Abstract
Preference analysis is a class of important issues in ordinal decision making. As available information is usually obtained from different evaluation criteria or experts, the derived preference decisions may be inconsistent and uncertain. Shannon entropy is a suitable measurement of uncertainty. This work proposes the concepts of preference inconsistence set and preference inconsistence degree. Then preference inconsistence entropy is introduced by combining preference inconsistence degree and Shannon entropy. A number of properties and theorems as well as two applications are discussed. Feature selection is used for attribute reduction and sample condensation aims to obtain a consistent preference system. Forward feature selection algorithm, backward feature selection algorithm and sample condensation algorithm are developed. The experimental results show that the proposed model represents an effective solution for preference analysis.
1. Introduction
Multiple attribute decision making refers to making preference decisions between available alternatives characterized by multiple, usually conflicting, attributes [1]. A multiple attributes decision making system can be depicted by using the alternative performance matrix, where element is the rating of alternative i with respect to attribute j. A weight vector is designed to indicate the significance of every attribute. Various methods for finding weights can be found in the literature, such as the analytic hierarchy process (AHP) method [2], weighted least squares method [3], Delphi method [4], the entropy method, multiple objective programming [5,6], principal element analysis [6], etc. Ordinal decision making is a class of important issues in multiple attribute decision making where the conditional attributes and the decision are all ordinal. There are numerous applications associated with an assignment of objects evaluated by a set of criteria to pre-defined preference-ordinal decision classes, such as credit approval, stock risk estimation, and teaching evaluations [7]. The alternative performance matrix and weights vector method cannot reflect the ordinal nature of decisions based on conditional attributes, therefore, is not a suitable tool for ordinal decision making.
Preference analysis is a class of important issues in ordinal decision making. Preference relations are very useful in expressing a decision maker’s preference information in decision problems in various fields. During the past years, the use of preference relations has received increasing attention, and a number of studies have focused on this issue, and various types of preference relations have been developed, such as, multiplicative preference relation introduced by Saaty [2], incomplete multiplicative preference relation introduced by Harker [8], interval multiplicative preference relation introduced by Saaty and Vargas [9], incomplete interval multiplicative preference relation introduced by Xu [10], triangular fuzzy multiplicative preference relation introduced by Van Laarhoven and Pedrycz [11], fuzzy preference relation introduced by Luce and Suppes [12], incomplete fuzzy preference relation introduced by Alonso et al. [13], interval fuzzy preference relation introduced by Xu and Herrera et al., and linguistic preference relation introduced by Herrera et al. [14,15,16].
One task of preference analysis is to predict a decision maker’s preference according to available information. A lot of methods for preference analysis can be found in the literature. Greco et al. introduced a dominance rough set model that is suitable for preference analysis [17,18]. They extracted dominance relations from multiple criteria, and constructed similarity relations and equivalence relations from numerical attributes and nominal features respectively. In [19], Hu et al. developed a rough set model based on fuzzy preference by integrating fuzzy preference relations with fuzzy rough set model, and generalized the dependency to compute relevance between the criteria and decision and obtain attribute reductions. In ordinal decision making, there exists a basic assumption that better conditions should result in better decisions, which usually holds for a single criterion. For multi-criteria ordinal decision system, however, the decision is made considering various sources of information which is usually obtained from different evaluation criteria or experts and thus the decision preference might be inconsistent with some criteria.
Preference inconsistence leads to decision uncertainty. One of the decision uncertainty measures which have been proposed by researchers is the Shannon entropy concept. The entropy concept is used in various scientific fields. In transportation models, entropy acts as a measure of dispersal of trips between origin and destinations. In physics, the word entropy has important physical implications as the amount of “disorder” of a system. Also the entropy associated with an event is a measure of the degree of randomness in the event. The concept of Shannon’s entropy has an important role in information theory and is used to refer to a general measure of uncertainty [1]. In preference analysis, some methods based on entropy have been introduced in the literature. Abbas presented an optimal question-selection algorithm to elicit von Neumann and Morgenstern utility values by using information theory and entropy-coding principles for a set of ordered prospects of a decision situation [20]. Lotfi extended the Shannon entropy method to interval data for obtaining the weights of criteria of a multiple attributes decision making problem [1]. Yang and Qiu proposed the expected utility-entropy (EU-E) measure of risk and a decision making model about preference orderings among gambles based on expected utility and entropy of an action involving risk [21]. Abbas introduced an analogy between probability and utility through the notion of a utility density function and illustrate the application of this analogy to the maximum entropy principle [22]. A normative method was presented to assign unbiased utility values when only incomplete preference information was available about the decision maker [23]. In this research, Shannon entropy has been expanded to preference inconsistence entropy and then is used to measure the uncertainty of preference decision to conditional attributes.
Based on this idea, the contributions of this work include: (1) this paper defines a preference inconsistence set and preference inconsistence degree, and some properties are given; (2) based on preference inconsistence degree and Shannon entropy, the notion of preference inconsistence entropy is proposed; (3) relative attribute significance is defined, feature selection is investigated, and meanwhile, a forward feature selection algorithm and backward feature selection algorithm are developed; (4) a sample condensation algorithm is also given; (5) finally, some experiments are completed to verify the proposed approach. The experimental results show that relative attribute significance based on preference inconsistence entropy can reflect the significance of features in a preference decision and the developed feature selection and sample condensation algorithms are helpful to make the data set preference consistent.
The remainder of the paper is organized as follows: Section 2 provides a brief overview of preference relations and Shannon entropy, and some basic formulas that will be used in the remaining sections of this paper are given. In Section 3, the concepts of preference inconsistence degree and preference inconsistence entropy (PIE) are proposed. Some properties of PIE are discussed and a series of theorems are put forward. Section 4 presents two applications of PIE: feature selection and sample condensation. Relative attribute significance is defined. A forward feature selection algorithm and backward feature selection algorithm as well as sample condensation algorithm are developed. Numerical experiments are reported in Section 5. Finally, Section 6 wraps up with conclusions.
2. Preliminary Knowledge
In this section, we will review some basic concepts about preference relation and information entropy, which have been addressed in [24,25,26,27,28,29,30,31].
2.1. Information Entropy
In 1948, Claude Shannon introduced the entropy term, nowadays named Shannon entropy. Shannon entropy is a simple quantitative measure of uncertainty. The following concepts are taken from Shannon’s original paper [30]. Let X be a random variable, taking a finite number of possible values with respective probabilities for i = 1, 2, …, n and . The Shannon entropy H(X) is defined as:
Suppose there are two events, X and Y, in question with m possibilities for the first and n for the second. Let p(i, j) be the probability of the joint occurrence of i for the first and j for the second. The entropy of the joint event is:
For any particular value i for X, we can assume there is a conditional probability where Y has the value i. The conditional entropy of Y, , is defined as the average of entropy of Y for each value of X weighted according to the probability of getting that particular X. That is:
The conditional entropy of Y when X is known is the joint event X, Y minus the entropy of X. We will use this property to calculate the relative attribute significance for our feature selection algorithm.
2.2. Preference Relation
A decision system is a tuple , where U is a nonempty finite set of objects, is a set of conditional attributes to characterize the objects, is the decision, is a mapping for any , where is called the value set of attribute a. The decision system DS is referred to as ordinal decision system, if , and , where is the value set of conditional attribute .
Let is an ordinal decision system. For preference analysis, the following relations are defined. :
where is attribute value of object x with respect to attribute a, and is the decision of object x.
and are referred to as conditional domination relation. are referred to as decision domination relation.
If , we say that object x is greater than or equal to object y with respect to C. In other word, object x is not less than object y with respect to .
If , we say that object x is less than or equal to object y with respect to C. In other word, object x is not greater than object y with respect to .
If , we say that the decision object x is better than or equal to object y. In other word, the decision of object x is not worse than that of y.
If , we say that the decision object x is worse than or equal to object y. In other word, the decision of object x is not better than that of y.
In preference analysis, x’s decision should not be worse than y’s if x is better than y in terms of criterion a; otherwise, the decision is inconsistent [14]. Similarly, x’s decision should not be better than y’s if x is less than y in terms of criterion a; otherwise, the decision is inconsistent. and stands only for relation of not less than and not greater than, respectively, but cannot represent relations strictly greater than and strictly less than. We extend the domination relation to strict preference relation:
If , we say object x is better than object y with respect to . If , we say object x is less than object x with respect to .
If , we say the decision of object x is better than that of y. If , we say the decision of object x is less than that of y.
In this work, and are all named as upward domination relations, and and are all named as downward domination relations. The preference information granulation can be represented as:
Let be an ordinal decision system, C is the set of conditional attributes and D is the decision, . , if , holds, we say object x is upward preference consistent in terms of attribute a. Otherwise, x is upward preference inconsistent in terms of a. Similarly, if , holds, we say object x is downward preference consistent in terms of attribute a, whereas, x is downward preference inconsistent in terms of a.
A lot of research has been done regarding preference consistent decision systems. In a real environment, however, we often need to face preference inconsistent cases. Preference inconsistence leads to preference analysis uncertainty. Those achievements for preference consistent system cannot be used to analyze preference inconsistent cases. Shannon entropy is a very good measure of uncertainty. Therefore, we will study the entropy based on preference inconsistence to deal with preference inconsistent issues.
3. Preference Inconsistence Based Entropy
In this section, two types of preference inconsistence entropy (PIE)—upward preference inconsistence entropy (UPIE) and downward preference inconsistence entropy (DPIE)—are introduced to measure the preference uncertainty. Some relative concepts and theorems will be discussed in detail.
Definition 1.
Given a preference inconsistent ordinal decision system , the preference inconsistent set (PIS) of x in terms of a can be denoted by:
- upward preference inconsistent set (UPIS):
- downward preference inconsistent set (DPIS):
For a set of attributes , we have:
For a set of attributes , object x is upward preference consistent in terms of B if , object x is upward preference consistent in terms of b, whereas, x is upward preference inconsistent in terms of B unless x is upward preference inconsistent in terms of each attribute in B. As to downward preference, a similar case occurs. If , object x is downward preference consistent in terms of b, x is downward preference consistent in terms of B. Otherwise, x is downward preference inconsistent in terms of B.
Theorem 1.
Let be a preference inconsistent ordinal decision system, U is nonempty finite set of objects, C is the set of conditional attributes and D is the decision, . Given two attributes , we have:
Proof:
☐
We can easily expand this theorem to a multiple attributes case:
Definition 2.
Let be a reference inconsistent ordinal decision system, C is the set of conditional attributes and D is the decision, Given , the preference inconsistent degree (PID) can be defined as:
- upward preference inconsistent degree (UPID):
- downward preference inconsistent degree (DPID):where are the set of upward and downward preference inconsistent set, respectively.
Theorem 2.
Let be a preference inconsistent ordinal decision system, U is a nonempty finite set of objects, C is the set of conditional attributes and D is the decision, . Given two attributes , we have:
Proof.
It can be proven easily by Definitions 2–4 and Theorem 1. □
The preference inconsistent information granule can be represented as follows:
Definition 3.
