1. Introduction
Real-time communication is desirable in many modern applications, e.g., Internet of Things [
1], audio transmission for hearing aids [
2], stereo audio signals [
3], on-line video conferencing [
4], or systems involving feedback, such as networked control systems [
5,
6,
7]. All these scenarios may operate under strict requirements on latency and reliability. Particularly, delays play a critical role in the performance or stability of these systems [
8].
In near real-time communication over unreliable networks, and where retransmissions are either not possible or not permitted, e.g., due to strict latency constraints, it is generally necessary to use an excessive amount of bandwidth for the required channel code in order to guarantee reliable communications and ensure satisfactory performance. Several decades ago, it was suggested to replace the channel code by cleverly designed data packets, called multiple descriptions (MDs) [
9]. Contrary to channel codes, MDs would allow for several reproduction qualities at the receivers and thereby admit a graceful degradation during partial network failures [
9]. In MD coding, retransmissions are not necessary, which is similar to the case of forward error correction coding. Thus, with MDs, one avoids the possible long delay due to loss of packets or acknowledgement. Hence, some compression (reproduction quality) is sacrificed for an overall lower latency [
9]. Interestingly, despite their potential advantages over channel codes for certain applications, MD codes are rarely used in practical communication systems with feedback. The reasons are that from a practical point of view, good MD codes are application-specific and hard to design, and from a theoretical point of view, zero-delay MD (ZDMD) coding and MD coding with feedback remain open and challenging topics.
1.1. Multiple Descriptions
MD coding can be described as a data compression methodology, where partial information about the data source is compressed into several data files (called descriptions or data packets) [
10,
11]. The descriptions can, for example, be individually transmitted over different channels in a network. The descriptions are usually constructed such that when any single description is decoded, it is possible to reconstruct an approximation of the original uncompressed source. Since this is only an approximation of the data source, there will inevitably be a reconstruction error, which yields a certain degree of distortion. The distinguishing aspect of MD coding over other coding methodologies is that if more than one description is retrieved, then a better approximation of the source is achieved than what is possible when only using a single description. As more descriptions are combined, the quality of the reproduced source increases. Similarly, this allows for a graceful degradation in the event of, e.g., packet dropouts on a packet-switched network such as the Internet.
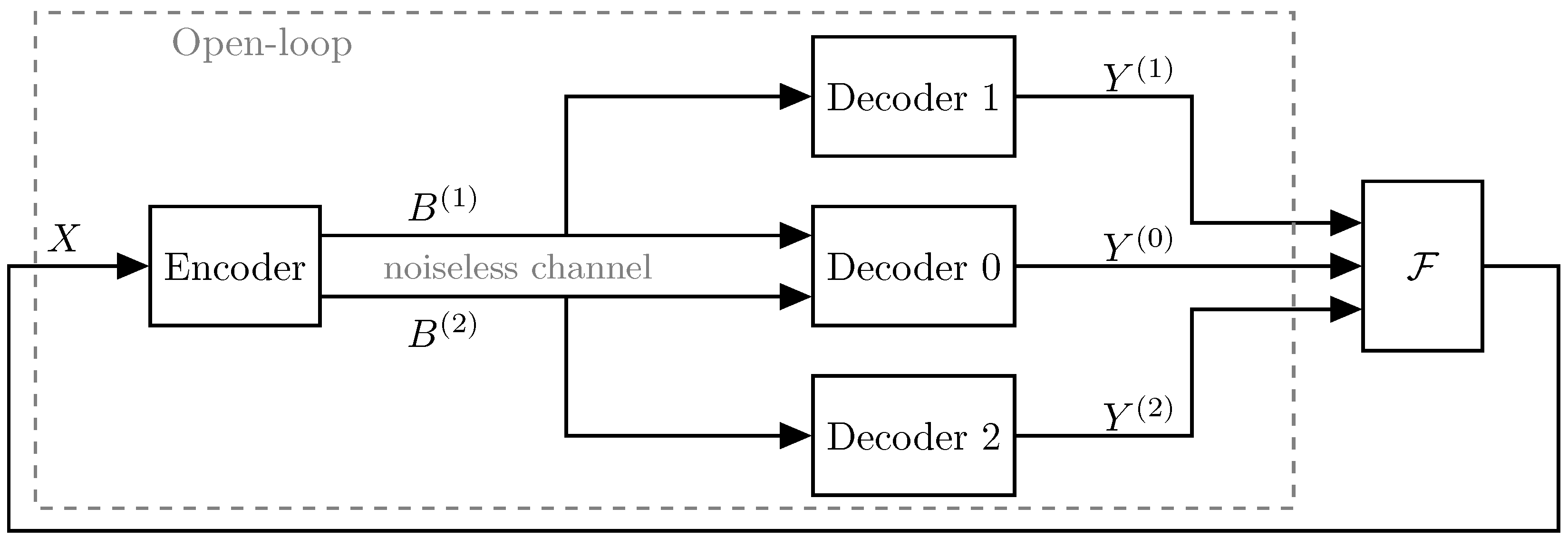
Figure 1 illustrates the two-description MD coding scenario in both a closed-loop and an open-loop system. In both cases, the encoder produces two descriptions which are transmitted across noiseless channels, i.e., no bit-errors are introduced in the descriptions between the encoder and decoders. Some work exists in the closed-loop scenario, but no complete solution has been determined. However, the noncausal open-loop problem has been more widely studied in the information-theory literature [
9,
10,
11,
12,
13,
14].
Since MD coding considers several data rates and distortions, MD rate-distortion theory is the determination of the fundamental limits on a rate-distortion region [
9]. That is, determine the minimum individual rates required to achieve a given set of individual and joint distortion constraints. A noncausal achievable MD rate-distortion region is only completely known in very few cases [
12]. El-Gamal and Cover [
11] gave an achievable region for two descriptions and memoryless source. This region was then shown to be tight for white Gaussian sources with mean-squared error (MSE) distortion constraints by Ozarow [
10]. In the high resolution limit, i.e., high rates, the authors of [
13] characterized the achievable region for stationary (time-correlated) Gaussian sources with MSE distortion constraints. This was then extended in [
14] to the general resolution case for stationary Gaussian sources. Recently, the authors of [
12] showed in the symmetric case, i.e., equal rates and distortions for each individual description, that the MD region for a colored Gaussian source subject to MSE distortion constraints can be achieved by predictive coding using filtering. However, similar to single-description source coding [
8], the MD source coders whose performance is close to the fundamental rate-distortion bounds impose long delays on the end-to-end processing of information, i.e., the total delay only due to source coding [
15].
