Abstract
As we move into the information age, the amount of data in various fields has increased dramatically, and data sources have become increasingly widely distributed. The corresponding phenomenon of missing data is increasingly common, and it leads to the generation of incomplete multi-source information systems. In this context, this paper’s proposal aims to address the limitations of rough set theory. We study the method of multi-source fusion in incomplete multi-source systems. This paper presents a method for fusing incomplete multi-source systems based on information entropy; in particular, by comparison with another method, our fusion method is validated. Furthermore, extensive experiments are conducted on six UCI data sets to verify the performance of the proposed method. Additionally, the experimental results indicate that multi-source information fusion approaches significantly outperform other approaches to fusion.
1. Introduction
Information fusion is used to obtain more accurate and definite inferences from the data provided by any single information source by integrating multiple information sources; several definitions have been proposed in the literature [1,2,3,4,5,6,7,8,9]. The theory of information fusion was first used in the military field; it is defined as a multi-level and multi-aspect process that handles problems. In fact, data fusion can be broadly summarized as such a process; namely, to synthesize comprehensive intelligence from multi-sensor data and information according to established rules and analysis methods, and on this basis, to provide the user-required information, such as decisions, tasks, or tracks. Therefore, the basic purpose of data fusion is to obtain information that is more reliable than data from any single input. Along with the progress of time, information fusion technology has become increasingly important in the field of information service. Multi-source information fusion is one of the most important parts of information service in the age of big data, and many productive achievements have been made. Many scholars have conducted research on multi-source information fusion. For example, Hai [10] investigated predictions of formation drillability based on multi-source information fusion. Cai et al. [11] researched multi-source information fusion-based fault diagnosis of a ground-source heat pump using a Bayesian network. Ribeiro et al. [12] studied an algorithm for data information fusion that includes concepts from multi-criteria decision-making and computational intelligence, especially fuzzy multi-criteria decision-making and mixture aggregation operators with weighting functions. Some relative papers have studied entropy measure with other fuzzy extensions. For instance, Wei et al. [13] proposed uncertainty measures of extended hesitant fuzzy linguistic term sets. Based on interval-valued intuitionistic fuzzy soft sets, Liu et al. [14] proposed a theoretical development on the entropy. Yang et al. [15] proposed cross-entropy measures of linguistic hesitant intuitionistic fuzzy systems.
An information system is the main expression of an information source and the basic structure underlying information fusion. An information system is a data table that describes the relationships among objects and attributes. There is a great deal of uncertainty in the process of information fusion. Rough set theory is usually used to measure the uncertainty in an information table. Rough set theory—which was introduced by Pawlak [16,17,18,19,20]—is an extension of classical set theory. In data analysis, it can be considered a mathematical and soft computational tool to handle imprecision, vagueness, and uncertainty. This relatively new soft computing methodology has received a great deal of attention in recent years, and its effectiveness has been confirmed by successful applications in many science and engineering fields, including pattern recognition, data mining, image processing, and medical diagnosis [21,22]. Rough set theory is based on the classification mechanism, and the theory is classified as an equivalence relation in a specific universe, and this equivalence relation constitutes a partition of the universe. A concept (or more precisely, the extension of a concept) is represented by a subset of a universe of objects, and is approximated by a pair of definable concepts in a logic language. The main idea of rough set theory is the use of known knowledge in a knowledge base to approximate inaccurate and uncertain knowledge. This seems to be of fundamental importance to artificial intelligence and cognitive science. An information system is the basic structure underlying information fusion, and rough set theory is usually used to measure the uncertainty in an information system. Therefore, it is feasible to use rough set theory for information fusion. Some scholars have conducted research in this field. For example, Grzymala-Busse [23] presented and compared nine different approaches to missing attribute values. For testing both naive classification and new classification techniques of LERS (Learning from Examples based on Rough Sets) were used. Dong et al. [24] researched the processing of information fusion based on rough set theory. Wang et al. [25] investigated multi-sensor information fusion based on rough sets. Huang et al. [26] proposed a novel method for tourism analysis with multiple outcome capability based on rough set theory. Luo et al. [27] studied incremental update of rough set approximation under the grade indiscernibility relation. Yuan et al. [28] considered multi-sensor information fusion based on rough set theory. In addition, Khan et al. [29,30] used views of the membership of objects to study rough sets and notions of approximates in multi-source situations. Md et al. [31] proposed a modal logic for multi-source tolerance approximation spaces based on the principle of considering only the information that sources have about objects. Lin et al. studied an information fusion approach based on combining multi-granulation rough sets with evidence theory [32]. Recently, Balazs and Velásquez conducted a systematic study of opinion mining and information fusion [33].
