Abstract
Text classification is one domain in which the naive Bayesian (NB) learning algorithm performs remarkably well. However, making further improvement in performance using ensemble-building techniques proved to be a challenge because NB is a stable algorithm. This work shows that, while an ensemble of NB classifiers achieves little or no improvement in terms of classification accuracy, an ensemble of fine-tuned NB classifiers can achieve a remarkable improvement in accuracy. We propose a fine-tuning algorithm for text classification that is both more accurate and less stable than the NB algorithm and the fine-tuning NB (FTNB) algorithm. This improvement makes it more suitable than the FTNB algorithm for building ensembles of classifiers using bagging. Our empirical experiments, using 16-benchmark text-classification data sets, show significant improvement for most data sets.
1. Introduction
In text classification, the task is to assign a document to a category of a predefined set of categories. It has many real-world applications, including information retrieval, spam filtering [1], email routing [2], sentiment analysis, and many other automated document processing applications. Text classification is also a challenging classification problem for several reasons [3,4]: A typical text classification data set consists of thousands of features, many of them redundant, which may cause overfitting and may violate the conditional independence assumption of NB. In addition, the data sets are likely to be imbalanced in the sense that the number of positive documents may be much smaller than the number of negative documents.
Building an ensemble of classifiers is a widely-used method to improve the accuracy of machine learning methods. Bagging [5] and boosting [6,7] are probably the most widely used methods for building ensembles of classifiers. They train the constituent classifiers using different samples of the training data. Different samples of training data are used to make sure that the classifiers are diverse because it would be meaningless to combine several classifiers that make the same predictions.
The naive Bayesian learning algorithm performs remarkably well for text classification [8,9,10,11]. However, making further improvement by building an ensemble of several NB classifiers is a challenge because NB is a stable algorithm [12], in the sense that a small change in the training data does not lead to a substantially different classifier. This has the advantage of making it robust to noisy data [13] but, at the same time, limits the improvements that can be achieved from building an ensemble of NB classifiers using bagging or boosting [7]. In [12], it was argued that, due to its stability, little or no improvement can be achieved by building an ensemble of NB classifiers using the AdaBoost algorithm [7].
In [14], a fine-tuning algorithm for NB classifiers (FTNB) was introduced. Although the algorithm significantly improves the classification accuracy of the NB algorithm in many application domains, the algorithm sacrifices the noise tolerance advantage of the NB algorithm [15]. This indicates that FTNB is less stable than NB and may, therefore, be more suitable for building an ensemble of classifiers than the NB algorithm. Moreover, the FTNB algorithm uses a learning rate parameter that can be set to different values to increase the diversity of classifiers.
In this work, we use the fine-tuning method to generate a diverse ensemble of NB classifiers for text classification. We also modify the fine-tuning algorithm to make it less stable and thus produce more diverse classifiers. The modifications also make the algorithm more accurate for text classification. We use Breiman’s bagging method [5] to build the ensembles.
The work is structured as follows: In Section 2, we review the related work on text classification and building ensembles of classifiers. In Section 3, we review the FTNB algorithm and propose some modifications. In Section 4, we present the results we obtained from bagging the NB, the FTNB, and the modified FTNB algorithms. Section 5 is the conclusion.
2. Related Work
This section is divided into two subsections: In the first, we review the related work on ensembles of classifiers in general, and building ensembles of NB classifiers in particular; in the second, we review the FTNB algorithm [14] for fine-tuning NB classifiers.
2.1. Building Ensembles of Classifiers
Building ensembles of classifiers has been an active research area since 1990s [16]. Entire books [16,17,18,19], have been devoted to the subject, which reflects the continuing interest in this field. Building ensembles of classifiers is widely used to enhance the classification accuracy of machine learning algorithms. The basic idea is to build an ensemble of classifiers that collectively gives better classification accuracy than any of the constituent classifiers. However, there are two conditions that must be satisfied for the ensemble to be more accurate than its constituent classifiers [20]: First, the error rate of each individual classifier must be less than 50%; second, the classifiers must be diverse. Diversity is a key and challenging issue [16], because it would be meaningless to combine several classifiers that make the same predictions. Diversity can be achieved in different ways, and perhaps the most widely used method is to build classifiers using different samples of the training data, which is usually done either by bagging [5] or boosting [6].
Bagging draws a random sample of the training set, and uses it to construct a constituent classifier. The sample is of the same size as the training set and, as a result, many of the training instances may occur more than once in a sample. Bagging uses a uniform probability distribution to construct each sample, giving all instances an equal probability of being selected. Boosting, on the other hand, uses a probability distribution in sampling that favors the instances that were misclassified by previous classifiers.
