1. Introduction
Let
be a finite or countably infinite alphabet, let
be a probability distribution on
, and define
, where
is the indicator function, to be the effective cardinality of
under
. An important quantity associated with
is entropy, which is defined by [
1] as
Here and throughout, we adopt the convention that
.
Many properties of entropy and related quantities are discussed in [
2]. The problem of statistical estimation of entropy has a long history (see the survey paper [
3] or the recent book [
4]). It is well-known that no unbiased estimators of entropy exist, and, for this reason, much energy has been focused on deriving estimators with relatively little bias (see [
5] and the references therein for a discussion of some (but far from all) of these). Perhaps the most commonly used estimator is the plug-in. Its theoretical properties have been studied going back, at least, to [
6], where conditions for consistency and asymptotic normality, in the case of finite alphabets, were derived. It would be almost fifty years before corresponding conditions for the countabe case would appear in the literature. Specifically, consistency, both in terms of almost sure and
convergence, was verified in [
7]. Later, sufficient conditions for asymptotic normality were derived in two steps in [
3,
8].
Despite a simple form and nice theoretical properties, the plug-in suffers from large finite sample bias, which has led to the development of modifications that aim to reduce this bias. Two of the most popular are the Miller–Madow estimator of [
6] and the jackknife estimator of [
9]. Theoretical properties of these have not been studied, as extensively, in the literature. In this paper, we give sufficient conditions for the asymptotic normality of these two estimators. This is important for deriving confidence intervals and hypothesis tests, and it immediately implies consistency (see e.g., [
4]).
We begin by introducing some notation. We say that a distribution is uniform if and only if its effective cardinality and for each either or . We write to denote and we write to denote . Furthermore, we write to denote convergence in law and to denote convergence in probability. If a and b are real number, we write to denote the maximum of a and b. When it is not specified, all limits are assumed to be taken as .
Let
be independent and identically distributed (
) random variables on
under
. Let
be the observed letter counts in the sample, i.e.,
, and let
, where
, be the corresponding relative frequencies. Perhaps the most intuitive estimator of
H is the plug-in, which is given by
When the effective cardinality,
K, is finite, [
10] showed that the bias of
is
One of the simplest and earliest approaches aiming to reduce the bias of
is to estimate the first order term. Specifically, let
be the number of letters observed in the sample and consider an estimator of the form,
This estimator is often attributed to [
6] and is known as the Miller–Madow estimator. Note that, for finite
K,
Since
, where
, decays exponentially fast, it follows that, for finite
K, the bias of
is
Among the many estimators in the literature aimed at reducing bias in entropy estimation, the Miller–Madow estimator is one of the most commonly used. Its popularity is due to its simplicity, its intuitive appeal, and, more importantly, its good performance across a wide range of different distributions including those on countably infinite alphabets. See, for instance, the simulation study in [
5].
The jackknife entropy estimator is another commonly used estimator designed to reduce the bias of the plug-in. It is calculated in three steps:
for each construct , which is a plug-in estimator based on a sub-sample of size obtained by leaving the ith observation out;
obtain for ; and then
compute the jackknife estimator
Equivalently, (
5) can be written as
The jackknife estimator of entropy was first described by [
9]. From (
2), it may be verified that, when
, the bias of
is
Both the Miller–Madow and the jackknife estimators are adjusted versions of the plug-in. When the effective cardinality is finite, i.e.,
, the asymptotic normalities of both can be easily verified. A question of theoretical interest is whether these normalities still hold when the effective cardinality is countably infinite. In this paper, we give sufficient conditions for
and
to have asymptotic normalities on countably infinite alphabets and provide several illustrative examples. The rest of paper is organized as follows. Our main results for both the Miller–Madow and the jackknife estimators are given in
Section 2. A small simulation study is given in
Section 3. This is followed by a brief discussion in
Section 4. Proofs are postponed to
Section 5.
2. Main Results
We begin by recalling a sufficient condition due to [
8] for the asymptotic normality of the plug-in estimator.
Condition 1. The distribution, , satisfiesand there exists an integer-valued function such that, as , - 1.
,
- 2.
, and
- 3.
.
Note that, by Jensen’s inequality (see e.g., [
2]), (
8) implies that
where equality holds, i.e.,
, if and only if
is a uniform distribution. Thus, when (
8) holds, we have
. The following result is given in [
8].
Lemma 1. Let be a distribution, which is not uniform, and setIf satisfies Condition 1, then ,and The following is useful for checking when Condition 1 holds.
Lemma 2. Let and be two distributions and assume that satisfies Condition 1. If there exists a such that, for large enough k,then satisfies Condition 1 as well. In [
8], it is shown that Condition 1 holds for
with
where
is a normalizing constant. It follows from Lemma 2 that any distribution with tails lighter than this satisfies Condition 1 as well.