However, these methods of information fusion are all based on complete information systems; a smaller amount of research has been conducted for incomplete information systems . Jin et al. [34] studied feature selection in incomplete multi-sensor information systems based on positive approximation in rough set theory. IISs occur as a result of the ability to acquire data, the production environment, and other factors that result in the presence of original data with unknown values of attributes. As science has developed, people have found many ways to obtain information. An information box [35] can have multiple information sources, and every information source can be used to construct an information system. If all information sources are incomplete, then they can be used to construct multiple incomplete information systems. Therefore, the motivation for this paper is shown as follows: From the current research situation, most methods of information system fusion are all based on complete information systems. In order to broaden the research background of information fusion, we study the method of incomplete information system fusion. In order to reduce the amount of information loss in the process of information system fusion, we proposed the method which used information entropy to fuse incomplete information systems. In particular, by comparison with another method, our fusion method is validated. In this paper, we discuss the multi-source fusion of incomplete information tables based on information entropy. It is concluded that the method proposed here is more effective after comparing it with the mean value fusion method.
This rest of this paper is organized as follows: Some relevant notions are reviewed in Section 2. In Section 3, we define conditional entropy in a multi-source decision system, propose a fusion method based on conditional entropy, and design an algorithm for creating a new information table from a multi-source decision table based on conditional entropy. In Section 4, we download some data sets from UCI to prove the validity and reliability of our method; furthermore, we analyze the results of the experiment. The paper ends with conclusions in Section 5.
2. Preliminaries
In this section, we simply review some basic concepts relating to rough set theory, incomplete information systems, incomplete decision systems, and conditional entropy in incomplete decision systems. More details can be found in the literature [16,36,37,38,39].
2.1. Rough Sets
In rough set theory, let be an information system. The is the object set. The is the attribute set. The is a set of corresponding attribute values. The is a mapping function.
Let and , the intersection of all the equivalence relations in P is called the equivalence relation on P or the indistinguishable relation is defined by .
Let X be a subset of U. Then, x is an object of U, the equivalence class of x about R is defined by
which represents the equivalence class that contains x.
When a set X expresses a union of equivalence classes, the set X can be precisely defined; otherwise, the set X can only be approximated; in rough set theory, upper and lower approximation sets are used to describe the set X. Given a finite nonzero set, U, which is called the domain, that R is an equivalence relation in the universe U and , the upper and lower approximations of X are defined by
The R positive region, negative region, and the boundary region of X are defined as follows, respectively.
The approximation accuracy and roughness of the concept X in an attribute set, A, are defined as follows:
respectively. They are often used for measuring uncertainty in rough set theory. refers to the cardinality of the set X.
The approximation accuracy for rough classification was proposed by Pawlak [19] in 1991. By employing the attribute set R, the approximation accuracy provides the percentage of possibly correct decisions when classifying objects.
Let be a decision system, be a classification of universe U, and R be an attribute set satisfying . Then, the R-lower and R-upper approximations of are defined as
The approximation accuracy of for R is defined as
Recently, Dai and Xu [40] extended this to incomplete decision systems; i.e.,
The corresponding approximation roughness of for R is defined as
2.2. Incomplete Information System
A quadruple is an information system. U is a nonempty finite set of objects, is a nonempty finite set of attributes, V=, where is the domain of a, and is an information function such that for each and . A decision system, , is a quadruple , where C is the condition attribute set, D is the decision attribute set, and , V is the union of the attribute domain.
If there exists and such that is equal to a missing value (denoted “∗”), then the information system is an incomplete information system . Otherwise, the information system is a complete information system . If but , then we call the decision system an incomplete decision system . If and , then the information system is a complete decision system .