Bagging and Boosting work well with learning algorithms that are not stable [16]. A learning algorithm is unstable if a small change in the training data produces a substantially different classifier. Diversity can also be achieved by using different learning parameters [21], such as the initial weights of connections in artificial neural networks. Other methods achieve diversity by using different features to build classifiers [22].
The NB algorithm is known to be a stable classifier [12]. Though stability makes the NB algorithm robust to noise [13], it also makes it difficult to construct an ensemble of NB classifiers using an ensemble building method that relies on data sample manipulation, such as bagging and boosting. This is actually the case with any stable classifier [16]. The reason behind it is the fact that slightly different data samples do not cause a base learner to generate sufficiently diverse classifiers [16]. In [12], it was shown that little or no improvement can be achieved by building an ensemble of NB classifiers using the AdaBoost algorithm, and it was suggested that a tree structure be built into the NB algorithm. In [23], it was reported that, unlike the case of neural network and decision tree classifiers, bagging NB classifiers did not reduce the classification error for morphological galaxy classification. In an attempt to increase the diversity of NB classifiers, [24] generalizes the random forest (RF) approach [25] to NB. The RF approach for building an ensemble of classifiers uses resampling by bagging and a random set of features to build each classifier. However, [24] reports a slight increase in the accuracy of NB as a result of generalizing RF to NB.In [26], an ensemble of heterogeneous Bayesian network classifiers were proposed, diversity was mainly achieved by building ensembles of Bayesian classifiers of different structures.
2.2. Fine-Tuning the NB Algorithm
The NB algorithm uses Bayes’ conditional probability rule for classifying instances. To classify an instance of the form , Bayes’ rule (Equation (1)) is used to find the class that has the maximum probability given the instance’s attribute values,
where is a vector of all class attribute values. is the probability of class c. is the probability that attributes 1, 2, …, m will take the values , respectively. is the probability that attributes 1, 2, …, m will take the values , given that the instance is of class c.
The algorithm makes the naive assumption that all attribute values are conditionally independent given the class values; therefore,
Additionally, because, given a certain instance, the denominator is the same for all classes, Equation (1) can be simplified as
Clearly, the accuracy of the NB algorithm depends on finding accurate estimates for the probability terms and , which are estimated using the available training data. This could be challenging, especially in domains with limited training data. The FTNB algorithm [14,15] aims to find better estimations for the probability terms used by the NB algorithm. Finding better estimations for the probability terms is particularly important in domains where the training data (labeled data) is limited. The algorithm builds an initial NB classifier and then uses it to determine the misclassified training instances. These misclassified instances are used in the fine-tuning stage to find better estimations of the probability terms responsible for the error. If a training instance, , of the form , is misclassified, it means that the predicted class, , has higher probability than the actual class, , given the instance’s other attribute values. During the fine-tuning stage, the probability terms involved are modified in such a way that decreases the conditional probability of given the instance’s other attribute values (i.e., ), and increases the conditional probability of given the instance’s other attribute values (i.e., . The process continues so long as the classification accuracy continues to improve. Algorithm 1 shows the details of the FTNB algorithm.
The probability terms that need to be decreased are those that are involved in computing , namely and , where is the value of the ith attribute of the instance. On the other hand, the probability terms and , which are involved in computing the , need to be increased.
Increasing and decreasing give little or no improvement in classification accuracy [14], probably because these two terms are estimated using a large number of instances compared to and . Following [14], we do not try to fine-tune these two terms in this work.
Equations (4) and (5) determine the amount to update and , respectively.
| Algorithm 1 FTNB (training_instances) |
| phase 1 |
| Use training_instances to estimate the values of each probability term used by the NB algorithm |
| phase 2 |
| while training classification accuracy improves do |
| for each training instance, , do |
| let be the actual class of |
| let |
| if //misclassified instance |
| compute classification error |
| for each attribute value, , of inst do |
| endfor |
| endif |
| endfor |
| let |
| endwhile |
The update steps and are proportional to the error, which is computed as
where
Equation (7) is used to normalize the probabilities.