Let be a preference inconsistent ordinal decision system, C is the set of conditional attributes and D is the decision, . The preference inconsistent entropy(PIE) can be defined as:
- upward preference inconsistent entropy (UPIE):
- downward preference inconsistent entropy (DPIE):where and are the upward preference inconsistence degree and downward preference inconsistence degree, respectively. As for preference consistent ordinal decision system, the preference decisions are certain, and and are all equal to 0, which is consistent with Shannon entropy.
Definition 4.
Let be a preference inconsistent ordinal decision system, C is the set of conditional attributes and D is the decision, . Given two attributes , the preference inconsistent joint entropy (PIJE) is expressed as:
- upward preference inconsistent joint entropy (UPIJE):
- downward preference inconsistent joint entropy (DPIJE):
Theorem 3.
Let be a preference inconsistent ordinal decision system, U is a nonempty finite set of objects, C is the set of conditional attributes and D is the decision, . Given two attributes , we have:
Proof.
It can be proven by Definition 2–4 and Theorem 2. ☐
Theorems 1–3 show that in a preference inconsistence set with less elements, smaller preference inconsistence degree and smaller preference inconsistence entropy can be obtain by adding conditional attributes. Obviously, a conditional attribute is redundant if it cannot decrease the preference inconsistence entropy.
Definition 5.
Let be a preference inconsistent ordinal decision system, C is the set of conditional attributes and D is the decision, . Given two attributes , the preference inconsistent conditional entropy of is expressed as:
- upward preference inconsistent conditional entropy:
- downward preference inconsistent conditional entropy:
The conditional entropy reflects the uncertainty of is given. Here, we give an instance to illustrate the information entropy model about preference inconsistence ordinal decision system.
Example 1.

Assume that we have 10 candidates x1, x2, …, x10 with two conditional attributes A1, A2, as shown in Table 1. D = {1, 2, 3} is the rank set of candidates.
Table 1.
Ordinal decision system DS1.
We can take the preference inconsistent information granules and preference inconsistence entropy as follows:
- upward preference inconsistent information granules:
- downward preference inconsistent information granules:
- upward reference inconsistent information entropy:
- downward preference inconsistent information entropy:
- upward reference inconsistent conditional entropy:
- downward reference inconsistent conditional entropy:
As is shown in the example above, upward reference inconsistence information entropy and downward preference inconsistence information entropy are all greater than or equal to 0, which is consistent with Theorem 2. As for preference inconsistence conditional entropy, however, it is less than or equal to 0. This can be explained easily by Theorem 3 and Definition 5. If the conditional entropy is equal to 0, attribute can be eliminated while not increasing the preference inconsistency degree. In next section, we will illustrate the usefulness of preference inconsistence entropy through selecting features and condensing samples.
4. The Application of PIE
4.1. Feature Selection
One of the most important applications of preference analysis is to calculate the reduction of attributes. We are usually required to analyze the relevance between criteria and decisions, and then select those features which are most significant for decision-making and eliminate those redundant or irrelevant features. Plenty of perfect models and algorithms are proposed. However, almost all current work which focuses on the preference consistent cases cannot be used in inconsistent preference cases. Here, we show a feature selection technique based on preference inconsistence entropy while not decreasing the preference consistent degree.
Definition 7.
Let be a preference inconsistent ordinal decision system, C is the set of conditional attributes and D is the decision, . Given two attributes , the relative significance of attribute subset can be defined as:
- upward relative significance:
- downward relative significance:
The greater the inconsistence entropy is, the smaller is the relevance of the decision to an attribute, that is, the attribute with greater inconsistence entropy has less significance. is used to evaluate the relative significance of attribute subset to attribute subset for upward preference. Similar to , is the evaluation measure of attribute significance for downward preference. Equations (60) and (61) can be used to find those important features which are indispensable to hold the preference consistence of conditional attributes to a decision. As a matter of fact, it is impractical to get the optimal feature subset from candidates through exhaustive search, where n is the number of features. The greedy search guided by some heuristics is usually more efficient than the plain brute-force exhaustive search [25]. A forward search algorithm (Algorithm 1) and a backward algorithm (Algorithm 2) for feature selection are expressed as follows, respectively. Here, UPIE and DPIE are denoted as PIE uniformly, UH and DH are denoted as H uniformly, and uSig and dSig are denoted as Sig uniformly.
| Algorithm 1 Forward feature selection (FFS) based on PIE |
| Input: the preference inconsistent ordinal decision system ; |
| Output: selected feature subset . |
| 1. foreach |
| 2. if |
| 3. |
| 4. end if |
| 5. end for |
| 6. foreach |
| 7. compute |
| 8. end for |
| 9. find the minimal and the corresponding attribute |
| 10. |
| 11. while |
| 12. for each |
| 13. compute ) |
| 14. end for |
| 16. find the maximal and the corresponding attribute |
| 17. if |
| 18. |
| 19. else |
| 20. exit while |
| 21. end if |
| 22. end while |
| 23. return |
| Algorithm 2 Backward feature selection (BFS) based on PIE |
| Input: the preference inconsistent ordinal decision system ; |
| Output: selected feature subset . |
| 1. foreach |
| 2. if |
| 3. |
| 4. end if |
| 5. end for |
| 6. |
| 7. for each |
| 8. compute ) |
| 9. if |
| 10. |
| 11. end if |
| 12. end for |
| 13. return |
The time complexities of algorithm FFS and BFS are and , respectively, where m is the number of features and n is the number of samples, respectively. Replacing with , we can get the algorithms for upward preference. Replacing with , we can get the algorithms for downward preference.
If we can get . Obviously, however, feature a has minimal inconsistence entropy and maximal significance but has no effect on the decision. For the forward algorithm, if features like a exist, the selected feature subset contains only one element like a. For the backward algorithm, we could get a similar result, so before starting the algorithms, we should eliminate all the features like a.
4.2. Sample Condensation
If an ordinal decision system is upward preference inconsistent, there exist some objects with greater attribute values and worse decision. Similarly, if an ordinal decision is downward preference inconsistent, there exist some samples with less attribute values and better decision. These samples are named as exceptional samples. Obviously, in this view, the inconsistent decision system would become preference consistent once the exceptional samples are all eliminated. A backward search algorithm (Algorithm 3) is written as follows: like feature selection algorithms, UPIE and DPIE are denoted as PIE uniformly, upicd and dpicd are denoted as picd, and UH and DH are denoted as H uniformly. The time complexity of this algorithm is O(mn), where m is the number of features and n is the number of samples.
| Algorithm 3 Sample Condensation based on PIE (BFS) |
| Input: the preference inconsistent ordinal decision system ; |
| Output: the preference consistent sample subset. |
| 1. for each |
| 2. |
| 3. compute the preference inconsistence entropy |
| 4. while |
| 5. for each |
| 6. Compute |
| 7. end for |
| 8. find the maximum and the corresponding sample x |
| 9. |
| 10. compute the preference inconsistence entropy |
| 11. end while |
| 12. end for |
| 13. ; |
| 14. for each |
| 15. ; |
| 16. end for |
| 17. return |
5. Experimental Analysis
In this section, we present experimental results obtained by using two real data sets named Pasture Production and Squash Harvest downloaded from WEKA (http://www.cs.waikato.ac.nz/ml/weka/). Three experiments are done for every data set. In the first experiment, preference inconsistence entropy and significance of single attribute are computed. In the second experiment, some features are selected based on the algorithms proposed in this work. Then we condense the data set and eliminate some samples causing inconsistence in the last experiment.
The Pasture Production data set was collected by Dave Barker from areas of grazed North Island hill country with recorded different management history during the period from 1793 to 1994. The objective was to analyze the influence of biophysical factors on pasture production. The Production of Pasture data set is composed of 36 tuples associated with 36 paddocks. Each tuple has 22 attributes, of which 19 are vegetation, and the others are soil chemical, physical and biological, and soil water variables, respectively. All the samples are partitioned into three classes, LO, MED and HI, representing low, medium and high production, respectively. Table 2 is the description of the features. For use in this work, we replaced these symbol values by integer 1, 2 and 3, respectively. Accordingly, the enumerated value (LL, LN, HN and HH) of attribute fertilizer are replaced by 1, 2, 3 and 4. Figure 1 shows the result of Experiment 1, Table 3 presents the selected features in the experiment, and the sample condensation result of Experiment 3 is listed in Table 4.
Table 2.
Features of Pasture Production.