Because there are missing values, the equivalence relation is not suitable for incomplete information systems. Therefore, Kryszkiewicz [36,37] defined a tolerance relation for incomplete information systems. Given an incomplete information system, , for any attribute subset , let denote the binary tolerance relation between objects that are possibly indiscernible in terms of B. is defined as
The tolerance class of object x with reference to an attribute set B is denoted . For , the lower and upper approximations of X with respect to B are defined as
3. Multi-Source Incomplete Information Fusion
With the development of science and technology, people have access to increasing numbers of channels from which to obtain information. The diversity of the channels has produced a large number of incomplete information sources—that is, a multi-source incomplete information system. Investigating some special properties of this system and fusing the information are the focus of the information technology field. In this section, we present a new fusion method for multi-source incomplete information systems and compare our fusion method with the mean value fusion method in a small experiment.
3.1. Multi-Source Information Systems
Let us consider the scenario in which we obtain information regarding a set of objects from different sources. Information from each source is collected in the above information system, and thus, a family of the single information systems with the same domain is obtained; it is called a multi-source information system [41].
Definition 1.
(see [32]) A multi-source information system can be defined as
where U is a finite non-empty set of objects, is a finite non-empty set of attributes of each subsystem, is the value of attribute , and such that for all and , .
In particular, a multi-source decision information system is given by , where D is a finite non-empty set of decision attributes and for any , where is the domain of decision attribute d. The multi-source information system includes s single information sources. Let the s overlapping pieces of single-source information system form an information box with s levels, as shown Figure 1, which comes from our previous study [35].
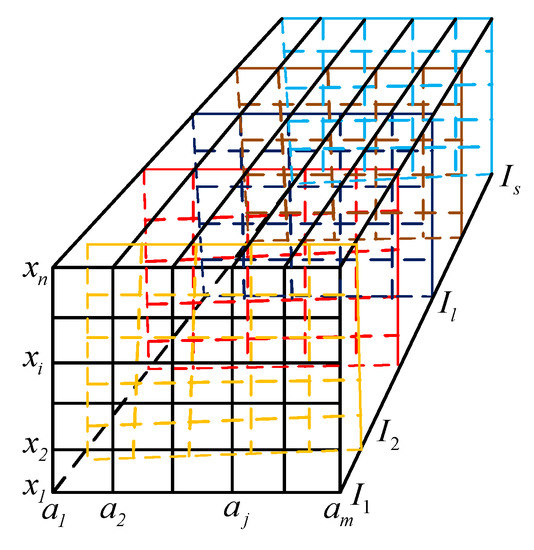
Figure 1.
A multi-source information box.
3.2. Multi-Source Incomplete Information System
Definition 2.
A multi-source incomplete information system is defined as , where
- is the incomplete information system of subsystem i;
- U is a finite non-empty set of objects;
- is the finite non-empty set of attributes for subsystem i;
- is the value of attribute ;
- such that for all and , .
In particular, a multi-source decision information system is given by , where D is a finite non-empty set of decision attributes and for any , where is the domain of decision attribute d.
3.3. Multi-Source Incomplete Information Fusion
Because the information box in each table is not complete, we propose a new fusion method.
Definition 3.
Let I be an incomplete information system and . , , we define the distance between any two objects in U with attribute a as follows.
Definition 4.
Given an incomplete information system , for any attribute , let denote the binary tolerance relation between objects that are possibly indiscernible in terms of a. is defined as
where indicates the threshold associated with attribute a. The tolerance class of object x with reference to attribute a is denoted by .
Definition 5.
Given an incomplete information system , for any attribute subset , let denote the binary tolerance relation between objects that are possibly indiscernible in terms of B. is defined as
The tolerance class of object x with respect to an attribute set B is denoted by .
In the literature [39], Dai et al. proposed a new conditional entropy to evaluate the uncertainty in an incomplete decision system. Given an incomplete decision system , . is a set of attributes, and . The conditional entropy of D with respect to B is defined as
Because the conditional entropy is monotonous and because the attribute set B increases in importance as the conditional entropy decreases, we have the following definitions:
Definition 6.
Let be s incomplete information systems and . , . The uncertainty of the information sources in D with respect to for attribute a is defined as
where is the tolerance class of the information sources in D with respect to for attribute a.
Because the conditional entropy of Dai [39] is monotonous, for attribute a is also monotonous, and for attribute a, the smaller the conditional entropy is, the more important the information source is. We have the following Definition 7:
Definition 7.