1.2. Zero Delay
Clearly, in near real-time communication, the source encoder and decoder must have zero delay. The term zero-delay (ZD) source coding is often used when both instantaneous encoding and decoding are required [
16]. That is, when the reconstruction of each input sample must take place at the same time-instant, the corresponding input sample has been encoded [
17]. For near instantaneous coding, the source coders must be causal [
18]. However, causality comes with a price. The results of [
17] showed that causal coders increase the bit-rate due to the space-filling loss of “memoryless” quantizers, and the reduced de-noising capabilities of causal filters. Additionally, imposing ZD increases the bit-rate due to memoryless entropy coding [
17].
In the single-description case, ZD rate-distortion theory has been increasingly more popular in recent decades, due to its significance in real-time communication systems and especially feedback systems. Some indicative results on ZD source coding for networked control systems and systems with and without feedback may be found in [
5,
6,
7,
8,
17,
19,
20,
21]. The results of [
5] establish a novel information-theoretic lower bound on the average data-rate for a source coding scheme within a feedback loop by the directed information rate across the channel. For open-loop vector Gauss-Markov sources, i.e., when the source is not inside a feedback loop, the optimal operational performance of a ZD source code subject to an MSE distortion constraint has been shown to be lower bounded by a minimization of the directed information [
22] from the source to the reproductions subject to the same distortion constraint [
5,
6,
7,
17,
19]. For Gaussian sources, the directed information is further minimized by Gaussian reproductions [
8,
20]. Very recently, Stavrou et al. [
8], extending upon the works of [
6,
7,
17,
19], showed that the optimal test channel that achieves this lower bound is realizable using a feedback realization scheme. Furthermore, Ref [
8] extended this to a predictive coding scheme providing an achievable upper bound on the operational performance subject to an MSE distortion constraint.
1.3. Zero-Delay Multiple Descriptions
Recently, the authors of [
15] proposed an analog ZDMD joint source-channel coding scheme, such that the analog source output is mapped directly into analog channel inputs, thus not suffering from the delays encountered in digital source coding. However, for analog joint source-channel coding to be effective, the source and channel must be matched, which rarely occurs in practice [
