Abstract
In high-dimensional data, many sparse regression methods have been proposed. However, they may not be robust against outliers. Recently, the use of density power weight has been studied for robust parameter estimation, and the corresponding divergences have been discussed. One such divergence is the -divergence, and the robust estimator using the -divergence is known for having a strong robustness. In this paper, we extend the -divergence to the regression problem, consider the robust and sparse regression based on the -divergence and show that it has a strong robustness under heavy contamination even when outliers are heterogeneous. The loss function is constructed by an empirical estimate of the -divergence with sparse regularization, and the parameter estimate is defined as the minimizer of the loss function. To obtain the robust and sparse estimate, we propose an efficient update algorithm, which has a monotone decreasing property of the loss function. Particularly, we discuss a linear regression problem with regularization in detail. In numerical experiments and real data analyses, we see that the proposed method outperforms past robust and sparse methods.
1. Introduction
In high-dimensional data, sparse regression methods have been intensively studied. The Lasso [1] is a typical sparse linear regression method with regularization, but is not robust against outliers. Recently, robust and sparse linear regression methods have been proposed. The robust least angle regression (RLARS) [2] is a robust version of LARS [3], which replaces the sample correlation by a robust estimate of correlation in the update algorithm. The sparse least trimmed squares (sLTS) [4] is a sparse version of the well-known robust linear regression method LTS [5] based on the trimmed loss function with regularization.
Recently, the robust parameter estimation using density power weight has been discussed by Windham [6], Basu et al. [7], Jones et al. [8], Fujisawa and Eguchi [9], Basu et al. [10], Kanamori and Fujisawa [11], and so on. The density power weight gives a small weight to the terms related to outliers, and then, the parameter estimation becomes robust against outliers. By virtue of this validity, some applications using density power weights have been proposed in signal processing and machine learning [12,13]. Among them, the -divergence proposed by Fujisawa and Eguchi [9] is known for having a strong robustness, which implies that the latent bias can be sufficiently small even under heavy contamination. The other robust methods including density power-divergence cannot achieve the above property, and the estimator can be affected by the outlier ratio. In addition, to obtain the robust estimate, an efficient update algorithm was proposed with a monotone decreasing property of the loss function.
In this paper, we propose the robust and sparse regression problem based on the -divergence. First, we extend the -divergence to the regression problem. Next, we consider a loss function based on the -divergence with sparse regularization and propose an update algorithm to obtain the robust and sparse estimate. Fujisawa and Eguchi [9] used a Pythagorean relation on the -divergence, but it is not compatible with sparse regularization. Instead of this relation, we use the majorization-minimization algorithm [14]. This idea is deeply considered in a linear regression problem with regularization. The MM algorithm was also adopted in Hirose and Fujisawa [15] for robust and sparse Gaussian graphical modeling. A tuning parameter selection is proposed using a robust cross-validation. We also show a strong robustness under heavy contamination even when outliers are heterogeneous. Finally, in numerical experiments and real data analyses, we show that our method is computationally efficient and outperforms other robust and sparse methods. The R language software package “gamreg”, which we use to implement our proposed method, can be downloaded at http://cran.r-project.org/web/packages/gamreg/.
2. Regression Based on -Divergence
The -divergence was defined for two probability density functions, and its properties were investigated by Fujisawa and Eguchi [9]. In this section, the -divergence is extended to the regression problem, in other words, defined for two conditional probability density functions.
2.1. -Divergence for Regression
We suppose that , and are the underlying probability density functions of , y given x and x, respectively. Let be another parametric conditional probability density function of y given x. Let us define the -cross-entropy for regression by:
The -divergence for regression is defined by:
The -divergence for regression was first proposed by Fujisawa and Eguchi [9], and many properties were already shown. However, we adopt the definition (2), which is slightly different from the past one, because (2) satisfies the Pythagorean relation approximately (see Section 4).
Theorem 1.
We can show that:
where
The proof is in Appendix A. In what follows, we refer to the regression based on the -divergence as the -regression.
2.2. Estimation for -Regression
Let be the conditional probability density function of y given x with parameter . The target parameter can be considered by:
When , we have .