Let be s incomplete information system. We define the incomplete information system, which is the most important for attribute a, as follows:
where represents the information source, which is the most important for attribute a.
Example 1.

Let us consider a real medical examination issue at a hospital. When diagnosing leukemia, there are 10 patients, , to be considered. They undergo medical examinations at four hospitals, which test 6 indicators, , where – are, respectively, the “hemoglobin count,” “leukocyte count,” “blood fat,” “blood sugar,” “platelet count,” and “ level”. Table 1, Table 2, Table 3 and Table 4 are incomplete evaluation tables based on the medical examinations performed at the four hospitals; the symbol “∗” means that an expert cannot determine the level of a project.
Table 1.
Information source .
Table 2.
Information source .
Table 3.
Information source .
Table 4.
Information source .
Suppose and , where , . Then, the conditional entropy of the information sources of D with respect to for attribute is as follows:
Because the conditional entropy can be used to evaluate the importance of information sources for attribute a, we can determine the importance of all attributes for all information sources by using Definition 7 and Table 5. The smaller the conditional entropy is, the more important the information sources are for attribute a. Therefore, is the most important for and , is the most important for and , and is the most important for and . is not the most important for any attribute. A new information system, is established by part of each table. Furthermore, we take for the value of a property for and , for the property’s value for and , and for the property’s value for and . That is, , where represents the range of attribute under , and we obtain the new information system after fusion. The new information system, , after fusion is shown in Table 6.
Table 5.
The conditional entropy of information sources for different attributes.
Table 6.
The result of multi-source information fusion.
The fusion process is shown in Figure 2. Suppose that there is a multi-source information system that contains s information systems and that there are n objects and m attributes in each information system . We calculate the conditional entropy of each attribute by using Definition 6. Then, we determine the minimum of the conditional entropy for each attribute of the values using Definition 7. For example, we use different colors of rough lines to express the corresponding attributes to select a source. Then, the selected attribute values are integrated into a new information system.
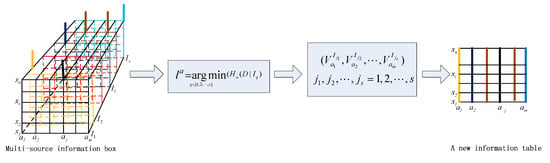
Figure 2.
The process of multi-source information fusion.
In practical applications, the mean value fusion method is one of the common fusion methods. We compare this type of method with conditional entropy fusion based on approximation accuracy. The results of two types of fusion method are presented in Table 6 and Table 7.
Table 7.
The result of mean value fusion of multiple information sources.
Using Table 6 and Table 7, we compute the approximation accuracy of the results of the two fusion methods and compare their approximation accuracy. Please see Table 8.
Table 8.
The approximation accuracies of two fusion methods.
By comparing the approximation accuracies, we see that multi-source fusion is better than mean value fusion. Therefore, we design a multi-source fusion algorithm (Algorithm 1) and analyze its computational complexity.
The given algorithm (Algorithm 1) is a new approach to multi-source information fusion. Its approximation accuracy is better than that of mean value fusion in the result of example Section 3.3. First, we can calculate all the similarity classes for any for attribute a. Then, the conditional entropy, , is computed for information source q and attribute a. Finally, the minimum of the conditional entropy of the information source is selected for attribute a, and the results are spliced into a new table. The computational complexity of Algorithm 1 is shown in Table 9.
Table 9.
Computational complexity of Algorithm 1.
| Algorithm 1: An algorithm for multi-source fusion. |
 |
In steps 4 and 5 of Algorithm 1, we compute all for any for attribute a. Steps 6–14 calculate the conditional entropy for information source q and attribute a. Steps 17–26 are to find the minimum of the conditional entropy of the corresponding source for any . Finally, the results are returned.
4. Experimental Evaluation
In this section, to further illustrate the correctness of the conclusions of the previous example, we conduct a series of experiments to explain why the approximate precision of conditional entropy fusion is generally higher than that of the mean value fusion based on standard data sets from the machine learning data repository of the University of California at Irvine (http://archive.ics.uci.edu/ml/datasets.html) called “Statlog (Vehicle Silhouettes)”, “Letter Recognition”, “Phishing Websites”, “Robot Execution Failures”, “Semeion Handwritten Digit”, and “SPECTF Heart” in Table 10. The experimental program is running on a personal computer with the hardware and software described in Table 11.
