High-Dimensional Brain in a High-Dimensional World: Blessing of Dimensionality




Abstract
:1. Introduction
2. Stochastic Separation Theorems
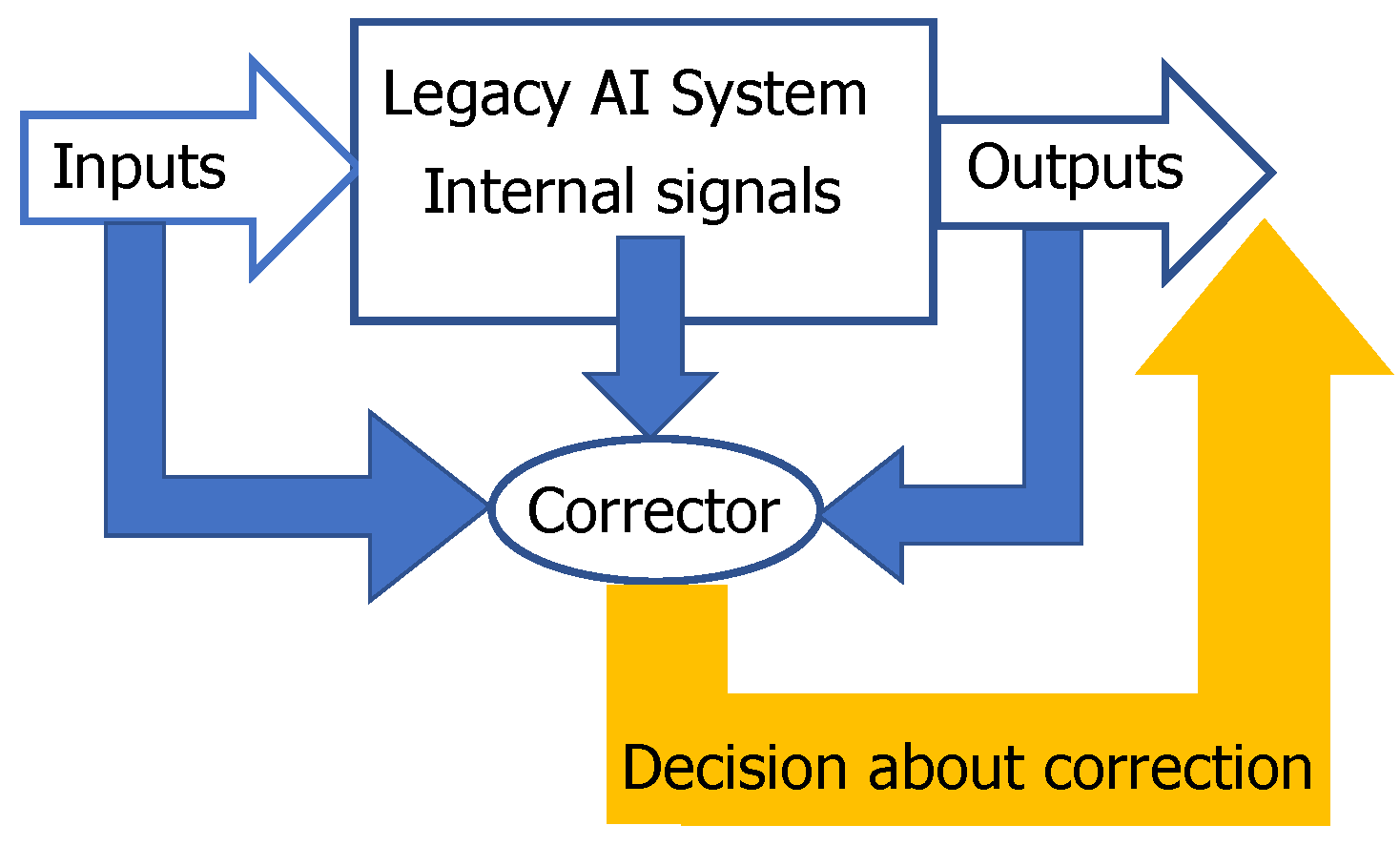
2.1. Blessing of Dimensionality Surprises and Correction of AI Mistakes
- be simple;
- not damage the existing skills of the AI system;
- allow fast non-iterative learning;
- correct new mistakes without destroying the previous fixes.
