Abstract
In the inference attacks studied in Quantitative Information Flow (QIF), the attacker typically tries to interfere with the system in the attempt to increase its leakage of secret information. The defender, on the other hand, typically tries to decrease leakage by introducing some controlled noise. This noise introduction can be modeled as a type of protocol composition, i.e., a probabilistic choice among different protocols, and its effect on the amount of leakage depends heavily on whether or not this choice is visible to the attacker. In this work, we consider operators for modeling visible and hidden choice in protocol composition, and we study their algebraic properties. We then formalize the interplay between defender and attacker in a game-theoretic framework adapted to the specific issues of QIF, where the payoff is information leakage. We consider various kinds of leakage games, depending on whether players act simultaneously or sequentially, and on whether or not the choices of the defender are visible to the attacker. In the case of sequential games, the choice of the second player is generally a function of the choice of the first player, and his/her probabilistic choice can be either over the possible functions (mixed strategy) or it can be on the result of the function (behavioral strategy). We show that when the attacker moves first in a sequential game with a hidden choice, then behavioral strategies are more advantageous for the defender than mixed strategies. This contrasts with the standard game theory, where the two types of strategies are equivalent. Finally, we establish a hierarchy of these games in terms of their information leakage and provide methods for finding optimal strategies (at the points of equilibrium) for both attacker and defender in the various cases.
1. Introduction
A fundamental problem in computer security is the leakage of sensitive information due to the correlation of secret values with observables, i.e., any information accessible to the attacker, such as, for instance, the system’s outputs or execution time. The typical defense consists of reducing this correlation, which can be done in, essentially, two ways. The first, applicable when the correspondence secret-observable is deterministic, consists of coarsening the equivalence classes of secrets that give rise to the same observables. This can be achieved with post-processing, i.e., sequentially composing the original system with a program that removes information from observables. For example, a typical attack on encrypted web traffic consists of the analysis of the packets’ length, and a typical defense consists of padding extra bits so as to diminish the length variety [1].
The second kind of defense, on which we focus in this work, consists of adding controlled noise to the observables produced by the system. This can be usually seen as a composition of different protocols via probabilistic choice.
Example 1 (Differential privacy).
Consider a counting query f, namely a function that, applied to a dataset x, returns the number of individuals in x that satisfies a given property. A way to implement differential privacy [2] is to add geometrical noise to the result of f, so as to obtain a probability distribution P on integers of the form , where c is a normalization factor. The resulting mechanism can be interpreted as a probabilistic choice on protocols of the form , where the probability assigned to and to decreases exponentially with n.
Example 2 (Dining cryptographers).
Consider two agents running the dining cryptographers protocol [3], which consists of tossing a fair binary coin and then declaring the exclusive or ⊕ of their secret value x and the result of the coin. The protocol can be thought of as the fair probabilistic choice of two protocols, one consisting simply of declaring x and the other declaring .
Most of the work in the literature of Quantitative Information Flow (QIF) considers passive attacks, in which the attacker only observes the system. Notable exceptions are the works [4,5,6], which consider attackers who interact with and influence the system, possibly in an adaptive way, with the purpose of maximizing the leakage of information.
Example 3 (CRIME attack).
Compression Ratio Info-leak Made Easy (CRIME) [7] is a security exploit against secret web cookies over connections using the HTTPS and SPDY protocols and data compression. The idea is that the attacker can inject some content a into the communication of the secret x from the target site to the server. The server then compresses and encrypts the data, including both a and x, and sends back the result. By observing the length of the result, the attacker can then infer information about x. To mitigate the leakage, one possible defense would consist of transmitting, along with x, also an encryption method f selected randomly from a set F. Again, the resulting protocol can be seen as a composition, using probabilistic choice, of the protocols in the set F.
Example 4 (Timing side-channels).
Consider a password-checker, or any similar system in which the user authenticates himself/herself by entering a secret that is checked by the system. An adversary does not know the real secret, of course, but a timing side-channel could reveal the part (e.g., which bit) of the secret in which the adversary’s input fails. By repeating the process with different inputs, the adversary might be able to fully retrieve the secret. A possible counter measure is to make the side channel noisy, by randomizing the order in which the secret’s bits are checked against the user input. This example is studied in detail in Section 7.
In all examples above, the main use of the probabilistic choice is to obfuscate the relation between secrets and observables, thus reducing their correlation; and hence, the information leakage. To achieve this goal, it is essential that the attacker never comes to know the result of the choice. In the CRIME example, however, if f and a are chosen independently, then (in general) it is still better to choose f probabilistically, even if the attacker will come to know, afterwards, the choice of f. In fact, this is true also for the attacker: his/her best strategies (in general) are to choose a according to some probability distribution. Indeed, suppose that are the defender’s choices and are the attacker’s and that leaks more than , while leaks less than . This is a scenario like the matching pennies in game theory: if one player selects an action deterministically, the other player may exploit this choice and get an advantage. For each player, the optimal strategy is to play probabilistically, using a distribution that maximizes his/her own gain for all possible actions of the attacker. In zero-sum games, in which the gain of one player coincides with the loss of the other, the optimal pair of distributions always exists, and it is called the saddle point. It also coincides with the Nash equilibrium, which is defined as the point at which neither of the two players gets any advantage in changing his/her strategy unilaterally.
Motivated by these examples, this paper investigates the two kinds of choice, visible and hidden (to the attacker), in a game-theoretic setting. Looking at them as language operators, we study their algebraic properties, which will help reason about their behavior in games. We consider zero-sum games, in which the gain (for the attacker) is represented by the leakage. While for the visible choice, it is appropriate to use the “classic” game-theoretic framework, for the hidden choice, we need to adopt the more general framework of the information leakage games proposed in [6]. This happens because, in contrast with standard game theory, in games with hidden choice, the payoff of a mixed strategy is a convex function of the distribution on the defender’s pure actions, rather than simply the expected value of their utilities. We will consider both simultaneous games, in which each player chooses independently, and sequential games, in which one player chooses his/her action first. We aim at comparing all these situations and at identifying the precise advantage of the hidden choice over the visible one.
To measure leakage, we use the well-known information-theoretic model. A central notion in this model is that of entropy, but here, we use its converse, vulnerability, which represents the magnitude of the threat. In order to derive results as general as possible, we adopt the very comprehensive notion of vulnerability as any convex and continuous function, as used in [4] and [8]. This notion has been shown [8] to be, in a precise sense, the most general information measure w.r.t. a set of fundamental information-theoretic axioms. Our results, hence, apply to all information measures that respect such fundamental principles, including the widely-adopted measures of Bayes vulnerability (also known as min-vulnerability, also known as (the converse of) Bayes risk) [9,10], Shannon entropy [11], guessing entropy [12] and g-vulnerability [13].
The main contributions of this paper are:
- We present a general framework for reasoning about information leakage in a game-theoretic setting, extending the notion of information leakage games proposed in [6] to both simultaneous and sequential games, with either a hidden or visible choice.
- We present a rigorous compositional way, using visible and hidden choice operators, for representing attacker’s and defender’s actions in information leakage games. In particular, we study the algebraic properties of visible and hidden choice on channels and compare the two kinds of choice with respect to the capability of reducing leakage, in the presence of an adaptive attacker.
- We provide a taxonomy of the various scenarios (simultaneous and sequential) showing when randomization is necessary, for either attacker or defender, to achieve optimality. Although it is well known in information flow that the defender’s best strategy is usually randomized, only recently has it been shown that when defender and attacker act simultaneously, the attacker’s optimal strategy also requires randomization [6].
- We compare the vulnerability of the leakage games for these various scenarios and establish a hierarchy of leakage games based on the order between the value of the leakage in the Nash equilibrium. Furthermore, we show that when the attacker moves first in a sequential game with hidden choice, the behavioral strategies (where the defender chooses his/her probabilistic distribution after he/she has seen the choice of the attacker) are more advantageous for the defender than the mixed strategies (where the defender chooses the probabilistic distribution over his/her possible functional dependency on the choice of the attacker). This contrast with the standard game theory, where the two types of strategies are equivalent. Another difference is that in our attacker-first sequential games, there may not exist Nash equilibria with deterministic strategies for the defender (although the defender has full visibility of the attacker’s moves).
- We use our framework in a detailed case study of a password-checking protocol. A naive program, which checks the password bit by bit and stops when it finds a mismatch, is clearly very insecure, because it reveals at each attempt (via a timing side-channel) the maximum correct prefix. On the other hand, if we continue checking until the end of the string (time padding), the program becomes very inefficient. We show that, by using probabilistic choice instead, we can obtain a good trade-off between security and efficiency.
Plan of the Paper
The remainder of the paper is organized as follows. In Section 2, we review some basic notions of game theory and quantitative information flow. In Section 3, we introduce our running example. In Section 4, we define the visible and hidden choice operators and demonstrate their algebraic properties. In Section 5, the core of the paper, we examine various scenarios for leakage games. In Section 6, we compare the vulnerability of the various leakage games and establish a hierarchy among those games. In Section 7, we show an application of our framework to a password checker. In Section 8, we discuss related work, and finally, in Section 9, we conclude.
A preliminary version of this paper appeared in [14]. One difference with respect to [14] is that in the present paper, we consider both behavioral and mixed strategies in the sequential games, while in [14], we only considered the latter. We also show that the two kinds of strategies are not equivalent in our context (Example 10: the optimal strategy profile yields a different payoff depending on whether the defender adopts mixed strategies or behavioral ones). In light of this difference, we provide new results that concern behavioral strategies, and in particular:
- Theorem 3, which concerns the defender’s behavioral strategies in the defender-first game with visible choice (Game II),
- the second half of Theorem 6, which deals with the adversary’s behavioral strategies in the attacker-first game with hidden choice (Game VI).
Furthermore, in this paper, we define formally all concepts and provide all the proofs. In particular, we provide a precise formulation of the comparison among games with visible/hidden choices (Propositions 4 and 5, Corollaries 3–5) in Section 6. Finally, in Section 7, we provide a new result, expressed by Theorem 7, regarding the optimal strategies for the defender in the presence of a uniform prior on passwords.
2. Preliminaries
In this section, we review some basic notions from game theory and quantitative information flow. We use the following notation: Given a set , we denote by the set of all probability distributions over . Given , its support is the set of its elements with positive probability. We use to indicate that a value is sampled from a distribution on . A set is convex if for all and . For such a set, a function is convex if for all , and concave if is convex.
2.1. Basic Concepts from Game Theory
2.1.1. Two-Player Games
Two-player games are a model for reasoning about the behavior of two players. In a game, each player has at its disposal a set of actions that he/she can perform, and he/she obtains some gain or loss depending on the actions chosen by both players. Gains and losses are defined using a real-valued payoff function. Each player is assumed to be rational, i.e., his/her choice is driven by the attempt to maximize his/her own expected payoff. We also assume that the set of possible actions and the payoff functions of both players are common knowledge.
