Abstract
A conditional Gaussian framework for understanding and predicting complex multiscale nonlinear stochastic systems is developed. Despite the conditional Gaussianity, such systems are nevertheless highly nonlinear and are able to capture the non-Gaussian features of nature. The special structure of the system allows closed analytical formulae for solving the conditional statistics and is thus computationally efficient. A rich gallery of examples of conditional Gaussian systems are illustrated here, which includes data-driven physics-constrained nonlinear stochastic models, stochastically coupled reaction–diffusion models in neuroscience and ecology, and large-scale dynamical models in turbulence, fluids and geophysical flows. Making use of the conditional Gaussian structure, efficient statistically accurate algorithms involving a novel hybrid strategy for different subspaces, a judicious block decomposition and statistical symmetry are developed for solving the Fokker–Planck equation in large dimensions. The conditional Gaussian framework is also applied to develop extremely cheap multiscale data assimilation schemes, such as the stochastic superparameterization, which use particle filters to capture the non-Gaussian statistics on the large-scale part whose dimension is small whereas the statistics of the small-scale part are conditional Gaussian given the large-scale part. Other topics of the conditional Gaussian systems studied here include designing new parameter estimation schemes and understanding model errors.
Keywords:
conditional Gaussian systems; multiscale nonlinear stochastic systems; physics-constrained nonlinear stochastic models; stochastically coupled reaction–diffusion models; conditional Gaussian mixture; superparameterization; conformation theory; model error; hybrid strategy; parameter estimation Contents
1. Introduction
Multiscale nonlinear dynamical systems are ubiquitous in different areas, including geoscience, engineering, neural science and material science [1,2,3,4,5,6,7,8]. They are characterized by a large dimensional phase space and a large dimension of strong instabilities which transfer energy throughout the system. Many non-Gaussian characteristics, such as extreme and rare events, intermittency and fat-tailed probability density functions (PDFs), are often observed in these multiscale nonlinear dynamical systems [1,9,10]. Key mathematical issues are their basic mathematical structural properties and qualitative features [2,3,11,12], short- and long-range forecasting [13,14,15], uncertainty quantification (UQ) [16,17,18], and state estimation, filtering or data assimilation [15,19,20,21,22]. Due to the lack of physical understanding or the inadequate resolution in the models because of the current computing power, coping with the inevitable model errors that arise in approximating such complex systems becomes a necessary and crucial issue in dealing with these multiscale nonlinear dynamical systems [16,23,24,25,26]. Understanding and predicting complex multiscale turbulent dynamical systems involve the blending of rigorous mathematical theory, qualitative and quantitative modelling, and novel numerical procedures [2,27].
Despite the fully nonlinearity in many multiscale turbulent dynamical systems and the non-Gaussian features in both the marginal and joint PDFs, these systems have conditional Gaussian structures [1,15,28,29]. Writing the state variables as , the conditional Gaussianity means that once the trajectories of are given, the dynamics of conditioned on these highly nonlinear observed trajectories become Gaussian processes. In this article, we develop a general conditional Gaussian framework for mathematical modeling, prediction, state estimation and UQ. One of the desirable features of such conditional Gaussian system is that it allows closed analytical formulae for updating the conditional statistics of given the trajectories of [28,30]. This facilitates the development of both rigorous mathematical theories and efficient numerical algorithms for these complex multiscale turbulent dynamical systems.
With the great progress in developing and improving the observational networks, a vast amount of observational data is now available. An important scientific issue is to make use of these observational data to build data-driven models that advance the understanding of the underlying physical processes and improve the prediction skill. Physics-constrained nonlinear stochastic models are the recent development of data-driven statistical-dynamical models for the time series of a partial subset of observed variables, which arise from observations of nature or from an extremely complex physical model [31,32]. The physics-constrained nonlinear stochastic modeling framework builds on early works for single layer models without memory effects, which uses physical analytic properties to constrain data-driven methods. They succeed in overcoming both the finite-time blowup and the lack of physical meaning issues in various ad hoc multi-layer regression models [31,33]. Many of the physics-constrained nonlinear stochastic models belong to the conditional Gaussian framework, including the noisy version of the famous Lorenz 63 and 84 models as well as a two-layer Lorenz 96 model [34,35,36]. In addition, two important conceptual models for turbulent dynamical systems [37,38] and a conceptual model of the coupled atmosphere and ocean [39] also fit perfectly into the physics-constrained nonlinear stochastic modeling framework with conditional Gaussian structures. These models are extremely useful for testing various new multiscale data assimilation and prediction schemes [1,38,40]. Other physics-constrained nonlinear stochastic models with conditional Gaussian structures include a low-order model of Charney–DeVore flows [29] and a paradigm model for topographic mean flow interaction [32]. Notably, the physics-constrained nonlinear stochastic models combining with the conditional Gaussian framework have been successfully applied for the real-time prediction and data assimilation of the Madden–Julian oscillation (MJO) and monsoon [41,42,43,44], which are the dominant modes of intraseasonal variabilities in nature.
In many multiscale turbulent dynamical systems, there is a natural time scale separation between different variables. Therefore, the MTV strategy [45,46,47,48] (named after Majda, Timofeyev and Vanden-Eijnden) can be applied to these systems for stochastic mode reduction. Using the MTV strategy, the equations of motion for the unresolved fast modes are modified by representing the nonlinear self-interactions terms between unresolved modes by damping and stochastic terms. The resulting systems then naturally belong to the conditional Gaussian framework and they also preserve physics-constrained properties. Examples include a simple stochastic model with key features of atmospheric low-frequency variability [49] and a simple prototype nonlinear stochastic model with triad interactions that mimics structural features of low-frequency variability of global circulation models (GCM) [50] .
In addition to the data-driven physics-constrained nonlinear stochastic models, many large-scale dynamical models in turbulence, fluids and geophysical flows also have conditional Gaussian structures. These stochastic partial differential equation (SPDE) models include the stochastic skeleton model for the MJO [51] and a coupled El Niño dynamical model capturing the El Niño diversity [52], where nonlinearity interacts with state-dependent (multiplicative) noise and many salient non-Gaussian features such as intermittency and fat-tailed PDFs are observed in these systems. The stochastically forced Boussinesq equation [11] for the Rayleigh–Bénard convection [53,54] and strongly stratified flows in geophysics [55] as well as its generalized version, namely the Darcy–Brinkman–Oberbeck–Boussinesq system [56] for the convection phenomena in porous media, also belong to the conditional Gaussian framework. Likewise, the multiscale shallow water equation [11] with coupled geostrophically balanced (GB) and gravity modes fits into the conditional Gaussian model family. On the other hand, quite a few stochastically coupled reaction–diffusion models in neuroscience and ecology illustrate conditional Gaussian structures as well. Examples include the stochastically coupled FitzHugh–Nagumo (FHN) models [57], the predator–prey models [58], a stochastically coupled Susceptible-Infectious-Recovered (SIR) epidemic model [59] and a nutrient-limited model for avascular cancer growth [60]. Furthermore, the conditional Gaussian framework can be applied to model the coupled observation-filtering systems for the state estimation of turbulent ocean flows using Lagrangian tracers [61,62,63]. The framework can also be utilized to develop cheap and effective stochastic parameterizations for turbulent dynamical systems [64,65].
One of the key issues in studying the complex multiscale nonlinear turbulent dynamical systems is to solve the time evolution of the associated PDFs, which is extremely useful in ensemble prediction, data assimilation as well as understanding the intermittency and extreme events. The time evolution of the PDFs associated with the underlying turbulent dynamical systems is described by the so-called Fokker–Planck equation [66,67]. Due to the complexity of many multiscale turbulent dynamical systems, the dimension of the systems can be quite large. However, solving the Fokker–Planck equation in high dimensions is a well-known notoriously difficult problem. Traditional numerical methods such as finite element and finite difference as well as the direct Monte Carlo simulations all suffer from the curse of dimension [68,69]. Nevertheless, for the conditional Gaussian systems, efficient statistically accurate algorithms can be developed for solving the Fokker–Planck equation in high dimensions and thus beat the curse of dimension. The algorithms involve a hybrid strategy that requires only a small number of ensembles [38]. Specifically, a conditional Gaussian mixture in a high-dimensional subspace via an extremely efficient parametric method is combined with a judicious non-parametric Gaussian kernel density estimation in the remaining low-dimensional subspace. The parametric method provides closed analytical formulae for determining the conditional Gaussian distributions in the high-dimensional subspace and is therefore computationally efficient and accurate. The full non-Gaussian PDF of the system is then given by a Gaussian mixture [38]. For even larger dimensional systems, a judicious block decomposition and statistical symmetry are further applied that facilitate an extremely efficient parallel computation and a significant reduction of sample numbers [36]. These algorithms are applied here to the statistical prediction of a stochastically coupled FHN model with 1500 dimensions and an inhomogeneous two-layer Lorenz 96 model with 240 dimensions. Significant prediction skill shows the advantages of these algorithms in terms of both accuracy and efficiency.
The conditional Gaussian framework also provides a power tool for the multiscale data assimilation. In fact, data assimilation of turbulent signals is an important challenging problem because of the extremely complicated large dimension of the signals and incomplete partial noisy observations that usually mix the large scale mean flow and small scale fluctuations. Due to the limited computing power, it is desirable to use multiscale forecast models which are cheap and fast to mitigate the curse of dimensionality in turbulent systems. An extremely cheap multiscale data assimilation scheme, called stochastic superparameterization [70,71,72,73], resolves the large-scale mean flow on a coarse grid and replaces the nonlinear small-scale eddy terms by quasilinear stochastic processes on formally infinite embedded domains where the stochastic processes are Gaussian conditional to the large scale mean flow. The key ingredient of such a multiscale data assimilation method is the systematic use of conditional Gaussian mixtures which make the methods efficient by filtering a subspace whose dimension is smaller than the full state. This conditional Gaussian closure approximation results in a seamless algorithm without using the high resolution space grid for the small scales and is much cheaper than the conventional superparameterization, with significant success in difficult test problems [71,72,74] including the Majda-McLaughlin-Tabak (MMT) model [71,75] and ocean turbulence [76,77,78]. The method uses particle filters [20,79] or ensemble filters on the large scale part [75,76] whose dimension is small enough so that the non-Gaussian statistics of the large scale part can be calculated from a particle filter, whereas the statistics of the small scale part are conditionally Gaussian given the large scale part. This framework is not restricted to superparameterization as the forecast model and other cheap forecast models can also be employed. In fact, another multiscale filtering algorithm with quasilinear Gaussian dynamically orthogonality method as the forecast method in an adaptively evolving low dimensional subspace has been developed [80]. The multiscale filtering also provides a mathematical framework for representation errors, which are due to the contribution of unresolved scales [81,82] in the observations. Other theoretic and applied studies of the conditional Gaussian framework include effective parameter estimation, model reduction and the understanding of various model errors using information theory.
The remaining of the article is organized as follows. Section 2 provides an overview of data, model and data-driven modeling framework as well as efficient data assimilation and prediction strategies with solvable conditional statistics. Section 3 summarizes the general mathematical structure of nonlinear conditional Gaussian systems, the physics-constrained nonlinear stochastic models and the application of the MTV strategy to the conditional Gaussian systems. Then, a gallery of examples of conditional Gaussian systems is shown in Section 4. Section 5 involves the effective statistically accurate algorithms that beat the curse of dimension for Fokker–Planck equation for conditional Gaussian systems together with their applications to statistical prediction. The topics related to the parameter estimation, model error and multiscale data assimilation utilizing the conditional Gaussian framework are shown in Section 6. The article is concluded in Section 7.
2. Overview: Data vs. Model, Data-Driven Modeling Framework, and Efficient Data Assimilation and Prediction Strategies with Solvable Conditional Statistics
A central contemporary issue for complex turbulent systems is to use data to improve scientific understanding of the underlying physics, make real-time predictions, and quantify the uncertainty in long range forecasting [1,27]. Recently, with the great progress in developing and improving the observational networks, vast amount of observational data are now available. Many purely data-driven statistical methods (regression, clustering and analog forecast etc.) [83,84,85,86,87] are thus developed and have become popular approaches in attempting to understand and predict nature. Despite the success in a crude understanding of nature in terms of explaining and forecasting some of the coarse-grained variables in the largest scale to some extent, these purely data-driven statistical methods usually cannot discover the nonlinear and intermittent nature in the underlying complex dynamics. They often fail to reveal the non-trivial interactions between physical processes in different scales either. In addition, these purely data-driven statistical methods typically require a large training dataset in order to obtain complete and unbiased information from nature, which is however infeasible in many areas, including climate, atmosphere and ocean science. In fact, satellite observations are only available for a few decades [88,89] which are far from enough in understanding decadal or interannual variabilities containing rare and extreme events. Note that many complex turbulent systems in nature are in high dimensions, and therefore most purely data driven statistical methods are extremely expensive to use.
Therefore, combining model with data becomes necessary in understanding and predicting nature. Suitable models involve important physical mechanisms and they can be used for real-time prediction by incorporating only a small amount of data. In many simple but natural scenarios, some low-dimensional physical variables are observed and low-order nonlinear stochastic models are preferred for describing their behavior. Using data outcome to fit a quadratic regression model [90,91] is a data-driven modeling strategy which outweighs the linear regression models and allows nonlinearity and memory in time. However, there is no physical information in such quadratic regression models. In fact, it has been shown in [33] via rigorous mathematical theory that such ad hoc nonlinear regression strategies can exhibit finite time blow-up and pathological invariant measures even though they fit the data with high precision. To include physical information into the models, systematic physics-constrained multi-level quadratic regression models have been developed [31,32]. These models avoid pathological behavior by incorporating physical constraints with nonlinear energy-conserving principles developed in the earlier stochastic climate modeling strategy [45]. Meanwhile, these physics-constrained models allow memory in effects. Although the number of the parameters in physics-constrained nonlinear models can be large, the models are in general robust with respect to the perturbation of the parameters around their optimal values [41]. This is crucial in practice because it requires only a crude estimation of the parameters for the model, which greatly reduces the computational cost for searching in high-dimensional parameter space. A striking real-world application of these physics-constrained nonlinear models is to assess the predictability limits of time series associated with the tropical intraseasonal variability such as the the Madden–Julian oscillation (MJO) and monsoon. It has been shown in [41,42,43] that these physics-constrained nonlinear models are able to reach the predictability limits of the large-scale MJO and monsoon and improves prediction skill using the low-order models. Notably, the physics-constrained nonlinear stochastic models require only a short training period [42,44] because the model development automatically involves a large portion of the information of nature. This is extremely important since practically only a limited observational data is available. In fact, comparable and even slightly more skillful prediction results have been found using the physics-constrained nonlinear model compared with those using non-parametric methods in predicting the MJO and monsoon intermittent time series [92,93], but the prediction using the physics-constrained nonlinear model adopted a much shorter training period [44].
Another important reason that entails the model in understanding and predicting nature is due to the fundamental limitations in measuring the observations. In fact, only partial observations are available in most applications and observational noise is inevitable. For example, the sea surface temperature is easy to measure, but the temperature in the deep ocean is hard to estimate. In addition, although the surface wind in the entire earth can be measured by satellites, the measured signals usually contain large noise. Therefore, models are combined with the available observations for the state estimation of the unobserved variables as well as reducing the noise in the observed ones. This is known as data assimilation or filtering [15,20,22]. Note that most of the complex multiscale dynamical systems involve strong nonlinearity and extreme events. Thus, the classical Kalman filter that works only for linear models [94] fails to capture the nonlinear and non-Gaussian features in nature. Although the so-called particle filter [95,96] is able to recover all the non-Gaussian statistics, it is computationally expensive and can only be applied to low-dimensional scenarios, which are typically not the case in most applications. In fact, even a global weather model with very coarse grid points at every 200 km already has about state variables. Other direct strategies in handling large dimensional systems, such as the ensemble Kalman filters [97,98], can also be problematic. For example, they are not immune from “catastrophic filter divergence” (diverge beyond machine infinity) when observations are sparse, even when the true signal is a dissipative system [99,100]. Therefore, designing new efficient strategies for data assimilation and prediction that are accurate and can overcome the curse of dimension is crucial in studying complex multiscale nonlinear dynamical systems with only noisy partial observations [20,27,65,101,102]. Since both the data assimilation and prediction involve running forward the dynamical models (known as the forecast models), the development of new strategies entails the understanding and utilization of model structures.
Due to the complexity in many complex multiscale turbulent dynamical systems, developing cheap and effective approximate models which nevertheless capture the main characteristics of the underlying dynamics becomes necessary in data assimilation, prediction and the understanding of nature. In particular, novel stochastic parameterization schemes play a significant role in reducing the model complexity while retaining the key features of various multiscale turbulent dynamical systems. These key features include the statistical feedback from small to large scales, accurate dynamical and statistical behavior in large scale variables, and the main effect of the large-scale variables on the statistical evolution of small scale processes. Then, efficient hybrid strategy can be developed for dealing with large and small scale variables, respectively.
A simple yet practically useful strategy in filtering nonlinear and intermittent signals is via the so-called stochastic parameterized extended Kalman filter (SPEKF) type of the forecast model [64,65]. The idea of the SKEPF model is that the small or unresolved scale variables are stochastically parameterized by cheap linear and Gaussian processes, representing stochastic damping, stochastic phase and stochastic forcing. Despite the model error in using such Gaussian approximations for the unresolved nonlinear dynamics, these Gaussian processes succeed in providing accurate statistical feedback from the unresolved scales to the resolved ones and thus the intermittency and non-Gaussian features as observed in the resolved variables can be accurately recovered. The statistics in the SPEKF model can also be solved with exact and analytic formulae, which allow an accurate and efficient estimation of the model states. The SPEKF type of model has been used for filtering mutiscale turbulent dynamical systems [20], stochastic superresolution [103] and filtering Navier–Stokes equations with model error [104]. A detailed description of the SPEKF model can be found in Section 4.5.1. Notably, the SPEKF model involves a hybrid approach, where certain cheap and statistically solvable Gaussian approximations are used to describe the statistical features of the unresolved (or small scale) variables in a large dimensional subspace while the highly nonlinear dynamical features of the resolved (or large scale) variables as well as their interactions with the unresolved variables are retained in a relatively low dimensional subspace. Such a strategy can be used as a guideline for designing suitable approximate forecast models for various complex multiscale turbulent dynamical systems.
For multiscale data assimilation of many realistic and complex turbulent dynamical systems, an extremely cheap scheme, called stochastic superparameterization [70,71,72,73], has been developed, which makes use of a similar hybrid strategy as discussed above but with a more refined setup. In the stochastic superparameterization, the large-scale mean flow is resolved on a coarse grid and the nonlinear small-scale eddy terms are replaced by quasilinear stochastic processes on formally infinite embedded domains where these stochastic processes are Gaussian conditional to the large scale mean flow. The key ingredient of such a multiscale data assimilation method is the systematic use of conditional Gaussian mixtures which make the methods efficient by filtering a subspace whose dimension is smaller than the full state. This conditional Gaussian closure approximation results in a seamless algorithm without using the high resolution space grid for the small scales and is thus extremely efficient. The method uses particle filters [20,79] or ensemble filters on the large scale part [75,76] whose dimension is small enough so that the non-Gaussian statistics of the large scale part can be calculated from a particle filter, whereas the statistics of the small scale part are conditionally Gaussian given the large scale part. See Section 6.3 for more details. Note that such ideas can also be applied to other cheap forecast models in addition to the superparameterization. For example, another multiscale filtering algorithm with quasilinear Gaussian dynamically orthogonality method as the forecast method in an adaptively evolving low dimensional subspace has been developed in [80].
Due to the significance in model approximation, data assimilation and prediction, it is necessary to develop a general framework for the complex multiscale nonlinear turbulent dynamical systems with conditional Gaussian structures. The key idea of such conditional Gaussian systems is that a hybrid strategy can be applied to deal with the state variables , where particle methods are used to solve the non-Gaussian statistics in the relatively low dimensional subspace associated with and extremely cheap algorithms with closed analytical formulae are adopted to solve the conditional Gaussian statistics of conditioned on in the remaining high dimensional subspace. The Gaussianity in the conditional statistics are usually quite accurate as approximations since the small or unresolved scales with the given (or fixed) large-scale variables usually represent fluctuations in multiscale systems and the statistics are close to Gaussian. Nevertheless, the marginal statistics of the small-scale variables themselves can be highly non-Gaussian, which is one of the salient features as in nature [37]. Notably, developing such computationally efficient models that explores conditional statistics also involves the mutual feedback between large scale and small scale variables. Thus, the full system is completely nonlinear and allows physics-constrained nonlinear interactions. The general conditional Gaussian nonlinear modeling framework provides a powerful tool in multiscale data assimilation, statistical prediction, solving high-dimensional PDFs as well as parameter estimation, causality analysis and understanding model errors.
3. A Summary of the General Mathematical Structure of Nonlinear Conditional Gaussian Systems
3.1. Conditional Gaussian Nonlinear Dynamical Systems
The conditional Gaussian systems have the following abstract form [28]:
Once for is given, conditioned on becomes a Gaussian process:
Despite the conditional Gaussianity, the coupled system (1) and (2) remains highly nonlinear and is able to capture the non-Gaussian features as in nature. The conditional Gaussian distribution in (3) has closed analytic form [30]
which can be solved in an exact and efficient way. The conditional Gaussian framework (1)-(2)-(5) is useful in the parameter estimation, data assimilation, prediction and uncertainty quantification of complex turbulent dynamical systems as will be discussed throughout this article.
In this article, many conditional Gaussian systems with complex turbulent dynamical structures will be studied. For the convenience of the reader, we will always use a blue color to represent the variables that belong to and use a magenta color to denote those for .
3.2. Kalman–Bucy Filter: The Simplest and Special Data Assimilation Example within Conditional Gaussian Framework
A special case of the general conditional Gaussian framework (1) and (2) is the so-called Kalman–Bucy filter [105,106,107,108]. The Kalman–Bucy filter is a continuous time version of the Kalman filter [21,94] and it deals with the linear coupled systems:
In (6) and (7), all the vectors and matrices and are functions of only t and they have no dependence on in order to guarantee the linearity in the coupled system. In the Kalman–Bucy filter, (7) is the underlying dynamics and (6) is the observational process. The observation cannot change the underlying dynamics and therefore no appears in (7).
The filter estimate (also known as the posterior distribution) is the conditional distribution of given the observation , i.e., . In light of (4) and (5), the mean and variance of has the following explicit expressions:
Corresponding to (4) and (5), Chapter 6 of Bensoussan’s book [109] includes rigorous mathematical derivations of the exact solutions of the Kalman–Bucy filter and some other more general conditional Gaussian filters. It is also pointed out in [109] that all these filters belong to the general conditional Gaussian filtering framework in (1)-(2)-(4)-(5) introduced in [110], which is an early version of the book authored by Liptser and Shiryaev [30].
3.3. Physics-Constrained Nonlinear Models with Conditional Gaussian Statistics
Physics-constrained nonlinear stochastic models are the recent development of data driven statistical-dynamical models for the time series of a partial subset of observed variables, which arise from observations of nature or from an extremely complex physical model [31,32]. The physics-constrained nonlinear stochastic modeling framework builds on early works for single layer models without memory effects, which uses physical analytic properties to constrain data driven methods. These physics-constrained nonlinear stochastic models succeed in overcoming both the finite-time blowup and the lack of physical meaning issues in various ad hoc multi-layer regression models [31,33].
The physics-constrained nonlinear stochastic models contain energy-conserving quadratic nonlinear interactions [1,31,32], namely
where and the dimensions of and are and , respectively. In (8), is a linear operator representing dissipation and dispersion. Here, is skew symmetric representing dispersion and is a negative definite symmetric operator representing dissipative process such as surface drag, radiative damping, viscosity, etc. is a bilinear term and it satisfies energy conserving property with .
Many of the physics-constrained nonlinear stochastic models belong to the conditional Gaussian framework. The goal here is to derive a general class of conditional Gaussian physics-constrained nonlinear stochastic models. To this end, we rewrite the Equation (8) in the following way:
where the explicit dependence of the coefficients on time t has been omitted for notation simplicity. In (9), , , and correspond to the the linear term in (8) while and represent the nonlinear terms in the processes associated with the variables in (1) and those in (2), respectively. Since the conditional Gaussian systems do not allow quadratic nonlinear interactions between and itself, both and can be written down as follows:
where stands for the quadratic terms involving only and represents the quadratic interactions between and . Given the nonlinear terms in (10), the energy-conserving quadratic nonlinearity in (8) implies
Inserting (10) into (9) yields the conditional Gaussian systems with energy-conserving quadratic nonlinear interactions,
We start with , which can be written as
where each is a skew-symmetric matrix with and is the j-th entry of . The energy-conserving property is easily seen by multiplying to in (14),
Due to the skew-symmetric property of . In fact, usually represents the internal oscillation with non-constant oscillation frequency that depends on .