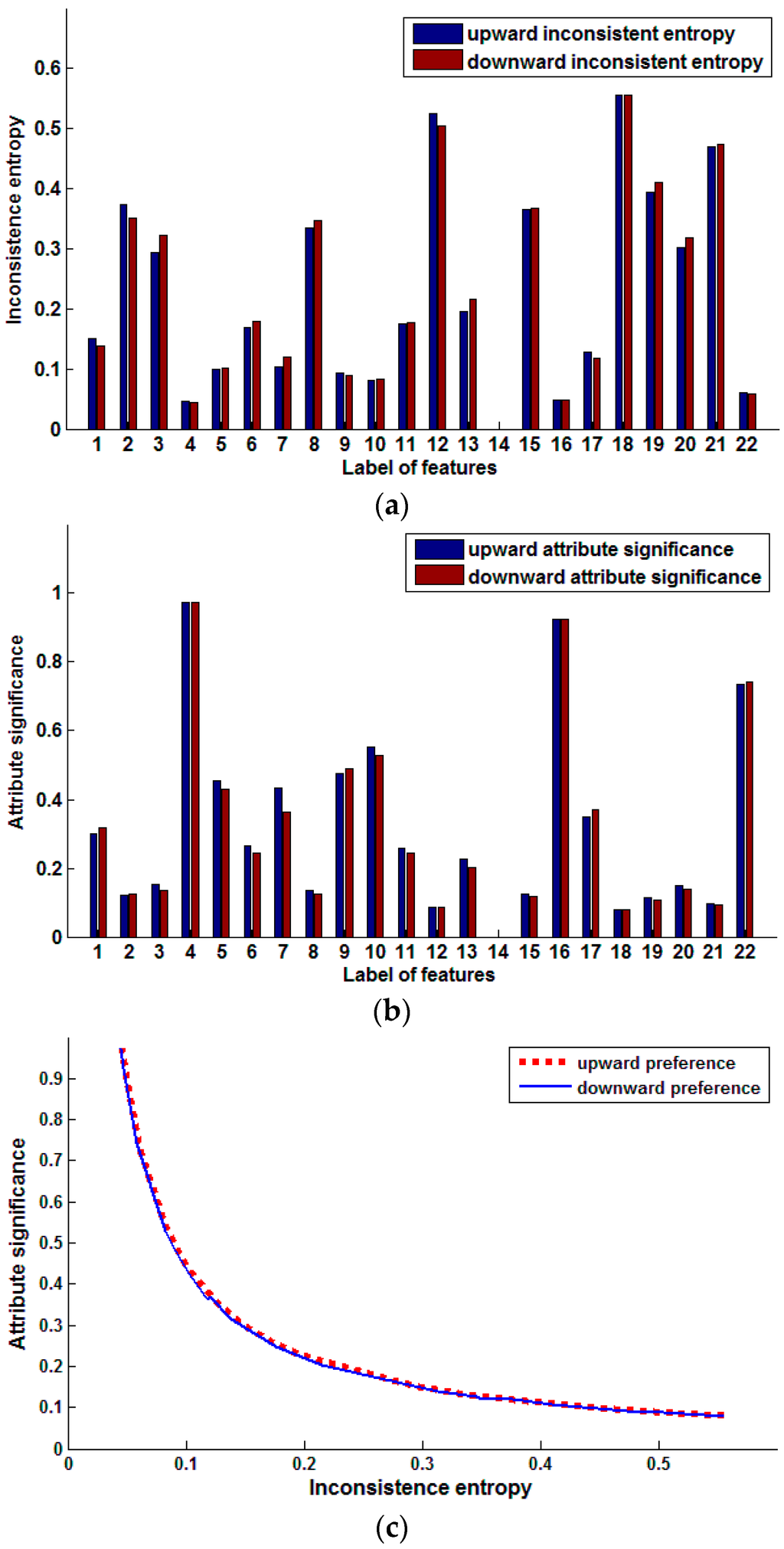
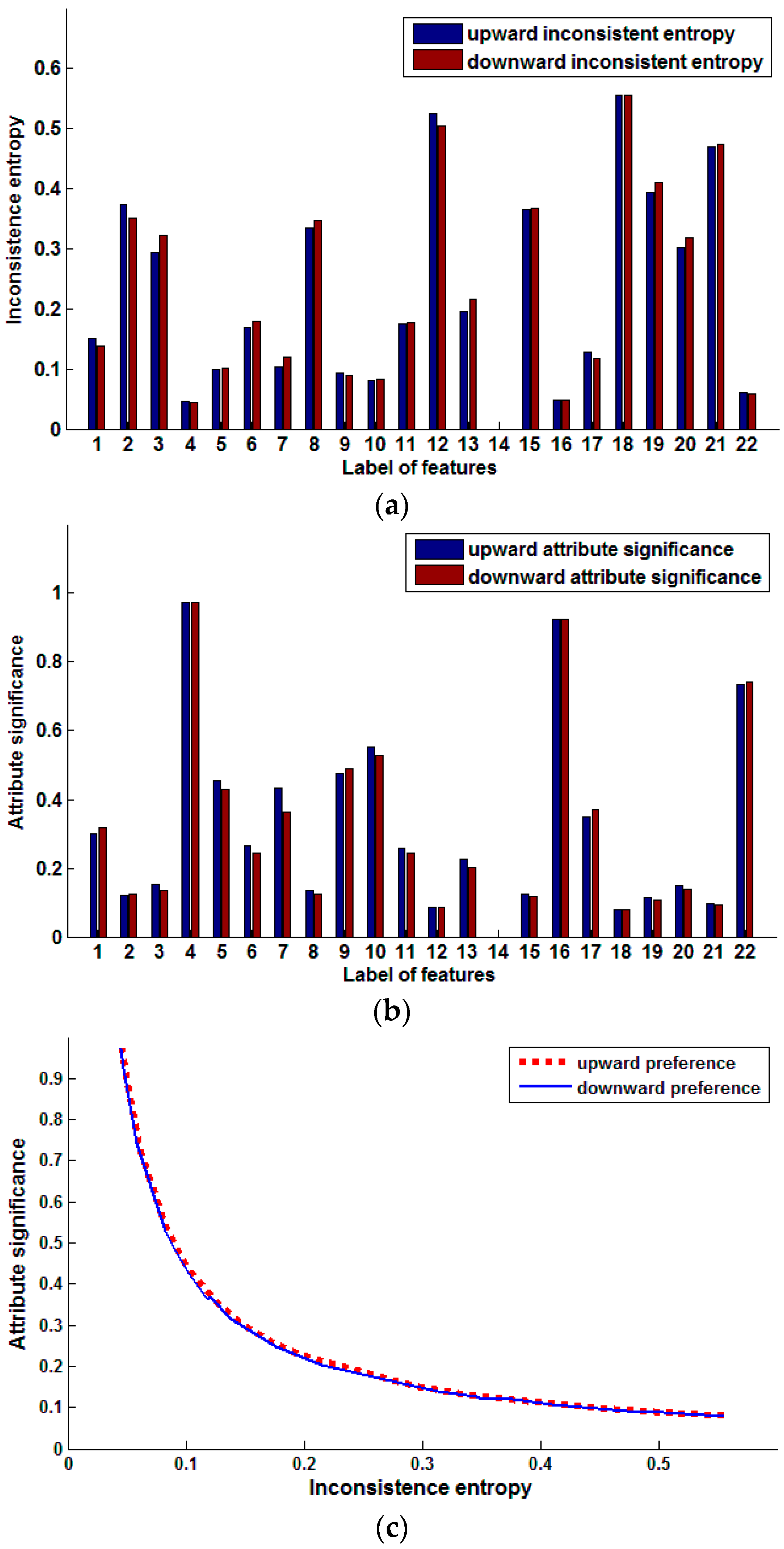
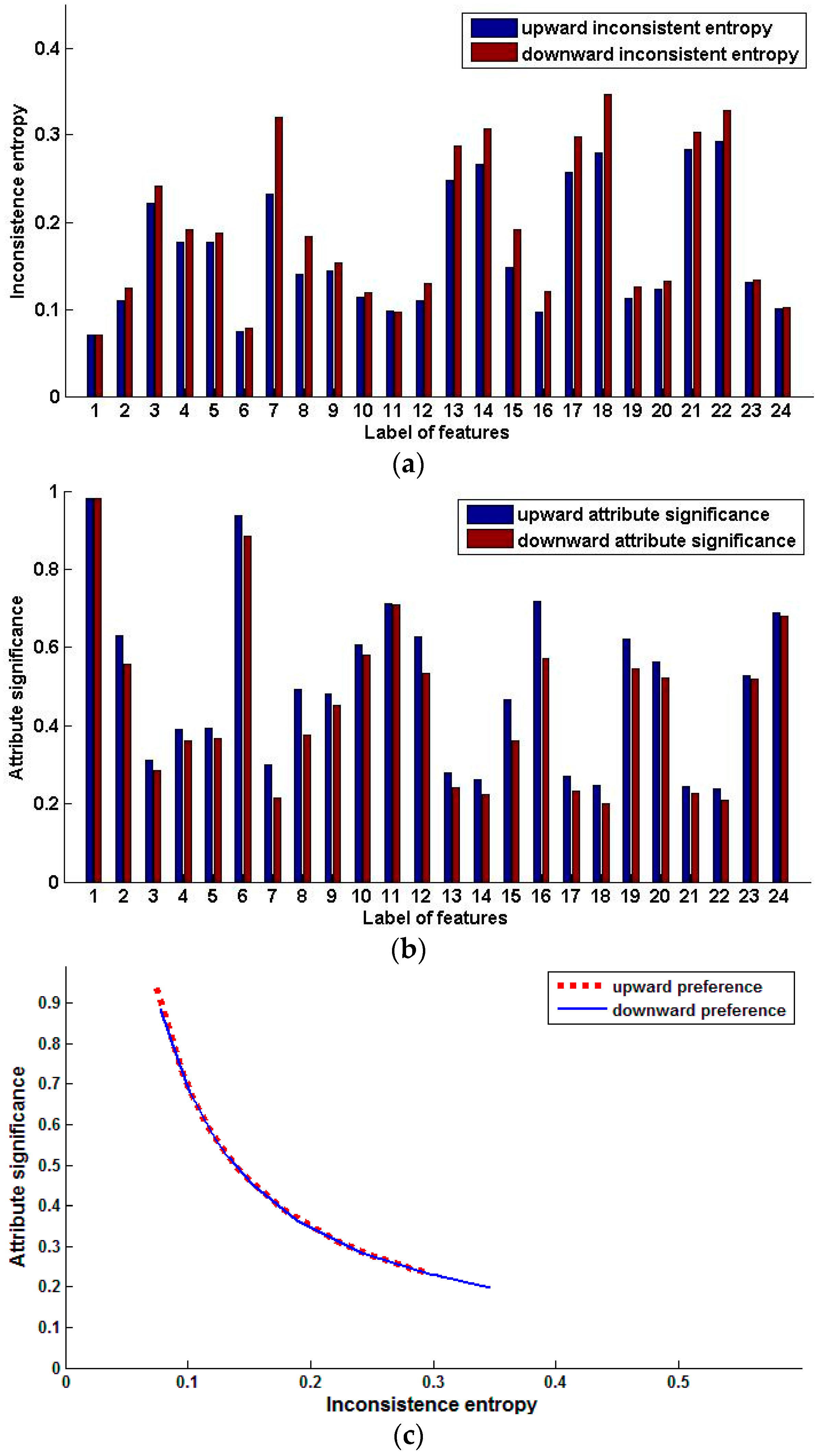
Figure 1.
Preference inconsistence entropy and attribute significance of single features (Pasture production). (a) Inconsistent entropy of single features; (b) Significance of single features; (c) Relation of inconsistence entropy and attribute significance.
Table 3.
Selected features for Pasture Production (original data set).
Table 4.
Selected samples (Pasture Production).
Figure 1a shows the inconsistence entropy comparison of single features based on upward and downward preference. Figure 1b shows the comparison of signification of single features based on upward and downward preference. The relation of inconsistence entropy and attribute significance is presented in Figure 1c.
The inconsistence entropy of every feature of the decision is different, which shows that those features are not of the same importance in predicting pasture production. The inconsistence entropy monotonically decreases with increasing feature significance. The greater the inconsistence entropy is, the less the feature helps predict the pasture production, but in some cases, exceptions also exist.
We arrange these features in descending order by upward significance {4, 16, 22, 10, 9, 5, 7, 17, 1, 6, 11, 13, 3, 20, 8, 15, 2, 19, 21, 12, 18, 14}, and arrange the features in ascending order by upward inconsistence entropy {14, 4, 16, 22, 10, 9, 5, 7, 17, 1, 6, 11, 13, 3, 20, 8, 15, 2, 19, 21, 12, 18}. Except for feature 14, those attributes at the head of the first series have smaller inconsistence entropy and greater significance in predicting pasture production, such as 4, 16, 22, and so on. Feature 14 is an exception. The inconsistence entropy of feature 14 is the smallest value 0, but its significance also has the smallest value of 0. We can find that all distances have the same value 0 in feature 14, so its inconsistence entropy is 0. But at the same time, feature 14 is not different for all samples and cannot reflect any preference, so the significance should be 0. This is consistent with our common knowledge. The forward feature selection algorithm output the same features for upward preference and downward preference. As for the backward method, a similar case occurs.