In this paper, we only consider finite games, in which the set of actions available to the players is finite, which are also zero-sum games, so the payoff of one player is the loss of the other. Next, we introduce an important distinction between simultaneous and sequential games. In the following, we will call the two players defender and attacker.
2.1.2. Simultaneous Games
In a simultaneous game, each player chooses his/her action without knowing the action chosen by the other. The term “simultaneous” here does not mean that the players’ actions are chosen at the same time, but only that they are chosen independently. Formally, such a game is defined as a tuple (following the convention of security games, we set the first player to be the defender) , where is a nonempty set of defender’s actions, is a nonempty set of attacker’s actions, is the defender’s payoff function and is the attacker’s payoff function.
Each player may choose an action deterministically or probabilistically. A pure strategy of the defender (respectively attacker) is a deterministic choice of an action, i.e., an element (respectively ). A pair is called pure strategy profile, and , represent the defender’s and the attacker’s payoffs, respectively. A mixed strategy of the defender (respectively attacker) is a probabilistic choice of an action, defined as a probability distribution (respectively ). A pair is called mixed strategy profile. The defender’s and the attacker’s expected payoff functions for mixed strategies are defined, respectively, as:
A defender’s mixed strategy is the best response to an attacker’s mixed strategy if . Symmetrically, is the best response to if . A mixed-strategy Nash equilibrium is a profile such that is the best response to and vice versa. This means that in a Nash equilibrium, no unilateral deviation by any single player provides better payoff to that player. If and are point distributions concentrated on some and , respectively, then is a pure-strategy Nash equilibrium and will be denoted by . While not all games have a pure strategy Nash equilibrium, every finite game has a mixed strategy Nash equilibrium.
2.1.3. Sequential Games
In a sequential game, players may take turns in choosing their actions. In this paper, we only consider the case in which each player moves only once, in such a way that one of the players (the leader) chooses his/her action first, and commits to it, before the other player (the follower) makes his/her choice. The follower may have total knowledge of the choice made by the leader, or only partial. We refer to the two scenarios by the terms perfect and imperfect information, respectively. Another distinction is the kind of randomization used by the players, namely whether the follower chooses probabilistically his/her action after he/she knows (partially or totally) the move of the leader, or whether he/she chooses at the beginning of the game a probabilistic distribution on (deterministic) strategies that depend on the (partial or total) knowledge of the move of the leader. In the first case, the strategies are called behavioral, in the second case mixed.
We now give the precise definitions assuming that the leader is the defender. The definitions for the case in which the leader is the attacker are analogous.
A defender-first sequential game with perfect information is a tuple where , , and are defined as in simultaneous games: The choice of an action represents a pure strategy of the defender. As for the attacker, his/her choice depends functionally on the prior choice d of the defender, and for this reason, the pure strategies of the attacker are functions . As for the probabilistic strategies, those of the defender are defined as in simultaneous games: namely, they are distributions . On the other hand, the attacker’s probabilistic strategies can be defined in two different ways: In the behavioral case, an attacker’s probabilistic strategy is a function . Namely, the attacker chooses a distribution on his/her actions after he/she sees the move of the defender. In the mixed case, an attacker’s probabilistic strategy is a probability distribution . Namely, the attacker chooses a priori a distribution on pure strategies. The defender’s and the attacker’s expected payoff functions for mixed strategies are defined, respectively, as:
The case of imperfect information is typically formalized by assuming an indistinguishability (equivalence) relation over the actions chosen by the leader, representing a scenario in which the follower cannot distinguish between the actions belonging to the same equivalence class. The pure strategies of the followers, therefore, are functions from the set of the equivalence classes on the actions of the leader to his/her own actions. Formally, a defender-first sequential game with imperfect information is a tuple where , , and are defined as in simultaneous games, and is a partition of . The expected payoff functions are defined as before, except that now the argument of and is the equivalence class of d. Note that in the case in which all defender’s actions are indistinguishable from each other in the eyes of the attacker (totally imperfect information), we have , and the expected payoff functions coincide with those of the simultaneous games. In contrast, in the games in which all defender’s actions are distinguishable from the viewpoint of the attacker (perfect information), we have .
In the standard game theory, under the assumption of perfect recall (i.e., the players never forget what they have learned), behavioral and mixed strategies are equivalent, in the sense that for any behavioral strategy, there is a mixed strategy that yields the same payoff, and vice versa. This is true for both cases of perfect and imperfect information; see [15], Chapter 11.4. In our leakage games, however, this equivalence does not hold anymore, as will be shown in Section 5 and Section 6.
2.1.4. Zero-Sum Games and the Minimax Theorem
A game is zero-sum if for any and any , the defender’s loss is equivalent to the attacker’s gain, i.e., . For brevity, in zero-sum games, we denote by u the attacker’s payoff function and by U the attacker’s expected payoff (Conventionally in game theory, the payoff u is set to be that of the first player, but we prefer to look at the payoff from the point of view of the attacker to be in line with the definition of payoff as vulnerability.). Consequently, the goal of the defender is to minimize U, and the goal of the attacker is to maximize it.
In simultaneous zero-sum games, the Nash equilibrium corresponds to the solution of the minimax problem (or equivalently, the maximin problem), namely the strategy profile such that . The von Neumann’s minimax theorem, in fact, ensures that such a solution (which always exists) is stable.
Theorem 1 (von Neumann’s minimax theorem).
Let and be compact convex sets, and be a continuous function such that is a convex function in and a concave function in . Then:
A related property is that, under the conditions of Theorem 1, there exists a saddle point s.t., for all and : .
The solution of the minimax problem can be obtained by using convex optimization techniques. In the case is affine in x and in y, we can also use linear optimization.
In the case and contain two elements each, there is a closed form for the solution. Let and , respectively. Let be the payoff of the defender on . Then, the Nash equilibrium is given by:
if these values are in . Note that, since there are only two elements, the strategy is completely specified by its value in and analogously for .
2.2. Quantitative Information Flow
Finally, we briefly review the standard framework of quantitative information flow, which is concerned with measuring the amount of information leakage in a (computational) system.
2.2.1. Secrets and Vulnerability
A secret is some piece of sensitive information the defender wants to protect, such as a user’s password, social security number or current location. The attacker usually only has some partial knowledge about the value of a secret, represented as a probability distribution on secrets called a prior. We denote by the set of possible secrets, and we typically use to denote a prior belonging to the set of probability distributions over .
The vulnerability of a secret is a measure of the payoff that it represents for the attacker. In this paper, we consider a very general notion of vulnerability, following [8], and we define a vulnerability to be any continuous and convex function of type . It has been shown in [8] that these functions coincide with the set of g-vulnerabilities, and are, in a precise sense, the most general information measures w.r.t. a set of fundamental information-theoretic axioms (more precisely, if posterior vulnerability is defined as the expectation of the vulnerability of posterior distributions, the measure respects the fundamental information-theoretic properties of data-processing inequality (i.e., that post-processing can never increase information, but only destroy it) and of non-negativity of leakage (i.e., that by observing the output of a channel, an actor cannot, on average, lose information) if, and only if, vulnerability is convex). This notion, hence, subsumes all information measures that respect such fundamental principles, including the widely-adopted measures of Bayes vulnerability (also known as min-vulnerability, also known as (the converse of) Bayes risk) [9,10], Shannon entropy [11], guessing entropy [12] and g-vulnerability [13].
2.2.2. Channels, Posterior Vulnerability and Leakage
Computational systems can be modeled as information theoretic channels. A channel is a function in which is a set of input values, is a set of output values and represents the conditional probability of the channel producing output when input is provided. Every channel C satisfies for all and , and for all .
A distribution and a channel C with inputs and outputs induce a joint distribution on , producing joint random variables with marginal probabilities and , and conditional probabilities if . For a given y (s.t. ), the conditional probabilities for each form the posterior distribution .
A channel C in which is a set of secret values and is a set of observable values produced by a system can be used to model computations on secrets. Assuming the attacker has prior knowledge about the secret value, knows how a channel C works and can observe the channel’s outputs, the effect of the channel is to update the attacker’s knowledge from to a collection of posteriors , each occurring with probability .
Given a vulnerability , a prior and a channel C, the posterior vulnerability is the vulnerability of the secret after the attacker has observed the output of the channel C. Formally: .
Consider, for instance, the example of the password-checker with a timing side-channel from the Introduction (Example 4, also discussed in detail in Section 7). Here, the set of secrets consists of all possible passwords (say, all strings of n bits), and a natural vulnerability function is Bayes-vulnerability, given by . This function expresses the adversary’s probability of guessing correctly the password in one try; assuming that the passwords are chosen uniformly, i.e., is uniform, any guess would be correct with probability , giving . Now, imagine that the timing side-channel reveals that the adversary’s input failed on the first bit. The adversary now knows the first bit of the password (say 0); hence, the posterior assigns probability zero to all passwords with first bit one and probability to all passwords with first bit zero. This happens for all possible posteriors, giving posterior vulnerability (two-times greater than the prior ).
It is known from the literature [8] that the posterior vulnerability is a convex function of . Namely, for any channel C, any family of distributions and any set of convex coefficients , we have:
The (information) leakage of channel C under prior is a comparison between the vulnerability of the secret before the system was run (called prior vulnerability) and the posterior vulnerability of the secret. Leakage reflects how much the observation of the system’s outputs increases the attacker’s information about the secret. It can be defined either additively () or multiplicatively (). In the password-checker example, the additive leakage is , and the multiplicative leakage is .
3. An Illustrative Example
We introduce an example that will serve as a running example throughout the paper. Although admittedly contrived, this example is simple and yet produces different leakage measures for all different combinations of visible/hidden choice and simultaneous/sequential games, thus providing a way to compare all different scenarios in which we are interested.
Consider that a binary secret must be processed by a program. As usual, a defender wants to protect the secret value, whereas an attacker wants to infer it by observing the system’s output. Assume the defender can choose which among two alternative versions of the program to run. Both programs take the secret value x as high input and a binary low input a whose value is chosen by the attacker. They both return the output in a low variable y (we adopt the usual convention in QIF of referring to secret variables, inputs and outputs in programs as high and to their observable counterparts as low). Program 0 returns the binary product of x and a, whereas Program 1 flips a coin with bias (i.e., a coin that returns heads with probability ) and returns x if the result is heads and the complement of x otherwise. The two programs are represented in Figure 1.

Figure 1.
Alternative programs for the running example.
The combined choices of the defender’s and of the attacker’s determine how the system behaves. Let represent the set of the defender’s choices, i.e., the index of the program to use, and represent the set of the attacker’s choices, i.e., the value of the low input a. We shall refer to the elements of and as actions. For each possible combination of actions and , we can construct a channel modeling how the resulting system behaves. Each channel is a function of type , where is the set of possible high input values for the system and is the set of possible output values from the system. Intuitively, each channel provides the probability that the system (which was fixed by the defender) produces output given that the high input is (and that the low input was fixed by the attacker). The four possible channels are depicted in Table 1.

Table 1.