The update steps are also proportional to a learning rate, , which is a value between zero and one that is used to decrease the update step. Equation (4), which calculates the update step size for the probability term , is designed so that the update step (the increment) is large for small terms and small for large terms. This explains why the update step is proportional to , where is a constant and is the value of the ith attribute with the maximum probability given . Equation (5), which computes the decrement for , ensures that large probability terms are decreased by a large step value while small terms are decreased by a smaller update step; we used , where is the value of the ith attribute with the minimum probability, given that . is a constant (greater than or equal to one), which is used to control the amount of update for and . Setting to one means these terms gets zero as the update step size. Following [14], we set to two in all our experiments. Algorithm 1 shows the FTNB algorithm in detail.
In [27], a fine-tuning method was proposed to fine-tune Bayesian networks. In [28], differential evolution was used to find better estimations for the probability terms used by NB for text classification. In [29], differential evolution was used to find better estimations for the probability terms used in some distance measures, used in instance-based learning [30], such as the VDM [31] and ISCDM [32].
3. Bagging NB and the Fine-Tuning Algorithms
In this section, we present the results we obtained by bagging the NB and the FTNB algorithms for text classification. Then, we propose some modifications to the FTNB algorithm to make it less stable and more accurate for text classification, and thus more suitable for bagging.
3.1. Bagging the NB and FTNB Algorithms for Text Classification
We conducted several experiments to verify our assumptions and claims, which were: (1) Bagging the NB for text classification does not produce significant improvement, whereas (2) bagging a set of fine-tuned NB classifiers achieves better results. In all experiments, we used 16-benchmark text-classification data sets obtained from the Weka [33] website. Table 1 gives a brief description of the used data sets. All ordinal attributes were discretized using Fayyad et al. [34] supervised discretization method, as implemented in Weka [33]. All of our algorithms were implemented within the Weka framework. Ten-fold cross validation was used in all our experiments. A paired t-test with a confidence level of 95% was used to determine if each difference was statistically significant.

Table 1.
A description of the data sets used in the experiments.
Our results showed that bagging the NB did not really improve the classification accuracy for text classification. Figure 1 summarizes our results as box plots. One box plot shows the results we obtained from bagging an ensemble of 10 NB classifiers, denoted in the figure as ENB. The figure also shows a box plot representing the results we obtained using NB classifiers (trained using all training instances). The figure shows that NB and ENB achieved comparable results. The two methods had very close minimum and maximum values, first quartiles, medians, and third quartiles. They also had close outliers, denoted in the figure using Xs. In fact, the ENB achieved slightly lower average classification accuracy than NB. It achieved an average classification accuracy of 81.96%, whereas NB achieved an 81.98% average accuracy. Moreover, the ensemble achieved significantly better results for one data set and significantly worse results for three data sets. The results show that bagging the NB does not really improve the classification accuracy for text classification.
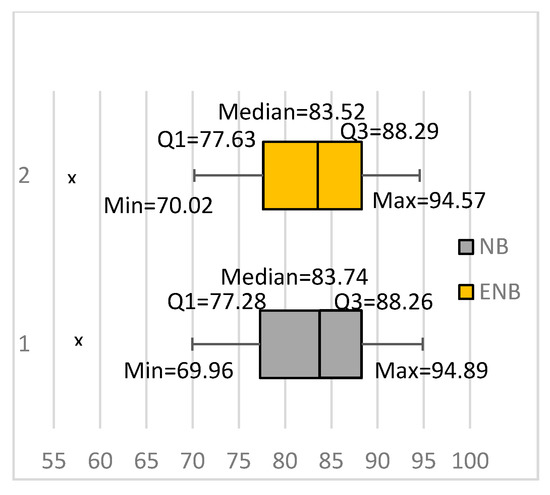
Figure 1.
Building ensembles using the naive Bayesian (NB) learning algorithm for text classification. ENB: Ensemble of NB classifiers.
In a similar way we conducted, a set of experiments to compare FTNB classifiers with an ensemble of 10 FTNB classifiers, built using bagging [5]. To ensure more diversity, we also used a random learning rate in the range 0–0.0099 to fine-tune each classifier. The results showed that the ensemble actually achieved better results than both the NB and FTNB algorithms, with an average accuracy of 85.26%. More importantly, the ensemble achieved significantly better results than the FTNB classifier for five data sets and worse results for two data sets. Compared with the NB algorithm, the ensemble achieved significantly better results for eight data sets and significantly worse results for four data sets. Figure 2 summarizes our results as two box plots denoted by EFTNB, for the ensemble of FTNB classifiers, and FTNB for the fine-tuned classifiers. The box plots show that the ensembles had higher values for the minimum, maximum, first quartiles, and third quartiles. The only exception was the median, where FTNB had a higher median than EFTNB. These results support our suspicion that the fine-tuning algorithm would produce diverse classifiers, which makes bagging them as an ensemble of classifiers worthwhile. Without being sufficiently diverse an ensemble of bagged classifiers cannot outperform a base classifier trained using all training instances.