We are interested in finding conditions under which the result of Lemma 1 can be extended to bias adjusted modifications of
. Let
be any bias-adjusted estimator of the form
where
is an estimate of the bias. Combining Lemma 1 with Slutsky’s theorem immediately gives the following.
Theorem 1. Let be a distribution, which is not uniform, and let and be as in (9). If Condition 1 holds and , then ,and For the Miller–Madow estimator and the jackknife estimator, respectively, the bias correction term,
, in (
10) takes the form
Below, we give sufficient conditions for when
and when
.
2.1. Results for the Miller–Madow Estimator
Condition 2. The distribution, , satisfies that, for sufficiently large k,where and are two sequences such that - 1.
as , and, furthermore,
- (a)
the function is eventually nondecreasing, and
- (b)
there exists an such that
- 2.
Since this condition only requires that , for sufficiently large k, is upper bounded in the appropriate way, we immediately get the following.
Lemma 3. Let and be two distributions and assume that satisfies Condition 2. If there exists a such that, for large enough k,then satisfies Condition 2 as well. We now give our main results for the Miller–Madow Estimator.
Theorem 2. Let be a distribution, which is not uniform, and let and be as in (9). If Condition 2 holds, then ,and In the proof of the theorem, we will show that Condition 2 implies that Condition 1 holds. Condition 2 requires
to decay slightly faster than
by two factors
and
, where
and
satisfy (
12) and (
13) respectively. While (
13) is clear in its implication on
, (
12) is much less so on
. To have a better understanding of (
12), we give an important situation where (
12) holds. Consider the case
. In this case, for any
We now give a more general situation, which shows just how slow
can be. First, we recall the iterated logarithm function. Define
, recursively for sufficiently large
, by
and
for
. By induction, it can be shown that
for
.
Lemma 4. The function satisfies (12) with for any . We now give three examples.
Example 1. Let be such that for sufficiently large k,where and are fixed constants. In this case, Condition 2 holds with and in (11). We can consider a more general form, which allows for even heavier tails.
Example 2. Let r be an integer with and let be such that, for sufficiently large k,where and are fixed constants. In this case, Condition 2 holds with and in (11). The fact that satisfies (13) follows by the integral test for convergence. It follows from Lemma 3 that any distribution with tails lighter than those in this example must satisfy Condition 2. On the other hand, the tails cannot get too much heavier.
Example 3. Let be such that , where is a normalizing constant. In this case, Condition 2 does not hold. However, Condition 1 does hold.
2.2. Results for the Jackknife Estimator
For any distribution , let be the bias of the plug-in based on a sample of size n.
Condition 3. The distribution, , satisfies Theorem 3. Let be a distribution, which is not uniform, and let and be as in (9). If Conditions 1 and 3 hold, then ,and It is not clear to us whether Conditions 1 and 3 are equivalent or, if not, which is more stringent. For that reason, in the statement of Theorem 3, both conditions are imposed. The proof of the theorem uses the following lemma, which gives some insight into and Condition 3.
Lemma 5. For any probability distribution , we haveand We now give a condition, which implies Condition 3 and tends to be easier to check.
Proposition 1. If the distribution is such that there exists an with , then Condition 3 is satisfied.
We now give an example where this holds.
Example 4. Let where is fixed and is a normalizing constant. In this case, the assumption of Proposition 1 holds and thus Condition 3 is satisfied.
To see that the assumption of Proposition 1 holds in this case, fix
. Note that
, and thus
3. Simulations
The main application of the asymptotic normality results given in this paper is the construction of asymptotic confidence intervals and hypothesis tests. For instance, if
satisfies the assumptions of Theorem 2, then an asymptotic
confidence interval for
H is given by
where
is a number such that
and
Z is a standard normal random variable. Similarly, if the assumptions of Theorem 3 are satisfied, then we can replace
with
, and if the assumptions of Lemma 1 are satisfied, then we can replace
with
. In this section, we give a small-scale simulation study to evaluate the finite sample performance of these confidence intervals.