23]. Furthermore, most modern communication systems rely on digital source coding. Thus, analog joint source-channel coding is only applicable in a very limited amount of settings. Digital low-delay MD coding for practical audio transmission has been explored in, e.g., [
2,
4,
24], as well as for low-delay video coding in [
25]. Some initial work regarding MDs in networked control systems may be found in [
26]. However, none of these consider the theoretical limitations of ZDMD coding in a rate-distortion sense.
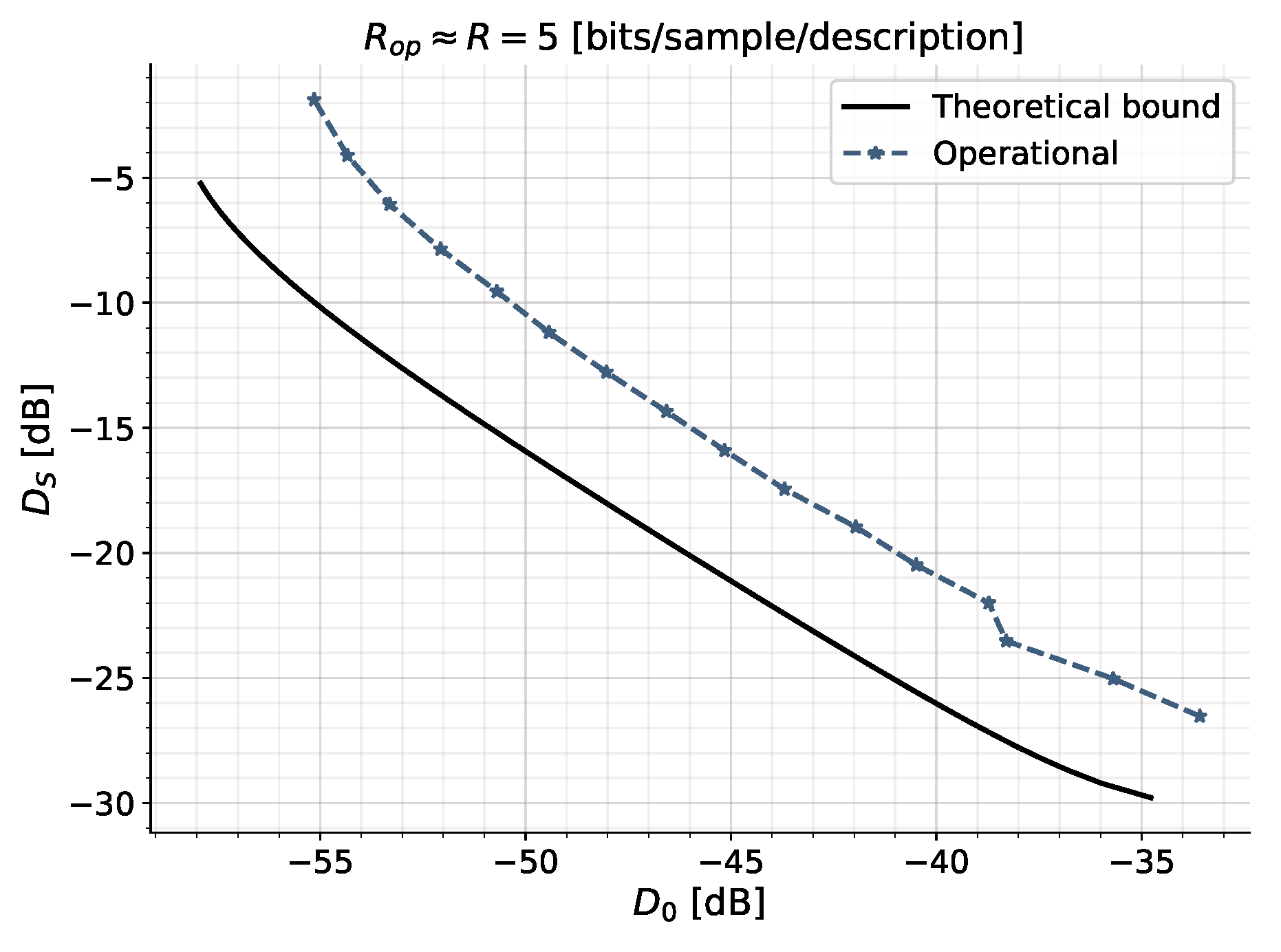
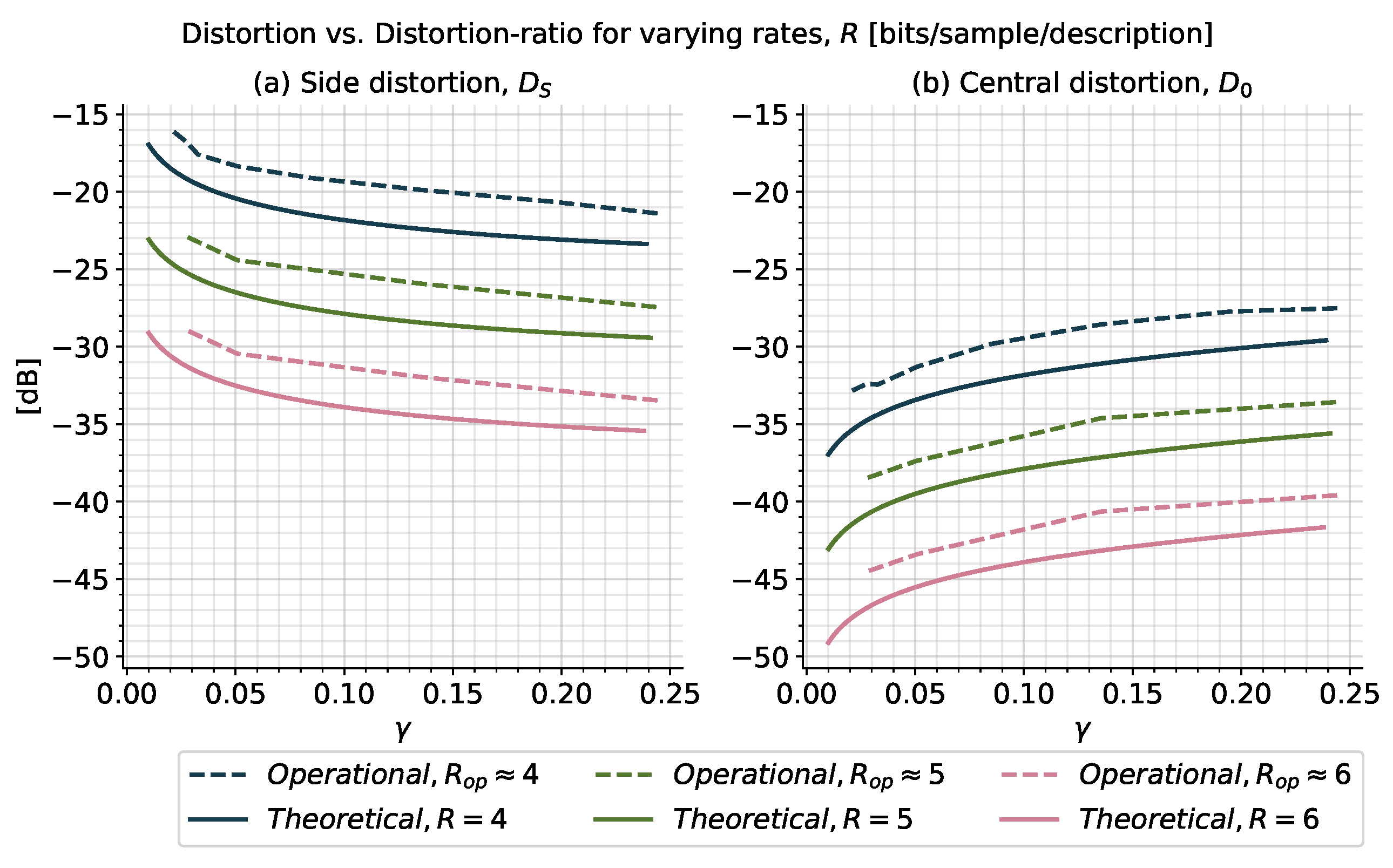
In this paper, we propose a combination of ZD and MD rate-distortion theory such that the MD encoder and decoders are required to be causal and of zero delay. For the case of discrete-time stationary scalar Gauss-Markov sources and quadratic distortion constraints, we present information-theoretic lower bounds on the average sum-rate in terms of the directed and mutual information rate between the source and the decoder reproductions. We provide proof of achievability via a new Gaussian MD test channel and show that this test channel can be realized by a feedback coding scheme that utilizes prediction and correlated Gaussian noises. We finally show that a simple scheme using differential pulse code modulation with staggered quantizers can get close to the optimal performance. Specifically, our simulation study reveals that for a wide range of description rates, the achievable operational rates are within
/
/
of the theoretical lower bounds. Further simulations and more details regarding the combination of ZD and MD coding are provided in the report [
27].
The rest of the paper is organized as follows. In
Section 2, we characterize the ZDMD source coding problem with feedback for stationary scalar Gauss-Markov sources subject to asymptotic MSE distortion constraints. Particularly, we consider the symmetric case in terms of the symmetric ZDMD rate-distortion function (RDF). In
Section 3, we introduce a novel information-theoretic lower bound on the average data sum-rate of a ZDMD source code. For scalar stationary Gaussian sources, we show this lower bound is minimized by jointly Gaussian MDs, given that certain technical assumptions are met. This provides an information-theoretic lower bound to the symmetric ZDMD RDF. In
Section 4, we determine an MD feedback realization scheme for the optimum Gaussian test-channel distribution. Utilizing this, we present a characterization of the Gaussian achievable lower bound as a solution to an optimization problem. In
Section 5, we evaluate the performance of an operational staggered predictive quantization scheme compared to the achievable ZDMD region. We then discuss and conclude on our results. Particularly, we highlight some important difficulties with the extension to the Gaussian vector case.