Let be the observations randomly drawn from the underlying distribution . Using the formula (1), the -cross-entropy for regression, , can be empirically estimated by:
By virtue of (3), we define the -estimator by:
In a similar way as in Fujisawa and Eguchi [9], we can show the consistency of to under some conditions.
Here, we briefly show why the -estimator is robust. Suppose that is an outlier. The conditional probability density can be expected to be sufficiently small. We see from and (4) that:
Therefore, the term is naturally ignored in (4). However, for the KL-divergence, diverges from . That is why the KL-divergence is not robust. The theoretical robust properties are presented in Section 4.
Moreover, the empirical estimation of the -cross-entropy with a penalty term can be given by:
where is a penalty for parameter and is a tuning parameter for the penalty term. As an example of the penalty term, we can consider (Lasso, Tibshirani [1]), elasticnet [16], group Lasso [17], fused Lasso [18], and so on. The sparse -estimator can be proposed by:
To obtain the minimizer, we propose the iterative algorithm by the majorization-minimization algorithm (MM algorithm) [14].
3. Parameter Estimation Procedure
3.1. MM Algorithm for Sparse -Regression
The MM algorithm is constructed as follows. Let be the objective function. Let us prepare the majorization function satisfying:
where is the parameter of the m-th iterative step for Let us consider the iterative algorithm by:
Then, we can show that the objective function monotonically decreases at each step, because:
Note that does not necessarily have to be the minimizer of . We only need:
We construct the majorization function for the sparse -regression by the following inequality:
where is a convex function, , , , and , and are positive. The inequality (5) holds from Jensen’s inequality. Here, we take , , , and in (5). We can propose the majorization function as follows:
where and is a term that does not depend on the parameter .
The first term on the original target function is a mixture type of densities, which is not easy to optimize, while the first term on is a weighted log-likelihood, which is often easy to optimize.
3.2. Sparse -Linear Regression
Let be the conditional density with , given by:
where is the normal density with mean parameter and variance parameter . Suppose that is the regularization . After a simple calculation, we have:
This function is easy to optimize by an update algorithm. For a fixed value of , the function is almost the same as Lasso except for the weight, so that it can be updated using the coordinate decent algorithm with a decreasing property of the loss function. For a fixed value of , the function is easy to minimize. Consequently, we can obtain the update algorithm in Algorithm 1 with the decreasing property:
| Algorithm 1 Sparse -linear regression. |
|
It should be noted that is convex with respect to parameter , and has the global minimum with respect to parameter , but the original objective function h is not convex with respect to them, so that the initial points of Algorithm 1 are important. This issue is discussed in Section 5.4.
In practice, we also use the active set strategy [19] in the coordinate decent algorithm for updating . The active set consists of the non-zero coordinates of . Specifically, for a given , we only update the non-zero coordinates of , until they are converged. Then, the non-active set parameter estimates are updated once. When they remain zero, the coordinate descent algorithm stops. If some of them do not remain zero, those are added to the active set, and the coordinate descent algorithm continues.
3.3. Robust Cross-Validation
In sparse regression, a regularization parameter is often selected via a criterion. Cross-validation is often used for selecting the regularization parameter. Ordinal cross-validation is based on the squared error, and it can also be constructed using the KL-cross-entropy with the normal density. However, the ordinal cross-validation will fail due to outliers. Therefore, we propose the robust cross-validation based on the -cross-entropy. Let be the robust estimate based on the -cross-entropy. The cross-validation based on the -cross-entropy can be given by:
where is the -estimator deleting the i-th observation and is an appropriate tuning parameter. We can also adopt the K-fold cross-validation to reduce the computational task [20].
Here, we give a small modification of the above. We often focus only on the mean structure for prediction, not on the variance parameter. Therefore, in this paper, is replaced by . In numerical experiments and real data analyses, we used as .
4. Robust Properties
In this section, the robust properties are presented from two viewpoints of latent bias and Pythagorean relation. The latent bias was discussed in Fujisawa and Eguchi [9] and Kanamori and Fujisawa [11], which is described later. Using the results obtained there, the Pythagorean relation is shown in Theorems 2 and 3.