In addition, from Figure 1, we can see that there is little difference between upward inconsistence entropy and downward inconsistence entropy. A similar case occurs for the significance of a single feature. In order to test how much the order of features impacts the output, we generated four different data sets by arranging the features in different order and executing the feature selection algorithms in all the data sets. All the features are labeled as 1, 2, ..., 22. The original data set is the first one. By arranging those features in a descending label order, we get the second data set. We compute the significance of every feature and get the third and the fourth data sets by arranging the features in the order of ascending and descending attribute significance, respectively. The forward algorithm is performed on data sets 1, 2 and 4, and the backward algorithm is executed on data sets 1, 2 and 3. Table 3 shows the experiment results.
For the forward algorithm, features 4, 11 and 1 are selected from data set 1, features 4, 11 and 1 are selected from data set 2, and features 4, 11 and 22 are selected from data set 4. Features 4 and 11 are included in all feature subset. The top two of three selected features are the same and only the last is different for all data sets. As for the backward algorithm, however, we have an entirely different situation. Features 17, 18, 20 and 22 are selected from data set 1, features 1, 3, 4 and 5 are selected from data set 2, and features 4, 10 and 16 are selected from data set 3. The selected feature subsets are totally different. Obviously, we can conclude that the forward algorithm is more stable and the backward algorithm is affected more by the order of features.