2. Problem Definition
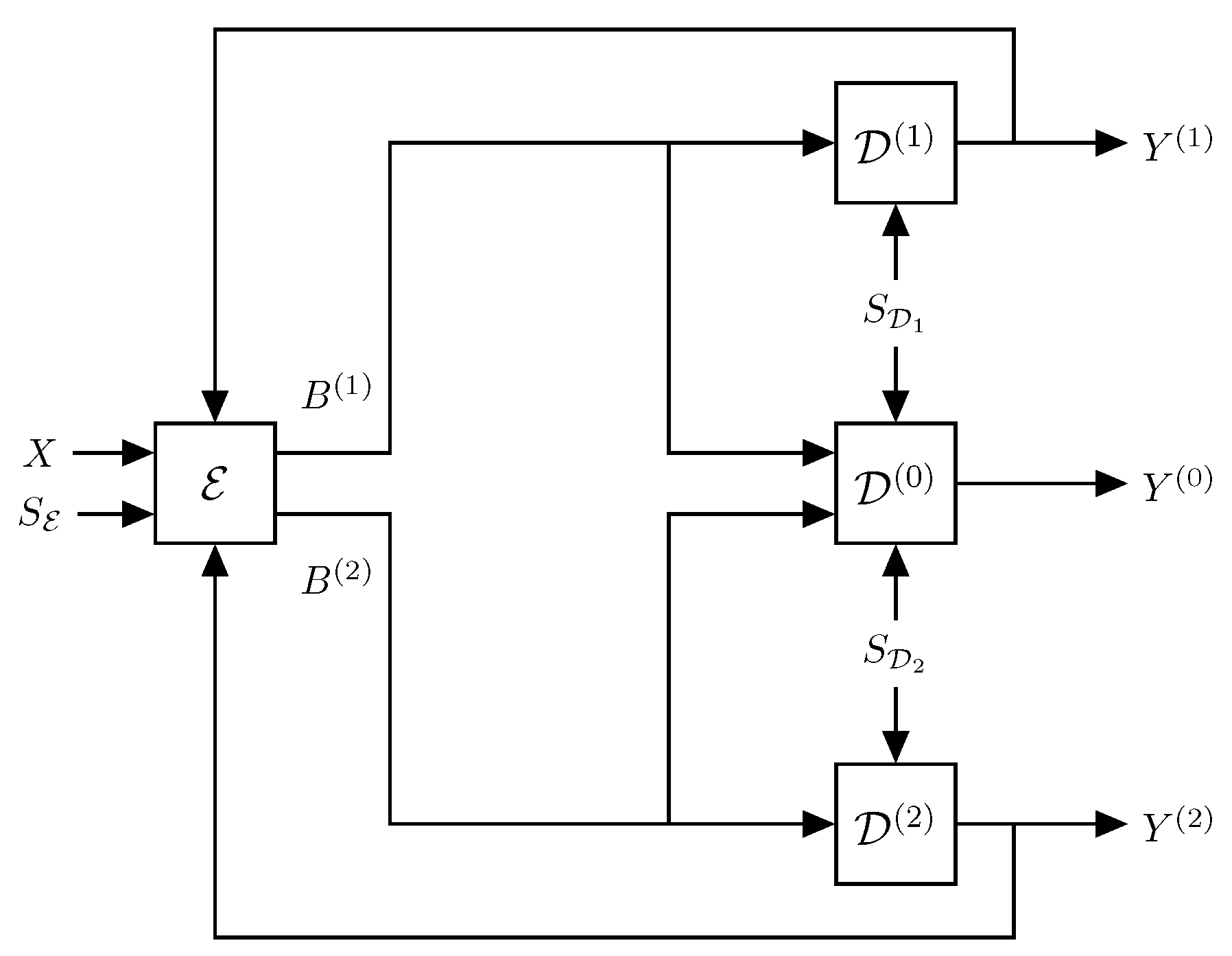
In this paper, we consider the ZDMD source coding problem with feedback illustrated in
Figure 2. The feedback channels are assumed to be noiseless digital channels and have a one-sample delay to ensure the operational feasibility of the system, i.e., at any time, the current encoder outputs only depend on previous decoder outputs.
Here, the stationary scalar Gauss-Markov source process is determined by the following discrete-time linear time-invariant model:
where
is the deterministic correlation coefficient,
is the initial state,
, and
is an independent and identically distributed (IID) Gaussian process independent of
. For each time step
, the ZDMD encoder,
, observes a new source sample
while assuming it has already observed the past sequence
. The encoder then produces two binary descriptions
with lengths
(in bits) from two predefined sets of codewords
, of at most a countable number of codewords, i.e., the codewords are discrete random variables. The codewords are transmitted across two instantaneous noiseless digital channels to the three reconstruction decoders,
, and
. The decoders then immediately decode the binary codewords. Upon receiving
, the
ith side decoder,
,
, produces an estimate
of the source sample
, under the assumption that
is already produced. Similarly, the central decoder,
, upon receiving
, produces an estimate
of
under the assumption
is already produced. Finally, before generating the current binary codewords, the encoder receives the two reproductions from the previous time step
while assuming it has already received the past,
.
We assume the encoder and all decoders process information without delay. That is, each sample is processed immediately and without any delays for each time step .
In the system,
is the side information that becomes available at time-instance
k at the encoder, and similarly,
is the new side information at reproduction decoder
i. We emphasize, this is not side information in the usual information-theoretic sense of multiterminal source coding or Wyner–Ziv source coding, where the side information is unknown, jointly distributed with the source, and only available at the decoder, e.g., some type of channel-state information [
28,