The four channels for for the running example.
Note that channel does not leak any information about the input x (i.e., it is non-interferent), whereas channels and completely reveal x. Channel is an intermediate case: it leaks some information about x, but not all.
We want to investigate how the defender’s and the attacker’s choices influence the leakage of the system. For that, we can just consider the (simpler) notion of posterior vulnerability, since in order to make the comparison fair, we need to assume that the prior is always the same in the various scenarios, and this implies that the leakage is in a one-to-one correspondence with the posterior vulnerability (this happens for both additive and multiplicative leakage).
For this example, assume we are interested in Bayes vulnerability [9,10], defined as for every . Assume for simplicity that the prior is the uniform prior . In this case, we know from [16] that the posterior Bayes vulnerability of a channel is the sum of the greatest elements of each column, divided by the total number of inputs. Table 2 provides the Bayes vulnerability of each channel considered above.
Table 2.
Bayes vulnerability of each channel for the running example.
Naturally, the attacker aims at maximizing the vulnerability of the system, while the defender tries to minimize it. The resulting vulnerability will depend on various factors, in particular on whether the two players make their choice simultaneously (i.e., without knowing the choice of the opponent) or sequentially. Clearly, if the choice of a player who moves first is known by an opponent who moves second, the opponent will be at an advantage. In the above example, for instance, if the defender knows the choice a of the attacker, the most convenient choice for him/her is to set , and the vulnerability will be at most . The other way around, if the attacker knows the choice d of the defender, the most convenient choice for him/her is to set . The vulnerability in this case will be one.
Things become more complicated when players make choices simultaneously. None of the pure choices of d and a are the best for the corresponding player, because the vulnerability of the system depends also on the (unknown) choice of the other player. Yet, there is a strategy leading to the best possible situation for both players (the Nash equilibrium), but it is mixed (i.e., probabilistic), in that the players randomize their choices according to some precise distribution.
Another factor that affects vulnerability is whether or not the defender’s choice is known to the attacker at the moment in which he/she observes the output of the channel. Obviously, this corresponds to whether or not the attacker knows what channel he/she is observing. Both cases are plausible: naturally, the defender has all the interest in keeping his/her choice (and hence, the channel used) secret, since then, the attack will be less effective (i.e., leakage will be smaller). On the other hand, the attacker may be able to identify the channel used anyway, for instance because the two programs have different running times. We will call these two cases hidden and visible choice, respectively.
It is possible to model players’ strategies, as well as hidden and visible choices, as operations on channels. This means that we can look at the whole system as if it were a single channel, which will turn out to be useful for some proofs of our technical results. The next section is dedicated to the definition of these operators. We will calculate the exact values for our example in Section 5.
4. Choice Operators for Protocol Composition
In this section, we define the operators of visible and hidden choice for protocol composition. These operators are formally defined on the channel matrices of the protocols, and since channels are a particular kind of matrix, we use these matrix operations to define the operations of visible and hidden choice among channels and to prove important properties of these channel operations.
4.1. Matrices and Their Basic Operators
Given two sets and , a matrix is a total function of type . Two matrices and are said to be compatible if . If it is also the case that , we say that the matrices have the same type. The scalar multiplication between a scalar r and a matrix M is defined as usual, and so is the summation of a family of matrices all of a same type.
Given a family of compatible matrices s.t. each has type , their concatenation is the matrix having all columns of every matrix in the family, in such a way that every column is tagged with the matrix from which it came. Formally, , if , and the resulting matrix has type . (We use to denote the disjoint union of the sets , , …, .) When the family has only two elements we may use the binary version ◊ of the concatenation operator. The following depicts the concatenation of two matrices and in tabular form.
4.2. Channels and Their Hidden and Visible Choice Operators
A channel is a stochastic matrix, i.e., all elements are non-negative, and all rows sum up to one. Here, we will define two operators specific for channels. In the following, for any real value , we denote by the value .
4.2.1. Hidden Choice
The first operator models a hidden probabilistic choice among channels. Consider a family of channels of the same type. Let be a probability distribution on the elements of the index set . Consider an input x is fed to one of the channels in , where the channel is randomly picked according to . More precisely, an index is sampled with probability , then the input x is fed to channel , and the output y produced by the channel is then made visible, but not the index i of the channel that was used. Note that we consider hidden choice only among channels of the same type: if the sets of outputs were not identical, the produced output might implicitly reveal which channel was used.
Formally, given a family of channels s.t. each has same type , the hidden choice operator is defined as .
Proposition 1 (Type of hidden choice).
Given a family of channels of type , and a distribution on , the hidden choice is a channel of type .
See Appendix A for the proof.
In the particular case in which the family has only two elements and , the distribution on indexes is completely determined by a real value s.t. and . In this case, we may use the binary version of the hidden choice operator: . The example below depicts the hidden choice between channels and , with probability .
4.2.2. Visible Choice
The second operator models a visible probabilistic choice among channels. Consider a family of compatible channels. Let be a probability distribution on the elements of the index set . Consider an input x is fed to one of the channels in , where the channel is randomly picked according to . More precisely, an index is sampled with probability , then the input x is fed to channel , and the output y produced by the channel is then made visible, along with the index i of the channel that was used. Note that visible choice makes sense only between compatible channels, but it is not required that the output set of each channel be the same.
Formally, given of compatible channels s.t. each has type , and a distribution on , the visible choice operator is defined as .
Proposition 2 (Type of visible choice).
Given a family of compatible channels s.t. each has type and a distribution on , the result of the visible choice is a channel of type .
See Appendix A for the proof.
In the particular case that the family has only two elements and , the distribution on indexes is completely determined by a real value s.t. and . In this case, we may use the binary version of the visible choice operator: . The following depicts the visible choice between channels and , with probability .
4.3. Properties of Hidden and Visible Choice Operators
We now prove algebraic properties of channel operators. These properties will be useful when we model a (more complex) protocol as the composition of smaller channels via hidden or visible choice.
Whereas the properties of hidden choice hold generally with equality, those of visible choice are subtler. For instance, visible choice is not idempotent, since in general (in fact, if C has type , has type ). However, idempotency and other properties involving visible choice hold if we replace the notion of equality with the more relaxed notion of “equivalence” between channels. Intuitively, two channels are equivalent if they have the same input space and yield the same value of vulnerability for every prior and every vulnerability function.
Definition 1 (Equivalence of channels).
Two compatible channels and with domain are equivalent, denoted by , if for every prior and every posterior vulnerability , we have .
Two equivalent channels are indistinguishable from the point of view of information leakage, and in most cases, we can just identify them. Indeed, nowadays, there is a tendency to use abstract channels [8,17], which capture exactly the important behavior with respect to any form of leakage. In this paper, however, we cannot use abstract channels because the hidden choice operator needs a concrete representation in order to be defined unambiguously.
The first properties we prove regard idempotency of operators, which can be used do simplify the representation of some protocols.
Proposition 3 (Idempotency).
Given a family of channels s.t. for all , and a distribution on , then: (a) ; and (b) .
See Appendix A for the proof.
The following properties regard the reorganization of operators, and they will be essential in some technical results in which we invert the order in which hidden and visible choice are applied in a protocol.
Proposition 4 (“Reorganization of operators”).
Given a family of channels indexed by sets and , a distribution on and a distribution on :
- (a)
- , if all ’s have the same type;
- (b)
- , if all ’s are compatible; and
- (c)
- , if, for each i, all ’s have the same type .
See Appendix A for the proof.
Finally, analogous properties of the binary operators are shown in Appendix B.
4.4. Properties of Vulnerability w.r.t. Channel Operators
We now derive some relevant properties of vulnerability w.r.t. our channel operators, which will be later used to obtain the Nash equilibria in information leakage games with different choice operations.
The first result states that posterior vulnerability is convex w.r.t. hidden choice (this result was already presented in [6]) and linear w.r.t. to visible choice.
Theorem 2 (Convexity/linearity of posterior vulnerability w.r.t. choices).
Let be a family of channels and be a distribution on . Then, for every distribution on and every vulnerability :
- 1.
- posterior vulnerability is convex w.r.t. to hidden choice: if all ’s have the same type.
- 2.
- posterior vulnerability is linear w.r.t. to visible choice: if all ’s are compatible.
Proof.
- Let us call the type of each channel in the family . Then:where .
- Let us call the type of each channel in the family . Then:where , and step (*) holds because in the vulnerability of a concatenation of matrices, every column will contribute to the vulnerability in proportion to its weight in the concatenation; hence, it is possible to break the vulnerability of a concatenated matrix as the weighted sum of the vulnerabilities of its sub-matrices.
☐
The next result is concerned with posterior vulnerability under the composition of channels using both operators.
Corollary 1 (Convex-linear payoff function).
Let be a family of channels, all with domain and with the same type, and let , and be any vulnerability. Define as follows: . Then, is convex on and linear on .
Proof.
To see that is convex on , note that:
To see that is linear on , note that:
☐
5. Information Leakage Games
In this section, we present our framework for reasoning about information leakage, extending the notion of information leakage games proposed in [6] from only simultaneous games with hidden choice to both simultaneous and sequential games, with either hidden or visible choice.
In an information leakage game, the defender tries to minimize the leakage of information from the system, while the attacker tries to maximize it. In this basic scenario, their goals are just opposite (zero-sum). Both of them can influence the execution and the observable behavior of the system via a specific set of actions. We assume players to be rational (i.e., they are able to figure out what is the best strategy to maximize their expected payoff) and that the set of actions and the payoff function are common knowledge.
Players choose their own strategy, which in general may be probabilistic (i.e., behavioral or mixed) and choose their action by a random draw according to that strategy. After both players have performed their actions, the system runs and produces some output value, which is visible to the attacker and may leak some information about the secret. The amount of leakage constitutes the attacker’s gain and the defender’s loss.
To quantify the leakage, we model the system as an information-theoretic channel (cf. Section 2.2). We recall that leakage is defined as the difference (additive leakage) or the ratio (multiplicative leakage) between posterior and prior vulnerability. Since we are only interested in comparing the leakage of different channels for a given prior, we will define the payoff just as the posterior vulnerability, as the value of prior vulnerability will be the same for every channel.
5.1. Defining Information Leakage Games
A (information) leakage game consists of:
- (1)
- two nonempty sets , of defender’s and attacker’s actions, respectively,
- (2)
- a function that associates with each pair of actions a channel ,
- (3)
- a prior on secrets and
- (4)
- a vulnerability measure , used to define the payoff function for pure strategies as . We have only one payoff function because the game is zero-sum.
Like in traditional game theory, the order of actions and the extent by which a player knows the move performed by the opponent play a critical role in deciding strategies and determining the payoff. In security, however, knowledge of the opponent’s move affects the game in yet another way: the effectiveness of the attack, i.e., the amount of leakage, depends crucially on whether or not the attacker knows what channel is being used. It is therefore convenient to distinguish two phases in the leakage game:
- Phase 1: determination of players’ strategies and the subsequent choice of their actions.Each player determines the most convenient strategy (which in general is probabilistic) for himself/herself, and draws his/her action accordingly. One of the players may commit first to his/her action, and his/her choice may or may not be revealed to the follower. In general, knowledge of the leader’s action may help the follower choose a more advantageous strategy.