Next, contains three components,
One of the components in (15), say , has its own energy conservation, i.e.,
Here, and therefore
where each column of is given by
with being a skew-symmetric matrix. Thus, with (17) in hand, (16) becomes
where is the j-th entry of .
The other two components of in (12) involve the interactions with in (13). On one hand, the energy-conserving property in the following two terms is obvious,
where each is a matrix, is the j-th entry of and is a vector of size with the j-th entry being . On the other hand, the remaining two terms and are similar to those in (18)–(20) but deal with the cross-interactions between different components of such as replacing by in (20). To this end, we define the following
which satisfies
In fact, (18)–(21) are important for generating the intermittent instability, where plays the role of both damping and anti-damping for the dynamics of .
Finally, involves any iterations between and itself that satisfies
3.4. Multiscale Conditional Gaussian with MTV Stochastic Modeling Strategy
Let’s start with a general nonlinear deterministic model with quadratic nonlinearity,
where the notations of vectors and matrices are the same as in Section 3.3. In (25), the state variables are again decomposed into . Here, has multiscale features, where denotes the resolved variables that evolve slowly in time (e.g., climate variables) while are unresolved or unobserved fast variables (e.g., weather variables). The system (25) can be written down into more detailed forms:
Different from (12) and (13), the nonlinear interaction between fast scale variables themselves and are also included in (26) and (27). To make the mutiscale system (26) and (27) fit into the conditional Gaussian framework, two modifications are needed. First, if we link (26) and (27) with the general conditional Gaussian framework (1) and (2), the quadratic terms involving the interactions between and itself, namely and , are not allowed there. Second, stochastic noise is required at least to the system of .
To fill in these gaps, the most natural way is to apply idea from the MTV strategy to the multiscale system (26) and (27). The MTV strategy [45,46,47,48], named after Majda, Timofeyev and Vanden-Eijnden, is a systematic mathematical strategy for stochastic mode reduction. The MTV strategy is a two-step procedure:
- The equations of motion for the unresolved fast modes are modified by representing the nonlinear self-interactions terms between unresolved modes by stochastic terms.
- The equations of motion for the unresolved fast modes are eliminated using the standard projection technique for stochastic differential equations.
In fact, we only need to take the first step in the MTV strategy here. Using to represent the time scale separation between and , the terms with quadratic nonlinearity of and itself are approximated by
That is, we replace the quadratic nonlinearity of by a linear damping and stochastic noise, where , , and are positive definite symmetric matrices. The motivation of (28) is that the nonlinear self-interacting terms of fast variables are responsible for the chaotic sensitive dependence on small perturbations and do not require a more detailed description if their effect on the coarse-grained dynamics for the climate variables alone is the main objective. On the other hand, the quadratic nonlinear interactions between and are retained.
Note that in the second step of the MTV strategy, standard techniques of averaging and adiabatic elimination of fast modes in stochastic equations are applied, assuming that . Here, we assume is a finite small value and thus do not apply the second step of the MTV strategy.
4. A Gallery of Examples of Conditional Gaussian Systems
This section includes various conditional Gaussian complex nonlinear dynamical systems and their applications.
4.1. Physics-Constrained Nonlinear Low-Order Stochastic Models
4.1.1. The Noisy Versions of Lorenz Models
Lorenz proposed three famous models in 1963, 1984 and 1996. These models are widely used as simplified models to mimic the turbulent and chaotic behavior and as test models for data assimilation and prediction in atmosphere and ocean science. By incorporating noise and other small-scale parameterizations, these models all belong to the conditional Gaussian family.
1. The Noisy Lorenz 63 (L-63) Model
The deterministic L-63 model ( in (31)) is proposed by Lorenz in 1963 [34]. It is a simplified mathematical model for atmospheric convection. The equations relate the properties of a two-dimensional fluid layer uniformly warmed from below and cooled from above. In particular, the equations describe the rate of change of three quantities with respect to time: x is proportional to the rate of convection, y to the horizontal temperature variation, and z to the vertical temperature variation. The constants , , and are system parameters proportional to the Prandtl number, Rayleigh number, and certain physical dimensions of the layer itself [111]. The L-63 model is also widely used as simplified models for lasers, dynamos, thermosyphons, brushless direct current DC motors, electric circuits, chemical reactions and forward osmosis [112,113,114,115,116,117,118]. the noisy version of the L-63 includes more turbulent and small-scale features and their interactions with the three large scale variables while retains the characteristics in the original L-63. The noisy L-63 model is a conditional Gaussian system (1) and (2) with and . It also belongs to the conditional Gaussian family with and .
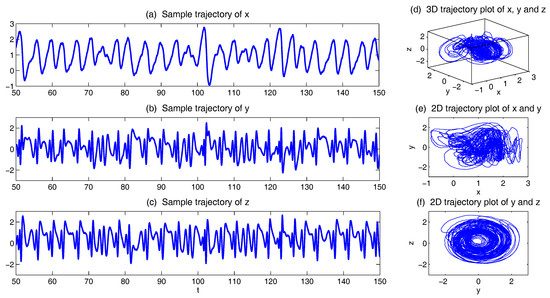
In Figure 1, we show some sample trajectories of the noisy L-63 model (31) with the typical values that Lorenz used [34],
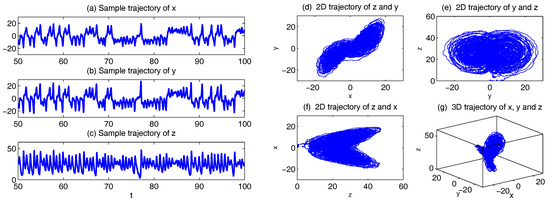
Figure 1.
Sample trajectories of the noisy L-63 model (31) with parameters = 28, = 10, = 8/3, . (a–c) 1D trajectories of x, y and z, respectively; (d–f) 2D trajectories of , and ; (g) 3D trajectory of .
Together with a moderate noise level
In addition to the chaotic behavior and the butterfly profile, the small fluctuations due to the noise are also clearly observed in these trajectories.
2. The Noisy Lorenz 96 (L-96) and Two-Layer L-96 Models
The original L-96 model with noise is given by
The model can be regarded as a coarse discretization of atmospheric flow on a latitude circle with complicated wave-like and chaotic behavior. It schematically describes the interaction between small-scale fluctuations with larger-scale motions. However, the noisy L-96 model in (34) usually does not have the conditional Gaussian structure unless a careful selection of a subset of for . Nevertheless, some two-layer L-96 models do belong to conditional Gaussian framework. These two-layer L96 models are conceptual models in geophysical turbulence that includes the interaction between small-scale fluctuations in the second layer with the larger-scale motions. They are widely used as a testbed for data assimilation and parameterization in numerical weather forecasting [36,40,119,120]. One natural choice of the two-layer L-96 model is the following [36]:
Linking the general conditional Gaussian framework (1) and (2) with the two-layer L-96 model in (35), represents the large-scale motions while involves the small-scale variables.
In Figure 2, Figure 3 and Figure 4, numerical simulations of the two-layer L-96 model in (35) with and are shown. Here, the damping and coupling coefficients are both functions of space with
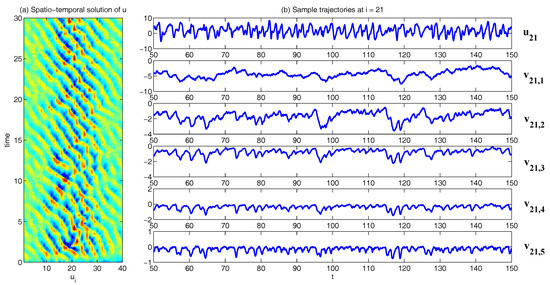
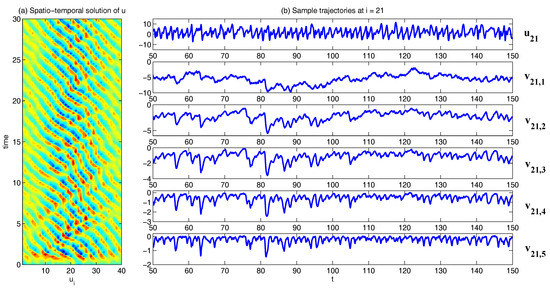
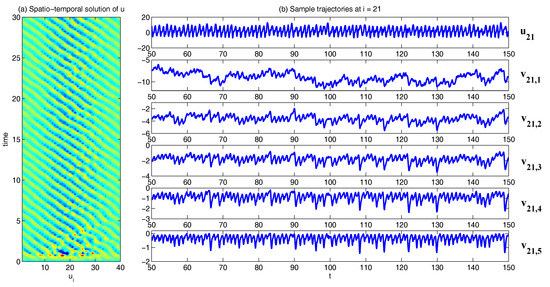
These mimic the situation that the damping and coupling above the ocean are weaker than those above the land since the latter usually have stronger friction or dissipation. Therefore the model is inhomogeneous and the large-scale wave patterns over the ocean are more significant, where a westward propagation is clearly seen in all these figures (Panel (a)). The other parameters are as follows:
which imply that the damping time is shorter in the smaller scales. The model in (35) has many desirable properties as in more complicated turbulent systems. Particularly, the smaller scales are more intermittent (Panel (b)) with stronger fat tails in PDFs. Different constant forcing and 16 are adopted in Figure 2, Figure 3 and Figure 4, which result in various chaotic behavior for the system. With the forcing increase, the oscillation patterns in u become more regular while the small scale variables at each fixed grid point show more turbulent behavior.
3. The Noisy Lorenz 84 (L-84) Model
The noisy L-84 model is an extremely simple analogue of the global atmospheric circulation [121,122], which has the following form [35,123]:
In (38), the zonal flow x represents the intensity of the mid-latitude westerly wind current (or the zonally averaged meridional temperature gradient, according to thermal wind balance), and a wave component exists with y and z representing the cosine and sine phases of a chain of vortices superimposed on the zonal flow. Relative to the zonal flow, the wave variables are scaled so that is the total scaled energy (kinetic plus potential plus internal). Note that these equations can be derived as a Galerkin truncation of the two-layer quasigeostrophic potential vorticity equations in a channel.
In the L-84 model (38), the vortices are linearly damped by viscous and thermal processes. The damping time defines the time unit and is a Prandtl number. The terms and represent the amplification of the wave by interaction with the zonal flow. This occurs at the expense of the westerly current: the wave transports heat poleward, thus reducing the temperature gradient, at a rate proportional to the square of the amplitudes, as indicated by the term . The terms and represent the westward (if ) displacement of the wave by the zonal current, and allows the displacement to overcome the amplification. The zonal flow is driven by the external force which is proportional to the contrast between solar heating at low and high latitudes. A secondary forcing g affects the wave, it mimics the contrasting thermal properties of the underlying surface of zonally alternating oceans and continents. When and , the system has a single steady solution , representing a steady Hadley circulation. This zonal flow becomes unstable for , forming steadily progressing vortices. For , the system clearly shows chaotic behavior.
Linking (38) to the general conditional Gaussian framework (1) and (2), it is clear that the zonal wind current is the variable for state estimation or filtering given the two phases of the large-scale vortices .
In Figure 5, we show the sample trajectories of the system with the following parameters:
which were Lorenz adopted [35]. Small noise is also added to the system. It is clear that y and z are quite chaotic and they appear as a pair (Panels (b,c,f)). On the other hand, x is less turbulent and occurs in a relatively slower time scale. It plays an important role in changing both the phase and amplitude of y and z.
4.1.2. Nonlinear Stochastic Models for Predicting Intermittent MJO and Monsoon Indices
Assessing the predictability limits of time series associated with the tropical intraseasonal variability such as the the Madden–Julian oscillation (MJO) and monsoon [41,42,43] is an important topic. They yield an interesting class of low-order turbulent dynamical systems with extreme events and intermittency. For example, Panels (c,d) in Figure 6 show the MJO time series [41], measured by outgoing longwave radiation (OLR; a proxy for convective activity) from satellite data [88]. These time series are obtained by applying a new nonlinear data analysis technique, namely nonlinear Laplacian spectrum analysis [124], to these observational data. To describe and predict such intermittent time series, the following model is developed:
with
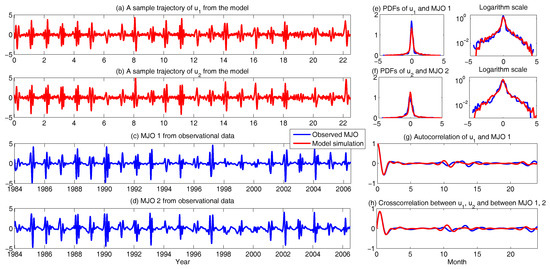
Figure 6.
Using physics-constrained nonlinear low-order stochastic model (6) to capture the key features of the observed MJO indices. (a,b) sample trajectories from the model (6); (c,d) MJO indices from observations; (e,f) comparison of the PDFs in both linear and logarithm scales; (g,h) comparison of the autocorrelation and cross-correlation functions.
Such a model is derived based on the physics-constrained nonlinear data-driven strategy [31,32]. In this model, are the two-dimensional indices obtained from observational data while are the two hidden unobserved variables representing other important underlying physical processes that interact with the observational ones. The coupled system is a conditional Gaussian one, which plays an important role here since there is no direct observational data for the two hidden processes v and . In fact, in order to obtain the initial values of v and for ensemble forecast, the data assimilation formula in (4) and (5) is used given the observational trajectories of and . The parameters here are estimated via information theory. With the calibrated parameters, the sample trajectories as shown in Panels (a,b) capture all the important features as in the MJO indices from observations. In addition, the non-Gaussian PDFs (Panels (e,f)) and the correlation and cross-correlation functions (Panels (g,h)) from the model nearly perfectly match those associated with the observations. In [41], significant prediction skill of these MJO indices using the physics-constrained nonlinear stochastic model (6) was shown. The prediction based on ensemble mean can have skill even up to 40 days. In addition, the ensemble spread accurately quantify the forecast uncertainty in both short and long terms. In light of a twin experiment, it was also revealed in [41] that the model in (6) is able to reach the predictability limit of the large-scale cloud patterns of the MJO.
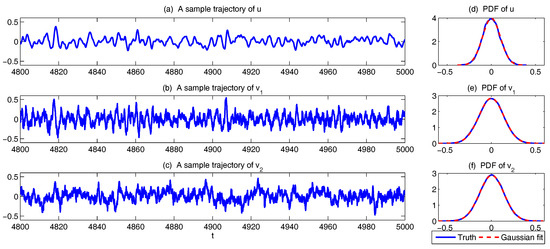
4.1.3. A Simple Stochastic Model with Key Features of Atmospheric Low-Frequency Variability
This simple stochastic climate model [49,125] presented below is set-up in such a way that it features many of the important dynamical features of comprehensive global circulation models (GCMs) but with many fewer degree of freedom. Such simple toy models allow the efficient exploration of the whole parameter space that is impossible to conduct with GCMs:
where . It contains a quadratic nonlinear part that conserves energy as well as a linear operator. Therefore, this model belongs to physics-constrained nonlinear stochastic model family. The linear operator includes a skew-symmetric part that mimics the Coriolis effect and topographic Rossby wave propagation, and a negative definite symmetric part that is formally similar to the dissipation such as the surface drag and radiative damping. The two variables and can be regarded as climate variables while the other two variables and become weather variables that occur in a much faster time scale when is small. In fact, the MTV strategy as described in Section 3.4 is applied to and that introduce this together with stochastic noise and damping terms. The coupling in different variables is through both linear and nonlinear terms, where the nonlinear coupling through produces multiplicative noise. Note that when , applying an explicit stochastic mode reduction results in a two-dimensional system for the climate variables [45,46]. Clearly, the 4D stochastic climate model (42) is a conditional Gaussian system with and .
In Figure 7, sample trajectories and the associated PDFs in two dynamical regimes are shown. The two regimes differ by the scale separation with (Regime I) and (Regime II), respectively. The other parameters are the same in the two regimes:
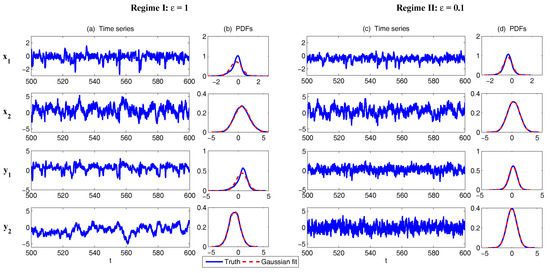
It is obvious that with , all the four variables lie in the same time scale. Both “climate variable” and “weather variable” can have intermittent behavior with non-Gaussian PDFs. On the other hand, with , a clear scale separation can be seen in the time series, where and occur in a much faster time scale than and . Since the memory time due to the strong damping becomes much shorter in and , the associated PDFs for these “weather variables” become Gaussian.
4.1.4. A Nonlinear Triad Model with Multiscale Features
The following nonlinear triad system is a simple prototype nonlinear stochastic model that mimics structural features of low-frequency variability of GCMs with non-Gaussian features [50] and it was used to test the skill for reduced nonlinear stochastic models for the fluctuation dissipation theorem [126]:
The triad model (44)–(46) involves a quadratic nonlinear interaction between and with energy-conserving property that induces intermittent instability. On the other hand, the coupling between and is linear and is through the skew-symmetric term with coefficient , which represents an oscillation structure of and . Particularly, when is large, fast oscillations become dominant for and while the overall evolution of can still be slow provided that the feedback from and is damped quickly. Such multiscale structure appears in the turbulent ocean flows described for example by shallow water equation, where stands for the geostrophically balanced part while and mimics the fast oscillations due to the gravity waves [11,122]. The large-scale forcing represents the external time-periodic input to the system, such as the seasonal effects or decadal oscillations in a long time scale [121,127]. In addition, the scaling factor plays the same role as in the 4D stochastic climate model (42) that allows a difference in the memory of the three variables. Note that the MTV strategy as described in Section 3.4 is applied to and that introduces the factor . The nonlinear triad model in (44)–(46) belongs to conditional Gaussian model family with and .
To understand the dynamical behavior of the nonlinear triad model (44)–(46), we show the model simulations in Figure 8 for the following two regimes:
In Regime I, and therefore and occur in the same time scale. Since a large noise coefficient is adopted in the dynamics of , the PDF of is nearly Gaussian and the variance is large. The latter leads to a skewed PDF of due to the nonlinear feedback term , where the extreme events are mostly towards the negative side of due to the negative sign in front of the nonlinear term. As a consequence, the also has a skewed PDF but the skewness is positive. On the other hand, in Regime I, where , and both have a short decorrelation time and the associated PDFs are nearly Gaussian. Nevertheless, the slow variable is highly non-Gaussian due to the direct nonlinear interaction between in which plays the role of stochastic damping and it results in the intermittent instability in the signal of .
4.1.5. Conceptual Models for Turbulent Dynamical Systems
Understanding the complexity of anisotropic turbulence processes over a wide range of spatiotemporal scales in engineering shear turbulence [128,129,130] as well as climate atmosphere ocean science [73,121,122] is a grand challenge of contemporary science. This is especially important from a practical viewpoint because energy often flows intermittently from the smaller scales to affect the largest scales in such anisotropic turbulent flows. The typical features of such anisotropic turbulent flows are the following: (A) The large-scale mean flow is usually chaotic but more predictable than the smaller-scale fluctuations. The overall single point PDF of the flow field is nearly Gaussian whereas the mean flow pdf is sub-Gaussian, in other words, with less extreme variability than a Gaussian random variable; (B) There are nontrivial nonlinear interactions between the large-scale mean flow and the smaller-scale fluctuations which conserve energy; (C) There is a wide range of spatial scales for the fluctuations with features where the large-scale components of the fluctuations contain more energy than the smaller-scale components. Furthermore, these large-scale fluctuating components decorrelate faster in time than the mean-flow fluctuations on the largest scales, whereas the smaller-scale fluctuating components decorrelate faster in time than the larger-scale fluctuating components; (D) The PDFs of the larger-scale fluctuating components of the turbulent field are nearly Gaussian, whereas the smaller-scale fluctuating components are intermittent and have fat-tailed PDFs, in other words, a much higher probability of extreme events than a Gaussian distribution.
Denote u the largest variable and a family of small-scale variables. One can think of u as the large-scale spatial average of the turbulent dynamics at a single grid point in a more complex system and as the turbulent fluctuations at the grid point. To add a sense of spatial scale, one can also regard as the amplitude of the k-th Fourier cosine mode evaluated at a grid point. A hallmark of turbulence is that the large scales can destabilize the smaller scales in the turbulent fluctuations intermittently and this increased small-scale energy can impact the large scales; this key feature is captured in the conceptual models. With the above discussion, here are the simplest models with all these features, the conceptual dynamical models for turbulence [37]:
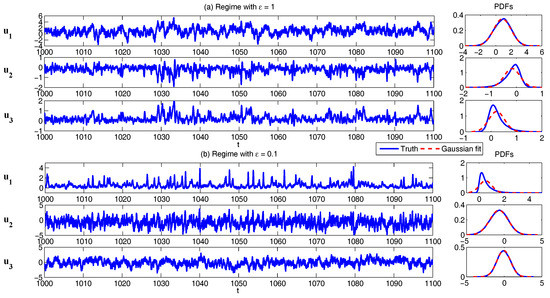
Now, let us take and use the following parameters which have been tested in [37] that represent the features of turbulent flows:
The sample trajectories and the associated PDFs are shown in Figure 9. The largest scale u is nearly Gaussian while more intermittent behavior is observed in the smaller scale variables. Here, the nonlinear interaction plays an important role in generating these turbulent features and the total energy in the nonlinear terms is conserved. Thus, all the features (A)–(D) above are addressed in this model. It is also clear that the conceptual turbulent model (48) is a conditional Gaussian system with , .
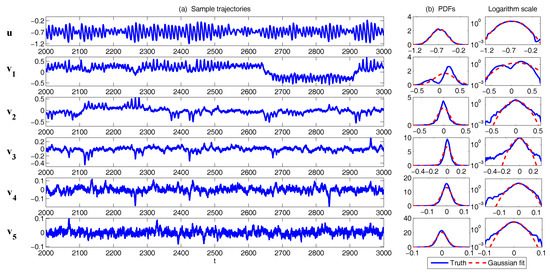
In [36], a modified version of the conceptual model was developed:
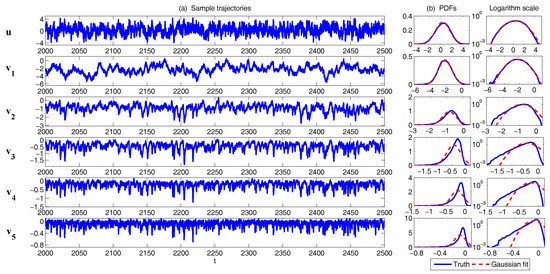
This modified conceptual turbulent model again fits into the conditional Gaussian framework, where includes the largest scale variable and represents small-scale ones. The modified conceptual turbulent model (50) and (51) inherits many important features from the dynamics in (48). For example, with suitable choices of parameters, the large-scale observed variable u is nearly Gaussian while small-scale variables becomes more intermittent with the increasing of k. In addition, the small-scale turbulent flows provide feedback to large scales through the nonlinear coupling with energy-conserving property. An example is shown in Figure 10 with the following choice of parameters:
4.1.6. A Conceptual Model of the Coupled Atmosphere and Ocean
In [39], the signatures of feedback between the atmosphere and the ocean are studied with a simple coupled model, which can be used to exam the effects of oceanic variability and seasonality.
The atmosphere component is the Lorenz 1984 model (38) discussed in Section 4.1.1, except that the forcing has an explicit form
which represents seasonal effect. Therefore, the atmosphere model reads
Again, x represents the amplitude of the zonally averaged meridional temperature gradient while y and z denote the amplitudes of the cosine and sine longitudinal phases of a chain of large-scale waves. The poleward heat transport is achieved by the eddies at a rate proportional to , and this heat transport reduces the zonally averaged temperature gradient. The term represents the zonally averaged forcing due to the equator-pole difference in solar heating and it varies on a seasonal timescale.
On the other hand, the oceanic module simulates the wind-driven circulation in a basin that occupies a fraction r of the longitudinal extent of the atmosphere. Its dynamics are described by a set of four ordinary differential equations, namely,
Here, p represents the zonally averaged meridional temperature gradient at the sea surface, while q represents the basin-averaged sea surface temperature. The poleward heat transport is achieved by a large-scale flow, at a rate proportional to . The average temperature Q is conserved in the absence of any coupling with the atmosphere. The transport is represented by two phases of the streamfunction, and . The streamfunction undergoes damped oscillations with a period, , of y and a decay time, , of 17 y. This damped oscillation is the only source of internal variability in the ocean and is due to the intrinsic decadal variability of the wind-driven circulation. Note that the equations for the two phases of the streamfunction can be derived as a Galerkin truncation of the one-and-a-half-layer quasigeostrophic potential vorticity equation for long linear Rossby waves. It is suggested in [131,132] that basin modes with decadal frequencies can be excited by stochastic atmospheric forcing and represent a resonant response of the ocean. This model essentially assumes that the intrinsic decadal variability of the ocean wind-driven circulation is described by one such mode. For weak flow, the wind-driven gyres reduce the zonally averaged north-south temperature gradient in a basin.