Let and be the target conditional probability density function and the contamination conditional probability density function related to outliers, respectively. Let and denote the outlier ratios, which are independent of and dependent on x, respectively. Under homogeneous and heterogeneous contaminations, we suppose that the underlying conditional probability density function can be expressed as:
Let:
and let:
Here, we assume that:
which implies that for any x (a.e.) and illustrates that the contamination conditional probability density function lies on the tail of the target conditional probability density function . For example, if is the Dirac function at the outlier given x, then we have , which should be sufficiently small because is an outlier. In this section, we show that is expected to be small even if or is not small. To make the discussion easier, we prepare the monotone transformation of the -cross-entropy for regression by:
4.1. Homogeneous Contamination
Here, we provide the following proposition, which was given in Kanamori and Fujisawa [11].
Proposition 1.
Recall that and are also the minimizers of and , , respectively. We can expect from the assumption if the tail behavior of is close to that of . We see from Proposition 1 and the condition that:
Therefore, under homogeneous contamination, it can be expected that the latent bias is small even if is not small. Moreover, we can show the following theorem, using Proposition 1.
Theorem 2.
Let . Then, the Pythagorean relation among , , approximately holds:
The proof is in Appendix A. The Pythagorean relation implies that the minimization of the divergence from to the underlying conditional probability density function is approximately the same as that to the target conditional probability density function . Therefore, under homogeneous contamination, we can see why our proposed method works well in terms of the minimization of the -divergence.
4.2. Heterogeneous Contamination
Under heterogeneous contamination, we assume that the parametric conditional probability density function is a location-scale family given by:
where is a probability density function, is a scale parameter and is a location function with a regression parameter , e.g., . Then, we can obtain:
That does not depend on the explanatory variable x. Here, we provide the following proposition, which was given in Kanamori and Fujisawa [11].
Proposition 2.
where and
The second term can be approximated to be zero from the condition and as follows:
We see from Proposition 2 and (7) that:
Therefore, under heterogeneous contamination in a location-scale family, it can be expected that the latent bias is small even if is not small. Moreover, we can show the following theorem, using Proposition 2.
Theorem 3.
Let . Then, the following relation among , , approximately holds:
The proof is in Appendix A. The above is slightly different from a conventional Pythagorean relation, because the base measure changes from to in part. However, it also implies that the minimization of the divergence from to the underlying conditional probability density function is approximately the same as that to the target conditional probability density function . Therefore, under heterogeneous contamination in a location-scale family, we can see why our proposed method works well in terms of the minimization of the -divergence.
4.3. Redescending Property
First, we review a redescending property on M-estimation (see, e.g., [21]), which is often used in robust statistics. Suppose that the estimating equation is given by . Let be a solution of the estimating equation. The bias caused by outlier is expressed as , where is the limiting value of and is the true parameter. We hope the bias is small even if the outlier exists. Under some conditions, the bias can be approximated to , where is a small outlier ratio and is the influence function. The bias is expected to be small when the influence function is small. The influence function can be expressed as , where A is a matrix independent of z, so that the bias is also expected to be small when is small. In particular, the estimating equation is said to have a redescending property if goes to zero as goes to infinity. This property is favorable in robust statistics, because the bias is expected to be sufficiently small when is very large.
Here, we prove a redescending property on the sparse -linear regression, i.e., when with for fixed x. Recall that the estimate of the sparse -linear regression is the minimizer of the loss function:
where Then, the estimating equation is given by:
where This can be expressed by the M-estimation formula given by:
where We can easily show that as goes to infinity, goes to zero and also goes to zero. Therefore, the function goes to zero as goes to infinity, so that the estimating equation has a redescending property.
5. Numerical Experiment
In this section, we compare our method (sparse -linear regression) with the representative sparse linear regression method, the least absolute shrinkage and selection operator (Lasso) [1], and the robust and sparse regression methods, sparse least trimmed squares (sLTS) [4] and robust least angle regression (RLARS) [2].