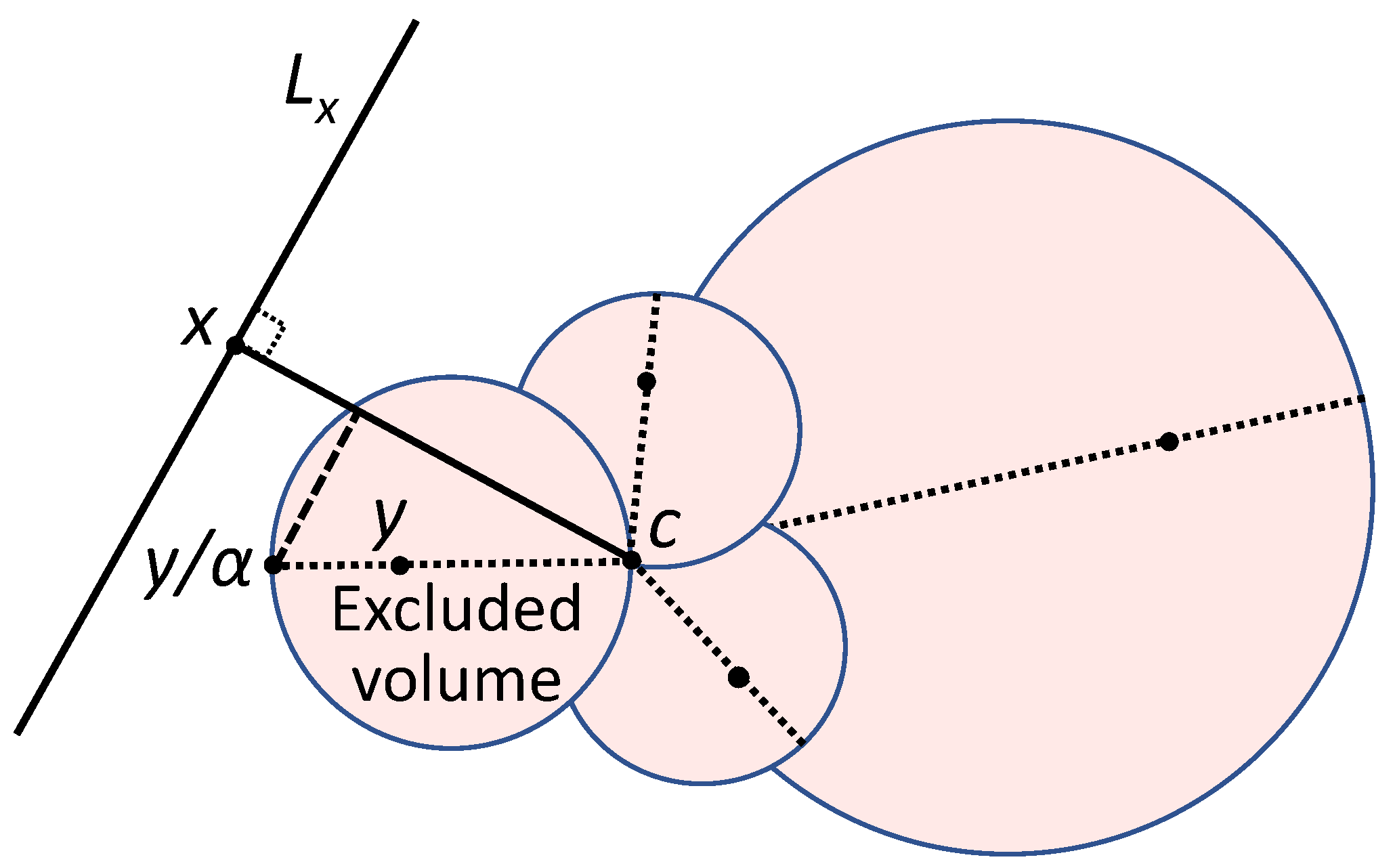
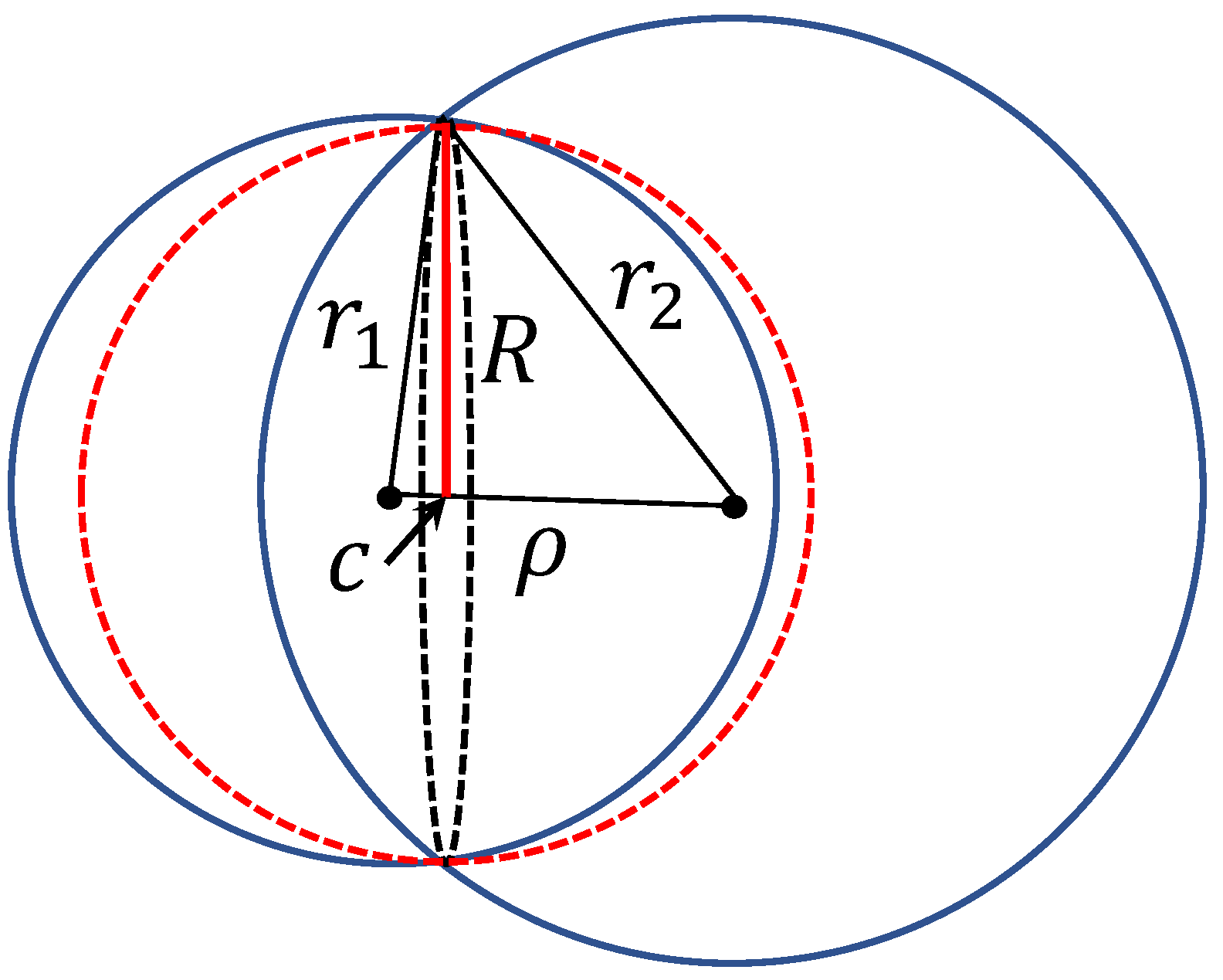
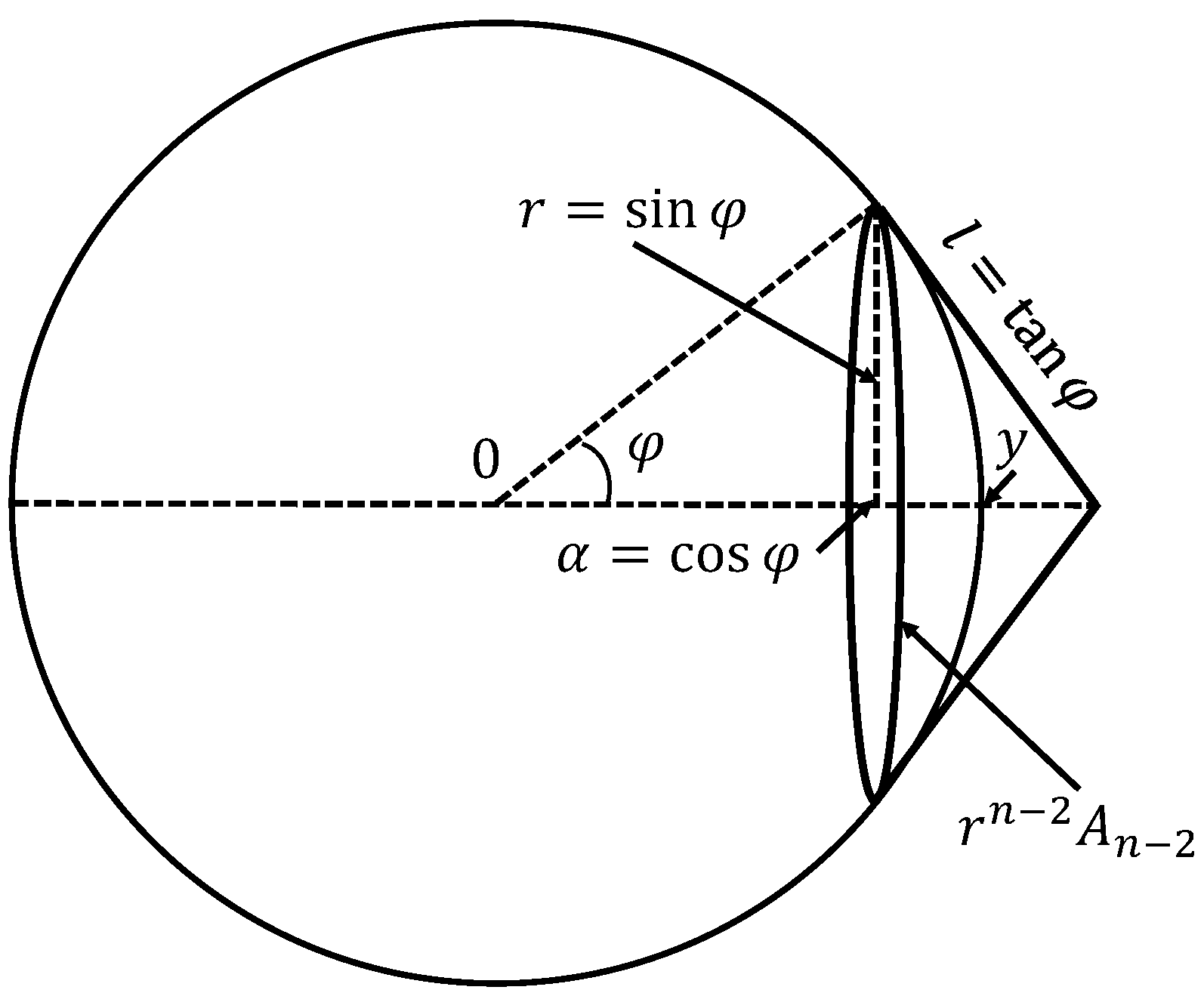
2.2. Fisher Separablity
2.3. Stochastic Separation for Distributions with Bounded Support
2.4. Generalisations
- Log-concave distributions (a distribution with density is log-concave if the set is convex and is a convex function on D). In this case, the possibility of an exponential (non-Gaussian) tail brings a surprise: the upper size bound of the random set , sufficient for Fisher-separability in high dimensions with high probability, grows with dimension n as , i.e., slower than exponential (Theorem 5, [39]).