The feedback between the ocean and the atmosphere are constructed so as to conserve total heat in the air–sea exchange. The coupled atmosphere-ocean model reads:
where the terms with underlines represent the coupling between atmosphere and ocean. In (55), the term on the right-hand side of the evolution of p is parameterized by a constant n such that the ocean part become a linear model. Therefore, (55) includes a nonlinear atmosphere model and a linear ocean model. The coupling is through linear terms. Thus, treating the atmosphere variables as and the ocean variables as , the coupled system (55) belongs to conditional Gaussian framework. It is also obvious that the coupled model belongs to the physics-constrained regression model family.
In (55), the air–sea heat fluxes are proportional to the difference between the oceanic and the atmospheric temperature: these are the terms and . The bulk transfer coefficient, m, is assumed to be constant. In the atmospheric model, this term needs to be multiplied by the fraction of earth covered by ocean, r. In the oceanic model, the air–sea flux is divided by c, which is the ratio of the vertically integrated heat capacities of the atmosphere and the ocean. The constant represents the fraction of solar radiation that is absorbed directly by the ocean. There is no heat exchange between the atmospheric standing wave z and the ocean because z represents the sine phase of the longitudinal eddies and has zero zonal mean across the ocean. A feedback between z and the ocean would appear if we added an equation for the longitudinal temperature gradient of the ocean. The effect of the wind stress acting on the ocean is represented as a linear forcing proportional to x and y in the equations for the streamfunction, . The coupling constants , , , and are chosen to produce realistic values for the oceanic heat transport. Detailed discussions of the parameter choices and model behaviors in different dynamical regimes are shown in [39].
4.1.7. A Low-Order Model of Charney–DeVore Flows
The concept of multiple equilibria in a severely truncated “low-order” image of the atmospheric circulation was proposed by Charney and DeVore [133] (the CdV model). The simplest CdV model describes a barotropic zonally unbounded flow over a sinusoidal topography in a zonal channel with quasigeostrophic dynamics. The vorticity balance of such a flow
needs an additional constraint to determine the boundary values of the streamfunction on the channel walls. The vorticity concept has eliminated the pressure field and its reconstruction in a multiconnected domain requires the validity of the momentum balance, integrated over the whole domain,
Here, U is the zonally and meridionally averaged zonal velocity and is the vorticity and the zonal momentum imparted into the system.
The depth of the fluid is and the topography height b is taken sinusoidal, with , where L is the length and the width of the channel. A heavily truncated expansion
represents the flow in terms of the zonal mean U and a wave component with sine and cosine amplitudes A and B. It yields the low-order model [29,133]:
where is the barotropic Rossby wave speed and . Apparently, (58) belongs to the conditional Gaussian framework when the zonal mean flow is treated as while the two wave components belong to . This model also belongs to physics-constrained nonlinear modeling family.
Without the stochastic noise, three equilibria are found if is well above . The three possible steady states can be classified according to the size of the mean flow U compared to the wave amplitudes: (a) The high zonal index regime is frictionally controlled, the flow is intense and the wave amplitude is low; (b) The low zonal index regime is controlled by form stress, the mean flow is weak and the wave is intense; (c) The intermediate state is transitional, it is actually unstable to perturbations. This “form stress instability” works obviously when the slope of the resonance curve is below the one associated with friction, i.e., , so that a perturbation must run away from the steady state.
4.1.8. A Paradigm Model for Topographic Mean Flow Interaction
A barotropic quasi-geostrophic equation with a large scale zonal mean flow can be used to solve topographic mean flow interaction. The full equations are given as follows [2]:
Here, q and are the small-scale potential vorticity and stream function, respectively. The large scale zonal mean flow is characterized by and the topography is defined by function . The parameter is associated with the -plane approximation to the Coriolis force. The domain considered here is a periodic box .
Now, we construct a set of special solutions to (59), which inherit the nonlinear coupling of the small-scale flow with the large-scale mean flow via topographic stress. Consider the following Fourier decomposition:
where and . By assuming and inserting (60) into (59), we arrive at the layered topographic equations in Fourier form:
where and . Consider a finite Fourier truncation. By adding extra damping and stochastic noise for compensating the information truncated in the finite Fourier decomposition in ,
We arrive at a conditional Gaussian system with and .
In [2], very rich chaotic dynamics are reached with two-layer topographic models. Here as a concrete example, we consider a single layer topography in the zonal direction [32],
where and H denotes the topography amplitude. Choose
and rotate the variables counterclockwise by 45° to coordinate . We arrive at
where = . This model is similar to the Charney and Devore model for nonlinear regime behavior without dissipation and forcing. Then, with additional damping and noise in and approximating the interaction with the truncated Rossby wave modes, we have the following system:
Linear stability is satisfied for while there is only neutral stability of u. The system in (62) satisfies the conditional Gaussian framework where and . Notably, this model also belongs to the physics-constrained nonlinear model family. One interesting property of this model is that, if the invariant measure exists, then, despite the nonlinear terms, the invariant measure is Gaussian. The validation of this argument can be easily reached following [31]. A numerical illustration is shown Figure 11 with the following parameters:
Note that, if stochastic noise is also added in the evolution equation of u, then the system (62) also belongs to the conditional Gaussian model family with and .
4.2. Stochastically Coupled Reaction–Diffusion Models in Neuroscience and Ecology
4.2.1. Stochastically Coupled FitzHugh–Nagumo (FHN) Models
The FitzHugh–Nagumo model (FHN) is a prototype of an excitable system, which describes the activation and deactivation dynamics of a spiking neuron [57]. Stochastic versions of the FHN model with the notion of noise-induced limit cycles were widely studied and applied in the context of stochastic resonance [134,135,136,137]. Furthermore, its spatially extended version has also attracted much attention as a noisy excitable medium [138,139,140,141].
One common representation of the stochastic FHN model is given by
where the time scale ratio is much smaller than one (e.g., ), implying that is the fast and is the slow variable. The coupled FHN system in (64) is obviously a conditional Gaussian system with and . The nonlinear function is one of the nullclines of the deterministic system. A common choice for this function is
where the parameter c is either 1 or . On the other hand, is usually a linear function of u. In (64), is an external source and it can be a time-dependent function. In the following, we set to be a constant external forcing for simplicity. Diffusion term is typically imposed in the dynamics of u. Thus, with these choices, a simple stochastically coupled spatial-extended FHN model is given by
With and , the model in (66) contains the model families with both coherence resonance and self-induced stochastic resonance [142]. Applying a finite difference discretization to the diffusion term in (66), we arrive at the FHN model in the lattice form
Note that the parameter is required in order to guarantee that the system has a global attractor in the absence of noise and diffusion. The random noise is able to drive the system above the threshold level of global stability and triggers limit cycles intermittently. The model behavior of (67) in various dynamical regimes has been studied in [36]. The model can show both strongly coherent and irregular features as well as scale-invariant structure with different choices of noise and diffusion coefficients.
There are several other modified versions of the FHN model that are widely used in applications. One that appears in the thermodynamic limit of an infinitely large ensemble is the so-called globally coupled FHN model
where . Different from the model in (67) where each is only directly coupled to its two nearest neighbors and , each in the globally coupled FHN model (68) is directly affected by all . In [57], various closure methods are developed to solve the time evolution of the statistics associated with the globally coupled FHN model (68).
Another important modification of the FHN model is to include the colored noise into the system as suggested by [57,143]. For example, the constant a on the right-hand side of (67) can be replaced by an OU process [143] that allows the memory of the additive noise. Below, by introducing a stochastic coefficient in front of the linear term u, a stochastically coupled FHN model with multiplicative noise is developed. The model reads
The stochastically coupled FHN model with multiplicative noise belongs to the conditional Gaussian framework with and .
To provide intuition about the dynamical behavior of the stochastically coupled FHN model with multiplicative noise (69), we show the time series of the model with , namely there is no diffusion term and the coupled model is three-dimensions. The three-dimensional model with no diffusion reads,
with the following parameters
Figure 12 shows the model simulations with different . Note that, when , the model (70) reduces to a two-dimensional model with . From Figure 12, it is clear that u is always intermittent. On the other hand, v has only a small variation when is nearly a constant while more extreme events in v are observed when increases (see the PDF of v). Note that the extreme events in v are strongly correlated with the quiescent phase of u according to the phase diagram. These extreme events do not affect the regular ones that form a closed loop with the signal of u. With the increase of , the periods of u becomes more irregular. This can be seen in (d), which shows the distribution of the time interval T between successive oscillations in u. With a large , this distribution not only has a large variance but also shows a fat tail.
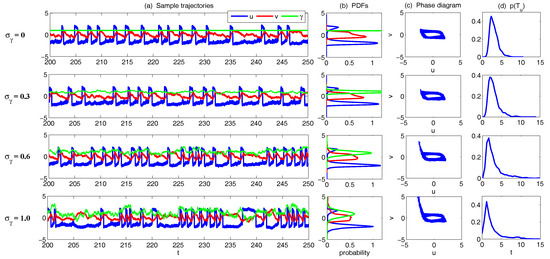
Figure 12.
Simulations of the three-dimensional stochastically coupled FHN model with multiplicative noise (70). Different values of noise coefficient are used here. (a) sample trajectories of u (blue), v (red) and (green); (b) the associated PDFs; (c) phase diagram of ; (d) distribution of the time interval T between successive oscillations in u.
Finally, Figure 13 shows the model simulation in the spatial-extended system (69), where . The same parameters as in (71) are taken and and for all i. Homogeneous initial conditions and are adopted for all . The four rows show the simulation with different , where is the noise coefficient at all the grid points, namely for all i. With the increase of , the spatial structure of u becomes less coherent and more disorganized, which is consistent with the temporal structure as shown in Figure 12. In addition, more extreme events can be observed in the field of v due to the increase of the multiplicative noise.
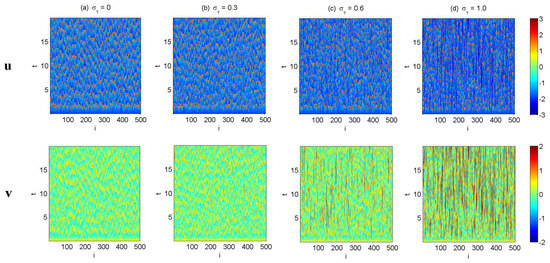
Figure 13.
Simulations of the stochastically coupled FHN model with multiplicative noise system with spatial-extended structure (69). The same parameters as in (71) are taken and and for all i. Homogeneous initial conditions and are adopted for all . (a–d) show the simulation with different and , where is the noise coefficient at all the grid points, namely for all i.
4.2.2. The Predator–Prey Models
The functioning of a prey–predator community can be described by a reaction–diffusion system. The standard deterministic predator–prey models have the following form [58]:
where u and v represent predator and prey, respectively. Here, , and are constants: is the maximal growth rate of the prey, b is the carrying capacity for the prey population, and H is the half-saturation abundance of prey. Introducing dimensionless variables
and, using the dimensionless parameters,
The non-dimensional system (by dropping the primes) becomes
Note that, in the predator–prey system, both u and v must be positive.
Clearly, the deterministic model is highly idealized and therefore stochastic noise is added into the system [144,145]. In order to keep the positive constraints for the variables u and v, multiplicative noise is added to the system. One natural choice of the noise is the following:
Here, is a function of u and its value vanishes at to guarantee the positivity of the system. The most straightforward choice of is , which leads to small noise when the signal of u is small and large noise when the amplitude of u is large. Another common choice of this multiplicative noise is such that the noise level remains nearly constant when u is larger than a certain threshold. Applying a spatial discretization to the diffusion terms, the stochastic coupled predator–prey in (74) belongs to the conditional Gaussian framework with and . Note that when , the conditional Gaussian estimation (4) and (5) will become singular due to the term . Nevertheless, the limit cycle in the dynamics will not allow the solution to be trapped at . Assessing this issue using rigorous analysis is an interesting future work.
Figure 14 shows sample trajectories and phase portraits under the simplest setup simulation of (74) without diffusion terms and . The parameters are given as follows:
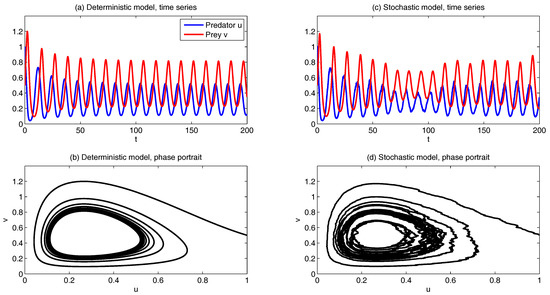
Panels (a,b) show the simulations without stochastic noise while Panels (c,d) show the results with a multiplicative noise . The intermittent behavior is found in both u and v.
In Figure 15, we show the simulations of the spatial-extended system in (74), where we take 30 and 90 grid points in x and y directions, respectively. Spatially periodic boundary conditions are used here. In all three of the simulations in Columns (a–c), the initial values for both u and v are the same. Column (a) shows the model simulation of (74) with diffusion terms and , but the noise coefficient is zero, namely . Therefore, the model is deterministic and spatial patterns can be seen in all the time instants. In Column (b), we ignore the diffusion terms and thus the system is spatially decoupled. Nevertheless, a stochastic noise is added to the system. The consequence is that the initial correlated structure will be removed by the noise and, at , the spatial structures are purely noisy. Finally, in Column (c), the simulations of the model with both the diffusion terms , and the stochastic noise are shown. Although after , the initial structure completely disappears, the diffusion terms correlate the nearby grid points and spatial structures are clearly observed in these simulations. Due to the stochastic noise, the patterns are polluted and are more noisy than those shown in Column (a). In addition, the structure in v is more clear since the noise is directly imposed only on u.
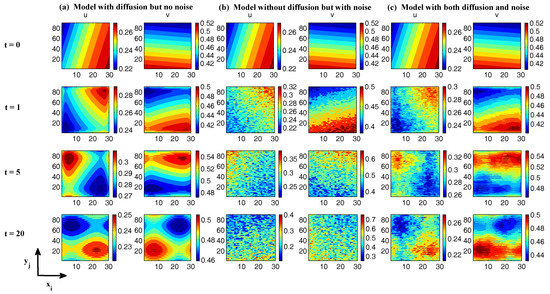
Figure 15.
Snapshots at and of the spatial-extended system (74). Spatially periodic boundary conditions are used here. The parameters are given in (75). In all the three simulations in (a–c), the initial values for both u and v are the same. (a) model simulation of (74) with diffusion terms and but the noise coefficient ; (b) model simulation of (74) without diffusion terms . Therefore, the system is spatially decoupled. However, a stochastic noise is added to the system; (c) simulations with both the diffusion terms and and the stochastic noise .
4.2.3. A Stochastically Coupled SIR Epidemic Model
The SIR model is one of the simplest compartmental models for epidemiology, and many models are derivations of this basic form [59,146]. The model consists of three compartments: “S” for the number susceptible, “I” for the number of infectious, and “R” for the number recovered (or immune). Each member of the population typically progresses from susceptible to infectious to recovered, namely
This model is reasonably predictive for infectious diseases which are transmitted from human to human, and where recovery confers lasting resistance, such as measles, mumps and rubella.
The classical SIR model is as follows:
where the total population size has been normalized to one and the influx of the susceptible comes from a constant recruitment rate b. The death rate for the and R class is, respectively, given by and . Biologically, it is natural to assume that . The standard incidence of disease is denoted by , where is the constant effective contact rate, which is the average number of contacts of the infectious per unit time. The recovery rate of the infectious is denoted by such that is the mean time of infection.
When the distribution of the distinct classes is in different spatial locations, the diffusion terms should be taken into consideration and random noise can also be added. Thus, an extended version of the above SIR system (77) can be described as the following [147,148,149]:
where the noise is multiplicative in order to guarantee the positivity of the three variables. Clearly, the SIR model in (78) is a conditional Gaussian system with and . It can be used to estimate and predict the number of both infectious and recovered given those susceptible. Note that the SIS model (the model with only S and I variables) [150] is a special case of SIR model and it naturally belongs to the conditional Gaussian framework.
4.2.4. A Nutrient-Limited Model for Avascular Cancer Growth
Here, we present a nutrient-limited model for avascular cancer growth [60], where the cell actions (division, migration, and death) are locally controlled by the nutrient concentration field. Consider a single nutrient field described by the diffusion equation:
in which and are the nutrient consumption rates of normal and cancer cells, respectively. The domain is the tissue which is represented by a square lattice of size and lattice constant . On the other hand, the growth factor (GF) concentration obeys the diffusion equation
which includes the natural degradation of GFs, also imposing a characteristic length for GFs diffusion, and a production term increasing linearly with the local nutrient concentration up to a saturation value . Therefore, we are assuming that the release of GFs involves complex metabolic processes supported by nutrient consumption. The boundary conditions satisfied by the GF concentration field is at a large distance from the tumor border. Define the non-dimensional variables:
with these new variables (dropping the primes) and stochastic noise, the system (79) and (80) becomes
The coupled system (81) is a conditional Gaussian system with the observations given by the GF concentration and the state estimation for the nutrient field .
4.3. Large-Scale Dynamical Models in Turbulence, Fluids and Geophysical Flows
4.3.1. The MJO Stochastic Skeleton Model
The Madden–Julian oscillation (MJO) is the dominant mode of variability in the tropical atmosphere on intraseasonal time scales and planetary spatial scales [151,152,153]. It affects both tropical and extratropical weather and climate. It can also possibly trigger and modify the El Niño-Southern Oscillation [154,155,156]. Understanding and predicting the MJO is a central problem in contemporary meteorology with large societal impacts.
In [51], a stochastic skeleton model was developed that recovers robustly the most fundamental MJO features: (1) a slow eastward speed of roughly 5 m/s; (2) a peculiar dispersion relation with ; (3) a horizontal quadrupole vortex structure; (4) the intermittent generation of MJO events; and (5) the organization of MJO events into wave trains with growth and demise, as seen in nature. In fact, the first three features are already covered by the deterministic version of the skeleton model [157,158]. The last two ones are significantly captured by the stochastic version [51]. Using a method based on theoretical waves structures, the MJO skeleton from the model is identified in the observational data [159]. In addition, the stochastic skeleton model is capable of reproducing observed MJO statistics such as the average duration of MJO events and the overall MJO activity [160].
The MJO stochastic skeleton model is given as follows [51]:
and the expectation of the convective activity a satisfies
where , and denote the derivatives with respect to time t zonal (east-west) coordinate x and meridional (north-south) coordinate y. In (82), u, v and are the zonal velocity, meridional velocity and the potential temperature, respectively, and a is the envelope of convective activity. The fourth equation describes the evolution of low-level moisture q. All variables are anomalies from a radiative-convective equilibrium, except a. The skeleton model contains a minimal number of parameters: is the background vertical moisture gradient, is a proportionality constant. is irrelevant to the dynamics but allows us to define a cooling/drying rate for the system in dimensional units. and are external sources of cooling and moistening that need to be prescribed in the system. Notably, the planetary envelope in particular is a collective representation of the convection/wave activity occurring at sub-planetary scale, the details of which are unresolved. A key part of the interaction is the assumption that q influences the tendency of a , where is a constant.
Next, the system (82) is projected onto the first Hermite function in the meridional direction such that , where . Such a meridional heating structure is known to excite only Kelvin waves and the first symmetric equatorial Rossby waves [11,161]. The resulting meridionally truncated equations are
The expectation of the convective activity A satisfies
Figure 16 shows one model simulation of different fields (Panels (a–d)) as well as the MJO patterns (Panel (e)) with realistic warm pool background heating and moisture sources [51]. The MJO patterns are calculated by the combination of different fields using eigen-decomposition [51]. All the features mentioned at the beginning of this subsection can be clearly seen in Panel (e).
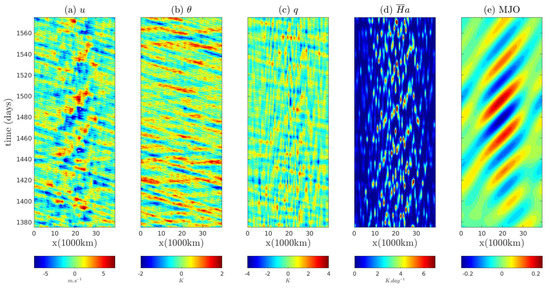
To provide intuition of forming a conditional Gaussian system from the original MJO skeleton model, we start with a simplified version of the full spatially extended system in (84)–(87) and (88), namely the stochastic skeleton single-column model,
where the expectation of the convective activity A satisfies
In the single-column model, the spatial derivative disappears and the coupled system becomes a four-dimensional stochastic ODEs. In the original stochastic skeleton model [51], the process of the convective activity A is driven by a stochastic birth-death process, which provides a clear physical interpretation of the evolution of the convective activity. Note that in the continuous limit of the stochastic birth-death process (the small jump between the two nearby states ), (92) converges to a continuous SDE
where is white noise. See [162] for more details. It is clear that (94) involves a multiplicative noise that guarantees the non-negativity of A. In addition, the expectation of the convective activity A converges to (93). Replacing (92) by (94), we arrive at the following system:
which is a conditional Gaussian system with and . Note that, in the content of data assimilation and prediction, judicious model errors [20,28] are often added to the system. These judicious model errors include extra damping and stochastic noise that balance the intrinsic model error and the observational error as well as improve the model capability in capturing the uncertainty. With these judicious model errors, the system (95)–(98) can be modified as
Now let us consider the spatially extended system (84)–(87). Making use of the finite Fourier decomposition of the state variables
and plugging them into the truncated system (84)–(87), we reach the following stochastic system:
where judicious model errors with extra damping and stochastic noise are added in these equations. In addition to improving the skill in data assimilation and prediction, these extra damping and stochastic noise also compensate the small scale information that has been truncated in the finite Fourier decomposition.
It is clear that the nonlinear model (103) is a conditional Gaussian system with
Linking (103) to the original system (82), u, v, and q belong to and the wave activity a is the observed variable . Note that there are several further studies of the stochastic skeleton model. By involving additional off equatorial components of convective heating and adding a simple seasonal cycle in a warm pool background [163], the skeleton model succeeds in reproducing the meridionally asymmetric intraseasonal events and a seasonal modulation of intraseasonal variability. Another extended version of the skeleton model involves the refined vertical structure of the MJO in nature [164]. All of these modified versions belong to the conditional Gaussian framework. Note that a rigorous proof has shown that the stochastic skeleton model has the geometric ergodicity property [165].
4.3.2. A Coupled El Niño Model Capturing Observed El Niño Diversity
The El Niño Southern Oscillation (ENSO) has significant impact on global climate and seasonal prediction [166,167,168]. It is the most prominent year-to-year climate variation on earth, with dramatic ecological and social impacts. The traditional El Niño consists of alternating periods of anomalously warm El Niño conditions and cold La Niña conditions in the equatorial Pacific every two to seven years, with considerable irregularity in amplitude, duration, temporal evolution and spatial structure of these events. In recent decades, a different type of El Niño has been frequently observed [169,170,171,172], which is called the central Pacific (CP) El Niño. Different from the traditional El Niño where warm sea surface temperature (SST) occurs in the eastern Pacific, the CP El Niño is characterized by warm SST anomalies confined to the central Pacific, flanked by colder waters to both east and west. Understanding and predicting El Niño diversity has significant scientific and social impacts [173,174].
In [52], a simple modeling framework has been developed that automatically captures the statistical diversity of ENSO. The starting model is a deterministic, linear and stable model that includes the coupled atmosphere, ocean and SST [175]. Then, key factors are added to the system in a systematic way. First, a stochastic parameterization of the wind bursts including both westerly and easterly winds is coupled to the starting model that succeeds in capturing both the eastern Pacific El Niño events and the statistical features in the eastern Pacific [175]. Secondly, a simple nonlinear zonal advection with no ad hoc parameterization of the background SST gradient and a mean easterly trade wind anomaly representing the multidecadal acceleration of the trade wind are both incorporated into the coupled model that enable anomalous warm SST in the central Pacific [176]. Then, a three-state stochastic Markov jump process is utilized to drive the wind burst activity that depends on the strength of the western Pacific warm pool in a simple and effective fashion [52]. It allows the coupled model to simulate the quasi-regular moderate traditional eastern Pacific El Niño, the super El Niño, the CP El Niño as well as the La Niña with realistic features [177]. In particular, the model succeeds in capturing and predicting different super El Niño events [178], including both the directly formed (similar to 1997–1998) and delayed events (similar to 2014–2016). An improved version of the model is also able to recover the season synchronization [179]. The coupled model is as follows:
- Atmosphere
- Ocean
- SST
- Coupling:
Here, x is zonal direction and is interannual time, while y and Y are meridional direction in the atmosphere and ocean, respectively. The are zonal and meridional winds, is potential temperature, are zonal and meridional currents, H is thermocline depth, T is SST, is latent heating, and is zonal wind stress. All variables are anomalies from an equilibrium state, and are non-dimensional. The coefficient is a non-dimensional ratio of time scales, which is of order . The term describes stochastic wind burst activity. The atmosphere extends over the entire equatorial belt with periodic boundary conditions, while the Pacific ocean extends over with reflection boundary conditions for the ocean model and zero normal derivative at the boundaries for the SST model. The wind bursts and easterly mean trade wind are parameterized as
where the noise is a state-dependent noise coefficient given by a three-state Markov jump process. In addition, and are the prescribed zonal and meridional bases.