- Phase 2: observation of the resulting channel’s output and payoff computation.The attacker observes the output of the selected channel and performs his/her attack on the secret. In case he/she knows the defender’s action, he/she is able to determine the exact channel being used (since, of course, the attacker knows his/her own action), and his/her payoff will be the posterior vulnerability . However, if the attacker does not know exactly which channel has been used, then his/her payoff will be smaller.
Note that the issues raised in Phase 2 are typical of leakage games; they do not have a correspondence (to the best of our knowledge) in traditional game theory. Indeed, in traditional game theory, the resulting payoff is a deterministic function of all players’ actions. On the other hand, the extra level of randomization provided by the channel is central to security, as it reflects the principle of preventing the attacker from inferring the secret by obfuscating the link between the secret and observables.
Following the above discussion, we consider various possible scenarios for games, along two lines of classification. The first classification concerns Phase 1 of the game, in which strategies are selected and actions are drawn, and consists of three possible orders for the two players’ actions.
- Simultaneous.The players choose (draw) their actions in parallel, each without knowing the choice of the other.
- Sequential, defender-first.The defender draws an action, and commits to it, before the attacker does.
- Sequential, attacker-first.The attacker draws an action, and commits to it, before the defender does.
Note that these sequential games may present imperfect information (i.e., the follower may not know the leader’s action) and that we have to further specify whether we use behavioral or mixed strategies.
The second classification concerns Phase 2 of the game, in which some leakage occurs as a consequence of the attacker’s observation of the channel’s output and consists of two kinds of knowledge the attacker may have at this point about the channel that was used.
- Visible choice.The attacker knows the defender’s action when he/she observes the output of the channel, and therefore, he/she knows which channel is being used. Visible choice is modeled by the operator .
- Hidden choice.The attacker does not know the defender’s action when he/she observes the output of the channel, and therefore, in general, he/she does not exactly know which channel is used (although in some special cases, he/she may infer it from the output). Hidden choice is modeled by the operator ⨊.
Note that the distinction between sequential and simultaneous games is orthogonal to that between visible and hidden choice. Sequential and simultaneous games model whether or not, respectively, the follower’s choice can be affected by knowledge of the leader’s action. This dichotomy captures how knowledge about the other player’s actions can help a player choose his/her own action, and it concerns how Phase 1 of the game occurs. On the other hand, visible and hidden choice capture whether or not, respectively, the attacker is able to fully determine the channel representing the system, once the defender and attacker’s actions have already been fixed. This dichotomy reflects the different amounts of information leaked by the system as viewed by the attacker, and it concerns how Phase 2 of the game occurs. For instance, in a simultaneous game, neither player can choose his/her action based on the choice of the other. However, depending on whether or not the defender’s choice is visible, the attacker will or will not, respectively, be able to completely recover the channel used, which will affect the amount of leakage.
If we consider also the subdivision of sequential games into perfect and imperfect information, there are 10 possible different combinations. Some, however, make little sense. For instance, the defender-first sequential game with perfect information (by the attacker) does not combine naturally with hidden choice ⨊, since that would mean that the attacker knows the action of the defender and chooses his/her strategy accordingly, but forgets it at the moment of computing the channel and its vulnerability (we assume perfect recall, i.e., the players never forget what they have learned). Yet, other combinations are not interesting, such as the attacker-first sequential game with (totally) imperfect information (by the defender), since it coincides with the simultaneous-game case. Note that the attacker and defender are not symmetric with respect to hiding/revealing their actions a and d, since the knowledge of a affects the game only in the usual sense of game theory (in Phase 1), while the knowledge of d also affects the computation of the payoff (in Phase 2). Note that the attacker and defender are not symmetric with respect to hiding/revealing their actions a and d, since the knowledge of a affects the game only in the usual sense of game theory, while the knowledge of d also affects the computation of the payoff (cf. “Phase 2” above). Other possible combinations would come from the distinction between behavioral and mixed strategies, but, as we will see, they are always equivalent except in one scenario, so for the sake of conciseness, we prefer to treat it as a case apart.
Table 3 lists the meaningful and interesting combinations. In Game V, we assume imperfect information: the attacker does not know the action chosen by the defender. In all the other sequential games, we assume that the follower has perfect information. In the remainder of this section, we discuss each game individually, using the example of Section 3 as a running example.
Table 3.
Kinds of games we consider. Sequential games have perfect information, except for Game V.
5.1.1. Game I (Simultaneous with Visible Choice)
This simultaneous game can be represented by a tuple . As in all games with visible choice , the expected payoff of a mixed strategy profile is defined to be the expected value of u, as in traditional game theory:
where we recall that .
From Theorem 2 (2), we derive that , and hence, the whole system can be equivalently regarded as the channel . Still from Theorem 2 (2), we can derive that is linear in and . Therefore the Nash equilibrium can be computed using the standard method (cf. Section 2.1).
Example 5.
Consider the example of Section 3 in the setting of Game I, with a uniform prior. The Nash equilibrium can be obtained using the closed formula from Section 2.1, and it is given by The corresponding payoff is .
5.1.2. Game II (Defender-First with Visible Choice)
This defender-first sequential game can be represented by a tuple . We will first consider mixed strategies for the follower (which in this case is the attacker), namely strategies of type . Hence, a (mixed) strategy profile is of the form , with and , and the corresponding payoff is:
where .
Again, from Theorem 2 (2), we derive: , and hence, the system can be expressed as a channel . From the same theorem, we also derive that is linear in and , so the mutually optimal strategies can be obtained again by solving the minimax problem. In this case, however, the solution is particularly simple, because there are always deterministic optimal strategy profiles. We first consider the case of attacker’s strategies of type .
Theorem 3 (Pure-strategy Nash equilibrium in Game II: strategies of type ).
Consider a defender-first sequential game with visible choice and attacker’s strategies of type . Let , and let be defined as (if there is more than one a that maximizes , we select one of them arbitrarily). Then, for every and , we have .
Proof.
Let and be arbitrary elements of and , respectively. Then:
☐
Hence, to find the optimal strategy, it is sufficient for the defender to find the action that minimizes , while the attacker’s optimal choice is the pure strategy such that , where d is the (visible) move by the defender.
Example 6.
Consider the example of Section 3 in the setting of Game II, with uniform prior. If the defender chooses zero, then the attacker chooses one. If the defender chooses one, then the attacker chooses zero. In both cases, the payoff is one. The game has therefore two solutions, and , with , and , .
Consider now the case of behavioral strategies. Following the same line of reasoning as before, we can see that under the strategy profile , the system can be expressed as the channel:
This is also in this case that there are deterministic optimal strategy profiles. An optimal strategy for the follower (in this case, the attacker) consists of looking at the action d chosen by the leader and then selecting with probability one the action a that maximizes .
Theorem 4 (Pure-strategy Nash equilibrium in Game II: strategies of type ).
Consider a defender-first sequential game with visible choice and attacker’s strategies of type . Let , and let be defined as if (if there is more than one such a, we select one of them arbitrarily), and otherwise. Then, for every and , we have: .
Proof.
Let be the action selected by , i.e., . Then, . Let and be arbitrary elements of and , respectively. Then:
☐
As a consequence of Theorems 3 and 4, we can show that in the games, we consider that the payoff of the optimal mixed and behavioral strategy profiles coincide. Note that this result could also be derived from the result from standard game theory, which states that, in the cases we consider, for any behavioral strategy, there is a mixed strategy that yields the same payoff, and vice versa [15]. However, the proof of [15] relies on Khun’s theorem, which is non-constructive (and rather complicated, because it is for more general cases). In our scenario, the proof is very simple, as we will see in the following corollary. Furthermore, since such a result does not hold for leakage games with hidden choice, we think it will be useful to show the proof formally in order to analyze the difference.
Corollary 2 (Equivalence of optimal strategies of types and in Game II).
Consider a defender-first sequential game with visible choice, and let , and be defined as in Theorems 3 and 4, respectively. Then,
Proof.
The result follows immediately by observing that . ☐
5.1.3. Game III (Attacker-First with Visible Choice)
This game is also a sequential game, but with the attacker as the leader. Therefore, it can be represented as a tuple of the form . It is the same as Game II, except that the roles of the attacker and the defender are inverted. In particular, the payoff of a mixed strategy profile is given by:
and by Theorem 2 (2), the whole system can be equivalently regarded as channel . For a behavioral strategy , the payoff is given by:
and by Theorem 2 (2), the whole system can be equivalently regarded as channel .
Obviously, the same results that we have obtained in the previous section for Game II hold also for Game III, with the role of attacker and defender switched. We collect all these results in the following theorem.
Theorem 5 (Pure-strategy Nash equilibria in Game III and equivalence of and ).
Consider a defender-first sequential game with visible choice. Let . Let be defined as , and let be defined as if . Then:
- 1.
- For every and , we have .
- 2.
- For every and , we have: .
- 3.
- .
Proof.
These results can be proven by following the same lines as the proofs of Theorems 3 and 4 and Corollary 2. ☐
Example 7.
Consider now the example of Section 3 in the setting of Game III, with uniform prior. If the attacker chooses zero, then the defender chooses zero, and the payoff is . If the attacker chooses one, then the defender chooses one, and the payoff is . The latter case is more convenient for the attacker; hence, the solution of the game is the strategy profile with , .
5.1.4. Game IV (Simultaneous with Hidden Choice)
The simultaneous game with hidden choice is a tuple . However, it is not an ordinary game in the sense that the payoff of a mixed strategy profile cannot be defined by averaging the payoff of the corresponding pure strategies. More precisely, the payoff of a mixed profile is defined by averaging on the strategy of the attacker, but not on that of the defender. In fact, when hidden choice is used, there is an additional level of uncertainty in the relation between the observables and the secret from the point of view of the attacker, since he/she is not sure about which channel is producing those observables. A mixed strategy for the defender produces a convex combination of channels (the channels associated with the pure strategies) with the same coefficients, and we know from previous sections that the vulnerability is a convex function of the channel and in general is not linear.
In order to define the payoff of a mixed strategy profile , we need therefore to consider the channel that the attacker perceives given his/her limited knowledge. Let us assume that the action that the attacker draws from is a. He does not know the action of the defender, but we can assume that he/she knows his/her strategy (each player can derive the optimal strategy of the opponent, under the assumption of common knowledge and rational players).
The channel the attacker will see is , obtaining a corresponding payoff of . By averaging on the strategy of the attacker, we obtain:
From Theorem 2 (2), we derive: , and hence, the whole system can be equivalently regarded as channel . Note that, by Proposition 4c, the order of the operators is interchangeable, and the system can be equivalently regarded as . This shows the robustness of this model.