- Strongly log-concave distributions. A log concave distribution is strongly log-concave if there exists a constant such thatIn this case, we return to the exponential estimation of the maximal allowed size of (Corollary 4, [39]). The comparison theorems [39] allow us to combine different distributions, for example the distribution from Theorem 2 in a ball with the log-concave or strongly log-concave tail outside the ball.
- The kernel versions of the stochastic separation theorem were found, proved and applied to some real-life problems [50].
- There are also various estimations beyond the standard i.i.d. hypothesis [39] but the general theory is yet to be developed.
2.5. Some Applications
3. Clustering in High Dimensions
4. What Does ‘High Dimensionality’ Mean?
- The classical Kaiser rule recommends to retain the principal components corresponding to the eigenvalues of the correlation matrix (or where is a selected threshold; often is selected). This is, perhaps, the most popular choice.
- Control of the fraction of variance unexplained. This approach is also popular, but it can retain too many minor components that can be considered ‘noise’.
- Conditional number control [39] recommends to retain the principal components corresponding to , where is the maximal eigenvalue of the correlation matrix and is the upper border of the conditional number (the recommended values are [58]). This recommendation is very useful because it provides direct control of multicollinearity.
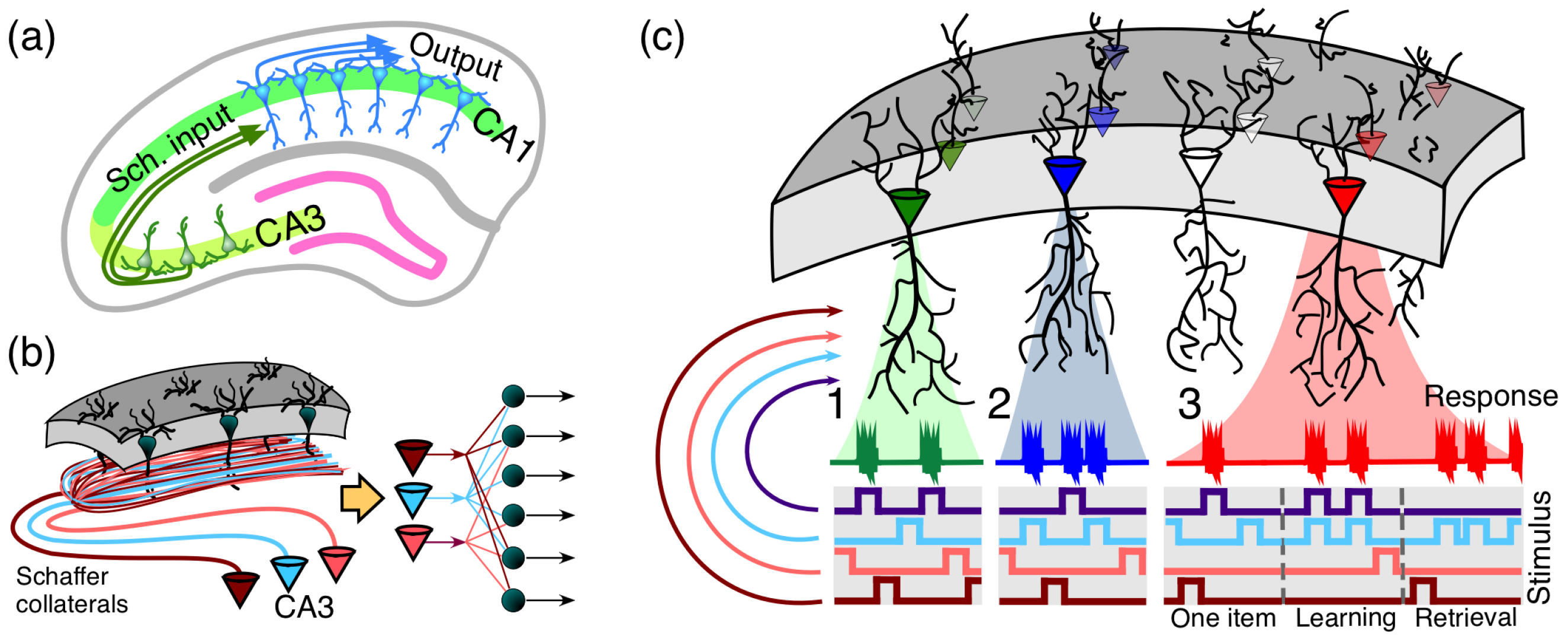
5. Discussion: The Heresy of Unheard-of Simplicity and Single Cell Revolution in Neuroscience
- the extreme selectivity of single neurons to the information content of high-dimensional data (Figure 5(c1)),
- simultaneous separation of several uncorrelated informational items from a large set of stimuli (Figure 5(c2)),
- dynamic learning of new items by associating them with already known ones (Figure 5(c3)).