Table 10.
Experimental data sets.
Table 11.
Description of the experimental environment.
To build a real multi-source incomplete information system, we propose a method for obtaining incomplete data from multiple sources. First, to obtain incomplete data, a complete data set with some data randomly deleted is used as the original incomplete data set. Then, a multi-source incomplete decision table is constructed by adding Gaussian noise and random noise to the original incomplete data set.
Let be a multi-source incomplete decision table constructed using the original incomplete information table, I.
First, s numbers that have an distribution, where is the standard deviation, are generated. The method of adding Gaussian noise is as follows:
where is the value of object x with attribute a in the original incomplete information table and represents object x with attribute a in the i-th incomplete information source.
Then, s random numbers between and e, where e is a random error threshold, are generated. The method of adding random noise is as follows:
where represents the value of object x for attribute a in the original incomplete information table and represents object x for attribute a in the i-th incomplete information source.
Next, 40% of the objects are randomly selected from the original incomplete information table, I, and Gaussian noise is added to these objects. Then, 20% of the objects are randomly selected from the rest of the original incomplete information table, I, and random noise is added to these objects.
Finally, a multi-source incomplete decision table, , can be created.
5. Related Works and Conclusion Analysis
In different fields of science, the standard deviation of Gaussian noise and the random error threshold of random noise may differ. In this paper, we conducted 20 experiments for each data set and set the standard deviation and the random error threshold e to values from 0 to 2, with an increase of 0.1 in each experiment. For CE fusion and mean value fusion, the approximation accuracy of for each data set is displayed in Table 12 and Figure 3, Figure 4, Figure 5, Figure 6, Figure 7 and Figure 8. CE and M stand for CE fusion and mean value fusion, respectively.
Table 12.
Approximation accuracies of conditional entropy fusion (CE) and mean value fusion (M) for each data set.
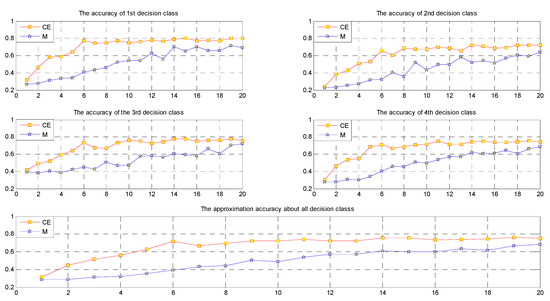
Figure 3.
Approximation accuracies for the decision classes in data set WC.
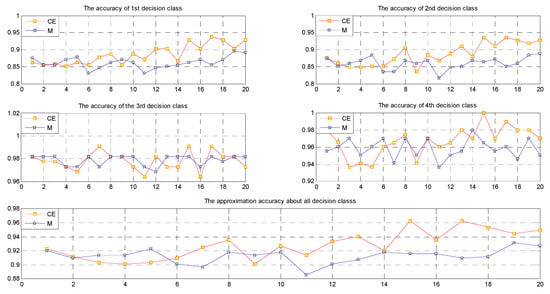
Figure 4.
Approximation accuracies for the decision classes in data set S (VS).
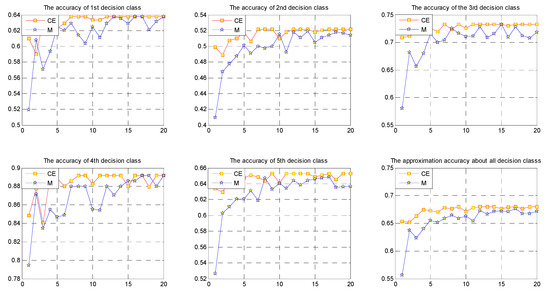
Figure 5.
Approximation accuracies for the decision classes in data set AS-N.