Applying the meridional truncation to the coupled system (104)–(108), the coupled model reduces to a set of PDEs that depends only on time t and zonal variables x. These equations describe the zonal propagation of atmosphere and ocean Kelvin and Rossby waves [52]. Figure 17 shows a model simulation. The El Niño diversity is clearly captured, where a traditional eastern Pacific ENSO cycle (), a series of CP El Niño () and a super El Niño () are all observed. Similar to the MJO skeleton model in Section 4.3.1, a suitable set of zonal bases are chosen and the coupled ENSO model becomes a large dimension of coupled ODE system. By adding judicious model errors with extra damping and stochastic forcing (as in the MJO skeleton model), the resulting system belongs to the conditional Gaussian framework, where includes SST and contains all the variables in atmosphere and ocean.
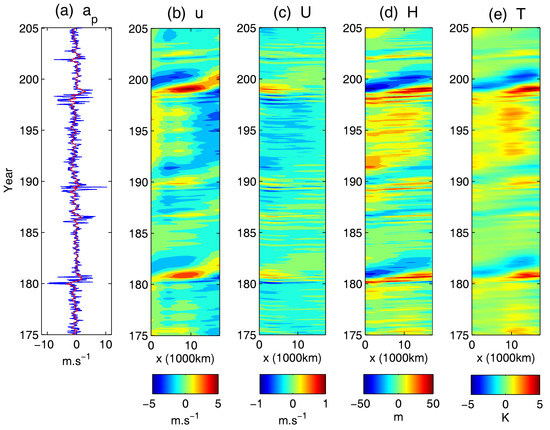
Figure 17.
Model simulations of the coupled ENSO model (104)–(108). The x-axis is the zonal region of the equatorial Pacific. The y-axis is time. (a) time series of the stochastic wind burst amplitude (blue) and its 90-day running mean; (b–e) atmosphere wind u, ocean current U, thermocline depth H and SST T.
4.3.3. The Boussinesq Equation
The Boussinesq approximation [11] is a way to solve nonisothermal flow without having to solve for the full compressible formulation of the Navier–Stokes equations. It assumes that variations in density have no effect on the flow field, except that they give rise to buoyancy forces. The Boussinesq equation is derived when the Boussinesq approximation is applied to the full Navier–Stokes equation:
where T is the temperature, is the velocity fields, is the reference density, p is the pressure, g is the acceleration due to gravity, and are the external forcing and is the diffusion coefficient. Note that the forcing terms and can involve both deterministic and stochastic forcing. The three equations in (109) are the continuity equation, the momentum equation and the thermal equation, respectively. The Boussinesq equation has a wide application, including modeling the Rayleigh–Bénard convection [53,54] and describing strongly stratified flows as in geophysics [55].
Here for simplicity, let us assume the boundary conditions are periodic. The framework below can be easily extended to the Boussinesq system with more general boundary conditions. Similar to the general procedure as described in Section 4.3.1, applying a finite Fourier truncation to (109) and adding judicious model errors with extra damping and noise if needed, the resulting system consists of a large dimension of stochastic ODEs. Here, the continuity equation with divergence free condition provides the eigen-directions of the each Fourier mode associated with the velocity field [11], namely,
where is the eigen-direction associated with the wavenumber . Note that the resulting system remains highly nonlinear due to the quadratic coupling between different Fourier modes in the advection and . The straightforward calculation shows that the system belongs to the conditional Gaussian framework with and , where the right-hand side should be understood as the Fourier modes. Such a setup allows the state estimation of the temperature T given the noisy velocity field using the closed form (4) and (5) in the conditional Gaussian framework.
In many applications, it is easier to observe the temperature T while the velocity field is required to be estimated. However, if we choose and , then (109) is not a conditional Gaussian system. To satisfy the requirement of the conditional Gaussian framework, the equation of the velocity field has to be linearized. Nevertheless, in the situation with large Pradlt number [54,180,181], which occurs quite often in applications (such as Rayleigh–Bénard convection), the nonlinear term can be dropped and the resulting system becomes
It is important to note that the coupled system remains nonlinear due to the nonlinear coupling . One interesting issue is to understand the model error by dropping the term in filtering the resulting conditional Gaussian systems.
4.3.4. Darcy–Brinkman–Oberbeck–Boussinesq System—Convection Phenomena in Porous Media
The problem considered in this subsection is the convection phenomena in porous media which is relevant to a variety of science and engineering problems ranging from geothermal energy transport to fiberglass insulation. Consider a Rayleigh–Bénard like problem: convection in a porous media region, , bounded by two parallel planes saturated with fluids. The bottom plate is kept at temperature and the top plate is kept at temperature with . One of the famous models is the following Darcy–Brinkman–Oberbeck–Boussinesq system in the non-dimensional form [56]:
where is the unit normal vector directed upward, is the non-dimensional seepage velocity, p is the non-dimensional kinematic pressure, T is the non-dimensional temperature. As in (109), and here are external forcing, which involve both deterministic and stochastic parts. The parameters in the system are given by the Prandtl–Darcy number, , which is defined as where is the kinematic viscosity of the fluid, h is the distance between the top and bottom plates, is the thermal diffusivity and K is the permeability of the fluid; the Brinkman–Darcy number, , which is given by , where is the effective kinematic viscosity of the porous media; and the Rayleigh–Darcy number, , which takes the form , where g is the gravitational acceleration constant, is the thermal expansion coefficient. The parameter is also called the non-dimensional acceleration coefficient.
As in the Boussinesq equation, by applying finite Fourier expansion and adding extra damping and noise to the Darcy–Brinkman–Oberbeck–Boussinesq model (111), a conditional Gaussian system is reached with and . Again, the right-hand side should be understood as Fourier coefficients.
On the other hand, applying linearization and dropping one of the nonlinear terms in (111), the temperature T can be viewed as the observed variable to filter the seepage velocity ,
The resulting system is given by
4.3.5. The Rotating Shallow Water Equations
The rotating shallow water equation is an appropriate approximation for atmospheric and oceanic motions in the midlatitudes with relatively large length and time scales [11]. In such regimes, the effects of the earth’s rotation are important when the fluid motions evolve on a time scale that is comparable or longer than the time scale of rotation. Note that the rotation shallow water equations do not include the effects of density stratification as observed in many other phenomena.
The rotating shallow water equation is as follows:
where is the two-dimensional velocity field in the -plane, h is the geophysical height. On the right-hand side of (113), and are forcing terms that include both deterministic and stochastic forcing. As discussed in the previous subsections, choosing and and applying the procedure in Section 4.3.1 with finite Fourier expansion and judicious model error, a conditional Gaussian system is formed.
Alternatively, in some applications, the height variable h can be measured and the velocity field is required to be filtered or estimated. Thus, it is natural to set
and then making use of data assimilation to estimate the velocity field. To allow such a problem to fit into conditional Gaussian framework, one of the nonlinear terms is dropped and the resulting system is given by
The equations in (114) are then put into the framework in Section 4.3.1 that forms a conditional Gaussian system.
As a side remark, linearizing the shallow water Equation (113) and writing into characteristic forms of the resulting equations provide two types of modes:
- Geostrophically balanced (GB) modes: ; incompressible.
- Gravity modes: ; compressible.
Let us denote and as the random coefficients of GB and gravity modes for each Fourier wavenumber, respectively. Following the idea in [20], a coupled system that describes the interactions between the GB and gravity modes are given by
Collecting the equations for different Fourier wavenumbers forms a coupled systems for the GB and gravity modes. Note that the GB modes are in slow time scale while the gravity modes occur in a fast time scale. Denote
The coupled system (115) including all the Fourier wavenumbers k belong to the conditional Gaussian framework.
4.4. Coupled Observation-Filtering Systems for Filtering Turbulent Ocean Flows Using Lagrangian Tracers
Lagrangian tracers are drifters and floaters that collect real-time information of fluid flows [182]. Filtering (or data assimilation) of the turbulent ocean flows using Lagrangian tracers provides a more accurate state estimation and reduces the uncertainty [183,184,185]. In [61,62,63], a first rigorous mathematical framework was developed and it was applied to study (1) the information barrier in filtering [61]; (2) the filtering skill of multiscale turbulent flows [62] and (3) the model error in various cheap and practical reduced filters with both linear and strongly nonlinear underlying flows [63].
Consider a d dimensional random flow modeled by a finite number of Fourier modes with random amplitudes in periodic domain ,
Each follows an OU process,
The observations are given by the trajectories of L noisy Lagrangian tracers,
which is highly nonlinear due to the appearance of the in the exponential term.
Collecting all the Fourier components of the velocity into a vector and including all the tracer displacements into another yields
Then, the coupled observation-filtering system is formed in a concise way,
This is obviously a conditional Gaussian system with and .
In [62], multiscale turbulent flows were studied. To include both the (slow) geophysically balanced (GB) modes and (fast) gravity modes, the simple flow field in (116) was replaced by
where with being a Rossby number [11,121].
4.5. Other Low-Order Models for Filtering and Prediction
4.5.1. Stochastic Parameterized Extended Kalman Filter Model
The stochastic parameterized extended Kalman filter (SPEKF) model [65,101] was introduced to filter and predict the highly nonlinear and intermittent turbulent signals as observed in nature:
In the SPEKF model (119), the process is driven by the stochastic damping , stochastic phase and stochastic forcing correction , all of which are specified as Ornstein–Uhlenbeck (OU) processes [66]. In (119), is a deterministic large-scale forcing, representing external effects such as the seasonal cycle. Physically, the variable in (119) represents one of the resolved modes (i.e., observable) in the turbulent signal, while and are hidden processes. In particular, and are surrogates for the nonlinear interaction between and other unobserved modes in the perfect model. The SPEKF model naturally belongs to conditional Gaussian filtering framework with the observed variable and filtering variables .
The nonlinear SPEKF system was first introduced in [65,101] for filtering multiscale turbulent signals with hidden instabilities and has been used for filtering and prediction in the presence of model error [1,20]. In addition to filtering and predicting intermittent signals from nature in the presence of model error [101,186,187,188], other important applications of using SPEKF to filter complex spatial-extended systems include stochastic dynamical superresolution [103] and effective filters for Navier–Stokes equations [104]. It has been shown that the SPEKF model has much higher skill than classical Kalman filters using the so-called mean stochastic model (MSM)
to capture the irregularity and intermittency in nature. Here, and in (120) are the constant mean states of the damping, phase and forcing and therefore the MSM is a linear model with Gaussian statistics.
To provide more intuition, we show in Figure 18 the model simulation of SPEKF together with the MSM for comparison. The following parameters are adopted here
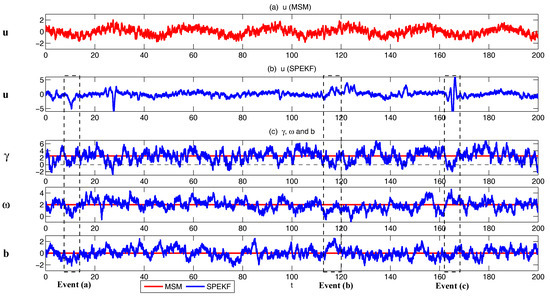
Figure 18.
Simulations of the SPEKF model and MSM. (a) the observed variable u from MSM (120); (b) the observed variable u from SPEKF model; (c) hidden variables. The parameters are given in (121). The red curves are for MSM and blue ones are for SPEKF. The black dashed line in the process indicates the threshold of zero. When is below this threshold, becomes anti-damping and the associated signal of u tends to have exponential growth.
In Panel (a), the simulation of the MSM is shown. As expected, the signal of u has a large-scale time-periodic behavior due to the time-periodic forcing . On top of the large-scale behavior, small fluctuations with nearly a constant oscillation is found, which is due to the constant phase . There is no intermittency since the damping always stabilizes the system.
On the other hand, with stochastic damping, stochastic phase and stochastic forcing, the variable has a rich dynamical behavior with intermittency and random oscillations. See Panels (b,c). In fact, when becomes negative, the anti-damping results in an exponential increase of the signal of u and generates intermittency. In addition, the stochastic phase leads to different phase oscillation frequency. For example, at Event (a) is much smaller than that at Event (c), and therefore the oscillation at the phase of Event (c) is much faster. Furthermore, the stochastic forcing also modifies the signal of . One example is shown in Event (b), where a large amplitude of forces the signal to go towards a positive value in the local area.
4.5.2. An Idealized Surface Wind Model
The following idealized surface wind model is a version of the model for stochastic surface momentum budget [189]. Here, tendencies in the horizontal wind vector averaged over a layer of thickness h are modelled as resulting from imbalances between the surface turbulent momentum flux (expressed using a bulk drag law with drag coefficient , taken to be constant) and the ageostrophic difference between the pressure gradient and Coriolis forces:
The model assumes that tendencies associated with horizontal momentum advection are negligible and that the “large-scale” ageostrophic residual between the pressure gradient and Coriolis forces can be expressed as a mean and fluctuations .
It is important to note that simply applying the white noise approximation for u and v (i.e., = ) has several limitations [190]. In particular, the white noise model requires unrealistically large values of h to produce serial dependence similar to that observed, and it is unable to account for the strong anisotropy in the autocorrelation structure of the wind components. Therefore, independent Ornstein–Uhlenbeck processes [66] are included in the coupled system.
With extra additive noise with amplitudes , the coupled system belongs to conditional Gaussian framework with and . The conditional Gaussian framework can be applied to filter the signal of , the filtered signal of which provides a clear view of the importance of such parameterization against simple white noise source.
5. Algorithms Which Beat the Curse of Dimension for Fokker–Planck Equation for Conditional Gaussian Systems: Application to Statistical Prediction
The Fokker–Planck equation is a partial differential equation (PDE) that governs the time evolution of the probability density function (PDF) of a complex system with noise [66,67]. For a general nonlinear dynamical system,
with state variables , noise matrix and white noise , the associated Fokker–Planck equation is given by
with . In many complex dynamical systems, including geophysical and engineering turbulence, neuroscience and excitable media, the solution of the Fokker–Planck equation in (123) involves strong non-Gaussian features with intermittency and extreme events [1,57,191]. In addition, the dimension of in these complex systems is typically very large, representing a variety of variability in different temporal and spatial scales [1,121] (see also the examples in Section 4). Therefore, solving the high-dimensional Fokker–Planck equation for both the steady state and transient phases with non-Gaussian features is an important topic. However, traditional numerical methods such as finite element and finite difference as well as the direct Monte Carlo simulations of (122) all suffer from the curse of dimension [68,69]. Nevertheless, for the conditional Gaussian systems (1) and (2), efficient statistically accurate algorithms can be developed for solving the Fokker–Planck equation in high dimensions and thus beat the curse of dimension. Since the conditional Gaussian system is able to capture many salient features of the turbulent behavior, such algorithms are quite useful in uncertainty quantification, data assimilation and statistical prediction of turbulent phenomena in nature.
5.1. The Basic Algorithm with a Hybrid Strategy
Here, we state the basic efficient statistically accurate algorithms developed in [38]. The only underlying assumption here is that the dimension of is low while the dimension of can be arbitrarily high.
First, we generate L independent trajectories of the variables , namely , where L is a small number. This first step can be done by running a Monte Carlo simulation for the full system, which is computationally affordable with a small L. Then, different strategies are adopted to deal with the parts associated with and , respectively. The PDF of is estimated via a parametric method that exploits the closed form of the conditional Gaussian statistics in (4) and (5),
See [38] for the details of the derivation of (124). Note that the limit in (124) (as well as (125) and (126) below) is taken to illustrate the statistical intuition, while the estimator is the non-asymptotic version. On the other hand, due to the underlying assumption of the low dimensionality of , a Gaussian kernel density estimation method is used for solving the PDF of the observed variables ,
where is a Gaussian kernel centered at each sample point with covariance given by the bandwidth matrix . The kernel density estimation algorithm here involves a “solve-the-equation plug-in” approach for optimizing the bandwidth [192] that works for any non-Gaussian PDFs. Finally, combining (124) and (125), a hybrid method is applied to solve the joint PDF of and through a Gaussian mixture,
Practically, is sufficient for the hybrid method to solve the joint PDF with and . See [38] for the illustration of various concrete examples. Note that the closed form of the L conditional distributions in (124) can be solved in a parallel way due to their independence [38], which further reduces the computational cost. Rigorous analysis [193] shows that the hybrid algorithm (126) requires a much less number of samples as compared with traditional Monte Carlo method especially when the dimension of is large.
5.2. Beating the Curse of Dimension with Block Decomposition
The basic algorithm in (126) succeeds in solving the Fokker–Planck equation with state variables. However, many complex turbulent dynamical systems in nature involve variables that have a much higher dimension (for example, those in Section 4.3). In such a situation, the update of the conditional covariance matrix becomes extremely expensive since the number of entries in the covariance matrix is , where is the total dimension of the variables. Therefore, new strategies are required to be incorporated into the basic algorithm in (126) in order to beat the curse of dimension. In this subsection, we develop an effective strategy with block decomposition [36], which combines with the basic algorithm and can efficiently solve the Fokker–Planck equation in much higher dimensions even with orders in the millions.
Consider the following decomposition of state variables:
where , and . Correspondingly, the full dynamics in (1) and (2) are also decomposed into K groups, where the variables on the left-hand side of the k-th group are . In addition, for notation simplicity, we assume both and are diagonal and thus the noise coefficient matrices associated with the equations of and are and , respectively.
To develop efficient statistically accurate algorithms that beat the curse of dimension, the following two conditions are imposed on the coupled system.
Condition 1: In the dynamics of each in (1) and (2), the terms and can depend on all the components of while the terms and are only functions of , namely,
In addition, only interacts with and on the right-hand side of the dynamics of . Therefore, the equation of each becomes
Note that in (128) and (129) each is fully coupled with other for all through and . There is no trivial decoupling between different state variables.
Condition 2: The initial values of and with are independent with each other.
These two conditions are not artificial and they are actually the salient features of many complex systems with multiscale structures [73], multilevel dynamics [119] or state-dependent parameterizations [103]. Under these two conditions, the conditional covariance matrix becomes block diagonal, which can be easily verified according to (5). The evolution of the conditional covariance of conditioned on is given by:
which has no interaction with that of for all since and do not enter into the evolution of the conditional covariance. Notably, the evolutions of different with can be solved in a parallel way and the computation is extremely efficient due to the small size of each individual block. This facilitates the algorithms to efficiently solve the Fokker–Planck equation in large dimensions.
Next, the structures of and in (127) allow the coupling among all the K groups of variables in the conditional mean according to (4). The evolution of , namely the conditional mean of conditioned on , is given by
Finally, let’s use concrete examples to illustrate the reduction in the computational cost with the block decomposition.
The first example is the two-layer L-96 model in (35). A typical choice of the number of grid points for the large scale variables () is and that of the equations for the small scale variables () is . Thus, the total number of the small-scale variables is and the size of conditional covariance is . Note that the two-layer L-96 model in (35) can be decomposed into the form in (128) and (129). Each block contains one element of and five elements of with and k fixed, and the number of the blocks is . Therefore, the conditional covariance matrix associated with each block is of size and the total number of the elements that need to be updated is , which is only compared with the total elements in the full conditional covariance matrix!
Another example is the stochastically coupled FHN models. In fact, the block decomposition can be applied to all the versions (67)–(69) of the stochastically coupled FHN models as discussed in Section 4.2.1. Here, we illustrate the one in (69) with multiplicative noise. Let’s take . Since the conditional statistics involves the information for both and with , the total size of the conditional covariance is . On the other hand, with the block decomposition that involves 500 blocks, where each block is of size and contains the information of only one and one , the total number of the elements that need to be updated is . Clearly, the computational cost in the conditional covariance update with the block decomposition is only compared with a full update! In Section 5.5, the statistical prediction of both the two-layer L-96 model and the stochastically coupled FHN model with multiplicative noise using the efficient statistically accurate algorithms will be demonstrated.
5.3. Statistical Symmetry
As was discussed in the previous two subsections, the hybrid strategy and the block decomposition provide an extremely efficient way to solve the high-dimensional Fokker–Planck equation associated with the conditional Gaussian systems. In fact, the computational cost in the algorithms developed above can be further reduced if the coupled system (1) and (2) has statistical symmetry [36]:
Namely, the statistical features for variables with different k are the same. The statistical symmetry is often satisfied when the underlying dynamical system represents a discrete approximation of some PDEs in a periodic domain with nonlinear advection, diffusion and homogeneous external forcing [2,20].
With the statistical symmetry, collecting the conditional Gaussian ensembles for a specific k in K different simulations is equivalent to collecting that for all k with 1 ≤ k ≤ K in a single simulation. This also applies to that are associated with . Therefore, the statistical symmetry implies that the effective sample size is , where K is the number of the group variables that are statistically symmetric and L is the number of different simulations of the coupled systems via Monte Carlo. If K is large, then a much smaller L is needed to reach the same accuracy as in the situation without utilizing statistical symmetry, which greatly reduces the computational cost.
Below, we discuss the details of constructing the joint PDFs obtaining from the algorithms with statistical symmetry. First, we adopt the one-dimensional case for the convenience of illustration. The method can be easily extended to systems with multivariables and multidimensions. Denote the mean values of the Gaussian ensembles at different grid points and the associated variance are . For simplicity, we only take one full run of the system. Therefore, the total number of Gaussian ensembles is K. Clearly, the 1D PDFs at different grid points are the same and are given by
The limit is taken for statistical intuition while a finite and small K is adopted in practice.
Now, we discuss the construction of the joint PDFs. We use the 2D joint PDF as an illustration. The joint PDF is a Gaussian mixture with K Gaussian ensembles, where the mean of each 2D Gaussian ensemble is
and the covariance matrix is given by
It is clear from the construction of the ensemble mean in (132) that the subscript in the second component equals that of the first component plus one. That is, the first component of each is treated as due to the statistical symmetry and the second component is treated as the corresponding associated with each k. The diagonal covariance matrix in (133) comes from the fact that each sample point is independent with each other. This is also true and more obvious for the block diagonal conditional covariance. Notably, the diagonal covariance matrix of each ensemble does not mean that the correlation between and is completely ignored. The correlation is reflected regarding how the points of ensemble means are distributed.
5.4. Quantifying the Model Error Using Information Theory
Before we apply the efficient statistically accurate algorithms to statistical prediction, we introduce a measurement for quantifying errors. The natural way to quantify the error in the predicted PDF related to the truth is through an information measure, namely the relative entropy (or Kullback–Leibler divergence) [2,187,194,195,196,197]. The relative entropy is defined as
where is the true PDF and is the predicted one from the efficient statistically accurate algorithms. This asymmetric functional on probability densities measures lack of information in compared with p and has many attractive features. First, with equality if and only if . Secondly, is invariant under general nonlinear changes of variables. Notably, the relative entropy is a good indicator of quantifying the difference in the tails of the two PDFs, which is particularly crucial in the turbulent dynamical systems with intermittency and extreme events. On the other hand, the traditional ways of quantifying the errors, such as the relative error , usually underestimate the lack of information in the PDF tails.
5.5. Applications to Statistical Prediction
Now, we apply the efficient statistically accurate algorithms developed in the previous subsections to statistical prediction. Two examples of nonlinear complex turbulent dynamical systems in high dimensions are shown below.
The first example is the stochastically coupled FHN model in (69) with multiplicative noise (Section 4.2.1) with ,
The parameters are given by (71).
The second example is the two-layer L-96 model in (35) (Section 4.1.1) with and . The parameters are given by (36) and (37):
Both the stochastically coupled FHN model (135) and the two-layer L-96 model (136) satisfy the model structure as described in Section 5.2 such that the block decomposition applies. Figure 19 provides a schematic illustration of the coupling between different variables in these models (for illustration purposes, is used in the figure). The multiscale and layered structures can be easily observed. It is also clear that all the variables are coupled to each other with no trivial decoupling. Note that the stochastically coupled FHN model (135) with the given parameters here also satisfies the statistical symmetry while the two-layer L-96 model (136) is inhomogeneous.
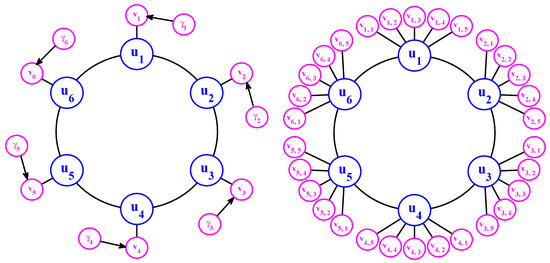
Figure 19.