Author Contributions
Funding
Conflicts of Interest
References
- Bellman, R. Dynamic Programming; Princeton University Press: Princeton, NJ, USA, 1957. [Google Scholar]
- Bellman, R. The theory of dynamic programming. Bull. Am. Math. Soc. 1954, 60, 503–515. [Google Scholar] [CrossRef] [Green Version]
- Bellman, R.; Kalaba, R. Reduction of dimensionality, dynamic programming, and control processes. J. Basic Eng. 1961, 83, 82–84. [Google Scholar] [CrossRef]
- Gorban, A.N.; Kazantzis, N.; Kevrekidis, I.G.; Öttinger, H.C.; Theodoropoulos, C. (Eds.) Model Reduction and Coarse–Graining Approaches for Multiscale Phenomena; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Jolliffe, I. Principal Component Analysis; Springer: Berlin/Heidelberg, Germany, 1993. [Google Scholar]
- Gorban, A.N.; Kégl, B.; Wunsch, D.; Zinovyev, A. (Eds.) Principal Manifolds for Data Visualisation and Dimension Reduction; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar] [CrossRef] [Green Version]
- Gorban, A.N.; Zinovyev, A. Principal manifolds and graphs in practice: from molecular biology to dynamical systems. Int. J. Neural Syst. 2010, 20, 219–232. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cichocki, A.; Lee, N.; Oseledets, I.; Phan, A.H.; Zhao, Q.; Mandic, D.P. Tensor networks for dimensionality reduction and large-scale optimization: Part 1 low-rank tensor decompositions. Found. Trends® Mach. Learn. 2016, 9, 249–429. [Google Scholar] [CrossRef] [Green Version]
- Cichocki, A.; Phan, A.H.; Zhao, Q.; Lee, N.; Oseledets, I.; Sugiyama, M.; Mandic, D.P. Tensor networks for dimensionality reduction and large-scale optimization: Part 2 applications and future perspectives. Found. Trends® Mach. Learn. 2017, 9, 431–673. [Google Scholar] [CrossRef]
- Beyer, K.; Goldstein, J.; Ramakrishnan, R.; Shaft, U. When is “nearest neighbor” meaningful? In Proceedings of the 7th International Conference on Database Theory (ICDT), Jerusalem, Israel, 10–12 January 1999; pp. 217–235. [Google Scholar] [CrossRef] [Green Version]
- Pestov, V. Is the k-NN classifier in high dimensions affected by the curse of dimensionality? Comput. Math. Appl. 2013, 65, 1427–1437. [Google Scholar] [CrossRef]
- Kainen, P.C. Utilizing geometric anomalies of high dimension: when complexity makes computation easier. In Computer-Intensive Methods in Control and Signal Processing: The Curse of Dimensionality; Warwick, K., Kárný, M., Eds.; Springer: New York, NY, USA, 1997; pp. 283–294. [Google Scholar] [CrossRef]
- Brown, B.M.; Hall, P.; Young, G.A. On the effect of inliers on the spatial median. J. Multivar. Anal. 1997, 63, 88–104. [Google Scholar] [CrossRef] [Green Version]
- Donoho, D.L. High-Dimensional Data Analysis: The Curses and Blessings of Dimensionality. Invited Lecture at Mathematical Challenges of the 21st Century. In Proceedings of the AMS National Meeting, Los Angeles, CA, USA, 6–12 August 2000; Available online: http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.329.3392 (accessed on 5 January 2020).