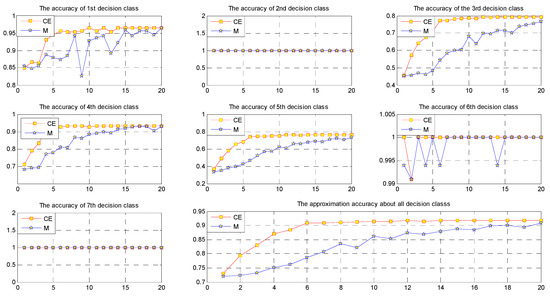
Figure 6.
Approximation accuracies for the decision classes in data set IS.
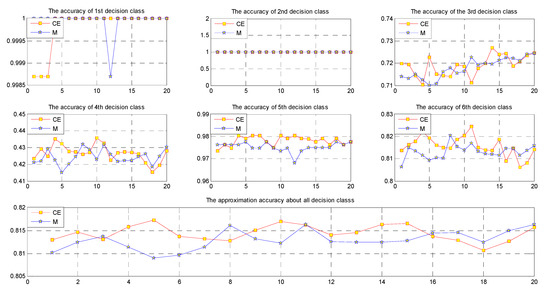
Figure 7.
Approximation accuracies for the decision classes in data set S (LS).
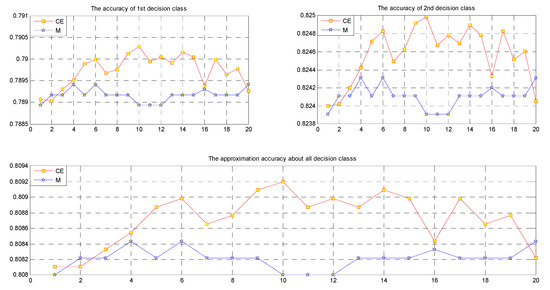
Figure 8.
Approximation accuracies for the decision classes in data set EES.
We can easily see from Figure 3, Figure 4, Figure 5, Figure 6, Figure 7 and Figure 8 and Table 12 that when the noise is small, in most cases, the approximation accuracy of CE fusion is slightly higher than that of mean value fusion. In a certain range, as the noise increases, the approximation accuracy of CE fusion becomes much better than that of mean value fusion.
By observing the approximation accuracies of the extensions of concepts of CE and mean value fusion for the six data sets, we find that in most cases, the approximation accuracy of CE fusion is higher than that of mean value fusion. In a certain range, as the amount of noise increases, the accuracies of the extensions of concepts of CE and mean value fusion trend upward, but they are not strictly monotonic.
6. Conclusions
In this paper, we studied multi-source information fusion in view of the conditional entropy. There are many null information sources in the age of big data. To solve the problem of integrating multiple incomplete information sources, we studied an approach based on multi-source information fusion. We transformed a multi-source information system into an information table by using this fusion method. Furthermore, we used rough set theory to investigate the fused information table, and compared the accuracy of our fusion method with that of the mean value fusion method. According to the accuracies, CE fusion is better than mean value fusion under most conditions. In this paper, we constructed six multi-source information systems, each containing 10 single information sources. Based on these data sets, a series of experiments was conducted; the results showed the effectiveness of the proposed fusion method. This study will be useful for fusing uncertain information in multi-source information systems. It provides valuable selections for data processing in multi-source environments.
Acknowledgments
The authors wish to thank the anonymous reviewer. This work is supported by the Natural Science Foundation of China (No. 61105041, No. 61472463 and No. 61402064), the National Natural Science Foundation of CQ CSTC (No. cstccstc2015jcyjA1390), the Graduate Innovation Foundation of Chongqing (No. CYS16217) and the Graduate Innovation Foundation of Chongqing University of Technology (No. YCX2016227).