Schematic illustration of the coupling between different variables in the stochastically coupled FHN model (135) (left) and the two-layer L-96 model (136) (right). For illustration purposes, is used in this figure while and in the model simulations. All the variables are coupled to each other with no trivial decoupling.
5.5.1. Application to the Stochastically Coupled FHN Model with Multiplicative Noise Using Statistical Symmetry
Here, we illustrate the statistical prediction of the stochastically coupled FHN model with multiplicative noise (135), where the number of grid points in space is . The noise coefficient in the process is for all i. The other parameters are the same as those in (71) and the noise coefficients are the same at different grid points i, namely
We also adopt homogeneous initial conditions and for all . Therefore, the model satisfies the statistical symmetry. The model simulations were shown in Figure 12 and Figure 13, where intermittent events are observed in both the fields of u and v.
Figure 20 shows the time evolution of the first four moments associated with and . Note that due to the statistical symmetry, the evolutions of these moments for different and are the same as and . The dot at indicates the time instant that u arrives at its most non-Gaussian phase while is a non-Gaussian phase, where u is nearly the statistical equilibrium while v is still transient. In Figure 21 and Figure 22, the statistical prediction of the 1D marginal and 2D joint PDFs are shown at these two time instants. At , most of the probability density of is concentrated around . However, there is a small but non-zero probability around (see the subpanel with the logarithm scale), which leads to large skewness and kurtosis of the statistics of as observed in Figure 20. The efficient statistically accurate algorithms succeed in predicting the PDFs at this transient phase and are able to accurately recover the statistics in predicting such extreme events. A similar performance is found in Figure 22, where the bimodal PDF of , the highly skewed PDF of and the Gaussian one of are all predicted with high accuracy. The fully non-Gaussian joint PDFs and are also predicted with almost no bias. These results indicate the skillful behavior of the algorithms developed above.
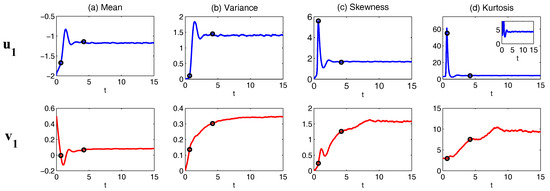
Figure 20.
Time evolution of the first four moments ((a) mean; (b) variance; (c) skewness and (d) kurtosis) associated with and of the stochastically coupled FHN model with multiplicative noise (135), where . Due to the statistical symmetry, the evolutions of these moments for different and are the same as and . The dots at and indicate the time instants that the statistical prediction using the efficient statistically accurate algorithms are tested. Note that corresponds to the time instant that u arrives at its most non-Gaussian phase while is a non-Gaussian phase where u is nearly the statistical equilibrium while v is still transient.
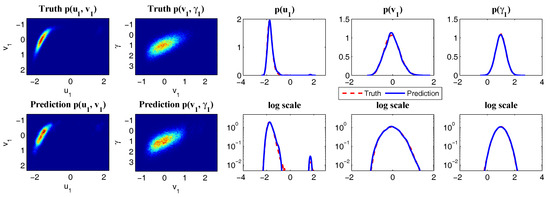
Figure 21.
Statistical prediction of the 1D and 2D PDFs of the stochastically coupled FHN model with multiplicative noise (135) at a transit phase , where . Note that there is a small but non-zero probability around (see the subpanel with the logarithm scale).
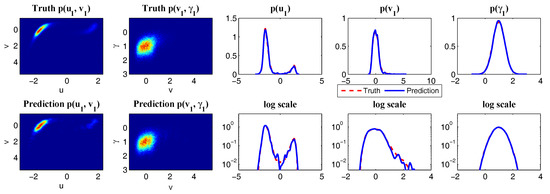
Figure 22.
Statistical prediction of the 1D and 2D PDFs of the stochastically coupled FHN model with multiplicative noise (135) at a transit phase , where .
Note that the total dimension of the stochastically coupled FHN model with multiplicative noise (135) is . Due to the statistical symmetry, the effective sample size in the statistical prediction as shown in Figure 21 and Figure 22 is , where L is the number of repeated simulations of the systems. In fact, the simulations in the efficient statistically accurate algorithms are achieved with only . This means we only run the model (135) once and apply the efficient statistically accurate algorithms that provide the accurate results in these figures. Therefore, the statistical prediction here is extremely cheap! On the other hand, we take in Monte Carlo simulations and again use statistical symmetry to generate the true PDFs and therefore the effective sample size in Monte Carlo simulation is .
5.5.2. Application to the Two-Layer L-96 Model with Inhomogeneous Spatial Structures
Now we apply the efficient statistically accurate algorithms to predict the two-layer L-96 model in (136). Here, and . The parameters are given by (36) and (37). The model behavior with different forcing F is shown in Figure 2, Figure 3 and Figure 4.
Although the two-layer inhomogeneous L-96 model in (136) has no statistical symmetry, the model structure nevertheless allows the effective block decomposition. Below, trajectories of each variable are simulated from (136) to implement the efficient statistically accurate algorithms. As a comparison, a direct Monte Carlo method requires = 150,000 samples for each of the 240 variables for an accurate estimation of at least the one-point statistics. This means the total number of samples is around ! For an efficient calculation of the truth, we focus only on the statistical equilibrium state here, but the algorithms are not restricted to the equilibrium statistics. The true PDFs are calculated using the Monte Carlo samples over a long time series in light of the ergodicity while the recovered PDFs from the efficient statistically accurate algorithms are computed at .
In Figure 23, Figure 24 and Figure 25, we show the statistical prediction in all the three regimes with and 16, respectively, using the efficient statistically accurate algorithm and compare them with the truth. Here, we only show the results at . Qualitative similar results are found at other grid points. In these figures, the diagonal subpanels here show the 1D marginal PDFs of and , where the blue one is the prediction and the red one is the truth. The -subpanel with (below the diagonal panel) shows the true 2D PDF using a large number of Monte Carlo samples (red colormap) while the one with (above the diagonal panels) shows the predicted one using the efficient statistically accurate algorithm (blue colormap). The -panel is compared with the -panel. Note that for the simplicity of comparison the labels and on the bottom and left of the -panel correspond to the x-axis and y-axis of the truth and the y-axis and x-axis of the predicted PDFs. On the other hand, Figure 26 shows several 2D joint PDFs of the large scale with different and . It is clear that all the strong non-Gaussian features, including highly skewed, multimodal and fat-tailed distribution, are accurately predicted by the statistically accurate algorithm. Finally, Figure 27 shows the error in the predicted PDF as a function of the sample points L compared with the truth, where the error is computed via the relative entropy (134). In fact, with samples in the efficient statistically accurate algorithms, the statistical prediction has already been accurate enough. Note that the small non-zero asymptotic values as a function of L in the error curves is due to the numerical error in computing the integral of the relative entropy (134) as well as the sampling in the Monte Carlo simulations.
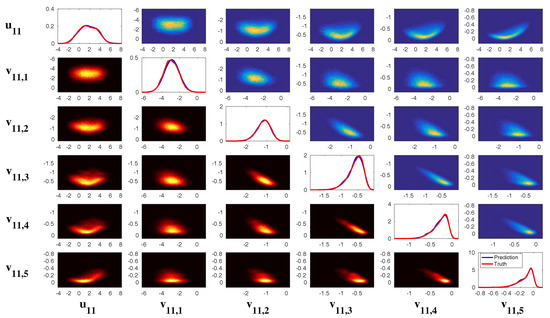
Figure 23.
Inhomogeneous two-layer L-96 model (35) with F = 5. The other parameters are given in (36) and (37). Comparison of the 1D and 2D true and recovered PDFs at . The diagonal subpanels here show the 1D marginal PDFs of and , where the blue one is the prediction and the red one is the truth. In this figure with subpanels, the -subpanel with (below the diagonal panel) shows the true 2D PDF using a large number of Monte Carlo samples (red colormap) while the one with (above the diagonal panels) shows the predicted one using the efficient statistically accurate algorithm (blue colormap). The -panel is compared with the -panel. Note that for the simplicity of comparison the labels and on the bottom and left of the -panel correspond to the x-axis and y-axis of the truth and the y-axis and x-axis of the predicted PDFs.
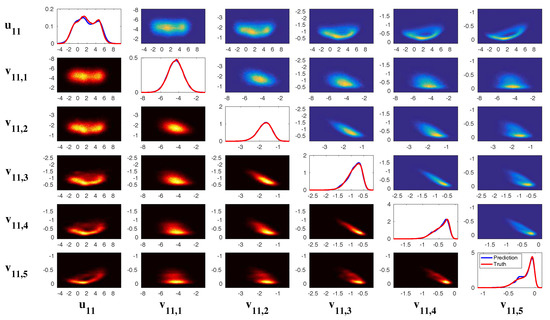
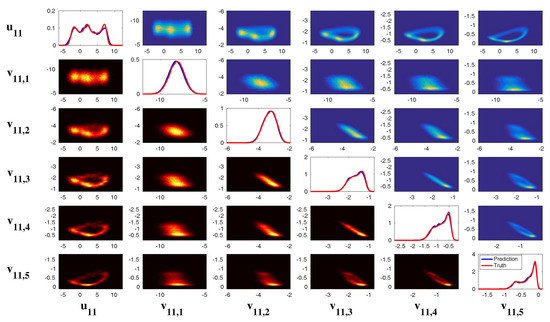
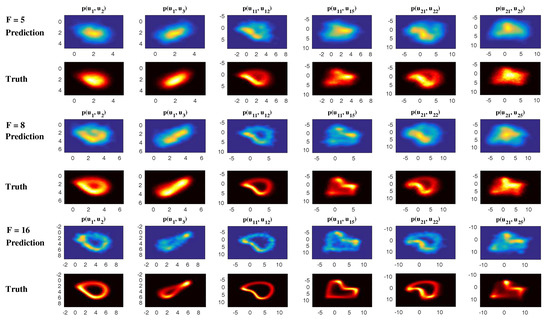
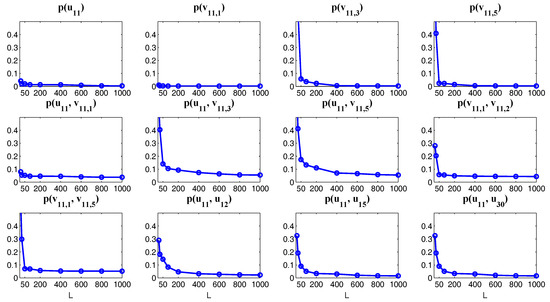
It is worthwhile pointing out that although only the predicted one-point and two-point statistics are shown in both the examples here, the algorithms can actually provide an accurate estimation of the full joint PDF of , using a small number of samples. This is because the sample size in these algorithms does not grow exponentially as the dimension of , which is fundamentally different from Monte Carlo methods. See [193] for a theoretical justification.
6. Multiscale Data Assimilation, Particle Filters, Conditional Gaussian Systems and Information Theory for Model Errors
6.1. Parameter Estimation
The conditional Gaussian system (1) and (2) and its closed analytic formula for solving the conditional statistics (4) and (5) also provide a framework for parameter estimation. In fact, can be written as
where in is physical process variables and denotes the model parameters. Here, . Rewriting the conditional Gaussian system (1) and (2) in terms of yields
The Equation (138) and (139) includes both the dynamics of and those of . Both the physical process variables and the parameters are coupled with any highly nonlinear functions of . Nevertheless, any monomial involving both and is not allowed since otherwise the conditional Gaussian structure will break. Notably, although and are named as model states and parameters, they can also be understood as stochastic parameterization and simplification of complex physical process via bulk average, respectively. Therefore, and often share the same role in providing extra information of that leads to various non-Gaussian characteristics. This is a typical feature in multiscale complex turbulent dynamical systems.
Below, we provide different frameworks for parameter estimation. Let’s temporally ignore for notation simplicity and the dynamics is given by
where is the true parameter.
6.1.1. Direct Parameter Estimation Algorithm
Since are constant parameters, it is natural to augment the dynamics with the following relationship,
where an initial uncertainty for the parameter is assigned. According to (4) and (5), the time evolutions of the mean and covariance of the estimate of are given by
The formula in (144) indicates that is a solution, plugging which into (143) results in . This means, by knowing the perfect model, the estimated parameters in (141) and (142) and (143) and (144) under certain conditions will converge to the truth.
As a simple test example, we consider estimating the three parameters and in the noisy L-63 model (31) with . Putting into the framework (141) and (142), the augmented system becomes
where and . Figure 28 shows the parameter estimation skill with . Here, the initial guess of all the three parameters are and the initial uncertainty is a identity matrix. It is clear that the estimated parameter converge quickly to the truth and the corresponding uncertainty in the estimated parameters goes to zero. In Figure 29, the parameter estimation skill with different noise level is compared. When the noise level and in the observed signals become larger, the convergence rate becomes slower.
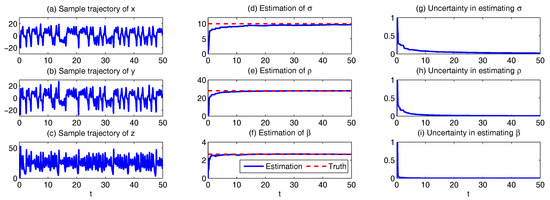
Figure 28.
Parameter estimation of the noisy L-63 system using the direct approach (145) with = = = 5. (a–c) sample trajectories of which are used as observations; (d–f) time evolution of the estimated parameters and the truth (red); (g–i) the uncertainty evolution of each estimated parameter.
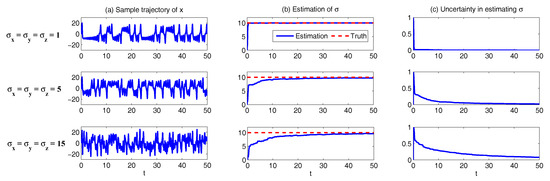
Figure 29.
Parameter estimation of the noisy L-63 system using the direct approach (145) with = = = 1, 5 and 15 for the three rows. For illustration purposes, only the trajectory of x and the estimation of is shown in all the three cases. (a) sample trajectory of x; (b,c) mean estimation of and the associated uncertainty.
In [28], systematic studies of both one-dimensional linear and nonlinear systems have revealed that the convergence rate depends on different factors, such as the observability, the signal-to-noise ratio and the initial uncertainty. In particular, both theoretical analysis and numerical simulations in [28] showed that the convergence rate can be extremely slow and sometimes with an undesirable initial guess the estimation even converges to a wrong solution for some highly nonlinear systems. Thus, alternative parameter estimation scheme is required.
6.1.2. Parameter Estimation Using Stochastic Parameterized Equations
Instead of augmenting the equation in a trivial but natural way for the parameters as shown in (142), a new approach of the augmented system can be formed in the following way [28]:
Here, is a negative-definite diagonal matrix, is a constant vector and is a diagonal noise matrix. Different from (142), a stochastic parameterized equation is used in (147) to describe the time evolution of each component of the parameter . This approach is motivated from the stochastic parameterized extended Kalman filter model [64,65] as discussed in Section 4.5.1. The stochastic parameterized equations in (147) serve as the prior information of the parameter estimation. Although certain model error will be introduced in the stochastic parameterized equations due to the appearance of , and , it has shown in [28] that the convergence rate will be greatly accelerated. In fact, in linear models, rigorous analysis reveals that the convergence rate using stochastic parameterized Equation (146) and (147) is exponential while that using the direct method (146) and (147) is only algebraic.
Now, we apply the parameter estimation using stochastic parameterized Equation (146) and (147) for the noisy L-63 model. The augmented system reads,
The same initial values are taken as those in the direct method. Recall in Figure 29 that the system with a large observational noise leads to a slow convergence rate. Below, we focus on this case and use the parameter estimation scheme (148) to improve the result. The parameters in the stochastic parameterized equation are chosen as follows:
Here, we introduce errors in all the mean states and . The variance of the stochastic parameters is given by and , respectively. Therefore, the truth is located at one standard deviation (square root of the variance) of the mean state. The decorrelation time of all the process is time units.
Figure 30 shows the results of parameter estimation using the method with stochastic parameterized Equations (146) and (147). Despite the error in and as the prior information, the estimation of the parameters is quite accurate. In fact, by using the averaged value over the time interval as the estimation, we compare the estimated parameters with the truth:
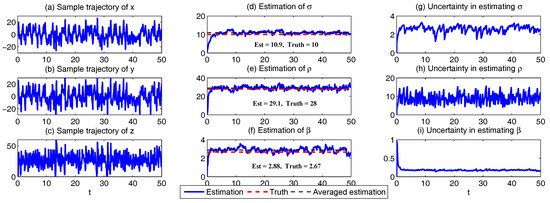
Figure 30.
Parameter estimation of the noisy L-63 system using the method with stochastic parameterized Equations (146) and (147) with . (a–c) sample trajectories of which are used as observations; (d–f) time evolution of the estimated parameters and the truth (red); the thin black line shows the average of the estimation from to ; (g)–(i) the uncertainty evolution of each estimated parameter.
The relative error in the three estimated parameters compared with the truth is and , respectively, all of which are much less than in and . This is because the conditional Gaussian framework (1) and (2) automatically makes use of the information in both the observations and the stochastic parameterized equations. The combination of these two components reduces the error even if the prior knowledge in the stochastic parameterized equations is biased (as in most of the real-world applications). Notably, the convergence of the estimated parameters as shown in Figure 30 is much faster than the direct method. This is one of the key features of the approach using stochastic parameterized equations and is practically quite useful since only limited observational data is known in many applications.
It is also important to note that the perfect model is unknown in most realistic situations. Therefore, dealing with model error in the parameter estimation is a crucial topic. The judicious model error in the approach using stochastic parameterized equations allows parameter uncertainties and provides more robust results compared with the direct method. Thus, the approach using stochastic parameterized equations has a wider application in real-world problems. More comparison between the two methods developed here can be found in [28].
6.1.3. Estimating Parameters in the Unresolved Processes
As discussed in Section 4.5.1 and Section 6.1.2, stochastic parameterizations are widely used in describing turbulent signals as observed in nature. One important step is to estimate the parameters in the equations associated with these stochastic parameterizations (e.g, and in (119)). Note that there are typically no direct observations of these stochastic parameterized processes since they usually represent unresolved variables or they may not have clear physical correspondence. However, they play important roles in describing the underlying complex turbulent dynamical system. An accurate estimation of these parameters is crucial. See examples in Section 4.5.1 and Section 6.1.2 and those in [65,101].
Traditional methods in estimating these parameters include Markov Chain Monte Carlo (MCMC) [198,199,200,201], maximum likelihood estimation [202,203] and the ensemble Kalman filter [204,205]. Note that, if both the state variables and the associated 9 parameters in these three equations are treated as unobserved variables , then the augmented system does not belong to the conditional Gaussian model family. Thus, the closed form in (4) and (5) cannot be applied in the two methods discussed in Section 6.1.1 and Section 6.1.2 and ensemble Kalman filter has to be adopted in these methods, which is computationally expensive.
Nevertheless, a judicious application of the conditional Gaussian framework still allows an efficient parameter estimation algorithm for the parameters in the stochastic parameterized equations. Below, we discuss the idea using the so-called SPEKF-M model, which is a simplified version of the SPEKF model (119) and contains only the multiplicative noise process (and “M” stands for multiplicative). The model reads
The goal here is to estimate the three parameters and by observing only one sample trajectory of u. First, choose an arbitrary initial estimation of the three parameters and . Then, run the conditional Gaussian filter (4) and (5), which gives a time series of the conditional mean and another time series of the conditional variance of conditioned on the trajectory of u. With the and , applying the same argument as that in (124) but changing the L Gaussian distributions associated with L different trajectories by those at L different time instants, the distribution can be obtained via a Gaussian mixture. Here, is also a Gaussian distribution due to its dynamical structure in (151). This Gaussian distribution provides two quantities—the mean and the variance . In addition, the sample autocorrelation function of the conditional mean can be easily computed. Therefore, these three quantities are used to update the iteration of the three parameters and with the relation
Then, run the conditional Gaussian filter (4) and (5) again using the same observed time series but with the updated parameters and . Repeating the above procedure leads to another update of the parameters and . Continue this process until the updates of the parameters converge. This fixed point iteration results in an efficient parameter estimation algorithm.
As a simple test example, the following parameters are adopted to generate the true signal in the SPEKF-M model (151),
A pair of sample trajectories is shown in Panel (a) of Figure 31 and the corresponding PDFs are shown in Panel (b). Clearly, these parameters result in a highly intermittent time series of with a non-Gaussian PDF with an one-side fat tail. Panel (c) shows the conditional mean and conditional variance of conditioned on the trajectory of u with the perfect parameters. The conditional mean does not equal the truth, but the conditional mean at the intermittent phases of u are close to the truth of with a small conditional variance. On the other hand, at quiescent phases, differs from the truth while the uncertainty (conditional variance) in the estimation is large.
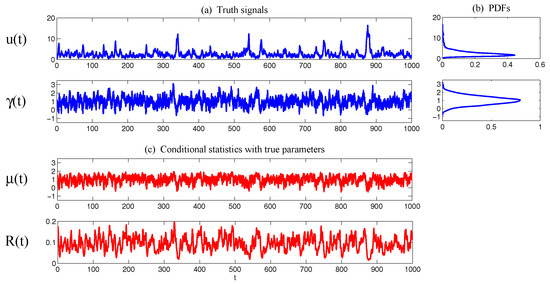
Now, we apply the algorithm above to estimate the three parameters and assuming the other two parameters and are known. The trajectory of u (with the length of 1000 time units) in Panel (a) of Figure 31 is used as the input of the algorithm. The iteration curve of the algorithm is shown in Figure 32, where the initial values and are far from the truth. It is clear that, after five iterations, the update of the parameters converges to fixed points. The parameter converges exactly to the truth while both and are slightly larger than the true values. Nevertheless, the variance of using the estimated parameters, namely , is close to that of the truth, which is . The slightly overestimation of the variance compensates the slightly underestimation of the damping time and therefore the model with the estimated parameters is able to generate essentially the same intermittent signals as in the observed period of u in Figure 31. Note that since the input of the time series of u is only of finite length (and is actually pretty short here), the estimated parameters reflect the features in the observed signal, which may be slightly different from the true underlying dynamics unless an infinitely long time series is used as the input. Next, the skill of the estimated parameters is examined via the model statistics. In Figure 33, both the trajectories and the associated PDFs of u and using the true parameters and the estimated parameters are shown. Due to the high skill in estimating both the mean and variance of , the PDFs of and are quite close to each other with only a slight overestimation of the variance in . The decorrelation time of the trajectory of is slightly shorter than that of as discussed above. Nevertheless, and provide quite similar feedback to and u. Therefore, the statistical features in , including the decorrelation time, mean, variance and highly non-Gaussian PDF, are almost the same as those in u.
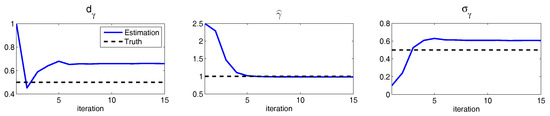
Figure 32.
Iteration of the updates of the parameters (blue curve). The initial values and are far from the truth (black dashed lines).
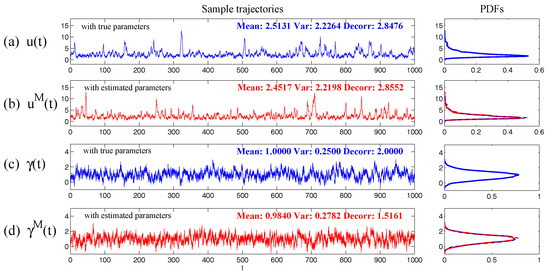
Figure 33.
Sample trajectories and the associated PDFs using the true parameters (blue) and the estimated ones (red). (a) ; (b) ; (c) ; (d) . The PDFs are calculated based on a long trajectory with time units but only 1000 time units are shown here. In the panels of the PDFs of and , those of u and are also illustrated (thin dashed blue curves) for comparison.
A more detailed study of this algorithm, including the application to the full SPEKF model (119) and the convergence rate dependence on different model ingredients, will be included in a follow-up work.
6.2. Data Assimilation with Physics-Constrained Forecast Models and Information Theory for Quantifying Model Errors
6.2.1. An Information Theoretical Framework for Data Assimilation and Prediction
The following two traditional path-wise measurements are widely used in assessing the skill in data assimilation and prediction [15,206,207,208,209,210]. Denote , the true signal and the filtering/prediction estimate. These measurements are given by
- The root-mean-square error (RMSE):
- The pattern correlation (PC):
where and denotes the mean of and , respectively.
While these two path-wise measurements are easy to implement and are able to quantify the data assimilation and prediction skill to some extent, they have fundamental limitations. It has been shown in [42,211] that these two measurements fail to quantify the skill of capturing the extreme events and other non-Gaussian features, which lead to misleading results. In fact, concrete examples even in the Gaussian models [42,211] showed that two different predictions can have the same RMSE and PC, but one is way more skillful than the other in capturing the extreme events.