- Chen, D.; Cao, X.; Wen, F.; Sun, J. Blessing of dimensionality: High-dimensional feature and its efficient compression for face verification. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3025–3032. [Google Scholar] [CrossRef]
- Liu, G.; Liu, Q.; Li, P. Blessing of dimensionality: Recovering mixture data via dictionary pursuit. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 47–60. [Google Scholar] [CrossRef]
- Murtagh, F. The remarkable simplicity of very high dimensional data: Application of model-based clustering. J. Classif. 2009, 26, 249–277. [Google Scholar] [CrossRef] [Green Version]
- Anderson, J.; Belkin, M.; Goyal, N.; Rademacher, L.; Voss, J. The More, the Merrier: The Blessing of Dimensionality for Learning Large Gaussian Mixtures. In Proceedings of the 27th Conference on Learning Theory, Barcelona, Spain, 13–15 June 2014; Balcan, M.F., Feldman, V., Szepesvári, C., Eds.; PMLR: Barcelona, Spain, 2014; Volume 35, pp. 1135–1164. [Google Scholar]
- Gorban, A.N.; Tyukin, I.Y.; Romanenko, I. The blessing of dimensionality: Separation theorems in the thermodynamic limit. IFAC-PapersOnLine 2016, 49, 64–69. [Google Scholar] [CrossRef]
- Li, Q.; Cheng, G.; Fan, J.; Wang, Y. Embracing the blessing of dimensionality in factor models. J. Am. Stat. Assoc. 2018, 113, 380–389. [Google Scholar] [CrossRef] [PubMed]
- Landgraf, A.J.; Lee, Y. Generalized principal component analysis: Projection of saturated model parameters. Technometrics 2019. [Google Scholar] [CrossRef]
- Donoho, D.L. Compressed sensing. IEEE Trans. Inf. Theory 2006, 52, 1289–1306. [Google Scholar] [CrossRef]
- Donoho, D.; Tanner, J. Observed universality of phase transitions in high-dimensional geometry, with implications for modern data analysis and signal processing. Phil. Trans. R. Soc. A 2009, 367, 4273–4293. [Google Scholar] [CrossRef] [PubMed]
- Candes, E.; Rudelson, M.; Tao, T.; Vershynin, R. Error correction via linear programming. In Proceedings of the 46th Annual IEEE Symposium on Foundations of Computer Science (FOCS’05), Pittsburgh, PA, USA, 23–25 October 2005; pp. 668–681. [Google Scholar] [CrossRef] [Green Version]
- Pereda, E.; García-Torres, M.; Melián-Batista, B.; Mañas, S.; Méndez, L.; González, J.J. The blessing of Dimensionality: Feature Selection outperforms functional connectivity-based feature transformation to classify ADHD subjects from EEG patterns of phase synchronisation. PLoS ONE 2018, 13, e0201660. [Google Scholar] [CrossRef] [PubMed]
- Kainen, P.; Kůrková, V. Quasiorthogonal dimension of Euclidian spaces. Appl. Math. Lett. 1993, 6, 7–10. [Google Scholar] [CrossRef] [Green Version]
- Hall, P.; Marron, J.; Neeman, A. Geometric representation of high dimension, low sample size data. J. R. Stat. Soc. B 2005, 67, 427–444. [Google Scholar] [CrossRef]
- Gorban, A.N.; Tyukin, I.; Prokhorov, D.; Sofeikov, K. Approximation with random bases: Pro et contra. Inf. Sci. 2016, 364–365, 129–145. [Google Scholar] [CrossRef] [Green Version]
- Dasgupta, S.; Gupta, A. An elementary proof of a theorem of Johnson and Lindenstrauss. Random Sruct. Algorithms 2003, 22, 60–65. [Google Scholar] [CrossRef]
- Gorban, A.N.; Tyukin, I.Y. Blessing of dimensionality: Mathematical foundations of the statistical physics of data. Philos. Trans. R. Soc. A 2018, 376, 20170237. [Google Scholar] [CrossRef] [Green Version]
- Vershynin, R. High-Dimensional Probability: An Introduction with Applications in Data Science; Cambridge Series in Statistical and Probabilistic Mathematics; Cambridge University Press: Cambridge, UK, 2018. [Google Scholar]
- Giannopoulos, A.A.; Milman, V.D. Concentration property on probability spaces. Adv. Math. 2000, 156, 77–106. [Google Scholar] [CrossRef] [Green Version]
- Ledoux, M. The Concentration of Measure Phenomenon; Number 89 in Mathematical Surveys & Monographs; AMS: Providence, RI, USA, 2005. [Google Scholar]
- Gibbs, J.W. Elementary Principles in Statistical Mechanics, Developed with Especial Reference to the Rational Foundation of Thermodynamics; Dover Publications: New York, NY, USA, 1960. [Google Scholar]
- Gromov, M. Isoperimetry of waists and concentration of maps. Geom. Funct. Anal. 2003, 13, 178–215. [Google Scholar] [CrossRef] [Green Version]