From Corollary 1, we derive that is convex in and linear in ; hence, we can compute the Nash equilibrium by the minimax method.
Example 8.
Consider now the example of Section 3 in the setting of Game IV. For and , let and . The system can be represented by the channel represented below.
For uniform π, we have , while is equal to if and equal to if . Hence the payoff, expressed in terms of p and q, is if and if . The Nash equilibrium can be computed by imposing that the partial derivatives of with respect to p and q are both zero, which means that we are in a saddle point. We have:
We can see that the equations and do not have solutions in for , while for , they have solution . The pair thus constitutes the Nash equilibrium, and the corresponding payoff is .
5.1.5. Game V (Defender-First with Hidden Choice)
This is a defender-first sequential game with imperfect information; hence, it can be represented as a tuple of the form , where is a partition of . Since we are assuming perfect recall, and the attacker does not know anything about the action chosen by the defender in Phase 2, i.e., at the moment of the attack (except the probability distribution determined by his/her strategy), we must assume that the attacker does not know anything in Phase 1 either. Hence, the indistinguishability relation must be total, i.e., . However, is equivalent to ; hence, this kind of game is equivalent to Game IV. It is also a well-known fact in game theory that when in a sequential game the follower does not know the leader’s move before making his/her choice, the game is equivalent to a simultaneous game. (However, one could argue that, since the defender has already committed, the attacker does not need to perform the action corresponding to the Nash equilibrium, and any payoff-maximizing solution would be equally good for him.)
5.1.6. Game VI (Attacker-First with Hidden Choice)
This game is also a sequential game with the attacker as the leader; hence, it is a tuple of the form . It is similar to Game III, except that the payoff is convex on the strategy of the defender, instead of linear. We will see, however, that this causes quite some deviation from the properties of Game III and from standard game theory.
The payoff of the mixed strategy profile is:
so the whole system can be equivalently regarded as channel .
The first important difference from Game III is that in Game VI, there may not exist optimal strategies, either mixed or behavioral, that are deterministic for the defender. On the other hand, for the attacker, there are always deterministic optimal strategies, and this is true independently of whether the defender uses mixed or behavioral strategies.
To show the existence of deterministic optimal strategies for the attacker, let us first introduce some standard notation for functions: given a variable x and an expression M, represents the function that on the argument x gives as a result the value of M. Given two sets X and Y where Y is provided with an ordering ≤, the point-wise ordering on is defined as follows: for , if and only if .
Theorem 6 (Attacker’s pure-strategy Nash equilibrium in Game VI).
Consider an attacker-first sequential game with hidden choice.
- 1.
- Mixed strategies, type . Let , and let . Then, for every and we have:
- 2.
- Behavioral strategies, type . Let , and let (the minimization is with respect to the point-wise ordering). Then, for every and , we have:
Proof.
- Let and be arbitrary elements of and , respectively. Then:
- Let and be arbitrary elements of and , respectively. Then:
☐
We show now, with the following example, that the optimal strategies for the defender are necessarily probabilistic.
Example 9.
Consider the channel matrices defined in Section 3 and define the following new channels: and . Define as the result of the hidden choice, with probability p, between and , i.e., , and observe that and . Furthermore, . The vulnerability of , for uniform π, is for and for ; hence, independently of the choice of the attacker, the best strategy for the defender is to choose . Every other value for p gives a strictly higher vulnerability. Therefore, the best mixed strategy for the defender is defined as . Similarly, the best behavioral strategy for the defender is defined as .
The second important difference from Game III is that in Game VI, behavioral strategies and mixed strategies are not necessarily equivalent. More precisely, there are cases in which the optimal strategy profile yields a different payoff depending on whether the defender adopts mixed strategies or behavioral ones. The following is an example in which this difference manifests itself.
Example 10.
Consider again the example of Section 3, this time in the setting of Game VI, and still with uniform prior π. Let us analyze first the case in which the defender uses behavioral strategies.
- 1.
- Behavioral strategies, type . If the attacker chooses zero, which corresponds to committing to the system , then the defender will choose , which minimizes its vulnerability. If he/she chooses one, which corresponds to committing to the system , then the defender will choose , which minimizes the vulnerability. In both cases, the leakage is ; hence, both of these strategies are solutions to the minimax. Note that in the first case, the strategy of the defender is probabilistic, while that of the attacker is pure in both cases.
- 2.
- Mixed strategies, type . Observe that there are only four possible pure strategies for the defender, corresponding to the four functions for defined as if and if . Consider a distribution , and let . Then, we have and . Observe that the attacker’s choice determines the matrix , with , whose vulnerability is . On the other hand, the attacker’s choice determines the matrix , with , whose vulnerability is for , and for . By geometrical considerations (cf. the red dashed line in Figure 2), we can see that the optimal solutions for the defender are all those strategies, which give and , which yield payoff .
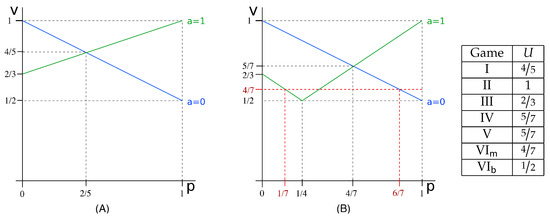 Figure 2. Summary of the results for the running example introduced in Section 3, for a uniform prior. Graph (A) is for the case of visible choice: it represents the Bayes vulnerability of and of (cases and , respectively), as a function of p; Graph (B) is for the case of hidden choice, and it represents the vulnerability of and of as a function of p. The table on the right gives the payoff in correspondence of the Nash equilibrium for the various games. VI and VI represent the attacker-first sequential games with defender strategy of type (mixed) and (behavioral), respectively.
Figure 2. Summary of the results for the running example introduced in Section 3, for a uniform prior. Graph (A) is for the case of visible choice: it represents the Bayes vulnerability of and of (cases and , respectively), as a function of p; Graph (B) is for the case of hidden choice, and it represents the vulnerability of and of as a function of p. The table on the right gives the payoff in correspondence of the Nash equilibrium for the various games. VI and VI represent the attacker-first sequential games with defender strategy of type (mixed) and (behavioral), respectively.
The fact that behavioral and mixed strategies are not equivalent is related to the non-existence of deterministic optimal strategies. In fact, it is easy to see that from a behavioral deterministic strategy, we can construct a (deterministic) mixed strategy, and vice versa.
Figure 2 illustrates the graphs of the vulnerability of the various channel compositions and summarizes the results of this section.
6. Comparing the Leakage Games
In previous section, we have computed the vulnerability for the running example in the various kinds of games introduced in Section 5. The values we have obtained, listed in decreasing order, are as follows: . This order is not accidental: in this section, we will prove that some of these relations between games hold for any vulnerability function, and for any prior. These results will allow us to reason about which kinds of scenarios and compositions are more convenient for the defender or, vice versa, for the attacker.
6.1. Simultaneous Games vs. Sequential Games
The relations between II, I and III and between IV–V and VI are typical in game theory: in any zero-sum sequential game, the leader’s payoff is less than or equal to his/her payoff in the corresponding simultaneous game. In fact, by acting first, the leader commits to an action, and this commitment can be exploited by the attacker to choose the best possible strategy relative to that action. (The fact that the leader has a disadvantage may seem counterintuitive because in many real games, it is the opposite: the player who moves first has an advantage. Such a discrepancy is due to the fact that these games feature preemptive moves, i.e., moves that, when made by one player, make impossible other moves for the other player. The games we are considering in this paper, on the contrary, do not consider preemptive moves.) In the following propositions, we give the precise formulation of these results in our framework, and we show how they can be derived formally.
Proposition 1 (Game II ⩾ Game I).
Proof.
We prove the first inequality as follows. Independently of , consider the attacker’s strategy that assigns probability one to the function defined as for any . Then, we have that:
☐
Note that the strategy is optimal for the attacker, so the first of the above inequalities is actually an equality. It is easy to see that the second inequalities comprise an equality, as well, because of the maximization on . Therefore, the only inequalities that may be strict are comprised by the third one, and the reason why it may be strict is that on the left-hand side, depends on d (and on ), while on the right-hand side, depends on , but not the actual d (that will be sampled from ). This corresponds to the fact that in the defender-first sequential game, the attacker chooses his/her strategy after he/she knows the action d chosen by the defender, while in the simultaneous game, the attacker knows the strategy of the defender (i.e., the distribution he/she will use to choose probabilistically his/her actions), but not the actual action d that the defender will choose.
Analogous considerations can be done for the simultaneous versus the attacker-first case, which we will examine next.
Proposition 2 (Game I ≥ Game III).
Proof.
Independently of , consider the defender’s strategy that assigns probability one to the function defined as for any . Then, we have that:
☐
Again, the strategy is optimal for the attacker, so the last of the above inequalities is actually an equality. Therefore, the only inequality that may be strict is the first one, and the strictness is due to the fact that on the left-hand side, does not depend on a, while on the right-hand side, it does. Intuitively, this corresponds to the intuition that if the defender knows the action of the attacker, then it may be able to choose a better strategy to reduce the leakage.
Proposition 3 (Game IV ⩾ Game VI).
Proof.
Given , let . For any , let be the constant function defined as for any , and define as for any . Let . Then, is convex in and linear in . Hence, we have:
☐
6.2. Visible Choice vs. Hidden Choice
We consider now the case of Games III and IV–V. In the running example, the payoff for III is lower than for IV–V, but it is easy to find other cases in which the situation is reversed. For instance, if in the running example, we set to be the same as , the payoff for III will be 1 (corresponding to the choice for the attacker), and that for IV–V will be (corresponding to the Nash equilibrium . Therefore, we conclude that Games III and IV–V are incomparable: there is no general ordering between them.
The relation between Games I and IV comes from the fact that they are both simultaneous games, and the only difference is the way in which the payoff is defined. The same holds for the case of Games III and VI, which are both attacker-first sequential games. The essence of the proof is expressed by the following proposition.
Proposition 4 (Visible choice ⩾ hidden choice).
For every and every , we have:
Proof.
☐
From the above proposition, we can derive immediately the following corollaries:
Corollary 3 (Game I ⩾ Game IV).
Corollary 4 (Game III ⩾ Game VI).
Finally, we show that the vulnerability for the optimal solution in Game VI is always greater than or equal to that of Game VI, which means that for the defender, it is always convenient to use behavioral strategies. We can state actually a more general result: for any mixed strategy, there is always a behavioral strategy that gives the same payoff.
Proposition 5.
For any and any , there exists such that:
Proof.
For , define as follows: for any and ,
and observe that for every , we have . ☐
From this proposition, we derive immediately the following corollary:
Corollary 5.
The lattice in Figure 3 illustrates the results of this section about the relations between the various games. These relations can be used by the defender as guidelines to better protect the system, if he/she has some control over the rules of the game. Obviously, for the defender, the games lower in the ordering are to be preferred to compose protocols, since they yield a lower vulnerability for the result.