For concreteness, we focus on the geometric distribution, which corresponds to
where
is a parameter. The true entropy of this distribution is given by
. In this case, Conditions 1, 2, and 3 all hold. For our simulations, we took
. The simulations were performed as follows. We began by simulating a random sample of size
n and used it to evaluated a
confidence interval for the given estimator. We then checked to see if the true value of
H was in the interval or not. This was repeated 5000 times and the proportion of times when the true value was in the interval was calculated. This proportion should be close to
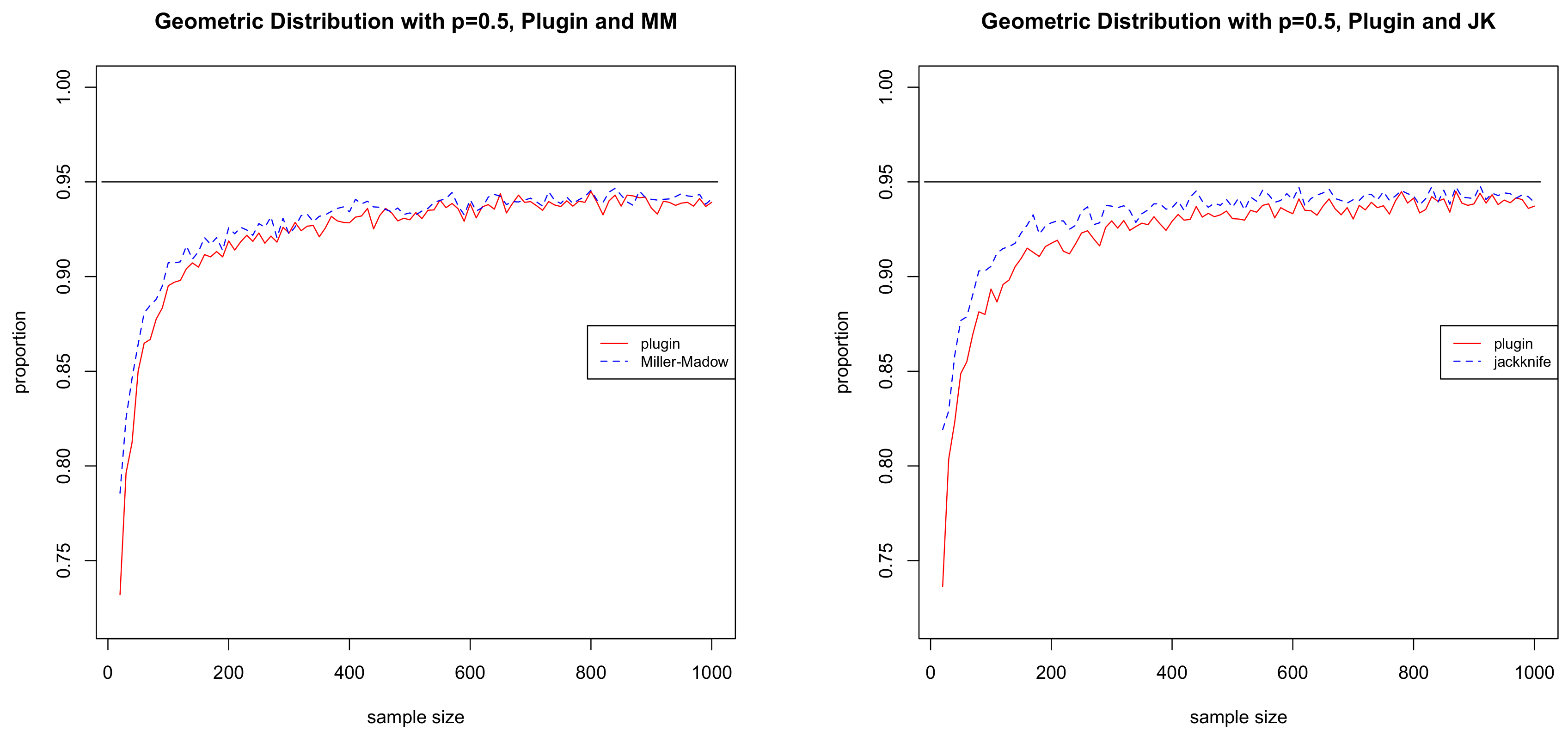
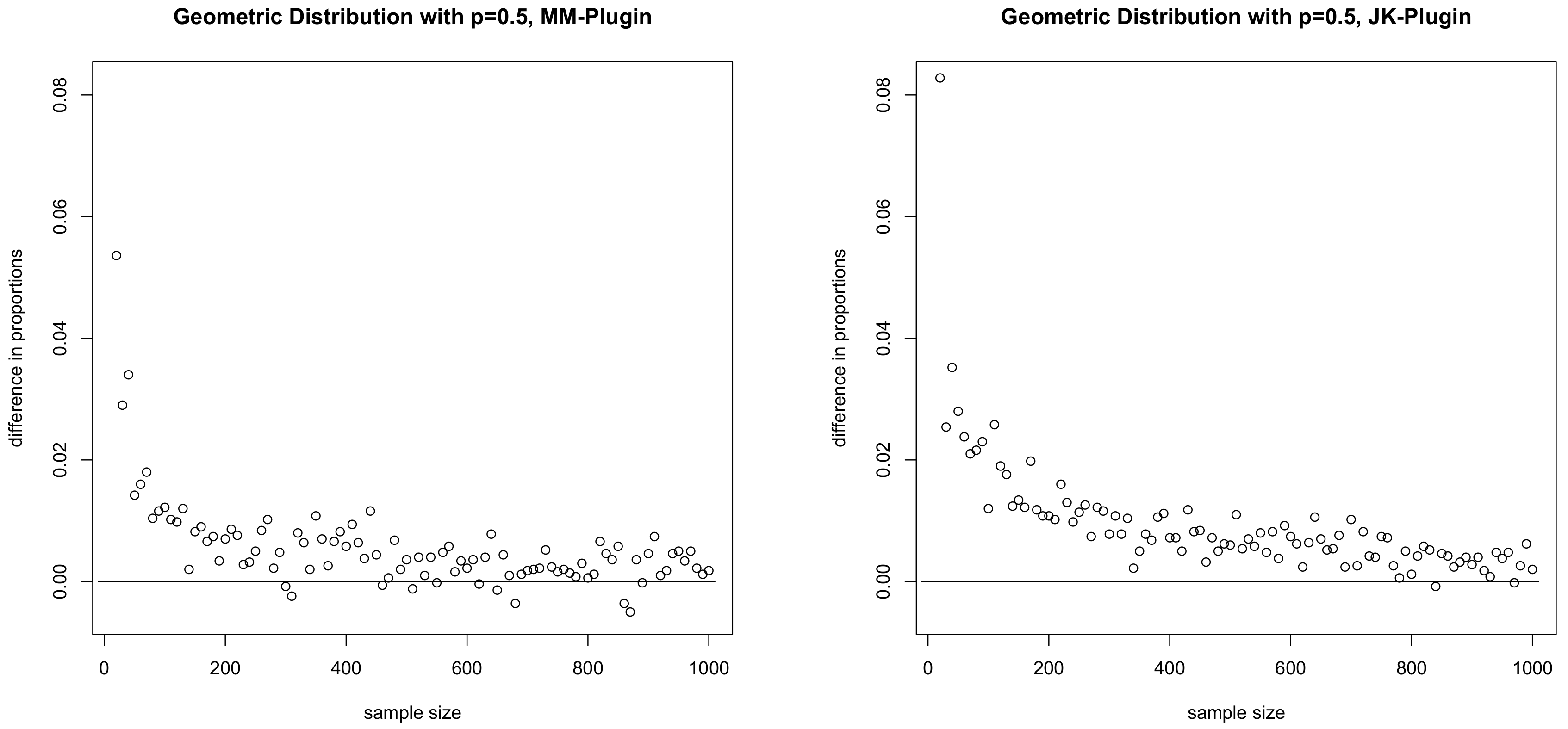
when the confidence interval works well. We repeated this for sample sizes ranging from 20 to 1000 in increments of 10. The results are given in
Figure 1. We can see that the Miller–Madow and jackknife estimators consistently outperform the plug-in. It may be interesting to note that, although the proofs of Theorems 1–3 are based on showing that the bias correction term approaches zero, it does not mean that the bias correction term is not useful. On the contrary, bias correction improves the finite sample performance of the asymptotic confidence intervals.
4. Discussion
In this paper, we gave sufficient conditions for the asymptotic normality of the Miller–Madow and the Jackknife estimators of entropy. While our focus is on the case of countably infinite alphabets, our results are formulated and proved in the case where the effective cardinality
K may be finite or countably infinite. As such, they hold in the case of finite alphabets as well. In fact, for finite alphabets, Conditions 1–3 always hold and we have asymptotic normality so long as the underlying distribution is not uniform. The difficulty with the uniform distribution is that it is the unique distribution for which
, as given by (
9), is zero (see the discussion just below Condition 1). When the distribution is uniform, the asymptotic distribution is chi-squared with
degrees of freedom (see [
6]).
In general, we do not know if our conditions are necessary. However, they cover most distributions of interest. The only distributions, which they preclude, are ones with extremely heavy tails. However, in complete generality, Conditions 1–3 may look complicated, and they are easily checked in many situations. For instance, Condition 2 always holds when, for large enough
k,
for some
, i.e., when
If the alphabet
is the set of natural numbers, then this is equivalent to the distribution
having a finite variance. Similarly, Conditions 1 and 3 both holding is the case when, for large enough
k,
for some
, i.e., when
If the alphabet
is the set of natural numbers, then this is equivalent to the distribution
having a finite mean.


{kind=link}
{kind=link}

