithms and 16 datasets, the Friedman statistic
Fr = 2.973 and
p < 0.004. Hence, we reject the null-hypotheses again. The average ranks of different classifiers are {NB(3.6), TAN(3.0), RTAN(2.833), KDB(2.867) and FKDB(2.7)}. Hence, the order of these algorithms is {FKDB, RTAN, KDB, TAN, NB}. The effectiveness of FKDB is proven from the perspectives of AUC.
To compare the relative performance of classifiers
A and B, the zero-one loss ratio (
ZLR) is proposed in this paper and defined as
ZLR(
A/B) =
∑ ξ
i (
A)/
∑ξi(
B).
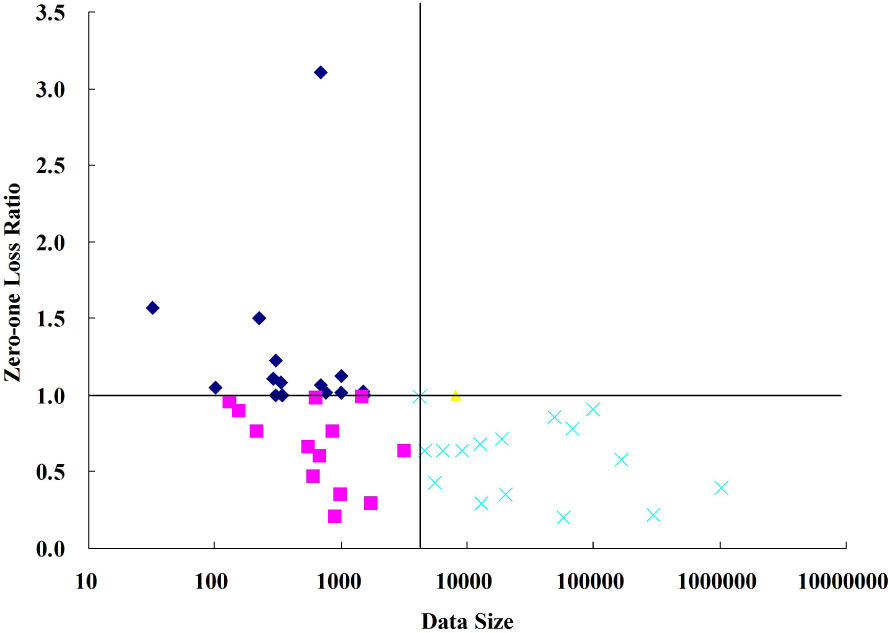
Figures 9–
12 compare FKDB with NB, TAN, RTAN and KDB, respectively. Each figure is divided into four parts by comparing data size and
ZLR. That is, the data size is greater than 4177 while
ZLR ≥ 1 or
ZLR < 1, and the data size is smaller than 4177 while
ZLR ≥ 1 or
ZLR < 1. In different parts, different symbols are used to represent different situations. When dealing with small datasets (data size <4177), the performance superiority of FKDB is not obvious when compared to the 0-dependence (NB) or 1-dependence Bayesian classifiers (TAN). For some datasets, e.g., “Lung Cancer” and “Hungarian”, NB even performs the best. Because precise estimation of conditional mutual information is determined by probability estimation, which is affected greatly by data size, the robustness of network structure will be affected negatively by imprecise probability estimation. For example, for dataset “Lung Cancer” with 32 instances and 56 attributes, it is almost impossible to ensure that the basic causal relationships learned are of a high confidence level. That is why a simple structure can perform better than a complicated one. Since each submodel of RTAN can represent only a small proportion of all dependencies, the complementarity of the bagging mechanism works and helps to improve the performance of TAN. KDB shows equivalent performance to FKDB.
As data size increases, high-dependence Bayesian classifiers gradually show their superiority, and the advantage of FKDB is almost overwhelming when compared to NB and TAN. Because almost all strong dependencies can be detected and illustrated in each submodel of RTAN, the high degree of uniformity in the basic structure cannot help to improve the prediction performance of TAN. Thus, RTAN shows equivalent performance to TAN. The prediction superiority of FKDB over KDB becomes much more obvious. Because they both are 2-dependence Bayesian classifiers, a minor difference in local structure may be the main cause of the performance difference. To further clarify this idea, we propose a new criterion,
Info_ratio(
A/B), to compare the information quantity implicated in Bayesian classifiers A and B.
The comparison results of
Info_ratio(
FKDB/KDB) are shown in
Figure 13, from which the superiority of FKDB in extracting information is much more obvious when dealing with large datasets. The increased information quantity does help to decrease zero-one loss. However, note that the growth rate of information quantity is not in proportion to the descent rate of zero-one loss. For some datasets, e.g., “Localization” and “Poker-hand”, KDB and FKDB achieve the same
Sum_MI, while their zero-one losses are different. The same
Sum_MI corresponds to the same causal relationships. The network structures learned from KDB and FKDB are similar, because the major dependencies are all implicated, except that the directions of some arcs are different. Dependence “
X3 –
X4” can be represented by conditional probability distribution
P(
x3|
x4,
c) or
P(
x4|
x3,
c). Just as we clarified in Section 3, although the basic structures described in
Figure 3a,b are the same, the corresponding joint probability distributions represented by
Equations (13) and
(14) are different. Since
ZLR ≈ 1 for these two datasets, the difference in zero-one loss can be explained from the perspective of probability distribution.
To prove the relevance of information quantity to zero-one loss,
Figure 14 is divided into four zones. Similar to the comparison of
Equations (13) and
(14), the same information quantity does not certainly correspond to the same Bayesian network and, then, the same zero-one loss. Zone A contains 27 datasets and describes the situation that
ZLR<1 and
Info_ratio ≥ 1. The performance superiority of FKDB over KDB can be attributed to mining more information or correct conditional dependence representation. Zone D contains 6 datasets and describes the situation that
ZLR>1 and
Info_ratio ≤ 1. The performance inferiority of FKDB over KDB can be attributed to mining less information. Thus, the information quantity is strongly correlated to zero-one loss on 73.3%
of all datasets. On the other hand, although FKDB has proven its effectiveness from the perspective of W/D/L results and the Friedman test, the information quantity is a very important score, but not the only one.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}