- Lévy, P. Problèmes Concrets D’analyse Fonctionnelle; Gauthier-Villars: Paris, France, 1951. [Google Scholar]
- Dubhashi, D.P.; Panconesi, A. Concentration of Measure for the Analysis of Randomized Algorithms; Cambridge University Press: Cambridge, UK, 2009. [Google Scholar]
- Ball, K. An Elementary Introduction to Modern Convex Geometry. In Flavors of Geometry; Cambridge University Press: Cambridge, UK, 1997; Volume 31. [Google Scholar]
- Gorban, A.N.; Golubkov, A.; Grechuk, B.; Mirkes, E.M.; Tyukin, I.Y. Correction of AI systems by linear discriminants: Probabilistic foundations. Inf. Sci. 2018, 466, 303–322. [Google Scholar] [CrossRef] [Green Version]
- Gorban, A.N.; Makarov, V.A.; Tyukin, I.Y. The unreasonable effectiveness of small neural ensembles in high-dimensional brain. Phys. Life Rev. 2019, 29, 55–88. [Google Scholar] [CrossRef] [PubMed]
- Bárány, I.; Füredi, Z. On the shape of the convex hull of random points. Probab. Theory Relat. Fields 1988, 77, 231–240. [Google Scholar] [CrossRef]
- Gorban, A.N.; Tyukin, I.Y. Stochastic separation theorems. Neural Netw. 2017, 94, 255–259. [Google Scholar] [CrossRef] [Green Version]
- Tyukin, I.Y.; Gorban, A.N.; McEwan, A.A.; Meshkinfamfard, S. Blessing of dimensionality at the edge. arXiv 2019, arXiv:1910.00445. [Google Scholar]
- Gorban, A.N.; Burton, R.; Romanenko, I.; Tyukin, I.Y. One-trial correction of legacy AI systems and stochastic separation theorems. Inf. Sci. 2019, 484, 237–254. [Google Scholar] [CrossRef] [Green Version]
- Fisher, R.A. The Use of Multiple Measurements in Taxonomic Problems. Ann. Eugenics 1936, 7, 179–188. [Google Scholar] [CrossRef]
- Kůrková, V. Some insights from high-dimensional spheres: Comment on “The unreasonable effectiveness of small neural ensembles in high-dimensional brain” by Alexander N. Gorban et al. Phys. Life Rev. 2019, 29, 98–100. [Google Scholar] [CrossRef]
- Gorban, A.N.; Makarov, V.A.; Tyukin, I.Y. Symphony of high-dimensional brain. Reply to comments on “The unreasonable effectiveness of small neural ensembles in high-dimensional brain”. Phys. Life Rev. 2019, 29, 115–119. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Grechuk, B. Practical stochastic separation theorems for product distributions. In Proceedings of the IEEE IJCNN 2019—International Joint Conference on Neural Networks, Budapest, Hungary, 14–19 July 2019. [Google Scholar] [CrossRef]
- Kůrková, V.; Sanguineti, M. Probabilistic Bounds for Binary Classification of Large Data Sets. In Proceedings of the International Neural Networks Society, Genova, Italy, 16–18 April 2019; Oneto, L., Navarin, N., Sperduti, A., Anguita, D., Eds.; Springer: Berlin/Heidelberg, Germany, 2019; Volume 1, pp. 309–319. [Google Scholar] [CrossRef]
- Tyukin, I.Y.; Gorban, A.N.; Grechuk, B. Kernel Stochastic Separation Theorems and Separability Characterizations of Kernel Classifiers. In Proceedings of the IEEE IJCNN 2019—International Joint Conference on Neural Networks, Budapest, Hungary, 14–19 July 2019. [Google Scholar] [CrossRef]
- Meshkinfamfard, S.; Gorban, A.N.; Tyukin, I.V. Tackling Rare False-Positives in Face Recognition: A Case Study. In Proceedings of the 2018 IEEE 20th International Conference on High Performance Computing and Communications; IEEE 16th International Conference on Smart City; IEEE 4th International Conference on Data Science and Systems (HPCC/SmartCity/DSS); IEEE: Exeter, UK, 2018; pp. 1592–1598. [Google Scholar] [CrossRef]
- Tyukin, I.Y.; Gorban, A.N.; Green, S.; Prokhorov, D. Fast construction of correcting ensembles for legacy artificial intelligence systems: Algorithms and a case study. Inf. Sci. 2019, 485, 230–247. [Google Scholar] [CrossRef] [Green Version]
- Tyukin, I.Y.; Gorban, A.N.; Sofeikov, K.; Romanenko, I. Knowledge transfer between artificial intelligence systems. Front. Neurorobot. 2018, 12. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Allison, P.M.; Sofeikov, K.; Levesley, J.; Gorban, A.N.; Tyukin, I.; Cooper, N.J. Exploring automated pottery identification [Arch-I-Scan]. Internet Archaeol. 2018, 50. [Google Scholar] [CrossRef]
- Romanenko, I.; Gorban, A.; Tyukin, I. Image Processing. U.S. Patent 10,489,634 B2, 26 November 2019. Available online: https://patents.google.com/patent/US10489634B2/en (accessed on 5 January 2020).