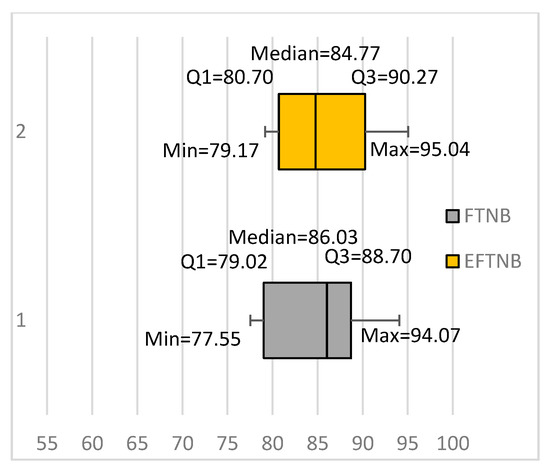
Figure 2.
Building ensembles using the fine-tuning NB (FTNB) algorithm classifiers for text classification. EFTNB: Ensemble of FTNB classifiers.
Our results also showed a substantial increase in the average classification accuracy of the FTNB algorithm compared to the NB algorithm. The average classification accuracy of the FTNB and NB algorithms were 85.14% and 81.98%, respectively. Furthermore, comparing the box plots for NB (Figure 1) and FTNB (Figure 2) showed that the FTNB had higher values for the minimum value, first quartile, median, and third quartile. The only exception was the maximum value, where FTNB had a slightly lower maximum value. Comparing the first quartiles of the two algorithms showed that 75% of the data sets had accuracies above 77.28% and 79.02% using NB and FTNB, respectively.
However, the FTNB algorithm achieved significantly better results than NB for seven data sets and significantly worse results for five data sets. This indicated that the FTNB algorithm was not well suited for the text classification problem. The average number of the fine-tuning iterations performed by the FTNB was 3.93 iterations. This number was relatively small, which indicated that, for the FTNB algorithm to achieve better results for text classification, the fine-tuning process should be more delicate and the update steps should be smaller. This finding was despite the fact that we used a learning rate of 0.001 in our experiments, which was much smaller, and gave better results, than the learning rate of 0.01 recommended in [14]. The parameter was set to two, as recommended by [14].
To further improve the results of the fine-tuned classifiers and the ensemble of classifiers, we believe that we need to make the fine-tuning process more gradual (or more delicate) and we need to increase the diversity of the produced classifiers. In the next section, we propose some modifications to the fine-tuning algorithm that makes it more gradual and less stable. By making it less stable, we aim to produce classifiers that are more diverse and thus more suitable for building ensembles of.
3.2. A More Gradual Fine-Tuning Algorithm (GFTNB)
As previously discussed, building an ensemble of classifiers is beneficial if the machine-learning algorithm used is unstable enough to produce diverse classifiers. For this reason, we introduce two modifications to the FTNB algorithm that makes it even less stable and thus more likely to produce diverse classifiers. Moreover, the modifications we propose make the weight update process more gradual by making the fine-tuning steps smaller.
3.2.1. Modifying the Update Equations
We modify the probability update Equations (4) and (5) by replacing each of them with Equation (8).
where t is the iteration number. Equation (8) is different from Equation (4) in two ways. First, it does not use the expression because this expression actually condenses the size of the update step and consequently makes the value of the probability terms, in the different classifiers, closer to each other. However, eliminating such subexpression increases the size of the update step, which is good for increasing diversity, but it could decrease the classification accuracy of each constituent classifier. To compensate for this, we use a decaying learning rate by dividing by the iteration number, t, which reduces the size of the update step in later iterations. Replacing Equation (5) with (8) aims to achieve the same result for .
Therefore, the modification ensures that we use relatively large update steps at early fine-tuning iterations, and that these steps get smaller at later iterations. This helps to diversify the classifiers by setting them on different paths. At later iterations, the fine-tuning steps become smaller and smaller, which makes the fine-tuning process more gradual.