29]. In this paper, our encoders and decoders are deterministic. However, to allow for probabilistic encoders and decoders, we let the deterministic encoders and decoders depend upon a stochastic signal, which we refer to as the side information. To make the analysis tractable, we require this side information to be independent of the source. The side information could, for example, represent dither signals in the quantizers, which is a common approach in the source coding literature [
30]. We shortly disucuss the possibility of removing this independence assumption in
Section 6.
We do not need feedback from the central decoder, since all information regarding
is already contained in
. That is, given the side information, the side decoder reproductions are sufficient statistics for the central reproduction, and the following Markov chain holds,
where
. We note, this Markov chain also requires the decoders are invertible as defined in Definition 5 on page 10. Requiring invertible decoders is optimal in causal source coding [
5].
Zero-delay multiple-description source coding with side information: We specify in detail the operations of the different blocks in
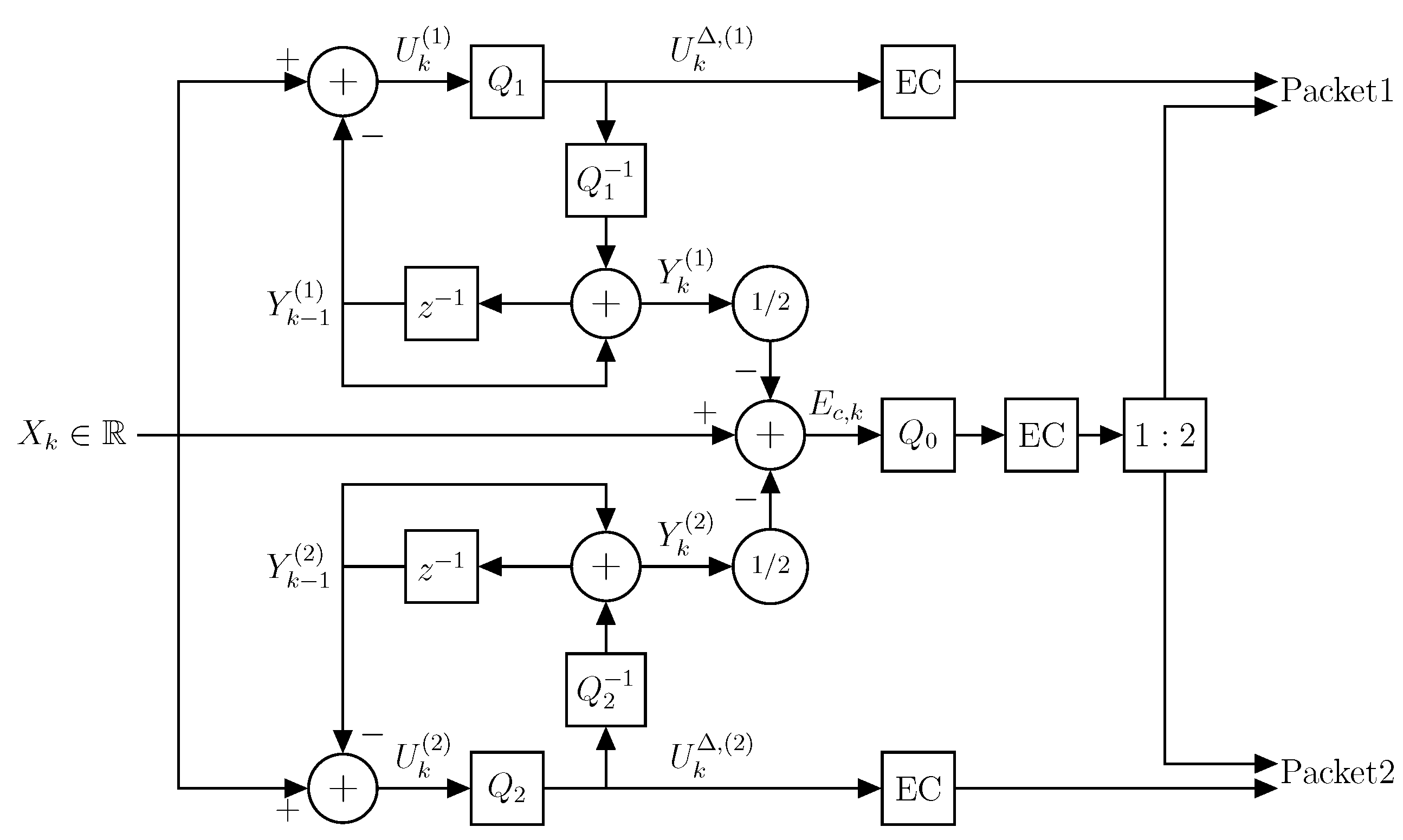
Figure 2. First, at each time step,
k, all source samples up to time
k,
, and all previous reproductions,
, are available to the encoder,
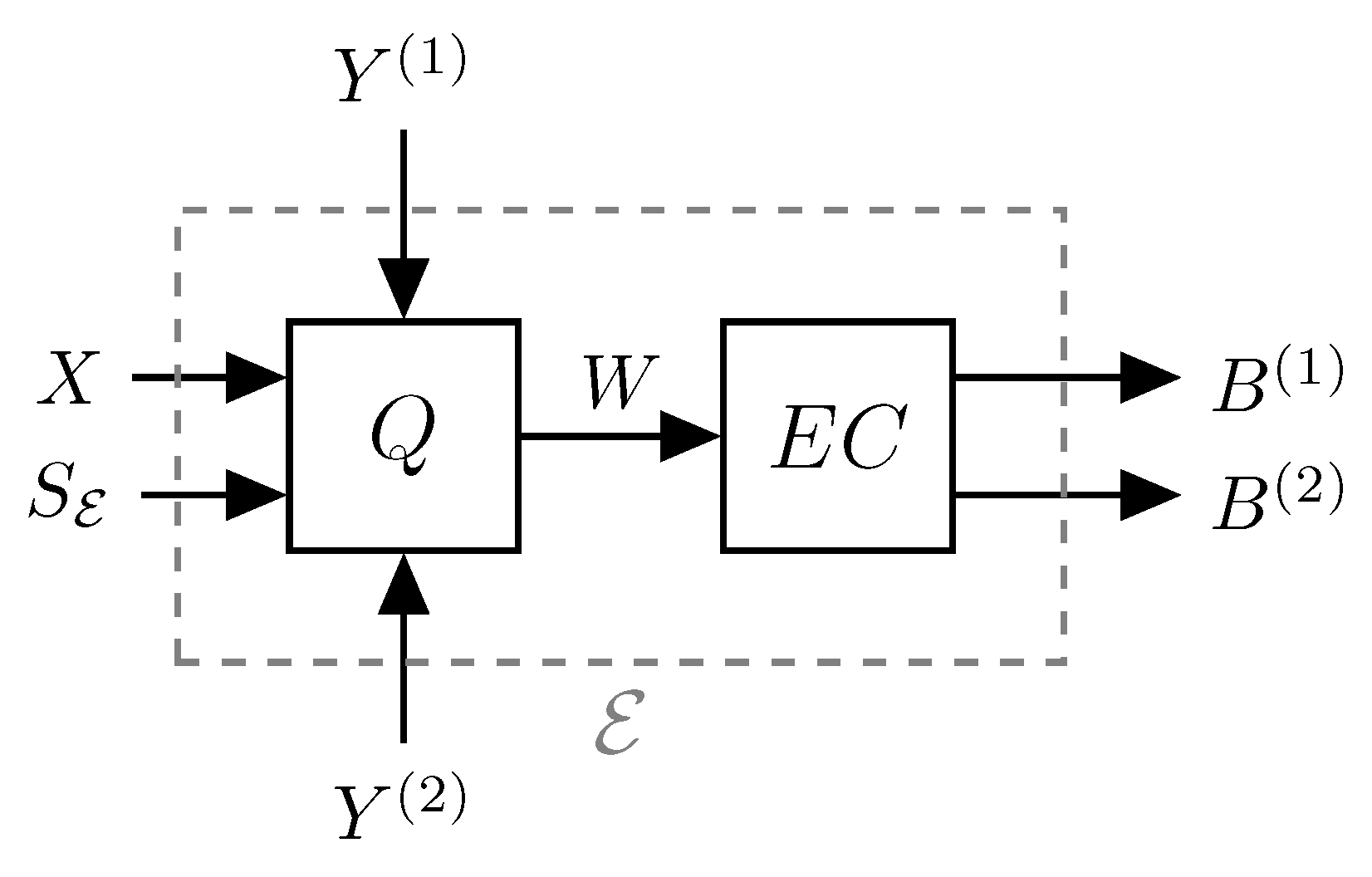
. The encoder then performs lossy source coding and lossless entropy coding to produce two dependent codewords. That is, the encoder block can be conceptualized as being split into a quantization step and an entropy coding step as illustrated in
Figure 3. This is a very simplified model, and each of the quantization and entropy coding steps may be further decomposed as necessary to generate the appropriate dependent messages. However, this is a nontrivial task, and therefore, for a more tractable analysis and ease of reading, we do not further consider this two-step procedure in the theoretical derivations.
The zero-delay encoder is specified by the sequence of functions
, where:
and at each time step
, the encoder outputs the messages:
with length
(in bits), where for the initial encoding, there are no past reproductions available at the encoder, hence
.
The zero-delay decoders are specified by the three sequences of functions
, where:
At each time step,
the decoders generate the outputs:
assuming
have already been generated, with:
The ZDMD source code produces two descriptions of the source; hence, we may associate the ZDMD code with a rate pair.