Due to the fundamental limitations of assessing the data assimilation and prediction skill based only on these two traditional path-wise measurements, various information measurements have been proposed to improve the quantification of the data assimilation and prediction [16,194,195,212,213,214,215,216,217,218]. In [218,219,220,221,222], an information measurement called Shannon entropy difference was introduced and was used to assess the data assimilation and prediction skill. The Shannon entropy difference takes into account the estimation of the extreme events and improves the insufficiency in the traditional path-wise measurements. However, relying solely on the Shannon entropy difference in assessing the data assimilation and prediction skill is also misleading. In fact, the Shannon entropy difference fails to capturing the model error in the mean state and it computes the uncertainty of the two distributions separately rather than considering the pointwise difference between the two PDFs.
Due to the fundamental limitations in the two classical path-wise measurement, RMSE and PC, as well as those in the Shannon entropy difference, a new information-theoretic framework [186] has developed to assess the data assimilation/prediction skill. Denote and the PDFs associated with truth u and the data assimilation/prediction estimate , respectively. Denote the joint PDF of u and . Let be the residual between the truth and the estimate. This information-theoretic framework involves three information measurements:
- The Shannon entropy residual,
- The mutual information,
- The relative entropy,
The Shannon entropy residual quantifies the uncertainty in the point-wise difference between u and . It is an information surrogate of the RMSE in the Gaussian framework. The mutual information quantifies the dependence between the two processes. It measures the lack of information in the factorized density relative to the joint density , which follows the identity,
The mutual information is an information surrogate of the PC in the Gaussian framework. On the other hand, the relative entropy quantifies the lack of information in related to and it is a good indicator of the skill of in capturing the peaks and extreme events of u. It also takes into account the pointwise discrepancy between and rather than only computing the difference between the uncertainties associated with the two individual PDFs (as in the Shannon entropy difference). Therefore, the combination of these three information measurements is able to capture all the features in assessing the data assimilation/prediction skill and overcomes the shortcomings as discussed in the previous subsection. Note that, when and are both Gaussian, then the above three information measurements have explicit expressions [215].
The information-theoretic framework (156)–(158) is usually defined in the super-ensemble sense [215]. Note that in many practical issues only one realization (trajectory) is available. Nevertheless, the information-theoretic framework can also be used in a pathwise way, where the statistics are computed by collecting all the sample points in the given realization. Some realistic applications of the information-theoretic framework for filtering and prediction can be found in [42,63,215].
6.2.2. Important Roles of Physics-Constrained Forecast Models in Data Assimilation
It has been shown in Section 3.3 that the physics-constrained nonlinear stochastic models are the recent development for data-driven statistical models with partial observations. The physics-constrained nonlinear stochastic models overcome the finite-time blowup and the lack of physical meaning issues in various ad hoc multi-layer regression models [31,32]. Here, our goal is to show that the physics-constrained nonlinear stochastic models also play important role in data assimilation (or filtering). Ignoring the energy-conserving nonlinear interactions in the forecast models will result in large model errors.
The test model below is a simple dyad model, which mimics the interactions between resolved large-scale mean flow and unresolved turbulent fluctuations with intermittent instability [37,50,223]. The dyad model reads
In (160) and (161), u is regarded as representing one of the resolved modes in a turbulent signal, which interacts with the unresolved mode v through quadratic nonlinearities. The conserved energy in the quadratic nonlinear terms in (160) and (161) is easily seen. Below, the physics-constrained dyad model (160) and (161) is utilized to generate true signals of nature. The goal here is to filter the unobserved process v given one single realization of the observed process u. In addition to adopting the perfect filter (160) and (161), an imperfect filter with no energy-conserving nonlinear interactions is studied for comparison. In this imperfect filter, the nonlinear feedback in v is dropped and the result is a stochastic parameterized filter [20],
In the stochastic parameterized filter (162) and (163), the parameters in the resolved variable u are assumed to be the same as nature (160) and (161). We further assume the statistics of the unobserved variable v of nature (160) and (161) are available. Thus, the parameters and in the unresolved process v are calibrated [187,188,224] by matching the mean, variance and decorrelation time of those in (160) and (161). Note that both (160) and (161) and (162) and (163) belong to the conditional Gaussian framework (1) and (2) by denoting and and (4) and (5) is used to efficiently calculate the filter estimates.
Note that in (160) and (161), if , then the fixed point associated with the deterministic part is = = 0. This leads to an important issue in the state estimation of v, namely the observability [207,225]. The coupled system (160) and (161) is said to lose its observability if the observed process u provides no information in determining the unobserved variable v. Intuitively, this corresponds to in (160) and (161), in which case v disappears in the observed process u. Therefore, if , then the filtering skill of v is expected to deteriorate especially with a small . Below, we consider two different dynamical regimes:
In Regime II, there is no practical observability in the quiescent phase (near the fixed point associated with the deterministic model) while in Regime I the forcing drives the signal out of the value with .
Figure 34 shows the model error in terms of RMSE, PC and relative entropy as a function of and . Both the perfect physics-constrained forecast model (160) and (161) and the stochastic parameterized filter (162) and (163) are used. Here, instead of showing the Shannon entropy residual and the mutual information, we still use the RMSE and PC since most readers are familiar with these two measurements. Nevertheless, the readers should keep in mind that the Shannon entropy residual and the mutual information are more suitable measurements in the non-Gaussian framework. On the other hand, the relative entropy is shown here in assessing the model error.
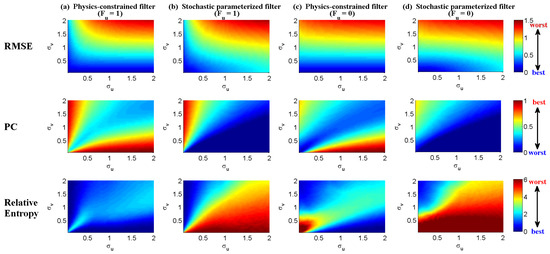
Figure 34.
Model error in terms of RMSE, PC and relative entropy as a function of and in the true signal. (a,b) Regime I with ; (c,d) Regime I with ; (a,c) show the model error using the perfect physics-constrained forecast model (160) and (161) while (b,d) uses the stochastic parameterized filter (162) and (163).
First, in Columns (a,b) of Figure 34, the filtering skill in Regime I with is illustrated. With a small , both filters have skillful estimation. This is because when is small, the filters trust more towards the observational process, which has a large signal to noise ratio and therefore it provides accurate estimates. However, when is large but is small in generating the true signal, the stochastic parameterized filter becomes much worse than the perfect filter using physics-constrained forecast model. In fact, a large leads to large signals in u and it also tells the filter to trust more towards the underlying process of v. This implies the filter estimate of v is then essentially driven by the feedback term . Since the stochastic parameterized filter has no such feedback mechanism, the error becomes large. See Panel (b) of Figure 35 for an example with path-wise trajectories. It is also important to note that in such a situation the PDF of the filter estimate is completely different from the truth and thus a large model error is found.
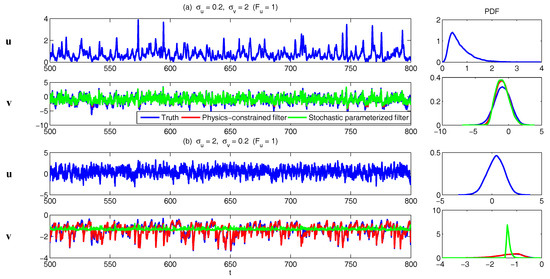
Columns (c,d) of Figure 34 show the filter estimates in Regime II with . Compared with the results in Regime I, it is clear that when is small in generating the true signal, the filter estimates become inaccurate. This is in fact due to the observability issue since small means the signal of u stays near original. This is clearly seen in Panel (a) of Figure 36, where the filter estimate is accurate only at intermittent phases. One interesting phenomenon is that although the filter estimate using the stochastic parameterized filter in Panel (b) of Figure 35 has a smaller RMSE compared with that in Panel (a) of Figure 36, the relative entropy clearly indicates a much worse filter estimates in the former case since they fail to capture any of the amplitudes. These facts all indicate the importance in including the physics-constrained structure in designing filters especially in the regimes that are dominated by the energy-conserving nonlinear interactions.
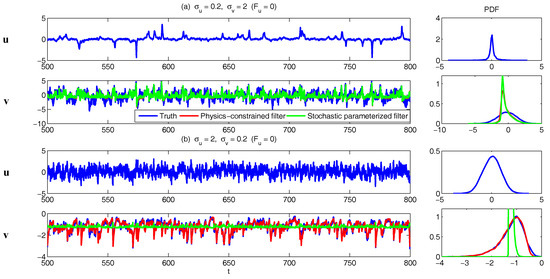
Finally, it is important to note that although the stochastic parameterized filter (162) and (163) is not able to recover the signal due to the strong feedback from the physics-constrained nonlinear interactions, the stochastic parameterized filter (162) and (163) is still quite useful in detecting the intermittent phases in turbulent signals. In fact, in Panel (a) of both Figure 35 and Figure 36, the intermittent phases are all accurately recovered by the stochastic parameterized filter. Other works showing the skillful behavior of the stochastic parameterized filter and its advantages over the mean stochastic models can be found in [16,64,65].
6.3. Multiscale Data Assimilation with Particles Interacting with Conditional Gaussian Statistics
6.3.1. A General Description
Data assimilation of turbulent signals is an important challenging problem because of the extremely complicated large dimension of the signals and incomplete partial noisy observations which usually mix the large scale mean flow and small scale fluctuations. See Chapter 7 of [20] for examples of new phenomena due to this multiscale coupling through the observations even for linear systems. Due to the limited computing power, it is desirable to use multi-scale forecast models which are cheap and fast to mitigate the curse of dimensionality in turbulent systems. Thus, model errors from imperfect forecast models are unavoidable in the development of a data assimilation method in turbulence.
Among different methods, conventional superparameterization is a multi-scale algorithm that was originally developed for the purpose of parameterizing unresolved cloud process in tropical atmospheric convection [73,226,227]. This conventional superparameterization resolves the large scale mean flow on a coarse grid in a physical domain while the fluctuating parts are resolved using a fine grid high resolution simulation on periodic domains embedded in the coarse grid. A much cheaper version of superparameterization, called stochastic superparameterization [70,71,72,73], replaces the nonlinear eddy terms by quasilinear stochastic processes on formally infinite embedded domains where the stochastic processes are Gaussian conditional to the large scale mean flow. The key ingredient of these multiscale data assimilation methods is the systematic use of conditional Gaussian mixtures which make the methods efficient by filtering a subspace whose dimension is smaller than the full state. This conditional Gaussian closure approximation results in a seamless algorithm without using the high resolution space grid for the small scales and is much cheaper than the conventional superparameterization, with significant success in difficult test problems [71,72,74] including the MMT model [71,75] and ocean turbulence [76,77,78].
The key idea of the multiscale data assimilation method is to use conditional Gaussian mixtures [80,228] whose distributions are compatible with superparameterization. The method uses particle filters (see [79] and Chapter 15 of [20]) or ensemble filters on the large scale part [75,76] whose dimension is small enough so that the non-Gaussian statistics of the large scale part can be calculated from a particle filter, whereas the statistics of the small scale part are conditionally Gaussian given the large scale part. This framework is not restricted to superparameterization as the forecast model and other cheap forecast models can also be employed. See [80] for another multiscale filter with quasilinear Gaussian dynamically orthogonality method as the forecast method in an adaptively evolving low dimensional subspace without using superparameterization. Note that data assimilation using superparameterization has already been discussed in [229] with noisy observations of the large scale part of the signal alone. There it was shown that, even in this restricted setting, ignoring the small scale fluctuations even when they are rapidly decaying can completely degrade the filter performance compared with the high skill using superparameterization. Here, in contrast to [229], we consider multiscale data assimilation methods with noisy observations with contributions from both the large and small scale parts of the signal, which is a more difficult problem than observing only the large scale because it requires accurate estimation of statistical information of the small scales [75,76,230]. In addition, mixed observations of the large and small scale parts occur typically in real applications. For example, in geophysical fluid applications, the observed quantities such as temperature, moisture, and the velocity field necessarily mix both the large and small scale parts of the signal [20,231]. Thus, the multiscale filtering also provides a mathematical framework for representation errors, which are due to the contribution of unresolved scales [81,82] in the observations.
6.3.2. Particle Filters with Superparameterization
Superparameterization retains the large scale variables by resolving them on a coarse grid while the effect of the small scales on the large scales is parameterized by approximating the small scales on local or reduced spaces. Stochastic superparameterization discussed in the previous section uses Gaussian closure for the small scales conditional to the large scale variable with [70,71,72,73]. Thus, we consider a multi-scale filtering algorithm with forecast prior distributions given by the conditional distribution
where is a Gaussian distribution conditional to
Here, we assume that is sufficiently small enough that particle filters (see Chapter 15 of [20]) can be applied to the large scales. For a low dimensional space , the marginal distribution of can be approximated by Q particles
where are particle weights such that . After the forecast step where superparameterization is applied to each particle member, we have the following general form for the prior distribution
which is a conditional Gaussian mixture distribution where each summand is a Gaussian distribution conditional to . The Gaussian mixture has already been used in data assimilation [232,233,234] but the multi-scale method developed here is different in that conditional Gaussian distributions are applied in the reduced subspace with particle approximations only in the lower dimensional subspace . Thus, the proposed multi-scale data assimilation method can be highly efficient and fast in comparison with conventional data assimilation methods which use the whole space for the filter.
Assume that the prior distribution from the forecast is in the from (168) and that the observations have the following structure:
where has rank M and is the observation noise error which is Gaussian. Then, the posterior distribution in the analysis step taking into account the observations (169) is in the form of (168)
The new mixture weights are
where and for each particle , the posterior mean and variance of , and , respectively, are
where the Kalman gain matrix is given by
See the supplementary material of [80] for more details.
6.3.3. Clustered Particle Filters and Mutiscale Data Assimilation
Clustered particle filters (CPFs) [40,235] are a new class of particle filters, introduced for high-dimensional dynamical systems such as geophysical systems. The clustered particle filters use relatively few particles compared with the standard particle filter and capture the non-Gaussian features of the true signal, which are typical in complex nonlinear systems. The method is also robust for the difficult regime of high-quality sparse and infrequent observations and does not show any filter divergence in our tests. In the clustered particle filter, coarse-grained localization is implemented through the clustering of state variables and particles are adjusted to stabilize the filter.
One of the key features of the CPF is particle adjustment. Particle adjustment updates the prior particles closer to the observation instead of reweighing the particles when the prior is too far from the observation likelihood. When observations are sparse, unobserved adjacent state variables must have the same particle weights with the observed variable as they are updated using cross-correlations. For this purpose, the CPF partitions the state variables into nonoverlapping clusters , where each cluster boundary is chosen as the midpoint of two adjacent observations, which is easily applicable to irregularly spaced observations. This yields clusters corresponding to observationlocations. Instead of using different weights for each state variable in the localized particle filter, the CPF uses scalar particle weights for the state variables in the same cluster . For the substate vector corresponding to cluster , the CPF considers the marginalized PDF,
and each observation updates only the marginalized PDF of the corresponding cluster that implements coarse-grained localization. Thus, the assimilation of the full state vector is decomposed into independent assimilation problems for each cluster of a dimension smaller than the full state dimension . Note that, in contrast to the localization using a smoothly varying correlation function with a localization radius parameter, the CPF has no adjustable parameter to tune localization. See [235] for more details.
The CPF can also be applied for multiscale particle filtering [40,235]. As a test example, it is shown below the skill of the multiscale cluster particle filter for the wave turbulence model introduced by Majda, McLaughlin and Tabak (MMT) [236,237] as a computationally tractable model of waveturbulence. The model is described by the following one dimensional partial differential equation for a complex scalar :
in a periodic domain of length L with large-scale forcing set to and dissipation D for both the large and small scales. It has several features of wave turbulence that make it a difficult test problem for data assimilation. The model has a shallow energy spectrum proportional to for wavenumber k and an inverse cascade of energy from small to large scales. It also has non-Gaussian extreme event statistics caused by intermittent instability and breaking of solitons. Because the unresolved small scales carry more than two-thirds of the total variance, it is a difficult filtering problem to estimate resolved large scales using mixed observations of the large- and small-scale components.
Here, we compare the filtering results of the ensemble-based multiscale data assimilation method [75] and the multiscale CPF for the MMT model. As the forecast model for both filtering methods, we use the stochastic superparameterization multiscale method [73] as discussed in the previous subsection. The forecast model uses only 128 grid points, whereas the full resolution uses 8192 grid points, which yields about 250 times cheaper computational savings. Because the forecast model has a low computational cost compared with the full-resolution model, the forecast model has significant model errors. Observations of the full-scale variables are available at uniformly distributed 64 grid points (which are extremely sparse compared with the full-resolution 8192 grid points) with an observation error variance corresponding to of the total climatological variance at every time interval of . The ensemble-based method uses the tuned parameters in [75] (i.e., a short localization radius 1 and covariance inflation). For the hard threshold version CPF, the particle adjustment is triggered if either real or imaginary parts are not in the convex hull of the corresponding predicted observations as we observe both parts of the true signal. Both particle and ensemble-based methods use 129 samples.
The time series of the large-scale estimation RMSE of the ensemble-based filter and clustered multiscale particle filter are shown in Figure 37. The dashed and dotted line is the effective observation error , which is defined as by treating the small-scale contribution as an additional error (i.e., a representation error). The dashed line is the climatological error , which is the standard deviation of the large-scale variables. The ensemble-based method has RMSE smaller than the effective observation error but larger than the climatological error. The CPF, however, shows skillful filter performance with RMSE smaller than the climatological error. The forecast PDFs and forecast error PDFs that show the prediction skill of the method are shown in Figure 37. The CPF has a better forecast PDF fit to the true signal and a narrower peak in the forecast error PDF than the ensemble-based method.
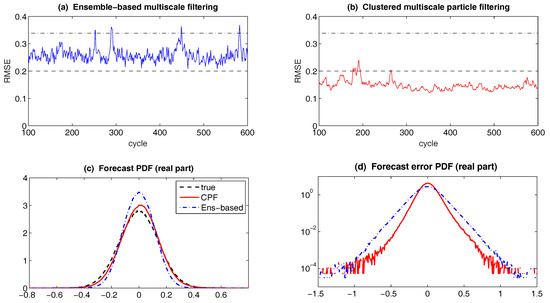
Figure 37.
(a,b) time series of the large-scale estimation RMSE of the ensemble-based multiscale data assimilation method [75] and the CPF with 64 observations for the MMT model. The dashed line is the climatological error . The dashed and dotted line is the effective observation error ; (c,d) large-scale forecast PDF and forecast error PDF using 64 observations.
6.3.4. Blended Particle Methods with Adaptive Subspaces for Filtering Turbulent Dynamical Systems
In the multi-scale data assimilation algorithms discussed above based on superparameterization, the subspace of particles defined by is fixed. An attractive idea is to change the subspace with particles adaptively in time to capture the non-Gaussian features as they change in time. Very accurate filtering algorithms based on these ideas for multi-scale filtering utilizing this adaptive strategy have been developed [80,238]. Nonlinear statistical forecast models such as the modified quasilinear Gaussian [17,239] are implemented in the adaptive algorithm. In particular, the paper [238] also contains many detailed numerical experiments and interesting counterexamples to more naive strategies for multi-scale data assimilation.
6.3.5. Extremely Efficient Multi-Scale Filtering Algorithms: SPEKF and Dynamic Stochastic Superresolution (DSS)
The SPEKF models as discussed in Section 4.5.1 are a class of nonlinear filters which are exact statistical equations for the mean and covariance for nonlinear forecast models that learn hidden parameters “on the fly” from the observed data. The parameters represent adaptive additive and multiplicative bias corrections from model error. They explicitly make judicious model error and utilize conditional Gaussian structure as developed in Section 4.5.1 above. The book [20] contains many examples and successful applications of this method.
Dynamical Stochastic Superresolution (DSS) uses the same idea but in addition exploits the aliased information in the observations to super-resolve a multi-scale turbulent signal [103,240]. Nontrivial applications of DSS including recovering geophysical turbulence from surface satellite observations [240] and filtering “black swans” and dispersive wave turbulence [103] with severe judicious model errors. An interesting mathematical problem is to understand the reasons for the skill of these radical methods. Recent progress in conceptual understanding of these methods for the two dimensional Navier–Stokes equations can be found in [104].
7. Conclusions
Multiscale nonlinear dynamical systems are ubiquitous in different areas, including geoscience, engineering, neural science and material science. In this article, a conditional Gaussian framework is developed and applied to the prediction, the state estimation and the uncertainty quantification of multiscale nonlinear stochastic systems. Despite the conditional Gaussianity, such systems are nevertheless highly nonlinear and are able to capture the non-Gaussian features of nature. The special structure of the system allows closed analytical formulae for solving the conditional statistics and is thus computationally efficient.
In Section 2, an overview of data, model and data-driven modeling framework is presented. Data and models are combined with each other to improve the understanding of nature and promote the filtering and prediction skill. However, solving the high-dimensional complex multiscale nonlinear dynamical systems in a direct way is computationally unaffordable and sometimes even not necessary. Therefore, cheap and effective approaches are required to efficiently solve the systems. Hybrid strategies can be used to greatly reduce the computational cost while they are able to preserve the key feature of the complex systems. In the hybrid strategies, particle methods are combined with analytically solvable conditional Gaussian statistics to deal with highly non-Gaussian characteristics in a relatively low dimensional subspace and the conditional Gaussian features in the remaining subspace, respectively. This indicates the importance of a systematic study of the conditional Gaussian system. Section 3 summarizes the general mathematical structure of nonlinear conditional Gaussian systems, the physics-constrained nonlinear stochastic models and the application of the MTV strategy to the conditional Gaussian systems. To show the wide application of the conditional Gaussian framework, a rich gallery of examples of conditional Gaussian systems are illustrated in Section 4, which includes data-driven physics-constrained nonlinear stochastic models, stochastically coupled reaction–diffusion models in neuroscience and ecology, large-scale dynamical models in turbulence, fluids and geophysical flow, and other models for filtering and predicting complex multiscale turbulent dynamical systems. Section 5 involves the effective statistically accurate algorithms that beat the curse of dimension for Fokker–Planck equation for conditional Gaussian systems. A hybrid strategy is developed where a conditional Gaussian mixture in a high-dimensional subspace via an extremely efficient parametric method is combined with a judicious non-parametric Gaussian kernel density estimation in the remaining low-dimensional subspace. For even larger dimensional systems, a judicious block decomposition and statistical symmetry are further applied that facilitate an extremely efficient parallel computation and a significant reduction of sample numbers. These algorithms are applied to the statistical prediction of a stochastically coupled FHN model with 1500 dimensions and an inhomogeneous two-layer Lorenz 96 model with 240 dimensions. Significant prediction skill shows the advantages of these algorithms in terms of both accuracy and efficiency. In Section 6, the conditional Gaussian framework is applied to develop extremely cheap multiscale data assimilation schemes, such as the stochastic superparameterization, which use particle filters to capture the non-Gaussian statistics on the large-scale part whose dimension is small whereas the statistics of the small-scale part are conditional Gaussian given the large-scale part. Other topics of the conditional Gaussian systems studied here include designing new parameter estimation schemes and understanding model errors using information theory.
The conditional Gaussian framework can also be used to study many other important topics. For example, the closed analytic formulae in the conditional statistics provide an efficient way to understand the causality between different processes in light of the information theory. The representation error is another important issue that requires a comprehensive study and the conditional Gaussian framework have great potentials to provide both theoretic and applied insights. In addition, model selection, model reduction and more studies on the parameter estimation are all important future works within the conditional Gaussian framework.
Author Contributions
Conceptualization, N.C. and A.J.M.; Data curation, N.C. and A.J.M.; Formal analysis, N.C. and A.J.M.; Funding acquisition, A.J.M.; Methodology, N.C. and A.J.M.; Visualization, N.C.; Writing—Original draft, N.C.; Writing—Review and editing, A.J.M.
Funding
The research of A.J.M. is partially supported by the Office of Naval Research (ONR) Multidisciplinary University Research Initiative (MURI) Grant N0001416-1-2161 and the New York University Abu Dhabi Research Institute. N.C. is supported as a postdoctoral fellow through A.J.M.’s ONR MURI Grant.
Acknowledgments
The authors thank Yoonsang Lee, Di Qi and Sulian Thual for useful discussion.
Conflicts of Interest
The authors declare no conflict of interest. The funding sponsors had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, and in the decision to publish the results.