Table 2 shows the results we obtained by the modified algorithm for the 16-benchmark text-classification data sets compared to the FTNB and NB algorithms. We call the new algorithm the Gradual FTNB (GFTNB) algorithm. We used the 16-benchmark text-classification data sets to compare the classification accuracy of the GFTNB algorithm with the FTNB and NB algorithms. The table shows the results of bagging an ensemble of 10 GFTNB classifiers (EGFTNB) compared with a single GFTNB classifier. Each figure in Table 2 is the average of the 10-fold experiments, as 10-fold cross validation was used in all experiments. The better results are highlighted in bold, and the significantly better results are highlighted in bold and underlined. The last two rows in the table present the number of data sets for which the methods achieved better accuracy and significantly better accuracy.
Table 2.
The results ofGFTNB and EGFTNB vs. NB and FTNB.
Our results showed that the GFTNB algorithm outperformed the FTNB algorithm in terms of the average classification accuracy for the 16 text-classification data sets, and in terms of the number of data sets for which it achieved better and significantly better average accuracy. The average accuracy of the GFTNB algorithm was 86.92%, whereas the average accuracy of the FTNB algorithm was 85.14%. The GFTNB algorithm achieved better results than the FTNB algorithm for 14 data sets; seven of them were significantly better results. On the other hand, the FTNB algorithm achieved better results for one data set but that result was not significantly better. The results were also statistically significant according to the Wilcoxon signed rank test at 95% confidence.
However, in terms of the fine-tuning iterations, the GFTNB algorithm required more fine-tuning iterations for most data sets. The average number of fine-tuning iterations for the GFTNB and FTNB algorithms were 5.23 and 3.93, respectively, which indicated that the GFTNB algorithm was actually a more gradual fine-tuning algorithm than the FTNB.
Compared with the NB algorithm, the GFTNB algorithm achieved better results for 12 data sets; 10 of which were significantly better results, whereas NB achieved better results for three data sets, only one of which was a significantly better result. The average accuracy of the NB algorithm for all data sets was 81.98%, which was lower by 4.94% than the average accuracy of the GFTNB algorithm.
Figure 3 summarizes our results using a box plot for each of the three algorithms: NB, FTNB, and GFTNB. It can be easily seen that the GFTNB algorithm had a higher minimum value, first quartile, median, and third quartile than the NB and FTNB algorithms. The NB algorithm had a slightly higher maximum value than the two fine-tuning algorithms. Comparing the medians of NB, FTNB, and GFTNB, showed that 50% of that data had an average accuracy above 83.74%, 86.03%, and 88.05%, respectively. Similarly, comparing the third quartiles showed that 25% of the data sets had a classification accuracy above 88.26%, 88.70%, 90.25%, using NB, FTNB, and GFTNB, respectively. All these results indicated that the proposed GFTNB outperformed FTNB and NB for text classification.
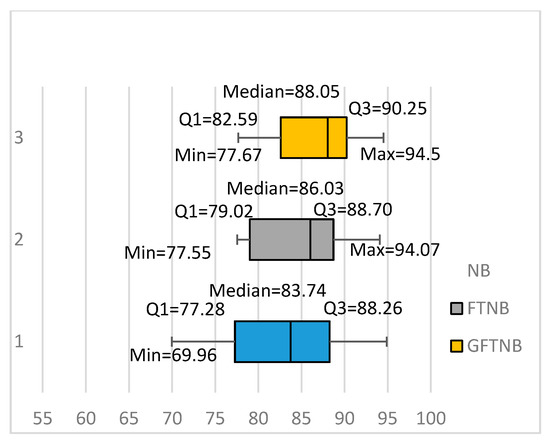
Figure 3.
Comparing the FTNB, GFTNB, and NB algorithms.
Table 2 also shows the result of an ensemble of 10 GFTNB (EGFTNB) classifiers compared with the GFTNB and NB classifiers. We constructed EGFTNB in the same way we constructed EFTNB. The ensemble was even more accurate than a single GFTNB classifier, trained using all training instances, for 13 data sets, 11 of which were significantly better results, and less accurate for three data sets, but none of which were significantly worse results. The average accuracy of the ensemble was 88.67%, which was higher by 1.75% than the average accuracy of GFTNB. Recall that EFTNB (an ensemble of 10 FTNB classifiers) achieved better results than FTNB for 10 data sets, only five of which were significantly better results. Moreover, EFTNB achieved worse results than FTNB for six data sets, two of which were significantly worse results. Comparing the box plots of EGFTNB and GFTNB (see Figure 4), showed that the ensemble had a higher minimum value, first quartile, median, third quartile, and maximum value, by more than 2% than the corresponding values of GFTNB. Comparing EGFTNB with NB showed that the EGFTNB outperformed NB for 15 data sets, of which 12 were significantly better results, whereas NB outperformed EGFTNB for one data set and that result was statistically significant (see Table 2). We compared the results of EFTNB and EGFTNB using Wilcoxon signed-rank test and found out that EGFTNB was significantly better at 99% confidence.