5.1. Regression Models for Simulation
We used the simulation model given by:
The sample size and the number of explanatory variables were set to be and , respectively. The true coefficients were given by:
We arranged a broad range of regression coefficients to observe sparsity for various degrees of regression coefficients. The explanatory variables were generated from a normal distribution with . We generated 100 random samples.
Outliers were incorporated into simulations. We investigated two outlier ratios () and two outlier patterns: (a) the outliers were generated around the middle part of the explanatory variable, where the explanatory variables were generated from and the error terms were generated from ; (b) the outliers were generated around the edge part of the explanatory variable, where the explanatory variables were generated from and the error terms were generated from .
5.2. Performance Measure
The root mean squared prediction error (RMSPE) and mean squared error (MSE) were examined to verify the predictive performance and fitness of regression coefficient:
where () is the test sample generated from the simulation model without outliers and ’s are the true coefficients. The true positive rate (TPR) and true negative rate (TNR) were also reported to verify the sparsity:
5.3. Comparative Methods
In this subsection, we explain three comparative methods: Lasso, RLARS and sLTS.
Lasso is performed by the R-package “glmnet”. The regularization parameter is selected by grid search via cross-validation in “glmnet”. We used “glmnet” by default.
RLARS is performed by the R-package “robustHD”. This is a robust version of LARS [3]. The optimal model is selected via BIC by default.
sLTS is performed by the R-package “robustHD”. sLTS has the regularization parameter and the fraction parameter of squared residuals used for trimmed squares. The regularization parameter is selected by grid search via BIC. The number of grids is 40 by default. However, we considered that this would be small under heavy contamination. Therefore, we used 80 grids under heavy contamination to obtain a good performance. The fraction parameter is 0.75 by default. In the case of , the ratio of outlier is less than 25%. We considered this would be small under heavy contamination and large under low contamination in terms of statistical efficiency. Therefore, we used 0.65, 0.75, 0.85 as under low contamination and 0.50, 0.65, 0.75 under heavy contamination.
5.4. Details of Our Method
5.4.1. Initial Points
In our method, we need an initial point to obtain the estimate, because we use the iterative algorithm proposed in Section 3.2. The estimate of other conventional robust and sparse regression methods would give a good initial point. For another choice, the estimate of RANSAC (random sample consensus) algorithm would also give a good initial point. In this experiment, we used the estimate of sLTS as an initial point.
5.4.2. How to Choose Tuning Parameters
In our method, we have to choose some tuning parameters. The parameter in the -divergence was set to or . The parameter in the robust cross-validation was set to . In our experience, the result via RoCVis not sensitive to the selection of when is large enough, e.g., . The parameter of regularization is often selected via grid search. We used 50 grids in the range with the log scale, where is an estimate of , which would shrink regression coefficients to zero. More specifically, in a similar way as in Lasso, we can derive , which shrinks the coefficients to zero in [6] with respect to , and we used it. This idea was proposed by the R-package “glmnet”.
5.5. Result
Table 1 is the low contamination case with Outlier Pattern (a). For the RMSPE, our method outperformed other comparative methods (the oracle value of the RMSPE is 0.5). For the TPR and TNR, sLTS showed a similar performance to our method. Lasso presented the worst performance, because it is sensitive to outliers. Table 2 is the heavy contamination case with Outlier Pattern (a). For the RMSPE, our method outperformed other comparative methods except in the case (p, , ) = (100, 0.3, 0.2) for sLTS with . Lasso also presented a worse performance, and furthermore, sLTS with showed the worst performance due to a lack of truncation. For the TPR and TNR, our method showed the best performance. Table 3 is the low contamination case with Outlier Pattern (b). For the RMSPE, our method outperformed other comparative methods (the oracle value of the RMSPE is 0.5). For the TPR and TNR, sLTS showed a similar performance to our method. Lasso presented the worst performance, because it is sensitive to outliers. Table 4 is the heavy contamination case with Outlier Pattern (b). For the RMSPE, our method outperformed other comparative methods. sLTS with showed the worst performance. For the TPR and TNR, it seems that our method showed the best performance. Table 5 is the no contamination case. RLARS showed the best performance, but our method presented comparable performances. In spite of no contamination case, Lasso was clearly worse than RLARS and our method. This would be because the underlying distribution can generate a large value in simulation, although it is a small probability.