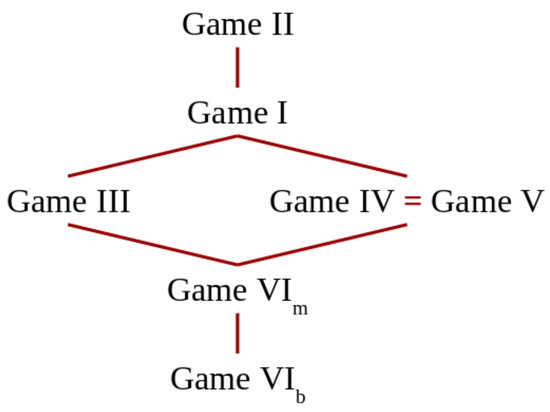
Figure 3.
Order of games w.r.t. the payoff in the Nash equilibrium. Games higher in the lattice have larger payoff.
7. Case Study: A Safer, Faster Password-Checker
In this section, we apply our game-theoretic, compositional approach to show how a defender can mitigate an attacker’s typical timing side-channel attack, while avoiding the usual burden imposed on the password-checker’s efficiency by measures that make time consumption constant.
The following sections are organized as follows: We first provide a formalization of the trade-off between efficiency and security in password checkers using our framework of leakage games. We then illustrate the approach in a simple instance of the program for 3-bit passwords. Finally, we provide general results for the n-bit case regarding the defender’s optimal strategy in equilibrium.
7.1. Modeling the Trade-Off between Efficiency and Security as a Game
Consider the password-checker PWD1…n of Algorithm 1, which performs a bitwise-check of an n-bit low-input provided by the attacker against an n-bit secret password . The bits are compared in increasing order (1, 2, …, n), with the low-input being rejected as soon as it mismatches the secret, and accepted otherwise.
| Algorithm 1: Password-checker PWD1…n. |
 |
The attacker can choose low-inputs to try to gain information about the password. Obviously, in case PWD1…n accepts the low-input, the attacker learns that the password value is . Yet, even when the low-input is rejected, there is some leakage of information: from the duration of the execution, the attacker can estimate how many iterations have been performed before the low-input was rejected, thus inferring a prefix of the secret password.
To model this scenario, let be the set of all possible n-bit passwords and be the set of observables produced by the system. Each observable is an ordered pair whose first element indicates whether or not the password was accepted (T or F, respectively), and the second element indicates the duration of the computation (1, 2, …, or n iterations).
For instance, consider a scenario with 3-bit passwords. Let PWD123 be a password checker that performs the bitwise comparison in increasing order (1, 2, 3). Channel in Table 4 models PWD123’s behavior when the attacker provides low-input . Note that this channel represents the fact that PWD123 accepts the low-input when the secret is (the channel outputs with probability one), and otherwise rejects the low-input in a certain number of steps (e.g., the checker rejects the low-input in two steps when the password is , so in this case, the channel outputs with probability one).
Table 4.
Channel modeling the case in which the defender compares bits in order (1, 2, 3) and the attacker picks low-input 101.
To quantify the password checker’s leakage of information, we will adopt Bayes vulnerability, so the prior Bayes vulnerability will correspond to the probability that the attacker guesses correctly the password in one try, whereas the posterior Bayes vulnerability will correspond to the probability that the attacker guesses correctly the password in one try, after he/she observes the output of the channel (i.e., after he/she has measured the time needed for the checker to accept or reject the low-input). For instance, in the 3-bit password scenario, if the prior distribution on all possible 3-bit passwords is , the corresponding prior Bayes vulnerability is . For prior above, the posterior Bayes vulnerability of channel is , which represents an increase in Bayes vulnerability of about ).
A way to mitigate this timing side-channel is to make the checker’s execution time independent of the secret. This can be done by by eliminating the break command within the loop in PWD1…n, so no matter when the matching among high and low input happens, the password checker will always need n iterations to complete. For instance, in the context of our 3-bit password example, we can let PWDcons be a constant-time 3-bit password checker that applies this counter measure. Channel from Table 5 models PWDcons’s behavior when the attacker’s low-input is . Note that this channel reveals only whether or not the low-input matches the secret value, but does not allow the attacker to infer a prefix of the password. Indeed, this channel’s posterior Bayes vulnerability is , which brings the multiplicative Bayes leakage down to an increase of only about .
Table 5.
Channel modeling the case in which the defender runs a constant-time checker and the attacker picks low-input 101.
However, the original program is substantially more efficient than the modified one. Consider the general case of n-bit passwords and assume that either the password, or the program’s low input, is chosen uniformly at random. Because of this assumption, each bit being checked in the original program has probability of being rejected. Hence, the program will finish after one iteration with probability , after two iterations with probability , and so on, up to the n-th iteration. After that, the program always finishes, so with the remaining probability , the program finishes after n iterations, giving a total expected time of:
The above derivation is based on the series . Hence, the expected running time of the original program (under the uniform assumption) is constant: always bounded by two, and converging to two as n grows. On the other hand, the running time of the modified constant-time program is n iterations, an -fold increase.
Seeking some compromise between security and efficiency, assume the defender can employ different versions of the password-checker, each performing the bitwise comparison among low-input a and secret password x in a different order. More precisely, there is one version of the checker for every possible order in which the index i ranges in the control of the loop in Algorithm 1.
To determine a defender’s best choice of which versions of the checker to run, we model this problem as a game. The attacker’s set of actions consists of all possible low-inputs to the checker, and the defender’s set of actions consists of all orders in which the checker can perform the bitwise comparison. There is, then, a channel for each possible combination of , . In our framework, the payoff of a mixed strategy profile is given by: For each pure strategy profile , the payoff of the game will be the posterior Bayes vulnerability of the resulting channel (since, if we are measuring the information leakage, the prior vulnerability is the same for every channel once the prior is fixed).
In the 3-bit password scenario, the attacker’s actions are all possible 3-bit low-inputs, and the defender’s are all possible versions of the password checker (each action represents the order in which the 3 bits are checked). Table 6 depicts the corresponding payoffs of all 48 possible resulting channels with , , when the prior is still . Note that the attacker’s and defender’s actions substantially affect the effectiveness of the attack: vulnerability ranges between 0.4934 and 0.9311 (and so, multiplicative leakage is in the range between an increase of and one of ). Using techniques from [6], we can compute the best (mixed) strategy for the defender in this game, which turns out to be:
Table 6.
Payoff for each pure strategy profile of 3-bit password scenario.
This strategy is part of an equilibrium and guarantees that for any choice of the attacker, the posterior Bayes vulnerability is at most (so the multiplicative leakage is bounded by , an intermediate value between the minimum of about and the maximum of about ).
The running time, on the other hand, of this new password-checker is the same as that of the original one. Under the assumption that either the password or the low-input is uniformly distributed, each check fails with probability , giving a total expected time of . Hence, this technique substantially decreases the program’s information leakage, without affecting at all its expected running time.
7.2. On Optimal Strategies for the Defender
Interestingly, in the 3-bit password case study from the previous section, the defender’s optimal strategy consists of uniformly sampling among all available versions of the checker. A uniform distribution seems to be an adequate candidate for the defender, but is it always the best choice for any prior and any number of bits?
We first answer this question in the case of a uniform prior for arbitrary n-bit passwords, which already turns out to be challenging. Under this prior, and exploiting a crucial symmetry of the password checker (see the proof of Theorem 7), we can show that all strategies for the adversary are in fact equivalent, namely:
For the defender, on the other hand, the situation is far from trivial: although all pure strategies d are still equivalent, does in general depend on . By exploiting another symmetry of the password checker together with the symmetry of , we can show that a uniform strategy is indeed optimal for the defender, as stated in the following result.
Theorem 7.
Consider the password checker program of Algorithm 1 for n-bit passwords, where the attacker controls the low input to the checker and the defender controls the order in which the bits are checked. If the prior on possible passwords is uniform and the payoff is given by the posterior Bayes-vulnerability: , then the strategy where is uniform and is arbitrary is an equilibrium strategy.
Perhaps surprisingly, however, Theorem 7 does not generalize to non-uniform priors (or to different vulnerability metrics). More precisely, when the prior on passwords is not uniform, the defender may benefit from assigning different probabilities to different versions of the password checker. This subtlety arises from the fact that the defender’s goal is not to maximize the attacker’s uncertainty about the selected password checker itself (i.e., the defender’s action), but it is rather to maximize the attacker’s uncertainty about the secret value. The following examples illustrate this (perhaps counter-intuitive) fact.
Consider again a 3-bit password scenario, similar to that of the previous section. Assume that the attacker knows only that the first bit of the password is surely zero, so that the prior on secrets is:
The payoff table for this case is presented in Table 7, and a corresponding equilibrium defender’s best strategy, computed using techniques from [6], is:
Table 7.
Payoff table for each pure strategy profile of the 3-bit password scenario, under prior .
Note that this equilibrium means that the defender never has to check the bits in the order (2, 1, 3) or in the order (3, 1, 2). The game’s payoff (i.e., posterior Bayes vulnerability) in this case is , which is smaller than the payoff of that would ensue in case the defender’s strategy were uniform. This means that, from the point of view of the defender, uniformly randomizing is not optimal.
Now, assume that the attacker knows that some passwords are more likely than others, even if all are possible, as reflected in the prior:
The payoff table for this case is presented in Table 8, and a corresponding equilibrium defender’s best strategy can be computed to be:
Table 8.
Payoff table for each pure strategy profile of the 3-bit password scenario, under prior .
Note that this equilibrium means that every version of the checker may be selected by the defender, but the probability distribution is not uniform. The game’s payoff (i.e., posterior Bayes vulnerability) in this case is , which is again smaller than the payoff of that would ensue in case the defender’s strategy were uniform.
8. Related Work
Many studies have applied game theory to analyses of security and privacy in networks [18,19,20], cryptography [21], anonymity [22], location privacy [23] and intrusion detection [24], to cite a few. See [25] for a survey.
In the context of quantitative information flow, most works consider only passive attackers. Boreale and Pampaloni [4] considered adaptive attackers, but not adaptive defenders, and show that in this case, the attacker’s optimal strategy can be always deterministic. Mardziel et al. [5] proposed a model for both adaptive attackers and defenders, but in none of their extensive case-studies did the attacker need a probabilistic strategy to maximize leakage. In this paper, we characterize when randomization is necessary, for either attacker or defender, to achieve optimality in our general information leakage games.
Security games have been employed to model and analyze payoffs between interacting agents, especially between a defender and an attacker. Korzhyk et al. [26] theoretically analyzed security games and studied the relationships between Stackelberg and Nash equilibria under various forms of imperfect information. Khouzani and Malacaria [27] studied leakage properties when perfect secrecy was not achievable due to constraints on the allowable size of the conflating sets and provided universally optimal strategies for a wide class of entropy measures and for g-entropies. In particular, they prove that designing a channel with minimum leakage is equivalent to computing Nash equilibria in a corresponding two-player zero-sum game of incomplete information for a range of entropy measures. These works, contrary to ours, do not consider games with hidden choice, in which optimal strategies differ from traditional game-theory.