Definition 1 (Rate pair of ZDMD code)
. For each time step, k, let be the length in bits of the ith encoder output in a ZDMD source code as described above. Then, the average expected data-rate pair, , measured in bits per source sample, are the rates: Asymptotic MSE distortion constraints: A rate pair
is said to be achievable with respect to the MSE distortion constraints
if there exists a rate-
ZDMD source code as described above, such that:
is satisfied.
Similarly to standard MD theory [
31], the main concern of ZDMD coding is to determine the ZDMD rate-region, constituting the set of all achievable rate pairs for given distortion constraints.
Definition 2 (ZDMD rate-region). For the stationary source process , the ZDMD rate-region is the convex closure of all achievable ZDMD rate pairs with respect to the MSE distortion constraints .
The ZDMD rate-region can be fully characterized by determining the bound between the sets of achievable and non-achievable rates, i.e., by determining the fundamental smallest achievable rates for given distortion constraints. Particularly, we consider so-called nondegenerate distortion constraints [
32], that is, triplets
that satistify:
where
is the stationary variance of the source.
The previous design requirements are summarized in the ZDMD coding problem with feedback.
Problem 1 (ZDMD coding problem with feedback)
. For a discrete-time stationary scalar source process , with nondegenerate MSE distortion constraints, . Determine the minimum operational rates of the ZDMD coding scheme with side information from Equations (
3)–(
8)
, such that the asymptotic average expected distortions satisfy:where the minimum is over all possible ZDMD encoder and decoder sequences that satisfy Equations (
3)–(
8)
. In this paper, we mainly consider the symmetric case of
and
. Here, the ZDMD region may be completely specified by an MD equivalent of the standard RDF [
12].
Definition 3 (Symmetric ZDMD RDF)
. The symmetric ZDMD RDF for a source, , with MSE distortion constraints, , is:That is the minimum rate R per description, which is achievable with respect to the distortion pair.
The operational symmetric ZDMD RDF can be expressed in terms of the sum-rate, .
Problem 2 (Operational symmetric scalar Gaussian ZDMD RDF)
. For a stationary scalar Gauss-Markov source process (
1)
, with nondegenerate MSE distortion constraints, , determine the operational symmetric ZDMD RDF, i.e., solve the optimization problem:where and the infimum is over all possible ZDMD encoder- and -decoder sequences , i.e., that satisfy Equations (
3)–(
8)
. Unfortunately, the solutions to Problems 1 and 2 are very hard to find, since they are determined by a minimization over all possible operational ZDMD codes. Similar to single description ZD rate-distortion theory [
17], where the classical RDF is a lower bound on the zero-delay RDF, the noncausal arbitrary delay MD region [
10,
14] is an outer bound on the ZDMD region. However, this is a conservative bound due to the space-filling losses, memoryless entropy coding, and causal filters suffered by the ZD coders. Therefore, we introduce a novel information-theoretic lower bound on the operational ZD coding rates. As in classical MD rate-distortion theory, this bound is given in terms of lower bounds on the marginal rates,
, and the sum-rate,
cf. [
10,
11].
3. Lower Bound on Average Data-Rate
In this section, we determine a novel information-theoretic lower bound on the sum-rate of ZDMD source coding with feedback. Using this lower bound, we present an information-theoretic counterpart of the operational symmetric Gaussian ZDMD RDF. Finally, we provide a lower bound to Problem 2 by showing, for stationary scalar Gaussian sources, that Gaussian reproductions minimize the information-theoretic lower bound, given some technical assumptions are met. Although our main concern is the symmetric case, some of our main results are provided in the general nonsymmetric case.
We study a lower bound on the sum-rate of the ZDMD coding problem with feedback, which only depends on the joint statistics of the source encoder input, X, and the decoder outputs, . To this end, we present in more detail the test-channel distribution associated with this minimization.
3.1. Distributions
We consider a source that generates a stationary sequence . The objective is to reproduce or reconstruct the source by , subject to MSE fidelity criteria .
Source. We consider open-loop source coding; hence, we assume the source distribution satisfies the following conditional independence:
This implies that the source,
X, is unaffected by the feedback from the reproductions,
. Hence, the next source symbol, given the previous symbols, is not further related to the previous reproductions [
22].
We assume the distribution at
is
. Furthermore, by Bayes’ rule [
8]:
For the Gauss-Markov source process (
1), this implies
is independent of the past reproductions
[
8].
Reproductions. Since the source is unaffected by the feedback from the reproductions, the MD encoder–decoder pairs from
to
, in
Figure 2, are causal if, and only if, the following Markov chain holds [
17]:
Hence, we assume the reproductions are randomly generated according to the collection of conditional distributions:
For the first time step,
, we assume:
3.2. Bounds
We define the directed information rate across a system with random input and random output processes.
Definition 4 (Directed information rate ([
5] Def. 4.3))
. The directed information rate across a system with random input, X, and random output, Y, is defined as:where is the directed information between the two sequences and , defined as: In order to establish an outer bound on the ZDMD rate-region, we need a lower bound on the marginal rates and the sum-rate. By the results of [
5,
8], it can be shown that the marginal operational rates,
are lower bounded by:
that is, by the directed information rate from the source to the side description. Thus, in order to determine a bound on the ZDMD rate-region, it remains to determine an information-theoretic lower bound on the sum-rate. Our derivation of the lower bound on the sum-rate requires the following assumption.
Assumption 1. The systemsi = 0,1,2, are causal, described by Equations (
3)–(
8)
, and , i.e., the side information is independent of the source sequence, . We consider this assumption to be reasonable in a ZD scenario, i.e., the deterministic encoders and decoders must be causal and use only past and present symbols, and side information that is not associated with the source signal [
5]. Similar to [
5], the channel is the only link between encoder and decoder. However, we further assume the channel to have perfect feedback.
Additionally, we require the decoders to be invertible given the side information.
Definition 5 (Invertible decoder ([
5] Def. 4.2))
. The decoders, , defined in Equations (
7)
and (
8)
are said to be invertible if, and only if, , there exists deterministic mappings , such that: If the decoders are invertible, then for each side decoder, knowledge of the side information and the output, e.g.,
, is equivalent to knowledge of the side information and the input,
[
5]. For the single description case, it is shown in [
5] that without loss of generality, we can restrict our attention to invertible decoders. Furthermore, when minimizing the average data-rate in a causal source coding scheme, it is optimal to minimize the average data-rate by focusing on schemes with invertible decoders [
5].
The following results are used to prove the first main result of this section and are a generalization of ([
5] Lemma 4.2) to the MD scenario.