Author Contributions
Mengmeng Li is the principal investigator of this work. He performed the simulations and wrote this manuscript. Xiaoyan Zhang contributed to the data analysis work and checked the whole manuscript. All authors revised and approved the publication.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Bleiholder, J.; Naumann, F. Data fusion. ACM Comput. Surv. 2008, 41, 1–41. [Google Scholar] [CrossRef]
- Lee, H.; Lee, B.; Park, K.; Elmasri, R. Fusion techniques for reliable information: A survey. Int. J. Digit. Content Technol. Appl. 2010, 4, 74–88. [Google Scholar]
- Khaleghi, B.; Khamis, A.; Karray, F.O. Multisensor data fusion: A review of the state of the art. Inf. Fusion 2013, 14, 28–44. [Google Scholar] [CrossRef]
- Han, C.Z.; Zhu, H.Y.; Duan, Z.S. Multiple-Source Information Fusion; Tsinghua University Press: Beijing, China, 2010. [Google Scholar]
- Peng, D. Theory and Application of Multi Sensor Multi Source Information Fusion; Thomson Learning Press: Beijing, China, 2010. [Google Scholar]
- Schueremans, L.; Gemert, D.V. Benef it of splines and neural networks in simulation based structural reliability analysis. Struct. Saf. 2005, 27, 246–261. [Google Scholar] [CrossRef]
- Pan, W.K.; Liu, Z.D.; Ming, Z.; Zhong, H.; Wang, X.; Xu, C.F. Compressed Knowledge Transfer via Factorization Machine for Heterogeneous Collaborative Recommendation. Knowl. Based Syst. 2015, 85, 234–244. [Google Scholar] [CrossRef]
- Wang, X.Z.; Huang, J. Editorial: Uncertainty in Learning from Big Data. Fuzzy Sets Syst. 2015, 258, 1–4. [Google Scholar] [CrossRef]
- Wang, X.Z.; Xing, H.J.; Li, Y.; Hua, Q.; Dong, C.R.; Pedrycz, W. A Study on Relationship between Generalization Abilities and Fuzziness of Base Classifiers in Ensemble Learning. IEEE Trans. Fuzzy Syst. 2015, 23, 1638–1654. [Google Scholar] [CrossRef]
- Hai, M. Formation drillability prediction based on multisource information fusion. J. Pet. Sci. Eng. 2011, 78, 438–446. [Google Scholar]
- Cai, B.; Liu, Y.; Fan, Q.; Zhang, Y.; Liu, Z.; Yu, S.; Ji, R. Multi-source information fusion based fault diagnosis of ground-source heat pump using Bayesian network. Appl. Energy 2014, 114, 1–9. [Google Scholar] [CrossRef]
- Ribeiro, R.A.; Falcão, A.; Mora, A.; Fonseca, J. FIF: A fuzzy information fusion algorithm based on multi-criteria decision. Knowl. Based Syst. 2014, 58, 23–32. [Google Scholar] [CrossRef]
- Wei, C.P.; Rodrguez, R.M.; Martnez, L. Uncertainty Measures of Extended Hesitant Fuzzy Linguistic Term Sets. IEEE Trans. Fuzzy Syst. 2017, 1. [Google Scholar] [CrossRef]
- Liu, Y.Y.; Luo, J.F.; Wang, B.; Qin, K. A theoretical development on the entropy of interval-valued intuitionistic fuzzy soft sets based on the distance measure. Int. J. Comput. Intell. Syst. 2017, 10, 569. [Google Scholar] [CrossRef]
- Yang, W.; Pang, Y.F.; Shi, J.R. Linguistic hesitant intuitionistic fuzzy cross-entropy measures. Int. J. Comput. Intell. Syst. 2017, 10, 120. [Google Scholar] [CrossRef]
- Pawlak, Z. Rough sets. Int. J. Comput. Inf. Sci. 1982, 11, 341–356. [Google Scholar] [CrossRef]
- Pawlak, Z. Rough set theory and its applications to data analysis. Cybern. Syst. 1998, 29, 661–688. [Google Scholar] [CrossRef]
- Pawlak, Z.; Skowron, A. Rough sets: Some extensions. Inf. Sci. 2007, 177, 28–40. [Google Scholar] [CrossRef]
- Pawlak, Z. Rough Sets: Theoretical Aspects of Reasoning About Data; Kluwer: Boston, MA, USA, 1991. [Google Scholar]
- Pawlak, Z. Vagueness and uncertainty: A rough set perspective. Comput. Intell. 1995, 11, 227–232. [Google Scholar] [CrossRef]