In the forward feature selection algorithm, the relative significance is computed in turn in the order of increasing feature label. As for the backward method, we compute the relative significance of features in the same turn. However, there exists an essential difference between the algorithms. For the forward algorithm, after the significances of all features are computed, the feature with maximal relative significance is selected, but for the backward method, if the relative significance is 0, the feature is immediately deleted from the features set. From Table 3, we can find that we can get similar feature subsets if we sort the data set by attribute significance. The backward algorithm selects features 4, 16 and 10 from data set 3 and the forward algorithm selects features 4, 16 and 11. We can see that features 4 and 16 appear in both the subsets. This shows that these features are important in term of different selection methods.
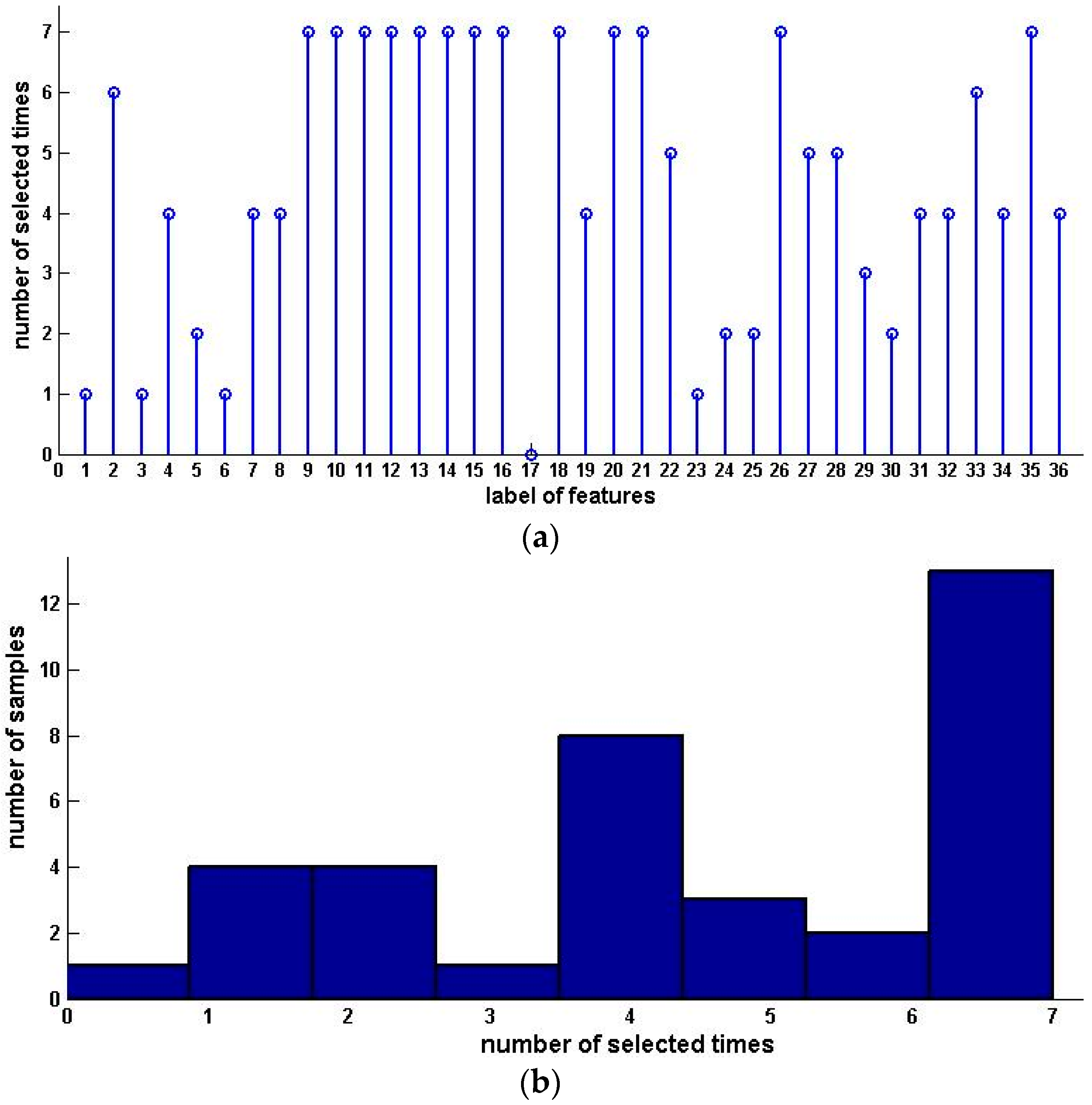
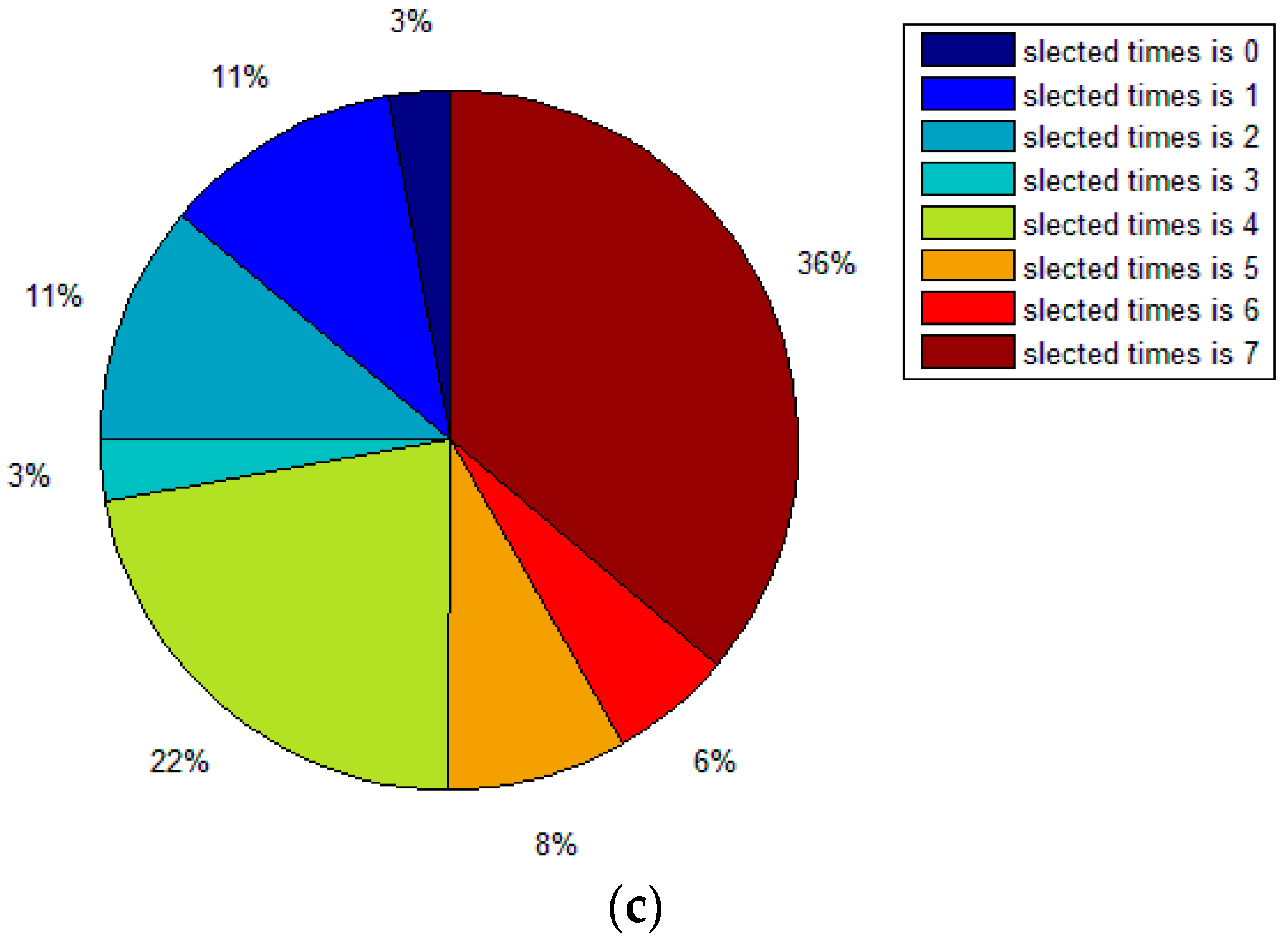
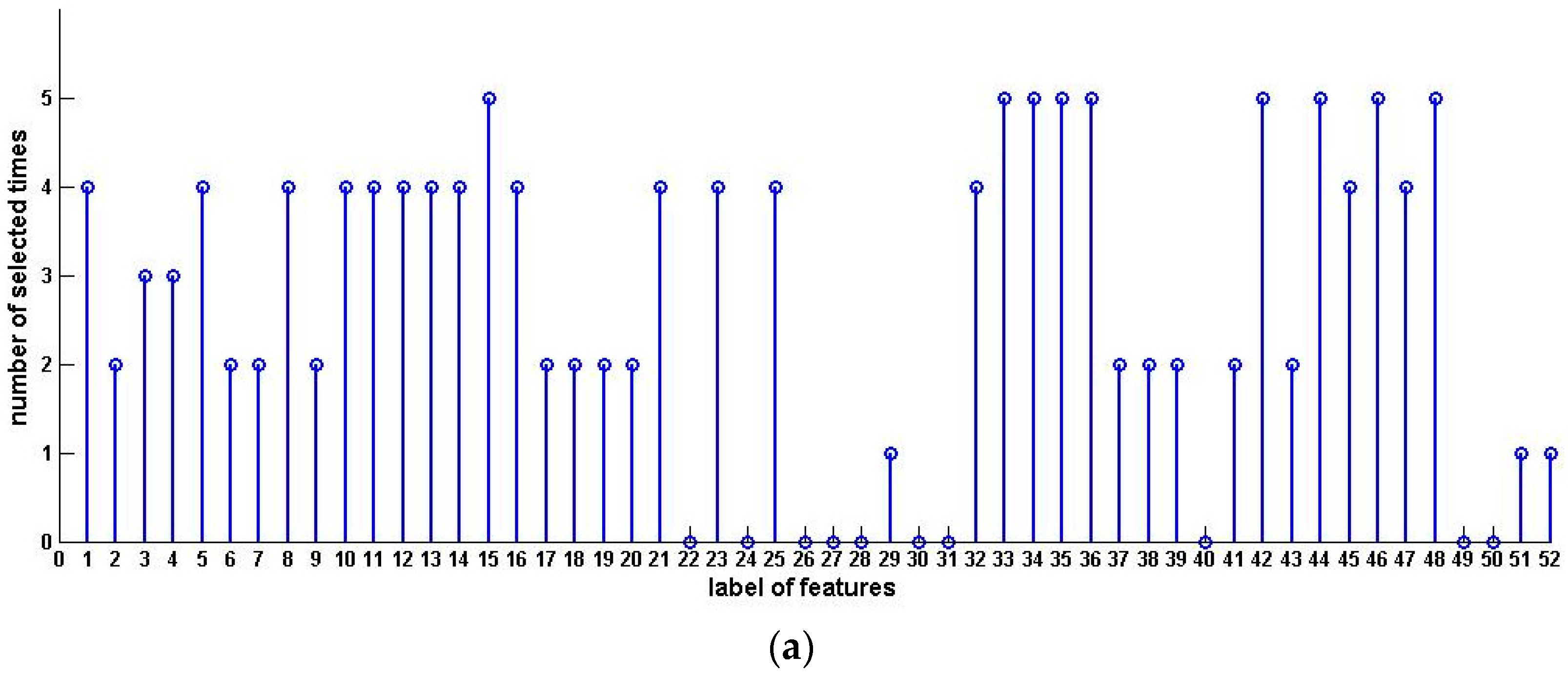
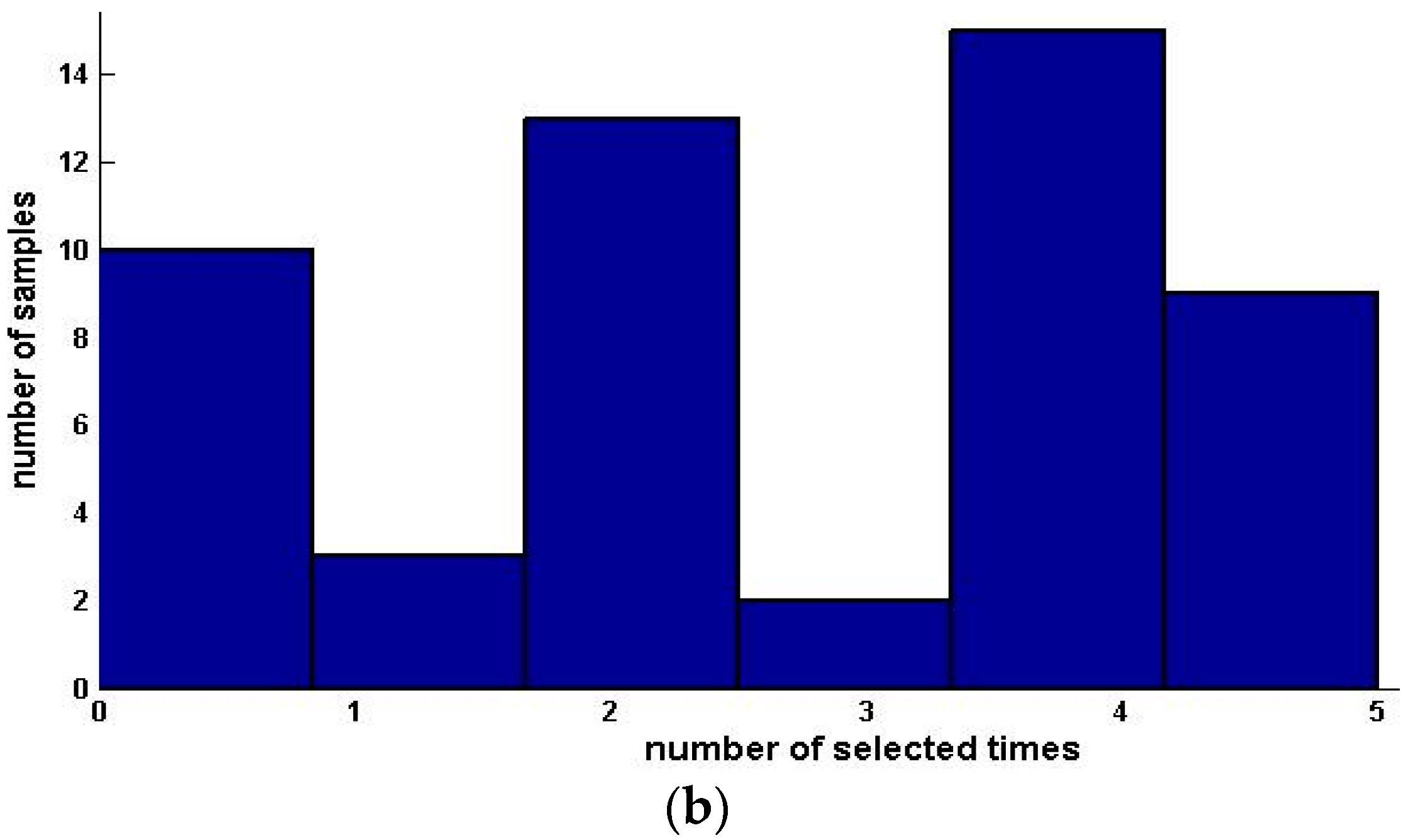
Table 4 shows the sample condensation results based on selected feature subsets in previous experiments. Figure 2 illustrates the distribution, histogram and pie of selected samples for upward preference. Figure 3 illustrates the distribution, histogram and pie of selected samples for downward preference.
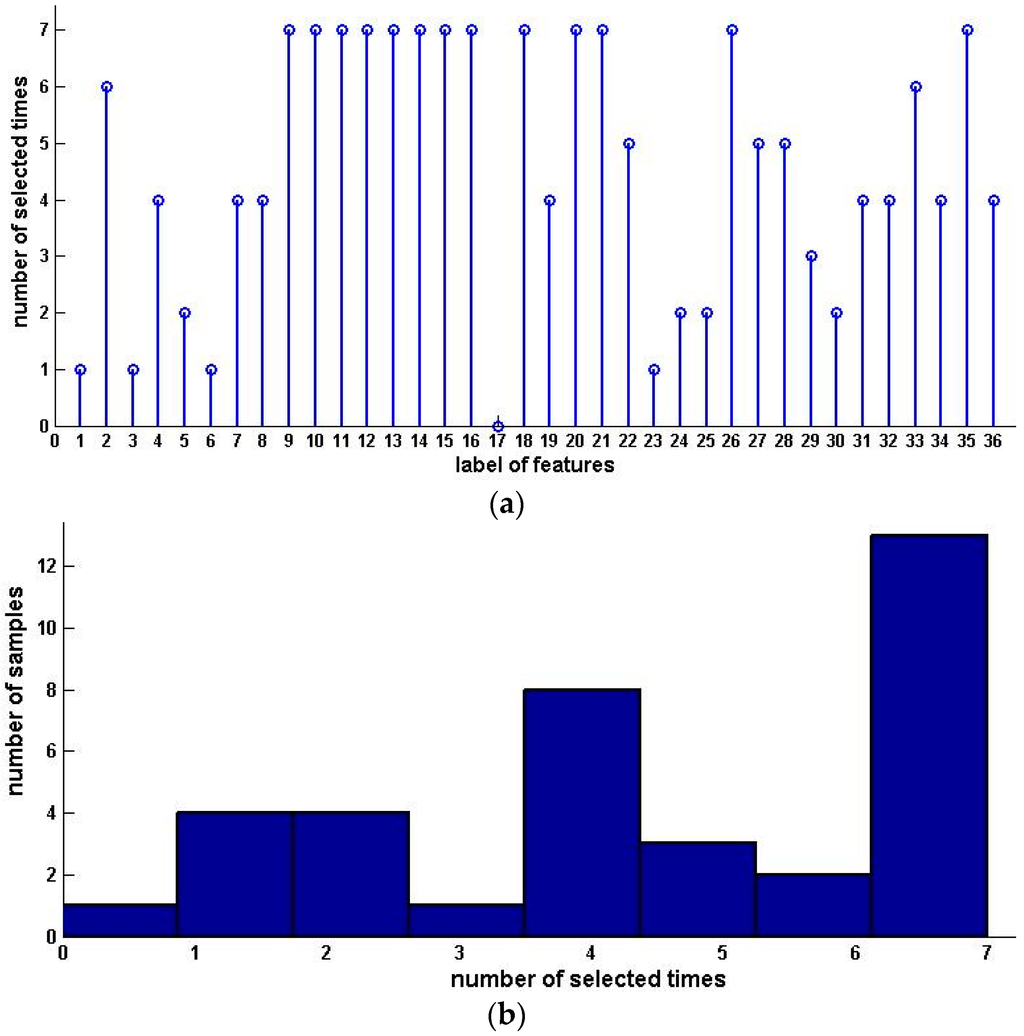
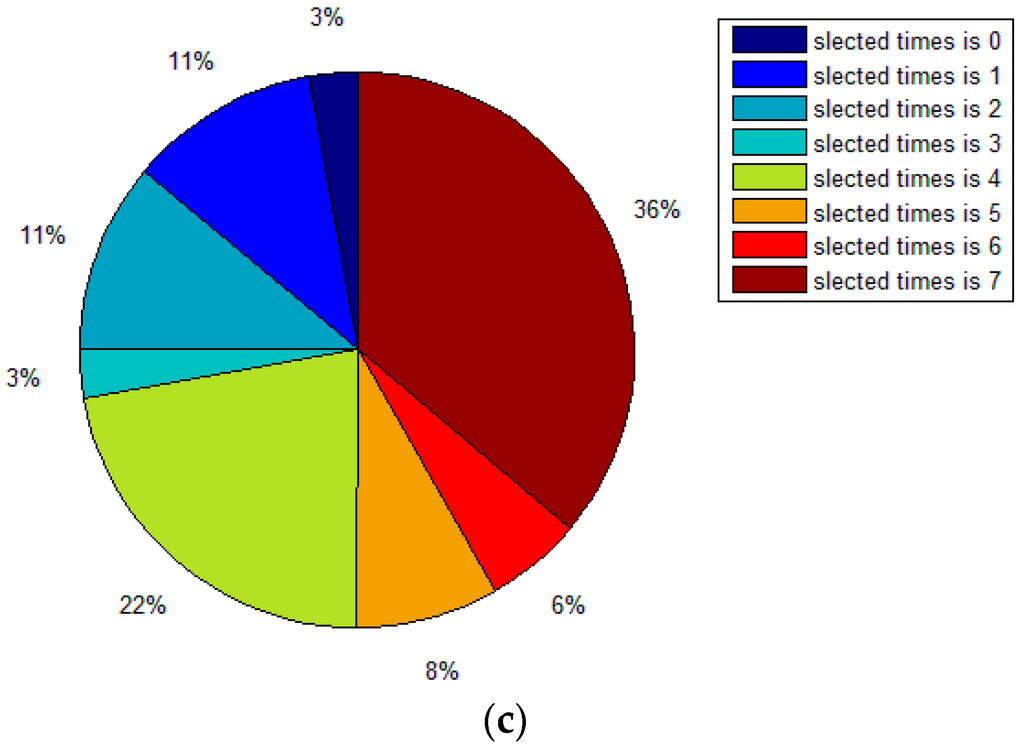
Figure 2.