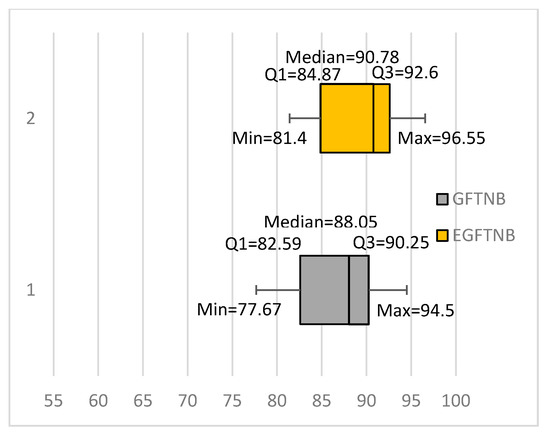
Figure 4.
Comparing GFTNB with an ensemble of 10 GFTNB classifiers.
These results show that the GFTNB algorithm produced more suitable classifiers for bagging than the classifiers produced by FTNB. The fact that an ensemble of GFTNB classifiers produced far better results than a single GFTNB classifier (trained using all training instances) indicates that the GFTNB algorithm produced a more diverse ensemble of classifiers.
It is worth mentioning that we also constructed an ensemble of 20 GFTNB classifiers (EGFTNB-20). EGFTNB-20 achieved an average accuracy of 89.18%, which was an increase of 0.51% compared to the average accuracy of EGFTNB (10 classifiers). However, the number of data sets for which EGFTNB-20 achieved better and significantly better results than the NB classifier remained the same as those of the EGFTNB. Fine-tuning EGFTNB-20 required an average of 97.36 fine-tuning iterations, whereas EGFTNB-10 required an average of 49.29 iterations.
3.2.2. Modifying the Termination Condition
To further increase the diversity among the constituent classifiers, we modified the fine-tuning termination condition. Each constituent classifier was fine-tuned for a random number of iterations, between 5 and 15, and the probability values that gave the best training accuracy were taken as the result of the fine-tuning process.
We constructed two ensembles of 10 classifiers and 20 classifiers. We called them GFTNB-10 and GFTNB-20, respectively. The latest modification increased the average classification accuracy of the ensemble of 10 classifiers from 88.67% (the average accuracy of EGFTNB) to 88.83%, whereas the ensemble of 20 classifiers increased the average to 89.17%. Moreover, the GFTNB-10 outperformed the NB classifier for 15 data sets, 12 of which were statistically significant, whereas the NB classifier outperformed the GFTNB-10 for only one data set, but not in a statistically significant way. The performance of the GFTNB-20 was even better; it outperformed the NB classifier for 15 data sets, 13 of which were statistically significant, whereas NB outperformed the GFTNB-20 for only one data set, but not in a statistically significant way. This modification increased the number of fine-tuning iterations. The GFTNB-10 required, on average, twice the number of iterations to fine-tune than the EGFTNB. Obviously, fine-tuning the twenty classifiers in the GFTNB-20 required even more iterations; the GFTNB-20 required, on average, 190.79 iterations. Figure 5 shows the box plots diagrams for GFTNB-10 and GFTNB-20.
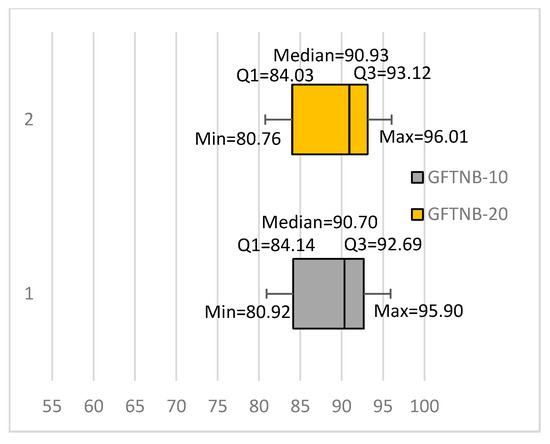
Figure 5.
An ensemble of 10 (GFTNB-10) and 20 classifiers (GFTNB-20) after modifying the termination condition.