- Li, H.L.; Chen, M.H. Induction of multiple criteria optimal classification rules for biological and medical data. Comput. Biol. Med. 2008, 38, 42–52. [Google Scholar] [CrossRef] [PubMed]
- Liu, J.F.; Hu, Q.H.; Yu, D.R. A weighted rough set based method developed for class imbalance learning. Inf. Sci. 2008, 178, 1235–1256. [Google Scholar] [CrossRef]
- Grzymala-Busse, J.W.; Hu, M. A Comparison of Several Approaches to Missing Attribute Values in Data Mining. In Proceedings of the Second International Conference on Rough Sets and Current Trends in Computing, Banff, AB, Canada, 16–19 October 2000; Springer-Verlag: Berlin, Germany, 2000; pp. 378–385. [Google Scholar]
- Dong, G.; Zhang, Y.; Dai, C.; Fan, Y. The Processing of Information Fusion Based on Rough Set Theory. J. Instrum. Meter China 2005, 26, 570–571. [Google Scholar]
- Wang, J.; Wang, Y. Multi-sensor information fusion based on Rough set. J. Hechi Univ. 2009, 29, 80–82. [Google Scholar]
- Huang, C.C.; Tseng, T.L.; Chen, K.C. Novel Approach to Tourism Analysis with Multiple Outcome Capability Using Rough Set Theory. Int. J. Comput. Intell. Syst. 2016, 9, 1118–1132. [Google Scholar] [CrossRef][Green Version]
- Luo, J.F.; Liu, Y.Y.; Qin, K.Y.; Ding, H. Incremental update of rough set approximation under the grade indiscernibility relation. Int. J. Comput. Intell. Syst. 2017, 10, 212. [Google Scholar] [CrossRef]
- Yuan, X.; Zhu, Q.; Lan, H. Multi-sensor information fusion based on rough set theory. J. Harbin Inst. Technol. 2006, 38, 1669–1672. [Google Scholar]
- Khan, M.A.; Banerjee, M. A study of multiple-source approximation systems. Lect. Notes Comput. Sci. 2010, 12, 46–75. [Google Scholar]
- Khan, M.A.; Banerjee, M. A perference-based multiple-source rough set model. Lect. Notes Comput. Sci. 2010, 6068, 247–256. [Google Scholar]
- Md, A.K.; Ma, M.H. A modal logic for multiple-source tolerance approximation spaces. Lect. Notes Comput. Sci. 2011, 6521, 124–136. [Google Scholar]
- Lin, G.P.; Liang, J.Y.; Qian, Y.H. An information fusion approach by combining multigranulation rough sets and evidence theory. Inf. Sci. 2015, 314, 184–199. [Google Scholar] [CrossRef]
- Balazs, J.A.; Velásquez, J.D. Opinion Mining and Information Fusion: A survey. Inf. Fusion 2016, 27, 95–110. [Google Scholar] [CrossRef]
- Zhou, J.; Hu, L.; Chu, J.; Lu, H.; Wang, F.; Zhao, K. Feature Selection from Incomplete Multi-Sensor Information System Based on Positive Approximation in Rough Set Theory. Sens. Lett. 2013, 11, 974–981. [Google Scholar] [CrossRef]
- Yu, J.H.; Xu, W.H. Information fusion in multi-source fuzzy information system with same structure. In Proceedings of the 2015 International Conference on Machine Learning and Cybernetics, Guangzhou, China, 12–15 July 2015; pp. 170–175. [Google Scholar]
- Kryszkiewicz, M. Rough set approach to incomplete information systems. Inf. Sci. 1998, 112, 39–49. [Google Scholar] [CrossRef]
- Kryszkiewicz, M. Rules in incomplete information systems. Inf. Sci. 1999, 113, 271–292. [Google Scholar] [CrossRef]
- Pawlak, Z.; Skowron, A. Rudiments of rough sets. Inf. Sci. 2007, 177, 3–27. [Google Scholar] [CrossRef]
- Dai, J.; Wang, W.; Xu, Q. An Uncertainty Measure for Incomplete Decision Tables and Its Applications. IEEE Trans. Cybern. 2013, 43, 1277–1289. [Google Scholar] [CrossRef] [PubMed]
- Dai, J.; Xu, Q. Approximations and uncertainty measures in incomplete information systems. Inf. Sci. 2012, 198, 62–80. [Google Scholar] [CrossRef]
- Khan, M.A.; Banerjee, M. Formal reasoning with rough sets in multiple-source approximation systems. Int. J. Approx. Reason. 2008, 49, 466–477. [Google Scholar] [CrossRef]








© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).