Lemma 1 (Feedback Markov Chains)
. Consider an MD source coding scheme inside a feedback loop as shown in Figure 2. If Assumption 1 applies and if the decoders are invertible when given the side information, then the Markov chain:holds, with .Furthermore, letthen:also holds. Additionally, for:holds. Finally, if the decoder side information is mutually independent, i.e.,, the Markov chains:hold. Proof. The Markov chain in Equation (
30) follows, since
depend deterministically upon
. Similarly, Equation (
31) holds, since
depends deterministically upon
. The Markov chain in Equation (
32) follows analogously.
By the system equations, we have that:
Since
, it follows that
. Furthermore, since
then
. Hence, Equation (
33) holds in the initial step. Now, in the next time step:
where we see that
depends on
only through
. Thus:
By the same arguments as before, we have for the second time step
and
. By the causality of the system components, it follows that
only depend on
through
, and by the independence of the side information,
; thus. we get Equation (
33).
For Equation (
34), since
, then
, and the Markov chain holds in the initial step. For the next step, since
depends on
only through
, the Markov chain holds. Therefore, by the causality of the system components,
only depends on
through
, and because
, it follows that
. Therefore, Equation (
34) holds. □
We note that requiring the side information to be mutually independent is not a hard assumption. For example, it is straightforward to generate independent dither signals for two quantizers. A short perspective on removing this assumption is given in
Section 6.
We define the mutual information rate between two random processes next.
Definition 6 (Mutual information rate ([
33] Equation (7.3.9)))
. The mutual information rate between two random processes and is defined as: We are now ready to state our first main result.
Theorem 1 (Lower bound on sum-rate)
. Consider a ZDMD source coding problem with feedback (Problem 1), as seen in Figure 2. If Assumption 1 holds, the decoders are invertible, and the decoder side information is mutually independent, then: The proof of Theorem 1 can be found in
Appendix A.
Theorem 1 shows that when imposing zero-delay constraints on MD coding with feedback, the directed information rate from the source to the central reconstruction together with the mutual information rate between the side reconstructions serve as a lower bound on the associated average data sum-rate, thus relating the operational ZDMD rates to the information-theoretic quantities of directed and mutual information rate.
To the best of the authors’ knowledge, Theorem 1 provides a novel characterization between the relationship of the operational sum-rate and directed and mutual information rates, for a ZDMD coding problem with feedback. This result extends on the novel single-description bound in [
5] and the MD results of [
11].
In relation to the El-Gamal and Cover region [
11], our result shows that the first term in the bound on the ZDMD sum-rate, i.e., the no excess sum-rate, is given by the directed information rate from the source to the side descriptions—that is, only the causally conveyed information, as would be expected for ZD coding. The second term is similar to that of El-Gamal and Cover. That is, the excess rate must be spent on communicating the mutual information between the side descriptions to reduce the central distortion.
Remark 1. The mutual information ratedoes not imply a noncausal relationship betweenand, i.e., thatmight depend on future values of. It only implies probabilistic dependence across time [22]. There is feedback betweenand, such that information flows between the two descriptions. However, the information flows in a causal
manner, i.e., the past values of affect the future values of and vice versa. This is also apparent from the “delayed” information flow from to in the proof, see Equation (
A7)
. Therefore, the MD code must convey this total information flow between the two descriptions to the central receiver. 3.3. Gaussian Lower Bound For Scalar Gauss-Markov Sources
Before showing Gaussian reproductions minimize the result of Theorem 1, we introduce the following technical assumptions required for our proof.
Assumption 2 (Sequential greedy coding)
. Consider the ZDMD coding problem in Figure 2. We say that we solve this problem using sequential greedy coding if sequentially for each time step : We minimize the bit-rate such that the MSE distortion constraints are satisfied for each .That is, sequentially for each, choose the codewordswith minimum codeword lengthssuch that: Since, in sequential greedy coding, we minimize the bit-rate for each
in the sequential order subject to the distortion constraints, this implies for the information rates in Equation (
57) that we minimize the sum:
by sequentially for each
selecting the optimal test-channel distribution
subject to the MSE distortion constraints:
and fixing this distribution for all following
Let
minimize the initial mutual informations for
, i.e.:
with equality if
, are distributed as
. Then, sequential greedy coding implies
must be distributed as
, for all
. Particularly for
:
where
is inserted on both sides of the conditioning.
The sequential greedy assumption is suitable in a zero-delay source coding perspective, since we must send the optimum description that minimizes the rate while achieving the desired distortion at each time step. We comment on the implications of sequential greedy coding in
Section 6.
We also need the following assumption on the minimum MSE (MMSE) predictors.
Assumption 3 (Conditional prediction residual independence)
. Let be a stationary source process, and let and be stationary arbitrarily distributed reproduction processes. We say the MMSE reproduction processes have conditional prediction residual independence if the MMSE prediction residuals satisfy for all :that is, the residuals are independent of the conditioning prediction variables. For mutual information, the conditional prediction residual independence implies:
Particularly, if
are jointly Gaussian, then the MMSE predictors have conditional prediction residual independence by the orthogonality principle ([
34] p. 45). Using these predictors may result in an increased rate, since we limit the amount of possible predictors. That is, by not imposing this condition, we may achieve a smaller distortion for the same rate by minimizing over all possible MMSE predictors.
We are now ready to state our second main result.
Theorem 2 (Gaussian lower bound)
. Let be a stable stationary scalar Gaussian process (
1)
with nondegenerate MSE distortion constraints, . Then, under the sequential greedy coding condition (Assumption 2), and if the reproduction sequences , satisfy conditional prediction residual independence (Assumption 3), the following inequality holds:where are jointly Gaussian random variables with first and second moments equal to those of The proof of Theorem 2 can be found in
Appendix B.
Theorem 2 shows that for stationary scalar Gaussian sources under sequential greedy coding and MSE distortion constraints, the mutual informations between the source and side reproductions, and the mutual information between the side reproductions are minimized by Gaussian reproductions. This would generally be expected, since this is the case for single description ZD source coding [
8].
To the best of the authors’ knowledge, this is a novel result that has not been documented in any publicly available literature. Similar results exist for single-description ZD source coding [
8] and for classical MD coding of white Gaussian sources [
35].
Remark 2. The main difficulty in proving Theorem 2, and the reason for the technical assumptions, is to minimize the excess information rate,, in Equation (
44)
and show the reconstructions, , should be jointly Gaussian when they are jointly Gaussian with the source. We speculate these technical assumptions may be disregarded, since by the results of [8], we have for a Gaussian source process :with equality if are jointly Gaussian with . Therefore, it seems reasonable should also be jointly Gaussian in the second term on the RHS of Equation (
44)
. However, we have not been able to prove this. Symmetric Case
Following the result of Theorem 1, we now formally define the information-theoretic symmetric Gaussian ZDMD RDF, , in terms of the directed and mutual information rate, as a lower bound to . Furthermore, we show that Gaussian reproductions minimize the lower bound.