Table 3 summarizes the performance of each algorithm compared with the NB algorithm, in terms of the number of the data sets for which the algorithm achieved significantly better results (wins), the number of data sets for which no algorithm achieved significantly better results (ties), and the number of data sets for which the NB algorithm achieved significantly better results (losses). Table 3 also shows the average improvement in accuracy achieved by each algorithm compared to the average of the NB algorithm (i.e., the difference in average).
Table 3.
The performance of each algorithm compared to NB.
4. Conclusions
This work addresses the issue of constructing an ensemble of NB classifiers for text classification using the bagging method [5]. It empirically shows that an ensemble of NB classifiers achieves little or no improvement in classification accuracy. However, an ensemble of fine-tuned NB classifiers achieves significantly more accurate results for many data sets. This study also proposes a more accurate fine-tuning algorithm for text classification, and empirically shows that this algorithm is more suitable for building an ensemble of fine-tuned classifiers than the original fine-tuning algorithm, using the bagging method. This work uses the bagging method for ensemble construction, combined with parameter modification (learning rate and the number of fine-tuning iterations) to increase diversity. Future work may investigate using boosting as a method for constructing an ensemble of fine-tuned NB classifiers for text classification. Fine-tuning other variants of NB for text classification, such as multinomial NB [35], and constructing ensembles of such fine-tuned classifiers might be an interesting future research area.
Author Contributions
K.E.H. proposed the idea and wrote the manuscript. All authors took part in designing the solution. H.A. and S.A.A. implemented the algorithms and compared between them. S.Q. validated the implementation and the analyzed the results. All authors reviewed and proofread the final manuscript.
Funding
This research received no external funding. However, it was internally funded by the Deanship of Scientific Research at King Saud University through research group No (RG-1439-35).
Acknowledgments
The authors extend their appreciation to the Deanship of Scientific Research at King Saud University for funding this work through research group No (RG-1439-35).
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, and in the decision to publish the results.
References
- Androutsopoulos, I.; Koutsias, J.; Chandrinos, K.V.; Spyropoulos, C.D. An Experimental Comparison of Naive Bayesian and Keyword-Based Anti-Spam Filtering with Personal E-mail Messages. In Proceedings of the 23rd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Athens, Greece, 24–28 July 2000. [Google Scholar]
- Stephan, S.; Sven, S.; Roman, G.A. Message classification in the call center. In Proceedings of the sixth Conference on Applied Natural Language Processing, Seattle, WA, USA, 29 April–4 May 2000. [Google Scholar]
- Eui-Hong, H.; George, K. Centroid-Based Document Classification: Analysis and Experimental Results. In Principles of Data Mining and Knowledge Discovery; Springer: Berlin/Heidelberg, Germany, 2000. [Google Scholar]
- Eui-Hong, H.; George, K.; Vipin, K. Text Categorization Using Weight Adjusted k-Nearest Neighbor Classification. In Advances in Knowledge Discovery and Data Mining; Springer: Berlin/Heidelberg, Germany, 2001. [Google Scholar]
- Leo, B. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef]
- Freund, Y. Boosting a Weak Learning Algorithm by Majority. Inf. Comput. 1995, 121, 256–285. [Google Scholar] [CrossRef]
- Robert, E.S. A brief introduction to Boosting. In Proceedings of the 16th International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 31 July–6 August 1999. [Google Scholar]
- Mitchell, T.M. Machine Learning; McGraw-Hill: Boston, MA, USA, 1997. [Google Scholar]
- Nigam, K.; McCallum, A.; Thrun, S.; Mitchell, T. Learning to classify text from labeled and unlabeled documents. In Proceedings of the Eleventh Annual Conference on Computational Learning Theory, Madisson, WI, USA, 24–26 July 1998. [Google Scholar]