Distribution, histogram and pie of selected samples for upward preference (Pasture Production). (a) Distribution of selected samples; (b) Histogram of selected samples; (c) Pie of selected samples.
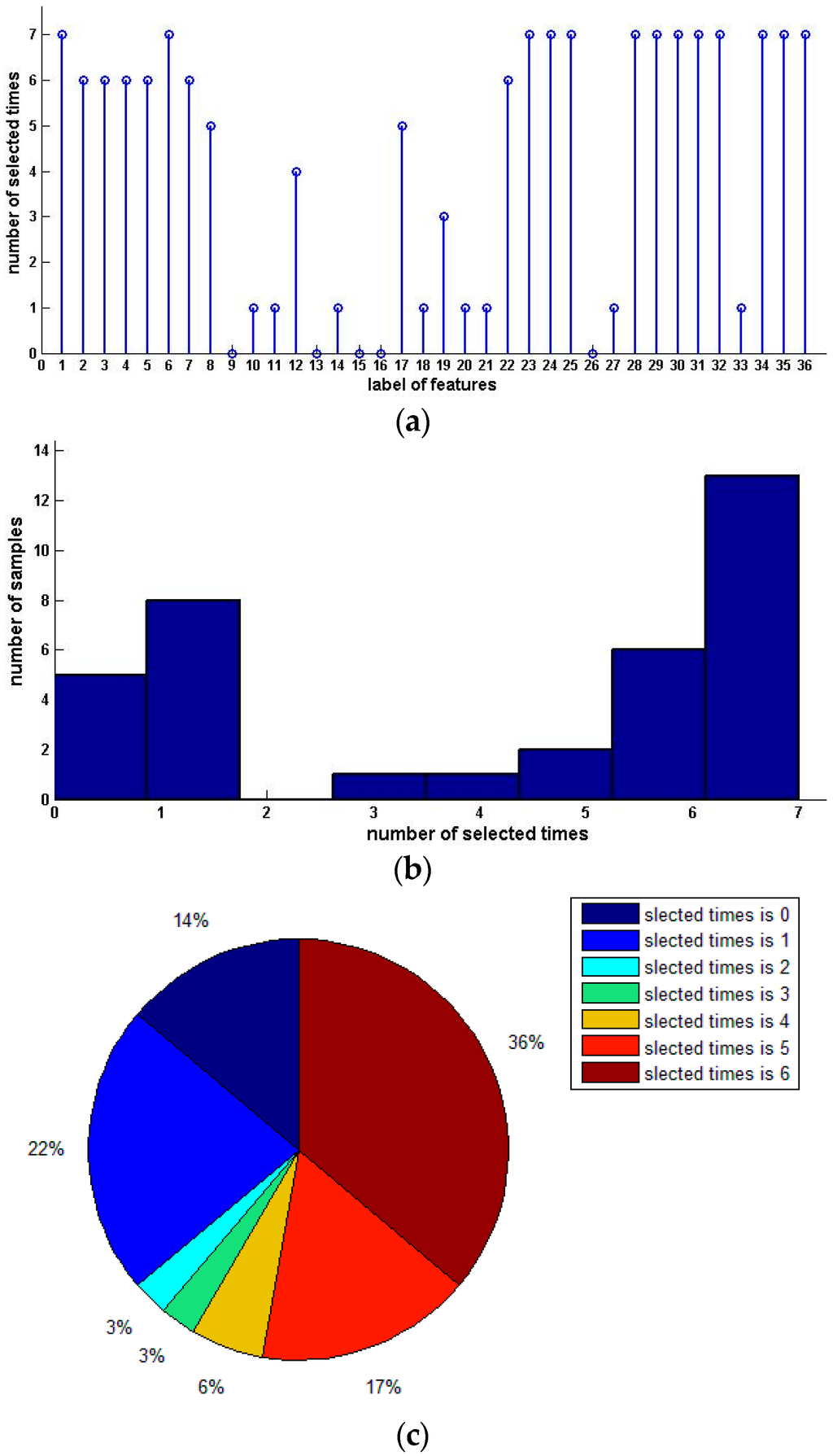
Figure 3.
Distribution, histogram and pie of selected samples for downward preference (Pasture Production). (a) Distribution of selected samples; (b) Histogram of selected samples; (c) Pie of selected samples.
The Squash Harvest data set, collected by Winna Harvey Crop & Food Research (Christchurch, New Zealand), aims to determine which pre-harvest variables are important to good tasting squash after different periods of storage time so as to pinpoint the best time to give the best quality at the marketplace. This is determined by whether a measure of acceptability found by classifying each squash as either unacceptable, acceptable or excellent. The name and the corresponding descriptions of those features are described in Table 5. There are 52 instances with 24 attributes. For use in this work, we replaced these class symbol values with integer 1, 2 and 3, respectively. We do the same tests on this data set.
Table 5.
Features of Squash Harvest.
We compute the inconsistence entropy and attribute significance of single features for upward preference and downward preference, as shown in Figure 4. Features 1, 2, 6, 11, 16 and 24 have greater single attribute significance, indicating that, as far as single features are concerned, site, number of days after flowering, maturity of fruit at harvest, the heat accumulation from flowering to harvesting, total number of glucose, fructose and sucrose and the amount of heat input before flowering are very important for good taste.
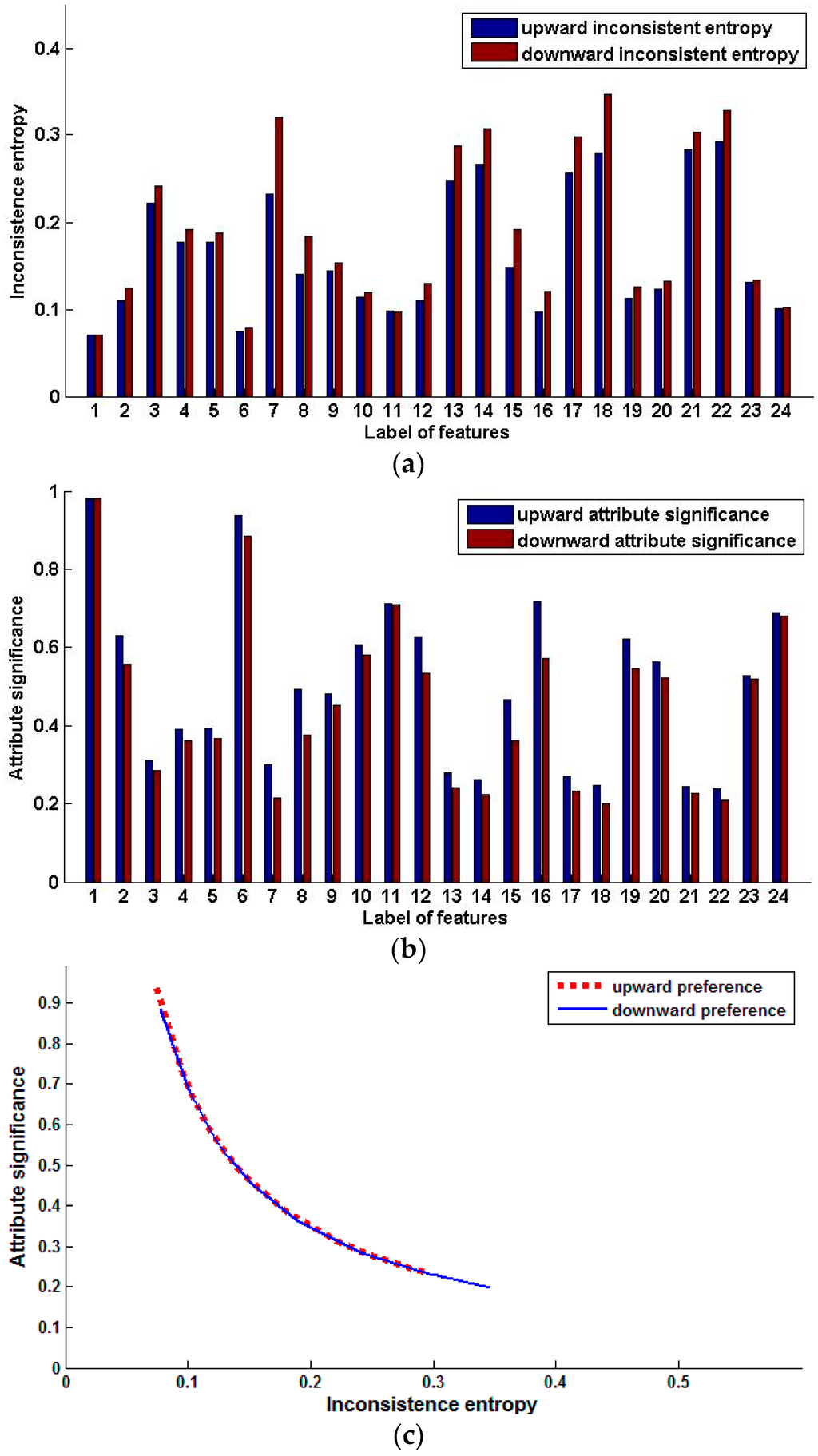
Figure 4.
Preference inconsistence entropy and attribute significance of single features (Squash Harvest). (a) Inconsistence entropy of single features; (b) Significance of single features; (c) Relation of attribute significance and inconsistence entropy.
We also extract the preference consistence feature subset. Similar to Pasture Production, we generate four data sets from Squash Harvest. All the features are labeled as 1, 2, ..., 24. The original data set is the first. By arranging those features in the order of descending label, we get the second data set.