Table 1.
Outlier Pattern (a) with , and . RMSPE, root mean squared prediction error (RMSPE); RLARS, robust least angle regression; sLTS, sparse least trimmed squares.
Table 2.
Outlier Pattern (a) with , and .
Table 3.
Outlier Pattern (b) with , and .
Table 4.
Outlier Pattern (b) with , and .
Table 5.
No contamination case with , and .
5.6. Computational Cost
In this subsection, we consider the CPU times for Lasso, RLARS, sLTS and our method. The data were generated from the simulation model in Section 5.1. The sample size and the number of explanatory variables were set to be and , respectively. In Lasso, RLARS and sLTS, all parameters were used by default (see Section 5.3). Our method used the estimate of the RANSAC algorithm as an initial point. The number of candidates for the RANSAC algorithm was set to 1000. The parameters and were set to and , respectively. No method used parallel computing methods. Figure 1 shows the average CPU times over 10 runs in seconds. All results were obtained in R Version 3.3.0 with an Intel Core i7-4790K machine. sLTS shows very high computational cost. RLARS is faster, but does not give a good estimate, as seen in Section 5.5. Our proposed method is fast enough even for .
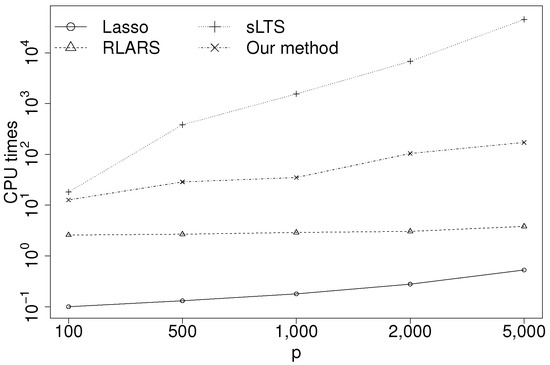
Figure 1.
CPU times (in seconds).
6. Real Data Analyses
In this section, we use two real datasets to compare our method with comparative methods in real data analysis. We show the best result of comparative methods among some parameter situations (e.g., Section 5.3).
6.1. NCI-60 Cancer Cell Panel
We applied our method and comparative methods to regress protein expression on gene expression data at the cancer cell panel of the National Cancer Institute. Experimental conditions were set in the same way as in Alfons et al. [4] as follows. The gene expression data were obtained with an Affymetrix HG-U133A chip and the normalized GCRMAmethod, resulting in a set of p = 22,283 explanatory variables. The protein expressions based on 162 antibodies were acquired via reverse-phase protein lysate arrays and transformed. One observation had to be removed since all values were missing in the gene expression data, reducing the number of observations to . Then, the KRT18 antibody was selected as the response variable because it had the largest MAD among 162 antibodies, i.e., KRT18 may include a large number of outliers. Both the protein expressions and the gene expression data can be downloaded via the web application CellMiner (http://discover.nci.nih.gov/cellminer/). As a measure of prediction performance, the root trimmed mean squared prediction error (RTMSPE) was computed via leave-one-out cross-validation given by:
where and are the order statistics of and . The choice of h is important because it is preferable for estimating prediction performance that trimmed squares does not include outliers. We set h in the same way as in Alfons et al. [4], because the sLTS detected 13 outliers in Alfons et al. [4]. In this experiment, we used the estimate of the RANSAC algorithm as an initial point instead of sLTS because sLTS required high computational cost with such high dimensional data.
Table 6 shows that our method outperformed other comparative methods for the RTMSPE with high dimensional data. Our method presented the smallest RTMSPE with the second smallest number of explanatory variables. RLARS presented the smallest number of explanatory variables, but a much larger RTMSPE than our method.
Table 6.