References
- Majda, A.J. Introduction to Turbulent Dynamical Systems in Complex Systems; Springer: New York, NY, USA, 2016. [Google Scholar]
- Majda, A.; Wang, X. Nonlinear Dynamics and Statistical Theories for Basic Geophysical Flows; Cambridge University Press: Cambridge, UK, 2006. [Google Scholar]
- Strogatz, S.H. Nonlinear Dynamics and Chaos: With Applications to Physics, Biology, Chemistry, and Engineering; CRC Press: Boca Raton, FL, USA, 2018. [Google Scholar]
- Baleanu, D.; Machado, J.A.T.; Luo, A.C. Fractional Dynamics and Control; Springer: New York, NY, USA, 2011. [Google Scholar]
- Deisboeck, T.; Kresh, J.Y. Complex Systems Science in Biomedicine; Springer: Boston, MA, USA, 2007. [Google Scholar]
- Stelling, J.; Kremling, A.; Ginkel, M.; Bettenbrock, K.; Gilles, E. Foundations of Systems Biology; MIT Press: Cambridge, MA, USA, 2001. [Google Scholar]
- Sheard, S.A.; Mostashari, A. Principles of complex systems for systems engineering. Syst. Eng. 2009, 12, 295–311. [Google Scholar] [CrossRef]
- Wilcox, D.C. Multiscale model for turbulent flows. AIAA J. 1988, 26, 1311–1320. [Google Scholar] [CrossRef]
- Mohamad, M.A.; Sapsis, T.P. Probabilistic description of extreme events in intermittently unstable dynamical systems excited by correlated stochastic processes. SIAM/ASA J. Uncertain. Quantif. 2015, 3, 709–736. [Google Scholar] [CrossRef]
- Sornette, D. Probability distributions in complex systems. In Encyclopedia of Complexity and Systems Science; Springer: New York, NY, USA, 2009; pp. 7009–7024. [Google Scholar]
- Majda, A. Introduction to PDEs and Waves for the Atmosphere and Ocean; American Mathematical Society: Providence, RI, USA, 2003; Volume 9. [Google Scholar]
- Wiggins, S. Introduction to Applied Nonlinear Dynamical Systems and Chaos; Springer: New York, NY, USA, 2003; Volume 2. [Google Scholar]
- Vespignani, A. Predicting the behavior of techno-social systems. Science 2009, 325, 425–428. [Google Scholar] [CrossRef] [PubMed]
- Latif, M.; Anderson, D.; Barnett, T.; Cane, M.; Kleeman, R.; Leetmaa, A.; O’Brien, J.; Rosati, A.; Schneider, E. A review of the predictability and prediction of ENSO. J. Geophys. Res. Oceans 1998, 103, 14375–14393. [Google Scholar] [CrossRef]
- Kalnay, E. Atmospheric Modeling, Data Assimilation and Predictability; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Majda, A.J.; Branicki, M. Lessons in uncertainty quantification for turbulent dynamical systems. Discret. Contin. Dyn. Syst. A 2012, 32, 3133–3221. [Google Scholar]
- Sapsis, T.P.; Majda, A.J. Statistically accurate low-order models for uncertainty quantification in turbulent dynamical systems. Proc. Natl. Acad. Sci. USA 2013, 110, 13705–13710. [Google Scholar] [CrossRef] [PubMed]
- Mignolet, M.P.; Soize, C. Stochastic reduced order models for uncertain geometrically nonlinear dynamical systems. Comput. Methods Appl. Mech. Eng. 2008, 197, 3951–3963. [Google Scholar] [CrossRef]
- Lahoz, W.; Khattatov, B.; Ménard, R. Data assimilation and information. In Data Assimilation; Springer: New York, NY, USA, 2010; pp. 3–12. [Google Scholar]
- Majda, A.J.; Harlim, J. Filtering Complex Turbulent Systems; Cambridge University Press: Cambridge, UK, 2012. [Google Scholar]
- Evensen, G. Data Assimilation: The Ensemble Kalman Filter; Springer: New York, NY, USA, 2009. [Google Scholar]
- Law, K.; Stuart, A.; Zygalakis, K. Data Assimilation: A Mathematical Introduction; Springer: New York, NY, USA, 2015; Volume 62. [Google Scholar]
- Palmer, T.N. A nonlinear dynamical perspective on model error: A proposal for non-local stochastic-dynamic parametrization in weather and climate prediction models. Q. J. R. Meteorol. Soc. 2001, 127, 279–304. [Google Scholar] [CrossRef]
- Orrell, D.; Smith, L.; Barkmeijer, J.; Palmer, T. Model error in weather forecasting. Nonlinear Process. Geophys. 2001, 8, 357–371. [Google Scholar] [CrossRef]
- Hu, X.M.; Zhang, F.; Nielsen-Gammon, J.W. Ensemble-based simultaneous state and parameter estimation for treatment of mesoscale model error: A real-data study. Geophys. Res. Lett. 2010, 37, L08802. [Google Scholar] [CrossRef]
- Benner, P.; Gugercin, S.; Willcox, K. A survey of projection-based model reduction methods for parametric dynamical systems. SIAM Rev. 2015, 57, 483–531. [Google Scholar] [CrossRef]
- Majda, A.J. Challenges in climate science and contemporary applied mathematics. Commun. Pure Appl. Math. 2012, 65, 920–948. [Google Scholar] [CrossRef]
- Chen, N.; Majda, A.J. Filtering nonlinear turbulent dynamical systems through conditional Gaussian statistics. Mon. Weather Rev. 2016, 144, 4885–4917. [Google Scholar] [CrossRef]
- Olbers, D. A gallery of simple models from climate physics. In Stochastic Climate Models; Springer: Berlin, Germany, 2001; pp. 3–63. [Google Scholar]
- Liptser, R.S.; Shiryaev, A.N. Statistics ofRandom Processes II: Applications. In Applied Mathematics; Springer: Berlin/Heidelberg, Germany, 2001; Volume 6. [Google Scholar]
- Majda, A.J.; Harlim, J. Physics constrained nonlinear regression models for time series. Nonlinearity 2012, 26, 201. [Google Scholar] [CrossRef]
- Harlim, J.; Mahdi, A.; Majda, A.J. An ensemble Kalman filter for statistical estimation of physics constrained nonlinear regression models. J. Comput. Phys. 2014, 257, 782–812. [Google Scholar] [CrossRef]
- Majda, A.J.; Yuan, Y. Fundamental limitations of ad hoc linear and quadratic multi-level regression models for physical systems. Discret. Contin. Dyn. Syst. B 2012, 17, 1333–1363. [Google Scholar] [CrossRef]
- Lorenz, E.N. Deterministic nonperiodic flow. J. Atmos. Sci. 1963, 20, 130–141. [Google Scholar] [CrossRef]
- Lorenz, E.N. Formulation of a low-order model of a moist general circulation. J. Atmos. Sci. 1984, 41, 1933–1945. [Google Scholar] [CrossRef]
- Chen, N.; Majda, A.J. Beating the curse of dimension with accurate statistics for the Fokker–Planck equation in complex turbulent systems. Proc. Natl. Acad. Sci. USA 2017, 114, 12864–12869. [Google Scholar] [CrossRef] [PubMed]
- Majda, A.J.; Lee, Y. Conceptual dynamical models for turbulence. Proc. Natl. Acad. Sci. USA 2014, 111, 6548–6553. [Google Scholar] [CrossRef] [PubMed]
- Chen, N.; Majda, A.J. Efficient statistically accurate algorithms for the Fokker–Planck equation in large dimensions. J. Comput. Phys. 2018, 354, 242–268. [Google Scholar] [CrossRef]
- Ferrari, R.; Cessi, P. Seasonal synchronization in a chaotic ocean–atmosphere model. J. Clim. 2003, 16, 875–881. [Google Scholar] [CrossRef]
- Lee, Y.; Majda, A. Multiscale data assimilation and prediction using clustered particle filters. J. Comput. Phys. 2017, in press. [Google Scholar]
- Chen, N.; Majda, A.J.; Giannakis, D. Predicting the cloud patterns of the Madden–Julian Oscillation through a low-order nonlinear stochastic model. Geophys. Res. Lett. 2014, 41, 5612–5619. [Google Scholar] [CrossRef]
- Chen, N.; Majda, A.J. Predicting the real-time multivariate Madden–Julian oscillation index through a low-order nonlinear stochastic model. Mon. Weather Rev. 2015, 143, 2148–2169. [Google Scholar] [CrossRef]
- Chen, N.; Majda, A.J. Predicting the Cloud Patterns for the Boreal Summer Intraseasonal Oscillation through a Low-Order Stochastic Model. Math. Clim. Weather Forecast. 2015, 1, 1–20. [Google Scholar] [CrossRef]
- Chen, N.; Majda, A.J.; Sabeerali, C.; Ajayamohan, R. Predicting Monsoon Intraseasonal Precipitation using a Low-Order Nonlinear Stochastic Model. J. Clim. 2018, 25, 4403–4427. [Google Scholar] [CrossRef]
- Majda, A.J.; Timofeyev, I.; Eijnden, E.V. Models for stochastic climate prediction. Proc. Natl. Acad. Sci. USA 1999, 96, 14687–14691. [Google Scholar] [CrossRef] [PubMed]
- Majda, A.J.; Timofeyev, I.; Vanden Eijnden, E. A mathematical framework for stochastic climate models. Commun. Pure Appl. Math. 2001, 54, 891–974. [Google Scholar] [CrossRef]
- Majda, A.; Timofeyev, I.; Vanden-Eijnden, E. A priori tests of a stochastic mode reduction strategy. Phys. D Nonlinear Phenom. 2002, 170, 206–252. [Google Scholar] [CrossRef]
- Majda, A.J.; Timofeyev, I.; Vanden-Eijnden, E. Systematic strategies for stochastic mode reduction in climate. J. Atmos. Sci. 2003, 60, 1705–1722. [Google Scholar] [CrossRef]
- Majda, A.J.; Franzke, C.; Khouider, B. An applied mathematics perspective on stochastic modelling for climate. Philos. Trans. R. Soc. Lond. A 2008, 366, 2427–2453. [Google Scholar] [CrossRef] [PubMed]
- Majda, A.J.; Franzke, C.; Crommelin, D. Normal forms for reduced stochastic climate models. Proc. Natl. Acad. Sci. USA 2009, 106, 3649–3653. [Google Scholar] [CrossRef] [PubMed]
- Thual, S.; Majda, A.J.; Stechmann, S.N. A stochastic skeleton model for the MJO. J. Atmos. Sci. 2014, 71, 697–715. [Google Scholar] [CrossRef]
- Chen, N.; Majda, A.J. Simple stochastic dynamical models capturing the statistical diversity of El Niño Southern Oscillation. Proc. Natl. Acad. Sci. USA 2017, 114, 201620766. [Google Scholar] [CrossRef] [PubMed]
- Castaing, B.; Gunaratne, G.; Heslot, F.; Kadanoff, L.; Libchaber, A.; Thomae, S.; Wu, X.Z.; Zaleski, S.; Zanetti, G. Scaling of hard thermal turbulence in Rayleigh-Bénard convection. J. Fluid Mech. 1989, 204, 1–30. [Google Scholar] [CrossRef]
- Wang, X. Infinite Prandtl number limit of Rayleigh-Bénard convection. Commun. Pure Appl. Math. 2004, 57, 1265–1282. [Google Scholar] [CrossRef]
- Majda, A.J.; Grote, M.J. Model dynamics and vertical collapse in decaying strongly stratified flows. Phys. Fluids 1997, 9, 2932–2940. [Google Scholar] [CrossRef]
- Kelliher, J.P.; Temam, R.; Wang, X. Boundary layer associated with the Darcy–Brinkman–Boussinesq model for convection in porous media. Phys. D Nonlinear Phenom. 2011, 240, 619–628. [Google Scholar] [CrossRef]
- Lindner, B.; Garcıa-Ojalvo, J.; Neiman, A.; Schimansky-Geier, L. Effects of noise in excitable systems. Phys. Rep. 2004, 392, 321–424. [Google Scholar] [CrossRef]
- Medvinsky, A.B.; Petrovskii, S.V.; Tikhonova, I.A.; Malchow, H.; Li, B.L. Spatiotemporal complexity of plankton and fish dynamics. SIAM Rev. 2002, 44, 311–370. [Google Scholar] [CrossRef]
- Shulgin, B.; Stone, L.; Agur, Z. Pulse vaccination strategy in the SIR epidemic model. Bull. Math. Biol. 1998, 60, 1123–1148. [Google Scholar] [CrossRef]
- Ferreira, S., Jr.; Martins, M.; Vilela, M. Reaction-diffusion model for the growth of avascular tumor. Phys. Rev. E 2002, 65, 021907. [Google Scholar] [CrossRef] [PubMed]
- Chen, N.; Majda, A.J.; Tong, X.T. Information barriers for noisy Lagrangian tracers in filtering random incompressible flows. Nonlinearity 2014, 27, 2133. [Google Scholar] [CrossRef]
- Chen, N.; Majda, A.J.; Tong, X.T. Noisy Lagrangian tracers for filtering random rotating compressible flows. J. Nonlinear Sci. 2015, 25, 451–488. [Google Scholar] [CrossRef]
- Chen, N.; Majda, A.J. Model error in filtering random compressible flows utilizing noisy Lagrangian tracers. Mon. Weather Rev. 2016, 144, 4037–4061. [Google Scholar] [CrossRef]
- Gershgorin, B.; Harlim, J.; Majda, A.J. Improving filtering and prediction of spatially extended turbulent systems with model errors through stochastic parameter estimation. J. Comput. Phys. 2010, 229, 32–57. [Google Scholar] [CrossRef]
- Gershgorin, B.; Harlim, J.; Majda, A.J. Test models for improving filtering with model errors through stochastic parameter estimation. J. Comput. Phys. 2010, 229, 1–31. [Google Scholar] [CrossRef]
- Gardiner, C.W. Handbook of Stochastic Methods for Physics, Chemistry and the Natural Sciences; Springer Series in Synergetics; Springer: Berlin/Heidelberg, Germany, 2004; Volume 13. [Google Scholar]
- Risken, H. The Fokker–Planck Equation—Methods of Solution and Applications; Springer Series in Synergetics; Springer: Berlin/Heidelberg, Germany, 1989; Volume 18, p. 301. [Google Scholar]
- Pichler, L.; Masud, A.; Bergman, L.A. Numerical solution of the Fokker–Planck equation by finite difference and finite element methods-a comparative study. In Computational Methods in Stochastic Dynamics; Springer: Dordrecht, The Netherlands, 2013; pp. 69–85. [Google Scholar]
- Robert, C.P. Monte Carlo Methods; Wiley Online Library: Hoboken, NJ, USA, 2004. [Google Scholar]
- Majda, A.J.; Grote, M.J. Mathematical test models for superparametrization in anisotropic turbulence. Proc. Natl. Acad. Sci. USA 2009, 106, 5470–5474. [Google Scholar] [CrossRef] [PubMed]
- Grooms, I.; Majda, A.J. Stochastic superparameterization in a one-dimensional model for wave turbulence. Commun. Math. Sci 2014, 12, 509–525. [Google Scholar] [CrossRef]
- Grooms, I.; Majda, A.J. Stochastic superparameterization in quasigeostrophic turbulence. J. Comput. Phys. 2014, 271, 78–98. [Google Scholar] [CrossRef]
- Majda, A.J.; Grooms, I. New perspectives on superparameterization for geophysical turbulence. J. Comput. Phys. 2014, 271, 60–77. [Google Scholar] [CrossRef]
- Grooms, I.; Lee, Y.; Majda, A.J. Numerical schemes for stochastic backscatter in the inverse cascade of quasigeostrophic turbulence. Multiscale Model. Simul. 2015, 13, 1001–1021. [Google Scholar] [CrossRef]
- Grooms, I.; Lee, Y.; Majda, A.J. Ensemble Kalman filters for dynamical systems with unresolved turbulence. J. Comput. Phys. 2014, 273, 435–452. [Google Scholar] [CrossRef]
- Grooms, I.; Lee, Y.; Majda, A.J. Ensemble filtering and low-resolution model error: Covariance inflation, stochastic parameterization, and model numerics. Mon. Weather Rev. 2015, 143, 3912–3924. [Google Scholar] [CrossRef]
- Grooms, I.; Majda, A.J. Efficient stochastic superparameterization for geophysical turbulence. Proc. Natl. Acad. Sci. USA 2013, 110, 4464–4469. [Google Scholar] [CrossRef] [PubMed]
- Grooms, I.; Majda, A.J.; Smith, K.S. Stochastic superparameterization in a quasigeostrophic model of the Antarctic Circumpolar Current. Ocean Model. 2015, 85, 1–15. [Google Scholar] [CrossRef]
- Bain, A.; Crisan, D. Fundamentals of stochastic filtering; Springer: New York, NY, USA, 2009; Volume 3. [Google Scholar]
- Majda, A.J.; Qi, D.; Sapsis, T.P. Blended particle filters for large-dimensional chaotic dynamical systems. Proc. Natl. Acad. Sci. USA 2014, 111, 7511–7516. [Google Scholar] [CrossRef] [PubMed]
- Janjić, T.; Cohn, S.E. Treatment of observation error due to unresolved scales in atmospheric data assimilation. Mon. Weather Rev. 2006, 134, 2900–2915. [Google Scholar] [CrossRef]
- Daley, R. Estimating observation error statistics for atmospheric data assimilation. Ann. Geophys. 1993, 11, 634–647. [Google Scholar]
- Qian, C.; Zhou, W.; Fong, S.K.; Leong, K.C. Two approaches for statistical prediction of non-Gaussian climate extremes: A case study of Macao hot extremes during 1912–2012. J. Clim. 2015, 28, 623–636. [Google Scholar] [CrossRef]
- Hjorth, J.U. Computer Intensive Statistical Methods: Validation, Model Selection, and Bootstrap; Routledge: London, UK, 2017. [Google Scholar]
- Alessandrini, S.; Delle Monache, L.; Sperati, S.; Cervone, G. An analog ensemble for short-term probabilistic solar power forecast. Appl. Energy 2015, 157, 95–110. [Google Scholar] [CrossRef]
- Alessandrini, S.; Delle Monache, L.; Sperati, S.; Nissen, J. A novel application of an analog ensemble for short-term wind power forecasting. Renew. Energy 2015, 76, 768–781. [Google Scholar] [CrossRef]
- Nair, P.; Chakraborty, A.; Varikoden, H.; Francis, P.; Kuttippurath, J. The local and global climate forcings induced inhomogeneity of Indian rainfall. Sci. Rep. 2018, 8, 6026. [Google Scholar] [CrossRef] [PubMed]
- Hodges, K.; Chappell, D.; Robinson, G.; Yang, G. An improved algorithm for generating global window brightness temperatures from multiple satellite infrared imagery. J. Atmos. Ocean. Technol. 2000, 17, 1296–1312. [Google Scholar] [CrossRef]
- Winker, D.M.; Vaughan, M.A.; Omar, A.; Hu, Y.; Powell, K.A.; Liu, Z.; Hunt, W.H.; Young, S.A. Overview of the CALIPSO mission and CALIOP data processing algorithms. J. Atmos. Ocean. Technol. 2009, 26, 2310–2323. [Google Scholar] [CrossRef]
- Kravtsov, S.; Kondrashov, D.; Ghil, M. Multilevel regression modeling of nonlinear processes: Derivation and applications to climatic variability. J. Clim. 2005, 18, 4404–4424. [Google Scholar] [CrossRef]
- Wikle, C.K.; Hooten, M.B. A general science-based framework for dynamical spatio-temporal models. Test 2010, 19, 417–451. [Google Scholar] [CrossRef]
- Alexander, R.; Zhao, Z.; Székely, E.; Giannakis, D. Kernel analog forecasting of tropical intraseasonal oscillations. J. Atmos. Sci. 2017, 74, 1321–1342. [Google Scholar] [CrossRef]
- Harlim, J.; Yang, H. Diffusion Forecasting Model with Basis Functions from QR-Decomposition. J. Nonlinear Sci. 2017, 1–26. [Google Scholar] [CrossRef]
- Kalman, R.E. A new approach to linear filtering and prediction problems. J. Basic Eng. 1960, 82, 35–45. [Google Scholar] [CrossRef]
- Arulampalam, M.S.; Maskell, S.; Gordon, N.; Clapp, T. A tutorial on particle filters for online nonlinear/non-Gaussian Bayesian tracking. IEEE Trans. Signal Process. 2002, 50, 174–188. [Google Scholar] [CrossRef]
- Ristic, B.; Arulampalam, S.; Gordon, N. Beyond the Kalman Filter: Particle Filters for Tracking Applications; Artech House: Norwood, MA, USA, 2003. [Google Scholar]
- Tippett, M.K.; Anderson, J.L.; Bishop, C.H.; Hamill, T.M.; Whitaker, J.S. Ensemble square root filters. Mon. Weather Rev. 2003, 131, 1485–1490. [Google Scholar] [CrossRef]
- Anderson, J.L. An ensemble adjustment Kalman filter for data assimilation. Mon. Weather Rev. 2001, 129, 2884–2903. [Google Scholar] [CrossRef]
- Harlim, J.; Majda, A.J. Catastrophic filter divergence in filtering nonlinear dissipative systems. Commun. Math. Sci. 2010, 8, 27–43. [Google Scholar] [CrossRef]
- Tong, X.T.; Majda, A.J.; Kelly, D. Nonlinear stability and ergodicity of ensemble based Kalman filters. Nonlinearity 2016, 29, 657. [Google Scholar] [CrossRef]
- Majda, A.J.; Harlim, J.; Gershgorin, B. Mathematical strategies for filtering turbulent dynamical systems. Discret. Contin. Dyn. Syst. 2010, 27, 441–486. [Google Scholar] [CrossRef]
- Frenkel, Y.; Majda, A.J.; Khouider, B. Using the stochastic multicloud model to improve tropical convective parameterization: A paradigm example. J. Atmos. Sci. 2012, 69, 1080–1105. [Google Scholar] [CrossRef]
- Branicki, M.; Majda, A.J. Dynamic stochastic superresolution of sparsely observed turbulent systems. J. Comput. Phys. 2013, 241, 333–363. [Google Scholar] [CrossRef]
- Branicki, M.; Majda, A.J.; Law, K.J.H. Accuracy of some approximate gaussian filters for the Navier–Stokes equation in the presence of model error. Multiscale Model. Simul. 2018. submitted. [Google Scholar]
- Kalman, R.E.; Bucy, R.S. New results in linear filtering and prediction theory. J. Basic Eng. 1961, 83, 95–108. [Google Scholar] [CrossRef]
- Brammer, K.; Siffling, G. Kalman–Bucy Filters; Artech House: Norwood, MA, USA, 1989. [Google Scholar]
- Bucy, R.S.; Joseph, P.D. Filtering for Stochastic Processes with Applications to Guidance; American Mathematical Society: Providence, RI, USA, 1987; Volume 326. [Google Scholar]
- Jazwinski, A.H. Stochastic Processes and Filtering Theory; Courier Corporation: Washington, DC, USA, 2007. [Google Scholar]
- Bensoussan, A. Stochastic Control of Partially Observable Systems; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Liptser, R.S.; Shiryaev, A. Statistics of Random Processes; Springer: New York, NY, USA, 1977. [Google Scholar]
- Sparrow, C. The Lorenz Equations: Bifurcations, Chaos, and Strange Attractors; Springer: New York, NY, USA, 2012; Volume 41. [Google Scholar]
- Haken, H. Analogy between higher instabilities in fluids and lasers. Phys. Lett. A 1975, 53, 77–78. [Google Scholar] [CrossRef]
- Knobloch, E. Chaos in the segmented disc dynamo. Phys. Lett. A 1981, 82, 439–440. [Google Scholar] [CrossRef]
- Gorman, M.; Widmann, P.; Robbins, K. Nonlinear dynamics of a convection loop: A quantitative comparison of experiment with theory. Phys. D Nonlinear Phenom. 1986, 19, 255–267. [Google Scholar] [CrossRef]
- Hemati, N. Strange attractors in brushless DC motors. IEEE Trans. Circuits Syst. I 1994, 41, 40–45. [Google Scholar] [CrossRef]
- Cuomo, K.M.; Oppenheim, A.V. Circuit implementation of synchronized chaos with applications to communications. Phys. Rev. Lett. 1993, 71, 65. [Google Scholar] [CrossRef] [PubMed]
- Poland, D. Cooperative catalysis and chemical chaos: A chemical model for the Lorenz equations. Phys. D Nonlinear Phenom. 1993, 65, 86–99. [Google Scholar] [CrossRef]
- Tzenov, S.I. Strange attractors characterizing the osmotic instability. arXiv, 2014; arXiv:1406.0979. [Google Scholar]
- Wilks, D.S. Effects of stochastic parametrizations in the Lorenz’96 system. Q. J. R. Meteorol. Soc. 2005, 131, 389–407. [Google Scholar] [CrossRef]