- Xu, R.; Wunsch, D. Clustering; Wiley: Hoboken, NJ, USA, 2008. [Google Scholar]
- Moczko, E.; Mirkes, E.M.; Cáceres, C.; Gorban, A.N.; Piletsky, S. Fluorescence-based assay as a new screening tool for toxic chemicals. Sci. Rep. 2016, 6, 33922. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dormann, C.F.; Elith, J.; Bacher, S.; Buchmann, C.; Carl, G.; Carré, G.; Marquéz, J.R.; Gruber, B.; Lafourcade, B.; Leitão, P.J.; et al. Collinearity: A review of methods to deal with it and a simulation study evaluating their performance. Ecography 2013, 36, 27–46. [Google Scholar] [CrossRef]
- Albergante, L.; Bac, J.; Zinovyev, A. Estimating the effective dimension of large biological datasets using Fisher separability analysis. In Proceedings of the IEEE IJCNN 2019—International Joint Conference on Neural Networks, Budapest, Hungary, 14–19 July 2019. [Google Scholar] [CrossRef] [Green Version]
- Artin, E. The Gamma Function; Courier Dover Publications: Mineola, NY, USA, 2015. [Google Scholar]
- Kreinovich, V. The heresy of unheard-of simplicity: Comment on “The unreasonable effectiveness of small neural ensembles in high-dimensional brain” by A.N. Gorban, V.A. Makarov, and I.Y. Tyukin. Phys. Life Rev. 2019, 29, 93–95. [Google Scholar] [CrossRef]
- Quian Quiroga, R.; Reddy, L.; Kreiman, G.; Koch, C.; Fried, I. Invariant visual representation by single neurons in the human brain. Nature 2005, 435, 1102–1107. [Google Scholar] [CrossRef]
- Barlow, H.B. Single units and sensation: a neuron doctrine for perceptual psychology? Perception 1972, 1, 371–394. [Google Scholar] [CrossRef] [Green Version]
- Quian Quiroga, R. Akakhievitch revisited: Comment on “The unreasonable effectiveness of small neural ensembles in high-dimensional brain” by Alexander N. Gorban et al. Phys. Life Rev. 2019, 29, 111–114. [Google Scholar] [CrossRef]
- Megías, M.; Emri, Z.S.; Freund, T.F.; Gulyás, A.I. Total number and distribution of inhibitory and excitatory synapses on hippocampal CA1 pyramidal cells. Neuroscience 2001, 102, 527–540. [Google Scholar] [CrossRef]
- Druckmann, S.; Feng, L.; Lee, B.; Yook, C.; Zhao, T.; Magee, J.C.; Kim, J. Structured synaptic connectivity between hippocampal regions. Neuron 2014, 81, 629–640. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Brivanlou, I.H.; Dantzker, J.L.; Stevens, C.F.; Callaway, E.M. Topographic specificity of functional connections from hippocampal CA3 to CA1. Proc. Natl. Acad. Sci. USA 2004, 101, 2560–2565. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tyukin, I.; Gorban, A.N.; Calvo, C.; Makarova, J.; Makarov, V.A. High-dimensional brain: A tool for encoding and rapid learning of memories by single neurons. Bull. Math. Biol. 2019, 81, 4856–4888. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Varona, P. High and low dimensionality in neuroscience and artificial intelligence: Comment on “The unreasonable effectiveness of small neural ensembles in high-dimensional brain” by A.N. Gorban et al. Phys. Life Rev. 2019, 29, 106–107. [Google Scholar] [CrossRef]
- Barrio, R. “Brainland” vs. “flatland”: how many dimensions do we need in brain dynamics? Comment on the paper “The unreasonable effectiveness of small neural ensembles in high-dimensional brain” by Alexander N. Gorban et al. Phys. Life Rev. 2019, 29, 108–110. [Google Scholar] [CrossRef]
- Van Leeuwen, C. The reasonable ineffectiveness of biological brains in applying the principles of high-dimensional cybernetics: Comment on “The unreasonable effectiveness of small neural ensembles in high-dimensional brain” by Alexander N. Gorban et al. Phys. Life Rev. 2019, 29, 104–105. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| n = 10 | n = 20 | n = 30 | n = 40 | n = 50 | n = 60 | n = 70 | n = 80 | |
|---|---|---|---|---|---|---|---|---|
| 5 | ||||||||
| 2 | 37 | 542 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gorban, A.N.; Makarov, V.A.; Tyukin, I.Y. High-Dimensional Brain in a High-Dimensional World: Blessing of Dimensionality. Entropy 2020, 22, 82. https://doi.org/10.3390/e22010082
Gorban AN, Makarov VA, Tyukin IY. High-Dimensional Brain in a High-Dimensional World: Blessing of Dimensionality. Entropy. 2020; 22(1):82. https://doi.org/10.3390/e22010082
Chicago/Turabian StyleGorban, Alexander N., Valery A. Makarov, and Ivan Y. Tyukin. 2020. "High-Dimensional Brain in a High-Dimensional World: Blessing of Dimensionality" Entropy 22, no. 1: 82. https://doi.org/10.3390/e22010082
APA StyleGorban, A. N., Makarov, V. A., & Tyukin, I. Y. (2020). High-Dimensional Brain in a High-Dimensional World: Blessing of Dimensionality. Entropy, 22(1), 82. https://doi.org/10.3390/e22010082