Root trimmed mean squared prediction error (RTMSPE) for protein expressions based on the KRT18 antibody (NCI-60 cancer cell panel data), computed from leave-one-out cross-validation.
6.2. Protein Homology Dataset
We applied our method and comparative methods to the protein sequence dataset used for KDD-Cup 2004. Experimental conditions were set in the same way as in Khan et al. [2] as follows. The whole dataset consists of 145,751 protein sequences, which has 153 blocks corresponding to native protein. Each data point in a particular block is a candidate homologous protein. There were 75 variables in the dataset: the block number (categorical) and 74 measurements of protein features. The first protein feature was used as the response variable. Then, five blocks with a total of protein sequences were selected because they contained the highest proportions of homologous proteins (and hence, the highest proportions of potential outliers). The data of each block were split into two almost equal parts to get a training sample of size and a test sample of size . The number of explanatory variables was , consisting of four block indicators (Variables 1–4) and 73 features. The whole protein, training and test dataset can be downloaded from http://users.ugent.be/~svaelst/software/RLARS.html. As a measure of prediction performance, the root trimmed mean squared prediction error (RTMSPE) was computed for the test sample given by:
where and are the order statistics of and . In this experiment, we used the estimate of sLTS as an initial point.
Table 7 shows that our method outperformed other comparative methods for the RTMSPE. Our method presented the smallest RTMSPE with the largest number of explanatory variables. It might seem that other methods gave a smaller number of explanatory variables than necessary.
Table 7.
Root trimmed mean squared prediction error in the protein test set.
7. Conclusions
We proposed robust and sparse regression based on the -divergence. We showed desirable robust properties under both homogeneous and heterogeneous contamination. In particular, we presented the Pythagorean relation for the regression case, although it was not shown in Kanamori and Fujisawa [11]. In most of the robust and sparse regression methods, it is difficult to obtain the efficient estimation algorithm, because the objective function is non-convex and non-differentiable. Nonetheless, we succeeded to propose the efficient estimation algorithm, which has a monotone decreasing property of the objective function by using the MM-algorithm. The numerical experiments and real data analyses suggested that our method was superior to comparative robust and sparse linear regression methods in terms of both accuracy and computational costs. However, in numerical experiments, a few results of performance measure “TNR” were a little less than the best results. Therefore, if more sparsity of coefficients is needed, other sparse penalties, e.g., the Smoothly Clipped Absolute Deviations (SCAD) [22] and the Minimax Concave Penalty (MCP) [23], can also be useful.
Acknowledgments
This work was supported by a Grant-in-Aid for Scientific Research of the Japan Society for the Promotion of Science.
Author Contributions
Takayuki Kawashima and Hironori Fujisawa contributed the theoretical analysis; Takayuki Kawashima performed the experiments; Takayuki Kawashima and Hironori Fujisawa wrote the paper. All authors have read and approved the final manuscript.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
Proof of Theorem 1.
For two non-negative functions and and probability density function , it follows from Hölder’s inequality that:
where and are positive constants and . The equality holds if and only if for a positive constant . Let , , and . Then, it holds that:
The equality holds if and only if , i.e., because and are conditional probability density functions. Properties (i), (ii) follow from this inequality, the equality condition and the definition of .
Let us prove Property (iii). Suppose that is sufficiently small. Then, it holds that . The -divergence for regression is expressed by:
☐
Proof of Theorem 2.
We see that:
It follows from the assumption that:
Hence,
Therefore, it holds that:
Then, it follows that:
☐
Proof of Theorem 3.