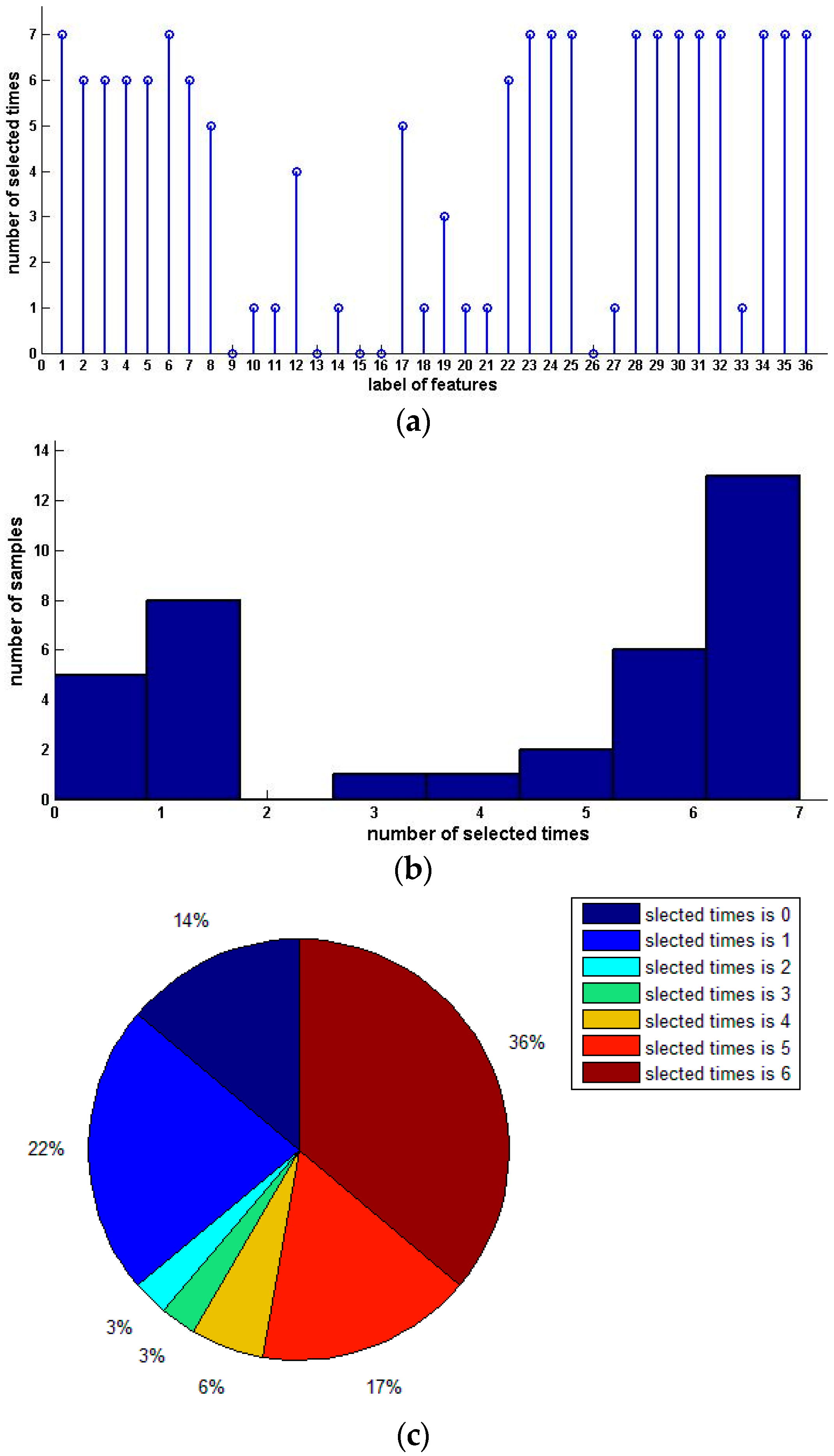
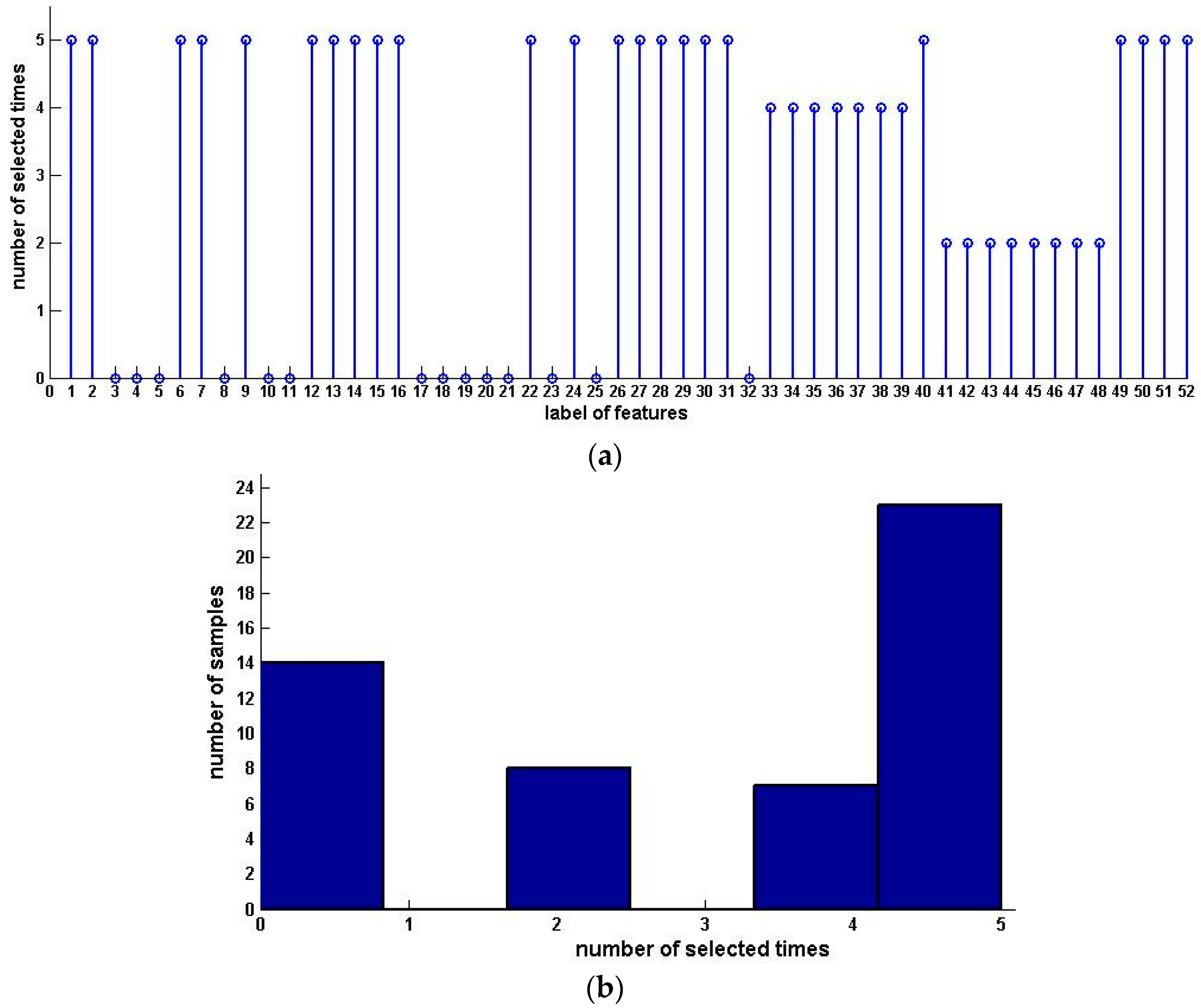
We compute the significance of every feature and get the third and the fourth data sets by arranging the features in the order of ascending and descending attribute significance, respectively. The forward algorithm is performed on data sets 1, 2 and 4, and the backward algorithm is executed on data sets 1, 2 and 3. Table 6 shows the experiment results. Finally, we condense the samples with selected features. The results are shown in Table 7. Figure 5 and Figure 6 show the distribution and histograms of selected samples.
Table 6.
Selected features for Squash Harvest (original data set).
Table 7.
Selected samples (Squash Harvest).
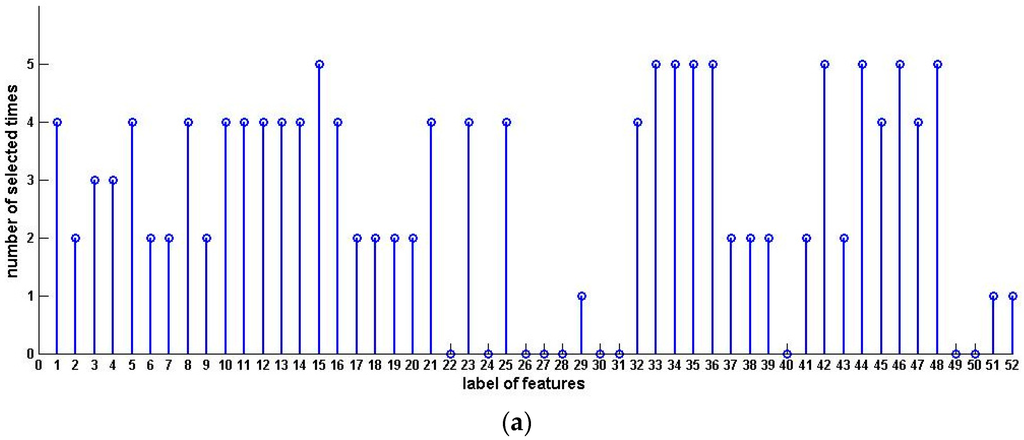
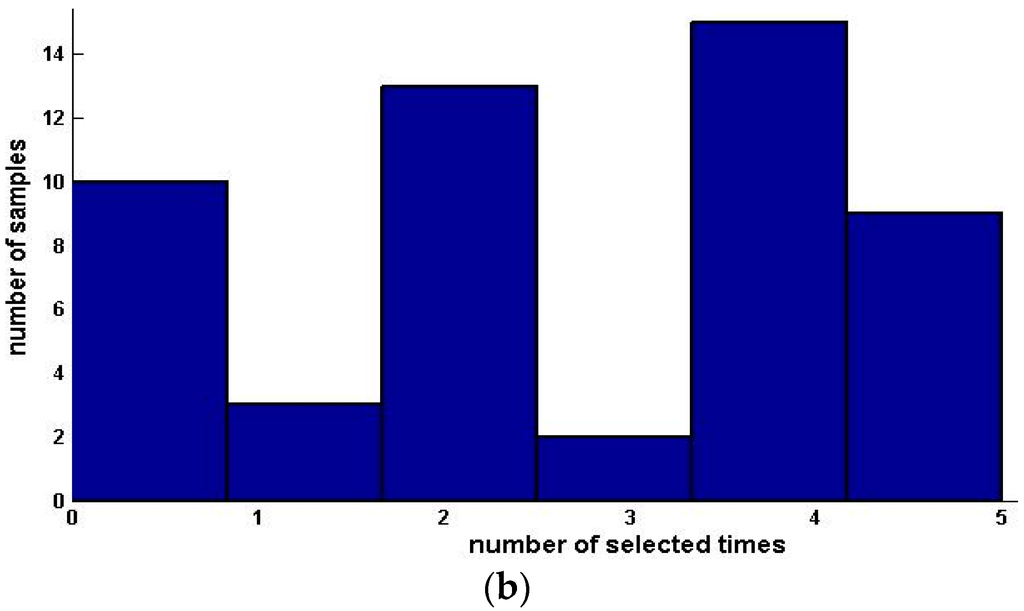
Figure 5.