- Jiang, L.X.; Cai, Z.H.; Harry, Z.; Wang, D.H. Naive Bayes text classifiers: A locally weighted learning approach. J. Exp. Theor. Artif. Intell. 2013, 25, 273–286. [Google Scholar] [CrossRef]
- Jiang, L.X.; Wang, D.H.; Cai, Z.H. Discriminatively weighted Naive Bayes and its application in text classification. Int. J. Artif. Intell. Tools 2012, 21, 1250007. [Google Scholar] [CrossRef]
- Kai, M.T.; Zheng, Z.J. A study of AdaBoost with Naive Bayesian classifiers: Weakness and improvement. Comput. Intell. 2003, 19, 186–200. [Google Scholar] [CrossRef]
- Nettleton, D.F.; Orriols-Puig, A.; Fornells, A. A study of the effect of different types of noise on the precision of supervised learning techniques. In Artificial Intelligence Review; Springer Netherlands: Berlin, Germany, 2010; Volume 33, pp. 275–306. [Google Scholar]
- Hindi, E.H. Fine tuning the Naïve Bayesian learning algorithm. AI Commun. 2014, 27, 133–141. [Google Scholar] [CrossRef]
- Hindi, E.H. A noise tolerant fine tuning algorithm for the Naïve Bayesian learning algorithm. J. King Saud Univ. Comput. Inf. Sci. 2014, 26, 237–246. [Google Scholar] [CrossRef]
- Zhou, Z.H. Ensemble Methods Foundations and Algorithms; CRS Press: Boca Raton, FL, USA, 2012. [Google Scholar]
- Rokach, L. Pattern Classification Using Ensemble Methods; World Scientific: Dancers, MA, USA, 2010. [Google Scholar]
- Zhang, C.; Ma, Y.Q. Ensemble Machine Learning: Methods and Applications; Springer: Berlin, Germany, 2012. [Google Scholar]
- Seni, G.; Elder, J.F. Ensemble Methods in Data Mining: Improving Accuracy Through Combining Predictions. Synth. Lect. Data Min. Knowl. Discov. 2010, 2, 1–126. [Google Scholar] [CrossRef]
- Dietterich, T.G. Machine learning research: Four current directions. Artif. Intell. Mag. 1997, 18, 97–135. [Google Scholar]
- Polikar, R. Ensemble based systems in decision making. IEEE Circuits Syst. Mag. 2006, 6, 21–45. [Google Scholar] [CrossRef]
- Ho, T.K. The random subspace method for constructing decision forests. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 832–844. [Google Scholar] [CrossRef]
- Bazell, D.; Aha, D.W. Ensembles of Classifiers for Morphological Galaxy Classification. Astrophys. J. 2001, 548, 219–223. [Google Scholar] [CrossRef]
- Prinzie, A.; Poel, D. Random Multiclass Classification: Generalizing Random Forests to Random MNL and Random NB. Database Expert Syst. Appl. 2007, 4653, 349–358. [Google Scholar] [CrossRef]
- Breiman, L. Random Forrest. Mach. Learn. 2001, 45, 1–33. [Google Scholar] [CrossRef]
- Alhussan, A.; Hindi, K.E. An Ensemble of Fine-Tuned Heterogeneous Bayesian Classifiers. Int. J. Adv. Comput. Sci. Appl. 2016, 7, 439–448. [Google Scholar] [CrossRef]
- Alhussan, A.; Hindi, K.E. Selectively Fine-Tuning Bayesian Network Learning Algorithm. Int. J. Pattern Recognit. Artif. Intell. 2016, 30, 1651005. [Google Scholar] [CrossRef]
- Diab, D.M.; Hindi, K.E. Using differential evolution for fine tuning naïve Bayesian classifiers and its application for text classification. Appl. Soft Comput. J. 2017, 54, 183–199. [Google Scholar] [CrossRef]
- Diab, D.M.; Hindi, K.E. Using differential evolution for improving distance measures of nominal values. Appl. Soft Comput. J. 2018, 64, 14–34. [Google Scholar] [CrossRef]
- Aha, D.W.; Kibler, D.; Albert, M.K. Instance-based learning algorithms. Mach. Learn. 1991, 6, 37–66. [Google Scholar] [CrossRef]
- Stanfill, C.; Waltz, D. Toward memory-based reasoning. Commun. ACM 1986, 29, 1213–1228. [Google Scholar] [CrossRef]
- Hindi, K.E. Specific-class distance measures for nominal attributes. AI Commun. 2013, 26, 261–279. [Google Scholar] [CrossRef]
- Witten, I.H.; Frank, E.; Hall, M.A.; Pal, C.J. Data Mining: Practical Machine Learning Tools and Techniques; Elsevier: Cambridge, MA, USA, 2011. [Google Scholar]
- Fayyad, U.M.; Irani, K.B. Multi-interval discretization of continuous-valued attribute for classification learning. Proc. Int. Jt. Conf. Uncertain. AI. 1993, 1022–1027. Available online: https://trs.jpl.nasa.gov/handle/2014/35171 (accessed on 31 October 2018).
- McCallum, A.; Nigam, K. A Comparison of Event Models for Naive Bayes Text Classification. In Proceedings of the AAAI-98 Workshop on Learning Text Category, Madison, WI, USA, 26–27 July 1998; pp. 41–48. [Google Scholar]





© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).