We see that:
It follows from the assumption that:
Hence,
Therefore, it holds that:
Then, it follows that:
☐
References
- Tibshirani, R. Regression shrinkage and selection via the lasso. J. R. Stat. Soc. Ser. B 1996, 58, 267–288. [Google Scholar]
- Khan, J.A.; Van Aelst, S.; Zamar, R.H. Robust linear model selection based on least angle regression. J. Am. Stat. Assoc. 2007, 102, 1289–1299. [Google Scholar] [CrossRef]
- Efron, B.; Hastie, T.; Johnstone, I.; Tibshirani, R. Least angle regression. Ann. Stat. 2004, 32, 407–499. [Google Scholar]
- Alfons, A.; Croux, C.; Gelper, S. Sparse least trimmed squares regression for analyzing high-dimensional large data sets. Ann. Appl. Stat. 2013, 7, 226–248. [Google Scholar] [CrossRef]
- Rousseeuw, P.J. Least Median of Squares Regression. J. Am. Stat. Assoc. 1984, 79, 871–880. [Google Scholar] [CrossRef]
- Windham, M.P. Robustifying model fitting. J. R. Stat. Soc. Ser. B 1995, 57, 599–609. [Google Scholar]
- Basu, A.; Harris, I.R.; Hjort, N.L.; Jones, M.C. Robust and efficient estimation by minimising a density power divergence. Biometrika 1998, 85, 549–559. [Google Scholar] [CrossRef]
- Jones, M.C.; Hjort, N.L.; Harris, I.R.; Basu, A. A Comparison of related density-based minimum divergence estimators. Biometrika 2001, 88, 865–873. [Google Scholar] [CrossRef]
- Fujisawa, H.; Eguchi, S. Robust Parameter Estimation with a Small Bias Against Heavy Contamination. J. Multivar. Anal. 2008, 99, 2053–2081. [Google Scholar] [CrossRef]
- Basu, A.; Shioya, H.; Park, C. Statistical Inference: The Minimum Distance Approach; CRC Press: Boca Raton, FL, USA, 2011. [Google Scholar]
- Kanamori, T.; Fujisawa, H. Robust estimation under heavy contamination using unnormalized models. Biometrika 2015, 102, 559–572. [Google Scholar] [CrossRef]
- Cichocki, A.; Cruces, S.; Amari, S.I. Generalized Alpha-Beta Divergences and Their Application to Robust Nonnegative Matrix Factorization. Entropy 2011, 13, 134–170. [Google Scholar] [CrossRef]
- Samek, W.; Blythe, D.; Müller, K.R.; Kawanabe, M. Robust Spatial Filtering with Beta Divergence. In Advances in Neural Information Processing Systems 26; Burges, C.J.C., Bottou, L., Welling, M., Ghahramani, Z., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2013; pp. 1007–1015. [Google Scholar]
- Hunter, D.R.; Lange, K. A tutorial on MM algorithms. Am. Stat. 2004, 58, 30–37. [Google Scholar] [CrossRef]
- Hirose, K.; Fujisawa, H. Robust sparse Gaussian graphical modeling. J. Multivar. Anal. 2017, 161, 172–190. [Google Scholar] [CrossRef]
- Zou, H.; Hastie, T. Regularization and variable selection via the Elastic Net. J. R. Stat. Soc. Ser. B 2005, 67, 301–320. [Google Scholar] [CrossRef]
- Yuan, M.; Lin, Y. Model selection and estimation in regression with grouped variables. J. R. Stat. Soc. Ser. B 2006, 68, 49–67. [Google Scholar] [CrossRef]
- Tibshirani, R.; Saunders, M.; Rosset, S.; Zhu, J.; Knight, K. Sparsity and smoothness via the fused lasso. J. R. Stat. Soc. Ser. B 2005, 67, 91–108. [Google Scholar] [CrossRef]
- Friedman, J.; Hastie, T.; Höfling, H.; Tibshirani, R. Pathwise coordinate optimization. Ann. Appl. Stat. 2007, 1, 302–332. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference and Prediction; Springer: New York, NY, USA, 2010. [Google Scholar]
- Maronna, R.A.; Martin, D.R.; Yohai, V.J. Robust Statistics: Theory and Methods; John Wiley and Sons: Hoboken, NJ, USA, 2006. [Google Scholar]
- Fan, J.; Li, R. Variable Selection via Nonconcave Penalized Likelihood and its Oracle Properties. J. Am. Stat. Assoc. 2001, 96, 1348–1360. [Google Scholar]
- Zhang, C.H. Nearly unbiased variable selection under minimax concave penalty. Ann. Stat. 2010, 38, 894–942. [Google Scholar] [CrossRef]
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).