- Arnold, H.; Moroz, I.; Palmer, T. Stochastic parametrizations and model uncertainty in the Lorenz’96 system. Phil. Trans. R. Soc. A 2013, 371, 20110479. [Google Scholar] [CrossRef] [PubMed]
- Vallis, G.K. Atmospheric and Oceanic Fluid Dynamics; Cambridge University Press: Cambridge, UK, 2017. [Google Scholar]
- Salmon, R. Lectures on Geophysical Fluid Dynamics; Oxford University Press: Oxford, UK, 1998. [Google Scholar]
- Lorenz, E.N. Irregularity: A fundamental property of the atmosphere. Tellus A 1984, 36, 98–110. [Google Scholar] [CrossRef]
- Giannakis, D.; Majda, A.J. Nonlinear Laplacian spectral analysis for time series with intermittency and low-frequency variability. Proc. Natl. Acad. Sci. USA 2012, 109, 2222–2227. [Google Scholar] [CrossRef] [PubMed]
- Majda, A.; Abramov, R.V.; Grote, M.J. Information Theory and Stochastics for Multiscale Nonlinear Systems; American Mathematical Society: Providence, RI, USA, 2005; Volume 25. [Google Scholar]
- Majda, A.J.; Gershgorin, B.; Yuan, Y. Low-frequency climate response and fluctuation–dissipation theorems: Theory and practice. J. Atmos. Sci. 2010, 67, 1186–1201. [Google Scholar] [CrossRef]
- Mantua, N.J.; Hare, S.R. The Pacific decadal oscillation. J. Oceanogr. 2002, 58, 35–44. [Google Scholar] [CrossRef]
- Hinze, J. Turbulence: An introduction to its mechanisms and theory. Mech. Eng. 1959, 1396. [Google Scholar] [CrossRef]
- Townsend, A.A. The Structure of Turbulent Shear Flow; Cambridge University Press: Cambridge, UK, 1980. [Google Scholar]
- Frisch, U. Turbulence: The Legacy of AN Kolmogorov; Cambridge University Press: Cambridge, UK, 1995. [Google Scholar]
- Cessi, P.; Primeau, F. Dissipative selection of low-frequency modes in a reduced-gravity basin. J. Phys. Oceanogr. 2001, 31, 127–137. [Google Scholar] [CrossRef]
- LaCasce, J.; Pedlosky, J. Baroclinic Rossby waves in irregular basins. J. Phys. Oceanogr. 2002, 32, 2828–2847. [Google Scholar] [CrossRef]
- Charney, J.G.; DeVore, J.G. Multiple flow equilibria in the atmosphere and blocking. J. Atmos. Sci. 1979, 36, 1205–1216. [Google Scholar] [CrossRef]
- Treutlein, H.; Schulten, K. Noise Induced Limit Cycles of the Bonhoeffer-Van der Pol Model of Neural Pulses. Ber. Bunsenges. Phys. Chem. 1985, 89, 710–718. [Google Scholar] [CrossRef]
- Lindner, B.; Schimansky-Geier, L. Coherence and stochastic resonance in a two-state system. Phys. Rev. E 2000, 61, 6103. [Google Scholar] [CrossRef]
- Longtin, A. Stochastic resonance in neuron models. J. Stat. Phys. 1993, 70, 309–327. [Google Scholar] [CrossRef]
- Wiesenfeld, K.; Pierson, D.; Pantazelou, E.; Dames, C.; Moss, F. Stochastic resonance on a circle. Phys. Rev. Lett. 1994, 72, 2125. [Google Scholar] [CrossRef] [PubMed]
- Neiman, A.; Schimansky-Geier, L.; Cornell-Bell, A.; Moss, F. Noise-enhanced phase synchronization in excitable media. Phys. Rev. Lett. 1999, 83, 4896. [Google Scholar] [CrossRef]
- Hempel, H.; Schimansky-Geier, L.; Garcia-Ojalvo, J. Noise-sustained pulsating patterns and global oscillations in subexcitable media. Phys. Rev. Lett. 1999, 82, 3713. [Google Scholar] [CrossRef]
- Hu, B.; Zhou, C. Phase synchronization in coupled nonidentical excitable systems and array-enhanced coherence resonance. Phys. Rev. E 2000, 61, R1001. [Google Scholar] [CrossRef]
- Jung, P.; Cornell-Bell, A.; Madden, K.S.; Moss, F. Noise-induced spiral waves in astrocyte syncytia show evidence of self-organized criticality. J. Neurophysiol. 1998, 79, 1098–1101. [Google Scholar] [CrossRef] [PubMed]
- DeVille, R.L.; Vanden-Eijnden, E.; Muratov, C.B. Two distinct mechanisms of coherence in randomly perturbed dynamical systems. Phys. Rev. E 2005, 72, 031105. [Google Scholar] [CrossRef] [PubMed]
- Casado, J. Noise-induced coherence in an excitable system. Phys. Lett. A 1997, 235, 489–492. [Google Scholar] [CrossRef]
- Sadhu, S.; Kuehn, C. Stochastic mixed-mode oscillations in a three-species predator–prey model. Chaos 2018, 28, 033606. [Google Scholar] [CrossRef] [PubMed]
- Sun, G.Q.; Jin, Z.; Liu, Q.X.; Li, B.L. Rich dynamics in a predator–prey model with both noise and periodic force. BioSystems 2010, 100, 14–22. [Google Scholar] [CrossRef] [PubMed]
- McCluskey, C.C. Complete global stability for an SIR epidemic model with delay-distributed or discrete. Nonlinear Anal. 2010, 11, 55–59. [Google Scholar] [CrossRef]
- Kim, K.I.; Lin, Z.; Zhang, Q. An SIR epidemic model with free boundary. Nonlinear Anal. 2013, 14, 1992–2001. [Google Scholar] [CrossRef]
- Allen, L.J.; Brauer, F.; Van den Driessche, P.; Wu, J. Mathematical Epidemiology; Springer: New York, NY, USA, 2008; Volume 1945. [Google Scholar]
- Gray, A.; Greenhalgh, D.; Hu, L.; Mao, X.; Pan, J. A stochastic differential equation SIS epidemic model. SIAM J. Appl. Math. 2011, 71, 876–902. [Google Scholar] [CrossRef]
- Zhou, Y.; Liu, H. Stability of periodic solutions for an SIS model with pulse vaccination. Math. Comput. Model. 2003, 38, 299–308. [Google Scholar] [CrossRef]
- Madden, R.A.; Julian, P.R. Observations of the 40–50-day tropical oscillation—A review. Mon. Weather Rev. 1994, 122, 814–837. [Google Scholar] [CrossRef]
- Zhang, C. Madden-julian oscillation. Rev. Geophys. 2005, 43, 2004RG000158. [Google Scholar] [CrossRef]
- Lau, W.K.M.; Waliser, D.E. Intraseasonal Variability in the Atmosphere-Ocean Climate System; Springer: Berlin, Germany, 2011. [Google Scholar]
- Hendon, H.H.; Wheeler, M.C.; Zhang, C. Seasonal dependence of the MJO–ENSO relationship. J. Clim. 2007, 20, 531–543. [Google Scholar] [CrossRef]
- McPhaden, M.J. Genesis and evolution of the 1997-98 El Niño. Science 1999, 283, 950–954. [Google Scholar] [CrossRef] [PubMed]
- Tang, Y.; Yu, B. MJO and its relationship to ENSO. J. Geophys. Res. Atmos. 2008, 113, D14106. [Google Scholar] [CrossRef]
- Majda, A.J.; Stechmann, S.N. The skeleton of tropical intraseasonal oscillations. Proc. Natl. Acad. Sci. USA 2009, 106, 8417–8422. [Google Scholar] [CrossRef] [PubMed]
- Majda, A.J.; Stechmann, S.N. Nonlinear dynamics and regional variations in the MJO skeleton. J. Atmos. Sci. 2011, 68, 3053–3071. [Google Scholar] [CrossRef]
- Stechmann, S.N.; Majda, A.J. Identifying the skeleton of the Madden–Julian oscillation in observational data. Mon. Weather Rev. 2015, 143, 395–416. [Google Scholar] [CrossRef]
- Stachnik, J.P.; Waliser, D.E.; Majda, A.J.; Stechmann, S.N.; Thual, S. Evaluating MJO event initiation and decay in the skeleton model using an RMM-like index. J. Geophys. Res. Atmos. 2015, 120, 11486–11508. [Google Scholar] [CrossRef]
- Biello, J.A.; Majda, A.J. Modulating synoptic scale convective activity and boundary layer dissipation in the IPESD models of the Madden–Julian oscillation. Dyn. Atmos. Oceans 2006, 42, 152–215. [Google Scholar] [CrossRef]
- Chen, N.; Majda, A.J. Filtering the stochastic skeleton model for the Madden–Julian oscillation. Mon. Weather Rev. 2016, 144, 501–527. [Google Scholar] [CrossRef]
- Thual, S.; Majda, A.J.; Stechmann, S.N. Asymmetric intraseasonal events in the stochastic skeleton MJO model with seasonal cycle. Clim. Dyn. 2015, 45, 603–618. [Google Scholar] [CrossRef]
- Thual, S.; Majda, A.J. A skeleton model for the MJO with refined vertical structure. Clim. Dyn. 2016, 46, 2773–2786. [Google Scholar] [CrossRef]
- Majda, A.J.; Tong, X.T. Geometric ergodicity for piecewise contracting processes with applications for tropical stochastic lattice models. Commun. Pure Appl. Math. 2016, 69, 1110–1153. [Google Scholar] [CrossRef]
- Clarke, A.J. An Introduction to the Dynamics of El Niño and the Southern Oscillation; Elsevier: Amsterdam, The Netherlands, 2008. [Google Scholar]
- Sarachik, E.S.; Cane, M.A. The El Nino-Southern Oscillation Phenomenon; Cambridge University Press: Cambridge, UK, 2010. [Google Scholar]
- Holton, J.R.; Dmowska, R. El Niño, La Niña, and the Southern Oscillation; Academic Press: New York, NY, USA, 1989; Volume 46. [Google Scholar]
- Lee, T.; McPhaden, M.J. Increasing intensity of El Niño in the central-equatorial Pacific. Geophys. Res. Lett. 2010, 37, L14603. [Google Scholar] [CrossRef]
- Kao, H.Y.; Yu, J.Y. Contrasting eastern-Pacific and central-Pacific types of ENSO. J. Clim. 2009, 22, 615–632. [Google Scholar] [CrossRef]
- Ashok, K.; Behera, S.K.; Rao, S.A.; Weng, H.; Yamagata, T. El Niño Modoki and its possible teleconnection. J. Geophys. Res. Oceans 2007, 112, C11. [Google Scholar] [CrossRef]
- Kug, J.S.; Jin, F.F.; An, S.I. Two types of El Niño events: Cold tongue El Niño and warm pool El Niño. J. Clim. 2009, 22, 1499–1515. [Google Scholar] [CrossRef]
- Capotondi, A.; Wittenberg, A.T.; Newman, M.; Di Lorenzo, E.; Yu, J.Y.; Braconnot, P.; Cole, J.; Dewitte, B.; Giese, B.; Guilyardi, E.; et al. Understanding ENSO diversity. Bull. Am. Meteorol. Soc. 2015, 96, 921–938. [Google Scholar] [CrossRef]
- Chen, D.; Lian, T.; Fu, C.; Cane, M.A.; Tang, Y.; Murtugudde, R.; Song, X.; Wu, Q.; Zhou, L. Strong influence of westerly wind bursts on El Niño diversity. Nat. Geosci. 2015, 8, 339. [Google Scholar] [CrossRef]
- Thual, S.; Majda, A.J.; Chen, N.; Stechmann, S.N. Simple stochastic model for El Niño with westerly wind bursts. Proc. Natl. Acad. Sci. USA 2016, 113, 10245–10250. [Google Scholar] [CrossRef] [PubMed]
- Chen, N.; Majda, A.J. Simple dynamical models capturing the key features of the Central Pacific El Niño. Proc. Natl. Acad. Sci. USA 2016, 113, 11732–11737. [Google Scholar] [CrossRef] [PubMed]
- Chen, N.; Majda, A.J.; Thual, S. Observations and mechanisms of a simple stochastic dynamical model capturing El Niño diversity. J. Clim. 2018, 31, 449–471. [Google Scholar] [CrossRef]
- Thual, S.; Majda, A.J.; Chen, N. Mechanisms of the 2014–2016 Delayed Super El Nino Captured by Simple Dynamical Models. Clim. Dyn. 2018, in press. [Google Scholar] [CrossRef]
- Thual, S.; Majda, A.; Chen, N. Seasonal synchronization of a simple stochastic dynamical model capturing El Niño diversity. J. Clim. 2017, 30, 10047–10066. [Google Scholar] [CrossRef]
- Wang, X. A Note on Long-Time Behavior of Solutions to the Boussinesq System at Large Prandtl Number. Contemp. Math. 2005, 371, 315. [Google Scholar]
- Constantin, P.; Doering, C.R. Infinite Prandtl number convection. J. Stat. Phys. 1999, 94, 159–172. [Google Scholar] [CrossRef]
- Boffetta, G.; Davoudi, J.; Eckhardt, B.; Schumacher, J. Lagrangian tracers on a surface flow: The role of time correlations. Phys. Rev. Lett. 2004, 93, 134501. [Google Scholar] [CrossRef] [PubMed]
- Ide, K.; Kuznetsov, L.; Jones, C.K. Lagrangian data assimilation for point vortex systems*. J. Turbul. 2002, 3. [Google Scholar] [CrossRef]
- Apte, A.; Jones, C.K.; Stuart, A.; Voss, J. Data assimilation: Mathematical and statistical perspectives. Int. J. Numerical Methods Fluids 2008, 56, 1033–1046. [Google Scholar] [CrossRef]
- Salman, H.; Ide, K.; Jones, C.K. Using flow geometry for drifter deployment in Lagrangian data assimilation. Tellus A 2008, 60, 321–335. [Google Scholar] [CrossRef]
- Branicki, M.; Gershgorin, B.; Majda, A.J. Filtering skill for turbulent signals for a suite of nonlinear and linear extended Kalman filters. J. Comput. Phys. 2012, 231, 1462–1498. [Google Scholar] [CrossRef]
- Branicki, M.; Chen, N.; Majda, A.J. Non-Gaussian test models for prediction and state estimation with model errors. Chin. Ann. Math. Ser. B 2013, 34, 29–64. [Google Scholar] [CrossRef]
- Harlim, J.; Majda, A.J. Filtering turbulent sparsely observed geophysical flows. Mon. Weather Rev. 2010, 138, 1050–1083. [Google Scholar] [CrossRef]
- Monahan, A.H. Temporal Filtering Enhances the Skewness of Sea Surface Winds. J. Clim. 2018. [Google Scholar] [CrossRef]
- Monahan, A.H. The temporal autocorrelation structure of sea surface winds. J. Clim. 2012, 25, 6684–6700. [Google Scholar] [CrossRef]
- Cousins, W.; Sapsis, T.P. Reduced-order precursors of rare events in unidirectional nonlinear water waves. J. Fluid Mech. 2016, 790, 368–388. [Google Scholar] [CrossRef]
- Botev, Z.I.; Grotowski, J.F.; Kroese, D.P. Kernel density estimation via diffusion. Ann. Stat. 2010, 38, 2916–2957. [Google Scholar] [CrossRef]
- Chen, N.; Majda, A.J.; Tong, X.T. Rigorous analysis for efficient statistically accurate algorithms for solving Fokker–Planck equations in large dimensions. arXiv, 2017; arXiv:1709.05585. [Google Scholar]
- Majda, A.J.; Gershgorin, B. Quantifying uncertainty in climate change science through empirical information theory. Proc. Natl. Acad. Sci. USA 2010, 107, 14958–14963. [Google Scholar] [CrossRef] [PubMed]
- Majda, A.J.; Gershgorin, B. Link between statistical equilibrium fidelity and forecasting skill for complex systems with model error. Proc. Natl. Acad. Sci. USA 2011, 108, 12599–12604. [Google Scholar] [CrossRef] [PubMed]
- Kullback, S.; Leibler, R.A. On information and sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Kullback, S. Letter to the editor: The Kullback-Leibler distance. Am. Stat. 1987, 41, 340–341. [Google Scholar]
- Chen, N.; Giannakis, D.; Herbei, R.; Majda, A.J. An MCMC algorithm for parameter estimation in signals with hidden intermittent instability. SIAM/ASA J. Uncertain. Quantif. 2014, 2, 647–669. [Google Scholar] [CrossRef]
- Andrieu, C.; De Freitas, N.; Doucet, A.; Jordan, M.I. An introduction to MCMC for machine learning. Mach. Learn. 2003, 50, 5–43. [Google Scholar] [CrossRef]
- Beskos, A.; Roberts, G.; Stuart, A.; Voss, J. MCMC methods for diffusion bridges. Stoch. Dyn. 2008, 8, 319–350. [Google Scholar] [CrossRef]
- Golightly, A.; Wilkinson, D.J. Bayesian inference for stochastic kinetic models using a diffusion approximation. Biometrics 2005, 61, 781–788. [Google Scholar] [CrossRef] [PubMed]
- Johansen, S.; Juselius, K. Maximum likelihood estimation and inference on cointegration-with applications to the demand for money. Oxf. Bull. Econ. Stat. 1990, 52, 169–210. [Google Scholar] [CrossRef]
- Bock, R.D.; Aitkin, M. Marginal maximum likelihood estimation of item parameters: Application of an EM algorithm. Psychometrika 1981, 46, 443–459. [Google Scholar] [CrossRef]
- Evensen, G. The ensemble Kalman filter for combined state and parameter estimation. IEEE Control Syst. 2009, 29, 83–104. [Google Scholar] [CrossRef]
- Annan, J.; Hargreaves, J.; Edwards, N.; Marsh, R. Parameter estimation in an intermediate complexity earth system model using an ensemble Kalman filter. Ocean Model. 2005, 8, 135–154. [Google Scholar] [CrossRef]
- Taylor, K.E. Summarizing multiple aspects of model performance in a single diagram. J. Geophys. Res. Atmos. 2001, 106, 7183–7192. [Google Scholar] [CrossRef]
- Houtekamer, P.L.; Mitchell, H.L. Data assimilation using an ensemble Kalman filter technique. Mon. Weather Rev. 1998, 126, 796–811. [Google Scholar] [CrossRef]
- Lermusiaux, P.F. Data assimilation via error subspace statistical estimation. Part II: Middle Atlantic Bight shelfbreak front simulations and ESSE validation. Mon. Weather Rev. 1999, 127, 1408–1432. [Google Scholar] [CrossRef]
- Hendon, H.H.; Lim, E.; Wang, G.; Alves, O.; Hudson, D. Prospects for predicting two flavors of El Niño. Geophys. Res. Lett. 2009, 36, L19713. [Google Scholar] [CrossRef]
- Kim, H.M.; Webster, P.J.; Curry, J.A. Seasonal prediction skill of ECMWF System 4 and NCEP CFSv2 retrospective forecast for the Northern Hemisphere Winter. Clim. Dyn. 2012, 39, 2957–2973. [Google Scholar] [CrossRef]
- Majda, A.J.; Chen, N. Model Error, Information Barriers, State Estimation and Prediction in Complex Multiscale Systems. Entropy 2018. submitted. [Google Scholar]
- Majda, A.J.; Gershgorin, B. Improving model fidelity and sensitivity for complex systems through empirical information theory. Proc. Natl. Acad. Sci. USA 2011, 108, 10044–10049. [Google Scholar] [CrossRef] [PubMed]
- Gershgorin, B.; Majda, A.J. Quantifying uncertainty for climate change and long-range forecasting scenarios with model errors—Part I: Gaussian models. J. Clim. 2012, 25, 4523–4548. [Google Scholar] [CrossRef]
- Branicki, M.; Majda, A.J. Quantifying uncertainty for predictions with model error in non-Gaussian systems with intermittency. Nonlinearity 2012, 25, 2543. [Google Scholar] [CrossRef]
- Branicki, M.; Majda, A. Quantifying Bayesian filter performance for turbulent dynamical systems through information theory. Commun. Math. Sci 2014, 12, 901–978. [Google Scholar] [CrossRef]
- Kleeman, R. Information theory and dynamical system predictability. Entropy 2011, 13, 612–649. [Google Scholar] [CrossRef]
- Kleeman, R. Measuring dynamical prediction utility using relative entropy. J. Atmos. Sci. 2002, 59, 2057–2072. [Google Scholar] [CrossRef]
- Majda, A.; Kleeman, R.; Cai, D. A mathematical framework for quantifying predictability through relative entropy. Methods Appl. Anal. 2002, 9, 425–444. [Google Scholar]
- Xu, Q. Measuring information content from observations for data assimilation: Relative entropy versus Shannon entropy difference. Tellus A 2007, 59, 198–209. [Google Scholar] [CrossRef]
- Barato, A.; Seifert, U. Unifying three perspectives on information processing in stochastic thermodynamics. Phys. Rev. Lett. 2014, 112, 090601. [Google Scholar] [CrossRef] [PubMed]
- Kawaguchi, K.; Nakayama, Y. Fluctuation theorem for hidden entropy production. Phys. Rev. E 2013, 88, 022147. [Google Scholar] [CrossRef] [PubMed]
- Pham, D.T. Stochastic methods for sequential data assimilation in strongly nonlinear systems. Mon. Weather Rev. 2001, 129, 1194–1207. [Google Scholar] [CrossRef]
- Majda, A.J. Statistical energy conservation principle for inhomogeneous turbulent dynamical systems. Proc. Natl. Acad. Sci. USA 2015, 112, 8937–8941. [Google Scholar] [CrossRef] [PubMed]
- Harlim, J.; Majda, A. Filtering nonlinear dynamical systems with linear stochastic models. Nonlinearity 2008, 21, 1281. [Google Scholar] [CrossRef]
- Gajic, Z.; Lelic, M. Modern Control Systems Engineering; Prentice-Hall, Inc.: Upper Saddle River, NJ, USA, 1996. [Google Scholar]
- Grabowski, W.W.; Smolarkiewicz, P.K. CRCP: A cloud resolving convection parameterization for modeling the tropical convecting atmosphere. Phys. D Nonlinear Phenom. 1999, 133, 171–178. [Google Scholar] [CrossRef]
- Grabowski, W.W. An improved framework for superparameterization. J. Atmos. Sci. 2004, 61, 1940–1952. [Google Scholar] [CrossRef]
- Doucet, A.; Godsill, S.; Andrieu, C. On sequential Monte Carlo sampling methods for Bayesian filtering. Stat. Comput. 2000, 10, 197–208. [Google Scholar] [CrossRef]
- Harlim, J.; Majda, A.J. Test models for filtering with superparameterization. Multiscale Model. Simul. 2013, 11, 282–308. [Google Scholar] [CrossRef]
- Lee, Y.; Majda, A.J. Multiscale methods for data assimilation in turbulent systems. Multiscale Model. Simul. 2015, 13, 691–713. [Google Scholar] [CrossRef]
- Daley, R. Atmospheric Data Analysis, Cambridge Atmospheric and Space Science Series; Cambridge University Press: Cambridge, UK, 1991; Volume 6966, p. 25. [Google Scholar]
- Sorenson, H.W.; Alspach, D.L. Recursive Bayesian estimation using Gaussian sums. Automatica 1971, 7, 465–479. [Google Scholar] [CrossRef]
- Hoteit, I.; Luo, X.; Pham, D.T. Particle Kalman filtering: A nonlinear Bayesian framework for ensemble Kalman filters. Mon. Weather Rev. 2012, 140, 528–542. [Google Scholar] [CrossRef]
- Alspach, D.L.; Samant, V.S.; Sorenson, H.W. Practical Control Algorithms for Nonlinear Stochastic Systems and Investigations of Nonlinear Filters; Technical Report for Statistics and Probability: San Diego, CA, USA, July 1980. [Google Scholar]
- Lee, Y.; Majda, A.J. State estimation and prediction using clustered particle filters. Proc. Natl. Acad. Sci. USA 2016, 113, 14609–14614. [Google Scholar] [CrossRef] [PubMed]
- Majda, A.; McLaughlin, D.; Tabak, E. A one-dimensional model for dispersive wave turbulence. J. Nonlinear Sci. 1997, 7, 9–44. [Google Scholar] [CrossRef]
- Cai, D.; Majda, A.J.; McLaughlin, D.W.; Tabak, E.G. Dispersive wave turbulence in one dimension. Phys. D Nonlinear Phenom. 2001, 152, 551–572. [Google Scholar] [CrossRef]
- Qi, D.; Majda, A.J. Blended particle methods with adaptive subspaces for filtering turbulent dynamical systems. Phys. D Nonlinear Phenom. 2015, 298, 21–41. [Google Scholar] [CrossRef]
- Sapsis, T.P.; Majda, A.J. Blended reduced subspace algorithms for uncertainty quantification of quadratic systems with a stable mean state. Phys. D Nonlinear Phenom. 2013, 258, 61–76. [Google Scholar] [CrossRef]
- Keating, S.R.; Majda, A.J.; Smith, K.S. New methods for estimating ocean eddy heat transport using satellite altimetry. Mon. Weather Rev. 2012, 140, 1703–1722. [Google Scholar] [CrossRef]





































© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).