Several security games have modeled leakage when the sensitive information is the defender’s choices themselves, rather than a system’s high input. For instance, Alon et al. [28] propose zero-sum games in which a defender chooses probabilities of secrets and an attacker chooses and learns some of the defender’s secrets. Then, they present how the leakage of the defender’s secrets has an influence on the defender’s optimal strategy. More recently, Xu et al. [29] showed zero-sum games in which the attacker obtains partial knowledge on the security resources that the defender protects and provided the defender’s optimal strategy under the attacker’s knowledge. Contrary to these studies, in this paper, we assume that a secret value is drawn from some prior distribution and is not the defender’s strategy itself.
Security games have also been used to provide optimal trade-offs between two conflicting desirable properties. Khouzani et al. [30] studied the clash between security and usability in the password selection and presented a game-theoretic framework for determining an optimal trade-off. They analyzed guessing attacks and derived the optimal policies for secret picking as Nash/Stackelberg equilibria. Yang et al. [31] proposed a game-theoretic framework to analyze user behavior in anonymity networks. They considered the cost of anonymity in terms of the loss of utility. They also considered incentives and their impact on users’ cooperation. Shokri et al. [32] presented a game-theoretic model for a designer to find the optimal privacy mechanism by taking the adversary’s knowledge into account. More specifically, they showed a Stackelberg Bayesian game in which a user first chooses a location obfuscation mechanism to maximize his/her location privacy and then an adversary tries to estimate the user’s location to minimize its error. In contrast, our work presents a more general framework that is not limited to a particular domain and focuses on protocol composition as a method to limit the leakage.
Regarding channel operators, the sequential and parallel composition of channels have been studied (e.g., [33]), but we are unaware of any explicit definition and investigation of hidden and visible choice operators. Although Kawamoto et al. [34] implicitly used the hidden choice to model a probabilistic system as the weighted sum of systems, they did not derive the set of algebraic properties we do for this operator, and for its interaction with the visible choice operator.
9. Conclusions and Future Work
In this paper, we used protocol composition to model the introduction of noise performed by the defender to prevent leakage of sensitive information. More precisely, we formalized visible and hidden probabilistic choices of different protocols. We then formalized the interplay between defender and attacker in a game-theoretic framework adapted to the specific issues of QIF, where the payoff is information leakage. We considered various kinds of leakage games, depending on whether players act simultaneously or sequentially, and whether the choices of the defender are visible or not to the attacker. We established a hierarchy of these games and provided methods for finding the optimal strategies (at the points of equilibrium) in the various cases. We also proved that in a sequential game with hidden choice, the behavioral strategies are more advantageous for the defender than the mixed strategies. This contrasts with the standard game theory, where the two types of strategies are equivalent.
As future research, we would like to extend leakage games to the case of repeated observations, i.e., when the attacker can observe the outcomes of the system in successive runs, under the assumption that both attacker and defender may change the channel in each run. We would also like to extend our framework to non zero-sum games, in which the costs of attack and defense are not equivalent, and to analyze differentially-private mechanisms.
Author Contributions
All authors contributed to the technical results and are listed in alphabetical order.
Acknowledgments
The authors are thankful to Arman Khouzani and Pedro O. S. Vaz de Melo for valuable discussions. This work was supported by JSPS and INRIAunder the project LOGIS of the Japan-France AYAMEProgram, by the PEPS 2018 project MAGIC and by the project Epistemic Interactive Concurrency (EPIC) from the STICAmSudProgram. Mário S. Alvim was supported by CNPq, CAPES and FAPEMIG. Yusuke Kawamoto was supported by JSPS KAKENHI Grant Number JP17K12667.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Proofs of Technical Results
In this section, we provide the proofs of the technical results, which are not in the main body of the paper.
Appendix A.1. Preliminaries for Proofs
We start by providing some necessary background for the subsequent technical proofs.
Definition 1 states that two compatible channels (i.e., with the same input space) are equivalent if yield the same value of vulnerability for every prior and every vulnerability function. The result below, from the literature, provides necessary and sufficient conditions for two channels being equivalent. The result employs the extension of channels with an all-zero column as follows. For any channel C of type , its zero-column extension is the channel of type , with , s.t. for all , , and for all .
Lemma A1
(Characterization of channel equivalence [13,17]). Two channels and are equivalent iff every column of is a convex combination of columns of , and every column of is a convex combination of columns of .
Note that the result above implies that for being equivalent, any two channels must be compatible.
Appendix A.2. Proofs of Section 4
Proposition 1 (Type of hidden choice).
Given a family of channels of type , and a distribution on , the hidden choice is a channel of type .
Proof.
Since hidden choice is defined as a summation of matrices, the type of is the same as the type of every in the family.
To see that is a channel (i.e., all of its entries are non-negative, and all of its rows sum up to 1), first note that, since each in the family is a channel matrix, lies in the interval for all , . Since is a set of convex coefficients, from the definition of hidden choice it follows that also must lie in the interval for every .
Second, note that for all :
☐
Proposition 2 (Type of visible choice).
Given a family of compatible channels s.t. each has type and a distribution on , the result of the visible choice is a channel of type .
Proof.
Visible choice applied to a family of channels scales each matrix by a factor , which preserves the type of each matrix, and then concatenates all the matrices so produced, yielding a result of type .
To see that is a channel (i.e., that all of its entries are non-negative, and that all rows sum-up to 1), note that each element of the visible choice on the family can be denoted by , where , , and . Then, note that for all , , and :
which is a non-negative value, since, both and are non-negative.
Finally, note that for all :
☐
Proposition 3 (Idempotency).
Given a family of channels s.t. for all , and a distribution on , then: (a) ; and (b) .
Proof.
- (a)
- Idempotency of hidden choice:
- (b)
- Idempotency of visible choice:In the above derivation, we can apply Lemma A1 because every column of the channel on each side of the equivalence can be written as a convex combination of the zero-column extension of the channel on the other side.
☐
Proposition 4 (“Reorganization of operators”).
Given a family of channels indexed by sets and , a distribution on and a distribution on :
- (a)
- , if all ’s have the same type;
- (b)
- , if all ’s are compatible; and
- (c)
- , if, for each i, all ’s have the same type .
Proof.
- (a)
- (b)
- In the above derivation, we can apply Lemma A1 because every column of the channel on each side of the equivalence can be written as a convex combination of the zero-column extension of the channel on the other side.
- (c)
- In the above derivation, we can apply Lemma A1 because every column of the channel on each side of the equivalence can be written as a convex combination of the zero-column extension of the channel on the other side.
☐
Appendix A.3. Proofs of Section 7
Theorem A1.
Consider the password checker program of Algorithm 1 for n-bit passwords, where the attacker controls the low input to the checker and the defender controls the order in which the bits are checked. If the prior on possible passwords is uniform and the payoff is given by the posterior Bayes-vulnerability: , then the strategy where is uniform and is arbitrary is an equilibrium strategy.
Proof.
We show that where is uniform and is arbitrary, is a saddle point of . The proof will rely on two crucial symmetries of the password checker, in combination with the use of a uniform prior. Note that, under uniform , the Bayes-vulnerability of a channel C is proportional to the sum of the column maxima of C, namely . Given a permutation of , define as C with its rows permuted, namely . Note that can be written as where is a permutation matrix. Permuting the rows does not affect the column maxima, hence .
For the attacker things are simple, since we can show that under a uniform all attacker strategies are equivalent, that is,
To show this, we use the first important symmetry of the password checker, which is due to the fact that the output of the algorithm only depends on whether is true or false for each bit. Hence, any modification on a can be matched with a modification on x that preserves the output, namely for all there exists a permutation of passwords such that for all d. Denote , we have that:
From , we have that for all pure strategies , which implies since is linear on . Therefore, in the remainder of the proof, we assume that the attacker plays the fixed pure strategy , having the zero bitstring as the low input.
For the defender, on the other hand, the situation is far from trivial: although all pure strategies d are still equivalent, is only convex on and as a consequence the payoff highly depends on . Our goal is to show that:
is minimized on the uniform . To do so, we show something stronger, namely that each addend of the y-sum is simultaneously minimized on the uniform . Fix an arbitrary y, and let:
where · is the dot product and is the vector defined by . Note that, since is deterministic, all elements of are either zero or one. Intuitively, if x produces the fixed output y when the bit checking order is d.
We need to show that is minimized on . However, f seen as a function on the whole has no global minimum. In our case, though, is a probability distribution taking values in . That is, only elements of are free, so we can reduce the dimension by one as follows: fix some and let be the same as with the element corresponding to removed. We have that , where is the “ones” vector; hence, we can rewrite as a function of :
Therefore, it is sufficient to show that is minimized on .
In the following, we use the fundamental concept of subgradients from convex analysis, which generalize gradients for non-differentiable functions. A vector v is a subgradient of a possibly non-differentiable convex function at iff:
It is well-known that g has a global minimum on iff the vector belongs to the set of subgradients of g at (this generalizes the fact that differentiable convex functions have zero gradient on their global minimum). Recall also that has a single subgradient v, while for , any subgradient of for any branch i giving the max, is also a subgradient of g. Finally, the set of subgradients is convex, so any convex combination of them is also a subgradient.
Hence, the subgradients of are , for any x giving the maximum, as well as their convex combinations. Our goal is to show that on these include the zero vector.
We finally arrive to the second important symmetry of the password checker. Let be a permutation of the set of password bits. Such a permutation could be seen both as a permutation on (i.e., ; note that has the same number of 0s and 1s as x), as well as a permutation on (a bit checking order d is itself a permutation of bits, so we can set ). Since all low bits of are the same, applying to both x and d does not change the outcome of the algorithm, that is .
Intuitively, if d is selected uniformly, then the attacker cannot distinguish x from since they produce the same output with the same probability. More concretely, let denote that for some bit permutation . Due to the aforementioned symmetry we have that and have the same number of 1s which means that . Now, let . We have that all also give the max; hence, all vectors:
are subgradients of f on . Finally, for any there is a bit permutation such that . Since , we have that (for some integer k) independently of d. Hence, letting and averaging all subgradients of (A2), we get that:
is also a subgradient, which concludes the proof. ☐
Appendix B. Properties of Binary Versions of Channel Operators
In this section, we derive some relevant properties of the binary versions of the hidden and visible choice operators. We start with results regarding each operator individually.
Proposition A1 (Properties of the binary hidden choice).
For any channels and of the same type, and any values , the binary hidden choice operator satisfies the following properties:
- (a)
- Idempotency:
- (b)
- Commutativity:
- (c)
- Associativity:if .
- (d)
- Absorption:
Proof.
We will prove each property separately.
- (a)
- Idempotency:
- (b)
- Commutativity:
- (c)
- Associativity:
- (d)
- Absorption: First note that:To complete the proof, note that in step (*) above, and form a valid binary probability distribution (they are both non-negative, and they add up to one), then apply the definition of hidden choice.