Distribution, histogram and pie of selected samples for upward preference (Squash Harvest). (a) Distribution of selected samples; (b) Histogram of selected samples.
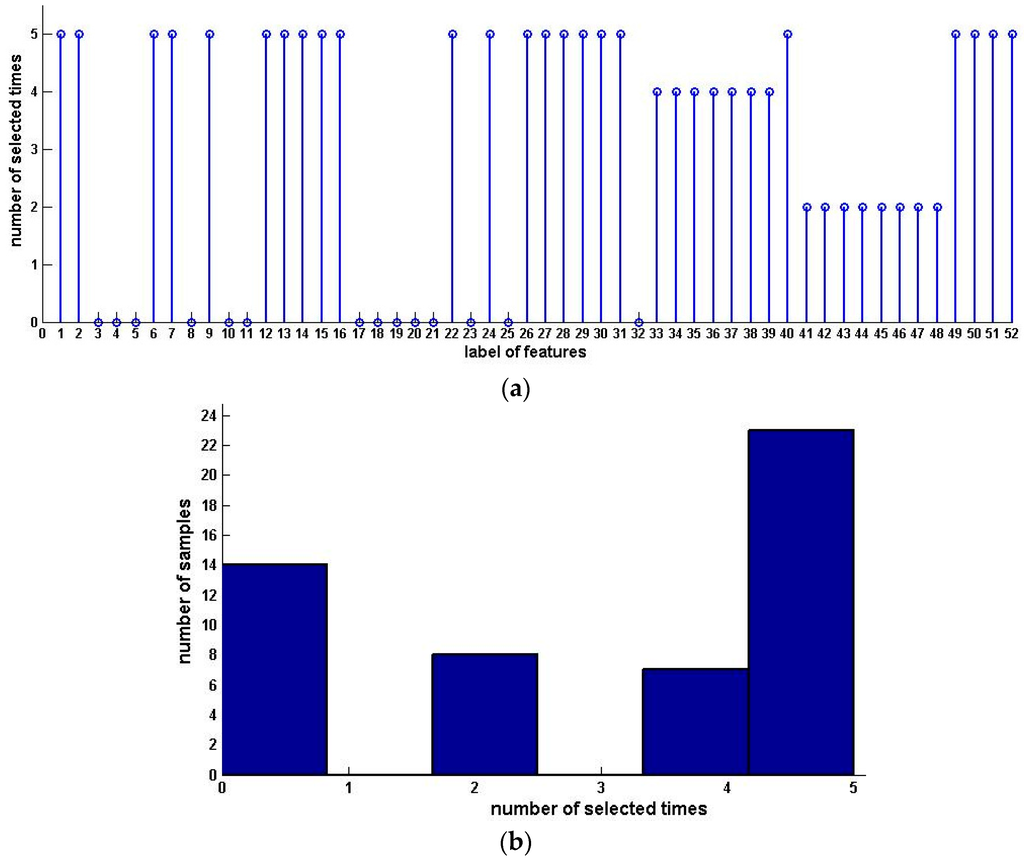
Figure 6.
Distribution and histogram of selected samples for downward preference (Squash Harvest). (a) Distribution of selected samples; (b) Histogram of selected samples.
For the forward algorithm, we get the same feature subset 1, 2 and 14. The attribute significance of features 1 is 0.98. Feature 2 has an attribute significance of 0.63 and 0.55 for upward preference and downward preference, respectively. Features 1 and 2 are important for good taste, but the significance of feature 14 is as low at 0.26 and 0.22 for upward preference and downward preference, respectively. This indicates that, more glucose can give better taste at harvest if the plant site is suitable and the number of days after flowering is enough.
6. Conclusions
In multiple attribute ordinal decision, the derived decisions may be inconsistent and uncertain since the available information is usually obtained from different evaluation criteria or experts. Shannon entropy is a suitable measurement of uncertainty. In this research, Shannon entropy is extended to preference inconsistence entropy for preference inconsistent ordinal decision systems. Two applications of preference inconsistence entropy, feature selection and sample condensation, are addressed and some algorithms are developed. The experimental result shows that preference inconsistence entropy is a suitable measurement of uncertainty of preference decision, and the proposed algorithms are effective solutions for preference analysis. Classification is another interesting issue for preference analysis, and further investigations on classification methods and algorithms based on preference inconsistence entropy are worthwhile.
Acknowledgments
The reported research was supported in part by an operating grant from the Natural Science Foundation of the Education Department of Sichuan Province (No. 12ZA178), Key Technology Support Program of Sichuan Province (Grant No. 2015GZ0102), and Foundation of Visual Computing and Virtual Reality Key Laboratory of Sichuan Province (Grant No. KJ201406). The authors would like to thank the anonymous reviewers for their useful comments. The authors would also like to thank the editor of the journal Entropy for his useful guidance and suggestions that improved the paper.
Author Contributions
Kun She conceived and designed the experiments; Pengyuan Wei performed the experiments and Wei Pan wrote the paper. All authors have read and approved the final manuscript.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Lotfi, F.H.; Fallahnejad, R. Imprecise Shannon’s entropy and multi attribute decision making. Entropy 2010, 12, 53–62. [Google Scholar] [CrossRef]
- Saaty, T.L. The Analytic Hierarchy Process; McGraw-Hill: New York, NY, USA, 1980. [Google Scholar]
- Chu, A.T.W.; Kalaba, R.E.; Spingarn, K. A comparison of two methods for determining the weights of belonging to fuzzy sets. J. Optim. Theory Appl. 1979, 27, 531–538. [Google Scholar] [CrossRef]
- Hwang, C.-L.; Lin, M.-J. Group Decision Making under Multiple Criteria: Methods and Applications; Springer: Berlin/Heidelberg, Germany, 1987. [Google Scholar]
- Choo, E.U.; Wedley, W.C. Optimal criterion weights in repetitive multicriteria decision-making. J. Oper. Res. Soc. 1985, 36, 983–992. [Google Scholar] [CrossRef]
- Fan, Z.P. Complicated Multiple Attribute Decision Making: Theory and Applications. Ph.D. Thesis, Northeastern University, Shenyang, China, 1996. [Google Scholar]
- Moshkovich, H.M.; Mechitov, A.I.; Olson, D.L. Rule induction in data mining: Effect of ordinal scales. Expert Syst. Appl. 2002, 22, 303–311. [Google Scholar] [CrossRef]
- Harker, P.T. Alternative modes of questioning in the analytic hierarchy process. Math. Model. 1987, 9, 353–360. [Google Scholar] [CrossRef]
- Saaty, T.L.; Vargas, L.G. Uncertainty and rank order in the analytic hierarchy process. Eur. J. Oper. Res. 1987, 32, 107–117. [Google Scholar] [CrossRef]
- Xu, Z.S. Method for group decision making with various types of incomplete judgment matrices. Control Decis. 2006, 21, 28–33. [Google Scholar]
- Van Laarhoven, P.J.M.; Pedrycz, W. A fuzzy extension of Saaty’s priority theory. Fuzzy Sets Syst. 1983, 11, 199–227. [Google Scholar] [CrossRef]
- Luce, R.D.; Suppes, P. Preferences Utility and Subject Probability. In Handbook of Mathematical Psychology; Luce, R.D., Bush, R.R., Galanter, E.H., Eds.; Wiley: New York, NY, USA, 1965; Volume 3, pp. 249–410. [Google Scholar]
- Alonso, S.; Chiclana, F.; Herrera, F.; Herrera-Viedma, E. A Learning Procedure to Estimate Missing Values in Fuzzy Preference Relations Based on Additive Consistency. In Modeling Decisions for Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 2004; pp. 227–238. [Google Scholar]
- Xu, Z.S. A practical method for priority of interval number complementary judgment matrix. Oper. Res. Manag. Sci. 2002, 10, 16–19. [Google Scholar]
- Herrera, F.; Herrera-Viedma, E.; Verdegay, J.L. A model of consensus in group decision making under linguistic assessments. Fuzzy Sets Syst. 1996, 78, 73–87. [Google Scholar] [CrossRef]
- Herrera, F.; Herrera-Viedma, E.; Verdegay, J.L. Direct approach processes in group decision making using linguistic OWA operators. Fuzzy Sets Syst. 1996, 79, 175–190. [Google Scholar] [CrossRef]
- Greco, S.; Matarazzo, B.; Slowinski, R. Rough approximation of a preference relation by dominance relations. Eur. J. Oper. Res. 1999, 117, 63–83. [Google Scholar] [CrossRef]
- Greco, S.; Matarazzo, B.; Slowinski, R. Rough approximation by dominance relations. Int. J. Intell. Syst. 2002, 17, 153–171. [Google Scholar] [CrossRef]
- Hu, Q.H.; Yu, D.R.; Guo, M.Z. Fuzzy preference based rough sets. Inf. Sci. 2010, 180, 2003–2022. [Google Scholar] [CrossRef]
- Abbas, A.E. Entropy methods for adaptive utility elicitation. IEEE Trans. Syst. Man Cybern. 2004, 34, 169–178. [Google Scholar] [CrossRef]
- Yang, J.; Qiu, W. A measure of risk and a decision-making model based on expected utility and entropy. Eur. J. Oper. Res. 2005, 164, 792–799. [Google Scholar] [CrossRef]
- Abbas, A.E. Maximum Entropy Utility. Oper. Res. 2006, 54, 277–290. [Google Scholar] [CrossRef]
- Abbas, A. An Entropy Approach for Utility Assignment in Decision Analysis. In Proceedings of the 22nd International Workshop on Bayesian Inference and Maximum Entropy Methods in Science and Engineering, Moscow, Russian Federation, 3–9 August 2002; pp. 328–338.
- Hu, Q.H.; Yu, D.R. Neighborhood Entropy. In Proceedings of the 2009 International Conference on Machine Learning and Cybernetics, Baoding, China, 12–15 July 2009; Volume 3, pp. 1776–1782.
- Jaynes, E.T. Information theory and statistical mechanics II. Phys. Rev. 1957, 108, 171–190. [Google Scholar] [CrossRef]
- Kullback, S.; Leibler, R.A. On information and sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Kullback, S. Information Theory and Statistics; Wiley: New York, NY, USA, 1959. [Google Scholar]
- Hu, Q.H.; Che, X.J.; Zhang, L.D.; Guo, M.Z.; Yu, D.R. Rank entropy based decision trees for monotonic classification. IEEE Trans. Knowl. Data Eng. 2012, 24, 2052–2064. [Google Scholar] [CrossRef]
- Jaynes, E.T. Information theory and statistical mechanics. Phys. Rev. 1957, 106, 620–630. [Google Scholar] [CrossRef]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423, 623–656. [Google Scholar] [CrossRef]
- Zeng, K.; Kun, S.; Niu, X.Z. Multi-Granulation Entropy and Its Application. Entropy 2013, 15, 2288–2302. [Google Scholar] [CrossRef]
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons by Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).