Definition 7 (Information-Theoretic Symmetric ZDMD RDF)
. The information-theoretic symmetric ZDMD RDF, for the stationary Gaussian source process , with MSE distortion constraints, , is:where the infimum is of all processes that satisfy: The minimization of all processes
that satisfy the Markov chain in Equation (
58) is equivalent to the minimization of all sequences of conditional test-channel distributions
.
For Gaussian reproductions, we have the following optimization problem.
Problem 3 (Gaussian Information-Theoretic Symmetric ZDMD RDF)
. For a stationary Gaussian source with MSE distortion constraints, , the Gaussian information-theoretic symmetric ZDMD RDF is:where the infimum is over all Gaussian processes , that satisfy: This minimization is equivalent to the minimization of all sequences of Gaussian conditional test-channel distributions
Finally, by Theorems 1 and 2, we have the following corollary, showing Problem 3 as a lower bound to Problem 2.
Corollary 1. Letbe a stable stationary scalar Gaussian process (
1)
, with MSE distortion constraints, . Then, under the sequential greedy coding condition (Assumption 2), and if the reproduction sequences , satisfy conditional prediction residual independence (Assumption 3), the following inequalities hold: This shows Gaussian reproduction processes minimize the information-theoretic symmetric ZDMD RDF. With this information-theoretic lower bound on , we now derive an optimal test-channel realization scheme that achieves this lower bound.
7. Conclusions
In this work, we studied the ZDMD source coding problem where the MD encoder and decoders are required to be causal and of zero delay. Furthermore, the encoder receives perfect decoder feedback, and side information is available to both encoder and decoders. Using this constructive system, we showed that the average data sum-rate is lower bounded by the sum of the directed information rate from the source, X, to the side descriptions, , and the mutual information rate between the side descriptions, thus providing a novel relation between information theory and the operational ZDMD coding rates.
For scalar stationary Gaussian sources with MSE distortion constraints subject to the technical assumptions of sequential greedy coding and conditional residual independence, we showed this information-theoretic lower bound is minimized by Gaussian reproductions, i.e., the optimum test-channel distributions are Gaussian. This bound provides an information-theoretic lower bound to the operational symmetric ZDMD RDF, .
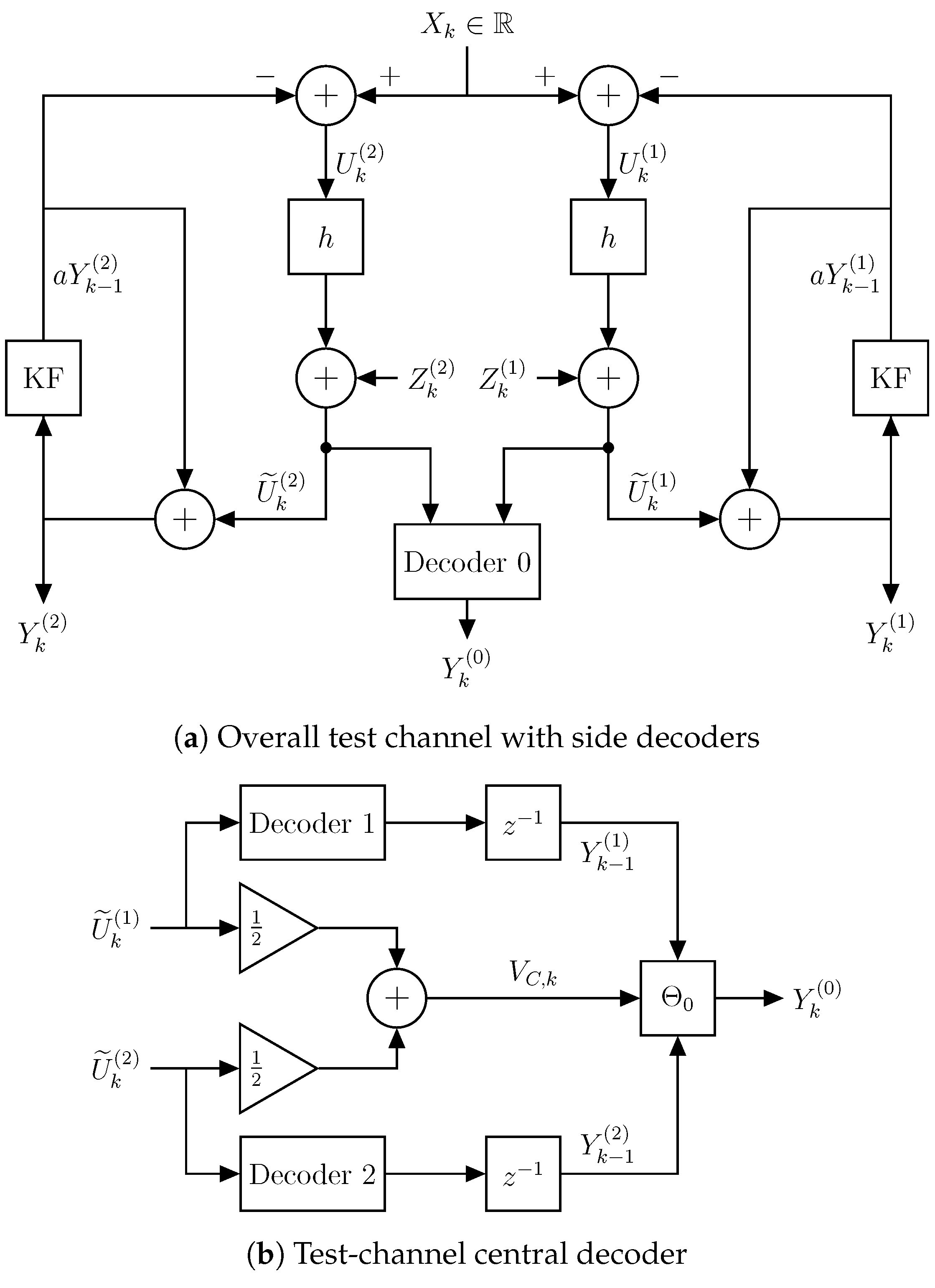
We showed the optimum test channel of the Gaussian information-theoretic lower bound is determined by a feedback realization scheme utilizing predictive coding and correlated Gaussian noises. This shows that the information-theoretic lower bound for first-order stationary scalar Gauss-Markov sources is achievable in a Gaussian coding scheme. Additionally, the optimum Gaussian test-channel distribution is characterized by the solution to an optimization problem.
We have not yet been able to extend the test channel into an operational quantization scheme that allows for an exact upper bound on the optimum operational performance limits.
Operational achievable results are determined for the high-rate scenario by utilizing the simple quantization scheme of [
41], resembling our test channel to some extent. Using this simple quantization scheme, it is possible to achieve operational rates within
/
/
of the theoretical lower bounds.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}