☐
Proposition A2 (Properties of binary visible choice).
For any compatible channels and , and any values , the visible choice operator satisfies the following properties:
- (a)
- Idempotency:
- (b)
- Commutativity:
- (c)
- Associativity: if .
Proof.
We will prove each property separately.
- (a)
- Idempotency: , by immediate application of Lemma A1, since every column of the channel on each side of the equivalence can be written as a convex combination of the zero-column extension of the channel on the other side.
- (b)
- Commutativity:In the above derivation, we can apply Lemma A1 because every column of the channel on each side of the equivalence can be written as a convex combination of the zero-column extension of the channel on the other side.
- (c)
- Associativity:In the above derivation, we can apply Lemma A1 because every column of the channel on each side of the equivalence can be written as a convex combination of the zero-column extension of the channel on the other side.
☐
Now, we turn our attention to the interaction between hidden and visible choice operators.
A first result is that hidden choice does not distribute over visible choice. To see why, note that and cannot be both defined: if the former is defined, then must have the same type as , whereas if the latter is defined, must have the same type as , but and do not have the same type (they have different output sets).
However, as the next result shows, visible choice distributes over hidden choice.
Proposition A3 (Distributivity of p over q⊕).
Let , and be compatible channels, and and have the same type. Then, for any values :
Proof.
In the above derivation, we can apply Lemma A1 because every column of the channel on each side of the equivalence can be written as a convex combination of the zero-column extension of the channel on the other side. ☐
References
- Sun, Q.; Simon, D.R.; Wang, Y.M.; Russell, W.; Padmanabhan, V.N.; Qiu, L. Statistical identification of encrypted web browsing traffic. In Proceedings of the 2002 IEEE Symposium on Security and Privacy, Berkeley, CA, USA, 12–15 May 2002; pp. 19–30. [Google Scholar]
- Dwork, C.; Mcsherry, F.; Nissim, K.; Smith, A. Calibrating noise to sensitivity in private data analysis. In Proceedings of the Theory of Cryptography Conference, New York, NY, USA, 4–7 March 2006; Lecture Notes in Computer Science. Springer: Berlin, Germany, 2006; Volume 3876, pp. 265–284. [Google Scholar]
- Chaum, D. The Dining Cryptographers Problem: Unconditional Sender and Recipient Untraceability. J. Cryptol. 1988, 1, 65–75. [Google Scholar] [CrossRef]
- Boreale, M.; Pampaloni, F. Quantitative information flow under generic leakage functions and adaptive adversaries. Log. Methods Comput. Sci. 2015, 11, 166–181. [Google Scholar] [CrossRef]
- Mardziel, P.; Alvim, M.S.; Hicks, M.W.; Clarkson, M.R. Quantifying Information Flow for Dynamic Secrets. In Proceedings of the 2014 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 18–21 May 2014; pp. 540–555. [Google Scholar]
- Alvim, M.S.; Chatzikokolakis, K.; Kawamoto, Y.; Palamidessi, C. Information Leakage Games. In Proceedings of the International Conference on Decision and Game Theory for Security, Vienna, Austria, 23–25 October 2017; Lecture Notes in Computer Science. Springer: Berlin, Germany, 2017; Volume 10575, pp. 437–457. [Google Scholar]
- Rizzo, J.; Duong, T. The CRIME attack. In Proceedings of the 2012 8th EKOparty Security Conference, Buenos Aires, Argentina, 19–21 September 2012. [Google Scholar]
- Alvim, M.S.; Chatzikokolakis, K.; McIver, A.; Morgan, C.; Palamidessi, C.; Smith, G. Axioms for Information Leakage. In Proceedings of the 2016 IEEE 29th Computer Security Foundations Symposium (CSF), Lisbon, Portugal, 27 June–1 July 2016; pp. 77–92. [Google Scholar]
- Smith, G. On the Foundations of Quantitative Information Flow. In Proceedings of the International Conference on Foundations of Software Science and Computational Structures, York, UK, 22–29 March 2009; Lecture Notes in Computer Science. Springer: Berlin, Germany, 2009; Volume 5504, pp. 288–302. [Google Scholar]
- Chatzikokolakis, K.; Palamidessi, C.; Panangaden, P. On the Bayes risk in information-hiding protocols. J. Comput. Secur. 2008, 16, 531–571. [Google Scholar] [CrossRef]
- Shannon, C.E. A Mathematical Theory of Communication. Bell Syst. Tech. J. 1948, 27, 379–423, 625–656. [Google Scholar] [CrossRef]
- Massey, J.L. Guessing and Entropy. In Proceedings of the IEEE International Symposium on Information Theory, Trondheim, Norway, 27 June–1 July 1994; IEEE: Piscataway, NJ, USA, 1994; p. 204. [Google Scholar]
- Alvim, M.S.; Chatzikokolakis, K.; Palamidessi, C.; Smith, G. Measuring Information Leakage Using Generalized Gain Functions. In Proceedings of the 2012 IEEE 25th Computer Security Foundations Symposium (CSF), Cambridge, MA, USA, 25–27 June 2012; pp. 265–279. [Google Scholar]
- Alvim, M.S.; Chatzikokolakis, K.; Kawamoto, Y.; Palamidessi, C. Leakage and protocol composition in a game-theoretic perspective. In Proceedings of the International Conference on Principles of Security and Trust, Thessaloniki, Greece, 16–19 April 2018; Lecture Notes in Computer Science. Springer: Berlin, Germany, 2018. [Google Scholar]
- Osborne, M.J.; Rubinstein, A. A Course in Game Theory; The MIT Press: Cambridge, MA, USA, 1994. [Google Scholar]
- Braun, C.; Chatzikokolakis, K.; Palamidessi, C. Quantitative Notions of Leakage for One-try Attacks. In Proceedings of the Proceedings of the 25th Conference on Mathematical Foundations of Programming Semantics, Oxford, UK, 3–7 April 2009; Electronic Notes in Theoretical Computer Science. Elsevier: New York, NY, USA, 2009; Volume 249, pp. 75–91. [Google Scholar]
- McIver, A.; Morgan, C.; Smith, G.; Espinoza, B.; Meinicke, L. Abstract Channels and Their Robust Information-Leakage Ordering. In Proceedings of the International Conference on Principles of Security and Trust, Grenoble, France, 5–13 April 2014; Lecture Notes in Computer Science. Springer: Berlin, Germany, 2014; Volume 8414, pp. 83–102. [Google Scholar]
- Basar, T. The Gaussian test channel with an intelligent jammer. IEEE Trans. Inf. Theory 1983, 29, 152–157. [Google Scholar] [CrossRef]
- Grossklags, J.; Christin, N.; Chuang, J. Secure or Insure?: A Game-theoretic Analysis of Information Security Games. In Proceedings of the 17th International Conference on World Wide Web, Beijing, China, 21–25 April 2008; pp. 209–218. [Google Scholar]
- Alpcan, T.; Buchegger, S. Security Games for Vehicular Networks. IEEE Trans. Mob. Comput. 2011, 10, 280–290. [Google Scholar] [CrossRef]
- Katz, J. Bridging Game Theory and Cryptography: Recent Results and Future Directions. In Proceedings of the Theory of Cryptography Conference, Zurich, Switzerland, 9–11 February 2008; pp. 251–272. [Google Scholar]
- Acquisti, A.; Dingledine, R.; Syverson, P.F. On the Economics of Anonymity. In Proceedings of the International Conference on Financial Cryptography, Guadeloupe, France, 27–30 January 2003; pp. 84–102. [Google Scholar]
- Freudiger, J.; Manshaei, M.H.; Hubaux, J.P.; Parkes, D.C. On Non-cooperative Location Privacy: A Game-theoretic Analysis. In Proceedings of the 16th ACM Conference on Computer and Communications Security, Chicago, IL, USA, 9–13 November 2009; pp. 324–337. [Google Scholar]
- Zhu, Q.; Fung, C.J.; Boutaba, R.; Basar, T. A game-theoretical approach to incentive design in collaborative intrusion detection networks. In Proceedings of the GameNets ’09 International Conference on Game Theory for Networks, Istanbul, Turkey, 13–15 May 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 384–392. [Google Scholar]
- Manshaei, M.H.; Zhu, Q.; Alpcan, T.; Bacşar, T.; Hubaux, J.P. Game Theory Meets Network Security and Privacy. ACM Comput. Surv. 2013, 45, 25. [Google Scholar] [CrossRef]
- Korzhyk, D.; Yin, Z.; Kiekintveld, C.; Conitzer, V.; Tambe, M. Stackelberg vs. Nash in Security Games: An Extended Investigation of Interchangeability, Equivalence, and Uniqueness. J. Artif. Intell. Res. 2011, 41, 297–327. [Google Scholar]
- Khouzani, M.H.R.; Malacaria, P. Relative Perfect Secrecy: Universally Optimal Strategies and Channel Design. In Proceedings of the 2016 IEEE 29th Computer Security Foundations Symposium (CSF), Lisbon, Portugal, 27 June–1 July 2016; pp. 61–76. [Google Scholar]
- Alon, N.; Emek, Y.; Feldman, M.; Tennenholtz, M. Adversarial Leakage in Games. SIAM J. Discret. Math. 2013, 27, 363–385. [Google Scholar] [CrossRef][Green Version]
- Xu, H.; Jiang, A.X.; Sinha, A.; Rabinovich, Z.; Dughmi, S.; Tambe, M. Security Games with Information Leakage: Modeling and Computation. In Proceedings of the 24th International Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015; pp. 674–680. [Google Scholar]
- Khouzani, M.H.R.; Mardziel, P.; Cid, C.; Srivatsa, M. Picking vs. Guessing Secrets: A Game-Theoretic Analysis. In Proceedings of the IEEE 28th Computer Security Foundations Symposium, Verona, Italy, 13–17 July 2015; pp. 243–257. [Google Scholar]
- Yang, M.; Sassone, V.; Hamadou, S. A Game-Theoretic Analysis of Cooperation in Anonymity Networks. In Proceedings of the International Conference on Principles of Security and Trust, Tallinn, Estonia, 24 March–1 April 2012; pp. 269–289. [Google Scholar]
- Shokri, R.; Theodorakopoulos, G.; Troncoso, C. Privacy Games Along Location Traces: A Game-Theoretic Framework for Optimizing Location Privacy. ACM Trans. Priv. Secur. 2017, 19, 11. [Google Scholar] [CrossRef]
- Kawamoto, Y.; Chatzikokolakis, K.; Palamidessi, C. On the Compositionality of Quantitative Information Flow. Log. Methods Comput. Sci. 2017, 13, 1–31. [Google Scholar]
- Kawamoto, Y.; Biondi, F.; Legay, A. Hybrid Statistical Estimation of Mutual Information for Quantifying Information Flow. In Proceedings of the International Symposium on Formal Methods, Limassol, Cyprus, 9–11 November 2016; pp. 406–425. [Google Scholar]




© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).